大数据的树表展现系统和树表展现方法
常用的数据展示方式

常用的数据展示方式数据在现代社会中起着至关重要的作用,我们需要将数据以合适的方式展示出来,以便更好地理解和分析。
下面介绍一些常用的数据展示方式。
一、表格(Table)表格是最常见的数据展示方式之一。
通过表格可以清晰地呈现数据的各个维度和指标。
表格一般由行和列组成,行表示不同的记录或实例,列表示不同的属性或指标。
表格可以对数据进行分类、排序和筛选,便于我们快速查找和比较数据。
二、柱状图(Bar chart)柱状图是用长方形的长度或高度来表示数据的大小,通常用于比较不同类别或时间段的数据。
柱状图可以直观地显示数据的差异和趋势,便于我们分析和理解数据。
柱状图可以横向或纵向展示,横向柱状图更适合展示较多类别的数据,纵向柱状图则更适合展示较多时间段的数据。
三、折线图(Line chart)折线图是用折线的形状来表示数据的变化趋势,通常用于展示随时间或其他连续变量而变化的数据。
折线图可以清晰地显示数据的上升或下降趋势,便于我们观察和预测数据的变化。
折线图还可以同时展示多组数据,方便我们进行比较和分析。
四、饼图(Pie chart)饼图是用圆形的扇区来表示数据的比例和占比,通常用于展示不同类别的数据在整体中的分布情况。
饼图可以直观地显示数据的相对大小和比例关系,便于我们了解各个类别的重要性和贡献度。
然而,饼图不适合展示过多的类别,否则会导致扇区过小难以区分。
五、雷达图(Radar chart)雷达图是用多边形的边和顶点来表示数据的多个维度和指标,通常用于展示多个变量在不同维度上的表现。
雷达图可以直观地显示数据的相对优劣和差异,便于我们进行综合评估和比较。
雷达图适用于展示多元数据,但对于维度过多的数据,会导致图形复杂难以解读。
六、散点图(Scatter plot)散点图是用坐标系中的点来表示数据的分布和相关关系,通常用于展示两个变量之间的关系。
散点图可以直观地显示数据的分布模式和趋势,便于我们观察和分析变量之间的关联程度。
树形展示
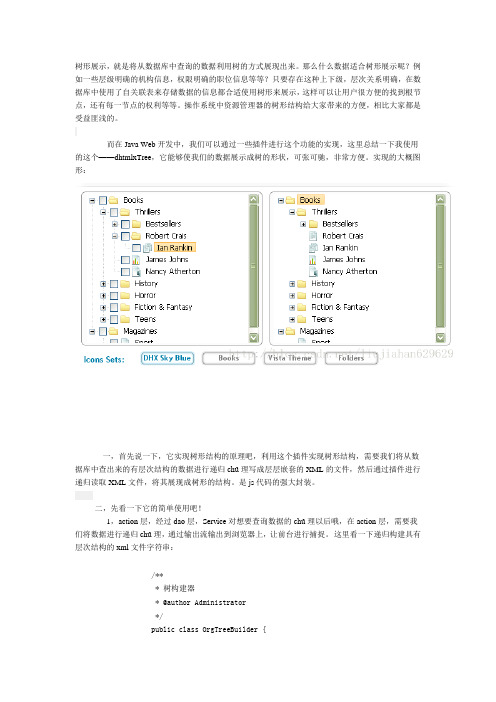
树形展示,就是将从数据库中查询的数据利用树的方式展现出来。
那么什么数据适合树形展示呢?例如一些层级明确的机构信息,权限明确的职位信息等等?只要存在这种上下级,层次关系明确,在数据库中使用了自关联表来存储数据的信息都合适使用树形来展示,这样可以让用户很方便的找到根节点,还有每一节点的权利等等。
操作系统中资源管理器的树形结构给大家带来的方便,相比大家都是受益匪浅的。
而在Java Web开发中,我们可以通过一些插件进行这个功能的实现,这里总结一下我使用的这个——dhtmlxTree,它能够使我们的数据展示成树的形状,可张可驰,非常方便。
实现的大概图形:一,首先说一下,它实现树形结构的原理吧,利用这个插件实现树形结构,需要我们将从数据库中查出来的有层次结构的数据进行递归chǔ理写成层层嵌套的XML的文件,然后通过插件进行递归读取XML文件,将其展现成树形的结构。
是js代码的强大封装。
二,先看一下它的简单使用吧!1,action层,经过dao层,Service对想要查询数据的chǔ理以后哦,在action层,需要我们将数据进行递归chǔ理,通过输出流输出到浏览器上,让前台进行捕捉。
这里看一下递归构建具有层次结构的xml文件字符串:/*** 树构建器* @author Administrator*/public class OrgTreeBuilder {//传入树的跟节点private Org root;//通过此来拼接xml文件,这里注意选取StringBuilder,效率更高private StringBuilder treeString = new StringBuilder(128);//构造方法,参数就是根节点public OrgTreeBuilder( Org root ) {this.root = root;}/*** 构建树* @return*/public String build() {//xml的表头treeString.append("<?xml version=\"1.0\" encodin g=\"utf-8\"?>");treeString.append("<tree id=\"0\">");//调用构建子节点的函数buildNode(root);treeString.append("</tree>");//将构建好的树,转换为字符串return,方便action的输出return treeString.toString();}/*** 构建树形节点的内容*/private void buildNode( Org org ) {//注意拼接字符串一些特殊符号的chǔ理treeString.append("<item text=\"");treeString.append(org.getName());treeString.append("\" id=\"");treeString.append(org.getId());treeString.append("\">");//查看此节点的子节点Set<Org> orgSet = org.getChildOrgSet();//如果有子节点,进行递归调用,调用自己这个函数for ( Org obj : orgSet ) {buildNode(obj);}treeString.append("</item>");}}而,在action层中只需要将其进行输出为xml格式即可:// 输出XML格式的字符串response.setContentType("text/xml;charset=UTF-8");response.getWriter().print(obj);2,这里需要注意生成的层次结构的xml文件是有一定规范的,看一下:<?xml version="1.0" encoding="utf-8"?><tree id="0"><item text="xxxxx" id="-1" open="1" checked="1"><item text="yyyy" id="1"><item text="zzzz" id="2"/></item></item></tree>简单说一下其中参数的含义:id : 表示节点的唯一xìng标识text : 表示节点的显示名称open : 表示节点是否需要展开,取值任意checked : 表示节点是否被完全选中,取值任意(这里需要注意,当一个节点的所有子节点都被选中时,表示完全选中,否则为不完全选中,在这里,树形的选中状态有三种。
大数据分析的关键要素和技术

大数据分析的关键要素和技术随着互联网及移动设备的普及,我们已经进入了一个“大数据时代”。
我们每天会产生大量的数据,这些数据包括我们的社交媒体信息、在线购物记录、搜索历史和移动应用数据等等。
这些数据对于企业、政府和个人都有着巨大的价值。
因此,大数据分析技术的应用正在逐渐普及。
大数据分析需要具备的关键要素包括:数据收集、数据处理、数据存储、分析和可视化。
以下是各种关键要素的详细解释。
1. 数据收集数据收集是大数据分析的首要任务,它涉及到数据的获取和整合。
大多数数据是通过互联网搜索、传感器、应用程序和社交媒体获取的。
在这个阶段,我们需要了解数据的来源、格式以及数据的质量和完整性。
2. 数据处理数据处理是指对数据进行清洗、整合和转换,以确保数据的准确性和一致性。
数据的清洗和转换通常涉及到去除重复记录、填补缺失值以及处理异常值。
数据的整合往往需要将来自不同源的数据统一格式后进行合并,以便后续分析处理。
3. 数据存储现在数据量越来越大,如何对数据进行存储和管理成为了一个重要的问题。
常用的数据存储方式包括传统的关系型数据库,以及新兴的非结构化数据存储方式,如Hadoop、NoSQL、MongoDB等。
数据存储需要满足高可用性、高性能和可扩展性的要求,以便快速检索和分析。
4. 分析在数据处理和存储完成后,接下来就是对数据进行分析了。
数据分析可以涉及到各种技术,如模式识别、机器学习、数据挖掘和统计分析等。
通过对数据的分析,我们可以发现数据中的规律和趋势,并提炼出对业务有价值的信息。
5. 可视化最后一个关键要素是数据可视化。
数据可视化是将处理后的数据以图表或其他形式表现出来,以便于人类理解和利用。
可视化可以帮助我们更清晰直观地了解数据的内在结构和关系。
可视化工具有很多,如Tableau、QlikView和D3.js等。
以上是大数据分析的五个关键要素,下面列出了一些大数据分析中常用的技术。
1. HadoopHadoop是一个开源的软件框架,可以用于处理大规模的数据集。
大数据可视化PPT第4章 数据可视化的常用方法

折线图适用于二维大数据集,尤其是那些趋势比单个数据点更重要的场合。
4.2.4 饼图
饼图适用于一维数据可视,尤其是能反映数据序列中各项大小、总和和相互之间比例大小。
4.2.5 散点图
散点图适用于三维数据集,但其中只有两维需要比较。
4.2.6 气泡图
气泡图是散点图的一种变形,通过每个点的面积大小,反应第三维。
4.4.5 聚类分析
(1)系统聚类法 将变量由多变少的一种方法,先将距离最小的变量归为一类,再将它们合并,合并后将新类 计算相互间的距离,再将距离最小的新类合并,直到所有变量归为一类为止。距离的定义有: 最短距离法、最长距离法、中心法、类平均法、中间距离法、离差平法和法等。 (2)动态聚类法 能较好地解决系统聚类当样本数量大时计算量大的问题。动态聚类先设定好数值K,然后将 所有样本分成K类作为聚核,再计算每个样本到聚核的距离,与聚核距离最小的样本归为一 类,这样样本被分为K类;然后依次继续进行分类,并按一定的标准停止分类。
三维柱状图的可视化效果更佳直观,而且能够在第三个坐标轴显示三维数据。三维柱状图采 用柱体来量化数据,同时对柱体可以采用不用的颜色编码,来表述不同的变量。
8 of 46
4.2 统计图表可视化方法
第四章 数据可视化的常用方法
4.2.2 条形图
排列在工作表的列或行中的数据可以绘制到条形图中。条形图显示各个项目之间的比较情况。
24 of 46
第四章 数据可视化的常用方法
4.1 视觉编码 4.2 统计图表可视化方法 4.3 图可视化方法 4.4 可视化分析方法的常用算法 4.5 可视化方法的选择 习题
25 of 46
4.5 可视化方法的选择
第四章 数据可视化的常用方法
大数据分析技术与方法有哪些

大数据分析技术与方法有哪些在当今信息化社会中,大数据的应用已经越来越广泛,成为企业决策、市场分析、科学研究等领域的重要工具。
而要对这些大数据进行分析,需要运用一系列的技术与方法。
本文将会介绍一些常见的大数据分析技术与方法。
一、数据收集与清洗技术在进行大数据分析之前,首先需要收集、整理和清洗数据。
数据收集技术包括传感器技术、网络爬虫技术、数据仓库技术等,通过这些技术可以从各种渠道采集到海量的数据。
而数据清洗技术则是对采集到的数据进行去重、去噪、填充缺失值等操作,以确保数据的准确性与完整性。
二、数据存储与管理技术大数据分析需要处理的数据量通常非常大,因此需要使用适当的数据存储与管理技术来存储、管理和检索数据。
常见的数据存储与管理技术包括关系数据库、分布式文件系统、NoSQL数据库等。
这些技术可以提供高效的数据存储与检索能力,以便后续的数据分析工作。
三、数据预处理技术由于大数据的复杂性和多样性,数据分析前往往需要进行一系列的预处理操作,以提高数据质量和分析效果。
数据预处理技术包括数据清洗、数据集成、数据变换和数据规约等。
通过这些技术可以对原始数据进行去噪、归一化、特征选择等操作,为后续的数据分析提供准备。
四、数据挖掘技术数据挖掘是大数据分析中的核心环节,通过利用统计学、机器学习和模式识别等方法,从大数据集中发现潜在的模式、规律和知识。
常见的数据挖掘技术包括聚类分析、分类分析、关联分析和异常检测等。
这些技术可以帮助人们深入挖掘数据背后隐藏的信息,并为决策提供支持。
五、数据可视化技术大数据分析的结果往往以图表、图像等形式展现给用户,以便用户更好地理解和分析数据。
数据可视化技术可以将复杂的数据结果通过直观的图形展示出来,让用户一目了然。
常见的数据可视化技术包括柱状图、折线图、热力图和地图等。
这些技术可以提高数据的可读性和可理解性,帮助用户更好地理解数据分析结果。
六、机器学习技术机器学习是大数据分析的重要工具之一,通过训练机器学习模型,可以自动从数据中学习并进行预测和分类。
有效展示数据的方法与技巧

有效展示数据的方法与技巧导言:数据是当今社会的核心资源之一,无论是企业管理还是科研分析,都离不开数据的支持。
然而,数据本身并没有任何实际意义,只有通过有效的展示和分析,才能为人们带来有价值的信息。
本文将探讨有效展示数据的方法与技巧,帮助读者更好地利用数据。
一、选择合适的展示形式1.图表展示数据可通过图表的形式图形化地展示,从而更直观地传达信息。
常见的图表类型包括折线图、柱状图、饼图等。
选择合适的图表类型可以根据数据的特点进行判断,比如折线图适合展示趋势变化,而柱状图适合展示分类数据的对比等。
2.地理信息系统(GIS)地理信息系统可以将数据与地理位置信息相结合,通过地图等方式展示出来。
这种展示形式使得数据更具空间性,有助于我们发现地理数据之间的关联关系。
例如,通过在地图上展示不同区域的销售额,可以更好地分析销售热点和盲点。
二、注意数据的可读性和可理解性1.简化信息尽量避免过多的数据信息,可以通过去除无关数据或者聚焦关键信息来简化数据内容。
同时,要注意用简洁的语言对数据进行注解,使读者更容易理解数据的含义。
2.使用可视化辅助工具借助可视化辅助工具,如颜色、字体、线条等,可以更好地突出数据的重要性和特点。
例如,在柱状图中使用不同颜色表示不同类别的数据,可以提升读者对数据的区分度。
三、正确选择数据维度1.时间维度时间是数据展示中常用的一种维度。
可以通过折线图等方式展示随时间变化的数据趋势。
此外,在时间维度上的对比分析也是有意义的,例如比较不同时间段内的销售额或用户行为等。
2.空间维度空间维度指的是根据地理位置将数据进行划分。
可以通过地图等方式展示不同地区的数据分布和差异,帮助我们更好地理解和分析数据。
四、注意数据的真实性和准确性为了让数据展示更加有信服力,我们需要确保数据的真实性和准确性。
在收集和整理数据时,要注意核实数据的来源和处理方法,避免因数据本身存在问题导致的信息错误和误导。
五、关注数据的合理性和逻辑性1.数据的合理性合理性主要指数据之间的关系是否合理,是否符合常理和经验。
大数据理论考试(习题卷12)

大数据理论考试(习题卷12)说明:答案和解析在试卷最后第1部分:单项选择题,共64题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]()试图学得一个属性的线性组合来进行预测的函数。
A)决策树B)贝叶斯分类器C)神经网络D)线性模2.[单选题]随机试验所有可能出现的结果,称为()A)基本事件B)样本C)全部事件D)样本空间3.[单选题]DWS实例中,下列哪项不是主备配置的:A)CMSB)GTMC)OMSD)coordinato4.[单选题]数据科学家可能会同时使用多个算法(模型)进行预测,并且最后把这些算法的结果集成起来进行最后的预测(集成学习),以下对集成学习说法正确的是()。
A)单个模型之间具有高相关性B)单个模型之间具有低相关性C)在集成学习中使用“平均权重”而不是“投票”会比较好D)单个模型都是用的一个算法5.[单选题]下面算法属于局部处理的是()。
A)灰度线性变换B)二值化C)傅里叶变换D)中值滤6.[单选题]中文同义词替换时,常用到Word2Vec,以下说法错误的是()。
A)Word2Vec基于概率统计B)Word2Vec结果符合当前预料环境C)Word2Vec得到的都是语义上的同义词D)Word2Vec受限于训练语料的数量和质7.[单选题]一位母亲记录了儿子3~9岁的身高,由此建立的身高与年龄的回归直线方程为y=7.19x+73.93,据此可以预测这个孩子10岁时的身高,则正确的叙述是()。
A)身高一定是145.83cmB)身高一定超过146.00cmC)身高一定高于145.00cmD)身高在145.83cm左右8.[单选题]有关数据仓库的开发特点,不正确的描述是()。
A)数据仓库开发要从数据出发;B)数据仓库使用的需求在开发出去就要明确;C)数据仓库的开发是一个不断循环的过程,是启发式的开发;D)在数据仓库环境中,并不存在操作型环境中所固定的和较确切的处理流,数据仓库中数据分析和处理更灵活,且没有固定的模式9.[单选题]由于不同类别的关键词对排序的贡献不同,检索算法一般把查询关键词分为几类,以下哪一类不属于此关键词类型的是()。
生物大数据技术的进化树构建方法与工具

生物大数据技术的进化树构建方法与工具随着现代生物学研究范式不断发展,生物大数据成为生物学研究的重要资源。
在生物大数据中,进化树构建是解决物种分类和亲缘关系的关键环节之一。
进化树提供了生物物种之间的演化关系,帮助我们理解生物多样性的起源和演化过程。
在本文中,我将介绍生物大数据技术中用于构建进化树的方法与工具。
进化树构建的方法包括距离法、最大简约法和贝叶斯法等。
距离法是一种基于物种间差异的测量方法,常用的距离指标有进化距离、遗传距离和相似性距离等。
最大简约法则基于进化过程中最简单的演化树,寻找一棵树,使得所有的观察数据与这棵树的解释最为一致。
贝叶斯法是一种基于概率统计的方法,利用贝叶斯统计推断物种之间的关系,它可以通过蒙特卡罗马尔科夫链蒙特卡罗(MCMC)方法来求解。
生物大数据技术的进化树构建方法中有许多重要的工具。
其中,最广泛使用的方法之一是分子系统学。
分子系统学利用生物大数据中的遗传序列信息来构建进化树,最常用的序列包括基因组序列和蛋白质序列。
常见的分子系统学工具有MEGA、PHYLIP、RAxML和MrBayes等。
MEGA是一个综合的分子进化分析软件,集成了多种进化模型和构建方法。
PHYLIP是最早的公开可用的构建进化树的软件包,其中包含了多种构建方法和分析工具。
RAxML是一种用于大规模物种分类研究的软件,它具有高效的计算性能和准确的模型选择。
MrBayes是一种基于贝叶斯统计学的软件,能够估计单个和多个基因的进化树。
此外,还有一些新兴的工具用于生物大数据中进化树的构建。
一种常见的方法是使用基于物种演化树的软件包,例如ASTRAL和PhyloNet。
ASTRAL利用结合物种组织树关系和基因树关系的联合推断来构建物种进化树,它能够处理物种树混淆或基因树不完整的情况。
PhyloNet是一种基于网络理论和统计学的方法,可以推断出复杂的物种进化网络,包括基因水平的基因转移和混合。
除了这些方法和工具外,还有一些改进的技术被用于生物大数据中的进化树构建。
数据可视化呈现的6种方法

数据可视化呈现的6种方法在当前互联网,数据可视化图表的类型层出不穷。
有关数据可视化的方法,如何将数据图形化,本文在这里归纳总结了方法。
一般,数据图表可以拆分成两类最基本的元素: 所描述的事物及这个事物的数值,我们暂且将其分别定义为指标和指标值。
比如一个性别分布中,男性占比30%,女性占比70%,那么指标就是男性、女性,指标值对应为30%、70%。
1.将指标值图形化一个指标值就是一个数据,将数据的大小以图形的方式表现。
比如用柱形图的长度或高度表现数据大小,这也是最常用的可视化形式。
传统的柱形图、饼图有可能会带来审美疲劳,如果你想创新,可以尝试从图形的视觉样式上下点功夫,常用的方法就是将图形与指标的含义关联起来。
我在网络上看到用FineBI统计的一个有趣的图,统计了东盟十国用户来广西的比例,采用用各国国旗来展示,图形与指标的含义相吻合。
2.将指标图形化一般用与指标含义相近的icon来表现,使用场景也比较多,如下:3.将指标关系图形化当存在多个指标时,挖掘指标之间的关系,并将其图形化表达,可提升图表的可视化深度。
常见有以下两种方式:借助已有的场景来表现联想自然或社会中有无场景与指标关系类似,然后借助此场景来表现。
比如有关流量研究院操作系统的分布,首先分为windows、mac 还有其他操作系统,windows又包含xp、2003等多种子系统。
根据这种关系联想,发现宇宙星系中也有类似的关系:宇宙中有很多星系,我们最为熟悉的是太阳系,太阳系中又包括各个行星,因此整体借用宇宙星系的场景,将熟知的windows比喻成太阳系,将xp、window7等比喻成太阳系中的行星,将mac和其他系统比喻成其他星系,表现如下:构建场景来呈现支付宝的年度账单中,在描述付款最多的三项时,构建了一个领奖台的形式:根据之前3步,可将指标、指标值和指标关系分别进行图形化处理。
以最简单的性别分布为例,可以得到一个线性的可视化过程,如下:4.将时间和空间可视化时间通过时间的维度来查看指标值的变化情况,一般通过增加时间轴的形式,也就是常见的趋势图。
前端开发技术中常见的数据可视化和图表展示方法

前端开发技术中常见的数据可视化和图表展示方法数据可视化在当今数字时代中扮演了重要的角色,不仅能够让数据更加直观、易懂,还可以帮助我们发现数据中的关联和趋势。
在前端开发技术中,有许多常见的数据可视化和图表展示方法,下面我们来一一介绍。
1. 折线图折线图是最常见的数据可视化方式之一。
它基于坐标系来展示数据的变化趋势。
通过连接各个数据点,我们可以清晰地看到数据的波动情况。
折线图通常用于展示时间序列数据,比如股票走势、气温变化等。
2. 柱状图柱状图通过不同长度或高度的柱子来表示数据的数量或比较不同类别的数据。
比如,我们可以使用柱状图来展示销售额的变化,或者比较不同地区的人口数量。
柱状图简洁明了,容易理解,适用于各种类型的数据。
3. 饼状图饼状图通过不同扇区的面积来表示数据的比例关系。
通常用于展示占比情况,比如各个国家的人口比例、不同类别产品的销售占比等。
饼状图直观,能够清楚地展示数据的组成,但不适合展示大量的数据。
4. 散点图散点图用于展示两个变量之间的关系。
通过在坐标系中绘制数据点,我们可以直观地分析变量之间的相关性。
散点图常用于探索数据之间的关联性,并能发现异常值。
5. 热力图热力图利用颜色的深浅来展示数据的密度。
通过在二维平面上将数据点映射为一个颜色值,我们可以直观地发现数据的分布情况。
热力图常用于展示地理数据,比如人口分布、犯罪率等。
6. 树状图树状图以树形结构展示数据之间的层次关系。
通过连接不同的节点,我们可以清晰地展示数据的组织结构。
树状图适用于展示部门架构、文件目录等。
7. 仪表盘仪表盘是一种常见的实时数据展示方式。
通过模拟仪器上的指针指示器,我们可以直观地展示数据的值,并实时更新。
仪表盘常用于展示工厂设备的运行状态、车辆的速度、能源消耗等。
除了以上常见的数据可视化方式,还有许多其他方法可以用于展示数据。
不同的场景和需求可能需要不同的可视化方式。
在选择合适的数据可视化方案时,我们需要考虑数据的特点、目标受众以及展示的目的等。
查询树状结构的数据显示形式

查询树状结构的数据显示形式
树状结构的数据显示形式是一种用于展示层级关系的数据结构。
在计算机科学和信息技术领域中,树状结构常用于表示组织结构、
文件系统、网站导航等具有层级关系的数据。
在树状结构中,顶层的节点称为根节点,它可以有零个或多个
子节点,每个子节点又可以有自己的子节点,以此类推,形成了树
状的层级结构。
树状结构的数据显示形式通常使用图形或者文本来
呈现。
在图形显示形式中,树状结构常呈现为一个根节点连接着多个
子节点的图形,通常使用圆圈或者方框来表示节点,用线条连接节
点之间的关系。
这种形式直观清晰,能够直观展现数据的层级结构。
在文本显示形式中,树状结构通常以缩进的方式来表示层级关系,每一层的缩进代表着不同的层级。
例如,可以使用缩进来表示
不同层级的节点,或者使用特定的符号(如"+"、"-"、"|"等)来表
示层级关系。
此外,树状结构的数据显示形式还可以通过树状图、表格、
JSON格式等方式来展现。
树状图以图形的方式直观展示树状结构,表格则以表格的形式展示节点之间的关系,而JSON格式则以一种轻量级的数据交换格式来表示树状结构的数据。
总的来说,树状结构的数据显示形式可以通过图形、文本、树状图、表格、JSON格式等多种方式来展现,具体的形式取决于数据的特点和展示的需求。
大数据的数据可视化与报表分析

大数据的数据可视化与报表分析随着信息技术的迅猛发展,大数据时代已经来临。
大数据是指数据量巨大、类型多样、速度快的数据集合,它们的处理和分析对于企业和组织来说至关重要。
而数据可视化与报表分析作为大数据分析的重要环节,为决策者提供了直观的数据展示和深入分析的手段。
本文将探讨大数据的数据可视化和报表分析技术以及其在实际应用中的作用和价值。
一、大数据的数据可视化技术数据可视化是将抽象的数据通过图形、图表等形式呈现出来,以帮助用户更好地理解和分析数据。
在大数据时代,数据量庞大、复杂度高的特点使得传统的数据分析方法已经无法胜任,而数据可视化技术能够将大数据以直观、易懂的方式展现出来,助于用户发现数据中的规律和趋势。
1.1 图表可视化图表是数据可视化的常见形式,它可以将数据以各种图形的方式展示出来,如柱状图、折线图、饼图等。
这些图表能够直观地展现大数据中的变化和关联关系,帮助用户更好地理解数据背后的规律。
1.2 地理可视化地理可视化是将数据与地理空间信息相结合,通过地图等形式展示出来。
地理可视化能够将大数据中的地理分布和空间关系直观地展示出来,帮助用户对地理现象和趋势有更清晰的认识。
1.3 交互可视化交互可视化是指用户可以主动参与到数据的可视化展示中,通过交互操作对数据进行探索和分析。
交互可视化技术使用户能够根据自己的需求灵活地选择和控制数据的展示方式,提高数据分析的效率和准确性。
二、大数据的报表分析技术报表分析是将大数据以表格的形式进行整理和汇总,便于用户对数据进行系统分析和比较。
报表分析以结构化的方式呈现数据,能够清晰地展示数据之间的差异和关联。
2.1 汇总报表汇总报表是将大数据按照特定的维度进行分类汇总,以便于对数据进行全面的分析和比较。
汇总报表可以展示大数据中的总体情况和分部情况,帮助用户发现数据中的规律和异常。
2.2 数据透视表数据透视表是一种多维度的数据分析工具,能够通过灵活的数据筛选和维度选择,对大数据进行多维度的分析和对比。
数据分析的基本流程和方法

数据分析的基本流程和方法随着大数据时代的到来,数据分析逐渐成为了一项热门的技能和职业。
数据分析不仅可以帮助企业了解消费者的需求和市场动态,还可以帮助个人提高他们的决策能力。
然而,数据分析并不是仅仅收集数据,然后用图表展现数据分布的过程。
数据分析涉及到很多复杂的步骤和技术。
本文将系统地探讨数据分析的基本流程和方法。
一、确定问题和目标在开始数据分析之前,我们需要明确所面对的问题和目标。
这样我们才可以确定“为什么要收集这些数据”和“我们要从这些数据中获取什么样的信息”。
例如,如果你在经营一家餐厅,你需要收集哪些数据?你可以收集月度销售情况、顾客独立购买的频率、顾客是否回头、每个菜品的销售情况等等。
既然有了数据,你会如何利用这些数据?你可能希望通过分析销售情况,发现哪个菜品的销售增加或下降,以便作出调整。
你可能会使用独立购买频率的数据,发现多数顾客是在周末来餐厅用餐,因此你可以提高周末的服务水平。
你可能会使用回头顾客的数据,找出他们经常点什么菜品,这些数据可以帮助你针对顾客的口味来创新菜品。
二、确定数据类型和收集方法在确定问题和目标之后,我们就可以确定需要收集哪些数据了。
面对每一个问题和目标,数据类型和收集方法都可能会有所不同。
那么我们需要了解的数据类型是哪些?有哪些收集方法可以使用?数据类型通常可以分为定量数据和定性数据。
定量数据指的是数值型数据,例如数量、价格、时间等等。
定性数据则是非数值型数据,例如颜色、风格、口味等等。
在收集数据的时候,我们可以使用多种方法。
比较常见的收集方法包括:调查问卷、面试、实地观察、实验研究等等。
三、数据清洗和准备在收集数据之后,我们需要进行数据清洗和准备。
这个步骤非常重要,因为收集到的数据总会有一些噪声和无用信息。
因此我们需要对数据进行清理和整理,以便更好地分析和利用数据。
首先,我们需要检查数据的完整性和准确性。
我们需要检查数据中是否有缺失值、异常值、重复数据等等。
对于缺失值,我们需要决定是删除这些数据还是将其填补。
数据的整理与展示

数据的整理与展示数据在现代社会中起着重要作用,可以帮助我们了解问题、做出决策以及展示结果。
然而,数据本身并没有意义,只有经过整理和展示后,才能更加清晰地呈现出来。
本文将探讨数据的整理和展示方法,并介绍一些常见的数据可视化工具。
一、数据整理数据整理是指对原始数据进行清理、筛选和整合的过程,旨在提取出有用的信息并使其更易于理解和分析。
数据整理的步骤一般包括以下几个方面:1. 收集数据:收集相关的数据源,可以是调查问卷、数据库、网站等。
2. 清理数据:排除重复、缺失或错误的数据,确保数据的准确性和完整性。
3. 筛选数据:根据需求选择合适的数据,去除不必要的信息。
4. 整合数据:将不同数据源的数据进行整合,以便于分析和比较。
二、数据展示数据展示是将整理后的数据以直观、清晰的方式呈现给用户的过程。
通过数据展示,可以更好地传达信息、发现规律和趋势,并帮助用户做出决策。
以下是一些常用的数据展示方式:1. 表格:表格是一种简洁明了的展示方式,适用于呈现详细的数据。
可以使用Excel等工具创建表格,并添加合适的标题和标签,使数据更易于理解和比较。
2. 图表:图表通过图形的形式展示数据,可以更直观地呈现数据之间的关系和变化趋势。
常见的图表类型包括柱状图、折线图、饼图等,可以根据数据类型和目的选择合适的图表进行展示。
3. 地图:地图可以用来展示地理位置相关的数据,例如销售分布、人口密度等。
可以使用专业的地图绘制工具或在线地图平台创建地图,并将数据与地图相结合展示。
4. 数据可视化工具:除了传统的表格和图表,还可以使用数据可视化工具来展示数据。
这些工具通常提供多种图表类型、交互功能和数据过滤等高级功能,能够更好地满足用户的需求。
三、常见数据可视化工具1. Tableau:Tableau是一款功能强大、易于使用的数据可视化工具,支持多种图表类型和数据源。
用户可以通过拖拽和点击操作创建交互式的数据图表,并进行数据过滤和分析。
大数据的特征介绍大数据技术主要分为哪几部分

大数据的特征介绍大数据技术主要分为哪几部分大数据的特征介绍大数据技术主要分为三部分:数据存储与处理、数据分析与挖掘、数据可视化与应用。
一、数据存储与处理数据存储与处理是大数据技术中最基础的一部分。
在大数据环境下,海量数据的存储和访问是一个巨大的挑战。
因此,大数据技术需要使用高效的数据存储与处理方案。
1. 分布式存储分布式存储是大数据技术中的重要组成部分。
它可以将海量数据分散存储到多个节点中,在不同的物理机上进行存储,以实现数据的高可用性和扩展性。
2. 数据压缩与编码为了减少存储空间的占用和提高数据访问效率,大数据技术常常使用数据压缩和编码技术。
数据压缩可以减小数据的存储空间,编码可以提高数据的读写效率。
3. 数据清洗与预处理在大数据中,原始数据往往存在着各种噪声和错误。
大数据技术可以运用数据清洗和预处理方法,去除不规范的数据并且进行数据规范化处理,以提高数据质量和准确性。
二、数据分析与挖掘数据分析与挖掘是大数据技术中的核心部分。
通过对大数据的深入分析和挖掘,可以从中发现隐藏的模式和规律,为决策提供有力支持。
1. 数据挖掘算法数据挖掘算法是大数据技术中的重要组成部分。
它可以对海量的数据进行自动化的模式发现、分类和预测等操作。
常用的数据挖掘算法包括关联规则挖掘、聚类分析、分类算法等。
2. 机器学习机器学习是大数据分析中的重要技术手段。
它可以通过训练模型,从数据中学习出隐含的模式和规律,进而进行预测和决策。
常用的机器学习算法包括决策树、支持向量机、神经网络等。
三、数据可视化与应用数据可视化与应用是大数据技术中的关键环节。
通过将数据以直观、易懂的方式展现出来,可以更好地理解和分析数据,进而支持决策和应用开发。
1. 可视化工具可视化工具是大数据可视化的基础设施。
它可以将大量的数据以图表、图像等形式展示出来,提供直观的数据呈现方式。
常用的可视化工具包括Tableau、D3.js等。
2. 应用开发大数据技术不仅仅是为了对数据进行分析和挖掘,还可以应用在各种领域中。
数据运用知识点归纳总结

数据运用知识点归纳总结数据在当今社会已经成为一种非常重要的资源,几乎所有的行业都在利用数据来做决策、分析和预测。
数据运用的知识点涵盖了数据的收集、清洗、存储、分析和可视化等方面。
本文将针对数据运用的知识点进行归纳总结,包括数据的基本概念、数据分析方法、数据存储技术、数据可视化等内容。
一、数据的基本概念1.1 数据的定义和类型数据是描述客观事物的符号,可以是文字、数字、图片、声音等形式。
根据数据的来源和特点,可以将数据分为结构化数据和非结构化数据。
结构化数据是指具有固定格式和结构的数据,比如数据库中的表格数据;非结构化数据是指没有固定格式和结构的数据,比如文本、图片、视频等。
1.2 数据的采集和清洗数据的采集是指从各种来源获取原始数据的过程,可以通过传感器、日志文件、调查问卷等方式进行采集。
数据清洗是指对原始数据进行处理,包括去除重复数据、填补缺失值、去除异常值等操作,以确保数据的质量和准确性。
1.3 数据的分析和应用数据的分析是指对数据进行挖掘和发现隐藏的规律和趋势的过程,可以使用统计分析、机器学习、深度学习等方法进行分析。
数据的应用是指将分析的结果应用到实际业务中,比如做决策、预测未来趋势、优化产品设计等。
二、数据分析方法2.1 统计分析统计分析是通过统计学方法对数据进行描述、分析和解释的过程,包括描述统计、推断统计等方法。
常用的统计分析方法包括平均值、中位数、标准差、相关系数、回归分析等。
2.2 机器学习机器学习是一种通过训练模型从数据中学习规律并做出预测的方法,包括监督学习、无监督学习、半监督学习和强化学习等。
常用的机器学习算法包括线性回归、逻辑回归、决策树、随机森林、支持向量机、神经网络等。
2.3 深度学习深度学习是一种通过多层神经网络学习特征并做出预测的方法,可以应用于图像识别、语音识别、自然语言处理等领域。
常用的深度学习模型包括卷积神经网络、循环神经网络、自编码器、生成对抗网络等。
三、数据存储技术3.1 数据库数据库是一种用于存储和管理数据的系统,可以分为关系型数据库和非关系型数据库。
element的table树形表格

让我们来措辞解释一下什么是element的table树形表格。
element是一款基于Vue.js的桌面端组件库,其中的table树形表格是一种展示数据结构的方式,可以更清晰地呈现出数据之间的层级关系和结构。
在实际应用中,table树形表格通常被用来展示具有层级关系的数据,比如组织架构、目录结构、分类信息等。
它将数据以树状结构的方式呈现出来,方便用户一目了然地了解数据之间的层级关系,对于理解和分析数据非常有帮助。
当我们谈到element的table树形表格时,我们不仅仅是在谈论它的外观和呈现方式,更重要的是要思考它在数据展现和分析方面的实际应用。
在实际项目中,我们通常会遇到需要展示层级关系数据的情况,而table树形表格正是为了解决这类问题而诞生的。
它可以帮助我们更清晰地展示出数据的层级关系,提高数据的可读性和易理解性,从而为用户带来更好的使用体验。
那么,为什么要选择使用element的table树形表格呢?它能够更直观地展现数据的层级结构,直观地展现数据之间的关系;它提供了丰富多样的功能和样式定制选项,可以根据实际需求进行定制化展示;它易于使用和集成,可以很方便地在Vue.js项目中使用,提高开发效率。
我们也要看到element的table树形表格并非完美无缺,它也存在一些局限性。
比如在大数据量的情况下,性能可能会受到一定影响;另外,一些特定的样式和展示效果可能需要自行实现。
针对以上观点,我们应该怎样正确地使用和理解element的table树形表格呢?我们应该在实际项目中合理运用它,根据实际情况选择合适的展现方式和样式;我们应该结合自身项目特点,对table树形表格进行适度定制,以满足项目需求,并提高用户体验;我们应该理性看待它的局限性,当数据量过大或者需要特殊展现效果时,应该考虑其他解决方案。
element的table树形表格作为一种展现数据层级关系的方式,具有很强的实用性和适用性。
在正确理解和使用的前提下,它能够为我们的项目带来更好的展现效果和用户体验。
treetable重载方法

treetable重载方法随着互联网和大数据时代的到来,数据的组织和展示变得愈发重要。
treetable作为一种常用的数据展示方式,被广泛应用于各种软件系统中。
而在使用过程中,我们常常需要对treetable进行一些定制化的操作和展示效果。
这时,treetable的重载方法就显得尤为重要。
一、treetable的基本概念在介绍treetable的重载方法之前,我们先来了解一下treetable 的基本概念。
treetable是一种将表格和树形结构相结合的数据展示方式,可以展示多层级的数据关系,并具备表格的排序、筛选和分页等功能。
通常情况下,treetable的第一列是用来展示树形结构的,后续列则用来展示具体的数据。
二、treetable的重载方法1. 表头重载:treetable的表头是展示列名的地方,我们可以通过重载表头的方式来定制列的样式和功能。
比如,可以通过重载表头的样式来改变列的宽度、高度、对齐方式等;还可以通过重载表头的功能来添加排序按钮、筛选框等。
2. 表格内容重载:treetable的表格内容是展示具体数据的地方,我们可以通过重载表格内容的方式来定制每个单元格的样式和内容。
比如,可以通过重载表格内容的样式来改变单元格的背景色、字体颜色等;还可以通过重载表格内容的内容来展示复杂的数据结构,如图片、链接等。
3. 树形结构重载:treetable的树形结构是展示数据层级关系的地方,我们可以通过重载树形结构的方式来定制每个节点的样式和展开/折叠状态。
比如,可以通过重载树形结构的样式来改变节点的图标、字体等;还可以通过重载树形结构的展开/折叠状态来控制节点的显示与隐藏。
4. 数据加载重载:treetable的数据加载是展示数据内容的关键,我们可以通过重载数据加载的方式来定制数据的加载方式和效果。
比如,可以通过重载数据加载的方式来实现懒加载,即只加载当前可见区域的数据;还可以通过重载数据加载的效果来展示加载中的动画或提示信息。
供应链管理赛题第5套

供应链管理赛题第5套一、单选题(每小题 2 分,共 30 道,共 60 分)1.基于采购订单跟进含义的说法,以下正确的是()。
[单选题] *○A.在订单发出后,采购员需要跟踪每个订单的所有过程,以保证完成企业规定的以及自购的订单跟踪任务○B.订单发出后采购专员不需要跟踪整个过程直至收获入库○C.采购专员不需完成企业规定的以及自购的订单跟踪任务○D.采购订单的取消、违反合同及其他未规定处理规范的问题的处理方案由相关权限审批人审批后方可执行2.采购订单异常的原因包括:仓库系统中库存数据的不准确、实际销售对比与预测失准、陈列变更引发订单量的变动、恶意订货、营销推广的影响、()。
[单选题] *○A.竞争品牌的销售量萎缩○B.竞争产品的质量○C.竞争产品的数量异常○D.竞争产品的预算过低3.回流物品尤其是危险性高的物品,如医疗垃圾、有毒的化学物品、生物实验室的废弃物等,必须保证运输和处理的()。
[单选题] *○A.稳定性○B.环保性○C.安全性○D.经济效益4.适用于常规订单,能够较为高效地处理订单审批流程的方法是()。
[单选题] *○A.传递评审法○B.会议评审法○C.授权评审法○D.直接评审法5.供应链结点企业产需率越接近 1,则说明()。
[单选题] *○A.企业综合管理水平低○B.下层结点企业准时交货率低○C.下层结点企业供需关系不协调○D.下层结点企业准时交货率高6.某航班的单程飞行的固定成本为 50000 元,可变成本为 100 元,单程机票售价为500 元,则盈亏平衡点的数量是( )。
[单选题] *○A.100 人○B.125 人○C.150 人○D.175 人7.影响物流业务外包选择的主要因素不包括()。
[单选题] *○A.物流业务技术含量○B.物流成本○C.管理水平○D.主管领导兴趣8.下列属于有效性供应链的特征的是() [单选题] *○A.配置多余的缓冲库存○B.采用模块化设计○C.绩效最大化.成本最小化○D.安排好零部件和成品的缓冲库存。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(10)申请公布号 CN 102999608 A(43)申请公布日 2013.03.27C N 102999608 A*CN102999608A*(21)申请号 201210477513.2(22)申请日 2012.11.21G06F 17/30(2006.01)(71)申请人用友软件股份有限公司地址100094 北京市海淀区北清路68号用友软件园(72)发明人高宁勃(74)专利代理机构北京友联知识产权代理事务所(普通合伙) 11343代理人尚志峰汪海屏(54)发明名称大数据的树表展现系统和树表展现方法(57)摘要本发明提供了一种大数据的树表展现系统,包括:数据展现单元,用于将大数据以树表形式进行展现;节点加载单元,用于在未感应到点击操作的情况下,仅加载所述树表中的根节点,并在感应到点击操作的情况下,对被点击的根节点的下一层级的关联数据进行加载和展现。
本发明还提出了一种大数据的树表展现方法。
通过本发明的技术方案,可以实现在对大数据进行树表展现时,对其中的节点数据进行异步加载,从而降低对网络速度的依赖,并利用分布式技术,提供了数据的客户端缓存机制,提升数据展现的流畅度。
(51)Int.Cl.权利要求书1页 说明书7页 附图3页(19)中华人民共和国国家知识产权局(12)发明专利申请权利要求书 1 页 说明书 7 页 附图 3 页1/1页1.一种大数据的树表展现系统,其特征在于,包括:数据展现单元,用于将大数据以树表形式进行展现;节点加载单元,用于在未感应到点击操作的情况下,仅加载所述树表中的根节点,并在感应到点击操作的情况下,对被点击的根节点的下一层级的关联数据进行加载和展现。
2.根据权利要求1所述的大数据的树表展现系统,其特征在于,还包括:监听控制单元,用于在首次感应到所述点击操作时添加监听器,以用于对后续发生的点击操作进行监听。
3.根据权利要求2所述的大数据的树表展现系统,其特征在于,所述节点加载单元还用于:确定所述后续发生的点击操作对应的节点,对该节点的下一层级的关联数据进行加载和展现。
4.根据权利要求1至3中任一项所述的大数据的树表展现系统,其特征在于,还包括:数据缓存单元,用于针对任意次发生的首次点击数据节点的操作,将对应加载的后继数据保存在客户端的缓存对象中,以用于当再次发生对该数据节点的点击操作时,直接从所述缓存对象中获取需要加载的后续数据。
5.根据权利要求1至3中任一项所述的大数据的树表展现系统,其特征在于,还包括:格式转换单元,用于针对任意次发生的首次点击数据节点的操作,将对应加载的后继数据转换为树表控件所识别的通用格式数据,以使加载的后继数据中的所有数据均被赋予新的标识位属性,并作为通用的数据源被所述树表控件进行加载。
6.一种大数据的树表展现方法,其特征在于,包括:步骤202,在将大数据以树表形式进行展现时,若未感应到点击操作,则仅加载其中的根节点;步骤204,根据感应到的点击操作,对被点击的根节点的下一层级的关联数据进行加载和展现。
7.根据权利要求6所述的大数据的树表展现方法,其特征在于,还包括:在首次感应到所述点击操作时添加监听器,以用于对后续发生的点击操作进行监听。
8.根据权利要求7所述的大数据的树表展现方法,其特征在于,还包括:确定所述后续发生的点击操作对应的节点,对该节点的下一层级的关联数据进行加载和展现。
9.根据权利要求6至8中任一项所述的大数据的树表展现方法,其特征在于,还包括:针对任意次发生的首次点击数据节点的操作,将对应加载的后继数据保存在客户端的缓存对象中,以用于当再次发生对该数据节点的点击操作时,直接从所述缓存对象中获取需要加载的后继数据。
10.根据权利要求6至8中任一项所述的大数据的树表展现方法,其特征在于,还包括:针对任意次发生的首次点击数据节点的操作,将对应加载的后继数据转换为树表控件所识别的通用格式数据,以使加载的后继数据中的所有数据均被赋予新的标识位属性,并作为通用的数据源被所述树表控件进行加载。
权 利 要 求 书CN 102999608 A大数据的树表展现系统和树表展现方法技术领域[0001] 本发明涉及数据处理技术领域,具体而言,涉及一种大数据的树表展现系统和一种大数据的树表展现方法。
背景技术[0002] 在网络和软件技术持续发展的情况下,应用数据也进入了大数据时代,从而催生了旨在增强用户体验、提高开发效率的大数据展示技术。
这些技术伴随着富客户端UI技术和软件分布式技术的发展而发展。
[0003] PLM(Product Life-Cycle Management,产品生命周期管理)作为一种技术将服务于多种行业,每个行业的产品门类众多,各不相同,即使是在同一个行业,不同企业之间的产品数据也不尽相同,呈现出不同行业、不同企业的多个业务数据和多条业务数据之间的业务关系链,这些业务数据和关系数据在实际业务中需要展现为树表样式。
[0004] 现有的UI控件中的树表控件只支持同步加载数据和简单的树的数据结构,一旦有大数据,网络传输就会很慢,用户的体验就会很差,PLM系统中的业务数据之间的业务关系链采用的是图的结构,而非树表结构。
[0005] 因此,需要一种新的大数据的树表展现技术,可以实现在对大数据进行树表展现时,对其中的节点数据进行异步加载,从而降低对网络速度的依赖,提升数据展现的流畅度。
发明内容[0006] 本发明正是基于上述问题,提出了一种新的大数据的树表展现技术,可以实现在对大数据进行树表展现时,对其中的节点数据进行异步加载,从而降低对网络速度的依赖,提升数据展现的流畅度。
[0007] 有鉴于此,本发明提出了一种大数据的树表展现系统,包括:数据展现单元,用于将大数据以树表形式进行展现;节点加载单元,用于在未感应到点击操作的情况下,仅加载所述树表中的根节点,并在感应到点击操作的情况下,对被点击的根节点的下一层级的关联数据进行加载和展现。
[0008] 在该技术方案中,当用户没有点击树表中的任意节点数据时,仅在树表结构中展现出根节点,而对于根节点的子节点或其他关联数据,则不进行加载,则这些根节点可以看做是一些“假”的节点。
而当用户针对某个根节点进行点击操作时,则说明用户对其子节点感兴趣,才对其子节点进行加载。
同时,针对用户的点击操作,仅展现当前根节点的下一层级的子节点,对于子节点的子节点,则不进行加载,因为用户可能并不一定感兴趣,从而加快系统响应速度,降低系统压力。
[0009] 在上述技术方案中,优选地,还包括:监听控制单元,用于在首次感应到所述点击操作时添加监听器,以用于对后续发生的点击操作进行监听。
[0010] 在该技术方案中,在用户首次点击树表上的根节点之后,就添加监听器,实现监听用户对树表进行的操作,以便对尚未加载的节点或其他数据进行异步加载,满足用户的查看或处理等操作。
[0011] 在上述技术方案中,优选地,所述节点加载单元还用于:确定所述后续发生的点击操作对应的节点,对该节点的下一层级的关联数据进行加载和展现。
[0012] 在该技术方案中,在用户对根节点(定义为第一层级)进行操作以展现出对应于该根节点的下一层级的节点(定义为第二层级)后,若用户继续对第二层级的节点进行点击等操作,才对第二层级的子节点(定义为第三层级)进行加载,若用户继续对第三层级的节点进行点击等操作,才对第三层级的子节点进行加载……由于每个节点下可能包含有数量众多的子节点等关联数据,而用户只可能对其中的某一个或几个感兴趣,因此,无需在首次生成树表或针对某一次用户操作就加载所有数据,而是针对用户的点击操作,仅加载对应的下一层级的关联数据,以供用户查看或继续操作。
通过上述异步加载方案,从而在网络环境不太好的情况下,也可以较为顺利地完成对树表的展现,并且有利于降低系统的处理压力。
[0013] 在上述技术方案中,优选地,还包括:数据缓存单元,用于针对任意次发生的首次点击数据节点的操作,将对应加载的后继数据保存在客户端的缓存对象中,以用于当再次发生对该数据节点的点击操作时,直接从所述缓存对象中获取需要加载的后续数据。
[0014] 在该技术方案中,当对某个节点的下一层级的关联数据进行加载后,可以将数据进行缓存,则当用户再次点击时,无需实时下载数据,只需要直接从缓存中调用即可,从而加快响应速度、降低对网络资源的占用。
当用户关闭当前浏览树表的页面后,再对客户端的缓存对象进行清除。
[0015] 在上述技术方案中,优选地,还包括:格式转换单元,用于针对任意次发生的首次点击数据节点的操作,将对应加载的后继数据转换为树表控件所识别的通用格式数据,以使加载的后继数据中的所有数据均被赋予新的标识位属性,并作为通用的数据源被所述树表控件进行加载。
[0016] 在该技术方案中,对于某个节点的下一层级的关联数据中,往往存在多个相同的数据,通过对这些数据进行转换、添加不同的标识信息后,使得系统可以对这些数据进行区分,从而能够同时出现在树表中,而不会被自动筛除。
[0017] 根据本发明的又一方面,还提出了一种大数据的树表展现方法,包括:步骤202,在将大数据以树表形式进行展现时,若未感应到点击操作,则仅加载其中的根节点;步骤204,根据感应到的点击操作,对被点击的根节点的下一层级的关联数据进行加载和展现。
[0018] 在该技术方案中,当用户没有点击树表中的任意节点数据时,仅在树表结构中展现出根节点,而对于根节点的子节点或其他关联数据,则不进行加载,则这些根节点可以看做是一些“假”的节点。
而当用户针对某个根节点进行点击操作时,则说明用户对其子节点感兴趣,才对其子节点进行加载。
同时,针对用户的点击操作,仅展现当前根节点的下一层级的子节点,对于子节点的子节点,则不进行加载,因为用户可能并不一定感兴趣,从而加快系统响应速度,降低系统压力。
[0019] 在上述技术方案中,优选地,还包括:在首次感应到所述点击操作时添加监听器,以用于对后续发生的点击操作进行监听。
[0020] 在该技术方案中,在用户首次点击树表上的根节点之后,就添加监听器,实现监听用户对树表进行的操作,以便对尚未加载的节点或其他数据进行异步加载,满足用户的查看或处理等操作。
[0021] 在上述技术方案中,优选地,还包括:确定所述后续发生的点击操作对应的节点,对该节点的下一层级的关联数据进行加载和展现。
[0022] 在该技术方案中,在用户对根节点(定义为第一层级)进行操作以展现出对应于该根节点的下一层级的节点(定义为第二层级)后,若用户继续对第二层级的节点进行点击等操作,才对第二层级的子节点(定义为第三层级)进行加载,若用户继续对第三层级的节点进行点击等操作,才对第三层级的子节点进行加载……由于每个节点下可能包含有数量众多的子节点等关联数据,而用户只可能对其中的某一个或几个感兴趣,因此,无需在首次生成树表或针对某一次用户操作就加载所有数据,而是针对用户的点击操作,仅加载对应的下一层级的关联数据,以供用户查看或继续操作。