DEA-SOLVER-LV(V3)
DEA视窗分析在技术创新效率评价中的应用

DEA视窗分析在技术创新效率评价中的应用作者:罗玲张祥翠朱乐君来源:《商场现代化》2009年第35期[摘要] 本文对DEA视窗分析模型进行了介绍,并将其运用于东北三省技术创新效率评价研究。
[关键词] DEA 视窗分析 window analysis 技术创新效率一、引言数据包络分析(Data Envelopment Analysis,简称DEA)是一种非参数前沿分析方法,可以用来评价具有多项投入与多项产出决策单元(Decision Maker Unit,简称DMU)的相对效率。
由于其具有可评价多指标投入产出效率、无需事先对指标量纲进行处理以及无需事先预设具体的函数关系和权重等优点,成为一种应用非常广泛的效率评价方法。
已经有许多学者将DEA方法应用于技术创新效率评价研究。
但是传统DEA方法在应用时,要求受评价的DMU数量要足够多,至少为变量(投入指标和产出指标)总数两倍以上,否则会出现大部分甚至全部DMU效率得分均为1(即有效率)的情况,使效率评价失去了意义。
此外,传统DEA方法只能用来分析横截面数据,让给定DMU与同一时间点上的其他DMU比较,忽略了时间的作用。
这样做并不合理,因为在某一时期内,某种资源的过多投入,导致当期效率得分较低,但却可能会对未来时期的产出产生正面影响。
DEA视窗分析(Windows Analysis)采用面板数据,将不同时期的同一DMU视为不同单元,从而增加了受评价的DMU数量,不仅能够对不同DMU之间的相对效率进行评价,而且还能够反映DMU的效率变化情况,从而解决了上述问题。
二、DEA视窗分析DEA视窗分析由G. Klopp(1985)首先提出,其基本思想是从动态角度出发,认为同一DMU在不同时期是不同的,与统计学中常用的平滑指数类似,能反映出投入与产出之间的时间连续性,可以较好地刻画研究对象的效率动态变化。
这样,对特定的DMU来说,在横截面上要同其它DMU进行比较,在时间序列上,同一DMU在不同时点上也要进行比较,因而更能反映DMU的真实效率。
三阶段DEA模型理论与操作步骤详解——02三阶段DEA模型理论与操作手册高清视频讲解每

三阶段DEA 模型理论与操作步骤详解1 三阶段DEA 模型 1.1 发展渊源Fried(1999,20××)指出传统DEA 模型没有考虑环境因素和随机噪声对决策单元效率评价的影响,其先后发表的两篇文章《Incorporating the Operating Environment Into a Nonparametric Measure of Technical Efficiency 》、《Accounting for Environmental Effects and Statistical Noise in Data Envelopment Analysis 》就探讨了如何将环境因素和随机噪声引入DEA 模型。
其中,前一篇论文仅剔除了环境因素,而后一篇论文同时考虑了环境因素和随机噪声,在国内被称为三阶段DEA 模型。
所谓的三阶段,关键在于第二阶段如何剔除环境因素和随机噪声。
国内学者关于该模型的介绍最早出现在20××年,随后有关该模型运用的论文开始大量出现。
在模型运用中也存在着大量的分歧,在后文我们将详细分析。
下面,我们详细分解三阶段的每一个阶段。
1.2 三阶段DEA 模型理论1.2.1 第一阶段:传统DEA 模型分析初始效率1978年由著名的运筹学家 A.Charnes(查恩斯), W.W.Cooper(库伯), 及E.Rhodes(罗兹)首先提出了一个被称为数据包络分析(Data Envelopment analysis, 简称DEA 模型)的方法,用于评价相同部门间的相对有效性(因此被称为DEA 有效)。
他们的第一个模型被命名为插入C 2R 模型。
从生产函数的角度看,这一模型是用来研究具有多个输入,特别是具有多个输出的“生产部门”同时为“规模有效”与“技术有效”的十分理想且卓有成效的方法。
在第一阶段,我们使用原始投入产出数据进行初始效率评价。
DEA 模型分为投入导向和产出导向的,根据具体的分析目的,可以选择不同的导向。
针对路面建模的Delaunay三角网格分治算法

的D e l a u n a y三角网分治算 法的差别 主要体 现在数据 划分 上 ,
作者简 介 : 刘 洋( 1 9 9 2 一 ) , 男, 硕士研究 生 , 主要研 究方 向: 虚拟现
为 了保证算法 的效率 , 使用 D C E L数 据结构保 存生 成 的三 角
网, D C E L边 由 2个半 边组成 , 一 个半边 保存该 边 的起点 , 连 同分别指 向下一条和上一条边 的指针 。这种数据结构寻找一
如下结果 : E =A x d+ , , d+ d+D 位置关系。 ( 3 )
其 中, E的正负代表 了 d 与。 、 b 、 c 构成 的平面相对 的 假设 o 、 b 、 c 三 点 的 坐 标 分 别 为 ( , Y 。 , ) ,( , Y ,
) ,( , Y , ) 。n 、 b 、 c 所在平面 的计算公式 为 :
生成一条边 ; 如果点数为 3 , 3 个点生成一个互相连接三角形 。
4 ) 如果 V R中的点数大 于 3 , 重复 2 ) ; 如果 点数为 2 , 2个 点生成一条边 ; 如果点数为 3 , 3 个点生成一个互相连接三角形。 5 ) 合并点集 V L和 V R 。
第 7卷
第2 期
智
能 计算机与应 Nhomakorabea用
Vo 1 . 7 No . 2
Ap r . 2 01 7
2 0 1 7年 4月
I nt e l l i g e n t Co mp u t e r a n d Ap p l i c a t i o n s
针对 路 面 建模 的 D e l a u n a y三 角 网格 分 治 算 法
治算法在路面三维建模领域的效果 。
股票数据筛选2000-2008标准化横好WSIVxin

流动资产 固定资产 管理费用 财务费用 支付职工 支付税费 利润总额 净利润
流动资产 1 0.49239 0.411373 0.874788 0.595121 0.501663 0.210599 0.108087
固定资产 0.49239 1 0.398248 0.738511 0.571539 0.517447 0.404234 0.234863
财务费用 0.290741 0.683915 0.482267 1 0.377995 0.412891
支付职工 0.567062 0.417927 0.903853 0.377995 1 0.908094
支付税费 0.50523 0.385095 0.841008 0.412891 0.908094 1
Workbook Name = C:\Documents and Settings\Administrator\桌面\股票数据筛选2000-2008标准化横 Data File = C:\Documents and Settings\Administrator\桌面\股票数据筛选2000-2008标准化横好WS DEA model = DEA-Solver LV3.0/ Window(Window-I-C) Problem = No. of DMUs = 17 No. of Input items = 6 Input(1) = 流动资产 Input(2) = 固定资产 Input(3) = 管理费用 Input(4) = 财务费用 Input(5) = 支付职工 Input(6) = 支付税费 No. of Output items = 2 Output(1) = 利润总额 Output(2) = 净利润 No. of Time periods = 9 Time period(1) = 2000 Time period(2) = 2001 Time period(3) = 2002 Time period(4) = 2003 Time period(5) = 2004 Time period(6) = 2005 Time period(7) = 2006 Time period(8) = 2007 Time period(9) = 2008 Returns to Scale = Constant (0 =< Sum of Lambda < Infinity) Statistics on Input/Output Data Time period = 2000 流动资产 固定资产 管理费用 财务费用 支付职工 支付税费 利润总额 净利润 Max 1000 1000 1000 1000 1000 1000 1000 1000 Min 100 100 100 100 100 100 100 100 Average 459.8309 242.802 402.5494 379.1854 395.1698 321.7138 436.9048 427.5213 SD 289.6091 206.6733 248.4191 264.9384 250.0743 224.1104 275.4639 278.4314 Correlation (Time 流动资产 流动资产 1 固定资产 0.363011 管理费用 0.738566 财务费用 0.290741 支付职工 0.567062 支付税费 0.50523 period = 固定资产 0.363011 1 0.44794 0.683915 0.417927 0.385095 2000) 管理费用 0.738566 0.44794 1 0.482267 0.903853 0.841008
基于DEA-Tobit二阶段法的城市商业银行效率评价——以中部六省9家城市商业银行为例

基于DEA-Tobit二阶段法的城市商业银行效率评价——以中部六省9家城市商业银行为例何意雄;蒋芳【摘要】For simplified methods and few regionalization research of evaluation on efficiency of city commercial banks, the paper evaluates its efficiency of the six provinces of central China using super efficiency model of data envelopment analysis (DEA).The results are analyzed further in projection, and the Tobit model is applied to analyze the factors affecting efficiency.The results of the study show that per capita operating expenses and Loan-to-deposit ratio are both negatively related to the efficiency of these banks while capital adequacy ratio is positively related to efficiency.%针对我国城市商业银行效率评价方法单一且区域化研究较少的问题,利用数据包络分析超效率模型对中部六省城市商业银行经营效率进行了评价,对其结果进行了进一步的投影分析,并在此基础上,运用Tobit模型分析了银行效率的影响因素.实证结果表明,人均营业费用和存贷比与银行经营效率成负相关,资本充足率与银行经营效率成正相关.【期刊名称】《科技和产业》【年(卷),期】2016(016)011【总页数】8页(P151-158)【关键词】城市商业银行;银行经营效率;数据包络分析;投影;Tobit回归【作者】何意雄;蒋芳【作者单位】南昌大学经济管理学院, 南昌 330031;南昌大学经济管理学院, 南昌330031【正文语种】中文【中图分类】F830城市商业银行已成为继五大商业银行和12家全国性股份制商业银行后我国银行业的第三梯队。
ANSYS命令解释(入门级学习必备)

ANSYS命令解释(入门级学习必备)编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(ANSYS命令解释(入门级学习必备))的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为ANSYS命令解释(入门级学习必备)的全部内容。
ANSYS命令集/EXIT,Slab,Fname,Ext,Dir Slab=ALL 保存所有资料Slab=NOSAVE所有更改资料不保存Slab=MODEL保存实体模型,有限元模型,负载的资料(系统默认)例:/EXIT,ALL ——————-———-—-—-—-—-—-——-----—---——---------—-------——-—-/FILNAM,Fname Fname=工作文件名称,不要扩展名例:/FILNAM,Sanpangzi—-—--—-———-——-——---———--—------—-—-----—---—-———-———————/SAVE,Fname,Ext,Dir 保存目前所有的Datebase资料,即更新Jobname.db——————--—--——--—--—-——-——-—----———-—————-——-——---—--——--/RESUME,Fname,Ext,Dir,NOPAR 回到最后SAVE时的Datebase状态—--——--—-----—-—-—-----———-----——--——-———----—-———-—----/CLEAR 清除所有Datebase资料---------—-———-—--—-—-—-——-—————-—---——-———-——-—--—-————LOCAL,KCN,KCS,XC,YC,ZC,THXY,THYZ,THZX,PAR1,PAR2定义区域坐标系统KCN 区域坐标系统代号,大于10的任何号码KCS=0,1,20=笛卡儿坐标 1=圆柱坐标 2=球面坐标XC,YC,ZC 该区域坐标原点与整体坐标原点的关系THXY,THYZ,THZX 该区域坐标与整体坐标XYZ轴的关系例:LOCAL,11,1,1,1,0———-----———--——-——-—--————--—-—--—--——-———————--——--—-—-CSYS,0,1,2声明当前坐标系统例:CSYS,0—--———----—————-----———---------—————---———-———-—--——--—/UNITS,LABEL 声明系统分析时所用的单位LABEL=SI (米,千克,秒)LABEL=CGS (厘米,克,秒)LABEL=BFT (英尺)LABEL=BIN (英寸)例:LABEL,SI—-—-——--———--—-—-—-—-—------——-—-—-———-—————-—-————-———-/PREP7进入通用前处理器-—----——————--—-—-——---—-——-———————---——--———-———--—————N,NODE,X,Y,Z,THXY,THYZ,THZX 定义节点NODE 节点号码 X,Y,Z 节点在当前坐标系中位置例:N,1,2,3,4--—--——-—-------—————-———————-—-—-—-———-—-————-—-—-——-—-NDELE,NODE1,NODE2,NINC 删除已建立的节点NODE1,NODE2 删除从NODE1到NODE2的节点,如1到100NINC 间隔号码,1为1到100全删,2为1,3,5... (99)例:NDELE,1,100,2-——----—--—-——---—--——-———————-——-—--——-—-———-----—--—-—NPLOT,KNUM 将节点显示在图形窗口中KNUM=0不显示节点号码KNUM=1显示节点号码——-----------—--———---—--———--———--——---——————-——---———-NLIST,NODE1,NODE2,NINC将节点资料列在窗口中例:NLIST--——--——-——————--—--—--——--——---——-—---—-—-—-—--—-——--—-NGEN,ITIME,INC,NODE1,NODE2,NINC,DX,DY,DZ,SPACE 复制节点ITIME 复制次数,包括本身INC复制时节点号码增量NODE1,NODE2,NINC 要复制的节点DX,DY,DZ 复制出的节点的位置改变量例:NGEN,4,5,1,5,1,1,2,3 将节点1到5复制4次,每次复制X,Y,Z方向分别移动1,2,3单位长度——--—--—————-———-——-——-----———-—-—--————-—-——--—---—-—--FILL,ITIME,INC,NODE1,NODE2,NINC,DX,DY,DZ,SPACE 填充节点(默认为均分填充)例:FILL,1,100 在节点1到100之间填充2,3... (99)——-—-—-————--—-————-————-—---——-———-————--——---—-—----——ET,ITYPE,Ename,KOPT1… …KOPT6,INOPR 定义元素ITYPE 元素类型编号Ename 所使用元素名称KOPT1—KOPT6 元素特性编码例:ET,1,LINK1 第1类元素为LINK1单元———-—---—---—-—-——-——————---—--——-—-—-————--—-——--———--—MP,Lab,MAT,C0,C1,C2,C3,C4 定义材料特性材料特性为固定值,其值为C0材料特性随温度变化,由C1-C4控制Lab 材料特性类别MAT 对应ET所定义的元素类型编号ITYPELab=EX,EY,EZ 杨氏系数Lab=DENS 密度Lab=PRXY,PRYZ,PRZX 泊松比Lab=GXY,GYZ,GZX 剪力模数例:MP,EX,1,207E9 第一类元素的杨氏系数为207E9——————--—-————-—-—-—----—----—-——-———-—-——--—--——-————-—R,NSET,R1… …R6 定义元素类型几何特性NSET 属性组别号码(系统默认值1)R1—R6所定义元素类型几何特性值例:R,1,1E—4,2。
多变量无约束优化牛顿法python代码

多变量无约束优化牛顿法python代码多变量无约束优化牛顿法是一种常用的数学优化算法,在机器学习、数据分析、统计学等领域广泛应用。
本文将介绍多变量无约束优化牛顿法的基本原理,并提供Python代码实现。
牛顿法是一种求解非线性方程和最优化问题的迭代方法。
它利用函数的二阶导数信息来确定函数的极值点。
对于多变量无约束优化问题,牛顿法的迭代公式为:x_{k+1} = x_k - H(f(x_k))^{-1}abla f(x_k)其中,x_k 是第k次迭代的值,H(f(x_k)) 是函数f在x_k处的Hessian矩阵,abla f(x_k) 是函数f在x_k处的梯度向量。
以下是使用Python实现多变量无约束优化牛顿法的代码:```pythonimport numpy as npdef newton_opt(f, f_grad, f_hess, x0, tol=1e-6,max_iter=100):'''多变量无约束优化牛顿法:param f: 目标函数:param f_grad: 目标函数的梯度:param f_hess: 目标函数的Hessian矩阵:param x0: 初始点:param tol: 迭代停止条件:param max_iter: 最大迭代次数:return: 迭代结果'''x = x0for i in range(max_iter):g = f_grad(x)H = f_hess(x)dx = np.linalg.solve(H, -g)x += dxif np.linalg.norm(dx) < tol:breakreturn x```其中,f_grad(x) 和 f_hess(x) 分别是目标函数f在点x处的梯度向量和Hessian矩阵。
np.linalg.solve(H, -g) 是用于求解线性方程组的函数,用于计算牛顿法中的方向dx。
(完整word版)DEA-solver软件操作中文版

B.5.1 CCR, BCC, IRS, DRS, GRS, SBM, Super-Efficinecy, Scale Elasticity, Congestion
和FDH 模型表B.1是这些模型输入数据的例子
1.第一行
第一行是变量的名称,例如A1是我们研究问题的名称(医院),B1是投入变量(医
生),C1是投入变量(护士),D1是产出变量(门诊病人),E1是产出变量(门诊病
人)。
需要注意的是,投入变量(I)和产出变量(O)必须得在变量名称前加I或者O,否则系
统将不识别。
2.第二行及之后行
第二行表示第一个DMU的名称以及投入变量和产出变量的值,第三行往后以此类
推。
3.数据的范围
数据集应该从A1单元往右往下扩展。
4.数据表名称
不要用"Score","Rank", "Projection", "Weight", "WeightedData", "Slack", "RTS", "Window","Decomposition, "Graphl" and "Graph2"这些名称,因为软件中这些名称已
被命名含有不同含义。
表B.1
B.5.13 坏产出(非期望产出)模型
在原始的投入(I)和产出(O)中加入坏(非期望)产出(OBad)。
如表 B.12所示,这个模型需要通过键盘输入两个供给;好产出的权重和坏产出的权重默认值都为 1.。
DEA软件使用说明

DEA软件使用说明
1、打开DEA-vsolver 5.0,点击“视图”—“宏”—“查看宏”,弹出如下对话框:
点击“执行”,弹出如下对话框:
2、点击“click here to start”,然后点击“ok”
3、选择CCR-I模型,如下图所示:
4、选择“ok”,弹出文件选择框,导入要计算的excel基础数据表
然后点击“打开”,弹出如下对话框,点击“OK”。
5、此时弹出如下对话框,该对话框表示:选择DEA运行结果的保存路径及文件名,如果选择桌面,文件名为“效率值”,则会在桌面生成excel文件效率值,即DEA的运营结果。
6、选择好路径以及输入要保存的文件名后,点击“保存”,弹出如下对话框:
7、最后点击“run”,软件将自动测算并在第5步中选择的路径处生成名为相应的excel文件。
注意事项
1、上述第4步中:导入要计算的excel基础数据表,该表只能有一个sheet,excel的指标名称格式必须如下:(I)表示投入指标,(O)表示产出指标。
A列本地网的名字无要求,可以随意起名。
2、结果说明:生成的excel文件有多个sheet,sheet“score”中即包含各本地网相对效率值以及排名。
DMU列为各个本地网的名字,SCORE为本地网的相对效率值,RANK为本地网的排名。
-----精心整理,希望对您有所帮助!。
DEA方法应用的若干思考

DEA方法应用的若干思考摘要:文章在dea模型及其主要参数分析的基础上,总结了dea 方法应用的10种经典模式,分析了dea方法应用的局限性和可能改进之处,进而提出了几种dea方法和其他定量分析方法的可能结合形式,为dea方法的科学应用与创新提供借鉴。
关键词:dea方法;dea应用;局限性一、引言数据包络分析(data envelopment analysis,dea)方法是a. charnes和w. w. cooper等(1978)以相对效率为基础,针对多个被评价单位的多指标投入与产出关系而进行相对有效性评价的一种系统分析方法。
自第一个dea模型提出以来,该方法就以其处理多输入-多输出的相对有效性评价优势而在各不同领域得到广泛应用,并得以不断改进完善。
dea方法在不断的应用过程中,为了结合不同应用领域的特征以及满足决策者对评价信息的偏好与要求,dea方法应用呈现出诸多的模式。
当然,虽然dea方法不断成熟,但dea方法本身所固有的局限性却也在限制着dea模型的进一步发展,于是有学者在试图改进,有学者在试图与其他方法相结合。
为此,本文在对前人dea研究与应用模式进行概括总结的基础上,明晰dea模型的局限性和可能改进之处,并探索dea方法与其他方法的可能结合方式,以利于进一步完善和发展dea模型,并拓展dea方法的应用领域。
二、 dea模型及主要参数dea模型其实是一类有着西方经济学基础的线性规划运筹学模型,它的两个基本模型是ccr模型和bcc模型,ccr模型测量的是决策单元的整体效率,而bcc模型测量的仅是技术效率。
dea模型的基本形式如式(1):求解dea模型可采用excel、lingo、lindo、deap、dea-solver-lv 等软件,根据求解结果,一般可得到效率(综合效率、技术效率、规模效率)、规模收益情况、权重、松弛变量与剩余变量值、投影值等主要参数。
不同参数值能够反映出不同的信息,在管理决策中有着不同的功能,因此,其应用领域也有所不同:1. 效率。
DEAP使用方法

DEAP使用方法有时我们会用到DEAP软件,DEAP软件下载下来后没有安装文件,它是直接在deap.exe 文件中运行,如下为具体步骤:操作步骤资料档1.Excel编制,按照产出项,投入项,(要素价格)排列2.将Excel工作表→"另存新档"3.档案名称为"数字或英文字母"4.档案类型为"格式化文字(空白分隔)" →避免格式走调..5.再按"储存" →储存位置须在"DEAP资料夹"中6.储存后,副档名为.prn,再以笔记本的另存新档方式,将副档名改为.dta.7.最后用deap.exe文件运行,输入第6步新保存在DEAP文件夹中所保存的prn文件名,按ENTER。
运行后在DEAP文件夹中会出现两个新的文件,将其中一个不是Ok的文件以EXCELL方式打开既可。
参考.au/economics/cepa/software.htm另外在:http://140.127.10.252/blue_designing/html/Download.html 也有。
另外:DEAP软件的下载地址为:/2006/economic/article.php?articleid=515deap 2.1软件分析过程及结果解释:第一步,设置参数,变量及选定所用模型,下述:16为DMU个数,即总体样本个数;1为面板数据中的年限,如果做横截面数据,就写1,面板数据则写选取的时序个数(如年数);4,3分别为产出指标、投入指标个数(在编辑EG1。
DTA文件时,产出指标放前面);0表示选取的是投入主导型模型,1表示产出主导型,二者区别不大,关键结合问题选取,一般选投入主导型;crs表示不考虑规模收益的模型即C^2 R模型,vrs表示考虑规模收益模型即BC^2模型;最后是内部算法,一般选0就可以。
eg1.dta DA TA FILE NAMEeg1.out OUTPUT FILE NAME16 NUMBER OF FIRMS1 NUMBER OF TIME PERIODS4 NUMBER OF OUTPUTS3 NUMBER OF INPUTS0 0=INPUT AND 1=OUTPUT ORIENTATED1 0=CRS AND 1=VRS0 0=DEA(MULTI-STAGE), 1=COST-DEA, 2=MALMQUIST-DEA, 3=DEA(1-STAGE), 4=DEA(2-STAGE)第二步,结果解释:1、效率分析EFFICIENCY SUMMARY:firm crste vrste scale四列数据分别表示:firm样本次序;crste不考虑规模收益是的技术效率(综合效率);vrste 考虑规模收益时的技术效率(纯技术效率);scale考虑规模收益时的规模效率(规模效率),纯技术效率和规模效率是对综合效率的细分;最后有一列irs,---,drs,分别表示规模收益递增、不变、递减。
多变量无约束优化牛顿法python代码

多变量无约束优化牛顿法python代码本文将介绍多变量无约束优化的牛顿法,并提供Python代码实现。
牛顿法是一种求解优化问题的有效方法,其思想是通过二阶泰勒展开式来逼近函数的局部极值点。
在多变量无约束优化中,牛顿法的迭代公式为:x_{k+1} = x_k - [H_f(x_k)]^{-1}abla f(x_k)其中,x_k 是第 k 次迭代得到的结果,H_f(x_k) 是 f(x_k) 的Hessian 矩阵,abla f(x_k) 是 f(x_k) 的梯度向量。
下面是用Python实现多变量无约束优化牛顿法的代码:import numpy as npdef newton_method(f, df, ddf, x0, max_iter=1000,tol=1e-6):# f: 目标函数# df: 目标函数梯度# ddf: 目标函数Hessian矩阵# x0: 初始点# max_iter: 最大迭代次数# tol: 迭代收敛精度x = x0iter_num = 0while iter_num < max_iter:# 计算梯度和Hessian矩阵grad = df(x)hessian = ddf(x)# 利用牛顿法更新xx_new = x - np.linalg.inv(hessian).dot(grad)# 检查是否收敛if np.linalg.norm(x_new - x) < tol:breakx = x_newiter_num += 1return x_new, f(x_new), iter_num上述代码中,f, df, ddf 分别是目标函数、目标函数梯度和Hessian矩阵的计算函数,x0 是初始点,max_iter 和 tol 分别为最大迭代次数和迭代收敛精度。
函数返回最优解、最优值和迭代次数。
使用示例:# 目标函数: f(x) = x1^2 + x2^2def f(x):return x[0]**2 + x[1]**2# 目标函数梯度: df(x) = [2x1, 2x2]^Tdef df(x):return np.array([2*x[0], 2*x[1]])# 目标函数Hessian矩阵: ddf(x) = [[2, 0], [0, 2]]def ddf(x):return np.array([[2, 0], [0, 2]])# 初始点: x0 = [1, 1]x0 = np.array([1, 1])# 运行牛顿法优化x_opt, f_opt, iter_num = newton_method(f, df, ddf, x0) # 输出结果print('最优解: ', x_opt)print('最优值: ', f_opt)print('迭代次数: ', iter_num)运行结果:最优解: [-4.86462990e-09 -4.86462990e-09]最优值: 4.722586927883174e-17迭代次数: 4可以看到,牛顿法能够快速地找到函数的最优解,并且迭代次数很少。
约束满足问题求解及ILOGSOLVER系统简介

2002 年1 月N o . 1吉林大学学报(理学版)JO URN A L OF J I L I N U NI VERSITY ( S CIEN CE EDITI O N)第1 期2002201约束满足问题求解及I LO G SO LVER姜英新, 孙吉贵(吉林大学计算机科学与技术学院, 长春130012)系统简介提要: 首先综述求解约束满足问题的基本算法和搜索策略, 然后介绍I LO G SOLVER 求解系统提供的类和函数的基本组成, 并给出用该系统求解的两个地图着色示例.关键词: 约束满足问题; 约束求解; 搜索策略文章编号: 167125489 (2002) 0120053208 中图分类号: TP31文献标识码: A约束满足问题( C onstraint Satisfacti on Problem , CSP) 的应用面很广, 如调度中的资源分配问题、N 皇后问题、地图着色问题等. 使用约束满足的方法来求解问题是将该问题用一组变量和一组约束来表示.然后在满足所有约束的条件下给每个变量赋值, 如果最终每个变量都至少被赋了1 个值, 则说明这个问题可解; 否则, 说明该问题不可解.本文研究的约束满足问题指有限的约束满足问题. 在有些问题中, 变量可以有无限的域, 或者变量的集合可以根据其中一个变量取值的不同而动态改变. 通常认为, 在问题求解时加入特殊的领域知识可得到更好的效率. 例如, 在仔细地分析了N 皇后问题后, 人们可以得到一个解决它的非常有效的方法 1 ,2. 然而, 研究一般的算法更为重要.本文着重介绍求解约束满足问题的基本算法和搜索策略.1求解CSP 的基本搜索策略1. 1 普通搜索算法在约束满足问题中, 普通的搜索策略在求解问题时没有用到约束可以传播这一性质. 然而, 由于搜索空间的特性, 普通的搜索策略 3 可能比其它的方法更适用.BT 算法(回溯算法) : 其基本思想是每次给1 个变量赋1 个其论域中的任意值, 然后检查这个变量的值与前面变量被赋值的相容性. 如果不相容, 则该变量的值被从论域中删除并给这个变量赋另一个值, 继续测试与其它变量值的相容性, 重复该过程, 直到这个变量被赋的值与前面所有变量的值都相容或者这个变量的值都被测试完毕且均不相容为止. 若结果是后者, 则把该变量的前一个变量先前被赋的值删除, 并给其重新赋一个值, 这个动作称为回溯, 重复这个过程, 直到所有的变量都被赋值或不能再回溯(如, 第一个变量的所有值都被拒绝) 为止. 后者表示这个约束满足问题无解. 回溯搜索算法是人工智能一个基本的搜索算法, 这里不再给出算法的具体描述和操作实例 4 .在BT 算法中, 并没有尝试删除搜索空间的任何部分. 它是一个穷举搜索策略, 并且是完全的( 问题的所有解都能找到) 和可靠的(算法找到的所有解都能满足所有的约束) .I B (iterative broadening) 算法 5 : 该算法基本上是带一个宽度切割门限值b 的深度优先搜索算法. 设b 为当前的门限值, 如果搜索树中一个节点(变量) 被访问了b 次( 包括第一次被访问和回溯) , 则其下面的未被访问的子节点可忽略. 如果在当前的门限值下没有发现解, 则门限值逐步增加. 如果发现解或者门限b 的值大于等于搜索树中最大的分支数, 算法终止.收稿日期: 2001204220 .作者简介: 姜英新(1977~) , 女, 硕士研究生. 联系人: 孙吉贵(1962~) , 男, 教授, 博士生导师.基金项目: 国家自然科学基金(批准号: 60073039) 、教育部骨干教师基金和吉林省自然科学基金(批准号: 2000540) .1. 2 预测策略预测算法的基本策略: 一次只给1 个变量赋值, 为了减少搜索空间和检测不可满足性, 在每一步都化简问题.FC (forward checking) 算法(前向检查算法) : 该算法的过程基本和BT 算法相同, 除要求每个未被赋值的变量的论域中都至少有1 个值外, 这些值和所有被赋值的变量的值都相容. 为保证这点, 每次给1个变量赋值时, FC 算法均从未被赋值的变量论域中删去与当前变量值不相容的值. 如果有未被赋值变量的论域变成空, 则当前变量的这个值被拒绝. 否则, FC 算法将继续给未被赋值的变量赋值, 直到所有的变量都被赋值. 如果当前变量的所有值都被拒绝, 则回溯到前一个变量. 如果没有变量可被回溯,则说明问题不可解决.例1. 1 用8 皇后问题来演示FC 算法.图1 演示了已放置4 个皇后的情形(皇后用“# ”号表示) . “?”号表示该变量值与前4 个皇后的值冲突. 例如, 第五行第一列处是“?”号, 因为它与第一个皇后的值冲突. 从例1 . 1 可看出, 第四行第二列处不能放置皇后, 因为在其放置了皇后后, 第六行的所有值都与前面所赋的值产生冲突.1. 3 在搜索中搜集信息策略事实上, 因为搜索树中的兄弟子树在搜索空间上非常相似, 所以在搜索时允许我们从经验中学习.当要求回溯时, 可以分析失败的原因, 使得将来避免犯类似错误.B J (Back J um ping) 算法: B J 算法的过程和BT 算法除了处理回溯时的差异外相似. 每次给1 个变量赋值, 并保证变量被赋的值与前面的变量所赋的值相容. 如果变量无值可赋, 则发生回溯. 然而, 在需要回溯时, 用B J 算法分析并找到引起失败的变量( 称为罪犯, culprit) . 若当前变量的每个值都与前面某个变量的值冲突, 则回溯到最近的罪犯节点, 而不是只回溯到上一个节点.如果当前变量被曾经赋过值, 在发生回溯时, 只回溯到上一个节点.例1. 2 用8 皇后问题演示B J 算法.图2 演示了已经放置了5 个皇后的情形. 要放第六个皇后时, 发现它的每个值都产生冲突. 在第六个皇后的每个格(值) 中, 都写明了使这个值冲突的罪犯. 如对于{6 ,B}产生冲突的罪犯是皇后3 . B J 算法将回溯到最近的罪犯皇后4 , 而不是回溯到皇后5 .因为从图2 中可以发现, 即使改变皇后5 的值也不能解决冲突.约束满足问题的搜索次序2被处理变量的次序和变量论域中的值被赋给变量的次序的不同在很大程度上影响了搜索策略的效率.在预测算法中, 被处理变量次序的不同将影响搜索空间被减少的数量.2. 1 搜索中变量的次序2. 1 . 1 启发式最小宽度排序(MWO)可应用变量的最小宽度排序问题应有如下特点: 在问题中, 一些变量比其它变量被更多的变量约束. 启发式最小宽度排序的策略首先是将所有的变量进行总的排序, 并要求在该排序下有最小宽度. 然后根据此排序来处理变量, 即该策略是把被更少的变量约束的变量放在后面处理, 这样可能使得要求的回溯减少.对所有节点进行排序时, 节点v 的宽度是排在v 前面并且与节点v 临近的节点的数目.一个排序下的宽度是指在这个排序下所有节点的最大宽度. 一个图的宽度是指在所有排序下的最小宽度.例2. 1 用一个简单的例子来演示MWO.变量A , B , C 的域都是{ r , b} , 并且A ≠B , A ≠C. 以图3 所示的约束图为例. 如果变量被标定的顺序是( B , C , A) , 节点 B 和C 的取值有可能是〈B , r〉和〈C , b〉这时, A 的任何值都不能满足所有的约束. 所以, 要找到解, C的取值必须修订. 如果先给变量A 赋值, 则无论A 被赋什么值都不需要回溯. 仔细观察可以发现, 变量的顺序是( B , C , A ) 时, 该排序下宽度是2 ; 而排序( A , B , C) 和排序( B , A , C) 的宽度都是图3 要被搜索的约束图1 , 如图4 所示.实验表明, 用回溯算法( B T 算法)和前向检查算法( FC 算法) 求解该问题时, 变量的排序为( A , B , C) 时的搜索空间都比变量的排序为( B , C , A)时的搜索空间小.图4 排序与宽度的关系2. 1 . 2 最先失败原则( F FP)最先失败原则建议最可能引起失败的任务应最先执行. 其目的是为了尽早地发现失败, 这样可以节省搜索的开销.根据这个策略, 下一个要处理的对象应是在其上约束最多的变量. 一个简单的方法是测量变量的论域, 使得下一个要被处理变量的论域是最小的. 在简单的回溯算法中, 如BT 算法, 变量的论域是静态的. 因此, 应用FFP 意味着在搜索开始前, 将变量按照它们论域的大小以上升次序排列. 当FFP 和预测算法一起使用时, 变量的排序是动态的. 在给每个变量赋值以后, 传播约束, 然后比较所有未被赋值的变量的论域, 选择拥有最小论域的变量.2 . 1 .3 最大基数排序(MC O)最大基数排序策略可看成与最小宽度排序大致相同的策略, 可用下面方法实现: 首先, 任意选择一个节点作为这个排序的最后一个节点. 然后, 在所有未被排序的节点中, 选择与排序节点相邻的数目最多的节点, 并把该节点作为这个排序中的倒数第二个节点. 如果与排序的节点相邻数最多的节点不止1 个, 则任选其一. 重复上述过程, 直到所有节点都被排序, 就可得到一个最大基数排序; 若将该排序顺序颠倒, 则得到一个新的排序. 新排序的宽度很小.例2. 2 用约束图5 显示一个给定的例子, 找到它的一个最大基数排序的步骤.首先, 任选节点 A , 在 A 被选后( 即现排序中只有节点A) , 节点B , C , F 都与节点A 相邻, 可以在和A 相邻节点中任选一个节点B ( C 或F) 进行排序.得到的最大基数排序是( G , F , E , D , C , B , A) ,其宽度为4 , 如图6 所示. 若将该排序的顺序颠倒,则可得到一个新的排序( A , B , C , D , E , F , G) , 它的宽度为2 , 如图7 所示.图5 给定一个约束图2. 2 搜索中值的排序2. 2. 1 基本原理当选择下一个要被处理的变量时, 应选择约束最多的变量. 因为, 如果能确定该变量产生冲突, 其它变量则不需测试. 如果要给1 个变量选择1 个值, 则应选择最可能成功的值.这样可以减少回溯, 因为如果失败发生就可能产生回溯.在值的排序策略中, 若存在解的可能性比较大的分支能被确认并最先搜索, 则可以更有效地发现第一个解. 然而, 除非使用学习算法, 否则值的排序不能减小搜索空间. 所以, 除非用到学习, 否则值图6 排序完成后得到最大基数排序的宽度图7 颠倒后排序的宽度的排序只能用来发现第一个解.2. 2. 2 最小冲突策略在给变量值排序时, 应将最有希望的值排在前面. 最小冲突策略在为变量值排序时是根据它们与未被标记变量之间的约束而定的, 并将最有可能成功的值放在最前面.程序最开始时有两个集合: LABL E S- L E FT 和LABL ES- DONE. LABL ES- L EFT 被初始化为每个变量和它的任意一个值组成的集合. LABL ES- DONE 被初始化为空集. 在LABL ES- L EFT 集合中, 发现变量x 的标签〈x , v〉(标签label 由1 个变量和它的1 个值组成) 和其它的标签有冲突, 就将它从该集合中删去.然后将x 论域中与集合LAB E LS- DONE 中的标签不发生冲突的所有值找到, 并将这些值按照和集合LAB E LS- L EFT 中的标签产生冲突的数目的大小排序, 产生冲突数目最小的值排在最前面. 再把被排序的值中的第一个值赋给x , 并将该标签放入集合LAB E LS- DONE 中. 若没有这样的值存在( 如x 的值域中所有的值都和集合LAB E LS- DONE 中的某些标签产生冲突) , 就发生回溯. 如果集合LAB E LS- L EFT 中所有的标签都无冲突或者标签的所有组合都已试过, 则程序终止.I LO G SOL VER 求解系统33. 1 系统简介SO LVER 中提供的基本类型有: Ilc Int , IlcAny , IlcFl oat , IlcB ool . 其中IlcAny 表示被SOLVER 枚举类型的变量和集合类型的变量处理的对象.任何对象的指针都被转换成IlcAny 型.大多数SOLVER6 实体都使用handle 类和实现类. handle 类的对象指向相应实现类的对象. 使用handle 的好处是不需要考虑它们的内存管理. 当一个类以I 结尾, 说明它实际上是一个实现类. handle 类的构造函数从一个指向其实现类实例的指针构造了一个handle 对象. 对于handle 类的每一个成员函数, 实现类中都有一个同名的成员函数.为了容易还原到先前的状态, SOLVER 为每个基本的类型都提供了一个类( 称为可逆类) . 这些类都有对应于基本类型的值数据成员, 当SOLVER 回溯时, 它们可被自动还原.可逆类有: IlcR evInt , Il2 cR evB ool , IlcR evFl oat , IlcR evAny.有限集合用来表示约束整型变量和约束枚举变量的论域, 也用来表示约束集合变量的值. SO LVER 提供了有限集合有效的实现方法: bit vectors. 指针的有限集合是类IlcAnySet 的实例.3 . 2 目标( G oal)SO LVER 中搜索算法可通过goals 来实现. 像其它的SOLVER 实体一样, 一个目标可由Ilc G oal 类和Ilc G oal I 类的实例两个对象来实现. Ilc G oal I 类有一个虚拟成员函数ex ecute , 可用来实现目标. 成员函数ex ecute 必须返回另一个目标, 即这个目标运行下的子目标. 若返回值为0 , 说明没有子目标. 目标通过目标栈的途径来运行. 函数Ilc I nit 建立了一个目标栈, 函数IlcS olve 建立了一个新的目标栈并把先前的目标栈隐藏起来. 运行结束后, IlcS olve 破坏掉它的目标栈, 并使先前的目标栈可见. 函数IlcActive 将一个目标放入当前的栈中, 函数IlcNex t S oluti on 控制目标栈的运行. 事实上, 一个目标可以被定义成一个不同目标间的选择, 这样的目标称为选择点. 选择点可通过下述步骤实现:(1)(2)(3)保存SO LVER 的状态, 包括目标栈的状态. 第一个子目标被加到目标栈的顶部.其它的子目标被保存为未运行的选择点.( 4) 第一个子目标从目标栈的顶部弹出并运行. 若这个子目标失败, 保存SOLVER 的状态, 并将第一个未被运行的选择点压入目标栈, 称为回溯.可采用两种方式控制目标的运行: 一个方式使用函数IlcS olve (它用其形参初始化目标栈) ; 另一种方式是使用函数IlcActive 和IlcNex t S oluti on. 第二种方式是针对目标是约束时使用的.(1) 函数IlcB ool IlcS olve ( I lc G oal goal , IlcB ool restore = IlcFalse) . 该函数建立了一个新的目标栈并用目标初始化这个栈. 这个新的目标栈暂时隐藏了先前的目标栈. 然后该函数从目标栈不断弹出目标目标的运行能将其它的目标压入栈, 设置选择点. 函数终止于两种情况: 第一, 如果它的目标栈为空则函数返回值为IlcT rue . 若参数restore 的值为IlcT rue , 则SO LVER 的状态被恢复; 第二, 如果发生失败并且没有未被测试的子目标, 则函数返回值为IlcFalse , 并且恢复到SOLVER 的状态. 函数IlcS olve 终止时, 它破坏掉自己的目标栈, 使得先前的目标栈成为可见.(2) 函数V oid IlcActive ( I lc G oal goal) . 该函数将目标压入当前目标栈.(3) 函数IlcB ool IlcNex t S oluti on ( ) . 该函数运行目标栈直到一个结果被发现. 第一次调用此函数它从目标栈中弹出目标并运行它. 函数IlcNex t S oluti on 的运行终止于两种情况. 第一, 目标栈为空, 函数返回真. 第二, 失败发生并且没有未被运行的子目标, 函数返回失败, 并恢复到SOLVER 的状态. 第二次及以后调用该函数则从上次停止的地方开始运行.SO LVER 提供了一个目标的子类IlcDem onI. 该类的实例称为dem ons. 这个类要求目标没有子目标.当目标在约束传播队列中时, 它为立即运行的目标.3. 3 约束在S OLVER 中, 约束是一个对象. 也可以把约束认为是一个布尔表达式. 表达式的值依赖于约束的可满足性: 如果不违反约束, 则表达式的值为真; 如果约束不被满足, 则表达式的值为假. 表达约束的布尔表达式可以用逻辑操作or , and , not 来结合.一个约束也是一个目标(因为约束类是目标类的子类) , 所以约束能被压入目标栈. 当IlcS olve 或IlcNex t S oluti on 执行约束时, 约束被告知SOLVER (通过IlcT ell) .3. 4 解的搜索通常, 约束问题中的未知量被表示成约束变量. 约束问题的解可通过给每个约束变量赋值得到,并使得所有的约束都被满足. 为了达到此目的, S OLVER 提供了枚举算法, 这个算法带有参数(为了选择变量被例化和值被测试的次序, 参数被设置) .3 .4 . 1 选择约束变量在最初开始寻找解时, 为了选择变量被例化的次序, SOLVER 允许设置参数. 可以通过用选择函数的途径来完成. 这部分地解释了为了选择变量而用宏来建立新的选择函数的预定义函数.对于约束整型、浮点、枚举和集合变量许多标准被预先定义. 例如, 函数Ilc I nt Il cC hooseF i rs2 tUnboundInt (const Ilc IntV arArray vars) , 这个函数的返回值是约束变量数组vars 中所有未被例化的变量中的第一个未被例化的变量的索引.对于约束整型变量的选择函数应该有如下类型的签字( s ignature) .typedef Ilc Int ( 3 IlcC hoose Int Index) ( Ilc IntV arArray) : 这个C + + 类型表示一个指向函数的指针, 该函数的参数类型是约束整型表达式数组, 返回值是整数. 在SOLVER 中, 可用下面的宏定义新的选择标准.如果只有一个整数标准, 应使用宏IlcC hoose I ndex 1 .IlcC hoose I ndex1 (n am e ,criteri on ,varT ype) : 这个宏为varT ype 类型的选择变量定义了一个选择函数. 函数的名字是nam e , 第二个参数criteri on 是一个整型的C + + 表达式. 名字为nam e 的函数的返回值是一个varT ype 类型的约束变量的索引, 该变量在表达式criteri on 中取最小值. 若所有约束变量都被例化, 则函数返回值为- 1 .3 .4 . 2 选择值SOLVER 允许用户控制约束变量论域中值被测试的次序. 下一个要测试的值的选择通过一个对象来实现, 这个对象的类依赖于约束变量的类. 这些类有: Ilc IntSelect , IlcAnySelect , Il2 c I ntSetSelect , IlcAnySetSelect .这些对象通常使用如下类型的评价函数:typedef Ilc I nt ( 3 Ilc E val I nt) ( I lc I nt val , I lc IntV ar var) ;这个类型表示指向函数的指针, 函数的第一个参数是整数, 第二个参数是约束整型变量, 返回值是一个整数.typedef Ilc I nt ( 3 Ilc E valAny) (const IlcAny val , I lcAnyV ar var) ;这个类型表示指向函数的指针, 函数的第一个参数是一个指针, 第二个参数是约束枚举变量, 返回值是一个整数.3 .4 . 3 例化约束表达式目标Ilc Instantiate 可用来给约束变量分配一个值, 它使用选择点. 若发生失败, 将分配给另一个值变量. 根据约束变量类型的不同, 目标Ilc I nstantiate 的行为略有不同.Ilc G oal Ilc I nstantiate (const Ilc I ntV ar var , Ilc I ntSelect select) ;如果var 已经被例化, 则Ilc Instantiate 不做任何事. 否则, 它设置一个选择点, 然后分配一个值给约束变量. 如果失败, 这个值被从约束变量的论域中去掉, 并分配另一个值给约束变量, 直到赋值成功或论域为空. 如果提供了select 对象, 则值通过select 对象被选择, 否则以升序被测试.对于整型约束变量有效的Ilc Instantiate 算法, 对约束浮点变量并不很有效. 因为, 约束浮点变量论域中的浮点值数目太多. 这样, 要采用完全不同的方法, 将约束浮点变量论域递归的分两部分.Ilc G oal Ilc I nstantiate (const IlcFlaotV ar var , IlcB ool IncreaseMinFirst = IlcTrue , IlcFl oat prec = 0) ;如果var 已经被例化, 则Ilc Instantiate 不做任何事. 否则, 它会设置一个选择点, 将变量的论域用论域本身的一半来代替, 并递归地调用它. 如果函数被例化, 或知道一个比prec 更小的precisi on , 则函数停止. 若发生失败, 则论域被另一半代替并递归地调用函数Ilc I nstantiate .3 .4 . 4 枚举和传播算法SO LVER 提供的带有参数的枚举算法可在搜索解时设置变量选择次序.函数: Ilc G oal Ilc G enerate (const Ilc I ntV arArray , IlcC hoose I nt I ndex chooseV ariabvle , Ilc I ntSelect) ; 目标是要例化数组中的每一个约束变量, 通过为它们中的每个调用函数Ilc I nstantiate .变量被例化的次序由函数choose I ndex 来控制. 当提供参数select 时, 该参数在每次调用函数Ilc I nstantiate 时被传递.3. 5 约束的实现SO LVER 提供了一个足够的预定义约束库来满足广泛的应用. 可以用逻辑操作将预定义操作结合起来, 为特殊问题建立更复杂的约束. 很少需要自己定义新的约束类. 然而, 在逻辑操作不能满足特定应用所需的约束时, 可以定义一个约束类. 因为定义一个约束类在很大程度上依赖于SOLVER 使用的传播算法, 所以算法被解释. 约束也是目标, 所以约束和目标的关系也被深入的解释.3 . 5 . 1 约束传播算法当通过函数IlcT ell 将约束告诉SOLVER (即公布一个约束) 时, 该约束立刻被用来减少它所包含变量的论域. SO LVER 通过将不满足约束的值删除来减少变量的论域. 将约束告诉SO LVER 的过程是可逆的, 当SOLVER 回溯到一个点, 且在该点上某个约束还未被公布时, 则这个约束可以被去掉.如果约束传播将变量的论域减少到只剩一个值时, 这个约束变量被所剩的那个值例化. 此外, 当把一个约束告诉S OLVER 时, 这个约束被保存. 要使约束所包含的任何一个变量改变时, 这个约束则被激活, 从而使这个约束所包含的其它变量的论域也被改变. 这个过程称为约束传播.SO LVER 中约束传播使用的算法的原则是简单的. SOLVER 维持了一个变量队列, 称为约束传播队列.当改变一个约束变量时, 如果该变量没在队列中, 则把它放入队列的尾部. 只要队列中有变量, 算法就从队列中取第一个变量, 并称这个被取的变量是在过程中.当一个变量在过程中时, 则先将它从传播队列中去掉. 与这个变量相关的每个约束都被检查. 对于每一个被检查的约束, 这个约束包含的所有变量都被检查, 它们的论域被减小以满足这个约束. 如果在这个动作中有一些变量的论域被减小, 则这些变量也被放入队列中. 如果所有论域中的值都满足约束, 或者有一个论域为空, 则算法停止.此算法有如下特性: (1)算法总可以停止; ( 2) 允许约束中包含两个以上的变量, 如算术约束;(3) 可以动态地处理问题, 即可在搜索解的过程中加入新的约束; (4) 不考虑约束的顺序, 论域总是以同样的方式被减小.3 . 5 . 2 传播事件变量上的任何改变都导致包含该变量的约束被检查. 依赖变量的类和变量共有几种改变, 把变量改变成为传播事件.共有以下3 种传播事件: (1) 值传播事件(指约束变量被赋给1 个值) ; (2) 范围传播事件( 指至少论域的一个边界被改变. 如果变量被例化, 这个事件也发生) ; ( 3) 论域传播事件( 指变量的论域被改变, 包括论域中的1 个值被去掉, 边界被改变, 变量被例化) .可能的传播事件依赖于约束变量的类型. 表1 显示了事件和约束变量之间的关系.表1 事件和约束变量的关系约束变量值传播事件范围传播事件论域传播事件3 3 3 3 3 33Ilc I n tV ar IlcAnyV arIlcFloatV ar Ilc I ntS etV ar 33这些事件用来控制何时约束被检查. 事实上, 对于一个给定的变量, 约束可只与一个事件相关联. 例如, 在约束传播算法中, 如果一个在过程中的变量只产生了域事件, 则所有与域事件相关的约束都被检查. 任何与范围传播事件和值传播事件相关的约束都不被检查.约束满足问题I LO G SOL VER 的求解示例4问题描述7 : 地图着色问题是指给地图上的国家( 或地区) 选择颜色, 要求最多使用4 种颜色, 并且两个相邻的国家(或地区) 不能使用相同的颜色.在这个例子中, 我们要给6 个国家用4 种颜色进行着色. 6 个国家是: Belgium , Denm ark , France , G ermany , Netherlands , Lux em bourg. 4 种颜色是: blue , white , red , green.为减少篇幅, 将这个例子的C + + 源程序代码做了部分省略. 从下面的程序代码中可看出, 程序员可以在自己的C + + 程序中直接使用ILO G SOLVER 提供的这些类及函数来完成约束满足问题的求解.这样既节省了用户的时间和精力, 又使得对约束满足问题不十分了解的用户可以完成问题的求解, 非常方便. 以下是C + + 源程序代码:# include〈ilsolverΠilcint . h〉int m ain ( ) {Ilc I nit ( ) ;Ilc I ntV ar Belgium (0 ,3) , Denmark (0 ,3) , France (0 ,3) , G erm any (0 ,3) , Netherlands (0 , 3) , Lux em bourg (0 ,3) ; ΠΠ0~3 分别对应上述4 种颜色Ilc I ntV arArray AllVars (6 , Belgium , Denm ark , France , G ermany , Netherlands , Lux em bourg) ;ΠΠ建立约束:IlcP ost ( France ! = Belgium) ; ΠΠ如果两个国家是相邻的, 则它们不能用相同的颜色.ΠΠ我们只需建立这样一个不相等的约束即可.。
DEAsolver使用说明

DEAsolver使用说明DEAsolver使用说明1.简介DEAsolver是一种用于解决数据包络分析(Data Envelopment Analysis,DEA)问题的软件工具。
它可以帮助用户评估单位(或决策单元)的相对效率,并找出最佳行动方案。
本文档将介绍如何使用DEAsolver进行数据包络分析。
2.安装和配置2.1 系统要求确保您的计算机满足DEAsolver的系统要求。
这包括操作系统版本、处理器要求和内存要求等。
可以在官方网站上查找关于DEAsolver的系统要求的更多信息。
2.2 和安装访问官方网站并DEAsolver的安装程序。
安装程序通常是一个可执行文件,双击运行即可开始安装过程。
按照安装向导的提示完成安装。
2.3 配置和更新一旦安装完成,您可以根据需要对DEAsolver进行配置。
配置选项包括设置默认的输入和输出路径、选择语言和启用自动更新等。
确保在应用配置更改后保存并重新启动DEAsolver。
3.使用DEAsolver3.1 创建项目首先,打开DEAsolver并创建一个新的项目。
在项目中,您将输入和管理数据以进行数据包络分析。
3.2 导入数据在项目中,您可以导入需要分析的数据。
数据通常包括单位的输入和输出变量,以及一些额外的参数。
确保数据格式正确,并按照DEAsolver的要求进行输入。
3.3 进行数据包络分析一旦数据导入完成,您可以开始进行数据包络分析。
选择适当的算法和方法来评估单位的效率,并相应的结果。
DEAsolver通常提供不同的分析选项,您可以根据需要进行选择。
4.结果解读和优化4.1 解读结果DEAsolver将为您分析结果。
这些结果通常包括单位的相对效率评分、最佳行动方案的建议等。
您应该仔细解读这些结果,并根据需要进行进一步分析。
4.2 优化行动方案一旦您了解了分析结果,您可以利用DEAsolver提供的优化功能来改进单位的效率。
优化方法通常包括调整输入和输出变量的比例、改进单位的管理和操作策略等。
DEAsolver使用说明
DEAsolver使⽤说明DEA-SOLVER 使⽤说明此说明为个⼈使⽤经验,如果实际情况有不同,望海涵。
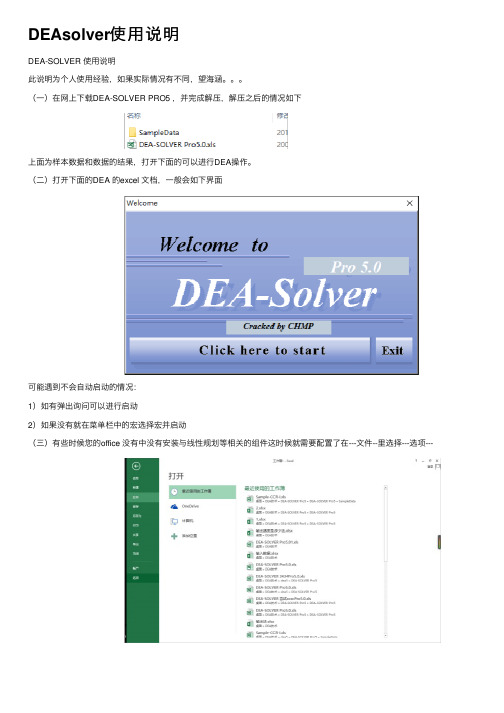
(⼀)在⽹上下载DEA-SOLVER PRO5 ,并完成解压,解压之后的情况如下上⾯为样本数据和数据的结果,打开下⾯的可以进⾏DEA操作。
(⼆)打开下⾯的DEA 的excel ⽂档,⼀般会如下界⾯可能遇到不会⾃动启动的情况:1)如有弹出询问可以进⾏启动2)如果没有就在菜单栏中的宏选择宏并启动(三)有些时候您的office 没有中没有安装与线性规划等相关的组件这时候就需要配置了在---⽂件--⾥选择---选项---选择信⽤中⼼设置选择信任对VBA⼯程对象模型的访问同时在宏设置中选择你喜欢的⽅式之后按确定(四)下⾯完成组件的加载选择加载项,可以看到本⼈excel中已经完成规划求解加载项的加载,使⽤的时候看能加载的就先加载上吧。
加载⽅式在下⾯的管理选择EXCEL加载项点击转到就可以看到下⾯的界⾯了,选择你想加载的宏,选择线性规划哦这样你就完成了配置。
(五)之后就可以使⽤了,使⽤前,选择相应的⽅法请您阅读DEA-Solver的实战运⽤_⾮常详细这个⽂档,掌握使⽤的⽅法主要是导⼊数据的格式,需要在数据名⾂前加(I)和(O)来表⽰输⼊输出变量(六)具体例⼦使⽤如下,⾸先准备好数据注意数据格式呀(七)打开DEA pro 5出现下⾯的结果,下⾯就要开始了(⼋)开始按照指导进⾏就好了click here to start选择⼀个模型,点击ok键,然后ok直到下⾯的界⾯,(不⽤害怕点过呀⼤胆的点ok就好了)这时候你就要选择你要导⼊的输⼊和输出数据了,在这⾥选择 1 的内容,就是刚才准备好的⽂档呀导⼊即可(九)然后继续ok下去再⼀次ok这时候就需要选择结果DEA计算结果导出的表格了,这⾥新建⼀个DEA-SOLVER Pro5.啦啦啦啦0.xls 如图,,位置随意了再⼀次ok就可以开始跑步了⼀般会闪⼀会⼉的下⾯就是完成了,然后去看你的保存的excel 吧⾥⾯会有结果的异常处理主要有以下两种第⼀打开之后出现下⾯的界⾯有时候打开开启使⽤DEA ⽂档时候会出现上图的状况,那就点确定就好,再次确定之后就会出现就会出现下⾯的结果也是可以使⽤的还有导⼊⽂件sheet1 有时候要改名为DAT。