蚁群算法简述及实现
蚁群算法的原理与实现

蚁群算法的原理与实现蚁群算法的原理与实现蚁群算法是一种基于蚁群行为觅食的启发式搜索算法,它模拟了蚁群觅食的过程,通过蚂蚁之间的信息交流和相互合作,最终找到最优解。
蚁群算法具有自组织、分布式计算和并行搜索等特点,被广泛应用于优化问题的求解。
蚁群算法的基本原理是模拟蚂蚁觅食的行为。
在蚂蚁觅食的过程中,蚂蚁们会释放信息素,并根据信息素的浓度选择路径。
当一只蚂蚁找到食物后,它会返回蚁巢,并释放更多的信息素,吸引其他蚂蚁跟随它的路径。
随着时间的推移,路径上的信息素浓度会逐渐增加,越来越多的蚂蚁会选择这条路径,形成正反馈的效应。
最终,蚂蚁们会找到一条最优路径连接蚁巢和食物。
蚁群算法的实现过程可以分为两个阶段,即路径选择阶段和信息素更新阶段。
在路径选择阶段,蚂蚁根据信息素的浓度和距离选择路径。
通常情况下,蚂蚁倾向于选择信息素浓度高且距离短的路径。
在信息素更新阶段,蚂蚁会根据路径的质量释放信息素。
一般来说,路径质量好的蚂蚁会释放更多的信息素,以吸引更多的蚂蚁跟随。
为了实现蚁群算法,需要定义一些重要的参数,如信息素浓度、信息素挥发率、蚂蚁的移动速度和路径选择的启发因子等。
信息素浓度表示路径上的信息素浓度大小,信息素挥发率表示信息素的衰减速度,蚂蚁的移动速度表示蚂蚁在路径上的移动速度,路径选择的启发因子表示蚂蚁在选择路径时信息素和距离的权重。
蚁群算法的优势在于它能够找到全局最优解,并且对解空间的搜索范围不敏感。
同时,蚁群算法还能够处理具有多个局部最优解的问题,通过信息素的传播和挥发,逐渐淘汰次优解,最终找到全局最优解。
然而,蚁群算法也存在一些不足之处。
首先,算法的收敛速度较慢,需要进行多次迭代才能达到较好的结果。
此外,算法的参数设置对算法的性能影响较大,需要进行调优。
最后,蚁群算法在处理大规模问题时,需要消耗较大的计算资源。
总的来说,蚁群算法是一种有效的优化算法,能够解决许多实际问题。
通过模拟蚂蚁的觅食行为,蚁群算法能够找到最优解,具有自组织、分布式计算和并行搜索等特点。
蚁群算法及案例分析精选全文

群在选择下一条路径的时
候并不是完全盲目的,而是
按一定的算法规律有意识
地寻找最短路径
自然界蚁群不具有记忆的
能力,它们的选路凭借外
激素,或者道路的残留信
息来选择,更多地体现正
反馈的过程
人工蚁群和自然界蚁群的相似之处在于,两者优先选择的都
是含“外激素”浓度较大的路径; 两者的工作单元(蚂蚁)都
正反馈、较强的鲁棒性、全
局性、普遍性
局部搜索能力较弱,易出现
停滞和局部收敛、收敛速度
慢等问题
优良的分布式并行计算机制
长时间花费在解的构造上,
导致搜索时间过长
Hale Waihona Puke 易于与其他方法相结合算法最先基于离散问题,不
能直接解决连续优化问题
蚁群算法的
特点
蚁群算法的特点及应用领域
由于蚁群算法对图的对称性以
及目标函数无特殊要求,因此
L_ave=zeros(NC_max,1);
%各代路线的平均长度
while NC<=NC_max
%停止条件之一:达到最大迭代次数
% 第二步:将m只蚂蚁放到n个城市上
Randpos=[];
for i=1:(ceil(m/n))
Randpos=[Randpos,randperm(n)];
end
Tabu(:,1)=(Randpos(1,1:m))';
scatter(C(:,1),C(:,2));
L(i)=L(i)+D(R(1),R(n));
hold on
end
plot([C(R(1),1),C(R(N),1)],[C(R(1),2),C(R(N),2)])
蚁群算法的原理及其应用

蚁群算法的原理及其应用1. 蚁群算法的介绍蚁群算法(Ant Colony Optimization, ACO)是一种启发式优化算法,它模拟了蚂蚁在寻找食物路径时的行为。
蚁群算法通过模拟蚂蚁在信息素的引导下进行行为选择,来寻找最优解。
蚁群算法的核心思想是利用分布式的信息交流和反馈机制来完成问题的求解。
2. 蚁群算法的原理蚁群算法的原理可简述为以下几个步骤:1.创建蚁群:随机生成一定数量的蚂蚁,将其放置在问题的初始状态上。
2.信息素初始化:对于每条路径,初始化其上的信息素浓度。
3.蚂蚁的移动:每只蚂蚁根据一定的规则,在解空间中移动,并根据路径上的信息素浓度决定移动的方向。
4.信息素更新:每只蚂蚁在移动到目标位置后,根据路径的质量调整经过路径上的信息素浓度。
5.更新最优路径:记录当前找到的最优路径,并更新全局最优路径。
6.蚂蚁迭代:重复进行2-5步骤,直到满足终止条件。
3. 蚁群算法的应用蚁群算法被广泛应用于许多优化问题的求解,特别是在组合优化、路径规划、图着色等领域。
3.1 组合优化问题蚁群算法在组合优化问题中的应用主要包括旅行商问题(TSP)、背包问题(KP)、调度问题等。
通过模拟蚂蚁的移动和信息素的更新,蚁群算法可以找到全局最优解或接近最优解的解决方案。
3.2 路径规划问题在路径规划问题中,蚁群算法常被用于解决无人车、无人机等的最优路径规划。
蚁群算法能够在搜索空间中寻找最短路径,并考虑到交通拥堵等实际情况,提供合适的路径方案。
3.3 图着色问题蚁群算法可以用于解决图着色问题,即给定一个图,用尽可能少的颜色对其顶点进行着色,使得相邻顶点的颜色不同。
蚁群算法通过模拟蚂蚁的移动和信息素的更新,能够找到一种较好的图着色方案。
4. 蚁群算法的优缺点4.1 优点•收敛性好:蚁群算法能够在相对较短的时间内找到较优解。
•分布式计算:蚂蚁的并行搜索使得蚁群算法能够处理大规模复杂问题。
•鲁棒性强:蚁群算法对问题的可行域和约束条件的适应性较强。
蚁群算法概述

蚁群算法概述一、蚁群算法蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来寻找最优解决方案的机率型技术。
它由Marco Dorigo于1992年在他的博士论文中引入,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为。
蚂蚁在路径上前进时会根据前边走过的蚂蚁所留下的分泌物选择其要走的路径。
其选择一条路径的概率与该路径上分泌物的强度成正比。
因此,由大量蚂蚁组成的群体的集体行为实际上构成一种学习信息的正反馈现象:某一条路径走过的蚂蚁越多,后面的蚂蚁选择该路径的可能性就越大。
蚂蚁的个体间通过这种信息的交流寻求通向食物的最短路径。
蚁群算法就是根据这一特点,通过模仿蚂蚁的行为,从而实现寻优。
这种算法有别于传统编程模式,其优势在于,避免了冗长的编程和筹划,程序本身是基于一定规则的随机运行来寻找最佳配置。
也就是说,当程序最开始找到目标的时候,路径几乎不可能是最优的,甚至可能是包含了无数错误的选择而极度冗长的。
但是,程序可以通过蚂蚁寻找食物的时候的信息素原理,不断地去修正原来的路线,使整个路线越来越短,也就是说,程序执行的时间越长,所获得的路径就越可能接近最优路径。
这看起来很类似与我们所见的由无数例子进行归纳概括形成最佳路径的过程。
实际上好似是程序的一个自我学习的过程。
3、人工蚂蚁和真实蚂蚁的异同ACO是一种基于群体的、用于求解复杂优化问题的通用搜索技术。
与真实蚂蚁通过外激素的留存/跟随行为进行间接通讯相似,ACO中一群简单的人工蚂蚁(主体)通过信息素(一种分布式的数字信息,与真实蚂蚁释放的外激素相对应)进行间接通讯,并利用该信息和与问题相关的启发式信息逐步构造问题的解。
人工蚂蚁具有双重特性:一方面,他们是真实蚂蚁的抽象,具有真实蚂蚁的特性,另一方面,他们还有一些在真实蚂蚁中找不到的特性,这些新的特性,使人工蚂蚁在解决实际优化问题时,具有更好地搜索较好解的能力。
人工蚂蚁与真实蚂蚁的相同点为:1.都是一群相互协作的个体。
蚂蚁群算法的原理与应用

蚂蚁群算法的原理与应用一、引言蚂蚁群算法(Ant Colony Algorithm)是一种仿生学算法,它从模拟蚂蚁寻找食物的行为中得到启示,通过模拟蚂蚁在一个环境中移动的过程,从而找到最优解。
二、蚂蚁群算法原理1. 蚂蚁行为模拟在蚂蚁群算法中,蚂蚁走的路线形成了图的结构,每个节点代表一个城市,边表示两个城市之间的路径。
蚂蚁执行一系列的行为,比如跟随其他蚂蚁、发现新的路径和留下路径信息等。
这些行为模拟蚂蚁在寻找食物时的行为。
2. 均衡信息素更新蚂蚁在走过一条路径后,会在路径上留下信息素,信息素的含量越多,蚂蚁就越有可能跟随这条路径。
然而,过多的信息素会导致所有蚂蚁只走这一条路径,无法寻找更优的路径。
因此,需要均衡信息素的含量,让所有路径都有被探索的机会。
3. 路径选择蚂蚁在走到一个城市后,需要选择下一个城市。
选择的概率与路径上的信息素含量以及该路径已经被其他蚂蚁走过的情况有关。
信息素含量高的路径以及没有被走过的路径,被选中的概率越高。
三、蚂蚁群算法应用1. 旅行商问题旅行商问题是一种经典的算法问题,它需要在多个城市之间找到一条最短的路径,使得每个城市都被访问,而且最终回到起点。
蚂蚁群算法可以用于解决这个问题,通过模拟蚂蚁在不同的路径上走过的情况,找到最短的路径。
2. 网络路由在一个复杂的网络中,需要选择不同的路径来传输数据。
传输路径的选择会影响网络的质量和效率。
蚂蚁群算法可以用于网络路由,通过蚂蚁在网络中寻找最优的路径,从而提高网络的稳定性和传输效率。
3.生产调度在生产过程中,需要对不同的任务进行调度,以保证生产效率和质量。
蚂蚁群算法可以用于生产调度,通过模拟蚂蚁在不同任务之间的选择过程,从而找到最优的调度方案。
四、结论蚂蚁群算法是一种有效的仿生学算法,在许多领域都有广泛的应用。
通过模拟蚂蚁在不同的环境中的行为,蚂蚁群算法可以找到最优的解决方案。
在未来,蚂蚁群算法有望在更多的领域得到应用,从而提高生产效率和质量。
马隆杰--蚁群算法

蚁群算法的基本思想
搜索环境
第一次搜索t=0搜索情况 人工蚁群例子
t=1 时刻搜索情况
基于TSP问题的基本蚁群算法
TSP求解中,假设蚁群算法中的每只蚂蚁是具有以下特征 的简单智能体: 每次周游,每只蚂蚁在其经过的支路(i,j)上都留下 信息素。 蚂蚁选择城市的概率与城市之间的距离和当前连接支路 上所包含的信息素余量有关。 为了强制蚂蚁进行合法的周游,直到一次周游完成后, 才允许蚂蚁游走已访问过的城市(这可由禁忌表来控 制)。
ik, j
L2 =BC+CD+DA+AE
Q if ( i , j ) t our Lk 0 ot herwise
2
[C,B,E,D,A]
L3 =CB+BE+ED+DA
3
[D,E,A,B,C]
L4 =DE+EA+AB+BC
4
[E,A,B,C,D]
L5 =EA+AB+BC+CD
蚁群系统
ACS与AS的区别?
① 蚂蚁的状态转移规则不同; ② 全局更新规则不同; ③ 新增了对各条路径信息量调整的局部更新 规则。
蚁群系统
蚂蚁的状态转移规则不同
基本蚁群算法(AS)
k pij
蚁群系统(ACS)
arg max{[ (i, s)] [ (i, s)] },q q 0
基于TSP问题的基本蚁群算法
两个过程: 1、状态转移 2、信息素更新
基于TSP问题的基本蚁群算法
蚂蚁k(k=1,2,…,m)根据各个城市间连接路径上的 信息素浓度和路径启发信息决定其下一个访问城市,这 里用禁忌表tabuk来记录蚂蚁k当前所走过的城市,在 t 时刻蚂蚁 k 由城市 i 转移到城市 j 的状态转移概率为:
蚁群算法——精选推荐
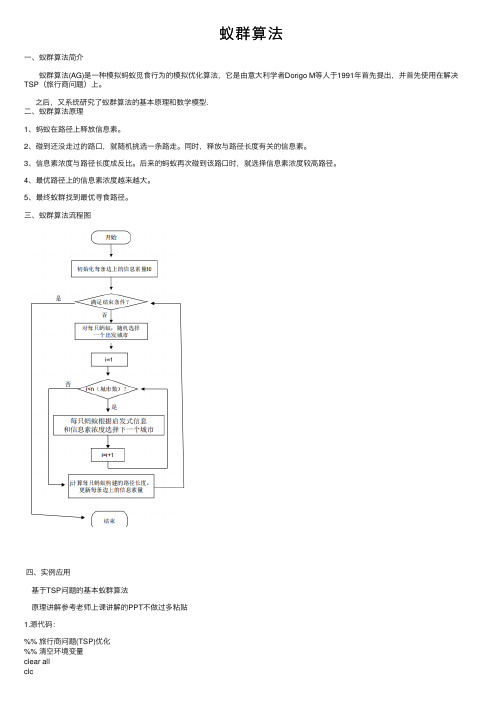
蚁群算法⼀、蚁群算法简介 蚁群算法(AG)是⼀种模拟蚂蚁觅⾷⾏为的模拟优化算法,它是由意⼤利学者Dorigo M等⼈于1991年⾸先提出,并⾸先使⽤在解决TSP(旅⾏商问题)上。
之后,⼜系统研究了蚁群算法的基本原理和数学模型.⼆、蚁群算法原理1、蚂蚁在路径上释放信息素。
2、碰到还没⾛过的路⼝,就随机挑选⼀条路⾛。
同时,释放与路径长度有关的信息素。
3、信息素浓度与路径长度成反⽐。
后来的蚂蚁再次碰到该路⼝时,就选择信息素浓度较⾼路径。
4、最优路径上的信息素浓度越来越⼤。
5、最终蚁群找到最优寻⾷路径。
三、蚁群算法流程图四、实例应⽤基于TSP问题的基本蚁群算法原理讲解参考⽼师上课讲解的PPT不做过多粘贴1.源代码:%% 旅⾏商问题(TSP)优化%% 清空环境变量clear allclc%% 导⼊数据citys = ceil(rand(50,2)*50000)%load newcitys.mat%% 计算城市间相互距离fprintf('Computing Distance Matrix... \n');n = size(citys,1);D = zeros(n,n);for i = 1:nfor j = 1:nif i ~= jD(i,j) = sqrt(sum((citys(i,:) - citys(j,:)).^2));elseD(i,j) = 1e-4;endendend%% 初始化参数fprintf('Initializing Parameters... \n');m = 50; % 蚂蚁数量alpha = 1; % 信息素重要程度因⼦beta = 5; % 启发函数重要程度因⼦rho = 0.05; % 信息素挥发因⼦Q = 1; % 常系数Eta = 1./D; % 启发函数Tau = ones(n,n); % 信息素矩阵Table = zeros(m,n); % 路径记录表iter = 1; % 迭代次数初值iter_max = 150; % 最⼤迭代次数Route_best = zeros(iter_max,n); % 各代最佳路径Length_best = zeros(iter_max,1); % 各代最佳路径的长度Length_ave = zeros(iter_max,1); % 各代路径的平均长度%% 迭代寻找最佳路径figure;while iter <= iter_maxfprintf('迭代第%d次\n',iter);% 随机产⽣各个蚂蚁的起点城市start = zeros(m,1);for i = 1:mtemp = randperm(n);start(i) = temp(1);endTable(:,1) = start;% 构建解空间citys_index = 1:n;% 逐个蚂蚁路径选择for i = 1:m% 逐个城市路径选择for j = 2:ntabu = Table(i,1:(j - 1)); % 已访问的城市集合(禁忌表)allow_index = ~ismember(citys_index,tabu);allow = citys_index(allow_index); % 待访问的城市集合P = allow;% 计算城市间转移概率for k = 1:length(allow)P(k) = Tau(tabu(end),allow(k))^alpha * Eta(tabu(end),allow(k))^beta; endP = P/sum(P);% 轮盘赌法选择下⼀个访问城市Pc = cumsum(P);target_index = find(Pc >= rand);target = allow(target_index(1));Table(i,j) = target;endend% 计算各个蚂蚁的路径距离Length = zeros(m,1);for i = 1:mRoute = Table(i,:);for j = 1:(n - 1)Length(i) = Length(i) + D(Route(j),Route(j + 1));endLength(i) = Length(i) + D(Route(n),Route(1));end% 计算最短路径距离及平均距离if iter == 1[min_Length,min_index] = min(Length);Length_best(iter) = min_Length;Length_ave(iter) = mean(Length);Route_best(iter,:) = Table(min_index,:);else[min_Length,min_index] = min(Length);Length_best(iter) = min(Length_best(iter - 1),min_Length);Length_ave(iter) = mean(Length);if Length_best(iter) == min_LengthRoute_best(iter,:) = Table(min_index,:);elseRoute_best(iter,:) = Route_best((iter-1),:);endend% 更新信息素Delta_Tau = zeros(n,n);% 逐个蚂蚁计算for i = 1:m% 逐个城市计算for j = 1:(n - 1)Delta_Tau(Table(i,j),Table(i,j+1)) = Delta_Tau(Table(i,j),Table(i,j+1)) + Q/Length(i); endDelta_Tau(Table(i,n),Table(i,1)) = Delta_Tau(Table(i,n),Table(i,1)) + Q/Length(i); endTau = (1-rho) * Tau + Delta_Tau;% 迭代次数加1,清空路径记录表% figure;%最佳路径的迭代变化过程[Shortest_Length,index] = min(Length_best(1:iter));Shortest_Route = Route_best(index,:);plot([citys(Shortest_Route,1);citys(Shortest_Route(1),1)],...[citys(Shortest_Route,2);citys(Shortest_Route(1),2)],'o-');pause(0.3);iter = iter + 1;Table = zeros(m,n);% endend%% 结果显⽰[Shortest_Length,index] = min(Length_best);Shortest_Route = Route_best(index,:);disp(['最短距离:' num2str(Shortest_Length)]);disp(['最短路径:' num2str([Shortest_Route Shortest_Route(1)])]);%% 绘图figure(1)plot([citys(Shortest_Route,1);citys(Shortest_Route(1),1)],...[citys(Shortest_Route,2);citys(Shortest_Route(1),2)],'o-');grid onfor i = 1:size(citys,1)text(citys(i,1),citys(i,2),[' ' num2str(i)]);endtext(citys(Shortest_Route(1),1),citys(Shortest_Route(1),2),' 起点');text(citys(Shortest_Route(end),1),citys(Shortest_Route(end),2),' 终点');xlabel('城市位置横坐标')ylabel('城市位置纵坐标')title(['蚁群算法优化路径(最短距离:' num2str(Shortest_Length) ')'])figure(2)plot(1:iter_max,Length_best,'b',1:iter_max,Length_ave,'r:')legend('最短距离','平均距离')xlabel('迭代次数')ylabel('距离')title('各代最短距离与平均距离对⽐')运⾏结果:利⽤函数citys = ceil(rand(50,2)*50000) 随机产⽣五⼗个城市坐标2.研究信息素重要程度因⼦alpha, 启发函数重要程度因⼦beta,信息素挥发因⼦rho对结果的影响为了保证变量唯⼀我重新设置五⼗个城市信息进⾏实验在原来设值运⾏结果:实验结果可知当迭代到120次趋于稳定2.1 alpha值对实验结果影响(1)当alpha=4时运⾏结果实验结果可知当迭代到48次左右趋于稳定(2)当alpha=8时运⾏结果:有图可知迭代40次左右趋于稳定,搜索性较⼩(3)当alpha= 0.5运⾏结果:有图可知迭代到140次左右趋于稳定(4)当alpha=0.2时运⾏结果:结果趋于110次左右稳定所以如果信息素因⼦值设置过⼤,则容易使随机搜索性减弱;其值过⼩容易过早陷⼊局部最优2.2 beta值对实验影响(1)当 beta=8时运⾏结果结果迭代75次左右趋于稳定(2)当 beta=1时运⾏结果:结果迭代130次左右趋于稳定所以beta如果值设置过⼤,虽然收敛速度加快,但是易陷⼊局部最优;其值过⼩,蚁群易陷⼊纯粹的随机搜索,很难找到最优解2.3 rho值对实验结果影响(1)当rho=3时运⾏结果:结果迭代75次左右趋于稳定(2)当rho=0.05运⾏结果:结果迭代125次左右趋于稳定所以如果rho取值过⼤时,容易影响随机性和全局最优性;反之,收敛速度降低总结:蚁群算法对于参数的敏感程度较⾼,参数设置的好,算法的结果也就好,参数设置的不好则运⾏结果也就不好,所以通常得到的只是局部最优解。
数据分析知识:数据挖掘中的蚁群算法

数据分析知识:数据挖掘中的蚁群算法蚁群算法是一种模拟蚂蚁觅食行为的启发式算法。
它是一种基于群体智能的方法,能够有效地用于数据挖掘和机器学习领域。
本文将介绍蚁群算法的基本原理和应用案例。
一、蚁群算法的基本原理蚁群算法受到了蚂蚁觅食行为的启发。
蚂蚁在觅食过程中会遵循一定的规则,例如在路径上释放信息素,吸引其他蚂蚁前往同一方向;在路径上的信息素浓度较高的路径更容易选择。
蚁群算法利用了这些规则,以一种群体智能的方式搜索解空间。
具体来说,蚁群算法由以下几个步骤组成:1.初始化:定义问题的解空间和初试信息素浓度。
解空间可以是任何基于排列、图形或其他对象的集合,例如TSP问题中的城市序列集合。
信息素浓度矩阵是一个与解空间大小相同的矩阵,用于反映每个解的吸引力。
2.移动规则:蚂蚁在解空间中移动的规则。
通常规则包括根据当前解和信息素浓度选择下一步解以及更新当前解的信息素浓度。
3.信息素更新:蚁群中的蚂蚁经过路径后,更新路径上的信息素浓度。
通常信息素浓度的更新涉及一个挥发系数和一个信息素增量。
4.终止条件:确定蚁群算法的运行时间,例如最大迭代次数或达到特定解的准确度。
蚁群算法是一种群体智能的方法,每只蚂蚁只能看到局部的解。
通过信息素的释放和更新,蚁群最终能够找到全局最优解。
二、蚁群算法的应用案例蚁群算法最常用于解决组合优化问题,例如TSP问题、车辆路径问题和任务分配问题。
下面将介绍蚁群算法在TSP问题和车辆路径问题中的应用。
1. TSP问题TSP问题是一个NP难问题,是指在旅行时,如何有效地走遍所有篮子,使得总的旅行距离最小。
蚁群算法是适用于TSP问题的一种有效的算法。
在每一代,蚂蚁会在城市之间移动,假设当前城市为i,则下一个选择的城市j是基于概率函数计算得到的。
概率函数考虑了当前城市的信息素浓度以及城市之间的距离。
每条路径释放的信息素浓度大小根据路径长度而定。
这样,蚂蚁可以在TSP问题上找到最优解。
2.车辆路径问题车辆路径问题是指在有限时间内如何合理地分配车辆到不同的客户,以最小化送货时间和车辆的旅行距离。
蚁群算法

4.蚁群算法应用
信息素更新规则
1.蚁群算法简述 2.蚁群算法原理
最大最小蚂蚁系统
3.蚁群算法改进
4.蚁群算法应用
最大最小蚂蚁系统(MAX-MIN Ant System,MMAS)在基本AS算法的基础 上进行了四项改进: (1)只允许迭代最优蚂蚁(在本次迭代构建出最短路径的蚂蚁),或者至今 最优蚂蚁释放信息素。(迭代最优更新规则和至今最优更新规则在MMAS 中会被交替使用)
p( B) 0.033/(0.033 0.3 0.075) 0.081 p(C ) 0.3 /(0.033 0.3 0.075) 0.74 p( D) 0.075 /(0.033 0.3 0.075) 0.18
用轮盘赌法则选择下城市。假设产生的 随机数q=random(0,1)=0.05,则蚂蚁1将会 选择城市B。 用同样的方法为蚂蚁2和3选择下一访问 城市,假设蚂蚁2选择城市D,蚂蚁3选择城 市A。
蚁群算法
1.蚁群算法简述 2.蚁群算法原理 3.蚁群算法改进 4.蚁群算法应用
1.蚁群算法简述 2.蚁群算法原理
3.蚁群算法改进
4.蚁群算法应用
蚁群算法(ant colony optimization, ACO),又称蚂蚁 算法,是一种用来在图中寻找优 化路径的机率型算法。 由Marco Dorigo于1992年在他 的博士论文中提出,其灵感来源 于蚂蚁在寻找食物过程中发现路 径的行为
4.蚁群算法应用
例给出用蚁群算法求解一个四城市的TSP 3 1 2 3 5 4 W dij 1 5 2 2 4 2
假设蚂蚁种群的规模m=3,参数a=1,b=2,r=0.5。 解:
满足结束条件?
昆虫群体行为学中的蚁群算法

昆虫群体行为学中的蚁群算法随着社会的发展和科技的不断进步,人们日常的各种活动都离不开计算机和信息技术的支持,人工智能、机器学习已经成为重要的研究领域。
而昆虫群体行为学中的蚁群算法也成为了这个领域中的热门算法之一。
本文将结合案例深入剖析蚁群算法的工作原理及其应用。
一、蚁群算法概述蚁群算法,又称蚁群优化算法,是一种基于群体智能的优化算法,源于自然界中蚂蚁生活方式的模拟。
自然界中蚂蚁以信息的方式寻找到食物和家,形成了一套完整的优化流程。
在这个过程中,蚂蚁会不断地散发信息素,当有蚂蚁发现了食物或者家后,会回到巢穴,散发出一种信息素,可以引起其他蚂蚁的注意。
一段时间过后,信息素会消失,这样就可以避免信息过时。
蚂蚁就利用这样的方式,在一片茫茫草地中快速找到食物和家。
而蚁群算法就是对这种生物的生命周期进行了模拟。
蚁群算法主要基于以下两大原理:正反馈和负反馈。
正反馈指的是蚂蚁在寻找食物和家的过程中,距离食物和家越近,越有可能被其他蚂蚁选择。
因此,经过一段时间的搜寻,食物或家附近的信息素浓度就会越来越高,吸引越来越多的蚂蚁。
负反馈指的是信息素的挥发时间有限,如果蚂蚁在搜寻过程中进入了死路,无法找到食物或家,很快就会失去它们的踪迹,寻找其它的目标。
二、蚁群算法的原理蚁群算法是一种基于贪心策略和启发式搜索的算法。
贪心策略是指在局部最优解的情况下选择全局最优解。
而启发式搜索则是通过评估函数进行深度优先或广度优先的搜索。
蚁群算法将这两种方法相结合,将其运用到求解优化问题的任务中。
在蚁群算法中,人们把寻优问题抽象成一个图论问题,称之为图。
设有m个蚂蚁在图中寻找最短路径,并假设每个蚂蚁可以移动的来源于强化自身链接的信息素来对图进行搜索,并通过蚁群算法来不断优化搜索的结果。
蚁群算法的核心在于挥发函数(Evaporation Rate)和信息素覆盖(Pheromone Coverage),通过这两个函数控制信息素在搜索过程中的流动和新建,在搜索过程中提高发现最优解的概率。
蚁群算法简介

蚁群算法简介蚁群算法是一种优化技术,受到自然界中蚂蚁寻找食物的行为的启发。
这种算法模拟了蚂蚁的信息共享和移动模式,用于解决复杂的组合优化问题,如旅行商问题(TSP)、车辆路径问题(VRP)等。
一、蚁群算法的基本原理在自然界中,蚂蚁寻找食物的行为非常有趣。
它们会在路径上留下信息素,后续的蚂蚁会根据信息素的强度选择路径,倾向于选择信息素浓度高的路径。
这样,一段时间后,大多数蚂蚁都会选择最短或最佳的路径。
这就是蚁群算法的基本原理。
二、蚁群算法的主要步骤1.初始化:首先,为每条边分配一个初始的信息素浓度。
通常,所有边的初始信息素浓度都是相等的。
2.路径选择:在每一步,每个蚂蚁都会根据当前位置和周围信息素浓度选择下一步的移动方向。
选择概率与信息素浓度成正比,与距离成反比。
这意味着蚂蚁更倾向于选择信息素浓度高且距离短的路径。
3.释放信息素:当蚂蚁完成一次完整的路径后,它会在其经过的边上留下信息素。
信息素的浓度与解决问题的质量成正比,即如果蚂蚁找到了一条更好的路径,那么这条路径上的信息素浓度会增加。
4.更新:经过一段时间后,信息素会随时间的推移而挥发,这使得那些不再被认为是最优的路径上的信息素浓度逐渐减少。
同时,每条边上的信息素浓度也会随着时间的推移而均匀增加,这使得那些从未被探索过的路径也有被选择的可能性。
5.终止条件:算法会在找到满足条件的最优解或达到预设的最大迭代次数后终止。
三、蚁群算法的优势和局限性蚁群算法的优势在于其对于组合优化问题的良好性能和其自然启发式的搜索过程。
这种算法能够有效地找到全局最优解,并且在搜索过程中能够避免陷入局部最优解。
此外,蚁群算法具有较强的鲁棒性,对于问题的规模和复杂性具有较强的适应性。
然而,蚁群算法也存在一些局限性。
首先,算法的性能高度依赖于参数的设置,如信息素的挥发速度、蚂蚁的数量、迭代次数等。
其次,对于一些复杂的问题,可能需要很长的计算时间才能找到最优解。
此外,蚁群算法可能无法处理大规模的问题,因为这可能导致计算时间和空间的复杂性增加。
蚁群算法的基本原理和应用

蚁群算法的基本原理和应用简介蚁群算法(Ant Colony Optimization,简称ACO)是一种模拟蚂蚁觅食行为的启发式算法,它源于对蚂蚁在寻找食物时的行为规律的研究。
蚁群算法模拟了蚂蚁在寻找最佳路径时释放信息素、选择路径的策略,通过蚁群成员之间的相互合作和信息共享来求解各类优化问题。
蚁群算法具有较高的适应性和鲁棒性,被广泛应用于优化问题求解中。
基本原理蚁群算法基于一种基本的反馈机制:蚂蚁在行动过程中释放信息素,并根据所释放的信息素密度来选择路径。
信息素在路径上的积累程度会影响蚂蚁选择路径的概率,从而引导整个蚁群向目标位置集中。
具体的基本原理如下:1.蚂蚁的行动规则:蚂蚁按照一定的规则进行移动,每个蚂蚁根据当前位置的信息素密度以及启发式信息(例如距离、路径质量等)选择下一步的移动方向。
2.信息素的更新:蚂蚁在路径上释放信息素,并且信息素的蒸发和更新过程会导致信息素的动态变化。
经过多次迭代后,信息素会逐渐积累在最优路径上,从而引导后续的蚂蚁选择该路径。
3.路径选择概率:蚂蚁在选择下一步移动方向时,会根据当前位置的信息素和启发式信息计算路径选择概率。
较高的信息素密度和启发式信息将增加路径的选择概率。
应用领域蚁群算法在众多领域中取得了广泛的应用,以下列举几个示例:1.路径规划问题:蚁群算法可以用于解决路径规划问题,例如在城市中找到最短路径。
蚁群算法通过模拟蚂蚁的觅食行为,可以在复杂的网络中找到最优路径,无论是在城市道路网络还是在电信网络中。
–寻找最短路径:蚁群算法可以应用于解决最短路径问题,例如在城市导航、物流路径规划等领域。
–车辆路径优化:蚁群算法可以优化车辆的路线,减少行驶距离和时间,提高运输效率。
2.优化问题:蚁群算法在求解各种优化问题中具有较好的性能,例如旅行商问题、装箱问题等。
–旅行商问题:蚁群算法可以应用于解决旅行商问题,找到最短的旅行路线,减少旅行的距离和时间。
–装箱问题:蚁群算法可以优化装箱问题,将不同大小的物品装入不同大小的容器中,减少空间浪费。
蚁群算法原理

蚁群算法原理一、什么是蚁群算法蚁群算法(Ant Colony Optimization,ACO)是一种仿生智能算法,它模拟蚂蚁搜索食物的行为,从而解决多种优化问题。
该算法旨在建立蚂蚁在搜索空间中的路径,并在这些路径上传播信息,从而使蚂蚁在搜索空间中最终能够找到最优解的路径。
二、蚁群算法的原理1、蚁群算法的基本原理蚁群算法建立在模拟生物天性的基础上,它的基本原理如下:蚂蚁在搜索过程中会搜索出一系列可能的路径,当它们回到搜索起点时,会把它们走过的路线信息传给其它蚂蚁,然后其它蚂蚁据此搜索出其它可能的路线,此过程一直持续,所有蚂蚁在搜索空间中随机探索,把自己走过的路线都留下越多的信息,这样就把多条路线的信息逐渐累积,最终能够找到最优解的路径,从而解决优化问题。
2、蚁群算法的过程(1)协作首先,许多蚂蚁在搜索空间中进行协作,它们在这个空间中进行随机搜索,并尝试找到最优解的路径。
(2)共嗅搜索过程中,蚂蚁会随机尝试搜索各种可能的路径,并在路径上沿途留下一些信息,这些信息就是蚂蚁在搜索过程中搜集到的数据,以这些数据为基础,一方面蚂蚁能够自动判断路径上的优劣,另一方面其它蚂蚁也可以共享这些信息,从而改进和优化搜索效率。
(3)路径搜索蚂蚁在搜索过程中会随机尝试搜索所有可能的路径,它们也会把自己走过的最好的路径留下,这个路径就是最后需要搜索的最优路径,当蚂蚁搜索完毕时,就能够把这条最优路径传给其它蚂蚁,从而解决优化问题。
三、蚁群算法的优势1、收敛性好蚁群算法拥有良好的收敛性,它可以较快地找到最优解。
2、实现简单蚁群算法实现简单,只需要定义蚂蚁在寻找最优路径时的行为模型即可,无需定义较多的参数,因此能够大大减少计算量。
3、鲁棒性高蚁群算法的鲁棒性很高,它可以有效地避免局部最优路径,从而更容易达到全局最优路径。
四、蚁群算法的应用1、旅行商问题蚁群算法可以用来解决旅行商问题,即给定一组城市,求解访问相关城市的最优路径。
毕业论文 蚁群算法

毕业论文蚁群算法蚁群算法(Ant Colony Optimization,ACO)是一种模拟蚂蚁寻找食物的行为而发展而来的一种计算智能算法。
该方法利用蚂蚁在寻找食物过程中留下的信息素来指导其他蚂蚁选择路径,从而达到最优路径的目的。
本文将介绍蚁群算法的基本原理、应用领域以及算法的优缺点。
一、算法原理1.1信息素在蚁群算法中,信息素是指蚂蚁在寻找食物时分泌的一种化学物质,它会留在路径上,用于指导其他蚂蚁选择路径。
当一条路径上的信息素浓度足够高时,其他蚂蚁会更倾向于选择这条路径。
1.2蚁群算法过程(1)初始化:随机放置一些蚂蚁并随机设置它们的起点和终点。
(2)蚂蚁选择路径:每个蚂蚁根据当前位置的信息素浓度,选择下一步要走的路径。
选择路径的规则可以根据具体问题来设计。
(3)信息素更新:当蚂蚁完成任务后,会在其经过的路径上留下一定量的信息素。
信息素的更新可以通过公式:$ T_{ij}=(1-ρ) ·T_{ij}+∑\\frac{\\Delta T_{ij}^{k}}{L_{k}} $ 来完成,其中 $ T_{ij} $ 表示在第 $i$ 个节点到第 $j$ 个节点之间路径的信息素,$ L_{k} $ 表示第 $k$ 只蚂蚁走过的路径长度,$ \\Delta T_{ij}^{k} $ 表示第 $k$ 只蚂蚁在第 $i$ 个节点到第$j$ 个节点之间路径上留下的信息素。
(4)重复执行步骤(2)和(3),直到满足算法终止条件。
二、应用领域由于蚁群算法具有寻优能力和适应性强等优点,因此在多个应用领域得到了广泛的应用:2.1路线规划将蚁群算法应用到路线规划中,可以帮助人们更快捷、更准确地规划出最优路径。
例如,在地图搜索、货车路径规划、船只导航等领域都有广泛的应用。
2.2优化问题蚁群算法能够在多种优化问题中得到应用,例如在图像处理、模式识别、网络优化中,通过不断地调节参数,可以找出最佳的结果。
2.3组合优化问题在组合优化问题中,由于问题的规模较大,常规优化算法很容易陷入局部最优解中无法跳出。
蚁群算法详细讲解

蚁群算法详细讲解蚁群算法(Ant Colony Optimization, ACO)是一种受到蚂蚁觅食行为启发的启发式优化算法。
它通过模拟蚂蚁在寻找食物过程中遗留下的信息以及相互之间的交流行为,来解决优化问题。
蚁群算法在组合优化问题中特别有效,如旅行商问题、车辆路径问题等。
蚂蚁在寻找食物的过程中会释放一种称为信息素的化学物质,并在路径上留下信息素的痕迹。
蚁群算法的核心思想就是利用信息素来引导蚂蚁的行动。
当蚂蚁找到食物后,会返回巢穴,并留下一条含有更多信息素的路径。
其他蚂蚁在寻找食物时,会更倾向于选择留有更多信息素的路径,从而使得这条路径的信息素浓度进一步增加。
随着时间的推移,信息素会在路径上逐渐积累,形成一条较优的路径。
蚁群算法的步骤如下:1.初始化信息素:根据问题设置信息素初始浓度,并随机分布在各个路径上。
2.蚂蚁移动:每只蚂蚁在一个时刻从起点出发,根据一定策略选择路径。
通常,蚂蚁选择路径的策略是基于信息素和启发式信息(如距离、路径通畅程度等)。
蚂蚁在移动过程中,会增加或减少路径上的信息素浓度。
3.更新信息素:当所有蚂蚁完成移动后,根据算法的更新规则,增加或减少路径上的信息素。
通常,路径上的信息素浓度会蒸发或衰减,并且蚂蚁留下的信息素会增加。
更新信息素时,通常会考虑到蚂蚁的路径质量,使得较好的路径上留下更多信息素。
4.终止条件判断:根据预设条件(如迭代次数、找到最优解等)判断是否达到算法的终止条件。
如果未达到终止条件,则返回到步骤2;否则,输出最优路径或最优解。
蚁群算法的优点包括:1.分布式计算:蚁群算法采用分布式计算方式,各个蚂蚁独立进行,在处理大规模问题时具有优势。
2.适应性:蚁群算法具有自适应性,能够根据问题的特性调整参数以及策略。
3.全局能力:蚁群算法能够在问题空间中全面,不容易陷入局部最优解。
蚁群算法的应用领域广泛,如路由优化、智能调度、图像处理等。
它在旅行商问题中经常被使用,能够找到较优的旅行路径。
蚂蚁群算法

蚂蚁群算法摘要:1.蚂蚁群算法的定义与原理2.蚂蚁群算法的应用领域3.蚂蚁群算法的优缺点4.我国在蚂蚁群算法研究方面的进展正文:蚂蚁群算法(Ant Colony Optimization, ACO)是一种受自然界蚂蚁觅食行为启发而设计的优化算法。
该算法主要通过模拟蚂蚁在寻找食物过程中的信息素更新和路径选择过程,以达到对复杂问题的求解。
在蚂蚁群算法中,信息素是蚂蚁在寻找食物过程中留下的一种化学物质,用于传递食物源的位置和质量信息。
当蚂蚁找到食物后,它会在返回路径上释放一种正向信息素,表示该路径是有效的。
而当蚂蚁走错路时,它会释放一种负向信息素,表示该路径是无效的。
随后,其他蚂蚁在寻找食物时会根据信息素的浓度来选择路径,从而实现整个蚁群的优化寻优。
蚂蚁群算法具有很强的全局搜索能力,适用于解决各种组合优化问题,如旅行商问题(Traveling Salesman Problem, TSP)、装载问题、排课问题等。
目前,蚂蚁群算法已经在多个领域取得了显著的应用成果,如物流、制造、交通、教育等。
尽管蚂蚁群算法在搜索优化问题方面具有很多优点,但同时也存在一些缺点,如算法收敛速度较慢、容易陷入局部最优解等。
为了克服这些问题,研究者们不断对算法进行改进和优化,如引入邻域搜索、自适应调整信息素浓度等策略,以提高算法的性能和效率。
我国在蚂蚁群算法研究方面取得了世界领先的成果。
研究人员不仅在理论层面深入探讨了蚂蚁群算法的原理和性能分析,还在实际应用中不断优化算法,使其更好地解决实际问题。
此外,我国还积极推动蚂蚁群算法与其他优化算法的融合研究,以期进一步拓展该算法的应用领域和实用性。
总之,蚂蚁群算法作为一种自然启发式优化算法,在解决复杂问题方面具有很大的潜力。
蚁群算法简述

3.蚁群算法的数学模型
蚁群的规模和停止规则
蚁群大小: 一般情况下蚁群中蚂蚁的个数不超过TSP图中节点的个数。
终止条件: 1 给定一个外循环的最大数目,表明已经有足够的蚂蚁工作; 2 当前最优解连续K次相同而停止,其中K是一个给定的整数,表 示算法已经收敛,不再需要继续; 3 目标值控制规则,给定优化问题(目标最小化)的一个下界和一 个误差值,当算法得到的目标值同下界之差小于给定的误差值时, 算法终止。
1.蚁群算法的提出
假设蚂蚁每经过一处所留下的信息素为一个单位,则经过36 个时间单位后,所有开始一起出发的蚂蚁都经过不同路径从D点取 得了食物,此时ABD的路线往返了2趟,每一处的信息素为4个单 位,而 ACD的路线往返了一趟,每一处的信息素为2个单位,其 比值为2:1。
寻找食物的过程继续进行,则按信息素的指导,蚁群在ABD路 线上增派一只蚂蚁(共2只),而ACD路线上仍然为一只蚂蚁。再 经过36个时间单位后,两条线路上的信息素单位积累为12和4,比 值为3:1。
2.蚁群算法的特征
移动规则 每只蚂蚁都朝向信息素最多的方向移,并且,当周围没有信息素指引的时候,
蚂蚁会按照自己原来运动的方向惯性的运动下去,并且,在运动的方向有一个随 机的小的扰动。为了防止蚂蚁原地转圈,它会记住刚才走过了哪些点,如果发现 要走的下一点已经在之前走过了,它就会尽量避开。 避障规则
1.蚁群算法的提出
1) 标有距离的路径图 2) 在0时刻,路径上没有信息素累积,蚂蚁选择路径为任意 3) 在1时刻,路径上信息素堆积,短边信息素多与长边,所以蚂蚁更倾向于选择
ABCDE
蚂蚁群算法

蚂蚁群算法【实用版】目录1.蚂蚁群算法的概念与原理2.蚂蚁群算法的运算过程3.蚂蚁群算法的应用领域4.蚂蚁群算法的优势与局限性正文一、蚂蚁群算法的概念与原理蚂蚁群算法(Ant Colony Optimization, ACO)是一种模拟自然界蚂蚁觅食行为的优化算法。
该算法是受生物学家对蚂蚁觅食过程的研究启发而提出的。
在自然界中,蚂蚁在寻找食物时会释放出一种名为信息素的物质,通过信息素在蚂蚁之间的传递,蚂蚁能够找到最短路径并迅速聚集到食物源。
蚂蚁群算法的基本思想是将待解决的问题看作一个寻找最优解的过程,通过模拟蚂蚁在寻找食物过程中释放和感知信息素的行为,来逐步优化问题的解。
二、蚂蚁群算法的运算过程1.初始化:在算法开始运行之前,需要对一些参数进行初始化,包括信息素浓度、启发式因子、蚂蚁数量、迭代次数等。
2.蚂蚁觅食:算法开始后,每只蚂蚁都会从自己的信息素浓度开始,按照一定的概率选择下一个路径,直到找到目标点。
在这个过程中,蚂蚁会在路径上释放信息素,信息素的浓度与路径的长度成反比。
3.更新信息素:当所有蚂蚁都完成觅食后,需要对信息素进行更新。
更新规则是:信息素的浓度与路径上蚂蚁数量成正比,与路径长度成反比。
4.检查停止条件:重复进行迭代,直到达到预设的最大迭代次数或者满足其他停止条件。
5.返回最优解:在所有迭代中,记录最优路径和对应的信息素浓度,算法结束后返回最优解。
三、蚂蚁群算法的应用领域蚂蚁群算法在很多领域都取得了显著的成果,主要应用领域包括:1.组合优化问题:如旅行商问题(Traveling Salesman Problem, TSP)、装载问题(Vehicle Routing Problem, VRP)等。
2.信号处理与通信:如无线通信中的信道编码和解码问题、信号处理中的参数估计问题等。
3.机器学习和数据挖掘:如分类问题、聚类问题等。
4.其他领域:如生物信息学、经济学、社会学等。
四、蚂蚁群算法的优势与局限性优势:1.适用于多种问题类型,具有较强的通用性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
蚁群算法简述及实现1 蚁群算法的原理分析蚁群算法是受自然界中真实蚁群算法的集体觅食行为的启发而发展起来的一种基于群体的模拟进化算法,属于随机搜索算法,所以它更恰当的名字应该叫“人工蚁群算法”,我们一般简称为蚁群算法。
M.Dorigo等人充分的利用了蚁群搜索食物的过程与著名的TSP问题的相似性,通过人工模拟蚁群搜索食物的行为来求解TSP问题。
蚂蚁这种社会性动物,虽然个体行为及其简单,但是由这些简单个体所组成的群体却表现出及其复杂的行为特征。
这是因为蚂蚁在寻找食物时,能在其经过的路径上释放一种叫做信息素的物质,使得一定范围内的其他蚂蚁能够感觉到这种物质,且倾向于朝着该物质强度高的方向移动。
蚁群的集体行为表现为一种正反馈现象,蚁群这种选择路径的行为过程称之为自催化行为。
由于其原理是一种正反馈机制,因此也可以把蚁群的行为理解成所谓的增强型学习系统(Reinforcement Learning System)。
引用M.Dorigo所举的例子来说明蚁群发现最短路径的原理和机制,见图1所示。
假设D 和H之间、B和H之间以及B和D之间(通过C)的距离为1,C位于D和B的中央(见图1 (a))。
现在我们考虑在等间隔等离散世界时间点(t=0,1,2……)的蚁群系统情况。
假设每单位时间有30只蚂蚁从A到B,另三十只蚂蚁从E到D,其行走速度都为1(一个单位时间所走距离为1),在行走时,一只蚂蚁可在时刻t留下浓度为1的信息素。
为简单起见,设信息素在时间区间(t+1,t+2)的中点(t+1.5)时刻瞬时完全挥发。
在t=0时刻无任何信息素,但分别有30只蚂蚁在B、30只蚂蚁在D等待出发。
它们选择走哪一条路径是完全随机的,因此在两个节点上蚁群可各自一分为二,走两个方向。
但在t=1时刻,从A到B的30只蚂蚁在通向H的路径上(见图1 (b))发现一条浓度为15的信息素,这是由15只从B走向H的先行蚂蚁留下来的;而在通向C的路径上它们可以发现一条浓度为30的信息素路径,这是由15只走向BC的路径的蚂蚁所留下的气息与15只从D经C到达B留下的气息之和(图1 (c))。
这时,选择路径的概率就有了偏差,向C走的蚂蚁数将是向H走的蚂蚁数的2倍。
对于从E到D来的蚂蚁也是如此。
(a)(b)(c)图1 蚁群路径搜索实例这个过程一直会持续到所有的蚂蚁最终都选择了最短的路径为止。
这样,我们就可以理解蚁群算法的基本思想:如果在给定点,一只蚂蚁要在不同的路径中选择,那么,那些被先行蚂蚁大量选择的路径(也就是信息素留存较浓的路径)被选中的概率就更大,较多的信息素意味着较短的路径,也就意味着较好的问题回答。
2人工蚁群算法描述蚁群算法可以看作为一种基于解空间参数化概率分布模型(Parameterized Probabilistic Model)的搜索算法框架(Model-based search algorithms)。
在蚁群算法中,解空间参数化概率,模型的参数就是信息素,因而这种参数化概率分布模型就是信息素模型。
在基于模型的搜索算法框架中,可行解通过在一个解空间参数化概率分布模型上的搜索产生,此模型的参数用以前产生的解来更新,使得在新模型上的搜索能够集中在高质量的解搜索空间内。
这种方法的有效性建立在高质量的解总是包含好的解构成元素的假设前提下。
通过学习这种解构成元素对解的质量的影响有助于找到一种机制,并通过解构成元素的最佳组合来构造出高质量的解。
一般来说,一个记忆模型的搜索算法通常使用以下两步迭代来解决优化问题:1)可行解通过在解空间参数化概率分布模型上的搜索产生。
2)用搜索产生的解来更新参数化概率模型,即更新解空间参数化概率分布的参数,使得在新模型上的参数搜索能够集中在高质量的解搜索空间内。
在蚁群算法中,基于信息素的解空间参数化概率模型(信息素模型)以解构造图的形式给出。
在解构造图上,定义了一种作为随机搜索机制的人工蚁群,蚂蚁通过一种分布在解构造图上被称为信息素的局部信息的指引,在解构造图上移动,从而逐步的构造出问题的可行。
信息素与解构造图上的节点或弧相关联,作为解空间参数化概率分布模型的参数。
由于TSP问题可以直接的映射为解构造图(城市为节点,城市间的路径为弧,信息素分布在弧上),加之TSP问题也是个NP难题,所以,蚁群算法的大部分应用都集中在TSP问题上。
一般而言,用于求解TSP问题、生产调度问题等优化问题的蚁群算法都遵循下面的统一算法框架。
算法1:求解组合优化问题的蚁群算法设置参数,初始化信息素踪迹While(不满足条件时)dofor蚁群中的每只蚂蚁for每个解构造步(直到构造出完整的可行解)1)蚂蚁按照信息素及启发式信息的指引构造一步问题的解;2)进行信息素局部更新。
(可选)endforendfor1)以某些已获得的解为起点进行邻域(局部)搜索;(可选)2)根据某些已获得的解的质量进行全局信息素更新。
endwhileend在算法1中,蚂蚁逐步的构造问题的可行解,在一步解的构造过程中,蚂蚁以概率方式选择信息素强且启发式因子高的弧到达下一个节点,直到不能继续移动为止。
此时蚂蚁所走过的路径对应求解问题的一个可行解。
局部信息素更新针对蚂蚁当前走过的一步路径上的信息素进行,全局信息素更新是在所有蚂蚁找到可行解之后,根据发现解的质量或当前算法找到的最好解对路径上的信息素进行更新。
3 蚁群算法与其他搜索算法比较3.1 蚁群算法与进化算法比较近年来,遗传算法(GA)、进化规划(Evolutionary Planning)、进化策略(Evolutionary Strategies)在理论和应用上发展迅速、效果显著并逐渐走向了融合,形成了一种新颖的模拟进化的计算理论,统称为进化计算(Evolutionary Computation)。
因此我们可以用进化计算作为代表与蚁群算法进行比较,从另一个角度来认识蚁群算法,加深对蚁群算法的理解。
蚁群算法与进化计算的相似之处有两点:首先,两种算法均采用群体表示问题的解;其次,新群体通过包含在群体中与问题相关的知识来生成。
两者的主要区别在于进化计算中所有问题的的知识都包含在当前群体中,而蚁群算法中代表过去所学的知识保存在信息素的踪迹中。
3.2 蚁群算法与模拟退火算法比较从模拟退火算法的搜索策略可以看出蚁群算法和模拟退火算法(SA)从本质上来讲是一致的。
SA对某个“固体的”一个微观状态i计算其能量E i的过程与蚂蚁的一次“周游”一样,都是对解空间的一次采样;“退火”与“分泌信息素”都是利用积累信息来增强对子空间的搜索;而“Metropolis准则”和“随机状态转移规则”类似,都是使算法能够跳出局部最优,在一定范围内接受恶化解,搜索新的子空间。
因此,SA已经非常成熟的收敛性研究对分析设置蚂蚁规模参数和信息素分布策略对最终解质量的影响有很大的借鉴意义。
对于SA的收敛性分析一般分两种情况,齐次Markov链和非齐次Markov链。
齐次Markov链的分析结果告诉我们,在任意温度t,SA都达到平衡分布的情况下,当t→0时,SA将收敛于全局最优。
也就是说,在任意温度t,SA都要遍历整个解空间。
那么,如果我们保留sA采样后的当前全局最优解,则即使在任何温度t,SA都会收敛于全局最优。
换句话说,对于蚁群算法,如果蚂蚁数量(规模)足够多,能够保证对解空间的遍历,那么即使不用信息素,也能保证全局收敛。
不过这种方法显然就是一种盲目随机搜索,没有任何实际的应用价值。
对于非其次Markov链的SA,即在某个固定温度t,采样次数有限,而t将无限趋近于0的情况下,结论告诉我们当控制参数序列满足一定条件时,SA才收敛于整体最优解集。
其更直接的表述方式是:控制参数t的衰减量与在温度t下的采样数之间存在一种均衡:t的衰减量越大,则在温度艺下的采样数就必须越多;反之,若t的衰减量缓慢,则在每个温度下SA只需进行少量采样。
那么。
从蚁群算法的角度可以看到:因为蚂蚁的规模实际上影响的只是信息素更新的频率,所以当规模设置较大时,每次更新信息素时,可以以较快的速度拉大不同状态上的信息素差距;当规模较小时,每次只对信息素进行少量更新,以免算法早熟。
由此可见,对蚁群算法的参数设置可以直接利用SA中对“冷却进度表”的研究成果。
此外,既然两者在本质上一致,那么SA的一些改进和变异可以直接用在蚁群算法上以改进其性能。
3.3 蚁群算法与神经网络比较由许多并发、局部交互的单元(人工蚂蚁)组成的蚁群,可以看成是一种“连接”系统。
“连接”系统最具代表性的例子是神经网络(Neural Network,简称NN)。
从结构上看,蚁群算法与通常的神经网络具有类似的并行机制。
蚂蚁访问过的每一个状态i对应于神经网络中的神经元i,与问题相关的状态i的邻域结构与神经元i中的突触连接相对应。
蚂蚁本身可以看成是通过神经网络的并发输入信号,以修改突触与神经元之间的连接强度。
信号经过随机转换函数的局部反传,使用的突触越多,两个神经元之间的连接越强。
蚁群算法中的学习规则可以解释为一种后天性的规则,即质量较好的解包含连接信号的强度高于质量较差的解。
4 基本蚁群算法及其实现4.1 引言蚁群在觅食过程中总能找到蚁巢和食物源之间的最短路径。
受蚂蚁的这种行为启发,意大利学者M.Dorigo 、V .Maniezzo 以及A.Colorni 首先提出了一种新型的随机搜索模拟进化算法—蚂蚁系统(Ant System,简称As)。
AS 算法是第一个蚁群算法的模型,被称为基本蚁群算法。
AS 算法首先被用来求解TSP 问题,并取得了巨大成功。
实验结果显示AS 算法具有很强的发现较好解的能力,但同时也存在一些缺点,如收敛速度较慢、易出现停滞现象等等。
针对AS 算法的不足之处,许多学者对其进行了深入的研究,提出了一些改进的蚁群算法,如带精英策略的蚂蚁系统(Ant System With elitist strategy,简称AS elitist 、蚁群系统(Ant Colorni System,简称ACS)、基于优化排序的蚂蚁系统(Rank-Based Version of Ant System,简称AS rank )、最大-最小蚂蚁系统(Max-Min Ant System,简称MMAS)以及最优-最差蚂蚁系统(Best-Worst Ant System,简称BW AS)等等。
4.2 蚂蚁系统的模型描述为了说明蚂蚁系统的模型,首先引入TSP 问题。
一般地来说,旅行商问题(Traveling Salesman Problem,简称TSP 问题)可以描述如下: 设C={c l ,c 2,…,c n }为n 个城市的集合,L= {L ij |c i 、c j ∈C }是c 中元素两两连接的集合,G=(C,L)是一个图,已知各城市之间的距离,TSP 问题的求解目的是从G 中找出长度最短的Hamiltonian 圈,即找出对C={c l ,c 2,…,c n }中n 个城市访问且只访问一次的最短的一条封闭曲线。