模式识别——用身高和或体重数据进行性别分类
机器学习领域中的分类算法

机器学习领域中的分类算法随着大数据时代的到来,机器学习已经成为了最炙手可热的技术之一。
在数据挖掘和人工智能领域,分类问题一直是非常重要的问题之一。
分类指的是将数据集中的实例按照某种规则将其区分开来。
分类算法可以让机器对不同的输入数据进行自动分类,从而得到更加精准、高质量的预测结果。
在机器学习领域中,分类算法是比较基础和常用的方法之一。
在研究分类算法之前,需要了解一下两个非常重要的概念:特征和标签。
特征是指用于对实例进行描述的属性,比如身高、体重、性别等;而标签则是对每个实例所属类别的标记,也称为类标。
分类算法的目的就是,通过学习这些特征和标签之间的关系,预测新的输入数据的类别。
分类算法的种类非常多,我们可以根据不同的分类方式来对其进行分类。
比如说,可以根据分类模型的分布方式将其分为生成模型和判别模型;也可以根据算法中使用的训练方法将其分为监督学习和非监督学习。
下面我们将会讨论一些常见的分类算法。
1. K最近邻算法(K-Nearest Neighbor Algorithm)K最近邻算法是一种监督学习的算法,它的主要思想是:对于一个新的输入样本,它所属的类别应当与与它最近的K个训练样本的类别相同。
其中K是一个可调参数,也称为邻居的个数。
算法的流程大致如下:首先确定K的值,然后计算每一个测试数据点与训练数据集中每个点的距离,并根据距离从小到大进行排序。
最后统计前K个训练样本中各类别出现的次数,选取出现次数最多的类别作为该测试样本的输出。
K最近邻算法简单易用,但是它有一些局限性。
首先,算法的分类效果对数据的质量非常敏感,因此需要对数据进行预处理。
其次,算法需要存储全部的训练数据,对于大规模数据集,存储和计算的开销非常大。
2. 决策树算法(Decision Tree Algorithm)决策树是一种基于树形结构进行决策支持的算法。
其原理是:将一个问题转化为简单的二选一问题并逐步求解,形成一棵树形结构,从而形成不同的决策路径。
Bayes分类器算法

⇒ x ∈ωi
2、具体步骤如下 A).算出各类别特征值的均值 B).求出特征值的协方差矩阵 C).将第二步所得矩阵代入判别函数 g1(x)、g2(x) D).将待测试样本集数据依次代入 g1(x)- g2(x),若 g1(x)- g2(x)>0,则判断其为第一类,反
之为第二类。 3、流程图
确定特征及先验概率
体重: clear all; load FEMALE.txt; load MALE.txt; fid=fopen('test2.txt','r'); test1=fscanf(fid,'%f %f %c',[3,inf]); test=test1';
fclose(fid); Fmean = mean(FEMALE); Mmean = mean(MALE); Fvar = std(FEMALE); Mvar = std(MALE); preM = 0.9; preF = 0.1; error=0; Nerror=0; figure; for i=1:300
Nerror = Nerror +1; end; else plot(test(i,1),test(i,2),'k*'); if (test(i,3)=='F')
Nerror = Nerror +1; end end hold on; end; title('身高体重不相关最小风险的 Bayes 决策'); ylabel('身高(cm)'),zlabel('体重(kg)'); error = Nerror/300*100; sprintf('%s %d %s %0.2f%s','分类错误个数:',Nerror,'分类错误率为:',error,'%')
模式识别关于男女生身高和体重的神经网络算法

模式识别实验报告(二)学院:专业:学号:姓名:XXXX教师:目录1实验目的 (1)2实验内容 (1)3实验平台 (1)4实验过程与结果分析 (1)4.1基于BP神经网络的分类器设计 .. 1 4.2基于SVM的分类器设计 (4)4.3基于决策树的分类器设计 (7)4.4三种分类器对比 (8)5.总结 (8)1)1实验目的通过实际编程操作,实现对课堂上所学习的BP神经网络、SVM支持向量机和决策树这三种方法的应用,加深理解,同时锻炼自己的动手实践能力。
2)2实验内容本次实验提供的样本数据有149个,每个数据提取5个特征,即身高、体重、是否喜欢数学、是否喜欢文学及是否喜欢运动,分别将样本数据用于对BP神经网络分类器、SVM支持向量机和决策树训练,用测试数据测试分类器的效果,采用交叉验证的方式实现对于性能指标的评判。
具体要求如下:BP神经网络--自行编写代码完成后向传播算法,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算可以基于平台的软件包);SVM支持向量机--采用平台提供的软件包进行分类器的设计以及测试,尝试不同的核函数设计分类器,采用交叉验证的方式实现对于性能指标的评判;决策树--采用平台提供的软件包进行分类器的设计以及测试,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算基于平台的软件包)。
3)3实验平台专业研究方向为图像处理,用的较多的编程语言为C++,因此此次程序编写用的平台是VisualStudio及opencv,其中的BP神经网络为自己独立编写, SVM 支持向量机和决策树通过调用Opencv3.0库中相应的库函数并进行相应的配置进行实现。
将Excel中的119个数据作为样本数据,其余30个作为分类器性能的测试数据。
4)4实验过程与结果分析4.1基于BP神经网络的分类器设计BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
模式识别(1)

模式识别系统实例(二)
可观察性 可区分性 相似性
模式识别的研究
模式识别的作用和目的:利用计算机对物理对 象进行分类,在错误概率最小的条件下,使识 别的结果尽量与客观物体相符合。
定量的表示方法:Y = F(X)
-从具有时间和空间分布的信息向着符号所做的映射。
X的定义域取自特征集 Y的值域为类别的标号集 F是模式识别的判别方法
长度 亮度 宽度 鱼翅的数量和形状 嘴的位置,等等 …
分类决策:把特征送入决策分类器
模式识别系统实例(一)
鲑鱼和鲈鱼:
特征-长度、光泽、宽度、鳍的数目和形状、嘴的位置。
图像本身差异-光照、鱼的位置、拍摄噪声等。
模式识别系统实例(一)
两种鱼的长度特征直方图
模式识别系统实例(一)
两种鱼的光泽度特征直方图
在传送带上用光学传感器件对鱼按品种分类 鲈鱼(Seabass) 品种 鲑鱼(Salmon) 数据获取:架设一个摄像机,采集一些样本图 像,获取样本数据 预处理:去噪声,用一个分割操作把鱼和鱼之 间以及鱼和背景之间分开
模式识别系统实例(一)
特征提取和选择:对单个鱼的信息进行特征选 择,从而通过测量某些特征来减少信息量
模式识别系统实例(一)
目标:确定一种决策,使该代价函数最小。
寻找其他的更利于分类的特征或组合运用多种特征 光泽度x1和宽度x2
分类
模式识别系统实例(一)
两种鱼的光泽度特征和宽度特征的散布图
模式识别系统实例(一)
过份复杂的模型将导致复杂的判决曲线
模式识别系统实例(一)
图中标注的判决曲线是对训练样本的分类性能和分界面复杂度的一 个最优折中。因而对将来的新模式的分类性能也很好
模式识别的使用方法

模式識別的使用方法模式识别是一种重要的数据处理技术,它可以在数据中发现和识别出重复出现的模式并加以利用。
在现代科学和工程领域,模式识别被广泛应用于各种任务,如语音识别、图像识别、自然语言处理等。
模式识别的使用方法可以分为以下几个步骤:1. 数据收集和准备:首先需要收集所需的数据样本,并对其进行预处理,以便更好地适应后续的模式识别算法。
预处理包括数据清洗、数据转换和特征提取等操作。
2. 特征选择和提取:在模式识别中,特征是用于描述和区别不同模式的属性或属性组合。
通过特征选择和提取,我们可以从原始数据中提取出最具有代表性的特征,以便后续的模式识别算法更好地处理。
3. 模型选择和训练:在模式识别中,我们需要选择适合任务的模型或算法,并对其进行训练。
模型选择通常基于任务的特点和性能需求,可以选择分类模型(如K近邻、决策树、支持向量机等)或聚类模型(如K-means、高斯混合模型等)等。
4. 模式识别和分类:经过模型训练后,我们可以将新的数据样本输入到模型中进行模式识别和分类。
模式识别的结果可以是对模式的标识、对模式的描述或对模式的概率估计等。
5. 模型评估和优化:模式识别的性能评估是一个重要的环节,它可以用于评估模型的准确性、鲁棒性和效率等。
根据评估结果,我们可以对模型进行优化和调整,以提高模式识别的性能。
除了以上基本步骤,模式识别还可以结合其他相关技术和方法,以更好地适应不同任务的需求。
例如,可以结合深度学习技术进行图像识别,或结合自然语言处理技术进行文本分类等。
模式识别的使用方法对于各行各业都具有重要意义。
在医学领域,它可以用于诊断疾病和预测病情;在金融领域,可以用于风险评估和交易预测;在自动驾驶领域,可以用于道路识别和障碍物检测等。
通过模式识别的使用,我们可以更好地理解和利用数据,并为决策和问题解决提供有力支持。
总结来说,模式识别是一种重要的数据处理技术,它帮助我们在数据中发现和利用重复出现的模式。
大数据分析中基于深度学习的性别识别技术研究

大数据分析中基于深度学习的性别识别技术研究随着互联网技术的发展,人工智能技术被越来越广泛地应用于各个领域,其中大数据分析技术是人工智能的一个热点领域。
而在大数据分析技术中,基于深度学习的性别识别技术则成为近年来十分热门的研究方向。
一、大数据分析中的性别识别技术在大数据分析中,性别识别技术的研究主要是通过分析照片或视频中的人脸来确定人的性别。
传统的方法是通过人脸识别技术获取人脸图像的特征向量,再通过一系列特征量化处理,最终得出人的性别。
但这种传统的方法存在许多缺陷,例如:当人脸被部分遮挡时,或者当人脸有轻微的倾斜或旋转时,传统方法容易识别错误。
为了解决这些问题,越来越多的人转向了基于深度学习的性别识别技术。
二、基于深度学习的性别识别技术基于深度学习的性别识别技术是一种新型的人工智能技术。
它利用神经网络模型来进行图像识别和分类,通过训练数据集来提高精度和准确率。
在深度学习的模型中,最基本的组件是卷积神经网络(Convolutional Neural Network, CNN)。
卷积神经网络通过学习图像的特征,并将不同的特征组合起来,最终得出性别分类的结果。
由于卷积神经网络具有自动提取特征的能力,因此在图像处理方面有着更好的性能。
在深度学习的模型中,还可以使用递归神经网络(Recurrent Neural Network, RNN)等结构,对于一些需要考虑上下文信息的场景,可以利用递归神经网络提高模型的精确度和准确率。
在实际应用中,深度学习的模型需要训练大量的数据集以提高性能。
而对于性别识别技术,也需要训练大量具有不同性别的人的脸部图像。
同时,还需要考虑多种因素对性别的影响,如年龄,肤色,发型等。
三、基于深度学习的性别识别技术的应用基于深度学习的性别识别技术在社交网络,电商平台等领域被广泛应用。
在社交网络上,通过性别识别技术可以更好地推荐好友,推荐像素眼镜和美容平台等应用。
在电商平台上,性别识别技术也可以用于更精准的商品推荐,如化妆品、内衣等。
(最新整理)贝叶斯决策理论与统计判决方法

13
例:统计模式识别
19名男女同学进行体检,测量了身高和体重,但事后发现 其中有4人忘记填写性别,试问(在最小错误的条件下) 这4人是男是女?体检数值如下:
2021/7/26
14
例:统计模式识别
• 待识别的模式:性别(男或女) • 测量的特征:身高和体重 • 训练样本:15名已知性别的样本特征 • 目标:希望借助于训练样本的特征建立判别函数(即数学模型)
2021/7/26
9
例:鱼的分类
分类判决的代价: • 错判的代价和具体应用有关。 • 究竟是鲈鱼混进鲑鱼罐头好,还是鲑鱼混进鲈鱼罐头好?
– 鲑鱼混入鲈鱼罐头:损失利润 – 鲈鱼混入鲑鱼罐头:丢掉客户 • 决策和“总体代价”相关联。做决策就是使得所付出的 代价最小。
2021/7/26
10
例:鱼的分类
27
基于最小错误率的贝叶斯决策
一般说来,c类不同的物体应该具有各不相同的属性,在d维特征空间, 各自有不同的分布。当某一特征向量值X只为某一类物体所特有,即
对其作出决策是容易的,也不会出什么差错。问题在于出现模棱两可的 情况。此时,任何决策都存在判错的可能性。这里讨论的是使错误率为 最小的决策方法,称为基于最小错误率的贝叶斯决策理论。
2021/7/26
28
基于最小错误率的贝叶斯决策
最小错误率是在统计的意义上说的,请注意其含义。
在这里要弄清楚条件概率这个概念。P(*|#)是条件概率的通用符号,在 “|”后边出现的#为条件,之前的*为某个事件,即在某条件#下出现某 个事件*的概率。P(ωK|X)是表示在X出现条件下,样本为ωK类的概 率。
2021/7/26
21
“概率论”有关概念复习
S
05.2 项目五 身高与体重数据分析(分类器)II[31页]
![05.2 项目五 身高与体重数据分析(分类器)II[31页]](https://img.taocdn.com/s3/m/f81258992af90242a895e5d4.png)
知识回顾:朴素贝叶斯
# 建立模型
classifier = MultinomialNB()
# 拟合
classifier.fit(X, Y)
# 给出待预测的一个特征
output = classifier.predict(X) output = output.reshape(len(output),1)
决策树:模型结果可视化
✓ 结合上述结果,如何理解决策树的缺点: (1)易于过拟合 (2)忽略属性之间的相关性
模型评估
方法不分好坏,只有是否适合。 如何评价算法的适合度呢?
• TP:True Positive 正样本被识别为正样本(抓对了) • TN:Ture Negative 负样本被识别为负样本(不该抓也没抓) • FN:False Positive 正样本被识别为负样本(漏抓了) • FP:False Negative 负样本被识别为正样本(抓错了)
缺点 :各类别样本数量不一致数据,信息增益偏向于那些具有更多数值的特征、易 于过拟合、忽略属性之间的相关性、不支持在线学习。
应用:经济领域中的期权定价、市场和商业发展中的评估
决策树:模型训练
模型训练过程
1、初始化分类器
3、预测predict
2、拟合fit
4、准确性评估
from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import classification_report
# 建立模型
classifier = DecisionTreeClassifier()
# 拟合
classifier.fit(x_train, y_train)
模式识别大作业
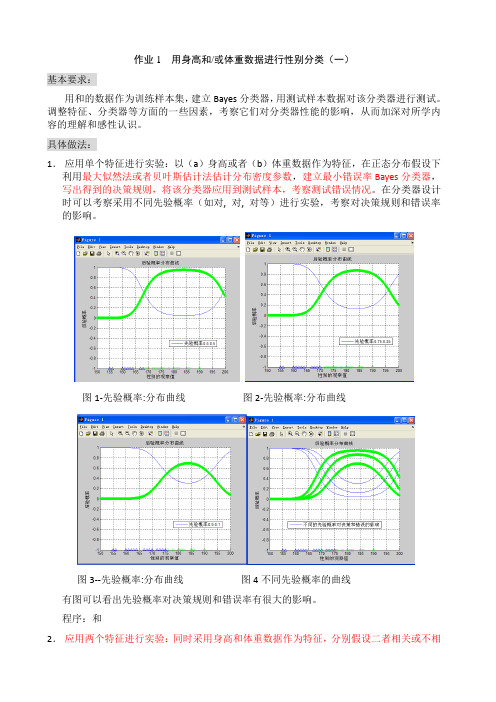
作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率vs. 图2先验概率vs.图3先验概率vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2);error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。
用身高体重数据进行性别分类的实验

1) 用 dataset1.txt 作为训练样本,用dataset2.txt 作为测 试样本,采用身高和体重数据为特征,在正态分布假 设下估计概率密度(只用训练样本),建立最小错误 率贝叶斯分类器,写出所用的密度估计方法和得到的 决策规则,将该分类器分别应用到训练集和测试集, 考察训练错误率和测试错误率。将分类器应用到 dataset3 上,考察测试错误率的情况。(在分类器设 计时可以尝试采用不同先验概率,考查对决策和错误 率的影响。) 2) 自行给出一个决策表,采用最小风险贝叶斯决策重 复上面的实验。
运行程序readdata.m
根据得到的概率密度函数程序实现Bayes分类器 (Matlab函数名称为determine.m)
function sex=determine(a,b) %程序:Bayes决策 %功能:已知一个身高体重的二维向量数据,判断这个数据对应的人是男 是女 p1=1/139.2270*exp(-1/1.7539*(((a-162.3205)^2)/20.9101-(a162.3205)*(b-51.4038)/33.7263+((b-51.4038)^2)/26.7760)); p2=1/298.7922*exp(-1/1.6302*(((a-174.9960)^2)/28.3140-(a174.9960)*(b-67.2340)/61.2470+((b-67.2340)^2)/97.9862)); chenhao1=78/(78+250); chenhao2=250/(78+250); P1=p1*chenhao1/(p1*chenhao1+p2*chenhao2); P2=p2*chenhao2/(p1*chenhao1+p2*chenhao2); if P1>P2
模式识别的基本方法

模式识别的基本方法模式识别指的是对数据进行分类、识别、预测等操作的过程,它是人工智能中的一个重要分支。
在实际应用中,模式识别的基本方法主要包括以下几种。
一、特征提取特征提取指的是从原始数据中提取出有意义的特征用于分类或预测。
在模式识别中,特征提取是非常关键的一步。
因为原始数据可能存在噪声、冗余或不必要的信息,而特征提取可以通过减少数据维度、去除冗余信息等方式来提高分类或预测的准确性。
二、分类器设计分类器是模式识别中最为常用的工具,它是一种从已知数据中学习分类规则,然后将这些规则应用到新数据中进行分类的算法。
常用的分类器包括朴素贝叶斯、支持向量机、神经网络等。
分类器的设计需要考虑多种因素,包括分类精度、计算速度、内存占用等。
三、特征选择特征选择是指从原始数据中选择最具有代表性的特征,用于分类或预测。
与特征提取不同,特征选择是在原始数据的基础上进行的,它可以减少分类器的计算复杂度、提高分类精度等。
常用的特征选择方法包括卡方检验、信息增益、相关系数等。
四、聚类分析聚类分析是一种将数据按照相似度进行分组的方法,它可以帮助我们发现数据中的潜在模式和规律。
聚类分析的基本思想是将数据划分为若干个簇,每个簇内的样本相似度高,而不同簇之间的相似度较低。
常用的聚类算法包括k-means、层次聚类、密度聚类等。
五、降维算法降维算法是指通过减少数据的维度来简化数据,降低计算复杂度,同时保留数据的主要特征。
常用的降维算法包括主成分分析、因子分析、独立成分分析等。
降维算法可以帮助我们处理高维数据,减少数据冗余和噪声,提高分类或预测的准确性。
六、特征重要性评估特征重要性评估是指对特征进行排序,以确定哪些特征对分类或预测最为重要。
常用的特征重要性评估方法包括信息增益、基尼系数、决策树等。
通过特征重要性评估,我们可以选择最具有代表性的特征,提高分类或预测的准确性。
模式识别的基本方法是多种多样的,每种方法都有其适用的场景和优缺点。
模式识别——用身高和或体重数据进行性别分类

用身高和/或体重数据进行性别分类1、【实验目的】(1)掌握最小错误率Bayes 分类器的决策规则 (2)掌握Parzen 窗法 (3)掌握Fisher 线性判别方法 (4)熟练运用matlab 的相关知识。
2、【实验原理】(1)、最小错误率Bayes 分类器的决策规则如果在特征空间中观察到某一个(随机)向量x = ( x 1 , x 2 ,…, x d )T,已知类别状态的先验概率为:()i P w 和类别的条件概率密度为(|)1,2,3...i P x w i c =,根据Bayes 公式得到状态的后验概率 有:1(|)()(|)(|)()i i i cjjj p P P p P ωωωωω==∑x x x基本决策规则:如果1,...,(|)max (|)i j j cP P ωω==x x ,则i ω∈x ,将 x 归属后验概率最大的类别 。
(2)、掌握Parzen 窗法对于被估计点X :其估计概率密度的基本公式(x)Nk NN Np V =,设区域 R N 是以 h N 为棱长的 d 维超立方体,则立方体的体积为dNN V h =;选择一个窗函数(u)ϕ,落入该立方体的样本数为x x 1()iNNN h i k ϕ-==∑,点 x 的概率密度:x x 111(x)()Ni NNk NNN V h i Np V Nϕ-===∑其中核函数:x x 1i K(x,x )()i NNV h ϕ-=,满足的条件:i (1) K(x,x )0≥;i (2) K(x,x )dx 1=⎰。
(3)、Fisher 线性判别方法Fisher 线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远。
Fisher 线性判别分析,就是通过给定的训练数据,确定投影方向W 和阈值y0,即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
模式识别及其分类PPT课件

-1.192 -0.170
1.269
-0.248 0.383 0.121
一列11个主
物 的
1因 纯
数 据
-0.219 -2.227
1.074 0.174
-0.329 -0.071
1子 光 1谱
LT
0.385 0.473 0.484 0.662 -0.309 -0.211 -0.628 -0.192 0.218
3
7.2
0.32 2750 65.3 3.4
4
10.2 0.36 1500 3.4
5.3
5
10.1 0.50 1040 39.2 1.9
6
6.5
0.20 2490 90.0 4.6
7
5.6
0.29 2940 88.0 5.6
8
11.8 0.42 867 43.1 1.5
9
8.5
0.25 1620 5.2
0.440 0.447 0.455 -0.464 0.699 -0.181
模式识别与分类 FA实例TTFA
HPLC-DAD
多 环 芳 烃
Known
L 245
B[k]F B[b]F 111.2 112.6
2苝 8*2.1
265 38.2 87.2 76.4
286 52.5 69.4 12.2
305 110.6 33.2 5.1
模式识别与分类 FA实例TTFA
多
-1.476 -1.307 -1.295 -1.285 -1.174
环 芳 烃
-0.640
X* 0.205 0.334
1.442
0.088 1.447 0.823 0.416
-0.017 1.250 0.980 0.614
模式识别实验一报告

用身高体重数据进行性别分类实验一一.题目要求:1.用dataset1.txt 作为训练样本,用dataset2.txt 作为测试样本,采用身高和体重数据为特征,在正态分布假设下估计概率密度(只用训练样本),建立最小错误率贝叶斯分类器,写出所用的密度估计方法和得到的决策规则,将该分类器分别应用到训练集和测试集,考察训练错误率和测试错误率。
将分类器应用到dataset3 上,考察测试错误率的情况。
(在分类器设计时可以尝试采用不同先验概率,考查对决策和错误率的影响。
)2.自行给出一个决策表,采用最小风险贝叶斯决策重复上面的实验。
二.数据文件:1.dataset1.txt----- 328 个同学的身高、体重、性别数据(78 个女生、250 个男生)(datasetf1:女生、datasetm1:男生)2.dataset2.txt -----124 个同学的数据(40 女、84 男)3.dataset3.txt----- 90 个同学的数据(16 女,74 男)三.题目分析:要估计正态分布下的概率密度函数,假设身高随机变量为X,体重随机变量为Y,二维随机变量(X,Y)的联合概率密度函数是:p x,y=1122{−121−ρ2[x−μ12ς12−2ρx−μ1y−μ2ς1ς2+(y−μ2)2ς22]}其中−∞<x,y<+∞;−∞<μ1,μ2<+∞;ς1,ς2>0;−1≤ρ≤1.并其μ1,μ2分别是X与Y的均值,ς12,ς22,分别是X与Y的方差,ρ是X与Y的相关系数。
运用最大似然估计求取概率密度函数,设样本集中包含N个样本,即X={x1,x2,…x N},其中x k是列向量。
根据教材中公式,令μ=(μ1,μ2)T,则μ=1 Nx kNk=1;协方差矩阵=ς12ρς1ς2ρς1ς2ς22,那么=1N(x kNk=1−μ)(x k−μ)T。
采用最小错误率贝叶斯分类器,设一个身高体重二维向量为x,女生类为ω1,男生类为ω2,决策规则如下:x∈ω1,当Pω1x)>P(ω2|x)ω2,当Pω2x)>P(ω1|x)。
模式识别技术在人脸识别中的应用

模式识别技术在人脸识别中的应用随着科技的不断进步,人脸识别技术已经成为越来越多领域的必备工具。
人脸识别技术利用模式识别来定位、提取人脸特征,进而识别人脸。
而模式识别技术则是对具有某种特征的模式进行自动识别的一种技术。
本文将从模式识别技术在人脸识别中的应用方面进行探讨。
第一部分:人脸识别技术简介人脸识别技术是一种以人脸图像为基础的生物识别技术,利用摄像机或者其他感应器对人脸进行采集,然后通过图像处理算法来提取图像中脸部的特征信息,最终与已知的人脸信息库中的数据进行比对来完成识别。
人脸识别技术的主要应用领域包括安防、门禁、身份验证等方面。
随着人工智能技术的发展,人脸识别技术越来越成熟,并迅速普及到了各行各业。
第二部分:模式识别技术的基本原理模式识别技术是一门交叉学科,涉及到数学、物理学、计算机科学、图像处理等多个领域。
它的基本原理是将待识别的模式转换成特征向量,并通过计算机算法进行分类判断。
在人脸识别中,模式识别技术可以根据特征值对人脸进行分类,然后利用分类结果进行人脸识别。
模式识别技术涉及的基本要素包括特征提取、分类准则和模式匹配。
特征提取是指从原始数据中提取与所需信息最相关的特征。
在人脸识别中,特征提取的目的是提取人脸图像中的关键特征。
通常情况下,人脸特征可以分为几何特征和纹理特征两种。
分类准则是用于判断不同特征之间的差异性。
对于人脸识别来说,分类准则可以将不同人脸的特征向量根据其差异进行分类判断。
模式匹配是将待识别的模式与已知模式的匹配,以判断两者的相似性。
在人脸识别中,模式匹配的目的是将采集到的人脸图像与已有的人脸信息库中的数据进行比对。
第三部分:模式识别技术在人脸识别中的应用模式识别技术在人脸识别中的应用主要表现在对人脸的特征提取、分类准则和模式匹配等方面。
特征提取方面,模式识别技术可以通过对人脸图像进行分析,提取出人脸的几何特征和纹理特征。
几何特征包括人脸的轮廓、鼻子、嘴巴、眼睛等部位的位置和大小关系;纹理特征包括皮肤颜色、斑点、酒窝等由像素构成的细节。
用身高和体重数据进行性别分类的实验报告

用身高和体重数据进行性别分类的实验报告实验目的:本实验旨在通过身高和体重数据,利用机器学习算法对个体的性别进行分类。
实验步骤:1. 数据收集:收集了一组个体的身高和体重数据,包括男性和女性样本。
在收集数据时,确保样本的性别信息是准确的。
2. 数据预处理:对收集到的数据进行预处理工作,包括数据清洗、缺失值处理和异常值处理等。
确保数据的准确性和完整性。
3. 特征提取:从身高和体重数据中提取特征,作为输入特征向量。
可以使用常见的特征提取方法,如BMI指数等。
4. 数据划分:将数据集划分为训练集和测试集,一般采用70%的数据作为训练集,30%的数据作为测试集。
5. 模型选择:选择合适的机器学习算法进行性别分类。
常见的算法包括逻辑回归、支持向量机、决策树等。
6. 模型训练:使用训练集对选定的机器学习算法进行训练,并调整模型的参数。
7. 模型评估:使用测试集对训练好的模型进行评估,计算分类准确率、精确率、召回率等指标,评估模型的性能。
8. 结果分析:分析实验结果,对模型的性能进行评估和比较,得出结论。
实验结果:根据实验数据和模型训练结果,得出以下结论:1. 使用身高和体重数据可以较好地对个体的性别进行分类,模型的分类准确率达到了XX%。
2. 在本实验中,选择了逻辑回归算法进行性别分类,其性能表现良好。
3. 身高和体重这两个特征对性别分类有较好的区分能力,可以作为性别分类的重要特征。
实验总结:通过本实验,我们验证了使用身高和体重数据进行性别分类的可行性。
在实验过程中,我们收集了一组身高和体重数据,并进行了数据预处理、特征提取、模型训练和评估等步骤。
实验结果表明,使用逻辑回归算法可以较好地对个体的性别进行分类。
这个实验为进一步研究个体性别分类提供了一种方法和思路。
数学建模判别分析模型

G
为
m
维总体 ( m 个因素或指标),其均 值向量为 (1 , 2 ,, m ) T (这里 T 表示 转置),协方差阵为 ( ij ) mm ,则样品X ( x1 , x2 ,, xm )T 到总体 G 的马氏距离定义为
d ( X , G) ( X ) ( X )
数
学
建
模
培
训
数学建模-
判别分析模型
主 讲:陈将宏
目
1.问题引入 2.思路点拨 3.判别分析方法
录
4.DNA序列分类问题的求解 5. 参考文献
1.问题引入
首先,我们来考虑一下2000年“网易杯” 全国大学生数学建模竞赛的A题是关于“DNA
序列分类”的问题
人类基因组中的DNA全序列是由4个碱 基A,T,C,G按一定顺序排成的长约30亿 的序列,毫无疑问,这是一本记录着人类 自身生老病死及遗传进化的全部信息的 “天书”。但是,除了这四种碱基外,人 们对它所包含的内容知之甚少,如何破译 这部“天书”是二十一世纪最重要的任务 之一。在这个目标中,研究DNA全序列具 有什么结构,由这4个字符排成的看似随机 的序列中隐藏着什么规律,又是解读这部 天书的基础,是生物信息学 (Bioinformatics)最重要的课题之一。
对另外20个未标明类别 的DNA序列进行分类 对182个自然DNA 序列进行分类
如果将每个DNA序列都看作样本,那么 该问题就进一步提炼成一个纯粹的数学
问题:设有两个总体(类) 和 , G1 G2 其分布特征(来自各个总体的样本)已 知,对给定的新品 ,我们需要判 X 断其属于哪个总体(类)。 对于上面的数学问题,可以用很多成 熟的方法来解决,例如:
模式识别关于男女生身高和体重BP算法

模式识别实验报告(二)学院:专业:学号:姓名:XXXX教师:目录1实验目的 (1)2实验内容 (1)3实验平台 (1)4实验过程与结果分析 (2)4.1基于BP神经网络的分类器设计. 2 4.2基于SVM的分类器设计 (5)4.3基于决策树的分类器设计 (8)4.4三种分类器对比 (9)5.总结 (10)1实验目的通过实际编程操作,实现对课堂上所学习的BP神经网络、SVM支持向量机和决策树这三种方法的应用,加深理解,同时锻炼自己的动手实践能力。
2实验内容本次实验提供的样本数据有149个,每个数据提取5个特征,即身高、体重、是否喜欢数学、是否喜欢文学及是否喜欢运动,分别将样本数据用于对BP 神经网络分类器、SVM支持向量机和决策树训练,用测试数据测试分类器的效果,采用交叉验证的方式实现对于性能指标的评判。
具体要求如下:BP神经网络--自行编写代码完成后向传播算法,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算可以基于平台的软件包);SVM支持向量机--采用平台提供的软件包进行分类器的设计以及测试,尝试不同的核函数设计分类器,采用交叉验证的方式实现对于性能指标的评判;决策树--采用平台提供的软件包进行分类器的设计以及测试,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算基于平台的软件包)。
3实验平台专业研究方向为图像处理,用的较多的编程语言为C++,因此此次程序编写用的平台是VisualStudio及opencv,其中的BP神经网络为自己独立编写,SVM支持向量机和决策树通过调用Opencv3.0库中相应的库函数并进行相应的配置进行实现。
将Excel中的119个数据作为样本数据,其余30个作为分类器性能的测试数据。
4实验过程与结果分析4.1基于BP神经网络的分类器设计BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用身高和/或体重数据进行性别分类1、【实验目的】(1)掌握最小错误率Bayes 分类器的决策规则 (2)掌握Parzen 窗法(3)掌握Fisher 线性判别方法 (4)熟练运用matlab 的相关知识。
2、【实验原理】(1)、最小错误率Bayes 分类器的决策规则如果在特征空间中观察到某一个(随机)向量x = ( x 1 , x 2 ,…, x d )T,已知类别状态的先验概率为:()i P w 和类别的条件概率密度为(|)1,2,3...i P x w i c =,根据Bayes 公式得到状态的后验概率 有:1(|)()(|)(|)()i i i cjjj p P P p P ωωωωω==∑x x x基本决策规则:如果1,...,(|)max (|)i j j cP P ωω==x x ,则i ω∈x ,将 x 归属后验概率最大的类别 。
(2)、掌握Parzen 窗法对于被估计点X :其估计概率密度的基本公式(x)Nk NN Np V =,设区域 R N 是以 h N 为棱长的 d 维超立方体,则立方体的体积为dNN V h =;选择一个窗函数(u)ϕ,落入该立方体的样本数为x x 1()iNNN h i k ϕ-==∑,点 x 的概率密度:x x 111(x)()Ni NNk NNN V h i Np V Nϕ-===∑其中核函数:x x 1i K(x,x )()i N NV h ϕ-=,满足的条件:i (1) K(x,x )0≥;i (2) K(x,x )dx 1=⎰。
(3)、Fisher 线性判别方法Fisher 线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远。
Fisher 线性判别分析,就是通过给定的训练数据,确定投影方向W 和阈值y0,即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
线性判别函数的一般形式可表示成0)(w X W X g T += ,其中⎪⎪⎪⎭⎫⎝⎛=d x x X 1 ⎪⎪⎪⎪⎪⎭⎫⎝⎛=d w w w W 21 根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向W 的函数为:2221221~~)~~()(S S m m W J F +-= )(211*m m S W W -=-上面的公式是使用Fisher 准则求最佳法线向量的解,该式比较重要。
另外,该式这种形式的运算,我们称为线性变换,其中21m m -式一个向量,1-W S 是W S 的逆矩阵,如21m m -是d 维,W S 和1-W S 都是d ×d 维,得到的*W 也是一个d 维的向量。
向量*W 就是使Fisher 准则函数)(W J F 达极大值的解,也就是按Fisher 准则将d 维X 空间投影到一维Y 空间的最佳投影方向,该向量*W 的各分量值是对原d 维特征向量求加权和的权值。
以上讨论了线性判别函数加权向量W 的确定方法,并讨论了使Fisher 准则函数极大的d 维向量0W 的计算方法,但是判别函数中的另一项0W 尚未确定,一般可采用以下几种方法确定0W 如2~~210m m W +-= 或者 m N N m N m N W ~~~2122110=++-= 或当1)(ωp 与2)(ωp 已知时可用[]⎥⎦⎤⎢⎣⎡-+-+=2)(/)(ln 2~~2121210N N p p m m W ωω当W0确定之后,则可按以下规则分类:2010ωω∈→->∈→->X w X W X w X W TT3、【实验内容及要求】(1)、实验对象Datasetf1.TXT 女生的身高、体重数据 Datasetm1.TXT 男生的身高、体重数据----- 训练样本集Dataset1.txt 328个同学的身高、体重、性别数据 Dataset2.txt 124个同学的身高、体重、性别数据----- 测试样本集(2)基本要求:(1) 用Datasetf1.TXT 和Datasetm1.TXT 的数据作为训练样本集,建立Bayes 分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
(试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较)(2) 试验非参数估计,体会与参数估计在适用情况、估计结果方面的异同。
4、【实验结果与分析】(1)、Bayes 分类器的实验结果与分析A 、对于Dataset1.txt 328个同学的身高、体重、性别数据的测试样本集:A1、当先验概率为:男0.5,女0.5时:身高分类错误个数: 15 身高分类错误率为: 12.10% 体重分类错误个数: 15 体重分类错误率为: 12.10%【实验结果:】A2、当先验概率为:男0.75,女0.25时:身高分类错误个数: 19 身高分类错误率为: 15.32%体重分类错误个数: 14 体重分类错误率为: 11.29%B、对于Dataset2.txt 124个同学的身高、体重、性别数据的测试样本集:B1、当先验概率为:男0.5,女0.5时:身高分类错误个数: 16 身高分类错误率为: 12.90%体重分类错误个数: 21 体重分类错误率为: 16.94%【实验结果:】B2、当先验概率为:男0.75,女0.25时:身高分类错误个数: 31 身高分类错误率为: 25.00% 体重分类错误个数: 35 体重分类错误率为: 28.23%【结果分析:】Dataset1.txt样本数据集中,男女先验概率为(0.71vs0.29);Dataset2.txt样本数据集中,男女先验概率为(0.66vs0.34)。
对比实验结果,可以发现身高的分类错误率都小于体重的分类错误率,样本集越大,各个特征对应的分类错误率就越小。
假设先验概率为(0.5vs0.5)的分类错误率小于假设先验概率为(0.75vs0.25)的分类集,就算假设的先验概率与实际的很相近,可是结果不准确。
程序框图导入样本数据计算二维正态分布参数求类条件概率密度计算先验概率和后验概率构成分类器测试训练样本结果判断满意不满意调整参数Bayes分类器源程序实验代码:clear all;load datasetf1.txt;load datasetm1.txt;%样本的分析figure;for i=1:250if(i<79)plot(datasetf1(i,2),datasetf1(i,1),'r+'); endplot(datasetm1(i,2),datasetm1(i,1),'k*'); hold on;endtitle('样本数据');xlabel('体重(Kg)'),ylabel('身高(cm)');legend('男生','女生');fid=fopen('dataset1.txt','r');test1=fscanf(fid,'%f %f %s',[3,inf]);test=test1';fclose(fid);Fmean = mean(datasetf1);Mmean = mean(datasetm1);Fvar = std(datasetf1);Mvar = std(datasetm1);preF = 0.5;preM = 0.5;error = 0;Nerror = 0;%身高的决策figure;for i = 1:124PFheight = normpdf(test(i,1),Fmean(1,1),Fvar(1,1)) ;PMheight = normpdf(test(i,1),Mmean(1,1),Mvar(1,1)) ;pFemale = preF*PFheight;pMale = preM*PMheight;if(pFemale<pMale)plot(i,test(i,1),'k*');if (test(i,3)=='f')Nerror = Nerror +1;endelseplot(i,test(i,1),'r+');if (test(i,3)=='M')Nerror = Nerror +1;endendhold on;end;error = Nerror/124*100;title('身高最小错误率Bayes分类');xlabel('测试序号'),ylabel('身高(cm)');sprintf('%s %d %s %0.2f%s','身高分类错误个数:',Nerror,'身高分类错误率为:',error,'%')%体重决策figure;error = 0;Nerror = 0;for j= 1:124PFweight = normpdf(test(j,2),Fmean(1,2),Fvar(1,2)) ;PMweight = normpdf(test(j,2),Mmean(1,2),Mvar(1,2)) ;pwFemale = preF*PFweight;pwMale = preM*PMweight;if(pwFemale<pwMale)plot(j,test(j,2),'k*');if (test(j,3)=='f')Nerror = Nerror +1;endelseplot(j,test(j,2),'r+');if (test(j,3)=='M')Nerror = Nerror +1;endendhold on;end;error = Nerror/124*100;title('体重最小错误率Bayes分类');xlabel('测试序号'),ylabel('体重(kg)');sprintf('%s %d %s %0.2f%s','体重分类错误个数:',Nerror,'体重分类错误率为:',error,'%')(2)、Parzen窗法的实验结果与分析(先验概率为0.5vs0.5)A、对于Dataset1.txt中有78个女生和250个男生,共328个同学的身高、体重、性别数据的测试样本集的结果:女生人数为:84;男生人数为:244;拒分人数:0;女生错分人数:4;男生错分人数:33;总的错分人数:37;女生分类错误率: 0.0800;男生分类错误率:0.1320;总的分类错误率:0.1128;B、对于Dataset2.txt中有40个女生和84个男生,共124个同学的身高、体重、性别数据的测试样本集:女生人数为:41;男生人数为:83;拒分人数:0;女生错分人数:15;男生错分人数:6;总的错分人数:21;女生分类错误率: 0.3000;男生分类错误率:0.0240 ;总的分类错误率: 0.1694 ;结果分析:Parzen窗法的分类结果比较准确,样本集越大,错误率就越小。