Development of Mixed Mode MPI OpenMP Applications
openmpi跨节点执行命令参数

openmpi跨节点执行命令参数【原创版】目录1.openmpi 概述2.openmpi 跨节点执行的命令参数3.实例说明正文1.openmpi 概述OpenMPI(Open-source MPI)是一个开源的并行计算框架,可以用于构建高性能计算(HPC)系统。
MPI(Message Passing Interface)是一种并行计算的通信协议,OpenMPI 是 MPI 的一种实现。
OpenMPI 提供了一种在分布式系统上实现并行计算的方法,它的设计目标是为了提供高性能、可移植性和易用性。
在 OpenMPI 中,可以通过 mpirun 命令来执行并行任务,这个命令可以跨节点分配任务和资源。
2.openmpi 跨节点执行的命令参数openmpi 跨节点执行的命令参数主要包括以下几个:- "-n":指定并行度,即并行处理的节点数目。
- "-l":指定每个节点上的进程数。
- "-o":指定输出文件。
- "-f":指定输入文件。
- "- Host":指定主机名,用于与主机进行通信。
- "- Port":指定端口号,用于与主机进行通信。
3.实例说明假设我们有一个名为“example.mpi”的并行计算程序,我们希望在两台节点(node1 和 node2)上执行它。
那么,我们可以使用以下命令:```mpirun -n 2 -l 2 -o output -f input example.mpi```这条命令的含义如下:- "-n 2":指定并行度为 2,即在两台节点上执行任务。
- "-l 2":指定每台节点上运行 2 个进程。
- "-o output":指定输出文件名为“output”。
- "-f input":指定输入文件名为“input”。
openmp语言标准

openmp语言标准
OpenMP(Open Multi-Processing)是一种支持共享内存并行编程的API,由OpenMP Architecture Review Board牵头提出,并已被广泛接受,用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive)。
OpenMP支持的编程语言包括C、C++和Fortran;而支持OpenMp 的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。
OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。
当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
OpenMP标准由一些具有国际影响力的软件和硬件厂商共同定义和提出,是一种在共享存储体系结构上的可移植编程模型,广泛应用于UNIX、Linux、Windows等多种平台上。
以上信息仅供参考,如有需要,建议您查阅相关网站。
基于SMP集群的MPI+OpenMP混合编程模型及有效实现

基于SMP集群的MPI+OpenMP混合编程模型及有效实现赵永华;迟学斌
【期刊名称】《微电子学与计算机》
【年(卷),期】2005(22)10
【摘要】SMP集群混合了两个内存模型:每个节点是一个共享存储的多处理器,而节点间使用分布存储。
这一多级体系结构引起了编程模型和性能方面的问题。
文章讨论了MPI+OpenMP混合编程模型的性能和不同的实现方法,提出了多粒度MPI+OpenMP混合编程方法。
建立了对称三对角特征问题的多粒度混合并行算法,并在深腾6800超级计算机上同纯MPI算法作了性能方面的比较。
结果表明,该混合并行算法具有更好的扩展性和加速比。
【总页数】5页(P7-11)
【关键词】SMP集群;混合编程模型;特征问题
【作者】赵永华;迟学斌
【作者单位】中国科学院计算机网络信息中心超级计算中心;中国科学院研究生院,北京100039
【正文语种】中文
【中图分类】TP338.6
【相关文献】
1.基于MPI+OpenMP混合编程模型的并行声纳信号处理技术研究 [J], 胡银丰;孔强
2.基于SMP集群的MPI+CUDA模型的研究与实现 [J], 许彦芹;陈庆奎
3.基于SMP集群的MPI+OpenMP混合编程模型研究 [J], 潘卫;陈燎原;张锦华;李永革;潘莉;夏凡
4.基于MPI+OpenMP混合编程模型的水声传播并行算法 [J], 张林;笪良龙;范培勤
因版权原因,仅展示原文概要,查看原文内容请购买。
openmp用法

openmp用法OpenMP是一种支持共享内存多线程编程的标准API。
它提供了一种简单而有效的方法,用于在计算机系统中利用多核和多处理器资源。
本文将逐步介绍OpenMP的用法和基本概念,从简单的并行循环到复杂的并行任务。
让我们一步一步来学习OpenMP吧。
第一步:环境设置要开始使用OpenMP,我们首先需要一个支持OpenMP的编译器。
常见的编译器如GCC、Clang和Intel编译器都支持OpenMP。
我们需要确保在编译时启用OpenMP支持。
例如,在GCC中,可以使用以下命令来编译包含OpenMP指令的程序:gcc -fopenmp program.c -o program第二步:并行循环最简单的OpenMP并行化形式是并行循环。
在循环的前面加上`#pragma omp parallel for`指令,就可以让循环被多个线程并行执行。
例如,下面的代码演示了如何使用OpenMP并行化一个简单的for循环:c#include <stdio.h>#include <omp.h>int main() {int i;#pragma omp parallel forfor (i = 0; i < 10; i++) {printf("Thread d: d\n", omp_get_thread_num(), i);}return 0;}在上面的例子中,`#pragma omp parallel for`指令会告诉编译器将for 循环并行化。
`omp_get_thread_num()`函数可以获取当前线程的编号。
第三步:数据共享与私有变量在并行编程中,多个线程可能会同时访问和修改共享的数据。
为了避免数据竞争和不一致的结果,我们需要显式地指定哪些变量是共享的,哪些变量是私有的。
我们可以使用`shared`和`private`子句来指定。
`shared`子句指定某个变量为共享变量,对所有线程可见。
MPI+OpenMp混合编程模式研究与效率分析

文章编号 :17 — 64 (0 9 4 0 3 — 3 6 1 44 2 0 )0 — 0 7 0
MP + e Mp混 合 编 程 模 式 研 究 与 效 率 分 析 I Op n
吴 兆 明
( 南京 交通 职 业技 术学 院 团委 ,江 苏 南京
摘
2 18 ) 118
要 :对 MP+ pn P混合编程模 式的 两种 类型进行 了分析 ,总结 了混合编 程模 式的要点 和优 化措施 ,讲述 了 IO eM
函数调用 )来完 成 的。但 是 ,MP 并 行 模 型也有 其 不足 之 I
处 ,比如 :细粒度 的并行会引发大量 的通信 ;动态负载平衡
困难 。
软件并行化 的全新 应用 模式 ,软 件设 计 的并行 时代 已经到
来。
O eM pn P使用 F r— o ok Ji n的并行 执 行模 式。开始 时 由一 个主线程执行程序 ,该线程一直 串行地执行 ,直到遇到第一
个进程 ,工作负载被分配 到每个计算节点 的 k 个线程 中 ,而 在通信过程 中只需要 m个 进程 ,从 而减 少 了通信 开销 ,在 通信密集型 的程序 中效率差别将 十分 明显 。因此 ,混合编程 模式充分利用 了 MP 的优点 ,采 用用 MP 解 决多 处理 器 间 I I 粗粒度通信 ,同时 ,采用 O e M pn P提供 的轻量级 线程解决点 内各处理器间的交互 ,是解决消息 的一种优化解决方案 。
程 间通 信 出现 在 O e M pn P的 fr ji 行域 外 ,由 主线 程 ok o / n并
共享存储体系结构上 ,而且允许静态任务调 度。M I P 使用显
示方式控制并行 ,因此提供 了一个 更好 的性能 和可移植 性 。
openmp和mpi环境配置
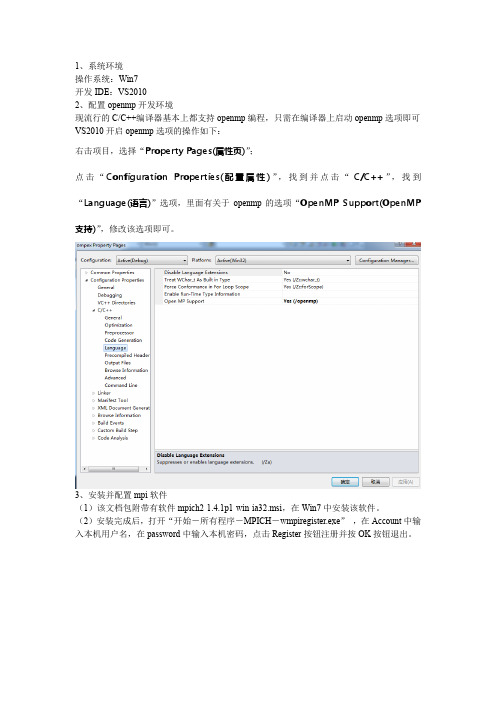
1、系统环境操作系统:Win7开发IDE:VS20102、配置openmp开发环境现流行的C/C++编译器基本上都支持openmp编程,只需在编译器上启动openmp选项即可VS2010开启openmp选项的操作如下:右击项目,选择“Property Pages(属性页)”;点击“Configuration Properties(配置属性)”,找到并点击“C/C++”,找到“Language(语言)”选项,里面有关于openmp的选项“OpenMP Support(OpenMP 支持)”,修改该选项即可。
3、安装并配置mpi软件(1)该文档包附带有软件mpich2-1.4.1p1-win-ia32.msi,在Win7中安装该软件。
(2)安装完成后,打开“开始-所有程序-MPICH-wmpiregister.exe”,在Account中输入本机用户名,在password中输入本机密码,点击Register按钮注册并按OK按钮退出。
(3)在VS2010中,配置VC++ Directories选项。
在VS2010中,VC++ Directories在Solution Explorer中,在项目名称上右键选择Properties,即进入Property Pages窗口。
(4)展开左边Configuration Properties,选中其中的VC++ Directories,在右边Include Directories加入“C:\Program Files\MPICH2\include;”(mpi安装目录里)(5)展开左边Configuration Properties,选中其中的VC++ Directories,在右边Library Directories加入“C:\Program Files\MPICH2\lib;”(6)展开左边Configuration Properties中的C/C++,选中其中的Preprocessor,在右边的Preprocessor Definitions中加入“MPICH_SKIP_MPICXX;”(7)同样展开C/C++,选中Code Generation,把右边的Runtime Library更改为“Multi-threaded Debug (/MTd)”(此外有下拉菜单可选到它)(8)展开左边的Linker,选中Input,在右边Additional Dependencies中加入“mpi.lib;”(9)运行MPI程序打开“开始-所有程序-MPICH-wmpiexec.exe”,在Applicationd右边浏览找到你在VS2010中生成的exe文件,设置Number of processes(即进程数目,用来模拟并行计算的CPU数目)。
并行编程——MPIOPENMP混合编程

并⾏编程——MPIOPENMP混合编程在⼤规模节点间的并⾏时,由于节点间通讯的量是成平⽅项增长的,所以带宽很快就会显得不够。
所以⼀种思路增加程序效率线性的⽅法是⽤MPI/OPENMP混合编写并⾏部分。
这⼀部分其实在了解了MPI和OPENMP以后相对容易解决点。
⼤致思路是每个节点分配1-2个MPI进程后,每个MPI进程执⾏多个OPENMP线程。
OPENMP部分由于不需要进程间通信,直接通过内存共享⽅式交换信息,不⾛⽹络带宽,所以可以显著减少程序所需通讯的信息。
Fortran:Program hellouse mpiuse omp_libImplicit NoneInteger :: myid,numprocs,rc,ierrInteger :: i,j,k,tidCall MPI_INIT(ierr)Call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr)Call MPI_COMM_SIZE(MPI_COMM_WORLD,numprocs,ierr)!$OMP Parallel private(tid)tid=OMP_GET_THREAD_NUM()write(*,*) 'hello from',tid,'of process',myid!$OMP END PARALLELCall MPI_FINALIZE(rc)StopEnd Program helloC++:# include <cstdlib># include <iostream># include <ctime># include "mpi.h"# include "omp.h"using namespace std;int main ( int argc, char *argv[] );//****************************************************************************80int main ( int argc, char *argv[] ){int myid;int nprocs;int this_thread;MPI::Init();myid=MPI::COMM_WORLD.Get_rank();nprocs=MPI::COMM_WORLD.Get_size();#pragma omp parallel private(this_thread){this_thread=omp_get_thread_num();cout <<this_thread<<" thread from "<<myid<<" is ok\n";}MPI::Finalize();return0;}这⾥值得要注意的是,似乎直接⽤mpif90/mpicxx编译的库会报错,所以需要⽤icc -openmp hello.cpp -o hello -DMPICH_IGNORE_CXX_SEEK -L/Path/to/mpi/lib/ -lmpi_mt -lmpiic -I/path/to/mpi/include其中-DMPICH_IGNORE_CXX_SEEK为防⽌MPI2协议中⼀个重复定义问题所使⽤的选项,为了保证线程安全,必须使⽤mpi_mt库对于intel的mpirun,必须在mpirun后加上-env I_MPI_PIN_DOMAIN omp使得每个mpi进程会启动openmp线程。
MPI的搭建及OpenMP的配置实验指导书

MPI的搭建及OpenMP的配置实验指导书1.MPI简介消息传递接口(Message Passing Interface,MPI)是目前应用较广泛的一种并行计算软件环境,是在集群系统上实现并行计算的软件接口。
为了统一互不兼容的的用户界面,1992年成立了MPI委员会,负责制定MPI的新标准,支持最佳的可移植平台。
MPI不是一门新的语言,确切地说它是一个C和Fortran的函数库,用户通过调用这些函数接口并采用并行编译器编译源代码就可以生成可并行运行的代码。
MPI的目标是要开发一个广泛用于编写消息传递程序的标准,要求用户界面实用、可移植,并且高效、灵活,能广泛应用于各类并行机,特别是分布式存储的计算机。
每个计算机厂商都在开发标准平台上做了大量的工作,出现了一批可移植的消息传递环境。
MPI吸收了它们的经验,同时从句法和语法方面确定核心库函数,使之能适用于更多的并行机。
MPI在标准化过程中吸收了许多代表参加,包括研制并行计算机的大多数厂商,以及来自大学、实验室与工业界的研究人员。
1992年开始正式标准化MPI,1994年发布了MPI的定义与实验标准MPI 1,相应的MPI 2标准也已经发布。
MPI吸取了众多消息传递系统的优点,具有很好的可以执行、易用性和完备的异步通信功能等。
MPI事实上只是一个消息传递标准,并不是软件实现并行执行的具体实现,目前比较著名的MPI具体实现有MPICH、LAM MPI等,其中MPICH是目前使用最广泛的免费MPI系统,MPICH2是MPI 2标准的一个具体实现,它具有较好的兼容性和可扩展性,目前在高性能计算集群上使用非常广泛。
MPICH2的使用也非常简单,用户只需在并行程序中包含MPICH的头文件,然后调用一些MPICH2函数接口将计算任务分发到其他计算节点即可,MPICH2为并行计算用户提供了100多个C和Fortran函数接口,表1-1列出了一些常用的MPICH2的C语言函数接口,用户可以像调用普通函数一样,只需要做少量的代码改动就可以实现程序的并行运行,MPICH并行代码结构如图1-1所示。
基于MPI与OpenMP混合并行计算技术的研究

基于MPI与OpenMP混合并行计算技术的研究李苏平,刘羽,刘彦宇(桂林理工大学信息科学与工程学院,广西桂林541004)摘要:针对多核机群系统的硬件体系结构特点,提出了节点间MPI消息传递、节点内部OpenMP共享存储的混合并行编程技术。
该编程模型结合了两者的优点,更为有效地利用了多核机群的硬件资源。
建立了单层混合并行的Jacobi求对称矩阵特征值算法。
实验结果表明,与纯MPI算法相比,混合并行算法能够取得更好的加速比。
关键词:混合编程模型;多核机群;MPI; OpenMPTP312:A:1672-7800(2010)03-0050-031 MPI与OpenMP混合模型MPI( Message Passing Interface)是消息传递并行编程模型的代表和事实标准,可以轻松地支持分布存储和共享存储拓扑结构;OpenMP是为共享存储环境编写并行程序而设计的一个应用编程接口,是当前支持共享存储并行编程的工业标准。
在SMP机群系统中,混合编程模型已经有一些成功的应用,对于多核PC机群的混合编程模型研究才开始起步。
在多核PC 机群中,结合MPI与OpenMP技术,充分利用这两种编程模型的优点,在付出较小的开发代价基础上,尽可能获得较高的性能。
按照在MPI进程间消息传递方式和时机,即消息何时由哪个或哪些线程在MPI进程间传递进行分类,混合模型可以分为以下两种:(1)单层混合模型(Hybrid master- only)。
MPI调用发生在应用程序多线程并行区域之外,MPI实现进程间的通信由主线程执行。
该混合模型编程易于实现,即在基于MPI模型程序的关键计算部分加上OpenMP循环命令#pramgma omp par-allel- -即可。
(2)多层混合模型(Hybrid multiple)。
MPI调用可以发生在应用程序多线程并行区域内,进程间通信的可由程序任何区域内的任何一个或一些线程完成。
在该模型中,当某些线程进行通信时,其它的非通信线程同时进行计算,实现了通信与计算的并行执行,优化了进程间的通信阻塞问题。
openmp与openmpi区别

Lammps Mac 的并行之路openmp与openmpi区别openmp比较简单,修改现有的大段代码也容易。
基本上openmp只要在已有程序基础上根据需要加并行语句即可。
而mpi有时甚至需要从基本设计思路上重写整个程序,调试也困难得多,涉及到局域网通信这一不确定的因素。
不过,openmp虽然简单却只能用于单机多CPU/多核并行,mpi才是用于多主机超级计算机集群的强悍工具,当然复杂。
(1)MPI=message passing interface:在分布式内存(distributed-memory)之间实现信息通讯的一种规范/标准/协议(standard)。
它是一个库,不是一门语言。
可以被fortran,c,c++等调用。
MPI允许静态任务调度,显示并行提供了良好的性能和移植性,用 MPI 编写的程序可直接在多核集群上运行。
在集群系统中,集群的各节点之间可以采用 MPI 编程模型进行程序设计,每个节点都有自己的内存,可以对本地的指令和数据直接进行访问,各节点之间通过互联网络进行消息传递,这样设计具有很好的可移植性,完备的异步通信功能,较强的可扩展性等优点。
MPI 模型存在一些不足,包括:程序的分解、开发和调试相对困难,而且通常要求对代码做大量的改动;通信会造成很大的开销,为了最小化延迟,通常需要大的代码粒度;细粒度的并行会引发大量的通信;动态负载平衡困难;并行化改进需要大量地修改原有的串行代码,调试难度比较大。
(2)MPICH和OpenMPI:它们都是采用MPI标准,在并行计算中,实现节点间通信的开源软件。
各自有各自的函数,指令和库。
Reference:They are two implementations of the MPI standard. In the late 90s and early 2000s, there were many different MPI implementations, and the implementors started to realize they were all re-inventing the wheel; there wassomething of a consolidation. The LAM/MPI team joined with the LA/MPI, FT-MPI, and eventually PACX-MPI teams to develop OpenMPI. LAM MPI stoppedbeing developed in 2007. The code base for OpenMPI was completely new, butit brought in ideas and techniques from all the different teams.Currently, the two major open-source MPI implementation code-bases are OpenMPI andMPICH2.而MPICH2是MPICH的一个版本。
mpi openmp 案例

mpi openmp 案例MPI和OpenMP是并行计算中常用的编程模型,它们可以在多核和分布式系统中实现并行计算,提高计算效率。
本文将介绍一些MPI和OpenMP的案例,以展示它们在实际应用中的优势和用法。
引言概述:MPI和OpenMP是并行计算中常用的编程模型,它们分别适用于分布式和共享内存系统。
MPI(Message Passing Interface)是一种消息传递的并行编程模型,适用于分布式系统中的并行计算;而OpenMP是一种共享内存的并行编程模型,适用于多核系统中的并行计算。
下面将分别介绍它们在实际应用中的案例。
正文内容:1. MPI案例1.1 分布式矩阵乘法- 使用MPI实现矩阵乘法可以将计算任务分配给不同的进程,每个进程负责计算一部分矩阵乘法的结果。
- 使用MPI的消息传递机制,进程之间可以相互通信,将计算结果进行汇总,得到最终的矩阵乘法结果。
- 这种分布式矩阵乘法可以充分利用分布式系统的计算资源,提高计算效率。
1.2 并行排序算法- 使用MPI可以将排序任务分配给不同的进程,每个进程负责排序一部分数据。
- 进程之间可以通过消息传递机制交换数据,实现分布式的排序算法。
- 这种并行排序算法可以大大减少排序的时间复杂度,提高排序的效率。
2. OpenMP案例2.1 并行矩阵运算- 使用OpenMP可以将矩阵运算任务分配给不同的线程,每个线程负责计算一部分矩阵运算的结果。
- 多个线程可以共享内存,可以直接访问共享的数据,减少了数据的拷贝和通信开销。
- 这种并行矩阵运算可以充分利用多核系统的计算资源,提高计算效率。
2.2 并行图像处理- 使用OpenMP可以将图像处理任务分配给不同的线程,每个线程负责处理一部分图像数据。
- 多个线程可以并行地对图像进行处理,提高了图像处理的速度。
- 这种并行图像处理可以广泛应用于图像处理领域,如图像滤波、图像分割等。
总结:MPI和OpenMP是并行计算中常用的编程模型,它们分别适用于分布式和共享内存系统。
日本高知工科大学博士生“科研特别奖学金”项目
-编程技能
-较强数学功
通过计算机建模模拟和心理物理的应用开发来对人类视觉信息处理进行阐释
人机交流
REN Xiangshi教授
用户端口软件设计,交互技术,人机交互模型
-编程技能(Java,C语言等)
-具备良好的数学基础
用户界面前沿的研究:对人类动作进行模型化,设计多模型的输入和输出界面
(采用激光脉冲的)超导体氧化膜的性能改善在线路上的运用
-固相物理和化学(尤其是结晶学和结晶化学)
-材料科学
-高温超导电性基本知识
高分子科学
SUMI Katsuhiro副教授
采用硝基系统进行多功能复方制剂的新方法开发
-有机合成化学
-无机化学
环境能源工程
HORII Shigeru副教授
采用高磁力领域进程和结晶技术进行能源氧化物的开发
大型地震力作用下钢筋混凝土框架的应力偏离(偏斜)的动态分析计算
混凝土工程
OUCHI Masahiro副教授
自密混凝土的设计、生产和建设
具有混凝土工程的基础知识
6、前沿工程
研究领域
导师
课程
知识要求
基础设施管理
WATANABE Tsunmi教授
当地环境管理中多方风险和不确定性
-能够坚持不懈地做人类和社会的基础研究
-有较强数学功底
通信
SHIMAMURA Kazunori教授
虚拟RF-Tags连接的通讯协议
-计算机编程
-高等数学
理论物理,两字工程
CHEON Taksu教授
量子技术基础
-高等数学
-计算机编程
视觉心理物理学
SHINOMORI Keizo 教授
并行编程标准更新:MPI、OpenMP和英特尔TBB

并行编程标准更新:MPI、OpenMP和英特尔TBB
Intel TBB的优点
Intel TBB替你指定合理的并行,代替自己线程化。
大多数线程包需要你指定线程。
直接对线程编程是冗长的并且导致无效的编程,因为线程是低阶的,需要接近硬件的重构造,直接利用线程编程强迫你把逻辑任务映射到线程中,相反,Intel TBB 运行时库自动把逻辑并行映射到现在中,有效利用处理器资源。
Intel TBB目标是性能。
大多数通用线程包支持许多不同种线程,例如异步事件线程,结果,通用包趋向提够基础的低阶工具,而不是解决方案。
替代,Intel TBB关注并行计算密集工作的目的,传递高阶,更简单的解决方案。
Intel TBB和其他线程包兼容。
因为库没有设计解决所有线程问题,它能和其他线程包无缝共处。
Intel TBB强调可扩展,数据并行编程。
把程序分成独立的函数块,。
MPI与OpenMP并行程序设计C语言版课程设计

MPI与OpenMP并行程序设计C语言版课程设计概述本课程设计旨在通过学习MPI和OpenMP并行程序设计,提高学生对C语言并行编程的基本理解和技能。
在本课程设计中,我们将探讨MPI和OpenMP并行程序设计的基本概念、方法和技巧,并通过实例演示并行程序设计的具体操作步骤和注意事项。
通过本课程设计的学习和实践,学生将会掌握MPI和OpenMP并行程序设计的基本技能,为今后进行并行程序设计工作提供基础。
课程设计的基本要求本课程设计要求完成以下任务:1.学习并掌握MPI和OpenMP并行程序设计的基本理论和概念;2.学习并掌握MPI和OpenMP并行程序设计的基本方法和技巧;3.根据给定的题目,设计并实现相应的MPI和OpenMP并行程序;4.进行实验测试,验证程序的正确性和性能;5.撰写实验报告,说明并行程序的设计过程、方法和实验结果等。
课程设计的具体内容和步骤第一阶段:MPI并行程序设计在本阶段中,我们将学习并掌握MPI并行程序设计的基本理论和概念。
同时,我们将以一个简单的矩阵乘法程序为例,演示MPI并行程序设计的基本方法和技巧。
具体步骤如下:1.学习MPI并行程序设计的基本概念、原理和应用场景;2.了解MPI并行编程模型和MPI函数库的基本用法和函数特性;3.设计并实现矩阵乘法的MPI并行程序;4.实验测试,比较串行程序和并行程序的性能差异;5.撰写实验报告,说明MPI并行程序的设计过程、方法和实验结果等。
第二阶段:OpenMP并行程序设计在本阶段中,我们将学习并掌握OpenMP并行程序设计的基本理论和概念。
同时,我们将以一个简单的奇偶排序程序为例,演示OpenMP并行程序设计的基本方法和技巧。
具体步骤如下:1.学习OpenMP并行程序设计的基本概念、原理和应用场景;2.了解OpenMP并行编程模型和OpenMP函数库的基本用法和函数特性;3.设计并实现奇偶排序的OpenMP并行程序;4.实验测试,比较串行程序和并行程序的性能差异;5.撰写实验报告,说明OpenMP并行程序的设计过程、方法和实验结果等。
MPI+OpenMP混合编程技术总结

MPI+OpenMP混合编程技术总结MPI+OpenMP混合编程一、引言MPI是集群计算中广为流行的编程平台。
但是在很多情况下,采用纯的MPI 消息传递编程模式并不能在这种多处理器构成的集群上取得理想的性能。
为了结合分布式内存结构和共享式内存结构两者的优势,人们提出了分布式/共享内存层次结构。
OpenMP是共享存储编程的实际工业标准,分布式/共享内存层次结构用OpenMP+MPI实现应用更为广泛。
OpenMP+MPI这种混合编程模式提供结点内和结点间的两级并行,能充分利用共享存储模型和消息传递模型的优点,有效地改善系统的性能。
二、OpenMP+MPI混合编程模式使用混合编程模式的模型结构图如图1在每个MPI进程中可以在#pragma omp parallel编译制导所标示的区域内产生线程级的并行而在区域之外仍然是单线程。
混合编程模型可以充分利用两种编程模式的优点MPI可以解决多处理器问的粗粒度通信而OpenMP提供轻量级线程可以和好地解决每个多处理器计算机内部各处理器间的交互。
大多数混合模式应用是一种层次模型MPI并行位于顶层OpenMP位于底层。
比如处理一个二维数组可以先把它分割成结点个子数组每个进程处理其中一个子数组而子数组可以进一步被划分给若干个线程。
这种模型很好的映射了多处理器计算机组成的集群体系结构MPI并行在结点问OpenMP并行在结点内部。
也有部分应用是不符合这种层次模型的比如说消息传递模型用于相对易实现的代码中而共享内存并行用于消息传递模型难以实现的代码中还有计算和通信的重叠问题等。
三、OpenMP+MR混合编程模式的优缺点分析3.1优点分析(1)有效的改善MPI代码可扩展性MPI代码不易进行扩展的一个重要原因就是负载均衡。
它的一些不规则的应用都会存在负载不均的问题。
采用混合编程模式,能够实现更好的并行粒度。
MPI仅仅负责结点间的通信,实行粗粒度并行:OpenMP实现结点内部的并行,因为OpenMP不存在负载均衡问题,从而提高了性能。
OpenMP和MPI之对比

OpenMP与MPI之对比OpenMP与MPI是并行编程的两个手段,对比如下:1. OpenMP:线程级(并行粒度);共享存储;隐式(数据分配方式);可扩展性差;2. MPI:进程级;分布式存储;显式;可扩展性好。
3. OpenMP采用共享存储,意味着它只适应于SMP、DSM机器,不适合于集群。
MPI虽适合于各种机器,但它的编程模型复杂:需要分析及划分应用程序问题,并将问题映射到分布式进程集合;需要解决通信延迟大与负载不平衡两个主要问题;4. 调试MPI程序麻烦;MPI程序可靠性差,一个进程出问题,整个程序将错误;5. 常采用mpi而不用openmp的原因是:openmp扩展性差,对机器要求高,要想运算的快点,机器就要很贵。
6. 一般双核,用openmp。
因为mpi用于分布式机器之间数据传输,单机内用mpi的时间开销大于OpenMP。
7. 在一台机器中有很多CPU共享其中的内存条,叫共享内存并行机(如今天的双核CPU台式机),它适合OpenMP,而把这样的机器用专用高速网连接就形成了分布式内存并行机,它适合于MPI。
此时,可以混合OpenMP,能提高一定的运行速度。
嵌套并行执行模型OpenMP 采用fork-join (分叉- 合并)并行执行模式。
线程遇到并行构造时,就会创建由其自身及其他一些额外(可能为零个)线程组成的线程组。
遇到并行构造的线程成为新组中的主线程。
组中的其他线程称为组的从属线程。
所有组成员都执行并行构造内的代码。
如果某个线程完成了其在并行构造内的工作,它就会在并行构造末尾的隐式屏障处等待。
当所有组成员都到达该屏障时,这些线程就可以离开该屏障了。
主线程继续执行并行构造之后的用户代码,而从属线程则等待被召集加入到其他组。
OpenMP 并行区域之间可以互相嵌套。
如果禁用嵌套并行操作,则由遇到并行区域内并行构造的线程所创建的新组仅包含遇到并行构造的线程。
如果启用嵌套并行操作,则新组可以包含多个线程。
MPI和OpenMP程序设计实验报告

一、实验目的及要求熟悉MPI编程环境,掌握MPI编程基本函数及MPI的相关通信函数用法,掌握MPI的主从模式及对等模式编程;熟悉OpenMP编程环境,初步掌握基于OpenMP的多线程应用程序开发,掌握OpenMP相关函数以及数据作用域机制、多线程同步机制等。
二、实验设备(环境)及要求Microsoft Visual Studio .net 2005MPICH2Windows 7 32位Intel Core2 Duo T5550 1.83GHz 双核CPU2GB内存三、实验内容与步骤1.配置实验环境/research/projects/mpich2/downloads/index.php?s =downloads 处下载MPICH2,并安装。
将安装目录中的bin目录添加到系统环境变量path中。
以管理员身份运行cmd.exe,输入命令smpd -install -phrase ***。
***为安装时提示输入的passphrase。
运行wmpiregister.exe,输入具有系统管理员权限的用户名及密码,进行注册。
配置vs2005,加入MPICH2的包含文件,引用文件和库文件,如下图。
配置项目属性,添加附加依赖项mpi.lib,如下图。
VS2005支持OpenMP,只需在项目属性中做如下配置。
2.编写MPI程序题目:一个小规模的学校想给每一个学生一个唯一的证件号。
管理部门想使用6位数字,但不确定是否够用,已知一个“可接受的”证件号是有一些限制的。
编写一个并行计算程序来计算不同的六位数的个数(由0-9组合的数),要求满足以下限制:●第一个数字不能为0;●两个连续位上的数字不能相同;●各个数字之和不能为7、11、13代码如下。
#include "mpi.h"#include <stdio.h>#include <math.h>#define NUM 6#define MAX 999999#define MIN 100000int check(int n){int i, x, y, sum;if (n < MIN){return -1;}sum = 0;for (i=1; i<NUM; i++){x = (n%(int)pow(10, i))/(int)pow(10,i-1);y = (n%(int)pow(10, i+1))/(int)pow(10, i);if (x == y){return -1;}sum = sum+x+y;}if (sum==7 || sum==11 || sum==13){return -1;}return 0;}void main(int argc, char **argv){int myid, numprocs, namelen;char processor_name[MPI_MAX_PROCESSOR_NAME];MPI_Status status;double startTime, endTime;int i, mycount, count;MPI_Init(&argc,&argv);MPI_Comm_rank(MPI_COMM_WORLD,&myid);MPI_Comm_size(MPI_COMM_WORLD,&numprocs);MPI_Get_processor_name(processor_name,&namelen);if (myid == 0){startTime = MPI_Wtime();}mycount = 0;for (i=myid; i<=MAX; i+=numprocs){if (check(i) == 0){mycount++;}}printf("Process %d of %d on %s get result=%d\n", myid, numprocs, processor_name, mycount);if (myid != 0){MPI_Send(&mycount, 1, MPI_INT, 0, myid, MPI_COMM_WORLD);}else{count = mycount;for (i=1; i<numprocs; i++){MPI_Recv(&mycount, 1, MPI_INT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status);count += mycount;}endTime = MPI_Wtime();printf("result=%d\n", count);printf("time elapsed %f\n", endTime-startTime);}MPI_Finalize();}计算量平均分给每个进程,每个进程将自己计算的部分结果发送给0号进程,由0号进程将结果相加,并输出。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Development of Mixed Mode MPI/OpenMPApplicationsLorna Smith and Mark BullEPCC,James Clark Maxwell Building,The King’s Buildings,The University of Edinburgh,Mayfield Road,Edinburgh,EH93JZ,Scotland,U.K.email:l.smith@ or m.bull@Abstract—MPI/OpenMP mixed mode codes could potentially offer the most ef-fective parallelisation strategy for an SMP cluster,as well as allowing the different characteristics of both paradigms to be exploited to give the best performance on a single SMP.This paper discusses the implementation,de-velopment and performance of mixed mode MPI/OpenMP applications.The results demonstrate that this style of programming will not always be the most effective mechanism on SMP systems and cannot be regarded as the ideal programming model for all codes.In some situations,however, significant benefit may be obtained from a mixed mode implementation. For example,benefit may be obtained if the parallel(MPI)code suffers from:poor scaling with MPI processes due to load imbalance or toofine a grain problem size,memory limitations due to the use of a replicated data strategy,or a restriction on the number of MPI processes combinations.In addition,if the system has a poorly optimised or limited scaling MPI imple-mentation then a mixed mode code may increase the code performance.Keywords—mixed mode,OpenMP,MPI,HPC applications,perfor-mance.I.I NTRODUCTIONShared memory architectures are gradually becoming more prominent in the HPC market,as advances in technology have allowed larger numbers of CPUs to have access to a single mem-ory space.In addition,manufacturers are increasingly clustering these SMP systems together to go beyond the limits of a single system.As clustered SMPs become more prominent,it becomes more important for applications to be portable and efficient on these systems.Message passing codes written in MPI are obviously portable and should transfer easily to clustered SMP systems.Whilst message passing is necessary to communicate between nodes,it is not immediately clear that this is the most efficient parallelisa-tion technique within an SMP node.In theory,a shared memory model such as OpenMP should offer a more efficient paralleli-sation strategy within an SMP node.Hence a combination of shared memory and message passing parallelisation paradigms within the same application(mixed mode programming)may provide a more efficient parallelisation strategy than pure MPI. Whilst mixed mode codes may involve other program-ming languages such as High Performance Fortran and POSIX threads,this paper will focus on mixed MPI and OpenMP codes. This is because these are likely to represent the most widespread use of mixed mode programming on SMP clusters due to their portability and the fact that they represent industry standards for distributed and shared memory systems respectively.Whilst SMP clusters offer the greatest reason for developing a mixed mode code,both the OpenMP and MPI paradigms have different advantages and disadvantages and by developing such a model these characteristics may be exploited to give the best performance on a single SMP system.This paper discusses the benefits of developing mixed mode MPI/OpenMP applications on both single and clustered SMPs. Section II describes related work on mixed mode programming whilst Section III provides a comparison of the different char-acteristics of the OpenMP and MPI paradigms.Section IV dis-cusses the implementation of mixed mode applications and Sec-tion V describes a number of situations where mixed mode pro-gramming is potentially beneficial.Section VI contains a case study and Section VII a real mixed mode application;in both cases we describe the implementation of a mixed mode applica-tion and compare and contrast the performance of the code with pure MPI and OpenMP versions.II.R ELATED W ORKHenty et al.[1]have developed an MPI,OpenMP and mixed mode version of a discrete element model(DEM)code and com-pared and contrasted the performance.This work is also dis-cussed further in Section V.Tafti et al.[2],[3]have studied irregular applications such as adaptive mesh refinement codes which suffer from load balance problems when parallelised us-ing MPI.By developing a mixed mode code for a clustered SMP system,MPI need only be used for communication between nodes.The OpenMP implementation does not suffer from load imbalance and hence the performance of the code would be im-proved.They have developed a technique called computational power balancing which dynamically adjusts the number of pro-cessors working on a particular calculation.This work is dis-cussed further in Section nucara et al.[4]have developed mixed OpenMP/MPI versions of two Conjugate-Gradients al-gorithms and compared their performance to pure MPI imple-mentations.The DoD High Performance Computing Modernisation Pro-gram(HPCMP)Waterways Experiment Station(WES)have de-veloped a mixed mode OpenMP/MPI version of the CGW A VE code[5].This code is used by the US Navy for forecasting and analysis of harbour conditions.The wave components are the parameter space and each wave component creates a separate partial differential equation that is solved on the samefinite ele-ment grid.MPI is used to distribute the wave components using a simple boss-worker strategy,resulting in a course grain par-allelism.Each wave component results in a large sparse linear system of equations that is parallelised using OpenMP.The de-velopment of a mixed mode code has allowed these simulations to be carried out on a grid of computers,in this case on two different computers at different locations simultaneously.This mixed mode code has been very successful and won the“most effective engineering methodology”award at SC98.Bova et al.[6]have developed mixed mode versions offive separate codes.These are the CGW A VE code mentioned above, the ab initio quantum chemistry package GAMESS,a Linear al-gebra study,a thin-layer Navier-Stokex solver(TLNS3D)and the seismic processing benchmark SPECseis96.Each model was developed for different reasons however most used multiple levels of parallelism,with distributed memory programming for the coarser grain parallelism and shared memory programming for thefiner-grained.Finally,a number of talks and presentations have also been given on comparing OpenMP and MPI and on mixed mode pro-gramming styles.For further information see references[7],[8], [9],[10],[11],[12],[13].III.P ROGRAMMING MODEL CHARACTERISTICSAs mentioned previously,as well as being potentially more effective on an SMP cluster,mixed mode programming may be of use on a single SMP,allowing the advantages of both mod-els to be exploited.This section briefly summarises the two paradigms and considers their potential advantages and disad-vantages.A.MPIThe message passing programming model is a distributed memory model with explicit control parallelism.MPI[14]is portable to both distributed and shared memory architecture and allows static task scheduling.The explicit parallelism often pro-vides a better performance and a number of optimised collec-tive communication routines are available for optimal efficiency. Data placement problems are rarely observed and synchronisa-tion occurs implicitly with subroutine calls and hence is min-imised naturally.However MPI suffers from a few deficiencies.Decomposi-tion,development and debugging of applications can be time consuming and significant code changes are often required. Communications can create a large overhead and the code gran-ularity often has to be large to minimise the latency.Finally, global operations can be very expensive.B.OpenMPOpenMP is an industry standard[15]for shared memory pro-gramming.Based on a combination of compiler directives,li-brary routines and environment variables it is used to specify parallelism on shared memory munication is implicit and OpenMP applications are relatively easy to imple-ment.In theory,OpenMP makes better use of the shared mem-ory architecture.Run time scheduling is allowed and bothfine and course grain parallelism are effective.OpenMP codes will however only run on shared memory machines and the place-ment policy of data may causes problems.Course grain paral-lelism often requires a parallelisation strategy similar to an MPI strategy and explicit synchronisation is required.C.Mixed mode programmingBy utilising a mixed mode programming model we should be able to take advantage of the benefits of both models.For example a mixed mode program may allow the data placement policies of MPI to be utilised with thefiner grain parallelism of OpenMP.The majority of mixed mode applications involve a hi-erarchical model;MPI parallelisation occurring at the top level, and OpenMP parallelisation occurring below.For example,Fig-ure1shows a2D grid which has been divided geometrically be-tween four MPI processes.These sub-arrays have then been fur-ther divided between three OpenMP threads.This model closely maps to the architecture of an SMP cluster,the MPI parallelisa-tion occurring between the SMP nodes and the OpenMP paral-lelisation within thenodes.process 0process 1process 2process 3thread 0thread 1thread 2thread 0thread 1thread 2thread 0thread 1thread 2thread 1thread 22D Arraythread 0Fig.1.Schematic representation of a hierarchical mixed mode programming model for a2D array.Whilst the majority of mixed mode programs implement this type of model,a number of authors have described non-hierarchical models(see Section II).For example,message passing could be used within a code when this is relatively sim-ple to implement and shared memory parallelism used where message passing is difficult[16].IV.I MPLEMENTING A MIXED MODE APPLICATION Although a large number of MPI implementations are thread-safe,this cannot be guaranteed.To ensure the code is portable, all MPI calls should be made within thread sequential regions of the code.This often creates little problem as the majority of codes involve the OpenMP parallelisation occurring beneath the MPI parallelisation and hence the majority of MPI calls occur outside the OpenMP parallel regions.When MPI calls occur within an OpenMP parallel region the calls should be placed inside a CRITICAL,MASTER or SINGLE region,depending on the nature of the code.Care should be taken with SINGLE regions,as different threads may execute the code on successive passes.Ideally,the number of threads should be set from within each MPI process using omp numNUMging and performance optimisation is most effectively carried out by treating the MPI and OpenMP separately.When writing a mixed mode application it is important to con-sider how each paradigm carries out parallelisation,and whether combining the two mechanisms provides an optimal paralleli-sation strategy.For example,a two dimensional grid problem may involve an MPI decomposition in one dimension and an OpenMP decomposition in one dimension.As two dimensional decomposition strategies are often more efficient than a one di-mensional strategy it is important to ensure that the two decom-positions occur in different dimensions.V.B ENEFITS OF MIXED MODE PROGRAMMINGThis section discusses various situations where a mixed mode code may be more efficient than a corresponding MPI imple-mentation,whether on an SMP cluster or single SMP system.A.Codes which scale poorly with MPIOne of the largest areas of potential benefit from mixed mode programming is with codes which scale poorly with increasing MPI processes.If,for example,the corresponding OpenMP version scales well then an improvement in performance may be expected for a mixed mode code.If,however,the equiva-lent OpenMP implementation scales poorly,it is important to consider the reasons behind the poor scaling and whether these reasons are different for the OpenMP and MPI implementa-tions.If both versions scale poorly for different reasons,for example the MPI implementation involves too much load im-balance and the OpenMP version suffers from cache misses due to data placement problems,then a mixed version may allow the code to scale to a larger number of processors before either of these problems become apparent.If however both the MPI and OpenMP codes scale poorly for the same reason,developing a mixed mode version of the algorithms may be of little use.A.1Load balance problemsOne of the most common reasons for an MPI code to scale poorly is load imbalance.For example irregular applications such as adaptive mesh refinement codes suffer from load balance problems when parallelised using MPI.By developing a mixed mode code for a clustered SMP system,MPI need only be used for communication between nodes,creating a coarser grained problem.The OpenMP implementation does not suffer from load imbalance and hence the performance of the code would be improved[2].A.2Fine grain parallelism problemsOpenMP generally gives better performance onfine grain problems,where an MPI application may become communica-tion dominated.Hence when an application requires good scal-ing with afine grain level of parallelism a mixed mode program may be more efficient.Obviously a pure OpenMP implementa-tion would give better performance still,however on SMP clus-ters MPI parallelism is still required for communication between nodes.By reducing the number of MPI processes required,the scaling of the code should be improved.For example,Henty et al.[1]have developed an MPI version of a discrete element model(DEM)code using a domain de-composition strategy and a block-cyclic distribution.In order to load balance certain problems afine granularity is required,but this results in an increase in parallel overheads.The equivalent OpenMP implementation involves a simple block distribution of the main loop,which effectively makes the calculation load balanced.In theory therefore,the performance of a pure MPI implementation should be poorer than a pure OpenMP imple-mentation for thesefine granularity situations.A mixed mode code could provide better performance,as load balance would only be an issue between SMPs,which may be achieved with coarser granularity.This specific example is more complicated with other factors affecting the OpenMP scaling:see[1]for fur-ther details.B.Replicated dataCodes written using a replicated data strategy often suffer from memory limitations and from poor scaling due to global communications.By using a mixed mode programming style on an SMP cluster,with the MPI parallelisation occurring across the nodes and the OpenMP parallelisation inside the nodes,the problem will be limited to the memory of an SMP node rather than the memory of a processor(or,to be precise,the memory of an SMP node divided by the number of processors),as is the case for a pure MPI implementation.This has obvious advan-tages,allowing more realistic problem sizes to be studied.C.Ease of implementationImplementing an OpenMP application is almost always re-garded as simpler and quicker than implementing an MPI ap-plication.Based on this the overhead in creating a mixed mode code over an MPI code is relatively small.In general,no signifi-cant advantage in implementation time can be gained by writing a mixed mode code over an MPI code,as the MPI implementa-tion still requires writing.There are possible exceptions where this is not the case.In a number of situations it is more effi-cient to carry out a parallel decomposition in multiple dimen-sions rather than in one,as the ratio of computation to com-munication increases with increasing dimension.It is however simpler to carry out a one dimensional parallel decomposition rather than a three dimensional decomposition using MPI.By writing a mixed mode version,the code would not need to scale well to as many MPI processes,as some MPI processes would be replaced by OpenMP threads.Hence,in some cases writing a mixed mode program may be easier than writing a pure MPI ap-plication,as the MPI implementation could be simpler and less scalable.D.Restricted MPI process applicationsA number of MPI applications require a specific number of processes to run.For example one code[18](which uses a time dependent quantum approach to scattering processes)distributes the work by assigning the tasks propagating the wavepacket at different vibrational and rotational numbers to different pro-cesses.Whilst a natural and efficient implementation,this limits the number of MPI processes to certain combinations.In addi-tion,a large number of codes only scale to powers of2,again limiting the number of processors.This can create a problem in two ways.Firstly the number of processes required may notequal the machine size,either being too large,making running impossible,or more commonly too small and hence making the utilisation of the machine inefficient.In addition,a number of MPP services only allow jobs of certain sizes to be run in an attempt to maximise the resource usage of the system.If the restricted number of processors does not match the size of one of the batch queues this can create real problems for running the code.By developing a mixed mode MPI/OpenMP code the natural MPI decomposition strategy can be used,running the desired number of MPI processes,and OpenMP threads used to further distribute the work,allowing all the available processes to be used effectively.E.Poorly optimised intra-node MPIAlthough a number of vendors have spent considerable amounts of time optimising their MPI implementations within a shared memory architecture,this may not always be the case. On a clustered SMP system,if the MPI implementation has not been optimised,the performance of a pure MPI application across the system may be poorer than a mixed MPI/OpenMP code.This is obviously vendor specific,but in certain cases a mixed mode code could offer significant performance improve-ment,for example on a Beowulf system.F.Poor scaling of the MPI implementationClustered SMPs open the way for systems to be built with ever increasing numbers of processors.In certain situations the scaling of the MPI implementation itself may not match these ever increasing processor numbers or may indeed be restricted to a certain maximum number[19].In this situation developing a mixed mode code may be of benefit(or required),as the num-ber of MPI processes needed will be reduced and replaced with OpenMP threads.putational power balancingA technique developed by D.Tafti and W.Huang[2],[3], computational power balancing dynamically adjusts the number of processors working on a particular calculation.The applica-tion is written as a mixed mode code with the OpenMP direc-tives embedded under the MPI processes.Initially the work is distributed between the MPI processes,however when the load on a processor doubles the code uses the OpenMP directives to spawn a new thread on another processor.Hence when an MPI process becomes overloaded the work can be redistributed.Tafti et al.have used this technique with irregular applications such as adaptive mesh refinement(AMR)codes which suffer from load balance problems.When load imbalance occurs for an MPI application either repartition of the mesh,or mesh migration is used to improve the load balance.This is often time consum-ing and costly.By using computational power balancing these procedures can be avoided.The advantages of this technique are limited by the operat-ing policy of the system.Most systems allocate afixed number of processors for one job and do not allow applications to grab more processors during execution.This is to ensure the most effective utilisation of the system by multiple users and it is dif-ficult to see these policies changing.The obvious exception is “free for all”SMPs which would accommodate such a model.VI.C ASE STUDYHaving discussed the possible benefits of writing a mixed mode application,this section looks at an example code which is implemented in OpenMP,MPI and as a mixed MPI/OpenMP code.A.The codeThe code used here is a Game of Life code,a simple grid-based problem which demonstrates complex behaviour.It is a cellular automaton where the world is a2D grid of cells which have two states,alive or dead.At each iteration the new state of the cell is entirely determined by the state of its eight nearest neighbours at the previous iteration.The basic structure of the code is:1.Initialise the2D cell.2.Carry out boundary swaps(for periodic boundary condi-tions).3.Loop over the2D grid,to determine the number of alive neighbours.4.Up-date the2D grid,based on the number of alive neighbours and calculate the number of alive cells.5.Iterate steps2–4for the required number of iterations.6.Write out thefinal2D grid.The majority of the computational time is spent carrying out steps2–4.B.ParallelisationThe aim of developing a mixed mode MPI/OpenMP code is to attempt to gain a performance improvement over a pure MPI code,allowing for the most efficient use of a cluster of SMPs. In general,this will only be achieved if a pure OpenMP version of the code gives better performance on an SMP system than a pure MPI version of the code(see Section V-A).Hence a number of pure OpenMP and MPI versions of the code have been developed and their performance compared.B.1MPI parallelisationThe MPI implementation involves a domain decomposition strategy.The2D grid of cells is divided between each process, each process being responsible for updating the elements of its section of the array.Before the states of neighbouring cells can be determined copies of edge data must be swapped between neighbouring processors.Hence halo-swaps are carried out for each iteration.On completion,all the data is sent to the mas-ter process,which writes out the data.This implementation in-volves a number of MPI calls to create virtual topologies and de-rived data types,and to determine and send data to neighbouring processes.This has resulted in considerable code modification, with around100extra lines of code.B.2OpenMP parallelisationThe most natural OpenMP parallelisation strategy is to place a number of PARALLEL DO directives around the computa-tionally intense loops of the code and an OpenMP version of the code has been implemented with PARALLEL DO directives around the outer loops of the three computationally intense com-ponents of the iterative loop(steps2–4).This has resulted in minimal code changes,with only15extra lines of code.The code has also been written using an SPMD model and the same domain decomposition strategy as the MPI code to provide a more direct comparison.The code is placed within a PARAL-LEL region.An extra index has been added to the main array of cells,based on the thread number.This array is shared and each thread is responsible for updating its own section of the array based on the thread index.Halo swaps are carried out between different sections of the array.Synchronisation is only required between nearest neighbour threads and,rather than force extra synchronisation between all threads using a BARRIER,a sep-arate routine,using the FLUSH directive,has been written to carry this out.The primary difference between this code and the MPI code is in the way in which the halo swaps are carried out.The MPI code carries out explicit message passing whilst the OpenMP code uses direct reads and writes to memory.C.PerformanceThe performance of the two OpenMP codes and the MPI code has been measured with two different array sizes.Table I shows the timings of the main loop of the code (steps 2–4)and Fig-ures 2and 3show the scaling of the code on array sizes 100100and 700700respectively for 10000iterations.123456789No of threads/processesS p e e d -u pFig.2.Scaling of the Game of Life code for array size 100.1234567123456789No of threads/processesS p e e d -u pFig.3.Scaling of the Game of Life code for array size 700.array size 100OpenMP (SPMD)OpenMP (Loop)5.59 4.822 4.002.98 2.3163.022.09 1.97MPI1264.20146.20120.34471.3852.2345.22846.21tion of the array.Halo-swaps are carried out for each itera-tion.In addition OpenMP PARALLEL DO directives have been placed around the relevant loops,creating further parallelisa-tion beneath the MPI parallelisation.Hence the work is firstly distributed by dividing the 2D grid between the MPI processes geometrically and then parallelised further using OpenMP loop based parallelisation.The performance of this code has been measured and scaling curves determined for increasing MPI processes and OpenMP threads.The results have again been measured with two differ-ent array sizes.Table II shows the timings of the main loop of the code for 10000iterations.Figure 4shows the scaling of the code on array sizes 100100and 700700.01234567123456789No of threads/processesS p e e d -u pFig.4.Scaling of the loop based and OpenMP /MPI Game of Life code forarray sizes 100and 700.It is clear that the scaling with OpenMP threads is similar to the scaling with MPI processes,for the larger problem size.However when compared to the performance of the pure MPI code the speed-up is very similar and no significant advantage has been obtained over the pure MPI implementation.The scaling is slightly better for the smaller problem size,again demonstrating OpenMP’s advantage on finer grain prob-lem sizes.Further analysis reveals that the poor scaling of the code is due to the same reasons as the pure MPI and OpenMP codes.The scaling with MPI processes is less than ideal due to the ad-ditional time spent carrying out halo swaps and the scaling with OpenMP threads is reduced because of the additional synchro-nisation creating a load balance issue.In an attempt to improve the load balance and reduce the amount of synchronisation involved the code has been modified.Rather than using OpenMP PARALLEL DO directives around the two principal OpenMP loops (the loop to determine the num-ber of neighbours and the loop to up-date the board based on the number of neighbours)these have been placed within a parallel region and the work divided between the threads in a geomet-ric manner.Hence,in a similar manner to the SPMD OpenMP implementation mentioned above,the 2D grid has been divided between the threads in a geometric manner and each thread is re-sponsible for its own section of the 2D grid.The 2D arrays are still shared between the threads.This has had two effects:firstly the amount of synchronisation has been reduced,as no synchro-nisation is required between each of the two loops.Secondly,Loop based mixed mode code Threads Threads (700)(100)1229.18 5.462121.77 3.76462.25 2.70645.58 2.94839.213.19Processes Processes (700)(100)302.41 5.22172.43 3.9292.69 3.8668.76 3.5258.513.56SPMD mixed mode codeThreads Threads (700)(100)1251.84 5.252133.18 3.59468.92 2.61649.87 2.73843.113.19TABLE IIT IMINGS OF THE MAIN LOOP OF THE MIXED MODE G AME OF L IFE CODESWITH ARRAY SIZES 100100AND 700700FOR 10000ITERATIONS .the parallelisation now occurs in two dimensions,whereas pre-viously parallelisation was in one (across the outer DO loops).This could have an effect on the load balance if the problem is relatively small.Figure 5shows the performance of this code,with scaling curves determined for increasing MPI processes and OpenMP processes.This figure demonstrates that the scaling of the code with OpenMP threads has decreased,and the scaling with MPI pro-cesses remained similar.Further analysis reveals that the poor scaling is still in part due to the barrier synchronisation creat-ing load imbalance.Although the number of barriers has been decreased,synchronisation between all threads is still necessary before the MPI halo swaps can occur for each iteration.When running with increasing MPI processes (and only one OpenMP thread),synchronisation only occurs between nearest neighbour processes,and not across the entire communicator.In addition,the 2D decomposition has had a detrimental effect on the per-formance.This may be due to the increased number of cache lines which must be read from remote processors.In order to eliminate this extra communication,the code has been re-written so that the OpenMP parallelisation no longer occurs underneath the MPI parallelisation.The threads and processes have each been given a global iden-tifier and divided into a global 2D topology.From this the near-est neighbour threads /processes have been determined and the nearest neighbour (MPI)rank has been stored.The 2D grid has been divided geometrically between the threads and processes based on the 2D topology.Halo swaps are carried out for each。