Redis集群研究
Redis 集群服务信息与性能指标详解

Redis 集群服务信息与性能指标详解在发现redis集群性能问题的时候,我们⾸首先需要考虑的是整个集群的各项指标数据,然后根据这些指标数据判断具体的问题所在,redis本来就提供了了⼀一套⽐比较完善的性能指标,具体如下:⼀一般情况下, used_memory_rss 的值应该只⽐比 used_memory 稍微⾼高⼀一些。
1、当 rss > used ,且两者的值相差较⼤大时,表示存在(内部或外部的)内存碎⽚片。
内存碎⽚片的⽐比率可以通过查看mem_fragmentation_ratio 得知。
2、当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了了,在这种情况下,操作可能会产⽣生明显的延迟。
3、当 Redis 释放内存时,分配器器可能会,也可能不不会,将内存返还给操作系统。
如果 Redis 释放了了内存,却没有将内存返还给操作系统,那么used_memory 的值可能和操作系统显示的 Redis 内存占⽤用并不不⼀一致。
查看 used_memory_peak 的值可以验证这种情况是否发⽣生。
Redis Info信息包括:Server,Clients,Memory,Persistence,Stats,Replication,CPU,Commandstats,Cluster,Keyspace# Server(服务器器信息)redis_version:4.0.10 #redis服务器器版本redis_git_sha1I00000000 #Git SHA1redis_git_dirty:0 #Git dirty flagredis_build_id:6c2c390b97607ff0 #redis build idredis_mode:cluster #运⾏行行模式,单机或者集群os:Linux 2.6.32-358.2.1.el6.x86_64 x86_64 #redis服务器器的宿主操作系统arch_bits:64 #架构(32或64位)multiplexing_api:epoll #redis所使⽤用的事件处理理机制gcc_version:4.4.7 #编译redis时所使⽤用的gcc版本process_id:12099 #redis服务器器进程的pidrun_id:63bcd0e57adb695ff0bf873cf42d403ddbac1565 #redis服务器器的随机标识符(⽤用于sentinel和集群)tcp_port:9021 #redis服务器器监听端⼝口uptime_in_seconds:26157730 #redis服务器器启动总时间,单位是秒uptime_in_days:302 #redis服务器器启动总时间,单位是天hz:10 #redis内部调度(进⾏行行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运⾏行行10次。
redis集群 配置参数

redis集群配置参数
在Redis集群中,需要配置以下参数:
1. cluster-enabled:设置为yes来启用集群模式。
2. cluster-config-file:指定集群配置文件的路径。
3. cluster-node-timeout:指定集群节点之间的超时时间。
4. cluster-announce-ip:指定集群节点的IP地址。
5. cluster-announce-port:指定集群节点的端口号。
6. cluster-announce-bus-port:指定集群节点之间通信的端口号。
7. cluster-require-full-coverage:设置为yes来要求所有槽位都要有节点才能正常工作。
8. cluster-migration-barrier:设置为yes来阻止在槽迁移期间的对数据的写入操作。
这些参数可以在Redis的配置文件redis.conf中进行设置。
在配置文件中找到对应的参数进行修改并重启Redis服务即可生效。
Redis集群性能测试分析

Redis集群性能测试分析柳皓亮;王丽;周阳辰【摘要】Redis是一个非关系型数据库,属于内存级数据库。
但是由于数据量的不断增大,单机的Redis物理内存远远无法满足大数据的需要,因此需要搭建分布式的Redis,可以动态扩展内存,弥补单机Redis物理内存不够的缺点。
本次测试旨在对Redis各方面性能有深入的了解,为今后的工作打好基础。
本次实验的目的主要是搭建Redis Cluster和TwemProxy Redis两种集群,分别对其进行性能测试,测试出集群性能的拐点,找出性能的瓶颈有哪些,并对两套集群进行比较,以便于在不同业务场景下择优选择。
%Redis is a non-relational database, which belongs to the memory database. However, with the amount of data increasing quickly, the single Redis is unable to meet the needs of the large data. So we need to build a distributed Redis, which can extend memory dynamicly and make up the faults that the single Redis doesn’ t have enough physical memory. In order to have a good design for the Redis Cluster and play a Redis high throughput characteristics of Redis Cluster, we make the experiment about this. In this experiment, we build two clusters, which are Redis Cluster and TwemProxy Cluster. We make experiment one by one to test out the clustering performance of inflection point, meanwhile, find out what are the performance bottlenecks. So we can make a good choice under different business scenarios.【期刊名称】《微型机与应用》【年(卷),期】2016(035)010【总页数】3页(P70-71,78)【关键词】Redis Cluster;TwemProxy Redis;性能测试【作者】柳皓亮;王丽;周阳辰【作者单位】中国科学院电子学研究所苏州研究院存储计算组,江苏苏州215123;中国科学院电子学研究所苏州研究院存储计算组,江苏苏州215123;中国科学院电子学研究所苏州研究院存储计算组,江苏苏州215123【正文语种】中文【中图分类】TP23本次存储测试是用Java程序调用Jedis提供的API向集群里面灌入数据。
redis集群动态扩容原理

redis集群动态扩容原理Redis是一款高性能的键值存储数据库,其可靠性和性能表现使其成为了许多企业的首选数据库。
但是在使用Redis时,当数据量增大或者访问压力增大,单节点的性能不能满足需求时,就需要使用Redis 的集群方案来解决问题。
对于Redis集群,动态扩容是其中一个重要的功能,它可以在不停止服务的情况下,动态扩展集群节点,从而使Redis集群更好地应对不断增长的负载。
Redis集群的动态扩容原理主要包括以下几个方面:1. 模式识别Redis集群的动态扩容需要首先进行模式识别,即识别出哪些节点需要扩容。
在Redis集群中,每个节点会维护一份关于集群状态的信息,从而实现集群的数据自动分片和数据复制。
在扩容前,Redis集群需要从每个节点获取其维护的集群状态信息。
这些信息包括了每个节点的哈希槽信息及其所属的分片,通过分析这些哈希槽信息,就可以得知哪些节点已经满载,需要进行扩容。
2. 分配哈希槽一旦识别出需要进行扩容的节点,Redis集群就需要对新增节点进行哈希槽的分配。
哈希槽是Redis集群中的一种逻辑概念,它将所有数据分成了一定数量的段,每个段称为一个哈希槽。
Redis在集群中使用哈希槽的方式来实现数据的自动分片和数据复制。
当新增节点加入集群时,Redis集群会根据当前所有节点的哈希槽信息,重新进行哈希槽的分配,从而将新的哈希槽均匀地分配给所有节点,并且避免了哈希槽的不均匀分配。
3. 数据迁移一旦新节点加入集群并分配了哈希槽,Redis集群就需要将属于这些哈希槽的数据迁移到新节点上。
Redis会将需要迁移的数据进行切片,然后通过网络将切片数据从旧节点传输到新节点。
在进行数据迁移时,Redis集群需要保证原有数据的完整性和一致性。
为了避免数据丢失和数据不一致问题,Redis集群采用了无数据丢失的迁移方式,即通过在新节点上建立临时节点,将原有节点和新节点之间的数据流量切换到临时节点,从而保证了数据在迁移之前和迁移之后的准确性和连续性。
redis集群工作原理

redis集群工作原理Redis集群工作原理概述:Redis是一款高性能的键值存储系统,它的集群模式可以通过分布在不同节点的多个Redis实例来提高系统的性能和容量。
本文将介绍Redis集群的工作原理,包括数据分片、主从复制、故障转移等关键技术。
一、数据分片Redis集群通过数据分片来将数据分布在多个节点上。
具体来说,Redis使用哈希槽(hash slot)将数据划分为16384个槽位,每个键值对根据其键通过哈希算法分配到一个槽位上。
这样,每个Redis节点就负责管理部分槽位上的数据。
二、主从复制为了提供数据的高可用性,Redis集群使用主从复制机制。
每个主节点可以有多个从节点,主节点负责处理读写请求,从节点则负责复制主节点的数据。
主节点将数据通过异步复制的方式发送给从节点,从节点将接收到的数据写入自己的数据库中。
三、故障转移当一个主节点出现故障时,Redis集群需要进行故障转移,确保数据的可用性。
故障转移的过程如下:1. 当主节点失效时,集群中的某个从节点会被选举为新的主节点。
2. 新的主节点会将自己的身份广播给其他节点,并开始接收客户端的读写请求。
3. 其他从节点会将原来的主节点切换为新的主节点,并开始复制新的主节点的数据。
4. 如果原来的主节点恢复,它将成为新的从节点,并开始复制新的主节点的数据。
四、节点间通信Redis集群中的节点之间通过gossip协议进行通信。
每个节点会定期与其他节点交换信息,包括节点的状态、槽位分配情况等。
通过这种方式,集群中的每个节点都能了解整个集群的状态,并根据需要进行数据迁移、故障转移等操作。
五、客户端路由在Redis集群中,客户端需要将请求发送到正确的节点上。
为了实现这一点,客户端会通过集群的握手过程获取到集群的拓扑信息,包括每个节点的地址和槽位分配情况。
然后,客户端根据键的哈希值将请求发送到对应的节点上。
六、集群维护Redis集群提供了一些维护命令,用于管理集群的状态和配置。
redis cluster--redis集群模式原理

redis cluster--redis集群模式原理Redis Cluster是Redis官方推出的分布式架构,它可以将多台Redis服务器看作是一个整体来使用,提供了高可用性、高扩展性等优点。
Redis Cluster基于分区的思想,将key映射到集群中的某一个节点上,每个节点负责一部分key。
通过互相通信来维护全局一致性和去重。
Redis Cluster集群模式分为以下几个部分:1、集群的节点数量不同,可以由多个Master节点和多个Slave节点组成。
2、每个节点都有一个唯一的名称(注意是名称不是IP地址),通过名称进行通信。
3、Redis Cluster将整个数据集分成16384个hash slot,每个节点可以处理其中一部分,节点之间通过Gossip协议交换信息,保持整个集群信息的一致性。
4、一个Redis节点可以既是Master,也可以是Slave。
Master节点负责处理客户端请求,而Slave节点则仅用于备份和读取数据,Master节点操作的数据会被同步到Slave节点。
5、在Redis Cluster中,如果一个Master节点宕机,它上面的所有Slave节点都不能升级为Master节点。
而是会自动进行故障转移,将失效的Master节点的Slot分配给其他运行正常的Master节点,并将其对应的Slave节点降级为Master节点,从而保证整个集群的可用性。
6、对于新加入的节点,可以使用resharding命令进行Slot的再分配。
重新分配Slot会导致数据迁移,因此需要慎重考虑。
总之,Redis Cluster集群模式的优点在于它能够提供高可用性、高扩展性、自动故障转移等特性。
但同时也需要注意一些坑点,如节点名称不能重复、节点之间的网络延迟等问题。
redis学习之集群报错Nodeisnotempty

redis学习之集群报错Node is not empty遇到的问题及解决办法在redis.conf里b i nd 真机ip后,接着重新执行每个red is.conf,最后再创建集群,但报错,如下图所示:图中报的错即:[ERR] Node 192.168.161.131:7000 is not empty. Either the node alrea d y knowsothernodes(checkwith CLUSTE R NODES)or contai ns some key in databa se 0.这就奇怪了,于是我又去检查了一下r e dis.conf,ip我确实改过来了想了一会发现这三个文件a ppen donly.aof dump.rdb nodes.conf是之前执行ip127.0.0.1时生成的,在我改为真机i p后在执行并没有生效。
这里解释一下d ump.rdb文件:dump.rdb是由R e dis服务器自动生成的默认情况下每隔一段时间r edis服务器程序会自动对数据库做一次遍历,把内存快照写在一个叫做“dump.rdb”的文件里,这个持久化机制叫做SN APSHO T。
有了SNAP SHOT后,如果服务器宕机,重新启动re dis服务器程序时r e dis会自动加载d u mp.rdb,将数据库状态恢复到上一次做SNA PSHOT时的状态。
知道原因后就好办了,解决办法:1)将每个节点下a of、rdb、nodes.conf本地备份文件删除;2)172.168.63.201:7001> flushd b #清空当前数据库(可省略)3)之后再执行脚本,成功执行;问题解决了之后就可以成功从jav a客户端测试了:ps:这里大家不要这样测试,可以将其写在配置文件里,我这里是为了方便。
Redis集群使用指南

Redis集群使用指南一、Redis集群简介Redis(Remote Dictionary Server)是一个开源的基于内存的键值对存储系统,经常用来作为缓存、消息队列和数据库。
在实际使用过程中,Redis可能会出现性能瓶颈和单点故障。
为了解决这些问题,Redis提供了集群模式。
Redis集群是对多个Redis节点进行逻辑分区和复制,从而实现高可用、高性能和可伸缩性。
Redis集群能够自动进行故障转移和重新分配,可以提供更好的可靠性和吞吐量。
二、Redis集群的工作原理Redis集群采用哈希槽(Hash Slot)的方式来实现数据的分片和复制。
一个Redis集群可以包含多个Redis节点,每个节点管理一部分哈希槽。
当客户端需要对某个键进行操作时,Redis首先计算该键对应的哈希值,然后将其分配到某个哈希槽中。
Redis集群根据哈希槽的分配情况,将该键的操作转发给相应的Redis节点进行处理。
如果某个节点出现故障,Redis集群会自动将该节点管理的哈希槽重新分配给其他节点。
Redis集群采用主从复制的方式来实现数据的持久化和高可用。
每个主节点可以有多个从节点,主节点负责处理读写请求,同时将数据复制到从节点。
如果主节点出现故障,其中的一个从节点会被自动选举为新的主节点,继续处理客户端请求。
三、搭建Redis集群的步骤1、安装Redis节点在Linux系统上安装Redis比较简单,可以使用以下命令:sudo apt-get updatesudo apt-get install redis-server安装完毕后,可以通过以下命令启动Redis服务:sudo service redis-server start2、配置Redis节点每个Redis节点都需要进行一些配置,以便加入到Redis集群中。
可以通过以下命令进入Redis配置文件:sudo vim /etc/redis/redis.conf需要修改的配置项有以下几个:cluster-enabled yes:启用Redis集群模式。
redis集群配置参数及优化

Redis集群配置参数及优化Redis的主要参数配置在redis.conf文件中。
1.conf内存值2.bindip默认情况下,如果没有指定“bind”配置指令,Redis将侦听服务器上可用的所有网络接口的连接。
默认情况:bind127.0.0.1实际配置:bind本机ip3.protected-modeyes启用默认保护模式。
只有当您确定您希望其他主机的客户端连接到Redis 时,您才应该禁用它,即使没有配置身份验证,也没有使用“bind”指令显式列出特定的接口集。
4.tcp-keepalive300如果非零,请使用SO_KEEPALIVE向没有通信的客户发送TCP协议。
这很有用,有两个原因:a)检测死同伴b)从中间的网络设备的角度进行连接在Linux上,指定的值(以秒为单位)是用于发送ack的周期。
注意,要关闭连接,需要双倍的时间。
这个选项的合理值是300秒,这是新的Redis默认值,从Redis3.2.1开始。
5.timeout0在客户机空闲N秒后关闭连接(0到禁用)6.port6379在指定端口上接受连接,默认值是63797.daemonizeyesredis后台运行8.pidfile/var/run/redis_6379.pid如果指定了一个pid文件,Redis会在启动时指定,并在退出时删除它。
当服务器运行非守护进程时,如果配置中没有指定pid文件,则不会创建pid文件。
当服务器被守护时,即使没有指定,也会使用pid文件,默认为“/var/run/redis.pid”。
创建一个pid文件是最好的工作:如果Redis不能创建它,那么服务器就会正常启动和运行。
9.loglevelnotice指定服务器冗余级别包括:a)debug:大量信息,用于开发/测试b)verbose:许多很少有用的信息,但不像debug级别那样混乱c)notice:适度详细,可能在生产中需要d)warning:只有非常重要/关键的消息被记录10.logfile""指定日志文件名。
redis集群同步规则

redis集群同步规则Redis集群同步规则随着互联网应用的快速发展,数据存储和同步成为了一个重要的问题。
为了保证数据的高可用性和一致性,Redis引入了集群同步规则。
本文将详细介绍Redis集群同步规则的原理和实现方式。
一、Redis集群概述Redis是一个开源的高性能键值对存储系统,广泛应用于缓存、消息队列、实时统计等场景。
为了提高Redis的可用性和容量,Redis 引入了集群模式。
Redis集群由多个节点组成,每个节点都可以存储数据,并且节点之间可以相互同步数据,实现高可用性和负载均衡。
二、Redis集群同步规则的原理Redis集群同步规则的核心思想是主从同步。
每个Redis集群节点都有一个主节点和多个从节点。
主节点负责接收客户端请求,并将数据同步到从节点。
从节点负责接收主节点的数据同步,并提供读取服务。
当主节点出现故障时,从节点可以自动选举出一个新的主节点,保证系统的可用性。
Redis集群同步规则主要包括以下几个方面:1. 数据同步策略Redis集群使用的是异步复制方式进行数据同步。
当主节点收到写入请求时,会先将数据写入到本地内存中,然后再将数据异步地发送给从节点进行复制。
这种方式可以保证主节点的写入性能,并且不会阻塞客户端请求。
2. 数据同步延迟由于数据同步是异步进行的,所以从节点的数据可能会有一定的延迟。
Redis集群通过心跳机制来检测从节点的状态,当发现从节点延迟过高或者无法连接时,会自动将其标记为下线状态,并从其他从节点中选举一个新的主节点。
3. 数据一致性Redis集群通过复制日志来保证数据一致性。
主节点将每次写操作记录到复制日志中,并发送给从节点进行复制。
从节点在接收到复制日志后,会按照顺序执行其中的写操作,从而保证数据的一致性。
4. 主节点选举当主节点出现故障时,Redis集群会自动进行主节点选举。
选举过程中,会根据节点的复制偏移量和复制偏移量积压情况来选择新的主节点。
选举完成后,集群中的其他节点会自动将新的主节点设置为自己的从节点。
redis集群三主三从原理

redis集群三主三从原理
Redis集群三主三从原理:
1、角色及关系:
(1)集群的三个主节点:主节点负责数据的写入,能够自动同步数据。
(2)三个从节点:从节点负责写入数据的复制,以实现高可用。
2、 Master-Slave关系:
(1)主节点之间的数据同步:两个主节点之间以双向复制的方式进行数据同步。
(2)从节点跟主节点的关系:从节点通过单向复制的方式从主节点上获取数据。
3、释放双写死锁问题:
(1)两个主节点之间的双写死锁:两个主节点之间的双写死锁,即一个主节点更新一个数据,另一个主节点也有相同的更新,以致无法在集群中达成一致。
(2)解决办法:使用CTOP协议,将两个主节点之间的更新操作合并,如果有冲突,以后者为准。
4、读写操作:
(1)写操作:请求将会发送给一个主节点,该主节点会将数据写入并
复制到其它两个主节点,而其它两个主节点会将数据复制到可用的从节点上。
(2)读操作:请求可能会发送给主节点或者从节点,如果请求发送给主节点,主节点将会处理该请求,如果请求发送给从节点,从节点会将请求转发给随机的主节点在进行处理。
5、高可用方案:
(1)增加节点:可以在原有三个主节点基础上,添加一个节点,并将该节点配置为主节点,以实现高可用。
(2)容灾方案:当一个节点出现故障,可以将其它从节点提升为主节点,实现服务的持续运行。
redis集群模式原理

Redis集群模式是一种在多个Redis实例之间分布数据和负载的解决方案,它提供了高可用性和可伸缩性。
以下是Redis集群模式的基本原理:
数据分片(Sharding):
Redis集群将数据分散存储在多个Redis节点上。
采用哈希算法(如CRC16)对键进行分片,根据键的哈希值将数据分配到不同的节点上。
每个节点负责一部分数据。
节点间通信:
Redis集群使用Gossip协议实现节点间的信息交换和发现。
每个节点通过集群总线(cluster bus)广播自己的状态信息和集群拓扑结构。
通过交换信息,节点能够了解其他节点的状态、可用性和负载情况。
主从复制:
Redis集群中的每个节点都可以配置为主节点或从节点。
主节点负责接收写入请求,并将数据复制到从节点。
从节点负责处理读取请求,并复制主节点的数据。
主从复制提供了数据的冗余和高可用性。
故障检测和故障转移:
Redis集群会监控节点的可用性。
如果某个主节点出现故障,集群会自动将从节点升级为新的主节点,并将数据迁移到新的主节点上。
故障转移过程中,集群会通过选举机制选择新的主节点,并更新集群的拓扑结构。
客户端路由:
客户端通过与集群中的任一节点通信来访问Redis集群。
客户端会根据键的哈希值将请求路由到相应的节点上。
节点会返回请求的数据或将请求转发给适当的节点。
通过以上机制,Redis集群实现了数据的分布存储、负载均衡和高可用性。
它允许在需要大规模数据处理和高并发访问的场景下,提供稳定可靠的性能和服务。
Redis缓存的集群部署与容灾方案

Redis缓存的集群部署与容灾方案随着互联网应用的普及和数据量的不断增加,对于高性能缓存的需求也越来越迫切。
Redis作为一种基于内存的高性能键值缓存数据库,被广泛应用于各种大规模系统中。
为了保证Redis缓存的高可用性和容灾能力,合理的集群部署和容灾方案是必要的。
一、Redis集群部署方案1. 主从复制模式主从复制模式是Redis集群中最常见也是最简单的部署方案。
在这种模式下,通过一个或多个主节点与多个从节点相连,主节点负责处理写操作,从节点负责处理读操作。
主从复制模式的部署步骤如下:(1)配置主节点:在主节点的配置文件中,设置"slaveof no one",并配置适当的密码验证和数据持久化选项。
(2)配置从节点:在从节点的配置文件中,设置"slaveof 主节点IP 主节点端口",并配置适当的密码验证和数据持久化选项。
(3)启动Redis实例:分别启动主节点和从节点的Redis实例。
(4)验证复制状态:通过命令"info replication"来查看主从节点的连接状态和复制效果。
2. 哨兵模式在主从复制模式下,当主节点发生故障时,需要手动将某个从节点提升为新的主节点。
为了解决这一问题,Redis提供了哨兵模式,通过哨兵节点监控主从节点的状态,实现自动故障切换。
哨兵模式的部署步骤如下:(1)配置哨兵节点:在每个哨兵节点的配置文件中,设置"sentinel monitor name 主节点IP 主节点端口 quorum",其中name为主节点的名称,quorum是多数节点的意思。
(2)启动哨兵实例:分别启动哨兵实例。
(3)验证故障切换:通过故障模拟或手动关闭主节点的方式,验证哨兵节点是否能够自动切换主节点。
二、Redis容灾方案1. 数据持久化Redis提供了两种数据持久化的方式,即RDB快照和AOF日志。
RDB快照是将Redis内存中的数据以快照的方式保存到磁盘上,而AOF日志是将每个写操作追加到日志文件中。
redis集群读写原理

redis集群读写原理Redis是一种基于内存的高性能键值存储系统,其集群模式可以提供更高的可用性和扩展性。
本文将介绍Redis集群的读写原理。
一、Redis集群简介Redis集群是由多个Redis节点组成的分布式系统。
每个节点都是一个独立的Redis实例,它们之间通过节点间通信协议进行数据同步和通信。
Redis集群采用数据分片的方式将数据分散存储在不同的节点上,实现数据的高可用性和负载均衡。
二、Redis集群的读写流程1. 写入数据流程当客户端发送写入请求时,首先会将请求发送到Redis集群中的任意一个节点,该节点被称为主节点。
主节点接收到写入请求后,将数据写入自己的内存中,并将写入请求广播给其他节点,这些节点被称为从节点。
从节点接收到写入请求后,也会将数据写入自己的内存中。
2. 读取数据流程当客户端发送读取请求时,请求会发送到任意一个节点。
该节点根据数据的哈希值确定数据所在的节点,并将读取请求转发给对应的节点。
被请求的节点会将数据返回给发起请求的节点,最终返回给客户端。
三、Redis集群的数据分片策略Redis集群采用哈希槽的方式进行数据分片,将数据分散存储在多个节点上。
具体的数据分片流程如下:1. 将整个数据空间分成固定数量的哈希槽,每个槽对应一个节点。
2. 当有新的节点加入集群或节点离开集群时,集群会自动进行数据的重新分片,保证数据的平衡性。
3. 客户端发送写入请求时,集群根据数据的哈希值确定数据所在的槽,并将写入请求发送到对应的节点。
4. 客户端发送读取请求时,集群也会根据数据的哈希值确定数据所在的槽,并将读取请求发送到对应的节点。
四、Redis集群的故障转移Redis集群通过监控节点的状态来实现故障转移。
当主节点出现故障时,集群会自动选举从节点中的一个节点作为新的主节点。
故障转移的流程如下:1. 当主节点出现故障时,集群会将该节点标记为下线状态。
2. 集群中的其他节点会进行选举,选出一个从节点作为新的主节点。
redis集群的节点通信机制

redis集群的节点通信机制Redis集群的节点通信机制主要采用两种方式:集群总线和Gossip协议。
1. 集群总线:Redis集群通过一个专门的集群总线来实现节点之间的通信。
这个总线可以通过Redis的Pub/Sub功能来实现,它使用了一个专门的频道(cluster.bus)进行消息发布和订阅。
当一个节点需要发送消息给其他节点时,它会将消息发布到该频道上,其他节点则会通过订阅这个频道,接收到这个消息。
这种方式的好处是实现简单,节点之间通过消息传递进行通信,并且可以快速地将消息广播给整个集群中的所有节点。
但是,由于该方式是异步的,节点之间的通信可能会有一定的延迟,并且消息的可靠性无法保证。
2. Gossip协议:Redis集群还引入了Gossip协议,用于节点之间的状态交换和信息传递。
每个节点周期性地向集群中的其他节点发送消息,这个消息中包含了节点自身的状态信息和集群中其他节点的状态信息。
通过这种方式,各个节点可以相互感知到彼此的存在,并及时更新自己的状态。
Gossip协议通过一种基于疏散算法的机制来实现节点信息的传递和状态同步。
当一个节点接收到其他节点的状态消息时,它会根据一定的规则来决定是否接受并将这个状态信息传播给其他节点。
同时,节点也会周期性地发送自身的状态信息给其他节点,以保持集群中节点状态的一致性。
Gossip协议具有良好的可扩展性和容错性,可以保证节点之间的状态一致性,并且可以自动适应节点的加入和离开。
通过使用集群总线和Gossip协议这两种机制,Redis集群可以实现节点之间的通信和状态同步,保证整个集群的高可用性和可靠性。
redis 集群原理

redis 集群原理Redis集群是通过分片技术实现数据的水平拆分和分布存储的一种方案。
它将数据分散存储在多个节点上,实现了横向扩展和负载均衡。
Redis集群的原理如下:1. 分片:Redis集群使用哈希槽(hash slot)来划分数据分片。
Redis Cluster 将整个数据分成16384个哈希槽,每个节点负责一部分槽的数据。
分片算法是将key通过CRC16计算出一个16位的哈希值,再对16384取模,将其分配到对应的槽中。
2. 槽迁移:当一个节点加入或离开集群时,槽的分配和迁移将自动进行。
当新节点加入集群时,集群会将一部分槽从现有节点中迁移到新节点上,实现负载均衡。
当节点离开或宕机时,集群会将该节点负责的槽迁移到其他节点上,保证数据的可用性。
3. 槽复制:Redis集群通过主从复制实现数据的高可用。
每个主节点都可以有一个或多个从节点。
主节点负责处理客户端请求和写操作,从节点则负责复制主节点的数据,实现读操作和故障转移。
4. 节点间通信:节点间通过Gossip协议进行通信,Gossip协议是一种去中心化的协议,节点之间相互交换集群信息,包括节点状态、槽分配和迁移等。
节点通过互相通信来保持集群的一致性。
5. 客户端路由:Redis集群的客户端会根据key的哈希值和槽的分布情况来决定将请求发送到哪个节点上。
客户端通过查询集群的槽分配表来确定数据所在的节点,并将请求直接发送到目标节点。
总体来说,Redis集群通过数据分片、槽迁移、槽复制和节点通信等技术来实现数据的分布存储和高可用性,提供了可扩展性和容错能力。
这些机制保证了Redis集群的性能和可靠性。
就publishsubscribe功能看redis集群模式下的队列技术(一)
就publishsubscribe功能看redis集群模式下的队列技术(⼀)Redis 简介Redis 是完全开源免费的,是⼀个⾼性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:Redis⽀持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进⾏使⽤。
Redis不仅仅⽀持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis⽀持数据的备份,即master-slave模式的数据备份。
性能极⾼ – Redis能读的速度是110000次/s,写的速度是81000次/s。
Redis的安装tar –zxvf redis-stable.tar.gz 解压make 编译可能出现问题make[3]: gcc: Command not found,未安装gcc编译⼯具编译成功后,进⼊src⽂件夹,执⾏make install进⾏Redis安装make install --> /usr/local/bin⽬录下有:redis-server,redis-cli,redis-check-aof,redis-check-dumpredis-server –v 检查是否安装成功启动redis,进⼊到redis.conf⽬录,执⾏redis-server redis.conf. 如果后⾯没有跟redis.conf则按照默认配置启动redis配置⽂件redis.conf 配置项说明如下:1. Redis默认不是以守护进程的⽅式运⾏,可以通过该配置项修改,使⽤yes启⽤守护进程daemonize yes2. 当Redis以守护进程⽅式运⾏时,Redis默认会把pid写⼊/var/run/redis.pid⽂件,可以通过pidfile指定pidfile /var/run/redis.pid3. 指定Redis监听端⼝,默认端⼝为6379,作者在⾃⼰的⼀篇博⽂中解释了为什么选⽤6379作为默认端⼝,因为6379在⼿机按键上MERZ 对应的号码,⽽MERZ取⾃意⼤利歌⼥Alessia Merz的名字port 63794. 绑定的主机地址bind 127.0.0.1 这个Ip要设置成你服务器的Ip5.当客户端闲置多长时间后关闭连接,如果指定为0,表⽰关闭该功能timeout 3006. 指定⽇志记录级别,Redis总共⽀持四个级别:debug、verbose、notice、warning,默认为verboseloglevel verbose7. ⽇志记录⽅式,默认为标准输出,如果配置Redis为守护进程⽅式运⾏,⽽这⾥⼜配置为⽇志记录⽅式为标准输出,则⽇志将会发送给/dev/nulllogfile stdout8. 设置数据库的数量,默认数据库为0,可以使⽤SELECT <dbid>命令在连接上指定数据库iddatabases 169. 指定在多长时间内,有多少次更新操作,就将数据同步到数据⽂件,可以多个条件配合save <seconds> <changes>Redis默认配置⽂件中提供了三个条件:save 900 1save 300 10save 60 10000分别表⽰900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
redis cluster的通信机制

redis cluster的通信机制【原创版】目录1.Redis 集群概述2.Redis 集群的通信机制3.通信机制的实现4.通信机制的优势和应用场景正文Redis 集群概述Redis 集群(Redis Cluster)是一种将多个 Redis 实例组合在一起工作的方式,旨在提供高可用性、可扩展性和弹性。
在 Redis 集群中,数据被分布在多个节点上,这使得系统能够处理更多的请求,同时保证数据的可靠性。
Redis 集群的通信机制Redis 集群的通信机制基于一种称为“gossip protocol”(闲聊协议)的技术。
这种协议使得集群中的每个节点都能够与其他节点进行通信,以实现节点之间的数据同步、状态交换和命令传递。
通信机制的实现1.节点发现:Redis 集群中的节点会周期性地向其他节点发送一个名为“Hello”的消息,以表明自己仍然处于活动状态。
其他节点收到这个消息后,会将发送方的 ID 和 IP 地址添加到它们的节点列表中。
这样,每个节点都可以知道集群中的其他节点,并与它们建立连接。
2.状态同步:当一个节点发生故障或者被从集群中移除时,其他节点需要知道这个情况,以便重新分布数据。
Redis 集群通过一种称为“failover protocol”(故障切换协议)的方法来实现这一目标。
当一个节点发生故障时,它会向其他节点发送一个“FAIL”消息,通知它们自己已经不可用。
接收到这个消息的节点会将故障节点从节点列表中移除,并将其对应的数据迁移到其他节点上。
3.命令传递:Redis 集群中的节点需要能够相互传递命令,以便执行诸如读写操作等任务。
为了实现这一点,Redis 集群使用了一种称为“pipeline”(管道)的技术。
客户端可以将一系列命令打包成一个管道,并将其发送给集群中的一个节点。
然后,这个节点会将这些命令转发给其他节点,以便在所有节点上执行这些命令。
通信机制的优势和应用场景Redis 集群的通信机制具有以下优势:1.高可用性:由于数据被分布在多个节点上,因此一个节点的故障不会导致整个系统崩溃。
Redis三种集群模式详解

Redis三种集群模式详解⽬录三种集群模式⼀、主从复制1、reids主从模式2、redis复制原理3、redis主从复制原理4、redis主从复制优缺点⼆、Sentinel 哨兵模式1、Sentinel系统2、Sentinel故障转移2.1、Sentinel 哨兵监控过程2.2、Sentinel 哨兵故障转移3、Sentinel 哨兵优缺点三、cluster 模式1、reids cluster2、Redis Cluster 数据分⽚原理3、Redis Cluster 复制原理4、redis Cluster 优缺点三种集群模式redis有三种集群模式,其中主从是最常见的模式。
Sentinel 哨兵模式是为了弥补主从复制集群中主机宕机后,主备切换的复杂性⽽演变出来的。
哨兵顾名思义,就是⽤来监控的,主要作⽤就是监控主从集群,⾃动切换主备,完成集群故障转移。
cluster 模式是redis官⽅提供的集群模式,使⽤了Sharding 技术,不仅实现了⾼可⽤、读写分离、也实现了真正的分布式存储。
⼀、主从复制redis主从复制1、reids主从模式2、redis复制原理redis 的复制分为两部分操作同步(SYNC)和命令传播(command propagate)同步(SYNC)⽤来将从服务器的状态更新到和主服务器⼀致。
⽩话⽂解释就是从服务器主动获取主服务器的数据。
保持数据⼀致。
具体实现是,主服务器收到SYNC命令后,⽣成RDB快照⽂件,然后发送给从服务器。
命令传播(command propagate)⽤于在主服务器数据被修改后,主从不⼀致,为了让从服务器保持和主服务器状态⼀致,⽽做的命令传播。
⽩话⽂解释就是主服务器收到客户端修改数据命令后,数据库数据发⽣变化,同时将命令缓存起来,然后将缓存命令发送到从服务器,从服务器通过载⼊缓存命令来达到主从数据⼀致。
这就是所谓的命令传播。
为什么需要有同步和命令传播的两种复制操作:当只有同步操作时候,那么在从服务器向主服务器发送SYNC命令时候,主服务器在⽣成RDB快照⽂件时候,仍然会收到客户端的命令修改数据状态,这部分数据如果不能传达给从服务器,那么就会出现主从数据不⼀致的现象。
RedisCluster集群数据分片机制原理
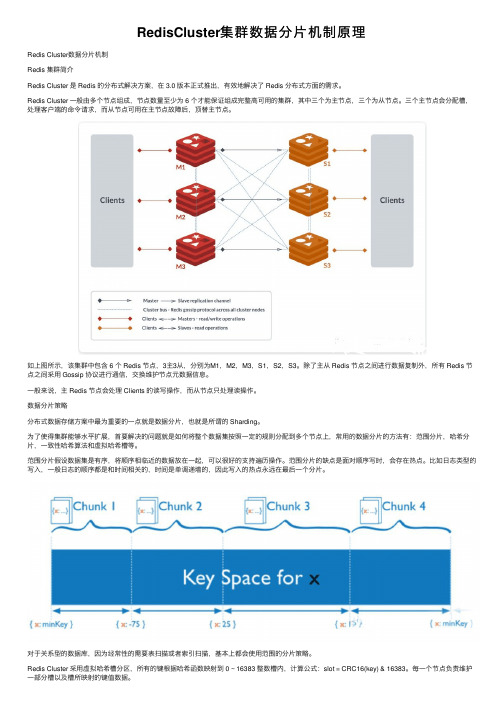
RedisCluster集群数据分⽚机制原理Redis Cluster数据分⽚机制Redis 集群简介Redis Cluster 是 Redis 的分布式解决⽅案,在 3.0 版本正式推出,有效地解决了 Redis 分布式⽅⾯的需求。
Redis Cluster ⼀般由多个节点组成,节点数量⾄少为 6 个才能保证组成完整⾼可⽤的集群,其中三个为主节点,三个为从节点。
三个主节点会分配槽,处理客户端的命令请求,⽽从节点可⽤在主节点故障后,顶替主节点。
如上图所⽰,该集群中包含 6 个 Redis 节点,3主3从,分别为M1,M2,M3,S1,S2,S3。
除了主从 Redis 节点之间进⾏数据复制外,所有 Redis 节点之间采⽤ Gossip 协议进⾏通信,交换维护节点元数据信息。
⼀般来说,主 Redis 节点会处理 Clients 的读写操作,⽽从节点只处理读操作。
数据分⽚策略分布式数据存储⽅案中最为重要的⼀点就是数据分⽚,也就是所谓的 Sharding。
为了使得集群能够⽔平扩展,⾸要解决的问题就是如何将整个数据集按照⼀定的规则分配到多个节点上,常⽤的数据分⽚的⽅法有:范围分⽚,哈希分⽚,⼀致性哈希算法和虚拟哈希槽等。
范围分⽚假设数据集是有序,将顺序相临近的数据放在⼀起,可以很好的⽀持遍历操作。
范围分⽚的缺点是⾯对顺序写时,会存在热点。
⽐如⽇志类型的写⼊,⼀般⽇志的顺序都是和时间相关的,时间是单调递增的,因此写⼊的热点永远在最后⼀个分⽚。
对于关系型的数据库,因为经常性的需要表扫描或者索引扫描,基本上都会使⽤范围的分⽚策略。
Redis Cluster 采⽤虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:slot = CRC16(key) & 16383。
每⼀个节点负责维护⼀部分槽以及槽所映射的键值数据。
Redis 虚拟槽分区的特点:解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Redis Sentinel数据库M-S配置(Redis的分片与复制集技术)
1.Redis Sentinel介绍
Redis Sentinel是Redis官方提供的集群管理工具,主要有三大功能:
监控,能持续监控Redis的主从实例是否正常工作;
通知,当被监控的Redis实例出问题时,能通过API通知系统管理员或其他程序;自动故障恢复,如果主实例无法正常工作,Sentinel将启动故障恢复机制把一个从实例提升为主实例,其他的从实例将会被重新配置到新的主实例,且应用程序会得到一个更换新地址的通知。
Redis Sentinel是一个分布式系统,可以部署多个Sentinel实例来监控同一组Redis实例,它们通过Gossip协议来确定一个主实例宕机,通过 Agreement协议来执行故障恢复和配置变更,一般在生产环境中部署多个实例来提高系统可用性,只要有一个Sentinel实例运行正常,就能保证被监控的Redis实例运行正常(类似Zookeeper,通过多个Zookeeper来提高系统可用性);
2.Redis HA方案
HA的关键在于避免单点故障及故障恢复,在Redis Cluster未发布之前,Redis 一般以主/从方式部署(这里讨论的应用从实例主要用于备份,主实例提供读写,有不少应用是读写分离的,读写操作需要取不同的Redis实例,该方案也可用于此种应用,原理都是相通的,区别在于数据操作层如何封装),该方式要实现HA主要有如下几种方案:
1).keepalived:通过keepalived的虚拟IP,提供主从的统一访问,在主出现问题时,通过keepalived运行脚本将从提升为主,待主恢复后先同步后自动变为主,该方案的好处是主从切换后,应用程序不需要知道(因为访问的虚拟IP 不变),坏处是引入keepalived增加部署复杂性;
2).zookeeper:通过zookeeper来监控主从实例,维护最新有效的IP,应用通过zookeeper取得IP,对Redis进行访问;
3).sentinel:通过Sentinel监控主从实例,自动进行故障恢复,该方案有个缺陷:因为主从实例地址(IP&PORT)是不同的,当故障发生进行主从切换后,应用程序无法知道新地址,故在Jedis2.2.2中新增了对Sentinel的支持,应用通过 redis.clients.jedis.JedisSentinelPool.getResource()取得的Jedis 实例会及时更新到新的主实例地址。
笔者所在的公司先使用了方案1一段时间后,发现keepalived在有些情况下会导致数据丢失,keepalived通过shell脚本进行主从切换,配置复杂,而且keepalived成为新的单点,后来选用了方案3,使用Redis官方解决方案;(方
案2需要编写大量的监控代码,没有方案3简便,网上有人使用方案2读者可自行查看)
Sentinel&Jedis看上去是个完美的解决方案,这句话只说对了一半,在无分片的情况是这样,但我们的应用使用了数据分片 -sharing,数据被平均分布到4个不同的实例上,每个实例以主从结构部署,Jedis没有提供基于Sentinel的ShardedJedisPool,也就是说在4个分片中,如果其中一个分片发生主从切换,应用所使用的ShardedJedisPool无法获得通知,所有对那个分片的操作将会失败。
本文提供一个基于Sentinel的ShardedJedisPool,能及时感知所有分片主从切换行为,进行连接池重建,源码见ShardedJedisSentinelPool.java
3.ShardedJedisSentinelPool实现分析
类似之前的Jedis Pool的构造方法,需要参数poolConfig提供诸如maxIdle,maxTotal之类的配置,masters是一个List,用来保存所有分片Master在Sentinel中配置的名字(注意master的顺序不能改变,因为Shard算法是依据分片位置进行计算,如果顺序错误将导致数据存储混乱),sentinels是一个Set,其中存放所有Sentinel的地址(格式:IP:PORT,如127.0.0.1:26379),顺序无关;
初始化连接池
在构造函数中,通过方法
取得当前所有分片的master地址(IP&PORT),对每个分片,通过顺次连接Sentinel实例,获取该分片的master地址,如果无法获得,即所有Sentinel 都无法连接,将休眠1秒后继续重试,直到取得所有分片的master地址,代码块如下:
通过
初始化连接池,到此连接池中的所有连接都指向分片的master;
监控每个Sentinel
在方法
最后,会为每个Sentinel启动一个Thread来监控Sentinel做出的更改:
该线程的run方法通过Jedis Pub/Sub API(实现JedisPubSub接口,并通过jedis.subscribe进行订阅)向Sentinel实例订阅“+switch-master” 频道,当Sentinel进行主从切换时,该线程会得到新Master地址的通知,通过master name判断哪个分片进行了切换,将新master地址替换原来位置的地址,并调用initPool(List masters)进行Jedis连接池重建;后续所有通过该连接池取得的连接都指向新Master地址,对应用程序透明;
4.应用示例
5.总结
本文通过现实中遇到的问题,即在Redis数据分片的情况下,在使用Sentinel 做HA时,如何做到主从的切换对应用程序透明,通过Jedis的 Pub/Sub功能,能同时监控多个分片的主从切换情况,并通过监听到的新地址重新构造连接池,后续从连接池中取得的所有连接都指向新地址。
该方案的关键是:使用sentinel做HA,Jedis版本必须2.2.2及以上,所有访问Redis实例的连接都必须从连接池中获取;
注意1:Redis的master/slave模式下,master提供数据读写服务,而slave 只提供读服务。
注意2:slave server如果因为网络或其他原因断与master server的连接,
当slave server重新连接时,需要重新获取master server的内存快照文件,slave server的数据会自动全部清空,然后再重新建立内存表,这样会让slave server 启动恢复服务比较慢,同时也给master server带来较大压力,可以看
出redis的复制没有增量复制的概念,这是redis主从复制的一个主要弊端,在实际环境中,尽量规避中途增加从库。