redis集群部署
基于Redis6.2.6版本部署Redis

基于Redis6.2.6版本部署Redis Cluster 集群的问题⽬录1.Redis6.2.6简介以及环境规划2.⼆进制安装Redis 程序2.1.⼆进制安装redis6.2.62.2.创建Reids Cluster 集群⽬录3.配置Redis Cluster 三主三从交叉复制集群3.1.准备六个节点的redis 配置⽂件3.2.将六个节点全部启动3.3.配置集群节点之间相互发现3.4.为集群中的充当Master 的节点分配槽位3.5.配置三主三从交叉复制模式4.快速搭建Redis Cluster 集群1.Redis6.2.6简介以及环境规划在Redis6.x 版本中主要增加了多线程的新特性,多线性对于⾼并发场景是⾮常有必要的。
多线程IO 重新设计了客户端缓存功能RESP3协议⽀持SSLACL 权限控制提升了RDB ⽇志加载速度发布官⽅的Redis 集群代理模块 Redis Cluster proxyRedis Cluster 集群原理可以查看之前发布的⽂章。
IP 主机名端⼝号节点192.168.20.10redis-cluster 6701master192.168.20.10redis-cluster 6702slave—>6705的master192.168.20.10redis-cluster 6703master192.168.20.10redis-cluster 6704slave—>6701的master192.168.20.10redis-cluster 6705master192.168.20.10redis-cluster 6706slave—>6703的master Reids 集群采⽤三主三从交叉复制架构,由于服务器数量有限,在⼀台机器中模拟出集群的效果,在实际⽣产环境中,需要准备三台机器,每台机器中分别部署两台Redis 节点,⼀主⼀从,交叉备份。
redis集群 配置参数

redis集群配置参数
在Redis集群中,需要配置以下参数:
1. cluster-enabled:设置为yes来启用集群模式。
2. cluster-config-file:指定集群配置文件的路径。
3. cluster-node-timeout:指定集群节点之间的超时时间。
4. cluster-announce-ip:指定集群节点的IP地址。
5. cluster-announce-port:指定集群节点的端口号。
6. cluster-announce-bus-port:指定集群节点之间通信的端口号。
7. cluster-require-full-coverage:设置为yes来要求所有槽位都要有节点才能正常工作。
8. cluster-migration-barrier:设置为yes来阻止在槽迁移期间的对数据的写入操作。
这些参数可以在Redis的配置文件redis.conf中进行设置。
在配置文件中找到对应的参数进行修改并重启Redis服务即可生效。
Redis集群Redis-cluster搭建及故障、性能测试

Redis集群Redis-cluster搭建及故障、性能测试⼀、Redis集群部署三台物理机:172.20.0.17、172.20.0.18、172.20.0.19⼆、安装Redis下载安装redis压缩包解压压缩包,进⼊redis-5.0.2⽂件夹,运⾏命令./make install安装redismv redis-5.0.2 /usr/local/redis/三、修改配置⽂件node1--17服务器:1、创建redis_cluster/700X的⽬录mkdir -p /usr/local/redis/redis_cluster/7001mkdir -p /usr/local/redis/redis_cluster/70022、修改Redis.conf的端⼝cp redis.conf /usr/local/redis/redis_cluster/7001修改端⼝为7001cp redis.conf /usr/local/redis/redis_cluster/7002修改端⼝为70023、同时将修改后的Redis.conf复制到另外两个节点(18、19)4、将redis-server复制到节点⽬录下,⽅便操作cp /usr/local/bin/redis-server /usr/local/redis/redis-5.0.2/redis_cluster/7001/5、开启redis-cluster配置,配置做以下改造#配置yes开启redis-clustercluster-enabled yes#配置节点之间超时时间cluster-node-timeout 15000#这个配置很重要,cluster开启必须重命名指定cluster-config-file,不能与别的节点相同,否则会启动失败,最好按主机+端⼝命名cluster-config-file nodes-17-7001.conf四、启动各节点17、18、19Rediscd /usr/local/redis/redis-5.0.2/redis_cluster/7001./redis-server redis.confcd /usr/local/redis/redis-5.0.2/redis_cluster/7002./redis-server redis.conf五、创建集群命令cd /usr/local/bin./redis-cli --cluster create 172.20.0.17:7001 172.20.0.18:7001 172.20.0.19:7001 172.20.0.17:7002 172.20.0.18:7002 172.20.0.19:7002 --cluster-replicas 1(replicas1 表⽰我们希望为集群中的每个主节点创建⼀个从节点。
Redis缓存多机房部署策略

Redis缓存多机房部署策略Redis是一种开源的内存数据存储系统,被广泛用于缓存、消息传递、实时分析等应用场景。
在多机房环境下,如何合理地部署Redis缓存,成为了一个重要的问题。
本文将探讨Redis缓存多机房部署的策略。
在多机房环境下,为了保证用户访问速度和服务的高可用性,需要将Redis缓存部署在各个机房分布式节点上。
常见的部署策略有以下几种:1. 主从复制策略主从复制是Redis的默认配置,适用于小规模的多机房部署。
该策略将一个Redis实例配置为主节点,其他实例配置为从节点。
主节点负责接收写请求并同步到从节点,从节点则用于读请求的负载均衡。
通过设置适当数量的从节点,可以提高读取的吞吐量和服务的可用性。
2. 哨兵模式策略哨兵模式是Redis提供的一种高可用解决方案。
该策略在主从复制的基础上,引入了哨兵节点。
哨兵节点通过监控主节点的状态,当主节点故障时,自动将一个从节点升级为新的主节点,并通知其他从节点更新配置。
这样可以实现自动故障转移,保证服务的高可用性。
在多机房环境下,可以在每个机房都配置一组主从节点和哨兵节点,来实现跨机房的故障转移。
3. 集群模式策略Redis的集群模式是一种分布式解决方案,适用于大规模的多机房部署。
集群模式将多个Redis实例组成一个分布式集群,每个实例负责管理一部分数据。
客户端使用Hash槽对数据进行分片,将数据分散存储在不同的实例上。
这样可以提高整个系统的读写吞吐量和扩展性。
在多机房环境下,可以将不同机房的实例组成多个分布式子集群,通过跨机房的网络来访问和操作数据。
除了以上策略外,还可以结合使用代理、负载均衡和分布式锁等技术,来进一步提高多机房的Redis部署效果。
例如,可以在每个机房设置一个代理节点,用于将请求路由到对应机房的Redis实例。
同时,可以使用负载均衡策略来均衡各个机房之间的请求流量,避免某个机房负载过高或过低。
在并发访问较高的情况下,可以使用分布式锁来保证对数据的互斥访问,避免并发冲突和数据不一致的问题。
redis集群搭建及配置

redis主从服务器搭建修改记录目录redis主从服务器搭建 (1)一.redis主从服务器搭建 (2)第一步:下载redis (2)第二步:解压redis tar包 (2)第三步:进入reidis目录 (2)第四步:make (2)第五步:make install (3)第六步:修改redis.conf 操作 (3)第七步:redis从服务器配置 (4)第八步:修改从服务redis.conf (4)二.redis测试 (4)第一步:编写redis客户端启动shell (4)第二步:启动客户端 (5)第三步:操作 (5)第四步:set name test (5)第五步:get name (5)第六步:从服务器端启动客户端 (5)第七步:从服务器端(10.105.76.100) get name (5)三.sentinel配置及启动 (5)第一步:修改sentinel.conf (6)第二步启动sentinel (6)第三步:启动sentinel (6)一.redis主从服务器搭建第一步:下载redis在redis官网下载redis2.8.17版本第二步:解压redis tar包将下载的redis-2.8.17.tar.gz放在10.105.76.99(主服务器)上/usr/local下然后解压tar包命令:tar -zxvf redis-2.8.17.tar.gz第三步:进入reidis目录进入redis-2.8.17目录命令: cd redis-2.8.17第四步:makemake 或者make MALLOC=libc 如果使用make时报错(zmalloc.h:50:31: error: jemalloc/jemalloc.h: No such file or directory)此时可使用make MALLOC=libc出现下图说明make完成第五步:make install第六步:修改redis.conf 操作进入redis安装目录cd /usr/local/redis-2.8.17,vi redis.conf将daemonize no改为yes ,意思是在后台运行logfile改为log的存放路径requirepass 前面的#去掉后面改为itmiredis此处为密码前六步已经完成了redis主端的安装及配置,如果需要可以写一个启动redis的shell脚本,touch start.sh,vi start.sh 里面的内容为src/redis-server redis.conf第七步:redis从服务器配置将安装好的redis拷贝到从服务器(10.105.76.100) 命令scp -r /usr/local/redis-2.8.17root@10.105.76.100:/usr/local第八步:修改从服务redis.conf拷贝完成后进入从服务器(10.105.76.100) ,cd /usr/local/redis-2.8.17,修改redis.confslaveof ip(10.105.76.99) 端口(6379) 此处为主服务的ip和端口因为主服务上设置了密码所以需要修改masterauth ,并将requirepass注释掉此时redis主从应配置完成通过start.sh分别启动redis(10.105.76.99)和(10.10.576.100) 通过ps -ef|grep redis查看进程,出现如下图说明redis启动完成二.redis测试第一步:编写redis客户端启动shell可以写一个shell脚本启动redis客户端cd /usr/local/redis-2.8.17/,touch startcli.sh,vi startcli.sh startcli.sh内容为src/redis-cli,并将此文件拷贝到从服务器10.105.76.100第二步:启动客户端在主服务器端(10.105.76.99) 命令:sh startcli.sh第三步:操作输入密码auth itmiredis第四步:set name test第五步:get name第六步:从服务器端启动客户端从服务器端启动客户端(10.105.76.100),sh startcli.sh第七步:从服务器端(10.105.76.100) get name此时说明主从服务已经搭建完成。
redis cluster--redis集群模式原理

redis cluster--redis集群模式原理Redis Cluster是Redis官方推出的分布式架构,它可以将多台Redis服务器看作是一个整体来使用,提供了高可用性、高扩展性等优点。
Redis Cluster基于分区的思想,将key映射到集群中的某一个节点上,每个节点负责一部分key。
通过互相通信来维护全局一致性和去重。
Redis Cluster集群模式分为以下几个部分:1、集群的节点数量不同,可以由多个Master节点和多个Slave节点组成。
2、每个节点都有一个唯一的名称(注意是名称不是IP地址),通过名称进行通信。
3、Redis Cluster将整个数据集分成16384个hash slot,每个节点可以处理其中一部分,节点之间通过Gossip协议交换信息,保持整个集群信息的一致性。
4、一个Redis节点可以既是Master,也可以是Slave。
Master节点负责处理客户端请求,而Slave节点则仅用于备份和读取数据,Master节点操作的数据会被同步到Slave节点。
5、在Redis Cluster中,如果一个Master节点宕机,它上面的所有Slave节点都不能升级为Master节点。
而是会自动进行故障转移,将失效的Master节点的Slot分配给其他运行正常的Master节点,并将其对应的Slave节点降级为Master节点,从而保证整个集群的可用性。
6、对于新加入的节点,可以使用resharding命令进行Slot的再分配。
重新分配Slot会导致数据迁移,因此需要慎重考虑。
总之,Redis Cluster集群模式的优点在于它能够提供高可用性、高扩展性、自动故障转移等特性。
但同时也需要注意一些坑点,如节点名称不能重复、节点之间的网络延迟等问题。
redis 集群安装(redis-trib.rb)
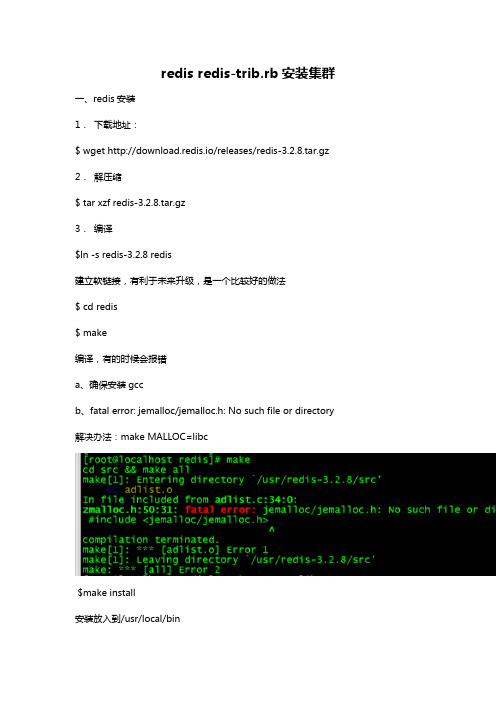
redisredis-trib.rb安装集群一、redis安装1.下载地址:$ wget http://download.redis.io/releases/redis-3.2.8.tar.gz 2.解压缩$ tar xzf redis-3.2.8.tar.gz3.编译$ln -s redis-3.2.8 redis建立软链接,有利于未来升级,是一个比较好的做法$ cd redis$ make编译,有的时候会报错a、确保安装gccb、fatal error: jemalloc/jemalloc.h: No such file or directory 解决办法:make MALLOC=libc$make install安装放入到/usr/local/bin$redis-cli -v查看redis版本redis集群一般由多个节点组成,节点数量至少6个才能保证组成完整高可用的集群。
操作系统centos7.2-mini版一、redis安装略二、使用redis-trib.rb 安装工具1、安装rubyyum install ruby -y2、安装rubygemredis依赖wget /downloads/redis-3.3.0.gemgem install -l redis-3.3.0 gemcp /{redishome}/scr/redis-trib.rb /usr/local/bin3、测试redis-trib.rb二、准备节点1、创建文件夹mkdir /redis-cluster-tribcd /redis-cluster-tribmkdir 6379 6380 6381 6382 6383 63842、创建并配置redis.conf分别在6379-6384六个文件夹中创建redis-node.conf文件,并添加配置,配置内容如下redis-6379.conf,每个文件根据对应名修改一下vim redis-6379.confport 6379daemonize yeslogfile "6379.log"dbfilename "dump-6379.rdb"dir "/redis-cluster-trib/6379/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6379.conf"vim redis-6380.confport 6380daemonize yeslogfile "6380.log"dbfilename "dump-6380.rdb"dir "/redis-cluster-trib/6380/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6380.conf"vim redis-6381.confport 6381daemonize yeslogfile "6381.log"dbfilename "dump-6381.rdb"dir "/redis-cluster-trib/6381/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6381.conf"vim redis-6382.confport 6382daemonize yeslogfile "6382.log"dbfilename "dump-6382.rdb"dir "/redis-cluster-trib/6382/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6382.conf"vim redis-6383.confport 6383daemonize yeslogfile "6383.log"dbfilename "dump-6383.rdb"dir "/redis-cluster-trib/6383/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6383.conf"vim redis-6384.confport 6384daemonize yeslogfile "6384.log"dbfilename "dump-6384.rdb"dir "/redis-cluster-trib/6384/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6384.conf"3、启动各个节点redis-server redis-6379.confredis-server redis-6380.confredis-server redis-6381.confredis-server redis-6382.confredis-server redis-6383.confredis-server redis-6384.conf4、检查启动情况cat 6379/6379.logcat 6380/6380.logcat 6381/6381.logcat 6382/6382.logcat 6383/6383.logcat 6384/6384.logps -ef |grep redis四、创建集群1、创建集群redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384replicas 表示为每个主节点设置多少个从节点,如果部署节点使用不同的ip,会尽可能保证主从不在一个节点上2、健康性检查redis-trib.rb check 127.0.0.1:6380四、扩容集群1、添加2个节点mkdir 6385 6386vim redis-6385.confport 6385daemonize yeslogfile "6385.log"dbfilename "dump-6385.rdb"dir "/redis-cluster-trib/6385/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6385.conf"vim redis-6386.confport 6386daemonize yeslogfile "6386.log"dbfilename "dump-6386.rdb"dir "/redis-cluster-trib/6386/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6386.conf"2、启动节点redis-server redis-6385.confredis-server redis-6386.conf3、添加入集群redis-trib.rb add-node 127.0.0.1:6385 127.0.0.1:6379redis-trib.rb add-node 127.0.0.1:6386 127.0.0.1:6379注意这里还是显示为主节点,要设置它为从节点要redis-trib.rb add-node 127.0.0.1:6386 127.0.0.1:6379 --slave --master-id<arg> 或者看后面变化(在缩减章节)4、迁移槽redis-trib.rb info127.0.0.1:6379可以看到各个主节点槽情况5、批量迁移redis-trib.rbreshard 127.0.0.1:6379数据迁移之前会打印迁移计划,确认后进行迁移四、收缩集群跟上面一样,将要清空节点移至其他节点上。
SpringBoot整合Redisson(集群版)

SpringBoot整合Redisson(集群版)之前写了⼀篇关于SpringBoot整合Redisson的单机版,这篇是集群版。
关于如何在Linux搭建Redis集群,可以参考这篇⽂章:⼀、导⼊Maven依赖<!-- redisson-springboot --><dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.11.4</version><exclusions><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></exclusion><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></exclusion></exclusions></dependency>⼆、核⼼配置⽂件redis:cluster:nodes: "192.168.52.1:7000,192.168.52.1:7001,192.168.52.1:7002,192.168.52.1:7003,192.168.52.1:7004,192.168.52.1:7005"password: 123456lettuce:pool:max-active: 1500max-wait: 5000max-idle: 500min-idle: 100shutdown-timeout: 1000timeout: 60000三、核⼼代码配置RedisConfigProperties.javaimport org.springframework.boot.context.properties.ConfigurationProperties;import ponent;import java.util.List;@Component@ConfigurationProperties(prefix = "spring.redis")public class RedisConfigProperties {private String password;private cluster cluster;public static class cluster {private List<String> nodes;public List<String> getNodes() {return nodes;}public void setNodes(List<String> nodes) {this.nodes = nodes;}}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}public RedisConfigProperties.cluster getCluster() {return cluster;}public void setCluster(RedisConfigProperties.cluster cluster) {this.cluster = cluster;}}RedissonConfig.javaimport org.redisson.Redisson;import org.redisson.config.ClusterServersConfig;import org.redisson.config.Config;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.util.ArrayList;import java.util.List;@Configurationpublic class RedissonConfig {@Autowiredprivate RedisConfigProperties redisConfigProperties;//添加redisson的bean@Beanpublic Redisson redisson() {//redisson版本是3.5,集群的ip前⾯要加上“redis://”,不然会报错,3.2版本可不加List<String> clusterNodes = new ArrayList<>();for (int i = 0; i < redisConfigProperties.getCluster().getNodes().size(); i++) {clusterNodes.add("redis://" + redisConfigProperties.getCluster().getNodes().get(i));}Config config = new Config();ClusterServersConfig clusterServersConfig = eClusterServers().addNodeAddress(clusterNodes.toArray(new String[clusterNodes.size()]));clusterServersConfig.setPassword(redisConfigProperties.getPassword());//设置密码return (Redisson) Redisson.create(config);}}四、启动项⽬,只要不报错就表⽰配置集群成功,同时启动过程中也会显⽰连接的各个redis。
Redis集群使用指南

Redis集群使用指南一、Redis集群简介Redis(Remote Dictionary Server)是一个开源的基于内存的键值对存储系统,经常用来作为缓存、消息队列和数据库。
在实际使用过程中,Redis可能会出现性能瓶颈和单点故障。
为了解决这些问题,Redis提供了集群模式。
Redis集群是对多个Redis节点进行逻辑分区和复制,从而实现高可用、高性能和可伸缩性。
Redis集群能够自动进行故障转移和重新分配,可以提供更好的可靠性和吞吐量。
二、Redis集群的工作原理Redis集群采用哈希槽(Hash Slot)的方式来实现数据的分片和复制。
一个Redis集群可以包含多个Redis节点,每个节点管理一部分哈希槽。
当客户端需要对某个键进行操作时,Redis首先计算该键对应的哈希值,然后将其分配到某个哈希槽中。
Redis集群根据哈希槽的分配情况,将该键的操作转发给相应的Redis节点进行处理。
如果某个节点出现故障,Redis集群会自动将该节点管理的哈希槽重新分配给其他节点。
Redis集群采用主从复制的方式来实现数据的持久化和高可用。
每个主节点可以有多个从节点,主节点负责处理读写请求,同时将数据复制到从节点。
如果主节点出现故障,其中的一个从节点会被自动选举为新的主节点,继续处理客户端请求。
三、搭建Redis集群的步骤1、安装Redis节点在Linux系统上安装Redis比较简单,可以使用以下命令:sudo apt-get updatesudo apt-get install redis-server安装完毕后,可以通过以下命令启动Redis服务:sudo service redis-server start2、配置Redis节点每个Redis节点都需要进行一些配置,以便加入到Redis集群中。
可以通过以下命令进入Redis配置文件:sudo vim /etc/redis/redis.conf需要修改的配置项有以下几个:cluster-enabled yes:启用Redis集群模式。
Redis-集群 - 三台服务器

Redis-集群安装详细步骤一、Redis集群部署文档(centos6系统)现有三台物理机10.18.154.2 10.18.154.3 10.18.154.4(要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下)10.18.154.2:700010.18.154.2:700110.18.154.3:700010.18.154.3:700110.18.154.4:700010.18.154.4:7001二、安装Redis(10.18.154.2、10.18.154.3、10.18.154.4)下载redis-3.2.1.tar.gz[root@localhost ~]# tar zxvf redis-3.2.1.tar.gz[root@localhost ~]# cd redis-3.2.1[root@localhost redis-3.2.1]# make[root@localhost redis-3.2.1]# make install[root@localhost ~]# mv redis-3.2.1 /usr/local/redis[root@localhost ~]# cd /usr/local/redis/[root@localhost ~]# mkdir /usr/local/cluster[root@localhost ~]# cp /usr/local/redis/redis.conf /usr/local/cluster/[root@localhost ~]# vi /usr/local/cluster/redis.conf##修改配置文件中的下面选项port 7000bind 10.18.154.2 127.0.0.1daemonize yes#如果你想让它在后台运行,你就把它改成yescluster-enabled yescluster-config-file nodes.confcluster-node-timeout 5000appendonly yes[root@localhost ~]# mkdir /usr/local/cluster/7000[root@localhost ~]# mkdir /usr/local/cluster/7001[root@localhost ~]# cp /usr/local/cluster/redis.conf /usr/local/cluster/7000[root@localhost ~]# cp /usr/local/cluster/redis.conf /usr/local/cluster/7001[root@localhost ~]# cp /usr/local/cluster/redis.conf /usr/local/cluster/7002[root@localhost 7000]# redis-server redis.conf ---启动redis服务##注意:拷贝完成之后要修改7001目录下面redis.conf文件中的port参数,分别改为对应的文件夹的名称##启动之后使用命令查看redis的启动情况ps -ef|grep redis三、执行redis的创建集群命令创建集群[root@localhost src]# cd /usr/local/redis/src/[root@localhost src]#./redis-trib.rb create --replicas 1 10.18.154.2:700010.18.154.2:7001 10.18.154.3:7000 10.18.154.3:7001 10.18.154.4:700010.18.154.4:7001执行上面的命令的时候会报错,因为是执行的ruby的脚本,需要ruby的环境错误内容:/usr/bin/env: ruby: No such file or directory所以需要安装ruby的环境,这里推荐使用yum install ruby安装yum install ruby然后再执行创建集群命令,报错,提示缺少rubygems组件,使用yum安装错误内容:./redis-trib.rb:24:in `require': no such file to load -- rubygems (LoadError)from ./redis-trib.rb:24yum install rubygems再次执行创建集群命令,报错提示不能加载redis,是缺少redis、ruby接口,gem 安装错误内容:/usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `gem_original_require': no such file to load -- redis (LoadError)from /usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `require'gem install redis这里可能无法安装,因为无法连接gem服务器:[root@localhost ~]# gem install redis --version 3.0.0ERROR: Could not find a valid gem 'redis' (= 3.0.0) in any repository#需要手工下载并安装:wget https:///gems/redis-3.2.1.gemgem install -l ./redis-3.2.1.gem输入yes,然后配置完成。
redis集群配置参数及优化

Redis集群配置参数及优化Redis的主要参数配置在redis.conf文件中。
1.conf内存值2.bindip默认情况下,如果没有指定“bind”配置指令,Redis将侦听服务器上可用的所有网络接口的连接。
默认情况:bind127.0.0.1实际配置:bind本机ip3.protected-modeyes启用默认保护模式。
只有当您确定您希望其他主机的客户端连接到Redis 时,您才应该禁用它,即使没有配置身份验证,也没有使用“bind”指令显式列出特定的接口集。
4.tcp-keepalive300如果非零,请使用SO_KEEPALIVE向没有通信的客户发送TCP协议。
这很有用,有两个原因:a)检测死同伴b)从中间的网络设备的角度进行连接在Linux上,指定的值(以秒为单位)是用于发送ack的周期。
注意,要关闭连接,需要双倍的时间。
这个选项的合理值是300秒,这是新的Redis默认值,从Redis3.2.1开始。
5.timeout0在客户机空闲N秒后关闭连接(0到禁用)6.port6379在指定端口上接受连接,默认值是63797.daemonizeyesredis后台运行8.pidfile/var/run/redis_6379.pid如果指定了一个pid文件,Redis会在启动时指定,并在退出时删除它。
当服务器运行非守护进程时,如果配置中没有指定pid文件,则不会创建pid文件。
当服务器被守护时,即使没有指定,也会使用pid文件,默认为“/var/run/redis.pid”。
创建一个pid文件是最好的工作:如果Redis不能创建它,那么服务器就会正常启动和运行。
9.loglevelnotice指定服务器冗余级别包括:a)debug:大量信息,用于开发/测试b)verbose:许多很少有用的信息,但不像debug级别那样混乱c)notice:适度详细,可能在生产中需要d)warning:只有非常重要/关键的消息被记录10.logfile""指定日志文件名。
redis集群模式原理

Redis集群模式是一种在多个Redis实例之间分布数据和负载的解决方案,它提供了高可用性和可伸缩性。
以下是Redis集群模式的基本原理:
数据分片(Sharding):
Redis集群将数据分散存储在多个Redis节点上。
采用哈希算法(如CRC16)对键进行分片,根据键的哈希值将数据分配到不同的节点上。
每个节点负责一部分数据。
节点间通信:
Redis集群使用Gossip协议实现节点间的信息交换和发现。
每个节点通过集群总线(cluster bus)广播自己的状态信息和集群拓扑结构。
通过交换信息,节点能够了解其他节点的状态、可用性和负载情况。
主从复制:
Redis集群中的每个节点都可以配置为主节点或从节点。
主节点负责接收写入请求,并将数据复制到从节点。
从节点负责处理读取请求,并复制主节点的数据。
主从复制提供了数据的冗余和高可用性。
故障检测和故障转移:
Redis集群会监控节点的可用性。
如果某个主节点出现故障,集群会自动将从节点升级为新的主节点,并将数据迁移到新的主节点上。
故障转移过程中,集群会通过选举机制选择新的主节点,并更新集群的拓扑结构。
客户端路由:
客户端通过与集群中的任一节点通信来访问Redis集群。
客户端会根据键的哈希值将请求路由到相应的节点上。
节点会返回请求的数据或将请求转发给适当的节点。
通过以上机制,Redis集群实现了数据的分布存储、负载均衡和高可用性。
它允许在需要大规模数据处理和高并发访问的场景下,提供稳定可靠的性能和服务。
Redis三种集群模式详解

Redis三种集群模式详解⽬录三种集群模式⼀、主从复制1、reids主从模式2、redis复制原理3、redis主从复制原理4、redis主从复制优缺点⼆、Sentinel 哨兵模式1、Sentinel系统2、Sentinel故障转移2.1、Sentinel 哨兵监控过程2.2、Sentinel 哨兵故障转移3、Sentinel 哨兵优缺点三、cluster 模式1、reids cluster2、Redis Cluster 数据分⽚原理3、Redis Cluster 复制原理4、redis Cluster 优缺点三种集群模式redis有三种集群模式,其中主从是最常见的模式。
Sentinel 哨兵模式是为了弥补主从复制集群中主机宕机后,主备切换的复杂性⽽演变出来的。
哨兵顾名思义,就是⽤来监控的,主要作⽤就是监控主从集群,⾃动切换主备,完成集群故障转移。
cluster 模式是redis官⽅提供的集群模式,使⽤了Sharding 技术,不仅实现了⾼可⽤、读写分离、也实现了真正的分布式存储。
⼀、主从复制redis主从复制1、reids主从模式2、redis复制原理redis 的复制分为两部分操作同步(SYNC)和命令传播(command propagate)同步(SYNC)⽤来将从服务器的状态更新到和主服务器⼀致。
⽩话⽂解释就是从服务器主动获取主服务器的数据。
保持数据⼀致。
具体实现是,主服务器收到SYNC命令后,⽣成RDB快照⽂件,然后发送给从服务器。
命令传播(command propagate)⽤于在主服务器数据被修改后,主从不⼀致,为了让从服务器保持和主服务器状态⼀致,⽽做的命令传播。
⽩话⽂解释就是主服务器收到客户端修改数据命令后,数据库数据发⽣变化,同时将命令缓存起来,然后将缓存命令发送到从服务器,从服务器通过载⼊缓存命令来达到主从数据⼀致。
这就是所谓的命令传播。
为什么需要有同步和命令传播的两种复制操作:当只有同步操作时候,那么在从服务器向主服务器发送SYNC命令时候,主服务器在⽣成RDB快照⽂件时候,仍然会收到客户端的命令修改数据状态,这部分数据如果不能传达给从服务器,那么就会出现主从数据不⼀致的现象。
Redis缓存的集群部署与容灾方案

Redis缓存的集群部署与容灾方案随着互联网应用的普及和数据量的不断增加,对于高性能缓存的需求也越来越迫切。
Redis作为一种基于内存的高性能键值缓存数据库,被广泛应用于各种大规模系统中。
为了保证Redis缓存的高可用性和容灾能力,合理的集群部署和容灾方案是必要的。
一、Redis集群部署方案1. 主从复制模式主从复制模式是Redis集群中最常见也是最简单的部署方案。
在这种模式下,通过一个或多个主节点与多个从节点相连,主节点负责处理写操作,从节点负责处理读操作。
主从复制模式的部署步骤如下:(1)配置主节点:在主节点的配置文件中,设置"slaveof no one",并配置适当的密码验证和数据持久化选项。
(2)配置从节点:在从节点的配置文件中,设置"slaveof 主节点IP 主节点端口",并配置适当的密码验证和数据持久化选项。
(3)启动Redis实例:分别启动主节点和从节点的Redis实例。
(4)验证复制状态:通过命令"info replication"来查看主从节点的连接状态和复制效果。
2. 哨兵模式在主从复制模式下,当主节点发生故障时,需要手动将某个从节点提升为新的主节点。
为了解决这一问题,Redis提供了哨兵模式,通过哨兵节点监控主从节点的状态,实现自动故障切换。
哨兵模式的部署步骤如下:(1)配置哨兵节点:在每个哨兵节点的配置文件中,设置"sentinel monitor name 主节点IP 主节点端口 quorum",其中name为主节点的名称,quorum是多数节点的意思。
(2)启动哨兵实例:分别启动哨兵实例。
(3)验证故障切换:通过故障模拟或手动关闭主节点的方式,验证哨兵节点是否能够自动切换主节点。
二、Redis容灾方案1. 数据持久化Redis提供了两种数据持久化的方式,即RDB快照和AOF日志。
RDB快照是将Redis内存中的数据以快照的方式保存到磁盘上,而AOF日志是将每个写操作追加到日志文件中。
springboot中使用redis集群操作步骤

springboot中使用redis集群操作步骤在Spring Boot中使用Redis集群,主要涉及以下几个步骤:1. 添加相关依赖:在`pom.xml`文件中添加Redis客户端依赖。
Spring Boot的官方推荐依赖是`spring-boot-starter-data-redis`,它包含了Spring Data Redis的依赖。
2. 配置Redis集群连接信息:在`application.properties`(或`application.yml`)文件中配置Redis集群的连接信息。
可以使用以下属性进行配置:```````spring.redis.cluster.nodes`用于指定Redis集群中各个节点的连接地址和端口。
`spring.redis.cluster.max-redirects`用于指定在进行节点重定向操作时,最大的重定向次数。
这些配置项可以根据实际情况进行修改。
3. 创建RedisTemplate实例:在Spring Boot的配置类中创建`RedisTemplate`的实例。
可以使用`LettuceConnectionFactory`作为Redis连接工厂,并将其注入到`RedisTemplate`中。
示例代码如下:```javapublic class RedisConfigprivate String clusterNodes;private Integer maxRedirects;public RedisConnectionFactory redisConnectionFactorRedisClusterConfiguration clusterConfiguration = new RedisClusterConfiguration(Arrays.asList(clusterNodes.split(",")) );clusterConfiguration.setMaxRedirects(maxRedirects);return new LettuceConnectionFactory(clusterConfiguration);}public RedisTemplate<String, Object> redisTemplatRedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(;redisTemplate.setConnectionFactory(redisConnectionFactory();return redisTemplate;}```4. 使用RedisTemplate进行操作:在代码中使用`RedisTemplate`的实例进行Redis操作。
【搭建rediscluster集群,JedisCluster带密码访问解决当中各种坑!】

【搭建rediscluster集群,JedisCluster带密码访问解决当中各种坑!】⼀.搭建redis单机本⽂搭建redis3.0版本,3.0主要增加了redis cluster集群功能。
2.解压源码:tar -zxvf redis-3.0.0.tar.gz3.编译源码:cd /usr/local/redis-3.0.0make4.安装到指定⽬录: cd /usr/local/redis-3.0.0make PREFIX=/usr/local/redis install5.进⼊源码⽬录,将redis.conf拷贝到安装路径:cd /usr/local/redismkdir confcp /usr/local/redis-3.0.0/redis.conf /usr/local/redis/bin6.修改redis.conf配置⽂件,以后端模式启动:daemonize yes7.启动redis:cd /usr/local/redis ./bin/redis-server ./redis.conf //在何处启动的server,⼀些配置⽂件就默认在该处⽣成(如果配置的相对路径)8.redis.conf配置⽂件主要配置:port 7001 //监听的端⼝# bind 127.0.0.1 //绑定ip,只允许该ip访问,不填默认为*,表⽰允许所有ip访问requirepass "你的密码" //开启密码loglevel debug //⽇志级别,开发模式尽量选⽤debuglogfile "redis.log" //⽇志⽂件路径,此处使⽤相对路径,将⽣成到/usr/local/redis下maxmemory 100000000 //允许最⼤内存占⽤100mappendonly yes //启⽤aofauto-aof-rewrite-percentage 80 //部署在同⼀机器的多个redis实例,建议把auto-aof-rewrite错开(可分别写80-100不等),防⽌瞬间fork,所有redis进程做rewrite,占⽤⼤量内存9.jedis连接redis单机:1<dependency>2<groupId>redis.clients</groupId>3<artifactId>jedis</artifactId>4<version>2.7.0</version>5</dependency>连接池整合spring:<!-- redis连接池(单例) --><bean id="jedisPool" class="redis.clients.jedis.JedisPool" destroy-method="close"><constructor-arg name="poolConfig" ref="jedisPoolConfig"/><constructor-arg name="host" value="${redis.host}"/><constructor-arg name="port" value="${redis.port}"/><constructor-arg name="timeout" value="${redis.timeout}"/><constructor-arg name="password" value="${redis.pass}"/></bean><!-- 连接池配置 --><bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"><!-- 最⼤连接数 --><property name="maxTotal" value="150"/><!-- 最⼤空闲连接数 --><property name="maxIdle" value="30"/><!-- 最⼩空闲连接数 --><property name="minIdle" value="10"/><!-- 获取连接时的最⼤等待毫秒数,⼩于零:阻塞不确定的时间,默认-1 --><property name="maxWaitMillis" value="3000"/><!-- 每次释放连接的最⼤数⽬ --><property name="numTestsPerEvictionRun" value="100"/><!-- 释放连接的扫描间隔(毫秒) --><property name="timeBetweenEvictionRunsMillis" value="3000"/><!-- 连接最⼩空闲时间 --><property name="minEvictableIdleTimeMillis" value="1800000"/><!-- 连接空闲多久后释放, 当空闲时间>该值且空闲连接>最⼤空闲连接数时直接释放 --><property name="softMinEvictableIdleTimeMillis" value="10000"/><!-- 在获取连接的时候检查有效性, 默认false --><property name="testOnBorrow" value="true"/><!-- 在空闲时检查有效性, 默认false --><property name="testWhileIdle" value="true"/><!-- 在归还给pool时,是否提前进⾏validate操作 --><property name="testOnReturn" value="true"/><!-- 连接耗尽时是否阻塞, false报异常,ture阻塞直到超时, 默认true --><property name="blockWhenExhausted" value="false"/></bean>1 @RunWith(SpringJUnit4ClassRunner.class) // 指定测试⽤例的运⾏器这⾥是指定了Junit42 @ContextConfiguration("classpath:spring/application*.xml")3public class RedisTest {4 @Autowired5private JedisPool pool;6 @Test7public void testJedisPool() {8 Jedis jedis = null;9 String name = null;10try {11 jedis = pool.getResource();12 jedis.set("testName", "RCL");13 name = jedis.get("testName");14 } catch (Exception ex) {15 ex.printStackTrace();16 } finally {17if (jedis != null) {18// 返回给池19 jedis.close();20 }21 Assert.assertEquals("RCL", name);22 }23 }10.如果连接不上,可查看是否防⽕墙没有将redis端⼝开放:/etc/sysconfig/iptables添加:-A INPUT -p tcp -m state --state NEW -m tcp --dport 7001 -j ACCEPT //7001即redis端⼝重启防⽕墙⼆、搭建redis集群1.安装ruby环境集群管理⼯具redis-trib.rb依赖ruby环境(1)安装ruby:yum install ruby yum install rubygems(2)安装ruby和redis的接⼝程序:拷贝redis-3.0.0.gem⾄/usr/local。
就publishsubscribe功能看redis集群模式下的队列技术(一)
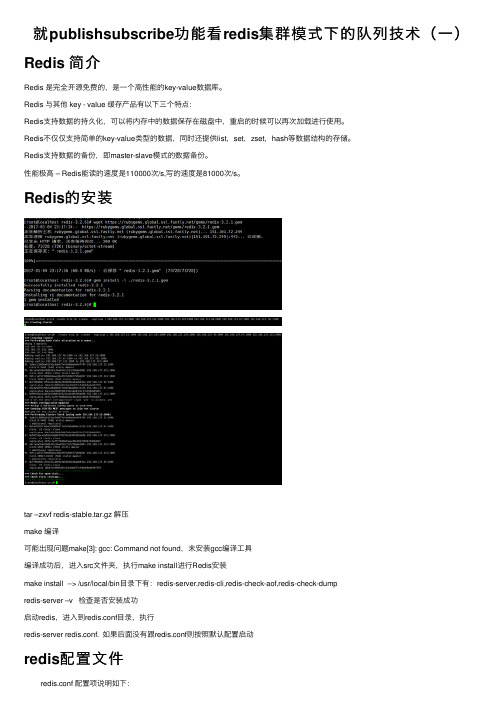
就publishsubscribe功能看redis集群模式下的队列技术(⼀)Redis 简介Redis 是完全开源免费的,是⼀个⾼性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:Redis⽀持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进⾏使⽤。
Redis不仅仅⽀持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis⽀持数据的备份,即master-slave模式的数据备份。
性能极⾼ – Redis能读的速度是110000次/s,写的速度是81000次/s。
Redis的安装tar –zxvf redis-stable.tar.gz 解压make 编译可能出现问题make[3]: gcc: Command not found,未安装gcc编译⼯具编译成功后,进⼊src⽂件夹,执⾏make install进⾏Redis安装make install --> /usr/local/bin⽬录下有:redis-server,redis-cli,redis-check-aof,redis-check-dumpredis-server –v 检查是否安装成功启动redis,进⼊到redis.conf⽬录,执⾏redis-server redis.conf. 如果后⾯没有跟redis.conf则按照默认配置启动redis配置⽂件redis.conf 配置项说明如下:1. Redis默认不是以守护进程的⽅式运⾏,可以通过该配置项修改,使⽤yes启⽤守护进程daemonize yes2. 当Redis以守护进程⽅式运⾏时,Redis默认会把pid写⼊/var/run/redis.pid⽂件,可以通过pidfile指定pidfile /var/run/redis.pid3. 指定Redis监听端⼝,默认端⼝为6379,作者在⾃⼰的⼀篇博⽂中解释了为什么选⽤6379作为默认端⼝,因为6379在⼿机按键上MERZ 对应的号码,⽽MERZ取⾃意⼤利歌⼥Alessia Merz的名字port 63794. 绑定的主机地址bind 127.0.0.1 这个Ip要设置成你服务器的Ip5.当客户端闲置多长时间后关闭连接,如果指定为0,表⽰关闭该功能timeout 3006. 指定⽇志记录级别,Redis总共⽀持四个级别:debug、verbose、notice、warning,默认为verboseloglevel verbose7. ⽇志记录⽅式,默认为标准输出,如果配置Redis为守护进程⽅式运⾏,⽽这⾥⼜配置为⽇志记录⽅式为标准输出,则⽇志将会发送给/dev/nulllogfile stdout8. 设置数据库的数量,默认数据库为0,可以使⽤SELECT <dbid>命令在连接上指定数据库iddatabases 169. 指定在多长时间内,有多少次更新操作,就将数据同步到数据⽂件,可以多个条件配合save <seconds> <changes>Redis默认配置⽂件中提供了三个条件:save 900 1save 300 10save 60 10000分别表⽰900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
Linux下Redis集群安装部署及使用详解(在线和离线两种安装+相关错误解决方案)

Linux下Redis集群安装部署及使⽤详解(在线和离线两种安装+相关错误解决⽅案)⼀、应⽤场景介绍 本⽂主要是介绍Redis集群在Linux环境下的安装讲解,其中主要包括在联⽹的Linux环境和脱机的Linux环境下是如何安装的。
因为⼤多数时候,公司的⽣产环境是在内⽹环境下,⽆外⽹,服务器处于脱机状态(最近公司要上线项⽬,就是⽆外⽹环境的Linux,被离线安装坑惨了,⾛了很多弯路,说多了都是⾎泪史啊%>_<%)。
这也是笔者写本⽂的初衷,希望其他⼈少⾛弯路,下⾯就介绍如何在Linux安装部署Redis集群。
⼆、安装环境及⼯具 系统:Red Hat Enterprise Linux Server release 6.6 ⼯具:XShell5及Xftp5 安装包:GCC-7.1.0 Ruby-2.4.1 Rubygems-2.6.12 Redis-3.2.9(3.x版本才开始⽀持集群功能)三、安装步骤 要搭建⼀个最简单的Redis集群,我们⾄少需要6个节点:3个Master和3个Slave。
那为什么需要3个Master呢?其实就是⼀个“铁三⾓”的关系,当1个Master下线的时候,其他2个Master 和对应的Salve⽴马就能顶替上去,确保集群能够正常使⽤,如果你之前了解Mongodb/Hadoop/Strom这些的话,你就很容易⽬标⼀般分布式的最低要求基数个数节点,这样便于选举(少数服从多数的原则)。
本⽂当中,我们就偷下懒,在⼀台Linux虚拟机上搭建6个节点的Redis集群(实际真正⽣产环境,需要3台Linux服务器分布存放3个Master)1、安装GCC环境安装Redis需要依托GCC环境,先检查Linux是否已经安装了GCC,如果没有安装,则需要进⾏安装检查GCC是否安装,可以看看版本号$ gcc -v如果已经安装了GCC,则会显⽰以下信息如果没有任何信息,则我们可以通过命令yum install gcc-c++进⾏在线安装$ yum install gcc-c++如果没有⽹络的时候,我们就需要下载GCC的安装包进⾏⼿动安装了,具体⽅法还是⽐较复杂的,具体离线安装GCC的⽅法,请参考我的另外⼀篇⽂章《》2、安装Ruby和Rubygems如果有⽹的话,则通过yum命令进⾏安装,⾃动将关联的依赖包全部安装$ yum install ruby$ yum install rubygems如果是离线的状态,我们则可以选择下载Ruby和Rubygems,解压⼿动进⾏安装,具体的⽅法请参考我的另外两篇⽂件《》和《》,这⾥我们不做多讲解。
redis单机安装以及集群搭建(redis-6.2.6)

redis单机安装以及集群搭建(redis-6.2.6)之前写过⼀篇基于redis-3.2.4版本的安装⽇记,这篇是基于redis-6.2.6改动不少,故再次记录⼀下两台电脑10.2.5.147,10.2.5.148,都是centos7.5本次搭建4主4从集群1.单机安装1.1.下载安装包直接从redis官⽹下载安装包,官⽹地址:https://redis.io/download直接使⽤命令下载:wget http://download.redis.io/releases/redis-6.2.6.tar.gz1.2.安装编译将安装包直接上传到了/opt⽬录解压 tar -zxvf redis-6.2.6.tar.gz 之后,得到⼀个redis-6.2.6的⽂件夹个⼈⽐较喜欢将⽂件信息放在/usr/local/redis⽬录下,所以cp /opt/redis-6.2.6/* /usr/local/redis接下来就是编译了进⼊到/usr/local/redis⽬录,执⾏make命令make编译报错make[3]: 进⼊⽬录“/usr/local/redis/deps/hiredis”cc -std=c99 -pedantic -c -O3 -fPIC -Wall -W -Wstrict-prototypes -Wwrite-strings -Wno-missing-field-initializers -g -ggdb alloc.cmake[3]: cc:命令未找到make[3]: *** [alloc.o] 错误 127make[3]: 离开⽬录“/usr/local/redis/deps/hiredis”make[2]: *** [hiredis] 错误 2make[2]: 离开⽬录“/usr/local/redis/deps”make[1]: [persist-settings] 错误 2 (忽略)CC adlist.o/bin/sh: cc: 未找到命令make[1]: *** [adlist.o] 错误 127make[1]: 离开⽬录“/usr/local/redis/src”安装更新gccyum isntall gcc-c++make编译报错致命错误:jemalloc/jemalloc.h:没有那个⽂件或⽬录分配器allocator,如果有MALLOC 这个环境变量,会有⽤这个环境变量的去建⽴Redis。
redis集群搭建+lua脚本的使用

redis集群搭建+lua脚本的使⽤详细参考这篇⽂章(windows)⼀、使⽤JAVA代码操作redis集群public static void main(String[] args) throws Exception {JedisPoolConfig poolConfig = new JedisPoolConfig();// 最⼤连接数poolConfig.setMaxTotal(1);// 最⼤空闲数poolConfig.setMaxIdle(1);// 最⼤允许等待时间,如果超过这个时间还未获取到连接,则会报JedisException异常:// Could not get a resource from the poolpoolConfig.setMaxWaitMillis(1000);Set<HostAndPort> nodes = new LinkedHashSet<HostAndPort>();nodes.add(new HostAndPort("127.0.0.1", 6379));nodes.add(new HostAndPort("127.0.0.1", 6380));nodes.add(new HostAndPort("127.0.0.1", 6381));nodes.add(new HostAndPort("127.0.0.1", 6382));nodes.add(new HostAndPort("127.0.0.1", 6383));nodes.add(new HostAndPort("127.0.0.1", 6384));JedisCluster cluster = new JedisCluster(nodes, poolConfig);String name = cluster.get("name");System.out.println(name);cluster.set("age", "18");System.out.println(cluster.get("age"));try {cluster.close();} catch (IOException e) {e.printStackTrace();}}⼆、使⽤JAVA代码操作lua脚本 1、编写lua脚本redis.call(\"SET\",KEYS[1],ARGV[1]);\n"+ "redis.call(\"SET\",KEYS[2],ARGV[2]); 2、java代码public static void main(String[] args) throws Exception {JedisPoolConfig poolConfig = new JedisPoolConfig();// 最⼤连接数poolConfig.setMaxTotal(1);// 最⼤空闲数poolConfig.setMaxIdle(1);// 最⼤允许等待时间,如果超过这个时间还未获取到连接,则会报JedisException异常:// Could not get a resource from the poolpoolConfig.setMaxWaitMillis(1000);Set<HostAndPort> nodes = new LinkedHashSet<HostAndPort>();nodes.add(new HostAndPort("127.0.0.1", 6379));nodes.add(new HostAndPort("127.0.0.1", 6380));nodes.add(new HostAndPort("127.0.0.1", 6381));nodes.add(new HostAndPort("127.0.0.1", 6382));nodes.add(new HostAndPort("127.0.0.1", 6383));nodes.add(new HostAndPort("127.0.0.1", 6384));JedisCluster cluster = new JedisCluster(nodes, poolConfig);String lua = "redis.call(\"SET\",KEYS[1],ARGV[1]);\n"+ "redis.call(\"SET\",KEYS[2],ARGV[2]);";String[] p = {"{a}a1","{a}a2","a","b"};Object eval = cluster.eval(lua, 2, p);try {cluster.close();} catch (IOException e) {e.printStackTrace();}需要注意的时,redis集群执⾏lua操作的时候,要求key值必须要在同⼀个solt上⾯,为了达到这个⽬的,可以在key值中增加“{xx}”内容,这样redis在计算hash槽的时候会按{}内的内容计算hash值;。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
redis 3.07的集群部署一:关于redis cluster
1:redis cluster的现状
1):节点自动发现
2):slave->master 选举,集群容错
3):Hot resharding:在线分片
4):进群管理:cluster xxx
5):基于配置(nodes-port.conf)的集群管理
6):ASK 转向/MOVED 转向机制.
2:redis cluster 架构
1) redis-cluster架构图
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护
node<->slot<->value
2) redis-cluster选举:容错
(1)领着选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail),当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成进群的slot映射[0-16383]不完成时进入fail状态.
b:如果进群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
二:redis cluster的使用
1:安装redis cluster所需软件
软件:
redis-3.0.7.tar.gz
redis-3.2.2.gem
ruby-2.2.4.tar.gz
rubygems-2.6.2.zip
报错解决:ERROR: Loading command: install (LoadError) no such file to load – zlib
(4)安装redis
2:配置redis cluster
2) redis修改后配置.
查看修改后的配置
重复上面的操作,生成其他配置文件和目录。
3:cluster 操作
4:redis cluster 运维操作
1)初始化并构建集群
(1)#启动集群相关节点(必须是空节点),指定配置文件和输出日志
(2):使用自带的ruby工具(redis-trib.rb)构建集群
(3):检查集群状态,
最后输出如下信息,没有任何警告或错误,表示集群启动成功并处于ok状态
2):添加新master节点
添加一个master节点:创建一个空节点(empty node),然后将某些slot移动到这个空节点上,这个过程目前需要人工干预
a):根据端口生成配置文件
c):加入空节点到集群
add-node 将一个节点添加到集群里面,第一个是新节点ip:port, 第二个是任意一个已存在节点ip:port
node:新节点没有包含任何数据,因为它没有包含任何slot。
新加入的加点是一个主节点,当集群需要将某个从节点升级为新的主节点时,这个新节点不会被选中
d):为新节点分配slot
3):添加新的slave节点
a):根据端口生成配置文件
c):加入空节点到集群
add-node 将一个节点添加到集群里面,第一个是新节点ip:port, 第二个是任意一个已存
d)第四步:redis-cli连接上新节点shell,输入命令:cluster replicate 对应master的node-id
note:在线添加slave 时,需要dump整个master进程,并传递到slave,再由slave加载rdb文件到内存,rdb传输过程中Master可能无法提供服务,整个过程消耗大量io,小心操作.
例如本次添加slave操作产生的rdb文件
4):在线reshard 数据:
对于负载/数据均匀的情况,可以在线reshard slot来解决,方法与添加新master的reshard 一样,只是需要reshard的master节点是老节点
6):删除一个master节点
a):删除master节点之前首先要使用reshard移除master的全部slot,然后再删除当前节点(目前只能把被删除master的slot迁移到一个节点上)
b):删除空master节点
三:redis cluster 客户端(Jedis) 1:客户端基本操作使用
参考文档:
http://redis.io/topics/cluster-spec http://redis.io/topics/cluster-tutorial。