1_compile_kernel
bootload、kernel、rootfs
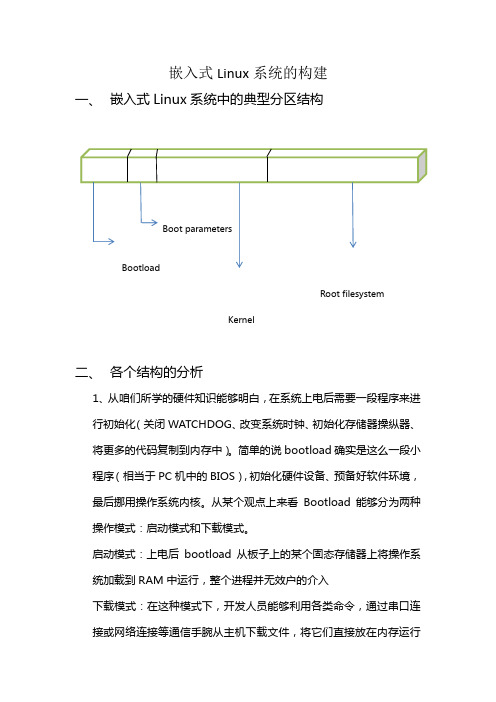
嵌入式Linux系统的构建一、嵌入式Linux系统中的典型分区结构Root filesystemKernel二、各个结构的分析1、从咱们所学的硬件知识能够明白,在系统上电后需要一段程序来进行初始化(关闭WATCHDOG、改变系统时钟、初始化存储器操纵器、将更多的代码复制到内存中)。
简单的说bootload确实是这么一段小程序(相当于PC机中的BIOS),初始化硬件设备、预备好软件环境,最后挪用操作系统内核。
从某个观点上来看Bootload能够分为两种操作模式:启动模式和下载模式。
启动模式:上电后bootload从板子上的某个固态存储器上将操作系统加载到RAM中运行,整个进程并无效户的介入下载模式:在这种模式下,开发人员能够利用各类命令,通过串口连接或网络连接等通信手腕从主机下载文件,将它们直接放在内存运行或是烧入Flash类固态存储设备中。
Bootload能够分为两个时期:第一时期实现的功能:硬件设备初始化、为加载Bootload的第二时期代码预备RAM空间、复制Bootload的第二时期代码到RAM空间中、设置好栈、跳转到第二时期代码的C入口点第二时期:初始化本时期要利用的硬件设备、检测系统内存映射、将内核镜像和根文件映像从Flash上读到RAM空间中、为内核设置启动参数、挪用内核2、内核的结构:Linux内核文件数量快要2万,除去其他构架CPU的相关文件,支持S3C2410、S3C2440这两款芯片的完整内核文件有1万多个。
这些文件组织结构并非复杂,他们别离位于顶层目录下的17个子目录,各个目录功能独立Linu内核Makefile文件分类3、根文件系统嵌入式Linux 中都需要构建根文件系统,构建根文件系统的规那么在FHS(FilesystemHierarchy Standard)文档中,下面是根文件系统顶层目录。
三、根文件系统的制作一、进入到/opt/studyarm 目录,新建成立根文件系统目录的脚本文create_rootfs_bash,利用命令chmod +x create_rootfs_bash 改变文件的可执行限,./create_rootfs_bash 运行脚本,就完成了根文件系统目录的创建。
vivi的配置与编译

vivi配置与编译(1) 建立编译环境1、安装标准Linux 操作系统虚拟机方式2、安装交叉编译器(2) 配置和编译vivi如果vivi的源代码已根据开发板作了相应改动,则需要对源代码进行配置和编译,以生成烧入flash的vivi 二进制映象文件。
由于vivi要用到kernel的一些头文件,所以需要kernel的源代码,所以先要把linux的kernel准备好。
将vivi和kernel都解到相应目录下(例如将光盘提供的vivi源代码解压到/home/chenjing目录下,光盘提供的Linux kernel源码kernel-h2410eb.041024.tar.gz也解压到/home/chenjing目录下,解压后的文件名为kerne-h2410eb)。
然后需修改/vivi/Makefile里的一些变量设置:1) LINUX_INCLUDE_DIR = /kernel/include/(LINUX_INCLUDE_DIR 为kernel/include的对应目录/home/chenjing/kerne-h2410eb /include/)修改为:LINUX_INCLUDE_DIR = /home/chenjing/ kerne-h2410eb/include/2) CROSS_COMPILE = /usr/local/arm/2.95.3/bin/arm-linux- (CROSS_COMPILE 为arm-linux安装的相应目录,我的是/usr/local/arm/2.95.3/bin/arm-linux-)修改为:CROSS_COMPILE = /usr/local/arm/2.95.3/bin/arm-linux-3) ARM_GCC_LIBS = /usr/local/arm/2.95.3/lib/gcc-lib/arm-linux/2.95.3 (需根据你arm-linux的安装目录修改,/usr/local/arm/2.95.3/lib/gcc-lib/arm-linux/2.95.3)进入/vivi目录:a) make distclean(目的是确保编译的有效性,在编译之前将vivi里所有的“*.o”和“*.o.flag”文件删掉)b) make menuconfig (选择配置,可以Load一个写好的配置文件也可以自己修改试试。
linux kernel5.15编译原理

linux kernel5.15编译原理Linux kernel 5.15编译原理Linux kernel是一个开源操作系统内核,其稳定版本的更新和发布对于整个Linux生态系统具有重要意义。
在内核更新的过程中,编译内核是一个重要的步骤。
本文将为您解释Linux kernel 5.15的编译原理,并逐步回答关于该主题的问题。
第一步:准备工作在开始编译内核之前,我们需要做一些准备工作。
1. 下载内核源代码要编译特定版本的Linux内核,首先需要从Linux官方网站(2. 安装必要的依赖项编译内核需要一些工具和依赖项。
在大多数Linux发行版中,您可以使用包管理器来安装它们。
例如,在Ubuntu上,您可以运行以下命令安装常见的依赖项:sudo apt-get install build-essential libncurses-dev bison flexlibssl-dev libelf-dev这些依赖项将帮助您构建所需的内核映像。
第二步:配置编译选项在编译内核之前,需要配置一些编译选项以满足特定需求。
1. 进入内核源代码目录解压下载的内核源代码,并在终端中进入解压后的目录。
例如:tar -xf linux-5.15.tar.xzcd linux-5.152. 清理旧的配置选项可以使用以下命令清理旧的内核配置选项:make mrproper3. 配置编译选项可以使用以下命令进入菜单式配置界面:make menuconfig在配置界面中,您可以选择不同的内核功能、驱动程序和选项。
根据需要进行选择,并保存配置文件。
第三步:编译内核完成配置后,我们可以开始编译Linux内核了。
1. 执行编译命令使用以下命令开始编译内核:make这个过程可能需要一些时间,具体取决于您的计算机性能。
2. 安装编译后的内核完成编译后,可以使用以下命令安装编译后的内核:sudo make install此命令将复制编译后的内核映像、模块和其他文件到适当的位置,并更新GRUB或其他引导程序配置。
kernel5.10 编译方法 -回复

kernel5.10 编译方法-回复标题:编译Linux Kernel 5.10的详细步骤在Linux的世界中,编译Kernel是一项基础且重要的技能。
本文将详细介绍如何从源代码编译Linux Kernel 5.10。
以下是一步一步的详细教程。
一、准备工作1. 确保系统环境首先,你需要一个运行中的Linux系统。
本文以Ubuntu 20.04为例,但大部分Linux发行版的步骤应该是类似的。
2. 更新系统确保你的系统已经更新到最新版本,可以使用以下命令:sudo apt-get updatesudo apt-get upgrade3. 安装必要的工具编译Kernel需要一些基本的开发工具和库,可以通过以下命令安装:sudo apt-get install build-essential libncurses5-dev bc flex bison openssl libssl-dev dkms二、下载Kernel源代码1. 创建工作目录在你的主目录下创建一个名为kernel的工作目录:mkdir ~/kernelcd ~/kernel2. 下载Kernel源代码你可以从Kernel官网(5.10的源代码:wget3. 解压源代码使用以下命令解压下载的源代码:tar xvf linux-5.10.tar.xz这将在当前目录下创建一个名为linux-5.10的目录,这是Kernel的源代码目录。
三、配置和编译Kernel1. 进入源代码目录cd linux-5.102. 配置Kernel配置Kernel是编译过程中最重要的一步,你可以根据你的硬件和需求选择要编译的功能。
对于大多数用户,使用以下命令进行基本配置应该足够:make menuconfig这将打开一个基于文本的配置界面。
你可以使用方向键和回车键浏览和选择选项。
完成后,保存并退出。
3. 开始编译配置完成后,可以开始编译Kernel了。
这个过程可能需要一些时间,取决于你的计算机性能:make -j(nproc)这里的-j参数表示使用多少个进程进行编译,(nproc)会自动获取你的CPU 核心数。
LINUX内核模块编译步骤

LINUX内核模块编译步骤编译Linux内核模块主要包括以下步骤:1.获取源代码2.配置内核进入源代码目录并运行make menuconfig命令来配置内核。
该命令会打开一个文本菜单,其中包含许多内核选项。
在这里,你可以配置内核以适应特定的硬件要求和预期的功能。
你可以选择启用或禁用各种功能、设备驱动程序和文件系统等。
配置完成后,保存并退出。
3. 编译内核(make)运行make命令开始编译内核。
这将根据你在上一步中进行的配置生成相应的Makefile,然后开始编译内核。
编译的过程可能需要一些时间,请耐心等待。
4.安装模块编译完成后,运行make modules_install命令将编译好的模块安装到系统中。
这些模块被安装在/lib/modules/<kernel-version>/目录下。
5.安装内核运行make install命令来安装编译好的内核。
该命令会将内核映像文件(通常位于/arch/<architecture>/boot/目录下)复制到/boot目录,并更新系统引导加载程序(如GRUB)的配置文件。
6.更新GRUB配置文件运行update-grub命令来更新GRUB引导加载程序的配置文件。
这将确保新安装的内核在下次启动时可用。
7.重启系统安装完成后,通过重启系统来加载新的内核和模块。
在系统启动时,GRUB将显示一个菜单,你可以选择要启动的内核版本。
8.加载和卸载内核模块现在,你可以使用insmod命令来加载内核模块。
例如,运行insmod hello.ko命令来加载名为hello.ko的模块。
加载的模块位于/lib/modules/<kernel-version>/目录下。
如果你想卸载一个已加载的内核模块,可以使用rmmod命令。
例如,运行rmmod hello命令来卸载已加载的hello模块。
9.编写和编译模块代码要编写一个内核模块,你需要创建一个C文件,包含必要的模块代码。
华为手机内核代码的编译及刷入教程【通过魔改华为P9AndroidKernel对抗反调试机制】

华为⼿机内核代码的编译及刷⼊教程【通过魔改华为P9AndroidKernel对抗反调试机制】0x00 写在前⾯攻防对⽴。
程序调试与反调试之间的对抗是⼀个永恒的主题。
在安卓逆向⼯程实践中,通过修改和编译安卓内核源码来对抗反调试是⼀种常见的⽅法。
但⽹上关于此类的资料⽐较少,且都是基于AOSP(即"Android 开放源代码项⽬",可以理解为原⽣安卓源码)进⾏修改,然后编译成⼆进制镜像再刷⼊Nexus 或者Pixel 等⾕歌亲⼉⼦⼿机。
但因为⾕歌的亲⼉⼦在国内没有⾏货销售渠道,市场占有率更多的是国产⼿机,⽽修改国产⼿机系统内核的教程却很少,加之部分国产⼿机的安卓内核和主线 AOSP 存在些许差异,照搬原⽣安卓代码的修改⽅法⽆法在国产⼿机上实现某些功能,甚⾄⽆法编译成功。
所以本⽂以某国产⼿机为例,通过研究其内核源码,对关键代码进⾏分析、修改,编译内核、打包成刷机镜像,对全过程予以展⽰。
0x01 常见反调试⼿段及对抗策略简介在安卓程序的开发过程中,反调试的⼿段有很多种,简单列举若⼲:(1) 检测特定进程或端⼝号。
如 IDA Pro 在对安卓应⽤进⾏调试时,需要在⼿机端启动调试程序 android_server ,该调试程序默认开启端⼝23946。
⽬标程序若发现⼿机⾥有 android_server 进程或开启了端⼝23946,⽬标程序就⾃动退出,以达到反调试的⽬的。
(2)检测某些关键⽂件的状态。
如⽬标程序在调试状态时,Linux内核会向部分系统⽂件内写⼊⼀些进程状态信息,包括但不限于向 “ /proc/⽬标程序pid/status ” 这⼀⽂件的 TracerPid 字段写⼊调试进程的 pid 。
有部分程序会检查这些字段,⽐如⽬标程序发现对应的 TracerPid 不等于 0 ,则说明⾃⼰本⾝正在被别的程序调试,⽐如:(Pid为19707的进程正在被Pid为24741的进程调试)(3)检测软件断点。
kali kernel编译

kali kernel编译Kali Linux是一种基于Debian的Linux发行版,被广泛应用于渗透测试和网络安全领域。
安装Kali Linux通常需要定制内核,以满足不同用户和场景的需求。
本文将介绍如何编译Kali Kernel。
编译Kali Kernel的过程相对复杂,需要一定的Linux系统和编译经验。
以下是编译Kali Kernel的一般步骤:1. 下载源代码:首先,从官方Kali Linux网站上下载源代码。
确保下载对应版本的源代码,以免与系统发生冲突。
2. 安装所需依赖:在开始编译之前,确保系统已安装所需的构建工具和依赖项。
这些包括gcc编译器、make工具、头文件等。
可以使用包管理器来安装这些依赖项。
3. 配置内核选项:进入源代码目录,并运行命令' make menuconfig'。
这将打开一个文本界面的配置菜单,您可以根据需要选择和配置内核功能和选项。
如果不确定如何配置,可以使用默认选项。
4. 运行编译命令:完成配置后,运行以下命令编译内核:' make'。
此命令将编译内核源代码并生成内核映像文件。
编译过程可能需要一些时间,取决于系统性能和源代码大小。
5. 安装编译生成的内核:一旦编译完成,您可以运行命令' make install'来安装编译生成的内核。
此命令将在系统中安装内核映像文件并更新引导加载程序。
6. 重新启动系统:最后,重新启动系统以加载新编译的内核。
在系统启动时,您应该能够选择新内核以启动Kali Linux。
请注意,编译Kali Kernel可能会因不同的系统配置和需求而有所不同。
因此,建议在执行这些步骤之前阅读官方Kali Linux文档和相关资源,以确保您完成了所有必要的步骤和设置。
总结起来,编译Kali Kernel是一项复杂且需要经验的任务。
但通过遵循上述步骤,并参考相关文档和资源,您应该能够成功自定义和编译适合您需求的Kali Linux内核。
嵌入式linux内核编译错误的一些解决办法

make[2]:***[drivers/video/console2] error 2
make[1]:***[drivers/video1] error 2
make:***[drivers] error 2
解决方法:
在make menuconfig 时选哪个设备驱动的选项进去在选Graphics support ->
scripts/basic/docproc.c: 在函数‘parse_file’中:
scripts/basic/docproc.c:296: 警告: 对指针赋值时目标与指针符号不一致
SHIPPED scripts/kconfig/zconf.tab.h
HOSTCC scripts/kconfig/conf.o
四:
make zImage和make xipImage
Kernel configured for XIP (CONFIG_XIP_KERNEL=y)
Only the xipImage target is available in this case
make[1]: *** [arch/arm/boot/zImage] Error 1
make: *** [.tmp_vmlinux1] 错误 1
ld链接时产生错误
对应行:
/home/kevin/ARMSystem/linux-2.6.12/arch/arm/kernel/vmlinux.lds
/* those must never be empty */
ASSERT((__proc_info_end - __proc_info_begin), "missing CPU support")
NVIDIA Kepler兼容性指南说明书

DA-06287-001_v1.0 | April 2012 Application NoteDOCUMENT CHANGE HISTORYTABLE OF CONTENTS Chapter 1.Kepler Compatibility (1)1.1About This Document (1)1.2Application Compatibility on Kepler (1)1.3Verifying Kepler Compatibility for Existing Applications (2)1.3.1Applications Using CUDA Toolkit 4.1 or Earlier (2)1.3.2Applications Using CUDA Toolkit 4.2 (2)1.4Building Applications with Kepler Support (3)1.4.1CUDA Runtime API Applications (3)1.4.2CUDA Driver API Applications (6)APPENDIX A.Revision History (8)A.1Version 1.0 (8)1.1ABOUT THIS DOCUMENTThis application note, Kepler Compatibility Guide for CUDA Applications, is intended to help developers ensure that their NVIDIA® CUDA TM applications will run effectively on GPUs based on the NVIDIA® Kepler Architecture. This document provides guidance to developers who are already familiar with programming in CUDA C/C++ and want to make sure that their software applications are compatible with Kepler.1.2APPLICATION COMPATIBILITY ON KEPLERThe NVIDIA CUDA C compiler, nvcc, can be used to generate both architecture-specific cubin files and forward-compatible PTX versions of each kernel. Each cubin file targets a specific compute-capability version and is forward-compatible only with CUDA architectures of the same major version number. For example, cubin files that target compute capability 2.0 are supported on all compute-capability 2.x (Fermi) devices but are not supported on compute-capability 3.0 (Kepler) devices. For this reason, to ensure forward compatibility with CUDA architectures introduced after the application has been released, it is recommended that all applications support launching PTX versions of their kernels.1Applications that already include PTX versions of their kernels should work as-is on Kepler-based GPUs. Applications that only support specific GPU architectures via cubin files, however, will need to be updated to provide Kepler-compatible PTX or cubin s.1 CUDA Runtime applications containing both cubin and PTX code for a given architecture will automatically use the cubin by default, keeping the PTX path strictly for forward-compatibility purposes.1.3VERIFYING KEPLER COMPATIBILITY FOREXISTING APPLICATIONSThe first step is to check that Kepler-compatible device code (at least PTX) is compiled in to the application. The following sections show how to accomplish this for applications built with different CUDA Toolkit versions.1.3.1Applications Using CUDA Toolkit 4.1 or Earlier CUDA applications built using CUDA Toolkit versions2.1 through 4.1 are compatible with Kepler as long as they are built to include PTX versions of their kernels. To test that PTX JIT is working for your application, you can do the following:④Download and install the latest driver from /drivers.④Set the environment variable CUDA_FORCE_PTX_JIT=1④Create an empty temporary directory on your system.④Set the environment variable CUDA_CACHE_PATH to be the path to this empty directory.④Launch your application.When starting a CUDA application for the first time with the above environment flag, the CUDA driver will JIT-compile the PTX for each CUDA kernel that is used into native cubin code. The generated cubin for the target GPU architecture is cached on disk by the CUDA driver.If you set the environment variables above and then launch your program and it works properly, and if the directory you specified with the CUDA_CACHE_PATH environment variable is now populated with cache files, then you have successfully verified Kepler compatibility. Note that it is not necessary to inspect the contents of the cache files themselves; just check that the previously empty cache directory is now non-empty.Be sure to unset these two environment variables when you are done testing if you do not normally use them. The temporary cache directory you created is safe to delete. 1.3.2Applications Using CUDA Toolkit 4.2CUDA applications built using CUDA Toolkit 4.2 are compatible with Kepler as long as they are built to include kernels in either Kepler-native cubin format (see Section 1.4) or PTX format (see Section 1.3.1 above) or both.1.4BUILDING APPLICATIONS WITH KEPLERSUPPORTThe methods used to build your application with support for Kepler depend on the version of the CUDA Toolkit used and on the choice of the CUDA Runtime API or CUDA Driver API.Note: The CUDA Runtime API is characterized by the use of functions named with the cuda*() prefix and by launching kernels using the triple-angle-bracket <<<>>> notation. The CUDA driver API functions use the cu*() prefix, including for kernel launch. 1.4.1CUDA Runtime API ApplicationsWhen a CUDA application launches a kernel, the CUDA Runtime determines the compute capability of each GPU in the system and uses this information to automatically find the best matching cubin or PTX version of the kernel that is available. If a cubin file supporting the architecture of the target GPU is available, it is used; otherwise, the CUDA Runtime will load the PTX and JIT-compile that PTX to the GP U’s native cubin format before launching it. If neither is available, then the kernel launch will fail.The main advantages of providing native cubin s are as follows:④It saves the end user the time it takes to PTX JIT a kernel that has been compiled asPTX. (However, since the CUDA driver will cache the cubin generated as a result of the PTX JIT, this is mostly a one-time cost for a given user.)④PTX JIT-compiled kernels often cannot take advantage of architectural features ofnewer GPUs, meaning that native-compiled code may be faster or of greater accuracy.1.4.1.1Applications Using CUDA Toolkit 4.1 or EarlierThe compilers included in CUDA Toolkit 4.1 or earlier generate cubin files native to earlier NVIDIA architectures such as Fermi, but they cannot generate cubin files native to the Kepler architecture. To allow support for Kepler and future architectures when using version 4.1 or earlier of the CUDA Toolkit, the compiler must generate a PTX version of each kernel.Below are compiler settings that could be used to build mykernel.cu to run on Fermi and earlier devices natively and on Kepler devices via PTX JIT. In these examples, the lines shown in blue provide compatibility with earlier architectures, and the lines shown in red provide a PTX path for compatibility with Kepler and later architectures.Note that compute_XX refers to a PTX version and sm_XX refers to a cubin version. The arch= clause of the -gencode= command-line option to nvcc specifies the front-end compilation target and must always be a PTX version. The code= clause specifies the back-end compilation target and can either be cubin or PTX or both. Only the back-end target version(s) specified by the code= clause will be retained in the resulting binary; at least one must be PTX to provide Kepler compatibility.Windows:nvcc.exe -ccbin "C:\vs2008\VC\bin"-Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT"–gencode=arch=compute_10,code=sm_10–gencode=arch=compute_20,code=sm_20–gencode=arch=compute_20,code=compute_20--compile -o "Release\mykernel.cu.obj" "mykernel.cu"Mac/Linux:/usr/local/cuda/bin/nvcc–gencode=arch=compute_10,code=sm_10–gencode=arch=compute_20,code=sm_20–gencode=arch=compute_20,code=compute_20-O2 -o mykernel.o -c mykernel.cuAlternatively, you may be familiar with the simplified nvcc command-line option -arch=sm_XX , which is a shorthand equivalent to the following more explicit –gencode= command-line options used above. -arch=sm_XX expands to the following:–gencode=arch=compute_XX,code=sm_XX–gencode=arch=compute_XX,code=compute_XXHowever, while the -arch=sm_XX command-line option does result in inclusion of a PTX back-end target by default, it can only specify a single target cubin architecture at a time, and it is not possible to use multiple -arch= options on the same nvcc command line, which is why the examples above use -gencode= explicitly.1.4.1.2Applications Using CUDA Toolkit 4.2Beginning with version 4.2 of the CUDA Toolkit, nvcc can generate cubin files native to the Kepler architecture (compute capability 3.0). When using CUDA Toolkit 4.2, to ensure that nvcc will generate cubin files for all released GPU architectures as well as a PTX version for forward compatibility with future GPU architectures, specify the appropriate -gencode= parameters on the nvcc command line as shown in the examples below.In these examples, the lines shown in blue provide compatibility with earlier architectures, the lines shown in green provide native cubin s for Kepler, and the lines in red provide a PTX path for compatibility with future architectures.Windows:nvcc.exe -ccbin "C:\vs2008\VC\bin"-Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT"-gencode=arch=compute_10,code=sm_10-gencode=arch=compute_20,code=sm_20-gencode=arch=compute_30,code=sm_30-gencode=arch=compute_30,code=compute_30--compile -o "Release\mykernel.cu.obj" "mykernel.cu"Mac/Linux:/usr/local/cuda/bin/nvcc-gencode=arch=compute_10,code=sm_10-gencode=arch=compute_20,code=sm_20-gencode=arch=compute_30,code=sm_30-gencode=arch=compute_30,code=compute_30-O2 -o mykernel.o -c mykernel.cuNote that compute_XX refers to a PTX version and sm_XX refers to a cubin version. The arch= clause of the -gencode= command-line option to nvcc specifies the front-end compilation target and must always be a PTX version. The code= clause specifies the back-end compilation target and can either be cubin or PTX or both. Only the back-end target version(s) specified by the code= clause will be retained in the resulting binary; at least one should be PTX to provide compatibility with future architectures.1.4.2CUDA Driver API ApplicationsApplications that use the CUDA Driver API load their own kernels explicitly. Therefore, the kernel-loading portions of such applications must include a path capable of loading PTX when native cubin s for the target GPU(s) are not available.④Compile CUDA kernel files to PTX, even if also compiling native cubin files forexisting architectures. If multiple compilation target types/versions are to be used, nvcc must be called separately for each generated output file of either type, and the type and version must be specified explicitly at compile time. (An advancedtechnique is to use a “fat binary” (fatbin) file, which contains both cubin and PTX formats. This technique is outside the scope of this document.)A common pattern in many applications is to include cubin s for all supported existingarchitectures plus PTX of the highest-available version for forward compatibility to future architectures.The example below demonstrates compilation of compute_20 PTX, which will work on devices of compute capability 2.x and 3.0, but not on devices of compute capability1.x. Presumably an application using this example as-is would also include cubin s forcompute capability 1.x and/or 2.x as well.Windows:nvcc.exe -ccbin "C:\vs2008\VC\bin"-Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT"-ptx -arch=compute_20-o "pute_20.ptx" "mykernel.cu"Mac/Linux:/usr/local/cuda/bin/nvcc-ptx -arch=compute_20-O2 -o pute_20.ptx "mykernel.cu"④At runtime, your application will need to explicitly check the compute capability ofthe current GPU with the CUDA Driver API function in order to select the best-available cubin or PTX to load. The deviceQueryDrv code sample from the NVIDIA GPU Computing SDK includes a detailed example of the use of this function.cuDeviceComputeCapability(&major, &minor, dev)④Refer to the “PTX Just-in-Time Compilation” (ptxjit) code sample GPU ComputingSDK, available at the URL below, which demonstrates how to use the CUDA Driver API to launch PTX kernels./cuda-cc-sdk-code-samplesA more complex example can be found in the matrixMulDrv code sample from the GPU Computing SDK, which follows a pattern similar to the following: CUmodule cuModule;CUfunction cuFunction = 0;string ptx_source;// Helper function load PTX source to a stringfindModulePath ("matrixMul_kernel.ptx",module_path, argv, ptx_source));// We specify PTX JIT compilation with parametersconst unsigned int jitNumOptions = 3;CUjit_option *jitOptions = new CUjit_option[jitNumOptions];void **jitOptVals = new void*[jitNumOptions];// set up size of compilation log bufferjitOptions[0] = CU_JIT_INFO_LOG_BUFFER_SIZE_BYTES;int jitLogBufferSize = 1024;jitOptVals[0] = (void *)(size_t)jitLogBufferSize;// set up pointer to the compilation log bufferjitOptions[1] = CU_JIT_INFO_LOG_BUFFER;char *jitLogBuffer = new char[jitLogBufferSize];jitOptVals[1] = jitLogBuffer;// set up maximum # of registers to be usedjitOptions[2] = CU_JIT_MAX_REGISTERS;int jitRegCount = 32;jitOptVals[2] = (void *)(size_t)jitRegCount;// Loading a module will force a PTX to be JITstatus = cuModuleLoadDataEx(&cuModule, ptx_source.c_str(),jitNumOptions, jitOptions,(void **)jitOptVals);printf("> PTX JIT log:\n%s\n", jitLogBuffer);A.1 VERSION 1.0Initial public release.Kepler Compatibility Guidefor CUDA Applications DA-06287-001_v1.0| 8 NoticeALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FORA PARTICULAR PURPOSE.Information furnished is believed to be accurate and reliable. However, NVIDIA Corporation assumes no responsibility for the consequences of use of such information or for any infringement of patents or other rights of third parties that may result from its use. No license is granted by implication of otherwise under any patent rights of NVIDIA Corporation. Specifications mentioned in this publication are subject to change without notice. This publication supersedes and replaces all other information previously supplied. NVIDIA Corporation products are not authorized as critical components in life support devices or systems without express written approval of NVIDIA Corporation.TrademarksNVIDIA and the NVIDIA logo are trademarks or registered trademarks of NVIDIA Corporation in the U.S. and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.Copyright© 2012 NVIDIA Corporation. All rights reserved.。
linux 安卓内核编译的方法

linux 安卓内核编译的方法Linux操作系统以其强大的功能和灵活的配置,吸引了越来越多的开发者。
安卓系统作为一款开源的移动设备操作系统,其内核编译对于开发者来说也是必不可少的技能。
本文将向大家介绍如何使用Linux系统进行安卓内核的编译。
一、准备工作1. 确保你的Linux系统已经安装了基本的开发工具,如gcc、make、patch等。
2. 下载安卓内核源码,可以选择从官网或者github获取。
3. 创建一个用于存放编译结果的目录,如/home/user/kernel_build。
二、配置内核1. 打开终端,导航到源码目录。
2. 使用patch工具对内核源码进行修补,确保源码与当前Linux 内核版本兼容。
3. 修改Makefile文件,指定编译选项和目标。
三、编译内核1. 运行make命令进行第一轮编译,生成中间文件。
2. 运行make menuconfig,进入配置界面,对内核选项进行进一步配置。
3. 退出menuconfig,再次运行make命令进行第二轮编译。
4. 等待编译完成,检查是否有错误信息。
四、安装驱动和模块1. 将驱动程序和模块提取出来,放在适当的目录下。
2. 运行make install命令,将驱动和模块安装到内核中。
3. 验证驱动和模块是否成功安装,可以运行一些测试程序来检查。
五、打包和测试1. 将编译后的内核映像打包,可以使用kimage工具或其他适合的打包工具。
2. 将打包后的内核映像刷入模拟器或实际设备中,进行测试。
3. 运行一些应用程序,检查内核是否能够正常工作。
4. 对测试结果进行分析和优化,根据实际需求进行进一步的调整和修改。
总结:安卓内核编译是一项需要一定技能的任务,但通过本文所述的步骤,你可以轻松完成这个过程。
在编译过程中,需要注意一些细节问题,如源码的兼容性、配置选项的选择等。
此外,为了确保编译的成功率,建议在虚拟机中进行操作,以避免对真实系统造成损坏。
内核VMLINUX配置分析

本文首先分析了Linux内核中的配置系统结构,然后,解释了Makefile和配置文件的格式以及配置语句的含义,最后,通过一个简单的例子--TEST Driver,具体说明如何将自行开发的代码加入到Linux内核中。
在下面的文章中,不可能解释所有的功能和命令,只对那些常用的进行解释,至于那些没有讨论到的,请读者参考后面的参考文献。
1.配置系统的基本结构Linux内核的配置系统由三个部分组成,分别是:Makefile:分布在Linux内核源代码中的Makefile,定义Linux内核的编译规则;配置文件(config.in):给用户提供配置选择的功能;配置工具:包括配置命令解释器(对配置脚本中使用的配置命令进行解释)和配置用户界面(提供基于字符界面、基于Ncurses图形界面以及基于Xwindows图形界面的用户配置界面,各自对应于Make config、Make menuconfig和make xconfig)。
这些配置工具都是使用脚本语言,如Tcl/TK、Perl编写的(也包含一些用C编写的代码)。
本文并不是对配置系统本身进行分析,而是介绍如何使用配置系统。
所以,除非是配置系统的维护者,一般的内核开发者无须了解它们的原理,只需要知道如何编写Makefile和配置文件就可以。
所以,在本文中,我们只对Makefile和配置文件进行讨论。
另外,凡是涉及到与具体CPU体系结构相关的内容,我们都以ARM为例,这样不仅可以将讨论的问题明确化,而且对内容本身不产生影响。
2.Makefile2.1Makefile概述Makefile的作用是根据配置的情况,构造出需要编译的源文件列表,然后分别编译,并把目标代码链接到一起,最终形成Linux内核二进制文件。
由于Linux内核源代码是按照树形结构组织的,所以Makefile也被分布在目录树中。
Linux 内核中的Makefile以及与Makefile直接相关的文件有:Makefile:顶层Makefile,是整个内核配置、编译的总体控制文件。
linux系统下uboot、kernel、android文件系统编译错误整理及解决办法

linux系统下uboot、kernel、android文件系统编译错误整理及解决办法Ver1.0作成者:雷鹏作成年月:2012/09/251、linux下编译应用程序时出现如下错误: /usr/bin/ld: cannot find -lxxx。
原因分析:编译过程找不到对应库文件。
其中,-lxxx表示链接库文件 libxxx.so。
由于库文件是编译过程临时生成的,如果前面编译过程出错也会导致出现这种情况,下面针对本机系统环境缺失而引起的错误进行分析。
一般出现这种错误有以下几种原因:⑴.系统缺乏对应的库文件;⑵.版本不对应;⑶.库文件的链接错误;⑷.库文件路径设置问题。
解决方法:对应第一第二种情况,可以通过下载安装lib来解决,ubuntu系统可以直接通过apt-get来安装:apt-get install libxxx-dev如果还是不能解决问题,那么,引起错误的原因不是链接错误就是库文件路径问题。
通过find或者locate指令定位到链接文件,查看链接文件是否正确的指向了编译需要的lib,如果不是,用下列指令修改它。
ln -sf */libxxx.so.x */libxxx.so如果是库文件路径引发的问题,可以到/etc/ld.so.conf.d目录下,修改其中任意一份conf文件,(可以自建conf,以方便识别)将lib所在目录写进去,然后在终端输入 ldconfig 更新缓存。
2、编译时出现错误提示:include/asm is a directory but a symlink was expected原因分析:linux/include/asm 文件夹是内核编译过程中创建的,创建结果就是一个指向文件夹asm-arm 的链接,表明该系统的平台是arm架构的,而编译系统内核之前,是没有asm这个链接的,所以,在编译过程中,创建该链接时文件名字与asm文件夹的名字发生冲突,于是系统报错了。
1.编译内核模块遇到的问题

1.编译内核模块遇到的问题问题:使⽤内核包编译驱动时常常提⽰如下:WARNING: Symbol version dump /usr/src/linux-2.6.26/Module.symversis missing; modules will have no dependencies and modversions.原因:通常头核⼼包中是没有Module.symvers这个⽂件的,要想获取这个⽂件只能到下载相同版本核⼼(2.6.26-1-686)的头⽂件,是下载不是apt-get install ,只有下载的头⽂件中才有这个Module.symvers。
把Module.symvers 复制到核⼼包中,然后执⾏如下步骤:make oldconfig && make prepare && make scripts。
然后重新编译驱动,将解决这个warning,同时也解决了版本不正确的问题我不知道有多少⼈会碰上这样的问题,反正google中我发现没有⼈能说明⽩这个问题ps:我遇到的问题是则是运⾏:make -C /usr/src/linux-2.6.34-12 SUBDIRS=$PWD modules出错如下:make: Entering directory `/usr/src/linux-2.6.34-12'ERROR: Kernel configuration is invalid.include/generated/autoconf.h or include/config/auto.conf are missing.Run 'make oldconfig && make prepare' on kernel src to fix it.WARNING: Symbol version dump /usr/src/linux-2.6.34-12/Module.symversis missing; modules will have no dependencies and modversions.scripts/Makefile.build:44: /usr/src/linux-2.6.34-12/PWD/Makefile: No such file or directorymake[1]: *** No rule to make target `/usr/src/linux-2.6.34-12/PWD/Makefile'. Stop.make: *** [_module_PWD] Error 2make: Leaving directory `/usr/src/linux-2.6.34-12'运⾏:make oldconfig && make prepare再次出错如下:make: Entering directory `/usr/src/linux-2.6.34-12'WARNING: Symbol version dump /usr/src/linux-2.6.34-12/Module.symversis missing; modules will have no dependencies and modversions.CC [M] /home/xxx/test/dr/drhello.oBuilding modules, stage 2.MODPOST 1 modules/bin/sh: scripts/mod/modpost: No such file or directorymake[1]: *** [__modpost] Error 127make: *** [modules] Error 2make: Leaving directory `/usr/src/linux-2.6.34-12'加上:make scripts可以了make: Entering directory `/usr/src/linux-2.6.34-12'WARNING: Symbol version dump /usr/src/linux-2.6.34-12/Module.symversis missing; modules will have no dependencies and modversions.CC [M] /home/xxx/test/dr/drhello.oBuilding modules, stage 2.MODPOST 1 modulesCC /home/test/dr/drhello.mod.oLD [M] /home/test/dr/drhello.komake: Leaving directory `/usr/src/linux-2.6.34-12'。
龙芯正确交叉编译过程完成最终版

5.龙芯派2代编译内核对于下载了kernel编译环境虚拟机镜像的朋友,请直接从第6步开始文档是流水账,需要有一定linux功底,不能面面俱到,抱歉!拷入gcc到/optvi .bashrc,在最后一行按o,添加一个空行,然后按i进入字符插入模式,键入export PATH=/opt/gcc-4.9.3-64-gnu/bin:$PATH 保存退出*注意:绝对文件目录路径如,/home/linux/opt…source .bashrc1. apt-get update2. apt-get install libncurses5-dev3. apt-get install bc4. apt-get install make5. apt-get install gcc6. 将从龙芯ftp上下载的内核源码拷贝到虚拟机中,如/root目录,解压,进入内核源码目录,跳到第10步修改内核源码。
7. make ARCH=mips CROSS_COMPILE=mips64el-linux- menuconfig8. make ARCH=mips CROSS_COMPILE=mips64el-linux-9. make ARCH=mips CROSS_COMPILE=mips64el-linux- modules_install第9的目的是在虚拟机/lib/modules/文件夹下生成2k内核模块的文件夹,3开头那个文件夹就是,整个打包,和生成的vmlinuz一起拷出来,就成为了内核镜像和模块。
10 .对于派2的内核需要删除下面2个文件的其中一行,不然会像下下图那样报错*注意:该步在留存的linux-3.10.tar.gz文件已修改,可以不做。
注意第7步make ARCH=mips CROSS_COMPILE=mips64el-linux- menuconfig 在弹出的配置界面对如下几项配置做出下列相应选择,其他项保持不变。
linux内核编译过程解释

linux内核编译过程解释
Linux内核是操作系统的核心部分,它控制着系统的资源管理、任务调度、驱动程序等重要功能。
编译Linux内核是一项非常重要的任务,因为它决定了系统的性能、稳定性和可靠性。
下面我们来了解一下Linux内核的编译过程。
1. 下载内核源代码:首先,我们需要从官方网站上下载Linux
内核的源代码。
这里我们可以选择下载最新的稳定版本或者是开发版,具体取决于我们的需求。
2. 配置内核选项:下载完源代码后,我们需要对内核进行配置。
这一步通常需要使用make menuconfig命令来完成。
在配置过程中,我们需要选择系统所需的各种驱动程序和功能选项,以及定制化内核参数等。
3. 编译内核:配置完成后,我们可以使用make命令开始编译内核。
编译过程中会生成一些中间文件和可执行文件,同时也会编译各种驱动程序和功能选项。
4. 安装内核:编译完成后,我们可以使用make install命令将内核安装到系统中。
这一步通常需要将内核文件复制到/boot目录下,并更新系统的引导程序以便正确加载新内核。
5. 重启系统:安装完成后,我们需要重启系统以使新内核生效。
如果新内核配置正确,系统应该能顺利地启动并正常工作。
总的来说,Linux内核的编译过程是一个相对复杂的过程,需要一定的技术和操作经验。
但是,通过了解和掌握相关的编译技巧和命
令,我们可以轻松地完成内核编译工作,并为系统的性能和稳定性做出贡献。
从oops中查找错误代码行-堆栈错误信息

从oops信息查找出错代码行分类:Linux Releated 2011-04-18 16:15 725人阅读评论(0) 收藏举报(1)从oops crash的地方开始查起,首先找到指针访问错误的代码行a)重新编译内核时,选上kernel hacking--->compile the kernel with debug info---->kernel debugging使得内核包含调试信息,b)然后从Oops信息中找到“PC is at free_block+0x8c/0x168”##########################################################Unable to handle kernel paging request at virtual address 000c0604 //非法指针地址pgd = 40004000[000c0604] *pgd=00000000Internal error: Oops: 817 [#1]Modules linked in:CPU: 0 Not tainted (2.6.27.18 #221)PC is at free_block+0x78/0x168 //当前指令地址LR is at release_console_sem+0x19c/0x1b8 //函数返回地址##########################################################从system_map中查到free_block地址0x40097ac0,+0x78得到0x40097B38c)在内核根目录运行arm-wrs-linux-gnueabi-armv6jel_vfp-uclibc_small-gdb vmlinux就可以得到出错行[root@kqyang-hikvision linux-2.6.27_svn_quyong]#arm-wrs-linux-gnueabi-armv6jel_vfp-uclibc_small-gdb vmlinuxGNU gdb (Wind River Linux Sourcery G++ 4.3-85) 6.8.50.20080821-cvs Copyright (C) 2008 Free Software Foundation, Inc.License GPLv3+: GNU GPL version 3 or later</licenses/gpl.html>This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details.This GDB was configured as "--host=i686-pc-linux-gnu--target=arm-wrs-linux-gnueabi".For bug reporting instructions, please see:<support@>...(gdb) l *0x40097B380x40097b38 is in free_block (include/linux/list.h:93).88 * the prev/next entries already!89 */90 #include <linux/kernel.h>91 static inline void __list_del(struct list_head * prev, struct list_head * next)92 {93 next->prev = prev;94 prev->next = next;95 }9697 /**(gdb)原文地址:linux内核的oops信息作者:XINUOops可看成是内核级(特权级)的Segmentation Fault。
编译kernel+xenomai+machinekit

编译kernel+xenomai+machinekit 搭建 qemu chroot 环境安装必要的包sudo apt-get install qemu qemu-user qemu-user-static binfmt-support debootstrap⽤debootstrap搭建最⼩chroot环境cd <working dir>sudo debootstrap --foreign --no-check-gpg --include=ca-certificates --arch=armhf wheezy rootfs <mirror>编辑/etc/qemu-binfmt.conf,加⼊下⾯这⾏:EXTRA_OPTS="-L/usr/lib/arm-linux-gnueabihf"复制qemu可执⾏⽂件然后chrootsudo cp $(which qemu-arm-static) rootfs/usr/binsudo chroot rootfs/ /debootstrap/debootstrap --second-stage --verbose将使⽤的镜像加⼊/etc/apt/sources.listsudo sh -c 'echo deb <mirror> wheezy main > rootfs/etc/apt/sources.list'sudo sh -c 'echo deb-src <mirror> wheezy main >> rootfs/etc/apt/sources.list'创建/etc/resolv.confsudo cp /etc/resolv.conf rootfs/etcChrootsudo chroot rootfs /bin/bash设定locale,否则会产⽣⼀堆警告LC_ALL=CLANGUAGE=CLANG=C安装必要的包apt-get updateapt-get install --no-install-recommends git-core kernel-package fakeroot build-essential devscripts lsb-release编译Linux内核下载源⽂件和补丁进⼊⼯作⽬录cd /usr/src下载内核git clone -b rpi-3.8.y --depth 1 git:///raspberrypi/linux.git linux-rpi-3.8.y下载Xenomaigit clone git:///xenomai-2.6.git xenomai-head下载最⼩config⽂件wget https:///s/dcju74md5sz45at/rpi_xenomai_config下载USB fiq补丁wget https:///kinsamanka/10256843/raw/4d5d3e02a443e4d17d9b82a1fe027ef17fb14470/usb_fiq.patch 打补丁打 ipipe core pre-patch(cd linux-rpi-3.8.y; patch -Np1 < ../xenomai-head/ksrc/arch/arm/patches/raspberry/ipipe-core-3.8.13-raspberry-pre-2.patch)打Xenomai ipipe核⼼补丁(先查看补丁编号是否有变化,补丁要与内核版本号⼀致)xenomai-head/scripts/prepare-kernel.sh --arch=arm --linux=linux-rpi-3.8.y \--adeos=xenomai-head/ksrc/arch/arm/patches/ipipe-core-3.8.13-arm-4.patch打 ipipe core post-patch(cd linux-rpi-3.8.y; patch -Np1 < ../xenomai-head/ksrc/arch/arm/patches/raspberry/ipipe-core-3.8.13-raspberry-post-2.patch)打usb fiq补丁(cd linux-rpi-3.8.y; patch -Np1 < ../usb_fiq.patch)编译内核编辑内核包维护者信息(名字、电邮之类的)vi /etc/kernel-pkg.conf安装必备的包apt-get install --no-install-recommends ncurses-dev bc配置内核cd linux-rpi-3.8.ycp ../rpi_xenomai_config .configmake oldconfig编译make-kpkg cleanmake-kpkg --append-to-version=-xenomai --revision=1.0 kernel_image kernel_headers编译Xenomai⽤户空间包变更⽬录cd /usr/src/xenomai-head安装必要的依赖包apt-get build-dep xenomai编译debuild -i -us -uc -b编译Machinekit变更⽬录cd /usr/src下载源码git clone -b master -o github-machinekit --depth 1 git:///machinekit/machinekit.git添加两个源,安装必要的包sudo sh -c \"echo 'deb wheezy main' > \/etc/apt/sources.list.d/machinekit.list"sudo apt-get updatesudo apt-get install dovetail-automata-keyringsudo apt-get updatesudo apt-get install libczmq-dev python-zmq libjansson-dev \libwebsockets-devsudo sh -c \"echo 'deb /debian wheezy-backports main' > \/etc/apt/sources.list.d/wheezy-backports.list"sudo apt-get updatesudo apt-get install -t wheezy-backports cythonsudo apt-get install git dpkg-dev安装内核和xenomaidpkg -i linux-image-3.8.13-xenomai+_1.0_armhf.debdpkg -i libxenomai1_2.6.3_armhf.debdpkg -i libxenomai-dev_2.6.3_armhf.deb安装依赖包sudo scripts/apt-installbuilddeps编辑/etc/fstab,加⼊none /dev/shm tmpfs rw,nosuid,nodev,noexec 00Mount shm(否则会报错error: failed to find required module pyftpdlib.servers)mount /dev/shm配置machinekitcd machinekitdebian/configure -px编译debuild -i -us -uc -b。
rk3588 linux kernel 编译解析

rk3588 linux kernel 编译解析在Linux系统中,编译内核是一项重要的任务。
对于rk3588处理器来说,编译Linux内核需要一定的步骤和技巧。
本文将对rk3588 Linux内核编译的解析进行详细说明。
了解相关基础知识是非常重要的。
rk3588处理器使用的是ARM架构,因此在编译内核之前,需要获取合适的内核源代码。
可以从官方网站或其他合适的资源获取最新的Linux内核源代码。
需要配置编译环境。
在Linux系统中,可以使用gcc工具链来编译内核。
确保系统中安装了合适版本的gcc,并进行相应的配置。
还需要安装一些必要的工具和依赖项,如make、perl等。
一旦环境配置完成,可以开始编译内核。
首先,需要进入内核源代码目录。
运行`make menuconfig`命令,可以进入内核配置界面。
在这个界面中,可以定制内核的功能和选项,根据需要进行相应的设置。
这包括启用或禁用特定的硬件支持、文件系统支持、设备驱动等。
完成配置后,保存并退出界面。
可以开始编译内核。
运行`make`命令,系统将开始编译内核。
这个过程可能需要一些时间,取决于内核源代码的大小和所选择的配置选项。
编译完成后,可以使用`make modules_install`安装模块。
将编译得到的内核镜像文件复制到系统中,以便后续的使用。
可以将内核镜像文件复制到启动分区中,并进行相应的配置,以确保系统能够正确地引导。
需要注意的是,编译内核可能会遇到一些问题和错误。
这些问题可能涉及到库文件、依赖项、配置选项等。
在解决问题时,可以参考官方文档、在线论坛和社区等资源,以获得帮助和指导。
编译rk3588 Linux内核需要进行一系列的步骤和配置。
通过了解基础知识、配置环境、进行内核配置、编译和安装,可以成功地完成内核编译工作。
编译内核是一个复杂的过程,需要一定的耐心和技术知识,但它也是学习和深入了解Linux系统的重要途径之一。
LINUX内核STARTINGKERNEL...串口无输出问题归纳

下面两篇文章是ARM9论坛上的讲解ramdisk文件系统的很不错的文章今天做了个试验,让Linux2.6.29.4从ramdisk根文件系统启动成功,总结一下。
其中涉及的内容较多,很多东西不再详述,如需深入研究请查阅相关资料(百度或谷歌一下一大堆)。
开发环境:Fedora 9交叉编译工具链:arm-linux-gcc 4.3.2 with EABI嵌入式Linux内核版本:2.6.29.4-FriendlyARM。
昨天写贴子的时候具体记不清了,今天起来启动开发板用uname -r查一下,就是叫做2.6.29.4-FriendlyARM,帖子已经改好了。
本文就是友善之臂的2.6.29.4-FriendlyARM的那个版本的内核的基础上改的。
其它版本的应该也类似,仅供参考。
开发板:mini2440-128M Nand FlashBootloader:u-boot-2009.11具体步骤如下:1.解压内核源码树解压linux-2.6.29-mini2440-20090708.tgz到自己的工作目录,会生成一个友善之臂修改过的并且有几个mini2440默认配置文件的内核源码目录linux-2.6.29。
具体步骤参照友善之臂mini2440开发板用户手册,具体不详述了。
2.修改内核配置选项进入内核源码目录linux-2.6.29目录#cp config_mini2440_t35 .config#make menuconfig ARCH=arm打开配置菜单,修改两个配置项,分别是:a):General setup-->选择Initial RAM filesystem and RAM disk...... 项b):Device Drivers-->Block devices-->选择RAM block device support 项并检查Optimize for size是否被选中,如果没有则选中,此项优化内核大小,根据需要进行配置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7
Linux 的核心
make install 安装编译的核心,系统会把 /usr/src/linux 目录内 的 System.map 与 /usr/src/linux/arch/i386/boot 目录内的 bzImage (或者是 zImage) 分别改名 成为 System-核心版本 与 Kernel-核心版本 并复制到 /boot 目录内,然后使用 ln -s 指令 建立 vmlinuz 与 System.map 档案连结 ln -sf System-2.2.16.map System.map ln -sf vmlinuz-2.2.16 vmlinuz
9
其他事项
使用 patch 更新 linux kernel 原始码版本 当抓取 linux-2.2.16 核心使用,已经有 linux-2.2.17 版本时,不需要重新抓取 linux-2.2.17 原始码档案, 可以直接抓取 patch 修正档案回来更新即可. patch 修正档案名称为 patch-xx.xx.xx.bz2 使用 bzip2 压缩的档案,或者是使用 gzip 压缩的 .gz 档案. patch 修正方式,到 /usr/src 目录内,使用: bzip2 -cd patch-xx.xx.xx.bz2 | patch -p0
3
Linux 的核心
编译核心: cd /usr/src 如果 linux 是一个实际的目录,请改名. 若是 linux 是一个连结档案,请删除 tar zxvf /path/linux-xx.xx.xx.tar.gz mv linux linux-xx.xx.xx ln -s linux-xx.xx.xx linux cd linux make menuconfig make dep;make clean;make bzImage;make install make modules;make modules_install
6
Linux 的核心
make modules_install (续) 注意的是,若是目前编译的核心版本与系统 使用一样的话,在 make modules_install 前, 先把 /lib/modules/xx.xx.xx/ 该目录整个改名 或者是删除. (xx.xx.xx 是目前使用的核心版本, 可以使用 uname -r 得知)
8
Linux 的核心
make install (续) 若是系统 SCSI 硬碟装置,而 root filesystem 在 SCSI 硬碟的情况.而若是编译核心时选择把 SCSI 装置的支援编译成为 module 的话,开机到一半 会因为无法使用 SCSI 硬碟而开机失败.这时候 需要 initrd 於开机配置一块 RAM於开机过程中 挂入驱动使用. usage: mkinitrd /boot/initrd-xx.xx.xx.img xx.xx.xx 视需要调整 /etc/lilo.conf 档案,修改后执行 lilo 程式更新,重新开机即心 取得 Linux Kernel :
ftp:// ftp://.tw/kernel
解开 Linux Kernel 压缩档案 tar zxvf linux-2.xx.xx-xx.tar.gz bzip2 -cd linux-2.xx.xx-xx.tar.bz2 | tar xvf -
5
Linux 的核心
make bzImage 这是开始建立核心,另外也可以使用make zImage 若是 make zImage 最后出现 Kernel is too Big 的 错误讯息,则可以改用 make bzImage. make modules 这是开始编译 module 模组的部分. make modules_install 编译模组完毕后,使用 make modules_install 来安装.档案会安装到 /lib/modules/核心版本 目录内.
Compile Kernel
kenduest (小州 小州) 小州 Kenduest@
last update: 2001/3/28
1
Linux 的核心
Kernel : Linux 核心版本,以 n.X.Y 来看: n : 主要版本 X : 偶数,为稳定版本. X: 奇数,实验测试中版本 Y : Release 发表的次数 Linux Kernel 目前为 2.4 版本
4
Linux 的核心
make menuconfig 会进入设定核心的项目部分,传统可以使用 make config 编辑.另外在 X Window 环境下 则可以使用 make xconfig 编辑设定 make dep 这是依照 make config 或者是 make menuconfig 所选择的项目产生相关编译资讯 make clean 这是清除先前编译产生的 object 物件档案 使用 make distclean 则为完整清除
11
相关注意事项
在 kernel 2.14 以前,kernel 并没有直接包含 cp950 codepage 的 support,请到 MyID Web 站 下载: .tw/~is84086/Project/kernel_cp950 目前现在 kernel 在 Linux Distribution 编译出厂时, 其实已经最佳化与模组化,一般需求情况下不大需要 重新编译核心.目前编译核心多半是为了去芜存菁. USB 介面部分,在 kernel 2.3 有实做加入,一般 kernel 2.2.x 内看不到 USB 项目部分.不过有些 Linux Distribution 厂商有把 Kernel 2.3 内的 USB 项目加入到 Kernel 内,如此就可以使用 USB 装置.
10
其他事项
使用 patch 更新 linux kernel 原始码版本 (续) patch 的使用,一般可以使用 patch < filename 的方式导向给 patch 程式.前面使用 bzip2 -cd patch-xx.xx.bz2 是把 patch-xx.xx.bz2 档案解压缩,然后输出到萤幕.透过 | 管线的 处理,就不需要解开 patch 档案再执行patch 程式. patch 后面有个 –p 参数,使用上接 -p0,-p1 等等. patch 档案内是抓 linux/xxxx/file.c 的话,使用 –p0 变成抓取 /xxxx.-p1 则变成抓取 xxxx/file.c
12
�