统计学实验—SPSS与R软件应用与实例-第10章数据的描述-R
《SPSS统计分析》第10章 相关分析

12.990 16.290 17.990 19.290
12.500 15.800 17.500 18.800
11.500 14.800 16.500 17.800
2.200 5.500 7.200 8.500
3.300 5.000 6.300
3.300
1.700 3.000
5.000 1.700
1.300
3.分析两个变量间线性关系的程度。往往因为第三个变量的作用,使相关系数不能真正反映两个 变量间的线性程度。 这是应该控制一个变量的变化求另两个变量间的相关系数,也就是说, 在第三个变量不变的情况下,两个变量的线性程度。
CORRELATIONS /VARIABLES=VCP with HEIGHT WEIGHT /PRINT=TWOTAIL NOSIG /MISSING=PAIRWISE .
6.300 3.000 1.300
1.800 1.500 3.200 4.500
2.700 6.000 7.700 9.000
5.000 8.300 10.000 11.300
12.000 15.300 17.000 18.300
9: 9 14.790 14.300 13.300
4.000 1.800 1.500 3.200 4.500
返回
典型相关分析
返回
典型相关分析概念
典型相关分析是用来描述两组随机变量间关 系的统计分析方法。
通过线性组合,可以将一组变量组合成一个 新的综合变量。虽然每组变量间的线性组合有无 数多个,但通过对其施加一些条件约束,能使其 具有确定性。
典型相关分析就是要找到使得这两个由线性 组合生成的变量之间的相关系数最大的系数。
学习通过编程解决偏相关问题
SPSS统计软件的操作与应用

SPSS统计软件的操作与应用SPSS(Statistical Package for the Social Sciences,社会科学统计软件包)是一种用于数据统计和分析的软件工具。
它提供了广泛的功能和分析选项,适用于各种研究领域和数据类型。
本文将介绍SPSS的操作步骤和应用场景。
一、SPSS的基本操作步骤:1.数据输入:在SPSS中,可以通过手动输入数据或导入其他文件格式的数据。
点击“文件”-“打开”命令,选择数据文件并确认导入选项。
4.数据转换与清洗:SPSS提供了强大的数据转换和清洗功能。
可以使用“计算变量”命令来创建新的变量,通过数学公式、逻辑操作或函数运算来计算新的变量。
可以使用“数据筛选”命令来选择特定的数据子集进行分析。
5.数据分析:SPSS提供了丰富的统计分析功能,包括描述性统计、频率分析、多元回归、因子分析、聚类分析、生存分析等。
可以使用“统计”-“描述统计”命令进行描述性统计分析,使用“分析”-“回归”命令进行回归分析。
6.图表绘制和结果解释:SPSS可以绘制各种类型的图表,如柱形图、线形图、散点图等,以可视化方式展示数据。
分析结果可以通过图表、表格和文字报告的方式进行解释。
7. 输出和导出结果:SPSS的分析结果可以输出为SPSS输出文件( .spo )或HTML格式,也可以导出为Microsoft Office软件(如Excel、Word、PowerPoint)或PDF格式。
二、SPSS的应用场景:1.社会科学研究:SPSS是社会科学研究中最常用的统计软件之一、它可用于分析民意调查数据、人口统计数据、教育问卷数据等。
可以进行统计描述、相关分析、卡方检验、T检验、方差分析、逻辑回归等分析。
2.医学研究:医学研究中需要对大量的数据进行分析和解释,SPSS 可以进行生存分析、队列研究、临床试验等统计分析,帮助研究人员发现疾病的原因、评估治疗方法的效果等。
3.市场研究:市场研究中需要对调查数据进行分析和预测,SPSS可以进行市场细分、购买选择行为分析、品牌忠诚度分析等统计分析,帮助企业了解市场需求和制定市场策略。
统计学原理与spss应用的案例报告

统计学原理与SPSS应用的案例报告引言本文旨在介绍统计学原理与SPSS应用的案例报告,首先介绍了统计学原理的基本概念和方法,然后讨论了SPSS软件在统计分析中的应用,并以一个典型案例来展示如何使用SPSS进行数据分析和统计结果解读。
统计学原理统计学是一门研究数据收集、整理、分析和解释的学科。
它的主要目的是通过对数据的统计分析来揭示数据背后的规律和趋势。
统计学原理包括以下几个核心概念:1.总体和样本:总体是指我们要研究的对象的全体,而样本则是从总体中抽取出来的一部分。
2.描述统计量:用来描述数据分布的特征的量,如均值、中位数、标准差等。
3.抽样误差:由于样本的随机性,样本统计量与总体参数之间存在的差异。
4.假设检验:通过对样本数据进行统计推断,推断总体参数是否显著不同于某个设定值。
5.方差分析:用于比较不同组之间的均值差异是否显著。
SPSS应用SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,它提供了丰富的统计方法和数据处理功能,方便研究者进行数据分析和统计结果的解读。
以下是SPSS在统计学中常用的功能:1.数据输入和清理:SPSS可以导入不同格式的数据文件,并进行数据清洗和转换,使数据符合统计分析的要求。
2.描述统计分析:SPSS可以计算数据的描述性统计量,如均值、中位数、标准差等,以便对数据分布进行描述。
3.假设检验:SPSS可以进行各类假设检验的计算,如t检验、方差分析、卡方检验等,帮助研究者判断样本数据与总体参数是否存在显著差异。
4.回归分析:SPSS可以进行线性回归、逻辑回归等分析,帮助研究者探究自变量与因变量之间的关系。
5.聚类分析:SPSS可以进行聚类分析,将样本数据进行分类,找出相似性较高的样本群体。
案例报告研究背景我们的研究旨在探讨不同年龄组的学生在数学成绩上的差异是否显著。
我们从一所中学抽取了200名学生,按照年龄分为两组,15岁以下组和15岁以上组。
SPSS概览数据分析实例详解

SPSS概览数据分析实例详解SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于各个领域的数据分析。
在SPSS中,数据分析可以通过不同的统计方法、图表和输出来进行。
下面是一个关于如何使用SPSS进行数据分析的实例详解。
假设我们有一个关于一所大学学生的调查数据集,包括以下信息:性别、年龄、所在学院、GPA(平均绩点)、社交媒体使用时间和每周学习时间等变量。
我们想要使用SPSS对这些数据进行一些分析,以了解学生的特征与他们的学习表现之间是否存在关联。
首先,我们需要导入数据集到SPSS中。
在SPSS中,你可以点击“File”菜单,选择“Open”选项来导入数据集(通常是一个Excel或CSV文件)。
导入后,你将在SPSS的“Data Editor”窗口中看到你的数据。
然后,我们可以开始进行数据的概览。
在SPSS中,你可以使用“Frequencies”命令来查看变量的分布情况。
点击“Analyze”菜单,选择“Descriptive Statistics”选项,然后点击“Frequencies”选项。
在弹出的对话框中,你需要选择你想要分析的变量。
比如,你可以选择年龄、GPA和每周学习时间这三个变量。
点击“OK”按钮后,SPSS会生成一个报告,展示这些变量的频数、百分比和其他统计信息。
接下来,我们可以使用SPSS的图表功能来可视化数据。
在SPSS中,你可以点击“Graphs”菜单,选择“Chart Builder”选项来创建图表。
在“Chart Builder”窗口中,你可以选择不同的图表类型,例如柱状图、散点图或箱线图。
比如,你可以选择创建一个散点图来展示GPA与每周学习时间之间的关系。
然后,你需要将变量拖动到图表的相应位置上。
比如,你可以将GPA拖动到纵坐标(Y轴)上,将每周学习时间拖动到横坐标(X轴)上。
点击“OK”按钮后,SPSS会生成一个散点图,展示这两个变量之间的关系。
第10章数据描述-R

10.1 常见统计图的绘制
10.1.1 分类数据和顺序数据的频数分布表
10.1.2 分类数据和顺序数据的条形图及饼 图
10.1.3 数值型数据的频数分布表
10.1.4 数值型数据的直方图、箱线图、线 图、茎叶图
10.2 描述性统计分析
2020/8/17
《统计学实验》第10章数据的描述
2-6
10.1 常见统计图的绘制
统计学实验 —SPSS和R软件应用与实例
主编:费宇
2020/8/17
《统计学实验》第10章数据的描述
2-1
第10章 数据的描述
2020/8/17
《统计学实验》第10章数据的描述
2-2
一、实验目的
1. 运用R中的barplot( )函数画条形图, hist( ) 函数画直方图,pie( )函数画饼图, boxplot( )函数画箱线图,plot( ) 函数画 线图,stem( )函数画茎叶图。
2-12
10.1.2 分类数据和顺序数据的条 形图及饼图
【例10.2】 (数据文件为li10.1.txt) 根据表10.1 资料, 用R软件绘制条形图。
(数据来源:费宇等,《统计学》第2章,高等教 育出版社,2010)
2020/8/17
《统计学实验》第10章数据的描述
2-13
【统计理论】
对分类数据和顺序数据,计算出每一类别 出现的频数或频率后,还可通过统计图来 展示,例如条形图。
序号
1 2 3 4 5 6 7 8 9 10
性别 职称 序号
男
讲师
11
女
助教
12
女 副教授 13
女 副教授 14
男
助教
15
统计学spss实验报告

统计学spss实验报告《统计学SPSS实验报告》在统计学领域,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,它能够帮助研究人员对数据进行分析和处理。
本实验报告将介绍使用SPSS进行统计分析的过程和结果。
实验目的:本实验旨在使用SPSS软件对一组数据进行统计分析,包括描述统计、相关分析和回归分析,以验证数据的相关性和预测能力。
实验步骤:1. 数据导入:首先将实验所需的数据导入SPSS软件中,确保数据格式正确。
2. 描述统计:对数据进行描述统计分析,包括均值、标准差、最大值、最小值等。
3. 相关分析:通过SPSS进行相关分析,探究变量之间的相关性。
4. 回归分析:进行回归分析,验证变量之间的预测能力。
实验结果:1. 描述统计结果显示,样本的平均值为X,标准差为X,最大值为X,最小值为X。
2. 相关分析结果表明,变量A与变量B之间存在显著的正相关关系(r=0.7,p<0.05)。
3. 回归分析结果显示,变量A对变量B的预测能力较高(R²=0.5,p<0.05)。
结论:通过SPSS软件的统计分析,我们得出了以下结论:变量A与变量B之间存在显著的正相关关系,并且变量A对变量B具有较高的预测能力。
这些结果为我们提供了对数据的深入理解和有效的预测能力。
总结:SPSS软件作为一种强大的统计分析工具,能够帮助研究人员对数据进行全面的统计分析。
通过本实验,我们深入了解了SPSS软件的使用方法和统计分析过程,为今后的研究工作提供了重要的参考和指导。
通过本次实验报告,我们对SPSS软件的统计分析能力有了更深入的了解,也为我们今后的科研工作提供了重要的参考和指导。
希望本实验报告能够对读者有所启发和帮助。
统计分析与spss的应用实验报告

统计分析与spss的应用实验报告统计分析与SPSS的应用实验报告引言:统计分析是一种重要的数据处理和解释工具,它在科学研究、商业决策和社会调查等领域具有广泛的应用。
SPSS是一款功能强大的统计分析软件,它提供了丰富的数据分析功能和友好的用户界面,使得统计分析变得更加简便和高效。
本实验报告将介绍统计分析与SPSS的应用实验,通过实际案例,探讨统计分析在实际问题中的应用和SPSS的使用方法。
实验目的:本实验旨在通过使用SPSS软件,对某公司销售数据进行统计分析,以探究不同因素对销售额的影响,并提出相应的建议。
实验设计:本实验选取了某公司过去一年的销售数据作为研究对象,包括销售额、广告投入、促销活动和竞争对手销售额等变量。
通过对这些变量进行统计分析,我们可以了解它们之间的关系,并找出对销售额影响最大的因素。
实验步骤:1. 数据导入:首先,我们需要将实验所需的数据导入SPSS软件中。
在导入过程中,我们需要注意数据的格式和结构,确保数据的准确性和完整性。
2. 数据清洗:在进行统计分析之前,我们需要对数据进行清洗,包括缺失值处理、异常值处理和数据转换等。
通过清洗数据,我们可以提高数据的质量和可靠性。
3. 描述性统计分析:通过对数据进行描述性统计分析,我们可以了解数据的分布情况和基本统计特征,如均值、标准差和分位数等。
这些统计指标可以帮助我们对数据有一个初步的认识。
4. 相关性分析:在本实验中,我们将进行相关性分析,以探究不同因素之间的相关性。
通过计算相关系数,我们可以判断变量之间的线性关系强度和方向,从而了解它们之间的相互作用。
5. 回归分析:为了进一步研究不同因素对销售额的影响,我们将进行回归分析。
通过建立回归模型,我们可以估计不同因素对销售额的贡献程度,并进行显著性检验,以确定哪些因素对销售额具有统计显著性影响。
实验结果:经过数据分析和统计建模,我们得到了以下结果:1. 广告投入和促销活动对销售额有显著正向影响,说明增加广告投入和促销活动可以提高销售额。
统计学实验—SPSS与R软件应用与实例-第10章数据的描述-R

2019/10/14
《统计学实验》第10章数据的描述
10-30
运行结果
图10.3 某大学50名教师年龄直方图
2019/10/14
《统计学实验》第10章数据的描述
10-31
【例10.6】(数据文件为li10.6.txt)某大学9名大一新 生英语、语文、数学考试成绩如表10.3所示,试 绘制多批箱线图,比较9名学生的各科成绩。
出版社,2019)
2019/10/14
《统计学实验》第10章数据的描述
10-17
【统计理论】
对分类数据和顺序数据,计算出每一类别 出现的频数或频率后,还可通过统计图来 展示,例如饼图 。
2019/10/14
《统计学实验》第10章数据的描述
10-18
【软件操作】
采用pie()函数作饼图
x=read.table("li10.1.txt",header=T) # 从li10.1.txt 中读入样本数据x
2019/10/14
《统计学实验》第10章数据的描述
10-24
【软件操作】
x=read.table("li10.4.txt",header=T) #从li10.4.txt 中读入样本数据x
fre<- table(x[,4]) #生成教师职称变量的分组频数
library(sca) # 加载扩展包sca
rbind(fre,per) # 合并表格命令,生成教师职称分 组频数分布表
2019/10/14
《统计学实验》第10章数据的描述
10-11
运行结果
副教授 讲师 教授 助教
fre "12"
"8"
统计学课SPSS数据分析实战案例

统计学课SPSS数据分析实战案例SPSS(统计分析系统)是一款常用的统计软件,被广泛应用于社会科学、商业、医学等领域的数据分析工作中。
通过这个案例,我们将运用SPSS软件进行数据分析,以展示统计学课的实战应用。
案例背景假设你是一位市场研究员,你的公司正在调查消费者对某产品的满意度。
你已经收集了一份随机抽样的数据集,包含了消费者的满意度评分以及他们的一些个人信息。
你的任务是对这些数据进行分析,以了解消费者满意度与个人信息之间是否存在关联。
数据集说明数据集包括了500个消费者的信息,具体变量如下:1. 变量1:满意度评分(连续变量,取值范围从1到10);2. 变量2:性别(分类变量,取值为男性和女性);3. 变量3:年龄(连续变量);4. 变量4:收入水平(分类变量,取值为低、中、高三个层次);5. 变量5:购买次数(连续变量,表示过去一年内购买该产品的次数)。
数据分析步骤以下是对这份数据集进行分析的步骤:1. 数据清洗和准备首先,我们需要检查数据集中是否存在缺失值或异常值,并进行数据清洗。
在SPSS中,我们可以使用数据查看和数据清洗的功能来完成这一步骤。
确保数据集中的每一列都没有缺失值,并且所有的异常值已经得到恰当的处理。
2. 描述性统计分析接下来,我们可以使用SPSS的描述性统计分析功能,对数据集进行描述性统计分析。
我们可以计算满意度评分、年龄和购买次数的平均值、标准差、最小值、最大值,并生成频数分布表和柱状图。
3. 相关性分析为了确定满意度评分与其他个人信息变量之间的关联性,我们可以使用SPSS的相关性分析功能。
通过计算满意度评分与性别、年龄、收入水平和购买次数之间的相关系数,我们可以评估它们之间的相关性。
4. 单因素方差分析我们可以使用SPSS进行单因素方差分析,以了解不同收入水平的消费者在满意度评分上是否存在显著差异。
通过观察方差分析表和显著性水平,我们可以得出初步结论。
5. 多元线性回归分析最后,我们可以使用SPSS的多元线性回归分析功能来建立一个回归模型,以预测满意度评分。
应用统计分析实验R软

可编辑ppt
12
• 通过用户自编程序, R语言很容易延伸和扩大. 它 就是这样成长的.
• R 是计算机编程语言. 类似于UNIX语言,C语 言,Pascal,Gauss语言等.
• 对于熟练的编程者, 它将觉得该语言比其他语言 更熟悉.
• 而对计算机初学者, 学习R语言使得学习下一步 的其他编程不那么困难.
可编辑ppt
14
下载R软件
学习网站 /pages/newhtm/r/schtml/
可编辑ppt
15
R软件
一.R软件的使用 1. 基本语法 2. 向量、矩阵 3. list与data.frame 4. 读写数据文件 5. 控制语句与自定义函数
二. 数据描述性分析
1.分布
2.统计量
3.一维数据的统计图形
4.多维数据的图形可编表辑pp示t
16
三. 回归分析 四. 判别分析 五. 聚类分析 六. 主成分分析
可编辑ppt
17
基本语法
1. 变量使用即定义,变量名区分大小写, 可用中文命名 变量赋值可采用4种形式:=,<-, ->, assign() 变量类型自动由变量赋值确定。
# 注释符号, 分号; 语句连接符
例子:
a=10 a<-10 10->a assign(“a”,10)
A=10 A<-10 10->A assgin(‘ab’,200) 中国=“中华人民共和国” #生成字符串变量
assign(“中国”, “中华人民共和国”)
a=10; A=10; a; A
可编辑ppt
主的软件,在工程上应用广泛。但是统计方法不
多。
可编辑ppt
7
spss数据分析简单案例

spss数据分析简单案例SPSS数据分析简单案例。
在社会科学研究中,SPSS(统计分析软件包)被广泛应用于数据分析。
本文将通过一个简单的案例来介绍如何使用SPSS进行数据分析。
首先,我们收集了一份关于学生学习成绩的数据,包括学生的性别、年龄、每周学习时间和期末考试成绩。
我们的研究问题是探讨性别、年龄和每周学习时间对学习成绩的影响。
我们首先打开SPSS软件,导入我们收集的数据。
然后,我们可以使用SPSS 的数据编辑功能对数据进行清洗和整理,确保数据的准确性和完整性。
接下来,我们可以使用SPSS的描述性统计功能对数据进行分析。
我们可以计算每个变量的均值、标准差、最大值和最小值,从而对数据的分布和特征有一个直观的了解。
然后,我们可以使用SPSS的相关分析功能来探讨不同变量之间的相关性。
我们可以计算不同变量之间的皮尔逊相关系数,从而了解它们之间的线性关系。
在接下来的分析中,我们可以使用SPSS的回归分析功能来探讨性别、年龄和每周学习时间对学习成绩的影响。
我们可以建立一个多元线性回归模型,从而探讨不同变量对学习成绩的预测作用。
最后,我们可以使用SPSS的图表功能来进行数据可视化分析。
我们可以绘制散点图、柱状图和折线图,从而直观地展示不同变量之间的关系和趋势。
通过以上步骤,我们可以利用SPSS对学生学习成绩的数据进行全面的分析,从而回答我们的研究问题。
在实际研究中,我们还可以进一步探讨其他统计分析方法,如方差分析、卡方检验等,以深入挖掘数据的内在规律。
总之,SPSS作为一款功能强大的统计分析软件,为社会科学研究提供了重要的数据分析工具。
通过本文的简单案例,希望读者能够对SPSS的数据分析功能有一个初步的了解,并能够在实际研究中灵活运用,从而为研究工作提供有力的支持。
spss数据分析简单案例

spss数据分析简单案例SPSS数据分析简单案例。
在实际的数据分析工作中,SPSS(Statistical Package for the Social Sciences)是一个非常常用的统计分析软件。
它提供了丰富的统计分析功能,可以帮助研究者对各种数据进行深入的分析和挖掘。
下面我们将通过一个简单的案例来介绍如何使用SPSS进行数据分析。
案例背景:假设我们是一家电商公司的数据分析师,我们需要分析一组销售数据,以便更好地了解产品销售情况,为未来的销售策略提供支持。
第一步,数据导入。
首先,我们需要将待分析的数据导入SPSS软件中。
在SPSS中,我们可以通过“文件”菜单中的“打开”命令来打开Excel或者CSV格式的数据文件。
在导入数据的过程中,我们需要注意数据的格式是否正确,确保数据的准确性。
第二步,数据清洗。
一般来说,原始数据中会存在一些缺失值、异常值或者重复值,这些数据对于我们的分析是不利的。
因此,在进行数据分析之前,我们需要对数据进行清洗。
在SPSS中,我们可以通过“数据”菜单中的“数据清理”命令来进行数据清洗工作。
在数据清洗的过程中,我们需要注意保留数据的完整性和准确性。
第三步,描述性统计分析。
在数据清洗完成之后,我们可以开始进行描述性统计分析。
描述性统计分析可以帮助我们了解数据的基本情况,包括数据的分布、中心趋势和离散程度等。
在SPSS中,我们可以通过“分析”菜单中的“描述统计”命令来进行描述性统计分析。
在描述性统计分析的过程中,我们可以生成各种统计指标,如均值、标准差、最大最小值等,以便更好地了解数据的特征。
第四步,相关性分析。
除了描述性统计分析之外,我们还可以进行相关性分析,以了解不同变量之间的相关关系。
在SPSS中,我们可以通过“分析”菜单中的“相关”命令来进行相关性分析。
在相关性分析的过程中,我们可以生成相关系数矩阵或者散点图,以便更好地了解变量之间的相关关系。
第五步,回归分析。
最后,我们还可以进行回归分析,以了解自变量和因变量之间的关系。
数据分析与SPSS软件应用(微课版)-课后习题答案1-10章全书章节练习题答案

第1章统计分析与SPSS软件概述习题与思考题(一)填空题1.定性数据,定序数据,定距数据,定比数据2.主成分分析,因子分析,聚类分析,判别分析,对应分析等3.数据清理,数据转换,缺失数据插补,数据的合并汇总拆分4.完全窗口菜单运行方式,程序运行方式5.SPSS Base(二)选择BADAD(三)判断√√×√×(四)简答题1.目前常用的统计分析工具或软件有哪些?你使用过哪些?它们之间的区别在哪里?解:常用的统计分析工具有SPSS、SAS、STATA、Python等。
2.试检查自己的SPSS软件共有几个模块,其中包括了哪些基本功能,并思考平时的统计分析需要哪些模块才能满足需要。
解:SPSS软件共有11个模块,分别是SPSS Base、SPSS Advance、SPSS Categories、SPSS Complex Sample、SPSS Conjoint、SPSS Exact Test、SPSS Maps、SPSS Missing Value Analysis、SPSS Regression、SPSS Tables和SPSS Trends。
其中SPSS Base是必需的,SPSS的整体框架、基本数据的获取、数据准备和整理等基本功能都集中在这一模块上,其他模块必须在该模块的基础上才能工作。
3.阐述定性、定序、定距、定比数据,并各举1例。
解:定性变量又称为名义变量。
这是一种测量精度最低、最粗略的基于“质”因素的变量,它的取值只代表观测对象的不同类别,如“班级”。
定序变量又称为有序变量、顺序变量,它取值的大小能够表示观测对象的某种顺序关系(等级、方位或大小等),也是基于“质”因素的变量,如“满意度”。
定距变量又称为间隔变量,它的取值之间可以比较大小,可以用加减法计算出差异的大小,如“重量”。
定比变量又称为比率变量,它与定距变量意义相近,差别在于定距变量中的“0”值只表示某一取值,定比数据变量表示“没有”,如“年龄”。
统计分析与spss的应用第三版第章课后习题详细答案(docX页)

统计分析与spss的应用(第三版)第10章课后习题详细答案1、(1)聚类分析的第1步,1号样本(广西瑶族)和3号样本(广西侗族)聚为一小类,它们的个体距离(欧氏距离)是3.722,这个小类将在下面第2步用到。
聚类分析的第2步,8号个体(贵州苗族)与第1步聚成的小类(1号和3号聚成的小类)又聚成一小类,它们的距离(个体与小类的距离,采用组间平均链锁距离)是9.970,这个小类将在下面第4步用到。
聚类分析的第3步,5号样本和7号样本聚成小类,它们的距离(个体与个体的距离)是11.556,这个小类将在第5步用到。
聚类分析的第4步,6号与第2步形成的小类(1号3号8号聚成的小类)聚为小类,它们的距离(个体与小类的距离)为18.607,这个小类将在第6步用到。
聚类分析的第5步,4号样本与第3步聚成的小类聚为小类,它们的距离(个体与小类的距离)为20.337,这个小类将在第6步用到。
聚类分析的第6步,第4步聚成的小类与第5步聚成的小类聚成小类,它们的距离(小类与小类的距离,采用组间平均链锁距离)是22.262,这个小类将在下面第7步中用到。
聚类分析的第7步,2号样本与第6步中聚成的小类聚成小类。
它们的距离(个体与小类的距离)是31.020。
经过7步,8个样本最后聚成了一大类。
(2)(3) 广西瑶族与广西侗族、贵州苗族、基诺族为一类,土家族与崩龙族、白族为一类,湖南侗族自成一类2、(1)凝聚状态表随着类数目不断减少,类间距离在逐渐增大。
3类后,聚间距离迅速增大,形成极为平坦的碎石路。
所以考虑聚成3类。
(2)北京自成一类,江苏广东上海湖南湖北聚为一类,剩余的聚省为一类。
(3)(4)通过该表可以看出,,对应P值-小于0.005,所以各指数的均值在3类中的差异是显著的。
3、答:聚类分析是以各种距离来度量个体间的“亲疏”程度的。
从各种距离的定义来看,数量级将对距离产生较大的影响,并影响最终的聚类结果。
进行层次聚类分析时,为了避免上述问题,聚类分析之前应首先消除数量级对聚类的影响,对数据进行标准化就是最常用的方法。
统计学原理SPSS实验报告
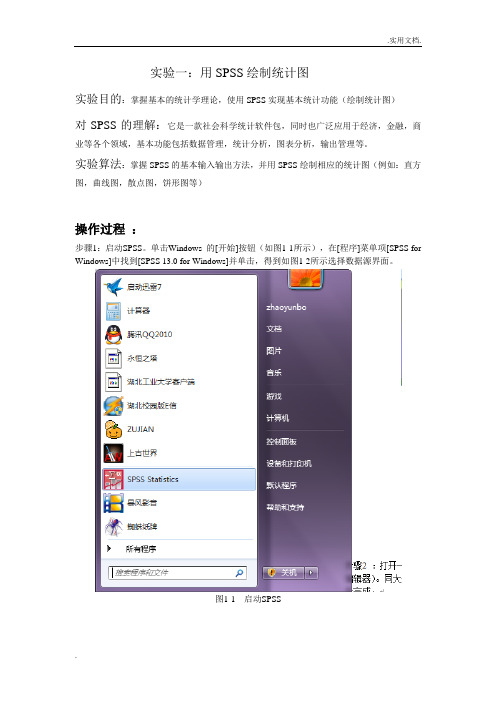
实验一:用SPSS绘制统计图实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图)对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。
实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等)操作过程:步骤1:启动SPSS。
单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示选择数据源界面。
图1-1 启动SPSS图1-2 选择数据源界面步骤2 :打开一个空白的SPSS数据文件,如图1-3。
启动SPSS 后,出现SPSS 主界面(数据编辑器)。
同大多数Windows 程序一样,SPSS 是以菜单驱动的。
多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件步骤3:数据的输入。
打开SPSS以后,直接进入变量视图窗口。
SPSS的变量视图窗口分为data view和variable view两个。
先在variable view中定义变量,然后在data view里面直接输入自定义数据。
命名为mydata并保存在桌面。
如图1-4所示。
图1-4 数据的输入步骤4:调用Graphs菜单的Bar过程,绘制直条图。
直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。
选择的数据源见表1。
步骤5:数据准备。
激活数据管理窗口,定义变量名:年龄标化发生率为RA TE,冠心病临床型为DISEASE,血压状态为BP。
RATE按原数据输入,DISEASE按冠状动脉机能不全=1、猝死=2、心绞痛=3、心肌梗塞=4输入,BP按正常=1、临界=2、异常=3输入。
步骤6:选Graphs菜单的Bar...过程,弹出Bar Chart定义选项框(图1-5)。
应用统计学实验报告(spss软件分析)

应⽤统计学实验报告(spss软件分析)多元回归分析——各项税收数据来⾃《中国统计年鉴2010》1.拟合优度检验图a *强制进⼊策略依据此表进⾏拟合优度检验。
由于是此分析多元回归分析,⽅程有多个解释变量,因此参考调整的判定系数(Adjusted R Square ),由上表:由于R2(1.000)等于1,因此认为拟合优度很⾼,被解释变量税收合计能被模型充分解释。
年份税收合计国内增值税营业税国内消费税关税企业所得税个⼈所得税 1980 571.733.531985 2040.79 147.7 211.07 205.21 696.061990 2821.86 400 515.75159.01 716 1991 2990.17 406.36 564 187.28 731.13 1992 3296.91 705.93 658.67 212.75 720.78 1993 4255.3 1081.48 966.09256.47 678.6 1994 5126.88 2308.34 670.02 487.4 272.68 708.49 1995 6038.04 2602.33 865.56 541.48 291.83 878.44 1996 6909.82 2962.81 1052.57 620.23 301.84 968.48 1997 8234.04 3283.92 1324.27 678.7 319.49 963.18 1998 9262.8 3628.46 1575.08 814.93 313.04 925.541999 10682.58 3881.87 1668.56 820.66 562.23 811.41 413.657 2000 12581.51 4553.17 1868.78 858.29 750.48 999.63 659.6373 2001 15301.38 5357.13 2064.09 929.99 840.52 2630.87 995.2563 2002 17636.45 6178.39 2450.33 1046.32 704.27 3082.79 1211.781 2003 20017.31 7236.54 2844.45 1182.26 923.13 2919.51 1418.033 2004 24165.68 9017.94 3581.97 1501.9 1043.77 3957.33 1737.056 2005 28778.54 10792.11 4232.46 1633.81 1066.17 5343.92 2094.91 2006 34804.35 12784.81 5128.71 1885.69 1141.78 7039.6 2453.709 2007 45621.97 15470.23 6582.17 2206.83 1432.57 8779.25 3185.58 2008 54223.79 17996.94 7626.39 2568.27 1769.95 11175.63 3722.31 200959521.5918481.229013.98 4761.221483.81 11536.84 3949.352.回归⽅程的显著性检验(F检验)图b*强制进⼊策略由此表进⾏回归⽅程的显著性检验。
最新《统计分析与SPSS的应用(第五版)》课后练习答案(第10章)
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第10章SPSS的聚类分析1、根据“高校科研研究.sav”数据,利用层次聚类分析对各省市的高校科研情况进行层次聚类分析。
要求:1)根据凝聚状态表利用碎石图对聚类类数进行研究。
2)绘制聚类树形图,说明哪些省市聚在一起。
3)绘制各类的科研指标的均值对比图。
4)利用方差分析方法分析各类在哪些科研指标上存在显著差异。
采用欧氏距离,组间平均链锁法利用凝聚状态表中的组间距离和对应的组数,回归散点图,得到碎石图。
大约聚成4类。
步骤:分析→分类→系统聚类→按如下方式设置……结果:凝聚计划阶段 组合的集群系数 首次出现阶段集群 下一个阶段集群 1集群 2集群 1集群 21 26 30 328.189 0 02 2 26 29 638.295 1 0 73 20 25 1053.423 0 0 54 4 12 1209.922 0 0 15 5 8 201505.035 0 3 6 6 8 16 1760.170 5 0 9 7 24 26 1831.926 0 2 10 8 7 11 1929.891 0 0 11 9 5 8 2302.024 0 6 22 10 24 31 2487.209 7 0 22 11 2 7 2709.887 0 8 16 12 22 28 2897.106 0 0 19 13 6 23 2916.551 0 0 17 14 10 19 3280.752 0 0 25 15 4 21 3491.585 4 0 21 16 2 3 4229.375 11 0 21 17 6 13 4612.423 13 0 20 18 9 18 5377.253 0 0 25 19 14 22 5622.415 0 12 24 20 6 15 5933.518 17 0 23 21 2 4 6827.276 16 15 26 22 5 24 7930.765 9 10 24 23 6 27 9475.498 20 0 26 24 5 14 14959.704 22 19 28 25 9 10 19623.050 18 14 27 26 2 6 24042.669 21 23 28 27 9 17 32829.466 25 0 29 28 2 5 48360.854 26 24 29 29 2 9 91313.530 28 27 30 3012293834.50329选中数据列,点击“插入”菜单 拆线图……碎石图:由图可知,北京自成一类,江苏、广东、上海、湖南、湖北聚成一类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
barplot(sort(ZHCH.table,decreasing=TRUE),ylab ="人数") # 其中sort命令是对列联表进行排序, decreasing=TRUE按升序排,参数ylab为y轴的标 签
2019/8/1
《统计学实验》第10章数据的描述
10-10
library(sca) # 加载扩展包sca
per<-percent(fre/sum(fre),d=1) # 使用扩展包sca 中的percent函数,可以用带%符号的表示方式显 示结果,参数d来指定小数点后的表示位数。在不 指定的情况下,小数点后的数字不表示。
女 副教授 30
性别 职称
男 副教授
女 副教授
男
讲师
女
助教
男 副教授
男
讲师
女
教授
男
讲师
男 副教授
女
教授
2019/8/1
《统计学实验》第10章数据的描述
10-8
【统计理论】
对分类数据和顺序数据,计算出每一类别 出现的频数或频率后,可通过频数分布表 来展示。
2019/8/1
《统计学实验》第10章数据的描述
10-12
10.1.2 分类数据和顺序数据的 条形图及饼图
【例10.2】 (数据文件为li10.1.txt) 根据表10.1资 料, 用R软件绘制条形图。
(数据来源:费宇等,《统计学》第2章,高等教育出版
社,2019)
2019/8/1
《统计学实验》第10章数据的描述
10-13
【统计理论】
对分类数据和顺序数据,计算出每一类别 出现的频数或频率后,还可通过统计图来 展示,例如条形图。
10.1.1 分类数据和顺序数据的频数分布表 10.1.2 分类数据和顺序数据的条形图及饼图 10.1.3 数值型数据的频数分布表 10.1.4 数值型数据的直方图、箱线图、线图、茎
叶图
10.2 描述性统计分析
2019/8/1
《统计学实验》第10章数据的描述
10-6
10.1 常见统计图的绘制
rbind(fre,per) # 合并表格命令,生成教师职称分 组频数分布表
2019/8/1
《统计学实验》第10章数据的描述
10-11
运行结果
副教授 讲师 教授 助教
fre "12"
"8"
"6"
per "40.0 %" "26.7 %" "20.0 %"
"4" "13.3 %"
2019/8/1
《统计学实验》第10章数据的描述
出版社,2019)
2019/8/1
《统计学实验》第10章数据的描述
10-17
【统计理论】
对分类数据和顺序数据,计算出每一类别 出现的频数或频率后,还可通过统计图来 展示,例如饼图 。
2019/8/1
《统计学实验》第10章数据的描述
10-18
【软件操作】
采用pie()函数作饼图
x=read.table("li10.1.txt",header=T) # 从li10.1.txt 中读入样本数据x
统计学实验 —SPSS和R软件应用与实例
主编:费宇
2019/8/1
《统计学实验》第10章数据的描述
10-1
第10章 数据的描述
2019/8/1
《统计学实验》第10章数据的描述
10-2
一、实验目的
1. 运用R中的barplot( )函数画条形图, hist( ) 函数画直方图,pie( )函数画饼图, boxplot( )函数画箱线图,plot( ) 函数画 线图,stem( )函数画茎叶图。
10-9
【软件操作】
采用table( )函数编制频数分布表
setwd(“D:/R-Statistics/data/chap-10”) #设定工作 路径
dat=read.table("li10.1.txt",header=T) #从li10.1.txt中 读入数据,记为dat
fre<-table(x$ZHCH) # 生成教师职称变量的分组频 数,如果绘制教师性别的频数分布表只需要把命令 改为fre<- table(x$ZHCH)即可
1. 常见统计图的绘制
(1) 分类数据和顺序数据的频数分布表 (2) 分类数据和顺序数据的条形图及饼图 (3) 数值型数据的频数分布表 (4) 数值型数据的直方图、箱线图、线图、茎叶图
2. 描述性统计分析
2019/8/1
《统计学实验》第10章数据的描述
10-5
第10章 数据的描述
10.1 常见统计图的绘制
10.1.1 分类数据和顺序数据的频数分布表
【例10.1】(数据文件为li10.1.txt)对某高校 经济系30名教师性别及职称登记结果,如 表10.1所示,试用R分别编制教师职称的频 数分布表。
2019/8/1
《统计学实验》第10章数据的描述
10-7
表10.1 某高校30名教师性别及职称情况统计表
2019/8/1
《统计学实验》第10章数据的描述
10-15
运行结果
图10.1
2019/8/1
某高校30名教师职称分布条形图
《统计学实验》第10章数据的描述
10-16
【例10.3】 (数据文件为li10.1.txt) 根据表 10.1资料, 用R软件绘制饼图。 (数据来源:费宇等,《统计学》第2章,高等教育
2. 掌握运用R软件中的函数对数据进行描 述性分析。
2019/8/1
《统计学实验》第10章数据的描述
10-3
二、实验环境
1. 系统软件Windows2000或WindowsXP或 Windows7;
2. 统计软件R2.13.2或更高版本。
2019/8/1
《统计学实验》第10章数据的描述
10-4
三、实验内容
2019/8/1
《统计学实验》第10章数据的描述
10-14
【软件操作】
采用barplot()函数画条形图
setwd(“D:/R-Statistics/data/chap-10”) #设定工 作路径
dat=read.table("li10.1.txt",header=T) #从 li10.1.txt中读入数据,记为dat
序号
1 2 3 4 5 6 7 8 9 10
性别 职称 序号
男
讲师
11
女ቤተ መጻሕፍቲ ባይዱ
助教
12
女 副教授 13
女 副教授 14
男
助教
15
男
教授
16
女
教授
17
男
讲师
18
女 副教授 19
男
教授
20
性别 职称 序号
男
教授
21
女 副教授 22
女 副教授 23
男
讲师
24
男
讲师
25
男 副教授 26
女
讲师
27
男
助教
28
女 副教授 29