Direct3D 10系统
DirectX3D SDK 基础教程(一)

DirectX3D SDK 基础教程(一)Direct3D 10 基础Tutorial 1: Direct3D 10 Basics概述在这第一篇教程中,我们将通过一些必要的元素去创建一个最小的Direct3D 10 应用. 每一个 Direct3D 10 应用都必须有这些功能元素对应功能属性. 这些元素包括设置窗口和设备对象,然后在窗口中显示一种颜色。
设置Direct3D 10 设备现在我们在一个只有一个空窗体的工程中, 去设置一个 Direct3D 10 设备, 如果你想去渲染任何一个3D 场景,设置3D 设备是非常必要的。
我们首先要做的是去创建2个对象:一个设备和一个交互链。
应用程序使用设备对象在缓冲区上执行渲染。
设备也包含了去创建资源的方法。
交互链对象的责任是从缓冲区中获得数据,这些数据是将被设备对象渲染并显示在显示器屏幕上。
交互链对象包含两个或更多地缓冲区,主要分为前端和后端缓冲区。
前端缓冲区是当前正在被显示给用户的数据,大多是设备对象渲染的材质,前端缓冲区是只读的,不能被修改。
后端缓冲区是渲染目标,就是设备将要渲染的材质。
一旦完成了绘画操作,这个交互链对象将显示后端缓冲区。
通过交互两个缓冲区,这个后端缓冲区变成了前端缓冲区。
为了创建交互链对象,我们要填写一个DXGI_SWAPCHAIN_DESC 结构体,这个结构体是我们要创建的交互链的描述。
有几个字段值的我们去说一下.BackBufferUsage 是一个标志字段,告诉应用程序怎样去使用后端缓冲区。
如果我们想去渲染后端缓冲区,我们就要设置 BackBufferUsage 标志为 DXGI_USAGE_RENDER_TARGET_OUTPUT.OutputWindow 字段代表窗口,交互链使用这个窗口去显示图像到屏幕上。
SampleDesc 被用来打开duo重采样. 由于这个教程不做多重采样,所以SampleDesc的 Count 被设置到 1,并且Quality被设置到 0 去关闭此功能。
什么是DirectX

Direct xDirectX是一种应用程序接口,它可让以windows为平台的游戏或多媒体程序获得更高的执行效率,加强3d图形和声音效果,并提供设计人员一个共同的硬件驱动标准,让游戏开发者不必为每一品牌的硬件来写不同的驱动程序,也降低用户安装及设置硬件的复杂度。
这样说是不是有点不太明白,其实从字面意义上说,Direct就是直接的意思,而后边的X则代表了很多的意思,从这一点上我们就可以看出DirectX的出现就是为了为众多软件提供直接服务的。
举个例子吧,骨灰级玩家(玩游戏比较长的)在DOS下玩游戏时,可不想我们现在,安装上就可以玩了,他们往往首先要先设置声卡的品牌和型号,然后还要设置IRQ(中断)、I/O(输入于输出)、DMA(存取模式),如果哪项设置的不对,那么游戏声音就发不出来。
这部分的设置不仅让玩家伤透脑筋,而且对游戏开发者来说就更头痛了,因为为了让游戏能够在众多电脑中正确运行,开发者必须在游戏制作之初,便需要把市面上所有声卡硬件数据都收集过来,然后根据不同的 API(应用编程接口)来写不同的驱动程序,这对于游戏制作公司来说,是很难完成的,所以说在当时多媒体游戏很少。
微软正是看到了这个问题,为众厂家推出了一个共同的应用程序接口——DirectX,只要这个游戏是依照Directx来开发的,不管你是什么显卡、声卡、统统都能玩,而且还能发挥更佳的效果。
当然,前提是你的显卡、声卡的驱动程序也必须支持Directx才行。
DirectX是由很多API组成的,按照性质分类,可以分为四大部分,显示部分、声音部分、输入部分和网络部分。
显示部分担任图形处理的关键,分为Direct Draw(DDraw)和Direct 3D(D3D),前者主要负责2D图像加速。
它包括很多方面:我们播放mpg、DVD电影、看图、玩小游戏等等都是用的DDraw,你可以把它理解成所有划线的部分都是用的DDraw。
后者则主要负责3D效果的显示,比如CS中的场景和人物、FIFA中的人物等等,都是使用了DirectX的Direct 3D。
DirectX 10

是在普通的 DL L中实现整个 AP I 的拦截工作 ,本文讨论的 即为用户 级拦截 。在 Wi n d o ws 平 台下拦截 A P I函数 一般有
以 下 3种 方 法 :
( 1 )修 改 函数 I AT ( I mp o r t Ad d r e s s T a b l e )表 和 E T
j 禽 入竭数 的敬攒信息 输 出蠡数 的数摧信息
个 图形库 的函数 ,加大 了截获难度。例如,若想截 获图形应
用 程 序 的帧 缓 存 更 新 ( P r e s e n t )以及 绘 制 函数 ( D r a w),我
图 1可执行 模 块的 P E结 构
们必须 同时完成对 d x g i . d l l 和d 3 d l 0 . d l l 动态链接库的截获工
Mi c r o c o mp u t e r A p p l i c a t i o n s V o 1 . 3 1 , No . 7 , 2 0 1 5
文章编号:1 0 0 7 — 7 5 7 X( 2 0 1 5 ) 0 7 — 0 0 2 2 - 0 5
研 究与 设计
微 型 电脑 应 用 2 0 1 5 年第 3 1 卷第 7 期
0 引言
图形应用程序主要使用两种 图形库: D i r e c t 3 D图形库和 O p e n G L 图形库 。D i r e c t 3 D 由微 软 开 发 , 在 微 软 平 台
( Wi n d o ws 和 X b o x) 上 提 供 图 形 应 用 程 序 开 发 接 口 。 O p e n G L定 义 了一 套 跨 平 台 、跨 语 言 的图 形 应 用 程 序 编 程接 口 。 由 于 多 数 图 形 应 用 程 序 可 以在 Wi n d o ws平 台 上 使 用
HLSL起步

图:图像去色效果
(注:这个例子是最简单的HLSL用于图像处理的例子,如果读者觉得到目前为止还很有难度,建议重新温习一遍Direct3D和HLSL的知识)。
通过这个例子,我们已经基本了解了RenderMonkey处理图像的步骤和流程,下面我们通过分析一些更加复杂一点的例子来体会HLSL的强大能力
1) Pass . 这个pass就是渲染中常提到的pass.代表一遍的渲染
2) 几何体。就是类红色茶壶表示的,它代表在渲染中使用的几何体。
3) 纹理对象和RenderTarget对象(用一个铅笔表示)
4) Shader中用到的参数,这些参数可以是自定义的,也可以是预定义的(ห้องสมุดไป่ตู้如当前的观察矩阵,摄像机的位置等参数)。
GPGPU简单介绍到这里。详细的GPGPU资料请参考。 同时nvidia的网站和发布的SDK上也有很多关于GPGPU的例子。
接下来我们使用RenderMonkey来搭建一个用于数字图像处理的架子,以实现类似PhotoShop的滤镜效果
RenderMonkey图像处理的架子-图像黑白化
本文会对Direct3D/HLSL做一个简单的介绍,但是假设读者已经了解和掌握了Direct3D/HLSL的基本知识。
简介.
1)Direct3D和HLSL
众所周知,Direct3D是微软开发的用于编写Windows下高性能图形程序的3D API。通过Direct3D,我们可以访问高速的图形加速卡。它是DirectX众多成员的一部分。
RenderMonkey是由前ATI开发的,用于编写Shader,并调试Shader的一个工具。由于RenderMonkey支持插件,所以RenderMonkey既可以编写OpenGL的GLSL也可以编写Direct3D的HLSL。它能支持创建RenderTarget,多Pass渲染,可以自由选择用哪个shader model来编译代码。并能加亮显示shader代码。
基于Direct3D 10的粒子系统的烟花效果

基于Direct3D 10的粒子系统的烟花效果陈建刚;徐守祥;黄国伟;何涛【摘要】粒子系统是3D技术中模拟不规则运动物体的一种有效方法。
为了模拟出具有实时性和逼真效果的烟花,文中利用硬件加速绘制技术和粒子系统进行烟花模拟,在Direct3D 10的着色器中实现粒子系统的类型变换和属性更新过程。
利用几何着色器、流输出、实例化和布告栏等技术,结合曲线数学模型,使用两个technique,分别用于更新粒子系统并进行流输出处理和用于绘制粒子系统到屏幕,模拟出具有三叶草、四叶草和8字形等不同形状及这些形状叠加效果的烟花。
实验表明,该方法达到了实时性要求。
%Particle system is an effective method in irregular moving object simulation in 3D technology. In order to simulate real time and realistic fireworks effect,firework simulation is realized by using hardware accelerated rendering technology and particle system. The type and attribute alternation of particle system is finished in Direct3D 10 shader. Using the technology of geometry shader,stream output,in-stancing and billboard,combined with the mathematical curve models,through two technique,one for updating and stream output of parti-cle,the other for rendering particle,the firework is realized with various of shapes such as clover-shaped,four-leaf-shaped,8-shaped and the blended effect. Examples illustrate that the method can meet the requirement of real time.【期刊名称】《计算机技术与发展》【年(卷),期】2013(000)009【总页数】4页(P241-244)【关键词】粒子系统;Direct3D 10;几何着色器;实例化【作者】陈建刚;徐守祥;黄国伟;何涛【作者单位】深圳信息职业技术学院计算机学院,广东深圳518172;深圳信息职业技术学院数字媒体学院,广东深圳518172;深圳信息职业技术学院计算机学院,广东深圳518172;深圳信息职业技术学院软件学院,广东深圳518172【正文语种】中文【中图分类】TP391.90 引言粒子系统是3D 技术中构造不规则运动物体计算模型的常用方法,包括自然界常见现象,如爆炸、烟、火、水流等。
什么是DirectX

什么是DirectXDirectX并不是一个单纯的图形API,它是由微软公司开发的用途广泛的API,它包含有Direct Graphics(Direct 3D+Direct Draw)、DirectInput、Direct Play、Direct Sound、Direct Show、Direct Setup、Direct Media Objects等多个组件,它提供了一整套的多媒体接口方案。
只是其在3D图形方面的优秀表现,让它的其它方面显得暗淡无光。
DirectX开发之初是为了弥补Windows 3.1系统对图形、声音处理能力的不足,而今已发展成为对整个多媒体系统的各个方面都有决定性影响的接口。
DirectX 5.0微软公司并没有推出DirectX 4.0,而是直接推出了DirectX 5.0。
此版本对Direct3D做出了很大的改动,加入了雾化效果、Alpha混合等3D特效,使3D游戏中的空间感和真实感得以增强,还加入了S3的纹理压缩技术。
同时,DirectX 5.0在其它各组件方面也有加强,在声卡、游戏控制器方面均做了改进,支持了更多的设备。
因此,DirectX发展到DirectX5.0才真正走向了成熟。
此时的DirectX性能完全不逊色于其它3D API,而且大有后来居上之势。
DirectX 6.0DirectX 6.0推出时,其最大的竞争对手之一Glide,已逐步走向了没落,而DirectX则得到了大多数厂商的认可。
DirectX 6.0中加入了双线性过滤、三线性过滤等优化3D图像质量的技术,游戏中的3D技术逐渐走入成熟阶段。
DirectX 7.0DirectX 7.0最大的特色就是支持T&L,中文名称是“坐标转换和光源”。
3D游戏中的任何一个物体都有一个坐标,当此物体运动时,它的坐标发生变化,这指的就是坐标转换;3D游戏中除了场景+物体还需要灯光,没有灯光就没有3D物体的表现,无论是实时3D游戏还是3D影像渲染,加上灯光的3D渲染是最消耗资源的。
WINDOWS 7系统细致核心图形架构

如现在大家所想的那样,Windows7其实是Windows Vista的改进版。
Windows 7在Windows Vista的基础上进行了大量的完善工作,也加入了不少新特性。
Vista与其上一代XP相比,提供了非常大的改进,然而一方面这些改进过于巨大,用户乃至相应软件厂商(如,DirectX 10应用开发商)一时无法完全接受,另一方面,由于特性的不完全具备,Vista的表现没有想象之中的那么好。
到了Windows 7,包括操作系统本身、软件厂商和用户都已经做好了准备,因此反响比Vista更好也就不难理解了。
图形界面一直是Windows系统的核心,而从ghost xp开始,Windows就开始将提供一个富图形化的桌面图形界面作为要目,不仅仅是因为Vista和7的桌面本身就是一个3D应用程序,而是因为 Vista和7可以更好地发挥图形加速硬件的作用。
从Windows Vista到Windows7,操作系统与GPU的结合越来越紧密。
虽然人们经常可以听到Windows7的大更新在于一个DirectX 11.0 API,然而对于Windows系统的图形架构来说,虽然DirectX也很重要,不过这还不是全部。
一个图形架构包括了如何利用GPU加速各种各样的图形应用(2D、3D、打印等)、如何显示到最终显示设备上,以及包括设备检测、控制。
Window 7在图形架构方面的更新主要有如下方面:WDDM 1.1:新的驱动模型DirectX 11:更新的Direct3D 11,以及相关的新Direct2D APIDXVA-HD:高清视频回放加速显示设备连接和配置色彩管理高DPI输出和可读性多GPU系统联合显示适配器(又叫联合渲染)下面,会就这些改进进行简单的介绍。
Windows 7核心图形架构Windows应用程序使用各种如GDI(Graphics Device Interface,2D时代系统的主要图形接口)、Direct3D、OpenGL这样的API和系统图形组件通信,而系统组件通过WDDM(Windows Display Driver Model,又名Longhorn Display Driver Model)与硬件交互,从Vista起,Windows就采用了和XP使用的XPDM不同的新的驱动模型:WDDM,使用的驱动模型在很大程度上决定了一个系统的图形特性。
direct用法

direct用法Direct用法详解Direct是一个英语单词,意思是“直接的”,在计算机领域中,它有着广泛的应用。
本文将从以下几个方面来详细介绍Direct的用法。
一、Direct的概述Direct是一个计算机领域中的术语,通常指代一些与硬件或操作系统直接相关的软件库或API。
这些库或API可以让开发人员更加方便地控制硬件或操作系统,从而实现更高效、更灵活、更精确的程序编写。
二、DirectX1. DirectX简介DirectX是一组由微软公司开发的多媒体技术,它包括了一系列与图形、音频、输入设备等相关的API和库。
它最初被设计为Windows平台上游戏开发所使用的技术,但随着时间推移,它已经成为了Windows 平台上多媒体应用程序开发不可或缺的一部分。
目前,最新版本的DirectX是DirectX 12,在Windows 10操作系统上得到了广泛应用。
此外,还有一些较老版本如下:- DirectX 11- DirectX 10- DirectX 9- DirectX 8- DirectX 73. DirectX功能DirectX提供了以下功能:- 游戏图形渲染- 2D和3D图形处理- 音频处理- 输入设备处理- 多媒体文件播放三、Direct3DDirect3D是DirectX中的一个重要组成部分,它是一个用于游戏和多媒体应用程序开发的3D图形API。
它提供了一些函数和接口,可以让开发人员更加方便地控制3D渲染、纹理贴图、光照等。
2. Direct3D版本目前,最新版本的Direct3D是Direct3D 12,在Windows 10操作系统上得到了广泛应用。
此外,还有一些较老版本如下:- Direct3D 11- Direct3D 10- Direct3D 94. Direct3D功能Direct3D提供了以下功能:- 几何变换- 纹理贴图- 光照计算- 多重采样抗锯齿技术- 阴影计算- 着色器编程支持四、DirectSound1. DirectSound简介DirectSound是DirectX中的一个重要组成部分,它是一个用于音频处理的API。
DirectX版本与功能

因为DirectX必须支持多媒体设备的最新技术和功能,而多媒体硬件(尤其是显卡[的3D性能])和技术始终处在高速发展过程中,所以DirectX的技术和版本也同样在不断地发展和演变,其中发展最快的是3D接口部分。
下面列出DirectX的主要版本的发布时间、引入的新模块和特性:l 1.0——1995年9月30日:DirectDraw、DirectSound、DirectInput、DirectPlay、DirectSetup;l 2.0——1996年6月5日:引入Direct3D(次版本有2.0a);l 3.0——1996年9月15日:支持MMX、为DirectSound 补充DirectSound3D API(次版本有3.0a);l 4.0——无此版本号;l 5.0——1997年7月16日:有许多改进,如受力反馈控制器、多显示器支持、新的游戏控制面板、用户界面的全面改进等(次版本有5.1和5.2);l 6.0——1998年8月7日:添加新的3D特性(如添加DXUT框架)、支持AMD公司的3DNow!技术、性能较5.0有提高。
在1999年2月3日推出的6.1版中,添加了DirectMusic模块;l 7.0——1999年9月22日:改进3D图形和声音、性能更快,为Direct3D API引入硬件传送、光照和纹理压缩、以及硬件加速,引入D3DX工具库。
使用Creative公司的EAX技术改进3D声音的算法(次版本有7.0a和7.1);l 8.0——2000年9月30日:将DirectDraw与Direct3D完全集成在一起、其中Direct3D的性能有了本质上的飞跃(引入顶点/像素shader[着色引擎/光照模型]、支持硬件点精灵和三维体纹理),将DirectMusic与 DirectSound更紧密地集成在一起构成DirectX Audio,更新了DirectInput与DirectPlay,添加了DirectShow、抛弃了其余的DirectX Media模块。
DirectX3D SDK 基础教程(一)
DirectX3D SDK 基础教程(一)Direct3D 10 基础Tutorial 1: Direct3D 10 Basics概述在这第一篇教程中,我们将通过一些必要的元素去创建一个最小的Direct3D 10 应用. 每一个 Direct3D 10 应用都必须有这些功能元素对应功能属性. 这些元素包括设置窗口和设备对象,然后在窗口中显示一种颜色。
设置Direct3D 10 设备现在我们在一个只有一个空窗体的工程中, 去设置一个 Direct3D 10 设备, 如果你想去渲染任何一个3D 场景,设置3D 设备是非常必要的。
我们首先要做的是去创建2个对象:一个设备和一个交互链。
应用程序使用设备对象在缓冲区上执行渲染。
设备也包含了去创建资源的方法。
交互链对象的责任是从缓冲区中获得数据,这些数据是将被设备对象渲染并显示在显示器屏幕上。
交互链对象包含两个或更多地缓冲区,主要分为前端和后端缓冲区。
前端缓冲区是当前正在被显示给用户的数据,大多是设备对象渲染的材质,前端缓冲区是只读的,不能被修改。
后端缓冲区是渲染目标,就是设备将要渲染的材质。
一旦完成了绘画操作,这个交互链对象将显示后端缓冲区。
通过交互两个缓冲区,这个后端缓冲区变成了前端缓冲区。
为了创建交互链对象,我们要填写一个DXGI_SWAPCHAIN_DESC 结构体,这个结构体是我们要创建的交互链的描述。
有几个字段值的我们去说一下.BackBufferUsage 是一个标志字段,告诉应用程序怎样去使用后端缓冲区。
如果我们想去渲染后端缓冲区,我们就要设置 BackBufferUsage 标志为 DXGI_USAGE_RENDER_TARGET_OUTPUT.OutputWindow 字段代表窗口,交互链使用这个窗口去显示图像到屏幕上。
SampleDesc 被用来打开duo重采样. 由于这个教程不做多重采样,所以SampleDesc的 Count 被设置到 1,并且Quality被设置到 0 去关闭此功能。
OpenGL与Direct3D

OpenGL与Direct3DOpenGL()/ OpenGL ES()是跨平台的,OpenGL⼴泛⽤于PC平台(windows、Linux、Unix、Mac OS X),OpenGLES则⽤于移动端平台(Android、iOS),以C的⽅式提供APIWebGL()是跨平台3D图形Web标准,被各⼤web浏览器⼚商⼴泛⽀持,使⽤JavaScript语⾔提供API,不使⽤插件的情况下在兼容的web浏览器的Canvas上呈现交互式3D图形Direct3D()是DirectX()套装的⼀部分,只能⽤于windows相关的平台,⽤C++实现,并以COM的⽅式提供APIOpenGL与Direct3D是多年的竞争关系,wiki上有⼀篇:固定管线到可编程管线进化版本3D API最后只⽀持固定管线的版本第⼀个⽀持可编程管线版本第⼀个只⽀持可编程管线版本OpenGL 1.5 2.0 3.1OpenGL ES1.1 2.0 2.0WebGL⽆ 1.0 1.0Direct3D7.08.010.0OpenGL、OpenGL ES和WebGLOpenGL版本Shader版本OpenGL ES WebGLOpenGL1.1(1997.3.4)OpenGL1.2(1998.3.16)OpenGL1.3(2001.8.14)OpenGL ES 1.0(2003.7.28)OpenGL1.4(2002.7.24)OpenGL1.5(2003.7.29)OpenGL ES 1.1(兼容1.0版本)OpenGL2.0(2004.9.7)GLSL 1.1OpenGL ES 2.0(2007.3) GLSL ES 1.0WebGL 1.0为GLSL ES 1.0的⼦集OpenGL2.1(2006.7.2)GLSL 1.2 OpenGL3.0(2008.8.11)GLSL 1.3 OpenGL3.1(2009.3.24)GLSL 1.4OpenGL3.2(2009.8.3)GLSL 1.5(Geometry Shaders)OpenGL3.3(2010.3.11)GLSL 3.30OpenGL4.0(2010.3.11)GLSL 4.00(Tessellation Shaders)OpenGL4.1(2010.7.26)GLSL 4.10 OpenGL4.2(2011.8.8)GLSL 4.20OpenGL4.3(2012.8.6)GLSL 4.30(ComputeShaders)OpenGL ES 3.0(2012.8,兼容2.0版本) GLSL ES3.0WebGL 2.0 GLSL ES 3.0OpenGL4.4(2013.7.22)GLSL 4.40OpenGL ES 3.1(2014.3,向前兼容⾄2.0版本) GLSL ES 3.1本) GLSL ES 3.1OpenGL4.5(2014.8.11)GLSL 4.50OpenGL ES 3.2(2015.8,向前兼容⾄2.0版本) GLSL ES 3.2OpenGL4.6(2017.7.31)GLSL 4.60扩展阅读:Direct3DD3D版本Shader版本OS版本Direct3D 7.0(1999.9.22)Win98 Direct3D 8.0(2000.10.12)PS1.1、VS1.1Win2000 Direct3D 8.1(2001.10.25)PS1.4、VS1.1WinXP Direct3D 9.0(2002.11.19)SM2.0WinXP Direct3D 9.0b(2003.8.13)PS2.0b、VS2.0WinXP Direct3D 9.0c2004.10~2010.6(每2⽉更新⼀个版本)DXSDK_Jun10.exe是其最后⼀个版本SM3.0WinXP Direct3D 9.0L(Direct3D 9Ex)在Vista上使⽤WDDM驱动来跑Direct3D 9.0c的程序SM3.0Vista Only Direct3D 10.0(2006.11.30)SM4.0(Geometry Shaders)Vista Direct3D 10.1(2008.2.4)SM4.1Vista SP1Direct3D 11.0(2009.10.22)(2011.2.16)SM5.0(Tessellation Shaders、Compute Shaders)Win7Win7 SP1Direct3D 11.1(2012.8.1)SM5.0Win7 SP1、Win8Direct3D 11.2(2013.10.18)SM5.0Win8.1Direct3D 12.0(2015.7.29)SM6.0Win10OpenGL与Direct3D对应关系OpenGL版本D3D版本OS版本OpenGL 2.1Direct3D 9.0(SM2.0)WinXPOpenGL 3.0~3.1Direct3D 9.0c(SM3.0)WinXPOpenGL 3.2~3.3Direct3D 10.0(SM4.0)VistaOpenGL 4.0~4.6Direct3D 11.0(SM5.0)Win7显卡与驱动显卡⽀持Direct3D和OpenGL版本由驱动程序决定的,在硬件不⽀持的情况下,可以由驱动退回到软件执⾏。
directx教程

directx教程DirectX是一个由微软开发的跨语言、跨平台的多媒体框架。
它提供了一组应用程序接口(API),用于处理游戏、音频和视频等多媒体内容的开发。
DirectX包含了多个组件,其中最常用的就是Direct3D、DirectSound和DirectInput。
Direct3D是DirectX中最重要的组件之一,它是用于游戏和图形应用程序的3D渲染API。
通过Direct3D,开发者可以利用硬件加速来呈现逼真的3D图形。
Direct3D提供了一系列的命令和函数,用于创建、操作和呈现3D场景。
它支持灯光、纹理、变换等常用的3D特性,同时还提供了高级功能,如像素着色器和顶点着色器,用于实现更高级别的渲染效果。
DirectSound是用于处理音频的组件,它提供了一系列的函数和工具,开发者可以用它来播放、录制和处理音频数据。
DirectSound支持多个音频设备、3D音效等高级功能,可以实现更加真实和生动的音频体验。
DirectInput是用于处理输入设备的组件,它提供了一系列的函数和工具,开发者可以用它来处理鼠标、键盘、游戏手柄等输入设备的输入。
通过DirectInput,开发者可以轻松地获取用户的输入数据,并进行相应的处理。
由于DirectX是跨语言、跨平台的框架,所以可以在多种操作系统上使用。
目前,DirectX主要支持Windows操作系统,但微软还推出了一些用于其他平台的版本,如DirectX for Xbox 和DirectX for Windows Phone等。
为了学习和使用DirectX,开发者通常需要了解一些基本的图形学和数学知识。
对于初学者来说,官方提供的文档和教程是最好的学习资源。
在开始学习之前,建议开发者对计算机图形学和3D数学有一定的了解,这样才能更好地理解和运用DirectX。
学习DirectX的过程中,开发者可以从简单的示例和小项目开始,逐渐深入理解和掌握各个组件的功能和用法。
direct3D入门

仅供个人学习之用,请勿用于任何商业用途翻译:claymanClayman_joe@第一章Direct3D入门创建设备Device类是DirectX里的所有绘图操作所必须的。
可以把这个类假想为真实的图形卡。
场景里所有图形对象都依赖于device。
一台计算机里可以有一个到几个device,在Mnaged DirctX3D里,你可以控制任意多个device。
Device共有三个构造函数,我们现在只讨论其中的一个,但会在后边的内容里讨论其他的。
先来看看具有如下函数签名的构造函数:public Device(int adapter,DeviceType deviceType,Control renderWindow,CreateFlags behaviorFlags, PresentParameters[] presentationParameters);(构造函数的第二种重载类似于上边这个,但它接受来自非托管(或者非windows form)的窗口句柄作为renderWindow。
而只接受一个IntPtr参数的重载是非托管com组建指向Idirect3Ddevice9的接口。
当你的代码需要和非托管的程序协作时则应用它)好了,这些参数是什么意思,以及我们怎样来使用呢?呵呵,参数adapter表示我们将要使用哪个物理图形卡。
计算机里的所有图形卡都有一个唯一的适配器标识符(通常是0到你的图形卡数量-1),默认的显卡总是标识为0 的图形卡。
下一个参数,DeviceType,告诉了DirectX3D你要创建哪种类型的device。
这里最常用的值是DeviceType.Hardware,表示你将创建一个硬件设备。
另一个选项DeviceType.Reference,这种设备允许你使用“参考光栅器”(reference rasterizer),所有的效果由DirectX3D运行时来实现,以很慢、很慢、很慢的速度运行^_^。
DirectX简介

虽然DirectX最初是为Windows操作系统设计的,但是随着技术的发展,其他操作系统也开始支持 DirectX。例如,Linux和Mac OS X等操作系统可以通过安装相应的驱动程序和工具链来支持DirectX 。
03
DirectX应用领域
游戏开发
3D图形渲染
DirectX提供了一组高效的3D图形渲染API,使得游戏开发者能够轻松地创建逼真的3D 游戏场景。
虚拟现实技术案例分析
3D模型渲染
DirectX可以用于实现高效率的3D模型渲染,是虚 拟现实技术中的重要组成部分。
实时场景构建
利用DirectX的图形渲染管线,可以实时构建复杂 的虚拟现实场景。
交互式操作
DirectX支持与虚拟现实设备的交互操作,如手柄 、头盔等,提高用户体验。
其他领域应用案例分析
要点二
后续版本
随着计算机硬件性能的提升,DirectX后续版本不断推出, 包括DirectX 4.0、DirectX 5.0、DirectX 6.0、DirectX 7.0、DirectX 8.0、DirectX 9.0、DirectX 10.0、DirectX 11.0等。这些版本逐渐增加了对更高性能硬件的支持,并 引入了新的技术,如着色器模型(Shader Model)、物 理效果(Physics Engines)等。
科学可视化
DirectX可以用于实现科学数据的高效可视化,如气象数据、地质 数据等。
建筑与工业设计
利用DirectX的3D渲染功能,建筑师和工程师可以创建逼真的建筑 和工业设计模型。
实时地图与导航
DirectX可以用于实现实时地图渲染和导航指示,提高地图应用的 用户体验。
06
【Visual C++】游戏开发笔记二十四 由DirectX的几个版本

【Visual C++】游戏开发笔记二十四由DirectX的几个版本说开去分类:【Visual C++】【Visual C++】游戏开发2012-06-04 06:34 13178人阅读评论(46) 收藏举报本系列文章由zhmxy555(毛星云)编写,转载请注明出处。
/zhmxy555/article/details/76292288作者:毛星云邮箱:happylifemxy@ 期待着与志同道合的朋友们相互交流本节是DirectX 11的一个开篇,都是些概念性的知识,希望在正式学习DirectX 11之前,对将要学习的内容有一个整体的认知,以便更好的掌握将要学习的知识。
一、引言在上个世纪,DirectX还没横空出世之前,游戏厂商都在努力克服着硬件不兼容造成的各种问题。
但不幸的是,市面上已经存在的各种繁杂而不统一的硬件配置,让想做出一款供大多数人们都可以畅玩的游戏的想法成为了泡影。
在这样的背景下,游戏行业急切需求一项统一的标准化的指标。
于是微软公司推出了基于Windows 95的Windows Game SDK,这就是DirectX的前身,之后Windows Game SDK就演变为了如今最新的DirectX 11。
DirectX为游戏开发厂商提供了一套单一的API 接口,基本上保证了在各种繁杂的PC硬件上的兼容性。
由于DirectX的发布,Windows平台下的游戏开发迎来了草长莺飞的春天,数量持续呈井喷式增长。
16年后的今天依然如此,基于DirectX的电脑游戏数量始终保持着疯狂的增长速率。
二、DirectX出现的必然性在Windows操作系统发行之前,开发者都为DOS写游戏。
这个单线程的,没GUI的操作系统在应用程序代码与程序运行的硬件之间提供给开发者一个直接的路径。
这又是优点又是不足。
举个例子吧,因为在游戏代码与硬件之间存在一个直接的路径,开发者能够拥有计算机的全部限权,能够将资源完全地分配给游戏运行。
10_1Direct3D中的混合技术(二).

3.了解alpha混合以及如何使用alpha值 来控制图元的透明度
5
1混合技术的工作机制
组合当前正在计算的像素值(源像素) 和那些已经光栅化过的像素值(目标像素) 的技术就是混合技术
源像素 source pixel :当前光栅化的像素
目标像素 destination pixel :已经光栅化过的 像素
…… } D3DBLEND;
例如: D3DBLEND_SRCALPHA -Blend factor is (As, As, As, As).
11
开启混合技术
SetRenderState (D3DRS_ALPHABLENDENABLE, true);
注意: 混合计算量较大,所以在渲染使用混合
技术的物体前才开启,而且把使用混合技 术的物体集中在一起渲染,渲染完就关闭
21
22
23
3.加载灰度图,填充纹理的alpha通道 File--Open Onto Alpha Channel Of This
Texture 选择代表alpha通道的灰度图
24
25
26
4.保存图片,这里把图片格式保存为dds格式
27
使用alpha分量
要使用alpha分量,就要设置混合因子:
12
alpha值
alpha值用于决定透明度
Alpha的取值范围[0,255],0表示完全透明,255表示完全 不透明
怎么设置混合因子?
alpha值可以有两种来源: 1 物体的材质
2 物体所用的纹理
13
物体材质中的alpha值: D3DMATERIAL9 -Diffuse -alpha分量 D3DCOLORVALUE rgba
Win10怎么启用directx3D加速2种方法快速开启3D加速的图文步骤
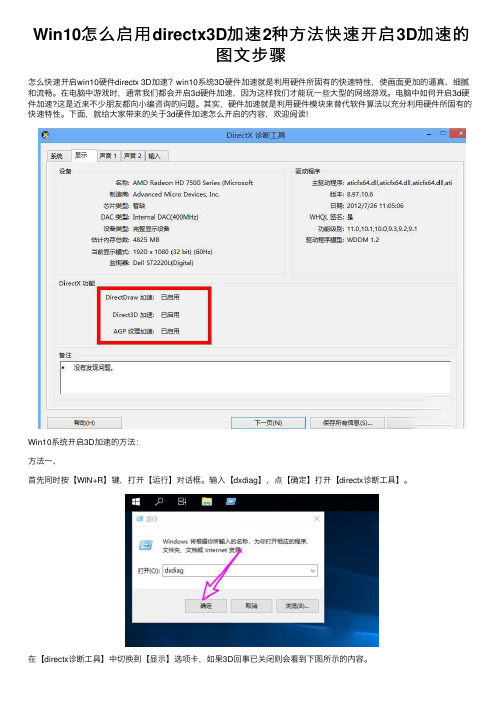
Win10怎么启⽤directx3D加速2种⽅法快速开启3D加速的图⽂步骤怎么快速开启win10硬件directx 3D加速?win10系统3D硬件加速就是利⽤硬件所固有的快速特性,使画⾯更加的逼真、细腻和流畅。
在电脑中游戏时,通常我们都会开启3d硬件加速,因为这样我们才能玩⼀些⼤型的⽹络游戏。
电脑中如何开启3d硬件加速?这是近来不少朋友都向⼩编咨询的问题。
其实,硬件加速就是利⽤硬件模块来替代软件算法以充分利⽤硬件所固有的快速特性。
下⾯,就给⼤家带来的关于3d硬件加速怎么开启的内容,欢迎阅读!Win10系统开启3D加速的⽅法:⽅法⼀、⾸先同时按【WIN+R】键,打开【运⾏】对话框。
输⼊【dxdiag】,点【确定】打开【directx诊断⼯具】。
在【directx诊断⼯具】中切换到【显⽰】选项卡,如果3D回事已关闭则会看到下图所⽰的内容。
要重新开启3D加速,⾸先在桌⾯空⽩处右键选择【新建】-【⽂本⽂档】。
之后单击选中新建的⽂档,右键选择【重命名】,将其重命名为【开启3d加速.reg】。
⼀定要修改⽂件的后缀名。
要显⽰⽂件的扩展名,可以参考之前的经验,我将链接也加在了下⽅。
0⽂本⽂档怎么显⽰txt之后⽤记事本打开上⾯的.reg⽂件,输⼊如下内容:Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\DirectDraw] "EmulationOnly"=dword:00000000[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Direct3D\Drivers] "SoftwareOnly"=dword:00000000[HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\DirectDraw] "EmulationOnly"=dword:00000000[HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Direct3D\Drivers] "SoftwareOnly"=dword:00000000保存并退出。
Direct3D纹理颜色混合方法分析

目录引言 (2)一、Direct3D多层纹理映射过程 (2)二、Direct3D多层纹理混合方法 (4)三、常用纹理颜色混合操作 (5)(一) 黑暗映射 (5)(二)混合纹理与材质漫反射颜色 (6)(三)混合黑暗贴图与材质漫反射颜色 (7)(四)发光映射 (9)(五)细节映射 (10)结束语 (12)参考文献 (13)摘要多层纹理映射是一种高级的纹理映射技术,纹理颜色混合是多层纹理映射的核心内容,它决定了多层纹理映射最后的效果。
使用多层纹理映射的关键是理解多层纹理之间的颜色混合方法,本文首先分析了Direct3D多层纹理混合的过程和方法,然后通过介绍了常用的几种多层纹理颜色混合应用。
关键词:Direct3D,纹理映射,多层纹理,纹理颜色混合Direct3D纹理颜色混合方法分析引言纹理映射是三维图形开发中的一个基本内容,多层纹理映射是一种高级的纹理映射技术,通过多层纹理映射可以一次将多个纹理图片映射到同一个物体表面。
纹理颜色混合是多层纹理映射的核心内容,它决定了多层纹理映射最后的效果。
Direct3D提供了多种多层纹理映射的颜色混合方法,以适应不同需要。
一、Direct3D多层纹理映射过程Direct3D最多支持8层纹理,也就是说在一个三维物体的表面可以同时拥有1~8张不同的纹理贴图。
Direct3D能够在一个渲染过程中把这些纹理颜色依次混合,渲染到同一个物体的表面。
每一个纹理层对应从0~7的索引序号,多层纹理映射能够模拟更为真实的三维世界。
例如,要显示具有周围景物倒影的光滑大理石地板,可以把大理石地板贴图设置为纹理层0,把具有周围景物倒影的贴图设置为纹理层1,然后通过设置Direct3D多层纹理混合操作,把纹理层0和纹理层1相混合,这是绘制出的三维物体就同时具有大理石地板和景物倒影的纹理颜色。
利用Direct3D多达8层的纹理混合,可以在图形显示系统中显示丰富多彩的图像。
Direct3D多层纹理混合过程如图1所示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
摘要本文描述了第四代PC平台上图形图像单元(GPU)的系统构架。
与上一代图形管道相比,新的管道有了重大改变,引入了一个新的可编程阶段(stage)用于生产额外的图元,并把图元流保存到内存中;扩展了所有可编程阶段的功能,涉及到顶点、图片内存资源,以及新的储存格式。
此外,我们还描述了API、运行时以及实现新管道的着色语言的结构性改变。
解决当前系统中的缺陷,是我们设计的基本思想。
文章不但描述了重要设计抉择背后的原理,同时也描述了那些最终被否决的方案。
1.前言过去10年,OpenGL和Direct3D所依赖的渲染管道构架已经取得了重大发展。
最近5年中,随着从固定管道到可编程管道的过渡,发生了许多戏剧性的变化。
虽然变化的进程很快,但每一步都反映出了设计者在通用性、性能以及成本上所做出的妥协。
我们一直在努力了解以及构建一个系统,来解决许多程序中对图形加速器的需求(呈现图形、CAD、多媒体处理,等等)。
但是,我们更想把注意力集中在交互式娱乐应用中。
这些程序需要管理数十亿字节的艺术品,包括几何体、纹理、动画数据以及着色程序,占用大量系统资源(CPU、内存、带宽),以可交互的速率渲染丰富的、充满细节的图片。
在处理海量数据的同时,保证渲染的灵活性,是对设计者的重大挑战之一。
在系统设计的方方面面,都可以反映出我们对这个问题的解决方案。
与上个版本的Direct3D一样,Direct3D 10同样是在应用程序开发者、硬件设计师以及API/运行时构架师三方的合作下设计的。
在三年多的设计过程中,合作者之间详细的交流是无价的,让我们更深入了软硬件部署的代价,以及在大量不同硬件进行权衡。
在开发Direct3D 10的过程中,调查显示应用程序开发者通常受以下限制的困扰,以及用来缓解这些问题的策略:1. 状态(state)改变的代价过高。
改变任何类型的状态(顶点格式、纹理、shader、shader参数、混合模式,等等)都会付出很大代价。
优化方法通常是通过查询对象状态来排序,减少API状态改变次数;减少外观的改变;或者使用基于shader的技术,使用shader来决定状态。
对于后者,例子之一就是把多张纹理打包为一张纹理地图(texture map)(也称为纹理地图集),通过纹理坐标变换,来索引相应的子纹理。
2. 硬件加速器性能变化太多。
应用程序不得不编写一系列分支语句,以保证在不同硬件上都能正常运行。
这些问题会影响到程序的特性设置,资源管理,算法精度,以及储存格式。
3. CPU和GPU之间频繁的同步。
传统的图形管道允许有限制的重新使用管道当前产生的数据,作为下一个处理步骤的输入数据。
Render-to-texture就是这种机制的最好例子之一,所渲染的图片接下来能被当作纹理使用,最小化CPU的干涉。
但是,产生新顶点数据,或者创建立方贴图就需要CPU与GPU进行更多的协调和通信,降低了效率。
4. 指令以及数据类型的限制。
通常都以精度和所支持的流程控制指令来衡量vertex shader,同样的方法也用来衡量pixel shader,但是,无论是pixel还是vertex shader都不支持整数指令。
此外,出于对pixel shader精确性的要求,还指定了浮点算法。
应用程序要么不使用这些额外的功能,要么模仿他们的使用。
基于表格功能的计算就是例子之一。
5. 资源限制。
纹理读取的次数、纹理范围、程序指令,等等,都受到限制。
应用程序不得不压缩算法,或者把它们分为多个shader pass。
因此,还出现了对自动划分shader程序的研究。
2.背景我们的系统建立于PC,工作站以及游戏机平台上的应用程序可编程渲染管道。
当前的图形管道分为两个编程阶段,一个用于处理顶点数据(vertex shader),一个用来处理像素或片断(fragment or pixel shader)。
在Lindholm2001里描述了设计早期vertex shader的思想和折中。
除了细小的差别以外,pixel shader也是按这样的轨迹来设计的。
可以把顶点以及像素着色器的发展分为4代(包括Direct3D 10),如表一所示:通过挖掘顶点和像素片断之间的独立性,硬件管道实现了很高的处理吞吐量。
大多数顶点和像素着色器都是以并行的状态来处理相互独立的顶点和像素片断。
典型的硬件实现中pixel shader的数量要比vertex shader多很多,反映出典型的渲染过程中,像素处理的工作量要比顶点多很多。
与vertex shader相比,这种特性将影响pixel shader的性能,因为pixel shader被过多的复制了。
可编程管道直接使用了较低的抽象层,比如OpenGL或Direct3D。
这些抽象层隐藏了不同硬件管道实现之间的差别,提供了一个方便的接口。
对特定的平台来说,比如游戏机,它的硬件管道与PC平台相比是不同的,底层细节也是由这些抽象层来暴露。
我们把这些抽象层称为运行时(runtime),并且通过它所提供的API对他进行控制。
运行时为设备提供了独立的资源管理(分配内存,控制生存期,初始化,虚拟技术,等等),所有纹理贴图,顶点缓冲,状态改变以及和硬件加速器的通信都通过特定设备的驱动程序来完成。
对可变成管道来说,运行时还加入了对照色程序的抽象和管理任务。
由于早期可编程处理器对指令储存空间的限制,为了在有限资源内,最大化对硬件的控制,不得不使用类似于汇编的语言来编写照色程序。
但是,随着硬件功能的增加,需要一种高级的编程抽象来提高程序员的生产力。
一种与C类似,并且添加了对潜在渲染管道进行定制的编程语言满足了这种需求。
此外,还发展出了一些其他的语言,利用浮点处理器和GPU内存带宽来完成渲染以外的一些计算,但是,我们不打算在这篇文章里对这些应用进行讨论。
虽然新的编程语言有必要与CPU编程语言(特别是C)类似,但我们还是进行了一些重要的修饰。
举例来说,硬件结构和编译模型更像是一台虚拟机,汇编着色语言扮演了独立于硬件的中间语言(IL),而不是特定的机器语言。
在离线环境下,Microsoft HLSL 之类的高级语言被编译为IL,在程序运行时,通过驱动程序内建的翻译器,实时转换为目标硬件的指令。
需要注意的是,OpenGL shading language使用了一种不同的方法来完成运行时的编译过程。
另一个重要的区别是,着色程序并不是孤立的程序,通过一个运行在CPU上的程序来协调渲染管道,它们通常是共同(in concert)执行的。
此外CPU程序还以纹理或填充寄存器常量的方式,为着色程序提供参数。
虽然本文没有具体描述特定硬件新图形管道的构架,但图形管道的设计很大程度上都是根据硬件实用性以及多硬件并行处理来设计的。
此外,当前硬件实现的结构体系也将延续或者影响我们的设计。
3.图形管道Direct3D保留了通用硬件加速器的3D管道结构。
我们添加了两个新的阶段,并对其他的阶段进行了简化或者进一步归纳(generalized)。
基本的图形管道如图1所示。
为了保证文章的连续性,我们将讨论图形管道的每一个阶段,而不是只讨论新增的两个阶段。
为了和以前的术语一致,使用了通用的术语,比如顶点(vertex),纹理(texture)以及像素(pixel),但需要注意,这些术语只表示普通用法中的某些特定含义。
Input Assembler(IA)从附加到顶点缓冲上的8个输入流中接收1D的顶点数据,并且把数据项转换为规范的格式(比如,float32)。
可以为每个流指定独立的顶点结构,每种结构最多包含16个域(也称为元素,element)。
每种元素可以由1到4个基本数据项组成(比如,float32s)。
通过读取当前的有效流来装配(assembled)顶点。
一般来说,将会连续的从顶点缓冲中读取顶点数据,但是,如果指定了索引缓冲,那么每个流将使用共享的索引来计算每个顶点缓冲中顶点数据的偏移值。
指定索引可以带来额外的性能优化,顶点处理器将根据索引值计算结果,通过用索引值作索引的结果缓存,可以避免使用相同索引重新计结果(译注:这里的结果因该是指顶点数据序列)。
此外,IA还提供了一种机制,允许IA高效的复制对象n次。
这种机制是实现instancing的解决方案,把包含k个顶点的数据块(block)复制n次。
同时,将使用当前的实体(instance),图元(primitive),以及顶点id对图元数据进行“标记(tagged)”,在可编程阶段,可以访问这些id,以便计算变换,材质等参数。
Vertex Shader(VS)通常用来把顶点从模型空间变换到裁剪空间。
VS读取一个顶点,输出一个顶点。
VS与其它可编程阶段一样,有一些共同的特性,包括支持扩展的浮点、整数、控制类型,可以访问128块内存缓冲(纹理)以及16个参数(常量)冲。
我们会在第四节详细讨论这些通用核心(common core)。
Geometry Shader(GS)把同一图元的所有顶点作为输入,产生新的顶点或者图元。
输入和输出图元的类型不一定要匹配,但对着色程序程序来说是固定的。
以发射额外图元对象的方式,GS程序可以增加输入图元的数量,每一次调用(per-invocation)最多产生1024个32-bit的顶点数据。
三角形和线段被输出为连续的顶点带。
在一次调用中,GS程序可以输出1个以上的图形带,或者删除输入的图元,不进行任何输出。
GS程序同样可以在不产生新几何体的情况下,把额外的属性附加到图元上,比如为每个图元计算额外的属性。
由于可以访问当前图元的所有顶点,因此,计算三角形平面方程(triangle’s plane equation)之类的几何属性将会容易。
除了输入图元之外,还可以处理三角形和线段的邻接顶点。
每个三角形包含三个顶点,以及三个邻接顶点,而每条线段则包含2个顶点以及2个邻接顶点。
对于三角形和线段来说,邻接顶点将作为顶点缓冲格式的一部份,当指定(渲染)了带邻接的图元拓扑之后,IA会对提取邻接顶点。
Stream Output(SO)将把GS输出的顶点信息复制为4个连续的输出缓冲子集。
理想情况下,SO的输出能力(不带索引)应该和IA(8 streams * 16 elements)的输入能力相匹配,但硬件代价是不合理的。
SO只能输出一个1~16元素的流,或者4个单一元素的流。
此外,IA可以读取8或者16bit的数据类型,并把他们转换为float32,而SO只能写入原始的32-bit的数据类型。
但是,数据类型转换和打包可以在GS程序中轻易实现,减少了固定功能的支持。
Set-up and Rasterization Stage(RS) 是一个功能固定的阶段,用来处理剪切(clipping),剔除(culling),透视划分,观察点变化,图元设置,裁剪(scissoring),深度偏移,以及片断(fragment)生成。