内核源代码类(DOC)
linux 编译ko的方式

linux 编译ko的方式
在Linux中,编译ko(内核对象)的方式通常涉及以下步骤:
1. 准备开发环境,确保已经安装了适当的编译工具链、内核源代码和开发包。
可以使用包管理器(如apt、yum等)来安装这些组件。
2. 进入内核源代码目录,使用终端进入内核源代码目录,通常位于`/usr/src/linux`或者`/usr/src/linux-<kernel_version>`。
3. 准备配置文件,可以选择使用现有的内核配置文件或生成新的配置文件。
使用`make oldconfig`命令可以生成一个新的配置文件,并根据提示进行必要的配置选择。
4. 编译内核,运行`make`命令开始编译内核。
这个过程可能需要一些时间,具体时间取决于你的硬件和内核源代码的大小。
5. 编译ko模块,进入你的ko模块所在的目录,运行`make`命令来编译ko模块。
如果你的模块有依赖关系,可能需要提前解决这些依赖关系。
6. 安装ko模块,编译完成后,你可以使用`insmod`命令将ko 模块加载到内核中。
例如,`insmod your_module.ko`。
7. 卸载ko模块,如果需要卸载已加载的ko模块,使用
`rmmod`命令。
例如,`rmmod your_module`。
需要注意的是,上述步骤只是一般的编译ko模块的方式,具体步骤可能会因为不同的内核版本和模块的特定要求而有所差异。
在实际操作中,你可能需要查阅相关文档或参考特定模块的编译指南以获得更准确的步骤和命令。
Linux操作系统源代码详细分析

linux源代码分析:Linux操作系统源代码详细分析疯狂代码 / ĵ:http://Linux/Article28378.html内容介绍: Linux 拥有现代操作系统所有功能如真正抢先式多任务处理、支持多用户内存保护虚拟内存支持SMP、UP符合POSIX标准联网、图形用户接口和桌面环境具有快速性、稳定性等特点本书通过分析Linux内核源代码充分揭示了Linux作为操作系统内核是如何完成保证系统正常运行、协调多个并发进程、管理内存等工作现实中能让人自由获取系统源代码并不多通过本书学习将大大有助于读者编写自己新 第部分 Linux 内核源代码 arch/i386/kernel/entry.S 2 arch/i386/kernel/init_task.c 8 arch/i386/kernel/irq.c 8arch/i386/kernel/irq.h 19 arch/i386/kernel/process.c 22 arch/i386/kernel/signal.c 30arch/i386/kernel/smp.c 38 arch/i386/kernel/time.c 58 arch/i386/kernel/traps.c 65arch/i386/lib/delay.c 73 arch/i386/mm/fault.c 74 arch/i386/mm/init.c 76 fs/binfmt-elf.c 82fs/binfmt_java.c 96 fs/exec.c 98 /asm-generic/smplock.h 107 /asm-i386/atomic.h 108 /asm-i386/current.h 109 /asm-i386/dma.h 109 /asm-i386/elf.h 113 /asm-i386/hardirq.h 114 /asm-i386/page.h 114 /asm-i386/pgtable.h 115 /asm-i386/ptrace.h 122 /asm-i386/semaphore.h 123 /asm-i386/shmparam.h 124 /asm-i386/sigcontext.h 125 /asm-i386/siginfo.h 125 /asm-i386/signal.h 127/asm-i386/smp.h 130 /asm-i386/softirq.h 132 /asm-i386/spinlock.h 133 /asm-i386/system.h 137/asm-i386/uaccess.h 139 //binfmts.h 146 //capability.h 147 /linux/elf.h 150 /linux/elfcore.h 156/linux/errupt.h 157 /linux/kernel.h 158 /linux/kernel_stat.h 159 /linux/limits.h 160 /linux/mm.h 160/linux/module.h 164 /linux/msg.h 168 /linux/personality.h 169 /linux/reboot.h 169 /linux/resource.h 170 /linux/sched.h 171 /linux/sem.h 179 /linux/shm.h 180 /linux/signal.h 181 /linux/slab.h 184/linux/smp.h 184 /linux/smp_lock.h 185 /linux/swap.h 185 /linux/swapctl.h 187 /linux/sysctl.h 188/linux/tasks.h 194 /linux/time.h 194 /linux/timer.h 195 /linux/times.h 196 /linux/tqueue.h 196/linux/wait.h 198 init/.c 198 init/version.c 212 ipc/msg.c 213 ipc/sem.c 218 ipc/shm.c 227 ipc/util.c 236 kernel/capability.c 237 kernel/dma.c 240 kernel/exec_do.c 241 kernel/exit.c 242 kernel/fork.c 248 kernel/info.c 255 kernel/itimer.c 255 kernel/kmod.c 257 kernel/module.c 259 kernel/panic.c 270 kernel/prk.c 271 kernel/sched.c 275 kernel/signal.c 295 kernel/softirq.c 307 kernel/sys.c 307kernel/sysctl.c 318 kernel/time.c 330 mm/memory.c 335 mm/mlock.c 345 mm/mmap.c 348mm/mprotect.c 358 mm/mremap.c 361 mm/page_alloc.c 363 mm/page_io.c 368 mm/slab.c 372mm/swap.c 394 mm/swap_state.c 395 mm/swapfile.c 398 mm/vmalloc.c 406 mm/vmscan.c 409第 2部分 Linux 内核源代码分析 第1章 Linux 介绍 让用户很详细地了解大多数现有操作系统实际工作方式是不可能大多数操作系统源代码都是严格保密除了些研究用及为操作系统教学而设计系统外尽管研究和教学目都很好但是这类系统很少能够通过对正式操作系统小部分实现来体现操作系统实际功能对于操作系统些特殊问题这种折衷系统所能够表现就更是少得可怜了 在以实际使用为目标操作系统中让任何人都可以自由获取系统源代码无论目是要了解、学习还是改进这样现实系统并不多本书主题就是这些少数操作系统中个:Linux Linux工作方式类似于Uinx它是免费源代码也是开放符合标准规范标准32位(在64位CPU上是64位)操作系统Linux拥有现代操作系统所具有内容例如: * 真正抢先式多任务处理支持多用户 * 内存保护 * 虚拟内存 * 支持对称多处理机SMP(symmetric multiprocessing)即多个CPU机器以及通常单CPU(UP)机器 * 符合POSIX标准 * 联网 * 图形用户接口和桌面环境(实际上桌面环境并不只个) * 速度和稳定性 严格说来Linux并不是个完整操作系统当我们在安装通常所说Linux时我们实际安装是很多工具集合这些工具协同工作以组成个功能强大实用系统Linux本身只是这个操作系统内核是操作系统心脏、灵魂、指挥中心(整个系统应该称为GNU/Linux其原因在本章后续内容中将会给以介绍)内核以独占方式执行最底层任务保证系统正常运行—协调多个并发进程管理进程使用内存使它们相互的间不产生冲突满足进程访问磁盘请求等等 在本书中我们给大家揭示就是Linux是如何完成这具有挑战性工作 1.1 Linux和Unix简明历史 为了让大家对本书所讨论内容有更清楚了解让我们先来简要回顾下Linux历史由于Linux是在Unix基础上发展而来我们话题就从Unix开始 Unix是由AT&T贝尔实验室Ken Thompson和Dennis Ritchie于1969年在台已经废弃了PDP-7上开发;它最初是个用汇编语言写成单用户操作系统不久Thompson和Ritchie成功地说服管理部门为他们购买更新机器以便该开发小组可以实现个文本处理系统Unix就在PDP-11上用C语言重新编写(发明C语言部分目就在于此)它果真变成了个文本处理系统—不久的后只不过问题是他们先实现了个操作系统而已…… 最终他们实现了该文本处理工具而且Unix(以及Unix上运行工具)也在AT&T得到广泛应用在1973年Thompson和Ritchie在个操作系统会议上就这个系统发表了篇论文该论文引起了学术界对Unix系统极大兴趣 由于1956年反托拉斯法案限制AT&T不能涉足计算机业务但允许它象征性地收取费用发售该系统就这样Unix被广泛发布首先是学术科研用户后来又扩展到政府和商业用户 伯克利加州大学是学术用户中个在这里Unix得到了计算机系统研究小组(CSRG)广泛应用并且在这里所进行修改引发了Unix大系列这就是广为人知伯克利软件Software开发(BSD)Unix除了AT&T所提供Unix系列的外BSD是最有影响力Unix系列BSD在Unix中增加了很多显著特性例如TCP/IP网络更好用户文件系统(UFS)工作控制并且改进了AT&T内存管理代码 多年以来BSD版本Unix直在学术环境中占据主导地位但最终发展成为 V版本AT&TUnix则成为商业领域领头羊从某种程度上来说这是有社会原因:学校倾向于使用非正式但通常更好用BSD风格Unix而商业界则倾向于从AT&T获取Unix 在用户需求和用户编程改进特性促进下BSD风格Unix般要比AT&TUnix更具有创新性而且改进也更为迅速但是在AT&T发布最后个正式版本 V Release 4(SVR4)时 V Unix已经吸收了BSD大多数重要优点并且还增加了些自己优势这部分由于从1984年开始AT&T逐渐可以将Unix商业化而伯克利Unix开发工作在1993年BSD4.4版本完成以后就逐渐收缩以至终止了然而BSD进步改进由外界开发者延续下来到今天还在继续进行正在进行Unix系列开发中至少有 4个独立版本是直接起源于BSD4.4这还不包括几个厂商Unix版本例如惠普HP-UX都是部分地或者全部基于BSD而发展起来 实际上Unix变种并不止BSD和 V由于Unix主要使用C语言来编写这就使得它移植到新机器上相对比较容易它简单性也使其重新设计和开发相对比较容易Unix这些特点大受商业界硬件供应商欢迎比如Sun、SGI、HP、IBM、DEC、Amdahl等等;IBM还不止次对Unix进行了再开发厂商们设计开发出新硬件并简单地将Unix移植到新硬件上这样新硬件经发布便具备定功能经过段时间的后这些厂商都拥有了自己专有Unix版本而且为了占有市场这些版本故意以区别侧重点发布出来以更好地占有用户版本混乱状态促进了标准化工作进行其中最主要就是POSIX系列标准它定义了套标准操作系统接口和工具从理论上说POSIX标准代码很容易移植到任何遵守POSIX标准操作系统中而且严格POSIX测试已经把这种理论上可移植性转化为现实直到今天几乎所有正式操作系统都以支持POSIX标准为目标 现在让我们回顾下在1984年杰出电脑黑客Richard Stallman独立开发出个类Unix操作系统该操作系统具有完全内核、开发工具和终端用户应用在GNU(“GNU誷 Not Unix”首字母缩写)计划配合下Stallman开发这个产品有自己技术理想:他想开发出个质量高而且自由操作系统Stallman使用了“自由”(free)这个词不仅意味着用户可以免费获取软件Software;而且更重要是它将意味着某种程度“解放”:用户可以自由使用、拷贝、查询、重用、修改甚至是分发这份软件Software完全没有软件Software使用限制这也正是Stallman创建自由软件Software基金会(FSF)资助GNU软件Software开发本意(FSF也在资助其他科研方面开发工作) 15年来GNU工程已经吸收、产生了大量这不仅包括Emacs、gcc(GNUC编译器)、bash(shell命令)还有大部分Linux用户所熟知许多应用现在正在进行开发项目是GNU Hurd内核这是GNU操作系统最后个主要部件(实际上Hurd内核早已能够使用了不过当前版本号为0.3系统在什么时候能够完成还是未知数)尽管Linux大受欢迎但是Hurd内核还在继续开发原因有几个方面其是Hurd体系结构十分清晰地体现了Stallman有关操作系统工作方式思想例如在运行期间任何用户都可以部分地改变或替换Hurd(这种替换不是对每个用户都是可见而是只对申请修改用户可见而且还必须符合规范标准)另个原因是据介绍Hurd对于多处理器支持比Linux本身内核要好还有个简单原因是兴趣驱动员们希望能够自由地进行自己所喜欢工作只要有人希望为Hurd工作Hurd开发就不会停止如果他们能够如愿以偿Hurd有朝日将成为Linux强劲对手不过在今天Linux还是自由内核王国里无可争议统治者 在GNU发展中期也就是1991年个名叫Linus Torvalds芬兰大学生想要了解Intel新CPU—80386他认为比较好学习思路方法是自己编写个操作系统内核出于这种目加上他对当时Unix变种版本对于80386类机器脆弱支持十分不满他决定要开发出个全功能、支持POSIX标准、类Unix操作系统内核该系统吸收了BSD和 V优点同时摒弃了它们缺点Linus(虽然我知道我应该称他为Torvalds但是所有人都称他为Linus)独立把这个内核开发到0.02版这个版本已经可以运行gcc、bash和很少些应用这些就是他开始全部工作了后来他又开始在因特网上寻求广泛帮助 不到 3年LinusUnix—Linux已经升级到1.0版本它源代码量也呈指数形式增长实现了基本TCP/IP功能(网络部分代码后来重写过而且还可能会再次重写)此时Linux就已经拥有大约10万用户了 现在Linux内核由150多万行代码组成Linux也已经拥有了大约1000万用户(由于Linux可以自由获取和拷贝获取具体统计数字是不可能)Linux内核GNU/Linux附同GNU工具已经占据了Unix 50%市场些公司正在把内核和些应用同安装软件Software打包在起生产出Linux发行版本这些公司包括Red Hat和Caldera 公司现在GNU/Linux已经备受瞩目得到了诸如Sun、IBM、SGI等公司广泛支持SGI最近决定在其基于IntelMerced系列机器上不再搭载自己Unix变种版本IRIX而是直接采用GNU/Linux;Linux甚至被指定为Amiga将要发布新操作系统基础1.2 GNU通用公共许可证 这样个如此流行操作系统当然值得我们学习按照通用公共许可证(GPLGeneral Public License)规定Linux源代码可以自由获取这满足了我们学习该系统强烈愿望GPL这份非同寻常软件Software许可证充分体现了上面提到Stallman思想:只要用户所做修改是同等自由用户可以自由地使用、拷贝、查询、重用、修改甚至重新发布这个软件Software通过这种方式GPL保证了Linux(以及同许可证保证下大量其他软件Software)不仅现在自由可用而且以后经过任何修改的后都仍然可以自由使用 请注意这里自由并不是说没有人靠这个软件Software盈利有些日益兴起公司比如发行最流行Linux发行版本Red Hat就是个例子(Red Hat自从上市以来市值已经突破数十亿美元每年盈利数十万美元而且这些数字还在不断增长)但是任何人都不能限制其他用户涉足本软件Software领域而且所做修改不能减少其自由程度 本书附录B中收录了GNU通用公共许可证全文1.3 Linux开发过程 如上所述由于Linux是个自由软件Software它可以免费获取以供学习研究Linux的所以值得学习研究是它是相当优秀操作系统如果Linux操作系统相当糟糕那它就根本不值得我们使用也就没有必要去研究相关书籍Linux是个十分优秀操作系统还在于几个相互关联原因 原因的在于它是基于天才思想开发而成在学生时代就开始推动整个系统开发Linus Torvalds是个天才他才能不仅展现在编程能力方面而且组织窍门技巧也相当杰出Linux内核是由世界上些最优秀员开发并不断完善他们通过Internet相互协作开发理想操作系统;他们享受着工作中乐趣而且也获得了充分自豪感 Linux优秀另外个原因在于它是基于组优秀概念Unix是个简单却非常优秀模型在Linux创建的前Unix已经有20年发展历史Linux从Unix各个流派中不断吸取成功经验模仿Unix优点抛弃Unix缺点这样做结果是Linux 成为了Unix系列中佼佼者:高速、健壮、完整而且抛弃了历史包袱 然而Linux最强大生命力还在于其公开开发过程每个人都可以自由获取内核源每个人都可以对源加以修改而后他人也可以自由获取你修改后源如果你发现了缺陷你可以对它进行修正而不用去乞求不知名公司来为你修正如果你有什么最优化或者新特点创意你也可以直接在系统中增加功能而不用向操作系统供应商解释你想法指望他们将来会增加相应功能当发现个漏洞后你可以通过编程来弥补这个漏洞而不用关闭系统直到你供应商为你提供修补由于你拥有直接访问源代码能力你也可以直接阅读代码来寻找缺陷或是效率不高代码或是安全漏洞以防患于未然 除非你是个员否则这点听起来仿佛没有多少吸引力实际上即使你不是员这种开发模型也将使你受益匪浅这主要体现在以下两个方面: * 可以间接受益于世界各地成千上万员随时进行改进工作 * 如果你需要对系统进行修改你可以雇用员为你完成工作这部分人将根据你需求定义单独为你服务可以设想这在源不公开操作系统中将是什么样子Linux这种独特自由流畅开发模型已被命名为bazaar(集市模型)它是相对于cathedral(教堂)模型而言在cathedral模型中源代码被锁定在个保密小范围内只有开发者(很多情况下是市场)认为能够发行个新版本这个新版本才会被推向市场这些术语在Eric S. Raymond教堂和集市(The Cathedral and the Bazaar)文中有所介绍大家可以在/~esr/writings/找到这篇文章bazaar开发模型通过重视实验征集并充分利用早期反馈对巨大数量脑力资源进行平衡配置可以开发出更优秀软件Software(顺便说下虽然Linux是最为明显使用bazaar开发模型例子但是它却远不是第个使用这个模型系统) 为了确保这些无序开发过程能够有序地进行Linux采用了双树系统个树是稳定树(stable tree)另个树是非稳定树(unstable tree)或者开发树(development tree)些新特性、实验性改进等都将首先在开发树中进行如果在开发树中所做改进也可以应用于稳定树那么在开发树中经过测试以后在稳定树中将进行相同改进按照Linus观点旦开发树经过了足够发展开发树就会成为新稳定树如此周而复始进行下去 源版本号形式为x.y.z对于稳定树来说y是偶数;对于开发树来说y比相应稳定树大(因此是奇数)截至到本书截稿时最新稳定内核版本号是2.2.10最新开发内核版本号是2.3.12对2.3树缺陷修正会回溯影响(back-propagated)2.2树而当2.3树足够成熟时候会发展成为2.4.0(顺便说下这种开发会比常规惯例要快每版本所包含改变比以前更少了内核开发人员只需花很短时间就能够完成个实验开发周期)及其镜像站点提供了最新可供内核版本而且同时包括稳定和开发版本如果你愿意话不需要很长时间这些站点所提供最新版本中就可能包含了你部分源代码第2章 代 码 初 识 本章首先从较高层次介绍Linux内核源概况这些都是大家关心些基本特点随后将简要介绍些实际代码最后介绍如何编译内核 2.1 Linux内核源部分特点 在过去段时期Linux内核同时使用C语言和汇编语言来实现这两种语言需要定平衡:C语言编写代码移植性较好、易于维护而汇编语言编写则速度较快般只有在速度是关键原因或者些因平台相关特性而产生特殊要求(例如直接和内存管理硬件进行通讯)时才使用汇编语言 正如实际中所做即使内核并未使用C对象特性部分内核也可以在g(GNUC编译器)下进行编译同其他面向对象编程语言相比较相对而言C开销是较低但是对于内核开发人员来说这已经是太多了 内核开发人员不断发展编程风格形成了Linux代码独有特色本节将讨论其中些问题 2.1.1 gcc特性使用 Linux内核被设计为必须使用GNUC编译器gcc来编译而不是任何种C编译器都可以使用内核代码有时要使用gcc特性本书将陆续介绍其中部分 些gcc特有代码只是简单地使用gcc语言扩展例如允许在C(不只是C)中使用inline关键字指示内联也就是说代码中被在每次时都会被扩充因而就可以节约实际开销 般情况下代码编写方式比较复杂对于某些类型输入gcc能够产生比其他输入效率更高执行代码从理论上讲编译器可以优化具有相同功能两种对等思路方法并且得到相同结果因此代码编写方式是无关紧要但在实际上用某种思路方法编写所产生代码要比用另外些思路方法编写所产生代码执行速度快许多内核开发人员知道怎样才能产生更高效执行代码这不断地在他们编写代码中反映出来 例如考虑内核中经常使用goto语句—为了提高速度内核中经常大量使用这种般要避免使用语句在本书中所包含不到40 000行代码中共有500多条goto语句大约是每80行个除汇编文件外精确统计数字是接近每72行个goto语句公平地说这是选择偏向结果:比例如此高原因的是本书中涉及是内核源核心在这里速度比其他原因都需要优先考虑整个内核比例大概是每260行个goto语句然而这仍然是我不再使用Basic进行编程以来见过使用goto频率最高地方 代码必需受特定编译器限制特性不仅和普通应用开发有很大区别而且也区别于大多数内核开发大多数开发人员使用C语言编写代码来保持较高可移植性即使在编写操作系统时也是如此这样做优点是显而易见最为重要点是旦出现更好编译器员们可以随时进行更换 内核对于gcc特性完全依赖使得内核向新编译器上移植更加困难最近Linus对这问题在有关内核邮件列表上表明了自己观点:“记住编译器只是个工具”这是对依赖于gcc特性个很好基本思想表述:编译器只是为了完成工作如果通过遵守标准还不能达到工作要求那么就不是工作要求有问题而是对于标准依赖有问题 在大多数情况下这种观点是不能被人所接受通常情况下为了保证和语言标准致开发人员可能需要牺牲某些特性、速度或者其他相关原因其他选择可能会为后期开发造成很大麻烦 但是在这种特定情况下Linus是正确Linux内核是个特例其执行速度要比向其他编译器可移植性远为重要如果设计目标是编写个可移植性好而不要求快速运行内核或者是编写个任何人都可以使用自己喜欢编译器进行编译内核那么结论就可能会有所区别了;而这些恰好不是Linux设计目标实际上gcc几乎可以为所有能够运行LinuxCPU生成代码因此对于gcc依赖并不是可移植性严重障碍 在第3章中我们将对内核设计目标进行详细介绍说明2.1.2 内核代码习惯用语 内核代码中使用了些显著习惯用语本节将介绍常用几个当通读源代码时真正重要问题并不在这些习惯用语本身而是这种类型习惯用语确存在而且是不断被使用和发展如果你需要编写内核代码你应该注意到内核中所使用习惯用语并把这些习惯用语应用到你代码中当通读本书(或者代码)时看看你还能找到多少习惯用语 为了讨论这些习惯用语我们首先需要对它们进行命名为了便于讨论笔者创造了这些名字而在实际中大家不定非要参考这些用语它们只是对内核工作方式描述而已 个普通习惯用语笔者称的为“资源获取”(resource acquisition idiom)在这个用语中个必须实现系列资源获取包括内存、锁等等(这些资源类型未必相同)只有成功地获取当前所需要资源的后才能处理后面资源请求最后该还必须释放所有已经获取资源而不必考虑没有获取资源 我采用“变量”这用语(error variable idiom)来辅助介绍说明资源获取用语它使用个临时变量来记录期望返回值当然相当多都能实现这个功能但是变量区别点在于它通常是用来处理由于速度原因而变得非常复杂流程控制中问题变量有两个典型值0(表示成功)和负数(表示有错) 如果执行到标号out2则都已经获取了r1和r2资源而且也都需要进行释放如果执行到标号out1(不管是顺序执行还是使用goto语句进行跳转到)则r2资源是无效(也可能刚被释放)但是r1资源却是有效而且必需在此将其释放同理如果标号out能被执行则r1和r2资源都无效err所返回是或成功标志 在这个简单例子中对err些赋值是没有必要在实战中实际代码必须遵守这种模式这样做原因主要在于同行中可能包含有多种测试而这些测试应该返回相同代码因此对变量统赋值要比多次赋值更为简单虽然在这个例子中对于这种属性必要性并不非常迫切但是我还是倾向于保留这种特点有关实际应用可以参考sys_shmctl(第21654行)在第9章中还将详细介绍这个例子 2.1.3 减少#和#def使用 现在Linux内核已经移植到区别平台上但是我们还必须解决移植过程中所出现问题大部分支持各种区别平台代码由于包含许多预处理代码而已经变得非常不规范标准例如: 这个例子试图实现操作系统可移植性虽然Linux关注焦点很明显是实现代码在各种CPU上可移植性但是 2者基本原理是致对于这类问题来说预处理器是种解决方式这些杂乱问题使得代码晦涩难懂更为糟糕是增加对新平台支持有可能要求重新遍历这些杂乱分布低质量代码段(实际上你很难能找到这类代码段全部) 和现有方式区别是Linux般通过简单(或者是宏)来抽象出区别平台间差异内核移植可以通过实现适合于相应平台(或宏)来实现这样不仅使代码主体简单易懂而且在移植过程中还可以比较容易地自动检测出你没有注意到内容:如引用未声明时会出现链接有时用预处理器来支持区别体系结构但这种方式并不常用而相对于代码风格变化就更是微不足道了 顺便说下我们可以注意到这种解决思路方法和使用用户对象(或者C语言中充满指针struct结构)来代替离散switch语句处理区别类型思路方法十分相似在某些层次上这些问题和解决思路方法是统 可移植性问题并不仅限于平台和CPU移植编译器也是个重要问题此处为了简化假设Linux只使用gcc来编译由于Linux只使用同个编译器所以就没有必要使用#块(或者#def块)来选择区别编译器 内核代码主要使用#def来区分需要编译或不需要编译部分从而对区别结构提供支持例如代码经常测试SMP宏是否定义过从而决定是否支持SMP机2.2 代码样例 了解Linux代码风格最好思路方法就是实际研究下它部分代码即使你不完全理解本节所讨论代码细节也无关紧要毕竟本节主要目不是理解代码些读者可以只对本节进行浏览本节主要目是让读者对Linux代码进。
linux、内核源码、内核编译与配置、内核模块开发、内核启动流程

linux、内核源码、内核编译与配置、内核模块开发、内核启动流程(转)linux是如何组成的?答:linux是由用户空间和内核空间组成的为什么要划分用户空间和内核空间?答:有关CPU体系结构,各处理器可以有多种模式,而LInux这样的划分是考虑到系统的安全性,比如X86可以有4种模式RING0~RING3 RING0特权模式给LINUX内核空间RING3给用户空间linux内核是如何组成的?答:linux内核由SCI(System Call Interface)系统调用接口、PM(Process Management)进程管理、MM(Memory Management)内存管理、Arch、VFS(Virtual File Systerm)虚拟文件系统、NS(Network Stack)网络协议栈、DD(Device Drivers)设备驱动linux 内核源代码linux内核源代码是如何组成或目录结构?答:arc目录存放一些与CPU体系结构相关的代码其中第个CPU子目录以分解boot,mm,kerner等子目录block目录部分块设备驱动代码crypto目录加密、压缩、CRC校验算法documentation 内核文档drivers 设备驱动fs 存放各种文件系统的实现代码include 内核所需要的头文件。
与平台无关的头文件入在include/linux子目录下,与平台相关的头文件则放在相应的子目录中init 内核初始化代码ipc 进程间通信的实现代码kernel Linux大多数关键的核心功能者是在这个目录实现(程序调度,进程控制,模块化)lib 库文件代码mm 与平台无关的内存管理,与平台相关的放在相应的arch/CPU目录net 各种网络协议的实现代码,注意而不是驱动samples 内核编程的范例scripts 配置内核的脚本security SElinux的模块sound 音频设备的驱动程序usr cpip命令实现程序virt 内核虚拟机内核配置与编译一、清除make clean 删除编译文件但保留配置文件make mrproper 删除所有编译文件和配置文件make distclean 删除编译文件、配置文件包括backup备份和patch补丁二、内核配置方式make config 基于文本模式的交互式配置make menuconfig 基于文本模式的菜单配置make oldconfig 使用已有的配置文件(.config),但配置时会询问新增的配置选项make xconfig 图形化配置三、make menuconfig一些说明或技巧在括号中按“y”表示编译进内核,按“m”编译为模块,按“n”不选择,也可以按空格键进行选择注意:内核编译时,编译进内核的“y”,和编译成模块的“m”是分步编译的四、快速配置相应体系结构的内核配置我们可以到arch/$cpu/configs目录下copy相应的处理器型号的配置文件到内核源目录下替换.config文件五、编译内核1.————————————————————————————make zImage 注:zImage只能编译小于512k的内核make bzImage同样我们也可以编译时获取编译信息,可使用make zImage V=1make bzImage V=1编译好的内核位于arch/$cpu/boot/目录下————————————————————————————以上是编译内核make menuconfig时先“m”选项的编译接下来到编译“y”模块,也就是编译模块2.make modules 编译内核模块make modules_install 安装内核模块------>这个选项作用是将编译好的内核模块从内核源代码目录copy至/lib/modules下六、制作init ramdiskmkinitrd initrd-$version $version/**** mkinitrd initrd-$(可改)version $version(不可改,因为这version是寻找/lib/modules/下相应的目录来制作) ****/七、内核安装复制内核到相关目录下再作grub引导也就可以了1.cp arch/$cpu/boot/bzImage /boot/vmlinux-$version2.cp $initrd /boot/3.修改引导器/etc/grub.conf(lio.conf)正确引导即可#incldue <linux/init.h>#include <linux/module.h>static int hello_init(void){printk(KERN_WARNING"Hello,world!\n");return 0;}static void hello_exit(void){printk(KERN_INFO"Good,world!\n");}module_init(hello_init);module_exit(hello_exit);___________hello,world!范例___________________一、必需模块函数1.加载函数module_init(hello_init); 通过module_init宏来指定2.卸载函数module_exit(hello_exit); 通过module_exit宏来指定编译模块多使用makefile二、可选模块函数1.MODULE_LICENSE("*******"); 许可证申明2.MODULE_AUTHOR("********"); 作者申明3.MODELE_DESCRIPTION("***"); 模块描述4.MODULE_VERSION("V1.0"); 模块版本5.MODULE_ALIAS("*********"); 模块别名三、模块参数通过宏module_param指定模块参数,模块参数用于在加载模块时传递参数模块module_param(neme,type,perm);name是模块参数名称type是参数类型type常见值:boot、int、charp(字符串型)perm是参数访问权限perm常见值:S_IRUGO、S_IWUSRS_IRUGO:任何用户都对sys/module中出现的参数具有读权限S_IWUSR:允许root用户修改/sys/module中出现的参数/*****——————范例————————*******/int a = 3;char *st;module_param(a,int,S_IRUGO);module_param(st,charp,S_IRUGO);/*********————结束——————**********//**********----makefile范例----*************/ifneq ($(KERNELRELFASE),)obj-m := hello.o //这里m值多用obj-(CONFIG_**)代替elseKDIR := /lib/modules/$version/buildall:make -C $(KDIR) M=$(PWD) modulesclean:rm -f *.ko *.o *.mod.o *.mod.c *.symyersendif/*****这里可以扩展多文件makefile 多个obj-m***********end***************//******模块参数*****/#include <linux/init.h>#include <linux/module.h>MODULE_LICENSE("GPL");static char *name = "Junroc Jinx";static int age = 30;module_param(arg,int,S_IRUGO);module_param(name,charp,S_IRUGO);static int hello init(void){printk(KERN_EMERG"Name:%s\n",name);printk(KERN_EMERG"Age:%d\n",age);return 0;}static void hello_exit(void){printk(KERN_INFA"Module Exit\n");}moduleJ_init(hello_init);module_exit(hello_exit);/****************/----------------------------------------------------------------------------/proc/kallsyms 文档记录了内核中所有导出的符号的名字与地址什么是导出?答:导出就是把模块依赖的符号导进内核,以便供给其它模块调用为什么导出?答:不导出依赖关系就解决不了,导入就失败符号导出使用说明:EXPORT_SYMBOL(符号名)EXPORT_SYMBOL_GPL(符号名)其中EXPORT_SYMBOL_GPL只能用于包含GPL许可证的模块模块版本不匹配问题的解决:1、使用modprobe --force-modversion 强行插入2、确保编译内核模块时,所依赖的内核代码版本等同于当前正在运行的内核uname -r ----------------------------------------------------------------------printk内核打印:printk允许根据严重程度,通过附加不同的“优先级”来对消息分类在<linux/kernel.h>定义了8种记录级别。
网站源码分类

商务二手综合类37个专业信息网完整版--013专业信息网完整版--014二手信息网站系统源代码--001企业信息综合网---030供求二手信息网站系统源代码--005供求二手信息网站系统源代码--006供求二手信息网站系统源代码--007供求信息网站系统源代码--002供求信息网站系统源代码--003供求信息网站系统源代码--004商务商贸网----015商务正式版-029商务网源码---020商务网源码---034商务网站系统源代码---012商情商贸网----016商贸通 V4[1].0 正式版市场信息综合网---017扬州摄影网 V1[1].0泸州生活频道电脑城商情网站系统源代码--024综合信息网站系统源代码--001综合信息网站系统源代码--002综合信息网站系统源代码--004综合信息网站系统源代码--005综合信息网站系统源代码--006综合信息网站系统源代码--007综合信息网站系统源代码--008综合信息网站系统源代码--009综合信息网站系统源代码--010综合信息网站系统源代码--011综合信息网站系统源代码--012行业网站系统源代码--039西部信息网西部信息网net餐饮类信息网站系统源代码--003餐饮综合信息网站系统源代码--013[1]新闻文章类35个大型文章新闻信息网站系统源代码--007 大型文章新闻信息网站系统源代码--030文章新闻信息网站系统源代码--001 文章新闻信息网站系统源代码--002 文章新闻信息网站系统源代码--003 文章新闻信息网站系统源代码--004 文章新闻信息网站系统源代码--005 文章新闻信息网站系统源代码--006 文章新闻信息网站系统源代码--008 文章新闻信息网站系统源代码--009 文章新闻信息网站系统源代码--010 文章新闻信息网站系统源代码--011 文章新闻信息网站系统源代码--012 文章新闻信息网站系统源代码--013 文章新闻信息网站系统源代码--014 文章新闻信息网站系统源代码--015 文章新闻信息网站系统源代码--016 文章新闻信息网站系统源代码--017 文章新闻信息网站系统源代码--018 文章新闻信息网站系统源代码--019 文章新闻信息网站系统源代码--020 文章新闻信息网站系统源代码--021 文章新闻信息网站系统源代码--022 文章新闻信息网站系统源代码--023 文章新闻信息网站系统源代码--024 文章新闻信息网站系统源代码--025 文章新闻信息网站系统源代码--026 文章新闻信息网站系统源代码--027 文章新闻信息网站系统源代码--028 文章新闻信息网站系统源代码--029 文章新闻信息网站系统源代码--031 文章新闻信息网站系统源代码--03 文章新闻信息网站系统源代码--033 文章新闻信息网站系统源代码--034 文章新闻信息网站系统源代码--035网址导航下载小偷程序其它类36个CP管理平台联盟系统源代码--006下载网站系统源代码--001下载网站系统源代码--002下载网站系统源代码--003下载网站系统源代码--004下载网站系统源代码--005八一中文BT联盟极速小偷天堂短信CP商务平台搜索系统源代码--008搜索系统源代码--009搜索系统源代码--011搜索系统源代码--013搜索音乐网站系统源代码--003格子阁网站管理系统--005相册网站系统源代码--002相册网站系统源代码--007网址导航系统源代码--001网址导航系统源代码--002网址导航系统源代码--003网址导航系统源代码--004网址导航系统源代码--005网址导航系统源代码--006网址导航系统源代码--007考试管理网站系统源代码--001联盟系统源代码--004自动采集小说书库网站源代码--001自动采集电影网站源代码(无后台)--004 自动采集音乐网站源代码(无后台)--005 自设广告电影小偷3.0虚拟主机管理系统源代码--001虚拟主机管理系统源代码--002许愿墙源代码--006许愿墙源代码--012许愿板源代码--010许愿树源代码--014黄页信息网站系统源代码--003网店类43个NET功能强大的购物商城系统源代码--009 NET购物商城系统源代码--043功能强大的购物商城系统源代码--038化妆品购物商城系统源代码--019多用户购物商城系统源代码--003多用户购物商城系统源代码--006多用户购物商城系统源代码--008多用户购物商城系统源代码--021淘宝多用户购物商城系统源代码--045肖遥程序正式版购物商城系统源代码--031 购物商城系统源代码--001购物商城系统源代码--002购物商城系统源代码--004购物商城系统源代码--005购物商城系统源代码--007购物商城系统源代码--010购物商城系统源代码--011购物商城系统源代码--018购物商城系统源代码--022购物商城系统源代码--023购物商城系统源代码--025购物商城系统源代码--026正式版支持支付宝购物商城系统源代码--027购物商城系统源代码--028购物商城系统源代码--032购物商城系统源代码--033购物商城系统源代码--035购物商城系统源代码--036购物商城系统源代码--037购物商城系统源代码--040购物商城系统源代码--041购物商城系统源代码--042购物商城系统源代码--044购物商城系统源代码--046购物商城系统源代码--047购物商城系统源代码--048购物商城系统源代码--049购物商城系统源代码--050购物商城系统源代码--051购物商城系统源代码--052购物商城系统源代码--053购物商城系统源代码--054购物商城系统源代码--055企业类70个中英文企业网站系统源代码--002中英文企业网站系统源代码--003中英文企业网站系统源代码--010中英文企业网站系统源代码--014中英文企业网站系统源代码--017中英文企业网站系统源代码--024中英文企业网站系统源代码--033中英文企业网站系统源代码--038中英文企业网站系统源代码--041中英文企业网站系统源代码--050中英文企业网站系统源代码--059中英文企业网站系统源代码--061企业商城网站系统源代码--065企业网站系统源代码--001企业网站系统源代码--004企业网站系统源代码--005企业网站系统源代码--006企业网站系统源代码--007企业网站系统源代码--008企业网站系统源代码--009企业网站系统源代码--011企业网站系统源代码--012企业网站系统源代码--013企业网站系统源代码--015企业网站系统源代码--016企业网站系统源代码--019企业网站系统源代码--020企业网站系统源代码--021企业网站系统源代码--022企业网站系统源代码--023企业网站系统源代码--025企业网站系统源代码--026大型程序0523bbs(1)054--漂亮公寓全站绝对漂亮企业网站系统源代码 50004音乐快搜引擎 v26和8茗茶网整站CityCN21flash日记本和flash留言本 v1K风黄页系统K-YellowPage Engine v4上海强安餐饮有限公司完整版亚特网站管理系统(TradeCMS) v2006产品发布系统二级分类亿时空间Cms 2005 SP4 免费版八零秀2004动易网站管理系统2005版sp2正式版国度社区 v3宁波电脑学堂 2005 sp2少年中国军事网全站程序常州电脑城源码思想吧微型论坛慧明江湖 v10数字人信息港程序 v4.0.7.2 +注册机+v4.0.7 旋木留言本 v2烦心网全站程序[动易2005美化版]福建联合闽津茶业有限公司全站衡阳家园音乐站最新版下载酷狗笑吧源码飞凌酷网留言系统 2005 正式版飞鸟个人相册 v3黑客站点[骇客基地]全站电影音乐flash类20个FLASH网站系统源代码--004全站HTML快闪动漫漂亮风格(带采集)网站系统源代码--001[1]生成文件后的音乐网站系统源代码--002电影网站系统源代码--001电影网站系统源代码--002电影网站系统源代码--003电影网站系统源代码--004电影网站系统源代码--005电影网站系统源代码--006电影网站系统源代码--007电影网站系统源代码--008电影网站系统源代码--009音乐DJ网站系统源代码--003音乐DJ网站系统源代码--005音乐DJ网站系统源代码--007音乐DJ网站系统源代码--008音乐MTV网站系统源代码--009音乐MTV网站系统源代码--010音乐网站系统源代码--006学校政府人才旅游房产类45个中英文旅游信息网站系统源代码---008中英文饭店信息网站系统源代码---007人才网站系统源代码---001人才网站系统源代码---002人才网站系统源代码---003人才网站系统源代码---004人才网站系统源代码---005医院网站系统源代码--008培训人才网站系统源代码--012培训网站,学校网站系统源代码--005学校网站源代码--001学校网站系统源代码--002学校网站系统源代码--004学校网站系统源代码--007学校网站系统源代码--008学校网站系统源代码--011学校网站系统源代码--013家教培训网站系统源代码--006山东家教网正式版培训网站系统源代码--003 幼儿园学校网站系统源代码--009 [1]幼儿天地学校网站系统源代码--010 [1]律师事务所网站系统源代码--004房产网站系统源代码---001房产网站系统源代码---002房产网站系统源代码---003房产网站系统源代码---004房产网站系统源代码---005政府招商网站系统源代码--005政府部门网站系统源代码--001政府部门网站系统源代码--002政府部门网站系统源代码--006政府部门网站系统源代码--007新疆赛德律师事务所旅游信息网站系统源代码---002旅游信息网站系统源代码---004旅游信息网站系统源代码---005旅游信息网站系统源代码---006旅游机票订购网站系统源代码---001旅游订房网站系统源代码---003泸州网上售楼系统活动中心学校网站系统源代码--006派出所网站系统源代码--003索特旅游线路发布管理系统VIP版西部成都房网额敏抗震办整站博客个人同学录交友类33个个人主页网站系统源代码--001个人主页网站系统源代码--002个人主页网站系统源代码--003个人主页网站系统源代码--004个人主页网站系统源代码--005个人主页网站系统源代码--006个人主页网站系统源代码--007个人主页网站系统源代码--008个人主页网站系统源代码--009个人主页网站系统源代码--010个人主页网站系统源代码--011个人主页网站系统源代码--012个人主页网站系统源代码--013博客系统源代码--001博客系统源代码--002博客系统源代码--003博客系统源代码--004博客系统源代码--005博客系统源代码--006博客系统源代码--007博客系统源代码--008博客系统源代码--009博客系统源代码--010同学录网站系统源代码--001同学录网站系统源代码--002 v3.2同学录网站系统源代码--003同学录网站系统源代码--004同学录网站系统源代码--006同学录网站系统源代码--007同学录网站系统源代码--008同学录网站系统源代码--009同学录网站系统源代码--010大型交友网站系统源代码BBSJBB2.3正式版lpcbbs bbsX.batYxBBs12动网bbs同策论坛TCBBS v7热门源码大型电影网站源码+1键采集最新仿优美电影网导航网源码仿起点中文网源码+杰奇1.7商业全功能版+送完美规则杰奇小说挂Q站美化版,心挂Q在线挂Q程序价值400卡盟点卡批发平台PHP源码价值100沙沙打码网赚价值500搜猫搜索程序商业版v8.5188旅游网站管理系统v5.02012新版精仿Q友乐园最新QQ空间素材网站源码315货源网源码456电影网源码整站打包光线CMS电影程序Android安卓智能手机门户织梦内核整站源码服装货源网站源码婚纱摄影公司企业网站源码芒果国际程序笑话网站源码,带1.6W数据QQ乐园QQ空间素材网站非主流门户源码织梦内核yicms糗事百科2.0最新商业版,完美破除域名限制YY签名网模板YY频道设计素材门户网站源码爱美眉美女图片站源码仿站精品织梦5.7程序百度影音电影网站源码光线CMS最新版一键采集草根站长网模板站长新闻资讯网站源码文章系统橙子婚庆网站源码大型游戏下载站程序51玩游戏社区网站源码极品7k7k动画片网站源码漫画模板程序最新91单机游戏下载站网站源码模板多多返利淘宝客V8最新商业破解版帆木网模板多多淘宝客返利系统商业源码程序313建站大师模板5173游戏物品虚拟货币交易网站商业源码世纪佳缘模板交友网站源码程序淘宝商城红色模板PHP淘宝客网站源码程序腾讯网地方新闻门户网源码天空软件站源码迅雷电影网站源码马克斯4.0内核带采集光线1.4最新迅播电影网站源码模板带数据带采集广告联盟程序PHP源码中易3.31商业版广告任务源码极品高仿QQ迷网QQ个性非主流空间素材门户网源码金典教育网站源码经典乐视电影网站源码马克斯4.0带数据带采站长中国zzchn站长门户网站源码带全套采集多套卡盟源码美女之家mmonly图片站源码某设计工作室网站源码七禧Discuz!音乐系统商业破解版汽车网站源码淘宝导航导购网源码图时尚淘宝客整站系统小游戏网站源码新版织梦腾讯3366小游戏门户网站模板源码原创818图片网站源码带采集7k7k小游戏模板FLASH网页游戏网站源码美女图片站69美女网站源码程序电影发布系统迅雷电影下载网站源码有意思吧网站源码好资源淘客系统网站源码母婴门户网站源码衡阳妈妈网源码中旅遨游网模板织梦旅游门户网站源码商业版最新电影网站源码7090电影网模板带采集带数据最新笑话网站源码高仿唧唧帝笑话蓝色源码2012最新极品电影网站源码仿步步高影院_带采集VIP学习网模板作业问答平台ASP商业源码程序多多淘宝客四色模板精仿糗事百科源码,极品程序淘宝开店素材门户免费淘模板下载网站源码微趣网源码-腾讯微博应用网站程序站长资源下载网站模板盒子织梦内核源码带数据好特软件站源码下载网站购买地址:。
linux kernel5.15编译原理

linux kernel5.15编译原理Linux kernel 5.15编译原理Linux kernel是一个开源操作系统内核,其稳定版本的更新和发布对于整个Linux生态系统具有重要意义。
在内核更新的过程中,编译内核是一个重要的步骤。
本文将为您解释Linux kernel 5.15的编译原理,并逐步回答关于该主题的问题。
第一步:准备工作在开始编译内核之前,我们需要做一些准备工作。
1. 下载内核源代码要编译特定版本的Linux内核,首先需要从Linux官方网站(2. 安装必要的依赖项编译内核需要一些工具和依赖项。
在大多数Linux发行版中,您可以使用包管理器来安装它们。
例如,在Ubuntu上,您可以运行以下命令安装常见的依赖项:sudo apt-get install build-essential libncurses-dev bison flexlibssl-dev libelf-dev这些依赖项将帮助您构建所需的内核映像。
第二步:配置编译选项在编译内核之前,需要配置一些编译选项以满足特定需求。
1. 进入内核源代码目录解压下载的内核源代码,并在终端中进入解压后的目录。
例如:tar -xf linux-5.15.tar.xzcd linux-5.152. 清理旧的配置选项可以使用以下命令清理旧的内核配置选项:make mrproper3. 配置编译选项可以使用以下命令进入菜单式配置界面:make menuconfig在配置界面中,您可以选择不同的内核功能、驱动程序和选项。
根据需要进行选择,并保存配置文件。
第三步:编译内核完成配置后,我们可以开始编译Linux内核了。
1. 执行编译命令使用以下命令开始编译内核:make这个过程可能需要一些时间,具体取决于您的计算机性能。
2. 安装编译后的内核完成编译后,可以使用以下命令安装编译后的内核:sudo make install此命令将复制编译后的内核映像、模块和其他文件到适当的位置,并更新GRUB或其他引导程序配置。
编译 linux 源代码

编译linux 源代码
编译 Linux 源代码需要以下步骤:
1.下载 Linux 源代码
可以从官方网站或者其它可靠的源下载 Linux 源代码。
2.解压源代码
使用解压工具将下载的源代码解压到一个目录下。
3.配置编译环境
在终端中输入以下命令来配置编译环境:
bash复制代码
export ARCH=arm64 # 根据自己的硬件架构选择合适的架构
export CROSS_COMPILE=arm64-linux-gnueabi- # 根据自己的硬件架构选择合适的编译器前缀
4.执行编译命令
在终端中输入以下命令来执行编译:
bash复制代码
make menuconfig # 配置内核选项,按上下键选择需要的选项,按空格键进行确认/取消选择,按Y 键保存更改,最后按 Esc 键退出配置菜单。
make # 开始编译内核,等待编译完成。
5.等待编译完成
编译完成后,会在arch/$ARCH/boot/目录下生成一个名为Image的文件,这就是编译好的 Linux 内核映像文件。
ubuntu命令安装内核源码及升级内核源码

sudo apt-get install linux-source 会自动安装当前版本内核的源代码到/usr/src升级内核源码:1.将下载过来linux源代码包(tar.bz2包)解压到/usr/src下。
如果你还不知道怎么解压,请google之~解压完毕后可以在/usr/src目录下看到一个linux-2.6.31.6的文件夹2.转移目录至linux-2.6.31.6用如下命令:cd /usr/src/linux-2.6.31.63.先配置Ubuntu内核:make menuconfig具体怎么配置我不清楚,不过这个基本上不用怎么配置的,直接选最后一项,save,exit 就OK了4.接着开始编译Ubuntu内核:make这是一个漫长的过程,慢慢等吧~~这个花了我将近一个半小时的时间5.加入模块:make modules_install6.生成可执行的Ubuntu内核引导文件:make bzImage (注意i字母要大写)7.将bzImage复制至/boot下:cp arch/i386/boot/bzImage /boot/vmlinuz-2.6.31.6 //2.6.32Ubuntu内核的bzImage目录为arch/x86/boot/bzImage8.清除多余的创建文件:make clean //这一步最好还是留到最后来做(现在可以先不跳过这一步),这样的话,即使你后面操作失误也可以回到这里重做,而不需要重新编译9.将System.map复制至/boot下:cp System.map /boot/System.map-2.6.31.610.生成initrd.img 这个很重要,我开始弄错了这个,害的我白重启了一次。
命令:cd /lib/modules/2.6.31.6sudo mkinitramfs -o /boot/initrd.img-2.6.31.6 //2.6.32可以为sudo update-initramfs -c - k 2.6.3211.自动查找新Ubuntu内核,并添加至grub引导:sudo update-grub这个过程也可以手动完成,方法是更改/boot/grub目录下menu.lst文件。
vmlinux生成流程

vmlinux生成流程vmlinux是Linux内核的可执行文件,它是内核源代码经过编译、链接等一系列处理后生成的。
下面我们将详细介绍vmlinux生成的流程。
1. 内核源代码编译vmlinux的生成过程首先需要对Linux内核的源代码进行编译。
编译器将源代码翻译成机器可以执行的目标代码,生成一系列的中间文件。
在编译过程中,需要注意选择合适的编译选项,以及处理一些与平台相关的代码。
2. 汇编代码生成在编译过程中,还会生成一些汇编代码。
汇编代码是与机器硬件直接相关的代码,它负责处理底层的硬件操作。
汇编代码一般保存在以".S"为后缀的文件中。
3. 链接过程编译完源代码和汇编代码后,需要进行链接操作。
链接器将各个模块的目标代码组合在一起,解析符号引用,生成最终的可执行文件。
在链接过程中,还需要处理一些与库相关的操作,如动态链接库和静态链接库的链接。
4. 符号表生成在链接过程中,还会生成符号表。
符号表是一个记录了各个符号(函数、变量等)地址和大小的表格,它有助于调试和动态加载等操作。
符号表一般保存在可执行文件的调试信息中。
5. 优化处理在生成vmlinux的过程中,还需要进行一些优化处理。
优化处理旨在提高代码的执行效率,减少资源占用。
优化处理涉及到很多技术,如代码折叠、循环展开、指令调度等。
6. 生成vmlinux经过以上的编译、汇编、链接和优化处理,最终可以生成vmlinux文件。
vmlinux是一个可执行的二进制文件,它包含了Linux内核的所有代码和数据。
vmlinux可以被直接加载到内存中执行,成为一个运行的操作系统。
总结:vmlinux的生成过程经历了源代码编译、汇编代码生成、链接过程、符号表生成、优化处理等多个阶段。
通过这些处理,我们可以得到一个完整的可执行的Linux内核文件。
vmlinux的生成过程是复杂而严谨的,需要编译器、链接器等工具的支持,同时也需要开发人员对内核源代码和底层硬件有深入的理解。
详细设计文档 (含系统说明书,源代码说明书)

东北师范大学外语培训机构数据库详细设计文档雷蕾张丽云丁鼎孔祥楠2009-11-1目录第一章引言 (1)1.1项目说明 (1)1.2文档目的 (1)1.3参考资料 (1)第二章设计流程图 (3)2.1注册功能流程图 (3)2.2用户登录功能流程图 (4)2.3搜索课程功能流程图 (5)2.3前台用户下载资料或留言功能流程图 (5)2.3后台管理员功能流程图 (6)第三章类规格说明 (7)2.1模块类图 (7)3.2 jsp页面说明 (8)3.3类说明 (10)第四章程序设计说明 (15)第一章引言1.1项目说明1、在互联网络高速发展的今天,网站是企业在因特网上全面介绍公司信息的一个发布平台:可以把任何想让人们知道的东西放入网站,如公司简介、公司的厂房、生产设施、研究机构、产品的外观、功能及其使用方法等,都可以展示于网上。
2、网站树立培训机构形象,让别人看到自己,展示培训机构的实力。
培训机构就能够在国内和世界"亮相",无疑是一种宣传机构、产品和服务的机会。
从广告意义上看,培训机构网站事关机构形象建设,没有网站也谈不上机构形象。
3、主动抢占先机,培训机构建设自己的网站,这是时代发展的必然,任何一家培训机构要想跟上时代发展的潮流,必须要有展示自己的一个信息平台。
为了不被竞争对手建立网站抢占先机,为了不落后于时代潮流,应该考虑建站的必要性。
4、可以扩大业务范围,可以与潜在客户建立商业联系:这是该网址最重要的功能之一,也是为什么那么多的国外企业非常重视网站建设的根本原因。
现在,世界各国大的采购商主要都是利用互联网络来寻找新的产品和新的供应商,因为这样做费用最低,效率最高。
原则上,全世界任何地方的人,只要知道了公司的网址,就可以看到公司的产品。
因此,关键在于如何将公司网址推介出去。
一种非常实用而有效的方法是将公司的网址登记在全球著名的搜索引擎(如Google,百度,雅虎等)上,并选择与公司的产品及服务有关的关键字,则可以使潜在的客户能够容易地找到公司和产品。
Linux内核源代码的阅读和工具具体介绍

Linux内核源代码的阅读和工具具体介绍Linux内核源代码的阅读和工具具体介绍Linux的内核源代码可以从很多途径得到。
一般来讲,在安装的linux系统下,/usr/src/linux目录下的东西就是内核源代码。
另外还可以从互连网上下载,解压缩后文件一般也都位于linux目录下。
内核源代码有很多版本,目前最新的版本是2.2.14。
许多人对于阅读Linux内核有一种恐惧感,其实大可不必。
当然,象Linux内核这样大而复杂的系统代码,阅读起来确实有很多困难,但是也不象想象的那么高不可攀。
只要有恒心,困难都是可以克服的。
任何事情做起来都需要有方法和工具。
正确的方法可以指导工作,良好的工具可以事半功倍。
对于Linux内核源代码的阅读也同样如此。
下面我就把自己阅读内核源代码的一点经验介绍一下,最后介绍Window平台下的一种阅读工具。
对于源代码的阅读,要想比较顺利,事先最好对源代码的知识背景有一定的了解。
对于linux内核源代码来讲,基本要求是:⑴操作系统的基本知识;⑵对C语言比较熟悉,最好要有汇编语言的知识和GNUC对标准C的扩展的知识的了解。
另外在阅读之前,还应该知道Linux内核源代码的整体分布情况。
我们知道现代的操作系统一般由进程管理、内存管理、文件系统、驱动程序、网络等组成。
看一下Linux内核源代码就可看出,各个目录大致对应了这些方面。
Linux内核源代码的组成如下(假设相对于linux目录):arch这个子目录包含了此核心源代码所支持的硬件体系结构相关的核心代码。
如对于X86平台就是i386。
include这个目录包括了核心的大多数include文件。
另外对于每种支持的`体系结构分别有一个子目录。
init此目录包含核心启动代码。
mm此目录包含了所有的内存管理代码。
与具体硬件体系结构相关的内存管理代码位于arch/*/mm目录下,如对应于X86的就是arch/i386/mm/fault.c。
内核编译的步骤

内核编译的步骤以内核编译的步骤为标题,写一篇文章。
一、概述内核编译是将操作系统内核的源代码转换为可以在特定硬件平台上运行的机器代码的过程。
通过编译内核,可以定制操作系统,优化性能,添加新的功能等。
二、准备工作1. 获取内核源代码:可以从官方网站或版本控制系统中获取内核源代码。
2. 安装编译工具链:需要安装交叉编译工具链,以便在主机上编译生成目标平台上的可执行文件。
3. 配置编译环境:设置编译选项,选择适合的配置文件,配置内核参数。
三、配置内核1. 进入内核源代码目录:在命令行中切换到内核源代码目录。
2. 启动配置界面:运行命令“make menuconfig”或“make config”启动配置界面。
3. 配置选项:在配置界面中,可以选择内核所支持的功能和驱动程序,根据需求进行配置。
例如,选择硬件平台、文件系统、网络协议等。
4. 保存配置:保存配置并退出配置界面。
四、编译内核1. 清理编译环境:运行命令“make clean”清理编译环境,删除之前的编译结果。
2. 开始编译:运行命令“make”开始编译内核。
编译过程可能需要一段时间,取决于硬件性能和代码规模。
3. 生成内核镜像:编译完成后,将生成内核镜像文件,通常为“vmlinuz”或“bzImage”。
4. 安装内核模块:运行命令“make modules_install”安装内核模块到指定目录。
五、安装内核1. 备份原始内核:在安装新内核之前,建议备份原始内核以防止意外情况发生。
2. 安装内核镜像:将生成的内核镜像文件复制到引导目录,通常为“/boot”。
3. 配置引导程序:根据使用的引导程序(如GRUB或LILO),更新引导配置文件,添加新内核的启动项。
4. 重启系统:重启计算机,并选择新内核启动。
六、验证内核1. 登录系统:使用新内核启动系统后,使用合法的用户凭证登录系统。
2. 检查内核版本:运行命令“uname -r”可查看当前正在运行的内核版本。
uCOS-II实时操作系统内核源代码注释

/*********************************************************************************************************** uC/OS-II* 实时操作内核* 内存管理** (c) 版权 1992-2002, Jean J. Labrosse, Weston, FL* All Rights Reserved** 文件名 : OS_MEM.C* 作者 : Jean J. Labrosse* 注释 : 彭森 2007/9/2**********************************************************************************************************/#ifndef OS_MASTER_FILE#include "includes.h"#endif#if (OS_MEM_EN > 0) && (OS_MAX_MEM_PART > 0)/*********************************************************************************************************** 创建一个内存分区** 说明 : 创建一个固定大小的内存分区,这个内存分区通过uC/OS-II管理。
** 参数 : addr 内存分区的起始地址** nblks 来自分区的内存块的数目.** blksize 每个内存分区中的内存块的大小.** err 指向一个变量包含错误的信息,这个信息通过这个函数或其他来设置:** OS_NO_ERR 内存分区创建正确返回值. * OS_MEM_INVALID_ADDR 指定的是无效地址作为分区的内存存储空间* OS_MEM_INVALID_PART 没有未使用的有用的分区* OS_MEM_INVALID_BLKS 使用者指定一个无效的内存块(必须 >= 2)* OS_MEM_INVALID_SIZE 使用者指定一个无效的内存空间值* (必须大于指针的空间大小) * 返回值 : != (OS_MEM *)0 分区被创建* == (OS_MEM *)0 分区没有被创建由于无效的参数,没有未使用的分区可用**********************************************************************************************************/OS_MEM *OSMemCreate (void *addr, INT32U nblks, INT32U blksize, INT8U *err){#if OS_CRITICAL_METHOD == 3 /* Allocate storage for CPU status register 为CPU状态寄存器分配存储空间 */OS_CPU_SR cpu_sr;#endifOS_MEM *pmem;INT8U *pblk;void **plink;INT32U i;#if OS_ARG_CHK_EN > 0if (addr == (void *)0) { /* Must pass a valid address for the memory part. 必须是一个有效的内存部分*/*err = OS_MEM_INVALID_ADDR;return ((OS_MEM *)0);}if (nblks < 2) { /* Must have at least 2 blocks per partition 每个分区至少有两个分区*/*err = OS_MEM_INVALID_BLKS;return ((OS_MEM *)0);}if (blksize < sizeof(void *)) { /* Must contain space for at least a pointer 必须包含空间至少有一个指针*/*err = OS_MEM_INVALID_SIZE;return ((OS_MEM *)0);}#endifOS_ENTER_CRITICAL();pmem = OSMemFreeList; /* Get next free memory partition 得到下一个未使用的内存分区*/if (OSMemFreeList != (OS_MEM *)0) { /* See if pool offree partitions was empty 查看是否有未使用的分区空间是空的*/OSMemFreeList = (OS_MEM *)OSMemFreeList->OSMemFreeList;}OS_EXIT_CRITICAL();if (pmem == (OS_MEM *)0) { /* See if we have a memory partition 查看是否我们有一个内存分区*/*err = OS_MEM_INVALID_PART;return ((OS_MEM *)0);}plink = (void **)addr; /* Create linked list of free memory blocks 创建未使用的内存块的可连接的列表*/pblk = (INT8U *)addr + blksize;for (i = 0; i < (nblks - 1); i++) {*plink = (void *)pblk;plink = (void **)pblk;pblk = pblk + blksize;}*plink = (void *)0; /* Last memory block points to NULL 最后的内存块指针指向NULL*/pmem->OSMemAddr = addr; /* Store start address of memory partition 保存内存分区的起始地址*/pmem->OSMemFreeList = addr; /* Initialize pointer to pool of free blocks 为未使用的内存块初始化指针*/pmem->OSMemNFree = nblks; /* Store number of free blocks in MCB 在内存控制块中保存许多未使用的内存块*/pmem->OSMemNBlks = nblks;pmem->OSMemBlkSize = blksize; /* Store block size of each memory blocks 保存每个内存块的块大小*/*err = OS_NO_ERR;return (pmem);}/*$PAGE*//********************************************************************** ************************************* 得到一个内存控制块** 说明 : 从分区中得到一个内存块** 参数 : pmem 指针指向一个内存分区控制块** err 指向一个变量包含一个错误信息,这个错误信息通过这个函数或其他来设计** OS_NO_ERR 假如内存分区被正确的创建. * OS_MEM_NO_FREE_BLKS 假如没有更多的内存块被分配给调用者* OS_MEM_INVALID_PMEM 假如已经为'pmem'通过一个空指针** 返回值 : 一个指针指向一个内存控制块,假如没有察觉错误* 一个指针指向空指针,假如有错误被察觉到********************************************************************* *************************************/void *OSMemGet (OS_MEM *pmem, INT8U *err){#if OS_CRITICAL_METHOD == 3 /* Allocate storage for CPU status register 为CPU状态寄存器分配存储空间 */OS_CPU_SR cpu_sr;#endifvoid *pblk;#if OS_ARG_CHK_EN > 0if (pmem == (OS_MEM *)0) { /* Must point to a valid memory partition 必须指向一个有效的内存分区 */*err = OS_MEM_INVALID_PMEM;return ((OS_MEM *)0);}#endifOS_ENTER_CRITICAL();if (pmem->OSMemNFree > 0) { /* See if there are any free memory blocks 查看是否有其他未使用的内存块*/pblk = pmem->OSMemFreeList; /* Yes, point to next free memory block 是的,指针指向下一个未使用的内存块*/ pmem->OSMemFreeList = *(void **)pblk; /* Adjust pointer to new free list 调整指针指向一个新的未使用的空间列表*/pmem->OSMemNFree--; /* Oneless memory block in this partition 在这个分区中减少一个内存块*/OS_EXIT_CRITICAL();*err = OS_NO_ERR; /* Noerror 没有错误*/return (pblk); /* Return memory block to caller 返回内存控制块给调用者*/}OS_EXIT_CRITICAL();*err = OS_MEM_NO_FREE_BLKS; /* No, Notify caller of empty memory partition 告知调用者是空的内存分区*/return ((void *)0); /* Return NULL pointer to caller 返回NULL个调用者*/}/*$PAGE*//********************************************************************** ************************************* 释放一个内存块** 说明 : 返回一个内存块给分区** 参数 : pmem 指针指向内存分区控制块** pblk 指针指向被保留的内存块.** 返回值 : OS_NO_ERR 假如内存块是被插入的分区* OS_MEM_FULL 假如返回一个已经全部内存分区的内存块* (你释放了更多你分配的内存块!)* OS_MEM_INVALID_PMEM 假如指针'pmem'指向NULL。
Linux0.01内核源代码及注释

Bootsect.s(1-9)!! SYS_SIZE is the number of clicks (16 bytes) to be loaded.! 0x3000 is 0x30000 bytes = 196kB, more than enough for current! versions of linux ! SYS_SIZE 是要加载的节数(16 字节为1 节)。
0x3000 共为1 2 3 4 5 60x7c000x00000x900000x100000xA0000system 模块代码执行位置线路0x90200! 0x30000 字节=192 kB(上面Linus 估算错了),对于当前的版本空间已足够了。
!SYSSIZE = 0x3000 ! 指编译连接后system 模块的大小。
参见列表1.2 中第92 的说明。
! 这里给出了一个最大默认值。
!! bootsect.s (C) 1991 Linus Torvalds!! bootsect.s is loaded at 0x7c00 by the bios-startup routines, and moves! iself out of the way to address 0x90000, and jumps there.!! It then loads 'setup' directly after itself (0x90200), and the system! at 0x10000, using BIOS interrupts.!! NOTE! currently system is at most 8*65536 bytes long. This should be no! problem, even in the future. I want to keep it simple. This 512 kB! kernel size should be enough, especially as this doesn't contain the! buffer cache as in minix!! The loader has been made as simple as possible, and continuos! read errors will result in a unbreakable loop. Reboot by hand. It! loads pretty fast by getting whole sectors at a time whenever possible.!! 以下是前面这些文字的翻译:! bootsect.s (C) 1991 Linus Torvalds 版权所有!! bootsect.s 被bios-启动子程序加载至0x7c00 (31k)处,并将自己! 移到了地址0x90000 (576k)处,并跳转至那里。
Linux KVM虚拟化源代码分析文档
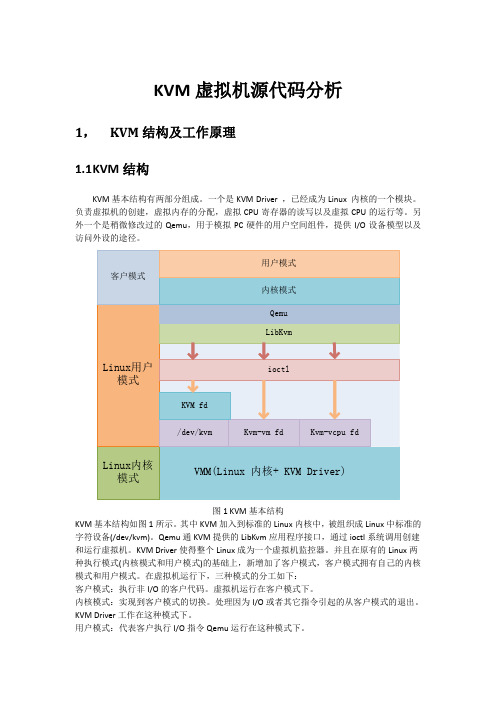
KVM虚拟机源代码分析1,KVM结构及工作原理1.1K VM结构KVM基本结构有两部分组成。
一个是KVM Driver ,已经成为Linux 内核的一个模块。
负责虚拟机的创建,虚拟内存的分配,虚拟CPU寄存器的读写以及虚拟CPU的运行等。
另外一个是稍微修改过的Qemu,用于模拟PC硬件的用户空间组件,提供I/O设备模型以及访问外设的途径。
图1 KVM基本结构KVM基本结构如图1所示。
其中KVM加入到标准的Linux内核中,被组织成Linux中标准的字符设备(/dev/kvm)。
Qemu通KVM提供的LibKvm应用程序接口,通过ioctl系统调用创建和运行虚拟机。
KVM Driver使得整个Linux成为一个虚拟机监控器。
并且在原有的Linux两种执行模式(内核模式和用户模式)的基础上,新增加了客户模式,客户模式拥有自己的内核模式和用户模式。
在虚拟机运行下,三种模式的分工如下:客户模式:执行非I/O的客户代码。
虚拟机运行在客户模式下。
内核模式:实现到客户模式的切换。
处理因为I/O或者其它指令引起的从客户模式的退出。
KVM Driver工作在这种模式下。
用户模式:代表客户执行I/O指令Qemu运行在这种模式下。
在KVM模型中,每一个Guest OS 都作为一个标准的Linux进程,可以使用Linux的进程管理指令管理。
在图1中./dev/kvm在内核中创建的标准字符设备,通过ioctl系统调用来访问内核虚拟机,进行虚拟机的创建和初始化;kvm_vm fd是创建的指向特定虚拟机实例的文件描述符,通过这个文件描述符对特定虚拟机进行访问控制;kvm_vcpu fd指向为虚拟机创建的虚拟处理器的文件描述符,通过该描述符使用ioctl系统调用设置和调度虚拟处理器的运行。
1.2K VM工作原理KVM的基本工作原理:用户模式的Qemu利用接口libkvm通过ioctl系统调用进入内核模式。
KVM Driver为虚拟机创建虚拟内存和虚拟CPU后执行VMLAUCH指令进入客户模式。
Linux的内核编译和内核模块的管理

Linux的内核编译和内核模块的管理一、内核的介绍内核室操作系统的最重要的组件,用来管理计算机的所有软硬件资源,以及提供操作系统的基本能力,RED hatenterpriselinux的许多功能,比如软磁盘整列,lvm,磁盘配额等都是由内核来提供。
1.1内核的版本与软件一样内核也会定义版本的信息,以便让用户可以清楚的辨认你用得是哪个内核的一个版本,linux内核以以下的的语法定义版本的信息MAJOR.MINOR.RELEASE[-CUSTOME]MAJOR:主要的版本号MINOR:内核的次版本号,如果是奇数,表示正在开发中的版本,如果是偶数,表示稳定的版本RELEASE:修正号,代表这个事第几次修正的内核CUSTOME 这个是由linux产品商做定义的版本编号。
如果想要查看内核的版本使用uname 来查看语法#uname [选项]-r --kernel-release 只查看目前的内核版本号码-s --kernel-name 支持看内核名称、-n --nodename 查看当前主机名字-v --kernel-version 查看当前内核的版本编译时间-m --machine 查看内核机器平台名称-p --processor 查看处理器信息-I --hard-platform 查看硬件平台信息-o --operating-system 查看操作系统的名称-a 查看所有1.2内核的组件内核通常会以镜像文件的类型来存储在REDHAT ENTERPRISE LINUX 中,当你启动装有REDHAT ENTERPRISE linux的系统的计算机时,启动加载器bootloader 程序会将内核镜像文件直接加载到程序当中,已启动内核与整个操作系统一般来说,REDHAT ENTERPRISE LINUX 会把内核镜像文件存储在/boot/目录中,文件名称vmlinuz-version或者vmlinux-version 其中version就是内的版本号内核模块组成linux内核的第二部分是内核模块,或者单独成为内核模块。
linux内核模块及内核编译过程

Linux内核模块及内核编译过程一、引言Linux内核是Linux操作系统的核心组件,负责管理系统的硬件和软件资源。
内核模块是一种动态加载到内核中的代码,用于扩展和添加新的功能。
本文将介绍Linux内核模块的概念、编写方法以及内核编译过程。
二、Linux内核模块内核模块是一种动态加载到内核中的代码,用于扩展和添加新的功能。
它是一种轻量级的解决方案,可以在不重新编译整个内核的情况下添加或删除功能。
内核模块可以使用内核提供的API,以实现与内核其他部分的交互。
编写内核模块需要了解内核的内部结构和API。
通常,内核模块是用C语言编写的,因为C语言与汇编语言有良好的交互性,并且内核本身也是用C语言编写的。
编写内核模块的基本步骤如下:1.编写模块的源代码:使用C语言编写模块的源代码,并确保遵循内核的编码风格和约定。
2.编译模块:使用内核提供的工具和方法将源代码编译成模块。
3.加载和卸载模块:使用insmod命令将模块加载到内核中,使用rmmod命令卸载模块。
三、内核编译过程内核编译是将源代码转换成可在计算机上运行的二进制代码的过程。
Linux内核的编译过程可以分为以下几个步骤:1.配置内核:使用make menuconfig或make xconfig等工具,根据需要选择要包含在内核中的功能和选项。
2.生成Makefile:根据配置结果生成Makefile文件,该文件用于指导make命令如何编译内核。
3.编译内核:使用make命令根据Makefile编译内核。
这个过程包括编译源代码、生成目标文件、链接目标文件等步骤。
4.安装内核:将编译好的内核映像安装到系统中,以便在启动时加载。
5.配置引导加载程序:将引导加载程序配置为加载新编译的内核映像。
四、总结本文介绍了Linux内核模块的概念、编写方法以及内核编译过程。
通过了解这些知识,我们可以更好地理解Linux操作系统的内部原理,并根据需要定制和优化系统的功能。
linux内核编译过程解释

linux内核编译过程解释
Linux内核是操作系统的核心部分,它控制着系统的资源管理、任务调度、驱动程序等重要功能。
编译Linux内核是一项非常重要的任务,因为它决定了系统的性能、稳定性和可靠性。
下面我们来了解一下Linux内核的编译过程。
1. 下载内核源代码:首先,我们需要从官方网站上下载Linux
内核的源代码。
这里我们可以选择下载最新的稳定版本或者是开发版,具体取决于我们的需求。
2. 配置内核选项:下载完源代码后,我们需要对内核进行配置。
这一步通常需要使用make menuconfig命令来完成。
在配置过程中,我们需要选择系统所需的各种驱动程序和功能选项,以及定制化内核参数等。
3. 编译内核:配置完成后,我们可以使用make命令开始编译内核。
编译过程中会生成一些中间文件和可执行文件,同时也会编译各种驱动程序和功能选项。
4. 安装内核:编译完成后,我们可以使用make install命令将内核安装到系统中。
这一步通常需要将内核文件复制到/boot目录下,并更新系统的引导程序以便正确加载新内核。
5. 重启系统:安装完成后,我们需要重启系统以使新内核生效。
如果新内核配置正确,系统应该能顺利地启动并正常工作。
总的来说,Linux内核的编译过程是一个相对复杂的过程,需要一定的技术和操作经验。
但是,通过了解和掌握相关的编译技巧和命
令,我们可以轻松地完成内核编译工作,并为系统的性能和稳定性做出贡献。
[重点]linux源码分析
![[重点]linux源码分析](https://img.taocdn.com/s3/m/0c4f44f3312b3169a551a443.png)
[重点]linux源码分析linux源码分析Linux内核源代码中的C语言代码Linux 内核的主体是以 GNU的 C 语言编写的,GNU为此提供了编译工具gcc。
GNU对 C 语言本身(在 ANSI C 基础上)做了不少扩充,可能是读者尚未见到过的。
另一方面,由于内核代码,往往会用到一些在应用程序设计中不常见的语言成分或编程技巧,也许使读者感到陌生。
本书并非介绍 GNU C语言的专著,也非技术手册,所以不在这里一一列举和详细讨论这些扩充和技巧。
再说,离开具体的情景和上下文,罗列一大堆规则,对于读者恐怕也没有多大帮助。
所以,我们在这里只是对可能会影响读者阅读 Linux 内核源程序,或使读者感到困惑的一些扩充和技巧先作一些简单的介绍。
以后,随着具体的情景和代码的展开,在需要时还会结合实际加以补充。
首先,gcc 从 C++语言中吸收了“inline”和“const”。
其实,GNU 的 C 和C++是合为一体的,gcc既是 C 编译又是 C++编译,所以从 C++中吸收一些东西到 C 中是很自然的。
从功能上说,inline 函数的使用与#define 宏定义相似,但更有相对的独立性,也更安全。
使用 inline函数也有利于程序调试。
如果编译时不加优化,则这些inline 就是普通的、独立的函数,更便于调试。
调试好了以后,再采用优化重新编译一次,这些 inline函数就像宏操作一样融入了引用处的代码中,有利于提高运行效率。
由于 inline 函数的大量使用,相当一部分的代码从.c 文件移入了.h 文件中。
还有,为了支持 64 位的CPU结构(Alpha 就是 64 位的),gcc 增加了一种新的基本数据类型“longlong int”,该类型在内核代码中常常用到。
许多 C 语言都支持一些“属性描述符”(attribute),如“aligned”、“packed”等等;gcc 也支持不少这样的描述符。
这些描述符的使用等于是在 C 语言中增加了一些新的保留字。
易语言内核变速齿轮源码

易语言内核变速齿轮源码(最新版)目录一、易语言变速齿轮源码概述二、易语言变速齿轮源码的实现思路三、易语言变速齿轮源码的编写技巧与注意事项四、易语言变速齿轮源码的应用场景与举例五、易语言变速齿轮源码的未来发展趋势与展望正文一、易语言变速齿轮源码概述易语言变速齿轮源码是指用易语言编写的一种可以改变计算机程序运行速度的源代码。
通过变速齿轮源码,用户可以自由调整程序的运行速度,从而达到快速运行或慢速运行的目的。
易语言变速齿轮源码在游戏辅助、程序优化等领域有着广泛的应用。
二、易语言变速齿轮源码的实现思路易语言变速齿轮源码的实现主要分为两个方面:线程控制和 Windows API 函数调用。
1.线程控制:通过创建线程,可以实现对程序运行速度的控制。
当线程启动时,可以通过调用 Sleep() 函数或创建定时器来暂停线程的执行,从而实现速度的控制。
2.Windows API 函数调用:通过调用 Windows API 函数,可以实现对系统时钟频率的修改,从而进一步控制程序的运行速度。
例如,可以通过调用 apihook 函数来拦截 sleep 函数,修改其参数,从而实现速度的变化。
三、易语言变速齿轮源码的编写技巧与注意事项1.编写变速齿轮源码时,需要熟练掌握易语言的基本语法和 Windows API 函数的使用方法。
2.为了保证源码的稳定性和可靠性,应尽量减少全局变量的使用,避免出现不必要的错误。
3.在编写源码时,应注意代码的结构和可读性,以便于他人阅读和理解。
4.在使用变速齿轮源码时,应注意避免对系统造成损害,以免导致系统崩溃或数据丢失。
四、易语言变速齿轮源码的应用场景与举例易语言变速齿轮源码在游戏辅助、程序优化等领域有着广泛的应用。
例如,在游戏过程中,通过使用变速齿轮源码,可以实现游戏速度的自由调整,从而达到快速通关或慢速体验的目的。
五、易语言变速齿轮源码的未来发展趋势与展望随着易语言编程的普及和计算机技术的不断发展,易语言变速齿轮源码在未来将继续保持其应用价值。
kbuild 编译过程

kbuild 编译过程kbuild是用于编译Linux内核的工具链,它提供了一种简洁而高效的方式来管理和构建内核源代码。
本文将详细介绍kbuild的编译过程,并逐步解答相关问题。
一、什么是kbuild?kbuild是Linux内核源代码的编译系统,它由Makefile和一些特殊的工具组成。
它的主要作用是根据Makefile中的规则和依赖关系,自动化地完成内核的编译、链接和安装等工作。
同时,kbuild还提供了很多功能强大且灵活的特性,如支持模块化编译、优化编译过程、生成调试信息等。
二、kbuild的工作原理kbuild的工作原理基于Makefile和一系列的规则。
Makefile是一种用于自动化构建的文件,它定义了编译的规则、依赖关系和操作指令等。
以Linux内核源代码为例,其Makefile通常包含了一系列的变量和规则,如编译器选项、目标文件列表和链接选项等。
kbuild会根据这些信息来生成编译命令,并自动地执行编译、链接和安装等操作。
三、kbuild的编译过程1. 配置内核参数在编译内核之前,需要先配置内核的一些参数,如硬件支持选项、调试选项和功能模块等。
这可以通过执行`make config`或`make menuconfig`等命令来完成。
配置完成后,会生成一个.config文件,里面包含了所有的配置信息。
2. 构建编译环境在配置完成后,需要准备编译所需的工具和库文件。
这可以通过执行`make prepare`命令来自动完成,它会检查系统的环境和依赖关系,并自动下载安装所需的工具链和库文件等。
3. 编译内核源代码一切就绪后,可以执行`make`命令来编译内核源代码。
在这一步中,kbuild 会遍历整个源代码树,并根据Makefile中的规则来确定每个目标文件的编译命令。
编译过程中,kbuild会自动管理依赖关系,并根据需要执行增量编译,以提高编译效率。
4. 链接内核编译完成后,会生成一系列的目标文件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Source code:Hello.c#include <linux/init.h>#include <linux/module.h>MODULE_LICENSE("Dual BSD/GPL");static int hello_init(void){printk(KERN_ALERT "Hello, world\n");return 0;}static void hello_exit(void){printk(KERN_ALERT "Goodbye, cruel world\n");}module_init(hello_init);module_exit(hello_exit);Makefileobj-m :=hello.oK_DIR = $(shell uname -r)PWD = $(shell pwd)all:make -C /lib/modules/$(K_DIR)/build M=$(PWD) modules clean:make -C /lib/modules/$(K_DIR)/build M=$(PWD) clean如果模块有多个文件,可以这样写obj-m :=scull.oscull-objs := main.o pipe.o access.o将生成scull.ko模块模块安装:insmod hello.ko显示已装载的模块:lsmod模块卸载:rmmod hello编译环境fedro9 kernel 2.6.25-14.fc9.i686安装内核源码包:rpm –Uvh kernel-2.6.25-14.fc9.i686.src.rpm这个命令将 RPM 内容写到路径 /usr/src/redhat/SOURCE我把代码2.6.25解到/usr/src/kernels/2.6.25-14.fc9.i686下,这和我的模块编译用的Makefile有关。
可能遇到的问题1.出现很多编译错误到kernel所在目录执行make prepare/ make config,这是没有配置好源码树的原因。
可能还需要KBUILD2.错误提示: /bin/sh: scripts/mod/modpost: No such file or directory出现这样的错误,说明scripts下没有生成相应的文件MODPOST,cd到kernel所在目录,执行: make scripts3.安装时失败,提示invalid module format,多是因为编译依据的内核与操作系统不一致(装载时会做很多检查,比如是否支持SMP,这些都是通过make config设置的,也可以将/boot/config-2.6.25-14.fc9.i686 拷贝到内核源代码目录下如/usr/src/kernels/2.6.25-14.fc9.i686 ),首先要保证内核与操作系统一致。
然后,需要修改kernel源代码根目录下的MakefileEXTRAVERSION = -14.fc9.i686 (这个值根据uname –r 的返回结果修改,我的为2.6.25-14.fc9.i686)4.如果没有看到打印信息可以到文件/var/log/messages中去找Fedora9中安装Vmware Tools安装失败问题2012-02-26 20:16:18分类:嵌入式今天我在Fedora9中安装VMware Tools的时候出现以下问题(一路回车过来):What is the location of the directory of C header files that match your running kernel?[/usr/src/linux/include]The path "/usr/src/linux/include" is not an existing directory.网上查找资料后得知出现这样的错误的主要原因是VMware无法找到内核的头文件,或者内核的头文件和当前的内核不相符,顺便查看目录/usr/src/ 根本没有linux这个目录,只有/usr/src/redhat.最终解决方案如下:第一步:下载相应的kernel devel包(即后面下载的kernel-devel-2.6.25-14.fc9.i686.rpm)先查看下内核版本号[root@localhost ~]# uname -r2.6.25-14.fc9.i686[root@localhost ~]# rpm -q kernel-i686-devel //-q 使用询问模式,当遇到任何问题时,rpm指令会先询问用户。
package kernel-xen-devel is not installed这是i686的内核,所以,要安装对应版本号的kernel-i686-devel rpm包:下载地址:/index.php3/stat/4/idpl/7201713/com/kernel-devel-2.6.25-14.fc9.i686.rpm. html第二步:安装kernel-devel-2.6.25-14.fc9.i686.rpm现在遇到个问题,怎么把PC机下载的文件放到虚拟机里面去,因为vmware tools没安装失败,不能用共享哪种方式了,这里借助于虚拟光驱UltraISO将kerc6.rpm另存为kernel-devel-2.6.25-14.fc9.i686.iso,然后再用虚拟机加载ISO文件,就可以在虚拟光驱的光驱里面看到kernel-devel-2.6.25-14.fc9.i686.rpm文件了把kernel-devel-2.6.25-14.fc9.i686.rpm复制到/usr/src目录下面[root@localhost ~]# rpm -ivh kernel-devel-2.6.25-14.fc9.i686.rpm//-v 显示指令执行过程-i安装rpm包-h或--hash安装时列出标记#完成安装后,在/usr/src/下已经多出了一个kernels目录注意:如果你解压后发现在/usr/src目录下没有kernels目录,但是有个usr目录,请把usr目录下的kernels 复制到/usr/src目录下(网友遇到情况)[root@localhost src]# cd kernels[root@localhost kernels]# ls2.6.20-2925.9.fc7.i686.rpm表明kernel-xen-devel已经装好了再次使用vmware-install.pl安装,./vmware-install.pl就一直enter,装完VMware Tools(可自动找到配套的the directory of C header files了,哈)在安装的最后阶段,会出现:Do you want to change your guest X resolution? (yes/no) [no] yPlease choose one of the following display sizes (1 - 13):[1] "640x480"[2]< "800x600"[3] "1024x768"[4] "1152x864"[5] "1280x800"[6] "1152x900"[7] "1280x1024"[8] "1376x1032"[9] "1400x1050"[10] "1680x1050"[11] "1600x1200"[12] "1920x1200"[13] "2364x1773"Please enter a number between 1 and 13:[3]重启系统reboot,OK了Sentimental编译时内核怎么生成的ko文件?2012-05-06 22:40:37发信人: Sentimental (Sentimental), 信区: Embedded标题: 编译时内核怎么生成的ko文件?发信站: 水木社区(Sun May 6 22:40:37 2012), 站内编译时内核怎么生成的ko文件?接我的上一贴,我用的是嵌入式Linux,在内核生成modules时出现问题。
1首先我在make menuconfig时选择了我想编译进内核的模块,比如CONFIG_USB_SERIAL, CONFIG_USB_STORAGE。
2编译内核成功3make *modules4make module module_install但是在我的开发板$(target)/lib/modules/(version)/kernel中却只有STORAGE的ko文件。
回到内核中查看,~usb/storage中生成了ko但是~usb/serial中只有o没有ko,说明根本没有生成。
比较了两个文件夹的Kconfig与Makefile,发现木有大的功能上的差别,也没有提到模块的生成问题。
查看了一下根目录的.config中CONFIG_USB_SERIAL明明定义了的,auto.conf也定义了。
现在实在不明白为什么没有生成我配置了的ko文件?在哪里改定义?估计现在生成以及安装的模块可能都是某个文件中默认的,不过在哪里改?希望板上大牛指教,或者交流一下!先多谢!※来源:·水木社区·[FROM: 220.181.118.*]Re: 编译时内核怎么生成的ko文2012-05-07 09:52:35lm件?发信人: lm (lm), 信区: Embedded标题: Re: 编译时内核怎么生成的ko文件?发信站: 水木社区(Mon May 7 09:52:35 2012), 站内生成ko文件,要make menuconfig的时候模块选择为“M”吧※来源:·水木社区·[FROM: 210.160.252.*]Re: 编译时内核怎么生成的ko文2012-05-07 12:28:17 Sentimental件?发信人: Sentimental (Sentimental), 信区: Embedded标题: Re: 编译时内核怎么生成的ko文件?发信站: 水木社区(Mon May 7 12:28:17 2012), 站内你好,我想问一下设成y与设成M有什么区别?有次我看网上说使用SCSI时设为y比较好,这些也设成y 了【在lm 的大作中提到: 】: 生成ko文件,要make menuconfig的时候模块选择为“M”吧Re: 编译时内核怎么生成的ko文2012-05-07 12:38:39 WinterChen件?发信人: WinterChen (Xiaohu), 信区: Embedded标题: Re: 编译时内核怎么生成的ko文件?发信站: 水木社区(Mon May 7 12:43:40 2012), 站内请参考{LINUX_DIR}/Documentation/kbuild/makefiles.txtm就是把该“功能”编译生成*.ko,需要手动insmod,loader负责运行相应的init_module。