【计算机科学】_连续型adaboost算法_期刊发文热词逐年推荐_20140725
【计算机科学】_bp算法_期刊发文热词逐年推荐_20140723
推荐指数 5 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
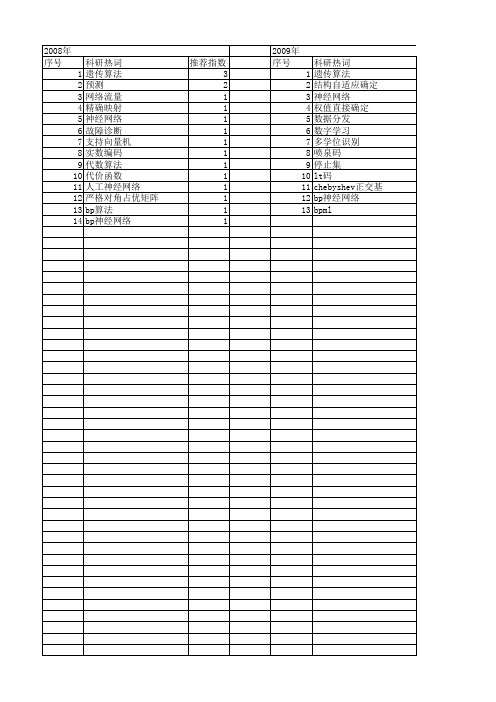
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14
科研热词 遗传算法 预测 网络流量 精确映射 神经网络 故障诊断 支持向量机 实数编码 代数算法 代价函数 人工神经网络 严格对角占优矩阵 bp算法 bp神经网络
推荐指数 3 2 1 1 1 1 1 1 1 1 1 1 1 1
推荐指数 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
2011年 科研热词 神经网络 预测误差 遗传算法 自适应 网络管理 粗糙集理论 短期负荷预测 混沌 数字识别 数字水印 故障诊断 改进bp网络 微粒群算法 小波变换 分布式 事件驱动 l-m优化法 bp算法 bp神经网络 推荐指数 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13
科研热词 遗传算法 结构自适应确定 神经网络 权值直接确定 数据分发 数字学习 多学位识别 喷泉码 停止集 lt码 chebyshe 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
科研热词 神经网络 隐神经元 遗传算法 网络流量特性 粒子群优化 神经网络算法 玉米病害 流量预测模型 正交基函数 模糊神经网络 权值与结构确定法 权值 最优结构 数学形态学 改进bp算法 建模 小波分析 学习算法 多输入 多目标优化 图像处理技术 函数逼近 人工神经网络 交通流量预测 matlab laguerre正交多项式 bp算法 bp神经网络
adaboost案例

adaboost案例摘要:1.简介2.AdaBoost 算法原理3.AdaBoost 算法应用案例4.总结正文:1.简介AdaBoost(Adaptive Boosting)是一种自适应增强算法,由Yoav Freund 和Robert Schapire 于1995 年提出。
它是一种基于Boosting 算法的集成学习方法,通过组合多个弱学习器(决策树)来提高预测性能。
AdaBoost 算法具有良好的泛化能力,广泛应用于数据挖掘、机器学习等领域。
2.AdaBoost 算法原理AdaBoost 算法主要包含两个核心部分:加权训练和加权组合。
(1)加权训练:对于每个训练样本,算法根据当前弱学习器的预测结果,赋予样本不同的权重。
错误分类的样本权重增加,正确分类的样本权重减小。
然后,根据新的权重对样本进行加权训练,得到新的弱学习器。
(2)加权组合:多次迭代训练弱学习器,每次迭代过程中,选择加权误差最小的弱学习器作为当前强学习器。
最后,将所有弱学习器按权重组合成最终的强学习器。
3.AdaBoost 算法应用案例假设有一个手写数字识别问题,我们可以使用AdaBoost 算法来提高识别准确率。
(1)收集数据:收集手写数字的数据集,如MNIST 数据集。
(2)特征提取:将数字图片转换为特征向量,如使用HOG(Histogram of Oriented Gradients)特征。
(3)训练弱学习器:使用决策树作为弱学习器,对训练数据进行加权训练。
(4)组合强学习器:将多个弱学习器按权重组合成强学习器。
(5)测试与评估:使用测试数据集评估强学习器的性能。
4.总结AdaBoost 算法是一种有效的集成学习方法,通过组合多个弱学习器来提高预测性能。
其核心思想是加权训练和加权组合,具有良好的泛化能力。
adaboost分类算法

adaboost分类算法
Adaboost(Adaptive Boosting)是一种集成学习(Ensemble Learning)方法,用于解决二分类问题。
它通过组合多个弱分类器(weak classifiers)来构建一个强分类器(strong classifier)。
以下是Adaboost分类算法的主要步骤:
1. 初始化权重:对于N个训练样本,初始化每个样本的权重为相等值,即w1=1/N, w2=1/N, ..., wN=1/N。
2. 对于每个弱分类器:
a. 训练一个弱分类器,该分类器在当前样本权重下能够取得较低的分类错误率。
b. 计算该弱分类器的权重,该权重取决于该分类器的分类错误率。
分类错误率越小,权重越大。
3. 更新样本权重:根据当前的弱分类器的权重,调整每个样本的权重。
如果某个样本被错误分类,则增加它的权重,反之减少。
4. 重复步骤2和步骤3,直到所有的弱分类器都被训练完毕。
5. 构建强分类器:将每个弱分类器的权重与它们的预测结果组合起来,得到最终的强分类器。
6. 对新样本进行分类:根据强分类器,对新的样本进行分类。
Adaboost算法通过迭代地调整样本权重,训练并组合多个弱
分类器来提高分类性能。
弱分类器通常是基于一些简单的特征或规则进行分类。
每个弱分类器的权重根据其分类性能进行调整,以便对常被错误分类的样本给予更多的关注。
Adaboost算法在实际应用中表现出较好的性能,能够有效地处理复杂的分类问题。
它具有较强的鲁棒性和泛化能力,能够自适应地调整样本权重,对数据中的异常或噪声具有较强的抵抗力。
adaboost算法程序matlab

adaboost算法程序matlabAdaboost算法是一种常用的集成学习方法,广泛应用于分类问题中。
它的核心思想是通过集成多个弱分类器,来构建一个强分类器,从而提高整体分类的准确性。
本文将介绍Adaboost算法的原理和主要步骤,并使用Matlab编写一个简单的Adaboost算法程序。
Adaboost算法的原理非常简单,它通过迭代的方式,每次训练一个弱分类器,并根据分类结果调整样本权重,使得分类错误的样本在下一轮训练中得到更多的关注。
最终,将所有弱分类器的结果进行加权投票,得到最终的分类结果。
Adaboost算法的主要步骤如下:1. 初始化样本权重。
将所有样本的权重初始化为相等值,通常为1/N,其中N为样本数量。
2. 迭代训练弱分类器。
在每一轮迭代中,根据当前样本权重训练一个弱分类器。
弱分类器可以是任何分类算法,如决策树、支持向量机等。
3. 计算分类误差率。
根据当前弱分类器的分类结果,计算分类误差率。
分类误差率定义为分类错误的样本权重之和。
4. 更新样本权重。
根据分类误差率,更新样本权重。
分类错误的样本权重会增加,而分类正确的样本权重会减少。
5. 计算弱分类器权重。
根据分类误差率,计算当前弱分类器的权重。
分类误差率越小的弱分类器权重越大,反之越小。
6. 更新样本权重分布。
根据弱分类器的权重,更新样本权重分布。
分类错误的样本权重会增加,而分类正确的样本权重会减少。
7. 终止条件判断。
如果达到预定的迭代次数或分类误差率满足终止条件,则停止迭代。
8. 构建强分类器。
将所有弱分类器的结果进行加权投票,得到最终的分类结果。
权重越大的弱分类器对分类结果的贡献越大。
接下来,我们使用Matlab编写一个简单的Adaboost算法程序。
假设我们有一个二分类问题的训练集,包含N个样本和D个特征。
我们使用决策树作为弱分类器。
我们需要定义一些参数,如迭代次数和弱分类器数量。
然后,我们初始化样本权重和弱分类器权重。
【计算机科学】_神经网络学习_期刊发文热词逐年推荐_20140724

科研热词 神经网络 风险评估 集成学习 遗传规划 遗传算法 进化泛函网络 语音识别 粒子群 神经元函数 特征项 混合基函数 权重 敏感系数 支持向量机 小波神经网络(wnn) 小波分析 函数逼近 入侵检测 信息 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
2011年 科研热词 神经网络 特征抽取 深网入口 机器学习 预测误差 粗逻辑神经网络 粗糙集 粗糙神经元 短期负荷预测 模糊神经网络 模糊推理 数字识别 改进bp网络 安全态势 天气预测 l-m优化法 bp算法 推荐指数 4 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
科研热词 隐神经元 贡献因子 蛋白质二级预测 结构信息 离散hopfield 神经网络 特征提取 正交基函数 正交化 样本属性 权值与结构确定法 权值 最优结构 径向基网络 学习算法 奇异值分解 多输入 噪声数字识别 函数逼近 人脸识别 rbf神经网络 laguerre正交多项式
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
科研热词 集成学习 连续学习 软件可靠性早期预测 蚁群算法 矩阵伪逆 特征选择 混沌神经网络 泛函神经元 概率神经网络 时空总和 忆阻器 布尔函数 学习算法 奇偶校验问题 基函数 分类 二进神经网络 lvq神经网络 lasso回归方法 lars算法 bp神经网络 bagging
adaboost算法原理

聚类和分类的区别是什么?一般对已知物体类别总数的识别方式我们称之为分类,并且训练的数据是有标签的,比如已经明确指定了是人脸还是非人脸,这是一种有监督学习。
也存在可以处理类别总数不确定的方法或者训练的数据是没有标签的,这就是聚类,不需要学习阶段中关于物体类别的信息,是一种无监督学习。
Haar分类器实际上是Boosting算法的一个应用,Haar分类器用到了Boosting算法中的AdaBoost算法,只是把AdaBoost算法训练出的强分类器进行了级联,并且在底层的特征提取中采用了高效率的矩形特征和积分图方法。
在2001年,Viola和Jones两位大牛发表了经典的《Rapid Object D etection u sing a Boosted》【2】,在AdaBoost》【1】和《Robust Real-Time Face DetectionCascade of Simple Features算法的基础上,使用Haar-like小波特征和积分图方法进行人脸检测,他俩不是最早使用提出小波特征的,但是他们设计了针对人脸检测更有效的特征,并对AdaBoost训练出的强分类器进行级联。
这可以说是人脸检测史上里程碑式的一笔了,也因此当时提出的这个算法被和Jochen Maydt两位大牛将这个称为Viola-Jones检测器。
又过了一段时间,Rainer Lienhart检测器进行了扩展《An Extended Set of Haar-like Features for Rapid Object Detection》【3】,最终形成了OpenCV现在的Haar分类器。
Haar分类器 = Haar-like特征 + 积分图方法 + AdaBoost + 级联;Haar分类器算法的要点如下:①使用Haar-like特征做检测。
)对Haar-like特征求值进行加速。
②使用积分图(Integral Image③使用AdaBoost算法训练区分人脸和非人脸的强分类器。
Adaboost算法应用论文

Adaboost算法应用论文摘要:在检测色情图片时,提取出人体关键部位特征信息与姿态信息,利用机器统计学习方法训练出一些分类器模型,进而形成一个决策分类器来实现对图片的分类,同时尽可能地优化算法,提高算法的时效性与准确性。
1 Adaboost算法简介Adaboost算法是数据挖掘技术中的常用的迭代算法之一,属于特征分类机器学习算法。
该算法解决问题的步骤如下:①选择训练样本集M,确定其中正例样本X和负例样本Y,并设定最大的训练循环次数T;②设置训练样本的初始化概率分布值为1/n,即初始化样本的权重值;③迭代过程:a根据样本的概率分布训练弱分类器;b求解计算出弱分类器的错误率;c再选择确定一个合适的阈值,减小误差,使误差最小;d根据上述结果更改样本权重值。
经过循环T次后,就会得到T个弱分类器,按照它们更新的权重进行叠加,将得到最终的强分类器,问题求解完成。
2 Adaboost算法在图像定位与过滤中的研究应用2.1 肤色检测模型色情网站中都含有大量的色情照片,而色情照片最典型的特征就是照片中皮肤裸露面积较大,肤色检测模型就是快速定位人体裸露区域的,该模型目前主要有基于像素、基于区域两大类建模方法。
目前大多采用归一化RGB和YIQ空间上基于像素定位的肤色检测模型。
在归一化的RGB颜色空间上计算某像素的r=R/(R+G+B)、g=G/(R+G+B),如果它们同时满足下面四个条件:0.333<r<0.664;0.246<g<0.398;r>g;g≥0.5-0.5r。
基本上就可以判定该像素是皮肤的颜色了,但是对于有些像素颜色还是不能准确判定的,这就需要引进YIQ颜色空间来进一步判断了。
YIQ颜色空间与RGB颜色空间的关系可用公式表示为:YIQ=0.299 0.587 0.1140.596 -0.274-0.3220.211 -0.523 -0.312·RGB利用上述公式可以求出I分量的值,如果15≤I≤80,这时就可以断定该像素属于皮肤的颜色了。
ADABOOST算法

目前因为做人脸识别的一个小项目,用到了AdaBoost的人脸识别算法,因为在网上找到的所有的AdaBoost的简介都不是很清楚,让我看看头脑发昏,所以在这里打算花费比拟长的时间做一个关于AdaBoost算法的详细总结.希望能对以后用AdaBoost的同学有所帮助.而且给出了关于AdaBoost实现的一些代码.因为会导致篇幅太长,所以这里把文章分开了,还请见谅.第二局部的地址请见:辛苦打字截图不容易,请标明出处.提到AdaBoost的人脸识别,不得不提的几篇大牛的文章可以看看,但是大牛的文章一般都是只有主要的算法框架,没有详细的说明.大牛论文推荐:1. Robust Real-time Object Detection, Paul Viola, Michael Jones2. Rapid Object Detection using a Boosted Cascade of Simple Features, 作者同上.还有一篇北大的本科生的毕业论文也不错:基于AdaBoost 算法的人脸检测,赵楠.另外,关于我写的AdaBoost的人脸识别程序的下载地址:1. C++版本:说明:需要自己配置opencv, 自己配置分类器.在程序运行前会捕捉10帧用户图像,计算人脸平均面积,这个过程不会有显示,但是程序没有出问题,稍等一会就会出现摄像头信息.2. C#版本:说明:使用了emgucv的库,需要自己重新添加引用动态库文件.两个版本的程序都能正确运行,没有任何问题.1. Adaboost方法的引入1.1 Boosting方法的提出和开展在了解Adaboost方法之前,先了解一下Boosting方法.回答一个是与否的问题,随机猜想可以获得50%的正确率.如果一种方法能获得比随机猜想稍微高一点的正确率,如此就可以称该得到这个方法的过程为弱学习;如果一个方法可以显著提高猜想的正确率,如此称获取该方法的过程为强学习.1994年,Kearns和Valiant证明,在Valiant的PAC〔Probably ApproximatelyCorrect〕模型中,只要数据足够多,就可以将弱学习算法通过集成的方式提高到任意精度.实际上,1990年,SChapire就首先构造出一种多项式级的算法,将弱学习算法提升为强学习算法,就是最初的Boosting算法.Boosting意思为提升、加强,现在一般指将弱学习提升为强学习的一类算法.1993年,Drucker和Schapire首次以神经网络作为弱学习器,利用Boosting算法解决实际问题.前面指出,将弱学习算法通过集成的方式提高到任意精度,是Kearns和Valiant在1994年才证明的,虽然Boosting方法在1990年已经提出,但它的真正成熟,也是在1994年之后才开始的.1995年,Freund提出了一种效率更高的Boosting算法.1.2 AdaBoost算法的提出1995年,Freund和Schapire提出了Adaboost算法,是对Boosting算法的一大提升.Adaboost是Boosting家族的代表算法之一,全称为Adaptive Boosting.Adaptively,即适应地,该方法根据弱学习的结果反应适应地调整假设的错误率,所以Adaboost不需要预先知道假设的错误率下限.也正因为如此,它不需要任何关于弱学习器性能的先验知识,而且和Boosting算法具有同样的效率,所以在提出之后得到了广泛的应用.首先,Adaboost是一种基于级联分类模型的分类器.级联分类模型可以用如下图表示:级联分类器介绍:级联分类器就是将多个强分类器连接在一起进展操作.每一个强分类器都由假如干个弱分类器加权组成,例如,有些强分类器可能包含10个弱分类器,有些如此包含20个弱分类器,一般情况下一个级联用的强分类器包含20个左右的弱分类器,然后在将10个强分类器级联起来,就构成了一个级联强分类器,这个级联强分类器中总共包括200假如分类器.因为每一个强分类器对负样本的判别准确度非常高,所以一旦发现检测到的目标位负样本,就不在继续调用下面的强分类器,减少了很多的检测时间.因为一幅图像中待检测的区域很多都是负样本,这样由级联分类器在分类器的初期就抛弃了很多负样本的复杂检测,所以级联分类器的速度是非常快的;只有正样本才会送到下一个强分类器进展再次检验,这样就保证了最后输出的正样本的伪正<false positive>的可能性非常低.也有一些情况下不适用级联分类器,就简单的使用一个强分类器的情况,这种情况下一般强分类器都包含200个左右的弱分类器可以达到最优效果.不过级联分类器的效果和单独的一个强分类器差不多,但是速度上却有很大的提升.级联结构分类器由多个弱分类器组成,每一级都比前一级复杂.每个分类器可以让几乎所有的正例通过,同时滤除大局部负例.这样每一级的待检测正例就比前一级少,排除了大量的非检测目标,可大大提高检测速度.其次,Adaboost是一种迭代算法.初始时,所有训练样本的权重都被设为相等,在此样本分布下训练出一个弱分类器.在第〔=1,2,3, …T,T为迭代次数〕次迭代中,样本的权重由第-1次迭代的结果而定.在每次迭代的最后,都有一个调整权重的过程,被分类错误的样本将得到更高的权重.这样分错的样本就被突出出来,得到一个新的样本分布.在新的样本分布下,再次对弱分类器进展训练,得到新的弱分类器.经过T次循环,得到T个弱分类器,把这T个弱分类器按照一定的权重叠加起来,就得到最终的强分类器.2. 矩形特征2.1 Haar特征\矩形特征AdaBoost算法的实现,采用的是输入图像的矩形特征,也叫Haar特征.下面简要介绍矩形特征的特点.影响Adaboost检测训练算法速度很重要的两方面是特征的选取和特征值的计算.脸部的一些特征可以由矩形特征简单地描绘.用图2示X:上图中两个矩形特征,表示出人脸的某些特征.比如中间一幅表示眼睛区域的颜色比脸颊区域的颜色深,右边一幅表示鼻梁两侧比鼻梁的颜色要深.同样,其他目标,如眼睛等,也可以用一些矩形特征来表示.使用特征比单纯地使用像素点具有很大的优越性,并且速度更快.在给定有限的数据情况下,基于特征的检测能够编码特定区域的状态,而且基于特征的系统比基于象素的系统要快得多.矩形特征对一些简单的图形结构,比如边缘、线段,比拟敏感,但是其只能描述特定走向〔水平、垂直、对角〕的结构,因此比拟粗略.如上图,脸部一些特征能够由矩形特征简单地描绘,例如,通常,眼睛要比脸颊颜色更深;鼻梁两侧要比鼻梁颜色要深;嘴巴要比周围颜色更深.对于一个24×24 检测器,其内的矩形特征数量超过160,000 个,必须通过特定算法甄选适宜的矩形特征,并将其组合成强分类器才能检测人脸.常用的矩形特征有三种:两矩形特征、三矩形特征、四矩形特征,如图:由图表可以看出,两矩形特征反映的是边缘特征,三矩形特征反映的是线性特征、四矩形特征反映的是特定方向特征.特征模板的特征值定义为:白色矩形像素和减去黑色矩形像素和.接下来,要解决两个问题,1:求出每个待检测子窗口中的特征个数.2:求出每个特征的特征值.子窗口中的特征个数即为特征矩形的个数.训练时,将每一个特征在训练图像子窗口中进展滑动计算,获取各个位置的各类矩形特征.在子窗口中位于不同位置的同一类型矩形特征,属于不同的特征.可以证明,在确定了特征的形式之后,矩形特征的数量只与子窗口的大小有关[11].在24×24的检测窗口中,矩形特征的数量约为160,000个.特征模板可以在子窗口内以"任意〞尺寸"任意〞放置,每一种形态称为一个特征.找出子窗口所有特征,是进展弱分类训练的根底.2.2子窗口内的条件矩形,矩形特征个数的计算如以下图的一个m*m大小的子窗口,可以计算在这么大的子窗口内存在多少个矩形特征.以m×m 像素分辨率的检测器为例,其内部存在的满足特定条件的所有矩形的总数可以这样计算:对于m×m 子窗口,我们只需要确定了矩形左上顶点A<x1,y1>和右下顶点B<x2,63> ,即可以确定一个矩形;如果这个矩形还必须满足下面两个条件〔称为<s, t>条件,满足<s, t>条件的矩形称为条件矩形〕:1> x 方向边长必须能被自然数s 整除〔能均等分成s 段〕;2> y 方向边长必须能被自然数t 整除〔能均等分成t 段〕;如此, 这个矩形的最小尺寸为s×t 或t×s, 最大尺寸为[m/s]·s×[m/t]·t 或[m/t]·t×[m/s]·s;其中[ ]为取整运算符.2.3条件矩形的数量我们通过下面两步就可以定位一个满足条件的矩形:由上分析可知,在m×m 子窗口中,满足<s, t>条件的所有矩形的数量为:实际上,<s, t>条件描述了矩形特征的特征,下面列出了不同矩形特征对应的<s, t>条件:下面以24×24 子窗口为例,具体计算其特征总数量:下面列出了,在不同子窗口大小内,特征的总数量:3. 积分图3.1 积分图的概念在获取了矩形特征后,要计算矩形特征的值.Viola等人提出了利用积分图求特征值的方法.积分图的概念可用图3表示:坐标A<x,y>的积分图是其左上角的所有像素之和〔图中的阴影局部〕.定义为:其中ii<x,y>表示积分图,i<x,y>表示原始图像,对于彩色图像,是此点的颜色值;对于灰度图像,是其灰度值,X围为0~255.在上图中,A<x,y>表示点<x,y>的积分图;s<x,y>表示点<x,y>的y方向的所有原始图像之和.积分图也可以用公式〔2〕和公式〔3〕得出:3.2 利用积分图计算特征值3.3 计算特征值由上一节已经知道,一个区域的像素值,可以由该区域的端点的积分图来计算.由前面特征模板的特征值的定义可以推出,矩形特征的特征值可以由特征端点的积分图计算出来.以"两矩形特征〞中的第二个特征为例,如如下图,使用积分图计算其特征值:第二局部的地址请见:1. 弱分类器在确定了训练子窗口中的矩形特征数量和特征值后,需要对每一个特征f ,训练一个弱分类器h<x,f,p,O> .在CSDN里编辑公式太困难了,所以这里和公式有关的都用截图了.特别说明:在前期准备训练样本的时候,需要将样本归一化和灰度化到20*20的大小,这样每个样本的都是灰度图像并且样本的大小一致,保证了每一个Haar特征〔描述的是特征的位置〕都在每一个样本中出现.2. 训练强分类器在训练强分类器中,T表示的是强分类器中包含的弱分类器的个数.当然,如果是采用级联分类器,这里的强分类器中的弱分类器的个数可能会比拟少,多个强分类器在级联起来.在c<2>步骤中,"每个特征f〞指的是在20*20大小的训练样本中所有的可能出现的矩形特征,大概要有80,000中,所有的都要进展计算.也就是要计算80,000个左右的弱分类器,在选择性能好的分类器.训练强分类器的步骤如图:3. 再次介绍弱分类器以与为可以使用Haar特征进展分类对于本算法中的矩形特征来说,弱分类器的特征值f<x>就是矩形特征的特征值.由于在训练的时候,选择的训练样本集的尺寸等于检测子窗口的尺寸,检测子窗口的尺寸决定了矩形特征的数量,所以训练样本集中的每个样本的特征一样且数量一样,而且一个特征对一个样本有一个固定的特征值.对于理想的像素值随机分布的图像来说,同一个矩形特征对不同图像的特征值的平均值应该趋于一个定值k.这个情况,也应该发生在非人脸样本上,但是由于非人脸样本不一定是像素随机的图像,因此上述判断会有一个较大的偏差.对每一个特征,计算其对所有的一类样本<人脸或者非人脸>的特征值的平均值,最后得到所有特征对所有一类样本的平均值分布.如下图显示了20×20 子窗口里面的全部78,460 个矩形特征对全部2,706个人脸样本和4,381 个非人脸样本6的特征值平均数的分布图.由分布看出,特征的绝大局部的特征值平均值都是分布在0 前后的X围内.出乎意料的是,人脸样本与非人脸样本的分布曲线差异并不大,不过注意到特征值大于或者小于某个值后,分布曲线出现了一致性差异,这说明了绝大局部特征对于识别人脸和非人脸的能力是很微小的,但是存在一些特征与相应的阈值,可以有效地区分人脸样本与非人脸样本.为了更好地说明问题,我们从78,460 个矩形特征中随机抽取了两个特征A和B,这两个特征遍历了2,706 个人脸样本和4,381 个非人脸样本,计算了每X图像对应的特征值,最后将特征值进展了从小到大的排序,并按照这个新的顺序表绘制了分布图如下所示:可以看出,矩形特征A在人脸样本和非人脸样本中的特征值的分布很相似,所以区分人脸和非人脸的能力很差.下面看矩形特征B在人脸样本和非人脸样本中特征值的分布:可以看出,矩形特征B的特征值分布,尤其是0点的位置,在人脸样本和非人脸样本中差异比拟大,所以可以更好的实现对人脸分类.由上述的分析,阈值q 的含义就清晰可见了.而方向指示符p 用以改变不等号的方向.一个弱学习器〔一个特征〕的要求仅仅是:它能够以稍低于50%的错误率来区分人脸和非人脸图像,因此上面提到只能在某个概率X围内准确地进展区分就已经完全足够.按照这个要求,可以把所有错误率低于50%的矩形特征都找到〔适当地选择阈值,对于固定的训练集,几乎所有的矩形特征都可以满足上述要求〕.每轮训练,将选取当轮中的最优弱分类器〔在算法中,迭代T 次即是选择T 个最优弱分类器〕,最后将每轮得到的最优弱分类器按照一定方法提升〔Boosting〕为强分类器4 弱分类器的训练与选取训练一个弱分类器〔特征f〕就是在当前权重分布的情况下,确定f 的最优阈值,使得这个弱分类器〔特征f〕对所有训练样本的分类误差最低.选取一个最优弱分类器就是选择那个对所有训练样本的分类误差在所有弱分类器中最低的那个弱分类器〔特征〕.对于每个特征f,计算所有训练样本的特征值,并将其排序.通过扫描一遍排好序的特征值,可以为这个特征确定一个最优的阈值,从而训练成一个弱分类器.具体来说,对排好序的表中的每个元素,计算下面四个值:5. 强分类器注意,这里所说的T=200个弱分类器,指的是非级联的强分类器.假如果是用级联的强分类器,如此每个强分类器的弱分类器的个数会相对较少.一般学术界所说的级联分类器,都是指的是级联强分类器,一般情况有10个左右的强分类器,每个强分类有10-20个弱分类器.当然每一层的强分类器中弱分类器的个数可以不相等,可以根据需要在前面的层少放一些弱分类器,后面的层次逐渐的增加弱分类器的个数.6. 图像检测过程在对输入图像进展检测的时候,一般输入图像都会比20*20的训练样本大很多.在Adaboost 算法中采用了扩大检测窗口的方法,而不是缩小图片.为扩大检测窗口而不是缩小图片呢,在以前的图像检测中,一般都是将图片连续缩小十一级,然后对每一级的图像进展检测,最后在对检测出的每一级结果进展汇总.然而,有个问题就是,使用级联分类器的AdaBoost的人脸检测算法的速度非常的快,不可能采用图像缩放的方法,因为仅仅是把图像缩放11级的处理,就要消耗一秒钟至少,已经不能达到Adaboost 的实时处理的要求了.因为Haar特征具有与检测窗口大小无关的特性〔想要了解细节还要读一下原作者的文献〕,所以可以将检测窗口进展级别方法.在检测的最初,检测窗口和样本大小一致,然后按照一定的尺度参数〔即每次移动的像素个数,向左然后向下〕进展移动,遍历整个图像,标出可能的人脸区域.遍历完以后按照指定的放大的倍数参数放大检测窗口,然后在进展一次图像遍历;这样不停的放大检测窗口对检测图像进展遍历,直到检测窗口超过原图像的一半以后停止遍历.因为整个算法的过程非常快,即使是遍历了这么屡次,根据不同电脑的配置大概处理一幅图像也就是几十毫秒到一百毫秒左右.在检测窗口遍历完一次图像后,处理重叠的检测到的人脸区域,进展合并等操作.程序代码样例请到第一节找下载地址.。
线 性 规 划 算 法 详 解

【机器学习】AdaBoost算法详解一、Boosting简介Boosting算法是一种通过多次学习来提升算法精度的方法,它采用的是综合的原则使得算法的效率明显改善,是一种将弱分类器提升为强分类器的方法。
通俗点讲,就是“三个臭皮匠赛过诸葛亮”,臭皮匠就好比弱分类器,综合起来就是一个强分类器。
Boosting算法是一种集成学习方案。
何谓集成学习?在理解集成学习之前,我们先介绍传统的学习方法,就是通过单个分类器来做决策,例如朴素贝叶斯分类器,SVM,人工神经网络等。
集成学习方法却是需要多个分类器来投票进行最终的决策。
好比领导开会,说:“赞成的请举手”,每个决策者就好比一个弱分类器进行投票,如果纷纷举手,结果自然没有什么悬念,这对于决策层而言,是最喜欢看到的,直接通过。
说了这么久的弱分类器,到底什么是弱分类器?先说弱学习算法吧。
它通常是对一定分布的训练样本给出的假设(给出假设的准确率仅仅强于随机猜测)。
它的思想起源于Valiant提出的计算学习理论一PAC (Probably Approximately Correct) 学习模型。
在Valiant 的PAC模型中,一个性能仅比随机猜测稍好的弱学习算法是否能被提升为一个具有任意精度的强学习算法呢?这个问题困扰着很多研究机器学习的研究者,而且很长一段时间都没有一个切实可行的办法来实现这个理想。
终于功夫不负有心人,Schapire先是在1990年证明了,如果将多个PAC分类器集成在一起,它将具有PAC强分类器的泛化能力,然后在1996年提出一个有效的算法来验证,它就是叫AdaBoost (AdaptiveBoosting)。
二、AdaBoost原理介绍AdaBoost方法的自适应在于:前一个分类器分错的样本会被用来训练下一个分类器。
AdaBoost方法是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。
每一个训练样本都被赋予一个权重,表明它被某个分类器选入训练集的概率。
AdaBoosts算法原理

AdaBoosts算法原理我们带着问题去思考:弱学习器的权重系数α如何计算?样本点的权重系数 w 如何更新?学习的误差率 e 如何计算?最后使⽤的结合策略是什么?⼀、AdaBoost基本原理介绍1,1AdaBoost分类问题以⼆分类为例,假设给定⼀个⼆类分类的训练数据集,其中表⽰样本点,表⽰样本对应的类别,其可取值为{-1,1}。
AdaBoost算法利⽤如下的算法,从训练数据中串⾏的学习⼀系列的弱学习器,并将这些弱学习器线性组合为⼀个强学习器。
AdaBoost算法描述如下:输⼊:训练数据集输出:最终的强分类器G(x)(2)对M个弱学习器,m=1,2,...,M:(a)使⽤具有权值分布的训练数据集进⾏学习,得到基本分类器,其输出值为{-1,1};(b)计算弱分类器在训练数据集上的分类误差率,其值越⼩的基分类器在最终分类器中的作⽤越⼤其中,取值为0或1,取0表⽰分类正确,取1表⽰分类错误。
其中就等于分类错误的权重*分类错误的个数(c)计算弱分类器的权重系数:(这⾥的对数是⾃然对数)⼀般情况下 em 的取值应该⼩于0.5,因为若不进⾏学习随机分类的话,由于是⼆分类错误率等于0.5,当进⾏学习的时候,错误率应该略低于0.5。
当 em 减⼩的时候 am 的值增⼤,⽽我们希望得到的是分类误差率越⼩的弱分类器的权值越⼤,对最终的预测产⽣的影响也就越⼤,所以将弱分类器的权值设为该⽅程式从直观上来说是合理地,具体的证明 am 为上式请继续往下读(d)更新训练数据集的样本权值分布:对于⼆分类,弱分类器的输出值取值为{-1,1},的取值为{-1,1},所以对于正确的分类,对于错误的分类,由于样本权重值在[0,1]之间,当分类正确时取值较⼩,⽽分类错误时取值较⼤,⽽我们希望得到的是权重值⾼的训练样本点在后⾯的弱学习器中会得到更多的重视,所以该上式从直观上感觉也是合理地,具体怎样合理,请往下读其中,是规范化因⼦,主要作⽤是将的值规范到0-1之间,使得。
adaboost算法

• Adaboost 算法分析
该算法其实是一个简单的弱分类算法提升过程, 这个过程通过不断的训练,可以提高对数据的 分类能力。
1、先通过对N个训练样本的学习得到第一个 弱分类器;
2、将分错的样本和其他的新数据一起构成一 个新的N个的训练样本,通过对这个样本的学 习得到第二个弱分类器;
3、将1和2都分错了的样本加上其他的新样本 构样成 本另的一学个习新得的到第N个三的个训弱练分样类本器,通过对这Bsca个hcokotlo
31
Thank you!
32
8
• Adaboost 算法分析
针对以上两个问题,AdaBoost算法进行了调整:
1. 使用加权后选取的训练数据代替随机选取的训 练样本,这样将训练的焦点集中在比较难分的训 练数据样本上;
2. 将弱分类器联合起来,使用加权的投票机制代
替平均投票机制。让分类效果好的弱分类器具有
较大的权重,而分类效果差的分类器具有较小的
4、最终经过提升的强分类器。即某个数据被
分为哪一类要通过......的多数表决。
7
• Adaboost 算法分析
对于boosting算法,存在两个问题: 1. 如何调整训练集,使得在训练集上训练的弱 分类器得以进行; 2. 如何将训练得到的各个弱分类器联合起来形 成强分类器。
Back to school
12
• Adaboost 算法步骤
Adaboost算法是经过调整的Boosting算法,其 能够对弱学习得到的弱分类器的错误进行适应性 (Adaptive)调整。上述算法中迭代了T次的主循环, 每一次循环根据当前的权重分布对样本x定一个 分布P,然后对这个分布下的样本使用弱学习算 法得到一个弱分类器,对于这个算法定义的弱学 习算法,对所有的样本都有错误率,而这个错误 率的上限并不需要事先知道,实际上。每一次迭 代,都要对权重进行更新。更新的规则是:减小 弱分类器分类效果较好的数据的概率,增大Bscah弱cokotl分o 类器分类效果较差的数据的概率。最终的分类器 是个弱分类器的加权平均。
AdaBoost算法的推广——一组集成学习算法

AdaBoost算法的推广——一组集成学习算法付忠良;赵向辉;苗青;姚宇【期刊名称】《四川大学学报(工程科学版)》【年(卷),期】2010(042)006【摘要】针对AdaBoost算法只适合于不稳定学习算法这一不足,基于增加新分类器总是希望降低集成分类器训练错误率这一思想,提出了利用样本权值来调整样本类中心的方法,使AdaBoost算法可以与一些稳定的学习算法结合成新的集成学习算法,如动态调整样本属性中心的集成学习算法、基于加权距离度量分类的集成学习算法和动态组合样本属性的集成学习算法,大大拓展了AdaBoost算法适用范围.针对AdaBoost算法的组合系数和样本权值调整策略是间接实现降低训练错误率目标,提出了直接面向目标的集成学习算法.在UCI数据上的实验与分析表明,提出的AdaBoost推广算法不仅有效,而且部分算法比AdaBoost算法效果更好.【总页数】8页(P91-98)【作者】付忠良;赵向辉;苗青;姚宇【作者单位】中国科学院成都计算机应用研究所,四川成都,610041;中国科学院研究生院,北京,100049;中国科学院成都计算机应用研究所,四川成都,610041;中国科学院研究生院,北京,100049;中国科学院成都计算机应用研究所,四川成都,610041;中国科学院研究生院,北京,100049;中国科学院成都计算机应用研究所,四川成都,610041;中国科学院研究生院,北京,100049【正文语种】中文【中图分类】TP391【相关文献】1.多标签AdaBoost算法的改进算法 [J], 付忠良;张丹普;王莉莉2.基于Adaboost算法选取和组合SVM的行人检测算法 [J], 张丽红;李林3.基于改进AdaBoost算法的快速人脸检测算法 [J], 何湘艳;姚敏;曹菊英;张雪飞;罗勇4.基于AdaBoost算法的在线连续极限学习机集成算法 [J], 蔡静5.基于AdaBoost算法的在线连续极限学习机集成算法 [J], 蔡静因版权原因,仅展示原文概要,查看原文内容请购买。
基于MCV划分的连续AdaBoost算法

基于MCV划分的连续AdaBoost算法李睿;张九蕊;贺宝鹏【摘要】The traditional finite division can not reflect the distribution of positive and negative samples. In this paper, a new continuous AdaBoort algorithm based on minimum class variance is developed. The new algorithm measures the similarity of the sample through calculating the class variance of every finite division in the process of finite division and selectes the best finite division corresponding to the minimum sum of class variance. Simulations show that the algorithm is of better detection rate and faster convergence.%传统连续AdaBoost算法因等距划分样本空间而无法体现正负样本各自的分布规律.针对该问题,提出一种基于最小类方差的样本空间划分算法.通过计算各种划分方式的类方差,衡量样本的相似性,选取最小类方差和对应的样本作为最佳划分.仿真结果表明,该算法具有较高的检测率和较快的收敛速度.【期刊名称】《计算机工程》【年(卷),期】2012(038)011【总页数】3页(P177-179)【关键词】人脸检测;连续AdaBoost算法;训练样本;类方差;空间划分【作者】李睿;张九蕊;贺宝鹏【作者单位】兰州理工大学计算机与通信学院,兰州730050;兰州理工大学计算机与通信学院,兰州730050;兰州理工大学计算机与通信学院,兰州730050【正文语种】中文【中图分类】TP3911 概述人脸检测是指在输入图像中确定所有人脸(如果存在)的位置、尺度和位姿的过程。
连续型Adaboost算法研究_严超

Research of the Real Adaboost Algorithm
YA N Chao WA N G Y ua n -qing
( Depart ment of Elect roni c Science and Engineering , Nanjin g U ni versi ty , N anjing 210093 , China)
( 1)
3) 设置弱分类器在 这个划分上的输出 : x ∈ X j , h(x) = W j+1 +ε 1 ln( j ), j =1 , 2 , … , m W -1 +ε 2 ( 2)
式中 , ε 为一小正 常数 。 4) 计算归一化因子 : Z =2 ∑
j
W j+1 W间中选择一个 h t , 使得 Z 最小 : Z t =min Z , h ∈ H ht =arg min Z , h ∈ H ③更新训 练样本概率分布 : exp[ - yi h t(xi ) ] D t +1 ( i)=D t( i) Zt % 式中 , Z t 为归一化因子 , 使得 D t +1 为一个概率分布 。 ( 3) 最终强分类器 H 为 : H(x)=sig n[ ∑ h t(x)-b]
pro ximately Co rr ec t) 学习模型 属于计算学习理论 的经典模型 之一 。 P AC 学习模型在大量实验的基础 上 , 对涉 及到的 一些 量进行假设估 计 , 在所使用的样本集样本数目增大 、样本结构 变复 杂的情况 下 , 依 据概率理论 研究上述 的估计量能 否一致 收敛到未知真 值的问题 。
Abstract In the cur rent ar tificial inte lligence and pattern recog nition , Real A dabo ost A lgo rithm , as for hig h accuracy rate and ve ry fa st speed , has been used mor e widely . A s a result , we researched the theo retical basis o f the Real A daboo st A lg orithm co nscientio usly and analy zed the training pro cedures of classifier s based o n the Real A daboo st A lgorithm meticulo usly . In this co urse, we probed into the rela tionship be tw een the mathematical va riables involved in the alg o rithm ;deduced the mathema tical pro ce ss inv olv ed in the alg orithm quantitativ ely , and analyzed the reasons of pro blems appearing in training pro cedures qualitatively . A t last , in o rde r to improve the Real Adabo ost A lg orithm , we brought up sev eral sugg estio ns . Keywords Real Adaboo st algo rithm , PCA model , No rmalizatio n facto r , T esting ra te , Excessive learning 如何快速通过训练方法获得准确率高的分类器是目前基 于学习的模式识别领域 的热点 问题 。 针对 这一问 题 , 近 几年 出现了一大批分析角度 不同 、处理方 法各异 的优秀 算法 。 其 中 , 由 F reund 和 Schapire 于 1990 年提出 的 Boo sting 算法 [ 1] 以训练速度 快 、所 得分类器准 确率高而 获得广泛的 研究和应 用 。 Boo sting 的原意为提 升 、加强 , 其算法的中心思 想是通过 整合和训练 , 将弱分类器提升为强分类器 。 所谓弱分类 器 , 是 指该分类器的 算 法正 确率 刚 刚超 过 50 %, 即 略好 于 随 机猜 想; 所谓强分类器 , 是指其算法正确 率远远 高于 50 %。 另外 , Boo sting 算法还 具有 不 需要 任何 训 练样 本的 先 验知 识 的优 点 。 但是 , 因为 Boo sting 算法中样 本的权 重无法 “ 自 适应” 地 调整 , 所以其对分类困难的样本的学习能力有 限 。 Adaboo st 算 法 的 全 称是 A daptive Boo sting 算 法 , 是 由 Freund 和 Schapir e 于 1995 年
Adaboost算法详解

1.2 AdaBoost 算法
输入: 训练数据集 T={(x1,y1),(x2,y2),…,(xN,yN)}, 其中 xi∈X⊆Rn, 表示输入数据, yi∈Y={-1,+1}, 表示类别标签;弱学习算法。 输出:最终分类器 G(x)。 流程: (1) 初始化训练数据的概率分布,刚开始为均匀分布 D1=(w11,w12,…,w1N), 其中 w1i=
对 AdaBoost 算法作如下说明:
(公式 7)
步骤(1) 初始时假设训练数据集具有均匀分布, 即每个训练样本在弱分类器的学习中作用相同。 步骤(2) (c) αm 表示 Gm(x)在最终分类器中的重要性。 由式(公式 2)可知, 当 em ≤1/2 时,意味着误差率越小的基本分类器在最终分类器中的作用越大。 (d) 式(公式 4)可以写成:
其中w1i表示在第m轮迭代开始前训练数据的概率分布或权值分布wmi表示在第i个样本的的训练数据集进行学习任意选一种模型都可以例如朴素贝叶斯决策树svm等并且每一轮迭代都可以用不同的模型得到一个弱分类器1111m1称为一个概率分布
提升方法(boosting)详解
作者博客:@灵魂机器 /soulmachine 最后更新日期:2012-12-11 提升方法(boosting)是一种常用的统计学习方法,应用广泛且有效。在分类问题中,它通过 改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。 本章首先介绍提升方法的思路和代表性的提升算法 AdaBoost,然后通过训练误差分析探讨 AdaBoost 为什么能够提高学习精度,并且从前向分布加法模型的角度解释 AdaBoost,最后叙述提 升方法更具体的事例——提升术 (boosting tree) 。 AdaBoost 算法是 1995 年由 Freund 和 Schapire 提 出的,提升树是 2000 年由 Friedman 等人提出的。
Adaboost 基本简介——【人工智能 精品讲义】

Adaptive Boosting Algorithm目录一、Adaboost(Adaptive Boosting)历史 (2)二、Adaboost算法基本原理 (2)三、AdaBoost算法的优点 (4)四、AdaBoost算法的缺点 (4)五、AdaBoost算法的应用 (4)六、AdaBoost改进 (4)七、总结 (5)1一、Adaboost(Adaptive Boosting)历史Adaboost的前身的Boosting算法。
Boosting是一种提高任意给定学习算法准确度的方法。
它的思想起源于Valiant提出的PAC(Probably Approximately Correct)学习模型。
Valiant和Kearns提出了弱学习和强学习的概念,识别错误率小于1/2,也即准确率仅比随机1猜测略高的学习算法称为弱学习算法;识别准确率很高并能在多项式时间内完成的学习算法称为强学习算法。
同时,Valiant和Kearns首次提出了PAC学习模型中弱学习算法和强学习算法的等价性问题,即任意给定仅比随机猜测略好的弱学习算法,是否可以将其提升为强学习算法?如果二者等价,那么只需找到一个比随机猜测略好的弱学习算法就可以将其提升为强学习算法,而不必寻找很难获得的强学习算法。
1990年, Schapire最先构造出一种多项式级的算法,对该问题做了肯定的证明,这就是最初的Boosting算法。
一年后,Freund提出了一种效率更高的Boosting算法。
但是,这两种算法存在共同的实践上的缺陷,那就是都要求事先知道弱学习算法学习正确率的下限。
1995年, Freund和schapire改进了Boosting算法,提出了AdaBoost(Adaptive Boosting)算法[5],该算法效率和Freund于1991年提出的Boosting算法几乎相同,但不需要任何关于弱学习器的先验知识,因而更容易应用到实际问题当中。
Adaboost算法原理及简单实现

合起来作为最后的决策分类器。
Adaboost原理简介
AdaBoost.M1 Discrete AdaBoost: 训练过程
1.初始化:初始赋予每个样本相等的权重 基分类器个数L; 2. For k = 1, 2, …, L Do • 根据分布 从训练数据集中抽取样本 ; • 将 用作训练数据集建立一个分类器 ; • 计算该分类器的加权训练误差
; • • • 若 否则,计算 则令 = ,重新训练分类器 ; 继而更新训练集上的权重分布 ;
;
结束循环
训练过程
3.给定测试数据,采用加权融合方式计算每一类 的支持度
4.预测此测试数据的类标签为支持度最大的类。
实验
数据集:LISSAJOUS FIGURE DATA (p42) 训练数据个数:700 测试数据个数:300 基分类器:决策树(p95-99)
实验
数据集:LISSAJOUS FIGURE DATA (p42) 训练数据个数:700 测试数据个数:300 基分类器:决策树(p95-99) 基分类器个数为1及20时分类结果
实验
数据集:LISSAJOUS FIGURE DATA (p42) 训练数据个数:700 测试数据个数:300 基分类器:决策树(p95-99) 分类误差随基分类器个数变化图 test_error =
Columns 1 through 15 0.1037 0.1070 0.1271 ห้องสมุดไป่ตู้.0836 0.1003 0.0970 0.0936 0.1037 0.0903 0.0870 0.0903 0.0836 0.0870 0.0970 0.0903 Columns 16 through 20 0.0903 0.0936 0.1003 0.0870 0.0903
一文读懂Adaboost

一文读懂Adaboost引言在正儿八经地介绍集成学习的内容之前,我们想先介绍一下Kaggle竞赛,这是我们要介绍集成学习的初衷之一。
Kaggle(kaggle)是由安东尼·戈德布卢姆在2010年创办的一个数据建模和数据分析平台,其目标就是使数据科学成为一项运动。
这个平台对所有的注册用户开放,企业和研究者可以在上面发布自己的数据并描述自己的目标,感兴趣的数据分析专家可在上面进行竞赛来解决问题。
Kaggle竞赛包括Featured,Recruitment,Research,Playground,Getting started和In class几种类别,其中Featured,Recruitment,Research是企业或研究机构发布的,提供一定数额的奖金,问题比较难;Playground,Getting started则是提供给数据分析爱好者们一些入门级的练习,难度较低,对于新手建议从这两个类别入手;最后In class则是提供给教学用的,老师布置一些任务同班同学可以在上面完成,这个一般是私密的不是外界都能参与的。
Kaggle在数据分析领域非常有影响力,在全球范围内拥有将近20万名数据科学家,其竞赛领域包括计算机科学、统计学、经济学和数学。
Kaggle的竞赛在艾滋病研究、棋牌评级和交通预测方面取得了成果并且基于这些成果产生了一系列的学术论文。
什么是集成学习在很多Kaggle竞赛以及很多工程实践中,集成学习的策略由于其良好的预测性能而备受青睐。
那么什么是集成学习?集成学习是一种机器学习框架,其主要思想就是将多个基础模型组合起来,提高整体模型的泛化能力。
集成学习的思想背后有比较成熟的数学理论作支撑,也即Valiant和Kearns提出的PAC (Probably approximately correct) 学习框架下的强可学习和弱可学习理论。
该理论指出:在PAC 的学习框架中,一个概念如果存在一个多项式的学习方法能够学习它,并且如果预测正确率很高,那么就称这个概念是强可学习的;如果正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。