声音信号的获取与处理
实验二声音信号的获取与处理

实验⼆声⾳信号的获取与处理计算机应⽤综合设计实验报告声⾳信号的获取与处理学院电⼦与信息学院专业电⼦信息科学类姓名学号提交⽇期2012年8 ⽉30⽇⾃评成绩良好⼀、实验⽬的本实验通过麦克风录制⼀段语⾳信号作为解说词并保存,通过线性输⼊录制⼀段⾳乐信号作为背景⾳乐并保存。
为录制的解说词配背景⾳乐并做相应处理,制作⼀段完整的带背景⾳乐的解说词。
⼆、实验内容及数据记录①⽤Windows录⾳机录制解说词◎执⾏【开始】|【所有程序】|【附件】|【娱乐】|【录⾳机】。
打开【录⾳机】,单击录⾳按钮开始录⾳。
当录制时间⼤于60秒时,继续点击按钮继续录制。
当朗读材料结束后单击停⽌按钮结束录制。
◎执⾏菜单栏【⽂件】|【另存为】命令,在出现的【另存为】对话框中的【格式】中单击【更改】按钮。
在弹出的【选择声⾳】对话框中修改【属性】项为【22.05kHz 16位86KB/s】,单击【确定】按钮,返回【另存为】对话框,选好保存的路径,⽂件名为【example_1】,类型保存为WA V。
②使⽤Cool Edit录制背景⾳乐◎打开Cool Edit Pro,单击⼯具栏的File按钮,在弹出的New Waveform对话框中,分别选择Sample Rate为44100,Channels为Stereo,Resolution为【16-bit】,单击OK按钮开始录⾳。
在录⾳结束后,单击⼯具栏的Stop按钮,完成录⾳。
◎单击⼯具栏的File|Save As,打开保存对话框,选择好保存路径,⽂件名为【example_2】,保存类型为Windows PCM(*.Wav),单击【保存】按钮,完成对背景⾳乐⽂件的录制。
③使⽤Cool Edit Pro进⾏混⾳处理Ⅰ⽤Cool Edit Pro打开【example_1】,执⾏Edit|Mix Paste命令,打开Mix Paste 对话框;设置L、R为90,选中Overlap,设置Crossfade值为50,选中From File,单击Select按钮选择作为背景⾳乐的⽂件【example_2】,设置Looppast为1,单击OK 按钮完成设置。
声音采集原理

声音采集原理
声音采集是指获取声音信号并将其转化为数字信号的过程。
声音采集原理可以简单地分为两个步骤:声音传感和模拟信号转换成数字信号。
声音传感是指使用麦克风等设备将声音的机械能量转化为电能信号。
麦克风包含一个薄膜和一个线圈,当声音波传播到薄膜上时,薄膜的振动会导致线圈与磁场之间的磁通量发生变化。
这个变化会在线圈中产生感应电流,进而将声音信号转化为模拟电信号。
模拟信号转换成数字信号是指使用模数转换器(ADC)将模
拟电信号转化为数字信号。
ADC首先将连续的模拟信号进行
采样,即定期测量模拟信号的电压,并将其转化为离散值。
然后,ADC对这些离散值进行量化,即将其映射到离散的数值
范围内。
最后,ADC使用编码器将量化后的数值转化为二进
制数字信号。
通过以上两个步骤,声音采集系统将声音信号从模拟领域转换为数字领域。
数字化的声音信号可以进一步处理、存储和传输,使得我们能够进行各种音频应用,如语音识别、音频编解码等。
声音检测报告1

声音检测报告11. 引言本报告旨在分析声音检测的结果,并就其重要性和应用领域进行讨论。
声音检测是一项关键技术,可用于识别和分析声音信号,对于人机交互、环境监测、安全防护等方面具有广泛应用。
2. 检测方法和过程声音检测采用了声音传感器获取环境中的声音信号,并通过信号处理算法对其进行分析和识别。
具体包括以下步骤:1. 传感器检测:使用合适的声音传感器进行声音信号的收集。
2. 信号采集:将传感器获得的模拟信号转换为数字信号,以便后续处理。
3. 信号处理:对采集到的信号进行滤波、增强、降噪等处理,以提高信号质量。
4. 特征提取:从处理后的信号中提取有用的特征,如频率、振幅、时域特征等。
5. 声音识别:通过机器研究算法或人工智能技术对提取的特征进行分类和识别。
3. 重要性和应用领域声音检测在各个领域中都具有重要的应用价值。
以下是几个常见的应用领域:3.1 人机交互声音检测可以用于人机交互领域,使得设备能够通过声音指令与人进行交互。
例如,智能音箱能够通过语音识别来执行用户的命令,实现智能家居控制、音乐播放等功能。
3.2 环境监测声音检测可用于环境监测,以实时检测和分析环境中的声音信号。
例如,在城市中可以通过声音检测系统监测交通流量、环境噪音等信息,用于城市规划和环境保护。
3.3 安全防护声音检测对于安全防护也具有重要作用。
例如,在公共场所可以通过声音检测系统实时监测异常声音,如爆炸声、枪声等,以及窃听器、监听器等非法设备,并发出警报。
4. 结论声音检测是一项重要的技术,具有广泛的应用领域。
通过声音检测可以实现人机交互、环境监测、安全防护等功能,对于提高生活质量和保障社会安全具有重要作用。
未来,声音检测技术将继续发展和完善,带来更多创新和应用。
以上是本报告对声音检测的分析和讨论,希望对您有所帮助。
多媒体技术之音频信息的获取与处理PPT课件( 75张)

常用音频采样率:8kHz、11.025kHz、16kHz、22.05kHz、44.1kHz 及 48kHz
2.2.2 数字音频获取
● 量化
量化概念
通过采样得到的表示声音强弱的函数 x(nT) 是连续的,为把 x(nT) 存入计 算机,就必须将采样值离散化,即量化成一个有限个幅度值的集合 x(nT)
多媒体技术及其应用
第二章 音频信息的获取与处理
● 主要知识点
2.1声音概述 2.2数字化音频 2.3音乐合成与 MIDI 2.4音频卡 2.5数字音频压缩标准
2.1.1 声音定义 ● 声音概念 ● 声音特性
2.1.2 声音基本特点 ● 声音传播 ● 声音频率 ● 声音传播方向 ● 声音三要素 ● 声音连续、相关及
实时性 声音具有实时性。对处理声音的计算机硬件和软件提出很高要求
2.2 数字化音频
转换
模拟信号
数字信号
音频数字化需要考虑的问题
采样、量化、编码
模 拟 信 号 的 数 字 化 过 程
100101100011101
音频信号处理过程流程
音
频采
开信 样
始
号 频
频 率
率
采 样
量 化
保 存 为 声 音 文 件
周期
用声音录制软件记录的英文单词“Hello”的语音 实际波形
2.1.2 声音特点
● 声音的传播方式
声音是依靠介质 ( 比如:空气、液体、固体 ) 的振动进行传播的 声源是一个振荡源,它使周围介质产生振动,并以波的形式传播 人耳感觉到这种传播过来的振动,反映到大脑,就意味听到声音 声音在不同的介质中传播,其传播速度和衰减速率都是不一样的
语音识别的技术实现原理

语音识别的技术实现原理随着人工智能技术的不断发展,语音识别技术越来越成熟。
语音识别技术是指将人的语音信号转换为文字信号的过程。
这种技术已经广泛应用于智能家居、车载导航、医疗诊断等领域,为人们生活的方方面面带来了很多的方便。
语音识别的基本流程语音识别的基本流程包括:信号的获取、预处理、特征提取、语音识别、后处理和结果输出等环节。
这些环节的主要作用是,首先将人的语音信号录制下来,然后对信号进行预处理和特征提取,最终生成可供计算机处理的数学模型,从而实现语音识别。
信号获取语音信号的获取是语音识别技术实现的第一步。
在实际应用中,人们通常使用麦克风等设备采集语音信号,然后将信号传输到计算机中,由计算机对信号进行处理。
预处理语音信号的预处理是为了提高语音识别的准确率。
预处理包括去除杂音、增加信号的能量、滤波等处理方法。
例如,如果语音信号中包含明显的环境噪声,就需要进行噪声消除处理,以提高信号的清晰度和可分辨性。
特征提取语音信号的特征提取是为了将其转化为计算机可以处理的数学模型。
在这个过程中,需要从语音信号中提取出一些特殊的特征,例如频率、音量、节奏等,然后将这些特征映射到数学模型中。
常见的特征提取方法包括Mel 频率倒谱系数(MFCC)、傅里叶变换等。
语音识别语音识别是将语音信号转化为文字信号的过程。
这一过程是通过计算机算法来实现的。
计算机首先将处理后的语音信号转化为数学模型,然后应用统计学知识来计算每个可能的字或词的概率,从而选择最有可能的单词或语句。
最终,计算机将文字结果输出。
后处理语音识别的后处理是为了减少识别错误,提高识别准确率。
后处理可以使用语言模型、上下文信息等进行修正和优化,从而减少识别错误率和提高识别准确率。
结果输出结果输出是将结果呈现给用户的过程。
结果可以直接输出为文字,也可以通过合成语音的方式,将结果直接转化为人类可以听懂的语音。
在实际的应用中,一般会综合考虑应用场景、用户需求等因素,选择输出方式。
实验二 声音的处理

2. MIDI是Musical Instrument Digital Interface的缩写,又称作乐器数字接口,是数字音乐/电子合成乐器的统一国际标准。它定义了计算机音乐程序、数字合成器及其它电子设备交换音乐信号的方式,规定了不同厂家的电子乐器与计算机连接的电缆和硬件及设备间数据传输的协议,可以模拟多种乐器的声音。MIDI文件就是MIDI格式的文件,在MIDI文件中存储的是一些指令。把这些指令发送给声卡,由声卡按照指令将声音合成出来。
所谓采样就是采集模拟信号的样本。是将时间上、幅值上都连续的模拟信号,在采样脉冲的作用,转换成时间上离散(时间上不再连续)、但幅值上仍连续的离散模拟信号。所以采样又称为波形的离散化过程。每秒钟的采样样本数叫做采样频率。采样频率越高,数字化后声波就越接近于原来的波形,即声音的保真度越高,但量化后声音信息量的存储量也越大。目前在多媒体系统中捕获声音的标准采样频率定为44.1kHz、22.05kHz和11.025kHz三种。而人耳所能接收声音频率范围大约为20Hz--20KHz,但在不同的实际应用中,音频的频率范围是不同的。例如根据CCITT公布的声
(3)“采样频率”是指将模拟声音波形数字化后每秒钟所抽取的声波幅度的样本次数,其单位为kHz(千赫兹)。采样频率高低决定了声音失真程度的大小,为保证声音不失真,采样频率应该在40kHz左右。采样频率一般有三种,44.1kHz是最常见的采样率标准(每秒取样44100次,用于CD品质的音乐);22.05kHz(适用于语音和中等品质的音乐);11.25kHz(低品质)。对于高于48KHz的采样频率人耳已无法辨别出来了,所以在电脑上没有多少使用价值。
7.选择“文件”|“存储为” ,打开如下所示的图2-12,为文件命名,并选择“保存类型”中的一种,为文件选择格式,单击保存即可。
实验二 声音的处理
2. 采取多种音频素材获取方法获取音频素材(网络下载、自己录制或音频片段截取),并用cooledit音频处理软件对获取的素材进行合成处理,使其符合课件需要。
自学资料
1.声音格式说明:
(1)wav格式:常被称为波形文件。没有压缩,文件很大;不过音质很高,可以用来记录语音、音乐等各种声音。
(2)mp3格式:最大优点是它的文件很小,且能保持接近CD音质的较高音质。mp3文件只有wav文件的十分之一容量大小。这种格式被广泛应用于互联网和日常生活中。
2.选择“mp3格式转换器”可以把其他格式(包括wav,cda,mid,mpg,dat,rm等)的文件转换成mp3或wav格式文件。单击后会弹出如图 2-3对话框:
3.“mp3数字CD抓轨”是专门把CD里的歌曲转换成mp3或wav格式。单击后会弹出如图2-4对话框:
音频信号处理的基本原理与方法

音频信号处理的基本原理与方法随着社会的发展和科技的进步,音频信号处理作为一种重要的技术手段在各个领域得到了广泛的应用,例如音乐、通信、广播、语音识别、智能家居等。
那么,什么是音频信号处理?它的基本原理和方法又是什么呢?一、音频信号的特点音频信号是指在时间域、频率域或谱域内表达声音信息的信号,其主要特点包括以下几个方面:1. 声压级:音频信号的功率很低,一般以微伏(µV)或毫伏(mV)的级别存在。
2. 频率分布:音频信号覆盖的频率范围比较广,一般在20Hz到20kHz之间。
3. 非线性:声音的响度和音调会因为感知器官的特性而呈非线性关系。
4. 同步性:音频信号具有实时性,需要在短时间内完成处理。
二、音频信号处理的基本技术1. 信号采集:音频信号必须通过麦克风等采集设备获取,通常采用模拟信号采集和数字信号采集两种方式。
2. 信号滤波:音频信号中包含噪声和干扰,需要通过滤波技术进行降噪、去除杂音等处理,以提高信号的纯度和质量。
3. 预加重:由于音频信号中低频成分比高频成分更容易受到衰减,预加重技术可以在记录信号前提高高频分量的幅度,降低低频分量的幅度,以达到更好的平衡。
4. 压缩和扩展:针对音频信号的动态范围较大,采用压缩和扩展技术可以调整音量,保证整个音频的响度均衡。
5. 频率变换:频率变换技术可以把音频转化为频谱图谱,以便进行频谱分析、合成等处理。
6. 频谱分析:将音频信号转化为频谱图谱,可以根据不同频率成分的强度和分布,进行干扰分析、信号识别等处理。
7. 音频编解码:针对音频信号的压缩、传输和存储,需要采用压缩编码技术,通常采用的编码格式包括MP3、AAC、OGG等。
三、音频信号处理的应用1. 音乐领域:音频信号处理在音乐合成、混音、降噪、音质改善等方面都有广泛的应用,能够提高音乐的质量和观感效果。
2. 通信领域:音频信号处理在电话、无线通信、语音会议等方面都有广泛应用,能够提高通信质量和稳定性。
学习“声音素材的获取与处理”心得体会

学习“声音素材的获取与处理”心得体会东风中学祁聪2014年11月6、13、20、27日,我学习了“声音素材的获取与处理”的课程,通过学习我的到了一些心得体会。
首先,学习了声音素材的的获取:一、声音素材主要包括背景音乐、解说词、郎诵、效果声及评语分析等等。
二、多媒体课件中的声音主要包括人声、音乐和音响效果三大类。
三、恰当的使用音乐和音响效果的作用四、设计声音素材时的注意事项五、数字声音、声音文件的采集和制作可以有以下7种方式、音频素材的获取方法、利用属性查找音频素材资源地址方法、利用属性查找音频素材资源地址方法、利用话筒录制声音的步骤、录音音量列表名词解释通过这些学习我知道了声音的获取、录制、格式、编辑等方法。
其次、学习了MP3、WAV格式的区别。
1——MP3(MPEG AUDIO LAYER 3)是一种具有高压缩率的音响信号文件。
虽然它音乐信号的压缩比例较高,但依然可以与CD/MD 的音质媲美。
MP3高达10比1的压缩比例。
使一张CD-R/RW上可以容纳10张普通CD的音乐。
达到可以长时间播放音乐。
您可以从互联网或其它渠道获取MP3格式的音乐。
2——WMA(WINDOW MEDIA AUDIO)是微软公司所开发的。
引导示来音乐的声音压缩技术。
其音质可以与MP3媲美,有较高的压缩。
有部分歌曲制成WMA格式音乐的大小可以达到MP3的三分之一!只要通过WINDOW MEDIA PLAYER 7.0以上的版本,就能将您喜爱的音乐编辑成WMA档案。
3——WAV(Waveform)格式是微软公司开发的一种声音文件格式,也叫波形声音文件,是最早的数字音频格式,被Windows平台及其应用程序广泛支持。
WAV格式支持许多压缩算法,支持多种音频位数、采样频率和声道,采用44.1kHz的采样频率,16位量化位数,因此WAV的音质与CD相差无几,但WAV格式对存储空间需求太大不便于交流和传播。
总之,学习了这个课程,我学会了很多的东西,特别是在计算机信息处理得到了很大的提升。
LabVIEW与声音处理技术音频信号的采集和处理

LabVIEW与声音处理技术音频信号的采集和处理音频信号的采集和处理在许多领域中都起到至关重要的作用。
LabVIEW是一种广泛应用于科学与工程领域的可视化编程环境,拥有丰富的工具和功能,可以用于音频信号的采集和处理。
本文将介绍如何利用LabVIEW进行音频信号的采集和处理,并探讨其中使用的技术。
一、LabVIEW的介绍与基本原理LabVIEW是由美国国家仪器公司(National Instruments)开发的一种图形化编程环境。
它以流程图的形式来表示程序的逻辑结构,使得编程变得直观而易于理解。
LabVIEW提供了丰富的工具箱和函数库,可以支持多种类型的数据处理和分析任务,包括音频信号的采集和处理。
在LabVIEW中,音频信号的采集是通过音频输入设备实现的。
LabVIEW提供了一系列的函数和工具,可以与音频设备进行通信,获取音频信号的输入。
用户可以根据需求选择不同的采样率和采样深度,以及设置其他采集参数来获取所需的音频数据。
二、音频信号的采集在LabVIEW中,进行音频信号的采集首先需要配置音频输入设备。
用户可以通过访问LabVIEW的音频设备设置界面,选择合适的音频输入设备,并设置采样率和采样深度等参数。
然后,利用LabVIEW提供的函数和工具,可以实现对音频输入设备的控制与数据获取。
通过调用LabVIEW中的音频输入函数,可以实现对音频信号的连续采集。
LabVIEW提供了循环结构,可以在循环中反复进行音频数据的获取,从而实现对连续音频信号的采集。
获取到的音频数据可以存储到LabVIEW的变量中,方便后续的处理和分析。
三、音频信号的处理LabVIEW提供了丰富的工具和函数用于音频信号的处理。
用户可以根据需求选择合适的工具和函数,并根据自己的需求进行配置和调试。
常见的音频信号处理任务包括音频滤波、音频增益调节、音频降噪等。
在LabVIEW中,这些任务可以通过调用相应的函数和工具来实现。
用户可以选择合适的函数和工具,并进行参数的设置和调整,从而达到对音频信号进行滤波、增益调节或降噪的目的。
声矢量传感器原理

声矢量传感器原理声矢量传感器是一种能够测量和记录声音特征的设备,它基于声学原理来实现声音信号的采集和分析。
声矢量传感器的主要原理是利用麦克风阵列采集声音,通过信号处理和算法分析,提取出声音的矢量特征。
声矢量传感器通常由多个麦克风组成,这些麦克风分布在空间中不同的位置,形成一个麦克风阵列。
每个麦克风都能够独立地接收声音信号,并将其转换为电信号。
通过对麦克风阵列中的麦克风信号进行时间和幅度上的差异分析,可以确定声源的位置和方向。
声矢量传感器利用阵列信号处理技术,将麦克风阵列中的信号进行采样和处理。
首先,对每个麦克风的信号进行放大和滤波处理,以增强声音信号的强度并去除噪音。
然后,对麦克风阵列中的信号进行时延估计,通过计算信号到达不同麦克风的时间差,可以确定声源的方向。
最后,通过对麦克风阵列中的信号进行幅度差异分析,可以确定声源的距离。
声矢量传感器还可以通过频域分析,提取声音信号的频率特征。
声音信号是由不同频率的声波振动组成的,通过对声音信号进行频谱分析,可以获取声音信号的频率成分。
声矢量传感器利用这些频率特征来判断声音的类型和特征,例如人声、噪音或乐器声等。
声矢量传感器还可以通过时域分析,提取声音信号的时序特征。
声音信号是随时间变化的,通过对声音信号进行时域分析,可以获取声音信号的时间变化规律。
声矢量传感器利用这些时序特征来判断声音的持续时间、起伏变化等。
声矢量传感器的应用非常广泛。
在通信领域,声矢量传感器可以用于语音识别和语音合成,通过分析声音的矢量特征,可以实现对语音信号的识别和合成。
在安防领域,声矢量传感器可以用于声纹识别和声场定位,通过分析声音的矢量特征,可以实现对声音的识别和定位。
在智能家居领域,声矢量传感器可以用于语音控制和环境监测,通过分析声音的矢量特征,可以实现对家居设备的控制和环境的监测。
声矢量传感器是一种基于声学原理的设备,通过麦克风阵列采集和分析声音信号的矢量特征。
它可以用于各种应用领域,如通信、安防和智能家居等。
声音的采集与处理
第三讲声音的采集与处理教学目标:1.了解常见声音文件的格式。
2.掌握制作声音文件的一般流程。
3.会用Sound Forge等录音软件录制声音。
4.掌握用Sound Forge编辑声音的基本方法,能熟练地对声音文件进行剪辑与合成。
5.掌握熔炼五音,用Sound Forge对声音进行特殊效果处理的方法。
重点:录音及对声音进行基本编辑的方法。
难点:声音的剪辑、合成及特殊效果处理方法。
一、常用声音文件格式常用的声音文件格式有:WAV格式、MIDI格式、MP3格式、CDA格式。
WAV格式:WAV格式是多媒体教学软件中常用的声音文件格式,它的兼容性非常好,但文件较大。
WAV格式的声音属性,如采样频率、采样位数、声道数直接影响到WAV格式文件的大小。
MIDI格式:是电子乐器声音文件格式, MIDI文件本身只是一些数字信号,占用磁盘空间较小,常作为多媒体教学软件的背景音乐文件。
MP3格式:是一种经过压缩的文件格式,播放时需要专门的MP3播放器。
占用磁盘空间较小。
CDA格式:CD唱片中的音乐文件常用CDA格式保存,一般为44kHz,16bits立体声音频质量。
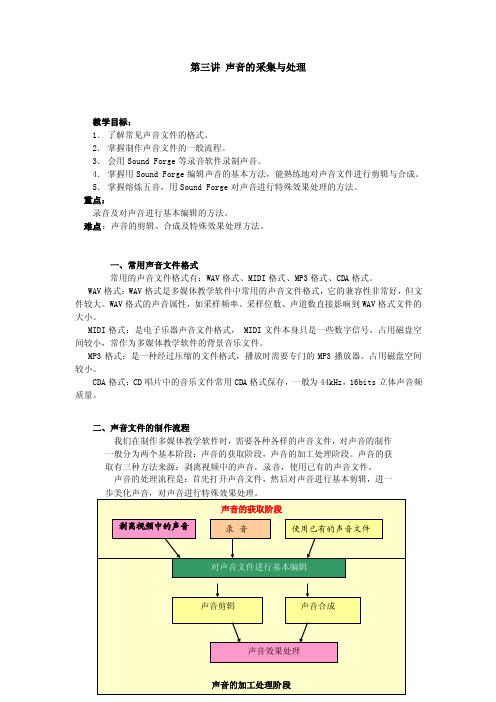
二、声音文件的制作流程我们在制作多媒体教学软件时,需要各种各样的声音文件,对声音的制作一般分为两个基本阶段:声音的获取阶段,声音的加工处理阶段。
声音的获取有三种方法来源:剥离视频中的声音,录音,使用已有的声音文件。
声音的处理流程是:首先打开声音文件,然后对声音进行基本剪辑,进一第一节走进Sound Forge三、走进Sound Forge我们可以把Sound Forge视为熔炼声音的熔炉,它能够对音频文件(.wav 文件)、视频文件(.avi文件)中的声音进行各种处理,打造出我们需要的声音效果。
在制作多媒体教学软件时,你想对获得的原始声音素材进行灵活的处理吗?那么走进Sound Forge,让我们来领略它神气强大的功能吧!好了,下面就让大家轻松亲身体验一下,为一多媒体教学软件制作声音。
信号处理music算法 -回复

信号处理music算法-回复信号处理在音乐算法中的应用信号处理是一种数学方法和技术,通过对信号的分析、处理和识别,从中提取有用的信息。
在音乐领域,信号处理算法可以帮助改进音频质量、音乐分类和音乐信息检索等方面。
本文将探讨信号处理在音乐算法中的应用,并逐步介绍与之相关的关键步骤。
第一步:信号获取音频信号的获取通常通过麦克风或音频采样设备进行。
这些设备将声音转化为电信号,并进行数字化处理。
信号通常由离散数据点组成,这些数据点是连续音频信号的抽样值。
在获取音频信号时,需要注意去除可能的噪音或干扰,以保证后续处理的准确性。
第二步:信号预处理信号预处理的目的是为了提高信号的质量,使其更适合下一步的分析。
在音乐算法中,常见的预处理技术包括去除杂音、滤波和均衡化等。
去除杂音是通过降噪算法来增强音乐信号的质量。
滤波则可以去除信号中的频率干扰。
均衡化能够调整信号的频谱平衡,提高音频的听感。
第三步:信号特征提取信号特征提取是音乐算法中至关重要的一步。
通过提取信号的特征,可以找到音频数据中的模式和规律。
音频信号的特征可以分为时域特征和频域特征。
时域特征包括音量、节奏、音调和声音强度等。
频域特征则是通过进行傅里叶变换将音频信号从时域转换为频域,在频谱分析的基础上提取特定频段的信息。
第四步:特征选择和分类在音乐算法中,不同的特征可以提供不同的音乐信息。
特征选择的目标是通过选择最相关的特征来提高算法的性能和准确性。
特征选择可以基于统计学方法,如相关性和方差分析,也可以使用机器学习算法,如决策树和神经网络。
选择好的特征后,可以使用分类算法对音频进行分类,例如支持向量机、K近邻等。
第五步:音乐信息检索音乐信息检索是信号处理在音乐算法中的一项重要任务。
它涉及对音乐数据库进行查询和检索,以查找与用户需求相匹配的音乐数据。
在音乐信息检索中,通过将用户提供的音乐查询与数据库中存储的音频进行比较,识别并返回与之相似的音乐曲目。
这一过程通常包括音频特征提取、特征匹配和相似度计算等步骤。
实验一 声音信号的获取与处理

实验一声音信号的获取与处理课程名称:多媒体技术实验学院:现代科技学院专业班级:计算机09-01学号: 2009100979学生姓名:吕阳指导老师:李海峰2012 4月 11日实验一声音信号的获取与处理一.实验名称:声音信号的获取与处理压缩算法六.实验心得:通过对Cool Edit音频编辑软件的研究,我了解了音乐制作的过程,cool edit 的功能之强大,可以对声音加载各种效果,使声音变得更好听,可以消除杂音,使声音的音质变得更好。
也可以为声音加载各种效果,比如回声之类的。
我也可以通过这个软件制作出很好听的声音。
实验二静态图像的处理及GIF动画制作一. 实验名称:静态图像的处理及gif动画制作二、实验任务:学习数字图像处理中的基本概念及特效处理方法,理解和掌握帧动画的基本概念和实现方法,实现简单的动画创意设计。
三、实验步骤:1.准备好实验的硬件(计算机)软件(Photoshop CS4)以《多媒体技术与应用》为主题,创作一个课件的封面动画。
具体要求如下:2.自选一张图像,作为主要前景对象,保存为abc.psd,前景是白色。
3.字体的设置:设置前景色为黑色,选择工具箱中的文字工具,在文件窗口中输入大小为65,字体为方正粗倩简体文字,在图层控制面板中的文字层上单击鼠标右键,在弹出的菜单中选择“栅格化文字”命令,将文字层为图像图层。
单击图层面板下方的“添加图层样式”按钮,在弹出的菜单中选择“投影”命令,在弹出的对话框中,将不透明度设置为100,距离为0,扩展为19,大小为13,单击图层面板下方的“添加图层样式”按钮,在弹出的菜单中选择“内阴影”命令,在弹出的对话框中,将不透明度设置为50,距离为21,大小为25,单击图层面板下方的“添加图层样式”按钮,在弹出的菜单中选择“斜面和浮雕”命令,在弹出的对话框中,将大小设置为17,高度为70,将光泽等高线设置为环形,将高光模式的不透明度设置为100,将暗调模式选项设置为颜色加深,透明度设置为26,其他默认。
简述声音信号的数字化过程

简述声音信号的数字化过程
声音信号数字化是将声音录音模拟信号转换为计算机和处理器
能够处理的数字信号的过程。
当今,声音信号数字化已经成为音频设备中不可或缺的一部分,广泛应用于录音室、音乐工作室、电影制作室以及家庭影院等领域。
在声音信号数字化的过程中,第一步是采集声音信号。
这一步是通过话筒或模拟输入设备采集声音,然后将声音变为模拟信号。
模拟信号是模拟设备所采集的电信号,它一般具有如音量大小、波形和频率等特征。
接下来是声音信号的抽样率转换。
抽样率是指模拟信号被转化为数字信号的每秒抽样次数,这一步通常采用数字转换器(DAC)进行。
DAC能够把模拟信号转换为数字信号,并且能够按照一定抽样率(如44.1KHZ、48KHZ等)获取声音信号数据。
最后,是数据编码转换。
数字信号通过数字音频编码器(DAE)进行转换,将数字信号按照一定的编码格式进行编码,例如MP3、WAV、AAC等格式。
这样,声音信号就完成了从模拟到数字的转换,大大提高了声音录制系统的精确度和稳定性。
声音信号数字化技术在近年来得到了很大的发展,及其应用范围日益广泛。
它使得家庭影院、汽车音响调节等系统都能更好地拥有与真实生活一样的声音环境,给人们的生活提供了更多的乐趣。
同时,声音信号数字化也为创作者提供了新的可能性,促进了音乐制作的发展。
总的来说,声音信号数字化的过程是将模拟信号转换成数字信号进行处理的过程,可以帮助人们更好地拥有贴近真实生活声音环境,并提高创作者的音乐制作能力。
音频信息的获取与处理

3. 数字音频音质与数据流量 3.1 音频信号经过数字系统重现后的音质与系统频率响应的范围成正比. 模拟信号 A/D→D/A 模拟信号
“音质”正比于“采样频率”× “量化位数” 3.2 音频数据流量单位(比特率,位数,码率) kb/s(kbps) , 8kbps = 1kBps = 采样频率 × 量化字节数 × 通道数 音频数据流量和数据量的计算 例: 对于调频广播级立体声,采样频率44.1 kHz,量化位数16 位,则音频信号 数字化后的数据量为: 44.1k×16 ×2 =1411.2 kb/s =176.4 kByte/s 采样频率 量化 声道数 数据量 电话: 11 kHz, 8位, 单声道, 88kb/s 收音机: 22kHz, 16位, 双声道, 352kb/s CD: 44.1kHz, 2Byte, 双声道, 1411 kb/s 音频数据总量=音乐时长×数据流量 例: 对于三分钟的乐曲,立体声总量=180s×176kB/s=31.68MB
第二章 音频信息的获取与处理
一.声音概述 二.数字化音频 三.音乐合成与MIDI 四.音频卡 五.数字音频压缩标准
2. 噪声 70dB: 50%的人的睡眠受到影响. 噪声性耳聋: 长期暴露在强噪声中, 听力不能复原, 引起心血管和消化系统疾病; 140dB ~160dB(高强度噪声): 会使鼓膜破裂, 双耳完 全失聪. 超音速飞机的轰声, 爆炸声: 玻璃震碎, 墙皮脱落 160dB以上的特强噪声: 使金属疲劳损坏
4.5 流式音频文件~ WMA扩展名 Microsoft 研制的一种压缩文件或流式文件, 相当于MP3, 压缩率较高和音质较好. 边下载边播放 4.6 流式音频文件~ RA扩展名 Real networks 推出的压缩格式,其压缩比可达到96:1. 4.7 数字音频文件~ PCM扩展名 模拟音频经A/D转换形成的二进制数字序列, 该文件没有文件头和文件结束标志. 音源信息完整, 冗余度过大, 音质好,数据量大. 较高保真水平, 被用于素材保存及音乐欣赏. 4.8 CD-DA音频文件~ CDA扩展名: 激光CD音乐盘格式. 音质好, 数据量大。 4.9 APE音频文件:是一种无损压缩音频技术,与MP3等有损压缩方式不同,在将CDA音 频数据文件压缩成APE格式后,还可将APE格式的文件还原为压缩前的CDA文件。APE 的文件大小约为CDA的一半。APE格式可用于通过网络传输CD质量的音乐. APE常用软件: CuteAPE(切割ape) Windows Media Player 11 千千静听 暴风影音和MPC等等。 5. 数字音频编辑:剪切粘贴, 左右声道剪切粘贴, 淡入淡出, 回声和混响, 模拟厅场。 6. 音频信号处理:声纹识别测谎,音乐合成,立体声模拟,采集,编解码和传输。
实验一声音信号的获取与处理

实验一声音信号的获取与处理 (1)1.1 实验目的和要求 (1)1.2 预备知识 (1)1.3 实验内容与步骤 (2)1.4 思考题 (9)实验一声音信号的获取与处理声音媒体是较早引入计算机系统的多媒体信息之一,从早期的利用PC机内置喇叭发声,发展到利用声卡在网上实现可视电话,声音一直是多媒体计算机中重要的媒体信息。
在软件或多媒体作品中使用数字化声音是多媒体应用最基本、最常用的手段。
通常所讲的数字化声音是数字化语音、声响和音乐的总称。
在多媒体作品中可以通过声音直接表达信息、制造某种效果和气氛、演奏音乐等。
逼真的数字声音和悦耳的音乐,拉近了计算机与人的距离,使计算机不仅能播放声音,而且能“听懂”人的声音是实现人机自然交流的重要方面之一。
采集(录音)、编辑、播放声音文件是声卡的基本功能,利用声卡及控制软件可实现对多种音源的采集工作。
在本实验中,我们将利用声卡及几种声音处理软件,实现对声音信号的采集、编辑和处理。
实验所需软件:Windows录音机(Windows内含)Creative WaveStudio (Creative Sound Blaster系列声卡自带)Cool Edit进行实验的基本配置:●Intel Pentium 120 CPU或同级100%的兼容处理器●大于16MB的内存●8位以上的DirectX兼容声卡1.1 实验目的和要求本实验通过麦克风录制一段语音信号作为解说词并保存,通过线性输入录制一段音乐信号作为背景音乐并保存。
为录制的解说词配背景音乐并作相应处理,制作出一段完整的带背景音乐的解说词。
1.2 预备知识1.数字音频和模拟音频模拟音频和数字音频在声音的录制和播放方面有很大不同。
模拟声音的录制是将代表声音波形的电信号转换到适当的媒体上,如磁带或唱片。
播放时将纪录在媒体上的信号还原为波形。
模拟音频技术应用广泛,使用方便。
但模拟的声音信号在多次重复转录后,会使模拟信号衰弱,造成失真。
声音的编码过程 -回复

声音的编码过程-回复声音的编码过程是指将声音信号经过一系列处理和转换的过程,最终转化为数字格式的过程。
在现代通信和媒体技术中,声音的编码过程是非常重要的,它使得人们能够方便地传输、存储和处理声音信息。
本文将分为以下几个方面来详细介绍声音的编码过程。
一、声音信号的采样声音是由空气中的震动产生的,震动会引起物质分子的位移,从而产生声波。
为了将声音信号转化为数字信号,首先需要对声音信号进行采样。
采样是指按照一定的时间间隔对声音信号的幅度进行测量,将连续的模拟信号转化为离散的数字信号。
在采样过程中,需要设定一个采样频率,即每秒钟进行多少次采样。
根据奈奎斯特定理,采样频率必须大于信号频率的两倍才能准确还原信号。
通常,CD音质的采样频率为44.1kHz,即每秒钟进行44100次采样。
二、量化量化是采样之后的一个重要步骤,它将采样得到的连续幅度取样值转化为离散的数字值。
量化的目的是将连续的模拟信号离散化,将每个取样值映射为一个有限的数字值,以便于存储和处理。
量化过程中,需要设定一个量化精度,即使用多少位来表示每个离散的数字值。
常用的量化精度有8位、16位、24位等。
量化精度越高,表示音频的质量就越好,但也会增加存储和传输的开销。
三、编码在量化之后,需要对量化得到的数字值进行编码,以便于传输和存储。
常用的编码方式有脉冲编码调制(PCM)、有损编码(例如MP3)、无损编码(例如FLAC)等。
PCM是一种基本的编码方式,它将每个采样值直接转化为一个固定位数的二进制数。
例如对于16位PCM编码,每个采样值将使用16位表示。
PCM编码具有无损的特点,能够完整地还原原始信号,但占用存储空间较大。
有损编码则是在保证一定程度质量损失的情况下,通过去除信号中的冗余和不可察觉的信息来减小文件的大小。
MP3是一种常用的有损编码方式,它利用了人耳对声音的不敏感性,通过压缩算法来减小文件大小,但会引入一定程度的失真。
无损编码则是在不损失音质的情况下,通过压缩算法来减小文件大小。
如何使用AI技术进行声音识别与合成

如何使用AI技术进行声音识别与合成一、引言声音是人类沟通的重要方式之一,而随着人工智能(AI)技术的快速发展,声音识别与合成领域也取得了巨大的进步。
本文将介绍如何使用AI技术进行声音识别与合成,并探讨其应用于语音识别、语音合成和语音助手等相关领域的优势。
二、声音识别1. 声音信号的采集与预处理声音信号是通过麦克风等设备采集得到的,但由于环境噪声和信号失真等因素,需要进行预处理以提高信号质量。
预处理包括去除噪声、滤波、增益调整等操作。
2. 特征提取与模型训练在声音识别中,基于AI技术的主要方法是使用深度学习模型进行特征提取和分类。
常用的深度学习模型包括卷积神经网络(CNN)、长短时记忆网络(LSTM)和注意力机制等。
通过对大量标注好的声音样本进行训练,建立准确的模型。
3. 声音识别应用声音识别广泛应用于语音命令控制、语音搜索、语音转写等场景。
例如,智能音箱可以根据用户的语音指令播放音乐、查询天气等;语音识别技术被应用于电话客服系统中,实现自动化的问题解答。
三、声音合成1. 文本到语音的转换声音合成是将文本信息转化为可听的声音信号。
通过AI技术,将文字转换为具有自然流畅和情感色彩的声音成为可能。
主要步骤包括文本分析、发音规则处理和波形生成等。
2. 合成模型训练与改进与声音识别类似,使用深度学习模型可以提取特征并进行声音合成。
常用的方法有基于循环神经网络(RNN)和生成对抗网络(GAN)等。
训练好的模型可以生成逼真的语音输出。
3. 声音合成应用声音合成广泛应用于电子书阅读、无障碍辅助功能、机器人交互等领域。
例如,在电子书阅读中,通过将文本内容以朗读的方式呈现给用户,使阅读更加便捷舒适;在无障碍辅助功能中,将文字转为语言帮助视觉障碍者获取信息。
四、语音助手1. 语音识别与合成的结合AI技术使得语音识别和声音合成能够相互结合,形成智能的语音助手。
通过在设备或系统中集成语音助手,用户可以通过声音进行交互,实现更加便捷、高效的操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
步骤 4:保存文件,完成编辑。
5.使用 Cool Edit 进行混音处理
步骤 1:打开【示例 1_1】,执行【Edit】/【Mix paste…】命令,打开【Mix paste】对话框 如图 1.14 所示。
图 1.14 【Mix paste】对话框
1)。在 Volume 框中,【Volume L,R】代表左右声道音量,若为单声道文件,则只有一个声 道 音 量 调 节 , 若 选 中 【 Invert 】, 则 文 件 在 被 粘 贴 前 声 音 数 据 将 会 颠 倒 。 当 【 Lock left/Right】被选中时,左右声道调节钮将被锁定,调节时将一齐变化。
2)Midi 格式 Midi 是 Musical Instrument Digital Interface(乐器数字接口)的缩写。它是由世界上
主要电子乐器制造厂商建立起来的一个通信标准,并于 1988 年正式提交给 MIDI 制造商协 会,便成为数字音乐的一个国际标准。MIDI 标准规定了电子乐器与计算机连接的电缆硬件 以及电子乐器之间、乐器与计算机之间传送数据的通信协议等规范。 MIDI 标准使不同厂家 生产的电子合成乐器可以互相发送和接收音乐数据。Midi 文件纪录的是一系列指令而不是 数字化后的波形数据,所以它占用存储空间比 Wav 文件要小很多。
单击【录音】按钮开始录音。Windows 录音机录制音频文件时一次能录制的时间 为 60 秒,当录制时间大于 60 秒后,按【录音】继续录制。当朗读文章结束后,单 击【停止】结束录音,如图 1.5 所示。
图 1.5 windows 录音机
步骤 3:执行菜单【文件】/【另存为】命令,在出现的【另存为】对话框中的【格式】项, 选【更改】。在【选择声音】对话框中修改【属性】项为【22.05Hz 16 位 86KB/s】, 单击【确定】返回【另存为】对话框,选好保存的路径,文件名存为【示例 1_1】, 保存类型选 Wav,如图 1.6 所示。
如图 1.7 所示。
图 1.7 Cool Edit 2000 主界面
步骤 2:单击工具栏的【Record】按钮,如图 1.8 所示。
图 1.8 Cool Edit 2000 的工具栏
出现【New Waveform】对话框,分别选择【Sample Rate】为 44100,【Channels】 为【Stereo】,【Resolution】为【16-bits】,单击【OK】按钮开始录音,如图 1.9 所示。
进行实验的基本配置: Intel Pentium 120 CPU 或同级 100%的兼容处理器 大于 16MB 的内存 8 位以上的 DirectX 兼容声卡
1.1 实验目的和要求
本实验通过麦克风录制一段语音信号作为解说词并保存,通过线性输入录制一段音 乐信号作为背景音乐并保存。为录制的解说词配背景音乐并作相应处理,制作出一段完整的 带背景音乐的解说词。
数字音频就是将模拟的(连续的)声音波形数字化(离散化),以便利用数字计算机进行 处理,主要包括采样和量化两个方面。
2.数字音频的质量 数字音频的质量取决于采样频率和量化位数这两个重要参数。采样频率是对声音波形每
秒钟进行采样的次数。人耳听觉的频率上限在 2OkHz 左右,根据采样理论,为了保证声音
不失真,采样频率应在 4OkHz 左右。经常使用的采样频率有 11.025kHz、22.05kHz 和 44.lkHz 等。采样频率越高,声音失真越小、音频数据量越大。量化数据位数(也称量化级)是每个采 样点能够表示的数据范围,经常采用的有 8 位、12 位和 16 位。例如,8 位量化级表示每个 采样点可以表示 256 个(0-255)不同量化值,而 16 位量化级则可表示 65536 个不同量化值。 量化位数越高音质越好,数据量也越大。反映数字音频质量的另一个因素是通道(或声道)个 数。单声道是比较原始的声音复制形式, 每次只能生成一个声波数据。立体声(双声道)技术 是每次生成二个声波数据,并在录制过程中分别分配到两个独立的声道出输出,从而达到了 很好的声音定位效果。四声道环绕(4.1 声道)是为了适应三维音效技术而产生的,四声道 环绕规定了 4 个发音点:前左、前右,后左、后右,并建议增加一个低音音箱,以加强对低 频信号的回放处理。Dolby AC-3 音效(5.1 声道)是由 5 个全频声道和一个超重低音声道组 成的环绕立体声。
图 1.1 麦克风、声卡、CD 音源、音箱
声卡后有几个接口,标有 Midi/Game 的梯形接口是接 Midi 键盘和游戏手柄的,标有 Audio Out 的圆口是接音箱的,标有 Mic 的圆口是接麦克风的,标有 Line In 的圆口是外接音 频输入设备的。声卡、音箱和麦克风的连接,如图 1.2 所示。
图 1.11 【加入回声】对话框
步骤 2:拖动鼠标选取声音波形开头的一部分,执行【特殊】/【淡入…】,设置【淡入】对 话框。在【幅度】中添入 50%,【淡入】为【两个通道】,单击【确定】进行处理,如图 1.12 所示。
图 1.12 【淡入】对话框
步骤 3:拖动鼠标选取声音波形结尾的一部分,执行【特殊】/【淡出…】,设置【淡出】对 话框。在【幅度】中添入 50%,【淡出】为【两个通道】,单击【确定】进行处理,如图 1.13 所示。
备(如 CD 唱机、录音机等),把麦克风、音箱、外界音源信号设备与声卡正确连接完 成硬件准备工作。在 Windows 的【控制面板】/【多媒体】中选择正确的录音和回放设 备,并对其进行调试。
2.用 Байду номын сангаасindows 录音机录制解说词
使用 Windows 录音机录制任意一段语音信号作为解说词,录制完毕后把文件存为 Wav 格式,文件名为【示例 1_1】。
一.实验内容:
1. 硬件与软件的准备
目前,多媒体计算机中的音频处理工作主要借助声卡,从对声音信息的采集、编辑 加工,直到声音媒体文件的回放这一整个过程都离不开声卡。声卡在计算机系统中的主 要作用是声音文件的处理、音调的控制、语音处理和提供 MIDI 接口功能等。
进行录制音频信号所需的硬件除了声卡,还有麦克风、音箱以及外界的音源信号设
实验一 声音信号的获取与处理
声音媒体是较早引入计算机系统的多媒体信息之一,从早期的利用 PC 机内置喇叭发声, 发展到利用声卡在网上实现可视电话,声音一直是多媒体计算机中重要的媒体信息。在软件 或多媒体作品中使用数字化声音是多媒体应用最基本、最常用的手段。通常所讲的数字化声 音是数字化语音、声响和音乐的总称。在多媒体作品中可以通过声音直接表达信息、制造某 种效果和气氛、演奏音乐等。逼真的数字声音和悦耳的音乐,拉近了计算机与人的距离,使 计算机不仅能播放声音,而且能“听懂”人的声音是实现人机自然交流的重要方面之一。
图 1.10 保存【Music.wav】音乐文件
4.使用 WaveStudio 编辑和处理背景音乐
步骤 1:打开【示例 1_2】文件,执行【特殊】/【回声】,设置【加入回声】对话框。在 【幅度】中添入 100%,在【回声延迟】中添入 300 毫秒,在【将回声加入】中选【两个通 道】。单击【确定】进行处理,如图 1.11 所示。
RealMedia,是目前在 Internet 上相当流行的跨平台的客户/服务器结构多媒体应用标准,它 采用音频/视频流和同步回放技术来实现在 Intranet 上全带宽地提供最优质的多媒体,同时 也能够在 Internet 上以 28.8Kbps 的传输速率提供立体声和连续视频。
1.3 实验内容与步骤
图 1.9 【New Waveform】对话框
步骤 3:录音结束,单击工具栏的【Stop】按钮完成录音,如图 1.8 所示。 步骤 4:执行【File】/【Save As…】,打开保存对话框,如图 1.10 所示。选择好路径,文件 名存为【示例 1_2】,保存类型选【Windows PCM(*.Wav)】,单击【保存】完成对音乐文 件的录制。
图 1.6 windows 录音机的保存及属性修改
这样一个完整语音音频文件便保存好了。
3.使用 Cool Edit 录制背景音乐
背景音乐可由录音机、CD 唱机等输出的模拟音频获取。首先保证外界音源设备与声卡 的 Line In 接口正确相连。 步骤 1:选择【开始】/【程序】/【Cool Edit 2000】/【Cool Edit 2000】,打开 Cool Edit 2000,
1.2 预备知识
1.数字音频和模拟音频 模拟音频和数字音频在声音的录制和播放方面有很大不同。模拟声音的录制是将代表声
音波形的电信号转换到适当的媒体上,如磁带或唱片。播放时将纪录在媒体上的信号还原为 波形。模拟音频技术应用广泛,使用方便。但模拟的声音信号在多次重复转录后,会使模拟 信号衰弱,造成失真。
在多媒体音频技术中,存储声音信息的文件有多种格式,如 Wav、Midi、Mp3、Rm、 VQF 等等。
1)Wav 格式 Wav 格式的文件又称波形文件,是用不同的采样率对声音的模拟波形进行采样得到的
一系列离散的采样点,以不同的量化位数(16 位、32 位或 64 位)把这些采样点的值转换成 二进制数得到的。Wav 是数字音频技术中最常用的格式,它还原的音质较好,但所需存储 空间较大。
为确保麦克风和线性输入能正常使用,双击位于桌面右下任务栏的喇叭 ,打开【播放 控制】对话框,确认话筒和线性输入的【静音】前没有打“√”,如图 1.4 所示。
图 1.4 【播放控制】的对话框
2.用 Windows 录音机录制解说词
步骤 1:首先准备一份所需录制的材料作为解说词。 步骤 2:执行【开始】/【程序】/【附件】/【娱乐】/【录音机】。打开【录音机】,
图 1.2 电脑连线图
在完成了硬件设备的连接后为了使声卡能正常工作还要进行软件的调试。 进入 Windows98,选择【开始】/【设置】/【控制面板】,选【多媒体】。在【多媒体 属性】 对话框中选择的【音频】,在【回放】和【录音】的首选设备中选择声卡所对应的输入和输 出选项,如图 1.3 所示。