CPU报告04008409沈昊骍
MIPS单周期CPU实验报告

MIPS单周期CPU实验报告一、实验目的本实验旨在设计一个基于MIPS指令集架构的单周期CPU,具体包括CPU的指令集设计、流水线的划分与控制信号设计等。
通过本实验,可以深入理解计算机组成原理中的CPU设计原理,加深对计算机体系结构的理解。
二、实验原理MIPS(Microprocessor without Interlocked Pipeline Stages)是一种精简指令集(RISC)架构的处理器设计,大大简化了指令系统的复杂性,有利于提高执行效率。
MIPS指令集由R、I、J三种格式的指令组成,主要包括算术逻辑运算指令、存储器访问指令、分支跳转指令等。
在单周期CPU设计中,每个指令的执行时间相同,每个时钟周期只执行一个指令。
单周期CPU的主要部件包括指令内存(IM)、数据存储器(DM)、寄存器文件(RF)、运算单元(ALU)、控制器等。
指令执行过程主要分为取指、译码、执行、访存、写回等阶段。
三、实验步骤1.设计CPU指令集:根据MIPS指令集的格式和功能,设计符合需求的指令集,包括算术逻辑运算指令、存储器访问指令、分支跳转指令等。
2.划分CPU流水线:将CPU的执行过程划分为取指、译码、执行、访存、写回等阶段,确定每个阶段的功能和控制信号。
3.设计控制器:根据CPU的流水线划分和指令集设计,设计控制器实现各个阶段的控制信号生成和时序控制。
4.集成测试:进行集成测试,验证CPU的指令执行功能和正确性,调试并优化设计。
5.性能评估:通过性能评估指标,如CPI(平均时钟周期数)、吞吐量等,评估CPU的性能优劣,进一步优化设计。
四、实验结果在实验中,成功设计了一个基于MIPS指令集架构的单周期CPU。
通过集成测试,验证了CPU的指令执行功能和正确性,实现了取指、译码、执行、访存、写回等阶段的正常工作。
同时,通过性能评估指标的测量,得到了CPU的性能参数,如CPI、吞吐量等。
通过性能评估,发现了CPU的性能瓶颈,并进行了相应的优化,提高了CPU的性能表现。
校级汇总表
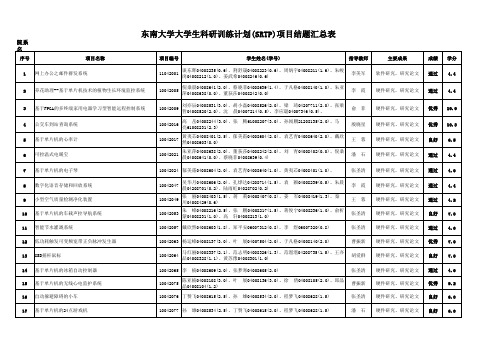
6.5 4.4 7.0 4.0 7.0 5.0 6.5 7.0 2.0
张兴稳04008209(1.0)、江 涛04008241(1.0)、谈冬晖04008235(1.2)、荆舒 晟04008223(1.0)、周炳宇04008211(0.2) 王加锋04208718(2.5)、胡雯婷04208712(2.0)、任 鑫04208720(1.0)、胡一苗04008437(0.5) 婧14509117(1.0)、张金
18 19
简易心电图的设计 短距离无线传输温度采集系统
团哲恒04008619(0.4)、朱晨晨04208701(2.0)、霍 鋆04008333(2.0)、尤 优04008528(2.0) 孟竟成04008610(2.0)、李 阳04008611(0.6)、王 10042090 磊04008636(0.6) 10042088 10042091
10042024 郁美霜04008604(2.0)、袁艺青04008640(1.0)、黄夷芯04008401(1.0)、 10042047 10042049 10042053 吴华月04008606(2.0)、孔烨达04208714(1.5)、袁 晨04208701(0.2)、陆雨虹04028702(0.2) 张 丽04008403(1.5)、蒋 川04008429(0.6) 莉04008407(0.8)、姜 颖04008239(0.5)、朱晨 军04008419(1.3)、秦
10042154 陈东杰04008631(2.6)、王文龙04008630(2.2)、陈恒磊04008636(2.2) 马朔昕04008109(0.2)、王从杰04008110(2.5)、牟学凯04008111(2.5)、仇 10042157 诚04008112(2.5)、黄昊泽04008113(0.7)、邱才生04008117(0.7)、刘 晶 04008114(0.7) 10042162 钱忠洋04008118(1.0)、秦为帅04008119(1.2)、邓文强04008121(1.0)、黄如 意04008122(1.0)
MIPS单周期CPU实验报告

MIPS单周期CPU实验报告一、实验目标本次实验的主要目标是设计并实现一个基于MIPS单周期CPU的计算机系统。
具体要求如下:1.能够识别并执行MIPS指令集中的常见指令,包括算术逻辑运算、分支跳转和存取指令等。
2.实现基本的流水线结构,包括指令译码阶段、执行阶段、访存阶段和写回阶段。
3.能够在基本结构的基础上添加异常处理和浮点数运算支持。
二、实验环境三、实验过程1.确定CPU的基本组成部分,包括指令存储器、数据存储器、寄存器、ALU和控制单元等,并进行电路设计。
2.编写MIPS汇编程序,并使用MARS进行仿真调试,验证指令的正确性和计算结果的准确性。
3.将MIPS汇编程序烧录到指令存储器中,并将数据存储器中的初始数据加载进去。
4.运行程序,观察CPU的工作状态,并进行时序仿真,验证CPU设计的正确性。
5.对CPU进行性能测试,包括执行时间、指令吞吐量和时钟周期等指标的测量。
四、实验结果经过实验和测试,我们成功地设计并实现了一个基于MIPS单周期CPU的计算机系统。
该系统能够正确执行MIPS指令集中的常见指令,并支持流水线结构、异常处理和浮点数运算。
1.指令执行的正确性:通过在MARS中进行调试和仿真,我们发现CPU能够正确地执行各种指令,包括算术逻辑运算、分支跳转和存取指令等。
并且,在时序仿真中,CPU的各个组件的信号波形也符合预期。
2.流水线结构的实现:我们根据MIPS指令的特点和处理流程,设计了基本的流水线结构,并在MARS中进行了时序仿真。
仿真结果表明,各个流水线级的操作都能够正确无误地进行,并且能够顺利地在一个时钟周期内完成。
3.异常处理和浮点数运算的支持:通过在MIPS汇编程序中加入异常处理和浮点数运算的指令,我们验证了CPU对这些功能的支持。
在异常处理时,CPU能够正确地转入异常处理程序,并根据异常类型进行相应的处理。
在浮点数运算时,CPU能够正确地进行浮点数的加减乘除等运算,并将结果正确地写回寄存器。
cpu过高的排查经历

在排查CPU过高的问题时,可以按照以下步骤进行:1. 查看物理机进程id:首先,通过使用top指令,可以查看物理机的进程ID。
在获得堡垒机权限后,登上机器运行top指令,可以发现CPU占用率高的进程。
例如,如果进程为623的机器CPU一直在高位,但内存不是很高,那么需要进一步查看该进程的相关信息。
2. 查看进程下各线程情况:通过使用top-H -p 623命令,可以查看该进程下所有线程的具体执行情况。
如果并没有非常突出的占用CPU高的线程存在,但CPU使用率仍然很高,那么需要继续查看具体执行情况。
3. 指定其中一个线程查看具体的执行情况:将指定的线程转换为16进制后,可以使用jstack命令查看具体的线程执行情况。
例如,可以通过这些信息来查看线程在执行什么任务,以及任务执行的具体情况。
如果排查后问题仍然存在,建议采取以下措施:1. 重启机器:在非线上环境出现CPU超过90%的告警时,首先尝试重启机器。
在重启后,如果CPU如期的下降了下来,那么可以暂时高枕无忧。
但需要注意的是,如果重启后问题仍然存在,那么需要继续进行排查。
2. 检查系统环境:在排查过程中,需要注意检查系统的环境变量设置是否正确。
同时,也需要确保系统中的其他软件或应用没有占用大量的CPU资源。
3. 检查应用程序:如果系统中没有其他软件或应用占用大量的CPU资源,那么需要进一步检查应用程序是否存在问题。
例如,可以尝试更新应用程序或重新安装应用程序,以解决可能存在的bug或问题。
4. 检查硬件设备:如果以上措施都无法解决问题,那么需要检查硬件设备是否存在问题。
例如,可以检查CPU的温度是否过高、风扇是否正常运转等。
如果硬件设备存在问题,那么需要采取相应的措施进行维修或更换。
总之,在排查CPU过高的问题时,需要一步步地进行排查,并采取相应的措施进行解决。
同时,也需要注意系统的环境变量设置是否正确、系统中是否存在其他软件或应用占用大量的CPU资源等问题。
深入理解CPU指令集对代码执行的影响

深入理解CPU指令集对代码执行的影响CPU指令集对代码执行的影响是一个十分重要的问题,它直接关系到代码执行的效率、性能以及一些架构相关的问题。
在本文中,我们将深入理解CPU指令集对代码执行的影响,并探索一些常见的指令集以及它们对代码执行的影响。
首先,我们需要了解什么是CPU指令集。
简单来说,CPU指令集是CPU能够理解和执行的一组指令。
CPU根据不同的指令集编码来执行不同的操作,比如加法、乘法、跳转等等。
常见的指令集有x86、ARM、MIPS等等。
不同的指令集对代码执行的影响主要体现在以下几个方面:1.指令集的种类和数量:不同指令集支持的不同操作和功能也不同。
一些指令集可能支持更多的操作和功能,从而可以更好地满足代码的需求。
比如,一些高级指令集支持向量操作,在处理大量数据时可以提高执行效率。
2.指令的执行速度:不同指令集的指令执行速度也不同。
一些指令集可能对某些操作进行了特殊优化,从而提高了执行速度。
比如,一些指令集支持乘法操作,可以用更少的指令完成一次乘法运算,从而提高了执行速度。
3.指令的编码和解码:不同指令集的指令编码也不同。
一些指令集可能采用更紧凑的编码方式,从而减少内存占用和指令传输的带宽。
此外,指令的解码也需要一定的时间和资源。
一些指令集的指令解码过程更加复杂,可能会导致指令执行的延迟增加。
4.指令的并行执行能力:一些指令集支持更高级的指令并行执行技术,从而提高了代码的执行效率。
比如,一些指令集支持超标量执行和超线程技术,可以同时执行多条指令。
这样可以减少指令的阻塞和延迟,提高代码的执行效率。
5.缓存命中率和内存访问模式:不同的指令集对内存的访问模式和缓存命中率的要求也不同。
一些指令集对内存的访问模式比较宽容,可以更好地适应各种代码访问模式。
而一些指令集对内存的访问模式要求比较严格,需要更高的缓存命中率和更合理的内存访问模式。
综上所述,CPU指令集对代码执行的影响是多方面的。
不同的指令集有不同的特点和优势,可以根据代码的需求来选择适合的指令集。
cpuinfo命令 cpuid level

cpuinfo命令 cpuid levelC P U ID L e v e l指的是C P U I D指令返回的信息中的一个字段,用于指示C P U支持的特定功能和功能级别。
本文将详细介绍CP U I D指令和CP U I DL e v e l的概念以及它们在计算机系统中的作用。
第一部分:C P U I D指令的介绍C P U I D指令是一条用于向CP U请求特定信息的指令,在x86架构的处理器中广泛使用。
它通常用于获取处理器的相关信息,如制造商、型号、插槽类型、支持的功能等。
C P U I D指令的格式为"C P U I D(E A X,E C X)",其中E A X和E C X是输入寄存器,用于指定查询的信息类别和子类别。
执行C P U I D指令后,处理器会将返回值存放在E A X、E B X、E C X和ED X这四个输出寄存器中。
第二部分:C P U I D L e v e l的概念C P U ID L e v e l是C P U I D指令返回的信息中的一个字段,用于指示C P U支持的特定功能和功能级别。
具体来说,C P U I D L e v e l字段标识了C P U支持的最高功能级别,即支持的最大子类别。
不同的C P U支持不同的功能和功能级别,在CP U I DL e v e l字段的值可以方便地确定C P U的支持能力。
第三部分:C P U I D L e v e l的解读C P U ID L e v e l字段的值以二进制形式表示,每一位都代表了一个具体的功能或功能级别。
例如,第0位表示第一个功能,第1位表示第二个功能,以此类推。
如果某一位上为1,表示该C P U支持对应的功能;如果某一位上为0,则表示该C P U不支持对应的功能。
第四部分:C P U I D L e v e l的应用C P U ID L e v e l对于操作系统和应用程序开发人员非常重要。
基于实验数据的不对中故障特性分析

DOI:10.15913/ki.kjycx.2024.01.017基于实验数据的不对中故障特性分析赵天,苏长青,王裕琳(沈阳航空航天大学,辽宁沈阳110136)摘要:用实验方式分析了不对中故障的相关振动特性。
在不对中故障实验中运用柔性单转子综合实验台分别进行了3种不同转速下的正常状态、轻微不对中和严重不对中实验。
利用水平和垂直2个方向的传感器,得到实验数据。
利用Origin 软件导入实验数据并绘制了不同条件下的频谱图和轴心轨迹图。
分别对比了不同转速下的不同故障状态,分析了相关的振动特性和故障特征。
整合后得出了最终的实验结论,并为以后的转子系统实验研究提供参考。
关键词:转子系统;不对中故障;频域分析;轴心轨迹中图分类号:TH133 文献标志码:A 文章编号:2095-6835(2024)01-0061-05转子系统是旋转机械的主要零件之一,而转子不对中故障是较为常见的转子故障,因此研究该类故障对生产生活有较大的意义。
转子系统不对中通常指相邻的2个转子的轴心线本应同轴,而在初始安装或实际运行中存在轴心线不同轴,即存在一定的偏移或倾斜量。
产生不对中的原因主要是制造误差、安装误差、热变形等。
转子不对中主要包括联轴器不对中和支点不对中2类,联轴器不对中包括平行不对中、偏角不对中、平行和偏角的复合不对中,支点不对中包括轴承偏角不对中和轴承标高变化。
不对中会引起轴向振动和径向振动,导致转子系统的轴向、径向交变力[1-6]。
针对转子系统不对中理论开展的理论研究工作,主要包括动力学建模、不对中转子系统的振动分析与动态设计、不对中故障诊断方法等方面,不对中转子系统动力学与振动方面的研究,主要集中在联轴器不对中方面,而支承不对中的研究相对较少,且大多针对滑动轴承不对中,专门针对滚动轴承不对中的研究更少[7-12]。
本文在大量阅读国内外文献的基础上,设计并进行了3种不同转速下的正常状态、轻微不对中和严重不对中的实验来验证不对中故障的故障特征及运动特性,为转子故障研究提供了实验数据支持。
智能车行走成绩表

初中457张浩宇第九中学一初中354吴沂泽河西少年宫一初中126许哲凡第102中学一初中251王健雄一初中250崔泊宁一初中279刘康文25中学二初中101齐柏寒实验中学二初中684苏之清61中学二初中356叶英杰河西少年宫二初中476郭瀚文南开翔宇学校二初中355张伯威河西少年宫二初中98吕馨悦41中二初中106张自强小东庄中学二初中103李鑫琦小东庄中学二初中276吴苡祯北师大天津附中二初中99程秀鹏实验中学二初中671刘端20中学二初中4刘子祺天津四中二初中220边昱泽25中学二初中460付振永第九中学二初中100王思博四中三初中107胡 宸小东庄中学三初中104吴杰浩小东庄中学三初中118邵 奇小东庄中学三初中277袁皓钰北师大天津附中三初中105李同旭小东庄中学三初中109焦荣盛小东庄中学三初中459代鹏第九中学三初中440刘欣远天大附中三初中217王振宇育才中学三初中102赵 然小东庄中学三初中149赵子林育才中学三初中150梁金第二中学三初中280孟昊亮21中学三初中489温馨育红中学三初中363刘泽昊翔宇中学三初中477陈浩云南开翔宇学校三初中478程盛南开翔宇学校三初中108刘万鑫小东庄中学三初中438张若凡天大附中三初中588张欣蕊61中学三初中458贾儒第九中学三初中218高钧育才中学三初中441曹琮旺天大附中三初中221魏欣五十四中学三初中439戚馨月天大附中无初中278李林森北师大天津附中无初中219刘瑀萱102中学无初中442马东珊天大附中无初中472陈成典南开翔宇学校无初中473周子钰南开翔宇学校无初中474崔明旭南开翔宇学校无初中475陈砚文南开翔宇学校无小学156邢东剑光明小学一小学127范文凝河东中心东道小学一小学216陈启雨和平中心小学一小学235滕磊友谊路小学一小学王一帆实验小学一小学204杜靖宇河东中心东道一小学223冯宇轩河东一中心小一小学224王小雨昆纬路第一小学一小学157晋子杰光明小学一小学246李建树友谊路小学一小学303王瑞松师大二附小一小学158袁梓枫光明小学一小学184童筠泽河东丽苑小学一小学312郝薏喧师大二附小一小学311白皓天师大二附小一小学297张凡俣 师大二附小二小学182张翼河东丽苑小学二小学198秦瑜河东二号桥小二小学307王辛梦玥师大二附小二小学152何雨轩 光明小学二小学247王汉春友谊路小学二小学202王翰宸河东中心东道二小学661刘根堉河东实验小学二小学359王悦晨河北江南寄宿小学二小学83孙皓妍平山道小学二小学151李一鸣 光明小学二小学239董帅友谊路小学二小学549董翰泽新开小学二小学185郭海涛河东丽苑小学二小学252顾馨悦东方小学二小学659赵玥河东实验小学二小学548徐浩然新开小学二小学154何仲仪 光明小学二小学207孙心怡河东香山道小二小学210梅维珊河东缘诚小学二小学155蔡新蕊 光明小学二小学688邵玟睿师大二附小二小学296杨智麟 师大二附小二小学214崔馨月河西闽侯路小二小学249刘婧仪台湾路小学二小学373郄晓辰马场道小学二小学642李泽雨河东实验小学二小学318桑异凡师大二附小二小学215徐盛煜和平岳阳道小二小学641张智皓河东实验小学二小学308吴尚昆师大二附小二小学245马媛友谊路小学二小学310刘思清师大二附小二小学195常鹏硕河东二号桥小二小学375金桓立河东第一中心小学二小学660刘信璞河东实验小学三小学305于瀚波师大二附小三小学97刘宸瑒闽侯路小学三小学241陈玥希友谊路小学三小学645姜文蔚河东实验小学三小学651王翔河东实验小学三小学648杨雨蒙河东实验小学三小学630齐涵湫河东实验小学三小学309何昊洋师大二附小三小学644尚毅河东实验小学三小学650胡选龙河东实验小学三小学145吴若凡互助道小学三小学191赵驿河东务实小学三小学669张伯菲20中附小三小学153徐漪泓 光明小学三小学190董泰河东务实小学三小学206张昊河东实验小学三小学674祝宇飞台湾路小学三小学200刘浩楠河东中心东道三小学306李铭瑞师大二附小三小学213张桐赫河西台湾路小三小学142唐博宇互助道小学三小学70王江宁平山道小学三小学141于凯民互助道小学三小学683赵顺臻台湾路小学三小学212刘治甫河西湘江道小三小学75陈阳平山道小学三小学76牛成莅平山道小学三小学197冯子怡河东二号桥小三小学80胡皓天平山道小学三小学537任成豪南开小学三小学146武文博互助道小学三小学193袁艺河东务实小学三小学72吴安南平山道小学三小学74于乾洋平山道小学三小学78郭力源平山道小学三小学497陆杰文南开科技实验小学三小学89董睿平山道小学三小学409张皓然南开中心小学三小学81纪柯羽平山道小学三小学244崔旭阳 友谊路小学三小学85褚天成平山道小学三小学144孙厚宇互助道小学三小学188齐星晨河东务实小学三小学189张辰阳河东务实小学三小学147郭鸿昊互助道小学三小学71杨彦隆平山道小学三小学591刘喜龙河东香山道小三小学408李金信南开中心小学三小学410张乐洋南开中心小学三小学411朱熙南开中心小学三小学416赵泽龙南开中心小学三小学498贾若晖南开科技实验小学三小学510黄天惠南开华苑小学三小学687崔顺诚河东实验小学三小学676姚宏泽台湾路小学三小学192张正阳河东务实小学三小学201李明康河东中心东道三小学194田群河东二号桥小三小学196田浩男河东二号桥小三小学199张贤泽河东中心东道三小学183赵雨辰河东丽苑小学三小学413蔡璐璠南开中心小学三小学677韩宗甫台湾路小学三小学211马淑淇河东缘诚小学三小学186郭云涛河东丽苑小学三小学205庞博洋河东中心东道三小学208李麒河东友爱道小三小学84朱禧隆平山道小学三小学148申鹏互助道小学三小学181滑清雅河东丽苑小学三小学65曾朵多五马路小学三小学69张佳航平山道小学三小学77王梓睿平山道小学三小学222韩汶澂河东一中心小三小学358周震寰河北江南寄宿小学三小学82郑永建平山道小学三小学592程凡宁河东香山道小三小学203李璐璐河东中心东道三小学68刘天华平山道小学三小学79刘庆然平山道小学三小学143武紫剑互助道小学三小学514杨子芃风湖里小学三小学516王宏森风湖里小学三小学519刘博闻风湖里小学三小学593莎日娜河东香山道小三小学496李美玉南开长治里小学三小学407马静怡南开中心小学三小学412郑静宇南开中心小学三小学414郭凡荻南开中心小学三小学415张馨戈南开中心小学三小学526李天予风湖里小学三小学527王智龙风湖里小学三小学187王帅河东务实小学无小学67何鑫淼平山道小学无小学73董睿平山道小学无小学517范子维风湖里小学无小学490伊家健南开长治里小学无小学494高扬南开长治里小学无小学304孙槐志师大二附小无小学499张世杰南开科技实验小学无小学511姚铭森南开华苑小学无小学525孟庆州风湖里小学无小学538林海东南开小学无小学539段誉南开小学无小学540刘嘉恺南开小学无小学647耿赫辰河东实验小学无小学649冯麟河东实验小学无小学652刘适宁河东实验小学无小学653张一鸣河东实验小学无小学640袁嘉仪河东实验小学无小学672刘荣华台湾路小学无小学678高天翼台湾路小学无小学679焦培钧台湾路小学无小学680周易飞台湾路小学无。
单周期CPU设计实验报告

单周期CPU设计实验报告一、引言计算机是现代信息社会必不可少的工具,而CPU作为计算机的核心部件,承担着执行指令、进行运算和控制系统资源的任务。
随着科技的进步和计算能力的需求,CPU的设计也趋于复杂和高效。
本次实验旨在设计一种单周期CPU,探究其设计原理和实现过程,并通过实验验证其正确性和性能。
二、理论基础1.单周期CPU概述单周期CPU即每个时钟周期内只完成一条指令的处理,它包括指令取址阶段(IF)、指令译码阶段(ID)、执行阶段(EX)、访存阶段(MEM)和写回阶段(WB)等多个阶段。
每条指令都顺序地在这些阶段中执行,而不同的指令所需的时钟周期可能不同。
2.控制信号单周期CPU需要根据不同的指令类型产生不同的控制信号来控制各个阶段的工作。
常见的控制信号包括时钟信号(clk)、使能信号(En)、写使能信号(WE)和数据选择信号(MUX)等。
这些信号的产生需要通过译码器、控制逻辑电路和时序逻辑电路等来实现。
三、实验设计本次实验采用的单周期CPU包括以下五个阶段:指令取址阶段、指令译码阶段、执行阶段、访存阶段和写回阶段。
每个阶段的具体操作如下:1.指令取址阶段(IF)在IF阶段,通过计数器实现程序计数器(PC)的自增功能,并从存储器中读取指令存储地址所对应的指令码。
同时,设置PC使能信号,使其可以更新到下一个地址。
2.指令译码阶段(ID)在ID阶段,对从存储器中读取的指令码进行解码,确定指令的操作类型和操作数。
同时,根据操作类型产生相应的控制信号,如使能信号、写使能信号和数据选择信号等。
3.执行阶段(EX)在EX阶段,根据ID阶段产生的控制信号和操作数,进行相应的算术逻辑运算。
这里可以包括加法器、乘法器、逻辑运算器等。
4.访存阶段(MEM)在MEM阶段,根据EX阶段的结果,进行数据存储器的读写操作。
同时,将读取的数据传递给下一个阶段。
5.写回阶段(WB)在WB阶段,根据MEM阶段的结果,将数据传递给寄存器文件,并将其写入指定的寄存器。
基于深度学习的女装图片分类探索

基于深度学习的女装图片分类探索叶锦;彭小江;乔宇;邢昊【摘要】互联网商品图像的属性分类是人工智能领域的重要研究课题之一,针对商品图像属性分布不平衡以及不同属性间存在相关性等问题,该文以女装图像为分类目标,提出了一种基于卷积神经网络的商品图像分类方法.首先,从电商网站获取大量商品图像,并进行人工标注;然后,基于卷积神经网络框架,采用了一种有效的采样策略,通过增加新的损失函数,实现了基于多任务学习方法的商品图像属性准确分类;最后,通过对不同策略下分类结果的对比分析,验证了该方法的有效性.结果显示,所提出方法具有较高的分类精度.【期刊名称】《集成技术》【年(卷),期】2019(008)002【总页数】10页(P1-10)【关键词】商品图像;卷积神经网络;采样;多任务【作者】叶锦;彭小江;乔宇;邢昊【作者单位】中国科学院深圳先进技术研究院深圳 518055;中国科学院深圳先进技术研究院深圳 518055;中国科学院深圳先进技术研究院深圳 518055;唯品会研究院广州 510000【正文语种】中文【中图分类】TG1561 引言随着互联网、手机设备等的快速发展,网上购物已经成为人们日常生活中不可缺少的一部分,天猫更是在 2014 年“双11”创造了 350 亿元的销售奇迹[1]。
网上购物相比传统的购物方式有许多优点,例如:在省去了租门面的成本后,网络购物能以更低的价格购买到相同的商品;对消费者来说,可以节约大量的时间和精力去实体店挑选;能买到许多本地不能买到的商品等。
伴随着网购的快速发展,相应的问题也应运而生,如当人们想要在淘宝、京东、唯品会等平台购买商品时,往往会根据商品的类别及其属性来筛选需要购买的目标商品,因此商家会为每件商品制定很多属性以便于用户检索。
面对海量的商品图像数据,如果使用人工标注的方式对商品图像的属性进行标注,需要花费大量的人力和时间。
因此,如何自动对商品属性正确分类便成了一个重要且具有实际意义的课题。
基于ARM9和QT的步进电机驱动控制系统设计与实现

基于ARM9和QT的步进电机驱动控制系统设计与实现朱耀麟;沈昕宇【摘要】This paper designs a S3C2440 microprocessor and the driving chip TA8435H control of the stepper motor drive system, and the Linux application Qt design and development of embedded control system and human-machine interface, through the touch screen to the stepper motor speed, direction, subdivision mode of control, the transfer process of QT applications is given, the transplantation process the cross compiler, the system interface is simple and intuitive, easy to operate, convenient.The motor control, so that it can be better applied to the field of industrial control.%本文设计了由S3C2440微处理器和驱动芯片TA8435H控制的步进电机驱动系统,并通过Linux 下应用Qt 设计开发嵌入式控制系统人机界面的方法,通过触摸屏对步进电机转速、方向、细分模式等进行控制,最后给出了QT应用程序的移植过程,移植过程采用交叉编译,系统界面直观简洁,易于操作,极大地方便了对电机的控制,使其更好地应用于工业控制领域。
【期刊名称】《电子设计工程》【年(卷),期】2014(000)021【总页数】4页(P149-152)【关键词】步进电机控制;SC2440;QT移植;人机交互【作者】朱耀麟;沈昕宇【作者单位】西安工程大学电子信息学院,陕西西安 710048;西安工程大学电子信息学院,陕西西安 710048【正文语种】中文【中图分类】TN6嵌入式控制系统以其低功耗、低成本、高性能等优势被广泛用于工业控制领域,而在嵌入式控制系统中步进电机驱动控制技术是关键技术之一 [1]。
基于SoC的非对称数字系统算法设计与实现

基于SoC的非对称数字系统算法设计与实现姜智;肖昊【期刊名称】《合肥工业大学学报(自然科学版)》【年(卷),期】2024(47)5【摘要】文章提出一种在片上系统(System on Chip,SoC)实现高吞吐率的有限状态熵编码(finite state entropy,FSE)算法。
通过压缩率、速度、资源消耗、功耗4个方面对所提出的编码器和解码器与典型的硬件哈夫曼编码(Huffman coding,HC)进行性能比较,结果表明,所提出的硬件FSE编码器和解码器具有显著优势。
硬件FSE(hFSE)架构实现在SoC的处理系统和可编程逻辑块(programmable logic,PL)上,通过高级可扩展接口(Advanced eXtensible Interface 4,AXI4)总线连接SoC 的处理系统和可编程逻辑块。
算法测试显示,FSE算法在非均匀数据分布和大数据量情况下,具有更好的压缩率。
该文设计的编码器和解码器已在可编程逻辑块上实现,其中包括1个可配置的缓冲模块,将比特流作为单字节或双字节配置输出到8 bit 位宽4096深度或16 bit位宽2048深度的块随机访问存储器(block random access memory,BRAM)中。
所提出的FSE硬件架构为实时压缩应用提供了高吞吐率、低功耗和低资源消耗的硬件实现。
【总页数】6页(P655-659)【作者】姜智;肖昊【作者单位】合肥工业大学微电子学院【正文语种】中文【中图分类】TN762;TN764【相关文献】1.基于IEEE 1500的数字SOC测试系统的设计与实现2.基于片上系统SoC的孤立词语音识别算法设计3.OMA DRM 2数字版权保护终端系统的SoC设计方案及其VLSI实现4.无线通信系统数字变频算法设计与实现因版权原因,仅展示原文概要,查看原文内容请购买。
基于物联网的人工智能图像检测系统设计与实现

基于物联网的人工智能图像检测系统设计与实现
沈佳琪
【期刊名称】《互联网周刊》
【年(卷),期】2022()14
【摘要】以小波能量算法和边缘噪声背景划分为基础的传统图像检测方法,图像检测的分辨率较低,精确度不足,整体的检测速度很慢,难以进行深度的图像分析,而近年来,在人工智能技术、物联网平台发展的过程中,以物联网技术为基础的智能化图像检测系统,通过人工智能像素特征点采集技术、提取技术和收集反馈技术等,对图像像素特征进行分析,有效完成数据信息的处理。
另外还可利用人工智能化图像信号合成的功能和图像转换处理输出功能等,提升反馈信号的处理效果,确保人工智能图像检测的精确度和分辨率,提升系统运行的稳定性。
因此,在人工智能图像检测方面,应重点采用互联网技术设计检测系统,改善图像检测的分辨率和精度,发挥物联网技术的价值。
【总页数】3页(P54-56)
【作者】沈佳琪
【作者单位】兰州职业技术学院
【正文语种】中文
【中图分类】TP3
【相关文献】
1.基于物联网的人工智能图像检测系统设计与实现
2.基于物联网的人工智能图像检测系统设计研究
3.基于图像识别的影视剧图像帧检测系统设计与实现
4.基于物联网技术的人工智能图像检测系统设计
5.基于物联网技术实现开关柜局放状态检测系统设计
因版权原因,仅展示原文概要,查看原文内容请购买。
一种基于FPGA的红外图像细节增强加速方法

一种基于FPGA的红外图像细节增强加速方法
史豪斌;胡航语
【期刊名称】《西北工业大学学报》
【年(卷),期】2022(40)3
【摘要】在机载、车载、舰载平台的众多座舱人机交互系统中,图像细节增强能够提升人员对红外图像的判读能力,具有非常重要的应用需求。
运行在嵌入式计算平台上的增强算法需要具有较高的处理速度和较低的算法延迟才能满足实时交互的需求。
当前红外视频传感器分辨率较低,图像细节增强算法在同构多核CPU处理平台上即可达到实时处理性能。
然而,随着平台传感器分辨率的持续增加,图像处理速度和延迟难以满足。
提出一种针对FPGA平台的红外图像细节增强加速方法,考虑FPGA的特定领域软硬件计算架构,采用基于局部缓存和查表等方式对传统的双边滤波图像细节算法进行加速,使得在4k分辨率输入图像下,依然能够达到实时处理性能,同时几乎不增加额外的访存延迟。
算法在保证处理效果的同时,极大地提升了处理和延迟指标,满足座舱人机交互系统等嵌入式装备特定领域应用需求。
【总页数】6页(P524-529)
【作者】史豪斌;胡航语
【作者单位】西北工业大学计算机学院
【正文语种】中文
【中图分类】TP391.41
【相关文献】
1.基于FPGA的高动态范围红外图像细节增强算法
2.一种基于双边滤波的红外图像细节增强方法
3.基于FPGA的红外图像细节增强算法设计与实现
4.一种改进的基于频域的红外图像细节增强方法
5.一种基于图像分层的红外图像目标细节增强算法
因版权原因,仅展示原文概要,查看原文内容请购买。
基于下一代MCU高算力与虚拟化技术的汽车软件研究与开发

基于下一代MCU高算力与虚拟化技术的汽车软件研究与开发单忠伟;刘宁
【期刊名称】《上海汽车》
【年(卷),期】2024()1
【摘要】随着汽车电子电气架构的演进,主流MCU(Micro-controllerUnit)供应商均推出了下一代MCU产品。
文章研究对象为下一代MCU的共性关键技术高算力与虚拟化。
首先,从MCU算力及其评价指标入手,介绍了下一代MCU提升算力的
总体策略,并从主算力、硬件加速、辅助算力、存储与内部总线几方面进行了分析。
在介绍虚拟化技术特点和Hypervisor方案的基础上,分析了MCU硬件虚拟化特性,以及基于MCU硬件虚拟化技术的软件开发流程。
然后,从控制器集成化、高算力
环境两方面,较为深入地剖析了它们对汽车软件开发的影响。
最后,分享了某公司电力驱动业务部软件研发团队在基于高算力与虚拟化技术的电力电子控制器软件开发方面的最新研究与实践成果。
文章提供了针对下一代MCU技术升级背后的底层逻辑洞察,旨在为汽车控制器、MCU芯片、基础软件等相关领域的研发人员提供有益的参考。
【总页数】15页(P21-35)
【作者】单忠伟;刘宁
【作者单位】联合汽车电子有限公司
【正文语种】中文
【中图分类】TP3
【相关文献】
1.基于仿真的汽车电子控制器软件开发方法研究
2.基于Aspice的汽车软件开发流程研究
3.基于 Revit 的高桩码头快速建模软件开发研究
4.面向汽车集中式EE架构下的MCU类域控制器软件开发集成过程研究
5.基于Aspice与ISO 26262标准融合的汽车软件开发过程研究
因版权原因,仅展示原文概要,查看原文内容请购买。
基于半监督学习Informer算法的工业机器人故障诊断方法

基于半监督学习Informer算法的工业机器人故障诊断方法宋俊杰;陈翀;王涛;程良伦
【期刊名称】《机电工程技术》
【年(卷),期】2024(53)2
【摘要】在工业领域中,六轴机器人的故障监测数据难以收集大量的故障标签数据。
传统的智能诊断方法通常依赖于大规模有标签数据的监督学习,但这在实际应用中
存在局限。
在解决这一问题的同时,针对单一模型特征提取能力不足、分类性能差
的问题,结合半监督学习机制与Informer在处理时序数据的优势,提出一种基于半
监督学习和概率稀疏注意力的Informer网络架构,实现对少量有标签数据和大量未标签数据的深度学习,以实现对设备故障的精准诊断。
对多组真实环境下采集的工
业六轴机器人试验数据进行验证,并与CNN、LSTM、GRU 3种深度学习网络对不同故障程度的辨识能力进行比较。
结果表明,在无标签数据为100%组的对比实验
中所提出方法的故障诊断准确率达到了90%,同时具有更高的分类准确率和更快的收敛速度;在10%标签数据的条件下所提出方法可实现的诊断准确率达到89.7%。
【总页数】5页(P24-28)
【作者】宋俊杰;陈翀;王涛;程良伦
【作者单位】广东工业大学广东省信息物理融合重点实验室
【正文语种】中文
【中图分类】TP242.2
【相关文献】
1.基于在线半监督学习的故障诊断方法研究
2.基于局部聚类与图方法的半监督学习算法
3.基于图像处理和半监督学习的变电设备故障诊断
4.基于抽样卷积交互网络和改进Informer的多元负荷预测方法
5.基于参数联合优化VMD-SVM的工业机器人旋转部件故障诊断方法
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Computer Organization and ArchitectureCourse DesignCPU1.PurposeThe purpose of this project is to design a simple CPU (Central Processing Unit). This CPU has basic instruction set, and we will utilize its instruction set to generate a very simple program to verify its performance. For simplicity, we will only consider the relationship among the CPU, registers, memory and instruction set. That is to say we only need consider the following items: Read/Write Registers, Read/Write Memory and Execute the instructions.At least four parts constitute a simple CPU: the control unit, the internal registers, the ALU and instruction set, which are the main aspects of our project design andwill be studied.2.Top block diagram of the simple computer3.The functions of the computerMAR (Memory Address Register)MAR contains the memory location of the word to be read from the memory or written into the memory. Here, READ operation is denoted as the CPU reads from memory, and WRITE operation is denoted as the CPU writes to memory. In our design, MAR has 8 bits to access one of 256 addresses of the memory.MBR (Memory Buffer Register)MBR contains the value to be stored in memory or the last value read from memory. MBR is connected to the address lines of the system bus. In the design, MBR has 16 bits.PC (Program Counter)PC keeps track of the instructions to be used in the program. In our design, PC has 8 bits.IR (Instruction Register)IR contains the opcode part of an instruction. In our design, IR has 8 bits.BR (Buffer Register)BR is used as an input of ALU, it holds other operand for ALU. In our design, BR has 16 bits.ALU (Accumulator)ACC holds one operand for ALU, and generally ACC holds the calculation result of ALU. In our design, ACC has 16 bits.The ALU supports :Arithmetic operation: ADD , SUB,MPY between ACC and BR;Logic operation:AND, OR between ACC and BR bit by bit.NOT complement the ACC bit by bit.SHIFTR\ SHIFTL shift the ACC to right\left one bit, theshiftr_in and shiftl_in are inputs for SHIFTR and SHIFTLoperation respectively. The results are stored into ACC at thepositive-edge of CLK.MR (Multiplier Register)MR is used for implementing the MPY instruction, holding the multiplier at the beginning of the instruction. When the instruction is executed, it holds high part of theproduct.LPM_RAM_DQ (Memory)LPM_RAM_DQ is a RAM with separate input and output ports, it works as memory, and its size is 256×16. Although it’s not an internal register of CPU, we need it to simulate and test the performance of CPU.LPM_ROM (Control memory)LPM_ROM is a ROM with input and output ports, it works as a part of Microprogrammed Control Unit. Its size is 256×32.Microinstructions and microprogram is stored in it.CONTROL_UNITCONTROL_UNIT is a control unit,according to opcode it received,it will determine the what address car bus will take.4.The control flowchart of each instruction(1)LOAD: (2)STORE: (3)ADD:(4)SUB: (5) SHIFTR:(6) SHIFTL:(7)AND:(9) NOT:(10) JMP: (11)MPY5.The meaning of all the control signals6.The content of the ROMWIDTH = 32;DEPTH = 256;ADDRESS_RADIX = HEX;DATA_RADIX = HEX;CONTENT BEGIN0 : 00000009 C3,C0 MBR←memory,CAR←CAR+11 : 00000011 C4,C0 IRopcode←MBR15-8,CAR←CAR+12 : 00000002 C1 CAR←**[3..f] : 0;10 : 00000061 C5,C6,C0 load: MAR←MBR7-0,PC←PC+1,CAR←CAR+111 : 00000009 C3,C0 MBR←memory, , CAR←CAR+112 : 00000181 C8,C7,C0 ACC←0, BR←MBR, CAR←CAR+113 : 00000201 C9,C0 ACC←ACC+BR, CAR←CAR+114 : 00000404 C10,C2 MAR←PC, CAR←0[15..1f] : 0;20 : 00000061 C5,C6,C0 store: MAR←MBR7-0,PC←PC+1,CAR←CAR+121 : 00001001 C12,C0 MBR←ACC, CAR←CAR+122 : 00000801 C11,C0 memory←MBR, CAR←CAR+123 : 00000404 C10,C2 MAR←PC,CAR←0[24..2f] : 0;30 : 00000061 C5,C6,C0 add: MAR←MBR7-0, PC←PC+1, CAR←CAR+131 : 00000009 C3,C0 MBR←memory, CAR←CAR+132 : 00000081 C7,C0 BR←MBR, CAR←CAR+133 : 00000201 C9,C0 ACC←ACC+BR, CAR←CAR+134 : 00000404 C10,C2 MAR←PC, CAR←0,[35..3f] : 0;40 : 00000061 C5,C6,C0 sub:MAR←MBR7-0, PC←PC+1, CAR←CAR+141 : 00000009 C3,C0 MBR←memory, CAR←CAR+142 : 00000081 C7,C0 BR←MBR, CAR←CAR+143 : 00010001 C16,C0 ACC←ACC-BR, CAR←CAR+144 : 00000404 C10,C2 MAR←PC, CAR←0[45..4f] : 050 : 00008104 C8,C15,C2, halt: ACC←0, CAR←0 ,PC←0[51..5f] : 0;60 : 00000061 C5,C6,C0 and: MAR←MBR7-0, PC←PC+1, CAR←CAR+161 : 00000009 C3,C0 MBR←memory, CAR←CAR+162 : 00000081 C7,C0 BR←MBR, CAR←CAR+163 : 10000001 C28,C0 ACC←ACC and BR, CAR←CAR+164 : 00000404 C10,C2 MAR←PC,CAR←0[65..6f] : 0;70 : 00000061 C5,C6,C0 or: MAR←MBR7-0 ,PC←PC+1, CAR←CAR+171 : 00000009 C3,C0 MBR←memory, CAR←CAR+172 : 00000081 C7,C0 BR←MBR, CAR←CAR+173 : 08000001 C27,C0 ACC←ACC or BR, CAR←CAR+174 : 00000404 C10,C2 MAR←PC, CAR←0[75..7f] : 0;80 : 04000041 C26, C6, C0 not: ACC←not ACC, CAR←CAR+181 : 00000404 C10,C2 MAR←PC, CAR←0[82..8f] : 0;90 : 00020044 C17,C6,C2 shiftr: ACC←ACC>>1, CAR←CAR+191 : 00000404 C10,C2 MAR←PC, CAR←0[92..9f] : 0;a0 : 02000044 C25,C6,C2 shiftl: ACC←ACC<<1, CAR←CAR+1a1 : 00000404 C10,C2 MAR←PC, CAR←0[a2..af] : 0;b0 : 00000061 C5,C6,C0 mpy: MAR←MBR7-0 ,PC←PC+1, CAR←CAR+1 b1 : 00000009 C3,C0 MBR←memory, CAR←CAR+1b2 : 00000081 C7,C0 BR←MBR , CAR←CAR+1b3 : 01000001 C24,C0 ACC←ACC*BR(L), CAR←CAR+1b4 : 00040001 C18,C0 MR←ACC*BR(H), CAR←CAR+1b5 : 00000404 C10,C2 MAR←PC , CAR←0[b8..ef]: 0F0 : 00000041 C6,C0 jumpez:(IF flag=1) PC←PC+1, CAR←CAR+1F1 : 00000404 C10,C2 CAR←0 ,MAR←PCF2 : 00004001 C14,C0 (IF flag =0) PC←MBR7-0, CAR←CAR+1F3 : 00000404 C10,C2 CAR←0 ,MAR←PC[F4..Ff] : 0;7.Test and Results:1.Calculate the sum of all integers from 1 to 100.Assume in the LPM_RAM_DQ:sum is stored at location a4,temp is stored at location a3,the content of location a0 is 0,the content of location a1 is 1,the content of location a2 is 100the content of location a3 is 0,the content of location a4 is 0,So the content of the LPM_RAM_DQ can be:WIDTH = 16;DEPTH = 256;ADDRESS_RADIX = HEX;DA TA_RADIX = HEX;CONTENT BEGIN0 : 02a0; --load A01 : 01a4; --store A4 sum=02 : 02a2; --load A23 : 01a3; --store A3 temp=1004 : 02a4; --loop: load A4 loop=045 : 03a3; --add A36 : 01a4; --store A4 sum=sum+temp7 : 02a3; --load A38 : 04a1; --sub A19 : 01a3; --store A3 temp=temp-1a : 0504; --jump loop if temp>=0 goto loopb : HALT; --halt[c..9f] 0;a0 : 0;a1 : 1;a2 : 0064;a3 : 0; --tempa4 : 0; --sum[a5..ff] : 0000;END;The result is as follows:We can see that the sum is A4=5050.2.Test the MPY instruction(1)Assume in the LPM_RAM_DQ:the content of location a0 is 6,the content of location a1 is 5,Calculate a0*a1.So the content of the LPM_RAM_DQ can be: WIDTH = 16;DEPTH = 256;ADDRESS_RADIX = HEX;DATA_RADIX = HEX;CONTENT BEGIN0 : 02a0;1 : 08a1;[2..9f] : 0000;A0 : 0006;A1 : 0005;[A2..FF] : 0000;END;The result is as follows:We can see the result of (a0*a1) is [mr acc]=(0000 001E)H=(30)D (2)Assume in the LPM_RAM_DQ:the content of location a0 is -6,the content of location a1 is 5,Calculate a0*a1.So the content of the LPM_RAM_DQ can be:WIDTH = 16;DEPTH = 256;ADDRESS_RADIX = HEX;DATA_RADIX = HEX;CONTENT BEGIN0 : 02a0;1 : 08a1;[2..9f] : 0000;A0 : FFFA;A1 : 0005;[A2..FF] : 0000;END;The result is as follows:We can see the result of (a0*a1) is [mr acc]=(FFFF FFE2)H=(-30)D (3) Assume in the LPM_RAM_DQ:the content of location a0 is -6,the content of location a1 is -5,Calculate a0*a1.So the content of the LPM_RAM_DQ can be:WIDTH = 16;DEPTH = 256;ADDRESS_RADIX = HEX;DATA_RADIX = HEX;CONTENT BEGIN0 : 02a0;1 : 08a1;[2..9f] : 0000;A0 : FFFA;A1 : FFFB;[A2..FF] : 0000;END;The result is as follows:We can see the result of (a0*a1) is [mr acc]=(0000 001E)H=(30)D。