常用分布的数学期望及方差
常见分布的数学期望和方差

E( X
2)
n k0
k 2Ckn
pkqnk
n
np
k 1
k
(k
(n 1)! 1)!(n
k )!
p k 1q n k
n np (k
k 1
1) (k
(n 1)! 1)!(n
k )!
pk1q nk
n k 1
(k
(n 1)! 1)!(n
k )!
pk1q nk
np[(n 1) p 1],
EX 2 4 ,试求 a 和 b( a b ).
解 DX EX 2 (EX )2 3 ;
ab 2
(b a)2 12
EX 1, DX 3
;
a b 2, b a 6 ;
a 2, b 4 .
因此 X 在区间[2,4] 上均匀分布.
21
第21页
例3 假设随机变量 X 和 Y 相互独立,且都在区间(0,1) 上 均匀分布,试求随机变量 Z X Y 的数学期望.
0.90 .
12
第12页
二、常见持续型分布旳数学盼望和方差
1. 均匀分布 X ~ U (a, b) .
1
f
(
x)
b
a
,
a xb
0 , 其它
b1
E( X ) xf ( x)dx x dx
a ba
1 b2 a2 a b .
ba 2
2
13
第13页
二、常见持续型分布旳数学盼望和方差
望 与
指数 分布
f
(
x)
e x
0,
,
x0 else
( 0)
p
npab 2 1源自pqnpq(b a)2 12 1
常用分布的数学期望及方差

−
t2 2
dt , (
x−µ
σ
= t)
=
σ
2π
∫ te
t2 − 2
dt +
∞
µ 2π
∫e
t2 − 2
dt = µ
−
DX = E ( X − µ ) =
2
=
σ2 =− te 2π
σ t 2π −∞
∞
∫
2 2
t2 − e 2
t2 − 2
−∞
∫ (x − µ)
σ
2 ∞
2
1 2π σ
且 X 1 ,L , X n 独立,令 X = X 1 + L + X n ,则 X 的可能 取值为 0,1,…n,
P{ X = k } = C nk p k q n − k , k = 0 , L , n
EX = ∑ EX i = np , DX = ∑ DX i = npq,
i =1 i =1 n n
n
= n ( n − 1) p 2 ∑
n! n! = p ( k − 1) p k −1 q n − k + p p k −1 q n − k ( k − 1)! ( n − k )! ( k − 1)! ( n − k )! k =1 k =1
∑
∑
n
( n − 2)! p k − 2 q n − 2 − ( k − 2 ) + np k = 2 ( k − 2)!( n − 2 − ( k − 2))!
泊 分 3. 松 布
设 X 服从参数为λ泊松分布, 其分布律为 P{ X = k} =
EX =
λk
∑
常用分布的数学期望及方差

方差的性质
方差具有可加性
对于两个独立的随机变量X和Y,有Var(X+Y) = Var(X) + Var(Y)。
方差具有对称性
对于一个常数a和随机变量X,有Var(aX) = |a|^2 * Var(X)。
方差具有非负性
对于随机变量X,有Var(X) >= 0,其中 Var(X) = 0当且仅当X是一个常数。
05 数学期望与方差的应用
在统计学中的应用
描述性统计
数学期望和方差用于描述一组数据的中心趋势和 离散程度,帮助我们了解数据的基本特征。
参数估计
通过样本数据的数学期望和方差,可以对总体参 数进行估计,如均值和方差的无偏估计。
假设检验
在假设检验中,数学期望和方差用于构建检验统 计量,判断原假设是否成立。
常见分布的数学期望
均匀分布的数学期望为
$E(X) = frac{a+b}{2}$,其中a和b是均匀分布的下限和上 限。
柯西分布的数学期望为
$E(X) = frac{pi}{beta} sinh(frac{1}{beta})$,其中β是柯西 分布的参数。
拉普拉斯分布的数学期望为
$E(X) = frac{beta}{pi} tan(frac{pi}{beta})$,其中β是拉普 拉斯分布的参数。
03
泊松分布
正态分布是一种常见的连续型随机变量 分布,其方差记作σ²。正态分布的方差 描述了随机变量取值的分散程度。
二项分布是一种离散型随机变量分布, 用于描述在n次独立重复的伯努利试验 中成功的次数。其方差记作σ²,且σ² = np(1-p),其中n是试验次数,p是单次 试验成功的概率。
泊松分布是一种离散型随机变量分布, 用于描述在一段时间内随机事件发生的 次数。其方差记作σ²,且σ² = λ,其中 λ是随机事件发生的平均速率。
常用分布函数及特征函数

1 q peit ,方差 2 ,特征函数 p p 1 qeit
k nk CM CN M , k 1, 2, , min M , N , M N n CN k nk
超几何分布
P X k
nM nM ,方差 数学期望 N N
帕斯卡分布
M 1 N
f x1 , , xn 2
帕累托(Pareto)分布
C
k k k 2 k k 1 , x ,k 2 f x x , k 1 ,方差 , 0 ,数学期望 2 k 1 k 1 k 2 0, x
X
i 1
n
i
~ n, 。
若 X ~ ,1 ,则 Y
X
~ , 。
若 X 1 , X 2 , , X n 相互独立,且 X i ~ N 0,1 ,则
X
i 1
n
2 i
n 1 ~ , 2 n 。 2 2
n
P X k
数学期望 ,方差 ,特征函数 e e 几何分布
it
k
k!
e , k 0,1, 2, , 0
1
P X k q k 1 p , k 1, 2, , 0 p 1, p q 1
2
威布尔分布
2 x 1e x , x 0 1/ 2 / 2 / 1 1/ 1 f x ,数学期望 1/ 1 ,方差 x0 0,
伽马(Gamma)分布 , ,形状参数 ,尺度参数
六个常用分布的数学期望和方差

即
12
若随机变量X~U( a , b ),则
ab
(b a)2
E(X)
, D( X )
2
12
五.指数分布
随机变量X服从参数为λ的指数分布,其概率密度为:
f
(
x)
1
θ
e
x θ
0
x0 x0
E(X )
xf ( x)dx
x
1
e
x θ
dx
x
( x)de θ
0
θ
0
(
x)e
x
x
e dx
X X1 X2 Xn
E( X ) E( X1 ) E( X 2 ) E( X n ) np
D( X ) D( X1 ) D( X 2 ) D( X n ) np(1 p)
即: 若随机变量X~B( n , p ),则
E( X ) np,D( X ) np(1 p)
E[3( X 2 1)] 3E( X 2 ) 3
3{D( X ) [E( X )]2 } 3 33
例2.已知X和Y相互独立,且X在区间(1,5)上服从
均匀分布, Y ~ N (1,求9)(1, ) (X,Y)的联合概率密度;(2)
E(3X 4Y 2) , D(3X 4Y 2)
E( X ) xf ( x)dx
b
x
1
dx
a ba
1 x2 b
ba 2 a
ab 2
E( X 2 ) b x 2
1
b3 a3 dx
a 2 ab b2
a ba
3(b a)
3
D( X )
E( X 2 ) [E( X )]2
某些常用分布的数学期望与方差

H (n ,M
, N ) (n , M , N为正整数;
n N ,M N)
概率论与数理统计教程(第四版)
目录
上一页 下一页
返回
结束
§3.5 某些常用分布的数学期望与方差
分布名称 及记号
泊松分布
P()
概率函数或概率密度
p(x) x e
x!
x 0 ,1,2, ( 0)
数学 期望
几何分布
p(x) pqx1 ,
M CnN
n1 k 0
k
CkM
Cn1k
1 N M
n1 k 0
CkM
Cn1k
1 N M
.
第二个和式等于
Cn1 N 1
,
与前面计算过程完全类似,
可知第一个和式等于
(M
1)
Cn2 N 2
:
E
(
X
2
)
M CnN
(M
1)
Cn2 N 2
Cn1 N 1
.
概率论与数理统计教程(第四版)
目录
上一页 下一页
返回
结束
ab 2
方差
(b a)2 12
指数分布
ex , x 0 ;
f (x)
e()
0 , x0
1
1
2
( 0)
概率论与数理统计教程(第四版)
目录
上一页 下一页
返回
结束
§3.5 某些常用分布的数学期望与方差
分布名称 及记号
概率函数或概率密度
数学 期望
正态分布
f (x)
1
e , (
x )2 2 2
m1
Cnm N M
数学期望和方差

数学期望和方差
第四章 数学期望和方差
分布函数能够完整地描述随机变量的统计特 性,但在实际问题中,随机变量的分布函数较 难确定,而它的一些数字特征较易确定.并且 在很多实际问题中,只需知道随机变量的某些 数字特征也就够了.
另一方面,对于一些常用的重要分布,如二 项分布、泊松分布、指数分布、正态分布等, 只要知道了它们的某些数字特征,就能完全确 定其具体的分布.
8 8
9 10 11 12 7 15 10 10 50
则这 50 个零件的平均直径为
8 8 9 7 1015 1110 1210 50 10.14cm
第四章
数学期望和方差
换个角度看,从这50个零件中任取一个,它 的尺寸为随机变量X , 则X 的概率分布为 X P 8
x
| x| 但 | x | f ( x ) dx dx 发散. 2 (1 x )
它的数学期望不存在.
注:虽然f(x)是偶函数,但不能用定理1.1.
第四章
数学期望和方差
§4.2 数学期望的性质
设已知随机变量X的分布,我们需要计算的不 是X的数学期望, 而是X的某个函数的数学期望, 比如说g(X)的数学期望. 那么应该如何计算呢? 更一般的,已知随机向量(X1 , X2 …,Xn ) 的联合分布, Y= g(X1, X2 …,Xn ) 是 (X1 , X2 …,Xn ) 的函数, 需要计算Y 的数学期 望,应该如何计算呢? 我们下面就来处理这个 问题.
8 50
12
9
7 50
10
15 50
12
11
10 50
12
10 50
则这 50 个零件的平均直径为
正态分布的期望和方差公式

正态分布的期望和方差公式
期望:Eξ=x1p1+x2p2+……+xnpn
方差公式:s=1/n{(x1-x)+(x2-x)+……+(xn-x)}。
正态分布又名高斯分布,是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力
扩展资料:当数据分布比较分散(即数据在平均数附近波动较大)时,各个数据与平均数的差的平方和较大,方差就较大;当数据分布比较集中时,各个数据与平均数的差的平方和较小。
因此方差越大,数据的波动越大;方差越小,数据的波动就越小。
样本中各数据与样本平均数的差的平方和的平均数为样本方差;样本方差的算术平方根为样本标准差。
样本方差和样本标准差都是衡量一个样本波动大小的量,样本方差或样本标准差越大,样本数据的波动就越大。
方差和标准差为测算离散趋势最重要、最常用的指标,它是测算数值型数据离散程度的最重要的方法。
标准差为方差的算术平方根,用S表示。
常见概率分布期望方差以及分布图汇总
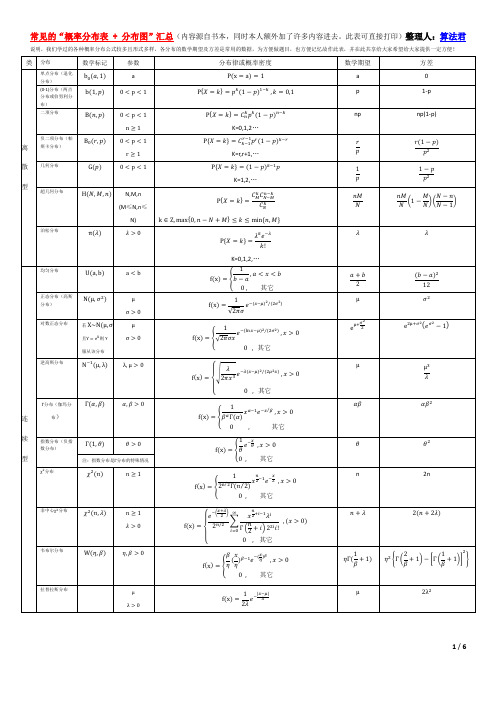
������������
������������ 2
指数分布(负指 数分布)
Γ(1, ������)
������ > 0
������
������ 2
注:指数分布是Γ分布的特殊情况 χ2 分布
������2 (������)
������ ≥ 1
负二项分布(帕
离 散 型
斯卡分布)
B0 (������, ������)
0<p<1 r≥1
K=r,r+1,… P{������ = ������} = (1 − ������)������−1 ������ K=1,2,…
������ ������ 1 ������ ������������ ������
������ 2 ∞ ������⁄ 2
0,n>1
������ , ������ > 2 ������ − 2
非中心 t 分布
������(������, ������)
������ ������ ≥ 1
������ − 1 ������Γ ( ) ������ 2 √ ������ 2 Γ( ) 2 (n>1)
常见的“概率分布表 + 分布图”汇总(内容源自书本,同时本人额外加了许多内容进去。此表可直接打印)整理人:算法君
说明,我们学过的各种概率分布公式较多且形式多样,各分布的数学期望及方差是常用的数据,为方便做题目,也方便记忆故作此表,并在此共享给大家希望给大家提供一定方便!
类
分布
单点分布(退化 分布) (0-1)分布(两点 分布或伯努利分 布) 二项分布
数学期望 a p np
多项分布的数学期望、协方差阵、特征函数及母函数

多项分布的数学期望、协方差阵、特征函数及母函数多项分布的数学期望、协方差阵、特征函数及母函数 1一、定义与性质设 X 为随机变量, I 是一个包含 0 的 ( 有限或无限的 ) 开区间,对任意t ∈ I ,期望 E e t x 存在设X为随机变量,I是一个包含0的(有限或无限的)开区间,对任意t∈I,期望Ee^{tx}存在设X为随机变量,I是一个包含0的(有限或无限的)开区间,对任意t∈I,期望Eetx存在则称函数M X ( t ) = E ( e t X ) = ∫ − ∞ + ∞ e t x d F ( x ) , t ∈ I 为 X 的矩母函数则称函数M_{X}(t)=E(e^{tX})=\int_{-\infin}^{+\infin}e^{tx}dF(x),t∈I为X的矩母函数则称函数MX(t)=E(etX)=∫−∞+∞etxdF(x),t∈I为X的矩母函数设 X 为任意随机变量,称函数φ X ( t ) = E ( e i t X ) = ∫ − ∞ + ∞ e i t x d F ( x ) 为 X 的特征函数设X为任意随机变量,称函数\varphi_{X}(t)=E(e^{itX})=\int_{-\infin}^{+\infin}e^{itx}dF(x)为X的特征函数设X为任意随机变量,称函数φX(t)=E(eitX)=∫−∞+∞eitxdF(x)为X 的特征函数一个随机变量的矩母函数不一定存在,但是特征函数一定存在。
一个随机变量的矩母函数不一定存在,但是特征函数一定存在。
一个随机变量的矩母函数不一定存在,但是特征函数一定存在。
随机变量与特征函数存在一一对应的关系随机变量与特征函数存在一一对应的关系随机变量与特征函数存在一一对应的关系二、离散型随机变量的分布0、退化分布(Degenerate distribution)若 X 服从参数为 a 的退化分布,那么 f ( k ;a ) = { 1 , k = a 0 , k ≠ a 若X服从参数为a的退化分布,那么f(k;a)=\left\{\begin{matrix} 1,k=a \\ 0,k\neq a \end{matrix}\right. 若X服从参数为a的退化分布,那么f(k;a)={1,k=a0,k=a M ( t ) = e t a M(t)=e^{ta}M(t)=eta φ ( t ) = e i t a \varphi(t)=e^{ita}φ(t)=eita M ′ ( t ) = a e t a M'(t)=ae^{ta}M′(t)=aeta E X = M ′ ( 0 ) = a EX=M'(0)=aEX=M′(0)=a M ′ ′ ( t ) = a 2 e t a M''(t)=a^2e^{ta} M′′(t)=a2eta E X 2 = M ′ ′ ( 0 ) = a 2EX^2=M''(0)=a^2 EX2=M′′(0)=a2 D X = E X 2 − ( E X ) 2 = 0 DX=EX^2-(EX)^2=0 DX=EX2−(EX)2=01、离散型均匀分布(Discrete uniform distribution)若 X 服从离散型均匀分布 D U ( a , b ) , 则 X 分布函数为 F ( k ; a , b ) = ⌊ k ⌋− a + 1 b −a + 1 若X服从离散型均匀分布DU(a,b) ,则X分布函数为F(k;a,b)=\frac{\lfloor k\rfloor -a+1}{b-a+1} 若X服从离散型均匀分布DU(a,b),则X分布函数为F(k;a,b)=b−a+1⌊k⌋−a+1 则矩母函数M ( t ) = ∑ k = a b e t k P ( x = k ) 则矩母函数M(t)=\sum_{k=a}^{b} e^{tk}P(x=k) 则矩母函数M(t)=k=a∑betkP(x=k) = ( ∑ k = a b e t k ) 1 b − a + 1 =(\sum_{k=a}^{b} e^{tk})\frac{1}{b-a+1} =(k=a∑b etk)b−a+11 = e a t − e ( b + 1 ) t ( 1 − e t ) ( b − a + 1 ) =\frac{e^{at}-e^{(b+1)t}}{(1-e^{t})(b-a+1)} =(1−et)(b−a+1)eat−e(b+1)t 特征函数φ ( t ) = ∑k = a b e i t k P ( x = k ) 特征函数\varphi(t)=\sum_{k=a}^{b} e^{itk}P(x=k) 特征函数φ(t)=k=a∑beitkP(x=k) = ( ∑ k = a b e i t k ) 1 b −a + 1 =(\sum_{k=a}^{b} e^{itk})\frac{1}{b-a+1}=(k=a∑beitk)b−a+11 = e a i t − e ( b + 1 ) i t ( 1 − e i t ) ( b − a + 1 ) =\frac{e^{ait}-e^{(b+1)it}}{(1-e^{it})(b-a+1)}=(1−eit)(b−a+1)eait−e(b+1)it M ′ ( t ) = 1 b − a + 1 ( a e a t − ( b + 1 ) e ( b + 1 ) t ) ( 1 − e t ) + ( e a t − e ( b + 1 ) t ) e t ( e t − 1 ) 2M'(t)=\frac{1}{b-a+1}\frac{(ae^{at}-(b+1)e^{(b+1)t})(1-e^t)+(e^{at}-e^{(b+1)t})e^t}{(e^{t}-1)^{2}} M′(t)=b−a+11(et−1)2(aeat−(b+1)e(b+1)t)(1−et)+(eat−e(b+1)t)et t = 0 为M ′ ( t ) 的可去间断点,补充定义M ′ ( 0 ) = lim t → 0 M ′ ( t ) t=0为M'(t)的可去间断点,补充定义M'(0)=\lim_{t\rightarrow0}M'(t) t=0为M′(t)的可去间断点,补充定义M′(0)=t→0limM′(t) E X = M ′ ( 0 ) = lim t → 0 1 b − a + 1 ( a 2 e at − ( b + 1 ) 2 e ( b + 1 ) t ) ( 1 − e t ) + ( e at − e ( b + 1 ) t ) e t 2 ( e t − 1 ) e tEX=M'(0)=\lim_{t\rightarrow0}\frac{1}{b-a+1}\frac{(a^2e^{at}-(b+1)^2e^{(b+1)t})(1-e^t)+(e^{at}-e^{(b+1)t})e^t}{2(e^{t}-1)e^t}EX=M′(0)=t→0limb−a+112(et−1)et(a2eat−(b+1)2e(b+1)t)(1−et)+(eat−e(b+1)t) et = lim t → 0 1 b − a + 1 ( a 2 e a t − ( b +1 )2 e ( b + 1 ) t ) ( e − t − 1 ) + ( e a t − e ( b + 1 ) t ) 2 ( e t − 1 )=\lim_{t\rightarrow0}\frac{1}{b-a+1}\frac{(a^2e^{at}-(b+1)^2e^{(b+1)t})(e^{-t}-1)+(e^{at}-e^{(b+1)t})}{2(e^{t}-1)} =t→0limb−a+112(et−1)(a2eat−(b+1)2e(b+1)t)(e−t−1)+(eat−e(b+1)t) = lim t → 0 1 b − a + 1 ( a 3 e a t − ( b + 1 ) 3 e ( b + 1 ) t ) ( e − t − 1 ) − ( a 2 e a t −( b + 1 ) 2 e ( b + 1 ) t ) e − t + ( a e a t − ( b + 1 ) e ( b + 1 ) t ) 2 e t=\lim_{t\rightarrow0}\frac{1}{b-a+1}\frac{(a^3e^{at}-(b+1)^3e^{(b+1)t})(e^{-t}-1)-(a^2e^{at}-(b+1)^2e^{(b+1)t})e^{-t}+(ae^{at}-(b+1)e^{(b+1)t})}{2e^{t}} =t→0limb−a+112et(a3eat−(b+1)3e(b+1)t)(e−t−1)−(a2eat−(b+1)2e(b+1)t)e−t+(aeat−(b+1)e(b+1)t) = − a 2 + ( b + 1 ) 2 +a − (b + 1 ) 2 ( b − a + 1 ) =\frac{-a^2+(b+1)^2+a-(b+1)}{2(b-a+1)} =2(b−a+1)−a2+(b+1)2+a−(b+1) = − a 2 + ( b + 1 ) 2 2 ( b − a + 1 ) − 1 2 =\frac{-a^2+(b+1)^2}{2(b-a+1)}-\frac{1}{2}=2(b−a+1)−a2+(b+1)2−21 = ( b + 1 − a ) ( b + 1 +a ) 2 (b − a + 1 ) − 1 2 =\frac{(b+1-a)(b+1+a)}{2(b-a+1)}-\frac{1}{2}=2(b−a+1)(b+1−a)(b+1+a)−21 = b + 1 + a 2 − 1 2=\frac{b+1+a}{2}-\frac{1}{2} =2b+1+a−21 = b + a 2=\frac{b+a}{2} =2b+a 由于对M ′ ( t ) 求导得到M ′ ′ ( t ) ,再求M ′ ′ ( 0 ) 的方法比较繁琐,而我们只需要 t = 0 时 M 的二阶导数值,由于对M'(t)求导得到M''(t),再求M''(0)的方法比较繁琐,而我们只需要t=0时M的二阶导数值,由于对M′(t)求导得到M′′(t),再求M′′(0)的方法比较繁琐,而我们只需要t=0时M的二阶导数值,因此可以考虑使用 T a y l o r 公式计算M ′ ′ ( 0 ) 因此可以考虑使用Taylor公式计算M''(0) 因此可以考虑使用Taylor公式计算M′′(0) 令 1 − e t = u , t = 0 时 , u = 0 令1-e^t=u,t=0时,u=0 令1−et=u,t=0时,u=0 M ( t ) = e a t − e ( b + 1 ) t ( 1 − e t ) ( b − a + 1 )M(t)=\frac{e^{at}-e^{(b+1)t}}{(1-e^{t})(b-a+1)}M(t)=(1−et)(b−a+1)eat−e(b+1)t = 1 b − a + 1 u a −u b + 1 u =\frac{1}{b-a+1}\frac{u^a-u^{b+1}}{u}=b−a+11uua−ub+1 = 1 b − a + 1 1 + a 1 ! ( − u ) + a ( a − 1 ) 2 ! u 2 + a ( a − 1 ) ( a − 2 ) 3 ! ( − u 3 ) + o ( u 3 ) − 1 − b + 1 1 ! ( − u ) −( b + 1 ) b 2 ! u 2 − ( b + 1 ) b ( b − 1 ) 3 ! ( −u 3 ) − o ( u 3 ) u =\frac{1}{b-a+1}\frac{1+\frac{a}{1!}(-u)+\frac{a(a-1)}{2!}u^2+\frac{a(a-1)(a-2)}{3!}(-u^3)+o(u^3)-1-\frac{b+1}{1!}(-u)-\frac{(b+1)b}{2!}u^2-\frac{(b+1)b(b-1)}{3!}(-u^3)-o(u^3)}{u} =b−a+11u1+1!a (−u)+2!a(a−1)u2+3!a(a−1)(a−2)(−u3)+o(u3)−1−1!b+1(−u)−2!(b+1)bu2−3!(b+1)b(b−1) (−u3)−o(u3) = 1 b − a + 1 a 1 ! ( − u ) + a ( a −1 ) 2 ! u 2 + a ( a − 1 ) ( a − 2 ) 3 ! ( − u 3 ) + o ( u 3 ) − b + 1 1 ! ( − u ) − ( b + 1 ) b 2 ! u 2 − ( b + 1 ) b ( b − 1 ) 3 ! ( − u 3 ) u=\frac{1}{b-a+1}\frac{\frac{a}{1!}(-u)+\frac{a(a-1)}{2!}u^2+\frac{a(a-1)(a-2)}{3!}(-u^3)+o(u^3)-\frac{b+1}{1!}(-u)-\frac{(b+1)b}{2!}u^2-\frac{(b+1)b(b-1)}{3!}(-u^3)}{u} =b−a+11u1!a(−u)+2!a(a−1)u2+3!a(a−1)(a−2)(−u3)+o(u3)−1!b+1 (−u)−2!(b+1)bu2−3!(b+1)b(b−1)(−u3) = 1 b − a + 1 ( ( b + 1 − a ) + a ( a − 1 ) 2 ! u + a ( a − 1 ) ( a − 2 ) 3 ! ( − u 2 ) + o ( u 2 ) − ( b + 1 ) b2 ! u − ( b + 1 ) b ( b − 1 )3 ! ( − u 2 ) )=\frac{1}{b-a+1}((b+1-a)+\frac{a(a-1)}{2!}u+\frac{a(a-1)(a-2)}{3!}(-u^2)+o(u^2)-\frac{(b+1)b}{2!}u-\frac{(b+1)b(b-1)}{3!}(-u^2)) =b−a+11((b+1−a)+2!a(a−1)u+3!a(a−1)(a−2)(−u2)+o(u2)−2!(b+1)bu−3!(b+1)b(b−1)(−u2)) = 1 + a ( a − 1 ) − ( b + 1 ) b 2 ! ( b − a + 1 ) u + ( b +1 ) b ( b − 1 ) − a ( a − 1 ) ( a −2 )3 ! ( b −a + 1 ) u 2 + o ( u 2 ) =1+\frac{a(a-1)-(b+1)b}{2!(b-a+1)}u+\frac{(b+1)b(b-1)-a(a-1)(a-2)}{3!(b-a+1)}u^2+o(u^2) =1+2!(b−a+1)a(a−1)−(b+1)bu+3!(b−a+1)(b+1)b(b−1)−a(a−1)(a−2)u2+o(u2) 而 u = 1 − e t = − t − t 2 2 ! + o ( t 2 ) 而u=1-e^t=-t-\frac{t^2}{2!}+o(t^2) 而u=1−et=−t−2!t2+o(t2) 因此M ( t ) = 1 − a ( a − 1 ) − ( b + 1 ) b 2 ! ( b −a + 1 ) t − a ( a − 1 ) − (b + 1 ) b 2 ! ( b − a + 1 ) t 2 2 ! + ( b + 1 ) b ( b − 1 ) − a ( a − 1 ) ( a − 2 ) 3 ! ( b − a + 1 ) t 2 + o ( t 2 ) 因此M(t)=1-\frac{a(a-1)-(b+1)b}{2!(b-a+1)}t-\frac{a(a-1)-(b+1)b}{2!(b-a+1)}\frac{t^2}{2!}+\frac{(b+1)b(b-1)-a(a-1)(a-2)}{3!(b-a+1)}t^2+o(t^2) 因此M(t)=1−2!(b−a+1)a(a−1)−(b+1)bt−2!(b−a+1)a(a−1)−(b+1)b2!t2+3!(b−a+1)(b+1)b(b−1)−a(a−1)(a−2)t2+o(t2) 又因为M ( t ) = M ( 0 ) + M ′ ( 0 ) t + M ′ ′ ( 0 ) 2 ! t 2 + o ( t 2 ) 又因为M(t)=M(0)+M'(0)t+\frac{M''(0)}{2!}t^2+o(t^2) 又因为M(t)=M(0)+M′(0)t+2!M′′(0)t2+o(t2) 因此M ′ ( 0 ) = − a ( a − 1 ) − ( b + 1 ) b 2 ! ( b − a + 1 ) = a + b 2 因此M'(0)=-\frac{a(a-1)-(b+1)b}{2!(b-a+1)}=\frac{a+b}{2} 因此M′(0)=−2!(b−a+1)a(a−1)−(b+1)b=2a+b E X = M ′( 0 ) = a + b 2 EX=M'(0)=\frac{a+b}{2} EX=M′(0)=2a+b 而M ′ ′ ( 0 ) = 2 ! ∗ ( − a ( a − 1 ) − ( b +1 ) b 4 ( b − a + 1 ) + ( b + 1 ) b ( b − 1 ) − a ( a − 1 ) ( a −2 )3 ! ( b − a + 1 ) ) 而M''(0)=2!*(-\frac{a(a-1)-(b+1)b}{4(b-a+1)}+\frac{(b+1)b(b-1)-a(a-1)(a-2)}{3!(b-a+1)}) 而M′′(0)=2!∗(−4(b−a+1)a(a−1)−(b+1)b+3!(b−a+1)(b+1)b(b−1)−a(a−1)(a−2)) = a + b 2 + ( b + 1 − a ) ( b 2 + a b − b + a 2 − 2 a ) 3 ( b − a + 1 ) =\frac{a+b}{2}+\frac{(b+1-a)(b^2+ab-b+a^2-2a)}{3(b-a+1)} =2a+b+3(b−a+1)(b+1−a)(b2+ab−b+a2−2a) = a + b 2 + b 2 + a b − b + a 2 − 2 a 3=\frac{a+b}{2}+\frac{b^2+ab-b+a^2-2a}{3} =2a+b+3b2+ab−b+a2−2a = 2 a 2 + 2 b 2 + 2 a b + b − a 6 =\frac{2a^2+2b^2+2ab+b-a}{6} =62a2+2b2+2ab+b−a D X = E X 2 − ( E X ) 2 = M ′ ′ ( 0 ) − ( E X ) 2DX=EX^2-(EX)^2=M''(0)-(EX)^2DX=EX2−(EX)2=M′′(0)−(EX)2 = 2 a 2 + 2 b 2 + 2 a b + b − a 6 − a 2 + 2 a b + b 2 4=\frac{2a^2+2b^2+2ab+b-a}{6}-\frac{a^2+2ab+b^2}{4}=62a2+2b2+2ab+b−a−4a2+2ab+b2 = ( b − a + 1 ) 2 − 1 12 =\frac{(b-a+1)^2-1}{12} =12(b−a+1)2−12、伯努利分布/两点分布(Bernoulli distribution)若 X 服从伯努利分布 B ( 1 , p ) , 则 X 满足 P ( x = 1 ) = p , P ( x = 0 ) = 1 − p = q 若X服从伯努利分布B(1,p) ,则X满足P(x=1)=p, P(x=0)=1-p=q 若X服从伯努利分布B(1,p),则X满足P(x=1)=p,P(x=0)=1−p=q M ( t ) = p e t + 1 − p M(t)=pe^{t}+1-p M(t)=pet+1−p φ ( t ) = p e i t + 1 − p \varphi(t)=pe^{it}+1-pφ(t)=peit+1−p M ′ ( t ) = p e t M'(t)=pe^{t}M′(t)=pet E X = M ′ ( 0 ) = p EX=M'(0)=p EX=M′(0)=pM ′ ′ ( t ) = p e t M''(t)=pe^{t} M′′(t)=pet E X 2 = M ′ ′ ( 0 ) = p EX^{2}=M''(0)=p EX2=M′′(0)=p D X = E X 2 − ( E X ) 2 = p ( 1 − p ) DX=EX^{2}-(EX)^{2}=p(1-p) DX=EX2−(EX)2=p(1−p)3、二项分布(Binomial distribution)若 X 服从二项分布 B ( n , p ) , 则 X 满足 f ( k ; n , p ) = P ( x = k ) = C n k p k ( 1 − p ) n − k ( n 为整数 ) 若X服从二项分布B(n,p) ,则X满足f(k;n,p)=P(x=k)=C_{n}^{k}p^k(1-p)^{n-k} (n为整数) 若X 服从二项分布B(n,p),则X满足f(k;n,p)=P(x=k)=Cnkpk(1−p)n−k(n为整数) 因为服从二项分布的变量可以看作 n 个独立相同的服从伯努利分布的变量之和因为服从二项分布的变量可以看作n个独立相同的服从伯努利分布的变量之和因为服从二项分布的变量可以看作n个独立相同的服从伯努利分布的变量之和因此M ( t ) = ( p e t + 1 − p ) n 因此M(t)=(pe^{t}+1-p)^{n} 因此M(t)=(pet+1−p)n φ ( t ) = ( p e i t + 1 − p ) n \varphi(t)=(pe^{it}+1-p)^{n}φ(t)=(peit+1−p)n M ′ ( t ) = n p ( p e t + 1 − p ) n − 1 e t M'(t)=np(pe^{t}+1-p)^{n-1}e^{t}M′(t)=np(pet+1−p)n−1et E X = M ′ ( 0 ) = n pEX=M'(0)=np EX=M′(0)=np M ′ ′ ( t ) = n ( n − 1 )p 2 ( p e t + 1 − p ) n − 2 e 2 t + n p ( p e t + 1 − p ) n − 1 e t M''(t)=n(n-1)p^{2}(pe^{t}+1-p)^{n-2}e^{2t}+np(pe^{t}+1-p)^{n-1}e^{t}M′′(t)=n(n−1)p2(pet+1−p)n−2e2t+np(pet+1−p)n−1et E X 2 = M ′ ′ ( 0 ) = n ( n − 1 ) p 2 + n pEX^{2}=M''(0)=n(n-1)p^{2}+np EX2=M′′(0)=n(n−1)p2+npD X =E X 2 − ( E X ) 2 = n p ( 1 − p ) DX=EX^{2}-(EX)^{2}=np(1-p) DX=EX2−(EX)2=np(1−p)4、几何分布(Geometric distribution)若 X 服从几何分布 G e ( p ) , 则 X 满足 f ( k ; p ) = P ( x = k ) = ( 1 − p ) k − 1 p ( k = 1 , 2 , 3...... ) 若X服从几何分布Ge(p), 则X满足f(k;p)=P(x=k)=(1-p)^{k-1}p (k=1,2,3......) 若X服从几何分布Ge(p),则X满足f(k;p)=P(x=k)=(1−p)k−1p(k=1,2,3......) M ( t ) = ∑ k = 1 ∞ ( 1 − p ) k − 1 p e t kM(t)=\sum_{k=1}^{\infin}(1-p)^{k-1}pe^{tk}M(t)=k=1∑∞(1−p)k−1petk = p e t ∑ k = 1 ∞ ( ( 1 − p ) e t ) k − 1 =pe^{t}\sum_{k=1}^{\infin}((1-p)e^t)^{k-1} =petk=1∑∞((1−p)et)k−1 = p e t 1 −( 1 − p ) e t =\frac{pe^{t}}{1-(1-p)e^{t}}=1−(1−p)etpet φ ( t ) = ∑ k = 1 ∞ ( 1 − p ) k −1 p e i t k \varphi(t)=\sum_{k=1}^{\infin}(1-p)^{k-1}pe^{itk} φ(t)=k=1∑∞(1−p)k−1peitk = p e i t ∑ k = 1 ∞ ( ( 1 − p ) e i t ) k − 1=pe^{it}\sum_{k=1}^{\infin}((1-p)e^{it})^{k-1}=peitk=1∑∞((1−p)eit)k−1 = p e i t 1 − ( 1 − p ) e i t =\frac{pe^{it}}{1-(1-p)e^{it}} =1−(1−p)eitpeit M ′ ( t ) = p e t ( 1 − ( 1 − p ) e t ) 2M'(t)=\frac{pe^t}{(1-(1-p)e^t)^2}M′(t)=(1−(1−p)et)2pet E X = M ′ ( 0 ) = 1 pEX=M'(0)=\frac{1}{p} EX=M′(0)=p1 M ′ ′ ( t ) = p e t ( e t − p e t + 1 ) ( 1 − ( 1 − p ) e t ) 3M''(t)=\frac{pe^t(e^t-pe^t+1)}{(1-(1-p)e^t)^3}M′′(t)=(1−(1−p)et)3pet(et−pet+1) E X 2 = M ′ ′( 0 ) = 2 − p p 2 EX^{2}=M''(0)=\frac{2-p}{p^2}EX2=M′′(0)=p22−p D X = E X 2 − ( E X ) 2 = 1 − p p 2 DX=EX^{2}-(EX)^{2}=\frac{1-p}{p^2}DX=EX2−(EX)2=p21−p5、负二项分布(Negative binomial distribution)若 X 服从负二项分布 N B ( r , p ) , 则 X 满足 f ( k ; r , p ) = ( k + r − 1 k ) p k ( 1 − p ) r , k = 0 , 1 , 2 , 3...... 若X服从负二项分布NB(r,p), 则X满足f(k;r,p)=\binom{k+r-1}{k}p^{k}(1-p)^{r} ,k=0,1,2,3...... 若X服从负二项分布NB(r,p),则X满足f(k;r,p)=(kk+r−1)pk(1−p)r,k=0,1,2,3...... ( r 可以为实数,此时的分布称为波利亚分布 ) (r可以为实数,此时的分布称为波利亚分布) (r可以为实数,此时的分布称为波利亚分布) M ( t ) = ∑ k = 0 ∞ ( k +r − 1 k ) p k ( 1 − p ) r e t kM(t)=\sum_{k=0}^{\infin}\binom{k+r-1}{k}p^k(1-p)^re^{tk} M(t)=k=0∑∞(kk+r−1)pk(1−p)retk = ∑ k = 0 ∞ ( − 1 ) k ( − r k ) p k ( 1 − p ) r e t k=\sum_{k=0}^{\infin}(-1)^k\binom{-r}{k}p^k(1-p)^re^{tk} =k=0∑∞(−1)k(k−r)pk(1−p)retk = ∑ k = 0 ∞ ( − p e t ) k ( − r k ) ( 1 − p ) r =\sum_{k=0}^{\infin}(-pe^t)^k\binom{-r}{k}(1-p)^r =k=0∑∞(−pet)k(k−r)(1−p)r = ( 1 − p ) r ∑ k = 0 ∞ ( − p e t ) k( − r k ) 1 − r − k =(1-p)^r\sum_{k=0}^{\infin}(-pe^t)^k\binom{-r}{k}1^{-r-k} =(1−p)rk=0∑∞(−pet)k(k−r)1−r−k = ( 1 − p ) r ( 1 − p e t ) −r =(1-p)^r(1-pe^t)^{-r} =(1−p)r(1−pet)−r φ ( t ) = ∑ k = 0 ∞ ( k + r − 1 k ) p k ( 1 − p ) r e i t k \varphi(t)=\sum_{k=0}^{\infin}\binom{k+r-1}{k}p^k(1-p)^re^{itk} φ(t)=k=0∑∞(kk+r−1)pk(1−p)reitk = ∑ k = 0 ∞ ( − 1 ) k ( − r k ) p k ( 1 − p ) r e i t k =\sum_{k=0}^{\infin}(-1)^k\binom{-r}{k}p^k(1-p)^re^{itk} =k=0∑∞(−1)k(k−r)pk(1−p)reitk = ∑ k = 0 ∞ ( − p e i t ) k ( − r k ) ( 1 − p ) r=\sum_{k=0}^{\infin}(-pe^{it})^k\binom{-r}{k}(1-p)^r=k=0∑∞(−peit)k(k−r)(1−p)r = ( 1 − p ) r ∑ k = 0 ∞ ( − p e i t ) k ( − r k ) 1 − r − k =(1-p)^r\sum_{k=0}^{\infin}(-pe^{it})^k\binom{-r}{k}1^{-r-k} =(1−p)rk=0∑∞(−peit)k(k−r)1−r−k = ( 1 − p ) r ( 1 − p e i t ) − r =(1-p)^r(1-pe^{it})^{-r}=(1−p)r(1−peit)−r M ′ ( t ) = ( 1 − p ) r ( − r ) ( 1 − p e t ) − r − 1 ( − p e t ) M'(t)=(1-p)^r(-r)(1-pe^{t})^{-r-1}(-pe^t)M′(t)=(1−p)r(−r)(1−pet)−r−1(−pet) = r p ( 1 −p ) r e t ( 1 − p e t ) − r − 1 =rp(1-p)^re^t(1-pe^t)^{-r-1} =rp(1−p)ret(1−pet)−r−1 E X = M ′( 0 ) = r p 1 − p EX=M'(0)=\frac{rp}{1-p}EX=M′(0)=1−prp M ′ ′ ( t ) = r p ( 1 − p ) r e t ( 1 − p e t ) − r − 1 + r p ( 1 − p ) r e t ( − r − 1 ) ( 1 − p e t ) − r − 2 ( − p e t )M''(t)=rp(1-p)^re^t(1-pe^t)^{-r-1}+rp(1-p)^re^t(-r-1)(1-pe^t)^{-r-2}(-pe^t)M′′(t)=rp(1−p)ret(1−pet)−r−1+rp(1−p)ret(−r−1) (1−pet)−r−2(−pet) E X 2 = r p ( 1 − p ) − 1 + r ( r + 1 ) p 2 ( 1 − p ) − 2 EX^2=rp(1-p)^{-1}+r(r+1)p^2(1-p)^{-2}EX2=rp(1−p)−1+r(r+1)p2(1−p)−2 = r p ( 1 − p ) + r ( r + 1 ) p 2 ( 1 − p ) 2 =\frac{rp(1-p)+r(r+1)p^2}{(1-p)^2} =(1−p)2rp(1−p)+r(r+1)p2 = r p + r 2 p 2 ( 1 − p ) 2 =\frac{rp+r^2p^2}{(1-p)^2}=(1−p)2rp+r2p2 D X = E X 2 − ( E X ) 2 = p r ( 1 −p ) 2 DX=EX^2-(EX)^2=\frac{pr}{(1-p)^2}DX=EX2−(EX)2=(1−p)2pr6、泊松分布(Poisson distribution)若 X 服从泊松分布P ( λ ) , 则 P ( X = k ) = e− λ λ k k ! , k = 0 , 1 , 2...... 若X服从泊松分布P(\lambda),则P(X=k)=\frac{e^{-\lambda}\lambda^k}{k!},k=0,1,2...... 若X服从泊松分布P(λ),则P(X=k)=k!e−λλk,k=0,1,2...... M ( t ) = ∑k = 0 ∞ e − λ λ k k ! e t kM(t)=\sum_{k=0}^{\infin}\frac{e^{-\lambda}\lambda^k}{k!}e^{tk} M(t)=k=0∑∞k!e−λλketk = e − λ ∑ k = 0 ∞ ( λ e t ) k k ! =e^{-\lambda}\sum_{k=0}^{\infin}\frac{(\lambda e^t)^k}{k!} =e−λk=0∑∞k!(λe t)k = e − λ e λ e t =e^{-\lambda}e^{\lambda e^t} =e−λeλet= e λ ( e t − 1 ) =e^{\lambda (e^t-1)} =eλ(et−1) φ ( t ) = ∑ k = 0∞ e − λ λ k k ! e i t k\varphi(t)=\sum_{k=0}^{\infin}\frac{e^{-\lambda}\lambda^k}{k!}e^{itk} φ(t)=k=0∑∞k!e−λλk eitk = e − λ ∑ k = 0 ∞ ( λ e i t ) k k ! =e^{-\lambda}\sum_{k=0}^{\infin}\frac{(\lambdae^{it})^k}{k!} =e−λk=0∑∞k!(λe it)k = e − λ e λ e i t =e^{-\lambda}e^{\lambda e^{it}} =e−λeλeit = e λ ( e i t − 1 ) =e^{\lambda (e^{it}-1)} =eλ(eit−1) M ′ ( t ) = e λ ( e t − 1 ) λ e t M'(t)=e^{\lambda (e^t-1)}\lambda e^t M′(t)=eλ(et−1)λe t E X = M ′ ( 0 ) = λ EX=M'(0)=\lambda EX=M′(0)=λM ′ ′ ( t ) = e λ ( e t − 1 ) λ e t + e λ ( e t − 1 ) λ e tλ e t M''(t)=e^{\lambda (e^t-1)}\lambdae^t+e^{\lambda (e^t-1)}\lambda e^t\lambda e^tM′′(t)=eλ(et−1)λe t+eλ(et−1)λe tλe t E X 2 =M ′ ′ ( 0 ) = λ + λ 2EX^2=M''(0)=\lambda+\lambda^2 EX2=M′′(0)=λ+λ2 D X = E X 2 − ( E X ) 2 = λ DX=EX^2-(EX)^2=\lambdaDX=EX2−(EX)2=λ三、连续型随机变量的分布1、连续型均匀分布(Uniform distribution (continuous))若 X 服从连续型均匀分布 U ( a , b ) , 则 f( x ) = 1 b − a I [ a , b ] ( x ) 若X服从连续型均匀分布U(a,b),则f(x)=\frac{1}{b-a}I_{[a,b]}(x) 若X服从连续型均匀分布U(a,b),则f(x)=b−a1I[a,b](x) M ( t ) = ∫ a b 1 b − a e t x d x M(t)=\int_{a}^{b}\frac{1}{b-a}e^{tx}dx M(t)=∫abb−a1etxdx = 1 b − a ∫ a b e t x d x =\frac{1}{b-a}\int_{a}^{b}e^{tx}dx =b−a1∫abetxdx = 1 b − a ( 1 t e t x ∣ a b ) =\frac{1}{b-a}(\frac{1}{t}e^{tx}\mid_{a}^{b}) =b−a1(t1etx∣ab) = e t b − e t a t ( b − a ) =\frac{e^{tb}-e^{ta}}{t(b-a)} =t(b−a)etb−eta φ ( t ) = ∫ a b 1 b − a e i t x d x \varphi(t)=\int_{a}^{b}\frac{1}{b-a}e^{itx}dxφ(t)=∫abb−a1eitxdx = 1 b − a ∫ a b e i t x d x=\frac{1}{b-a}\int_{a}^{b}e^{itx}dx =b−a1∫abeitxdx = 1 b − a ( 1 i t e i t x ∣ a b ) =\frac{1}{b-a}(\frac{1}{it}e^{itx}\mid_{a}^{b}) =b−a1(it1eitx∣ab) = e i t b − e i t a i t ( b − a ) =\frac{e^{itb}-e^{ita}}{it(b-a)} =it(b−a)eitb−eita M ′ ( t ) = 1 b − a ( b e t b − a e t a ) t − ( e t b − e t a ) t 2 M'(t)=\frac{1}{b-a}\frac{(be^{tb}-ae^{ta})t-(e^{tb}-e^{ta})}{t^2} M′(t)=b−a1t2(betb−aeta)t−(etb−eta) t = 0 为M ′ ( t ) 的可去间断点,补充定义M ′ ( 0 ) = lim t → 0 M ′ ( t ) t=0为M'(t)的可去间断点,补充定义M'(0)=\lim_{t\rightarrow0}M'(t) t=0为M′(t)的可去间断点,补充定义M′(0)=t→0limM′(t) E X = M ′ ( 0 ) = lim t → 0 ( b e t b − a e t a ) + ( b 2 e t b − a 2 e t a ) t − ( b e t b − a e ta ) 2 t (b − a )EX=M'(0)=\lim_{t\rightarrow0}\frac{(be^{tb}-ae^{ta})+(b^2e^{tb}-a^2e^{ta})t-(be^{tb}-ae^{ta})}{2t(b-a)} EX=M′(0)=t→0lim2t(b−a)(betb−aeta)+(b2etb−a2eta)t−(betb−aeta) = lim t → 0 ( b 2 e t b − a 2 e t a ) 2 ( b − a ) =\lim_{t\rightarrow0}\frac{(b^2e^{tb}-a^2e^{ta})}{2(b-a)} =t→0lim2(b−a)(b2etb−a2eta) = b 2 − a 2 2 ( b − a ) =\frac{b^2-a^2}{2(b-a)} =2(b−a)b2−a2 = a + b 2 =\frac{a+b}{2} =2a+b M ′ ′ ( t ) = 1 b − a ( ( b 2 e t b − a 2 e t a ) t + ( b e t b − a e t a ) −( b e t b − a e t a ) ) t − 2 ( ( b e t b − a e ta ) t − ( e tb − e t a ) ) t 3 M''(t)=\frac{1}{b-a}\frac{((b^2e^{tb}-a^2e^{ta})t+(be^{tb}-ae^{ta})-(be^{tb}-ae^{ta}))t-2((be^{tb}-ae^{ta})t-(e^{tb}-e^{ta}))}{t^3} M′′(t)=b−a1t3((b2etb−a2eta)t+(betb−aeta)−(betb−aeta))t−2((be tb−aeta)t−(etb−eta)) = 1 b − a t 2 ( b 2 e t b −a 2 e t a ) − 2 t (b e t b − a e t a ) + 2 ( e t b − e t a ) t 3 =\frac{1}{b-a}\frac{t^2(b^2e^{tb}-a^2e^{ta})-2t(be^{tb}-ae^{ta})+2(e^{tb}-e^{ta})}{t^3} =b−a1t3t2(b2etb−a2eta)−2t(betb−aeta)+2(etb−eta) t = 0 为M ′ ′ ( t ) 的可去间断点,补充定义M ′ ′ ( 0 ) = lim t → 0 M ′ ′ ( t ) t=0为M''(t)的可去间断点,补充定义M''(0)=\lim_{t\rightarrow0}M''(t) t=0为M′′(t)的可去间断点,补充定义M′′(0)=t→0limM′′(t) E X 2 =M ′ ′ ( 0 ) = lim t → 0 1 b − a t 2 ( b 3 e t b − a 3 e t a ) + 2 t ( b 2 e t b − a 2 e t a ) − 2 t ( b 2 e t b − a 2 e t a ) − 2 ( b e t b − a e t a ) + 2 ( b e t b − a e t a ) 3 t 2EX^2=M''(0)=\lim_{t\rightarrow0}\frac{1}{b-a}\frac{t^2(b^3e^{tb}-a^3e^{ta})+2t(b^2e^{tb}-a^2e^{ta})-2t(b^2e^{tb}-a^2e^{ta})-2(be^{tb}-ae^{ta})+2(be^{tb}-ae^{ta})}{3t^2}EX2=M′′(0)=t→0limb−a13t2t2(b3etb−a3eta)+2t(b2etb−a2eta)−2t(b2etb−a2eta)−2(betb−aeta)+2(betb−aeta) = 1 b − a lim t → 0 t 2 ( b 3 e t b − a 3 e t a ) 3 t 2 =\frac{1}{b-a}\lim_{t\rightarrow0}\frac{t^2(b^3e^{tb}-a^3e^{ta})}{3t^2} =b−a1t→0lim3t2t2(b3etb−a3eta) = 1 b − a lim t → 0 ( b 3 e t b − a 3 e t a ) 3=\frac{1}{b-a}\lim_{t\rightarrow0}\frac{(b^3e^{tb}-a^3e^{ta})}{3} =b−a1t→0lim3(b3etb−a3eta) = 1 b − a ( b 3 − a 3 ) 3 =\frac{1}{b-a}\frac{(b^3-a^3)}{3}=b−a13(b3−a3) = b 2 + a b + a 2 3=\frac{b^2+ab+a^2}{3} =3b2+ab+a2 D X = E X 2 − ( E X ) 2 = ( b − a ) 2 12 DX=EX^2-(EX)^2=\frac{(b-a)^2}{12} DX=EX2−(EX)2=12(b−a)22、指数分布(Exponential distribution)若 X 服从指数分布 E ( λ ) ,则 f ( x ) = λ e− λ x I [ 0 , + ∞ ) ( x ) 若X服从指数分布E(\lambda),则f(x)=\lambda e^{-\lambdax}I_{[0,+\infin)}(x) 若X服从指数分布E(λ),则f(x)=λe−λx I[0,+∞)(x) M ( t ) = ∫ 0 + ∞ λ e −λ x e t x d x M(t)=\int_{0}^{+\infin} \lambda e^{-\lambda x}e^{tx}dx M(t)=∫0+∞λe−λx etxdx = λ ∫ 0 + ∞ e ( t − λ ) x d x =\lambda \int_{0}^{+\infin} e^{(t-\lambda)x}dx =λ∫0+∞e(t−λ)xdx = λ t − λ ( e ( t − λ ) x ∣ 0 + ∞ ) =\frac{\lambda}{t-\lambda}(e^{(t-\lambda)x}\mid_{0}^{+\infin}) =t−λλ(e(t−λ)x∣0+∞) t < λ 时,M ( t ) = λ t − λ ( 0 − 1 ) t<\lambda时,M(t)=\frac{\lambda}{t-\lambda}(0-1) t<λ时,M(t)=t−λλ(0−1) = λ λ − t =\frac{\lambda}{\lambda-t} =λ−tλφ ( t ) = λ λ − i t \varphi(t)=\frac{\lambda}{\lambda-it}φ(t)=λ−itλM ′ ( t ) = λ ( λ − t ) 2M'(t)=\frac{\lambda}{(\lambda-t)^2} M′(t)=(λ−t)2λE X = M ′ ( 0 ) = 1 λ EX=M'(0)=\frac{1}{\lambda}EX=M′(0)=λ1 M ′ ′ ( t ) = 2 λ ( λ − t ) 3M''(t)=\frac{2\lambda}{(\lambda-t)^3}M′′(t)=(λ−t)32λ E X 2 = M ′ ′ ( 0 ) = 2 λ 2 EX^2=M''(0)=\frac{2}{\lambda^2} EX2=M′′(0)=λ22 D X = E X 2 − ( E X ) 2 = 1 λ 2 DX=EX^2-(EX)^2=\frac{1}{\lambda^2} DX=EX2−(EX)2=λ213、正态分布(Normal distribution)若 X 服从正态分布N ( μ , σ 2 ) , 则 f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 若X服从正态分布N(\mu,\sigma^2),则f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} 若X服从正态分布N(μ,σ2),则f(x)=2πσ1e−2σ2(x−μ)2 引理 1 :∫ − ∞ + ∞ e − t 2 2 d t = 2 π 引理1:\int_{-\infin}^{+\infin}e^{-\frac{t^2}{2}}dt=\sqrt{2\pi} 引理1:∫−∞+∞e−2t2dt=2π证明:( ∫ − ∞ + ∞ e − t 2 2 d t ) 2 = ∫ − ∞ + ∞ ∫ − ∞ + ∞ e − x 2 + y 2 2 d x d y 证明:(\int_{-\infin}^{+\infin}e^{-\frac{t^2}{2}}dt)^2=\int_{-\infin}^{+\infin}\int_{-\infin}^{+\infin}e^{-\frac{x^2+y^2}{2}}dxdy 证明:(∫−∞+∞e−2t2dt)2=∫−∞+∞∫−∞+∞e−2x2+y2dxdy = ∫ 0 2 π d θ ∫ 0 + ∞ e − r 2 2 r d r=\int_{0}^{2\pi}d\theta \int_{0}^{+\infin}e^{-\frac{r^2}{2}}rdr =∫02πdθ∫0+∞e−2r2rdr = 2 π ∫ 0 + ∞ e − r 2 2 r d r =2\pi \int_{0}^{+\infin}e^{-\frac{r^2}{2}}rdr =2π∫0+∞e−2r2rdr = 2 π ( − e −r 2 2 ∣0 + ∞ ) =2\pi (-e^{-\frac{r^2}{2}}\mid_{0}^{+\infin}) =2π(−e−2r2∣0+∞) = 2 π =2\pi =2π因此∫ − ∞ + ∞ e − t 2 2 d t = 2 π 因此\int_{-\infin}^{+\infin}e^{-\frac{t^2}{2}}dt=\sqrt{2\pi} 因此∫−∞+∞e−2t2dt=2πM ( t ) = ∫ − ∞ + ∞ 1 2 π σ e − ( x − μ ) 2 2 σ 2 e t x d x M(t)=\int_{-\infin}^{+\infin}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}e^{tx}dx M(t)=∫−∞+∞2πσ1e−2σ2(x−μ)2etxdx = 1 2 π σ ∫ − ∞ + ∞ e −( x − μ ) 2 2 σ 2 + t x d x=\frac{1}{\sqrt{2\pi}\sigma}\int_{-\infin}^{+\infin}e^{-\frac{(x-\mu)^2}{2\sigma^2}+tx}dx =2πσ1∫−∞+∞e−2σ2(x−μ)2+txdx 令 w = x − μ σ 令w=\frac{x-\mu}{\sigma} 令w=σx−μ原式= 1 2 π ∫ − ∞ + ∞ e − w 2 2 + t ( w σ + μ ) d w 原式=\frac{1}{\sqrt{2\pi}}\int_{-\infin}^{+\infin}e^{-\frac{w^2}{2}+t(w\sigma+\mu)}dw 原式=2π1∫−∞+∞e−2w2+t(wσ+μ)dw = e μ t 1 2 π ∫ − ∞ + ∞ e − w 2 2 + t σ w d w =e^{\mut}\frac{1}{\sqrt{2\pi}}\int_{-\infin}^{+\infin}e^{-\frac{w^2}{2}+t\sigma w}dw=eμt2π1∫−∞+∞e−2w2+tσw dw = e μ t 1 2 π ∫ − ∞ + ∞ e − ( w − t σ ) 2 − t 2 σ 2 2 d w =e^{\mut}\frac{1}{\sqrt{2\pi}}\int_{-\infin}^{+\infin}e^{-\frac{(w-t\sigma)^2-t^2\sigma^2}{2}}dw=eμt2π1∫−∞+∞e−2(w−tσ)2−t2σ2dw = e μ t + t 2 σ 2 2 1 2 π ∫ − ∞ + ∞ e − ( w − t σ ) 2 2 d w=e^{\mut+\frac{t^2\sigma^2}{2}}\frac{1}{\sqrt{2\pi}}\int_{-\infin}^{+\infin}e^{-\frac{(w-t\sigma)^2}{2}}dw=eμt+2t2σ22π1∫−∞+∞e−2(w−tσ)2dw = e μ t + t 2 σ 2 2 1 2 π 2 π =e^{\mut+\frac{t^2\sigma^2}{2}}\frac{1}{\sqrt{2\pi}}\sqrt{2\p i} =eμt+2t2σ22π12π= e μ t + t 2 σ 2 2 =e^{\mu t+\frac{t^2\sigma^2}{2}} =eμt+2t2σ2 φ ( t ) = ∫ − ∞ + ∞ 1 2 π σ e −( x − μ ) 2 2 σ 2 e i t x d x \varphi(t)=\int_{-\infin}^{+\infin}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}e^{itx}dx φ(t)=∫−∞+∞2πσ1e−2σ2(x−μ)2eitxdx = 1 2 π σ ∫ − ∞ + ∞ e − ( x − μ ) 2 2 σ 2 + i t x d x=\frac{1}{\sqrt{2\pi}\sigma}\int_{-\infin}^{+\infin}e^{-\frac{(x-\mu)^2}{2\sigma^2}+itx}dx=2πσ1∫−∞+∞e−2σ2(x−μ)2+itxdx 令 w = x − μ σ 令w=\frac{x-\mu}{\sigma} 令w=σx−μ原式= 1 2 π ∫ − ∞ + ∞ e − w 2 2 + i t ( w σ + μ ) d w 原式=\frac{1}{\sqrt{2\pi}}\int_{-\infin}^{+\infin}e^{-\frac{w^2}{2}+it(w\sigma+\mu)}dw 原式=2π1∫−∞+∞e−2w2+it(wσ+μ)dw = e i μ t 1 2 π ∫ −∞ + ∞ e − w 2 2 + i t σ w d w =e^{i\mut}\frac{1}{\sqrt{2\pi}}\int_{-\infin}^{+\infin}e^{-\frac{w^2}{2}+it\sigma w}dw=e iμt2π1∫−∞+∞e−2w2+itσw dw = e i μ t 1 2 π ∫ − ∞ + ∞ e − ( w − i t σ ) 2 + t 2 σ 2 2 d w =e^{i\mut}\frac{1}{\sqrt{2\pi}}\int_{-\infin}^{+\infin}e^{-\frac{(w-it\sigma)^2+t^2\sigma^2}{2}}dw=e iμt2π1∫−∞+∞e−2(w−itσ)2+t2σ2dw = e i μ t − t 2 σ 2 2 1 2 π ∫ − ∞ + ∞ e − ( w − i t σ ) 2 2 d w =e^{i\mu t-\frac{t^2\sigma^2}{2}}\frac{1}{\sqrt{2\pi}}\int_{-\infin}^{+\infin}e^{-\frac{(w-it\sigma)^2}{2}}dw=e iμt−2t2σ22π1∫−∞+∞e−2(w−itσ)2dw = e i μ t − t 2 σ 2 2 12 π 2 π =e^{i\mu t-\frac{t^2\sigma^2}{2}}\frac{1}{\sqrt{2\pi}}\sqrt{2\pi} =e iμt−2t2σ22π12π= e i μ t − t 2 σ 2 2 =e^{i\mu t-\frac{t^2\sigma^2}{2}} =e iμt−2t2σ2 M ′ ( t ) = eμ t + t 2 σ 2 2 ( μ + σ 2 t ) M'(t)=e^{\mut+\frac{t^2\sigma^2}{2}}(\mu+\sigma^2t)M′(t)=eμt+2t2σ2(μ+σ2t) E X = M ′ ( 0 ) = μEX=M'(0)=\mu EX=M′(0)=μM ′ ′ ( t ) = e μ t + t 2 σ 2 2 ( μ + σ 2 t ) 2 + e μ t + t 2 σ 2 2 σ 2M''(t)=e^{\mut+\frac{t^2\sigma^2}{2}}(\mu+\sigma^2t)^2+e^{\mut+\frac{t^2\sigma^2}{2}}\sigma^2 M′′(t)=eμt+2t2σ2 (μ+σ2t)2+eμt+2t2σ2σ2 E X 2 = M ′ ′ ( 0 ) = μ 2 + σ 2 EX^2=M''(0)=\mu^2+\sigma^2 EX2=M′′(0)=μ2+σ2 D X = E X 2 − ( E X ) 2 = σ 2 DX=EX^2-(EX)^2=\sigma^2 DX=EX2−(EX)2=σ2 特别地 , X 服从标准正态分布 N ( 0 , 1 ) 时特别地,X服从标准正态分布N(0,1)时特别地,X服从标准正态分布N(0,1)时 M ( t )= e t 2 2 M(t)=e^{\frac{t^2}{2}} M(t)=e2t2 φ ( t ) = e − t 2 2 \varphi(t)=e^{-\frac{t^2}{2}} φ(t)=e−2t2 E X = 0 , D X = 1 EX=0,DX=1 EX=0,DX=14、伽马分布(Gamma distribution)若 X 服从伽马分布Γ ( α , β ) ( α , β > 0 ) , 则 f ( x ) = β α Γ ( α ) x α − 1 e − β x I( 0 , + ∞ ) ( x ) 若X服从伽马分布\Gamma(\alpha,\beta)(\alpha,\beta>0),则f(x)=\frac{\beta^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\beta x}I_{(0,+\infin)}(x) 若X服从伽马分布Γ(α,β)(α,β>0),则f(x)=Γ(α)βαxα−1e−βx I(0,+∞)(x) 其中,Γ ( α ) = ∫ 0 + ∞ t α − 1 e − t d t , α > 0 其中,\Gamma(\alpha)=\int_{0}^{+\infin}t^{\alpha-1}e^{-t}dt,\alpha>0 其中,Γ(α)=∫0+∞tα−1e−tdt,α>0 指数分布 E ( λ ) 是伽马分布Γ ( 1 , λ ) , χ 2 分布χ n 2 是伽马分布Γ ( n 2 , 1 2 ) 指数分布E(\lambda)是伽马分布\Gamma(1,\lambda),\chi^2分布\chi^2_n是伽马分布\Gamma(\frac{n}{2},\frac{1}{2}) 指数分布E(λ)是伽马分布Γ(1,λ),χ2分布χn2是伽马分布Γ(2n,21) M ( t ) = ∫ 0 + ∞ β α Γ ( α ) x α −1 e − β x e t x d xM(t)=\int_{0}^{+\infin}\frac{\beta^\alpha}{\Gamma(\alp ha)}x^{\alpha-1}e^{-\beta x}e^{tx}dx M(t)=∫0+∞Γ(α)βαxα−1e−βx etxdx = ∫ 0 + ∞ β α Γ ( α ) x α − 1 e ( t − β ) x d x=\int_{0}^{+\infin}\frac{\beta^\alpha}{\Gamma(\alpha)} x^{\alpha-1}e^{(t-\beta) x}dx =∫0+∞Γ(α)βαxα−1e(t−β)xdx = β α ∫ 0 + ∞ 1 Γ ( α ) x α− 1 e ( t − β ) x d x=\beta^\alpha\int_{0}^{+\infin}\frac{1}{\Gamma(\alpha) }x^{\alpha-1}e^{(t-\beta) x}dx =βα∫0+∞Γ(α)1xα−1e(t−β)xdx t < β 时,令v = ( β − t ) x ,原式= β α β − t ∫ 0 + ∞ 1 Γ ( α ) ( v β −t ) α − 1 e − v d v t<\beta时,令v=(\beta-t)x,原式=\frac{\beta^\alpha}{\beta-t}\int_{0}^{+\infin}\frac{1}{\Gamma(\alpha)}(\frac{v}{ \beta-t})^{\alpha-1}e^{-v}dv t<β时,令v=(β−t)x,原式=β−tβα∫0+∞Γ(α)1(β−tv)α−1e−vdv = ( β β − t ) α 1 Γ ( α ) ∫ 0 + ∞ v α − 1 e − v d v =(\frac{\beta}{\beta-t})^\alpha\frac{1}{\Gamma(\alpha)}\int_{0}^{+\infin}v^ {\alpha-1}e^{-v}dv =(β−tβ)αΓ(α)1∫0+∞vα−1e−vdv = ( β β − t ) α 1 Γ ( α ) Γ ( α ) =(\frac{\beta}{\beta-t})^\alpha\frac{1}{\Gamma(\alpha)}\Gamma(\alpha)=(β−tβ)αΓ(α)1Γ(α) = ( β β − t ) α=(\frac{\beta}{\beta-t})^\alpha =(β−tβ)αφ ( t ) = ( β β − i t ) α \varphi(t)=(\frac{\beta}{\beta-it})^\alpha φ(t)=(β−itβ)αM ′ ( t ) = β α ( β − t ) − α − 1 α M'(t)=\beta^\alpha(\beta-t)^{-\alpha-1}\alpha M′(t)=βα(β−t)−α−1α E X = M ′ ( 0 ) = α β EX=M'(0)=\frac{\alpha}{\beta}EX=M′(0)=βαM ′ ′ ( t ) = β α ( β − t ) − α − 2 α ( α + 1 ) M''(t)=\beta^\alpha(\beta-t)^{-\alpha-2}\alpha(\alpha+1)M′′(t)=βα(β−t)−α−2α(α+1) E X 2 = α ( α + 1 ) β 2 EX^2=\frac{\alpha(\alpha+1)}{\beta^2}EX2=β2α(α+1) D X = E X 2 − ( E X ) 2 = α β 2。
常见分布的数学期望和方差

分布
k!
数
k 0,1,2,
pq
npq
学 期
均匀 分布
f (x)
1 b
a
,
a
x
b
0 , else
望 与
指数 分布
f
(
x)
e x
0,
,
x0 else
( 0)
ab 2 1
(b a)2 12 1
2
方 差
正态 分布
f (x)
1
e ,
(
x) 2 2
2
x
2
( 0)
2
例1
设X
~
N
(
1
,
2 1
E( X i ) p , D( X i ) p(1 p) ,
而 X= X1+X2+…+Xn , Xi 相互独立,
n
n
所以 E( X ) E( X i ) E( X i ) np .
i 1
i 1
n
n
D( X ) D( X i ) D( X i ) np(1 p) .
i 1
i 1
所以 D( X ) np(np p 1) (np)2 np(1 p) .
4
下面利用期望和方差的性质重新求二项分布的
数学期望和方差.
设 X ~ B ( n, p ),X表示n重伯努利试验中的成功次数.
设
1 X i 0
如第i次试验成功 如第i次试验失败
i=1,2,…,n
则
Xi
P
10
p 1 p
与 2X 的关系是则( ).
A.有相同的分布
B.数学期望相等
C.方差相等
六个常用分布的数学期望和方差

0
θ
0
(
x)e
x
x
e dx
0
0
x
e
θ
0
E( X 2 )
x 2 f ( x)dx
x2
1
x
eθ
dx
0
θ
x
( x 2)de θ 0
(
x
2)e
x
x
2xe dx
0
0
(
ቤተ መጻሕፍቲ ባይዱ
2θx)de
x θ
0
(
2x)e
x
2
x
e dx
0
0
2
2
e
x
2θ 2, D( X ) E( X 2 ) [E( X )]2
X X1 X2 Xn
E( X ) E(X1 ) E(X 2 ) E(X n ) np
D( X ) D( X 1 ) D( X 2 ) D( X n ) np(1 p)
即: 若随机变量X~B( n , p ),则
E( X ) np,D( X ) np(1 p)
1
t2
( t )e 2 d t
t2
e 2 dt
2
2
D( X ) E{[ X E( X )]2 }
(x
)2
2
t2
t
2
e
2
dt
(令
t x )
2
1
( x )2
e 2 2 dx
2
2
2
t2
( t )de
2
2 2
t2
te 2
t 2
e 2 dt
2
2
即
概率分布期望方差汇总

概率分布期望方差汇总概率分布是描述随机变量取值的概率的数学模型。
期望是对随机变量取值的平均值的度量,方差则是衡量随机变量取值分散程度的度量。
在概率论和统计学中,期望和方差是两个重要的概念,对于理解和应用概率分布非常关键。
一、期望期望是对随机变量取值的平均值的度量,也可以理解为随机变量的中心位置。
对于离散随机变量X,其期望计算公式为E(X) = Σ x*p(x),即随机变量各取值乘以其对应的概率之和。
对于连续随机变量X,其期望计算公式为E(X) = ∫ x*f(x) dx,其中f(x)是X的概率密度函数。
二、方差方差是对随机变量取值分散程度的度量。
方差越大,表示随机变量的取值更分散;方差越小,表示随机变量的取值更集中。
方差计算公式为Var(X) = E[(X-E(X))^2],即随机变量取值与其期望之差的平方的期望。
方差的平方根称为标准差。
三、常见概率分布的期望和方差1.二项分布二项分布是最常见的离散概率分布之一,描述在n次独立重复试验中成功次数的分布。
设X为成功次数,则X服从参数为n和p的二项分布记作X~B(n,p)。
期望:E(X) = np方差:Var(X) = np(1-p)2.泊松分布泊松分布描述单位时间或单位空间内事件发生的次数的概率。
设X为单位时间或单位空间内事件发生的次数,则X服从参数为λ的泊松分布记作X~P(λ)。
期望:E(X)=λ方差:Var(X) = λ3.均匀分布均匀分布是最简单的连续概率分布之一,描述在一个区间上随机取值的概率。
设X在[a,b]区间上服从均匀分布,则X服从均匀分布记作X~U(a,b)。
期望:E(X)=(a+b)/2方差:Var(X) = (b-a)^2/124.正态分布正态分布是最常见的连续概率分布之一,其概率密度函数呈钟型曲线。
设X服从参数为μ和σ^2的正态分布记作X~N(μ,σ^2)。
期望:E(X)=μ方差:Var(X) = σ^25.指数分布指数分布描述连续随机事件发生的时间间隔的概率。
多项式分布的期望和方差

多项式分布的期望和方差
有限微积分中,多项式分布是一种常用的概率分布。
它由一个有限数量的有限状态组成,每一状态都有固定的概率。
多项式分布具有许多独特的性质,其中一个最重要的性质就是它的期望和方差。
期望是一种特殊的数学量度,可以衡量特定概率分布的中心值。
而方差则反映了这一概率分布的方差,是衡量分布离散性的关键参数。
多项式分布的期望和方差可以用相应的公式求得。
根据多项式概率分布的定义,期望是概率乘以可能的值的总和,即奇异期望:即E(X)=∑Xi*pi ,其中Xi为可能出现的值,pi为Xi 对应的概率。
方差的公式为VAR(X)=∑[Xi–E(X)(Xi–E(X))]*pi , 其中Xi和E(X)的含义与期望的公式相同。
因此,多项式分布的期望和方差可以用相应的公式求得。
期望体现了概率分布的中心值,方差为算法衡量离散程度提供了有效的指标。
通过熟练掌握多项式分布的期望和方差计算方法,对包含有限状态的各类概率分布进行精确计算更容易。
只有了解多项式分布期望和方差的知识,我们才能正确合理地分析不同分布的性质和表现特征,更好地应用它们。
标准正态分布的期望和方差
在概率论和统计学中,数学期望(mean)(或均值,亦简称期望)为试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。
若随机变量X服从一个数学期望为μ、方差为σ^2的高斯分布,记为N(μ,σ^2)。
其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。
因其曲线呈钟形,因此人们又经常称之为钟形曲线。
我们通常所说的标准正态分布是μ = 0,σ = 1的正态分布。
若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。
其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。
当μ = 0,σ = 1时的正态分布是标准正态分布。
在统计描述中,方差用来计算每一个变量(观察值)与总体均数之间的差异。
为避免出现离均差总和为零,离均差平方和受样本含量的影响,统计学采用平均离均差平方和来描述变量的变异程度。
由于一般的正态总体其图像不一定关于y轴对称,对于任一正态总体,其取值小于x的概率。
只要会用它求正态总体在某个特定区间的概率即可。
为了便于描述和应用,常将正态变量作数据转换。
将一般正态分布转化成标准正态分布。
对于连续型随机变量X,若其定义域为(a,b),概率密度函数为f(x),连续型随机变量X方差计算公式:D(X)=(x-μ)^2 f(x) dx方差刻画了随机变量的取值对于其数学期望的离散程度。
(标准差、方差越大,离散程度越大)若X的取值比较集中,则方差D(X)较小,若X的取值比较分散,则方差D (X)较大。
因此,D(X)是刻画X取值分散程度的一个量,它是衡量取值分散程度的一个尺度。
概率计算中的期望与方差计算

概率计算中的期望与方差计算概率论是数学中的一个重要分支,其中期望值和方差是计算概率分布特征的核心概念。
在概率计算中,期望值和方差的计算可以帮助我们了解随机事件的平均趋势和离散程度。
本文将介绍期望值和方差的概念、计算方法以及其在概率计算中的应用。
1. 期望值的定义与计算方法期望值是一组数据中各数值与其概率加权平均的结果。
它可以理解为随机变量的平均取值。
设随机变量X有n个取值x1, x2, ... , xn,并且对应的概率为p1, p2, ... , pn,则期望值的计算公式为:E(X) = x1 * p1 + x2 * p2 + ... + xn * pn其中E(X)表示X的期望值。
通过计算,可以得到随机变量X的平均取值。
2. 方差的定义与计算方法方差是一组数据中各数值与其期望值的差的平方与其概率加权平均的结果。
它可以理解为随机变量取值与其平均取值的离散程度。
方差的计算公式为:Var(X) = (x1 - E(X))^2 * p1 + (x2 - E(X))^2 * p2 + ... + (xn - E(X))^2 * pn其中Var(X)表示X的方差。
通过计算,可以得到随机变量X的离散程度大小。
3. 期望值与方差的应用举例在实际应用中,期望值和方差有着广泛的应用。
以下是一些常见的应用举例:3.1 投掷硬币假设投掷一枚公平的硬币,正面朝上的概率为p,反面朝上的概率为1-p。
则硬币的期望值为E(X) = p * 1 + (1-p) * 0 = p,方差为Var(X)= (1-p)^2 * p + p^2 * (1-p) = p(1-p)。
通过计算可以知道,硬币投掷的平均结果为正面与反面的概率加权平均,且平均偏离程度由p(1-p)表示。
3.2 随机抽样在随机抽样中,假设有n个样本,每个样本的概率为p,被抽中的概率为1-p。
则样本的期望值为E(X) = p,方差为Var(X) = p(1-p)/n。
通过计算可以得到,样本的平均结果由单个样本的概率加权平均,且偏离程度与样本数量n成反比。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
n
k
n!
pk qnk
k 0 k!(n k)!
n
np
(n 1)!
p k 1q n1(k 1)
k1 (k 1)!(n 1 (k 1))!
返回主目录
第十三章 随机变量的数字特征
n
n1 §3 几种期望与
EX np Cnk11 p k 1q n1(k 1) np Cni方1差p i q n1i
x
b
。
b
EX xf (x)dx x 1 dx a b
ba
2
a
返回主目录
第十三章 随机变量的数字特征
§3 几种期望与
b
DX EX 2 (EX )2 x2
1
dx ( a b)2 方(b差 a)2
a ba
2
12
5.正态分布 X ~ N(, 2)
EX x
1
(x)2
e 2 2 dx
k 1
i0
np( p q)n1 np
EX 2
n
k 2 Cnk pk qnk
k 0
n
k2
n!
pk qnk
k 0
k!(n k)!
n
p
k
1
k
(k
n! 1)!(n
k)!
pk
1q n k
n
p (k 1)
n!
n
pk1qnk p
n!
p k 1q nk
k 1
n(n 1)
p2
(k
n
1)!(n
EX n EXi np , DX n DX i npq,
i 1
i 1
3.泊松分布
设 X 服从参数为泊松分布,
其分布律为P{X k} k e ,k=0,1,...
k!
EX k k e e k1 e e
k 0 k!
k1 (k 1)!
返回主目录
第十三章 随机变量的数字特征
e2
dt
2
返回主目录
第十三章 随机变量的数字特征
§3 几种期望与
P{| X | } P{ X } 方差
( ) ( ) (1) (1) 2(1) 1 0.6826
P{| X | 2} P{ 2 X 2}
2(2) 1 0.9544
2
1
(t
t2
)e 2
dt,
(
x
t)
2
t2
te 2 dt
t2
e 2 dt
2
2
DX E( X )2 (x )2
1
( x )2
e
2 2
dx, ( x t)
2
2t2
t2
e2
dt
2
t
2
e
t2 2
dt
2
t2
tde 2
2
2
2
2 2
t2
te 2
|
2 2
t2
第十三章 随机变量的数字特征
方法2:
§3 几种期望与
Xi
服从(0-1)分布, P{ X i
0}
q, P{Xi
方差
1}
p,i
1,2,
,n
且 X1, , X n 独立,令 X X1 X n ,则 X 的可能
取值为 0,1,…n,
P{X k} Cnk pk qnk , k 0, , n
P{| X | 3} P{ 3 X 3}
2(3) 1 0.9974 因此,对于正态随机变量来说,它的值落在区间 [ 3 , 3 ] 内几乎是肯定的。
在上一节用切比晓夫不等式估计概率有:
P{| X | 3} 0.8889
返回主目录
k )!
(n
2)!
k np
k2 (k 2)!(n 2 (k 2))!
n(n 1) p 2 ( p q) n2 np n 2 p 2 np 2 np
DX EX 2 (EX )2 n2 p2 n p2 np n2 p2 np(1 p) npq
EX 2 k 2 k e k k e
k 0
k!
k 1 (k 1)!
§3 几种期望与 方差
(k 1)
k
e
k e
k 1
(k 1)!
k 1 (k 1)!
2e
k 2 ee 2
k 2 (k 2)!
DX EX 2 (EX )2 2 2
4.均匀分布
f
(x)
1/(b a), a 0, 其它
第十三章 随机变量的数字特征
§3.几种重要随机变量的数学期望及方差 1.两点分布
X 01
pk 1 p p
EX=p, DX EX 2 (EX )2 p p2 pq 。
2. 二项分布
方法1:
P{X k} Cnk pk qnk , k 0,1, , n 。
EX
n
k Cnk pk qnk