BP神经网络预测代码
python实现BP神经网络回归预测模型

python实现BP神经网络回归预测模型神经网络模型一般用来做分类,回归预测模型不常见,本文基于一个用来分类的BP神经网络,对它进行修改,实现了一个回归模型,用来做室内定位。
模型主要变化是去掉了第三层的非线性转换,或者说把非线性激活函数Sigmoid换成f(x)=x函数。
这样做的主要原因是Sigmoid函数的输出范围太小,在0-1之间,而回归模型的输出范围较大。
模型修改如下:代码如下:#coding: utf8''''author: Huangyuliang'''import jsonimport randomimport sysimport numpy as np#### Define the quadratic and cross-entropy cost functionsclass CrossEntropyCost(object):@staticmethoddef fn(a, y):return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))@staticmethoddef delta(z, a, y):return (a-y)#### Main Network classclass Network(object):def __init__(self, sizes, cost=CrossEntropyCost):self.num_layers = len(sizes)self.sizes = sizesself.default_weight_initializer()self.cost=costdef default_weight_initializer(self):self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x)/np.sqrt(x)for x, y in zip(self.sizes[:-1], self.sizes[1:])] def large_weight_initializer(self):self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x)for x, y in zip(self.sizes[:-1], self.sizes[1:])] def feedforward(self, a):"""Return the output of the network if ``a`` is input."""for b, w in zip(self.biases[:-1], self.weights[:-1]): # 前n-1层a = sigmoid(np.dot(w, a)+b)b = self.biases[-1] # 最后一层w = self.weights[-1] a = np.dot(w, a)+breturn adef SGD(self, training_data, epochs, mini_batch_size, eta,lmbda = 0.0,evaluation_data=None,monitor_evaluation_accuracy=False): # 用随机梯度下降算法进行训练n = len(training_data)for j in xrange(epochs):random.shuffle(training_data)mini_batches = [training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)]for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta, lmbda, len(training_data))print ("Epoch %s training complete" % j)if monitor_evaluation_accuracy:print ("Accuracy on evaluation data: {} / {}".format(self.accuracy(evaluation_data), j))def update_mini_batch(self, mini_batch, eta, lmbda, n):"""Update the network's weights and biases by applying gradientdescent using backpropagation to a single mini batch. The``mini_batch`` is a list of tuples ``(x, y)``, ``eta`` is thelearning rate, ``lmbda`` is the regularization parameter, and``n`` is the total size of the training data set."""nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y)nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw in zip(nabla_w,delta_nabla_w)] self.weights = [(1-eta*(lmbda/n))*w-(eta/len(mini_batch))*nwfor w, nw in zip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nbfor b, nb in zip(self.biases, nabla_b)]def backprop(self, x, y):"""Return a tuple ``(nabla_b, nabla_w)`` representing thegradient for the cost function C_x. ``nabla_b`` and``nabla_w`` are layer-by-layer lists of numpy arrays, similarto ``self.biases`` and ``self.weights``."""nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = xactivations = [x] # list to store all the activations, layer by layerzs = [] # list to store all the z vectors, layer by layerfor b, w in zip(self.biases[:-1], self.weights[:-1]): # 正向传播前n-1层z = np.dot(w, activation)+bzs.append(z)activation = sigmoid(z)activations.append(activation)# 最后一层,不用非线性b = self.biases[-1] w = self.weights[-1] z = np.dot(w, activation)+bzs.append(z)activation = zactivations.append(activation)# backward pass 反向传播delta = (self.cost).delta(zs[-1], activations[-1], y) # 误差 Tj - Ojnabla_b[-1] = deltanabla_w[-1] = np.dot(delta, activations[-2].transpose()) # (Tj - Oj) * O(j-1)for l in xrange(2, self.num_layers):z = zs[-l] # w*a + bsp = sigmoid_prime(z) # z * (1-z)delta = np.dot(self.weights[-l+1].transpose(), delta) * sp # z*(1-z)*(Err*w) 隐藏层误差nabla_b[-l] = deltanabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) # Errj * Oireturn (nabla_b, nabla_w)def accuracy(self, data):results = [(self.feedforward(x), y) for (x, y) in data] alist=[np.sqrt((x[0][0]-y[0])**2+(x[1][0]-y[1])**2) for (x,y) in results] return np.mean(alist)def save(self, filename):"""Save the neural network to the file ``filename``."""data = {"sizes": self.sizes,"weights": [w.tolist() for w in self.weights],"biases": [b.tolist() for b in self.biases],"cost": str(self.cost.__name__)}f = open(filename, "w")json.dump(data, f)f.close()#### Loading a Networkdef load(filename):"""Load a neural network from the file ``filename``. Returns aninstance of Network."""f = open(filename, "r")data = json.load(f)f.close()cost = getattr(sys.modules[__name__], data["cost"])net = Network(data["sizes"], cost=cost)net.weights = [np.array(w) for w in data["weights"]] net.biases = [np.array(b) for b in data["biases"]] return netdef sigmoid(z):"""The sigmoid function."""return 1.0/(1.0+np.exp(-z))def sigmoid_prime(z):"""Derivative of the sigmoid function."""return sigmoid(z)*(1-sigmoid(z))调用神经网络进行训练并保存参数:#coding: utf8import my_datas_loader_1import network_0training_data,test_data = my_datas_loader_1.load_data_wrapper()#### 训练网络,保存训练好的参数net = network_work([14,100,2],cost = network_0.CrossEntropyCost)rge_weight_initializer()net.SGD(training_data,1000,316,0.005,lmbda =0.1,evaluation_data=test_data,monitor_evaluation_accuracy=True) filename=r'C:\Users\hyl\Desktop\Second_158\Regression_Model\parameters.txt'net.save(filename)第190-199轮训练结果如下:调用保存好的参数,进行定位预测:#coding: utf8import my_datas_loader_1import network_0import matplotlib.pyplot as plttest_data = my_datas_loader_1.load_test_data()#### 调用训练好的网络,用来进行预测filename=r'D:\Workspase\Nerual_networks\parameters.txt' ## 文件保存训练好的参数net = network_0.load(filename) ## 调用参数,形成网络fig=plt.figure(1)ax=fig.add_subplot(1,1,1)ax.axis("equal")# plt.grid(color='b' , linewidth='0.5' ,linestyle='-') # 添加网格x=[-0.3,-0.3,-17.1,-17.1,-0.3] ## 这是九楼地形的轮廓y=[-0.3,26.4,26.4,-0.3,-0.3] m=[1.5,1.5,-18.9,-18.9,1.5] n=[-2.1,28.2,28.2,-2.1,-2.1] ax.plot(x,y,m,n,c='k')for i in range(len(test_data)):pre = net.feedforward(test_data[i][0]) # pre 是预测出的坐标bx=pre[0] by=pre[1] ax.scatter(bx,by,s=4,lw=2,marker='.',alpha=1) #散点图plt.pause(0.001)plt.show()定位精度达到了1.5米左右。
BP神经网络预测的matlab代码

BP神经网络预测的matlab代码附录5:BP神经网络预测的matlab代码: P=[ 00.13860.21970.27730.32190.35840.38920.41590.43940.46050.47960.49700.52780.55450.59910.60890.61820.62710.63560.64380.65160.65920.66640.67350.72220.72750.73270.73780.74270.74750.75220.75680.76130.76570.7700]T=[0.4455 0.323 0.4116 0.3255 0.4486 0.2999 0.4926 0.2249 0.48930.2357 0.4866 0.22490.4819 0.2217 0.4997 0.2269 0.5027 0.217 0.5155 0.1918 0.5058 0.2395 0.4541 0.2408 0.4054 0.2701 0.3942 0.3316 0.2197 0.2963 0.5576 0.1061 0.4956 0.267 0.5126 0.2238 0.5314 0.2083 0.5191 0.208 0.5133 0.18480.5089 0.242 0.4812 0.2129 0.4927 0.287 0.4832 0.2742 0.5969 0.24030.5056 0.2173 0.5364 0.1994 0.5278 0.2015 0.5164 0.2239 0.4489 0.2404 0.4869 0.2963 0.4898 0.1987 0.5075 0.2917 0.4943 0.2902 ]threshold=[0 1]net=newff(threshold,[11,2],{'tansig','logsig'},'trainlm');net.trainParam.epochs=6000net.trainParam.goal=0.01LP.lr=0.1;net=train(net,P',T')P_test=[ 0.77420.77840.78240.78640.79020.7941 ] out=sim(net,P_test')友情提示:以上面0.7742为例0.7742=ln(47+1)/5因为网络输入有一个元素,对应的是测试时间,所以P只有一列,Pi=log(t+1)/10,这样做的目的是使得这些数据的范围处在[0 1]区间之内,但是事实上对于logsin命令而言输入参数是正负区间的任意值,而将输出值限定于0到1之间。
BP神经网络MATLAB代码

BP神经网络matlab代码p=[284528334488;283344884554;448845542928;455429283497;29283497 2261;...349722616921;226169211391;692113913580;139135804451;35804451 2636;...445126363471;263634713854;347138543556;385435562659;35562659 4335;...265943352882;433528824084;433528821999;288219992889;19992889 2175;...288921752510;217525103409;251034093729;340937293489;37293489 3172;...348931724568;317245684015;]';%====期望输出=======t=[4554292834972261692113913580445126363471385435562659... 4335288240841999288921752510340937293489317245684015... 3666];ptest=[284528334488;283344884554;448845542928;455429283497;29283497 2261;...349722616921;226169211391;692113913580;139135804451;35804451 2636;...445126363471;263634713854;347138543556;385435562659;35562659 4335;...265943352882;433528824084;433528821999;288219992889;19992889 2175;...288921752510;217525103409;251034093729;340937293489;37293489 3172;...348931724568;317245684015;456840153666]';[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t);%将数据归一化NodeNum1=20;%隐层第一层节点数NodeNum2=40;%隐层第二层节点数TypeNum=1;%输出维数TF1='tansig';TF2='tansig';TF3='tansig';net=newff(minmax(pn),[NodeNum1,NodeNum2,TypeNum],{TF1TF2 TF3},'traingdx');%网络创建traingdmnet.trainParam.show=50;net.trainParam.epochs=50000;%训练次数设置net.trainParam.goal=1e-5;%训练所要达到的精度net.trainParam.lr=0.01;%学习速率net=train(net,pn,tn);p2n=tramnmx(ptest,minp,maxp);%测试数据的归一化an=sim(net,p2n);[a]=postmnmx(an,mint,maxt)%数据的反归一化,即最终想得到的预测结果plot(1:length(t),t,'o',1:length(t)+1,a,'+');title('o表示预测值---*表示实际值')grid onm=length(a);%向量a的长度t1=[t,a(m)];error=t1-a;%误差向量figureplot(1:length(error),error,'-.')title('误差变化图')grid on%结束下面的是我把索%======ÔʼÊý¾ÝÊäÈë========p=[0.0358680.0385570.0220440.0171700.0104820.0120810.0037350.004663;0.0388910.0397780.0181150.0184190.0098570.0105140.0059380.006051;0.0374130.0384490.0185320.0171410.010221 0.0101030.0089230.009008;0.0332140.0371330.0206900.0145240.0111610.0106640.0066470.007862;0.0375960.0379980.0201270.0186020.0104910.0116430.0055090.004373;0.0303130.0340310.018255 0.0163330.0080200.0091640.0066560.004936;0.0366990.0371520.0202510.0154910.0121800.012924 0.0075200.008002;...0.2809400.1993590.1128910.0797500.0619890.0477980.0390930.035339;0.2352230.1675010.095537 0.0674510.0518210.0407670.0356960.028659;0.2258100.1612220.0914630.0637270.0492210.038668 0.0327730.030023;0.2282550.1619520.0921190.0654410.0509320.0381480.0341810.028801;0.230465 0.1639260.0936220.0676940.0514080.0377460.0347800.030020;0.2338510.1675610.0958520.068036 0.0507980.0399780.0350310.029043;0.2359590.1691130.0969030.0679360.0516860.0389350.034297 0.032020;...0.0182320.0140600.0059230.0040330.0007420.0058400.0018000.002859;0.0155060.0211870.008724 0.0067840.0025160.0024680.0042380.001484;0.0109790.0114670.0035370.0045270.0016230.002313 0.0019850.000662;0.0175400.0188050.0032210.0079770.0036650.0057530.0042850.003807;0.008817 0.0126570.0024340.0065130.0011920.0019030.0049040.003188;0.0124950.0161250.0064830.005098 0.0047510.0014300.0042500.004460;0.0081280.0200870.0064080.0102490.0045140.0027180.002576 0.002896;]';%====ÆÚÍûÊä³ö=======t=[000000000000001010101010101001010101010101];ptest=[0.0399850.0401500.0229320.0148890.0102450.0103300.0072850.008245;0.0395970.041301 0.0210420.0172060.0090620.0107090.0043790.007461;0.0347410.0382610.0230350.0185850.009328 0.0099880.0075210.006008;...0.2468790.1764940.1022420.0713890.0571930.0403130.0368370.030813;0.2569540.1800370.101773 0.0723390.0572040.0444510.0373170.033529;0.2809400.1993590.1128910.0797500.0619890.047798 0.0390930.035339;...0.0161200.0141350.0017940.0051930.0023760.0015300.0021690.001995;0.0163150.0207470.006796 0.0059240.0043230.0038880.0059570.002633;0.0024230.0293810.0174550.0108740.0032110.002222 0.0045590.002341;]';[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t);%½«Êý¾Ý¹éÒ»»¯NodeNum1=20;%Òþ²ãµÚÒ»²ã½ÚµãÊýNodeNum2=40;%Òþ²ãµÚ¶þ²ã½ÚµãÊýTypeNum=1;%Êä³öάÊýTF1='tansig';TF2='tansig';TF3='tansig';net=newff(minmax(pn),[NodeNum1,NodeNum2,TypeNum],{TF1TF2TF3},'traingdx');%ÍøÂç´´½¨traingdmnet.trainParam.show=50;net.trainParam.epochs=50000;%ѵÁ·´ÎÊýÉèÖÃnet.trainParam.goal=1e5;%ѵÁ·ËùÒª´ïµ½µÄ¾«¶Ènet.trainParam.lr=0.01;%ѧϰËÙÂÊnet=train(net,pn,tn);p2n=tramnmx(ptest,minp,maxp);%²âÊÔÊý¾ÝµÄ¹éÒ»»¯an=sim(net,p2n);[a]=postmnmx(an,mint,maxt)%Êý¾ÝµÄ·´¹éÒ»»¯£¬¼´×îÖÕÏëµÃµ½µÄÔ¤²â½á¹ûplot(1:length(t),t,'o',1:length(t)+1,a,'+');title('o±íʾԤ²âÖµ*±íʾʵ¼ÊÖµ')grid onm=length(a);%ÏòÁ¿aµÄ³¤¶Èt1=[t,a(m)];error=t1a;%Îó²îÏòÁ¿figureplot(1:length(error),error,'.')title('Îó²î±ä»¯Í¼')grid on。
python实现BP神经网络回归预测模型

python实现BP神经⽹络回归预测模型神经⽹络模型⼀般⽤来做分类,回归预测模型不常见,本⽂基于⼀个⽤来分类的BP神经⽹络,对它进⾏修改,实现了⼀个回归模型,⽤来做室内定位。
模型主要变化是去掉了第三层的⾮线性转换,或者说把⾮线性激活函数Sigmoid换成f(x)=x函数。
这样做的主要原因是Sigmoid函数的输出范围太⼩,在0-1之间,⽽回归模型的输出范围较⼤。
模型修改如下:代码如下:#coding: utf8''''author: Huangyuliang'''import jsonimport randomimport sysimport numpy as np#### Define the quadratic and cross-entropy cost functionsclass CrossEntropyCost(object):@staticmethoddef fn(a, y):return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))@staticmethoddef delta(z, a, y):return (a-y)#### Main Network classclass Network(object):def __init__(self, sizes, cost=CrossEntropyCost):self.num_layers = len(sizes)self.sizes = sizesself.default_weight_initializer()self.cost=costdef default_weight_initializer(self):self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]self.weights = [np.random.randn(y, x)/np.sqrt(x)for x, y in zip(self.sizes[:-1], self.sizes[1:])]def large_weight_initializer(self):self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]self.weights = [np.random.randn(y, x)for x, y in zip(self.sizes[:-1], self.sizes[1:])]def feedforward(self, a):"""Return the output of the network if ``a`` is input."""for b, w in zip(self.biases[:-1], self.weights[:-1]): # 前n-1层a = sigmoid(np.dot(w, a)+b)b = self.biases[-1] # 最后⼀层w = self.weights[-1]a = np.dot(w, a)+breturn adef SGD(self, training_data, epochs, mini_batch_size, eta,lmbda = 0.0,evaluation_data=None,monitor_evaluation_accuracy=False): # ⽤随机梯度下降算法进⾏训练n = len(training_data)for j in xrange(epochs):random.shuffle(training_data)mini_batches = [training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)]for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta, lmbda, len(training_data))print ("Epoch %s training complete" % j)if monitor_evaluation_accuracy:print ("Accuracy on evaluation data: {} / {}".format(self.accuracy(evaluation_data), j)) def update_mini_batch(self, mini_batch, eta, lmbda, n):"""Update the network's weights and biases by applying gradientdescent using backpropagation to a single mini batch. The``mini_batch`` is a list of tuples ``(x, y)``, ``eta`` is thelearning rate, ``lmbda`` is the regularization parameter, and``n`` is the total size of the training data set."""nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x, y)nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]self.weights = [(1-eta*(lmbda/n))*w-(eta/len(mini_batch))*nwfor w, nw in zip(self.weights, nabla_w)]self.biases = [b-(eta/len(mini_batch))*nbfor b, nb in zip(self.biases, nabla_b)]def backprop(self, x, y):"""Return a tuple ``(nabla_b, nabla_w)`` representing thegradient for the cost function C_x. ``nabla_b`` and``nabla_w`` are layer-by-layer lists of numpy arrays, similarto ``self.biases`` and ``self.weights``."""nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]# feedforwardactivation = xactivations = [x] # list to store all the activations, layer by layerzs = [] # list to store all the z vectors, layer by layerfor b, w in zip(self.biases[:-1], self.weights[:-1]): # 正向传播前n-1层z = np.dot(w, activation)+bzs.append(z)activation = sigmoid(z)activations.append(activation)# 最后⼀层,不⽤⾮线性b = self.biases[-1]w = self.weights[-1]z = np.dot(w, activation)+bzs.append(z)activation = zactivations.append(activation)# backward pass 反向传播delta = (self.cost).delta(zs[-1], activations[-1], y) # 误差 Tj - Ojnabla_b[-1] = deltanabla_w[-1] = np.dot(delta, activations[-2].transpose()) # (Tj - Oj) * O(j-1)for l in xrange(2, self.num_layers):z = zs[-l] # w*a + bsp = sigmoid_prime(z) # z * (1-z)delta = np.dot(self.weights[-l+1].transpose(), delta) * sp # z*(1-z)*(Err*w) 隐藏层误差 nabla_b[-l] = deltanabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) # Errj * Oireturn (nabla_b, nabla_w)def accuracy(self, data):results = [(self.feedforward(x), y) for (x, y) in data]alist=[np.sqrt((x[0][0]-y[0])**2+(x[1][0]-y[1])**2) for (x,y) in results]return np.mean(alist)def save(self, filename):"""Save the neural network to the file ``filename``."""data = {"sizes": self.sizes,"weights": [w.tolist() for w in self.weights],"biases": [b.tolist() for b in self.biases],"cost": str(self.cost.__name__)}f = open(filename, "w")json.dump(data, f)f.close()#### Loading a Networkdef load(filename):"""Load a neural network from the file ``filename``. Returns aninstance of Network."""f = open(filename, "r")data = json.load(f)f.close()cost = getattr(sys.modules[__name__], data["cost"])net = Network(data["sizes"], cost=cost)net.weights = [np.array(w) for w in data["weights"]]net.biases = [np.array(b) for b in data["biases"]]return netdef sigmoid(z):"""The sigmoid function."""return 1.0/(1.0+np.exp(-z))def sigmoid_prime(z):"""Derivative of the sigmoid function."""return sigmoid(z)*(1-sigmoid(z))调⽤神经⽹络进⾏训练并保存参数:#coding: utf8import my_datas_loader_1import network_0training_data,test_data = my_datas_loader_1.load_data_wrapper()#### 训练⽹络,保存训练好的参数net = network_work([14,100,2],cost = network_0.CrossEntropyCost)rge_weight_initializer()net.SGD(training_data,1000,316,0.005,lmbda =0.1,evaluation_data=test_data,monitor_evaluation_accuracy=True) filename=r'C:\Users\hyl\Desktop\Second_158\Regression_Model\parameters.txt'net.save(filename)第190-199轮训练结果如下:调⽤保存好的参数,进⾏定位预测:#coding: utf8import my_datas_loader_1import network_0import matplotlib.pyplot as plttest_data = my_datas_loader_1.load_test_data()#### 调⽤训练好的⽹络,⽤来进⾏预测filename=r'D:\Workspase\Nerual_networks\parameters.txt' ## ⽂件保存训练好的参数net = network_0.load(filename) ## 调⽤参数,形成⽹络fig=plt.figure(1)ax=fig.add_subplot(1,1,1)ax.axis("equal")# plt.grid(color='b' , linewidth='0.5' ,linestyle='-') # 添加⽹格x=[-0.3,-0.3,-17.1,-17.1,-0.3] ## 这是九楼地形的轮廓y=[-0.3,26.4,26.4,-0.3,-0.3]m=[1.5,1.5,-18.9,-18.9,1.5]n=[-2.1,28.2,28.2,-2.1,-2.1]ax.plot(x,y,m,n,c='k')for i in range(len(test_data)):pre = net.feedforward(test_data[i][0]) # pre 是预测出的坐标bx=pre[0]by=pre[1]ax.scatter(bx,by,s=4,lw=2,marker='.',alpha=1) #散点图plt.pause(0.001)plt.show()定位精度达到了1.5⽶左右。
神经网络BP算法源代码(C++)

void CBP_TView::OnBpLearn() { Simu(); //获得网络输入 out0[i][0] 和参考输出 targ[i][0] Random_w(); //随机获得网络初始权值 BeginWaitCursor(); double sum, dw; for (q=0; q<nRepeat; q++) // nRepeat: 最大重复次数 { for (p = 0; p < nLp; p++) //nLp = st/dt, Simu()中得到 { Work(p); //网络输出计算 //计算反向传播的 delta for (i = 0; i < nOut; i++) //输出层 delta = (targ-y)*y*(1-y) delta2[p][i] = (targ[p][i] - out2[p][i])*out2[p][i]*(1.0-out2[p][i]); for(int h = 0; h <nHide; h++) { //隐层 (1 yh ) yh out who sum = 0; for(j = 0;j < nOut;j++) sum+=delta2[p][j]*w2[j][h]; delta1[p][h] = sum*out1[p][h]*(1.0-out1[p][h]); } } //调整隐层-输出层权值 for ( j=0;j<nOut;j++) { sum = 0; for(p = 0; p<nLp; p++) sum+=delta2[p][j]; //得到每个输出节点的偏置的权值 w(nHide), // eta: 学习率, alpha: 动量因子 dw = eta*sum + alpha*delw2[j][nHide]; // w2[j][nHide] += dw; // delw2[j][nHide] = dw; // //得到其它的权值 for (h = 0; h < nHide; h++) { sum = 0; for(p = 0; p < nLp; p++) sum+=delta2[p][j]*out1[p][h]; dw = eta*sum + alpha*delw2[j][h]; w2[j][h] += dw; delw2[j][h] = dw; } } //调整输入层-隐层权值 for (h= 0;h < nHide; h++) { sum = 0; for (p = 0; p < nLp; p++) sum += delta1[p][h]; //得到每个隐层节点的偏置的权值 w(nIn) , //eta: 学习率, alpha: 动量因子 dw = eta*sum+alpha*delw1[h][nIn]; w1[h][nIn] += dw; delw1[h][nIn] = dw; //得到其它的权值 for(i = 0; i < nIn; i++) { sum = 0; for (p = 0; p < nLp; p++) sum+=delta1[p][h]*out0[p][i]; dw = eta*sum+alpha*delw1[h][i]; w1[h][i]+=dw;
求用matlab编BP神经网络预测程序

求用编神经网络预测程序求一用编的程序[。
];输入[。
];输出创建一个新的前向神经网络((),[],{'',''},'')当前输入层权值和阈值{}{}当前网络层权值和阈值{}{}设置训练参数;;;;;调用算法训练网络[]();对网络进行仿真();计算仿真误差;()[。
]'测试()不可能啊我对初学神经网络者的小提示第二步:掌握如下算法:.最小均方误差,这个原理是下面提到的神经网络学习算法的理论核心,入门者要先看《高等数学》(高等教育出版社,同济大学版)第章的第十节:“最小二乘法”。
.在第步的基础上看学习算法、和近邻算法,上述算法都是在最小均方误差基础上的改进算法,参考书籍是《神经网络原理》(机械工业出版社,著,中英文都有)、《人工神经网络与模拟进化计算》(清华大学出版社,阎平凡,张长水著)、《模式分类》(机械工业出版社, . 等著,中英文都有)、《神经网络设计》(机械工业出版社, . 等著,中英文都有)。
(自适应谐振理论),该算法的最通俗易懂的读物就是《神经网络设计》(机械工业出版社, . 等著,中英文都有)的第和章。
若看理论分析较费劲可直接编程实现一下节的算法小节中的算法.算法,初学者若对误差反传的分析过程理解吃力可先跳过理论分析和证明的内容,直接利用最后的学习规则编个小程序并测试,建议看《机器学习》(机械工业出版社, . 著,中英文都有)的第章和《神经网络设计》(机械工业出版社, . 等著,中英文都有)的第章。
神经网络实例()分类:实例采用工具箱函数建立神经网络,对一些基本的神经网络参数进行了说明,深入了解参考帮助文档。
例采用动量梯度下降算法训练网络。
训练样本定义如下:输入矢量为[]目标矢量为[ ]——生成一个新的前向神经网络,函数格式:(,[ ],{ }) ,(对于维输入,是一个的矩阵,每一行是相应输入的边界值)第层的维数第层的传递函数, ''反向传播网络的训练函数, ''反向传播网络的权值阈值学习函数, ''性能函数, ''——对神经网络进行训练,函数格式:(),输入参数:所建立的网络网络的输入网络的目标值,初始输入延迟,初始网络层延迟,验证向量的结构, []测试向量的结构, []返回值:训练之后的网络训练记录(训练次数及每次训练的误差)网络输出网络误差最终输入延迟最终网络层延迟——对神经网络进行仿真,函数格式:[] ()参数与前同。
BP神经网络算法的C语言实现代码

BP神经网络算法的C语言实现代码以下是一个BP神经网络的C语言实现代码,代码的详细说明可以帮助理解代码逻辑:```c#include <stdio.h>#include <stdlib.h>#include <math.h>#define INPUT_SIZE 2#define HIDDEN_SIZE 2#define OUTPUT_SIZE 1#define LEARNING_RATE 0.1//定义神经网络结构体typedef structdouble input[INPUT_SIZE];double hidden[HIDDEN_SIZE];double output[OUTPUT_SIZE];double weights_ih[INPUT_SIZE][HIDDEN_SIZE];double weights_ho[HIDDEN_SIZE][OUTPUT_SIZE];} NeuralNetwork;//激活函数double sigmoid(double x)return 1 / (1 + exp(-x));//创建神经网络NeuralNetwork* create_neural_networNeuralNetwork* nn =(NeuralNetwork*)malloc(sizeof(NeuralNetwork));//初始化权重for (int i = 0; i < INPUT_SIZE; i++)for (int j = 0; j < HIDDEN_SIZE; j++)nn->weights_ih[i][j] = (double)rand( / RAND_MAX * 2 - 1;}}for (int i = 0; i < HIDDEN_SIZE; i++)for (int j = 0; j < OUTPUT_SIZE; j++)nn->weights_ho[i][j] = (double)rand( / RAND_MAX * 2 - 1;}}return nn;//前向传播void forward(NeuralNetwork* nn)//计算隐藏层输出for (int i = 0; i < HIDDEN_SIZE; i++)double sum = 0;for (int j = 0; j < INPUT_SIZE; j++)sum += nn->input[j] * nn->weights_ih[j][i];}nn->hidden[i] = sigmoid(sum);}//计算输出层输出for (int i = 0; i < OUTPUT_SIZE; i++)double sum = 0;for (int j = 0; j < HIDDEN_SIZE; j++)sum += nn->hidden[j] * nn->weights_ho[j][i];}nn->output[i] = sigmoid(sum);}void backpropagation(NeuralNetwork* nn, double target)//计算输出层误差double output_error[OUTPUT_SIZE];for (int i = 0; i < OUTPUT_SIZE; i++)double delta = target - nn->output[i];output_error[i] = nn->output[i] * (1 - nn->output[i]) * delta;}//更新隐藏层到输出层权重for (int i = 0; i < HIDDEN_SIZE; i++)for (int j = 0; j < OUTPUT_SIZE; j++)nn->weights_ho[i][j] += LEARNING_RATE * nn->hidden[i] * output_error[j];}}//计算隐藏层误差double hidden_error[HIDDEN_SIZE];for (int i = 0; i < HIDDEN_SIZE; i++)double delta = 0;for (int j = 0; j < OUTPUT_SIZE; j++)delta += output_error[j] * nn->weights_ho[i][j];}hidden_error[i] = nn->hidden[i] * (1 - nn->hidden[i]) * delta;}//更新输入层到隐藏层权重for (int i = 0; i < INPUT_SIZE; i++)for (int j = 0; j < HIDDEN_SIZE; j++)nn->weights_ih[i][j] += LEARNING_RATE * nn->input[i] * hidden_error[j];}}void train(NeuralNetwork* nn, double input[][2], double target[], int num_examples)int iteration = 0;while (iteration < MAX_ITERATIONS)double error = 0;for (int i = 0; i < num_examples; i++)for (int j = 0; j < INPUT_SIZE; j++)nn->input[j] = input[i][j];}forward(nn);backpropagation(nn, target[i]);error += fabs(target[i] - nn->output[0]);}//判断误差是否已达到允许范围if (error < 0.01)break;}iteration++;}if (iteration == MAX_ITERATIONS)printf("Training failed! Error: %.8lf\n", error); }void predict(NeuralNetwork* nn, double input[]) for (int i = 0; i < INPUT_SIZE; i++)nn->input[i] = input[i];}forward(nn);printf("Prediction: %.8lf\n", nn->output[0]); int maiNeuralNetwork* nn = create_neural_network(; double input[4][2] ={0,0},{0,1},{1,0},{1,1}};double target[4] =0,1,1,};train(nn, input, target, 4);predict(nn, input[0]);predict(nn, input[1]);predict(nn, input[2]);predict(nn, input[3]);free(nn);return 0;```以上代码实现了一个简单的BP神经网络,该神经网络包含一个输入层、一个隐藏层和一个输出层。
MATLAB程序代码 bp神经网络通用代码

实用标准文案MATLAB程序代码--bp神经网络通用代码matlab通用神经网络代码学习了一段时间的神经网络,总结了一些经验,在这愿意和大家分享一下,希望对大家有帮助,也希望大家可以把其他神经网络的通用代码在这一起分享感应器神经网络、线性网络、BP神经网络、径向基函数网络%通用感应器神经网络。
P=[-0.5 -0.5 0.3 -0.1 -40;-0.5 0.5 -0.5 1 50];%输入向量T=[1 1 0 0 1];%期望输出plotpv(P,T);%描绘输入点图像net=newp([-40 1;-1 50],1);%生成网络,其中参数分别为输入向量的范围和神经元感应器数量hold onlinehandle=plotpc(net.iw{1},net.b{1});net.adaptparam.passes=3;for a=1:25%训练次数[net,Y,E]=adapt(net,P,T);linehandle=plotpc(net.iw{1},net.b{1},linehandle);drawnow;end%通用newlin程序%通用线性网络进行预测time=0:0.025:5;T=sin(time*4*pi);Q=length(T);P=zeros(5,Q);%P中存储信号T的前5(可变,根据需要而定)次值,作为网络输入。
精彩文档.实用标准文案P(1,2:Q)=T(1,1:(Q-1));P(2,3:Q)=T(1,1:(Q-2));P(3,4:Q)=T(1,1:(Q-3));P(4,5:Q)=T(1,1:(Q-4));P(5,6:Q)=T(1,1:(Q-5));plot(time,T)%绘制信号T曲线xlabel('时间');ylabel('目标信号');title('待预测信号');net=newlind(P,T);%根据输入和期望输出直接生成线性网络a=sim(net,P);%网络测试figure(2)plot(time,a,time,T,'+')xlabel('时间');ylabel('输出-目标+');title('输出信号和目标信号');e=T-a;figure(3)plot(time,e)hold onplot([min(time) max(time)],[0 0],'r:')%可用plot(x,zeros(size(x)),'r:')代替hold offxlabel('时间');ylabel('误差');精彩文档.实用标准文案title('误差信号');%通用BP神经网络P=[-1 -1 2 2;0 5 0 5];t=[-1 -1 1 1];net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingd');%输入参数依次为:'样本P范围',[各层神经元数目],{各层传递函数},'训练函数'%训练函数traingd--梯度下降法,有7个训练参数.%训练函数traingdm--有动量的梯度下降法,附加1个训练参数mc(动量因子,缺省为0.9)%训练函数traingda--有自适应lr的梯度下降法,附加3个训练参数:lr_inc(学习率增长比,缺省为1.05;% lr_dec(学习率下降比,缺省为0.7);max_perf_inc(表现函数增加最大比,缺省为1.04)%训练函数traingdx--有动量的梯度下降法中赋以自适应lr的方法,附加traingdm和traingda的4个附加参数%训练函数trainrp--弹性梯度下降法,可以消除输入数值很大或很小时的误差,附加4个训练参数:% delt_inc(权值变化增加量,缺省为1.2);delt_dec(权值变化减小量,缺省为0.5);% delta0(初始权值变化,缺省为0.07);deltamax(权值变化最大值,缺省为50.0)% 适合大型网络%训练函数traincgf--Fletcher-Reeves共轭梯度法;训练函数traincgp--Polak-Ribiere共轭梯度法;%训练函数traincgb--Powell-Beale共轭梯度法%共轭梯度法占用存储空间小,附加1训练参数searchFcn(一维线性搜索方法,缺省为srchcha);缺少1个训练参数lr %训练函数trainscg--量化共轭梯度法,与其他共轭梯度法相比,节约时间.适合大型网络% 附加2个训练参数:sigma(因为二次求导对权值调整的影响参数,缺省为5.0e-5);% lambda(Hessian阵不确定性调节参数,缺省为5.0e-7)% 缺少1个训练参数:lr精彩文档.实用标准文案%训练函数trainbfg--BFGS拟牛顿回退法,收敛速度快,但需要更多内存,与共轭梯度法训练参数相同,适合小网络%训练函数trainoss--一步正割的BP训练法,解决了BFGS消耗内存的问题,与共轭梯度法训练参数相同%训练函数trainlm--Levenberg-Marquardt训练法,用于内存充足的中小型网络net=init(net);net.trainparam.epochs=300; %最大训练次数(前缺省为10,自trainrp后,缺省为100)net.trainparam.lr=0.05; %学习率(缺省为0.01)net.trainparam.show=50; %限时训练迭代过程(NaN表示不显示,缺省为25)net.trainparam.goal=1e-5; %训练要求精度(缺省为0)%net.trainparam.max_fail 最大失败次数(缺省为5)%net.trainparam.min_grad 最小梯度要求(前缺省为1e-10,自trainrp后,缺省为1e-6)%net.trainparam.time 最大训练时间(缺省为inf)[net,tr]=train(net,P,t); %网络训练a=sim(net,P) %网络仿真%通用径向基函数网络——%其在逼近能力,分类能力,学习速度方面均优于BP神经网络%在径向基网络中,径向基层的散步常数是spread的选取是关键%spread越大,需要的神经元越少,但精度会相应下降,spread的缺省值为1%可以通过net=newrbe(P,T,spread)生成网络,且误差为0%可以通过net=newrb(P,T,goal,spread)生成网络,神经元由1开始增加,直到达到训练精度或神经元数目最多为止%GRNN网络,迅速生成广义回归神经网络(GRNN)P=[4 5 6];T=[1.5 3.6 6.7];精彩文档.实用标准文案net=newgrnn(P,T);%仿真验证p=4.5;v=sim(net,p)%PNN网络,概率神经网络P=[0 0 ;1 1;0 3;1 4;3 1;4 1;4 3]';Tc=[1 1 2 2 3 3 3];%将期望输出通过ind2vec()转换,并设计、验证网络T=ind2vec(Tc);net=newpnn(P,T);Y=sim(net,P);Yc=vec2ind(Y)%尝试用其他的输入向量验证网络P2=[1 4;0 1;5 2]';Y=sim(net,P2);Yc=vec2ind(Y)%应用newrb()函数构建径向基网络,对一系列数据点进行函数逼近P=-1:0.1:1;T=[-0.9602 -0.5770 -0.0729 0.3771 0.6405 0.6600 0.4609...0.1336 -0.2013 -0.4344 -0.500 -0.3930 -0.1647 -0.0988...0.3072 0.3960 0.3449 0.1816 -0.0312 -0.2189 -0.3201];%绘制训练用样本的数据点plot(P,T,'r*');title('训练样本');精彩文档.实用标准文案xlabel('输入向量P');ylabel('目标向量T');%设计一个径向基函数网络,网络有两层,隐层为径向基神经元,输出层为线性神经元%绘制隐层神经元径向基传递函数的曲线p=-3:.1:3;a=radbas(p);plot(p,a)title('径向基传递函数')xlabel('输入向量p')%隐层神经元的权值、阈值与径向基函数的位置和宽度有关,只要隐层神经元数目、权值、阈值正确,可逼近任意函数%例如a2=radbas(p-1.5);a3=radbas(p+2);a4=a+a2*1.5+a3*0.5;plot(p,a,'b',p,a2,'g',p,a3,'r',p,a4,'m--')title('径向基传递函数权值之和')xlabel('输入p');ylabel('输出a');%应用newrb()函数构建径向基网络的时候,可以预先设定均方差精度eg以及散布常数sceg=0.02;sc=1; %其值的选取与最终网络的效果有很大关系,过小造成过适性,过大造成重叠性net=newrb(P,T,eg,sc);%网络测试精彩文档.实用标准文案plot(P,T,'*')xlabel('输入');X=-1:.01:1;Y=sim(net,X);hold onplot(X,Y);hold offlegend('目标','输出')%应用grnn进行函数逼近P=[1 2 3 4 5 6 7 8];T=[0 1 2 3 2 1 2 1];plot(P,T,'.','markersize',30)axis([0 9 -1 4])title('待逼近函数')xlabel('P')ylabel('T')%网络设计%对于离散数据点,散布常数spread选取比输入向量之间的距离稍小一些spread=0.7;net=newgrnn(P,T,spread);%网络测试A=sim(net,P);hold onoutputline=plot(P,A,'o','markersize',10,'color',[1 0 0]);精彩文档.实用标准文案title('检测网络')xlabel('P')ylabel('T和A')%应用pnn进行变量的分类P=[1 2;2 2;1 1]; %输入向量Tc=[1 2 3]; %P对应的三个期望输出%绘制出输入向量及其相对应的类别plot(P(1,:),P(2,:),'.','markersize',30)for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Tc(i)))endaxis([0 3 0 3]);title('三向量及其类别')xlabel('P(1,:)')ylabel('P(2,:)')%网络设计T=ind2vec(Tc);spread=1;net=newgrnn(P,T,speard);%网络测试A=sim(net,P);Ac=vec2ind(A);%绘制输入向量及其相应的网络输出plot(P(1,:),P(2,:),'.','markersize',30)精彩文档.实用标准文案for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Ac(i)))endaxis([0 3 0 3]);title('网络测试结果')xlabel('P(1,:)')ylabel('P(2,:)')P=[13, 0, 1.119, 1, 26.3;22, 0, 1.135, 1, 26.3;-15, 0, 0.9017, 1, 20.4;-30, 0, 0.9172, 1, 26.7;24,0,1.238,0.9704,28.2;3,24,1.119,1,26.3;0,52,1.089,1,26.3;0,-73,1.0889,1,26.3;1,28,0.8748,1,2 6.3;-1,-39,1.1168,1,26.7;-2, 0, 1.495, 1, 26.3;0, -1, 1.438, 1, 26.3;4, 1,0.4964,0.9021, 26.3;3, -1, 0.5533, 1.2357, 26.7;-5, 0, 1.7368, 1, 26.7;1, 0, 1.1045, 0.0202,26.3;-2, 0, 1.1168, 1.3764, 26.7;-3, -1, 1.1655, 1.4418,27.5;3, 2, 1.0875, 0.748, 27.5;-3, 0, 1.1068, 2.2092, 26.3;4, 1, 0.9017, 1, 13.7;3, 2, 0.9017, 1, 14.9;-3, 1, 0.9172, 1, 13.7;-2, 0, 1.0198, 1.0809, 16.1;0, 1, 0.9172, 1, 13.7]T=[1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1 ];%期望输出plotpv(P,T);%描绘输入点图像精彩文档.。
BP神经网络详细代码

运用BP神经网络进行预测代码如下:clcclear allclose all%bp神经网络预测%输入输出赋值p=[493 372 445;372 445 176;445 176 235;176 235 378;235 378 429;378 429 561;429 561 651;561 651 467;651 467 527;467 527 668;527 668 841; 668 841 526;841 526 480;526 480 567;480 567 685]';t=[176 235 378 429 561 651 467 527 668 841 526 480 567 685 507];%数据归一化[p1ps]=mapminmax(p);[t1ts]=mapminmax(t);%数据集分配[trainsample.pvalsample.ptestsample.p] =dividerand(p0.70.150.15);[alsample.ttestsample.t] =dividerand(t0.70.150.15);%建立BP神经网络TF1='tansig';TF2='purelin';net=newff(minmax(p)[101]{TF1 TF2}'traingdm');%网络参数的设置net.trainParam.epochs=10000;%训练次数设置net.trainParam.goal=1e-7;%训练目标设置net.trainParam.lr=0.01;%学习率设置net.trainParam.mc=0.9;%动量因子的设置net.trainParam.show=25;%显示的间隔次数% 指定训练参数net.trainFcn='trainlm';[nettr]=train(nettrainsample.ptrainsample.t);%计算仿真[normtrainoutputtrainPerf]=sim(nettrainsample.p[][]trainsample.t);%训练数据,经BP得到的结果[normvalidateoutputvalidatePerf]=sim(netvalsample.p[][]valsample.t);%验证数据,经BP得到的结果[normtestoutputtestPerf]=sim(nettestsample.p[][]testsample.t);%测试数据,经BP得到的结果%计算结果反归一化,得到拟合数据trainoutput=mapminmax('reverse'normtrainoutputts);validateoutput=mapminmax('reverse'normvalidateoutputts);testoutput=mapminmax('reverse'normtestoutputts);%输入数据反归一化,得到正式值trainvalue=mapminmax('reverse'trainsample.tts);%正式的训练数据validatevalue=mapminmax('reverse'valsample.tts);%正式的验证数据testvalue=mapminmax('reverse'testsample.tts);%正式的测试数据%输入要预测的数据pnewpnew=[313256239]';pnewn=mapminmax(pnew);anewn=sim(netpnewn);anew=mapminmax('reverse'anewnts);%绝对误差的计算errors=trainvalue-trainoutput;%plotregression拟合图figureplotregression(trainvaluetrainoutput)%误差变化图figureplot(1:length(errors)errors'-b')title('误差变化图')%误差值的正态性的检验figurehist(errors);%频数直方图figurenormplot(errors);%Q-Q图[muhatsigmahatmucisigmaci]=normfit(errors);%参数估计均值方差均值的0.95置信区间方差的0.95置信区间[h1sigci]= ttest(errorsmuhat);%假设检验figure ploterrcorr(errors);%绘制误差的自相关图figure parcorr(errors);%绘制偏相关图。
BP及RBF神经网络代码及时间序列预测问题

k1=f(x(n))-b*x(k); k2=f(x(n))-b*(x(k)+h*k1/2); k3=f(x(n))-b*(x(k)+k2*h/2); k4=f(x(n))-b*(x(k)+k3*h); x(k+1)=x(k)+(k1+2*k2+2*k3+k4)*h/6; end end figure hold on grid plot(t,x); SamNum=3000; h=0.1; TestSamNum=500; InDim=4; ClusterNum=88; Overlap=1.0; rand('state',sum(3000*clock)) NoiseVar=0.1; Noise=NoiseVar*rand(1,SamNum); SamIn=rand(InDim,SamNum); SamOutNoNoise=rand(1,SamNum); TestSamIn=rand(InDim,TestSamNum); TestSamOut=rand(1,TestSamNum); for k=201:3200 SamIn(1,k-200)=x((k-18)/h+1); SamIn(2,k-200)=x((k-12)/h+1); SamIn(3,k-200)=x((k-6)/h+1); SamIn(4,k-200)=x((k)/h+1); SamOutNoNoise(k-200)=x((k+85)/h+1); end SamOut=SamOutNoNoise+Noise; for l=5001:5500 TestSamIn(1,l-5000)=x((l-18)/h+1); TestSamIn(2,l-5000)=x((l-12)/h+1); TestSamIn(3,l-5000)=x((l-6)/h+1); TestSamIn(4,l-5000)=x((l)/h+1); TestSamOut(l-5000)=x((l+85)/h+1); end Centers=SamIn(:,1:ClusterNum); NumberInClusters=zeros(ClusterNum,1); IndexInClusters=zeros(ClusterNum,SamNum); while 1, NumberInClusters=zeros(ClusterNum,1);
BP神经网络算法代码

BP神经网络算法代码以下是一个简单实现的BP神经网络算法代码,实现了一个简单的二分类任务。
代码主要分为四个部分:数据准备、网络搭建、训练和预测。
```pythonimport numpy as np#数据准备def prepare_data(:X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # 输入数据return X, y#网络搭建def build_network(X, y, hidden_dim):input_dim = X.shape[1] # 输入维度output_dim = y.shape[1] # 输出维度#初始化权重和偏置np.random.seed(0)W1 = np.random.randn(input_dim, hidden_dim) /np.sqrt(input_dim)b1 = np.zeros((1, hidden_dim))W2 = np.random.randn(hidden_dim, output_dim) / np.sqrt(hidden_dim)b2 = np.zeros((1, output_dim))return W1, b1, W2, b2#前向传播def forward_propagation(X, W1, b1, W2, b2):z1 = np.dot(X, W1) + b1a1 = sigmoid(z1)z2 = np.dot(a1, W2) + b2a2 = sigmoid(z2)return a1, a2#激活函数def sigmoid(x):return 1 / (1 + np.exp(-x))#反向传播def backward_propagation(X, y, a1, a2, W1, W2): m = X.shape[0] # 样本数量#计算损失loss = np.sum((a2-y)**2) / (2*m)#计算梯度delta2 = 1/m * (a2-y) * a2 * (1-a2)dW2 = np.dot(a1.T, delta2)db2 = np.sum(delta2, axis=0, keepdims=True)delta1 = np.dot(delta2, W2.T) * a1 * (1-a1)dW1 = np.dot(X.T, delta1)db1 = np.sum(delta1, axis=0)return loss, dW1, db1, dW2, db2#更新参数def update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate):W1 -= learning_rate * dW1b1 -= learning_rate * db1W2 -= learning_rate * dW2b2 -= learning_rate * db2return W1, b1, W2, b2#训练def train(X, y, hidden_dim, num_epochs, learning_rate):W1, b1, W2, b2 = build_network(X, y, hidden_dim)for epoch in range(num_epochs):a1, a2 = forward_propagation(X, W1, b1, W2, b2)loss, dW1, db1, dW2, db2 = backward_propagation(X, y, a1, a2, W1, W2)W1, b1, W2, b2 = update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate)if (epoch+1) % 100 == 0:print("Epoch {}: loss = {}".format(epoch+1, loss))return W1, b1, W2, b2#预测def predict(X, W1, b1, W2, b2):_, a2 = forward_propagation(X, W1, b1, W2, b2)predictions = (a2 > 0.5).astype(int)return predictions#主函数def main(:X, y = prepare_datahidden_dim = 3num_epochs = 1000learning_rate = 0.1W1, b1, W2, b2 = train(X, y, hidden_dim, num_epochs, learning_rate)predictions = predict(X, W1, b1, W2, b2)print("Predictions:", predictions)if __name__ == "__main__":main```注意:这段代码只是一个简单的实现,可能在复杂任务上效果不佳。
【2019年整理】神经网络BP算法程序C语言

1 1 -1 1 -1 1 0 1 0 1神经网络BP算法(C程序)文件输入输出目录为: F:\BP\训练样本文件名: 训练样本.txt值为:1 1 -1 1 -1 1 0 1 0 1 输出文件名为: 阈值.txt 权值.txt=========================#include "stdlib.h"#include "math.h"#include "conio.h"#include "stdio.h"#define N 2 /*/学习样本个数*/#define IN 3 /*/输入层神经元数目*/#define HN 3 /*/隐层神经元数目*/#define ON 2 /*/输出层神经元数目*/#define Z 20 /*旧权值保存,每次study的权值都保存下来*/ double P[IN]; /*单个样本输入数据*/double T[ON]; /*单个样本输出数据*/double W[HN][IN]; /*/输入层至隐层权值*/double V[ON][HN]; /*/隐层至输出层权值*/double X[HN]; /*/隐层的输入*/double Y[ON]; /*/输出层的输入*/double H[HN]; /*/隐层的输出*/double O[ON]; /*/输出层的输出*/double YU_HN[HN]; /*/隐层的阈值*/double YU_ON[ON]; /*/输出层的阈值*/double err m[N]; /*/第m个样本的总误差*/double a; /*/输出层至隐层的学习效率*/double b; /*/隐层至输入层学习效率*/double alpha; /*/动量因子, 改进型bp算法使用*/ double d err[ON];FILE *fp;/*定义一个放学习样本的结构*/struct {double input[IN];double teach[ON];}Study_Data[N];/*改进型bp算法用来保存每次计算的权值*/struct {double old_W[HN][IN];double old_V[ON][HN];}Old_WV[Z];显示开始界面int Start_Show(){clrscr();printf("\n ***********************\n");printf(" * Welcome to use *\n");printf(" * this program of *\n");printf(" * calculating the BP *\n");printf(" * model! *\n");printf(" * Happy every day! *\n");printf(" ***********************\n");printf("\n\n Before starting, please read the follows carefully:\n\n");printf(" 1.Please ensure the Path of the '训练样本.txt'(xunlianyangben.txt) is \n correct, like 'F:\BP\训练样本.txt'!\n");printf(" 2.The calculating results will be saved in the Path of 'F:\\BP\\'!\n");printf(" 3.The program will load 10 datas when running from 'F:\\BP\\训练样本.txt'!\n");printf(" 4.The program of BP can study itself for no more than 30000 times.\n And surpassing the number, the program will be ended by itself in\n preventing running infinitely because of error!\n");printf("\n\n\n");printf("Now press any key to start...\n");getch();getch();clrscr();}显示结束界面int End_Show(){printf("\n\n---------------------------------------------------\n");printf("The program has reached the end successfully!\n\n Press any key to exit!\n\n");printf("\n ***********************\n");printf(" * This is the end *\n");printf(" * can calculate the BP*\n");printf(" * model! *\n");printf(" ***********************\n");printf(" * Thanks for using! *\n");printf(" * Happy every day! *\n");printf(" ***********************\n");getch();exit(0);}获取训练样本GetTrainingData() /*OK*/{ int m,i,j;int datr;if((fp=fopen("f:\\bp\\训练样本.txt","r"))==NULL) /*读取训练样本*/{printf("Cannot open file and strike any key exit!");getch();exit(1);}m=0;i=0;j=0;while(fscanf(fp,"%d",&datr)!=EOF){ j++;if(j<=(N*IN)) /*N为学习样本个数;IN为输入层神经元数目*/{if(i<IN){Study_Data[m].input[i]=datr;/*printf("\nthe Study_Datat[%d].input[%d]=%f\n",m,i,Study_Data[m].input[i]);getch();*/ /*use to check the loaded training datas*/}if(m==(N-1)&&i==(IN-1)){m=0;i=-1;}if(i==(IN-1)){m++;else if((N*IN)<J&&J<=(N*(IN+ON))){if(i<ON){Study_Data[m].teach[i]=datr;/*printf("\nThe Study_Data[%d].teach[%d]=%f",m,i,Study_Data[m].teach[i]);getch();*/ /*use to check the loaded training datas*/}if(m==(N-1)&&i==(ON-1))printf("\n");if(i==(ON-1)){m++;i=-1;}}i++;}fclose(fp);printf("\nThere are [%d] datats that have been loaded successfully!\n",j);/*show the data which has been loaded!*/printf("\nShow the data which has been loaded as follows:\n");for(m=0;m<N;M++){for(i=0;i<IN;I++){printf("\nStudy_Data[%d].input[%d]=%f",m,i,Study_Data[m].input[i]);}for(j=0;j<ON;J++){printf("\nStudy_Data[%d].teach[%d]=%f",m,j,Study_Data[m].teach[j]);}}printf("\n\nPress any key to start calculating...");getch();return 1;}/*///////////////////////////////////*//*初始化权、阈值子程序*//*///////////////////////////////////*/initial(){int i;int ii;int j;/*隐层权、阈值初始化*/for(i=0;i<HN;i++){for(j=1;j<IN;j++){W[i][j]=(double)((rand()/32767.0)*2-1); /*初始化输入层到隐层的权值, 随机模拟0 和1 -1 */ printf("w[%d][%d]=%f\n",i,j,W[i][j]);}}for(ii=0;ii<ON;II++){for(jj=0;jj<HN;JJ++){V[ii][jj]= (double)((rand()/32767.0)*2-1); /*初始化隐层到输出层的权值, 随机模拟0 和1 -1*/ printf("V[%d][%d]=%f\n",ii,jj,V[ii][jj]);}}for(k=0;k<HN;K++){YU_HN[k] = (double)((rand()/32767.0)*2-1); /*隐层阈值初始化,-0.01 ~ 0.01 之间*/printf("YU_HN[%d]=%f\n",k,YU_HN[k]);}for(kk=0;kk<ON;KK++){YU_ON[kk] = (double)((rand()/32767.0)*2-1); /*输出层阈值初始化,-0.01 ~ 0.01 之间*/}return 1;}/*子程序initial()结束*//*//////////////////////////////////////////*//*第m个学习样本输入子程序*//*/////////////////////////////////////////*/input_P(int m){ int i,j;for(i=0;i<IN;I++){P[i]=Study_Data[m].input[i];printf("P[%d]=%f\n",i,P[i]);}/*获得第m个样本的数据*/return 1;}/*子程序input_P(m)结束*//*/////////////////////////////////////////*//*第m个样本教师信号子程序*//*/////////////////////////////////////////*/input_T(int m)for(k=0;k<ON;k++)T[k]=Study_Data[m].teach[k];return 1;}/*子程序input_T(m)结束*/H_I_O(){double sigma;int i,j;for(j=0;j<HN;j++){sigma=0;for(i=0;i<IN;i++){sigma+=W[j][i]*P[i];/*求隐层内积*/}X[j]=sigma-YU_HN[i];/*求隐层净输入, 为什么减隐层的阀值*/ H[j]=1.0/(1.0+exp(-X[j]));/*求隐层输出siglon算法*/}return 1;}/*子程序H_I_O()结束*/O_I_O(){int k;int j;double sigma;for(k=0;k<ON;k++){sigma=0.0;for(j=0;j<HN;j++){sigma+=V[k][j]*H[k];}Y[k]=sigma-YU_ON[k];O[k]=1.0/(1.0+exp(-Y[k]));}return 1;}int Err_O_H(int m){int k;double abs_err[ON];double sqr_err=0;for (k=0;k<ON;k++){abs_err[k]=T[k]-O[k];sqr_err+=(abs_err[k])*(abs_err[k]);err_m[m]=sqr_err/2;}return 1;}double e_err[HN];int Err_H_I(){int j,k;double sigma;for(j=0;j<HN;j++){sigma=0.0;for(k=0;k<ON;k++){sigma+=d_err[k]*V[k][j];}e_err[j]=sigma*H[j]*(1-H[j]);}return 1;}saveWV(int m){int i;int ii;int j;int jj;for(i=0;i<HN;i++){for(j=0;j<IN;j++){Old_WV[m].old_W[i][j] = W[i][j];}}for(ii=0;ii<ON;ii++){for(jj=0;jj<HN;jj++){Old_WV[m].old_V[ii][jj] = V[ii][jj];}}return 1;}int Delta_O_H(int n) /*(int m,int n)*/ {int k,j;for (k=0;k<ON;k++){for (j=0;j<HN;j++){V[k][j]=V[k][j]+a*d_err[k]*H[j];}YU_ON[k]+=a*d_err[k];}}else if(n>1){for (k=0;k<ON;k++){for (j=0;j<HN;j++){V[k][j]=V[k][j]+a*d_err[k]*H[j]+alpha*(V[k][j]-Old_WV[(n-1)].old_V[k][j]);}YU_ON[k]+=a*d_err[k];}}return 1;}Delta_H_I(int n) /*(int m,int n)*/{ int i,j;if(n<=1) /*n<=1*/{for (j=0;j<HN;j++){for (i=0;i<IN;i++){W[j][i]=W[j][i]+b*e_err[j]*P[i];}YU_HN[j]+=b*e_err[j];}}else if(n>1){for(j=0;j<HN;j++){for(i=0;i<IN;i++){W[j][i]=W[j][i]+b*e_err[j]*P[i]+alpha*(W[j][i]-Old_WV[(n-1)].old_W[j][i]);}YU_HN[j]+=b*e_err[j];return 1;}double Err_Sum(){int m;double total_err=0;for(m=0;m<N;m++){total_err+=err_m[m];}return total_err;}void savequan(){ int i,j,k;int ii,jj,kk;if((fp=fopen("f:\\bp\\权值.txt","a"))==NULL) /*save the result at f:\hsz\bpc\*.txt*/{printf("Cannot open file strike any key exit!");getch();exit(1);}fprin tf(fp,"Save the result of “权值”(quanzhi) as follows:\n");for(i=0;i<HN;i++){for(j=0;j<IN;j++)fprintf(fp,"W[%d][%d]=%f\n",i,j,W[i][j]);}fprintf(fp,"\n");for(ii=0;ii<ON;ii++){for(jj=0;jj<HN;jj++)fprintf(fp,"V[%d][%d]=%f\n",ii,jj,V[ii][jj]);}fclose(fp);printf("\nThe result of “权值.txt”(quanzhi) has been saved successfully!\nPress any key to continue..."); getch();if((fp=fopen("f:\\bp\\阈值.txt","a"))==NULL) /*save the result at f:\hsz\bpc\*/{printf("Cannot open file strike any key exit!");getch();exit(1);}fprintf(fp,"Save the result of “输出层的阈值”(huozhi) as follows:\n");for(k=0;k<ON;K++)fprintf(fp,"\nSave the result of “隐层的阈值为”(huozhi) as follows:\n");for(kk=0;kk<HN;KK++)fprintf(fp,"YU_HN[%d]=%f\n",kk,YU_HN[kk]);fclose(fp);printf("\nThe result of “阈值.txt”(huozhi) has been saved successfully!\nPress any key to continue..."); getch ();}/**********************//**程序入口, 即主程序**//**********************/void main(){double Pre_error;double sum_err;int study;int flag;flag=30000;a=0.7;b=0.7;alpha=0.9;study=0;Pre_error=0.0001;/*实际值为Pre_error=0.0001;*/Start_Show(); /*调用函数, 显示开始界面*/GetTrainingData();initial ();do{int m;++study;for(m=0;m<N;m++){input_P(m);input_T(m);H_I_O();O_I_O();Err_O_H(m);Err_H_I();saveWV(m); /****************/Delta_O_H(m); /*(m,study)*/Delta_H_I(m); /*(m,study)*/}sum_err=Err_Sum();printf("sum_err=%f\n",sum_err);printf("Pre_error=%f\n\n",Pre_error);if(study>flag){printf("\n*******************************\n");printf("*****************************\n");getch();break;}} while (sum_err>Pre_error);printf("\n****************\n");printf("\nThe program have studyed for [%d] times!\n",study); printf("\n****************\n");savequan(); /*save the results, 保存计算权值*/End_Show();}==========================权值.txt{Save the result of “权值”(quanzhi) as follows:W[0][0]=0.350578W[0][1]=-1.008697W[0][2]=-0.962250W[1][0]=0.055661W[1][1]=-0.372367W[1][2]=-0.890795W[2][0]=0.129752W[2][1]=-0.332591W[2][2]=-0.521561V[0][0]=-2.932654V[0][1]=-3.720583V[0][2]=-2.648183V[1][0]=2.938970V[1][1]=1.633281V[1][2]=1.944077}阈值.txt{Save the result of “输出层的阈值”(huozhi) as follows:YU_ON[0]=-4.226843YU_ON[1]=1.501791Save the result of “隐层的阈值为”(huozhi) as follows:YU_HN[0]=-0.431459YU_HN[1]=0.452127YU_HN[2]=0.258449}==================================。
BP神经网络算法的C语言实现代码

//BP神经网络算法,c语言版本//VS2010下,无语法错误,可直接运行//添加了简单注释//欢迎学习交流#include <yerNum>#include <yerNum>#include <yerNum>#include <yerNum>#define N_Out 2 //输出向量维数#define N_In 3 //输入向量维数#define N_Sample 6 //样本数量//BP人工神经网络typedef struct{int LayerNum; //中间层数量double v[N_In][50]; //中间层权矩阵i,中间层节点最大数量为50double w[50][N_Out]; //输出层权矩阵double StudyRate; //学习率double Accuracy; //精度控制参数int MaxLoop; //最大循环次数} BPNet;//Sigmoid函数double fnet(double net){return 1/(1+exp(-net));}//初始化int InitBpNet(BPNet *BP);//训练BP网络,样本为x,理想输出为yint TrainBpNet(BPNet *BP, double x[N_Sample][N_In], int y[N_Sample][N_Out]) ; //使用BP网络int UseBpNet(BPNet *BP);//主函数int main(){//训练样本double x[N_Sample][N_In] = {{0.8,0.5,0},{0.9,0.7,0.3},{1,0.8,0.5},{0,0.2,0.3},{0.2,0.1,1.3},{0.2,0.7,0.8}};//理想输出int y[N_Sample][N_Out] = {{0,1},{0,1},{0,1},{1,1},{1,0},{1,0}};BPNet BP;InitBpNet(&BP); //初始化BP网络结构TrainBpNet(&BP, x, y); //训练BP神经网络UseBpNet(&BP); //测试BP神经网络return 1;}//使用BP网络int UseBpNet(BPNet *BP){double Input[N_In];double Out1[50];double Out2[N_Out]; //Out1为中间层输出,Out2为输出层输出//持续执行,除非中断程序while (1){printf("请输入3个数:\n");int i, j;for (i = 0; i < N_In; i++)scanf_s("%f", &Input[i]);double Tmp;for (i = 0; i < (*BP).LayerNum; i++){Tmp = 0;for (j = 0; j < N_In; j++)Tmp += Input[j] * (*BP).v[j][i];Out1[i] = fnet(Tmp);}for (i = 0; i < N_Out; i++){Tmp = 0;for (j = 0; j < (*BP).LayerNum; j++)Tmp += Out1[j] * (*BP).w[j][i];Out2[i] = fnet(Tmp);}printf("结果:");for (i = 0; i < N_Out; i++)printf("%.3f ", Out2[i]);printf("\n");}return 1;}//训练BP网络,样本为x,理想输出为yint TrainBpNet(BPNet *BP, double x[N_Sample][N_In], int y[N_Sample][N_Out]) {double f = (*BP).Accuracy; //精度控制参数double a = (*BP).StudyRate; //学习率int LayerNum = (*BP).LayerNum; //中间层节点数double v[N_In][50], w[50][N_Out]; //权矩阵double ChgH[50], ChgO[N_Out]; //修改量矩阵double Out1[50], Out2[N_Out]; //中间层和输出层输出量int MaxLoop = (*BP).MaxLoop; //最大循环次数int i, j, k, n;double Tmp;for (i = 0; i < N_In; i++)// 复制结构体中的权矩阵for (j = 0; j < LayerNum; j++)v[i][j] = (*BP).v[i][j];for (i = 0; i < LayerNum; i++)for (j = 0; j < N_Out; j++)w[i][j] = (*BP).w[i][j];double e = f + 1;//对每个样本训练网络for (n = 0; e > f && n < MaxLoop; n++){e = 0;for (i= 0; i < N_Sample; i++){//计算中间层输出向量for (k= 0; k < LayerNum; k++){Tmp = 0;for (j = 0; j < N_In; j++)Tmp = Tmp + x[i][j] * v[j][k];Out1[k] = fnet(Tmp);}//计算输出层输出向量for (k = 0; k < N_Out; k++){Tmp = 0;for (j = 0; j < LayerNum; j++)Tmp = Tmp + Out1[j] * w[j][k];Out2[k] = fnet(Tmp);}//计算输出层的权修改量for (j = 0; j < N_Out; j++)ChgO[j] = Out2[j] * (1 - Out2[j]) * (y[i][j] - Out2[j]);//计算输出误差for (j = 0; j < N_Out ; j++)e = e + (y[i][j] - Out2[j]) * (y[i][j] - Out2[j]);//计算中间层权修改量for (j = 0; j < LayerNum; j++){Tmp = 0;for (k = 0; k < N_Out; k++)Tmp = Tmp + w[j][k] * ChgO[k];ChgH[j] = Tmp * Out1[j] * (1 - Out1[j]);}//修改输出层权矩阵for (j = 0; j < LayerNum; j++)for (k = 0; k < N_Out; k++)w[j][k] = w[j][k] + a * Out1[j] * ChgO[k];for (j = 0; j < N_In; j++)for (k = 0; k < LayerNum; k++)v[j][k] = v[j][k] + a * x[i][j] * ChgH[k];}if (n % 10 == 0)printf("误差: %f\n", e);}printf("总共循环次数:%d\n", n);printf("调整后的中间层权矩阵:\n");for (i = 0; i < N_In; i++){for (j = 0; j < LayerNum; j++)printf("%f ", v[i][j]);printf("\n");}printf("调整后的输出层权矩阵:\n");for (i = 0; i < LayerNum; i++) {for (j = 0; j < N_Out; j++)printf("%f ", w[i][j]);printf("\n");}//把结果复制回结构体for (i = 0; i < N_In; i++)for (j = 0; j < LayerNum; j++)(*BP).v[i][j] = v[i][j];for (i = 0; i < LayerNum; i++)for (j = 0; j < N_Out; j++)(*BP).w[i][j] = w[i][j];printf("BP网络训练结束!\n");return 1;}//初始化int InitBpNet(BPNet *BP){printf("请输入中间层节点数,最大数为100:\n");scanf_s("%d", &(*BP).LayerNum);printf("请输入学习率:\n");scanf_s("%lf", &(*BP).StudyRate); //(*BP).StudyRate为double型数据,所以必须是lf printf("请输入精度控制参数:\n");scanf_s("%lf", &(*BP).Accuracy);printf("请输入最大循环次数:\n");scanf_s("%d", &(*BP).MaxLoop);int i, j;srand((unsigned)time(NULL));for (i = 0; i < N_In; i++)for (j = 0; j < (*BP).LayerNum; j++)(*BP).v[i][j] = rand() / (double)(RAND_MAX);for (i = 0; i < (*BP).LayerNum; i++)for (j = 0; j < N_Out; j++)(*BP).w[i][j] = rand() / (double)(RAND_MAX);return 1;}。
用matlab编BP神经网络预测程序加一个优秀程序

求用matlab编BP神经网络预测程序求一用matlab编的程序P=[。
];输入T=[。
];输出% 创建一个新的前向神经网络net_1=newff(minmax(P),[10,1],{'tansig','purelin'},'traingdm')% 当前输入层权值和阈值inputWeights=net_1.IW{1,1}inputbias=net_1.b{1}% 当前网络层权值和阈值layerWeights=net_1.LW{2,1}layerbias=net_1.b{2}% 设置训练参数net_1.trainParam.show = 50;net_1.trainParam.lr = 0.05;net_1.trainParam.mc = 0.9;net_1.trainParam.epochs = 10000;net_1.trainParam.goal = 1e-3;% 调用TRAINGDM 算法训练BP 网络[net_1,tr]=train(net_1,P,T);% 对BP 网络进行仿真A = sim(net_1,P);% 计算仿真误差E = T - A;MSE=mse(E)x=[。
]';%测试sim(net_1,x) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%不可能啊我200928对初学神经网络者的小提示第二步:掌握如下算法:2.最小均方误差,这个原理是下面提到的神经网络学习算法的理论核心,入门者要先看《高等数学》(高等教育出版社,同济大学版)第8章的第十节:“最小二乘法”。
3.在第2步的基础上看Hebb学习算法、SOM和K-近邻算法,上述算法都是在最小均方误差基础上的改进算法,参考书籍是《神经网络原理》(机械工业出版社,Simon Haykin著,中英文都有)、《人工神经网络与模拟进化计算》(清华大学出版社,阎平凡,张长水著)、《模式分类》(机械工业出版社,Richard O. Duda等著,中英文都有)、《神经网络设计》(机械工业出版社,Martin T. Hargan等著,中英文都有)。
BP神经网络源代码(basic)

Private Sub Command5_Click()Dim tempNum AsDoubleFactTimes = 0For loopt = 0 To times - 1 '学习次数FactTimes= FactTimes + 1tempNum = 0If FactTimes < 2000 Then '学习率的变化前大后小alpha = 0.5beta = 0.5ElseIfFactTimes > 2000 And FactTimes < 5000 Then alpha= 0.4beta= 0.4Elsealpha = 0.3beta= 0.3End IfEnd If'开始神经网络计算'/*---Beginning of neural computting---*/For loopl = 1 To LearnExampleNums '学习模式个数'/*forward computting */'/* inputlayer */For i = 1To InputUnitNumsOutofInputLayer(i) = inDatas(loopl, i)Next i'/* hidelayer */For i = 1To HideUnitNumsinival = CDbl(0)For j= 1 To InputUnitNumsinival = inival + w_InputHide(i, j) * OutofInputLayer(j) Nextjinival = inival + Cw_Hide(i)OutofHideLayer(i) = Sigmf(inival)Next i'/* outputlayer */For i = 1To OutUnitNumsFor j= 1 To HideUnitNumsinival = inival + w_HideOut(i, j) *OutofHideLayer(j)Nextjinival = inival + Cw_Out(i)OutofOutLayer(i) = Sigmf(inival)Next i'/*---Backpropagation---*/'/* deltacaclculate*/Error = 0#For i = 1To OutUnitNumswk = OutofOutLayer(i)wkb = Teacher(loopl, i) - wk'计算每个学习模式中各个输出结点的误差平方和Error = Error + wkb * wkbDEL_Out(i) = wkb * wk * (1# - wk)Next i'/* deltacaclculate*/For i = 1To HideUnitNumsForj = 1 To OutUnitNumsinival = inival + (DEL_Out(j) * w_HideOut(j, i))Nextjwk =OutofHideLayer(i)DEL_Hide(i) = inival * wk * (1# - wk)Next i'/*updating for weights from Hide Layer */For i = 1To OutUnitNumsDCw_Out(i) = alpha * DEL_Out(i)Forj = 1 To HideUnitNumsDw_HideOut(i, j) = alpha *DEL_Out(i) * OutofHideLayer(j) Next jNext i'/*updating for weights from Input Layer */For i= 1 To HideUnitNumsDCw_Hide(i) = beta * DEL_Hide(i)For j = 1 To InputUnitNumsDw_InputHide(i, j) = beta * DEL_Hide(i) * OutofInputLayer(j) Next jNext i'*input layer to hide layerFor i= 1 To HideUnitNumswk = moment * OCw_Hide(i) +DCw_Hide(i)Cw_Hide(i) = Cw_Hide(i) + wkOCw_Hide(i) = wkFor j = 1 To InputUnitNumswk = moment * Ow_InputHide(i, j) + Dw_InputHide(i, j) w_InputHide(i, j) =w_InputHide(i, j) + wkOw_InputHide(i, j) = wkNext jNext i'*hide layer to output layerFor i= 1 To OutUnitNumswk = moment * OCw_Out(i) + DCw_Out(i)Cw_Out(i) = Cw_Out(i) + wkOCw_Out(i) = wkFor j = 1 To HideUnitNumswk = moment * Ow_HideOut(i, j) + Dw_HideOut(i, j) w_HideOut(i, j) = w_HideOut(i, j) + wkOw_HideOut(i, j) = wkNext jNexti'所有学习模式的误差总和tempNum = tempNum + ErrorNext loopl'如果达到了要求的误差范围,就可以退出循环If((tempNum / 2) <= ErLimit) ThenExitForEnd IfNext looptList1.ClearFor i = 1 To OutUnitNumsFor j = iTo HideUnitNumsList1.AddItem "w_HideOut(" & i & "," & j& ")=" & w_HideOut(i, j) Next jList1.AddItem "OutofOutLayer(" & i & ") "& OutofOutLayer(i)Next iFor i = 1 To HideUnitNumsFor j = 1To InputUnitNumsList1.AddItem "w_InputHide( " & i & ", "& j & ")=" & w_InputHide(i, j) Next jList1.AddItem "OutofHideLayer(" & i & ")="& OutofHideLayer(i)Next iList1.AddItem "全局误差=" & Format$(tempNum/ 2, "##.###,#")List1.AddItem "预测误差=" &Format$(Sqr(tcmpNum / 2), "##.###")List1.AddItem "循环次数=" & FactTimes'cmdSave. Enabled= True'cmdNetCal.Enabled = FalseBeepvsFlexArray3.Rows = HideUnitNums + 1vsFlexArray3.Cols = InputUnitNums + 1vsFlexArray5.Rows = HideUnitNums + 1For i = 1 To HideUnitNumsvsFlexArray5.TextMatrix(i, 1) = Cw_Hide(i)For j = 1To InputUnitNumsvsFlexArray3.TextMatrix(i, j) = w_InputHide(i, j) Next jNext ivsFlexArray3.SaveGrid App.Path &"WeightlN_HD.dat", flexFileAll vsFlexArray5.SaveGrid App.Path &"OffsetHIDE.dat", flexFileAll vsFlexArray4.Rows = OutUnitNums + 1vsFlexArray4.Cols = HideUnitNums + 1vsFlexArray6.Rows = OutUnitNums + 1For i = 1 To OutUnitNumsvsFlexArray6.TextMatrix(i, 1) = Cw_Out(i)For j = 1To HideUnitNumsvsFlexArray4.TextMatrix(i, j) = w_HideOut(i, j) Next jNext ivsFlexArray4.SaveGrid App.Path &"WeightHD_OT.dat", flexFileAll vsFlexArray6.SaveGrid App.Path & "OffsetOUT.dat", flexFileAllEnd SubPrivate Sub Command6_Click() vsFlexArray1.Rows = 2vsFlexArray1.Cols = Text1.Text + 1 vsFlexArray2.Rows = 2vsFlexArray2.Cols = Text3.Text + 1 vsFlexArray3.Rows = Text2.Text + 1 vsFlexArray3.Cols = Text1.Text + 1 vsFlexArray4.Rows = Text3.Text + 1 vsFlexArray4.Cols = Text2.Text + 1 vsFlexArray5.Rows = Text2.Text + 1 vsFlexArray5.Cols = 2vsFlexArray6.Rows = Text3.Text + 1 vsFlexArray6.Cols = 2 LearnExampleNums = 1 '每次只验证一个数据vsFlexArray1.ClearvsFlexArray2.ClearvsFlexArray2.Enabled = FalsevsFlexArray2.Editable = FalsevsFlexArray1.SetFocusMsgBox "请在学习样本网格中输入数据!"End SubPrivate Sub Command7_Click()Dim Nums() As DoubleReDim Nums(vsFlexArray1.Cols - 1)For i = 1 To Text1.TextNums(i) =vsFlexArray1.TextMatrix(1, i)Next i'读入INPUT TO HIDE 权值文件vsFlexArray3.LoadGrid App.Path &"WeightlN_ttD.dat", flexFileAll '读入HIDE TO OUTPUT 权值文件vsFlexArray4.LoadGrid App.Path &"WeightHD_OT.dat", flexFileAll '读入HIDE 层偏置文件vsFlexArray5.LoadGrid App.Path &"OffsetHIDE.dat", flexFileAll'读入OUTPUT 层偏置值文件vsFlexArray6.LoadGrid App.Path &"OffsetOUT.dat", flexFileAll'/* hide layer */For i = 1 To HideUnitNumsinival = 0#For j = 1To InputUnitNumsinival = inival + vsFlexArray3.TextMatrix(i, j) * Nums(j) Next jinival =inival + vsFlexArray5.TextMatrix(i, 1)OutofHideLayer(i) = Sigmf(inival)Next i'/* output layer */For i = 1 To OutUnitNumsinival = 0#For j = 1To HideUnitNumsinival = inival + vsFlexArray4.TextMatrix(i, j) * OutofHideLayer(j) Next jinival =inival + vsFlexArray6.TextMatrix(i, 1)OutofOutLayer(i) = Sigmf(inival)Label2.Caption = "验证结果:"vsFlexArray2.TextMatrix(1, i) = Format(OutofOutLayer(i),"#,###.###,#")Next iCommand9.Enabled = True End SubPrivate Sub Command8_Click() EndEnd Sub。
神经网络(BP)算法Python实现及应用

神经⽹络(BP)算法Python实现及应⽤本⽂实例为⼤家分享了Python实现神经⽹络算法及应⽤的具体代码,供⼤家参考,具体内容如下⾸先⽤Python实现简单地神经⽹络算法:import numpy as np# 定义tanh函数def tanh(x):return np.tanh(x)# tanh函数的导数def tan_deriv(x):return 1.0 - np.tanh(x) * np.tan(x)# sigmoid函数def logistic(x):return 1 / (1 + np.exp(-x))# sigmoid函数的导数def logistic_derivative(x):return logistic(x) * (1 - logistic(x))class NeuralNetwork:def __init__(self, layers, activation='tanh'):"""神经⽹络算法构造函数:param layers: 神经元层数:param activation: 使⽤的函数(默认tanh函数):return:none"""if activation == 'logistic':self.activation = logisticself.activation_deriv = logistic_derivativeelif activation == 'tanh':self.activation = tanhself.activation_deriv = tan_deriv# 权重列表self.weights = []# 初始化权重(随机)for i in range(1, len(layers) - 1):self.weights.append((2 * np.random.random((layers[i - 1] + 1, layers[i] + 1)) - 1) * 0.25)self.weights.append((2 * np.random.random((layers[i] + 1, layers[i + 1])) - 1) * 0.25)def fit(self, X, y, learning_rate=0.2, epochs=10000):"""训练神经⽹络:param X: 数据集(通常是⼆维):param y: 分类标记:param learning_rate: 学习率(默认0.2):param epochs: 训练次数(最⼤循环次数,默认10000):return: none"""# 确保数据集是⼆维的X = np.atleast_2d(X)temp = np.ones([X.shape[0], X.shape[1] + 1])temp[:, 0: -1] = XX = tempy = np.array(y)for k in range(epochs):# 随机抽取X的⼀⾏i = np.random.randint(X.shape[0])# ⽤随机抽取的这⼀组数据对神经⽹络更新a = [X[i]]# 正向更新for l in range(len(self.weights)):a.append(self.activation(np.dot(a[l], self.weights[l])))error = y[i] - a[-1]deltas = [error * self.activation_deriv(a[-1])]# 反向更新for l in range(len(a) - 2, 0, -1):deltas.append(deltas[-1].dot(self.weights[l].T) * self.activation_deriv(a[l])) deltas.reverse()for i in range(len(self.weights)):layer = np.atleast_2d(a[i])delta = np.atleast_2d(deltas[i])self.weights[i] += learning_rate * layer.T.dot(delta)def predict(self, x):x = np.array(x)temp = np.ones(x.shape[0] + 1)temp[0:-1] = xa = tempfor l in range(0, len(self.weights)):a = self.activation(np.dot(a, self.weights[l]))return a使⽤⾃⼰定义的神经⽹络算法实现⼀些简单的功能:⼩案例:X: Y0 0 00 1 11 0 11 1 0from NN.NeuralNetwork import NeuralNetworkimport numpy as npnn = NeuralNetwork([2, 2, 1], 'tanh')temp = [[0, 0], [0, 1], [1, 0], [1, 1]]X = np.array(temp)y = np.array([0, 1, 1, 0])nn.fit(X, y)for i in temp:print(i, nn.predict(i))发现结果基本机制,⽆限接近0或者⽆限接近1第⼆个例⼦:识别图⽚中的数字导⼊数据:from sklearn.datasets import load_digitsimport pylab as pldigits = load_digits()print(digits.data.shape)pl.gray()pl.matshow(digits.images[0])pl.show()观察下:⼤⼩:(1797, 64)数字0接下来的代码是识别它们:import numpy as npfrom sklearn.datasets import load_digitsfrom sklearn.metrics import confusion_matrix, classification_report from sklearn.preprocessing import LabelBinarizerfrom NN.NeuralNetwork import NeuralNetworkfrom sklearn.cross_validation import train_test_split# 加载数据集digits = load_digits()X = digits.datay = digits.target# 处理数据,使得数据处于0,1之间,满⾜神经⽹络算法的要求X -= X.min()X /= X.max()# 层数:# 输出层10个数字# 输⼊层64因为图⽚是8*8的,64像素# 隐藏层假设100nn = NeuralNetwork([64, 100, 10], 'logistic')# 分隔训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y)# 转化成sklearn需要的⼆维数据类型labels_train = LabelBinarizer().fit_transform(y_train)labels_test = LabelBinarizer().fit_transform(y_test)print("start fitting")# 训练3000次nn.fit(X_train, labels_train, epochs=3000)predictions = []for i in range(X_test.shape[0]):o = nn.predict(X_test[i])# np.argmax:第⼏个数对应最⼤概率值predictions.append(np.argmax(o))# 打印预测相关信息print(confusion_matrix(y_test, predictions))print(classification_report(y_test, predictions))结果:矩阵对⾓线代表预测正确的数量,发现正确率很多这张表更直观地显⽰出预测正确率:共450个案例,成功率94%以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。
用Python实现BP神经网络(附代码)
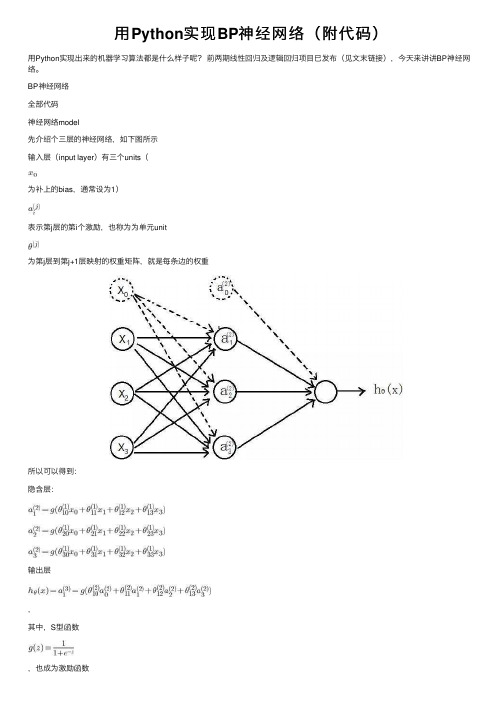
⽤Python实现BP神经⽹络(附代码)⽤Python实现出来的机器学习算法都是什么样⼦呢?前两期线性回归及逻辑回归项⽬已发布(见⽂末链接),今天来讲讲BP神经⽹络。
BP神经⽹络全部代码神经⽹络model先介绍个三层的神经⽹络,如下图所⽰输⼊层(input layer)有三个units(为补上的bias,通常设为1)表⽰第j层的第i个激励,也称为为单元unit为第j层到第j+1层映射的权重矩阵,就是每条边的权重所以可以得到:隐含层:输出层,其中,S型函数,也成为激励函数为3x4的矩阵,为1x4的矩阵==》j+1的单元数x(j层的单元数+1)代价函数假设最后输出的,即代表输出层有K个单元,其中,代表第i个单元输出与逻辑回归的代价函数差不多,就是累加上每个输出(共有K个输出)正则化L-->所有层的个数-->第l层unit的个数正则化后的代价函数为共有L-1层,然后是累加对应每⼀层的theta矩阵,注意不包含加上偏置项对应的theta(0)正则化后的代价函数实现代码:# 代价函数def nnCostFunction(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda):length = nn_params.shape[0] # theta的中长度# 还原theta1和theta2Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1) Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1) # np.savetxt("Theta1.csv",Theta1,delimiter=',')m = X.shape[0]class_y = np.zeros((m,num_labels)) # 数据的y对应0-9,需要映射为0/1的关系for i in range(num_labels):class_y[:,i] = np.int32(y==i).reshape(1,-1) # 注意reshape(1,-1)才可以赋值'''去掉theta1和theta2的第⼀列,因为正则化时从1开始'''Theta1_colCount = Theta1.shape[1]Theta1_x = Theta1[:,1:Theta1_colCount]Theta2_colCount = Theta2.shape[1]Theta2_x = Theta2[:,1:Theta2_colCount]# 正则化向theta^2term = np.dot(np.transpose(np.vstack((Theta1_x.reshape(-1,1),Theta2_x.reshape(-1,1)))),np.vstack((Theta1_x.reshape(-1,1),Theta2_x.reshape(-1,1))))'''正向传播,每次需要补上⼀列1的偏置bias'''a1 = np.hstack((np.ones((m,1)),X))z2 = np.dot(a1,np.transpose(Theta1))a2 = sigmoid(z2)a2 = np.hstack((np.ones((m,1)),a2))z3 = np.dot(a2,np.transpose(Theta2))h = sigmoid(z3)'''代价'''J = -(np.dot(np.transpose(class_y.reshape(-1,1)),np.log(h.reshape(-1,1)))+np.dot(np.transpose(1-class_y.reshape(-1,1)),np.log(1-h.reshape(-1,1)))-Lambda*term/2)/m return np.ravel(J)反向传播BP上⾯正向传播可以计算得到J(θ),使⽤梯度下降法还需要求它的梯度BP反向传播的⽬的就是求代价函数的梯度假设4层的神经⽹络,记为-->l层第j个单元的误差《===》(向量化)没有,因为对于输⼊没有误差因为S型函数的倒数为:,所以上⾯的和可以在前向传播中计算出来反向传播计算梯度的过程为:(是⼤写的)for i=1-m:--正向传播计算(l=2,3,4...L)-反向计算、...;--最后,即得到代价函数的梯度实现代码:# 梯度def nnGradient(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda):length = nn_params.shape[0]Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1)Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1)m = X.shape[0]class_y = np.zeros((m,num_labels)) # 数据的y对应0-9,需要映射为0/1的关系# 映射yfor i in range(num_labels):class_y[:,i] = np.int32(y==i).reshape(1,-1) # 注意reshape(1,-1)才可以赋值'''去掉theta1和theta2的第⼀列,因为正则化时从1开始'''Theta1_colCount = Theta1.shape[1]Theta1_x = Theta1[:,1:Theta1_colCount]Theta2_colCount = Theta2.shape[1]Theta2_x = Theta2[:,1:Theta2_colCount]Theta1_grad = np.zeros((Theta1.shape)) #第⼀层到第⼆层的权重Theta2_grad = np.zeros((Theta2.shape)) #第⼆层到第三层的权重Theta1[:,0] = 0;Theta2[:,0] = 0;'''正向传播,每次需要补上⼀列1的偏置bias'''a1 = np.hstack((np.ones((m,1)),X))z2 = np.dot(a1,np.transpose(Theta1))a2 = sigmoid(z2)a2 = np.hstack((np.ones((m,1)),a2))z3 = np.dot(a2,np.transpose(Theta2))h = sigmoid(z3)'''反向传播,delta为误差,'''delta3 = np.zeros((m,num_labels))delta2 = np.zeros((m,hidden_layer_size))for i in range(m):delta3[i,:] = h[i,:]-class_y[i,:]Theta2_grad = Theta2_grad+np.dot(np.transpose(delta3[i,:].reshape(1,-1)),a2[i,:].reshape(1,-1))delta2[i,:] = np.dot(delta3[i,:].reshape(1,-1),Theta2_x)*sigmoidGradient(z2[i,:])Theta1_grad = Theta1_grad+np.dot(np.transpose(delta2[i,:].reshape(1,-1)),a1[i,:].reshape(1,-1))'''梯度'''grad = (np.vstack((Theta1_grad.reshape(-1,1),Theta2_grad.reshape(-1,1)))+Lambda*np.vstack((Theta1.reshape(-1,1),Theta2.reshape(-1,1))))/mreturn np.ravel(grad)BP可以求梯度的原因实际是利⽤了链式求导法则因为下⼀层的单元利⽤上⼀层的单元作为输⼊进⾏计算⼤体的推导过程如下,最终我们是想预测函数与已知的y⾮常接近,求均⽅差的梯度沿着此梯度⽅向可使代价函数最⼩化。
bp神经网络代码

bp神经网络代码
BP神经网络代码,是一种用于训练深度学习模型的反向传播算法。
它使用一系列的步骤,以每次迭代的方式来调整神经网络中权重的大小,从而使得它能够更准确地识别数据集中的特征。
BP神经网络代码的基本步骤如下:
1. 初始化权重:首先,选择一组随机初始权重参数。
2. 输入数据:然后,将数据输入神经网络,并将输入与权重相乘以计算输出。
3. 计算错误:接下来,通过比较预期输出和实际输出,计算网络的误差。
4. 反向传播:使用反向传播算法,根据误差调整权重参数,以减少误差。
5. 重复步骤2-4:重复步骤2-4,直到误差低到满足要求为止。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
129988???
130756???
131448???
132129???
132802???
134480???
135030???
135770???
136460???
137510]';
%该脚本用来做NAR神经网络预测
%作者:Macer程
lag=3;???%自回归阶数
iinput=x;%x为原始序列(行向量)
net=fitnet(hiddenLayerSize);
%===15/100;
%训练网络
[net,tr]=train(net,inputs,targets);
%%根据图表判断拟合好坏
yn=net(inputs);
errors=targets-yn;
figure,ploterrcorr(errors)?????????????????????%绘制误差的自相关情况(20lags)
n=length(iinput);
%准备输入和输出数据
inputs=zeros(lag,n-lag);
fori=1:n-lag
???inputs(:,i)=iinput(i:i+lag-1)';
end
targets=x(lag+1:end);
%创建网络
hiddenLayerSize=10;%隐藏层神经元个数
f_out=zeros(1,fn);?%预测输出
%多步预测时,用下面的循环将网络输出重新输入
fori=1:fn
???f_out(i)=neห้องสมุดไป่ตู้(f_in);
???f_in=[f_in(2:end);f_out(i)];
end
%画出预测图
figure,plot(1949:2013,iinput,'b',2013:2020,[iinput(end),f_out],'r')
78534???
80671???
82992???
85229???
87177???
89211???
?90859???
?92420???
?93717???
?94974???
?96259???
?97542???
?98705???
100072???
101654???
103008???
104357???
105851???
%figure,ploterrhist(errors)?????????????????????%误差直方图
%figure,plotperform(tr)?????????????????????????%误差下降线
%%下面预测往后预测几个时间段
fn=7;?%预测步数为fn。
f_in=iinput(n-lag+1:end)';
107507???
109300???
111026???
112704???
114333???
115823???
117171???
118517???
119850???
121121???
122389???
123626???
124761???
125786???
126743???
127627???
128453???
figure,parcorr(errors)?????????????????????????%绘制偏相关情况
%[h,pValue,stat,cValue]=lbqtest(errors)????????%Ljung-BoxQ检验(20lags)
figure,plotresponse(con2seq(targets),con2seq(yn))%看预测的趋势与原趋势
x=[54167???
55196???
56300???
57482???
58796???
60266???
61465???
62828???
64653???
65994???
67207???
66207???
65859???
67295???
69172???
70499???
72538???
74542???
76368???