BP网络以及深度学习讲解
bp使用方法

bp使用方法
BP(Back Propagation)是一种常用的神经网络训练算法,用于训练多层感知器(MLP)等神经网络。
以下是BP的用方法:
1.初始化神经网络:首先,需要初始化一个神经网络,包括输入层、隐藏层和输出层。
每个层包含一定数量的神经元,每个神经元都通过权重与其他神经元相连。
权重初始化为随机值。
2.前向传播:输入数据通过输入层进入神经网络,然后依次经过隐藏层和输出层,最终得到输出结果。
在前向传播过程中,每个神经元将输入值与其权重相乘,加上偏置项,然后通过激活函数得到输出值。
3.计算误差:根据实际标签和神经网络的输出结果,计算误差。
误差是实际标签与输出结果之间的差异,通常使用平方误差或交叉熵误差等函数计算。
4.反向传播:根据计算出的误差,通过反向传播算法更新神经网络的权重。
反向传播算法将误差从输出层逐层反向传播到输入层,并根据梯度下降法更新权重。
5.迭代训练:重复步骤2-4多次,直到神经网络的输出结果收敛或达到预设的训练轮数。
在每次迭代中,权重都会被更新以减小误差。
6.测试与预测:训练完成后,可以使用测试数据对神经网络进行测试或进行预测。
将测试数据输入神经网络,得到输出结果,并根据输出结果进行评估和比较。
BP算法是一种监督学习算法,需要使用已知标签的数据进行训练。
在训练过程中,需要注意选择合适的激活函数、学习率和迭代次数等参数,以获得最佳的训练效果。
同时,为了避免过拟合和欠拟合等问题,可以使用正则化、Dropout 等技术来优化神经网络的性能。
BP神经网络详细讲解

載师信号(期望输出信号)图1-7神经网络学习系统框图输入部接收外来的输入样本X,由训练部进行网络的权系数W调整,然后由输岀部输岀结果。
在这个过程中,期望的输出信号可以作为教师信号输入,由该教师信号与实际输出进行比较,产生的误差去控制修改权系数W学习机构可用图1—8所示的结构表示。
在图中,X,X2,…,X n,是输入样本信号,W,W,…,W是权系数。
输入样本信号X可以取离散值0”或1”输入样本信号通过权系数作用,在u产生输岀结果口WX,即有:u=B/VX =WX i +WX2 + …+WX n再把期望输岀信号丫(t)和u进行比较,从而产生误差信号e。
即权值调整机构根据误差e去对学习系统的权系数进行修改,修改方向应使误差e变小,不断进行下去,使到误差e为零,这时实际输出值u和期望输出值丫(t)完全一样,则学习过程结束。
期望辑出y图学可机构神经网络的学习一般需要多次重复训练,使误差值逐渐向零趋近,最后到达零。
则这时才会使输岀与期望一致。
故而神经网络的学习是消耗一定时期的,有的学习过程要重复很多次,甚至达万次级。
原因在于神经网络的权系数W有很多分量W,W,----W n ;也即是一个多参数修改系统。
系统的参数的调整就必定耗时耗量。
目前,提高神经网络的学习速度,减少学习重复次数是十分重要的研究课题,也是实时控制中的关键问题。
、感知器的学习算法感知器是有单层计算单元的神经网络,由线性元件及阀值元件组成。
感知器如图感知器的数学模型:v=f[加讯-e] (1-12)其中:f[.]是阶跃函数,并且有pl 2二主W凶-0工01 —1>u=SW i X^-0<O“1(1-13)9是阀值。
感知器的最大作用就是可以对输入的样本分类,故它可作分类器,感知器对输入信号的分类如下:卩,A类Y = * —B 类(1-14)1-9所示。
f [sw iX£-O]1时,输入样本称为A类;输岀为-1时,输入样本称为B类。
BP神经网络概述

BP神经网络概述BP神经网络由输入层、隐藏层和输出层组成。
输入层接收外界输入的数据,隐藏层对输入层的信息进行处理和转化,输出层输出最终的结果。
网络的每一个节点称为神经元,神经元之间的连接具有不同的权值,通过权值的调整和激活函数的作用,网络可以学习到输入和输出之间的关系。
BP神经网络的学习过程主要包括前向传播和反向传播两个阶段。
前向传播时,输入数据通过输入层向前传递到隐藏层和输出层,计算出网络的输出结果;然后通过与实际结果比较,计算误差函数。
反向传播时,根据误差函数,从输出层开始逆向调整权值和偏置,通过梯度下降算法更新权值,使得误差最小化,从而实现网络的学习和调整。
BP神经网络通过多次迭代学习,不断调整权值和偏置,逐渐提高网络的性能。
学习率是调整权值和偏置的重要参数,过大或过小的学习率都会导致学习过程不稳定。
此外,网络的结构、激活函数的选择、错误函数的定义等也会影响网络的学习效果。
BP神经网络在各个领域都有广泛的应用。
在模式识别中,BP神经网络可以从大量的样本中学习特征,实现目标检测、人脸识别、手写识别等任务。
在数据挖掘中,BP神经网络可以通过对历史数据的学习,预测未来的趋势和模式,用于市场预测、股票分析等。
在预测分析中,BP神经网络可以根据历史数据,预测未来的房价、气温、销售额等。
综上所述,BP神经网络是一种强大的人工神经网络模型,具有非线性逼近能力和学习能力,广泛应用于模式识别、数据挖掘、预测分析等领域。
尽管有一些缺点,但随着技术的发展,BP神经网络仍然是一种非常有潜力和应用价值的模型。
BP神经网络及深度学习研究-综述(最新整理)

BP神经网络及深度学习研究摘要:人工神经网络是一门交叉性学科,已广泛于医学、生物学、生理学、哲学、信息学、计算机科学、认知学等多学科交叉技术领域,并取得了重要成果。
BP(Back Propagation)神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
本文将主要介绍神经网络结构,重点研究BP神经网络原理、BP神经网络算法分析及改进和深度学习的研究。
关键词:BP神经网络、算法分析、应用1 引言人工神经网络(Artificial Neural Network,即ANN ),作为对人脑最简单的一种抽象和模拟,是人们模仿人的大脑神经系统信息处理功能的一个智能化系统,是20世纪80 年代以来人工智能领域兴起的研究热点。
人工神经网络以数学和物理方法以及信息处理的角度对人脑神经网络进行抽象,并建立某种简化模型,旨在模仿人脑结构及其功能的信息处理系统。
人工神经网络最有吸引力的特点就是它的学习能力。
因此从20世纪40年代人工神经网络萌芽开始,历经两个高潮期及一个反思期至1991年后进入再认识与应用研究期,涌现出无数的相关研究理论及成果,包括理论研究及应用研究。
最富有成果的研究工作是多层网络BP算法,Hopfield网络模型,自适应共振理论,自组织特征映射理论等。
因为其应用价值,该研究呈愈演愈烈的趋势,学者们在多领域中应用[1]人工神经网络模型对问题进行研究优化解决。
人工神经网络是由多个神经元连接构成,因此欲建立人工神经网络模型必先建立人工神经元模型,再根据神经元的连接方式及控制方式不同建立不同类型的人工神经网络模型。
现在分别介绍人工神经元模型及人工神经网络模型。
1.1 人工神经元模型仿生学在科技发展中起着重要作用,人工神经元模型的建立来源于生物神经元结构的仿生模拟,用来模拟人工神经网络[2]。
人们提出的神经元模型有很多,其中最早提出并且影响较大的是1943年心理学家McCulloch和数学家W. Pitts在分析总结神经元基本特性的基础上首先提出的MP模型。
BP神经网络的基本原理_一看就懂

BP神经网络的基本原理_一看就懂BP神经网络(Back Propagation Neural Network)是一种常用的人工神经网络模型,用于解决分类、回归和模式识别问题。
它的基本原理是通过反向传播算法来训练和调整网络中的权重和偏置,以使网络能够逐渐逼近目标输出。
1.前向传播:在训练之前,需要对网络进行初始化,包括随机初始化权重和偏置。
输入数据通过输入层传递到隐藏层,在隐藏层中进行线性加权和非线性激活运算,然后传递给输出层。
线性加权运算指的是将输入数据与对应的权重相乘,然后将结果进行求和。
非线性激活指的是对线性加权和的结果应用一个激活函数,常见的激活函数有sigmoid函数、ReLU函数等。
激活函数的作用是将线性运算的结果映射到一个非线性的范围内,增加模型的非线性表达能力。
2.计算损失:将网络输出的结果与真实值进行比较,计算损失函数。
常用的损失函数有均方误差(Mean Squared Error)和交叉熵(Cross Entropy)等,用于衡量模型的输出与真实值之间的差异程度。
3.反向传播:通过反向传播算法,将损失函数的梯度从输出层传播回隐藏层和输入层,以便调整网络的权重和偏置。
反向传播算法的核心思想是使用链式法则。
首先计算输出层的梯度,即损失函数对输出层输出的导数。
然后将该梯度传递回隐藏层,更新隐藏层的权重和偏置。
接着继续向输入层传播,直到更新输入层的权重和偏置。
在传播过程中,需要选择一个优化算法来更新网络参数,常用的优化算法有梯度下降(Gradient Descent)和随机梯度下降(Stochastic Gradient Descent)等。
4.权重和偏置更新:根据反向传播计算得到的梯度,使用优化算法更新网络中的权重和偏置,逐步减小损失函数的值。
权重的更新通常按照以下公式进行:新权重=旧权重-学习率×梯度其中,学习率是一个超参数,控制更新的步长大小。
梯度是损失函数对权重的导数,表示了损失函数关于权重的变化率。
BP神经网络的简要介绍及应用

BP神经网络的简要介绍及应用BP神经网络(Backpropagation Neural Network,简称BP网络)是一种基于误差反向传播算法进行训练的多层前馈神经网络模型。
它由输入层、隐藏层和输出层组成,每层都由多个神经元(节点)组成,并且每个神经元都与下一层的神经元相连。
BP网络的训练过程可以分为两个阶段:前向传播和反向传播。
前向传播时,输入数据从输入层向隐藏层和输出层依次传递,每个神经元计算其输入信号的加权和,再通过一个激活函数得到输出值。
反向传播时,根据输出结果与期望结果的误差,通过链式法则将误差逐层反向传播至隐藏层和输入层,并通过调整权值和偏置来减小误差,以提高网络的性能。
BP网络的应用非常广泛,以下是一些典型的应用领域:1.模式识别:BP网络可以用于手写字符识别、人脸识别、语音识别等模式识别任务。
通过训练网络,将输入样本与正确的输出进行匹配,从而实现对未知样本的识别。
2.数据挖掘:BP网络可以用于分类、聚类和回归分析等数据挖掘任务。
例如,可以用于对大量的文本数据进行情感分类、对客户数据进行聚类分析等。
3.金融领域:BP网络可以用于预测股票价格、外汇汇率等金融市场的变动趋势。
通过训练网络,提取出对市场变动有影响的因素,从而预测未来的市场走势。
4.医学诊断:BP网络可以用于医学图像分析、疾病预测和诊断等医学领域的任务。
例如,可以通过训练网络,从医学图像中提取特征,帮助医生进行疾病的诊断。
5.机器人控制:BP网络可以用于机器人的自主导航、路径规划等控制任务。
通过训练网络,机器人可以通过感知环境的数据,进行决策和规划,从而实现特定任务的执行。
总之,BP神经网络是一种强大的人工神经网络模型,具有较强的非线性建模能力和适应能力。
它在模式识别、数据挖掘、金融预测、医学诊断和机器人控制等领域有广泛的应用,为解决复杂问题提供了一种有效的方法。
然而,BP网络也存在一些问题,如容易陷入局部最优解、训练时间较长等,因此在实际应用中需要结合具体问题选择适当的神经网络模型和训练算法。
bp神经网络基本原理

bp神经网络基本原理
BP神经网络,指的是反向传播算法(Back Propagation),它是深度学习里面几乎用最多
的算法,也是机器学习里最重要的一种算法之一。
BP神经网络可以看成是一个节点网络,由复杂的连接层组成。
每个节点的输入是一系列的数据,
这些数据会被权重(Weight)乘法处理,得到一个有着一定函数关系的节点输出。
这个输出会激
活其它节点,以此形成一个层与层之间连接,最
后输出我们制定的标准输出。
正如人类的大脑一样,BP神经网络通过积极学习来逐步改善对外界变化做出更加合理的反应,
从而更长久的记忆。
在机器学习里,它就是通过
反复训练调整神经元之间的权重,来使得神经网路得到更好的调整,以便学习效果最佳的状态。
由此可见,BP神经网络是互联网领域中一种极其重要的算法,对于一些比较繁杂的业务运行场景,通过分层的处理,不但能提高计算效率,同时也能较好的处理复杂的数据训练,从而给用户带来更加可靠准确的服务体验。
机器学习-BP(back propagation)神经网络介绍
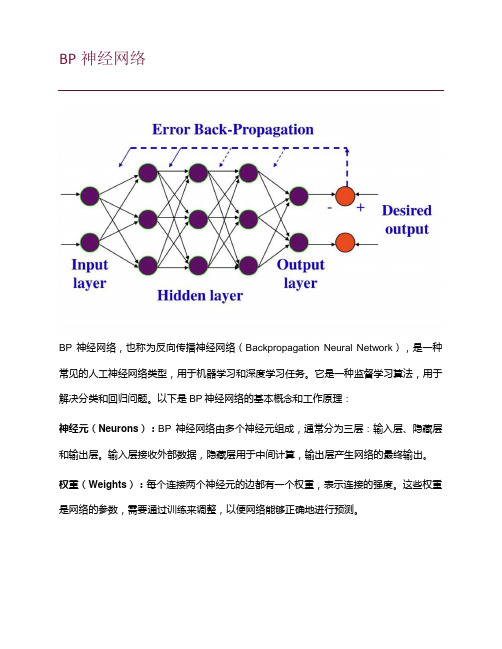
BP神经网络BP神经网络,也称为反向传播神经网络(Backpropagation Neural Network),是一种常见的人工神经网络类型,用于机器学习和深度学习任务。
它是一种监督学习算法,用于解决分类和回归问题。
以下是BP神经网络的基本概念和工作原理:神经元(Neurons):BP神经网络由多个神经元组成,通常分为三层:输入层、隐藏层和输出层。
输入层接收外部数据,隐藏层用于中间计算,输出层产生网络的最终输出。
权重(Weights):每个连接两个神经元的边都有一个权重,表示连接的强度。
这些权重是网络的参数,需要通过训练来调整,以便网络能够正确地进行预测。
激活函数(Activation Function):每个神经元都有一个激活函数,用于计算神经元的输出。
常见的激活函数包括Sigmoid、ReLU(Rectified Linear Unit)和tanh(双曲正切)等。
前向传播(Forward Propagation):在训练过程中,输入数据从输入层传递到输出层的过程称为前向传播。
数据经过一系列线性和非线性变换,最终产生网络的预测输出。
反向传播(Backpropagation):反向传播是BP神经网络的核心。
它用于计算网络预测的误差,并根据误差调整网络中的权重。
这个过程分为以下几个步骤:1.计算预测输出与实际标签之间的误差。
2.将误差反向传播回隐藏层和输入层,计算它们的误差贡献。
3.根据误差贡献来更新权重,通常使用梯度下降法或其变种来进行权重更新。
训练(Training):训练是通过多次迭代前向传播和反向传播来完成的过程。
目标是通过调整权重来减小网络的误差,使其能够正确地进行预测。
超参数(Hyperparameters):BP神经网络中有一些需要人工设置的参数,如学习率、隐藏层的数量和神经元数量等。
这些参数的选择对网络的性能和训练速度具有重要影响。
BP神经网络在各种应用中都得到了广泛的使用,包括图像分类、语音识别、自然语言处理等领域。
BP神经网络的基本原理+很清楚

BP神经网络的基本原理简介BP神经网络是一种前馈式的人工神经网络,也是最常用的人工神经网络之一。
由于其强大的非线性处理能力和适应性,BP神经网络在许多领域中都具有广泛的应用,如模式识别、预测、分类等。
BP神经网络的基本原理是通过一次或多次前向传输和反向传输的过程,来训练神经网络的权值和偏置,从而使神经网络的输出误差最小化。
在训练过程中,利用误差反向传播算法将误差从输出层向输入层进行传递,并根据误差大小对网络的权值和偏差进行调整,直到误差小于设定的阈值为止。
BP神经网络的结构BP神经网络由多个神经元组成,通常分为输入层、输出层和至少一个隐藏层。
隐藏层的数量可以根据应用需求进行设置。
每个神经元都与其他神经元相连,权值和阈值决定了神经元之间的连接强度。
输入层接收输入信号,输出层输出网络的输出结果,隐藏层则负责处理和转换输入层到输出层之间的信息传递。
每个神经元都有一个激活函数,用于将输入信号转化为输出信号。
BP神经网络的训练过程BP神经网络的训练过程包含以下几个步骤:1.初始化权值和偏置,通常使用随机数进行初始化。
2.将训练数据集输入神经网络,网络输出结果和期望结果进行比较,计算误差。
3.根据误差反向传播算法,计算每个神经元的误差,并更新权值和偏置。
4.计算整个训练集的平均误差,直到误差小于设定的阈值为止。
反向传播算法是BP神经网络训练中的关键步骤,其基本原理是将误差从输出层反向传播到输入层,并根据误差大小训练每个神经元的权值和偏置。
该算法通过链式法则计算每个神经元的输出、误差和权值的梯度,并利用梯度下降法来更新权值和偏置。
BP神经网络的优缺点BP神经网络具有以下优点:1.具有强大的非线性处理能力。
2.可以对任意复杂的输入输出关系进行建模和预测。
3.训练过程不需要先验知识,具有较高的自适应性。
BP神经网络的不足之处:1.训练过程需要大量的计算资源和时间。
2.容易受到局部最优解的影响。
3.容易出现过拟合的问题。
阐述bp神经网络的原理

阐述bp神经网络的原理
BP神经网络全称为反向传播神经网络,是一种常用的人工神经网络模型。
其原理基于两个基本思想:前向传播和反向误差传播。
前向传播:BP神经网络是一个多层感知器,由输入层、隐藏层和输出层组成。
输入层接收外部输入的数据,隐藏层负责处理输入,并传递给输出层,输出层根据处理结果生成输出。
隐藏层和输出层的每个神经元都有一个权重向量,用于对输入数据进行线性组合。
然后,通过激活函数对线性组合结果进行非线性变换,得到该神经元的输出。
隐藏层和输出层的每个神经元的输出都会作为下一层神经元的输入。
反向误差传播:当神经网络的输出与期望输出之间存在差异时,需要通过反向传播算法来调整权重,以减小这个误差。
算法的基本思想是将误差从输出层向隐藏层逐层传递,通过调整每个神经元的权重,最终使得网络的输出与期望输出尽可能接近。
具体实现时,首先计算输出层的误差,然后根据误差调整输出层的权重。
接下来,将误差反向传播到隐藏层,再根据误差调整隐藏层的权重。
这个过程会不断迭代,直到网络的输出与期望输出的误差足够小。
通过反向误差传播算法,BP神经网络可以学习到输入-输出的映射关系,从而能
够对未知输入进行预测或分类。
然而,BP神经网络也存在一些问题,例如容易陷入局部极小值、对初始权重较敏感等,因此在实际应用中需要进行一定的调优和训练策略。
bp神经网络的基本原理

bp神经网络的基本原理
BP神经网络是一种常用的人工神经网络模型,用于解决分类和回归问题。
它的基本原理是通过反向传播算法来调整网络的权重和偏置,从而使网络能够学习和逼近输入输出之间的非线性关系。
BP神经网络由输入层、隐藏层和输出层组成。
输入层接收外部输入的数据,隐藏层是网络中间的处理层,输出层给出最终的结果。
每个神经元都与前一层的神经元以及后一层的神经元相连接,每个连接都有一个权重值。
BP神经网络的学习过程首先需要给定一个训练数据集,并设置好网络的结构和参数。
然后,通过前向传播将输入数据从输入层传递到隐藏层和输出层,计算网络的输出结果。
接着,根据输出结果与实际输出之间的差异,使用误差函数来评估网络的性能。
在反向传播阶段,根据误差函数的值,利用链式法则计算每个连接的权重和偏置的梯度。
然后,根据梯度下降法更新连接的权重和偏置,使误差不断减小。
这个过程反复进行,直到网络输出的误差达到了可接受的范围或者训练次数达到了预设的最大值。
通过不断地调整权重和偏置,BP神经网络可以逐渐学习到输入输出之间的映射关系,从而在面对新的输入数据时能够给出合理的输出。
同时,BP神经网络还具有一定的容错性和鲁棒性,可以处理一些噪声和不完整的数据。
总的来说,BP神经网络的基本原理是通过反向传播算法来训练网络,将输入数据从输入层传递到输出层,并且根据实际输出与期望输出之间的差异来优化网络的权重和偏置,以达到学习和逼近输入输出之间关系的目的。
bp神经网络的应用综述

bp神经网络的应用综述近年来,随着人工智能(AI)发展的飞速发展,神经网络技术也在迅速发展。
BP神经网络是一种能够将输入大量信息并有效学习并做出正确决策的广泛应用的深度学习算法。
它的强大的学习能力令人印象深刻,从很多方面来看都是一种具有潜在潜力的技术。
在科学和工程方面,BP神经网络的应用非常广泛。
它可以用于模式识别,数据挖掘,图像处理,语音识别,机器翻译,自然语言处理和知识发现等等。
当可用的数据量很大时,BP神经网络可以有效地自动分析和提取有用的信息,从而有效地解决问题。
例如,在图像处理领域,BP神经网络可以用于图像分类、目标检测和图像语义分析。
它能够以准确的速度检测目标图像,包括人脸、行人、汽车等等,这在过去难以实现。
在机器翻译等技术中,BP神经网络可以用于语义分析,以确定机器翻译的正确语义。
此外,BP神经网络还可以用于人工智能的自动控制,例如机器人与机器人感知、模式识别、语音识别和控制系统。
除此之外,BP神经网络还可以用作在计算机游戏和科学研究中的决策支持系统,以便帮助决策者做出正确的决策。
总而言之,BP神经网络是一种具有广泛应用的深度学习算法,它能够自动处理大量复杂的信息,并能够做出正确的决策。
它可以用于各种科学和工程任务,如模式识别、机器翻译、图像处理、语音识别、机器人感知及自动控制等领域。
此外,它还可以用于决策支持系统,以便帮助决策者做出正确的决策。
BP神经网络在许多领域都具有巨大的潜力,希望以后能得到更多的研究和应用。
因为随着计算机技术的发展,BP神经网络在未来有望发挥更大的作用,帮助人们实现和科学研究的突破。
BP神经网络的潜力巨大,尽管它的应用前景十分广阔,但许多研究仍然存在挑战。
因此,有必要开展更多的研究,并利用其强大的特性,尽可能多地发掘它的潜力,以便最大限度地利用它的优势。
我们期待着BP神经网络会给人类的发展带来更多的惊喜。
bp网络的基本原理

bp网络的基本原理bp网络是一种常用的人工神经网络模型,用于模拟和解决复杂问题。
它是一种前馈型神经网络,通过前向传播和反向传播的过程来实现信息的传递和参数的更新。
在bp网络中,首先需要定义输入层、隐藏层和输出层的神经元。
输入层接收外部输入的数据,隐藏层用于处理和提取数据的特征,输出层用于输出最终的结果。
每个神经元都有一个对应的权重和偏置,用于调节输入信号的强弱和偏移。
前向传播是bp网络中的第一步,它从输入层开始,将输入的数据通过每个神经元的加权和激活函数的运算,逐层传递到输出层。
加权和的计算公式为:S = Σ(w * x) + b其中,w是权重,x是输入,b是偏置。
激活函数则负责将加权和的结果转换为神经元的输出。
常用的激活函数有sigmoid 函数、ReLU函数等。
反向传播是bp网络的第二步,它通过比较输出层的输出与实际值之间的误差,反向计算每个神经元的误差,并根据误差调整权重和偏置。
反向传播的目标是不断减小误差,使神经网络的输出与实际值更加接近。
具体的反向传播算法是通过梯度下降法实现的,它通过计算每个神经元的误差梯度,按照梯度的方向更新权重和偏置。
误差梯度表示误差对权重和偏置的变化率,通过链式法则可以计算得到。
在更新权重和偏置时,一般使用学习率来调节更新的步长,避免权重和偏置的变化过大。
通过多次迭代的前向传播和反向传播过程,bp网络不断优化和调整参数,最终使得输出与实际值的误差达到最小。
这样的训练过程可以使bp网络逐渐学习到输入数据之间的关联性和规律性,从而达到对问题进行分类、回归等任务的目的。
总结起来,bp网络的基本原理是通过前向传播将输入的数据逐层传递并计算每个神经元的输出,然后通过反向传播根据实际输出与目标输出之间的误差来调整权重和偏置,最终达到训练和优化神经网络的目标。
BP神经网络的基本原理_一看就懂

BP神经网络的基本原理_一看就懂BP神经网络(Back propagation neural network)是一种常用的人工神经网络模型,也是一种有监督的学习算法。
它基于错误的反向传播来调整网络权重,以逐渐减小输出误差,从而实现对模型的训练和优化。
1.初始化网络参数首先,需要设置网络的结构和连接权重。
BP神经网络通常由输入层、隐藏层和输出层组成。
每个神经元与上下层之间的节点通过连接权重相互连接。
2.传递信号3.计算误差实际输出值与期望输出值之间存在误差。
BP神经网络通过计算误差来评估模型的性能。
常用的误差计算方法是均方误差(Mean Squared Error,MSE),即将输出误差的平方求和后取平均。
4.反向传播误差通过误差反向传播算法,将误差从输出层向隐藏层传播,并根据误差调整连接权重。
具体来说,根据误差对权重的偏导数进行计算,然后通过梯度下降法来更新权重值。
5.权重更新在反向传播过程中,通过梯度下降法来更新权重值,以最小化误差。
梯度下降法的基本思想是沿着误差曲面的负梯度方向逐步调整权重值,使误差不断减小。
6.迭代训练重复上述步骤,反复迭代更新权重值,直到达到一定的停止条件,如达到预设的训练轮数、误差小于一些阈值等。
迭代训练的目的是不断优化模型,使其能够更好地拟合训练数据。
7.模型应用经过训练后的BP神经网络可以应用于新数据的预测和分类。
将新的输入数据经过前向传播,可以得到相应的输出结果。
需要注意的是,BP神经网络对于大规模、复杂的问题,容易陷入局部最优解,并且容易出现过拟合的情况。
针对这些问题,可以采用各种改进的方法,如加入正则化项、使用更复杂的网络结构等。
综上所述,BP神经网络通过前向传播和反向传播的方式,不断调整权重值来最小化误差,实现对模型的训练和优化。
它是一种灵活、强大的机器学习算法,具有广泛的应用领域,包括图像识别、语音识别、自然语言处理等。
BP神经网络模型教案

BP神经网络模型教案一、教学目标1. 让学生了解BP神经网络的基本概念和原理。
2. 使学生掌握BP神经网络的训练过程和应用场景。
3. 培养学生利用BP神经网络解决实际问题的能力。
二、教学内容1. BP神经网络的基本概念1.1 人工神经网络1.2 神经元与突触1.3 BP神经网络的结构与工作原理2. BP神经网络的训练过程2.1 初始化网络参数2.2 前向传播与计算损失2.3 反向传播与更新权重2.4 训练过程的终止条件3. BP神经网络的应用场景3.1 手写数字识别3.2 图像分类与识别3.3 自然语言处理4. BP神经网络的扩展与改进4.1 隐藏层数与隐藏单元数的选择4.2 激活函数的选取与应用4.3 优化算法与学习率调整5. BP神经网络在实际问题中的应用案例分析三、教学方法1. 讲授法:讲解BP神经网络的基本概念、原理和训练过程。
2. 案例分析法:分析实际问题,展示BP神经网络的应用场景。
3. 实践操作法:让学生动手编写代码,训练BP神经网络模型。
4. 讨论法:引导学生探讨BP神经网络的改进方法和应用前景。
四、教学准备1. 教学PPT:制作包含教学内容的PPT课件。
2. 编程环境:为学生提供Python编程环境和相关库(如TensorFlow、Keras 等)。
3. 数据集:准备手写数字识别、图像分类等数据集。
五、教学过程1. 引入:介绍人工神经网络的发展历程,引出BP神经网络。
2. 讲解:详细讲解BP神经网络的基本概念、原理和训练过程。
3. 案例分析:分析实际问题,展示BP神经网络的应用场景。
4. 实践操作:让学生动手编写代码,训练BP神经网络模型。
5. 讨论:引导学生探讨BP神经网络的改进方法和应用前景。
7. 作业布置:布置相关编程练习,巩固所学知识。
六、教学评估1. 课堂问答:通过提问方式检查学生对BP神经网络基本概念的理解。
2. 编程练习:评估学生在实践操作中运用BP神经网络解决实际问题的能力。
对训练BP神经网络的步骤进行总结

对训练BP神经网络的步骤进行总结训练多层反向传播(BP)神经网络是一种常用的机器学习算法,用于解决分类、回归等问题。
BP神经网络具有良好的非线性建模能力和逼近能力,但其训练过程较为复杂。
下面是BP神经网络的训练步骤的详细总结。
1.数据准备:训练BP神经网络首先需要准备训练数据集,包括输入数据和目标输出数据。
输入数据是网络接收的输入特征,而目标输出数据是对应的期望输出结果。
这些数据应该经过预处理,如归一化或标准化,以确保数据在合适的范围内。
2.网络结构定义:定义BP神经网络的结构,包括网络的层数、每层的神经元数量以及神经元之间的连接权重。
网络的结构设计需要根据具体问题的性质和需求进行选择,一般包括输入层、隐藏层和输出层。
3.初始化网络参数:初始化网络参数,包括各层之间的连接权重和偏置项的取值。
通常可以随机初始化这些参数。
4.前向传播:输入数据通过网络的前向传播过程,从输入层经过隐藏层到达输出层。
在前向传播过程中,每个神经元接收到输入信号后,根据激活函数计算输出值并传递给下一层。
5.计算误差:计算网络的输出误差,通过将网络的实际输出与期望输出进行比较得到。
常用的误差函数包括均方误差(MSE)和交叉熵误差等。
6.反向传播:反向传播是BP神经网络的关键步骤,通过计算每个连接权重对误差的贡献来调整网络参数。
首先,计算输出层的误差,然后逐层向后传递误差,计算隐藏层和输入层的误差。
这个过程利用链式法则计算每个神经元的误差,并保存在反向传播过程中用于更新权重的临时变量中。
7.更新权重和偏置项:根据反向传播过程中计算得到的误差,使用梯度下降法或其他优化算法来更新网络中的权重和偏置项。
通过调整权重和偏置项来最小化总体误差,以提高网络的性能。
8.重复迭代训练:通过重复迭代上述步骤,直到网络达到预定的停止条件。
通常,可以设定一个最大的迭代次数,或者当误差降低到一定程度时停止训练。
9.结果评估:训练完成后,使用测试数据验证网络的性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
神经网络1 BP 网图:三层BP 网信号正向传播和误差反向传播)(k k net f o = ∑==mj j jk k y net 0ω k=1,2……l 有l 个输出(l 常常为1)。
中间隐层有m 层:)(j j net f y = ∑==ni i ij j x net 0υ i=1,2,……m n 个输入。
j=1,2……m其中Sigmoid 函数:xex f -+=11)( (单极性) ko k net E∂∂-=δ 1.1 计算流程不同样本误差:21)(∑=-=lk M kM kMo dEE=((T-Ok)'*(T-Ok))/2;一般使用211)(21∑∑==-=lk p kp kMp o dE 总1.2 影响参数:1.2.1 隐层节点数nn=n m + +a ,其中 m 为输出神经元数, n 为输入神经元数, a 为[1,10]之间的常数。
nn=n 2log nn=2n+1; nn=mn1.2.2 学习率学习率η,太大会影响训练稳定性,太小使训练收敛速度慢。
一般在0.01--0.8之间。
我取0.2E min 一般在0.1--之间。
1.3 样本/输入1.3.1 训练样本训练样本数:M εwn ≈,w n 为权值阈值总数,一般为连接权总数的5~10倍。
训练数据必须作平衡处理,不同类别的样本需要交叉输入,轮流输入--时间延长。
1.3.2 输入形式字符:形状格填充、边缘距离 曲线:采样 变化大可以密集采样 输出:不同的输出用不同的码表示1.3.3 归一化:样本分布比较均匀 [0,1]区间:minmax minx x x x x i i--=[-1,1]区间:mid mid i i x x x x x --=max )(2 其中2minmax x x x mid+= 不均匀:对数 平方根[coef,score,latent,t2] = princomp(x);(个人观点):x :为要输入的n 维原始数据。
带入这个matlab 自带函数,将会生成新的n 维加工后的数据(即score )。
此数据与之前的n 维原始数据一一对应。
score :生成的n 维加工后的数据存在score 里。
它是对原始数据进行的分析,进而在新的坐标系下获得的数据。
他将这n 维数据按贡献率由大到小排列。
(即在改变坐标系的情况下,又对n 维数据排序)latent :是一维列向量,每一个数据是对应score 里相应维的贡献率,因为数据有n 维所以列向量有n 个数据。
由大到小排列(因为score 也是按贡献率由大到小排列)。
coef :是系数矩阵。
通过cofe 可以知道x 是怎样转换成score 的。
1.4 权值/阈值1.4.1 初始权值初始权值足够小,初始值为1和-1的权值数相等。
1.4.2 权值学习算法P99traingd:标准梯度下降算法 traingdm:附加动量项traingda:自适应学习速率,效果比上者好。
traingdx: 附加动量项、自适应学习速率 更好的算法如下: trainlm:1.5 优化1 提高训练速度:附加动量法:)(t w w w jk jk ∆+=其中)1()(-∆+=∆t w y t w j o k αηδ)1(*)1()(-∆+-=∆t w mc y mc t w j o k ηδ)1(*)1()(-∆+-=∆t b mc mc t b o k ηδ 见P852 k net k k e net f o -+==11)(改为λ/11)(k net k k enet f o -+==,一般λ=1 k k o d E -≈∆,0较大时,进入平坦区,令λ>1常用的改进方法有附加冲量项、自适应学习参数、模拟退火法等,1.6 技巧若show 设为NaN ,则不显示训练过程一篇论文中案例:初始权值不可过大过小。
网络1的初始权值和偏差定为-0.25--0.25的随机数,网络2的定为-0.5--0.5的随机数。
目标误差:0.05 两个连续迭代过程平均相差小于910-, 样本数:2001.7 常用函数归纳1.7.1 train 之前net.trainParam.show=10; %show interval 25 %net.trainParam.showWindow=flase;net.trainParam.epochs=5000;%train times.default:10 net.trainParam.goal=0.0001;%0net.trainParam.lr=0.2;%0.15net.trainParam.max_fail=5;% max times of affirm failurenet.trainParam.min_grad=1e-10;%min gradientnet.trainParam.time=inf;%max train timenet.trainParam.mc=0.95; %momentum factor when use traingdm,default:0.9 1.7.2%net.iw{1,1}=iw;net.lw{2,1}=lw;net.b{1}=theta1;net.b{2}=theta2;%yers{1}.initFcn ='initlay';Plotpv(p,t,v)Plotpc(net.iw{1,1},net.b{1})初始化网络:Net.inputWeights{1,1}.initFcn=’rands’; %initialize weightNet.biases{1}.initFcn=’rands’; %initialize deviationnet=init(net)误差平方和:sumsqrNewff newcf1.8 评价标准实际为正类实际为负类预测为正类TP FP预测为负类FN TN查准率/精度:precision=TP/(TP+FP)真正类率(TPR)/查全率/真阳性率/灵敏度/召回率/敏感性(sensitivity):recall=TP/(TP+FN)正确率:accuracy=(TP+TN)/ALL特异性(specificity)/真阴性率/1-假阳性率:TN/(FP+TN)2 前馈神经网络无隐层:线性单隐层:凸域双隐层:任意复杂形状区域,所以一般使用单隐层,较少情况下可以使用双隐层。
解决已知的线性问题,使用感知器或者自适应网络更好,非线性使用BP。
2.1 单层感知器方程组求解的形式,只能做 线性划分 Newp检验:hardlim(W+P,B)2.2 Adaline 自适应线性元件神经元有一个激活函数, 因此输出可以是任意值。
可以做线性逼近。
采用LMS (最小均方差规则,又称W-H 学习规则):j ok ij y ηδω=∆不用求导 newlin newlind带有延时的自适应线性网络3 深度神经网络在语音识别和图像识别等领域获得了巨大的成功4 递归神经网络反馈神经网络4.1 全局反馈递归神经网络4.1.1 ARX 和NARX 网络4.1.2 Hopfield 网络4.1.3 约旦网络4.2 前向递归神经网络4.2.1 局部连接 4.2.2 全连接型 Elman记忆递归神经网络 4.3 混合型网络5 RBF网络/zhangchaoyang/articles/2591663.html/zouxy09/article/details/13297881径向基函数解决插值问题完全内插法要求插值函数经过每个样本点,即。
样本点总共有P个。
RBF的方法是要选择P个基函数,每个基函数对应一个训练数据,各基函数形式为,由于距离是径向同性的,因此称为径向基函数。
||X-X p||表示差向量的模,或者叫2范数。
基于为径向基函数的插值函数为:输入X是个m维的向量,样本容量为P,P>m。
可以看到输入数据点X p是径向基函数φp的中心。
隐藏层的作用是把向量从低维m映射到高维P,低维线性不可分的情况到高维就线性可分了。
将插值条件代入:写成向量的形式为,显然Φ是个规模这P对称矩阵,且与X的维度无关,当Φ可逆时,有。
对于一大类函数,当输入的X各不相同时,Φ就是可逆的。
下面的几个函数就属于这“一大类”函数:1)Gauss(高斯)函数2)Reflected Sigmoidal(反常S型)函数3)Inverse multiquadrics(拟多二次)函数σ称为径向基函数的扩展常数,它反应了函数图像的宽度,σ越小,宽度越窄,函数越具有选择性。
完全内插存在一些问题:1)插值曲面必须经过所有样本点,当样本中包含噪声时,神经网络将拟合出一个错误的曲面,从而使泛化能力下降。
由于输入样本中包含噪声,所以我们可以设计隐藏层大小为K,K<P,从样本中选取K个(假设不包含噪声)作为Φ函数的中心。
2)基函数个数等于训练样本数目,当训练样本数远远大于物理过程中固有的自由度时,问题就称为超定的,插值矩阵求逆时可能导致不稳定。
拟合函数F的重建问题满足以下3个条件时,称问题为适定的:1.解的存在性2.解的唯一性3.解的连续性不适定问题大量存在,为解决这个问题,就引入了正则化理论。
正则化理论正则化的基本思想是通过加入一个含有解的先验知识的约束来控制映射函数的光滑性,这样相似的输入就对应着相似的输出。
寻找逼近函数F(x)通过最小化下面的目标函数来实现:加式的第一项好理解,这是均方误差,寻找最优的逼近函数,自然要使均方误差最小。
第二项是用来控制逼近函数光滑程度的,称为正则化项,λ是正则化参数,D是一个线性微分算子,代表了对F(x)的先验知识。
曲率过大(光滑度过低)的F(x)通常具有较大的||DF||值,因此将受到较大的惩罚。
直接给出(1)式的解:权向量********************************(2)G(X,X p)称为Green函数,G称为Green矩阵。
Green函数与算子D的形式有关,当D具有旋转不变性和平移不变性时,。
这类Green函数的一个重要例子是多元Gauss函数:。
代码%// This is a RBF network trained by BP algorithm%// Author : zouxy%// Date : 2013-10-28%// HomePage : /zouxy09%// Email : zouxy09@close all; clear; clc;%%% ************************************************%%% ************ step 0: load data ****************display('step 0: load data...');% train_x = [1 2 3 4 5 6 7 8]; % each sample arranged as a column of train_x % train_y = 2 * train_x;train_x = rand(5, 10);train_y = 2 * train_x;test_x = train_x;test_y = train_y;%% from matlab% rbf = newrb(train_x, train_y);% output = rbf(test_x);%%% ************************************************%%% ******** step 1: initialize parameters ********display('step 1: initialize parameters...');numSamples = size(train_x, 2);rbf.inputSize = size(train_x, 1);rbf.hiddenSize = numSamples; % num of Radial Basis function rbf.outputSize = size(train_y, 1);rbf.alpha = 0.1; % learning rate (should not be large!)%% centre of RBFfor i = 1 : rbf.hiddenSize% randomly pick up some samples to initialize centres of RBFindex = randi([1, numSamples]);rbf.center(:, i) = train_x(:, index);end%% delta of RBFrbf.delta = rand(1, rbf.hiddenSize);%% weight of RBFr = 1.0; % random number between [-r, r]rbf.weight = rand(rbf.outputSize, rbf.hiddenSize) * 2 * r - r;%%% ************************************************%%% ************ step 2: start training ************display('step 2: start training...');maxIter = 400;preCost = 0;for i = 1 : maxIterfprintf(1, 'Iteration %d ,', i);rbf = trainRBF(rbf, train_x, train_y);fprintf(1, 'the cost is %d \n', rbf.cost);curCost = rbf.cost;if abs(curCost - preCost) < 1e-8disp('Reached iteration termination condition and Termination now!');break;endpreCost = curCost;end%%% ************************************************%%% ************ step 3: start testing ************display('step 3: start testing...');Green = zeros(rbf.hiddenSize, 1);for i = 1 : size(test_x, 2)for j = 1 : rbf.hiddenSizeGreen(j, 1) = green(test_x(:, i), rbf.center(:, j), rbf.delta(j));endoutput(:, i) = rbf.weight * Green;enddisp(test_y);disp(output);function [rbf] = trainRBF(rbf, train_x, train_y)%%% step 1: calculate gradientnumSamples = size(train_x, 2);Green = zeros(rbf.hiddenSize, 1);output = zeros(rbf.outputSize, 1);delta_weight = zeros(rbf.outputSize, rbf.hiddenSize);delta_center = zeros(rbf.inputSize, rbf.hiddenSize);delta_delta = zeros(1, rbf.hiddenSize);rbf.cost = 0;for i = 1 : numSamples%% Feed forwardfor j = 1 : rbf.hiddenSizeGreen(j, 1) = green(train_x(:, i), rbf.center(:, j),rbf.delta(j));endoutput = rbf.weight * Green;%% Back propagationdelta3 = -(train_y(:, i) - output);rbf.cost = rbf.cost + sum(delta3.^2);delta_weight = delta_weight + delta3 * Green';delta2 = rbf.weight' * delta3 .* Green;for j = 1 : rbf.hiddenSizedelta_center(:, j) = delta_center(:, j) + delta2(j) .* (train_x(:, i) - rbf.center(:, j)) ./ rbf.delta(j)^2;delta_delta(j) = delta_delta(j)+ delta2(j) * sum((train_x(:, i) - rbf.center(:, j)).^2) ./ rbf.delta(j)^3;endend%%% step 2: update parametersrbf.cost = 0.5 * rbf.cost ./ numSamples;rbf.weight = rbf.weight - rbf.alpha .* delta_weight ./ numSamples; rbf.center = rbf.center - rbf.alpha .* delta_center ./ numSamples; rbf.delta = rbf.delta - rbf.alpha .* delta_delta ./ numSamples;endfunction greenValue = green(x, c, delta)greenValue = exp(-1.0 * sum((x - c).^2) / (2 * delta^2));end五、代码测试首先,我测试了一维的输入,需要拟合的函数很简单,就是y=2x。