性能测试-linux资源监控
Linux操作系统内核性能测试与调优

Linux操作系统内核性能测试与调优操作系统是计算机系统中最核心的软件之一,它负责协调和管理计算机硬件资源以及提供统一的用户界面。
Linux操作系统因其开放源代码、稳定性和安全性而备受欢迎。
然而,在大规模和高负载的环境中,Linux操作系统的性能可能会出现瓶颈。
因此,进行内核性能测试与调优是非常重要的。
一、性能测试的重要性在处理大量数据和并发用户请求时,操作系统的性能会成为瓶颈。
通过性能测试,我们可以了解操作系统在不同负载情况下的表现,进而定位和解决性能瓶颈。
性能测试有助于提高系统的响应时间、吞吐量和并发性能,从而确保系统的稳定运行。
二、性能测试的分类1. 压力测试:通过模拟实际用户行为或产生大量虚拟用户,并观察系统在负载增加的情况下的响应时间和吞吐量。
常用的压力测试工具包括Apache JMeter和Gatling等。
2. 负载测试:通过模拟实际业务场景,并且能够测试系统在高负载情况下的响应能力和稳定性。
这种测试方法可以帮助我们发现系统在繁忙时是否仍然能够正常工作,并识别可能存在的性能瓶颈。
3. 并发测试:通过模拟多个并发用户并行执行相同或不同的操作,以验证系统在并发访问下的性能表现。
这种测试方法可以评估系统的并发处理能力和资源利用率。
三、内核性能调优的重要性Linux操作系统的性能与其内核配置息息相关。
对内核的性能调优可以提高系统的响应速度、降低延迟和提高吞吐量。
通过调整内核参数和优化内核模块,可以使操作系统更好地适应特定的工作负载。
四、内核性能调优的方法1. 内核参数调整:根据系统的工作负载特点,适当调整内核参数。
例如,可以通过修改TCP/IP堆栈参数来提高网络性能,或者通过修改文件系统参数来提高磁盘I/O性能。
2. 内核模块优化:优化内核使用的模块,选择性加载和卸载不必要的模块,以减少内核的资源占用和启动时间。
3. 中断处理优化:通过合理分配和调整中断处理的优先级,减少中断处理的开销,提高系统的性能。
linux操作系统监控工具

linux操作系统监控工具监控你的WEB服务器或者WEB主机运行是否正常与健康是非常重要的。
你要确保用户始终可以打开你的网站并且网速不慢。
服务器监控工具允许你收集和分析有关你的Web服务器的数据。
这里店铺就与大家谈谈Linux操作票撒谎那个面都有一些什么样的系统监控工具。
linux操作系统监控工具一、基于命令行的性能监控工具1.dstat - 多类型资源统计工具该命令整合了vmstat,iostat和ifstat三种命令。
同时增加了新的特性和功能可以让你能及时看到各种的资源使用情况,从而能够使你对比和整合不同的资源使用情况。
通过不同颜色和区块布局的界面帮助你能够更加清晰容易的获取信息。
它也支持将信息数据导出到cvs 格式文件中,从而用其他应用程序打开,或者导入到数据库中。
你可以用该命令来监控cpu,内存和网络状态随着时间的变化。
2.atop - 相比top更好的ASCII码体验这个使用ASCII码显示方式的命令行工具是一个显示所有进程活动的性能监控工具。
它可以展示每日的系统日志以进行长期的进程活动分析,并高亮显示过载的系统使用资源。
它包含了CPU,内存,交换空间,磁盘和网络层的度量指标。
所有这些功能只需在终端运行atop即可。
# atop当然你也可以使用交互界面来显示数据并进行排序。
3.Nmon - 类Unix系统的性能监控Nmon是Nigel's Monitor缩写,它最早开发用来作为AIX的系统监控工具。
如果使用在线模式,可以使用光标键在屏幕上操作实时显示在终端上的监控信息。
使用捕捉模式能够将数据保存为CSV格式,方便进一步的处理和图形化展示。
更多的信息参考我们的nmon性能监控文章。
4.slabtop - 显示内核slab缓存信息这个应用能够显示缓存分配器是如何管理Linux内核中缓存的不同类型的对象。
这个命令类似于top命令,区别是它的重点是实时显示内核slab缓存信息。
它能够显示按照不同排序条件来排序显示缓存列表。
Linux系统性能测试脚本使用Shell脚本实现对Linux系统性能的压力测试和评估

Linux系统性能测试脚本使用Shell脚本实现对Linux系统性能的压力测试和评估在开发和运维过程中,评估和测试系统性能是至关重要的。
这有助于发现可能存在的瓶颈和问题,以便及时采取措施进行优化和改进。
Linux系统提供了丰富的工具和命令来评估和测试系统性能,而其中使用Shell脚本来实现性能测试可以更加方便和有效。
一、性能测试的目的和重要性性能测试是为了评估计算机系统或软件在特定条件下的运行性能。
它可用于评估系统的稳定性、可靠性、可扩展性、响应时间等指标。
通过性能测试,我们可以发现系统的瓶颈,优化资源的利用,提高系统的吞吐量和响应速度。
二、Shell脚本的优势Shell脚本是Linux系统中常用的脚本语言,具有以下优势:1. 简单易用:Shell脚本语法相对简单,易于理解和学习,而且可以直接在终端运行,不需要编译和链接过程。
2. 灵活性高:Shell脚本可以通过调用系统命令和工具来实现各种功能,包括性能测试。
并且可以结合其他脚本语言进行更复杂的操作。
3. 命令丰富:在Linux系统中,有大量的命令和工具可供使用,可以通过Shell脚本集成这些命令和工具来完成性能测试任务。
三、Shell脚本实现性能测试的步骤1. 设定测试环境:在开始性能测试之前,需要准备适当的环境,并安装必要的工具和软件。
例如,可以使用yum命令安装sysstat工具和其他性能测试工具。
2. 编写Shell脚本:Shell脚本负责执行性能测试的具体步骤和命令。
可以使用循环结构和计时器来模拟实际的压力测试情况。
3. 运行脚本:通过运行Shell脚本,可以执行性能测试并获取测试结果。
测试结果可以保存到文件中以便后续分析和比较。
4. 分析测试结果:根据测试结果,可以进行性能评估和分析,找出性能瓶颈,并提出相应的优化建议。
四、Shell脚本示例下面是一个简单的Shell脚本示例,用于实现Linux系统的CPU、内存和磁盘性能测试。
```bash#!/bin/bash# 测试CPU性能echo "CPU性能测试开始..."sysbench --test=cpu --cpu-max-prime=20000 runecho "CPU性能测试结束。
性能测试中的资源监控和管理方法

性能测试中的资源监控和管理方法性能测试是软件开发过程中非常重要的一项工作,它用于评估系统的性能以及性能瓶颈,并针对性地优化系统。
在进行性能测试的过程中,资源监控和管理是不可或缺的环节。
本文将介绍一些常用的性能测试中的资源监控和管理方法。
一、资源监控1. CPU监控在性能测试中,CPU的使用率是衡量系统性能的重要指标之一。
通过监控CPU的使用率,我们可以了解系统在不同负载下的处理能力和性能瓶颈。
通常可以使用系统自带的性能监控工具,如Windows系统的任务管理器或Linux系统的top命令来实时监控CPU的使用率。
2. 内存监控内存的使用情况对系统性能有着重要的影响。
在进行性能测试时,需要监控系统的内存使用情况,包括内存占用量、内存峰值等指标。
可以使用操作系统的性能监控工具或第三方监控工具,如JConsole、Grafana等来监控系统的内存使用情况。
3. 磁盘IO监控磁盘IO是性能测试中的另一个重要指标,它反映了系统对存储资源的利用情况。
通过监控磁盘IO,可以了解系统在不同负载下的IO操作能力和性能瓶颈。
类似地,可以使用操作系统的性能监控工具或第三方监控工具来监控系统的磁盘IO情况。
4. 网络带宽监控对于网络应用来说,网络带宽是一个关键的性能指标。
在进行性能测试时,需要监控系统的网络带宽使用情况,包括带宽利用率、吞吐量等指标。
可以使用网络监控工具,如Wireshark等来实时监控系统的网络带宽使用情况。
二、资源管理1. 资源分配在进行性能测试时,需要合理地分配系统资源,以模拟真实的运行环境。
根据被测系统的特点和性能测试的目标,可以合理配置CPU、内存、磁盘和网络等资源。
例如,可以通过修改系统设置或使用虚拟化技术来控制资源的分配。
2. 资源优化性能测试的目的之一是发现系统的性能瓶颈并进行优化。
在进行资源优化时,可以通过监控系统资源的使用情况,找到资源使用过高或过低的情况,并进行相应的调整。
例如,可以通过调整系统参数、优化代码或增加硬件设备等方式来提高系统的性能。
Linux系统性能测试脚本使用Python编写的用于测试Linux系统性能的工具

Linux系统性能测试脚本使用Python编写的用于测试Linux系统性能的工具Linux系统是一种广泛使用的操作系统,为了确保其高效运行和稳定性,对系统性能进行测试和调优是至关重要的。
为此,开发了许多性能测试工具,其中一种常用的工具就是使用Python编写的Linux系统性能测试脚本。
本文将介绍该测试脚本的使用方法和功能。
一、引言随着计算机技术的不断发展,对Linux系统的性能要求也越来越高。
为了满足这一需求,测试工程师们开发了许多性能测试工具,其中之一就是使用Python编写的Linux系统性能测试脚本。
该脚本可以帮助用户评估系统性能,并找出性能瓶颈,以便进一步优化系统配置。
二、脚本功能Linux系统性能测试脚本使用Python语言编写,具有以下功能:1. CPU性能测试:通过执行一系列CPU密集型任务,测试CPU的计算能力和稳定性。
2. 内存性能测试:通过分配和释放大量内存,测试系统在高负载情况下的内存管理和性能。
3. 磁盘性能测试:通过模拟大量文件的读写操作,测试磁盘I/O性能和吞吐量。
4. 网络性能测试:通过发送和接收大量网络数据包,测试网络传输性能和延迟。
5. IO性能测试:通过模拟大量输入输出操作,测试系统对外部设备的响应速度。
三、脚本使用方法使用Linux系统性能测试脚本非常简单,只需按照以下步骤操作:1. 下载脚本:从开发者的网站或指定的软件仓库下载最新版本的测试脚本。
2. 安装依赖:根据脚本的要求,安装相关的依赖库和软件包。
3. 配置测试参数:根据需要,修改测试脚本中的参数,如测试任务的数量、持续时间等。
4. 运行测试脚本:在终端中执行测试脚本,并等待测试结果生成。
5. 分析测试结果:根据测试结果,评估系统性能并找出性能瓶颈。
6. 优化系统配置:根据性能测试结果,进行系统配置的优化,以提升系统性能。
四、脚本示例以下是一个示例脚本,用于测试系统的CPU性能:```#!/usr/bin/env pythonimport timedef cpu_test():start_time = time.time()# Perform a series of CPU-intensive tasks hereend_time = time.time()elapsed_time = end_time - start_timeprint(f"CPU performance test completed in {elapsed_time} seconds") if __name__ == "__main__":cpu_test()```该脚本通过计算执行CPU密集型任务的时间来评估CPU性能。
性能测试通常需要监控的指标

性能测试通常需要监控的指标在进行性能测试时,需要监控以下指标以评估系统的性能和效率:1.响应时间:响应时间是衡量系统响应请求的速度。
它是从发送请求到收到相应的时间间隔。
较短的响应时间表示系统运行速度快,用户获得结果的等待时间短。
2.吞吐量:吞吐量是单位时间内系统处理的请求数量。
它表示系统的处理能力,较高的吞吐量意味着系统能够同时处理更多的请求。
3.并发用户数:并发用户数指同时访问系统的用户数量。
它反映了系统能够同时支持的用户数量,较高的并发用户数表示系统能够处理更多的并发请求。
4.CPU使用率:CPU使用率表示当前系统的CPU利用率。
它反映了系统的负载情况,较高的CPU使用率可能导致系统性能下降。
5.内存使用率:内存使用率表示当前系统的内存利用率。
它反映了系统内存的负载情况,较高的内存使用率可能导致系统出现内存不足的情况。
6.网络延迟:网络延迟是从发送请求到接收到响应的时间间隔。
它反映了网络传输的速度和稳定性,较短的网络延迟表示网络传输速度快。
7.数据库响应时间:对于涉及数据库的系统,需要监控数据库的响应时间。
较短的数据库响应时间表示数据库访问效率高。
8.磁盘I/O:磁盘I/O是指磁盘的读写操作。
需要监控磁盘的读写速度和响应时间,较高的磁盘I/O可能影响系统的性能和效率。
9.错误率:错误率表示系统处理请求时出现错误的比率。
较低的错误率表示系统稳定性高,较高的错误率可能表示系统存在问题。
10.带宽利用率:带宽利用率表示当前网络带宽的利用率。
较高的带宽利用率可能导致网络拥堵和传输速度下降。
11.日志记录:性能测试还需要监控系统的日志记录,以便分析和诊断问题。
需要记录系统的运行日志、错误日志和性能日志等。
通过监控这些指标,可以评估系统的性能和效率,并及时发现和解决潜在的性能问题。
Linux命令行中的进程监控技巧htopatop和nmon命令详解

Linux命令行中的进程监控技巧htopatop和nmon命令详解Linux命令行中的进程监控技巧:htop、atop和nmon命令详解在Linux系统中,进程监控是一项重要的任务,它可以帮助我们了解系统的运行状态、资源利用情况以及解决性能瓶颈等问题。
本文将详细介绍三个常用的命令行工具:htop、atop和nmon,它们都可以用于进程监控,但在功能和用法上有些许差异。
一、htop命令htop是一个交互式的进程监控工具,提供了比top命令更加直观和友好的界面。
使用htop,我们可以轻松地查看系统中运行的进程,并实时了解它们的CPU、内存和I/O等资源的使用情况。
下面是htop命令的使用示例及相关说明:1. 安装htop命令:sudo apt-get install htop2. 运行htop命令:htop3. htop界面说明:htop的界面由多个区域组成,包括进程列表、系统摘要、进程树、CPU和内存占用情况等。
通过上下左右箭头键可以在不同区域之间切换,按F1键可以查看帮助文档。
在进程列表中,我们可以看到每个进程的PID、用户、CPU占用率、内存占用率等信息,并可以通过快捷键对进程进行操作,如杀死进程、跟踪进程等。
二、atop命令atop是另一个功能强大的进程监控工具,它可以提供比top和htop 更为详细的系统状态信息,并且支持日志记录功能。
下面是atop命令的使用示例及相关说明:1. 安装atop命令:sudo apt-get install atop2. 运行atop命令:sudo atop3. atop界面说明:atop的界面分为多个区域,包括系统摘要、进程列表、资源占用情况、磁盘IO、网络流量等。
在进程列表中,我们可以看到每个进程的PID、用户、CPU占用率、内存占用率、磁盘IO等信息,并且atop支持按字段排序和过滤功能,方便我们查找和分析进程。
同时,atop可以记录系统状态信息到日志文件中,我们可以使用atop命令读取和分析这些日志。
linux性能测试命令top使用方法教程

linux性能测试命令top使用方法教程推荐文章Windows7系统进程优化方法教程热度: Win7如何提高性能和速度方法有哪些热度:Win10如何优化系统性能有什么技巧热度:linux怎么用命令卸载内核模块热度: Linux里怎么用命令查看所有用户热度:和Windows一样,Linux系统除了利用软件,还可以使用命令进行性能测试,具体方法是什么呢。
下面由店铺为大家整理linux性能测试命令的相关知识,希望对大家有帮助!linux性能测试命令——top命令top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
top可以显示CPU占用率为前几位的进程,并提供CPU的实时活动情况语法:top [-s time] [-d count] [-q] [-u] [-h] [-n number] [-f filename]-s time 设置屏幕刷新的延时,单位为秒,默认值5秒-d count 设置屏幕刷新的次数,刷新显示完count次后退出-q 如果经过nice授权,使用-q可以使top运行的更快一些-u 用显示User ID代替username,提高命令运行速度 -h 当系统由多个CPU时,个别CPU的状态信息被隐藏,只显示平均状态值-n number 设置每一屏幕显示的进程数目,number值超过进程最大数目,则设置无效-f filename 输出重定向到给定的文件名,默认为16个进程信息相关阅读:Linux常用基本命令文件名--testmkdir test 创建一个文件夹mkdir test/test1/test2 -p 在创建test1时候,继续创建test2目录,一起创建mv test test1 修改文件名称mv test /位置复制文件到指定位置cat test 查看文件内容unzip 解压包解压当前文件unzip 解压包 -d /位置解压压缩包到指定位置rm test 删除一个文件rm -rf test 删除一个带文件或者文件夹的文件目录cp test test1 复制一个文件cp -r test test1 复制一个文件夹(包含文件夹下的文件)vi 文件名修改文件内容按i键,下方出现insert,开始编辑内容编辑完内容,按esc,退出编辑模式:wq 保存退出:q! 不保存文件退出启动报错,给权限chmod 777 ./startup.shchmod -R 777 catalina.sh重启nginx:进入到nginx的sbin目录,重启: ./nginx -s reload(也意指在不关机的情况下,刷新配置文件)启动nginx:进入到nginx的sbin目录,命令./nginx 开启服务。
性能测试常用监控工具简介

一、 LINUX监控工具--NMON
NMON简介
● Nmon是一种在Aix与Linux操作系统上 广泛使用的监控与分析工具
● Nmon所记录的信息非常全面 ● Nmon可以产生数据文件与图形化结果
NMON监控内容
● cpu占用率 ● 内存使用情况 ● 磁盘I/O速度、传输和读写比率 ● 文件系统的使用率 ● 网络I/O速度、传输和读写比率、错误统计率与传输包的大小 ● 消耗资源最多的进程 ● 计算机详细信息和资源 ● 页面空间和页面I/O速度 ● 用户自定义的磁盘组 ● 网络文件系统
Spotlight on oracle监控top session
TopSessions面板可以查看当前哪个session当前占用了大量的资源;单 击session列表,会在session Information中显示该会话的所有详细信息 ,可以查看执行计划,判断是否存在全表扫描
Spotlight on oracle监控top sql
● 举例:./nmon –F test.nmon –s 5 –c 1000
NMON生成数据文件
● nmon analyser生成数据文件 ● 需要将nmon analyser的宏安全模式调至低
NMON数据文件分析
NMON数据文件分析
主要关注TAB: ● SYSSUM ● CPU_ALL ● CPU_SUMM ● DISK_SUMM ● DISKBUSY ● MEM ● NET
Jconsole启动
服务器端启动:
在catalina.sh的JAVA_OPTS参数中添加-Djava.awt.headless=true 在Xshell的参数选项中,将X11连接选中:
Jconsole启动
远程连接:
Linux下系统如何监控服务器硬件、操作系统、应用服务和业务

Linux下系统如何监控服务器硬件、操作系统、应⽤服务和业务1.Linux监控概述Linux服务器要保证系统的⾼可⽤性,需要实时了解到服务器的硬件、操作系统、应⽤服务等的运⾏状况,各项性能指标是否正常,需要使⽤各种LINUX命令。
做到⾃动化运维就需要,将上述各项监控指标在同⼀个软件中展显出来,图形化监控,消息报警机制,⽇志检看,资产管理等等2.Linux监控的对象2.1 硬件监控(1)服务器:如电源,风扇,磁盘,CPU等,可以使⽤IPMI监控,在LINUX下安装IPMITOOL不同的服务器⼚商都在服务器上配有远程控制卡BMC: 如DELL(iDRAC) ,IBM (IMM) ,HP(ILO)LINUX下只需安装:#yum install -y OpenIPMI ipmitool 这⼆个⼯具就可以IPMI命令可以在服务器本地运⾏,也可以通过⽹络远程调⽤,IPMI在服务器上可以配置单独的IP地址和访问密码(2)⽹络设备:交换机,防⽕墙,路由器等,使⽤SNMP进⾏监控在被监控的设备上开启SNMP代理,到时可以通过⼯具进⾏获取数据,如ZABBIX1.LINUX上安装#yum list |grep snmp#yum install -y net-snmp net-snmp-utils安装好后要配置snmpd.conf⽂件rocommunity snmptest 172.16.20.89 #172.16.20.89表⽰仅这IP地址才可以来访问snmp信息#systemctl start snmpd 启动SNMP ,netstat -nulp ,netstat -ntlp 查看snmp启来的端⼝udp=161 ,TCP=199通过SNMP命令可以获取监控信息:#snmpget -v2c -c snmptest 172.16.20.89 1.3.6.1.2.1.1.3.0 #1.3.6.1.2.1.1.3.0为OID2.交换机上开启snmp-server community public ro(3)定期机房巡检,查看设备运⾏情况2.2 操作系统监控安装sysstat⼯具,包括了iostat、vmstat、sar、mpstat、nfsiostat、pidstat (yum install -y sysstat #rpm -ql sysstat)(1)CPU (CPU调度上下⽂切换,运⾏队列负载,CPU使⽤率)确定服务类型:IO密集型(如:数据库),CPU密集型(如:WEB)1.cpu利⽤率内核态: 30%和⽤户态:70%2.cpu运⾏队列:1~3线程 1CPU=4核队列不超过12个3.上下⽂切换:尽量少,结合cpu利⽤率4.#top命令(显⽰CPU和内存信息,M按内存使⽤率排序,P按CPU使⽤率排序,Q退出)CPU百分⽐各项指标: us:⽤户态 sy:内核态 ni:进程间优先级更换 id:空闲 wa:IO等待 hi:硬中断 si:软件中 st:虚拟5.CPU监控的各种命令:top ,vmstat , mpstat, uptime ,ps cpu进程情况,pstree 以树形结构显⽰进程之间的关系(2)内存1. free -m :显⽰内存信息2.vmstat :来监控虚拟内存 #vmstat 1 10 每隔1秒共10次获取监控信息(3)磁盘1.iostat:命令⽤来显⽰存储⼦系统的详细信息,通常⽤它来监控磁盘 I/O 的情况。
Linux系统监控脚本使用Shell脚本实现对Linux系统的实时监控

Linux系统监控脚本使用Shell脚本实现对Linux系统的实时监控一、监控脚本介绍Linux系统监控脚本是一种使用Shell脚本编写的工具,能够实时监控Linux系统的各项指标并生成监控报告。
通过监控脚本,系统管理员可以及时了解系统运行状态,识别并解决潜在的问题,确保系统的正常运行和稳定性。
二、脚本编写1. 脚本环境设置在开始编写监控脚本之前,先在脚本的开头设置环境变量,包括脚本解释器、脚本名称和脚本存放路径等。
例如:```#!/bin/bashSCRIPT_NAME="Linux监控脚本"SCRIPT_PATH="/usr/local/scripts"```2. 监控项定义根据需要监控的指标,定义相关的变量并赋初始值。
例如,我们可以定义变量来监控CPU、内存和磁盘的使用情况:CPU_USAGE=0MEMORY_USAGE=0DISK_USAGE=0```3. 监控函数编写编写监控函数来获取系统的各项指标数值,并将其赋给相应的变量。
例如,我们可以编写获取CPU使用率的函数:```get_cpu_usage() {CPU_USAGE=$(top -b -n 1 | grep '%Cpu(s)' | awk '{print $2}')}```类似地,我们可以编写获取内存和磁盘使用情况的函数,并将其整合到脚本中。
4. 监控脚本主体在监控脚本的主体部分,通过循环调用各个监控函数,实时获取系统的指标数值,并输出监控报告。
例如,我们可以编写一个监控函数,将各项指标输出到文件中:monitor() {while true; doget_cpu_usageget_memory_usageget_disk_usageecho "$(date): CPU使用率: ${CPU_USAGE}% 内存使用率: ${MEMORY_USAGE}% 磁盘使用率: ${DISK_USAGE}%" >> ${SCRIPT_PATH}/monitor.logsleep 60done}```5. 脚本执行与定时任务将监控脚本保存为可执行文件,并将其加入系统的定时任务中,以实现定期执行监控脚本。
Linux监控工具介绍系列——OSWatcherBlackBox

Linux监控⼯具介绍系列——OSWatcherBlackBox OSWatcher Balck Box简介OSWatcher Black Box (oswbb)是Oracle开发、提供的⼀个⼩巧,但是实⽤、强⼤的系统⼯具,它可以⽤来抓取操作系统的性能指标,⽤于辅助监控系统的资源使⽤。
其安装部署、卸载都⾮常简单;资源消耗也⽐较⼩,原理也⼗分简单,它通过调⽤OS的的⼀些命令(例如vmstat、iostat等)来采集、存储CPU/Memory/Swap/Disk IO/Nentwork相关数据。
安装和运⾏oswbba可以帮助在性能诊断时提供丰富多样的各类性能数据、图⽂报表⽀持。
OSWatcher 在4.0的版本时被命名为OSWatcher Black Box,简称为oswbb,同时增加了数据分析功能,即OSWatcher Black Box Analyzer (OSWbba)这个绘图和分析⼯具,其捆绑在 OS Watcher Black Box当中。
替代了之前的OSWg。
也就是说在OSWatcher 4.0 之前是:OSWatcher 和 OSWg的关系,OSWatcher 4.0 后变成了: OSWbb 与 OSWbba 的关系。
OSWatcher Black Box(oswbb)⽀持多个操作系统,也分Linux与Window版本,当然这两个版本有所差别,本篇只讲述Linux版本。
另外,OSWatcher Black Box(oswbb)由两个部分组成:1. oswbb: ⼀个Unix的 shell script脚本集合,其⽤来收集和归档数据,从⽽帮助定位问题。
2. oswbba: ⼀个Java⼯具来⾃动分析数据,提供建议,并且⽣成⼀个包含图形的 html ⽂档。
OSWatcher Black Box(oswbb)的官⽅下载地址以及相关资料如下(Oracle Metalink上的资料需要账号)How To Start OSWatcher Black Box (OSWBB) Every System Boot Using RPM oswbb-service(⽂档 ID 580513.1)OSWatcher Analyzer User Guide (⽂档 ID 461053.1)官⽅介绍⽂档对oswbb,oswbba的介绍如下:OSWatcher (oswbb) is a collection of UNIX shell scripts intended to collect and archive operating system and network metrics to aid support in diagnosing performance issues. OSWatcher operates as a set of background processes on the server and gathers OS data on a regular basis, invoking such Unix utilities as vmstat, netstat and iostat. OSWatcher can be downloaded from this note. OSWatcher is also included in the RAC-DDT script file, but is not installed by RAC-DDT. For more information on RAC-DDT see RAC-DDT User Guide. OSWatcher is installed on each node where data is to be collected. Installation instructions for OSWatcher are provided in this user guide.The OSWatcher Analyzer (oswbba) is a graphing and analysis utility which comes bundled with OSWatcher v4.0 and higher. oswbba allows the user to graphically display data collected, generate reports containing these graphs and provides a built in analyzer to analyze the data and provide details on any performance problems it detects. The ability to graph and analyze this information relieves the user of manually inspecting all the files.NOTE: oswbba replaces the utility OSWg. This was done to eliminate the confusion caused by having multiple tools in support named OSWatcher. oswbba is only supported for data collected by oswbb and no other tool.安装OSWatcherLinux平台的安装简单到了不能再简单,如下所⽰,解压安装包⽣成oswbb⽂件夹。
atop iops read指标

atop iops read指标关于"atop iops read指标" 的文章第一步:介绍atop iops read指标atop是一种性能监控工具,主要用于监测Linux系统的资源使用情况和进程活动。
其中,iops read指标是用来衡量系统的读取操作(input/output operations per second,每秒IO操作数)。
第二步:解释iops read指标的重要性iops read指标是衡量系统性能的重要指标之一。
它可以反映系统对于读取操作的处理能力。
在数据密集型的应用中,读取操作通常占据了相当大的比例。
因此,了解系统在读取操作上的性能,对于优化系统的整体性能非常重要。
第三步:解释如何使用atop监测iops read指标要使用atop监测iops read指标,可以按照以下步骤进行操作:1. 安装atop:首先需要在系统中安装atop。
这可以通过包管理工具来完成,比如使用apt-get、yum或者zypper等。
2. 启动atop:安装完成后,可以使用atop命令来启动atop进程,并开始监测系统的性能。
默认情况下,atop会每隔10秒输出一次监测结果。
3. 查看iops read指标:在atop的输出结果中,可以找到关于iops read指标的信息。
具体的位置可能会有所不同,取决于atop 版本和配置。
在默认配置下,可以在输出结果的最后一行找到“DSK”(磁盘)部分的信息。
在该部分中,会显示每个磁盘的读取和写入操作的数量,其中包括iops read指标。
第四步:解释如何分析iops read指标的结果分析iops read指标的结果可以帮助我们了解系统在读取操作上的性能状况。
以下是一些常见的分析方法:1. 基准测试:可以通过在系统上运行一些读取操作密集型的任务,比如文件读取、数据库查询等,来测试系统的iops read指标。
然后,根据测试结果来评估系统的性能表现。
linux系统常用监控指标

linux系统常用监控指标Linux系统常用监控指标Linux系统中,监控指标是评估系统性能和健康状况的重要依据。
通过监控指标,可以及时发现问题并及时采取措施,保证系统的稳定和高效运行。
本文将介绍Linux系统常用的监控指标。
一、CPU使用率CPU使用率是衡量系统负载的重要指标之一。
通过监控CPU使用率可以了解系统的运行状况,判断是否存在CPU资源瓶颈。
通常使用top命令或者sar命令来查看CPU使用率。
二、内存使用情况内存是系统性能的关键因素之一,合理的内存使用可以提升系统的运行效率。
通过监控内存使用情况,可以了解系统内存的分配和使用情况,判断是否存在内存不足的情况。
常用的命令有free和top 命令。
三、磁盘I/O磁盘I/O是指计算机与硬盘之间的数据传输,磁盘I/O的性能直接影响系统的整体性能。
通过监控磁盘I/O指标,可以了解磁盘的读写速度和响应时间,判断是否存在磁盘I/O瓶颈。
常用的命令有iostat和sar命令。
四、网络流量网络流量是指数据在网络中的传输情况,网络流量的监控可以帮助我们了解网络的负载情况,判断是否存在网络瓶颈。
通过监控网络流量指标,可以了解网络的带宽使用情况,常用的命令有netstat 和iftop命令。
五、进程状态进程是系统中正在运行的程序的实例,进程的状态可以反映系统的运行情况。
通过监控进程状态指标,可以了解系统中各个进程的运行情况,判断是否存在进程过多或者进程阻塞的情况。
常用的命令有ps和top命令。
六、系统负载系统负载是指系统中正在运行的进程数目,系统负载的大小可以反映系统的工作负荷。
通过监控系统负载指标,可以了解系统的繁忙程度,判断是否存在系统负载过高的情况。
常用的命令有uptime 和top命令。
七、文件打开数文件打开数是指系统中打开的文件数量,文件打开数的过高可能会导致系统资源的浪费。
通过监控文件打开数指标,可以了解系统中打开文件的情况,判断是否存在文件句柄泄漏或者文件描述符不足的情况。
linux tcp监控指标

在Linux系统中,可以使用多种工具来监控TCP连接和性能指标。
以下是一些常用的监控工具和指标:
stat:netstat命令可以显示网络连接、路由表、接口统计等网络相关信息。
使用netstat -an可以查看所有活动的TCP连接。
2.ss:ss是netstat的替代工具,用于获取socket统计信息。
使用ss -tuln可以查看TCP和UDP的监听端口和连接状态。
3.iftop:iftop可以实时显示网络连接和流量情况,它可以显示每个连接的源IP、目标IP、连接状态和传输的数据量等信息。
4.nload:nload是一个基于控制台的网络流量监控工具,可以显示每个网络接口的入/出流量图,并提供了一些其他有用的网络统计信息。
5.tcpdump:tcpdump是一个强大的网络分析工具,可以捕获和分析网络流量,并提供详细的协议信息和数据包内容。
使用tcpdump -i eth0
tcp可以监听特定接口上的TCP流量。
6.iperf:iperf是一个网络性能测试工具,可以测试TCP和UDP带宽和延迟等性能指标。
使用iperf -s可以启动服务器模式,监听指定端口上
的连接请求,并测试网络性能。
除了以上工具外,还有一些其他的监控工具和指标可以帮助您评估TCP连接和网络性能,例如:
•TCP连接数和连接状态:可以反映系统的并发处理能力和资源使用情况。
•丢包率:丢包率过高可能表明网络不稳定或服务器资源不足。
•延迟和抖动:延迟和抖动会影响用户体验和应用程序的性能。
•带宽使用率:带宽使用率过高可能表明网络拥塞或带宽不足。
最新监控系统运行测试报告

最新监控系统运行测试报告一、引言监控系统能够对目标对象进行实时监测,提供准确的数据和信息,为管理决策提供参考依据,因此在各个领域都得到广泛应用。
为了验证最新监控系统的运行稳定性和功能完备性,本次测试报告将对监控系统进行全面的测试,包括功能测试、性能测试、稳定性测试和兼容性测试等。
二、功能测试1.监控对象:系统能够正确识别和监控目标对象,包括人员、车辆等。
2.实时监测:系统能够实时获取监控对象的数据,并能够及时显示在监控界面上。
3.数据分析:系统能够对监控数据进行分析,包括数据统计、分布情况等,并能够生成相应的报表。
4.报警功能:当监控对象出现异常情况时,系统能够及时报警并提供相应的预警信息。
三、性能测试1.监控对象数量:增加监控对象的数量,观察系统是否能够正常处理和显示监控数据。
2.数据处理速度:对系统进行压力测试,观察系统处理大量数据时的响应速度和稳定性。
3.系统资源占用:测试系统对计算机资源的占用情况,包括CPU占用率、内存占用等。
四、稳定性测试1.长时间运行:让系统连续运行24小时以上,观察系统是否会出现崩溃或卡顿的情况。
2.异常处理:模拟各种异常情况,包括网络断开、数据库故障等,观察系统的异常处理能力。
五、兼容性测试1. 浏览器兼容性:测试系统在不同浏览器上的兼容性,包括Chrome、Firefox、Safari等。
2. 操作系统兼容性:测试系统在不同操作系统上的兼容性,包括Windows、Linux、MacOS等。
六、测试结论经过全面的功能测试、性能测试、稳定性测试和兼容性测试,最新监控系统表现出良好的运行稳定性和功能完备性。
系统能够正常识别和监控目标对象,实时获取监控数据,并能够进行数据分析和报警功能。
系统在处理大量数据时响应迅速,并占用系统资源较少。
系统能够长时间运行并处理异常情况,同时也具备较好的浏览器和操作系统兼容性。
七、改进建议1.进一步提升系统的响应速度和处理能力,以适应更高强度的数据处理需求。
Linux下Jmeter+nmon+nmonanalyser实现性能监控及结果分析

Linux 下Jmeter+nmon+nmonanalyser 实现性能监控及结果分析⼀、概述 前段时间讲述了Jmeter 利⽤插件PerfMon Metrics Collector 来监控压测过程中服务器资源的消耗,⼀个偶然机会,我发现nmon 这个⼯具挺不错,和Jmeter 插件⽐起来,nmon 记录的信息更加全⾯⼀些。
nmon ,⼀款开源性能监控⼯具,⽤于监控linux 系统的资源消耗信息,并能把结果输出到⽂件中,然后通过nmon_analyser ⼯具产⽣数据⽂件与图形化结果。
⼆、nmon 及nmon analyser 的下载安装 nmon根据⾃⼰系统版本下载对应的安装包,本次测试使⽤的是 ,nmon analyser下载最新的安装包,本次测试使⽤的是 。
1.将下载的nmon安装包上传到Linux新建⽬录并解压 2.根据⾃⼰系统的版本,给命令赋予可执⾏权限3.在命令⾏输⼊ 即可打开nmon界⾯ 在上⾯的交互式窗⼝中,可以使⽤nmon 快捷键来显⽰不同的系统资源统计数据:q : 停⽌并退出 Nmonh : 查看帮助c : 查看 CPU 统计数据m : 查看内存统计数据d : 查看硬盘统计数据k : 查看内核统计数据n : 查看⽹络统计数据N : 查看 NFS 统计数据j : 查看⽂件系统统计数据t : 查看⾼耗进程V : 查看虚拟内存统计数据v : 详细模式 此时,我们可以通过快捷键来调取关⼼的系统资源进⾏显⽰,该种⽅式显⽰信息实时性强,能够及时掌握系统承受压⼒下的运⾏情况。
nmon16m_helpsystems.tar.gz nmon_analyser_v66.zip [test@node06 ~]$ cd /usr/local[test@node06 local]$ mkdir nmon[test@node06 local]$ cd nmon[test@node06 nmon]$ tar -zxvf nmon16m_helpsystems.tar.gz1 [test@node06 nmon]$ cat /etc/redhat-release2 CentOS release 6.9 (Final)3 [test@node06 nmon]$ chmod +x nmon_x86_64_centos6./nmon_x86_64_centos6三、配置nmon 的环境变量 完成以上的配置后,已经可以正常使⽤nmon了。
Linux记录-linux系统常用监控指标

Linux记录-linux系统常⽤监控指标1.Linux运维基础采集项做运维,不怕出问题,怕的是出了问题,抓不到现场,两眼摸⿊。
所以,依靠强⼤的监控系统,收集尽可能多的指标,意义重⼤。
但哪些指标才是有意义的呢,本着从实践中来的思想,各位⼯程师在长期摸爬滚打中总结出来的经验最有价值。
在各位运维⼯程师长期的⼯作实践中,我们总结了在系统运维过程中,经常会参考的⼀些指标,主要包括以下⼏个类别:CPULoad内存磁盘IO⽹络相关内核参数ss 统计输出端⼝采集核⼼服务的进程存活信息采集关键业务进程资源消耗NTP offset采集DNS解析采集每个类别,具体的详细指标如下,这些指标,都是open-falcon的agent组件直接⽀持的。
falcon-agent每隔⼀定时间间隔(⽬前是60秒)会采集⼀次相关的指标,并汇报给server端。
2. CPU相关采集项计算⽅法:通过采集/proc/stat来得到,⼤家可以参考sar命令的统计输出来理解。
cpu.idle:Percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.cpu.busy:与cpu.idle相对,他的值等于100减去cpu.idle。
cpu.guest:Percentage of time spent by the CPU or CPUs to run a virtual processor.cpu.iowait:Percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.cpu.irq:Percentage of time spent by the CPU or CPUs to service hardware interrupts.cpu.softirq:Percentage of time spent by the CPU or CPUs to service software interrupts.cpu.nice:Percentage of CPU utilization that occurred while executing at the user level with nice priority.cpu.steal:Percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.cpu.system:Percentage of CPU utilization that occurred while executing at the system level (kernel).er:Percentage of CPU utilization that occurred while executing at the user level (application).t:cpu核数。
性能测试指标

浅谈软件性能测试中关键指标的监控与分析一、软件性能测试需要监控哪些关键指标?软件性能测试的目的主要有以下三点:评价系统当前性能,判断系统是否满足预期的性能需求。
寻找软件系统可能存在的性能问题,定位性能瓶颈并解决问题。
判定软件系统的性能表现,预见系统负载压力承受力,在应用部署之前,评估系统性能。
而对于用户来说,则最关注的是当前系统:是否满足上线性能要求?系统极限承载如何?系统稳定性如何?因此,针对以上性能测试的目的以及用户的关注点,要达到以上目的并回答用户的关注点,就必须首先执行性能测试并明确需要收集、监控哪些关键指标,通常情况下,性能测试监控指标主要分为:资源指标和系统指标,如下图所示,资源指标与硬件资源消耗直接相关,而系统指标则与用户场景及需求直接相关。
性能测试监控关键指标说明:资源指标CPU使用率:指用户进程与系统进程消耗的CPU时间百分比,长时间情况下,一般可接受上限不超过85%。
内存利用率:内存利用率=(1-空闲内存/总内存大小)*100%,一般至少有10%可用内存,内存使用率可接受上限为85%。
磁盘I/O: 磁盘主要用于存取数据,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据的时候对应的是写IO操作,取数据的时候对应的是是读IO操作,一般使用% Disk Time(磁盘用于读写操作所占用的时间百分比)度量磁盘读写性能。
网络带宽:一般使用计数器Bytes Total/sec来度量,Bytes Total/sec表示为发送和接收字节的速率,包括帧字符在内。
判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较。
系统指标:并发用户数:某一物理时刻同时向系统提交请求的用户数。
在线用户数:某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求。
平均响应时间:系统处理事务的响应时间的平均值。
事务的响应时间是从客户端提交访问请求到客户端接收到服务器响应所消耗的时间。
对于系统快速响应类页面,一般响应时间为3秒左右。
linux监控指标和命令
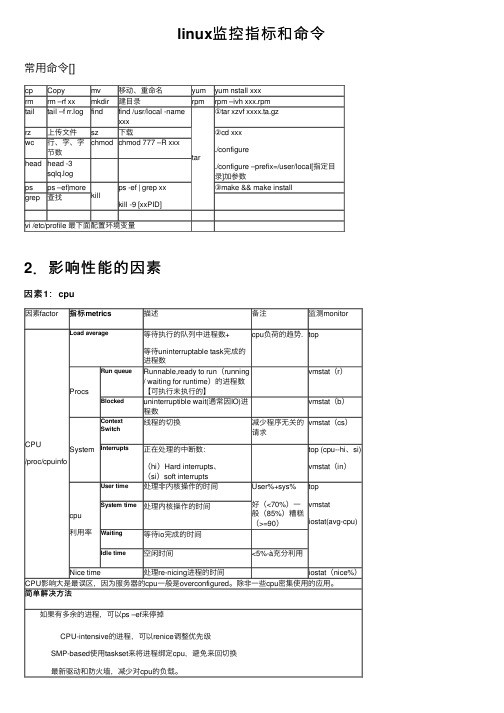
linux 监控指标和命令常⽤命令[]cp Copymv 移动、重命名yum yum nstall xxx rm rm –rf xx mkdir 建⽬录rpm rpm –ivh xxx.rpm tailtail –f rr.logfindfind /usr/local -name xxxtar①tar xzvf xxxx.ta.gz rz 上传⽂件sz 下载②cd xxx ./configure./configure –prefix=/user/local[指定⽬录]加参数wc ⾏、字、字节数chmod chmod 777 –R xxxhead head -3sqlq.logps ps –ef|morekill ps -ef | grep xxkill -9 [xxPID]③make && make install grep查找vi /etc/profile 最下⾯配置环境变量2.影响性能的因素因素1:cpu因素factor指标metrics描述备注监测monitorCPU /proc/cpuinfoLoad average等待执⾏的队列中进程数+等待uninterruptable task 完成的进程数cpu 负荷的趋势.topProcsRun queueRunnable,ready to run (running / waiting for runtime )的进程数【可执⾏未执⾏的】vmstat (r )Blocked uninterruptible wait(通常因IO)进程数vmstat (b )System Context Switch线程的切换减少程序⽆关的请求vmstat (cs )Interrupts正在处理的中断数:(hi )Hard interrupts 、(si )soft interruptstop (cpu--hi 、si)vmstat (in )cpu 利⽤率User time 处理⾮内核操作的时间User%+sys%好(<70%)⼀般(85%)糟糕(>=90)topvmstat iostat(avg-cpu) System time处理内核操作的时间Waiting 等待io 完成的时间Idle time空闲时间<5%-à充分利⽤Nice time 处理re-nicing 进程的时间 iostat (nice%)CPU 影响⼤是最误区,因为服务器的cpu ⼀般是overconfigured 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目录:Linux硬件基础CPU:就像人的大脑,主要负责相关事情的判断以及实际处理的机制。
CPU:CPU的性能主要体现在其运行程序的速度上。
影响运行速度的性能指标包括CPU的工作频率、Cache容量、指令系统和逻辑结构等参数。
查询指令:cat /proc/cpuinfo内存:大脑中的记忆区块,将皮肤、眼睛等所收集到的信息记录起来的地方,以供CPU 进行判断。
内存:影响内存的性能主要是内存主频、内容容量。
查询指令:cat /proc/meminfo硬盘:大脑中的记忆区块,将重要的数据记录起来,以便未来再次使用这些数据。
硬盘:容量、转速、平均访问时间、传输速率、缓存。
查询指令:fdisk -l (需要root权限)Linux监控命令linux性能监控分析命令vmstatvmstat使用说明vmstat可以对操作系统的内存信息、进程状态、CPU活动、磁盘等信息进行监控,不足之处是无法对某个进程进行深入分析。
vmstat [-a] [-n] [-S unit] [delay [ count]]-a:显示活跃和非活跃内存-m:显示slabinfo-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。
如果不指定,只显示一条结果。
count:刷新次数。
如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示各个磁盘相关统计信息。
Sarsar是非常强大性能分析命令,通过sar命令可以全面的获取系统的CPU、运行队列、磁盘I/O、交换区、内存、cpu中断、网络等性能数据。
sar 命令行的常用格式:sar [options] [-A] [-o file] t [n]在命令行中,n 和t 两个参数组合起来定义采样间隔和次数,t为采样间隔,是必须有的参数,n为采样次数,是可选的,默认值是1,-o file表示将命令结果以二进制格式存放在文件中,file 在此处不是关键字,是文件名。
options 为命令行选项,sar命令的选项很多,下面只列出常用选项:-A:所有报告的总和。
-u:CPU利用率-v:进程、节点、文件和锁表状态。
-p:像是当前系统中指定CPU使用信息。
-d:硬盘使用报告。
-r:显示系统内存的使用情况。
-n:显示网络运行状态。
参数后面可跟DEV、EDEV、SOCK和FULL。
DEV显示网络接口信息,EDEV显示网络错误的统计数据,SOCK显示套接字信息,FULL显示前三参数所以信息。
-q:显示运行队列的大小,它与系统当时的平均负载相同-B:内存分页情况-R:显示进程在采样时间内的活动情况。
-g:串口I/O的情况。
-b:缓冲区使用情况。
-a:文件读写情况。
-c:系统调用情况。
-R:进程的活动情况。
-y:终端设备活动情况。
-W:系统交换活动。
Iostatiostat是对系统的磁盘I/O操作进行监控,它的输出主要显示磁盘读写操作的统计信息,同时给出CPU的使用情况。
同vmstat一样,iostat不能对某个进程进行深入分析,仅对操作系统的整体情况进行分析。
iostat命令行的常用格式:iostat [ -c | -d ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ device [ ... ] | ALL ] [ -p [ device | ALL ] ] [ interval [ count ] ]各选项以及参数含义如下:-c:仅显示CPU统计信息.与-d选项互斥.-d :仅显示磁盘统计信息.与-c选项互斥.-k :以K为单位显示每秒的磁盘请求数,默认单位块.-p :device | ALL与-x选项互斥,用于显示块设备及系统分区的统计信息.也可以在-p后指定一个设备名,如:# iostat -p had或显示所有设备# iostat -p ALL-t :在输出数据时,打印搜集数据的时间.-V :打印版本号和帮助信息.-x device 输出指定要统计的磁盘设备名称,默认为所有磁盘设备.interval :指两次统计间隔时间- count :按照interval 指定的时间间隔统计的次数Toptop命令能够实时监控系统的运行状态,并且可以按照CPU、内存和执行时间进行排序,同时top命令还可以通过交互式命令进行设定显示,通过top命令可以查看即时活跃的进行。
命令行启动参数:用法: top -hv | -bcisSHM -d delay -n iterations [-u user | -U user] -p pid [,pid ...]-b : 批次模式运行。
通常用作来将top的输出的结果传送给其他程式或储存成文件-c : 显示执行任务的命令行-d : 设定延迟时间-h : 帮助-H : 显示线程。
当这个设定开启时,将显示所有进程产生的线程-i : 显示空闲的进程-n : 执行次数。
一般与-b搭配使用-u : 监控指定用户相关进程-U : 监控指定用户相关进程-p : 监控指定的进程。
当监控多个进程时,进程ID以逗号分隔。
这个选项只能在命令行下使用-s : 安全模式操作-S : 累计时间模式-v : 显示top版本,然后退出。
-M : 自动显示内存单位(k/M/G)回车、空格: 刷新显示信息?、h : 帮助= : 移除所有任务显示的限制A : 交替显示模式切换B : 粗体显示切换d、s : 更改界面刷新时间间隔G : 选择其它窗口/栏位组I : Irix或Solaris模式切换u、U : 监控指定用户相关进程k : 结束进程q : 退出topr : 重新设定进程的nice值W : 存储当前设定Z : 改变颜色模板2.摘要区命令l : 平均负载及系统运行时间显示开关m : 内存及交换空间使用率显示开关t : 当前任务及CPU状态显示开关1 : 汇总显示CPU状态或分开显示每个CPU状态3.任务区命令外观样式b : 黑体/反色显示高亮的行/列。
控制x和y交互命令的显示样式x : 高亮显示排序的列y : 高亮显示正在运行的任务z : 彩色/黑白显示。
显示内容c : 任务执行的命令行或进程名称f、o : 增加和移除进程信息栏位及调整进程信息栏位显示顺序H : 显示线程S : 时间累计模式u : 监控指定用户相关进程任务显示的数量i : 显示空闲的进程n或# : 设置任务显示最大数量任务排序(shift+f)M : 按内存使用率排序N : 按PID排序P : 按CPU使用率排序T : 按Time+排序< : 按当前排序栏位左边相邻栏位排序> : 按当前排序栏位右边相邻栏位排序F 或O : 选择排序栏位Freefree命令是监控linux内存使用最常用的命令参数说明:-m:以M为单位查看内存使用情况(默认为kb)-b:以字节为单位查看内存使用情况-s:可以在指定时间段内不简单监控内存的使用情况Uptime uptime命令是监控系统性能最常用的一个命令,主要是来统计系统当前的运行状态输出信息依次是:系统现在的时间,系统从上次开机到现在运行了多长时间,系统当前有多少个登录用户,系统在一分钟内、5分钟内、15分钟内的平均负载注意点:如果load average值长期大于系统CPU的个数则说明CPU很繁忙,负载很高,可能会影响系统性能NetstatNetstat命令用于显示本机网络连接、运行端口、路由表等信息命令行启动参数:netst at [选项]-a (all):显示一个所有的有效连接信息列表,包括已建立的连接(ESTABLISHED),也包括监听连接请求(LISTENING)的那些连接,断开连接(CLOSE_W AIT)或者处于联机等待状态的(TIME_WAIT)等-t (tcp):显示tcp相关选项-u (udp):仅显示udp相关选项-n :拒绝显示别名,能显示数字的全部转化成数字。
-l :仅列出有在Listen (监听) 的服務状态-p :显示建立相关链接的程序名-r :显示路由信息,路由表,除了显示有效路由外,还显示当前有效的连接-e :显示扩展信息,例如uid等-s :按各个协议进行统计-c :每隔一个固定时间,执行该netstat命令。
-v :显示当前的有效连接,与-n选项类似-I :显示自动匹配接口的信息-e :显示关于以太网的统计数据。
它列出的项目包括传送的数据报的总字节数、错误数、删除数、数据报的数量和广播的数量。
这些统计数据既有发送的数据报数量,也有接收的数据报数量。
这个选项可以用来统计一些基本的网络流量。
提示:LISTEN和LISTENING的状态只有用-a或者-l才能看到Psps命令就是最基本同时也是非常强大的进程查看命令.使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等.总之大部分信息都是可以通过执行该命令得到的。
psa:显示现行终端机下的所有程序,包括其他用户的程序。
ps -A :显示所有程序。
ps c :列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
ps -e :此参数的效果和指定"A"参数相同。
ps e :列出程序时,显示每个程序所使用的环境变量。
ps f :用ASCII字符显示树状结构,表达程序间的相互关系。
ps -H:显示树状结构,表示程序间的相互关系。
ps –N:显示所有的程序,除了执行ps指令终端机下的程序之外。
ps s:采用程序信号的格式显示程序状况。
ps S :列出程序时,包括已中断的子程序资料。
ps -t<终端机编号> :指定终端机编号,并列出属于该终端机的程序的状况。
ps u:以用户为主的格式来显示程序状况。
ps x:显示所有程序,不以终端机来区分。
Ps -l:较长较详细的显示该pid信息最常用的方法是ps -aux,然后再利用一个管道符号导向到grep去查找特定的进程,然后再对特定的进程进行操作。
Stracestrace常用来跟踪进程执行时的系统调用和所接收的信号。
在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。
strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间strace使用参数-p:跟踪指定的进程。
-f:跟踪由fork子进程系统调用。
-F:尝试跟踪vfork子进程系统调吸入,与-f同时出现时, vfork不被跟踪。
-o filename:默认strace将结果输出到stdout。
通过-o可以将输出写入到filename文件中。
-ff:常与-o选项一起使用,不同进程(子进程)产生的系统调用输出到filename.PID文件。