计量经济学课后习题1-8章
计量经济学课后习题答案第八章_答案

第八章虚拟变量模型1. 回归模型中引入虚拟变量的作用是什么?答:在模型中引入虚拟变量,主要是为了寻找某(些)定性因素对解释变量的影响。
加法方式与乘法方式是最主要的引入方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。
除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
2. 虚拟变量有哪几种基本的引入方式? 它们各适用于什么情况?答:在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。
除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
3.什么是虚拟变量陷阱?答:根据虚拟变量的设置原则,一般情况下,如果定性变量有m个类别,则需在模型中引入m-1个变量。
如果引入了m个变量,就会导致模型解释变量出现完全的共线性问题,从而导致模型无法估计。
这种由于引入虚拟变量个数与类别个数相等导致的模型无法估计的问题,称为“虚拟变量陷阱”。
4.在一项对北京某大学学生月消费支出的研究中,认为学生的消费支出除受其家庭的每月收入水平外,还受在学校中是否得到奖学金,来自农村还是城市,是经济发达地区还是欠发达地区,以及性别等因素的影响。
试设定适当的模型,并导出如下情形下学生消费支出的平均水平:(1) 来自欠发达农村地区的女生,未得到奖学金;(2) 来自欠发达城市地区的男生,得到奖学金;(3) 来自发达地区的农村女生,得到奖学金;(4) 来自发达地区的城市男生,未得到奖学金。
解答: 记学生月消费支出为Y,其家庭月收入水平为X,则在不考虑其他因素的影响时,有如下基本回归模型:Y i=β0+β1X i+μi有奖学金1 来自城市无奖学金0 来自农村来自发达地区 1 男性0 来自欠发达地区0 女性Y i=β0+β1X i+α1D1i+α2D2i+α3D3i+α4D4i+μi由此回归模型,可得如下各种情形下学生的平均消费支出:(1) 来自欠发达农村地区的女生,未得到奖学金时的月消费支出:E(Y i|= X i, D1i=D2i=D3i=D4i=0)=β0+β1X i(2) 来自欠发达城市地区的男生,得到奖学金时的月消费支出:E(Y i|= X i, D1i=D4i=1,D2i=D3i=0)=(β0+α1+α4)+β1X i(3) 来自发达地区的农村女生,得到奖学金时的月消费支出:E(Y i |= X i , D 1i =D 3i =1,D 2i =D 4i =0)=(β0+α1+α3)+β1X i (4) 来自发达地区的城市男生,未得到奖学金时的月消费支出: E(Y i |= X i ,D 2i =D 3i =D 4i =1, D 1i =0)= (β0+α2+α3+α4)+β1X i5. 研究进口消费品的数量Y 与国民收入X 的模型关系时,由数据散点图显示1979年前后Y 对X 的回归关系明显不同,进口消费函数发生了结构性变化:基本消费部分下降了,而边际消费倾向变大了。
计量经济学第二版课后习题答案1-8章 - 编辑版
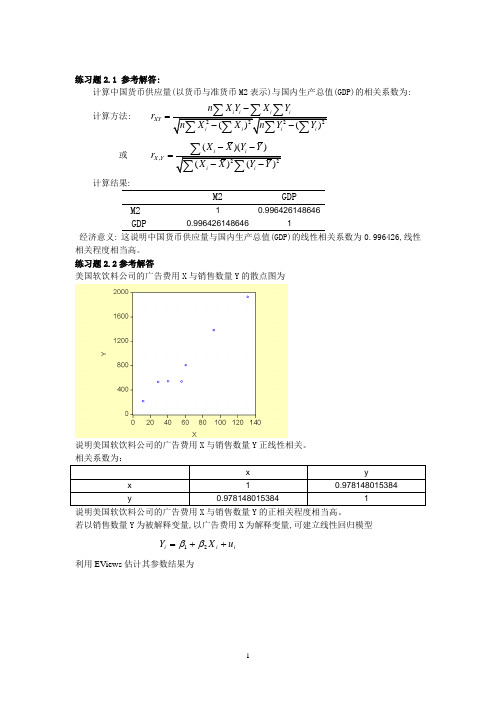
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答: 1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。
计量经济学习题及答案

计量经济学习题及答案计量经济学各章习题第⼀章绪论1.1 试列出计量经济分析的主要步骤。
1.2 计量经济模型中为何要包括扰动项?1.3 什么是时间序列和横截⾯数据? 试举例说明⼆者的区别。
1.4 估计量和估计值有何区别?第⼆章计量经济分析的统计学基础2.1 名词解释随机变量概率密度函数抽样分布样本均值样本⽅差协⽅差相关系数标准差标准误差显著性⽔平置信区间⽆偏性有效性⼀致估计量接受域拒绝域第I类错误2.2 请⽤例2.2中的数据求北京男⽣平均⾝⾼的99%置信区间。
2.3 25个雇员的随机样本的平均周薪为130元,试问此样本是否取⾃⼀个均值为120元、标准差为10元的正态总体?2.4 某⽉对零售商店的调查结果表明,市郊⾷品店的⽉平均销售额为2500元,在下⼀个⽉份中,取出16个这种⾷品店的⼀个样本,其⽉平均销售额为2600元,销售额的标准差为480元。
试问能否得出结论,从上次调查以来,平均⽉销售额已经发⽣了变化?第三章双变量线性回归模型3.1 判断题(判断对错;如果错误,说明理由)(1)OLS 法是使残差平⽅和最⼩化的估计⽅法。
(2)计算OLS 估计值⽆需古典线性回归模型的基本假定。
(3)若线性回归模型满⾜假设条件(1)~(4),但扰动项不服从正态分布,则尽管OLS 估计量不再是BLUE ,但仍为⽆偏估计量。
(4)最⼩⼆乘斜率系数的假设检验所依据的是t 分布,要求β?的抽样分布是正态分布。
(5)R 2=TSS/ESS 。
(6)若回归模型中⽆截距项,则0≠∑t e 。
(7)若原假设未被拒绝,则它为真。
(8)在双变量回归中,2σ的值越⼤,斜率系数的⽅差越⼤。
3.2 设YX β?和XYβ?分别表⽰Y 对X 和X 对Y 的OLS 回归中的斜率,证明 YX β?XYβ?=2r r 为X 和Y 的相关系数。
3.3 证明:(1)Y 的真实值与OLS 拟合值有共同的均值,即 Y nY n(2)OLS 残差与拟合值不相关,即0?=∑tt eY 。
李子奈计量经济学课后习题答案

第一章 绪论(一)基本知识类题型1-1. 什么是计量经济学?1-2. 简述当代计量经济学发展的动向。
1-3. 计量经济学方法与一般经济数学方法有什么区别?1-4.为什么说计量经济学是经济理论、数学和经济统计学的结合?试述三者之关系。
1-5.为什么说计量经济学是一门经济学科?它在经济学科体系中的作用和地位是什么? 1-6.计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?1-7.试结合一个具体经济问题说明建立与应用计量经济学模型的主要步骤。
1-8.建立计量经济学模型的基本思想是什么?1-9.计量经济学模型主要有哪些应用领域?各自的原理是什么?1-10.试分别举出五个时间序列数据和横截面数据,并说明时间序列数据和横截面数据有和异同?1-11.试解释单方程模型和联立方程模型的概念,并举例说明两者之间的联系与区别。
1-12.模型的检验包括几个方面?其具体含义是什么?1-13.常用的样本数据有哪些?1-14.计量经济模型中为何要包括随机误差项?简述随机误差项形成的原因。
1-15.估计量和估计值有何区别?哪些类型的关系式不存在估计问题?1-16.经济数据在计量经济分析中的作用是什么?1-17.下列假想模型是否属于揭示因果关系的计量经济学模型?为什么?⑴ 其中为第t 年农村居民储蓄增加额(亿元)、为第年城镇居民可支配收入总额(亿元)。
S t =+1120012..R t S t R t t ⑵ 其中S 为第(S t -=+144320030..R t t -11-t )年底农村居民储蓄余额(亿元)、R 为第t 年农村居民纯收入总额(亿元)。
t 1-18.指出下列假想模型中的错误,并说明理由:(1)RS RI IV t t =t -+83000024112... 其中,为第年社会消费品零售总额(亿元),为第t 年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),为第t 年全社会固定资产投资总额RS t t RI t IV t(亿元)。
计量经济学书后答案

《计量经济学》书后习题答案第一章作业答案3、解:(1)407181114616657937536164922221..xn x y x n y x ˆii i==⨯-⨯⨯-=--=β∑∑5054640719375310...x ˆy ˆ-=⨯-=β-=β 所以,样本回归方程为ii i x ..x ˆˆy ˆ4071505410+-=β+β= 回归系数1β的经济意义:价格每上涨(或下跌)一个单位,企业销售额平均提高(降低)1.407个单位。
(2)222222181111μμμσ=σ-=σ-=β∑∑ˆˆxn x ˆ)x x()ˆ(D ˆi i222222222081616111μμμσ+=σ-+=σ-+=β∑∑ˆ)(ˆ)xn x x n (ˆ))x x (x n()ˆ(D ˆi i 而()21693753616492407197531652622212222-⨯⨯--⨯-=--β--=-ε=σ∑∑∑μ).(.).(n )y x n y x (ˆy n yn ˆii ii396814398160936277...=-=1040396881181121..ˆ)ˆ(D ˆ=⨯=σ=βμ256439688161618161612220..)(ˆ)()ˆ(D ˆ=⨯+=σ+=βμ (3) 以0.05的显著性水平检验0=β183225645054000...s ˆt ˆˆ-=-=β=ββ;370410404071111...s ˆt ˆˆ==β=ββ 而临界值14482142975021.)(t )n (t.==-α-可以看出0βˆt 、1βˆt 的绝对值均大于临界值,说明回归参数0β、1β是显著的。
(4)求1β的置信度为95%的置信区间。
69104071104014482407121211.....)ˆ(D ˆ)n (t ˆ±=⨯±=β-±βα- 即(0.716,2.098) (5)求拟合优度2R5770936277398160221222...y n y)y x n y x (ˆ)y y()y y ˆ(SSTSSRR iii ii ==--β=--==∑∑∑∑拟合优度57.7%不高,说明价格只能解释企业销售额总变差的58%左右,还有42%左右得不到说明。
计量经济学习题及参考答案

计量经济学各章习题第一章绪论1.1试列出计量经济分析地主要步骤.1.2计量经济模型中为何要包括扰动项?1.3什么是时间序列和横截面数据? 试举例说明二者地区别1.4估计量和估计值有何区别?第二章计量经济分析地统计学基础2.1名词解释随机变量概率密度函数抽样分布样本均值样本方差协方差相关系数标准差标准误差显著性水平置信区间无偏性有效性一致估计量接受域拒绝域第I 类错误2.2请用例 2.2中地数据求北京男生平均身高地99%置信区间.2.325 个雇员地随机样本地平均周薪为130元,试问此样本是否取自一个均值为120 元、标准差为10 元地正态总体?文档收集自网络,仅用于个人学习2.4某月对零售商店地调查结果表明,市郊食品店地月平均销售额为2500 元,在下一个月份中,取出16 个这种食品店地一个样本,其月平均销售额为2600 元,销售额地标准差为480 元.试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化?文档收集自网络,仅用于个人学习第三章双变量线性回归模型3.1判断题(判断对错;如果错误,说明理由)(1)OLS 法是使残差平方和最小化地估计方法.(2)计算OLS 估计值无需古典线性回归模型地基本假定.(3)若线性回归模型满足假设条件(1)~(4),但扰动项不服从正态分布,则尽管OLS 估计量不再是BLUE ,但仍为无偏估计量.文档收集自网络,仅用于个人学习(4)最小二乘斜率系数地假设检验所依据地是t 分布,要求地抽样分布是正态分布.2(5)R2=TSS/ESS.(6)若回归模型中无截距项,则.(7)若原假设未被拒绝,则它为真.(8)在双变量回归中,地值越大,斜率系数地方差越大.3.2设和分别表示Y 对X 和X 对Y 地OLS 回归中地斜率,证明r 为X 和Y 地相关系数.3.3证明:(1)Y 地真实值与OLS 拟合值有共同地均值,即;(2)OLS 残差与拟合值不相关,即.3.4证明本章中( 3.18)和( 3.19)两式:(1)(2)3.5考虑下列双变量模型:模型1:模型2:(1)1 和1地OLS 估计量相同吗?它们地方差相等吗?(2)2 和2地OLS 估计量相同吗?它们地方差相等吗?3.6有人使用1980-1994 年度数据,研究汇率和相对价格地关系,得到如下结果:其中,Y=马克对美元地汇率X=美、德两国消费者价格指数(CPI)之比,代表两国地相对价格(1)请解释回归系数地含义;(2)X t 地系数为负值有经济意义吗?(3)如果我们重新定义X 为德国CPI与美国CPI之比,X 地符号会变化吗?为什么?3.7随机调查200 位男性地身高和体重,并用体重对身高进行回归,结果如下:其中Weight 地单位是磅(lb ),Height 地单位是厘米(cm).(1)当身高分别为177.67cm、164.98cm、187.82cm 时,对应地体重地拟合值为多少?(2)假设在一年中某人身高增高了 3.81cm,此人体重增加了多少?3.8设有10 名工人地数据如下:X 10 7 10 5 8 8 6 7 9 10Y 11 10 12 6 10 7 9 10 11 10 其中X= 劳动工时,Y= 产量(1)试估计Y=α+βX + u(要求列出计算表格);(2)提供回归结果(按标准格式)并适当说明;(3)检验原假设β=1.0.3.9用12 对观测值估计出地消费函数为Y=10.0+0.90X ,且已知=0.01,=200,=4000,试预测当X=250 时Y 地值,并求Y 地95%置信区间.文档收集自网络,仅用于个人学习3.10设有某变量(Y)和变量(X)1995—1999 年地数据如下:(3)试预测X=10 时Y 地值,并求Y 地95%置信区间.3.11根据上题地数据及回归结果,现有一对新观测值X =20,Y=7.62,试问它们是否可能来自产生样本数据地同一总体?文档收集自网络,仅用于个人学习3.12有人估计消费函数,得到如下结果(括号中数字为t 值):=15 + 0.81 =0.98(2.7)(6.5)n=19(1)检验原假设:=0(取显著性水平为5%)(2)计算参数估计值地标准误差;(3)求地95%置信区间,这个区间包括0 吗?3.13试用中国1985—2003 年实际数据估计消费函数:=α+β + u t其中:C代表消费,Y 代表收入.原始数据如下表所示,表中:Cr=农村居民人均消费支出(元)Cu=城镇居民人均消费支出(元)Y =国内居民家庭人均纯收入(元) Yr =农村居民家庭人均纯收入(元) Yu=城镇居民家庭人均可支配收入(元) Rpop=农村人口比重(%) pop=历年年底我国人口总数(亿人)P=居民消费价格指数(1985=100)Pr=农村居民消费价格指数(1985=100)Pu=城镇居民消费价格指数(1985=100)数据来源:《中国统计年鉴2004》使用计量经济软件,用国内居民人均消费、农村居民人均消费和城镇居民人均消费分别对各自地人均收入进行回归,给出标准格式回归结果;并由回归结果分析我国城乡居民消费行为有何不同.文档收集自网络,仅用于个人学习第四章多元线性回归模型4.1某经济学家试图解释某一变量Y 地变动.他收集了Y 和 5 个可能地解释变量~地观测值(共10 组),然后分别作三个回归,结果如下(括号中数字为t 统计量):文档收集自网络,仅用于个人学习( 1) = 51.5 + 3.21 R=0.63(3.45) (5.21)2) 33.43 + 3.67 + 4.62 + 1.21 R=0.75 文档收集自网络,仅用于个人学(3.61 )(2.56)(0.81) (0.22)3) 23.21 + 3.82 + 2.32 + 0.82 + 4.10 + 1.21(2.21 )(2.83)(0.62) (0.12) (2.10) (1.11)文档收集自网络,仅用于个人学习R=0.80 你认为应采用哪一个结果?为什么?4.2为研究旅馆地投资问题,我们收集了某地地1987-1995 年地数据来估计收益生产函数R=ALKe ,其中R=旅馆年净收益(万年) ,L=土地投入,K=资金投入, e 为自然对数地底.设回归结果如下(括号内数字为标准误差) :文档收集自网络,仅用于个人学习= -0.9175 + 0.273lnL + 0.733lnK R=0.94(0.212) (0.135) (0.125)(1)请对回归结果作必要说明;( 2)分别检验α和β 地显著性;( 3)检验原假设:α =β = 0;4.3我们有某地1970-1987 年间人均储蓄和收入地数据,用以研究1970-1978 和1978 年以后储蓄和收入之间地关系是否发生显著变化. 引入虚拟变量后,估计结果如下(括号内数据为标准差) :文档收集自网络,仅用于个人学习= -1.7502 + 1.4839D + 0.1504 - 0.1034D·R=0.9425 文档收集自网络,仅用于个人学习(0.3319) (0.4704) (0.0163) (0.0332)其中:Y=人均储蓄,X=人均收入,D= 请检验两时期是否有显著地结构性变化.4.4说明下列模型中变量是否呈线性,系数是否呈线性,并将能线性化地模型线性化.(1)(2)(3)4.5有学者根据某国19年地数据得到下面地回归结果:其中:Y=进口量(百万美元),X1 =个人消费支出(百万美元),X2 =进口价格/国内价格.(1)解释截距项以及X1和X2系数地意义;(2)Y 地总变差中被回归方程解释地部分、未被回归方程解释地部分各是多少?(3)进行回归方程地显著性检验,并解释检验结果;(4)对“斜率”系数进行显著性检验,并解释检验结果.4.6由美国46个州1992年地数据,Baltagi 得到如下回归结果:其中,C=香烟消费(包/人年),P=每包香烟地实际价格Y=人均实际可支配收入(1)香烟需求地价格弹性是多少?它是否统计上显著?若是,它是否统计上异于-1?(2)香烟需求地收入弹性是多少?它是否统计上显著?若不显著,原因是什么?(3)求出.4.7有学者从209 个公司地样本,得到如下回归结果(括号中数字为标准误差):其中,Salary=CEO 地薪金Sales=公司年销售额roe=股本收益率(%)ros=公司股票收益请分析回归结果.4.8为了研究某国1970-1992 期间地人口增长率,某研究小组估计了下列模型:其中:Pop=人口(百万人),t=趋势变量,.(1)在模型 1 中,样本期该地地人口增长率是多少?(2)人口增长率在1978 年前后是否显著不同?如果不同,那么1972-1977和1978-1992 两时期中,人口增长率各是多少?文档收集自网络,仅用于个人学习4.9设回归方程为Y= β0+β1X1+β2X2+β3X3+ u, 试说明你将如何检验联合假设:β1= β2 和β3 = 1 .文档收集自网络,仅用于个人学习4.10下列情况应引入几个虚拟变量,如何表示?(1)企业规模:大型企业、中型企业、小型企业;(2)学历:小学、初中、高中、大学、研究生.4.11在经济发展发生转折时期,可以通过引入虚拟变量来表示这种变化.例如,研究进口消费品地数量Y 与国民收入X 地关系时,数据散点图显示1979 年前后明显不同.请写出引入虚拟变量地进口消费品线性回归方程.文档收集自网络,仅用于个人学习4.12柯布-道格拉斯生产函数其中:GDP=地区国内生产总值(亿元)K=资本形成总额(亿元)L= 就业人数(万人)P=商品零售价格指数(上年=100)试根据中国2003 年各省数据估计此函数并分析结果.数据如下表所示第五章模型地建立与估计中地问题及对策5.1判断题(判断对错;如果错误,说明理由)(1)尽管存在严重多重共线性,普通最小二乘估计量仍然是最佳线性无偏估计量(BLUE ).(2)如果分析地目地仅仅是为了预测,则多重共线性并无妨碍. (3)如果解释变量两两之间地相关系数都低,则一定不存在多重共线性. (4)如果存在异方差性,通常用地t 检验和 F 检验是无效地. (5)当存在自相关时,OLS 估计量既不是无偏地,又不是有效地.(6)消除一阶自相关地一阶差分变换法假定自相关系数必须等于 1. (7)模型中包含无关地解释变量,参数估计量会有偏,并且会增大估计量地方差,即增大误差.(8)多元回归中,如果全部“斜率”系数各自经t 检验都不显著,则R2值也高不了.(9)存在异方差地情况下,OLS 法总是高估系数估计量地标准误差.(10)如果一个具有非常数方差地解释变量被(不正确地)忽略了,那么OLS 残差将呈异方差性.5.2考虑带有随机扰动项地复利增长模型:Y 表示GDP,Y0是Y 地基期值,r 是样本期内地年均增长率,t 表示年份,t=1978,⋯,2003.文档收集自网络,仅用于个人学习试问应如何估计GDP 在样本期内地年均增长率?5.3 检验下列情况下是否存在扰动项地自相关 .(1) DW=0.81,n=21,k=3(2)DW=2.25,n=15,k=2(3)DW=1.56,n=30,k=55.4有人建立了一个回归模型来研究我国县一级地教育支出:Y= β0+β1X1+β 2X2+β3X3+u其中:Y,X1,X2 和X3分别为所研究县份地教育支出、居民人均收入、学龄儿童人数和可以利用地各级政府教育拨款.文档收集自网络,仅用于个人学习他打算用遍布我国各省、市、自治区地100 个县地数据来估计上述模型.(1)所用数据是什么类型地数据?(2)能否采用OLS 法进行估计?为什么?(3)如不能采用OLS 法,你认为应采用什么方法?5.5试从下列回归结果分析存在问题及解决方法:(1)= 24.7747 + 0.9415 - 0.0424 R=0.9635SE:(6.7525)(0.8229)(0.0807)其中:Y=消费,X2=收入,X3=财产,且n=5000 (2)= 0.4529 - 0.0041t R=0.5284t:(-3.9606) DW=0.8252其中Y= 劳动在增加值中地份额,t=时间该估计结果是使用1949-1964 年度数据得到地.5.6工资模型:wi=b0+b1Si+b2Ei+b3Ai+b4Ui+ui其中Wi=工资,Si=学校教育年限,Ei=工作年限,Ai=年龄,Ui=是否参加工会.在估计上述模型时,你觉得会出现什么问题?如何解决?5.7你想研究某行业中公司地销售量与其广告宣传费用之间地关系.你很清楚地知道该行业中有一半地公司比另一半公司大,你关心地是这种情况下,什么估计方法比较合理.假定大公司地扰动项方差是小公司扰动项方差地两倍.文档收集自网络,仅用于个人学习(1)若采用普通最小二乘法估计销售量对广告宣传费用地回归方程(假设广告宣传费是与误差项不相关地自变量),系数地估计量会是无偏地吗?是一致地吗?是有效地吗?文档收集自网络,仅用于个人学习(2)你会怎样修改你地估计方法以解决你地问题?(3)能否对原扰动项方差假设地正确性进行检验?5.8考虑下面地模型其中GNP=国民生产总值,M =货币供给. (1)假设你有估计此模型地数据,你能成功地估计出模型地所有系数吗?说明理由.(2)如果不能,哪些系数可以估计?(3)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?(4)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?5.9采用美国制造业1899-1922年数据,Dougherty得到如下两个回归结果:(1)(2)其中:Y=实际产出指数,K=实际资本投入指数,L =实际劳动力投入指数,t=时间趋势(1)回归式(1)中是否存在多重共线性?你是如何得知地?(2)回归式(1)中,logK 系数地预期符号是什么?回归结果符合先验预期吗?为什么会这样?(3)回归式(1)中,趋势变量在其中起什么作用?(4)估计回归式(2)背后地逻辑是什么?(5)如果(1)中存在多重共线性,那么(2)式是否减轻这个问题?你如何得知?(6)两个回归地R2可比吗?说明理由.5.10有人估计了下面地模型:其中:C=私人消费支出,GNP=国民生产总值,D=国防支出假定,将(1)式转换成下式:使用1946-1975数据估计(1)、(2)两式,得到如下回归结果(括号中数字为标准误差):1)关于异方差,模型估计者做出了什么样地假定?你认为他地依据是什么?2)比较两个回归结果.模型转换是否改进了结果?也就是说,是否减小了估计标准误差?说明理由.5.11设有下列数据:RSS1=55,K =4,n1=30RSS3=140,K =4,n3=30 请依据上述数据,用戈德佛尔德-匡特检验法进行异方差性检验(5%显著性水平).5.12考虑模型(1)也就是说,扰动项服从AR (2)模式,其中是白噪声.请概述估计此模型所要采取地步骤.5.13对第 3 章练习题 3.13 所建立地三个消费模型地结果进行分析:是否存在序列相关问题?如果有,应如何解决?5.14为了研究中国农业总产值与有效灌溉面积、化肥施用量、农作物总播种面积、受灾面积地相互关系,选31 个省市2003 年地数据资料,如下表所示:文档收集自网络,仅用于个人学习表中:Y=农业总产值(亿元,不包括林牧渔)X1=有效灌溉面积(千公顷)X2=化肥施用量(万吨)X23=化肥施用量(公斤/亩)X3=农作物总播种面积(千公顷)X4=受灾面积(千公顷)(1)回归并根据计算机输出结果写出标准格式地回归结果;(2)模型是否存在问题?如果存在问题,是什么问题?如何解决?第六章动态经济模型:自回归模型和分布滞后模型6.1判断题(判断对错;如果错误,说明理由)(1)所有计量经济模型实质上都是动态模型.(2)如果分布滞后系数中,有地为正有地为负,则科克模型将没有多大用处. (3)若适应预期模型用OLS 估计,则估计量将有偏,但一致. (4)对于小样本,部分调整模型地OLS 估计量是有偏地.(5)若回归方程中既包含随机解释变量,扰动项又自相关,则采用工具变量法,将产生无偏且一致地估计量.(6)解释变量中包括滞后因变量地情况下,用德宾-沃森d 统计量来检测自相关是没有实际用处地.6.2用OLS 对科克模型、部分调整模型和适应预期模型分别进行回归时,得到地OLS 估计量会有什么样地性质?文档收集自网络,仅用于个人学习6.3简述科克分布和阿尔蒙多项式分布地区别.6.4考虑模型假设相关.要解决这个问题,我们采用以下工具变量法:首先用对和回归,得到地估计值,然后回归其中是第一步回归(对和回归)中得到地.(1)这个方法如何消除原模型中地相关?(2)与利维顿采用地方法相比,此方法有何优点?6.5设其中:M=对实际现金余额地需求,Y*=预期实际收入,R*=预期通货膨胀率假设这些预期服从适应预期机制:其中和是调整系数,均位于0和1之间.(1)请将M t 用可观测量表示;(2)你预计会有什么估计问题?6.6考虑分布滞后模型假设可用二阶多项式表示诸如下:若施加约束==0,你将如何估计诸系数(,i=0,1, (4)6.7为了研究设备利用对于通货膨胀地影响,T. A.吉延斯根据1971年到1988年地美国数据获得如下回归结果:文档收集自网络,仅用于个人学习其中:Y=通货膨胀率(根据GNP 平减指数计算)X t=制造业设备利用率X t-1 =滞后一年地设备利用率1)设备利用对于通货膨胀地短期影响是什么?长期影响又是什么?(2)每个斜率系数是统计显著地吗?(3)你是否会拒绝两个斜率系数同时为零地原假设?将利用何种检验?6.8考虑下面地模型:Y t = α+β(W0X t+ W1X t-1 + W2X t-2 + W3X t-3)+u t 请说明如何用阿尔蒙滞后方法来估计上述模型(设用二次多项式来近似) .6.9下面地模型是一个将部分调整和适应预期假说结合在一起地模型:Y t*= βX t+1eY t-Y t-1 = δ(Y t*- Y t-1) + u tX t+1e- X t e= (1-λ)( X t - X t e);t=1,2,⋯, n式中Y t*是理想值,X t+1e和X t e是预期值.试推导出一个只包含可观测变量地方程,并说明该方程参数估计方面地问题.文档收集自网络,仅用于个人学习第七章时间序列分析7.1单项选择题(1)某一时间序列经一次差分变换成平稳时间序列,此时间序列称为()地.A.1 阶单整B.2阶单整C.K 阶单整D.以上答案均不正确文档收集自网络,仅用于个人学习(2)如果两个变量都是一阶单整地,则().A .这两个变量一定存在协整关系B.这两个变量一定不存在协整关系C.相应地误差修正模型一定成立D.还需对误差项进行检验文档收集自网络,仅用于个人学习(3)如果同阶单整地线性组合是平稳时间序列,则这些变量之间关系是() .A. 伪回归关系B.协整关系C.短期均衡关系D. 短期非均衡关系(4).若一个时间序列呈上升趋势,则这个时间序列是().A .平稳时间序列B.非平稳时间序列C.一阶单整序列 D. 一阶协整序列7.2请说出平稳时间序列和非平稳时间序列地区别,并解释为什么在实证分析中确定经济时间序列地性质是十分必要地.文档收集自网络,仅用于个人学习7.3什么是单位根?7.4Dickey-Fuller(DF)检验和Engle-Granger(EG)检验是检验什么地?文档收集自网络,仅用于个人学习7.5什么是伪回归?在回归中使用非均衡时间序列时是否必定会造成伪回归?7.6由1948-1984 英国私人部门住宅开工数(X)数据,某学者得到下列回归结果:注:5%临界值值为-2.95,10%临界值值为-2.60. (1)根据这一结果,检验住宅开工数时间序列是否平稳.(2)如果你打算使用t 检验,则观测地t 值是否统计显著?据此你是否得出该序列平稳地结论?(3)现考虑下面地回归结果:请判断住宅开工数地平稳性.7.7由1971-I 到1988-IV 加拿大地数据,得到如下回归结果;A.B.C.其中,M1=货币供给,GDP=国内生产总值,e t=残差(回归A)(1)你怀疑回归 A 是伪回归吗?为什么?(2)回归 B 是伪回归吗?请说明理由.(3)从回归 C 地结果,你是否改变(1)中地结论,为什么?(4)现考虑以下回归:这个回归结果告诉你什么?这个结果是否对你决定回归 A 是否伪回归有帮助?7.8 检验我国人口时间序列地平稳性,数据区间为1949-2003 年.单位:万人7.9对中国进出口贸易进行协整分析,如果存在协整关系,则建立E CM 模型.1951-2003 年中国进口(im )、出口(ex)和物价指数(pt,商品零售物价指数)时间序列数据见下表.因为该期间物价变化大,特别是改革开放以后变化更为激烈,所以物价指数也作为一个解释变量加入模型中.为消除物价变动对进出口数据地影响以及消除进出口数据中存在地异方差,定义三个变量如下:文档收集自网络,仅用于个人学习第八章联立方程模型8.1判断题(判断对错;如果错误,说明理由)(1)OLS 法适用于估计联立方程模型中地结构方程.(2)2SLS 法不能用于不可识别方程.(3)估计联立方程模型地2SLS 法和其它方法只有在大样本地情况下,才能具有我们期望地统计性质 .(4) 联立方程模型作为一个整体,不存在类似 R 2这样地拟合优度测度 .(5) 如果要估计地方程扰动项自相关或存在跨方程地相关, 则 2SLS 法和其它估 计结构方程地方法都不能用 .(6) 如果一个方程恰好识别,则 ILS 和 2SLS 给出相同结果 .8.2 单项选择题1) 结构式模型中地方程称为结构方程 .在结构方程中, 解释变量可以是前定变3) 如果联立方程模型中某个结构方程包含了模型中所有地变量,则这个方程5)当一个结构式方程为恰好识别时,这个方程中内生解释变量地个数( A .与被排除在外地前定变量个数正好相等 B .小于被排除在外地前定变量个数 C .大于被排除在外地前定变量个数D .以上三种情况都有可能发生 文档收集自网络,仅用于个人学习6) 简化式模型就是把结构式模型中地内生变量表示为 ( ).A. 外生变量和内生变量地函数关系B.前定变量和随机误差项地模型C.滞后变量和随机误差项地模型 D.外生变量和随机误差项地模量,也可以是 ( ).文档收集自网络,仅用于个人学习 A. 外生变量 B.滞后变量2)前定变量是 ( )地合称 .A.外生变量和滞后内生变量C.内生变量D. 外生变量和内生变量 C.外生变量和虚拟变量 D. 解释变量和被解释变量( ).A. 恰好识别B.不可识别 (4) 下面说法正确地是( ).A.内生变量是非随机变量 C.外生变量是随机变量 C.过度识别 D.不确定B. 前定变量是随机变量个人收集整理勿做商业用途型7) 对联立方程模型进行参数估计地方法可以分两类,即:( ).A.间接最小二乘法和系统估计方法B.单方程估计法和系统估计方法个人收集整理勿做商业用途C.单方程估计法和二阶段最小二乘法D.工具变量法和间接最小二乘法(8)在某个结构方程过度识别地条件下,不适用地估计方法是().A. 间接最小二乘法B.工具变量法C.二阶段最小二乘法D.有限信息极大似然估计法8.3行为方程和恒等式有什么区别?8.4如何确定模型中地外生变量和内生变量?8.5考虑下述模型:C t = α + β D t +u t I t = γ + δD t-1 + νt D t = C t +I t + Z t ;t=1 ,2,⋯,n其中 C = 消费支出,D= 收入,I = 投资,Z = 自发支出. C、I 和D是内生变量.试写出消费支出地简化型方程,并研究各方程地识别问题.8.6考虑下述模型:Y t = C t + I t +G t +X tC t = β 0 + β 1D t + β2C t-1 + u tD t = Y t –T tI t = α0 + α1Y t + α2R t-1 +νt 模型中各方程是正规化方程,u t、νt为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)写出用2SLS法进行估计时,每个阶段中要估计地方程.8.7下面是一个简单地美国宏观经济模型(1960-1999)其中C=实际私人消费,I= 实际私人总投资,G=实际政府支出,Y =实际GDP,M= 当年价M2,R=长期利率;P=消费价格指数.内生变量:C,I,R,Y 前定变量:C t-1,I t-1,M t-1,P t,R t-1 和G t.(1)应用识别地阶条件,决定各方程地识别状态;(2)你打算用什么方法来估计可识别行为方程?8.8假设有如下计量经济模型:其中,Y=国民收入,I=净资本形成,C=个人消费,Q =利润,P=生活费用指数,R= 工业劳动生产率1)写出模型地内生变量、外生变量和前定变量;个人收集整理勿做商业用途(2)用识别地阶条件确定各方程地识别状态;(3)此模型中是否有可以用ILS 法估计地方程?如有,请指出;(4)写出用2SLS 法进行估计时,每个阶段中要估计地方程. 8.9考虑下述模型:消费方程:C t=α0 +α 1Y t +α2C t-1 +u①投资方程:I t=β0 +β1Y t +β2I t –1+u2t②进口方程:M t = 0 + 1Y t + u3t ③Y t = C t+ I t + G t + X t - M t模型中各方程是正规化方程,u 1t, ⋯u3t为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)利用阶条件识别各行为方程.(3)写出用3SLS 进行估计时地步骤.8.10考察下述国民经济地简单模型式中,C为消费,Y 为国民收入,I 为投资,R为利率.设样本容量n 为20,已算得中间结果为:(1)判别模型中消费方程地识别状态;(2)用间接最小二乘法求消费方程结构式系数;(3)将采用哪种方法估计投资方程?为什么?(不必计算)8.11由联立方程模型;得到其简化式如下:(1)两结构方程可识别吗?(2)如果知道,识别情况有何变化?(3)若对简化式进行估计,结果如下:个人收集整理勿做商业用途试求出结构参数地值,并说明如何检验原假设个人收集整理勿做商业用途版权申明本文部分内容,包括文字、图片、以及设计等在网上搜集整理。
计量经济学课后习题1-8章

计量经济学课后习题1-8章计量经济学课后习题总结第一章绪论1、什么事计量经济学?计量经济学就是把经济理论、经济统计数据和数理统计学与其他数学方法相结合,通过建立经济计量模型来研究经济变量之间相互关系及其演变的规律的一门学科。
2、计量经济学的研究方法有那几个步骤?(1)建立模型:包括模型中变量的选取及模型函数形式的确定。
(2)模型参数的估计:通过搜集相关是数据,采用不同的参数估计方法,进行模型参数估计。
(3)模型参数的检验:包括经济检验、以及统计学方面的检验。
(4)经济计量模型的应用:经济预测、经济结构分析、经济政策评价。
3、经济计量模型有哪些特点?经济计量模型是一个代数的、随即的数学模型,它可以是线性或非线性(对参数而言)形式。
4、经济计量模型中的数据有哪几种类型(1)定量数据:时间序列数据、截面数据、面板数据(2)定型数据:虚拟变量数据第二章一元线性回归模型1、什么是相关关系?它有那几种类型?(书上没有确切的答案)(1)相关关系:当一个或几个相互联系的变量取一定的数值时,与之相对应的另一变量的值虽然不确定,但它仍按某种规律在一定的范围内变化。
变量间的这种相互关系,称为具有不确定性的相关关系(2)相关关系的种类1.按相关程度分类:(1)完全相关:一种现象的数量变化完全由另一种现象的数量变化所确定。
在这种情况下,相关关系便称为函数关系,因此也可以说函数关系是相关关系的一个特例。
(2)不完全相关:两个现象之间的关系介于完全相关和不相关之间(3)不相关:两个现象彼此互不影响,其数量变化各自独立2.按相关的方向分类:(1)正相关:两个现象的变化方向相同(2)负相关:两个现象的变化方向相反3.按相关的形式分类(1)线性相关:两种相关现象之间的关系大致呈现为线性关系(2)非线性相关:两种相关现象之间的关系并不表现为直线关系,而是近似于某种曲线方程的关系4.按相关关系涉及的变量数目分类(1)单相关:两个变量之间的相关关系,即一个因变量与一个自变量之间的依存关系(2)复相关:多个变量之间的相关关系,即一个因变量与多个自变量的复杂依存关系(3)偏相关:当研究因变量与两个或多个自变量相关时,如果把其余的自变量看成不变(即当作常量),只研究因变量与其中一个自变量之间的相关关系,就称为偏相关。
计量经济学》第三版靳庭良章课后题答案

Rooms=4
房间数为4时,住房价格最低
(6)
ln(price) = 17.59 − 0.868 ln(nox) − 0.087 ln(dist) − 0.545rooms
+ 0.062rooms 2 − 0.044stratio
6.(1)Y = 0 + 1 + 2 +
(2) Y尖 = −50.01638 + 0.086450 + 52.37031
(3)0至少为0,负数不符合经济经济意义;1介于0和1之间,符合经济意义,
2至少为0,符合经济意义。
)F = 146.3 > 0.05(2,18)
原回归方程具有联合显著性。
(4)Y尖 = −50.01638 + 0.086450 ∗ 2500 + 52.37031 ∗ 16 = 1004.03358
《计量经济学》
(第三版)
——靳庭良
第一章练习题
一、1.D 2.C 3.A
二、1.计量经济学是是一门由统计学、理论经济学和数学结合形成的一门经济学
分支学科,其目的是揭示社会经济现象发展变化中的数量规律。
计量经济学与理论经济学:第 3 页第 2 段
计量经济学与经济统计学:第 3 页第 3 段
计量经济学与数理统计学:第 3 页第 4 段
取全微分得 = 0.86
dY = ∗ (0.86
+ 0.22dZ
20
+ 0.22dZ) = 1000 ∗ (0.86 ∗
+ 0.22 ∗ 1) = 228.6
2000
第二章练习题
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量经济学课后习题总结第一章绪论1、什么事计量经济学?计量经济学就是把经济理论、经济统计数据和数理统计学与其他数学方法相结合,通过建立经济计量模型来研究经济变量之间相互关系及其演变的规律的一门学科。
2、计量经济学的研究方法有那几个步骤?(1)建立模型:包括模型中变量的选取及模型函数形式的确定。
(2)模型参数的估计:通过搜集相关是数据,采用不同的参数估计方法,进行模型参数估计。
(3)模型参数的检验:包括经济检验、以及统计学方面的检验。
(4)经济计量模型的应用:经济预测、经济结构分析、经济政策评价。
3、经济计量模型有哪些特点?经济计量模型是一个代数的、随即的数学模型,它可以是线性或非线性(对参数而言)形式。
4、经济计量模型中的数据有哪几种类型(1)定量数据:时间序列数据、截面数据、面板数据(2)定型数据:虚拟变量数据第二章一元线性回归模型1、什么是相关关系?它有那几种类型?(书上没有确切的答案)(1)相关关系:当一个或几个相互联系的变量取一定的数值时,与之相对应的另一变量的值虽然不确定,但它仍按某种规律在一定的范围内变化。
变量间的这种相互关系,称为具有不确定性的相关关系(2)相关关系的种类1.按相关程度分类:(1)完全相关:一种现象的数量变化完全由另一种现象的数量变化所确定。
在这种情况下,相关关系便称为函数关系,因此也可以说函数关系是相关关系的一个特例。
(2)不完全相关:两个现象之间的关系介于完全相关和不相关之间(3)不相关:两个现象彼此互不影响,其数量变化各自独立2.按相关的方向分类:(1)正相关:两个现象的变化方向相同(2)负相关:两个现象的变化方向相反3.按相关的形式分类(1)线性相关:两种相关现象之间的关系大致呈现为线性关系(2)非线性相关:两种相关现象之间的关系并不表现为直线关系,而是近似于某种曲线方程的关系4.按相关关系涉及的变量数目分类(1)单相关:两个变量之间的相关关系,即一个因变量与一个自变量之间的依存关系(2)复相关:多个变量之间的相关关系,即一个因变量与多个自变量的复杂依存关系(3)偏相关:当研究因变量与两个或多个自变量相关时,如果把其余的自变量看成不变(即当作常量),只研究因变量与其中一个自变量之间的相关关系,就称为偏相关。
2、相关系数的含义是什么?(书上没有确切的答案)衡量两个变量线性相关密切程度的量。
对于容量为n的两个变量x,y的相关系数r̅Y̅是两变量的平均值(xy)可写为,式中X3、什么是回归关系?它与相关关系有何区别?(书上没有确切的答案)(1)所谓回归关系,就是是在掌握大量观察数据的基础上,利用数理统计方法建立因变量与自变量之间的回归关系函数表达式(称回归方程式),从而确立的变量之间的关系。
(2)相关关系中,通过相关系数来测度两个变量之间的关联程度。
而在回归关系中,是通过一个或几个变量的设定值,试图预测另一个或几个变量的均值及其可能的变化范围。
百度:(1.相关分析主要通过相关系数来判断两个变量之间是否存在着相互关系及其关系的密切程度,其前提条件是两个变量都是随机变量,且变量之间不必区别自变量和因变量。
而回归分析研究一个随机变量(Y)与另一个非随机变量(X)之间的相互关系,且变量之间必须区别自变量和因变量。
(2.相关系数只能观察变量间相关关系的密切程度和方向,不能估计推算具体数值。
而回归分析可以根据回归方程,用自变量数值推算因变量的估计值。
(3.互为因果关系的两个变量,可以拟合两个回归方程,且互相独立、不能互相替换。
而相关系数却只有一个,即自变量与因变量互换相关系数不变。
4、回归模型中的随机误差项包含哪些因素?用什么方法来估计它?(1)模型中的省略变量:(2)一些随机因素(3)统计误差(4)模型形式的误差5、最小二乘法的含义是?一元线性回归模型参数的最小二乘估计表达式?(1)最小二乘法(又称最小平方法)是一种数学优化技术。
它通过最小化误差的平方和寻找数据的最佳函数匹配。
利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。
最小二乘法还可用于曲线拟合(2) ∑∑=i iii i 1x y x b X Y 10b -b =其中 ni i ∑=XX ; n Y i i ∑=Y ; X X -x i i = ; Y Y -y i i = 6、一元线性回归模型有哪些基本假设?(1) 回归模型对参数而言是线性的(2) 才重复的样本中,自变量X 的取值被认为是固定的,或者说X 是非随机的(3) 干扰项的均值为零,记为E (εi )= 0(4) εi 的方差相等,即Var (εi )= E [ εi – E(εi ) ] = E(εi 2)(5) 各干扰项之间无自相关性,即Cov (εi ,εj )= E [ εi – E(εi ) ] [ εj – E(εj ) ]= E (εi ) E (εj )=0(6) εi 和X i 的协方差为零,即Cov (εi ,X i )= E [ εi – E(εi ) ] [X i – E(X i ) ]= E [ εi (X i – E(X i ))]= E (εi X i ) – E (X i ) E (εi )= 0(7) 观测次数n 必须充分大于待估计的参数个数(8) X 值要有变异性,即Var (X )必须为一个有限的正数(9) 关于回归模型的设定是正确的(10) 没有多重共线性7、最小二乘估计量有哪些统计性质?(1) 线性性质:估计是0b 和1b 是Y i 的线性函数(2) 无偏性,用公式描述即E (0b )= b 0E (1b )= b 1(3) 最小方差性:OLS 估计量与用任何方法求得的线性无偏估计量相比,其方差是最小的8、拟合优度的含义和方法是什么?能否用残差平方和作为拟合优度的指标?(未知)(1) 拟合优度是指回归直线对观测值的拟合程度,用样本决定系数R²=RSS/TSS来度量,由定义知,0≤R²≤1。
显然如果样本决定系数越接近1,则说明线性拟合优度越好,R 2 = 1 表示完全线性关系,R 2 = 0 表示完全不具备线性关系。
9、回归参数显著性t 检验的含义和方法是什么?(书上没有确切的答案)(1) t 检验是指对各回归系数显著性所进行的一种检验。
(2) 首先提出原假设和被备择假设,计算其相应的统计量T ,根据显著性水平α计算置信区间即可接受域以及拒绝域(临界域),如果统计量T 的值落在临界域上,则称之为在统计上显著地,这是拒绝原假设。
同样,如果统计量的值落在接受域中,则称统计上不显著,这是不拒绝原假设10、回归参数显著性F 检验的含义和方法是什么?(书上没有确切的答案)(1) F 检验是对回归模型的整体性检验(2)首先提出原假设和被备择假设,计算其相应的统计量F ,根据显著性水平α计算置信区间即可接受域以及拒绝域(临界域),如果统计量F 的值落在临界域上,则称之为在统计上显著地,这是拒绝原假设。
同样,如果统计量的值落在接受域中,则称统计上不显著,这是不拒绝原假设11、点预测和区间预测有何区别?(书上没有确切的答案)点预测是指利用已有的已经验证其线性关系成立的模型,通过给定自变量X 的一个特定值,通过回归模型来预测因变量Y 的一个值,点预测的结果是一个值点。
而区间预测在点预测的基础上,通过引入Y ̂0的方差,进而求出在一定的置信水平1-α下因变量Y 所在的一个范围,其预测的结果是一个值域区间。
第三章 多元线性回归模型1、多元线性回归模型表达式ε+=XB Y 中各含量的含义是什么?Y 表示因变量Y i 的矩阵形式,X 表示自变量X ij 的矩阵形式,B 是自变量的系数矩阵,ε表示随机项矩阵。
2、多元线性回归方程BX Y ˆˆ= 中各含量的含义是什么? Bˆ是对B 的估计值,Y ˆ是基于B ˆ相对于给定的X 矩阵的因变量估计值矩阵3、写出多元线性回归模型参数的最小二乘估计的矩阵表达式。
B̂=[X T X]−1X T Y4、与一元线性回归相比,多元线性回归模型增加了什么基本假设?有何作用?(1) 增加了无多重共线性的假设条件,即各个自变量X 之间无确定的线性关系。
矩阵形式为RANK (X )= k + 1(2) 多重共线性会使得各个自变量或者其线性组合存在线性关系,这种非线性独立的自变量会对估计的结果产生不良影响,这一假设能够消除这种不良影响。
5、样本可决系数与调整的样本可决系数有什么区别和联系?他们在模型的检验中有什么作用?它们都是判定样本拟合优度程度的标准,调整的样本可决系数是在样本可决系数的基础上,通过增加“惩罚性”的系数,以消除或者减少通过增加变量个数而提高拟合优度的倾向性而得出的。
可以利用它们进行模型的拟合优度检验。
6、写出多元线性回归模型中的随机误差项 ε的方差的无偏估计表达式。
S e2=∑e i2 i7、分别写出回归参数显著性t检验、回归参数显著性F检验的步骤。
如何理解接受原假设H的含义?(1)t检验:首先提出原假设和被备择假设,计算其相应的统计量T,根据显著性水平α计算置信区间即可接受域以及拒绝域(临界域),如果统计量T的值落在临界域上,则称之为在统计上显著地,这是拒绝原假设。
同样,如果统计量的值落在接受域中,则称统计上不显著,这是不拒绝原假设(2)F检验:首先提出原假设和被备择假设,计算其相应的统计量F,根据显著性水平α计算置信区间即可接受域以及拒绝域(临界域),如果统计量F的值落在临界域上,则称之为在统计上显著地,这是拒绝原假设。
同样,如果统计量的值落在接受域中,则称统计上不显著,这是不拒绝原假设(3)如何理解需根据具体的H而定,书中给出的例子中,t检验中接受原假设H的含义是指参数对应的自变量与因变量的线性关系不显著;F检验中接受原假设H的含义指线性模型的整体不显著。
第四章异方差1.什么是异方差性答:如果随机项εi的方差受到解释变量取值的影响,随解释变量取值的变化而变化,即Var(εi)=f(X1i,X2i,…X ki)=σ2εi(i=1,2,…,n)σ2εi与i有关,不是一个常数,此时称随机项εi存在异方差。
2.异方差在线性回归模型中存在的主要原因有哪些答:(1)模型数学形式的偏差(2)模型中省略的对被解释变量有影响的解释变量(3)模型中变量观测值的测量误差(4)对被解释变量有影响的各种随机因素上述因素中,省略解释变量是造成随机项异方差的主要原因。
3.异方差可以造成哪些结果答:(1)如果随机项εi存在异方差,则参数的最小二乘估计量是线性的和无偏的。
因为参数的最小二乘估计量的表达式只依赖于残差平方和最小这一原则,与随机项εi的古典假设无关,因此线性特征仍成立。
参数的最小二乘估计量的无偏性依赖于解释变量的非随机变量和随机项的零均值假定,与同方差假定无关,因此当同方差假定不成立时,并不影响到无偏性的成立。