SQL Server 2008数据挖掘全过程详解
《SQL Server 2008数据库设计教程》教学课件 第2章

默认情况下,SQL Server Management Studio中将显示两个窗格,如以下 图所示。
“SQL Server Management Studio〞窗口
〔1〕“对象资源管理器〞窗格 “对象资源管理器〞窗格位于窗口的左侧,其中显示了效劳器中所有数据库 对象的树视图。单击各工程前的“+〞号可展开该工程列表,此时“+〞号将变 为“-〞号;单击“-〞号可收起工程列表,此时“-〞号将变为“+〞号。另 外,双击各工程也可依次展开或收起工程列表。
SQL Server Management Studio是一个集成环境,用于访问、配置和管 理所有SQL Server 组件。它组合了大量图形工具和丰富的脚本编辑器,使各 种技术水平的开发人员和管理员都能访问SQL Server。
SQL Server Management Studio将以前版本的 SQL Server 中包括的企业 管理器和查询分析器的各种功能,集成到一个单一环境中。此外,它还用于管 理Analysis Services,Integration Services,Reporting Services和XQuery, 从而为数据库开发人员及数据库管理人员提供了更大的工作便利。
报表效劳为用户提供了支持Web方式的企业级报表功能。
集成效劳是一个数据集成平台,负责完成与数据有关的提 取、转换和加载等操作。
SQL Server 2021提供两种类型的数据库,即系统数据库和用户数据库,如 以下图所示。
SQL Server 2021的数据库
当SQL Server 2021安装成功后,系统将自动创立5个系统数据库。这些系 统数据库用于存放系统级信息,如系统配置、登录账户信息、数据库文件信息、 警报、作业等。SQL Server 2021使用这些系统级信息管理和控制整个数据库效 劳器系统,如下表所示。
《数据仓库与数据挖掘技术》-Sqlserver2008r2的使用

《数据仓库与数据挖掘技术》实验报告Sqlserver2008r2的使用一、实验目的1.掌握在SQL Server中使用对象资源管理器和SQL命令创建数据库与修改数据库的方法。
2.掌握在SQL Server中使用对象资源管理器或者SQL命令创建数据表和修改数据表的方法(以SQL命令为重点)。
3. 掌握在SQL Server中的查询操作二、实验环境计算机window7三、实验内容与实验过程及分析(写出详细的实验步骤,并分析实验结果)实验内容:一.给定如表3.6、表3.7和表3.8所示的学生信息。
续表课程号学号作业1成绩作业2成绩作业3成绩K006 0591 80 80 80M001 0496 70 70 80M001 0591 65 75 75S001 0531 80 80 80S001 0538 60 801.在SQL Server中使用对象资源管理器和SQL命令创建学生作业管理数据库,数据库的名称自定。
(1)使用对象资源管理器创建数据库,请给出重要步骤的截图。
(2)删除第(1)步创建的数据库,再次使用SQL命令创建数据库,请给出SQL代码。
create database学生作业on(name=学生作业_data,filename='E:\学生作业.mdf',size=10,MAXSIZE=500,FILEGROWTH=10)log on(name=学生作业_log,filename='E:\学生作业.ldf',size=10,MAXSIZE=500,filegrowth=10)(3)创建数据库之后,如果有需要,可以修改数据库。
2.对表3.6,表3.7和表3.8,分别以下表的方式给出各字段的属性定义和说明。
3.使用SQL命令在学生作业管理数据库中建立学生表、课程表和学生作业表,在实验报告中给出SQL代码。
create table student(学号char(4)primary key,姓名nchar(4)not null,性别char(2)not null,专业班级nchar(4)not null,出生日期smalldatetime not null,练习电话char(11),)create table course(课程号char(4)primary key,课程名nvarchar(10)not null,学分数real not null,学时数tinyint not null,任课老师nchar(4)not null,)create table work(课程号char(4),学号char(4),作业1成绩tinyintconstraint one_ck check (作业1成绩<= 100),作业2成绩tinyintconstraint two_ck check (作业2成绩<= 100),作业3成绩tinyintconstraint three_ck check (作业3成绩<= 100),constraint test_pk primary key(课程号,学号))4.在各个表中输入表3.6、表3.7和表3.8中的相应内容。
第7章 使用SQL Server 2008操作

使用COMPUTE BY子句 7.1.12 使用COMPUTE BY子句
使用COMPUTE函数可以对查询结果进行简单的计算,而在 函数可以对查询结果进行简单的计算, 使用 函数可以对查询结果进行简单的计算 实际运用中, 实际运用中,可以需要对不同类别的查询结果进行不同 的分类计算。 的分类计算。
使用GROUP BY子句 7.1.13 使用GROUP BY子句
使用IN IN关键字判定查询结果范围 7.1.8 使用IN关键字判定查询结果范围
在很多情况下,可能存在多个查询条件并列的情况, 在很多情况下,可能存在多个查询条件并列的情况,可以使 关键字将它们并列连接, 用OR关键字将它们并列连接,也可以使用 关键字进行 关键字将它们并列连接 也可以使用IN关键字进行 查询。这样比使用两个OR运算符进行查询更为简单,并 运算符进行查询更为简单, 查询。这样比使用两个 运算符进行查询更为简单 且易于阅读和理解。 且易于阅读和理解。
使用WHERE WHERE子句设定查询条件 7.1.6 使用WHERE子句设定查询条件
使用WHERE子句可以限制查询的范围。通常情况下,必须 子句可以限制查询的范围。通常情况下, 使用 子句可以限制查询的范围 定义一个或多个条件限制查询选择的数据行。 定义一个或多个条件限制查询选择的数据行。WHERE子 子 句指定逻辑表达式(返回值为真或假的表达式), ),结果 句指定逻辑表达式(返回值为真或假的表达式),结果 集将返回表达式为真的数据行。 集将返回表达式为真的数据行。 在WHERE子句中,可以包含比较运算符、逻辑运算符。比 子句中,可以包含比较运算符、逻辑运算符。 子句中 较运算符有=(等于)、 )、<>(不等于)、 )、!=(不等于)、 较运算符有 (等于)、 (不等于)、 (不等于)、 >(大于)、 (大于等于)、 (不大于)、 (小于 )、>=(大于等于)、 )、!>(不大于)、 )、<( (大于)、 )、<=(小于等于)、 )、!< 不小于)。 )。逻辑运算符有 )、 (小于等于)、 (不小于)。逻辑运算符有 AND(与)、 ( )、QR(或)、 ( )、NOT(非),用来连接表达式 ( ),用来连接表达式 。通过使用比较运算符能够查询一定的取值范围。 通过使用比较运算符能够查询一定的取值范围。
SQL server 2008数据库详细解析

SQL server 2008篇一、数据库系统概述1、数据的概念2、数据处理的概念3、数据库的发展阶段4、数据库系统的组成5、数据库的概念6、数据库管理系统的概念7、数据库管理系统的功能8、常见的数据模型以及特点9、数据结构的概念10、数据操作的概念11、数据的完整性约束的概念12、元组的概念13、关系数据库的概念二、数据库设计1、数据库设计的概念2、概念结构设计的方法三、SQL server 2008基础1、SQL server 2008的新增功能2、SQL server 2008的安装过程3、SQL server 2008的版本4、T-SQL语言概念5、T-SQL语言的特点6、T-SQL语言分类四、数据库的概念和操作5、SQL server 2008物理数据库的概念6、SQL server 2008数据库文件的类型7、SQL server 2008数据库文件组的概念8、SQL server 2008文件组的应用规则9、SQL server 2008逻辑数据库的概念10、SQL server 2008逻辑数据库的分类11、master数据库的作用12、model数据库的作用13、msdb数据库的作用14、tempdb数据库的作用15、使用T-SQL语句创建数据库16、使用T-SQL语句修改数据库17、使用T-SQL语句删除数据库文件18、使用T-SQL语句更名数据库19、使用T-SQL语句删除数据库五、SQL server 2008表的操作1、数据类型2、创建表的T-SQL语句3、修改表的T-SQL语句4、约束的概念5、列约束的概念6、表约束的概念7、SQL server约束的类型8、创建修改和删除主键约束的T-SQL语句9、PRIMARY KEY约束的作用10、创建修改和删除唯一性约束的T-SQL语句11、UNIQUE约束的作用12、创建修改和删除外键约束的T-SQL语句13、FOREING KEY约束的作用14、创建修改和删除限制约束的T-SQL语句15、FHECK约束的作用16、创建修改和删除DEFAULT约束的T-SQL语句17、DEFAULT约束的作用18、对表中插入数据的T-SQL语句19、对表中修改数据的T-SQL语句20、对表中删除数据的T-SQL语句21、清空表的T-SQL语句22、MERGE语句的作用和用法23、删除表的T-SQL语句24、数据的导入和导出六、数据库查询1、SELECT查询语法2、简单查询的分类3、投影查询的使用方法4、改变查询结果的显示标题(= AS)5、选择查询的使用的方法6、常用的查询条件(1)关系表达式的使用(2)逻辑表达式的使用(3)确定范围关键字的使用(4)确定集合关键字的使用(5)字符匹配关键字的使用(6)空值关键字的使用7、聚合函数查询的使用方法8、常用的聚合函数功能(1)sum(列名)(2)avg(列名)(3)min(列名)(4)max(列名)(5)count(列名)(6)count(*)9、分组的T-SQL语句10、WITH CUBE的使用11、WITH ROLLUP的使用12、数据汇总compute的使用13、连接查询的概念和使用(1)内连接的概念和T-SQL语句(2)自连接的概念和T-SQL语句(3)外连接的概念和分类1)左外连接的概念和T-SQL语句2)右外连接的概念和T-SQL语句3)全外连接的概念和T-SQL语句4)交叉连接的概念的T-SQL语句14、子查询的概念15、子查询的分类(1)无关子查询的概念和T-SQL语句(2)相关子查询的概念和T-SQL语句1)存在性测试子查询的概念2)EXISTS和NOT EXISTS查询的T-SQL语句16、联合查询的概念和T-SQL语句17、EXCEPT和INTERSECT查询的概念和T-SQL语句18、对查询结果排序的T-SQL语句19、排序的分类20、存储查询结果的T-SQL语句21、insert语句中使用select子句的用法22、update语句中使用select子句的用法23、delete语句中使用select子句的用法七、T-SQL编程基础1、标识符的分类2、常规标识符格式规则3、变量分类4、全局变量的概念5、局部变量的概念6、全局变量与局部变量的区别7、局部变量的T-SQL语句8、局部变量的赋值方法9、运算符的分类(1)算术运算符(+ - * / %)(2)赋值运算符(=)(3)位运算符(& | ^)(4)比较运算符(5)逻辑运算符(6)字符串连接运算符(7)一元运算符10、运算符的优先级与结合性11、批处理的概念12、注释的概念13、注释的分类14、流程控制语句的概念15、流程控制语句的类别(1)赋值语句的T-SQL语句(2)定义语句的T-SQL语句(3)条件语句的T-SQL语句(4)多分支语句的T-SQL语句(5)循环语句的T-SQL语句(6)重新开始下一次循环语句的T-SQL语句(7)退出循环的T-SQL语句(8)无条件转移语句的T-SQL语句(9)无条件退出语句的T-SQL语句16、函数的概念17、函数的分类18、游标的概述19、游标的分类20、游标的操作八、视图和索引1、视图的概念2、视图的优点3、视图的分类4、创建视图的原则5、创建视图的T-SQL语句6、修改视图的T-SQL语句7、删除视图的T-SQL语句8、索引的概念9、索引的优点10、索引的类型(1)聚集索引的概念(2)非聚集索引的概念11、创建索引时应考虑的问题12、创建索引的T-SQL的语句13、间接创建索引的T-SQL语句14、创建视图索引的T-SQL语句15、使用系统存储过程查看索引的T-SQL语句16、删除索引的T-SQL语句九、存储过程和触发器1、存储过程的概念2、存储过程的类型3、创建存储过程的T-SQL语句4、执行存储过程的T-SQL语句5、使用系统存储过程查看存储过程的T-SQL语句6、修改存储过程的T-SQL语句7、删除存储过程的T-SQL语句8、触发器的概念9、触发器的分类(1)DML触发器的概念(2)DDL触发器的概念10、创建触发器要注意的问题11、创建触发器的T-SQL语句12、插入表(Inserted)和删除表(Delete)的区别13、查看触发器信息T-SQL语句14、修改触发器的T-SQL语句15、禁止触发器的T-SQL语句16、启用触发器的T-SQL语句17、删除触发器的T-SQL语句十、事务与并发控制1、事务的概念2、事务的类型3、事务处理语句十一、数据库的安全管理1、SQL Server2008的身份验证模式2、SQL Server2008账号管理3、SQL Server2008权限管理十二、数据库的备份与还原1、SQL Server2008数据库备份的类型2、SQL Server2008数据库恢复模式3、SQL Server2008中使用T-SQL语句备份数据库4、SQL Server2008数据库还原操作5、SQL Server2008中使用T-SQL语句还原数据库6、SQL Server2008数据库的分离7、SQL Server2008中使用T-SQL语句分离数据库8、SQL Server2008数据库的附加9、SQL Server2008中使用T-SQL语句附加数据库。
基于SQL Server的数据挖掘步骤-以聚类分析为例
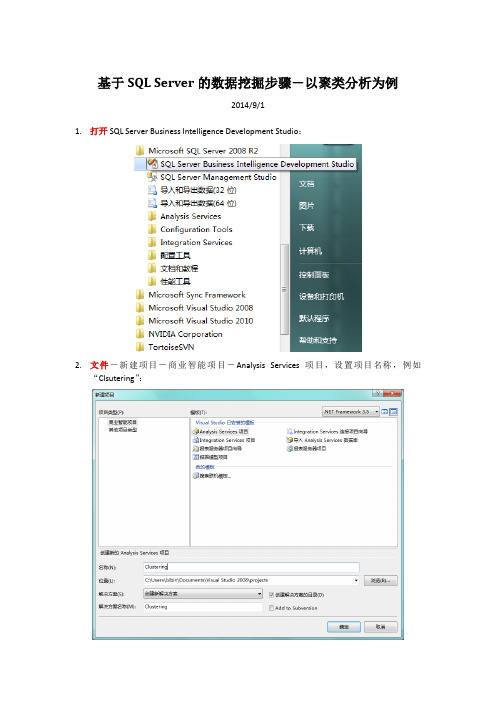
基于SQL Server的数据挖掘步骤-以聚类分析为例2014/9/11.打开SQL Server Business Intelligence Development Studio:2.文件-新建项目-商业智能项目-Analysis Services项目,设置项目名称,例如“Clsutering”:3.新建数据源-数据源向导,下一步-服务器名称(本机请点击下拉选择ADMIN-PC,网络数据库请填写IP地址)-使用SQL Server身份验证(建议勾选“保存密码”)-连接到一个数据库(下拉选择待分析数据所在数据库)-测试连接,确定-下一步-点选“使用服务帐户”,下一步-数据源名称(默认即数据库名称),完成:4.新建数据源视图-数据源视图向导,下一步-双击上一步中新建的关系数据源如test-下一步-添加与分析相关的所有表,下一步-命名数据源视图,如MultiFactors:5.新建多维数据集-多维数据集向导,下一步-使用现有表,下一步-勾选与分析相关的表,下一步-勾选度量值(与分析相关的输入、输出)-自动创建维度,下一步-命名多维数据集,如MDD,完成:6.新建挖掘结构-数据挖掘向导,下一步-选择从现有关系数据库或数据仓库,下一步-选择挖掘结构,如聚类分析,下一步-选择前面建立的数据源视图,下一步-下一步-指定键列、输入列、待预测列,下一步-个别挖掘算法需要修改数据类型,如Discretized,下一步-将数据划分为训练集、测试集,默认测试集占30%,下一步-命名挖掘结构、模型,允许钻取,完成:7.设置算法参数-阅读每个参数的说明,进行相关设置:8.挖掘模型查看器-生成和部署项目,是-是-运行-关闭-关闭,等待数据挖掘结果分类关系图:9.挖掘模型预测-选择输入表-如建立单独查询,选择源、字段(待预测),输入输入列值,转到查询结果:。
SQL Server 2008 Analysis Services 入门教程
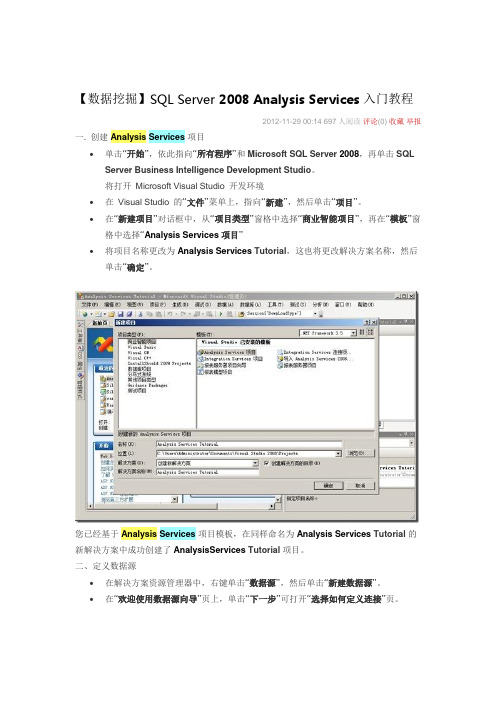
【数据挖掘】SQL Server 2008Analysis Services入门教程2012-11-29 00:14 697人阅读评论(0) 收藏举报一. 创建Analysis Services项目∙单击“开始”,依此指向“所有程序”和Microsoft SQL Server 2008,再单击SQL Server Business Intelligence Development Studio。
将打开Microsoft Visual Studio 开发环境∙在Visual Studio 的“文件”菜单上,指向“新建”,然后单击“项目”。
∙在“新建项目”对话框中,从“项目类型”窗格中选择“商业智能项目”,再在“模板”窗格中选择“Analysis Services项目”∙将项目名称更改为Analysis Services Tutorial,这也将更改解决方案名称,然后单击“确定”。
您已经基于Analysis Services项目模板,在同样命名为Analysis Services Tutorial的新解决方案中成功创建了AnalysisServices Tutorial项目。
二、定义数据源∙在解决方案资源管理器中,右键单击“数据源”,然后单击“新建数据源”。
∙在“欢迎使用数据源向导”页上,单击“下一步”可打开“选择如何定义连接”页。
∙∙在“选择如何定义连接”页上,可以基于新连接、现有连接或以前定义的数据源对象来定义数据源。
在本教程中,将基于新连接定义数据源。
确保已选中“基于现有连接或新连接创建数据源”,再单击“新建”。
∙在“连接管理器”对话框中,为数据源定义连接属性。
在“提供程序”列表中,确保已选中“本机OLE DB\SQL Server Native Client 10.0”。
Analysis Services还支持“提供程序”列表中显示的其他访问接口。
∙在“服务器名称”文本框中,键入localhost。
SQL Server 2008 数据挖掘插件

新的时序算法
Demonstration - 创建一个时序算法模型
总结
使用熟悉的界面显示了功能更为强大的数据挖 掘能力 使挖掘结构和模型的开发更为流畅 使用交叉验证来评估模型的准确性 新的时序算法:可以预测10个步长以内
对挖掘结果准确性的交叉验证
Demonstration - 对一个模型使用交叉验证
Agenda
Excel数据挖掘插件新增工具 挖掘结构的改进 对挖掘结果准确性的交叉验证 新的时序算法
新的时序算法
ARTxp算法 ‐仍然包含在Microsoft时序算法中 ‐时间序列中预测下一步的最佳算法 ARIMA算法 ‐新加到Microsoft时序算法中 ‐长期预测的最佳算法 新的Microsoft时序算法 ‐可以使用ARTxp算法训练一个模型而使用 ARIMA算法训练另一个模型 ‐最终的结果为最佳预测
Agenda
Excel数据挖掘插件新增工具 挖掘结构的改进 对挖掘结果准确性的交叉验证 新的时序算法
挖掘结构的改进
数据分区( Data Partitioning )
Training Set
Test Set
挖掘结构的改进
设置挖掘模型列别名
挖掘结构的改进
设置数据挖掘筛选器
挖掘结构的改进
向下钻取到挖掘结构数据
SQL Server 2008 Excel数据挖掘插件(Add-Ins)
Agenda
Excel数据挖掘插件新增工具 挖掘结构的改进 对挖掘结果准确性的交叉验证 新的时序算法
Excel数据挖掘插件新增工具
预测计算器(Prediction Calculator)
Input cost and profit values Calculated Score Threshold Profit by threshold
SQL Server 2008中的9种数据挖掘算法

SQL Server 2008中的9种数据挖掘算法1.决策树算法决策树,又称判定树,是一种类似二叉树或多叉树的树结构。
决策树是用样本的属性作为结点,用属性的取值作为分支,也就是类似流程图的过程,其中每个内部节点表示在一个属性上的测试,每个分支代表一个测试输出,而每个树叶节点代表类或类分布。
它对大量样本的属性进行分析和归纳。
根结点是所有样本中信息量最大的属性,中间结点是以该结点为根的子树所包含的样本子集中信息量最大的属性,决策树的叶结点是样本的类别值。
从树的根结点出发,将测试条件用于检验记录,根据测试结果选择适当的分支,沿着该分支或者达到另一个内部结点,使用新的测试条件或者达到一个叶结点,叶结点的类称号就被赋值给该检验记录。
决策树的每个分支要么是一个新的决策节点,要么是树的结尾,称为叶子。
在沿着决策树从上到下遍历的过程中,在每个节点都会遇到一个问题,对每个节点上问题的不同回答导致不同的分支,最后会到达一个叶子节点。
这个过程就是利用决策树进行分类的过程。
决策树算法能从一个或多个的预测变量中,针对类别因变量,预测出个例的趋势变化关系。
在SQL Server 2008中,我们可以通过挖掘模型查看器来查看决策树模型。
如图1所示。
在图1中,我们可以看到决策树显示由一系列拆分组成,最重要的拆分由算法确定,位于“全部”节点中查看器的左侧。
其他拆分出现在右侧。
依赖关系网络显示了模型中的输入属性和可预测属性之间的依赖关系。
并能通过滑块来筛选依赖关系强度。
2.聚类分析算法聚类分析算法就是衡量个体间的相似度,是依据个体的数据点在几何空间的距离来判断的,距离越近,就越相似,就越容易归为一类。
在最初定义分类后,算法将通过计算确定分类表示点分组情况的适合程度,然后尝试重新定义这些分组以创建可以更好地表示数据的分类。
该算法将循环执行此过程,直到它不能再通过重新定义分类来改进结果为止。
简单得说,聚类就是将数据对象的集合分组成为由类似的对象组成的多个类的过程。
SQL_Server中的数据挖掘工具

SQL Server中的数据挖掘工具一、实验目的1. 了解SQL Server 提供的数据挖掘模型;2. 掌握用决策树和聚集算法创建OLAP挖掘模型;3. 掌握用决策树和聚集算法创建关系挖掘模型;二、实验工具SQL Server 2000 Analysis Manager三、实验内容(一)用决策树创建OLAP挖掘模型——“客户模式”使用Microsoft 决策树创建OLAP 数据挖掘模型数据挖掘模型是一种包含运行特定数据挖掘任务所需的全部设置的模型。
为什么?数据挖掘对查找和描述特定多维数据集中的隐藏模式非常有用。
因为多维数据集中的数据增长很快,所以手动查找信息可能非常困难。
数据挖掘提供的算法允许自动模式查找及交互式分析。
管理员可以在Analysis Services 中设置将要训练数据的数据挖掘模型。
然后,用户可以使用ISV 客户端工具对受训数据运行高级分析。
方案:市场部想提高客户满意度和客户保有率。
于是实行了两个创造性的方法以达到这些目标。
对会员卡方案重新进行定义,以便更好地为客户提供服务并且使所提供的服务能够更加密切地满足客户的期望。
创办《每周赠券》杂志,将杂志送给客户群,以鼓励他们访问FoodMart 商店。
为了重新定义会员卡方案,市场部想分析当前销售事务并找出客户人口统计信息(婚姻状况、年收入、在家子女数等等)和所申请卡之间的模式。
然后根据这些信息和申请会员卡的客户的特征重新定义会员卡。
本节将创建一个数据挖掘模型以训练销售数据,并使用“Microsoft 决策树”算法在客户群中找出会员卡选择模式。
请将要挖掘的维度(事例维度)设置为客户,再将Member_Card 成员的属性设置为数据挖掘算法识别模式时要使用的信息。
然后选择人口统计特征列表,算法将从中确定模式:婚姻状况、年收入、在家子女数和教育程度。
下一步需要训练模型,以便能够浏览树视图并从中读取模式。
市场部将根据这些模式设计新的会员卡,使其适应申请各类会员卡的客户类型。
SQL_Server 数据挖掘分析经典全集

本章将回顾Analysis Services工具集,同时介绍有效创建挖掘模型和分析挖掘模型的技巧。
在学习本章之前,读者应该已经熟悉了第3章介绍的模型构建的概念,而且对挖掘结构、挖掘模型、挖掘模型列、事例表和嵌套表的概念也有了较深入的理解。
对于初学者来说,本章可以帮助他们入门,对于有一定SQL Server数据挖掘经验的用户来说,本章可以为他们提供一些技术,以帮助他们最有效地发挥该工具集的作用。
但是这并不意味着本章可以取代产品的帮助文档中优秀的帮助和教程。
更确切地说,本章讲述如何使用Analysis Services提供的通用工具,特别是用于数据挖掘的工具。
本章将通过用户界面来讲述如何使用Analysis Services的功能,并提供详细的操作步骤来示范如何创建一组挖掘模型。
本章还将穿插介绍相关的一些概念。
如果您偏离这些操作太远,则可以重新开始操作,也可以从本书的Web站点(/go/ data_mining_SQL_2008)上获得完整的项目文件,以便随时使用。
本章将会使用附录A描述的MovieClick数据库来举例说明工具的用法。
本章将学习:●使用Business Intelligence Development Studio(BI Dev Studio)●理解即时模式和脱机模式●创建及修改数据源、数据源视图和数据挖掘对象●浏览数据和评估模型4.1 BI Dev Studio介绍在使用SQL Server数据挖掘功能的过程中,大部分时间将会花费在商业智能应用程序开发工具集(Business Intelligence Development Studio,BI Dev Studio)上。
BI Dev Studio环境已经集成到Microsoft Visual Studio(VS)框架中,为商业智能操作提供了完整的开发环境。
在使用Visual Studio时,数据挖掘项目是一组项目中的一部分,这组项目也称为解决方案。
数据挖掘基础教程SQLServer2008

数据挖掘基础教程欢迎使用 MicrosoftAnalysis Services 数据挖掘基础教程。
MicrosoftSQL Server 提供了一个用来创建和处理数据挖掘模型的集成环境。
在本数据挖掘基础教程中,您将完成一个用于目标邮寄活动的方案,在此方案中您将创建三个模型,用来分析客户购买行为并确定潜在购买目标。
本教程说明了MicrosoftSQL ServerAnalysis Services 中所包含的数据挖掘算法、挖掘模型查看器和数据挖掘工具的使用方法。
虚构公司 Adventure Works Cycles 用于所有的示例。
熟练使用数据挖掘工具后,建议您完成数据挖掘中级教程,该教程说明了预测、市场篮分析、时序、关联模型、嵌套表以及顺序分析和聚类分析的使用方法。
教程方案在本教程中,您是 Adventure Works Cycles 的一名员工,需要根据历史购买情况来详细了解该公司的客户,然后使用这些历史数据进行可用于营销的预测。
公司以前从未进行过数据挖掘,因此您必须创建一个专门用于数据挖掘的新数据库并建立几个数据挖掘模型。
学习内容本教程将讲述如何创建和使用数种不同类型的数据挖掘模型。
还将述如何创建挖掘模型的副本以及如何对掘模型应用筛选器。
随后,您将处理新模型并使用提升图评估该模型。
在该模型完成之后,将使用钻取功能从基础挖掘结构检索其他数据。
在 SQL Server 2008 中,Microsoft 引入了几个新功能,可帮助您开发自定义数据挖掘模型并且更有效地使用结果。
维持测试集 - 现在,当创建挖掘结构时,可以将挖掘结构中的数据分为定型集和测试集。
挖掘模型筛选器 - 现在,可以将筛选器附加到挖掘模型,并在定型和测试期间应用筛选器。
钻取到结构事例和结构列 - 现在,可以从挖掘模型中的通用模式方便地移到数据源中的可行详细信息。
本教程分为以下几课:第 1 课:准备 Analysis Services 数据库〔数据挖掘基础教程在本课程中,您将学习如何创建新的 Analysis Services 数据库,添加数据源和数据源视图,以及准备将用于数据挖掘的新数据库。
SQL Server 2008数据库任务教程

任务一 数据操作
任务实施
一、添加表数据 二、修改表数据 三、删除表数据
任务一 数据操作
实训练习
实训 数据操作
任务二 数据查询
任务引
01
入
任务实
04
施
任务目
02
标
知识拓
05
展
必备知
03
识
任务小
06
结
任务二 数据查询
实训练习
任务二 数据查询
任务实施
一、检索表中的部分列 二、使用(*)检索表中所有列 三、修改检索结果中的列标题 四、使用TOP n[PERCENT]返回前n行 五、使用DISTINCT消除重复行 六、在检索结果中增加字符串 七、条件查询 八、排序查询(ORDER BY子句)
实训 创建和使用触发 器
05 学习情景三 管理数据库
任务一 数据库的安全管理
任务引
01
入
任务实
04
施
任务目
02
标
知识拓
05
展
必备知
03
识
任务小
06
结
任务一 数据库的 安全管理
实训练习
任务一 数据库的安全管理
必备知识
一、理解SQL Server的身份验证模式 二、角色管理 三、权限管理
任务一 数据库的安全管理
感谢聆听
任务一 数据操作
任务引
01
入
任务实
04
施
任务目
02
标
知识拓
05
展
必备知
03
识
任务小
06
结
任务一 数据操作
实训练习
任务一 数据操作
SQL Server 2008 R2 数据分析解决方案

2005 backup
Katmai
file copy
线性 (Katmai)
线性 (file copy)
#;
.
用户需求
当前问题
AS 2008的 解决方案
我们需要一个将多维数据扩展到多台服务器的简单方 法。
当MOLAP多维数据集为只读数据库时,两台服务器并丌 共享相同的数据目录。 多维数据库同步可以帮助解决数据同步问题,但同步的 延时问题是业务应用解决方案丌能接受的。
AS 2008 的解决方案
为资源监控信息收集以及报告的新服务器结构
#;
. #;
.
•
分析服务
Default Resource
多维数据集
资源表(DMV)
#;
报表服务
客户端分析 应用程序
即席查询 Select * from Session_Resources
.
DEMO
分析服务的资源监控
#;
.
• 块计算 • 回写性能 • 备份可扩展性 • 针对外扩部署的只读数据库
#;
.
SQL Server分析服务内置数据挖掘技术
• •
− − − − − − − −
• •
• • • • • • • • •
#;
. #;
.
• • •
#;
.
#;
.
• 块计算 • 回写性能 • 备份可扩展性 • 针对外扩部署的只读数据库
#;
• AMO警示 • 维度设计 • 多维数据集设计 • 聚合设计器 + 算法改进
•
− − −
•
− − −
#;
.
DEMO
新的聚合设计界面
SQL Server 2008中运用数据挖掘模型

SQL Server 2008中运用数据挖掘模型日期:2009年4月9日为一个数据挖掘模型定型后,可以通过运用 SQL Server Management Studio 或 Business Intelligence Development Studio 中提供的自定义查看器来阅读此模型。
但是,如果您希望执行预测或者从模型中获取更深入的或更具体的信息,则必须依据此数据挖掘模型建立一个查询。
在以下情况下,查询可帮助您更好地理解和处理模型中的信息:执行单个预测和批预测。
了解有关模型发觉的模式的更多信息。
查看有关模型的特定模式或子集的细致信息或定型事例。
在挖掘模型中钻取到事例的细致信息。
提取有关全部或部分模型和数据的公式、准则或统计信息。
SQL Server Analysis Services 提供用于建立查询的图形设计界面,以及一种称为数据挖掘扩展插件 (DMX) 的查询语言,这种语言对于建立自定义预测和复杂查询很有用。
若要生成 DMX 预测查询,可以运用 SQL Server Management Studio 和 Business Intelligence Development Studio 中均提供的查询生成器。
SQL Server Management Studio 中还提供了一组 DMX 查询模板。
有关如何运用查询生成器的细致信息,请参阅运用预测查询生成器建立 DMX 预测查询。
有关如何运用 DMX 查询模板的细致信息,请参阅在 SQL Server Management Studio 中建立 DMX 查询或如何在 SQL Server Management Studio 中运用模板。
预测查询许多数据挖掘项目的主要目标是运用挖掘模型来执行预测。
例如,您可能要在十二月期间预测公司明年销售的产品数量,或者可能要预测在某个广告活动后潜在客户能不能会购买产品。
建立预测时,通常会提供一些新数据,并要求模型基于新数据生成一个预测。
SQL Server 2008中的9种数据挖掘算法
SQL Server 2008中的9种数据挖掘算法1.决策树算法决策树,又称判定树,是一种类似二叉树或多叉树的树结构。
决策树是用样本的属性作为结点,用属性的取值作为分支,也就是类似流程图的过程,其中每个内部节点表示在一个属性上的测试,每个分支代表一个测试输出,而每个树叶节点代表类或类分布。
它对大量样本的属性进行分析和归纳。
根结点是所有样本中信息量最大的属性,中间结点是以该结点为根的子树所包含的样本子集中信息量最大的属性,决策树的叶结点是样本的类别值。
从树的根结点出发,将测试条件用于检验记录,根据测试结果选择适当的分支,沿着该分支或者达到另一个内部结点,使用新的测试条件或者达到一个叶结点,叶结点的类称号就被赋值给该检验记录。
决策树的每个分支要么是一个新的决策节点,要么是树的结尾,称为叶子。
在沿着决策树从上到下遍历的过程中,在每个节点都会遇到一个问题,对每个节点上问题的不同回答导致不同的分支,最后会到达一个叶子节点。
这个过程就是利用决策树进行分类的过程。
决策树算法能从一个或多个的预测变量中,针对类别因变量,预测出个例的趋势变化关系。
在SQL Server 2008中,我们可以通过挖掘模型查看器来查看决策树模型。
如图1所示。
在图1中,我们可以看到决策树显示由一系列拆分组成,最重要的拆分由算法确定,位于“全部”节点中查看器的左侧。
其他拆分出现在右侧。
依赖关系网络显示了模型中的输入属性和可预测属性之间的依赖关系。
并能通过滑块来筛选依赖关系强度。
2.聚类分析算法聚类分析算法就是衡量个体间的相似度,是依据个体的数据点在几何空间的距离来判断的,距离越近,就越相似,就越容易归为一类。
在最初定义分类后,算法将通过计算确定分类表示点分组情况的适合程度,然后尝试重新定义这些分组以创建可以更好地表示数据的分类。
该算法将循环执行此过程,直到它不能再通过重新定义分类来改进结果为止。
简单得说,聚类就是将数据对象的集合分组成为由类似的对象组成的多个类的过程。
SQLServer数据挖掘功能介绍
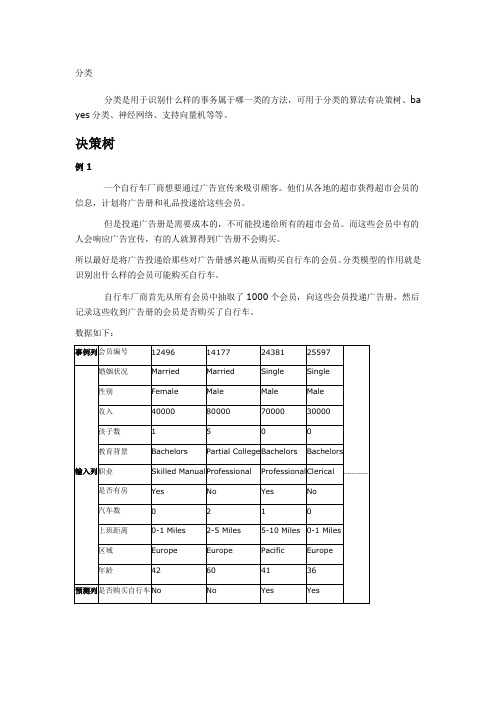
分类分类是用于识别什么样的事务属于哪一类的方法,可用于分类的算法有决策树、ba yes分类、神经网络、支持向量机等等。
决策树例1一个自行车厂商想要通过广告宣传来吸引顾客。
他们从各地的超市获得超市会员的信息,计划将广告册和礼品投递给这些会员。
但是投递广告册是需要成本的,不可能投递给所有的超市会员。
而这些会员中有的人会响应广告宣传,有的人就算得到广告册不会购买。
所以最好是将广告投递给那些对广告册感兴趣从而购买自行车的会员。
分类模型的作用就是识别出什么样的会员可能购买自行车。
自行车厂商首先从所有会员中抽取了1000个会员,向这些会员投递广告册,然后记录这些收到广告册的会员是否购买了自行车。
数据如下:在分类模型中,每个会员作为一个事例,居民的婚姻状况、性别、年龄等特征作为输入列,所需预测的分类是客户是否购买了自行车。
使用1000个会员事例训练模型后得到的决策树分类如下:※图中矩形表示一个拆分节点,矩形中文字是拆分条件。
※矩形颜色深浅代表此节点包含事例的数量,颜色越深包含的事例越多,如全部节点包含所有的1000个事例,颜色最深。
经过第一次基于年龄的拆分后,年龄大于67岁的包含36个事例,年龄小于32岁的133个事例,年龄在39和67岁之间的602个事例,年龄32和39岁之间的229个事例。
所以第一次拆分后,年龄在39和67岁的节点颜色最深,年龄大于67岁的节点颜色最浅。
※节点中的条包含两种颜色,红色和蓝色,分别表示此节点中的事例购买和不购买自行车的比例。
如节点“年龄>=67”节点中,包含36个事例,其中28个没有购买自行车,8个购买了自行车,所以蓝色的条比红色的要长。
表示年龄大于67的会员有74.62%的概率不购买自行车,有23.01%的概率购买自行车。
在图中,可以找出几个有用的节点:1. 年龄小于32岁,居住在太平洋地区的会员有72.75%的概率购买自行车;2. 年龄在32和39岁之间的会员有68.42%的概率购买自行车;3. 年龄在39和67岁之间,上班距离不大于10公里,只有1辆汽车的会员有66.08%的概率购买自行车;4. 年龄小于32岁,不住在太平洋地区,上班距离在1公里范围内的会员有51.92%的概率购买自行车;在得到了分类模型后,将其他的会员在分类模型中查找就可预测会员购买自行车的概率有多大。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三详细步骤讲解第一部分OLAP讲解1目的针对现在企业存在海量数据,需要对其中隐藏的数据进行分析,从而帮助决策这一事实,我们设计了一个虚拟情景:我们是一家大型连锁超市的技术顾问,我们要分析企业现存的数据,从而了解此超市的运营现状,针对分析出的信息提出企业的改进目标。
2安装SQL Server 20082.1实验环境:操作系统:windows 7;处理器:AMD Turion(tm) x2 Dual-Core Moblie RM-72,2.10GHz;系统类型:32 位操作系统;内存:3GB2.2步骤详解选择安装文件中的setup.exe开始安装。
上图为安装主界面,包含了有关SQL Server 2008 的各种信息,很直观,开始安装选择:全新SQL Server 独立安装或向现有安装添加功能;一些必需条件检查;然后是产品序列号输入,这也是SQL Server 首次采用此种授权管理方式;从微软网站下载的版本其实和正式版本无异,你如果有正式的序列号,在此输入即可成为正式版;当然在此处你也可以选择安装企业评估版,待以后通过上图的安装中心界面可将试用版升级为其它版本的正式版。
这里,我们输入企业版序列号:JD8Y6-HQG69-P9H84-XDTPG- 34MBB;SQL Server 2008 企业版授权协议;这里需要一些组件的安装点击安装过后,有一小段等待的时间另外一些必要条件的检查安装组件选择,默认情况下什么也没有选中,根据情况选择即可,一般情况下,不明白的就全选;配置实例并选择安装路径;从图中可以看出,虽然实例安装到了 D 盘,但只用了784M,将近2G 的内容都安装到了 C 盘,因此我们选择直接安装在C盘默认文件夹下;这里为实例配置,我们只需选择默认的,然后”下一步”;显示安装后预计战胜的硬盘空间配置各SQL Server 服务的帐户名和启动类型,对开发人员来说非常实用;配置身份验证模式,和以往版本没有什么不同;但新增了一个”指定SQL Server 管理员”的必填项,该管理员是指Windows 帐户,你可以新建一个专门用于SQL Server 的帐户,或点击”添加当前用户”添加当前用户为管理员;同时”数据目录”页可指定各种类型数据文件的存储位置,不过我们这里只需要选择”添加当前用户”,其他的默认就好;接下来,根据选择项目,会有一些不同的项目要配置,对于非专业人员来说,基本原则就是”添加当前用户”,这样简洁并且不易出错;Reporting Sevice配置,直接默认,选择”下一步”;错误和使用情况报告,这里我们不选择向微软发送错误报告,直接”下一步”;再一次对必要信息进行检查;安装信息汇总,安装前的最后一步开始安装并安装完成用时大约 1 小时,当然这取决于你安装的组件。
之后安装成功,从开始菜单中选择相应的程序,Microsoft SQL Server 2008——SQL Server Management Studio单击即可打开。
安装后运行图例至此SQL Server 2008安装成功安装中的注意事项:安装sql server 2008前可能需要安装visual studio,我们建议最好最好安装最新的版本,以免出现一些不必要的问题。
3OLAP分析3.1目的:联机分析处理(简写为OLAP)是共享多维信息的、针对特定问题的联机数据访问和分析的快速软件技术。
它通过对信息的多种可能的观察形式进行快速、稳定一致和交互性的存取,允许管理决策人员对数据进行深入观察。
决策数据是多维数据,多维数据就是决策的主要内容。
OLAP专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况,了解对象的需求,制定正确的方案。
联机分析处理具有灵活的分析功能、直观的数据操作和分析结果可视化表示等突出优点,从而使用户对基于大量复杂数据的分析变得轻松而高效,以利于迅速做出正确判断。
它可用于证实人们提出的复杂的假设,其结果是以图形或者表格的形式来表示的对信息的总结。
它并不将异常信息标记出来,是一种知识证实的方法。
总之,OLAP(联机分析处理)是帮助用户理解、分析大量数据并建立模型的一种解决方案,而Microsoft SQL Server 2008中的SQL Server Business Intelligence Development Studio则是完成这一任务的出色工具。
3.2相关知识介绍:Microsoft SQL Server 2008中的BI(商业智能)模块集成了一些我们在商业应用领域上的技术,在真正应用时,我们将BI分为五层,即BI 五层模型:*数据源层*数据转换层*数据存取层*分析层*表示层我们将BI模块中的Integration services项目对应于数据源层和数据转换层;SQL Server Management Studio对应于数据存取层;analysis services项目对应于分析层;最后将报表模型项目对应于表示层。
下面我们将结合我们的案例背景,即我们作为大型超市的技术顾问,为企业决策者提供相应的运营信息。
3.3具体步骤:3.3.1数据源的转换:开始——Microsoft SQL Server 2008——SQL Server Business Intelligence Development Studio,打开如下图所示界面:然后单击新建文件——新建——项目,出现如下图所示界面,然后选择integration services 项目:之后出现下图所示界面:此时选择菜单栏上的项目——SSIS导入和导出向导,单击后选择相应的数据源文件,结果如下图:单击下一步(注意选择自己的服务器名称):此时我们要将导入的数据放到一个数据库中,所以单击右下方的新建按钮,我们这里将新建立的数据库命名为DB market,出现的界面如下:然后单击确定——下一步,来到如下图所示的界面:因为,我们只是用最原始的表,不需要对表进行额外的操作,所以,选择复制一个或多个表或试图的数据,然后按下一步,选择我们需要的表:选择之后,按下一步最后单击完成,如运行成功,则出现下图所示的界面:然后将解决方案资源管理器中的SSIS包中的package1.dtsx设为启动对象,方法是右击其,选择设为启动对象。
然后单击工具栏中的三角按钮,开始调试,结果如下图:之后单击上图下方的蓝色字“包执行完毕。
单击此处以……”,至此我们完成了数据源转换这一步骤。
3.3.2数据分析准备工作:接着,我们按照上面的方法新建立一个analysis services 项目,名为AS_market,开始做数据分析的准备工作,之后右击右侧解决方案资源管理器中的数据源,选择新建数据源,出现如下图所示的图:然后单击,新建按钮,选择相应的服务器和数据库,如下:按确定,单击下一步,然后,选择使用服务账户,如图:再单击下一步,最后单击完成,至此数据源选择完成。
然后如上所示,右击数据源视图,也是新建,然后选择关系数据源,如下图:然后下一步,保持默认选项,如图:然后选择所有经过之前经过筛选的表,如图:然后下一步,完成。
此时,程序的主界面应该如下图所示:我们下一步要将这七张表联系起来,使之如下图所示(注意箭头的方向):之后,我们便可以建立多维数据集,如上右击新建,出现如下图的界面:保持默认选项,使用现有表,然后下一步,选选择度量值(即数据挖掘中所说的事实):然后单击下一步,去掉sales fact 1998计数的钩钩,单击下一步:然后单击下一步,完成。
之后,我们修改维度,便于我们后面查看,具体方法如下:单击左下角要修改的维度,此时列表会展开,出现一个编辑Store的蓝色文字,如图:然后单击此蓝色文字,主界面变为:从右侧的数据源试图中拖动你想要看到的属性列到左侧的属性窗口中,操作结果如下图:同理,将除了time by day之外的维度,都做类似的操作。
至于time by day这个时间维度比较特别,下面做详细介绍:在time by day上右击,选择浏览数据,出现如下图:通过观察分析,我们可以知道,the_date指的是年月日时间;the_day指的是星期几;the_month指的是几月份;the_year指的是年份;day_of_month指的是这个月的第几天(这里就列举这么多),然后我们根据这个,给每个属性选择类型,具体操作如下:右侧下方有the date 的属性列表,其中有一个type选项,我们根据数据的实际含义,选择日期——日历——date。
其他的也如法炮制。
所有的维度都修改好后,选择新生成的多维数据集,单击工具条上的小三角,启动调试。
成功后,双击多维数据集,在选择浏览器,出现下图:现在就可以从左侧拖动相关的属性到中间,从而实现olap分析了。
终于说完了这一部分~~ 大家一定要动手实践。
3.3.3数据分析:举个小小例子,领导想查看每个分店的营业情况,那么我们可以建立如下的数据透视图:行属性为store name;列属性为两级的,一级是store state,一级为store city;这样我们就可以以州或是城市为最小粒度查看各分店的营业情况了。
4小结数据分析是企业进行总结和计划的基础操作,SQL Server 2008的BI模块,让我们可以很好的实现这个功能,通过数据分析我们可以为企业的决策者提供很好的总结,从而指导下一步的企业计划。
好了,就说这么多,关键还是要动手操作呀!第二部分Data Mining详解建立模型Step 1在建立数据挖掘模型前须保证已经建立“数据源”和“数据源视图”,如(Figure 1)所示:Figure 1Step2解决方案资源管理器——挖掘结构——右键(新建挖掘结构)——进入数据库挖掘向导(下一步)——选择定义方法(选择从现有关系数据库或数据仓库),下一步——创建数据挖掘结构(以Microsoft 决策树为例),下一步——选择数据源视图(选择自己之前创建的),下一步——指定表类型(以customer为事例表)——指定定性数据(键:Customer_id 输入:Member_card 可预测:Member_card),然后点建议,之后确定,下一步——指定列的内容和数据类型(点检测)下一步——下一步(默认)——自己命名,完成。
Step3 选中建立的模型,点启动调试,模型建立完毕,(如figure2)所示,大家可以自行查看各个选型卡所表示的含义(注意结合挖掘图例进行理解)Figure 22、挖掘结果分析挖掘完成之后,可以发现每个挖掘模型都有5个选项卡,“挖掘结构”、“挖掘模型”、:“挖掘模型查看器”、“挖掘准确性图表”、“挖掘模型预测”。