Python正则表达式
python 正则表达式判断

python 正则表达式判断摘要:1.Python 正则表达式的概念2.Python 正则表达式的语法3.Python 正则表达式的应用4.Python 正则表达式的判断方法正文:一、Python 正则表达式的概念正则表达式(Regular Expression,简称regex)是一种用于匹配字符串模式的字符集,通常用于文本搜索和数据提取等场景。
Python 作为一种广泛应用的编程语言,也提供了正则表达式的支持。
二、Python 正则表达式的语法Python 中的正则表达式主要通过`re`模块进行操作。
以下是一些常用的正则表达式语法:1.`.`:匹配任意字符(除了换行符)。
2.`*`:匹配前面的字符0 次或多次。
3.`+`:匹配前面的字符1 次或多次。
4.`?`:匹配前面的字符0 次或1 次。
5.`{n}`:匹配前面的字符n 次。
6.`{n,}`:匹配前面的字符n 次或多次。
7.`{n,m}`:匹配前面的字符n 到m 次。
8.`[abc]`:匹配方括号内的任意一个字符(a、b 或c)。
9.`[^abc]`:匹配除方括号内字符以外的任意字符。
10.`(pattern)`:捕获括号内的模式,并将其存储以供以后引用。
11.`|`:表示或(or),匹配两个模式之一。
三、Python 正则表达式的应用Python 正则表达式广泛应用于文本处理、数据分析等场景,例如:验证邮箱地址、提取网页链接、筛选特定字符等。
四、Python 正则表达式的判断方法在Python 中,我们可以使用`re`模块的函数来判断字符串是否符合正则表达式的规则。
以下是一些常用的判断方法:1.`re.match(pattern, string)`:从字符串的开头开始匹配,如果匹配成功则返回一个匹配对象,否则返回None。
2.`re.search(pattern, string)`:在整个字符串中搜索匹配,如果匹配成功则返回一个匹配对象,否则返回None。
Python系列之正则表达式详解

Python系列之正则表达式详解Python 正则表达式模块 (re) 简介Python 的 re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,和 Perl 脚本的正则表达式功能类似,使⽤这⼀内嵌于 Python 的语⾔⼯具,尽管不能满⾜所有复杂的匹配情况,但⾜够在绝⼤多数情况下能够有效地实现对复杂字符串的分析并提取出相关信息。
Python 会将正则表达式转化为字节码,利⽤ C 语⾔的匹配引擎进⾏深度优先的匹配。
表 1. 正则表达式元字符和语法符号说明实例.表⽰任意字符,如果说指定了 DOTALL 的标识,就表⽰包括新⾏在内的所有字符。
'abc' >>>'a.c' >>>结果为:'abc'^表⽰字符串开头。
'abc' >>>'^abc' >>>结果为:'abc'$表⽰字符串结尾。
'abc' >>>'abc$' >>>结果为:'abc'*, +, ?'*'表⽰匹配前⼀个字符重复 0 次到⽆限次,'+'表⽰匹配前⼀个字符重复 1次到⽆限次,'?'表⽰匹配前⼀个字符重复 0 次到1次'abcccd' >>>'abc*' >>>结果为:'abccc''abcccd' >>>'abc+' >>>结果为:'abccc''abcccd' >>>'abc?' >>>结果为:'abc'*?, +?, ??前⾯的*,+,?等都是贪婪匹配,也就是尽可能多匹配,后⾯加?号使其变成惰性匹配即⾮贪婪匹配'abc' >>>'abc*?' >>>结果为:'ab''abc' >>>'abc??' >>>结果为:'ab''abc' >>>'abc+?' >>>结果为:'abc'{m}匹配前⼀个字符 m 次'abcccd' >>>'abc{3}d' >>>结果为:'abcccd' {m,n}匹配前⼀个字符 m 到 n 次'abcccd' >>> 'abc{2,3}d' >>>结果为:'abcccd' {m,n}?匹配前⼀个字符 m 到 n 次,并且取尽可能少的情况'abccc' >>> 'abc{2,3}?' >>>结果为:'abcc'\对特殊字符进⾏转义,或者是指定特殊序列 'a.c' >>>'a\.c' >>> 结果为: 'a.c'[]表⽰⼀个字符集,所有特殊字符在其都失去特殊意义,只有: ^ - ] \ 含有特殊含义'abcd' >>>'a[bc]' >>>结果为:'ab'|或者,只匹配其中⼀个表达式,如果|没有被包括在()中,则它的范围是整个正则表达式'abcd' >>>'abc|acd' >>>结果为:'abc' ( … )被括起来的表达式作为⼀个分组. findall 在有组的情况下只显⽰组的内容 'a123d' >>>'a(123)d' >>>结果为:'123'(?#...)注释,忽略括号内的内容特殊构建不作为分组 'abc123' >>>'abc(?#fasd)123' >>>结果为:'abc123'(?= …)表达式’…’之前的字符串,特殊构建不作为分组在字符串’ pythonretest ’中 (?=test) 会匹配’pythonre ’(?!...)后⾯不跟表达式’…’的字符串,特殊构建不作为分组如果’ pythonre ’后⾯不是字符串’ test ’,那么(?!test) 会匹配’ pythonre ’(?<=… )跟在表达式’…’后⾯的字符串符合括号之后的正则表达式,特殊构建不作为分组正则表达式’ (?<=abc)def ’会在’ abcdef ’中匹配’def ’(?:)取消优先打印分组的内容'abc' >>>'(?:a)(b)' >>>结果为'[b]'?P<>指定Key'abc' >>>'(?P<n1>a)>>>结果为:groupdict{n1:a}表 2. 正则表达式特殊序列特殊表达式序列说明\A只在字符串开头进⾏匹配。
python正则表达式

python正则表达式正则表达式应⽤场景特定规律字符串的查找替换切割等邮箱格式、url等格式的验证爬⾍项⽬,提取特定的有效内容很多应⽤的配置⽂件使⽤原则只要能够通过字符串等相关函数能够解决的,就不要使⽤正则正则的执⾏效率⽐较低,会降低代码的可读性世界上最难读懂的三样东西:医⽣的处⽅、道⼠的神符、码农的正则提醒:正则是⽤来写的,不是⽤来读的,不要试着阅读别⼈的正则;不懂功能时必要读正则。
基本使⽤说明:正则是通过re模块提供⽀持的相关函数:match:从开头进⾏匹配,找到就⽴即返回正则结果对象,没有就返回Nonesearch:匹配全部内容,任意位置,只要找到,⽴即返回正则结果对象,没有返回None# python依赖次模块完成正则功能import re# 从开头进⾏匹配,找到⼀个⽴即返回正则结果对象,没有返回Nonem = re.match('abc', 'abchelloabc')# 匹配全部内容,任意位置,只要找到,⽴即返回正则结果对象,没有返回Nonem = re.search('abc', 'helloabcshsjsldj')if m:print('ok')# 获取匹配内容print(m.group())# 获取匹配位置print(m.span())findall:匹配所有内容,返回匹配结果组成的列表,没有的返回⼀个空列表# 匹配所有内容,返回匹配结果组成的列表,没有返回Nonef = re.findall('abc', 'abcsdisuoiabcsjdklsjabc')if f:print(f)compile:根据字符串⽣成正则表达式的对象,⽤于特定正则匹配,通过match、search、findall匹配# 根据字符串⽣成正则表达式的对象,⽤于正则匹配c = pile('abc')# 然后进⾏特定正则匹配# m = c.match('abcdefghijklmn')m = c.search('abcdefghijklmn')if m:print(m)print(c.findall('abcueywiabcsjdkaabc'))将re模块中的match、search、findall⽅法的处理过程分为了两步完成。
python正则表达式详解

python正则表达式详解python 正则表达式详解1. 正则表达式模式模式描述^匹配字符串的开头$匹配字符串的末尾。
.匹配任意字符,除了换⾏符,当re.DOTALL标记被指定时,则可以匹配包括换⾏符的任意字符。
[...]⽤来表⽰⼀组字符,单独列出:[amk] 匹配 'a','m'或'k'[^...]不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。
re*匹配0个或多个的表达式。
re+匹配1个或多个的表达式。
re?匹配0个或1个由前⾯的正则表达式定义的⽚段,⾮贪婪⽅式re{ n}匹配n个前⾯表达式。
例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。
re{ n,}精确匹配n个前⾯表达式。
例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。
"o{1,}"等价于"o+"。
"o{0,}"则等价于"o*"。
re{ n,m}匹配 n 到 m 次由前⾯的正则表达式定义的⽚段,贪婪⽅式a| b匹配a或b(re)匹配括号内的表达式,也表⽰⼀个组(?imx)正则表达式包含三种可选标志:i, m, 或 x 。
只影响括号中的区域。
(?-imx)正则表达式关闭 i, m, 或 x 可选标志。
只影响括号中的区域。
(?: re)类似 (...), 但是不表⽰⼀个组(?imx:re)在括号中使⽤i, m, 或 x 可选标志(?-imx:re)在括号中不使⽤i, m, 或 x 可选标志(?#...)注释.(?= re)前向肯定界定符。
如果所含正则表达式,以 ... 表⽰,在当前位置成功匹配时成功,否则失败。
python常用的正则表达式大全
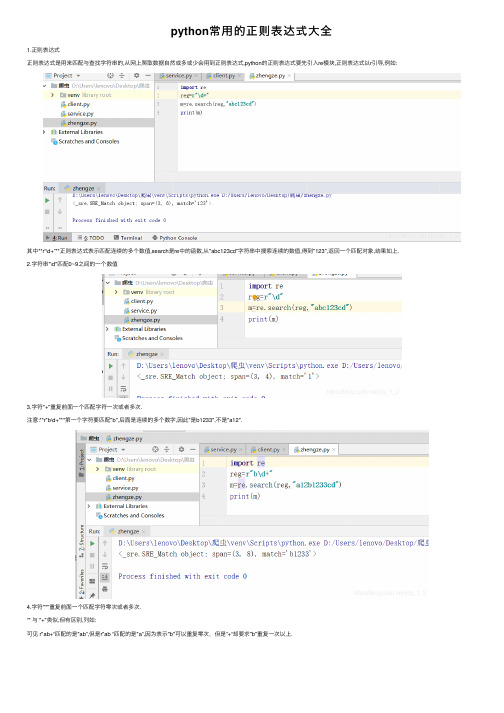
python常⽤的正则表达式⼤全1.正则表达式正则表达式是⽤来匹配与查找字符串的,从⽹上爬取数据⾃然或多或少会⽤到正则表达式,python的正则表达式要先引⼊re模块,正则表达式以r引导,例如:其中**r“\d+”**正则表达式表⽰匹配连续的多个数值,search是re中的函数,从"abc123cd"字符串中搜索连续的数值,得到"123",返回⼀个匹配对象,结果如上.2.字符串"\d"匹配0~9之间的⼀个数值3.字符"+"重复前⾯⼀个匹配字符⼀次或者多次.注意:**r"b\d+"**第⼀个字符要匹配"b",后⾯是连续的多个数字,因此"是b1233",不是"a12".4.字符"*"重复前⾯⼀个匹配字符零次或者多次.“" 与 "+"类似,但有区别,列如:可见 r"ab+“匹配的是"ab”,但是r"ab “匹配的是"a”,因为表⽰"b"可以重复零次,但是”+“却要求"b"重复⼀次以上.5.字符"?"重复前⾯⼀个匹配字符零次或者⼀次.匹配结果"ab”,重复b⼀次.6.字符".“代表任何⼀个字符,但是没有特别声明时不代表字符”\n".结果“.”代表了字符"x".7."|"代表把左右分成两个部分 .结果匹配"ab"或者"ba"都可以.8.特殊字符使⽤反斜杠"“引导,例如”\r"、"\n"、"\t"、"\"分别表⽰回车、换⾏、制表符号与反斜线⾃⼰本⾝.9.字符"\b"表⽰单词结尾,单词结尾包括各种空⽩字符或者字符串结尾.结果匹配"car",因为"car"后⾯是⼀个空格.10."[]中的字符是任选择⼀个,如果字符ASCll码中连续的⼀组,那么可以使⽤"-"字符连接,例如[0-9]表⽰0-9的其中⼀个数字,[A-Z]表⽰A-Z的其中⼀个⼤写字符,[0-9A-z]表⽰0-9的其中⼀个数字或者A-z的其中⼀个⼤写字符.11."^"出现在[]的第⼀个字符位置,就代表取反,例如[ ^ab0-9]表⽰不是a、b,也不是0-9的数字.12."\s"匹配任何空⽩字符,等价"[\r\n 20\t\f\v]"13."\w"匹配包括下划线⼦内的单词字符,等价于"[a-zA-Z0-9]"14."$"字符⽐配字符串的结尾位置匹配结果是最后⼀个"ab",⽽不是第⼀个"ab"15.使⽤括号(…)可以把(…)看出⼀个整体,经常与"+"、"*"、"?"的连续使⽤,对(…)部分进⾏重复.结果匹配"abab","+“对"ab"进⾏了重复16.查找匹配字符串正则表达式re库的search函数使⽤正则表达式对要匹配的字符串进⾏匹配,如果匹配不成功返回None,如果匹配成功返回⼀个匹配对象,匹配对象调⽤start()函数得到匹配字符的开始位置,匹配对象调⽤end()函数得到匹配字符串的结束位置,search虽然只返回匹配第⼀次匹配的结果,但是我们只要连续使⽤search函数就可以找到字符串全部匹配的字符串.匹配找出英⽂句⼦中所有单词我们可以使⽤正则表达式r”[A-Za-z]+\b"匹配单词,它表⽰匹配由⼤⼩写字母组成的连续多个字符,⼀般是⼀个单词,之后"\b"表⽰单词结尾.程序开始匹配到⼀个单词后m.start(),m.end()就是单词的起始位置,s[start:end]为截取的单词,之后程序再次匹配字符串s=s[end:],即字符串的后半段,⼀直到匹配完毕为⽌就找出每个单词.总结到此这篇关于python常⽤正则表达式的⽂章就介绍到这了,更多相关python正则表达式内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
python正则表达式详解

python正则表达式详解Python正则表达式详解正则表达式是一种强大的文本处理工具,它可以用来匹配、查找、替换文本中的特定模式。
在Python中,正则表达式是通过re模块来实现的。
本文将详细介绍Python中正则表达式的使用方法。
一、基本语法正则表达式是由一些特殊字符和普通字符组成的字符串。
其中,特殊字符用来表示一些特定的模式,普通字符则表示普通的文本。
下面是一些常用的正则表达式特殊字符:1. ^:匹配字符串的开头。
2. $:匹配字符串的结尾。
3. .:匹配任意一个字符。
4. *:匹配前面的字符出现0次或多次。
5. +:匹配前面的字符出现1次或多次。
6. ?:匹配前面的字符出现0次或1次。
7. []:匹配方括号中的任意一个字符。
8. [^]:匹配不在方括号中的任意一个字符。
9. ():将括号中的内容作为一个整体进行匹配。
10. |:匹配左右两边任意一个表达式。
二、常用函数Python中re模块提供了一些常用的函数来操作正则表达式,下面是一些常用的函数:1. re.match(pattern, string, flags=0):从字符串的开头开始匹配,如果匹配成功则返回一个匹配对象,否则返回None。
2. re.search(pattern, string, flags=0):在字符串中查找第一个匹配成功的子串,如果匹配成功则返回一个匹配对象,否则返回None。
3. re.findall(pattern, string, flags=0):在字符串中查找所有匹配成功的子串,返回一个列表。
4. re.sub(pattern, repl, string, count=0, flags=0):将字符串中所有匹配成功的子串替换为repl,返回替换后的字符串。
三、实例演示下面是一些实例演示,展示了正则表达式的使用方法:1. 匹配邮箱地址import reemail='*************'pattern = r'\w+@\w+\.\w+' result = re.match(pattern, email) if result:print(result.group())else:print('匹配失败')2. 匹配手机号码import rephone='138****5678' pattern = r'^1[3-9]\d{9}$' result = re.match(pattern, phone) if result:print(result.group())else:print('匹配失败')3. 查找所有数字import retext = 'abc123def456ghi789' pattern = r'\d+'result = re.findall(pattern, text)print(result)4. 替换字符串中的空格import retext = 'hello world'pattern = r'\s+'result = re.sub(pattern, '-', text)print(result)四、总结本文介绍了Python中正则表达式的基本语法和常用函数,并通过实例演示展示了正则表达式的使用方法。
python正则表达式基础,以及pattern.match(),re.match(),pa。。。

python正则表达式基础,以及pattern.match(),re.match(),pa。
正则表达式(regular expression)是⼀个特殊的字符序列,描述了⼀种字符串匹配的模式,可以⽤来检查⼀个字符串是否含有某种⼦字符串。
将匹配的⼦字符串替换或者从某个字符串中取出符合某个条件的⼦字符串,或者是在指定的⽂章中抓取特定的字符串等。
Python处理正则表达式的模块是re模块,它是Python语⾔中拥有全部的正则表达式功能的模块。
正则表达式由⼀些普通字符和⼀些元字符组成。
普通字符包括⼤⼩写的字母、数字和打印符号,⽽元字符是具有特殊含义的字符。
正则表达式⼤致的匹配过程是:拿正则表达式依次和字符串或者⽂本中的字符串做⽐较,如果每⼀个字符都匹配,则匹配成功,只要有⼀个匹配不成功的字符,则匹配不成功。
正则表达式模式正则表达式是⼀种⽤来匹配字符串得强有⼒的武器。
它的设计思想是⽤⼀种描述性的语⾔来给字符串定义⼀个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,就是匹配不成功。
模式字符串使⽤特殊的语法来表⽰⼀个正则表达式:字母和数字匹配它们⾃⾝;多数字母和数字前加⼀个反斜杠(\)时会有特殊的含义;特殊的标点符号,只有被转义以后才能匹配⾃⾝;反斜杠本⾝需要反斜杠来转义;注意:由于正则表达式通常包含反斜杠等特殊字符,所以我们最好使⽤原始字符串来表⽰他们。
如:r’\d’,等价于’\\d’,表⽰匹配⼀个数字。
Python正则表达式中,数量词默认都是贪婪的,它们会尽⼒尽可能多的去匹配满⾜的字符,但是如果我们在后⾯加上问号“?”,就可以屏蔽贪婪模式,表⽰匹配尽可能少的字符。
如字符串:“xyyyyzs”,使⽤正则“xy*”,就会得到“xyyyy”;如果使⽤正则“xy*?”,将只会匹配“x”下表列出了正则表达式模式语法中的特殊元素。
如果你是使⽤模式的同时提供了可选的标志参数,某些模式元素含义就会改变。
编译正则表达式基础Python通过re模块提供对正则表达式的⽀持。
python python正则表达式匹配不包含某几个字符的字符串方法

python python正则表达式匹配不包含某几个字符的字符串方法Python是一种高级编程语言,具有强大的正则表达式匹配功能。
在Python中,可以使用正则表达式来匹配不包含某几个字符的字符串。
下面介绍一些方法。
方法一:使用“^”符号在正则表达式中,“^”符号表示匹配字符串的开头。
因此,如果要匹配不包含某几个字符的字符串,可以在正则表达式中使用“^”符号,并在其后面跟上这些字符。
例如,要匹配不包含字母a、b、c的字符串,可以使用如下正则表达式:^[^abc]*$其中,“^”表示匹配字符串的开头,“[^abc]”表示不包含字母a、b、c,“*”表示匹配任意数量的字符,“$”表示匹配字符串的结尾。
方法二:使用“(?!...)”语法在正则表达式中,“(?!...)”语法表示否定预测先行断言,即匹配不包含某个模式的字符串。
例如,要匹配不包含字母a、b、c的字符串,可以使用如下正则表达式:^(?!.*[abc]).*$其中,“^”表示匹配字符串的开头,“(?!.*[abc])”表示不包含字母a、b、c,“.*”表示匹配任意数量的字符,“$”表示匹配字符串的结尾。
方法三:使用re.sub()函数在Python中,可以使用re.sub()函数来替换字符串中的匹配项。
因此,如果要匹配不包含某几个字符的字符串,可以使用re.sub()函数将这些字符替换为空字符串。
例如,要匹配不包含字母a、b、c的字符串,可以使用如下代码:import res = "hello world"s = re.sub("[abc]", "", s)print(s)输出结果为:“hello world”。
以上是Python中匹配不包含某几个字符的字符串的几种方法。
这些方法都可以有效地解决这个问题,具体使用哪种方法取决于具体的需求和场景。
在使用正则表达式时,需要注意一些细节,例如转义字符的使用、匹配模式的选择等。
python正则表达式匹配结尾

Python是一种功能强大的编程语言,它提供了丰富的库和工具,以便开发者能够轻松地处理各种任务。
正则表达式是Python中的一个重要工具,它能够帮助开发者进行字符串匹配和替换操作。
在使用正则表达式时,掌握如何匹配结尾的字符串是非常重要的。
本文将介绍Python正则表达式中匹配结尾的方法,内容包括如下几个部分:一、Python正则表达式简介二、Python正则表达式匹配结尾的方法三、示例演示四、总结一、Python正则表达式简介正则表达式是一种强大的字符串匹配工具,它使用特定的符号和语法规则来描述字符串的模式。
Python中的re模块提供了对正则表达式的支持,开发者可以借助re模块对字符串进行匹配、替换和提取等操作。
二、Python正则表达式匹配结尾的方法在Python中,要匹配结尾的字符串,可以使用'$'符号。
'$'符号用来表示字符串的结束位置,在正则表达式中使用它可以精确匹配结尾的字符串。
示例如下:import repattern = r'ing$'text = "I am running"result = re.search(pattern, text)if result:print("匹配成功")else:print("匹配失败")在上面的示例中,使用了正则表达式'ing$'来匹配以'ing'结尾的字符串,结果会返回匹配成功。
三、示例演示接下来,我们通过一个实际的示例来演示如何在Python中使用正则表达式匹配结尾的字符串。
示例代码如下:import repattern = r'ing$'text = "I am running"result = re.search(pattern, text)if result:print("匹配成功")else:print("匹配失败")通过运行上述代码,我们可以得到匹配结果。
python常用正则表达式

python常用正则表达式
正则表达式是一种用于匹配文本模式的工具,是Python中的一项重要功能。
以下是Python中常用的正则表达式:
1. 匹配任意字符:使用“.”符号表示任意一个字符(除了换行符)
2. 匹配特定字符:使用方括号“[]”表示需要匹配的字符集合,如[abc]表示匹配a、b、c三个字符中的任意一个。
3. 匹配某个范围内的字符:使用“-”符号表示要匹配的字符范围,如[a-z]表示匹配小写字母a到z中的任意一个。
4. 匹配重复字符:使用“*”符号表示前面的字符可以重复出现任意次数,如a*表示匹配0个或多个a字符。
5. 匹配固定数量的字符:使用“{n}”表示前面的字符必须出现n次,如a{3}表示匹配3个a字符。
6. 匹配至少n次、至多m次的字符:使用“{n,m}”表示前面的字符必须出现至少n次、至多m次,如a{1,3}表示匹配1到3个a 字符。
7. 匹配任意多个字符:使用“+”符号表示前面的字符可以出现1次或多次,如a+表示匹配至少一个a字符。
8. 匹配开头或结尾的字符:使用“^”符号表示以指定字符开头,使用“$”符号表示以指定字符结尾,如^a表示以a字符开头,a$表示以a字符结尾。
以上是Python中常用的正则表达式,掌握这些基本规则可以帮
助开发者更快、更准确地匹配文本模式。
Python正则表达式总结

Python正则表达式总结正则表达式练习:1、匹配⼀⾏⽂字中的所有开头的字母内容import res = "I love you not because of who you are, but because of who i am when i am with you"content = re.findall(r'\b\w', s)print(content)['I', 'l', 'y', 'n', 'b', 'o', 'w', 'y', 'a', 'b', 'b', 'o', 'w', 'i', 'a', 'w', 'i', 'a', 'w', 'y']2、匹配⼀⾏⽂字中的最后的数字内容import res = "I love you not because 12sd 34er 56df e4 54434"content = re.findall(r'\d\b', s)print(content)['4', '4']3、匹配⼀⾏⽂字中的所有开头的数字内容import reprint(re.match(r'\w+', '123sdf').group())123sdf4、只匹配包含字母和数字的⾏import res = "i love you not because\n12sd 34er 56\ndf e4 54434"content = re.findall(r'\w\d', s, re.M)print(content)['12', '34', '56', 'e4', '54', '43']5、写⼀个正则表达式,使其能同时识别下⾯所有的字符串:'bat', 'bit', 'but', 'hat', 'hit', 'hut‘import res = "'bat', 'bit', 'but', 'hat', 'hit', 'hut"content = re.findall(r'..t', s)print(content)['bat', 'bit', 'but', 'hat', 'hit', 'hut']6、匹配所有合法的python标识符import res = "awoeur awier !@# @#4_-asdf3$^&()+?><dfg$\n$"content = re.findall(r'.*', s, re.DOTALL)print(content)['awoeur awier !@# @#4_-asdf3$^&()+?><dfg$\n$', '']7、提取每⾏中完整的年⽉⽇和时间字段import res = """se234 1987-02-09 07:30:001987-02-10 07:25:00"""content = re.findall(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', s, re.M)print(content)['1987-02-09 07:30:00', '1987-02-10 07:25:00']8、使⽤正则表达式匹配合法的邮件地址:import res = """xiasd@, sdlfkj@.com sdflkj@ solodfdsf@ sdlfjxiaori@ oisdfo@""" content = re.findall(r'\w+@\w+.com', s)print(content)['xiasd@', 'sdflkj@', 'solodfdsf@', 'sdlfjxiaori@']9、将每⾏中的电⼦邮件地址替换为你⾃⼰的电⼦邮件地址import res = """693152032@, werksdf@, sdf@sfjsdf@, soifsdfj@pwoeir423@"""content = re.sub(r'\w+@\w+.com', '1425868653@', s)print(content)1425868653@, 1425868653@, 1425868653@1425868653@, 1425868653@1425868653@10、匹配\home关键字:import reprint(re.findall(r'\\home', "skjdfoijower \home \homewer"))['\\home', '\\home']11、使⽤正则提取出字符串中的单词import res = """i love you not because of who 234 you are, 234 but 3234ser because of who i am when i am with you"""content = re.findall(r'\b[a-zA-Z]+\b', s)print(content)['i', 'love', 'you', 'not', 'because', 'of', 'who', 'you', 'are', 'but', 'because', 'of', 'who', 'i', 'am', 'when', 'i', 'am', 'with', 'you']摘抄供参考学习:校验数字的表达式1. 数字:^[0-9]*$2. n位的数字:^\d{n}$3. ⾄少n位的数字:^\d{n,}$4. m-n位的数字:^\d{m,n}$5. 零和⾮零开头的数字:^(0|[1-9][0-9]*)$6. ⾮零开头的最多带两位⼩数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$7. 带1-2位⼩数的正数或负数:^(\-)?\d+(\.\d{1,2})?$8. 正数、负数、和⼩数:^(\-|\+)?\d+(\.\d+)?$9. 有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$10. 有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$11. ⾮零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$12. ⾮零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$13. ⾮负整数:^\d+$ 或 ^[1-9]\d*|0$14. ⾮正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$15. ⾮负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$16. ⾮正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$17. 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$18. 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$19. 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$校验字符的表达式1. 汉字:^[\u4e00-\u9fa5]{0,}$2. 英⽂和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$3. 长度为3-20的所有字符:^.{3,20}$4. 由26个英⽂字母组成的字符串:^[A-Za-z]+$5. 由26个⼤写英⽂字母组成的字符串:^[A-Z]+$6. 由26个⼩写英⽂字母组成的字符串:^[a-z]+$7. 由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$8. 由数字、26个英⽂字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$9. 中⽂、英⽂、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$10. 中⽂、英⽂、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$11. 可以输⼊含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+ 12 禁⽌输⼊含有~的字符:[^~\x22]+特殊需求表达式1. Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2. 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?4. ⼿机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5. 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6. 国内电话号码(0511-*******、021-********):\d{3}-\d{8}|\d{4}-\d{7}7. ⾝份证号(15位、18位数字):^\d{15}|\d{18}$8. 短⾝份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9. 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10. 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11. 强密码(必须包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12. ⽇期格式:^\d{4}-\d{1,2}-\d{1,2}13. ⼀年的12个⽉(01~09和1~12):^(0?[1-9]|1[0-2])$14. ⼀个⽉的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15. 钱的输⼊格式:16. 1.有四种钱的表⽰形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$17. 2.这表⽰任意⼀个不以0开头的数字,但是,这也意味着⼀个字符"0"不通过,所以我们采⽤下⾯的形式:^(0|[1-9][0-9]*)$18. 3.⼀个0或者⼀个不以0开头的数字.我们还可以允许开头有⼀个负号:^(0|-?[1-9][0-9]*)$19. 4.这表⽰⼀个0或者⼀个可能为负的开头不为0的数字.让⽤户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下⾯我们要加的是说明可能的⼩数部分:^[0-9]+(.[0-9]+)?$20. 5.必须说明的是,⼩数点后⾯⾄少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$21. 6.这样我们规定⼩数点后⾯必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$22. 7.这样就允许⽤户只写⼀位⼩数.下⾯我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$23 8.1到3个数字,后⾯跟着任意个逗号+3个数字,逗号成为可选,⽽不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$24. 备注:这就是最终结果了,别忘了"+"可以⽤"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在⽤函数时去掉去掉那个反斜杠,⼀般的错误都在这⾥25. xml⽂件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$26. 中⽂字符的正则表达式:[\u4e00-\u9fa5]27. 双字节字符:[^\x00-\xff] (包括汉字在内,可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1))28. 空⽩⾏的正则表达式:\n\s*\r (可以⽤来删除空⽩⾏)29. HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (仅仅能匹配部分,对于复杂的嵌套标记⽆能为⼒)30. ⾸尾空⽩字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式)31. 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)32. 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)33. IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有⽤)34. IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))。
Python正则表达式模式匹配和替换

Python正则表达式模式匹配和替换正文:Python正则表达式(Regular Expression)是一种用来匹配、搜索和替换文本的强大工具。
它通过使用一种特殊的字符序列,可以帮助我们快速地定位、匹配和提取符合特定模式的字符串。
在本文中,我们将探讨Python正则表达式的应用,包括模式匹配和替换的实例。
一、正则表达式的基本语法要使用Python的正则表达式模块re,我们需要先导入该模块。
以下是一个基本的Python正则表达式语法示例:import repattern = r"abc"# 定义一个正则表达式模式"abc"match = re.search(pattern, "abcdefg")# 在字符串中搜索匹配模式if match:print("找到了匹配的模式")else:print("未找到匹配的模式")以上代码中,我们首先导入re模块,然后定义一个字符串模式"abc",接着使用re模块的search函数,在字符串"abcdefg"中搜索是否存在匹配模式"abc"。
如果找到则输出"找到了匹配的模式",否则输出"未找到匹配的模式"。
二、元字符和限定符在正则表达式中,有一些特殊字符被称为元字符,用于表示模式中的一些特定意义。
例如,使用点号(.)表示任何字符,而使用星号(*)表示任意数量的前一个字符。
以下是一些常用的元字符和限定符的示例:- . :匹配任意单个字符- * :匹配前一个字符的零次或多次出现- + :匹配前一个字符的一次或多次出现- ? :匹配前一个字符的零次或一次出现- \d :匹配任意一个数字- \w :匹配任意一个字母或数字或下划线- \s :匹配任何空白字符三、模式匹配与提取除了基本的元字符和限定符,正则表达式还可以使用一些特殊的语法来进行模式匹配和提取。
python正则表达式嵌套用法

在探讨Python正则表达式嵌套用法的主题时,我们首先要了解正则表达式的基本概念和语法结构。
正则表达式是一种强大的文本匹配和处理工具,能够帮助我们更高效地进行字符串操作。
Python作为一种流行的编程语言,拥有内置的re模块,可用于处理正则表达式。
在这篇文章中,我们将深入探讨正则表达式的嵌套用法,帮助你更好地理解和运用这一技术。
一、基本概念和语法结构1.1 什么是正则表达式正则表达式是一种特殊的字符序列,它能帮助我们在文本中进行模式匹配和搜索。
使用正则表达式,我们可以快速地找到符合特定模式的字符串,实现文本的提取、替换和匹配等操作。
1.2 正则表达式的基本语法正则表达式包含多种特殊字符和语法结构,如字符类、限定符、分组等。
`.`表示匹配任意字符,`*`表示匹配前面的字符零次或多次,`()`表示分组等。
这些语法结构是正则表达式的基础,我们需要对其有一个清晰的了解,才能更好地运用正则表达式。
二、嵌套用法的实际应用2.1 嵌套分组在正则表达式中,我们可以使用嵌套的分组结构来实现更复杂的匹配逻辑。
我们可以使用`(…) (…)`的形式来进行嵌套分组,从而实现多层次的模式匹配。
这种嵌套分组的用法可以帮助我们更准确地提取和处理目标文本。
2.2 嵌套引用除了嵌套分组外,正则表达式还支持嵌套引用的用法。
通过在正则表达式中使用`\n`来引用前面的分组,我们可以实现嵌套引用的功能。
这种用法在处理复杂的文本匹配时非常有用,能够提高匹配的准确性和灵活性。
三、个人观点和总结通过对Python正则表达式嵌套用法的深入探讨,我们可以发现正则表达式的强大之处。
嵌套用法能够帮助我们处理更为复杂和多样化的文本匹配需求,提高我们的开发效率和代码质量。
在实际开发中,我们应当充分利用正则表达式的嵌套用法,灵活运用各种语法结构,从而更好地应对不同的匹配场景。
Python正则表达式嵌套用法是一项非常有价值的技术,它能够帮助我们更好地处理文本匹配和处理问题。
python 常用正则表达式

python 常用正则表达式
正则表达式是一种强大的文本处理工具,在Python中也得到了
广泛的应用。
下面是Python中常用的正则表达式:
1. 匹配任意字符
. 表示匹配任意一个字符,但不包括换行符。
2. 匹配特定字符
表示转义字符,可以用来匹配一些特殊字符,如匹配反斜杠本身需要使用。
[] 表示匹配括号内的任意一个字符。
例如 [abc] 表示匹配 a、b、c中的任意一个字符。
^ 表示在括号内使用时表示取反,例如 [^abc] 表示匹配除了 a、
b、c之外的任意一个字符。
3. 匹配多个字符
* 表示匹配前面的字符0次或多次。
+ 表示匹配前面的字符1次或多次。
?表示匹配前面的字符0次或1次。
{n} 表示匹配前面的字符恰好n次。
{n,} 表示匹配前面的字符至少n次。
{n,m} 表示匹配前面的字符至少n次,但不超过m次。
4. 匹配字符串的开头和结尾
^ 表示字符串的开头,例如 ^hello 表示字符串以 hello开头。
$ 表示字符串的结尾,例如 world$ 表示字符串以 world结尾。
5. 匹配单词边界
b 表示单词的边界,例如bhellob表示匹配单词 hello。
6. 分组
() 表示分组,可以对文本进行分组,例如 ([a-z]+) 表示匹配一个或多个小写字母。
7. 贪婪匹配与非贪婪匹配
默认情况下,正则表达式是贪婪匹配的,即会尽可能多地匹配文本。
使用?可以实现非贪婪匹配。
以上是Python中常用的正则表达式,掌握这些正则表达式可以帮助你更高效地处理文本。
python常用正规表达式

python常用正规表达式Python中的正则表达式是用于匹配字符串的强大工具。
它们可以用于各种目的,例如:1.验证数据2.提取信息3.替换文本Python中的正则表达式使用re模块来实现。
该模块提供了各种方法来匹配和操作字符串。
以下是一些Python中常用的正则表达式:匹配数字●import re●匹配任意数字●pattern=d+●匹配至少一位数字●pattern=d{1,}●匹配1到2位数字●pattern=d{1,2}匹配字母●Python●import re●匹配任意字母●pattern=[a-zA-Z]+●匹配至少一位字母●pattern=[a-zA-Z]{1,}●匹配1到2位字母●pattern=[a-zA-Z]{1,2}匹配特定字符●Python●import re●匹配字符a●pattern=a●匹配字符a或b●pattern=a|b●匹配字符串abc●pattern=abc匹配特殊字符●Python●import re●匹配空格●pattern=s●匹配换行符●pattern=n●匹配点号●pattern=.匹配模式●Python●import re●匹配任意字符,至少一次●pattern=.+●匹配任意字符,最多一次●pattern=.●匹配零次或一次●pattern=.?组合模式●Python●import re●匹配字符串abc●pattern=(abc)●匹配字符串a后跟任意字符●pattern=a.●匹配字符串a后跟零次或一次任意字符●pattern=a.?边界符●import re●匹配字符串abc开头●pattern=^abc●匹配字符串abc结尾●pattern=abc$●匹配字符串abc两侧有空格●pattern=sabc\s反向引用●Python●import re●匹配字符串abc两侧有空格●pattern=s(abc)\s●匹配字符串abc后跟任意字符,但不能是d ●pattern=abc(?!d)其他模式●import re●匹配字符串abc的所有匹配项●pattern=abc●result=re.findall(pattern,abcabcabc)●print(result)●[abc,abc,abc]●匹配字符串abc的第一个匹配项●pattern=abc●result=re.search(pattern,abcabcabc)●print(result)●<_sre.SRE_Match object;span=(0,3),match=abc>●匹配字符串abc是否存在●pattern=abc●result=re.search(pattern,abcabcabc)●print(result is not None)●TruePython中的正则表达式非常强大,可以用于各种目的。
python匹配正则表达式

python匹配正则表达式正则表达式(Regular Expression)是一种用来匹配字符串的强大工具,它在数据处理中得到了广泛的应用。
Python作为一门高效且易于学习的编程语言,自然不会错过正则表达式的应用。
在Python中,我们可以通过re模块来进行正则表达式的匹配,本文将为大家介绍re 模块的相关知识。
1. re模块的基本介绍re模块是Python用于正则表达式操作的基本模块,它提供了一系列函数用于对字符串进行匹配和查找。
使用re模块之前,需要先进行模块的导入:import re2. re模块的基本函数2.1 匹配函数match()函数match()用来检查字符串是否以某个指定的模式开头。
语法如下:re.match(pattern, string, flags=0)其中,参数pattern表示要匹配的正则表达式,参数string表示要匹配的字符串,参数flags表示匹配模式,常见的匹配模式有:- re.I:忽略大小写- re.M:多行匹配,改变^和$的行为- re.S:让'.'匹配任何字符,包括换行符- re.U:考虑Unicode字符- re.X:正则表达式内的空格和注释将被忽略掉如果匹配成功,该函数会返回一个匹配对象,如果匹配失败,则返回None。
下面是一个例子:import res = 'hello, world!'pattern = r'hello'result = re.match(pattern, s)if result:print('Matched:', result.group())else:print('Not Matched')输出结果为:Matched: hello这个例子检查了字符串s是否以hello开头,由于s的开头正好是hello,因此匹配成功,返回了一个匹配对象。
2.2 搜索函数search()函数search()用来搜索字符串中的指定模式,如果能找到,则返回一个匹配对象。
python中常用的正则表达式符号

python中常⽤的正则表达式符号'.'默认匹配除\n之外的任意⼀个字符,若指定flag DOTALL,则匹配任意字符,包括换⾏'^'匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)'$'匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以'*'匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']'+'匹配前⼀个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']'?'匹配前⼀个字符1次或0次'{m}'匹配前⼀个字符m次'{n,m}'匹配前⼀个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']'|'匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC''(...)'分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c'\A'只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的'\Z'匹配字符结尾,同$'\d'匹配数字0-9'\D'匹配⾮数字'\w'匹配[A-Za-z0-9]'\W'匹配⾮[A-Za-z0-9]'s'匹配空⽩字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果'\t''(?P<name>...)'分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481************").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}最常⽤的匹配语法:1 re.match 从头开始匹配2 re.search 匹配包含3 re.findall 把所有匹配到的字符放到以列表中的元素返回4 re.splitall 以匹配到的字符当做列表分隔符5 re.sub 匹配字符并替换。
python正则表达式匹配加减乘除运算

在Python编程中,正则表达式是一种强大的工具,可以用来匹配字符串中的特定模式。
而加减乘除运算则是数学中基本的四则运算,是我们在日常生活中经常会用到的计算方法。
本篇文章将从简到繁地探讨如何利用Python中的正则表达式来进行加减乘除运算,以帮助读者更深入地理解这一主题。
1. 正则表达式简介让我们简要回顾一下正则表达式的基本知识。
正则表达式是用来描述字符序列的一种方法,可以用来匹配、查找和替换字符串中的特定模式。
在Python中,我们可以使用re模块来操作正则表达式,实现对字符串的模式匹配和提取。
2. 匹配加减乘除运算现在,让我们开始探讨如何利用正则表达式来匹配加减乘除运算。
假设我们有一个包含加减乘除运算的字符串,我们希望能够用正则表达式来提取出运算符和操作数,以便进行计算。
这就需要我们编写一个合适的正则表达式模式,来匹配这些运算符和操作数。
3. 编写正则表达式模式对于加减乘除运算,我们可以将正则表达式模式设计为匹配两个操作数和一个运算符的形式。
我们可以使用如下的正则表达式模式来匹配加法运算:```(\d+)[\s]*\+[\s]*(\d+)```这个正则表达式模式中,`(\d+)`匹配一个或多个数字作为操作数,`[\s]*`匹配零个或多个空格,`\+`匹配加号运算符。
通过类似的方式,我们还可以设计模式来匹配减法、乘法和除法运算。
4. 使用正则表达式进行运算一旦我们设计好了匹配加减乘除运算的正则表达式模式,就可以利用Python中re模块提供的函数来进行匹配和提取操作。
我们可以使用re.match和re.search函数来寻找字符串中匹配的模式,并提取出操作数和运算符,然后进行相应的运算。
5. 个人观点和理解通过使用正则表达式进行加减乘除运算,我们可以实现对包含运算式的字符串进行自动化的计算,极大地提高了程序的灵活性和效率。
正则表达式的灵活性和强大功能也为我们提供了更多处理字符串的方法。
总结通过本文的讨论,我们了解了如何利用Python中的正则表达式来进行加减乘除运算。
Python高级——正则表达式re模块1.match方法

Python⾼级——正则表达式re模块1.match⽅法本⽂⾮原创,转⾃:本⽂链接:python:正则表达式⼀、什么是正则表达式正则表达式也叫做匹配模式(Pattern),它由⼀组具有特定含义的字符串组成,通常⽤于匹配和替换⽂本。
正则表达式,是⼀个独⽴的技术,很多编程语⾔⽀持正则表达式处理。
Wiki:正则表达式(英语:Regular Expression、regex或regexp,缩写为RE),也译为正规表⽰法、常规表⽰法,在计算机科学中,是指⼀个⽤来描述或者匹配⼀系列符合某个句法规则的字符串的单个字符串。
在很多⽂本编辑器或其他⼯具⾥,正则表达式通常被⽤来检索和/或替换那些符合某个模式的⽂本内容。
许多程序设计语⾔都⽀持利⽤正则表达式进⾏字符串操作。
正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
通常情况下,如果⼀个⽂本中出现了多个匹配,正则表达式返回第⼀个匹配,如果将 global 设置为 true,则会返回全部匹配;匹配模式是⼤⼩写敏感的,如果设置了 ignore case 为 true,则将忽略⼤⼩写区别。
有时侯正则表达式也简称为表达式、匹配模式或者模式,它们可以互换。
这⾥默认 global 和 ignore case 均为 true。
为什么要使⽤正则表达式在软件开发过程中,经常会涉及到⼤量的关键字等各种字符串的操作,使⽤正则表达式能很⼤程度的简化开发的复杂度和开发的效率,所以在Python中正则表达式在字符串的查询匹配操作中占据很重要的地位⼆、Python中的re模块1.Python为了⽅便⼤家对于正则的使⽤,专门为⼤家提供了re模块供我们使⽤。
查看字符串是否是以“lili”开头import re # 导⼊re模块dir(re) # 查看re模块的⽅法和属性['A', 'ASCII', 'DEBUG', 'DOTALL', 'I', 'IGNORECASE', 'L', 'LOCALE', 'M', 'MULTILINE', 'RegexFlag', 'S', 'Scanner', 'T', 'TEMPLATE', 'U', 'UNICODE', 'VERBOSE', 'X', '_MAXCACHE', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '__version__', '_alphanum_bytes', '_alphanum_str', '_cache', '_compile', '_compile_repl', '_expand', '_locale', '_pattern_type', '_pickle', '_subx', 'compile', 'copyreg', 'enum', 'error', 'escape', 'findall', 'finditer', 'fullmatch', 'functools', 'match', 'purge', 'search', 'split', 'sre_compile', 'sre_parse', 'sub', 'subn', 'template']在Python 2.7.12 查看re的⽅法的界⾯import re # 导⼊re模块str = "lili" # 定义⼀个字符串等于lili# 查看"lili is a good girl"是否以lili开头,结果保存到res中res = re.match(str,"mayun is very good shangren")# 使⽤res.group()提取匹配结果,如果是,则返回匹配对象(Match Object),否则返回None,res.group() # 将匹配的结果显⽰结果如下:‘lili'请看在命令⾏运⾏的例⼦:注意:re.match( )⽅法匹配的是以xxx开头的字符串,若不是开头的,尽管属于str内,则⽆法匹配。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c
\z
匹配字符串结束
\G
匹配最后匹配完成的位置。
\b
匹配一个单词边界,也就是指单词和空格间的位置。例如,'er\b'可以匹配"never"中的'er',但不能匹配"verb"中的'er'。
\B
匹配非单词边界。'er\B'能匹配"verb"中的'er',但不能匹配"never"中的'er'。
\n, \t,等.
匹配一个换行符。匹配一个制表符。等
\1...\9
匹配第n个分组的子表达式。
\10
匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。
(Байду номын сангаас! re)
前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功
(?> re)
匹配的独立模式,省去回溯。
\w
匹配字母数字
\W
匹配非字母数字
\s
匹配任意空白字符,等价于[\t\n\r\f].
\S
匹配任意非空字符
\d
匹配任意数字,等价于[0-9].
\D
匹配任意非数字
\A
匹配字符串开始
(?-imx)
正则表达式关闭i, m,或x可选标志。只影响括号中的区域。
(?: re)
类似(...),但是不表示一个组
(?imx: re)
在括号中使用i, m,或x可选标志
(?-imx: re)
在括号中不使用i, m,或x可选标志
(?#...)
注释.
(?= re)
前向肯定界定符。如果所含正则表达式,以...表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。
^
匹配字符串的开头
$
匹配字符串的末尾。
.
匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
[...]
用来表示一组字符,单独列出:[amk]匹配'a','m'或'k'
[^...]
不在[]中的字符:[^abc]匹配除了a,b,c之外的字符。
re*
匹配0个或多个的表达式。
re+
匹配1个或多个的表达式。
re?
匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
re{ n}
re{ n,}
精确匹配n个前面表达式。
re{ n, m}
匹配n到m次由前面的正则表达式定义的片段,贪婪方式
a| b
匹配a或b
(re)
G匹配括号内的表达式,也表示一个组
(?imx)
正则表达式包含三种可选标志:i, m,或x。只影响括号中的区域。