数据统计研究分析-第一次作业
统计学原理作业答案(1).doc

宁大专科《统计学原理》作业第一次作业一、单项选择题1、社会经济统计学研究对象(C )。
A、社会经济现象总体B、社会经济现象个体C、社会经济现象总体的数量方面D、社会经济现象的数量方面2、统计研究在( B )阶段的方法属于大量观察法。
A、统计设计B、统计调查C、统计整理D、统计分析3、、研究某市工业企业生产设备使用状况,那么,统计总体为( A )。
A、该市全部工业企业B、该市每一个工业企业C、该市全部工业企业每一台生产设备D、该市全部工业企业所有生产设备4、下列标志属于品质标志的是( C )。
A、工人年龄B、工人工资C、工人性别D、工人体重5、下列变量中,属于连续变量的是( C )。
A、企业数B、职工人数C、利润额D、设备台数6、把一个工厂的工人组成总体,那么每一个工人就是( A )。
A、总体单位B、数量标志C、指标D、报告单位7、几位工人的工资分别为1500元、1800元和2500元,这几个数字是( C )。
A、指标B、变量C、变量值D、标志8、变异的涵义是( A )。
A、统计中标志的不同表现。
B、总体单位有许多不同的标志。
C、现象总体可能存在各种各样的指标。
D、品质标志的具体表现。
9、销售额和库存额两指标( D )。
A、均为时点指标B、均为时期指标C、前者是时点指标,后者是时期指标D、前者是时期指标,后者是时点指标10、下列指标中属于时期指标的有( B )。
A、机器台数B、产量C、企业数D、库存额11、不同时点的指标数值( B )。
A、具有可加性B、不具有可加性C、可加或可减D、以上都不对12、某企业计划规定劳动生产率比上年提高5%,实际提高8%,则该企业劳动生产率计划完成程度为( B )。
A、86%B、102.86%C、60%D、160%13、某市2004年重工业增加值为轻工业增加值的85%,该指标是( C )。
A、比较相对指标B、结构相对指标C、比例相对指标D、计划相对指标二、简答题1、什么是总体和单位,举例说明。
东北师范大学秋心理统计学第一次作业及答案

单选题(共10道试题,共30分。
)1.已知n=10的两个相关样本的平均数差是10.5,其自由度为 A.92.用从总体抽取的一个样本统计量作为总体参数的估计值称为 B.点估计3.双侧检验是关于()的检验 B.只强调差异而不强调方向性4.某一事件在无限测量中所能得相对出现的次数是 C.概率5.从变量的测量水平来看,以下数据与其他不同类的变量取值 D.1克6.在3×2×2的设计当中有多少个一级交互作用 A.37.方差分析的基本原理是 C.综合的F检验8.进行分组次数分布统计时,关键的一点是 A.确定每组的取值范围9.()表明了从样本得到的结果相比于真正总体值的变异量 D.取样误差10.关于独立组和相关组的说法错误的是A.独立组问题往往来自组内设计B.相关组问题往往来自组内设计C.独立组的两个样本的容量可以不同D.相关组的两个样本容量必然相同满分:3分多选题(共10道试题,共30分。
)1.统计分组需要注意的问题是A.分组以被研究对象本质特征为基础B.分组以被研究对象的具体特征为基础C.分组标志要明确D.分组要包含所有数据E.分组要适当剔除极端数据满分:3分2.对于HSD检验和Scheffe检验,以下说法正确的是A.两种检验都是事后检验B.HSD 检验比Scheffe 检验更加敏感C.HSD 检验只能用于n 相等的情况D.只有Scheffe 检验控制了族系误差E.以上说法均正确3.次数分布图可以清晰直观的给出数据的分布趋势,有不同的类型A.直方图B.棒图C.折线图D.茎叶图E.饼图4.二项分布涉及的问题中A.个体要么具有某种特征,要么不具有某种特征B.要么发生事件X ,要么发生事件YC.一个事件具有两个特征D.XY 时间可以同时发生E.XY 可以同时发生,也可不同时发生5.次数分布图包括:A.直方图B.圆形图C.次数多边形图D.累加次数分布图E.折线图6.下列属于非参数检验的方法有 A.卡方检验B.符号检验C.符号等级检验法D.秩和检验E.中位数检验等。
JZX高等数值分析第一次实验作业
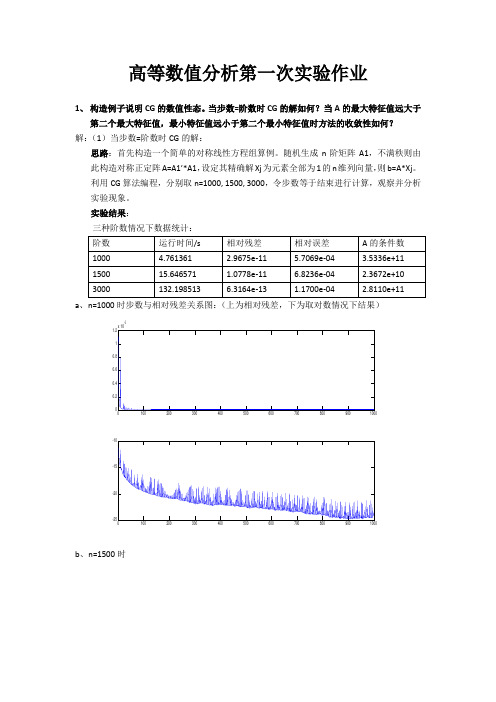
相对残差 6.1302e-16 8.7797e-09 8.0295e-09 8.5677e-09 9.1433e-09
a、 m=1 (左为相对残差,右为取对数情况)
1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1
0 1
1.5
0
-5
-10
-15
-20
-25
-30
-35
-40
1000
4.761361
2.9675e-11
5.7069e-04
3.5336e+11
1500
15.646571
1.0778e-11
6.8236e-04
2.3672e+10
3000
132.198513
6.3164e-13
1.1700e-04
2.8110e+11
a、n=1000 时步数与相对残差关系图:(上为相对残差,下为取对数情况下结果)
(2)当 A 最大特征值远大于第二个特征值,最小特征值远小于第二个最小特征值时收敛
性情况。
思路:构造题目要求的矩阵 A。首先随机生成 n 阶矩阵 B,B 不满秩,构造对角阵 A1(最
大特征值远大于第二个最大特征值,最小特征值远小于第二个最小特征值),则由此构
造出对称正定矩阵 A: b1=B’*B; A=b1’*A1*b1。同样设定精确解 Xj 为元素全部为 1 的 n
5、 构造对称不定的矩阵,验证 Lanczos 方法的近似中断,观察收敛曲线中的峰点个数和特
征值的分布关系;观察当出现峰点时,MINRES 方法的收敛性态怎样。
解:思路:类似前两题,首先构造出一个 n 阶对角阵 D,其对角线上有 m 个负值,再对随
临床试验数据统计标准操作规程

临床试验数据统计标准操作规程
1、制定统计分析计划:由生物统计人员配合主要研究者在
制定试验方案时写成初稿,在试验的进行中,不断完善分析计划,但必须在数据锁定前定稿。
2、盲态审核:在最后一个病例报告表输入数据库以后,直
到第一次揭盲之前,由主要研究者、生物统计人员、数据管理员和申办者对数据库内数据进行核对和评价。
审核内容包括:对统计计划书的修改和确认;对研究方案中主要内容的确认;对全部入组病例和全部数据的确认(包括脱落病例,主要疗效,安全性数据等)。
3、盲态审核完后,将数据锁定。
4、第一次揭盲:打开第一次揭盲信封,将A、B两组数据进
行统计分析。
5、第二次揭盲:在临床试验总结报告会上,在药品监督管
理部门工作人员监督下进行第二次揭盲。
统计学第一次作业(工商专升本)

一.单选题(共20题,48.0分)1一个研究者应用有关车祸的统计数据估计在车祸中死亡的人数,在这个例子中使用的统计属于( )。
•A、推断统计学;•B、描述统计学;•C、既是描述统计学,又是推断统计学;•D、既不是描述统计学,有不是推断统计学。
我的答案:A得分:2.4分2某研究部门准备在全市200万个家庭中抽取2000个家庭,推断该城市所有职工家庭的年人均收入。
这项研究的总体是( )。
•A、2000个家庭•B、200万个家庭•C、2000个家庭的年人均收入•D、200万个家庭的总收入我的答案:B得分:2.4分3对某地区5000个企业的企业注册类型、产值和利润总额等调查数据进行分析,下列说法中正确的是( )。
•A、企业注册类型是定序变量•B、利润总额是品质标志•C、产值是定类变量•D、产值和利润总额都是连续变量我的答案:D得分:2.4分4为了了解居民对小区物业服务的意见和看法,管理人员随机抽取了50户居民,上门通过问卷进行调查。
这种数据收集方法称为( )。
•A、面访式问卷调查•B、实验调查•C、观察式调查•D、自填式问卷调查我的答案:A得分:2.4分5对同一总体选择两个或两个以上标志重叠起来进行分组,称为( )。
•A、简单分组•B、平行分组•C、一次性分组•D、复合分组我的答案:D得分:2.4分6统计表的横行标题表明( )。
•A、全部统计资料的内容•B、研究总体及其组成部分•C、总体特征的统计指标的名称•D、现象的具体数值我的答案:B得分:2.4分7下列指标属于比例相对指标的是( )。
•A、2000年北京市失业人员再就业率为73%•B、三项社会保险统筹基金收缴率95%•C、北京人口性别比为103•D、北京每百户居民拥有电脑32台我的答案:C得分:2.4分8一组数据排序后处于25%和75%的位置上的值称为( )。
•A、众数•B、中位数•C、四分位数•D、算术平均数我的答案:C得分:2.4分9权数对加权算术平均数的影响作用,决定于( )。
西南大学《数理统计》作业及答案

数理统计第一次1、设总体X 服从正态分布),(2σμN ,其中μ已知,2σ未知,n X X X ,,,21 为其样本,2≥n ,则下列说法中正确的是( )。
(A )∑=-ni i X n122)(μσ是统计量 (B )∑=ni i X n122σ是统计量(C )∑=--ni iX n 122)(1μσ是统计量 (D )∑=ni iX n12μ是统计量2、设两独立随机变量)1,0(~N X ,)9(~2χY ,则YX 3服从( )。
)(A )1,0(N )(B )3(t )(C )9(t )(D )9,1(F3、设两独立随机变量)1,0(~N X ,2~(16)Y χ)。
)(A )1,0(N )(B (4)t )(C (16)t )(D (1,4)F4、设n X X ,,1 是来自总体X 的样本,且μ=EX ,则下列是μ的无偏估计的是( ).)(A ∑-=-1111n i i X n )(B ∑=-n i i X n 111 )(C ∑=n i i X n 21 )(D ∑-=111n i i X n 5、设4321,,,X X X X 是总体2(0,)N σ的样本,2σ未知,则下列随机变量是统计量的是( ).(A )3/X σ; (B )414ii X=∑; (C )σ-1X ; (D )4221/ii Xσ=∑6、设总体),(~2σμN X ,1,,n X X 为样本,S X ,分别为样本均值和标准差,则下列正确的是( ).2() ~(,)A X N μσ 2() ~(,)B nX N μσ22211()()~()ni i C X n μχσ=-∑)()~()X D t n Sμ-7、设总体X 服从两点分布B (1,p ),其中p 是未知参数,15,,X X ⋅⋅⋅是来自总体的简单随机样本,则下列随机变量不是统计量为( )( A ) . 12X X +( B ){}max ,15i X i ≤≤( C ) 52X p +( D )()251X X -8、设1,,n X X ⋅⋅⋅为来自正态总体2(,)N μσ的一个样本,μ,2σ未知。
《统计学》第一次作业题答案

第一章绪论练习题一、填空题:1.统计总体的特征可概括成同质性、大量性和差异性。
2.现实生活中,“统计”一词有三种涵义,即统计工作、统计资料及统计学。
3.统计的作用主要体现在它的三大职能上,即信息职能、咨询职能及监督职能。
4.从认识的特殊意义上看,一个完整的统计过程,一般可分为三个阶段,即统计调查、统计整理及统计分析。
5. 当某一标志的具体表现在各个总体单位上都相同时,则为不变标志。
6. 当某一标志的具体表现在各个总体单位上不尽相同时,则为可变标志。
7. 同一变量往往有许多变量值,变量按变量值是否连续可分为离散变量和连续变量。
8. 凡是客观存在的,并在某一相同性质基础上结合起来的许多个别事物组成的整体,我们称之为总体。
二、单项选择题:1. 要了解某市工业企业的技术装备情况,则统计总体是()。
A、该市全部工业企业B、该市每一个工业企业C、该市全部工业企业的某类设备D、该市工业企业的全部设备2. 对交院学生学习成绩进行调查,则总体单位是()。
A、交院所有的学生B、交院每一位学生C、交院所有的学生成绩D、交院每一位学生成绩3. 对全国城市职工家庭生活进行调查,则总体单位是()。
A、所有的全国城市职工家庭B、所有的全国城市职工家庭生活C、每一户城市职工家庭D、每一户城市职工家庭生活4. 对全国机械工业企业的设备进行调查,则统计总体是()。
A、全国所有的机械工业企业B、全国所有的机械工业企业的设备C、全国每一个机械工业企业E、全国每一个机械工业企业的设备5. 对食品部门零售物价进行调查,则总体单位是()。
A、所有的食品部门零售物B、每一个食品部门零售物C、所有的食品部门零售物价D、每一个食品部门零售物价6. 港口货运情况调查,则统计总体是()。
A、所有的港口货运B、每一个港口货运C、所有的港口货运情况D、每一个港口货运情况7. 某班学生数学考试成绩分别为65分、71分、80分和87分,这四个数字是()。
A、指标B、标志C、变量D、变量值8. 下列属于品质标志的是()。
统计学第一次作业答案

统计学第一次作业答案问题1 统计一词包含统计工作、统计资料、统计学等三种涵义。
对错问题2 全面调查和非全面调查是根据调查结果所取得的资料是否全面来划分的对错问题3 重点调查中的重点单位是标志值较大的单位对错问题4 所谓组距是指每个组变量值中的最大值与最小值之差,也就是组的上限与下限之差对错问题5 某企业计划产值比上年提高10%,实际比上年提高15%,则其计划完成程度为150%5%4。
56% 104.55%问题6 某厂生产了三批产品,第一批产品的废品率为1%,第二批产品的废品率为1。
5%,第三批产品的废品率为2%;第一批产品数量占这三批产品总数的25%,第二批产品数量占这三批产品总数的30%,则这三批产品的废品率为1.50% 1。
60% 4.50%1。
48%问题7 在全国人口普查中男性是品质标志人的年龄是变量人口的平均寿命是数量标志某家庭的人口数是统计指标问题8 指标是说明总体特征的,标志是说明总体单位特征的,所以标志和指标之间的关系是固定不变的标志和指标之间的关系是可以变化的标志和指标都是可以用数值表示的只有指标才可以用数值表示问题9 属于数量指标的是粮食总产量粮食平均亩产量人均粮食生产量人均粮食消费量问题10 重点调查中的重点单位是指这些单位举足轻重这些单位是工作重点这些单位的数量占总体全部单位的很大比重这些单位的标志总量在总体标志总量中占绝大比重问题11 对全国各铁路交通枢纽的货运量、货物、种类等进行调查,以了解我国铁路的货运量的基本情况和问题,这种调查方式属于普查抽样调查典型调查重点调查问题12 抽样调查与重点调查的主要区别是作同不同组织方式不同灵活程度不同选取调查单位的方法不同问题13 统计整理阶段最关键的问题是对调查资料的审核统计分组统计汇总编制统计表问题14某管理局对其所属企业的生产计划完成百分比采用如下分组,请指出哪项是正确的80—89% 90—99%100—109%110%以上80以下80.1—90% 90.1-100% 100。
曹县第二初级中学初一第一次月考成绩分析与总结
曹县第二初级中学初一第一次月考成绩分析与总结初级级部:杨玉汉经过各位老师的精心制卷、严格监场,及时改卷,认真统分,第一次月考已经落下了帷幕,现进行本级部成绩分析总结如下:一.数据统计与分析:1.班级平均分:2、各科成绩分段人数统计2017年上学期七年级第一次月考各科成绩分段人数统计表2017/10/24 语文英语历史生物3排名与两率语文数学历史地理生物3、缺乏良好的思维品质与学习习惯差,如课堂中上课被动,不会主动思考,不能提出高质量的问题,不能静心看教材,不能主动做笔记,课堂效率低,课后作业慢;课后不能及时整理与消化,没有专门笔记本进行归纳总结与提升;语文、英语背诵及英语听写不能按时过关。
4.作业不能及时完成,总为拖欠作业找借口与理由,有抄袭作业现象,科代表工作不能积极主动。
5.不懂得利用时间,一些边角时间的利用率更也是非常低,譬如上课前乱哄哄讲话、下课后急着走人、第八节课利用、早读到位、晚自习到位、周末时间利用等等,其实也是缺乏勤学、苦学精神。
6.不能处理好学科问题,有些同学严重偏科,从而对有些学科失去兴趣,既影响自己知识的学习,又纵容自己的懒散。
7.班干部工作缺乏积极主动与严格、严谨,个别班干部不能以身作责,不能主动管理,对班主任与班委会的管理精神执行力度不够,不能营造良好班级舆论导向。
8.个别同学要注重个体良好素养与优秀气质的培养,个别同学喜欢议论别人的缺点,喜欢起哄,喜欢孤立别人;个别同学对别人要求高,自己情绪变化快,说话不注意分寸与轻重;个别同学心理素质、意志力薄弱。
三.后期管理策略与措施:1.充满信心与斗志,敢于挑战,师生齐心,众志成城,共创期末辉煌。
2.每位同学加强反思,重新明确学习目标;团支部组织开展理想教育、立志教育及主题班会,激发同学们学习热情。
3.加强班干的管理,每个班干部明确自己责任,以身做责,积极主动做好本职工作,对班干部工作,三位纪检员做好过程纪录,并定期向班主任汇报,班主任不定期对班干部工作进行评议,对不称职的班干部随时进行罢免,被罢免的班干部不能参与本学期的评优。
统计学原理作业及答案

《统计学原理》第一次作业一、单项选择题1,统计研究在( B )阶段的方法属于大量观察法。
A,统计设计 B,统计调查 C,统计整理 D,统计分析2,把一个工厂的工人组成总体,那么每一个工人就是( A )。
A,总体单位 B,数量标志 C,指标 D,报告单位3,几位工人的工资分别为1500元、1800元和2500元,这几个数字是( C )。
A,指标 B,变量 C,变量值 D,标志4,变异的涵义是( A )。
A,统计中标志的不同表现。
B,总体单位有许多不同的标志。
C,现象总体可能存在各种各样的指标。
D,品质标志的具体表现。
5,下列各项中,属于统计指标的是( D )。
A,老王今年55岁。
B,钢材 C,宁波至北京机票1480元。
D,公司今年利润50万。
6,某市进行一次零售业质量与价格抽查,其调查单位是( C )。
A,该市所有食品商店 B,每一个食品商店 C,每一种零售食品 D,全部零售食品7,某市组织一次物价大检查,要求12月1日至12月15日全部调查完毕,这一时间规定则是( B )。
A,调查时间 B,调查期限 C,标准时间 D,登记时间8,规定普查标准时点旨在保证调查的( A )。
A,准确性 B,时效性 C,周期性 D,可比性9,对于生产过程中产品质量的检查和控制应采用( D )的方法。
A,重点调查 B,典型调查 C,普查 D,抽样检验10,对现象总体最有代表性的调查单位要推( D )单位。
A,典型调查 B,重点调查 C,抽样调查 D,普查11,某市工业企业2004年生产经营成果年报时间规定在2005年1月31日,则调查期限为( B )。
A,一日 B,一个月 C,一年 D,一年零一个月12,在全国人口普查中,( B )。
A,男性是品质标志 B,人的年龄是变量 C,人口的平均寿命是数量标志 D,全国人口是统计指标二、填空题1.社会经济统计学所研究的数量问题有自己的特点,即(数量性)、总体性和(变异性)三个。
统计学作业1

统计学第一次作业〔2012年3月15日〕注意:作业全部为课后习题,请将必要的推导过程写出,不能只写答案。
本次作业共包括前四章的14道题目,个别题目有删减:第一章统计学的性质1-3答:〔1〕对于简单随机抽样,置信度为95%的置信区间公式为:表:历年盖洛普对总统选举的调查结果〔n=1500〕年度共和党民主党民主党候选人P*(1-P)/n 95%置信度总体比例的置信区间〔%〕实际选举结果〔%〕1960 尼克松49% 肯尼迪51% 0.0001666 51±2.5298 肯尼迪50.11964 戈德沃特36% 约翰逊64% 0.0001536 ☆64±2.4291 约翰逊61.31968 尼克松57% 汉弗莱50% 0.0001634 50±2.5303 汉弗莱49.71972 尼克松62% 麦戈文38% 0.0001571 38±2.4564 麦戈文38.21976 福特49% 卡特51% 0.0001666 51±2.5298 卡特51.11980 里根52% 卡特48% 0.0001664 ☆48±2.5283 卡特44.7〔2〕注☆:实际选举结果证明错误的置信区间2-2、在中国台湾的一项《夫妻对电视传播媒介观念差距的研究》中,访问了30对夫妻,其中丈夫所受教育X(以年为单位)的数据如下:18 20 16 6 16 17 12 14 16 1814 14 16 9 20 18 12 15 13 1616 2l 2l 9 16 20 14 14 16 16第二章描述性统计学2-2答:1) 将数据分组,使组中值分别为6,9,12,15,18,21,作出X的频数分布表;解:〔1〕数据分组如下:表:丈夫所受教育年限X频数分布表〔n=30〕分组编号组下、上限组中值X值〔年〕频数〔f〕相对频率〔 f / n 〕累积频率〔%〕1 [4.5,7.5〕6 6 1 0.0333 3.332 [7.5,10.5〕9 9、9 2 0.0666 10.003 [10.5,13.5〕12 12、12、13 3 0.1000 20.004 [13.5,16.5〕15 14、14、14、14、14、15、16、16、16、16、16、16、16、16、16 15 0.5000 70.005 [16.5,19.5〕18 17、18、18、18 4 0.1333 83.006 [19.5,22.5〕21 20、20、20、21、21 5 0.1666 100.00总计463 30 1.00002) 作出频数分布的直方图;解:〔图〕丈夫所受教育年限X数据直方图〔单位:年;n=30〕3) 问10.5年的教育在第几百分位数上?13年呢?解:10.5年的教育,累积频率为10.00%,前面有10.00%个样本,所以在第10个百分位数上;13年的教育,累积频率为20.00%,前面有20.00%个样本,所以在第20个百分位数上。
概率论与数理统计作业及解答

概率论与数理统计作业及解答第一次作业★1. 甲 乙 丙三门炮各向同一目标发射一枚炮弹 设事件A B C 分别表示甲 乙 丙击中目标 则三门炮最多有一门炮击中目标如何表示. 事件E {事件,,A B C 最多有一个发生},则E 的表示为;E ABC ABC ABC ABC =+++或;AB AC BC =U U 或;AB AC BC =U U或;AB ACBC =或().ABC ABC ABC ABC =-++(和A B +即并A B U ,当,A B 互斥即AB φ=时A B U 常记为A B +) 2. 设M 件产品中含m 件次品 计算从中任取两件至少有一件次品的概率.221M mM C C --或1122(21)(1)m M m m MC C C m M m M M C -+--=- ★3. 从8双不同尺码鞋子中随机取6只 计算以下事件的概率.A {8只鞋子均不成双},B {恰有2只鞋子成双},C {恰有4只鞋子成双}. ★4. 设某批产品共50件 其中有5件次品 现从中任取3件 求 (1)其中无次品的概率 (2)其中恰有一件次品的概率(1)34535014190.724.1960C C == (2)21455350990.2526.392C C C ==5. 从1~9九个数字中 任取3个排成一个三位数 求(1)所得三位数为偶数的概率 (2)所得三位数为奇数的概率(1){P 三位数为偶数}{P =尾数为偶数4},9=(2){P 三位数为奇数}{P =尾数为奇数5},9=或{P 三位数为奇数}1{P =-三位数为偶数45}1.99=-=6. 某办公室10名员工编号从1到10任选3人记录其号码求(1)最小号码为5的概率(2)最大号码为5的概率记事件A {最小号码为5}, B {最大号码为5}.(1) 253101();12C P A C ==(2) 243101().20C P B C ==7. 袋中有红、黄、白色球各一个每次从袋中任取一球记下颜色后放回共取球三次求下列事件的概率:A ={全红}B ={颜色全同}C ={颜色全不同}D ={颜色不全同}E ={无黄色球}F ={无红色且无黄色球}G ={全红或全黄}.☆.某班n 个男生m 个女生(mn 1)随机排成一列 计算任意两女生均不相邻的概率.☆.在[0 1]线段上任取两点将线段截成三段 计算三段可组成三角形的概率. 第二次作业1. 设A B 为随机事件 P (A ) P (B ) (|)0.85P B A = 求(1)(|)P A B (2)()P A B ∪(1) ()()0.85(|),()0.850.080.068,()10.92P AB P AB P B A P AB P A ====⨯=- (2)()()()()P A B P A P B P AB =+-U 0.920.930.8620.988.=+-= 2. 投两颗骰子已知两颗骰子点数之和为7求其中有一颗为1点的概率. 记事件A {(1,6),(2,5),(3,4),(4,3),(5,2),(6,1)}, B {(1,6),(6,1)}.★.在1—2000中任取一整数 求取到的整数既不能被5除尽又不能被7除尽的概率记事件A {能被5除尽}, B {能被7除尽}.4001(),20005P A ==取整2000285,7⎡⎤=⎢⎥⎣⎦28557(),2000400P B ==200057,57⎡⎤=⎢⎥⨯⎣⎦57(),2000P AB = 3. 由长期统计资料得知 某一地区在4月份下雨(记作事件A )的概率为4/15刮风(用B 表示)的概率为7/15 既刮风又下雨的概率为1/10 求P (A |B )、P (B |A )、P (AB )4 设某光学仪器厂制造的透镜第一次落下时摔破的概率是1/2若第一次落下未摔破第二次落下时摔破的概率是7/10若前二次落下未摔破第三次落下时摔破的概率是9/10试求落下三次而未摔破的概率. 记事件i A ={第i 次落下时摔破}1,2,3.i =5 设在n 张彩票中有一张奖券有3个人参加抽奖分别求出第一、二、三个人摸到奖券概率.记事件i A ={第i 个人摸到奖券}1,2,3.i =由古典概率直接得1231()()().P A P A P A n ===或212121111()()()(|),1n P A P A A P A P A A n n n -====-或 第一个人中奖概率为11(),P A n=前两人中奖概率为12122()()(),P A A P A P A n +=+=解得21(),P A n=前三人中奖概率为1231233()()()(),P A A A P A P A P A n ++=++=解得31().P A n=6 甲、乙两人射击 甲击中的概率为08 乙击中的概率为07 两人同时射击 假定中靶与否是独立的求(1)两人都中靶的概率 (2)甲中乙不中的概率 (3)甲不中乙中的概率记事件A ={甲中靶}B ={乙中靶}.(1) ()()()0.70.70.56,P AB P A P B ==⨯= (2) ()()()0.80.560.24,P AB P A P AB =-=-= (3) ()()()0.70.560.14.P AB P B P AB =-=-=★7 袋中有a 个红球 b 个黑球 有放回从袋中摸球 计算以下事件的概率 (1)A {在n 次摸球中有k 次摸到红球}(2)B {第k 次首次摸到红球}(3)C {第r 次摸到红球时恰好摸了k 次球}(1) ();()k n kk n kk k nnna b a b P A C C a b a b a b --⎛⎫⎛⎫== ⎪ ⎪+++⎝⎭⎝⎭(2) 11();()k k kb a ab P B a b a b a b --⎛⎫== ⎪+++⎝⎭ (3) 1111().()rk rr k rr r k k ka b a b P C CCa b a b a b ------⎛⎫⎛⎫== ⎪ ⎪+++⎝⎭⎝⎭8一射手对一目标独立地射击4次 已知他至少命中一次的概率为80.81求该射手射击一次命中目标的概率 设射击一次命中目标的概率为,1.p q p =-4801121,,1.818133q q p q =-===-=9 设某种高射炮命中目标的概率为 问至少需要多少门此种高射炮进行射击才能以的概率命中目标(10.6)10.99,n -<-0.40.01,n <由50.40.01024,=60.40.01,<得 6.n ≥ ☆.证明一般加法(容斥)公式证明 只需证分块111,,k k n k i i i i i i A A A A A A +⊂L L L 只计算1次概率.(1,,n i i L 是1,,n L 的一个排列1,2,,.k n =L )分块概率重数为1,,k i i A A L 中任取1个-任取2个1(1)k -++-L 任取k 个即将,U I 互换可得对偶加法(容斥)公式☆.证明 若A B 独立 A C 独立 则A B ∪C 独立的充要条件是A BC 独立. 证明充分性:⇐(())()()()()(),P A B C P A P B P A P C P ABC =+-U 代入()()()P ABC P A P BC = ()(()()())P A P B P C P BC =+-()(),P A P B C =U 即,A B C U 独立. 必要性:⇒()()(),P ABC P A P BC =即,A BC 独立.☆.证明:若三个事件A 、B 、C 独立,则A ∪B 、AB 及A -B 都与C 独立. 证明 因为所以A ∪B 、AB 及A -B 都与C 独立. 第三次作业1 在做一道有4个答案的选择题时 如果学生不知道问题的正确答案时就作随机猜测 设他知道问题的正确答案的概率为p 分别就p 和p 两种情形求下列事件概率(1)学生答对该选择题 (2)已知学生答对了选择题求学生确实知道正确答案的概率记事件A ={知道问题正确答案}B ={答对选择题}.(1) 由全概率公式得()()(|)()(|)P B P A P B A P A P B A =+113,444p pp -=+=+当0.6p =时13130.67()0.7,444410p P B ⨯=+=+== 当0.3p =时13130.319()0.475.444440p P B ⨯=+=+==(2) 由贝叶斯公式得()4(|),13()1344P AB p pP A B p P B p ===++当0.6p =时440.66(|),13130.67p P A B p ⨯===++⨯ 当0.3p =时440.312(|).13130.319p P A B p ⨯===++⨯ 2 某单位同时装有两种报警系统A 与B 当报警系统A 单独使用时 其有效的概率为 当报警系统B 单独使用时 其有效的概率为.在报警系统A 有效的条件下 报警系统B 有效的概率为.计算以下概率 (1)两种报警系统都有效的概率 (2)在报警系统B 有效的条件下 报警系统A 有效的概率 (3)两种报警系统都失灵的概率.(1) ()()(|)0.70.840.588,P AB P A P B A ==⨯=(2) ()0.588(|)0.735,()0.8P AB P A B P B === (3) ()()1()1()()()P AB P A B P A B P A P B P AB ==-=--+U U☆.为防止意外 在矿内同时设有两种报警系统A 与B 每种系统单独使用时 其有效的概率系统A 为0 92 系统B 为 在A 失灵的条件下 B 有效的概率为 求: (1)发生意外时 两个报警系统至少有一个有效的概率 (2) B 失灵的条件下 A 有效的概率3 设有甲、乙两袋 甲袋中有n 只白球 m 只红球 乙袋中有N 只白球 M 只红球从甲袋中任取一球放入乙袋 在从乙袋中任取一球 问取到白球的概率是多少 记事件A ={从甲袋中取到白球}B ={从乙袋中取到白球}. 由全概率公式得☆.设有五个袋子 其中两个袋子 每袋有2个白球 3个黑球 另外两个袋子 每袋有1个白球 4个黑球 还有一个袋子有4个白球 1个黑球 (1)从五个袋子中任挑一袋 并从这袋中任取一球 求此球为白球的概率 (2)从不同的三个袋中任挑一袋 并由其中任取一球 结果是白球 问这球分别由三个不同的袋子中取出的概率各是多少★4 发报台分别以概率06和04发出信号 “·” 及 “” 由于通信系统受到于扰 当发出信号 “·” 时 收报台分别以概率08及02收到信息 “·” 及 “” 又当发出信号 “” 时 收报台分别以概率09及0?l 收到信号 “” 及 “·” 求: (1)收报台收到 “·”的概率(2)收报台收到“”的概率(3)当收报台收到 “·” 时 发报台确系发出信号 “·” 的概率(4)收到 “” 时 确系发出 “” 的概率记事件B ={收到信号 “·”}1A ={发出信号 “·”}2A ={发出信号“”}. (1) )|()()|()()(2211A B P A P A B P A P B P +=;52.01.04.0)2.01(6.0=⨯+-⨯= (2) ()1()10.520.48;P B P B =-=-=(3) 1111()()(|)(|)()()P A B P A P B A P A B P B P B ==0.60.8120.923;0.5213⨯=== (4)2222()()(|)(|)()()P A B P A P B A P A B P B P B ==0.40.930.75.0.484⨯=== 5 对以往数据分析结果表明 当机器调整良好时 产品合格率为90% 而机器发生某一故障时 产品合格率为30% 每天早上机器开动时 机器调整良好的概率为75%(1)求机器产品合格率(2)已知某日早上第一件产品是合格品 求机器调整良好的概率 记事件B ={产品合格}A ={机器调整良好}. (1) 由全概率公式得(2) 由贝叶斯公式得()()(|)(|)()()P AB P A P B A P A B P B P B ==0.750.90.9.0.75⨯== ☆.系统(A) (B) (C)图如下 系统(A) (B)由4个元件组成 系统(C)由5个元件组成 每个元件的可靠性为p 即元件正常工作的概率为p 试求整个系统的可靠性.(A) (B) (C) 记事件A ={元件5正常}B ={系统正常}.(A) 222(|)(1(1)(1))(44),P B A p p p p p =---=-+(B) 2222(|)1(1)(1)(2),P B A p p p p =---=- (C) 由全概率公式得 第四次作业1 在15个同型零件中有2个次品 从中任取3个 以X 表示取出的次品的个数 求X 的分布律.☆.经销一批水果 第一天售出的概率是 每公斤获利8元 第二天售出的概率是 每公斤获利5元 第三天售出的概率是 每公斤亏损3元 求经销这批水果每公斤赢利X2 抛掷一枚不均匀的硬币 每次出现正面的概率为2/3 连续抛掷8次 以X 表示出现正面的次数 求X 的分布律.3 一射击运动员的击中靶心的命中率为 以X 表示他首次击中靶心时累计已射击的次数 写出X 的分布律 并计算X 取偶数的概率解得0.6513()=0.394.110.6533q P X q ==++B 偶 4 一商业大厅里装有4个同类型的银行刷卡机 调查表明在任一时刻每个刷卡机使用的概率为求在同一时刻(1)恰有2个刷卡机被使用的概率(2)至少有3个刷卡机被使用的概率 (3)至多有3个刷卡机被使用的概率(4)至少有一个刷卡机被使用的概率 在同一时刻刷卡机被使用的个数(4,0.1).X B n p ==:(1) 2224(2)0.10.90.00486,P X C ==⨯⨯= (2) 3344(3)(3)(4)0.10.90.10.0037,P X P X P X C ≥==+==⨯⨯+= (3) 4(3)1(4)10.10.9999,P X P X ≤=-==-=(4)4(1)1(0)10.910.65610.3439.P X P X ≥=-==-=-=5 某汽车从起点驶出时有40名乘客 设沿途共有4个停靠站 且该车只下不上每个乘客在每个站下车的概率相等 并且相互独立 试求 (1)全在终点站下车的概率 (2)至少有2个乘客在终点站下车的概率 (3)该车驶过2个停靠站后乘客人数降为20的概率记事件A ={任一乘客在终点站下车}乘客在终点站下车人数(40,1/4).X B n p ==:(1) 40231(40)8.271810,4P X -⎛⎫===⨯ ⎪⎝⎭(2) 403940140313433(2)1(0)(1)1144434P X P X P X C ⎛⎫⎛⎫⎛⎫≥=-=-==--⨯=-⨯ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭(3) 记事件B ={任一乘客在后两站下车}乘客在后两站下车人数(40,1/2).Y B n p ==:2020202040404011(20)0.1268.222C P Y C ⎛⎫⎛⎫==== ⎪ ⎪⎝⎭⎝⎭(精确值)应用斯特林公式!,nn n e ⎫⎪⎭其中 1.7724538509.π==参贝努利分布的正态近似6 已知瓷器在运输过程中受损的概率是 有2000件瓷器运到 求 (1)恰有2个受损的概率 (2)小于2个受损的概率 (3)多于2个受损的概率 (4)至少有1个受损的概率受损瓷器件数(2000,0.002),X B n p ==:近似为泊松分布(4).P n p λ=⨯=(1) 2441480.146525,2!P e e --=== (2) 4424150.0915782,1!P e e --⎛⎫=+== ⎪⎝⎭(3) 431211130.761897,P P P e-=--=-= (4) 4410.981684.P e -=-=7 某产品表面上疵点的个数X 服从参数为的泊松分布 规定表面上疵点的个数不超过2个为合格品 求产品的合格品率产品合格品率2 1.2 1.21.2 1.212.920.879487.1!2!P e e --⎛⎫=+=== ⎪⎝⎭★8 设随机变量X求X 的分布函数 5),(||5).P X ≤ 随机变量X 的分布函数为 第五次作业1 学生完成一道作业的时间X 是一个随机变量(单位 小时) 其密度函数是 试求 (1)系数k (2)X 的分布函数 (3)在15分钟内完成一道作业的概率 (4)在10到20分钟之间完成一道作业的概率 (1) 0.50.52320111(0.5),21,32248kk F kx xdx x x k ⎛⎫==+=+=+= ⎪⎝⎭⎰(2) 23200,01()()217,00.5,2(0.5)1,0.5.x x F x P X x x xdx x x x F x <⎧⎪⎪=≤=+=+≤<⎨⎪=≥⎪⎩⎰(3) 322011119()2170.140625,442464x F P X x x xdx ⎛⎫⎛⎫⎛⎫=≤=+=+== ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎰(4) 3212316111111129217.6336424108P X F F x xdx ⎛⎫⎛⎫⎛⎫⎛⎫⎛⎫≤≤=-=+=+= ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭⎝⎭⎰2 设连续型随机变量X 服从区间[a a ](a 0)上的均匀分布 且已知概率1(1)3P X >= 求 (1)常数a (2)概率1()3P X <(1) 1111(1),3,223aa P X dx a a a ->====⎰(2) 13311115()3.36639P X dx -⎛⎫<==+= ⎪⎝⎭⎰3 设某元件的寿命X 服从参数为 的指数分布 且已知概率P (X 50)e4 试求(1)参数 的值 (2)概率P (25X 100)补分布()()|,0.x x xx x S x P X x e dx e ex θθθθ+∞--+∞->==-=>⎰@ (1) 504502(50)(50),0.08,25x S P X e dx e e θθθθ+∞---=>=====⎰(2) 由()(),,0,rx r S rx e S x r x θ-==>取50,x =依次令1,2,2r =得其中 2.7182818284.e B4 某种型号灯泡的使用寿命X (小时)服从参数为1800的指数分布 求 (1)任取1只灯泡使用时间超过1200小时的概率 (2)任取3只灯泡各使用时间都超过1200小时的概率 (1) 1312008002(1200)0.2231301602,P X ee-⨯->===1.6487212707001.= (2) 932(1200)0.0111089965.P X e->==5 设X ~N (0 1) 求 P (X 061) P (262X 125) P (X 134) P (|X |213) (1) (0.61)(0.61)0.72907,P X <=Φ=(2) ( 2.62 1.25)(1.25)( 2.62)(1.25)(2.62)1P X -<<=Φ-Φ-=Φ+Φ- (3) ( 1.34)1(1.34)10.909880.09012,P X >=-Φ=-= (4)(|| 2.13)22(2.13)220.983410.03318.P X >=-Φ=-⨯=6 飞机从甲地飞到乙地的飞行时间X ~N (4 19) 设飞机上午10 10从甲地起飞 求 (1)飞机下午2 30以后到达乙地的概率 (2)飞机下午2 10以前到达乙地的概率 (3)飞机在下午1 40至2 20之间到达乙地的概率 (1)131331/34111(1)10.841340.15866,331/3P X P X -⎛⎫⎛⎫⎛⎫>=-≤=-Φ=-Φ=-= ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭(2) (4)(0)0.5,P X <=Φ=(3) 72525/647/24261/31/3P X --⎛⎫⎛⎫⎛⎫<<=Φ-Φ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭★7 设某校高三女学生的身高X ~N (162 25) 求 (1)从中任取1个女学生 求其身高超过165的概率 (2)从中任取1个女学生 求其身高与162的差的绝对值小于5的概率 (3)从中任取6个女学生 求其中至少有2个身高超过165的概率 (1)162165162(165)0.61(0.6)10.72580.2742,55X P X P --⎛⎫>=>==-Φ=-= ⎪⎝⎭(2) 162(|162|5)12(1)120.8413410.6827,5X P X P ⎛-⎫-<=<=Φ-=⨯-= ⎪⎝⎭(3) 记事件A ={任一女生身高超过165} ()(165)0.2742,p P A P X ==>= 随机变量Y :贝努利分布(6,0.2742),B n p == 第六次作业★1.设随机变量X 的分布律为 (1)求Y |X |的分(2)求YX 2X 的分布律(1)(2)★.定理设连续型变量X 密度为()X f x ,()y g x =严格单调,反函数()x x y =导数连续,则()Y g X =是连续型变量,密度为证明 1)若()0,x x y ''=>{}{()()}{},Y y g X g x X x ≤=≤=≤ 两边对y 求导,2)若()0,x x y ''=<{}{()()}{},Y y g X g x X x ≤=≤=≥ 两边对y 求导,因此总有()(())|()|,.Y X f y f x y x y y αβ'=<< 或证明两边对y 求导,或两边微分2 设随机变量X 的密度函数是f X (x ) 求下列随机变量函数的密度函数 (1)Y tan X (2)1Y X=(3)Y |X | (1) 反函数()arctan ,x y y ='21(),1x y y =+由连续型随机变量函数的密度公式得 或 反函数支()arctan ,i x y i y i π=+为整数,'21(),1i x y y=+(2) 1,X Y =反函数1,y x y ='211()()().Y X y y X f y f x x f y y==(3) ()()(||)()()()Y X X F y P Y y P X y P y X y F y F y =≤=≤=-≤≤=-- 两边对y 求导得Y 的密度函数为()()(),0.Y X X f y f y f y y =+-> ★3 设随机变量X ~U [2 2] 求Y 4X 21的密度函数 两边对y 求导得随机变量Y 的密度为或解 反函数支12()()x y x y ==★4 设随机变量X 服从参数为1的指数分布 求YX 2的密度函数(Weibull 分布) 当0y ≤时, 2Y X =的分布()0Y F y =,当0y >时, 两边对y 求导得或 反函数y x ='()()0.Y X y y f y f x x y ==>★5 设随机变量X~N (0 1) 求(1)Ye X 的密度函数 (2)YX 2的密度函数(Gamma 分布)(1) 当0y ≤时, e X Y =的分布()0Y F y =,当0y >时, 因而Y 的密度为 或反函数ln ,X Y =ln ,y x y ='1()()(ln )Y y y f y x x y y ϕϕ=={}2(ln ),0.2y y =->(2) 当0y ≤时,()0Y F y =;当0Y >时,2()()()((Y X X F y P Y y P X y P X F F =≤=≤=≤=-两边对y 求导得Y的密度函数为2,0,()0.yY y f y ->=⎩或反函数支12()()x y x y ==6 设随机变量X 的密度函数是21,1()0,1X x f x x x ⎧>⎪=⎨⎪≤⎩ 求Y ln X 的概率密度 反函数,y y x e ='()()(),0.y y y Y X y y X f y f x x f e e e y -===>第七次作业☆.将8个球随机地丢入编号为1 2 3 4 5的五个盒子中去 设X 为落入1号盒的球的个数 Y 为落入2号盒的球的个数 试求X 和Y 的联合分布律 1 袋中装有标上号码1 2 2的3个球 从中任取一个并且不再放回 然后再从袋中任取一球 以X Y 分别记第一、二次取到球上的号码数 求 (1)(X Y )的联合分布律(设袋中各球被取机会相等) (2)X Y 的边缘分布律 (3)X 与Y 是否独立 (1)(X Y )的联合分布律为(2) X Y 的分布律相同12(1),(2).33P X P X ==== (3) X 与Y 不独立2 设二维连续型变量(,)X Y 的联合分布函数35(1)(1),,0,(,)0,.x y e e x y F x y --⎧-->=⎨⎩其它 求(,)X Y 联合密度★3 设二维随机变量(X Y )服从D 上的均匀分布 其中D 是抛物线yx 2和xy 2所围成的区域 试求它的联合密度函数和边缘分布密度函数 并判断Y X ,是否独立分布区域面积213123200211,333x S x dx x x ⎛⎫===-= ⎪⎝⎭⎰⎰联合密度213,1,(,)0,.x y f x y S ⎧=<<<⎪=⎨⎪⎩其它边缘X的密度为22()),01,X x f x dy x x ==<<边缘Y的密度为22()),0 1.Y yf y dy y y ==<<(,)()(),X Y f x y f x f y ≠⋅因此X 与Y 不独立.或(,)f x y 非零密度分布范围不是定义在矩形区域上,因此X 与Y 不独立.4. 设二维离散型变量),(Y X 联合分布列是问,p q 取何值时X 与Y 两行成比例1/151/52,1/53/103q p ===解得12,.1015p q == ★5.设(,)X Y 的联合密度为2,11,0,(,)0,.y Ax e x y f x y -⎧-<<>=⎨⎩其它求(1)常数A (2)概率1(0,1);2P X Y <<>(3)边缘概率密度f X (x ) f Y (y ) (4)X 与Y 是否相互独立(1) 2220()(,),11,y y X f x f x y dy Ax e dy Axe dy Ax x +∞+∞+∞--====-<<⎰⎰⎰(2) 112201113(0,1)(0)(1).22216y e P X Y P X P Y x dx e dy -+∞-<<>=<<>==⎰⎰ (3) 23(),11,2X f x x x =-<<(4)由23,11,0()()(,),20,yX Yx e x y f x f y f x y -⎧-<<>⎪⋅==⎨⎪⎩其它得X 与Y 独立. 或因为2(,),11,0,y f x y Ax e x y -=-<<>可表示为x 的函数与y 的函数的积且分布在矩形区域上,所以X 与Y 相互独立.由此得(),0;y Y f y e y -=>2(),11,X f x Ax x =-<<6. 设X 服从均匀分布(0,0.2),U Y 的密度为55,0,()0,y Y e y f y -⎧>=⎨⎩其它.且,X Y 独立.求(1)X 的密度(2) (,)X Y 的联合密度 (1)X 的密度为()5,00.2,X f x x =≤≤(2)(,)X Y 的联合密度为525,00.2,0,(,)0,y e x y f xy -⎧≤≤>=⎨⎩其它.第八次作业★1 求函数(1)Z 1XY (2) Z 2min{X Y } (3) Z 3max{X Y }的分布律 (1)11(0)(0),6P Z P X Y =====1111(1)(0,1)(1,0),362P Z P X Y P X Y ====+===+=(2)2111(1)(1,1)(1,2),1264P Z P X Y P X Y ====+===+=223(0)1(1).4P Z P Z ==-==(3) 31(0)(0),6P Z P X Y =====2 设随机变量求函数Z X /Y 的分布律3 设X 与Y 相互独立 概率密度分别为220()00,xX e x f x x -⎧>=⎨≤⎩0()00,y Y e y f y x -⎧>=⎨≤⎩试求ZXY 的概率密度★4 设X ~U (0 1) Y ~E (1) 且X 与Y 独立 求函数ZXY 的密度函数 当01z <≤时 当1z >时 因此★5 设随机变量(X Y )的概率密度为()101,0(,)10x y e x y f x y e -+-⎧⎪<<<<+∞=⎨-⎪⎩其它(1)求边缘概率密度f X (x ) f Y (y ) (2)求函数U max (X , Y )的分布函数 (3)求函数V min (X , Y )的分布函数(1) 1,01,()10,x X e x f x e --⎧<<⎪=-⎨⎪⎩其它.,0,()0,yY e y f y -⎧>=⎨⎩其它. (2) 11000,0,1()(),01,111,1x xx x X X x e e F x f x dx dx x e e x ----≤⎧⎪-⎪===<<⎨--⎪≥⎪⎩⎰⎰.min{,1}10,0,1,01x x e x e --≤⎧⎪=⎨->⎪-⎩. (3) 111,0,()1(),01,10,1x X X x e eS x F x x e x ---≤⎧⎪-⎪-=<<⎨-⎪≥⎪⎩@.6 设某种型号的电子管的寿命(以小时计)近似地服从N (160 202)分布 随机地选取4只求其中没有一只寿命小于180小时的概率随机变量2(160,20),X N :180160(180)(1)0.84134,20P X -⎛⎫≤=Φ=Φ= ⎪⎝⎭没有一只寿命小于180小时的概率为 第九次作业★1.试求 E (X ) E (X 25) E (|X |)2. 设随机变量X 的概率密度为0 0,() 01, 1.x x f x x x Ae x -⎧≤⎪=<≤⎨⎪>⎩求 (1)常数A (2)X 的数学期望(1) 1100111(),2x f x dx xdx Ae dx Ae +∞+∞--==+=+⎰⎰⎰,2e A =(2) 12100114()2.2323x e e EX xf x dx x dx xe dx e +∞+∞--==+=+⨯=⎰⎰⎰★3. 设球的直径D 在[a b ]上均匀分布试求 (1)球的表面积的数学期望(表面积2D π)(2)球的体积的数学期望(体积316D π)(1) 22222()();3ba x E D ED dx a ab b b a ππππ===++-⎰ (2) 33322()().6624b a x E D ED dx a b a b b a ππππ⎛⎫===++ ⎪-⎝⎭⎰ ★4.求E (X ) E (Y ) E (XY ) ★ 5. 设随机变量X 和Y 独立 且具有概率密度为2,01,()0,X x x f x <<⎧=⎨⎩其它,3(1)3,1,()0, 1.y Y e y f y y --⎧>=⎨≤⎩(1)求(25)E X Y + (2)求2()E X Y(1) 112002()2,3X EX xf x dx x dx ===⎰⎰或随机变量1Z Y =-:指数分布(3),E 141,,33EZ EY EY =-==(2) 11223001()2,2X EX x f x dx x dx ===⎰⎰由X 和Y 独立得22142().233E X Y EX EY ==⨯=第十次作业1.试求 (1) D (X ) (2) D (3X 2)(1) 20.110.210.320.130.10.4,i i iEX x p ==-⨯-⨯+⨯+⨯+⨯=∑(2) 2(32)(3)9 2.0418.36.D X DX -+=-=⨯=★2. 设随机变量X 具有概率密度为22,02,()0,Ax x x f x ⎧+<<=⎨⎩其他,试求 (1)常数A (2)E (X ) (3) D (X ) (4) D (2X 3)(1) 22081()(2)4,3f x dx Ax x dx A +∞-∞==+=+⎰⎰解得9.8A =-(2) 22095()(2).86EX xf x dx x x x dx +∞-∞==-+=⎰⎰(3)22222094()(2),85EX x f x dx x x x dx +∞-∞==-+=⎰⎰2224519.56180DX EX E X ⎛⎫=-=-= ⎪⎝⎭(4) 21919(23)24.18045D X DX -==⨯=★ 3. 设二维随机变量(,)X Y 联合概率密度为2,01,01,(,)0,x y x y f x y --<<<<⎧=⎨⎩其他,试求 (1),X Y 的协方差和相关系数A (2)(21).D X Y -+(1) 103()(,)(2),01,2X f x f x y dy x y dy x x +∞-∞==--=-<<⎰⎰由,x y 的对称性3(),0 1.2Y f y y y =-<<因此(2) 由随机变量和的方差公式()2(,)D X Y DX DX Cov X Y +=++得 ★4. 设二维随机变量(,)X Y 具有联合分布律试求,,,EX DX EY DY 以及X 和Y 的相关系数 (1) X 的分布列为由变量X 分布对称得0,EX =或10.4500.4510.450,i i iEX x p ==-⨯+⨯+⨯=g(2) Y(,)X Y 取值关于原点中心对称由变量Y分布对称得0,EY =或20.20.250.2520.20,j j iEY y p ==-⨯-++⨯=∑g(3) 由二维变量(,)X Y 的联合分布列关于两坐标轴对称得,()0,i j i j ijE XY x y p ==∑∑(,)()0,Cov X Y E XY EXEY =-=因此,0.X Y ρ==5. 设随机变量X 服从参数为2的泊松分布(2)P 随机变量Y 服从区间(0,6)上的均匀分布(0,6),U 且,X Y 的相关系数,X Y ρ=记2,Z X Y =-求,.EZ DZ (1) 2,EX =063,2EY +==(2)2223 4.EZ E X Y EX EY =-=-=-⨯=-(2) 2(60)2, 3.12DX DY -===由,X Y ρ==得(,)1,Cov X Y = 由随机变量和的方差公式()2(,)D X Y DX DY Cov X Y +=++得 第十一次作业★1. 试用切比雪夫不等式估计下一事件概率至少有多大 掷1000次均匀硬币 出现正面的次数在400到600次之间出现正面的次数~(1000,0.5),X B n p == 应用切比雪夫不等式有2. 若每次射击目标命中的概率为 不断地对靶进行射击 求在500次射击中 击中目标的次数在区间(49 55)内的概率击中目标的次数~(500,0.1),X B n p ==根据中心极限定理,X 近似服从正态分布(50,45).N EX DX ==★3. 计算器在进行加法时 将每个加数舍入最靠近它的整数.设所有舍入误差是独立的且在( 上服从均匀分布 (1)若将1500个数相加 问误差总和的绝对值超过15的概率是多少(2)最多可有几个数相加使得误差总和的绝对值小于10的概率不小于(1) 误差变量,1,2,.i X i =⋅⋅⋅独立同均匀分布(0.5,0.5),X U -:10,.12EX DX ==由独立变量方差的可加性150011500125,12i i D X =⎛⎫== ⎪⎝⎭∑15001i i X =∑近似(0,125).N :(2) 1||10n i i P X =⎧⎫<⎨⎬⎩⎭∑1|n i P X =⎧⎪=<=⎨⎪⎩210.90,⎛≈Φ-≥ ⎝ 因此最多可有4个数相加误差总和的绝对值小于10的概率不小于★4. 一个系统由n 个相互独立的部件所组成 每个部件的可靠性(即部件正常工作的概率)为 至少有80%的部件正常工作才能使整个系统正常运行 问n 至少为多大才能使系统正常运行的可靠性不低于 正常工作的部件数~(,),X B n p 其中0.9.p =0.9,EX np n ==0.09.DX npq n ==1.645,24.354.n ≥≥因此n 至少取25. ★5. 有一大批电子元件装箱运往外地 正品率为 为保证以的概率使箱内正品数多于1000只 问箱内至少要装多少只元件正品数~(,),X B n p 其中0.8.p =0.8,EX np n ==0.16.DX npq n == 解得1637.65,n ≥因此n 至少取1638.★.贝努利分布的正态近似.投掷一枚均匀硬币40次出现正面次数20X =的概率.正面次数(40,1/2),X B n p ==:400.520,400.50.510.EX np DX npq ==⨯===⨯⨯=离散值20X =近似为连续分组区间19.520.5,X << 第十二次作业★1. 设X 1 X 2 X 10为来自N (0 032)的一个样本 求概率1021{ 1.44}i i P X =>∑标准化变量(0,1),1,2,...,10.0.3iX N i =:由卡方分布的定义10222211~(10).0.3i i X χχ==∑略大卡方分布上侧分位数20.1(10)15.9872.χ= ★2. 设X 1 X 2 X 3 X 4 X 5是来自正态总体X ~(0 1)容量为5的样本 试求常数c 使得统计量服从t 分布 并求其自由度由独立正态分布的可加性12(0,2),X X N +:标准化变量(0,1),U N =:由卡方分布的定义22222345~(3),X X X χχ=++U 与2χ独立由t 分布的定义(3),T t ===:因此c =自由度为3. ★3 设112,,,n X X X L 为来自N (1 2)的样本 212,,,nY Y Y L为来自N (2 2)的样本 且两样本相互独立 2212,S S 分别为两个样本方差 222112212(1)(1)2pn S n S S n n -+-=+- 试证明22().p E S σ=证 由221112(1)~(1),n S n χσ--及()211(1)1E n n χ-=-得类似地222.ES σ=★4 设1,...,n X X 为总体2(,)N μσ的简单样本样本均值和样本方差依次为2,.X S 求满足下式的k 值()0.95.P X kS μ>+=统计量(1),X T t n =-:因此k = ☆.设正态总体2(,)N μσ的容量为12n =的简单样本为112,...,X X 样本均值和样本方差依次为2,.X S 求满足下式的k 值()0.95.P X kS μ>+=正态总体样本方差未知统计量(1),12.X T t n n =-=:★5 设N ( 2)的样本 记11nii X X n ==∑ 2211()1ni i S X X n ==--∑ 证明 T (1)t n - 证由独立正态分布的可加性21(,),ni i XN n n μσ=∑:211,,ni i X X N n n σμ=⎛⎫= ⎪⎝⎭∑:1n X +及2S 相互独立()2110,n n X X N nσ++-:和2S 独立标准化变量(0,1),U N =:2222(1)~(1),n S n χχσ-=-/,S σ=由t 分布的定义第十三次作业★1 设总体的密度函数为22(),0,(;)0,x x f x αααα-⎧<<⎪=⎨⎪⎩其他,求参数α的矩估计总体期望23220002()2(;),33x x x EX xf x dx x dx ααααααααα⎛⎫-==⋅=-= ⎪⎝⎭⎰⎰3,EX α= 用样本均值X 估计(或替换)总体期望EX 即ˆ,EXX =得α矩估计为ˆ3.X α= ★2 设总体的密度函数为1(1)(1),01(;)0,x x x f x θθθθ-⎧+-<<=⎨⎩其他 求参数 的矩估计总体期望解得2,1EX EX θ=-用样本均值X 估计(或替换)总体期望EX 即ˆ,EX X =得 矩估计为2ˆ.1X Xθ=- 3 设总体的密度函数为||1(;),2x f x e x σσσ-=-∞<<+∞ 求参数 的最大似然估计似然函数1111()(;)exp ||,2nn i i n n i i L f x x σσσσ==⎧⎫==-⎨⎬⎩⎭∑∏取对数得对数似然函数11ln ()ln 2ln ||,ni i L n n x σσσ==---∑令21ln ()1||0,ni i L n x σσσσ=∂=-+=∂∑ 解得σ的最大似然估计为11ˆ||.nL i i x n σ==∑ 4 设总体的密度函数为222,0(;)0,0x x e x f x x θθθ-⎧⎪>=⎨⎪<⎩求参数 的最大似然估计 似然函数2122111()(;)exp ,ninn i i i ni i xL f x x θθθθ===⎧⎫==-⎨⎬⎩⎭∏∑∏取对数得对数似然函数22111ln ()ln 2ln ,nn i i i i L x n x θθθ===--∑∑令231ln ()220,n i i L n x θθθθ=∂=-+=∂∑ 解得θ的最大似然估计为ˆLθ= ★5 设总体X 的均值和方差分别为与 2 X 1 X 2 X 3是总体的一个样本, 试验证统计量(1)112311ˆ4412X X X μ=++; (2)2123111ˆ333X X X μ=++; (3)3123311ˆ882X X X μ=++均为 的无偏估计量, 并比较其有效性(1)1123123111111ˆ.442442E E X X X EX EX EX μμ⎛⎫=++=++= ⎪⎝⎭ (2)1123123111111ˆ.333333E E X X X EX EX EX μμ⎛⎫=++=++= ⎪⎝⎭ (3)1123123311311ˆ.882882E E X X X EX EX EX μμ⎛⎫=++=++= ⎪⎝⎭ 因此123ˆˆˆ,,μμμ均为μ的无偏估计量 由独立变量方差的可加性因此无偏估计量123ˆˆˆ,,μμμ中2ˆμ最有效,1ˆμ比3ˆμ有效 ★7. 设2ˆθ为 2的无偏估计, 且ˆ()0D θ>, 试证ˆθ不是 的无偏估计 反之, 若ˆθ为 的无偏估计, ˆ()0D θ>, 则2ˆθ也不是 2的无偏估计证(1) 22ˆ,E θθ=2222ˆˆˆˆ0,D E E E θθθθθ=-=->22ˆˆ,,E E θθθθ<≠得ˆθ不是 的无偏估计(2) ˆ,E θθ=222222ˆˆˆˆˆ0,,D E E E E θθθθθθθ=-=->>得2ˆθ不是2θ的无偏估计 8设$$12,θθ是参数θ的两个相互独立的无偏估计量,且$$124D D θθ=,找出常数12,k k ,使$$1212k k θθ+也是θ的无偏估计量,并使它在所有这种形状的估计量中方差最小.$$$$1212121212()()E k k k E k E k k θθθθθθ+=+=+=,121k k +=,$$$$$222212122121212()(4)D k k k D k D k k D θθθθθ+=+=+,121222121,0,1,min{4}.k k k k s k k +=≤≤⎧⎨=+⎩ 求最小值得1214,55k k ==,4min 5s =,$$$121124min ().5D k k D θθθ+=第十四次作业★1. 某车间生产滚珠, 从长期实践中知道, 滚珠直径X 可以认为服从正态分布.从某天的产品里随机抽取6个, 测得直径(单位:mm)为, , , , ,若已知总体方差为, 试求平均直径的置信区间.(置信度为 若总体方差未知, 试求平均直径的置信区间.(置信度为 (1)μ的置信区间中心当20.06σ=时,μ的95.01=-α置信区间半长为 因此μ的0.95置信区间为(2) 样本方差2211()0.051,1ni S X X n =-=-∑ μ的95.01=-α置信区间半长为因此μ的0.95置信区间为★2. 为了解某型号灯泡使用寿命X (单位:小时)的均值μ和标准差 今测量10只灯泡 测得1500x = S20 若已知X 服从正态分布N ( 2), 求 (1)置信度为的总体均值 的置信区间 (2)置信度为的总体方差2的置信区间(1) 置信区间半长/20.025( 2.262 6.32214.3,t n t α-==⨯= 当2σ未知时,μ的95.01=-α置信区间为(2) 已知参数2210,20,0.10,n S α===上侧分位数为 置信区间两端(下限,上限)为因此灯泡使用寿命方差2σ置信度为10.90α-=的置信区间为★3. 对方差220σσ=为已知的正态总体 问须抽取容量n 为多大的样本, 方能使总体均值 的置信度为1的置信区间的长度不大于L总体均值μ的置信区间长度为/22,u L α≤取220/224n u L ασ≥的整数 ★4 已知某种元件的寿命X ~N ( 2) 现随机地抽取10个试件进行试验, 测得数据如下82, 93, 57, 71, 10, 46, 35, 18, 94, 69. (1)若已知 3, 求平均抗压强度 的95%的置信区间(2)求平均抗压强度的95%的置信区间 (3)求 的95%的置信区间 (1)μ的置信区间中心当223σ=时,μ的95.01=-α置信区间半长/2 1.96 1.861,u α==因此μ的0.95置信区间为(2) 上侧分位数220.02510.025(9)19.023,(9) 2.700,χχ-== 样本方差σ的10.95α-=的置信区间两端(下限,上限)为因此元件寿命标准差σ的0.95置信区间为★.两正态总体均值差21μμ-的1α-置信区间.当22212σσσ==未知时 由于22,,,x y X Y S S 相互独立构造服从分布(2)t m n +-的统计量(枢轴量) 记222(1)(1)2x ywm S n S S m n -+-=+-,则21μμ-的二样本t 置信区间为★5 随机地抽取A 批导线4根 B 批导线5根 测得起电阻为(单位 欧姆)A B设测得数据分别服从正态分布N (1 2) N (2 2) 且它们相互独立 1 2 均未知 求12的95%的置信区间上侧分位数20.025(2)(7) 2.3646,t m n t α+-==当22212σσσ==未知时,21μμ-的1α-置信区间半长为 21μμ-的95.01=-α置信区间为★6 假设人体身高服从正态分布, 今抽测甲、乙两地区18岁~ 25岁女青年身高得数据如下: 甲地区抽取10名, 样本均值米, 样本标准差0.2米; 乙地区抽取10名, 样本均值米, 样本标准差0.4米. 求 (1)两正态总体均值差的95%的置信区间 (2)两正态总体方差比的95%的置信区间 (1) 分位数20.025(2)(18) 2.1009,t m n t α+-==当22212σσσ==未知时,21μμ-的1α-置信区间半长为 21μμ-的95.01=-α置信区间为★(2)两正态总体(期望未知)的方差比2212/σσ的1α-置信区间.由于22111(1)/n S σ-~21(1),n χ-22222(1)/n S σ-~22(1),n χ-且2212,S S 独立,构造统计量(枢轴量) 2211122222~(1,1),S F F n n S σσ=-- 对给定的置信度α-1,由其中/2211/2121(1,1),(1,1)F n n F n n αα-=---- 因此2212/σσ的α-1置信区间为第十五次作业★1 某工厂生产的固体燃料推进器的燃烧率服从正态分布N ( 2) 40cm/s, 2cm/s 现在用新方法生产了一批推进器 从中随机抽取25只 测得燃烧率的样本均值为X s 设在新方法下总体均方差仍为2cm/s 问这批推进器的燃烧率是否较以往生产的推进器的燃烧率有显着的改变取显着性水平 1).提出原假设及备择假设.0010:40;:.H H μμμμ==≠ 2).选取统计量并确定其分布.~(0,1).X U N =3).确定分位数及拒绝域.上侧分位数0.025 1.96,u =拒绝域{|| 1.96}.W U =≥4).计算统计量的观测值并作出统计推断.因此拒绝原假设,认为在显着性水平0.05α=下,推进器的燃烧率显着改变.★2 某苗圃规定平均苗高60(cm)以上方能出圃 今从某苗床中随机抽取9株测得高度分别为 62 61 59 60 62 58 63 62 63 已知苗高服从正态分布 试问在显着性水平 下 这些苗是否可以出圃 1).原假设及备择假设0010:60;:.H H μμμμ≥=< 2).取统计量(8).X T t =: 3).上侧分位数0.05(8) 1.8595,t =得拒绝域(, 1.8595).W =-∞-4).由样本计算得61.11,X=0,.T T W S ==>∉因此接受原假设0,H 即认为在显着性水平0.05α=下,这些苗可以出圃.★3 5名测量人员彼此独立地测量同一块土地 分别测得这块土地面积(单位 km 2)为, , , ,算得平均面积为 设测量值总体服从正态分布 由这批样本值能否说明这块土地面积不到(1).原假设及备择假设0010: 1.25;:.H H μμμμ≥=< 2).取统计量(4).X T t =:3).上侧分位数0.05(4) 2.1318,t =得拒绝域(, 2.1318).W =-∞-4).样本方差为2211()0.00123,1ni S X X n =-=-∑0.035,S = 统计量的实现值为因此接受原假设0,H 认为在显着性水平0.05下,这块土地面积达到. ★4 设某电缆线的抗拉强度X 服从正态分布N (10600 822) 现从改进工艺后生产的一批电缆线中随机抽取10根 测量其抗拉强度 计算得样本均值x 10653 方差S 26962 当显着水平时 能否据此样本认为(1)新工艺下生产的电缆线抗拉强度比过去生产的电缆线抗拉强度有显着提高 (2)新工艺下生产的电缆线抗拉强度的方差有显着变化 (1)提出原假设及备择假设.0010:10600;:.H H μμμμ≥=< 选取统计量并确定其分布.(9).X T t =: 确定分位数及拒绝域.0.05(9) 1.8331,t =得拒绝域(, 1.8331).W =-∞- 计算统计量的观测值并作出统计推断.因此接受原假设,认为在显着性水平0.05α=下,新工艺电缆抗拉强度比过去工艺有显着提高.(2)提出原假设及备择假设222220010:82;:.H H σσσσ==≠ 在原假设成立的前提下,构造统计量2222(1)~(9).n S χχσ-=确定上侧分位数2210.0250.025(9) 2.700,(9)19.023,χχ-==得拒绝域 计算2χ统计量的观测值并作出统计推断因而接受原假设0,H 即认为新工艺下的电缆抗拉强度的方差无显着变化.★5 设某涤纶强度X ~N ( 2) 用老方法制造的涤纶强度均值是 标准差 现改进工艺后 从新生产的产品中随机抽取9个样品 测得起强度如下在显着性水平0.05α=下,涤纶强度的均值和标准差是否发生了改变 (1)提出原假设及备择假设.0010:0.528;:.H H μμμμ==≠ 选取统计量并确定其分布.~(0,1).X U N =确定分位数及拒绝域.上侧分位数0.025 1.96,u =拒绝域{|| 1.96}.W U =≥ 计算统计量的实现值并作出统计推断.样本均值为 统计量的实现值为因此接受原假设0,H 即认为在显着性水平0.05α=下,涤纶强度均值未改变.(2)提出原假设及备择假设222220010:0.016;:,H H σσσσ==≠ 在原假设成立的前提下,构造统计量2222(1)~(8).n S χχσ-=确定上侧分位数2210.0250.025(8) 2.180,(8)17.535,χχ-==得拒绝域计算2χ统计量的观测值并作出统计推断样本平方和样本偏差平方和 统计量的观测值因而接受原假设0,H 即认为涤纶强度的标准差未改变.★6 测定某饮料中糖份的含量 测得10个观察值的均值X %标准差S % 设饮料中糖份的含量服从正态分布N ( 2) 试在显着性水平下 分别检验(1) 0010:0.05%;:.H H μμμμ==≠ (2) 0010:0.04%;:.H H σσσσ==≠ (1)提出原假设及备择假设.0010:0.05%;:.H H μμμμ==≠ 选取统计量并确定其分布.~(1).X T t n =-。
数据分析作业

数据分析作业数据分析作业是数据分析课程中的一项重要任务,通过对给定的数据进行分析和解读,帮助学生提高数据分析能力和对实际问题的理解能力。
本篇文档将以一个具体的数据分析作业为例,介绍数据分析的基本流程和方法。
一、项目背景本次数据分析作业的背景是一个电商平台的销售数据分析。
该电商平台每天有大量用户在上面购买各种商品,平台方希望通过对这些销售数据的分析,了解用户的购买行为、商品的销售情况以及运营策略的有效性,以便为未来的决策提供参考。
二、数据收集与清洗在进行数据分析之前,首先需要收集和清洗原始数据。
本次数据分析作业使用的数据集包含了一段时间内的用户购买记录、商品信息、用户信息等。
数据集以CSV格式存储,包含多个字段,如用户ID、商品ID、购买数量、购买时间等。
在进行数据清洗时,需要检查数据的完整性和准确性,删除重复数据和异常值,并对缺失值进行处理。
三、数据探索与可视化分析数据清洗完成后,接下来可以进行数据探索和可视化分析。
数据探索的目的是通过使用统计学和可视化方法,对数据的特征和分布进行了解。
通过对用户购买记录和商品销售情况的分析,可以探索以下问题:1.用户消费行为的特征:如用户购买次数、购买金额分布、用户活跃度等。
2.商品销售情况的分析:如畅销商品排名、商品销售额分布、商品的销售趋势等。
3.不同时间维度的分析:如不同时间段内销售情况的变化、季节性特征等。
4.用户购买行为的特征与商品属性的关联:如用户购买的商品类别分布、商品属性对用户购买行为的影响等。
在数据探索的过程中,可以使用各种统计学和可视化工具,如直方图、散点图、箱型图、折线图等。
通过这些分析和可视化结果,可以发现数据的规律和趋势,为后续建模和预测做准备。
四、数据建模与预测在数据探索的基础上,可以进行数据建模和预测。
数据建模是指使用数学或统计的方法,通过对已有数据进行拟合和预测,得到对未来数据的预测结果。
常见的数据建模方法包括回归分析、时间序列分析、聚类分析、关联规则挖掘等。
概率论与数理统计第一阶段作业答案◆

沈阳铁路局学习中心第一部分:必须掌握的重点理论知识习题。
一、 填空:1、设{1,2,3,4,5,6}Ω=,{2,3,4}A =,{3,5}B =,{4,6}C =,那么A B ⋃= {1,2,3,4,6} ,AB = {1,6} ,()A BC = Φ空集 。
2、设随机变量X 与Y 相互独立,X 服从二项分布(5,0.6)B ,Y 服从二项分布2(,)N μσ,且()6,() 1.36E X Y D X Y +=-=,则μ=6-5=1 ;σ=根号0.76。
3则α= (1-0.2-0.1-0.25-0.15) 0.3 ,X 的期望()E x = (XP )0.1 4、离散型随机变量ξ的分布律为P(ξ=k)=2,1,2,3ck k=,则c= 36/49 c(1+1/4+1/9)=1,解得c; 5、从总体X 中抽取样本,得到5个样本值为5、2、3、4、1。
则该总体平均数的矩估计值是___5____,总体方差的矩估计是___15/2____。
6、设两个事件A 、B 相互独立,()0.6P A =,()0.7P B =,则()P A B -= 0.18 ,()P A B -= 0.12 。
7、设随机变量X 服从正态分布(2,16)N -,则{02}P X ≤<= Φ(1)-Φ(0.5) ,{6}P X ≥-= Φ(1) ,{22}P x -≥= 1-Φ(1.5)+Φ(0.5) 。
8则()E x = 0.05 ,2()E x = 1.75 。
9、 离散型随机变量ξ的分布律为P(ξ=k)=.3,2,1,2=k kc,则c= 12/11 10、甲、乙两人独立的对同一目标射击一次,其命中率分别为0.6,0.5。
现已知目标被命中,则它是甲射中的概率为0.75。
11、设随机事件,A B 及其和事件A B ⋃的概率分别为0.4,0.3和0.6。
若B 表示B 的对立事件,那说明: ①阶段测试作业必须由学生书写完成,打印复印不计成绩。
高一第一次月考质量分析

高一第一次月考质量分析分析会议纪要尊敬的领导、老师们:大家好!已经过去一个月,第一次月考也已经结束。
今天,我们召开第一次月考质量分析会议,一方面对上一段工作进行总结,另一方面交流和部署后续工作。
一、月考统计分析一)数据统计1.从表一可以看出,本次月考共有78人参加,参考科目为9科。
语文、历史、政治科目的两率和差距比较大。
2.从表二的分布情况可以看出:A.高分段的人数比较少。
学科教师应该更加关注有升学希望的学生,这是九年级教学的重中之重。
B.608-700分有19人,这部分学生基础较好,应该受到学科教师的关注。
教师应该对这些学生进行逐个分析,提出针对性措施,促进他们稳步提升成绩。
对于偏科的学生,班主任应该与科任教师联系,进行实效性的辅导,增强学生纠偏的信心,引导他们探索自己的研究方法。
这些学生完全有能力进入到高分段。
C.456-608分有49人,这部分学生是支撑良好研究环境的主要力量,我们不应该忽视他们,应该给这部分学生以升学的希望,引导他们提高研究的主动性。
D.456分以下(30人),这部分学生需要更注重思想教育和情感疏导,要力求稳定。
二)前段教学工作取得成绩的原因从开学到现在,我们的教学秩序总体上是稳定的,老师们敬业精神强。
XXX虽然年龄较大,但为我们高中部老师树立了良好的榜样;XXX、XXX工作热情,讲解方法得当,为任课老师轻松上课,顺利推进进度打下基础。
其他老师虽然工作繁忙,但仍然坚守岗位。
可以说,正是老师们的这种积极向上精神,才使我们的教学出现了和谐、愉快、奋发的局面。
三)前段教学中存在的问题从这次月考中,我发现在我们的教学中还存在着一些问题,值得我们关注:1.辅优挖潜力度不够。
2.学生进办公室问题目的风气尚未形成。
3.课堂讲课时学法指导少,学生活动少。
我认为老师上课不只是为了完成这节课的教学任务。
4.老师们与学生沟通交流少。
5.有些时间段负责老师还没有踩到位,或者任务式走过场。
存在早早自空堂的现象,早早自均有未按时到位的现象。
海致大数据建模第一次作业中级

海致大数据建模第一次作业中级一、作业要求与目标在海致大数据建模课程中,第一次作业的目标是帮助学员掌握大数据分析的基本流程和方法。
本作业要求学员对给定的数据进行处理和分析,通过数据建模实现对数据特征的挖掘,从而达到对现实问题进行预测或解释的目的。
二、数据准备与处理1.收集数据:学员需要从给定的数据源中选取合适的数据集。
数据集应具有现实意义,以便能更好地应用于实际问题。
2.数据预处理:对收集到的数据进行清洗,包括去除重复记录、缺失值处理、数据类型转换等。
此外,还需对数据进行归一化或标准化处理,以消除数据量纲对分析结果的影响。
3.数据拆分:将数据集分为训练集、验证集和测试集,以便进行模型训练、参数调整和模型性能评估。
三、数据可视化与探索1.描述性统计分析:通过绘制柱状图、箱线图、散点图等,对数据进行初步可视化分析,了解数据的分布、相关性等特点。
2.数据探索:利用数据探索方法,如聚类、关联规则挖掘等,发现数据中的潜在规律和关联关系。
四、数据建模与优化1.选择模型:根据实际问题和数据特点,选取合适的建模方法,如线性回归、逻辑回归、决策树、支持向量机等。
2.模型训练:利用训练集对所选模型进行训练,通过调整模型参数提高模型性能。
3.模型优化:根据验证集的性能指标,对模型进行优化,如调整权重、学习率等。
五、结果评估与分析1.模型评估:利用测试集对模型进行评估,计算各项性能指标,如准确率、召回率、R方等。
2.结果分析:对建模结果进行解读,分析模型在实际问题中的应用价值,并提出改进措施。
六、总结与展望本次作业旨在帮助学员掌握大数据建模的基本方法和技巧。
通过完成作业,学员应能独立完成数据处理、可视化、建模和评估等环节,为解决现实问题提供数据支持。
《卫生统计学》第一次作业及答案

【补充选择题】A型题1.统计资料的类型可以分为A 定量资料和等级资料B 分类资料和等级资料C 正态分布资料和离散分布的资料D 定量资料和分类资料E 二项分布资料和有序分类资料2.以下符号中表示参数的为A SB uCD tE X3.统计学上所说的随机事件发生的概率P,其取值范围为A P≤1B P≥1C P≥0D1≥P≥0E1>P>04.小概率事件在统计学上的含义是A 指的是发生概率P≤0.5的随机事件B 指一次实验或者观察中绝对不发生的事件C 在一次实验或者观察中发生的可能性很小的事件,普通指P≤0.05D 以上说法均不正确E A和C正确5.描述定量资料集中趋势的指标有A 均数、几何均数、变异系数B 均数、几何均数、四分位数间距C 均数、变异系数、几何均数D 均数、四分位数间距、变异系数E 均数、几何均数、中位数6.关于频数表的说法正确的选项是A 都分为10个组段B 每一个组段必须组距相等C 从频数表中可以初步看出资料的频数分布类型D 不是连续型的资料没有方法编制频数表E 频数表中的每一个组段不一定是半开半闭的区间,可以任意指定7. 关于偏态分布资料说法不正确的选项是A 正偏态资料的频数分布集中位置偏向数值大的一侧B 负偏态资料的频数分布集中位置偏向数值大的一侧C 偏态分布资料频数分布摆布不对称D 不宜用均数描述其集中趋势E 不宜用变异系数来描述其离散程度8. 对于一个两端都没有切当值的资料,宜用以下哪个指标来描述其集中趋势A 几何均数B 均数C 方差D 中位数E 四分位数间距9.以下关于标准差的说法中哪种是错误的A 对于同一个资料,其标准差一定小于均数B 标准差一定大于0C 同一个资料的标准差可能大于均数,也可能小于均数D 标准差可以用来描述正态分布资料的离散程度E 如果资料中观察值是有单位的,那末标准差一定有相同单位10. 以下关于标准差S和样本含量n的说法,正确的选项是A 同一个资料,其他条件固定不变,随着n增大,S一定减小B 同一个资料,即使其他条件固定不变,随着n增大,也不能确定S一定减小C 同一个资料,其他条件固定不变,随着n增大,S一定增大D 以上说法均正确E 以上说法均错误11. 用以下哪两个指标可以较全面地描述正态分布特征A 均数和中位数B 中位数和方差C 均数和四分位数间距D 均数和标准差E 几何均数和标准差12. 以下哪个资料适宜用几何均数来描述其集中趋势A 偏态分布的资料B 对称分布的资料C 等比级数资料D 一端不确定的资料E 正态分布资料13. 以下关于变异系数的说法,错误的选项是A 与标准差一样都是用来描述资料变异程度的指标,都有单位B 可以比拟计量单位不同的几组资料的离散程度C 可以比拟均数相差悬殊的几组资料的离散程度D 变异系数的实质是同一个资料的标准差与均数的比值E 变异系数可以用来描述正态分布资料的变异程度14. 假设将一个正态分布的资料所有的原始数据都加之一个正数,以下说法正确的选项是A 均数将增大,标准差不改变B 均数和标准差均增大C 均数不变,标准差增大D 不一定E 均数和标准差均没有变化15. 假设将一个正态分布的资料所有的原始数据都乘以一个大于1的常数,以下说法正确的选项是A 均数不发生改变B 标准差将不发生改变C 均数是否变化不一定D 变异系数不发生改变E 中位数不发生改变16. 以下关于正态分布曲线的两个参数μ和σ说法正确的选项是A μ和σ越接近于0时,曲线越扁平B 曲线形状只与μ有关,μ值越大,曲线越扁平C 曲线形状只与σ有关,σ值越大,曲线越扁平D 曲线形状与两者均无关,绘图者可以随意画E 以上说法均不正确17. 对于正态分布曲线的描述正确的选项是A 当σ不变时,随着μ增大,曲线向右移B 当σ不变时,随着μ增大,曲线向左移C 当μ不变时,随着σ增大,曲线向右移D 当μ不变时,随着σ增大,曲线将没有变化E 以上说法均不正确18. 在正态曲线下,以下关于μ-1.645σ说法正确的选项是A μ-1.645σ到曲线对称轴的面积为90%B μ-1.645σ到曲线对称轴的面积为10%C μ-1.645σ到曲线对称轴的面积为5%D μ-1.645σ到曲线对称轴的面积为45%E μ-1.645σ到曲线对称轴的面积为47.5%19. 在正态曲线下,小于μ-2.58σ包含的面积为A 1%B 99%C 0.5%D 0.05%E 99.5%20. 在正态曲线下,大于μ-2.58σ包含的面积为A 1%B 99%C 0.5%D 0.05%E 99.5%21. 以下关于标准正态分布的说法中错误的选项是A 标准正态分布曲线下总面积为1B 标准正态分布是μ=0并且σ=1的正态分布C 任何一种资料只要通过σμ-=X u 变换均能变成标准正态分布D 标准正态分布的曲线是惟一的E 因为标准正态分布是对称分布,所以u ≥-1.96与u ≤1.96所对应的曲线下面积相等22. 某年某中学体检,测得100名高一女生的平均身高X =154cm, S =6.6cm ,该校高一女生中身高在143~170cm 者所占比重为(0.00780.04752.42, 1.67uu =-=-) A 90% B 95% C 97.5% D 94.5% E 99%23. 以下关于确定正常人肺活量参考值范围说法正确的选项是A 只能为单侧,并且惟独上限B 只能为单侧,并且惟独下限C 只能为双侧,这样才干反映全面D 单双侧都可以E 以上说法均不切当24. 以下关于医学参考值范围的说法中正确的选项是A 医学参考值范围是根据大局部“健康人〞的某项指标制定的B 医学参考值范围的制定方法不受分布资料类型的限制C 在制定医学参考值范围时,最好用95%范围,因为这个范围最能说明医学问题D 在制定医学参考值范围时,最好用95%范围,因为这样比拟好计算E 以上说法均不正确25. 为了制定尿铅的正常值范围,测定了一批正常人的尿铅含量,以下哪种说法正确A 无法制定,要制定正常值范围必须测定健康人的尿铅含量B 可以制定,应为单侧上限C 可以制定,应为单侧下限D 可以制定,但是无法确定是上侧范围还是下侧范围E 可以制定双侧95%的参考值范围B型题26~30题A 中位数B 四分位数间距C 均数D 几何均数E 对数标准差的反对数26. 对于惟独上限不知道下限的资料,欲描述其集中趋势宜用〔A〕27. 某学校测定了大学一年级新生乙肝疫苗的抗体滴度,欲描述其集中位置,宜用〔D〕28. 描述偏态资料的离散程度,可用〔B〕29. 描述近似正态分布的资料的集中趋势,最适宜用〔C〕30. 偏态分布的资料,如果经对数变换后服从正态分布,那末欲描述其离散程度,应选用〔E〕【补充选择题】A 型题 1. XS 表示A 样本中实测值与总体均数之差B 样本均数与总体均数之差C 样本的抽样误差D 样本中各实测值分布的离散情况E 以上都不是2. 标准误越小,说明此次抽样所得样本均数A 离散程度越小B 可比性越好C 可靠程度越小D 系统误差越小E 抽样误差越小3. 对样本均数X 作t 变换的是 A X X Sμ- B X X μσ- C X μσ- D X μσ- E XX X S - 4. t 分布与正态分布的关系是A 均以0为中心,摆布对称B 总体均数增大时,分布曲线的中心位置均向右挪移C 曲线下两端5%面积对应的分位点均是±1.96D 随样本含量的增大,t 分布逼近标准正态分布E 样本含量无限增大时,二者分布彻底一致5. 标准差与标准误的关系中,正确的选项是A 二者均反映抽样误差的大小B 总体标准差不变时,增大样本例数可以减小标准误C 总体标准差增大时,总体的标准误也增大D 样本例数增大时,样本的标准差和标准误都会减小E 标准差用于计算可信区间,标准误用于计算参考值范围6. 以下哪个说法是统计判断的内容A 区间估计和点估计B 参数估计与假设检验C 统计预测和统计控制D 统计描述和统计图表E 参数估计和统计预测7. 可信区间估计时可信度是指A αB βC 1α-D 1β-E 以上均不是8. σ未知且n 很小时,总体均数的95%可信区间估计的通式为 A 1.96X S ± B 1.96XX S ± C 1.96X X σ± D 0.05/2,XX tS ν± E 0.05/2,X t S ν±9. 关于假设检验,以下说法正确的选项是A 备择假设用H 0表示B 检验水准的符号为βC P 可以事先确定D 一定要计算检验统计量E 假设检验是针对总体的特征进行10. 两样本均数比拟的t 检验,差异有统计学意义时,P 越小A 说明两总体均数差异越大B 说明两样本均数差异越大C 越有理由认为两总体均数不同D 越有理由认为两样本均数不同E 犯I 型错误的可能性越大11. 方差齐性检验时,检验水准取以下哪个时,II 型错误最小A 0.20α=B 0.10α=C 0.05α=D 0.02α=E 0.01α=12. 假设检验的普通步骤中不包括哪项A 建立检验假设,确定检验水准B 对总体参数的可信区间作出估计C 选定检验方法,计算检验统计量D 确定P 值,作出统计判断结论E 直接计算P 值13. 假设检验时,应该使用单侧检验却误用了双侧检验,可导致A 增大了I 型错误B 增大了II 型错误C 减小了可信度D 增大了把握度E 统计结论更准确14. 假设检验中,P 与α的关系是A P 越大,α越大B P 越小,α越大C 二者均可事先确定D 二者均需通过计算确定E P 值的大小与α的大小无关15. 假设检验在设计时应确定的是A 总体参数B 检验统计量C 检验水准D P 值E 以上均不是16. 计量资料配对t 检验的无效假设〔双侧检验〕可写为A 0d μ=B 0d μ≠C 12μμ=D 12μμ≠E 0μμ= 17. II 型错误是指A 拒绝了实际上成立的H 0B 不拒绝实际上成立的H 0C 拒绝实际上不成立的H 0D 不拒绝实际上不成立的H 0E 拒绝H 0时所犯的错误18. 以下关于I 型错误和II 型错误说法不正确的选项是A I 型错误的概率用α表示B II 型错误的概率用β表示C 样本量固定时,I 型错误的概率越大,II 型错误的概率也越大D 样本量固定时,I 型错误的概率越大,II 型错误的概率越小E 要同时减小I 型错误和II 型错误的概率,需增大样本量19. 不合用于正态分布计量资料的假设检验的统计量是A tB uC FD 'tE T20. 彻底随机设计的方差分析中,成立的是A SS 组内 < SS 组间B MS 组内 < MS组间 C MS 组间 >1 D SS 总=SS 组间+SS 组内E MS总=MS组间+MS组内21. 随机区组设计方差分析中,成立的是A SS总=SS组间+SS组内B SS总=SS组间+SS区组C SS总=SS组间+SS区组+SS误差D SS总=SS组间-SS组内E SS总=SS区组+SS误差22. 成组设计方差分析,假设处理因素无作用,那末理论上有A F=1B F<1C F>1D F=0E F<1.9623. 方差分析中,组间变异主要反映A 随机误差B 抽样误差C 测量误差D 个体差异E 处理因素的作用24. 彻底随机设计的方差分析中,组内变异反映的是A 随机误差B 抽样误差C 测量误差D 个体差异E 系统误差25. 多组均数的两两比拟中,假设用t检验不用q检验,那末A 会将有差异的总体判断为无差异的概率增大B 会将无差异的总体判断为有差异的概率增大C 结果更加合理D 结果会一致E 以上都不对26. 随机区组方差分析中,总例数为N,处理组数为k,配伍组数b,那末处理组组间变异的自由度为A N-kB b-1C (b-1)(k-1)D k-1E N-127. 关于检验效能,以下说法错误的选项是A 两总体均数确有差异时,按 水准发现这种差异的能力B 两总体均数确有差异时,按1β-水准发现这种差异的能力C 与α有关D 与样本例数有关E 与两总体均数间的位置有关28. 为研究新旧两种仪器测量血生化指标的差异,分别用这两台仪器测量同 一批样品,那末统计检验方法应用A 成组设计t 检验B 成组设计u 检验C 配对设计t 检验D 配对设计u 检验E 配对设计2χ检验29. 两样本均数比拟的t 检验,t =1.20,0.05α=时统计判断结论为A 两样本均数的差异有统计学意义B 两样本均数的差异无统计学意义C 两总体均数的差异有统计学意义D 两总体均数的差异无统计学意义E 未给出自由度,无法进行统计判断30. 两大样本均数比拟,判断12μμ=是否成立,可用 A t 检验 B u 检验C 方差分析D 以上三种均可以E 2χ检验31~35题某药物研究中心为研究减肥药的效果,将40只体重接近的雄性大白鼠随机分为4组,分别赋予高剂量、中剂量、低剂量减肥药和空白对照4种处理方式,两个月后对这些大白鼠的体重进行了测定31. 上述资料所用的设计方法为A 彻底随机设计B 随机区组设计C 交叉设计D 析因设计E 序贯试验32. 比拟四组大白鼠的体重有无差异,宜用A 两两比拟的 t 检验B 两两比拟的u 检验C 方差分析D 2χ检验E 直线回归33. 比拟四组大白鼠的体重有无差异,无效假设为A 12μμ=B 1234μμμμ=== C 0μμ= D 12ππ= E 0dμ= 34. 假设规定0.05α=,方差分析得P <0.01,那末A 各总体均数不同或者不全相同B 各样本均数不同或者不全相同C 各总体均数均不相同D 各样本均数均不相同E 四组总体均数的差异很大35. 为比拟各剂量组与空白对照组间的差异,宜用A LSD 法B SNK 法C 新复极差法D 两两t 检验E 两两u 检验B 型题36~40题A μB σC Xσ D ν E 以上均不是 36. 决定t 分布位置的是 〔E 〕37. 决定t 分布形态的是〔D 〕38. 决定正态分布位置的是〔A 〕39. 决定正态分布形状的是〔B 〕40. 反映抽样误差大小的是〔C 〕41~45题A 样本均数与总体均数的t 检验B 配对t 检验C 成组t 检验D 成组u 检验E 以上都不是41. A地150名7岁女童与B地150名7岁女童的体重均数差异的检验,为简便计算,可选用〔D〕42. A地20名7岁女童与B地20名7岁女童的体重均数差异的检验用〔C〕43. A地15名7岁女童服用某保健品先后体重的变化的检验用〔B〕44. 检验B地70名7岁女童的体重是否服从正态分布用〔E〕45. B地20名女童的体重均数与同年人口普查得到的全国7岁女童的体重均数比拟用〔A〕46~50题A SS总=SS组间+SS组内B SS总=SS处理+SS区组+SS误差C SS总=SSA+SSB+SSAB+SS误差D SS总=SS阶段+SS处理+SS个体+SS误差E 以上均不是46. 析因设计方差分析总变异的分解为〔C〕47. 彻底随机设计方差分析总变异的分解为〔A〕48. 交叉设计方差分析总变异的分解为〔D〕49. 随机区组设计方差分析总变异的分解为〔B〕50. 重复测量方差分析总变异的分解为〔E〕。
统计学第一次作业答案

4
2
2
0
60分以 下
60-70
70-80
80-90
90分以 上
人数 2
7
分19数
15
7
练习
1、设某班50名学生的统计学原理考试成绩如下: 50 70 71 72 73 73 72 71 60 68 69 70 70 81 82 75 76 78 77 80 81 83 84 85 90 92 95 86 87 83 89 90 92 93 94 78 79 81 76 73 55 72 69 70 80 81 84 67 68 69 上述数据比较分散凌乱,不宜直接看出其基本
2,分组/编制频数分布表(分组依据参考Sturges提出的经
公
式)
组数=1+lgN/lg2=1+lg50/lg2≈7
组距=全距/组数=45/7≈6
由于成绩统计通常分组习惯组距为10,所以本次成绩排
组距参考值为10
Байду номын сангаас按分数分组
次数 频率(%)
较小制累计 次数 频率(%)
较大制累计 次数 频率(%)
2 60分以下
2
4.00%
2
4.00%
50 100.00%
7 60-70
7
14.00%
9
18.00% 48 96.00%
19 70-80
19 38.00% 28 56.00% 41 82.00%
15 80-90
15 30.00% 43 86.00% 22 44.00%
7 90分以上
7
14.00% 50 100.00% 7
特征,试将这些数据由小到大顺序排列,确定最大
spss统计学第一次实验作业答案
实验作业1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D. 较差;E.差。
调查结果见book3.01.xls。
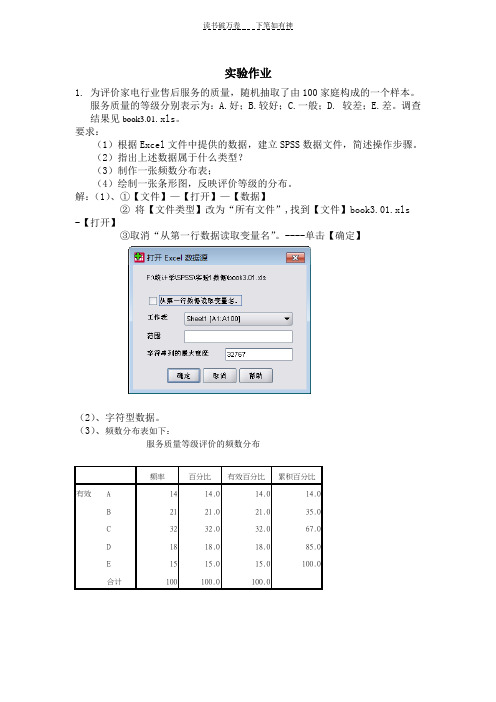
要求:(1)根据Excel文件中提供的数据,建立SPSS数据文件,简述操作步骤。
(2)指出上述数据属于什么类型?(3)制作一张频数分布表;(4)绘制一张条形图,反映评价等级的分布。
解:(1)、①【文件】—【打开】—【数据】②将【文件类型】改为“所有文件”,找到【文件】book3.01.xls -【打开】③取消“从第一行数据读取变量名”。
----单击【确定】(2)、字符型数据。
(4)、见数据实验2.某行业管理局所属40个企业20XX年的产品销售收入数据(单位:万元)见book3.02.xls。
要求:(1)根据Excel文件中提供的数据,建立SPSS数据文件。
(2)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(3)如果按规定:销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
解:(1)、见文件夹book3.02.sav(2)、理论分组数目:K= 1+ln(40)/ln(2)=6.32≈6组距=(最大值-最小值)/组数=(152-87)/6≈10.83≈11(3)按题目要求分组并进行统计,得到分组表如下:某管理局下属40个企分组表按销售收入分组(万元)企业数(个)频率(%)先进企业良好企业一般企业落后企业11119927.527.522.522.5合计40 100.03.为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果见book3.04.xls。
(1)根据Excel文件中提供的数据,建立SPSS数据文件。
(2)利用计算机对上面的数据进行排序;(3)以组距为10进行等距分组,整理成频数分布表,并绘制直方图。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据统计分析-第一次作业
————————————————————————————————作者:————————————————————————————————日期:
简答题:
1 什么是统计学?请结合自己的课题介绍统计学的内含
答:统计学是一门研究随机现象,以推断为特征的方法论科学,“由部分推及全体”的思想贯
穿于统计学的始终。
具体地说,它是研究如何搜集、整理、分析反映事物总体信息的数字资料,并以此为依据,对总体特征进行推断的原理和方法;是关于收集、整理、分析和解释统计数据的科学,是一门认识方法论性质的科学,其目的是探索数据内在的数量规律性,以达到对客观事物的科学认识。
我的研究课题是用生物信息学的方法来研究微卫星方面的问题。
本课题的研究最初就是用统计学的方法对不同基因组中的微卫星进行统计,分析微卫星与物种的相关性及联系。
进行本课题的研究,首先,收集数据,在NCBI中下载多条基因组数据,之后,根据生物不同的特征,对数据进行分类及整理,接下来,运用统计学的相关概念比如相对密度、相对风度、回归方程等进行基因组中微卫星的分布的计算,之后,运用R语言作图,将微卫星的分布可视化,更深入地进行研究分析分布规律与生物功能及进化的联系。
2 举例说明总体,样本,参数,统计量,变量这几个概念
答:总体是包含所研究的全部个体(数据)的集合。
样本是从总体中抽取的一部分元素的集合。
参数是用来描述总体特征的概括性数字度量。
统计量是用来描述样本特征的概括性数字度量。
变量是说明现象某种特征的概念。
比如欲调查某高校的2017届研究生毕业生就业率情况,那么该高校的所有2017届研究生毕业生则构成一个总体,其中的每一个研究生毕业生都是一个个体。
若从该高校的所有2017届研究生毕业生中按某种抽样规则抽出了100位毕业生,则这100位毕业生就构成了一个样本。
在这项调查中就业情况感兴趣,那么就业率就是一个变量。
通常关心某高校的2017届研究生毕业生平均就业率,这里这个平均值就是一个参数。
只有样本的有关就业率的数据,用此样本计算的平均值就是统计量。
3 比较概率抽样和非概率抽样的特点,指出各自适用情况
答:概率抽样:抽样时按一定的概率以随机原则抽取样本。
每个单位别抽中的概率已知或
可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽到的概率。
技术含量和成本都比较高。
如果调查目的在于掌握和研究对象总体的数量特征,得到总体参数的置信区间,就使用概率抽样。
非概率抽样:操作简单,时效快,成本低,而且对于抽样中的统计学专业技术要求不是很高。
它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。
它同样使用市场调查中的概念测试(不需要调查结果投影到总体的情况)。
4 简述异众比率、四分位差、方差或标准差的适用场合
答:异众比率主要是衡量众数对一组数据的代表程度主要适合测度分类数据的离散程度;
四分位差主要适合于测度顺序数据的离散程度;
方差能够较好的反映出数据的离散程度,是实际中应用最广的离散程度测量值,标准差和方差基本上同时应用。
5 简述众数、中位数和平均数的特点和应用场合。
答:众数主要用于测度分类数据的集中趋势,也适用于作为顺序数据以及数值型数据集中
趋势的测度值。
一般情况下,只有在数据量较大的情况下,众数才有意义。
中位数主要用于测量顺序数据的集中趋势,适用于测量数值型数据的集中趋势,但不适用于分类数据。
平均数是集中趋势的最主要测度值,主要适用于数值型数据,而不适用于分类数据和顺序数据。
6 根据自己的经验体会举几个服从正态分布的随机变量的实例。
答:如某种仪器每月出现故障的次数、一本书一页中的印刷错误、某一医院在某一天内的
急诊病人数、某班某次的考试成绩、某地区成年男性的身高、某公司年销售量、同一车间产品的质量等。
7请解释中心极限定理并结合自身经验列举中心极限定理的应用场景
答:中心极限定理是概率论中讨论随机变量序列部分和分布渐近于正态分布的一类定理。
这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量累积分布函数逐点收敛到正态分布的积累分布函数的条件。
它是概率论中最重要的一类定理,有广泛的实际应用背景。
中心极限定理:设从均值为μ、方差为σ^2;(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为(σ^2)/n 的正态分布。
中心极限定理则表明变量在分布上的特征.
例如对一千居民收入随机调查,发现无论低收入还是高收入都是少数,而中等收入占多数,即为正态分布.
计算题(要求使用R语言计算,列出计算过程中用到的R命令)
1 一种产品需要人工组装,现有三种可供选择的组装方法。
为检验哪种方法更好,随机抽取15个工人,让他们分别用三种方法组装。
下面是15个工人分别用三种方法在相同的时间内组装的产品数量:
单位:个
方法A 方法B 方法C
164 167 168 165 170 165 164 168 164 162 163 166 167 166 165 129
130
129
130
131
]30
129
127
128
128
127
128
128
125
132
125
126
126
127
126
128
127
126
127
127
125
126
116
126
125
要求:(1)你准备采用什么方法来评价组装方法的优劣?
如果让你选择一种方法,你会作出怎样的选择?试说明理由
答:应该用组装数量的平均数和标准差来评价组装方法的优劣。
平均数反映了
组装数据的多少,标准差反映了组装方法的稳定性。
要评价各种方法的优劣,需要计算每种方法的平均组装数量、标准差,并用离散系数比较每种方法的离散程度,有关结果如下表:
方法A 方法B 方法C
平均数=165.60分钟标准差=2.13分钟离散系数=0.013 平均数=128.73分钟
标准偏差1.75分钟
离散系数=0.014
平均数=125.53分钟
标准偏差=2.77分钟
离散系数=0.022
应选择方法A,因为其平均组装数量多,而且离散系数小,说明该种方法也比较稳定。
> x <- c(164,167,168,165,170,165,164,168,164,162,163,166,167,166,165)
>x <- c(129,130,129,130,131,130,129,127,128,128,127,128,128,125,132)
>x <-c (125,126,126,127,126,128,127,126,127,127,125,126,116,126,125)
> mean(x)
> sd(x)
2 调节一个装瓶机使其对每个瓶子的灌装量均值为μ盎司,通过观察这台装瓶机对每个瓶子的灌装量服从标准差 1.0
σ=盎司的正态分布。
随机抽取由这台机器灌装的9个瓶子形成一个样本,并测定每个瓶子的灌装量。
试确定样本均值偏离总体均值不超过0.3盎司的概率。
解:依题意,总体方差已知,均值的抽样分布服从N(μ,σ2/n)的正态分布,
由正态分布,标准化得到标准正态分布:z=~N(0,1),因此,样本均值不超过总体均值的概率P为:
P(|x-μ|
=P(-0.9z0.9)
=2(0.9)-1 (查表)
=2*0.8159-1
=0.6318
综上:(P(|x-μ|=0.6318
3 某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
(2)在95%的置信水平下,求边际误差。
(3)如果样本均值为120元,求总体均值的95%的置信区间。
解:(1)依题意知:假定总体标准差为σ=15,
则样本均值的抽样标准误差:
(2)已知置信水平1-α=95%,得Zα/2=1.96
则边际误差为
(3)已知样本均值 x=120,置信水平1-α=95%, 得Zα/2=1.96
这时总体均值置信区间为:,即置信区间为
(120-4.199,120+4.199)=(115.801,124.199)
4 根据流行病学调查的数据,某种儿童疾病的发生率为1%。
如果要求99%的置信区间,若要求边际误差不超过2%,请问应该抽取多少样本才能够达到上述要求?
解:p=0.01 α=0.01 Zα/2=2.58 △<=0.02
根据公式
n = 2.58*2.58*0.01*0.99/(0.02*0.02)
≈165
应该抽取165个样本才能达到上述要求。