基于图像映射的时间序列相似度网络分析
基于投影学习的图像聚类与相似度分析

基于投影学习的图像聚类与相似度分析图像聚类与相似度分析是计算机视觉中的重要课题之一。
随着大数据和深度学习的发展,图像数据的规模越来越庞大,传统的聚类算法在效果和效率上都难以满足实际需求。
基于投影学习的图像聚类与相似度分析成为了当前研究的热点。
投影学习是一种通过学习映射函数,将原始数据投影到低维空间中的方法。
投影学习可以通过降维,减少数据的维度,提高计算效率;也可以通过学习特征表达,提取数据的重要特征,从而提高聚类和相似度分析的准确性。
在图像聚类中,投影学习可以帮助将高维的图像数据投影到低维子空间中进行聚类。
传统的聚类算法如K-means、层次聚类等往往需要在高维空间中进行计算,面临计算复杂度高和聚类效果差的问题。
而通过投影学习,我们可以将原始的图像数据映射到低维空间中,从而减少计算量,并且在低维空间中进行聚类,可以取得更好的聚类效果。
基于投影学习的图像聚类通常分为两个步骤:特征学习和聚类。
在特征学习阶段,我们首先需要选择一个合适的特征学习算法,例如主成分分析(PCA)、独立成分分析(ICA)等。
这些算法可以提取出图像数据中最具代表性的特征。
然后,通过学习映射函数,将原始图像数据映射到低维特征空间中。
在聚类阶段,我们可以使用传统的聚类算法,如K-means、谱聚类等,在低维特征空间中对图像数据进行聚类。
除了图像聚类,基于投影学习的相似度分析也具有广泛的应用前景。
相似度分析可以帮助我们找到图片库中与查询图片最相似的图像,从而实现图像检索的功能。
传统的相似度分析方法往往依赖于手工设计的特征,并且效果受限。
而基于投影学习的相似度分析方法可以学习到更具有判别性的特征,从而提高相似度分析的准确性。
除了特征学习和聚类算法,基于投影学习的图像聚类与相似度分析中还有其他的关键问题需要解决。
首先,选择合适的投影学习算法和聚类算法非常重要。
不同的数据集和任务可能需要不同的算法。
其次,数据预处理也是一个关键的环节,合适的数据预处理可以帮助提取出更具有代表性的特征。
相似性分析及其应用

相似性分析及其应用相似性分析是一种常用的数据分析技术,其基本原理是在一组数据中找到相似性较大的数据项或者对象。
相似性分析可以应用于不同领域的问题,如推荐系统、图像识别等。
本文将介绍相似性分析的基本原理以及其在不同领域中的应用。
一、相似性分析基本原理相似性分析的基本原理是通过一定的指标或者算法计算数据项间的相似度,然后将相似度高的数据项进行归类或者推荐。
相似性度量方法一般分为两类:基于距离的相似性度量和基于特征的相似性度量。
1. 基于距离的相似性度量基于距离的相似性度量是通过计算数据项间的距离来评判其相似程度。
距离度量常用的有欧几里得距离、曼哈顿距离等。
例如,在推荐系统中,通过计算用户间的欧几里得距离来评判他们之间的相似性,进而给用户推荐相似的商品。
2. 基于特征的相似性度量基于特征的相似性度量是通过计算数据项在多个特征上的相似度来评判其相似程度。
例如,在图像识别中,通过提取图像特征,例如颜色、纹理等,来计算图像间的相似度,进而进行分类识别。
二、相似性分析的应用1. 推荐系统推荐系统是一种通过分析用户偏好和历史行为,为用户推荐合适的商品或者服务的系统。
相似性分析是推荐系统中的重要组成部分。
通过计算用户间或者商品间的相似度,对用户进行个性化推荐,提高推荐准确度和用户满意度。
2. 图像识别图像识别是一种通过计算机算法将图像转化为可识别的语义信息的技术。
相似性分析在图像识别中起到了重要作用。
例如,在人脸识别中,通过计算两张人脸图像间的相似度,判断是否为同一个人,提高识别率和准确度。
3. 文本分类文本分类是一种将文本数据按照特定的标准进行分类的技术。
相似性分析在文本分类中也有广泛应用。
例如,在情感分析中,通过计算两个句子间的相似度,来判断其情感倾向性,进而实现情感分类。
三、结论相似性分析是一种重要的数据分析技术。
它可以应用于不同领域的问题,如推荐系统、图像识别、文本分类等。
在实际应用中,相似性分析需要根据具体问题和数据特点选择合适的相似性度量方法,以提高准确度和效率。
时间序列分析相似性度量基本方法

时间序列分析相似性度量基本⽅法前⾔时间序列相似性度量是时间序列相似性检索、时间序列⽆监督聚类、时间序列分类以及其他时间序列分析的基础。
给定时间序列的模式表⽰之后,需要给出⼀个有效度量来衡量两个时间序列的相似性。
时间序列的相似性可以分为如下三种:1、时序相似性时序相似性是指时间序列点的增减变化模式相同,即在同⼀时间点增加或者减少,两个时间序列呈现⼀定程度的相互平⾏。
这个⼀般使⽤闵可夫斯基距离即可进⾏相似性度量。
2、形状相似性形状相似性是指时间序列中具有共同的形状,它通常包含在不同时间点发⽣的共同的趋势形状或者数据中独⽴于时间点相同的⼦模式。
两个时间序列整体上使⽤闵可夫斯基距离刻画可能不相似,但是他们具有共同相似的模式⼦序列,相似的模式⼦序列可能出现在不同的时间点。
这个⼀般使⽤DTW动态时间规整距离来进⾏相似性刻画。
3、变化相似性变化相似性指的是时间序列从⼀个时间点到下⼀个时间点的变化规律相同,两个时间序列在形状上可能并不⼀致,但是可能来⾃于同⼀个模型。
这个⼀般使⽤ARMA或者HMM等模型匹配⽅法进⾏评估。
时间序列相似性度量可能会受到如下因素影响:时间序列作为真实世界的系统输出或者测量结果,⼀般会夹杂着不同程度的噪声扰动;时间序列⼀般会呈现各种变形,如振幅平移振幅压缩时间轴伸缩线性漂移不连续点等时间序列之间可能存在不同程度的关联;以上因素在衡量时间序列相似性度量的时候要根据具体情况进⾏具体分析。
闵可夫斯基距离给定两条时间序列:P=(x_1,x_2,...x_n),\ \ Q(y_1,y_2,...y_n)闵可夫斯基距离的定义如下:dist(P,Q) = \left(\sum\limits_{i=1}^n|x_i-y_i|^p\right)^{\frac{1}{p}}注:1. 当p=1时,闵可夫斯基距离⼜称为曼哈顿距离:dist(P,Q)=\sum\limits_{i=1}^n |x_i-y_i|2.3. 当p=2时,闵可夫斯基距离⼜称为欧⽒距离:dist(P,Q) = \left(\sum\limits_{i=1}^n|x_i-y_i|^2\right)^{\frac{1}{2}}4. 当p\rightarrow\infty时,闵可夫斯基距离⼜称为切⽐雪夫距离:\lim\limits_{p\rightarrow\infty}\left(\sum\limits_{i=1}^n|x_i-y_i|^p\right)^{\frac{1}{p}} = \max\limits_{i}|x_i-y_i|5. 闵可夫斯基距离模型简单,运算速度快。
序列数据相似度计算

序列数据相似度计算
摘要:
1.序列数据相似度计算的定义与重要性
2.常用的序列数据相似度计算方法
3.实例分析
4.总结
正文:
序列数据相似度计算是研究序列数据之间相似性的一种方法,它在生物学、语言学、信息检索等领域有着广泛的应用。
对于序列数据,我们通常关心的是它们之间的相似程度,而序列数据相似度计算就是用来量化这种相似程度的。
常用的序列数据相似度计算方法有动态规划法、最长公共子序列法、最小编辑距离法等。
动态规划法是一种基于数学模型的算法,它通过计算两个序列之间的最长递增子序列来确定它们的相似度。
最长公共子序列法则是通过寻找两个序列中最长的公共子序列来计算它们的相似度。
最小编辑距离法则是通过计算将一个序列转换成另一个序列所需的最小操作次数来计算它们的相似度。
以蛋白质序列比对为例,科学家们可以通过比较两个蛋白质序列的相似度,来推测它们的功能和结构是否相似。
这种方法在生物信息学领域被广泛应用,有助于我们理解基因和蛋白质之间的关系。
总的来说,序列数据相似度计算是一种重要的数据分析方法,它在许多领域都有着广泛的应用。
基于深度学习的图像相似性度量算法研究

基于深度学习的图像相似性度量算法研究随着移动互联网和数字化技术的不断发展,图像处理技术的应用也越来越广泛。
图像相似性度量算法是图像处理技术中的重要一部分,它可以帮助我们实现图像的内容分析、图像检索等应用。
传统的图像相似性度量算法主要基于传统的图像特征描述子,但这种方法存在许多问题。
近年来,基于深度学习的图像相似性度量算法得到了广泛的研究,这种方法能够有效地提高图像的相似性度量精度。
一、深度学习的发展与应用深度学习是一种人工智能的技术,它可以通过训练大量的数据来学习模型和特征,得到更高质量的数据处理结果。
深度学习在语音识别、自然语言处理、图像识别等领域有着广泛的应用。
在图像处理领域中,深度学习可以通过卷积神经网络(CNN)等技术来提取图像的特征。
二、传统的图像相似性度量算法存在的问题传统的图像相似性度量算法主要基于传统的图像特征描述子,这种方法存在一些问题。
首先,传统的特征描述子往往是手工设计的,需要经过大量的实验才能得到较好的性能。
其次,传统的特征描述子不能有效地处理多样的图像场景,不能适应图像处理技术的发展需求。
三、基于深度学习的图像相似性度量算法的原理和方法基于深度学习的图像相似性度量算法可以通过深度学习提取图像特征,然后利用这些特征来衡量图像之间的相似程度。
在基于深度学习的图像相似性度量算法中,CNN是一种很常用的技术。
CNN可以通过多层卷积和池化操作来提取图像的高阶特征。
在图像相似性度量算法的训练阶段,可以使用大量的图像数据来训练CNN模型,得到更好的特征提取能力。
在测试阶段,可以使用训练好的CNN模型提取图像的特征,然后利用这些特征计算图像之间的相似度。
四、基于深度学习的图像相似性度量算法在实际应用中的效果基于深度学习的图像相似性度量算法在实际应用中能够取得较好的效果。
例如,在图像检索应用中,基于深度学习的图像相似性度量算法能够根据输入的关键词自动检索相关的图像。
在图像分类和图像识别应用中,基于深度学习的图像相似性度量算法能够提高图像分类和识别的准确度。
相似矩阵的实际应用

相似矩阵的实际应用相似矩阵在实际应用中有广泛的用途,以下是一些常见的应用领域:1. 图像处理:自相似矩阵可用于图像压缩和去噪。
通过对图像中重复出现的自相似块进行建模,可以有效地压缩图像数据并减少噪声。
2. 时间序列分析:自相似矩阵可用于分析时间序列数据中的周期性和重复模式。
这对于预测和模式识别非常有用。
3. 金融市场分析:自相似矩阵可用于分析金融市场数据中的周期性和自相似性。
它可以帮助识别市场中的模式和趋势,以便进行更准确的预测。
4. 网络流量分析:自相似矩阵可用于分析网络流量数据中的周期性和自相似性。
这对于优化网络资源分配和检测异常流量非常有用。
5. DNA序列分析:自相似矩阵可用于分析DNA序列中的重复结构和模式。
这有助于了解基因组的功能和进化。
6. 机器学习:在机器学习中,相似性矩阵(或称为距离矩阵、核矩阵等)经常用于衡量数据点之间的相似性或距离。
例如,在K-means聚类算法中,需要使用相似性矩阵来确定数据点之间的归属;在支持向量机(SVM)中,核矩阵用于在高维空间中计算数据点的内积。
7. 推荐系统:推荐系统利用用户的历史行为和偏好来预测他们可能感兴趣的内容。
相似性矩阵可以用于计算用户或物品之间的相似度,从而为用户提供个性化的推荐。
8. 人脸识别:在人脸识别中,相似性矩阵用于比较不同人脸图像之间的相似度。
通过计算人脸特征向量之间的相似性矩阵,可以实现人脸的识别、验证和聚类等功能。
9. 社交网络分析:在社交网络分析中,相似性矩阵可用于衡量用户之间的社交距离和关系强度。
这有助于发现社交网络中的社区结构、关键节点和传播路径等信息。
相似矩阵在实际应用中发挥着重要作用,涉及图像处理、时间序列分析、金融市场分析、网络流量分析、DNA序列分析以及机器学习、推荐系统、人脸识别和社交网络分析等多个领域。
通过利用相似矩阵的特性,可以有效地处理和分析各种类型的数据,为实际应用提供有力支持。
时间序列相似性查询的研究与应用

时间序列相似性查询的研究与应用随着大数据时代的到来,时间序列数据的重要性逐渐凸显。
时间序列数据是指按照时间顺序排列的一组数据,例如股票价格、气温变化、心电图等。
时间序列相似性查询作为一种重要的数据分析技术,旨在寻找与查询样本相似的时间序列数据,从而揭示隐藏在数据背后的规律和趋势。
在各个领域的实际应用中,时间序列相似性查询已经发挥了重要的作用。
时间序列相似性查询的研究主要包括两个方面:相似性度量和相似性查询算法。
相似性度量是衡量两个时间序列数据之间相似程度的方法,常用的度量方法包括欧氏距离、曼哈顿距离、动态时间规整等。
相似性查询算法是根据相似性度量方法,对大规模时间序列数据进行高效查询的方法,常用的算法包括基于索引的查询、基于哈希的查询、基于树结构的查询等。
这些研究成果为时间序列数据的分析和挖掘提供了基础。
时间序列相似性查询在实际应用中具有广泛的应用前景。
首先,在金融领域,通过对历史股票价格的相似性查询,可以预测未来股票价格的走势,为投资者提供决策依据。
其次,在气象领域,通过对历史气温变化的相似性查询,可以预测未来天气的变化,为气象预报提供支持。
再次,在医疗领域,通过对心电图的相似性查询,可以诊断心脏疾病,为医生提供治疗方案。
另外,在工业生产领域,通过对传感器数据的相似性查询,可以提前预测设备故障,进行维护和修复,提高生产效率。
然而,时间序列相似性查询也面临一些挑战。
首先,大规模时间序列数据的查询效率是一个问题,传统的查询算法无法满足实时查询的需求。
其次,相似性度量方法的选择也是一个难题,不同领域的数据可能需要采用不同的度量方法。
此外,在多维时间序列数据的查询中,如何考虑多个维度之间的相似性也是一个研究方向。
总之,时间序列相似性查询作为一种重要的数据分析技术,在各个领域的实际应用中发挥了重要作用。
未来,我们需要进一步研究相似性度量方法和查询算法,提高查询效率和准确性,以更好地应对大数据时代的挑战。
图像相似度计算

图像相似度计算图像相似度计算主要用于对于两幅图像之间内容的相似程度进行打分,根据分数的高低来判断图像内容的相近程度。
可以用于计算机视觉中的检测跟踪中目标位置的获取,根据已有模板在图像中找到一个与之最接近的区域。
然后一直跟着。
已有的一些算法比如BlobTracking,Meanshift,Camshift,粒子滤波等等也都是需要这方面的理论去支撑。
还有一方面就是基于图像内容的图像检索,也就是通常说的以图检图。
比如给你某一个人在海量的图像数据库中罗列出与之最匹配的一些图像,当然这项技术可能也会这样做,将图像抽象为几个特征值,比如Trace变换,图像哈希或者Sift特征向量等等,来根据数据库中存得这些特征匹配再返回相应的图像来提高效率。
下面就一些自己看到过的算法进行一些算法原理和效果上的介绍。
(1)直方图匹配。
比如有图像A和图像B,分别计算两幅图像的直方图,HistA,HistB,然后计算两个直方图的归一化相关系数(巴氏距离,直方图相交距离)等等。
这种思想是基于简单的数学上的向量之间的差异来进行图像相似程度的度量,这种方法是目前用的比较多的一种方法,第一,直方图能够很好的归一化,比如通常的256个bin条的。
那么两幅分辨率不同的图像可以直接通过计算直方图来计算相似度很方便。
而且计算量比较小。
这种方法的缺点:1、直方图反映的是图像像素灰度值的概率分布,比如灰度值为200的像素有多少个,但是对于这些像素原来的位置在直方图中并没有体现,所以图像的骨架,也就是图像内部到底存在什么样的物体,形状是什么,每一块的灰度分布式什么样的这些在直方图信息中是被省略掉得。
那么造成的一个问题就是,比如一个上黑下白的图像和上白下黑的图像其直方图分布是一模一样的,其相似度为100%。
2、两幅图像之间的距离度量,采用的是巴氏距离或者归一化相关系数,这种用分析数学向量的方法去分析图像本身就是一个很不好的办法。
3、就信息量的道理来说,采用一个数值来判断两幅图像的相似程度本身就是一个信息压缩的过程,那么两个256个元素的向量(假定直方图有256个bin条)的距离用一个数值表示那么肯定就会存在不准确性。
利用计算机视觉进行图像搜索与相似度匹配的实践方法

利用计算机视觉进行图像搜索与相似度匹配的实践方法随着计算机视觉技术的飞速发展,图像搜索和相似度匹配在各个领域得到了广泛应用。
利用计算机视觉进行图像搜索和相似度匹配可以帮助人们更快速、准确地找到自己感兴趣的图像,并且对于商业领域的产品推荐、版权保护等方面也具有重要意义。
本文将介绍利用计算机视觉进行图像搜索与相似度匹配的实践方法。
首先,图像搜索是指根据用户输入的关键词,在大规模的图像数据库中找到与关键词相关的图像。
图像搜索可以分为基于文本的搜索和基于图像内容的搜索两种方式。
基于文本的搜索方法是通过将图像与关键词相关的文本信息进行关联,从而实现图像搜索。
一种常见的方法是利用图像的标签信息,并通过词袋模型将关键词与图像进行匹配。
这种方法的优点是实现简单,但也存在标签质量不高、语义不明确等问题。
而基于图像内容的搜索方法则是通过分析图像的视觉特征,从而实现对图像的搜索。
图像的视觉特征包括颜色、纹理、形状、边缘等信息。
常用的方法有颜色直方图、SIFT特征、SURF特征等。
这些特征可以用来度量图像之间的相似度,从而实现图像搜索和相似度匹配。
接下来,相似度匹配是指在给定一个查询图像的情况下,在图像数据库中找到与查询图像最相似的图像。
相似度匹配的目标是找到与查询图像在内容和结构上最类似的图像。
常用的相似度匹配方法有两种:基于特征的方法和基于深度学习的方法。
基于特征的方法利用图像的局部特征描述符进行相似度度量,如SIFT特征、SURF特征等。
通过计算两个图像之间的特征相似度,我们可以得到它们的相似程度。
而基于深度学习的方法则是利用卷积神经网络(CNN)等深度学习模型将图像映射到特征空间中,通过计算特征空间中图像之间的距离来度量相似程度。
深度学习方法具有更强的表达能力和更准确的匹配效果,但需要更大量的数据和更高的计算资源支持。
在实践中,我们可以利用开源的计算机视觉工具和库来实现图像搜索和相似度匹配。
例如,OpenCV是一个广泛使用的计算机视觉库,提供了丰富的图像处理和特征提取方法。
遥感图像时序分析方法与技巧

遥感图像时序分析方法与技巧遥感技术是通过获取和解译地球表面的影像和数据来研究地球系统的一种重要工具。
其中,遥感图像时序分析是一种通过对多个时间点的遥感图像进行定量分析来揭示地表变化的方法。
本文将探讨遥感图像时序分析的方法、技巧以及其在不同领域的应用。
一、时序数据获取时序数据是指在不同时间点上获取的遥感图像数据。
为了进行时序分析,首先需要收集大量高质量的遥感数据。
目前,卫星遥感技术已经相当成熟,包括MODIS、Landsat等卫星可以提供高分辨率、高空间覆盖的遥感图像。
此外,还可以利用无人机等载具获取高分辨率的时序数据。
二、时序数据处理时序数据处理是指将一系列的遥感图像进行预处理,以便进行更深入的分析。
预处理包括大气矫正、几何矫正、辐射矫正、影像融合等步骤。
对于不同的时序分析任务,可能需要进行不同的预处理步骤。
通过预处理,可以有效减少噪音、辐射偏差等因素的影响,提高时序分析结果的质量。
三、时序分析方法1. 基于统计分析的方法统计分析是一种常见的时序分析方法,可以通过计算一系列遥感图像的光谱、纹理、形状等特征参数来揭示地表的时空变化规律。
常用的统计分析方法有时序图、相关分析、聚类分析等。
例如,通过计算每个时间点的NDVI(归一化植被指数)值,可以研究植被的季节性变化。
2. 机器学习方法机器学习方法在遥感图像时序分析中也得到了广泛应用。
通过使用监督学习算法,可以训练分类器来自动检测和分类遥感图像中的特定目标。
例如,可以使用卷积神经网络(CNN)来识别遥感图像中的建筑物、道路等。
此外,还可以使用聚类算法、支持向量机等机器学习方法进行时序变化检测和分类。
3. 时间序列分析方法时间序列分析是一种通过对时序数据进行统计和模型建立来揭示地表变化的方法。
时间序列分析方法可以识别出遥感图像中的周期性、趋势和规律等,从而更好地理解地表的时空演变。
常用的时间序列分析方法包括ARIMA模型、平滑技术、小波分析等。
四、时序分析应用领域1. 土地利用/覆盖变化研究遥感图像时序分析可以提供宝贵的信息,用于监测和评估土地利用/覆盖的变化。
基于图卷积网络的时空数据特征分析与应用

基于图卷积网络的时空数据特征分析与应用摘要:随着移动互联网和物联网的发展,大量的时空数据被产生和积累,为我们理解和探索城市的时空特征提供了宝贵的机会。
然而,时空数据的特征分析和应用面临着许多挑战,例如数据的高维性、复杂的时空关联以及数据的稀疏性等。
本文提出了一种方法,通过构建时空图模型,利用图卷积网络来学习时空数据的特征表示,并探索了其在城市交通预测和异常检测中的应用。
1. 引言随着城市化进程的加速,城市交通、环境、人口等时空数据规模不断增大。
时空数据的特征分析和应用对于城市规划、交通管理、环境保护等领域具有重要意义。
然而,时空数据的特征分析面临着许多挑战,例如数据的高维性、复杂的时空关联以及数据的稀疏性等。
2. 基于图卷积网络的时空数据特征分析方法为了解决时空数据的特征分析问题,本文提出了一种基于图卷积网络的方法。
首先,我们将时空数据转化为时空图模型,其中节点表示地理位置或时间点,边表示地理位置或时间点之间的关系。
然后,我们利用图卷积网络来学习时空数据的特征表示,通过节点之间的信息传播和特征聚合来提取时空数据的特征。
3. 基于图卷积网络的时空数据应用本文将基于图卷积网络的时空数据特征分析方法应用于城市交通预测和异常检测。
在城市交通预测中,我们利用时空数据的特征表示来预测交通流量和拥堵情况,提供实时交通信息和路线规划。
在异常检测中,我们利用时空数据的特征表示来检测交通事故、交通违法等异常情况,提供及时的预警和响应。
4. 实验结果与分析我们在真实的城市交通数据集上进行了实验,验证了基于图卷积网络的时空数据特征分析方法的有效性和性能。
实验结果表明,我们的方法在城市交通预测和异常检测中取得了较好的效果,能够提供准确和实用的时空数据分析结果。
5. 结论与展望本文提出了一种基于图卷积网络的时空数据特征分析与应用方法,通过构建时空图模型和利用图卷积网络来学习时空数据的特征表示,实现了城市交通预测和异常检测等应用。
时间序列相似性度量
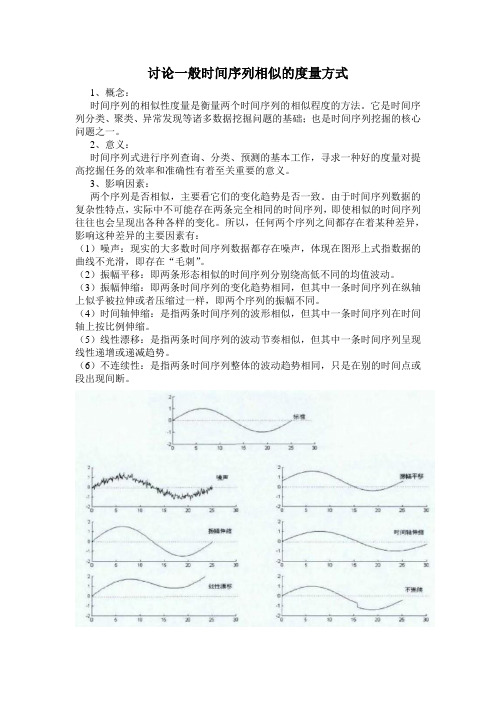
讨论一般时间序列相似的度量方式1、概念:时间序列的相似性度量是衡量两个时间序列的相似程度的方法。
它是时间序列分类、聚类、异常发现等诸多数据挖掘问题的基础;也是时间序列挖掘的核心问题之一。
2、意义:时间序列式进行序列查询、分类、预测的基本工作,寻求一种好的度量对提高挖掘任务的效率和准确性有着至关重要的意义。
3、影响因素:两个序列是否相似,主要看它们的变化趋势是否一致。
由于时间序列数据的复杂性特点,实际中不可能存在两条完全相同的时间序列,即使相似的时间序列往往也会呈现出各种各样的变化。
所以,任何两个序列之间都存在着某种差异,影响这种差异的主要因素有:(1)噪声:现实的大多数时间序列数据都存在噪声,体现在图形上式指数据的曲线不光滑,即存在“毛刺”。
(2)振幅平移:即两条形态相似的时间序列分别绕高低不同的均值波动。
(3)振幅伸缩:即两条时间序列的变化趋势相同,但其中一条时间序列在纵轴上似乎被拉伸或者压缩过一样,即两个序列的振幅不同。
(4)时间轴伸缩:是指两条时间序列的波形相似,但其中一条时间序列在时间轴上按比例伸缩。
(5)线性漂移:是指两条时间序列的波动节奏相似,但其中一条时间序列呈现线性递增或递减趋势。
(6)不连续性:是指两条时间序列整体的波动趋势相同,只是在别的时间点或段出现间断。
然而,在实际应用中情况要复杂得多,往往是以上多种因素交织在一起。
时间序列的相似性并没有一个客观的定义,具有一定的个人偏好性,也就是说,不同的人或不同的应用场合对各种差异影响的重视程度是不一样的。
给定两条时间序列 {}12,,....,n X x x x =和{}12=,,....m Y y y y ,相似性度量的问题就是在各种各样差异因素的影响下,寻求一个合适的相似性度量函数(),Sim X Y ,使得该函数能很好地反映时间序列数据的特点。
4、方法:目前时间序列相似性度量,最常用的有Minkowski 距离和动态时间弯曲。
序列相似性

序列相似性序列相似性是表明两个序列在结构和空间上的相似程度的一个概念,它在许多领域有着广泛的用途,如生物信息学,语音识别,自然语言处理,算法应用,地理信息系统和统计学等等。
序列相似性可以用来比较两个序列,并通过检测两个序列中重复出现的字符或模式来测量它们之间的相似程度。
在生物信息学中,序列相似性被用于比较基因,蛋白质,DNA等序列之间的相似性,以提高构基因组学研究的效率。
序列相似性分析常常使用度量距离(measurement distance)或相关度(correlation)来判断两个序列之间的相似程度。
其中,度量距离依赖于两者之间的相似性,它用于度量两个序列之间的编辑距离,它可以用替换,插入或删除操作来表示,基于此,可以推导出编辑距离的最小值。
另一方面,相关度可以用来比较两个序列之间的相似度,例如,可以用欧氏距离来衡量两个向量之间的距离,所得的结果可用来判断两个序列之间的相似程度。
序列相似性分析有两个主要步骤:特征提取和模式比较。
第一步,即特征提取,是把序列转换成特征向量,并且把这些特征向量用于模式比较。
第二步,模式比较,则是把两个特征向量进行比较,以确定相似程度。
常用的序列相似性方法有基于概率模型的方法,如HMM(隐马尔可夫模型)和RNA分析,也有基于模式匹配的方法,如Smith-Waterman 算法和Needleman-Wunsch算法。
HMM主要用于生物信息学,它能够比较某一特定基因,核酸或蛋白质序列的不同状态间的相似性。
RNA分析则用于检测序列中的编码功能蛋白质的基因组。
Smith-Waterman 算法和Needleman-Wunsch算法是基于模式匹配技术的序列相似性分析方法,它们分别用于检测DNA序列的相似性和蛋白质序列的相似性。
序列相似性分析的应用非常广泛,如果能够准确测量两者序列之间的相似程度,就可以极大地提高生物信息学和蛋白质结构分析的效率。
此外,序列相似性分析也可以用于人工智能、自然语言处理、机器学习和模式识别等领域,从而帮助提高这些领域的研究效率。
聚类分析中的相似性度量及其应用研究

聚类分析中的相似性度量及其应用研究一、本文概述聚类分析是一种无监督的机器学习方法,旨在将相似的对象归为一类,不同的对象归为不同的类。
这种分析方法在多个领域中都得到了广泛的应用,包括数据挖掘、模式识别、图像处理、市场研究等。
聚类分析的核心在于相似性度量,即如何定义和计算对象之间的相似性。
本文将对聚类分析中的相似性度量进行深入探讨,并研究其在不同领域的应用。
本文将介绍聚类分析的基本概念、原理和方法,包括常见的聚类算法如K-means、层次聚类、DBSCAN等。
然后,重点讨论相似性度量的定义、分类和计算方法,包括距离度量、相似系数等。
我们将分析各种相似性度量方法的优缺点,并探讨它们在不同聚类算法中的应用。
接下来,本文将通过案例研究的方式,探讨相似性度量在各个领域中的应用。
我们将选择几个具有代表性的领域,如数据挖掘、模式识别、图像处理等,分析相似性度量在这些领域中的具体应用,以及取得的成果和存在的问题。
本文将对相似性度量在聚类分析中的未来发展进行展望,探讨可能的研究方向和应用领域。
我们希望通过本文的研究,能够为聚类分析中的相似性度量提供更加深入的理解和应用指导,推动聚类分析在各个领域的广泛应用和发展。
二、相似性度量方法及其优缺点聚类分析是一种无监督的机器学习方法,用于将数据集中的样本按照其相似性进行分组。
相似性度量是聚类分析中的关键步骤,它决定了样本之间的相似程度,进而影响了聚类的结果。
在聚类分析中,常用的相似性度量方法主要包括距离度量、相似系数和核函数等。
距离度量是最常用的相似性度量方法之一。
常见的距离度量有欧氏距离、曼哈顿距离、切比雪夫距离等。
欧氏距离是最直观和最常用的距离度量,它衡量了样本在多维空间中的直线距离。
然而,欧氏距离对数据的尺度敏感,因此在处理不同尺度的数据时需要进行标准化处理。
曼哈顿距离和切比雪夫距离则对数据的尺度变化不太敏感,适用于处理不同尺度的数据。
相似系数是另一种常用的相似性度量方法,它衡量了样本之间的相似程度。
时间序列数据挖掘中相似性和趋势预测的研究

时间序列数据挖掘中相似性和趋势预测的研究时间序列数据挖掘中相似性和趋势预测的研究摘要:时间序列数据在各个领域中广泛使用,如金融、交通、气象等。
本文旨在探讨时间序列数据挖掘中的相似性和趋势预测方法,从而提供基于数据挖掘的决策支持。
1. 引言随着技术的快速发展,我们正面临着大量的时间序列数据,如股票价格、气温、销售记录等。
利用这些数据进行相似性分析和趋势预测对于提高决策过程的准确性和效率至关重要。
因此,时间序列数据挖掘的研究变得越来越重要。
2. 相似性分析2.1 相似度度量相似度度量是相似性分析的基础。
常见的相似度度量方法包括欧氏距离、曼哈顿距离、皮尔逊相关系数等。
根据具体的需求和数据特点,选择合适的相似度度量方法可以得到更准确的结果。
2.2 时间序列相似性时间序列数据的相似性分析是指在时间上比较两个或多个时间序列的趋势和结构。
其中,主要方法包括动态时间规整(DTW)和自相似性分析。
2.2.1 动态时间规整(DTW)动态时间规整是一种基于序列对齐的方法。
它通过比较时间序列中各个时间点之间的距离和相似性,将两个时间序列规整成同样的长度。
DTW方法已经广泛用于语音识别、基因序列分析等领域。
2.2.2 自相似性分析自相似性分析是指寻找时间序列中的自相似模式。
通过计算时间序列的局部相似性,可以发现周期性、趋势性和重复性等模式。
其中常用的方法包括小波变换和自回归模型。
3. 趋势预测趋势预测是时间序列数据挖掘中的一项重要任务。
根据时间序列数据的特点和背景知识,我们可以采用不同的预测方法。
3.1 统计模型统计模型是常用的趋势预测方法之一。
它基于时间序列数据的历史数据,通过时间序列模型建立数学模型,并进行预测。
常见的统计模型有ARIMA模型、指数平滑模型等。
3.2 机器学习方法随着机器学习技术的发展,越来越多的方法被应用于趋势预测中。
例如,支持向量回归(SVR)、随机森林(Random Forest)、深度学习等。
遥感图像中的变化检测和时间序列分析

遥感图像中的变化检测和时间序列分析遥感技术被广泛应用于地表变化的监测。
利用遥感图像数据,可以实现对大面积范围内的地表信息进行全面、精准的监测与分析。
而变化检测和时间序列分析是其中最重要、最基础的应用之一。
变化检测是以遥感图像为数据源,通过对同一地区多时相遥感图像的分析,检测并分析研究区域内地表特征、覆盖类型、土地利用等方面的变化。
遥感图像变化检测已经成为城市规划、生态环境评估、森林资源监测等领域中不可或缺的一个重要工具,具有广泛的应用前景。
时间序列分析是指一系列按照时间顺序排列的数据所形成的序列,是遥感数据中的常见数据形式之一。
时间序列分析主要通过对遥感图像序列数据的处理和分析,挖掘数据序列中所蕴含的信息,并剖析数据序列背后的物理及生态学特征、规律、趋势与变异等。
时间序列分析是遥感信息应用的重要手段之一,可以用于农业生态环境监测、农田作物生长监测等领域。
下面,我们将对变化检测和时间序列分析进行详细的介绍。
一、变化检测变化检测的主要目的是检测、识别不同时相或同一时相中不同区域的地表特征、覆盖类型、土地利用等方面的变化。
其核心原理是基于多时相遥感影像数据进行比对,通过图像处理、图像匹配等方法来发现、分析和提取出变化信息。
通过分析变化信息,可以较快较准地地反映一个地区内环境变化情况,便于对环境问题进行跟踪、分析和预测。
变化检测的流程一般包括以下几个步骤:1、获取多时相遥感数据:收集数幅遥感图像数据,这些数据之间时间跨度可以根据研究需求和采集周期而定,比如获取1980年、1990年、2000年这三个年份的遥感数据;2、遥感数据预处理:对获取的遥感数据进行辐射校正、大气校正、几何校正等预处理,以提高遥感数据的准确度和可靠性;3、遥感影像匹配:在多时相遥感影像间进行匹配,并运用图像处理算法消除遥感影像之间的几何差异;4、变化检测与分析:在完成遥感影像匹配后,通过像元比较或对象比较等方法,检测出变化部分,进而对变化和未变化的部分进行分析。
时间序列数据挖掘中相似性和趋势预测的研究

时间序列数据挖掘中相似性和趋势预测的研究时间序列是指按照时间顺序进行排列的一组数据,具有非常广泛的应用,包括经济预测、环境监测、医疗诊断等领域。
时间序列数据挖掘是指通过机器学习、数据挖掘等方法,对于时间序列数据进行分析和处理,以达到对数据的深度理解、事件预测、系统优化等目的。
其中,相似性分析和趋势预测是时间序列数据挖掘中的两个重要方面,本文将着重对这两个方面进行综述和分析。
一、相似性分析相似性分析是对于时间序列中的不同数据进行比较和匹配,以寻找数据之间的相似性和相关性。
在时间序列数据挖掘中,相似性分析有非常广泛的应用,包括图像和声音识别、交通流量预测等。
下面我们将从数据表示、距离度量、相似性度量、采样率和插值等几个方面来讨论相似性分析的方法和技术。
1.数据表示对于时间序列数据的表示,常见的方式包括时间区间和时间点。
时间区间表示是指将时间序列数据分段表示,每一段代表一个时间区间的数据;时间点表示则是在时间轴上标注数据采集的时间戳,随着采集时间的增加,时间序列也在不断地增加。
时间区间表示的优点在于可以更好地处理时序数据的不确定性和噪声,但需要更多的计算资源;时间点表示则更直观和易于理解,但需要特殊处理不规则或不完整的数据。
根据具体应用场景和数据的特点,选择合适的数据表示方法非常重要。
2.距离度量距离度量是指对于两个时间序列的距离进行计算的方法。
常见的距离度量包括欧氏距离、曼哈顿距离、切比雪夫距离等,具体选择方法要根据数据特征进行处理。
例如,在处理具有线性关系的数据时可以使用欧氏距离;而在处理非线性数据时则可以使用切比雪夫距离。
3.相似性度量相似性度量是指对于两个时间序列相似性程度进行计算的方法。
常见的相似性分析方法包括最近邻方法、K-Means聚类和模式匹配等。
最近邻方法是指寻找与目标时间序列最相似的历史序列,并将其作为预测结果的依据。
K-Means聚类是指对于时间序列进行聚类分析,确定各个聚类中心,以此来寻找相似性更高的时间序列。
相似模型知识点总结

相似模型知识点总结在本文中,我们将介绍几种常见的相似模型,包括文本相似模型、图像相似模型和音频相似模型,并详细讨论它们的原理、应用和训练方法。
1. 文本相似模型文本相似模型是用于比较两个文本之间的相似性的模型。
在自然语言处理领域,文本相似模型有着广泛的应用,例如在搜索引擎中用于文本匹配、推荐系统中用于相似文本推荐等。
常见的文本相似模型包括词向量模型(Word Embedding)、文本向量模型(Text Embedding)、语义匹配模型(Semantic Matching)等。
词向量模型是一种将词表示为实数向量的模型,通过将每个词映射到一个向量空间中的点,来表征词之间的相似性。
常见的词向量模型有Word2Vec、GloVe、FastText等。
这些模型通过训练词向量,使得相似意思的词在向量空间中距离较近,而不相似的词在向量空间中距离较远。
文本向量模型是一种将整个文本表示为一个实数向量的模型,通过将文本映射到向量空间中的点,来表征文本之间的相似性。
常见的文本向量模型有Doc2Vec、BERT等。
这些模型通过训练文本向量,使得相似内容的文本在向量空间中距离较近,而不相似的文本在向量空间中距离较远。
语义匹配模型是一种将两个文本进行比较的模型,通过计算两个文本之间的语义相似度,来评估它们的相似程度。
常见的语义匹配模型有Siamese Network、MatchPyramid等。
这些模型通过训练学习两个文本之间的语义表示,从而实现文本相似度的计算。
除了上述模型外,还有一些其他的文本相似模型,如LSTM、GRU等循环神经网络模型,以及深度学习模型、迁移学习模型等。
这些模型都可以用于比较文本之间的相似性,但具体选择哪种模型取决于具体的应用场景和需求。
在训练文本相似模型时,通常需要大量的文本数据和相应的标签。
数据预处理包括分词、去停用词、构建词表等,而模型训练过程则包括损失函数的选择、优化器的选择、超参数的调整等。
基于图神经网络的多变量时间序列异常检测

基于图神经网络的多变量时间序列异常检测Graph Neural Network-Based Anomaly Detection in Multivariate Time Series 简述给定高维时间序列数据(例如传感器数据),我们如何检测异常事件,例如系统故障和攻击?更具挑战性的是,我们如何以一种捕获复杂的传感器间关系的方式来做到这一点,并检测和解释偏离这些关系的异常情况?最近,深度学习方法改进了高维数据集中的异常检测;然而,现有方法并没有明确学习变量之间现有关系的结构,也没有使用它们来预测时间序列的预期行为。
我们的方法将结构学习方法与图神经网络相结合,另外使用注意力权重为检测到的异常提供可解释性。
对具有真实异常的两个真实传感器数据集进行的实验表明,我们的方法比基线方法更准确地检测异常,准确捕获传感器之间的相关性,并允许用户推断检测到的异常的根本原因。
主要内容•我们提出了GDN(GraphDeviationNetwork),这是一种新颖的基于注意力的图神经网络方法,它学习传感器之间的依赖关系图,并识别和解释这些关系的偏差。
•我们对具有真实异常的两个水处理厂数据集进行了实验。
我们的结果表明,GDN检测异常比基线方法更准确。
•我们使用案例研究表明,GDN通过其嵌入和学习图提供了一个可解释的模型。
我们表明,基于检测到偏差的子图、注意力权重,并通过比较这些传感器上的预测和实际行为,它有助于解释异常。
模型框架GDN方法旨在以图形的形式学习传感器之间的关系,然后识别和解释与学习模式的偏差。
它涉及四个主要部分:1.SensorEmbedding:使用嵌入向量来捕捉每个传感器的独特特征;2.图结构学习:学习一个表示传感器之间依赖关系的图结构;3.GraphAttention-BasedForecasting:根据相邻传感器的图注意力函数预测每个传感器的未来值;4.图偏差评分:识别与学习关系的偏差,并定位和解释这些偏差。
大数据开发基础(习题卷1)

大数据开发基础(习题卷1)第1部分:单项选择题,共57题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]数据资产维护是指为保证数据质量,对数据进行()等处理的过程。
A)更正B)删除C)补充录入D)以上答案都正确答案:D解析:数据资产维护是指为保证数据质量,对数据进行更正、删除、补充录入等处理的过程。
2.[单选题]企业数据分析平台在根据不同的业务场景需求,搭建不同的大数据分析平台,如适应离线批处理的Hadoop平台;适应实时处理的流计算平台等,这种架构属于哪种类型的架构?A)分离架构B)单一架构C)融合架构D)多维架构答案:A解析:3.[单选题]将两篇文本通过词袋模型变为向量模型,通过计算向量的( )来计算两个文本间的相似度。
A)正弦距离B)余弦距离C)长度D)方向答案:B解析:4.[单选题]下图为 Flume 数据传输架构,图中“?”号处的组件是?A)InterceptorB)Channel ProcessorC)Channel SelectorD)以上全不正确答案:C解析:5.[单选题]以下说法结果错误的是()A)10==11 结 果:FalseB)10!= 10 结 果:FalseC)10>=10 结 果:FalseD)5 < 10 结 果:True答案:C解析:6.[单选题]使用SELECT语句随机地从表中挑出指定数量的行,可以使用的方法是( )A)在LIMIT子句中使用RAND()函数指定行数,并用ORDER BY子句定义一个排序规则C)只要在ORDER BY子句中使用RAND()函数,不使用LIMIT子句D)在ORDER BY子句中使用RAND()函数,并用LIMIT子句定义行数答案:D解析:7.[单选题]下列哪个选项可以来判断Hbase表是否存在?A)table.containskey(tableName)B)admin.getTable(TableName)C)adminTableExists(TableNamevalueOf(tableName))D)adminTableExists(tableName)答案:D解析:8.[单选题]一个输入为(32,32,3)的数据集,通过一个卷积核个数为8,大小为5*5,步长为1的卷积层,输出()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
时间进 度安排
时间进度安排
2018.01-03 阅读文献
2018.03-06 编写小论文
2018.07-12 编写大论文
2019.01-02 准备毕业答辩
PPT模板下载:/moban/ 节日PPT模板:/jieri/ PPT背景图片:/beijing/ 优秀PPT下载:/xiazai/ Word教程: /word/ 资料下载:/ziliao/ 范文下载:/fanwen/ 教案下载:/jiaoan/
PPT模板下载:/moban/ 节日PPT模板:/jieri/ PPT背景图片:/beijing/ 优秀PPT下载:/xiazai/ Word教程: /word/ 资料下载:/ziliao/ 范文下载:/fanwen/ 教案下载:/jiaoan/
研究方法 和内容
研究方法和内容
以股票对数价格收益的皮尔逊相关系 数为基础,构建复杂网络,分析股票 之间的关系及相互影响。
首先对股票的多个属性进行特征选择, 然后通过时间序列转化成灰度图像并 融合成彩色图像,以图像相似度构建 复杂网络,分析股票之间的影响及关 系。
研究方法和内容
时间序列 转化图像
计算图像 相似度
PPT模板下载:/moban/ 节日PPT模板:/jieri/ PPT背景图片:/beijing/ 优秀PPT下载:/xiazai/ Word教程: /word/ 资料下载:/ziliao/ 范文下载:/fanwen/ 教案下载:/jiaoan/
国内外研 究现状
国内外研究现状
R.N. Mantegna (1999)首先以最小生成树 法(MST)构建对数价格收益股票网络。
M. Tumminello(2005)通过提取代表 性连接的子图过滤复杂数据来构建网 络。
Wei-Qiang Huang (2009)采用阈值法 构建中国股票相关网络,进而研究网 络的结构性质和拓扑稳定性。
国内外研究现状
A. Namaki(2011)使用随机矩阵理论 (RMT)概念来指定相关矩阵的最大 特征向量作为股票网络的市场模式。
吴翎燕(2013)构建基于相关系数和最佳阈 值的股票网络模型,发现股票网络中拓扑性 质有稳定性。
Lisi Xia(2017)等提出了构建中国股市网 络的阈值模型,并研究了这些网络的拓扑性 质。
完成工作 及问题
完成工作及问题
数据采集
初步验证结果
数据处理
PPT模板下载:/moban/ 节日PPT模板:/jieri/ PPT背景图片:/beijing/ 优秀PPT下载:/xiazai/ Word教程: /word/ 资料下载:/ziliao/ 范文下载:/fanwen/ 教案下载:/jiaoa选择
相似度算 法选择
网络阈 值选择
PPT模板下载:/moban/ 节日PPT模板:/jieri/ PPT背景图片:/beijing/ 优秀PPT下载:/xiazai/ Word教程: /word/ 资料下载:/ziliao/ 范文下载:/fanwen/ 教案下载:/jiaoan/
行业PPT模板:/hangye/ PPT素材下载:/sucai/ PPT图表下载:/tubiao/ PPT教程: /powerpoint/ Excel教程:/excel/ PPT课件下载:/kejian/ 试卷下载:/shiti/ PPT论坛:
行业PPT模板:/hangye/ PPT素材下载:/sucai/ PPT图表下载:/tubiao/ PPT教程: /powerpoint/ Excel教程:/excel/ PPT课件下载:/kejian/ 试卷下载:/shiti/ PPT论坛:
行业PPT模板:/hangye/ PPT素材下载:/sucai/ PPT图表下载:/tubiao/ PPT教程: /powerpoint/ Excel教程:/excel/ PPT课件下载:/kejian/ 试卷下载:/shiti/ PPT论坛:
行业PPT模板:/hangye/ PPT素材下载:/sucai/ PPT图表下载:/tubiao/ PPT教程: /powerpoint/ Excel教程:/excel/ PPT课件下载:/kejian/ 试卷下载:/shiti/ PPT论坛:
行业PPT模板:/hangye/ PPT素材下载:/sucai/ PPT图表下载:/tubiao/ PPT教程: /powerpoint/ Excel教程:/excel/ PPT课件下载:/kejian/ 试卷下载:/shiti/ PPT论坛:
参考文献
参考文献
[1]Newman M E J. The Structure and Function of Complex Networks[J]. Siam Review, 2003, 45(2):167-256. [2]R.N. Mantegna. Information and hierarchical structure in financial markets[J]. The European Physical Journal B - Condensed Matter and Complex Systems, 1999, 11(1):193-197. [3]Kenett D Y, Raddant M, Lux T, et al. Evolvement of Uniformity and Volatility in the Stressed Global Financial Village[J]. Plos One, 2012, 7(2):e31144. [4]L. da F. Costa, F. A. Rodrigues, G. Travieso, et al. Characterization of complex networks: A survey of measurements[J]. Advances in Physics, 2007, 56(1):167-242. [5]Gopikrishnan P, Rosenow B, Plerou V, et al. Quantifying and interpreting collective behavior in financial markets[J]. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2001, 64(2):035106. [6]Peron T K D, Rodrigues F A. Collective behavior in financial market[J]. Quantitative Finance, 2011, 96(4):48004. [7]Barthélemy M, Barrat A, Pastorsatorras R, et al. Velocity and hierarchical spread of epidemic outbreaks in scale-free networks.[J]. Physical Review Letters, 2004, 92(17):178701.
构建阈 值网络
研究方法和内容
研究方法和内容
研究方法和内容
PPT模板下载:/moban/ 节日PPT模板:/jieri/ PPT背景图片:/beijing/ 优秀PPT下载:/xiazai/ Word教程: /word/ 资料下载:/ziliao/ 范文下载:/fanwen/ 教案下载:/jiaoan/
基于图像映射的时间序列 相似度复杂网络分析
姓名:黄宗文
PPT模板下载:/moban/ 节日PPT模板:/jieri/ PPT背景图片:/beijing/ 优秀PPT下载:/xiazai/ Word教程: /word/ 资料下载:/ziliao/ 范文下载:/fanwen/ 教案下载:/jiaoan/
目录
研究背景及意义 国内外研究现状 研究方法和内容 研究难点及预期 完成工作及问题 时间进度安排 参考文献
PPT模板下载:/moban/ 节日PPT模板:/jieri/ PPT背景图片:/beijing/ 优秀PPT下载:/xiazai/ Word教程: /word/ 资料下载:/ziliao/ 范文下载:/fanwen/ 教案下载:/jiaoan/
行业PPT模板:/hangye/ PPT素材下载:/sucai/ PPT图表下载:/tubiao/ PPT教程: /powerpoint/ Excel教程:/excel/ PPT课件下载:/kejian/ 试卷下载:/shiti/ PPT论坛:
研究背景 及意义
研究背景及意义
股市规模2010
年已是全球市值 第二大的股市,开
户数达千万。
经济晴雨表
经济一体化,各个 行业间的经济合作 越来越紧密,彼此 间的影响越来越密
切。
大数据对数
据相互关系的挖 掘与融合去发现 事物之间的联系 变得越来越重要。
经济监管对于
股市内在关系越是了 解越有利于对市场进 行监管。
行业PPT模板:/hangye/ PPT素材下载:/sucai/ PPT图表下载:/tubiao/ PPT教程: /powerpoint/ Excel教程:/excel/ PPT课件下载:/kejian/ 试卷下载:/shiti/ PPT论坛:
行业PPT模板:/hangye/ PPT素材下载:/sucai/ PPT图表下载:/tubiao/ PPT教程: /powerpoint/ Excel教程:/excel/ PPT课件下载:/kejian/ 试卷下载:/shiti/ PPT论坛: