第九讲MATLAB基本统计分析说课讲解
如何使用Matlab进行统计分析

如何使用Matlab进行统计分析引言:统计分析是一种重要的数据处理和解释手段,在科学研究、工程设计、市场调研等领域起着至关重要的作用。
Matlab作为一款强大的数值计算软件,也提供了丰富的统计分析工具和函数,使得用户可以方便地进行各种统计任务。
本文将介绍如何使用Matlab进行统计分析的一些基本方法和技巧,并结合实例进行演示。
一、统计数据的导入与预处理在进行统计分析之前,首先需要将所需的数据导入到Matlab中,并做一些必要的预处理工作。
1. 导入数据:Matlab提供了各种导入数据的函数,如readtable、xlsread等。
根据需要选择适合的函数,将数据导入到Matlab的工作空间中。
2. 数据清洗:在进行统计分析之前,需要对数据进行清洗,如删除异常值、处理缺失数据等。
Matlab提供了一系列用于数据清洗的函数,如isoutlier、fillmissing等,用户可以根据具体情况选择合适的函数进行处理。
二、统计数据的可视化分析可视化分析是统计分析的重要环节之一,能够直观地展示数据的特征和规律,帮助我们更好地理解数据。
1. 直方图:直方图是一种常用的数据可视化方法,可以用来展示各个数值区间的频数分布情况。
在Matlab中,可以使用histogram函数来绘制直方图。
2. 散点图:散点图可以用来观察两个变量之间的关系及其分布情况。
在Matlab中,可以使用scatter函数来绘制散点图。
3. 箱线图:箱线图可以反映数据的分布情况、异常值和离群点等。
在Matlab中,可以使用boxplot函数来绘制箱线图。
4. 折线图:折线图可以用来展示数据的变化趋势和周期性变化等。
在Matlab中,可以使用plot函数来绘制折线图。
三、统计数据的描述性分析描述性分析是统计分析的基本内容,它能够对数据进行整体性和个体性的描述,以及提取数据的主要特征。
1. 均值和中位数:均值和中位数是描述数据集中趋势的指标,可以用来衡量数据集的集中程度。
第九讲MATLAB基本统计分析
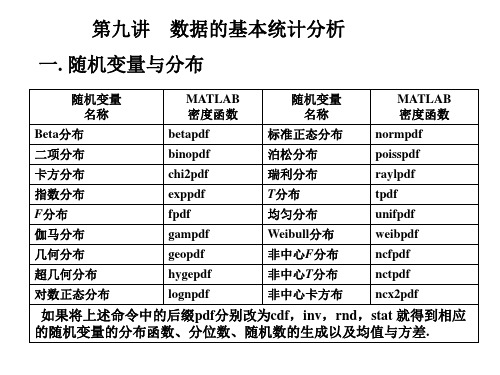
四. 矩统计量 在MATLAB中给出了计算矩统计量、峰度、偏度 和变异系数的函数命令,如下表所示:
名称 命令 n阶中心矩 moment(x,n) 峰度系数 kurtosis(x) 偏度系数 Skewness(x) 变异系数 Std(x)./abs(mean(x))
775 859 755 649 697 515 628 954 771 609 402 960 885 610 292 837 473 677 358 638 699 634 555 570 84 416 606 1062 484 120 447 654 564 339 280 246 687 539 790 581 621 724 531 512 577 496 468 499 544 645 764 558 378 765 666 763 217 715 310 851];
变异系数用于刻画数据的变化大小,不同指标的变 异系数常用来计算客观性权重. 例7. 下表给出了15种资产的收益率ri(%)和风险损 失率qi(%),计算峰度与偏度.
Si ri(%) qi(%) Si ri(%) qi(%)
S1
S2 S3 S4 S5 S6 S7
9.6
18.5 49.4 23.9 8.1 14 40.7
中位数
切尾平均 几何平均
599.5
600.64 559.68
方差
标准差 四分位极差
38663.03
196.629 243.5
调和平均
499.06
平均绝对偏差
150.86
例5. 已知数据:1,1,1,1,1,1,100;计算其数 据特征,由此你有何发现? 解:x=[1,1,1,1,1,1,100]; y=[mean(x),median(x),geomean(x),harmmean(x),trimmean(x,25);
利用MATLAB进行统计分析

利用MATLAB进行统计分析使用 MATLAB 进行统计分析引言统计分析是一种常用的数据分析方法,可以帮助我们理解数据背后的趋势和规律。
MATLAB 提供了一套强大的统计工具箱,可以帮助用户进行数据的统计计算、可视化和建模分析。
本文将介绍如何利用 MATLAB 进行统计分析,并以实例展示其应用。
一、数据导入和预处理在开始统计分析之前,首先需要导入数据并进行预处理。
MATLAB 提供了多种导入数据的方式,可以根据实际情况选择合适的方法。
例如,可以使用`readtable` 函数导入Excel 表格数据,或使用`csvread` 函数导入CSV 格式的数据。
导入数据后,我们需要对数据进行预处理,以确保数据的质量和准确性。
预处理包括数据清洗、缺失值处理、异常值处理等步骤。
MATLAB 提供了丰富的函数和工具,可以帮助用户进行数据预处理。
例如,可以使用 `fillmissing` 函数填充缺失值,使用 `isoutlier` 函数识别并处理异常值。
二、描述统计分析描述统计分析是对数据的基本特征进行概括和总结的方法,可以帮助我们了解数据的分布、中心趋势和变异程度。
MATLAB 提供了多种描述统计分析的函数,可以方便地计算数据的均值、标准差、方差、分位数等指标。
例如,可以使用 `mean` 函数计算数据的均值,使用 `std` 函数计算数据的标准差,使用 `median` 函数计算数据的中位数。
此外,MATLAB 还提供了 `histogram`函数和 `boxplot` 函数,可以绘制数据的直方图和箱线图,从而更直观地展现数据的分布特征。
三、假设检验假设检验是统计分析中常用的推断方法,用于检验关于总体参数的假设。
MATLAB 提供了多种假设检验的函数,可以帮助用户进行单样本检验、双样本检验、方差分析等分析。
例如,可以使用 `ttest` 函数进行单样本 t 检验,用于检验一个总体均值是否等于某个给定值。
可以使用 `anova1` 函数进行单因素方差分析,用于比较不同组之间的均值差异是否显著。
Matlab中常用的统计分析技巧介绍

Matlab中常用的统计分析技巧介绍统计分析是研究数据的特征、规律和变化趋势的一种方法。
作为一款功能强大的科学计算软件,Matlab提供了丰富的统计分析工具和函数,可用于处理和分析各种类型的数据。
本文将介绍Matlab中常用的统计分析技巧,帮助读者更好地利用Matlab进行数据分析和解释。
一、数据导入与处理在进行统计分析之前,首先需要将数据导入Matlab并进行相应的处理。
Matlab 提供了多种导入数据的函数,如`xlsread`、`csvread`和`importdata`等,可根据数据的来源和格式选择合适的函数进行导入。
同时,Matlab还提供了丰富的数据处理函数,如`reshape`、`sort`和`filter`等,可用于数据的重塑、排序和滤波等操作,便于后续的分析和计算。
二、描述性统计分析描述性统计分析是了解和概括数据特征的一种方法。
在Matlab中,我们可以使用`mean`、`median`、`std`、`max`和`min`等函数计算数据的均值、中位数、标准差、最大值和最小值等统计量。
此外,Matlab还提供了`hist`和`boxplot`等函数,可用于绘制数据的直方图和箱线图,直观展示数据的分布和离散情况。
三、假设检验假设检验是统计学中经典的方法之一,用于判断样本数据与假设之间的差异是否显著。
在Matlab中,我们可以使用`ttest`、`anova1`和`chisquare`等函数进行假设检验。
例如,`ttest`函数可以用于对比两组样本的均值是否存在显著差异,`chisquare`函数可以用于分析分类数据的关联性。
假设检验结果一般会给出显著性水平和p值,以帮助我们判断差异是否具有统计学意义。
四、回归和相关性分析回归和相关性分析是研究变量之间关系的一种常用方法。
Matlab中提供了`regress`和`corrcoef`等函数,可用于简单线性回归和相关性分析。
例如,`regress`函数可以用于求解线性回归模型的回归系数和拟合优度,`corrcoef`函数可以用于计算变量之间的相关系数矩阵。
利用Matlab进行数据分析与统计方法详解

利用Matlab进行数据分析与统计方法详解数据分析和统计方法在现代科学、工程和商业领域中是非常重要的工具。
而Matlab作为一种强大的计算软件和编程语言,提供了丰富的功能和工具,可以帮助我们进行数据分析和统计。
一、Matlab数据分析工具介绍Matlab提供了许多数据分析工具,包括数据可视化、数据处理、统计分析等。
其中,数据可视化是数据分析中重要的一环,可以用于展示数据的分布、趋势和关系。
Matlab中的绘图函数可以绘制各种类型的图形,如折线图、散点图、柱状图等。
我们可以利用这些图形来直观地理解数据并发现潜在的模式。
二、常用的数据处理方法在进行数据分析之前,我们通常需要对数据进行预处理,以去除噪声、填补缺失值和标准化数据等。
Matlab提供了丰富的函数和工具来处理这些问题。
例如,可以使用滤波函数对信号进行平滑处理,使用插值函数填补缺失值,并使用标准化函数将数据转化为标准分布。
三、基本的统计分析方法在进行统计分析时,我们常常需要计算各种统计量,如均值、方差、标准差等。
Matlab提供了一系列统计函数,如mean、var和std等,可以轻松计算这些统计量。
此外,Matlab还提供了假设检验、方差分析、回归分析等高级统计方法的函数,方便我们进行进一步的研究。
四、数据挖掘和机器学习方法数据挖掘和机器学习是数据分析的前沿领域,能够从大量的数据中发现隐藏的模式和规律。
Matlab作为一种强大的计算工具,提供了丰富的数据挖掘和机器学习函数。
例如,可以利用聚类分析函数对数据进行聚类,使用分类函数进行分类,还可以使用神经网络函数构建和训练神经网络模型。
五、案例分析:利用Matlab进行股票市场分析为了更好地理解Matlab在数据分析和统计方法中的应用,我们以股票市场分析为例进行讲解。
股票市场是一个涉及大量数据和复杂关系的系统,利用Matlab可以对其进行深入分析。
首先,我们可以利用Matlab的数据导入和处理函数,将股票市场的历史数据导入到Matlab中,并对数据进行预处理,如去除异常值和填补缺失值。
使用Matlab进行统计分析的基本步骤

使用Matlab进行统计分析的基本步骤统计分析是指通过对收集到的数据进行整理、描述、分析和解释,从而揭示数据背后的规律和关联性。
Matlab是一种强大的数值计算和科学工程软件,广泛应用于各个领域的数据分析和建模。
本文将介绍使用Matlab进行统计分析的基本步骤。
一、数据准备和导入进行任何统计分析之前,首先需要准备和导入数据。
数据可以来自于实验、调查、采样等方式收集得到。
在Matlab中,可以通过各种途径导入数据,如文本文件、Excel文件、数据库等。
在导入数据之前,需要确保数据格式正确、无误,并进行必要的清洗和预处理。
二、数据的描述统计描述统计是对数据进行描述和分析的过程。
通过描述统计,可以获得数据的中心趋势、离散程度、分布特征等信息。
在Matlab中,可以使用一系列函数进行描述统计分析。
例如,mean函数可以计算数据的均值,std函数可以计算标准差,median函数可以计算中位数,hist函数可以绘制直方图等。
三、数据的可视化分析数据可视化是将数据以图形或图表的形式展示出来,以便更直观地理解数据之间的关系和趋势。
Matlab提供了强大的绘图功能,可以绘制散点图、柱状图、折线图等多种图形。
通过调用相应的绘图函数,可以将数据可视化展示出来,并进行进一步的分析和解读。
四、假设检验与推断统计假设检验与推断统计是统计学中重要的分析方法,用于对总体参数、分布或数据之间的关系进行推断。
在Matlab中,可以使用ttest函数进行单样本或双样本的假设检验,使用anova 函数进行方差分析,使用corrcov函数计算相关系数矩阵等。
这些函数可以帮助我们进行假设检验和推断统计,以得出对总体或样本的推断性结论。
五、回归分析和建模回归分析是研究变量之间相互依赖关系的一种统计方法,常用于预测、数据建模和因果推断。
在Matlab中,可以通过调用regress函数实现线性回归分析,使用fitlm函数进行多元线性回归分析,使用glm函数进行广义线性模型分析等。
MATLAB中的统计分析方法详解

MATLAB中的统计分析方法详解序言:统计分析是现代科学研究中不可或缺的一环,为研究者提供了从大量数据中提取有用信息的方法。
MATLAB作为一种功能强大的科学计算软件,拥有丰富的统计分析工具,可用来进行数据分析、模型拟合、参数估计等,为科学研究提供了强有力的支持。
本文将深入探讨MATLAB中的统计分析方法,并详细介绍它们的原理与应用。
一、描述统计分析方法描述统计分析是指从数据总体中获得有关特征和趋势的方法,常用的统计量有均值、方差、标准差等。
在MATLAB中,可以使用`mean`、`var`和`std`等函数来计算数据的均值、方差和标准差。
例如,给定一组数据`data`,可以通过以下代码计算其均值、方差和标准差:```matlabmean_data = mean(data); % 计算均值var_data = var(data); % 计算方差std_data = std(data); % 计算标准差```此外,在描述统计分析中,盒须图也是常用的图表形式之一,可以直观地展示数据的分布情况。
在MATLAB中,可以使用`boxplot`函数绘制盒须图。
以下是一个示例代码:```matlabboxplot(data);```二、假设检验方法假设检验是统计分析的重要方法之一,用来评估某个问题的真实性和确定性。
常用的假设检验方法包括t检验、方差分析、卡方检验等。
1. t检验:t检验用于比较两组样本的均值是否存在显著差异。
在MATLAB中,可以使用`ttest`函数进行t检验。
以下是一个示例代码:```matlab[h, p] = ttest(data1, data2);```其中,`data1`和`data2`分别表示两组样本的数据,`h`表示检验的假设是否成立(1表示拒绝原假设,0表示接受原假设),`p`表示假设检验的p值。
2. 方差分析:方差分析用于比较多组样本的均值是否存在显著差异。
在MATLAB中,可以使用`anova1`函数进行一元方差分析,或使用`anova2`函数进行二元方差分析。
利用Matlab进行统计分析的基本步骤与方法

利用Matlab进行统计分析的基本步骤与方法随着数据的产生与积累,统计分析成为了解数据背后规律和趋势的重要手段。
Matlab作为一种强大的计算工具,在统计分析中扮演着不可或缺的角色。
本文将介绍利用Matlab进行统计分析的基本步骤与方法,帮助读者快速了解如何利用该工具进行数据处理。
一、数据准备与导入在进行统计分析之前,首先需要准备好待分析的数据。
数据可以来自各种来源,比如实验数据、调查问卷、市场调研等。
在Matlab中,常用的数据存储格式包括文本文件、Excel文件和数据库等。
针对不同的数据格式,Matlab提供了相应的函数进行导入。
例如,使用`readtable`函数可以导入Excel文件,而使用`readmatrix`函数可以读取文本文件。
导入数据后,可以使用`whos`命令查看数据大小和类型等信息,以确保数据导入正确。
二、数据处理与整理在进行统计分析之前,通常需要对数据进行处理和整理,以便更好地进行后续分析。
数据处理的具体步骤包括数据清洗、缺失值处理、异常值检测等。
数据清洗是指对数据进行去除重复值、空值等不合理值的操作。
Matlab提供了多种函数来处理这些问题。
例如,使用`unique`函数可以去除重复值,使用`isnan`函数可以检测缺失值。
对于缺失值的处理,常见的方法有删除、插补和替换。
删除是指直接将含有缺失值的行或列删除,而插补则是通过一定的方法进行填补。
Matlab中提供了`rmmissing`和`fillmissing`函数来实现这些操作。
异常值检测是指对数据中存在的离群值进行识别和处理。
Matlab中常用的异常值检测方法有Grubbs检验、箱线图和3σ法。
使用Matlab可以方便地对数据进行这些操作,以获得更准确的统计结果。
三、统计分析方法1. 描述统计分析描述统计分析是对数据进行整体性描述的分析方法。
主要通过计算数据的中心趋势和离散程度来揭示数据的特征。
中心趋势即代表数据的集中位置,常见的统计量有均值、中位数和众数等。
如何利用Matlab进行统计分析

如何利用Matlab进行统计分析利用Matlab进行统计分析概述:Matlab是一种功能强大的数值分析和科学计算工具,广泛应用于统计分析领域。
本文将介绍如何利用Matlab进行统计分析,包括数据预处理、描述性统计分析、假设检验和回归分析等内容。
通过学习和运用Matlab的统计工具箱,可以更高效、准确地进行统计分析。
数据预处理:在进行统计分析之前,首先需要对数据进行预处理。
Matlab提供了多种数据导入和处理的函数,可轻松处理各种格式的数据文件。
例如,可以使用"readtable"函数读取Excel文件,使用"csvread"函数读取CSV文件。
同时,Matlab还提供了数据清洗的功能,例如删除空值、异常值或重复值等。
数据预处理的目的是减少数据集中的噪音和错误,以获得高质量的统计结果。
描述性统计分析:描述性统计分析是统计学中最基础的方法,用于对数据集的各个属性进行描述和总结。
Matlab提供了丰富的描述性统计函数,可用于计算数据的均值、中位数、标准差、方差等基本统计量。
通过这些函数,我们可以对数据的分布、偏态和峰度等特征进行直观的描述和分析。
假设检验:假设检验是统计分析中常用的方法,用于对样本数据与总体假设之间的差异进行验证。
Matlab提供了多种假设检验函数,包括单样本t检验、双样本t检验、方差分析等。
用户可以根据实际需求选择相应的假设检验方法,并通过统计结果得出结论。
通过假设检验,我们可以验证某种观察结果是否显著,从而对研究问题提供可靠的解释和支持。
回归分析:回归分析是统计学中常用的方法,用于研究变量之间的相关性和预测。
Matlab 提供了多种回归分析函数,包括线性回归、多项式回归、逻辑回归等。
通过这些函数,可以拟合数据并得出回归模型,进一步进行预测和模型评估。
回归分析在经济学、社会学、市场研究等领域具有重要应用,能帮助我们深入理解和预测变量之间的关系。
matlab数据的统计分析与描述课件

s n
,X
t 1 2
s ]. n
(二)方差的区间估计
DX
在置信水平
1-
下的置信区间为
[
(n 1)
2 1
s
2
,
(n
1)s 2
2
].
2
2
返回
学习交流PPT
14
对总体X的分布律或分布参数作某种假设,根据 抽取的样本观察值,运用数理统计的分析方法,检 验这种假设是否正确,从而决定接受假设或拒绝假 设.
(n
1)
Ⅲ
s2
s
2 0
s
2
s
2 0
2
2
(n)
2
2
(n
1)
学习交流PPT
18
(三)两个正态总体均值的检验
1.
s
2 1
与
s
2 2
已知时
构造统计量
z
2.s
2 1
与
s
2 2
未知但相等时
X Y
.
s
2 1
s
2 2
n1 n2
构 造 统 计 量 t
XY
n1n2(n1n22),
(n11)s1 2(n21)s2 2
2p s
其中 m 为均值,s 2 为方差, x .
1
e dy x
( ym)2 2s 2
2ps
标准正态分布:N(0,1)
密度函数
j(x)
1
x2
e2
2p
分布函数
F(x)
1
x
y2
e 2 dy
2p
0.4
0.35
0.3
MATLAB中的统计分析方法介绍

MATLAB中的统计分析方法介绍引言:统计分析是一种重要的数据分析技术,它可以帮助我们从数据中获取有用的信息和洞察力。
作为一种强大的数值计算工具,MATLAB提供了丰富的统计分析函数和工具箱,本文将介绍一些MATLAB中常用的统计分析方法。
一、描述统计分析方法描述统计分析是对数据进行整体性的概括和描述,通常包括中心趋势和离散度两方面的指标。
在MATLAB中,我们可以使用mean、median、mode、std等函数计算这些指标。
例如,使用mean函数可以计算数据的平均值:```matlabdata = [1, 2, 3, 4, 5];avg = mean(data);disp(avg);```除了计算单个变量的描述统计量外,我们还可以使用corrcov函数计算协方差矩阵和相关系数矩阵,从而评估数据之间的相关性。
二、概率分布和假设检验概率分布是统计分析中最基本的工具之一,它描述了随机变量的取值概率。
MATLAB提供了多种概率分布函数,例如正态分布、指数分布、泊松分布等。
我们可以使用这些函数生成服从特定概率分布的随机数,并进行各种假设检验。
例如,我们可以使用normrnd函数生成服从正态分布的随机数,并使用normfit 函数计算正态分布的参数。
另外,我们还可以使用chi2gof函数对数据进行卡方检验,用ttest函数对均值进行假设检验等。
三、回归分析和方差分析回归分析和方差分析是一类广泛应用于数据建模和预测的统计分析方法。
MATLAB提供了regress函数和anova函数用于执行这两类分析。
在回归分析中,我们可以使用regress函数根据给定的自变量和因变量数据拟合出一个线性回归模型,并可视化模型结果。
此外,我们还可以使用polyfit函数进行多项式回归分析,或使用fitlm函数进行更复杂的线性回归分析。
对于方差分析,我们可以使用anova1函数进行单因素方差分析,进行不同样本之间的差异性比较。
(完整版)matlab第九讲教案

(完整版)matlab第九讲教案西南科技⼤学本科⽣课程备课教案计算机技术在安全⼯程中的应⽤——Matlab⼊门及应⽤授课教师:徐中慧班级:专业:安全技术及⼯程第九章⾼级绘图课型:新授课教具:多媒体教学设备,matlab 教学软件⼀、⽬标与要求掌握matlab 如何处理三种不同类型的图形⽂件,使⽤句柄图形指定绘图的句柄并调整特性,通过matlab 两种技术的任意⼀种创建动画。
⼆、教学重点与难点本堂课教学的重点与难点在于引导学⽣掌握句柄图形的使⽤,并掌握matlab 创建动画的⽅法。
三、教学⽅法本课程主要通过讲授法、演⽰法、练习法等相结合的⽅法来引导学⽣掌控本堂课的学习内容。
四、教学内容(1)⽕箭垂直向上发射。
在t=0时⽕箭发动机关闭,此时⽕箭的⾼度为海拔500,速度为125m/s ,考虑重⼒加速度,根据等式29.8()125500,02h t t t t =-++f ①创建函数heigh t ,以时间为输⼊变量,⽕箭的飞⾏⾼度为输出变量。
利⽤函数对下⾯的②和③进⾏求解。
②时间增量为0.5秒,变化范围0到30秒,画出函数height 与时间的关系曲线。
③计算⽕箭开始向地⾯降落的时间(可以使⽤函数max )。
④创建函数height 的函数句柄height_handle 。
⑤以height_handle 作为函数fplot 的输⼊参数,画出0到60秒内的函数曲线。
⑥⽤函数fzero 求⽕箭返回地⾯所⽤的时间(当⽕箭返回地⾯时,函数height 的值应该等于0)。
fzero 是复合函数,可以⽤函数或函数句柄作为输⼊参数。
调⽤⽅法如下:fzero(function_handl e ,x_guess)函数fzero 的两个输⼊参数分别是函数句柄和函数值接近0时的x 的估算值。
读者可以根据绘出的曲线选择合理的x_guess 值。
①function output=height(t)output=-4.9.*t.^2+125.*t+500;②%% two t=0:0.5:30; h=height(t); plot(t,h,'o-r') hold on %% three [a,b]=max(h); t_max=t(b) %% fourheight_handle=@(t) height(t);%% fivefplot(height_handle,[0,60]);%% sixfzero(height_handle,30)(2)①创建匿名函数my_function,计算下式:253x---+x x e②⽤函数fplot画出x在-5到+5之间的函数曲线。
Matlab中常用的统计分析方法介绍

Matlab中常用的统计分析方法介绍统计分析是一种通过对数据的收集、整理、分析和解释,来推测并描述数据所呈现出的规律和规律性的方法。
作为一种重要的数据处理工具,Matlab提供了许多功能强大的统计分析方法,以帮助研究人员对数据进行深入的研究和解读。
在本文中,我们将介绍一些常用的统计分析方法,并对其原理和应用进行简要概述。
一、描述统计分析方法1. 均值与方差:均值是对样本数据的集中趋势进行度量的指标,可以通过Matlab的mean函数计算得到。
方差则是数据的离散程度度量,可以通过Matlab的var函数计算。
均值和方差是描述一个数据集的基本统计指标,可以帮助我们快速了解数据的分布情况。
2. 频数分布:频数分布可以将数据按照一定的区间划分,并统计每个区间中数据的数量。
Matlab提供了hist函数可以直接绘制频数直方图,进而帮助我们了解数据的分布情况和集中区间。
3. 分位数:分位数是将数据按大小顺序排列后分成若干部分的值。
常见的分位数有四分位数、百分位数等。
Matlab的quantile函数可以帮助我们计算任意分位数,从而得到数据分布的具体信息。
二、假设检验分析方法1. 单样本t检验:单样本t检验是一种用于判断样本均值与总体均值之间是否存在显著差异的方法。
在Matlab中,可以使用ttest函数进行单样本t检验。
通过设置显著性水平和计算得到的t值,我们可以对样本数据是否足够代表总体数据进行判断。
2. 独立样本t检验:独立样本t检验是一种用于比较两组独立样本均值是否存在显著差异的方法。
在Matlab中,可以使用ttest2函数进行独立样本t检验。
通过设置显著性水平和计算得到的t值,我们可以得出两组样本均值是否存在显著差异的结论。
3. 方差分析:方差分析是一种用于比较多组样本均值之间是否存在显著差异的方法。
在Matlab中,可以使用anova1或anova2函数进行方差分析。
通过计算得到的F值和p值,我们可以判断样本组间的差异是否显著。
Matlab技术统计分析方法解读

Mat1ab技术统计分析方法解读引言:在各个领域,统计分析方法在研究和决策过程中发挥着重要的作用。
Mat1ab作为一种强大的数值计算和编程软件,提供了多种统计分析方法的功能和工具。
本文将解读Mat1ab 中常用的技术统计分析方法,并探讨其在实际应用中的价值和限制。
一、描述性统计分析方法描述性统计分析方法是对数据进行统计描述和总结的方法。
在MatIab中,可以使用一系列函数来计算数据的均值、中位数、标准差等,以及绘制直方图、箱线图等可视化图形。
这些方法能够帮助我们对数据进行初步的了解和判断。
然而,由于描述性统计分析方法只能提供数据的整体情况,并不能对数据之间的关系和趋势进行分析,因此有时需要结合其他统计分析方法来进行深入研究。
二、假设检验方法假设检验方法用于根据已知数据样本对总体参数进行推断。
在MaUab中,可以使用t 检验、方差分析、卡方检验等常见的假设检验方法。
这些方法通过计算样本与理论分布之间的差异,判断总体参数是否具有统计显著性。
然而,需要注意的是统计显著性并不意味着实际意义上的显著性。
因此,在使用假设检验方法时,需要综合考虑具体问题和实际背景,慎重解读结果。
三、回归分析方法回归分析方法用于研究变量之间的相关关系和预测问题。
在Mat1ab中,可以使用线性回归、非线性回归等方法进行回归分析。
通过拟合模型,计算回归系数和拟合优度等指标,我们可以了解变量之间的线性或非线性关系,并通过预测结果进行决策。
然而,需要注意的是回归分析只能提供变量之间的相关性,并不能说明因果关系。
因此,在进行回归分析时,需谨慎解读结果,并结合领域知识和实际情境。
四、聚类分析方法聚类分析方法用于将数据对象进行分类和分组,以发现潜在的数据结构和规律。
在MaUab中,可以使用k均值聚类、层次聚类等方法进行聚类分析。
这些方法通过计算对象之间的相似性和距离,将相似的数据对象划分到同一组中。
聚类分析可以帮助我们对数据进行分类、发现异常点和预测未知数据。
如何用Matlab进行统计分析

如何用Matlab进行统计分析导言统计分析是数据科学中最核心的部分之一,在各个领域中都扮演着重要的角色。
而Matlab作为一种强大的计算科学工具,可以帮助我们进行各种复杂的统计分析。
本文将介绍如何使用Matlab进行统计分析的基本步骤和常用方法,以帮助读者更好地利用这一工具进行数据分析。
一、数据处理与探索在进行统计分析之前,首先需要对数据进行处理和探索。
Matlab提供了丰富的函数和工具,可以快速地进行数据的导入、清洗和可视化。
1.1 数据导入Matlab支持多种格式的数据导入,包括文本文件、Excel表格、MAT文件等。
通过使用内置的函数(如`csvread`、`xlsread`等)或工具箱(如“数据导入导出工具箱”)可以方便地将数据导入到Matlab中进行进一步的分析。
1.2 数据清洗在进行统计分析之前,需要对数据进行清洗,以确保数据的质量和准确性。
Matlab提供了一系列的函数,如`isnan`、`isinf`等,用于检测和处理缺失值和异常值。
通过使用这些函数,可以剔除无效的数据,从而减少分析结果的偏差。
1.3 数据可视化数据可视化是数据分析过程中的重要环节,可以帮助我们更好地理解数据的特征和规律。
Matlab提供了丰富的绘图函数,如`plot`、`bar`、`histogram`等,可以创建各种类型的图表。
通过绘制直方图、散点图、箱线图等,可以快速地探索数据的分布、关系和异常情况。
二、描述统计分析描述统计分析是对数据进行总结和归纳的过程,旨在通过统计指标和图表来描述和概括数据的特征。
2.1 基本统计指标Matlab提供了一系列函数,如`mean`、`median`、`var`等,用于计算数据的均值、中位数、方差等基本统计指标。
通过计算这些指标,可以 quant 认识数据的集中趋势、离散程度和分布形态。
2.2 频率分布分析频率分布分析是研究数据的频率分布和形态的方法。
Matlab的`histogram`函数可以快速创建直方图,进而了解数据的分布情况。
201109公选课教案第九讲 MATLAB数据统计分析

第九讲 数据统计分析提要● 数据筛选 ● 随机数生成 ● 均值 方差 中指● 线性回归(最小二乘拟合) Find Rand Randn Mean std插值与拟合插值与拟合是来源于实际、又广泛应用于实际的两种重要方法。
随着计算机的不断发展及计算水平的不断提高,它们已在国民生产和科学研究等方面扮演着越来越重要的角色。
下面对插值中分段线性插值、拟合中的最为重要的最小二乘法拟合加以介绍。
7.1.1 分段线性插值所谓分段线性插值就是通过插值点用折线段连接起来逼近原曲线,这也是计算机绘制图形的基本原理。
实现分段线性插值不需编制函数程序,MA TLAB 自身提供了内部函数interp1其主要用法如下:interp1(x,y,xi) 一维插值 ◆ yi=interp1(x,y,xi)对一组点(x,y) 进行插值,计算插值点xi 的函数值。
x 为节点向量值,y 为对应的节点函数值。
如果y 为矩阵,则插值对y 的每一列进行,若y 的维数超出x 或 xi 的维数,则返回NaN 。
◆ yi=interp1(y,xi)此格式默认x=1:n ,n 为向量y 的元素个数值,或等于矩阵y 的size(y,1)。
◆ yi=inter p1(x,y,xi,’method’)method 用来指定插值的算法。
默认为线性算法。
其值常用的可以是如下的字符串。
● nearest 线性最近项插值。
● linear 线性插值。
● spline 三次样条插值。
● cubic 三次插值。
所有的插值方法要求x 是单调的。
x 也可能并非连续等距的。
正弦曲线的插值示例: >> x=0:0.1:10; >> y=sin(x); >> xi=0:0.25:10; >> yi=interp1(x,y,xi); >> plot(x,y,’0’,xi,yi)则可以得到相应的插值曲线(读者可自己上机实验)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(图7.1)
二. 数据特征
设X 1,X 2,..X .n,是取自总体X的一个简单随机样本, 在n次抽样以后得到样本的一组观测值 x1,x2,.我.x.n, 们通过对数据的分析研究可以得到总体X的有关信息, 在MATLAB中有专门的函数分析数据特征,如下表所 示.
位置特征 算术平均
MATLAB函 数
解:x=[1,1,1,1,1,1,100]; y=[mean(x),median(x),geomean(x),harmmean(x),trimmean(x,25);
range(x),var(x),std(x),iqr(x),mad(x)]
计算结果为: y= 15.143 1 1.9307 1.1647 1 99 1400.1 37.418 0 24.245
mean
变异特征 极差
MATLAB函数 range
中位数
median
方差
var
切尾平均
trimmean
标准差
std
几何平均
geomean
四分位极差 iqr
调和平均
harmmean 平均绝对偏差 mad
例4. 已知数据:
459 362 624 542 509 584 433 748 815 505 612 452 434 982 640 742 565 706 593 680 926 653 164 487 734 608 428 1153 593 844 527 552 513 781 474 388 824 538 862 659 775 859 755 649 697 515 628 954 771 609 402 960 885 610 292 837 473 677 358 638 699 634 555 570 84 416 606 1062 484 120 447 654 564 339 280 246 687 539 790 581 621 724 531 512 577 496 468 499 544 645 764 558 378 765 666 763 217 715 310 851
1.数据的下、上截断点
计算上、下截断点的公式如下: Q 1 1 .5R , Q 3 1 .5R
其中,R为四分位极差,Q1,Q3 分别称为下四分位数与 上四分位数 .
对于0≤p<1,和样本容量为n的样本 X 1,X 2,..X .n其, 次序统计量记为: X(1),X(2),...,X(n) 于是计算样本的P分位数的公式为:
621 724 531 512 577 496 468 499 544 645 764 558 378 765 666 763 217 715 310 851];
b=a(:); %将矩阵变成数列
T=[mean(b),median(b), trimmean(b,10), geomean(b), harmmean(b),range(b),var(b),std(b),iqr(b),mad(b)]
计算该数据特征.
解:a=[459 362 624 来自42 509 584 433 748 815 505 612 452 434 982 640 742 565 706 593 680
926 653 164 487 734 608 428 1153 593 844 527 552 513 781 474 388 824 538 862 659
775 859 755 649 697 515 628 954 771 609 402 960 885 610 292 837 473 677 358 638
699 634 555 570 84 416 606 1062 484 120 447 654 564 339 280 246 687 539 790 581
第九讲MATLAB基本统计分析
已知X的均值和标准差及概率p=P{X<x},求x的命令为:
X = NORMINV(P,MU,SIGMA) 例2. X~N(1,0.04) , p{X<x}=0.6827 求x 解:x = norminv(0.6827,1,0.2)= 1.0951
NORMSPEC([a,b],MU,SIGMA) 用于做出随机变量在区间[a,b]上的正态密度曲线 例3. 若X~N(2,4),作出 X在[-1,3]上的曲线 解: normspec([-1,3],2,2)
Mpxx(([nnpp)]1)x(np1)/2, ,npn不 p是 是 整 整 数 数
显然
Q 1 M 0 .2,Q 5 3 M 0 .75
例6. 判别例4中的数据有无异常值.
解:由x=sort(a(:)) 得到原数据从小到大的次序统计量,因为np为整数, 故有:
Q1=(x(25)+x(26))/2=485.5, Q3=(x(75)+x(76))/2=729, R = 243.5 于是,Q1-1.5R=120.25,Q3+1.5R=1094.25, 由此可知: 80,120,1153是异常值.
2. 位于 (-3 ,3 )以外的点
若数据服从正态分布 N(,2 ),则称位于
(-3 ,3 )以外的点 为异常点.
四. 矩统计量 在MATLAB中给出了计算矩统计量、峰度、偏度
和变异系数的函数命令,如下表所示:
如果例5的数据全部为1,则各种平均值都应等于1, 所有的变异特征全部为零,由于有一个异常值100,于 是导致上述的一些特征受影响(不稳健),但是中位数、 切尾平均与四分位极差没有改变,它们对异常值是稳健 的.
三. 异常值的判别 在探索性数据分析时,有一种判别异常值的简单
方法,首先计算数据的下、上截断点,数据中小于下截 断点的数据为特小值,大于上截断点的数据为特大值, 二者都是异常值.
计算结果如下:
位置特征
计算结果
算术平均 中位数 切尾平均 几何平均 调和平均
600 599.5 600.64 559.68 499.06
变异特征 极差 方差 标准差 四分位极差 平均绝对偏差
计算结果 1069 38663.03 196.629 243.5 150.86
例5. 已知数据:1,1,1,1,1,1,100;计算其数 据特征,由此你有何发现?