STATA在统计与计量分析中的应用Ch1-5程序
使用Stata进行统计分析的方法与实例

使用Stata进行统计分析的方法与实例第一章:导言统计分析是一种基于数据的科学方法,主要用于搜集、整理、分析和解释数据,以便更好地理解和描述现象、随机事件或人类行为。
Stata是一款功能强大且广泛应用于统计学和经济学领域的统计分析软件。
本文将介绍使用Stata进行统计分析的方法和实例,并按以下章节进行详细说明。
第二章:数据导入与清洗在使用Stata进行统计分析之前,首先需要导入和清洗数据。
Stata支持多种数据导入格式,如文本文件、Excel表格和数据库等。
通过使用Stata的数据管理命令,我们可以对数据进行清洗和预处理,包括删除缺失值、处理离群值和进行变量转换等。
第三章:描述性统计分析描述性统计分析是研究对象的基本特征和总体分布的方法。
在Stata中,我们可以使用各种命令来计算和展示数据的描述性统计量,如平均值、标准差、中位数和频数分布等。
此外,可以使用图表工具来可视化数据的分布和特征,如直方图、箱线图和散点图等。
第四章:推断统计分析推断统计分析是通过抽样来推断总体参数的方法。
Stata提供了一系列统计模型和命令,用于进行参数估计、假设检验和置信区间估计等推断统计分析。
常见的推断统计方法包括回归分析、方差分析和非参数检验等。
通过Stata的命令和函数,我们可以轻松地应用这些方法,从而得出关于总体的推断结论。
第五章:多元统计分析多元统计分析是研究多个变量之间关系的方法。
Stata提供了多元统计模型和命令,用于探索和解释多个变量之间的关系。
其中包括多元线性回归分析、主成分分析和因子分析等。
通过使用Stata的多元统计分析功能,我们可以深入研究变量之间的相关性和潜在结构等。
第六章:时间序列分析时间序列分析是研究时间变化规律的方法。
在Stata中,我们可以使用时间序列模型和命令,对时间序列数据进行建模和预测分析。
其中包括平稳性检验、自回归移动平均模型和差分自回归移动平均模型等。
通过利用Stata的时间序列分析功能,我们可以分析和预测各种经济和社会现象的发展趋势。
STATA实用教程

STATA实用教程STATA是一种统计分析软件,广泛应用于数据分析、统计建模、数据可视化等领域。
它具有强大的数据处理能力和丰富的统计功能,能够快速、准确地处理大规模的数据集。
下面是一些STATA实用教程,帮助初学者快速上手该软件。
1.STATA基本操作STATA的基本操作包括数据导入和导出、数据集处理、变量管理等。
首先要学会使用STATA命令行界面和菜单栏来进行操作,了解STATA常用的命令和语法,掌握STATA常用的数据结构,如数据集、变量类型等。
同时,还需要学会使用STATA的帮助文档和网络资源,解决自己在使用过程中遇到的问题。
2.数据的描述性统计STATA可以进行各种描述性统计,例如计算均值、中位数、标准差、四分位数等,了解数据的分布情况。
可以利用summarize、describe等命令来进行描述性统计,还可以使用tabulate、histogram等命令进行变量的频数统计和画出直方图。
3.数据清洗和转换在实际应用中,数据往往需要进行清洗和转换。
STATA提供了一系列的命令,用于数据的清洗和转换。
比如,drop、keep命令可以删除不需要的变量或观察值;rename、recode命令可以对变量进行重命名和重新编码;reshape、merge命令可以进行数据重塑和合并等操作。
4.统计分析STATA提供了许多常用的统计方法和模型,可以进行统计分析。
例如,t检验、方差分析、线性回归、Logistic回归、生存分析、聚类分析等。
用户可以使用STATA内置的命令来进行统计分析,也可以使用STATA扩展包来进行更加复杂的分析。
5.高级数据处理STATA还提供了一些高级数据处理方法,如面板数据分析、时间序列分析、密度估计、非参数统计等。
这些方法对于处理复杂的数据结构和模型非常有用。
通过学习STATA的面板数据命令如xtreg、xtsum等,可以进行面板数据分析;通过学习STATA的时间序列命令如arima、xtdes等,可以进行时间序列分析。
STATA使用教程

STATA使用教程第一章:介绍 StataStata 是一款统计分析软件,广泛应用于经济学、社会科学、健康科学和医学研究等领域。
本章将介绍 Stata 软件的基本特点、适用范围和主要功能。
1.1 Stata 的特点Stata 是一款功能强大、易于使用的统计软件。
不同于其他统计软件,Stata 具有灵活性高、数据处理效率好的优点。
它支持多种数据文件格式,可以处理大规模的数据集,并且具有丰富的数据处理、统计分析和图形展示功能。
1.2 Stata 的适用范围Stata 软件适用于各类研究领域,涵盖了经济学、社会科学、医学、健康科学等多个领域。
它广泛应用于定量分析、回归分析、面板数据分析、时间序列分析等领域,可用于统计推断、数据可视化和模型建立等任务。
1.3 Stata 的主要功能Stata 软件提供了丰富的功能模块,包括数据导入导出、数据清洗、数据管理、描述性统计、推断统计、回归分析、面板数据分析、时间序列分析、图形展示等。
这些功能模块为用户提供了全面且灵活的数据分析工具。
第二章:Stata 数据处理数据处理是统计分析的前置工作,本章将介绍 Stata 软件的数据导入导出、数据清洗和数据管理等功能。
2.1 数据导入导出Stata 支持导入多种文件格式的数据,如文本文件、Excel 文件和 SAS 数据集等。
用户可以使用内置命令或者图形界面进行导入操作,导入后的数据可以存储为 Stata 数据文件(.dta 格式),方便后续的数据处理和分析。
2.2 数据清洗数据清洗是数据处理的重要环节,Stata 提供了多种数据清洗命令,如缺失值处理、异常值处理和数据类型转换等。
用户可以根据实际情况选择合适的数据清洗操作,确保数据的准确性和完整性。
2.3 数据管理数据管理是有效进行数据处理的关键,Stata 提供了许多数据管理命令,如数据排序、数据合并、数据分割和数据标记等。
这些命令可以帮助用户高效地对数据进行管理和组织,提高数据处理效率。
STATA使用指南(CCER研 邹传伟)

Stata介绍作为流行的计量经济学软件,Stata的功能十分地全面和强大。
可以毫不夸张地说,凡是成熟的计量经济学方法,在Stata中都可以找到相应的命令,而这些命令都有许多选项以适应不同的环境或满足不同的需要。
即使是最详细的Stata手册,也难免有遗珠之憾,更何况本文仅是一个粗浅的介绍。
掌握Stata最好的办法是在实践中学习:Stata 本身提供了非常强大的帮助系统,并且关于Stata的书籍和网络资源都不少。
本文拟根据如下顺序介绍Stata:1.界面;2.文件和数据;3.语法和命令;4.数据管理;5.描述统计;6.画图;7.回归和回归分析;8.常用命令。
第3和第4部分是最体现Stata灵活性的地方,也是应用Stata的基础。
第5和第6部分介绍如何用Stata完成基本的统计功能。
Stata的功能很多,比如回归,曲线拟合,生存分析,主成分分析,因子分析,聚类分析,时间序列分析等等。
但回归无疑是其中最重要的功能。
第7部分介绍如何用Stata作线性回归和Logistic回归。
本文第2和第3部分包含了作者的观点,难免有偏颇之处。
其余部分主要来自文献的归纳和总结。
限于水平有限,错误在所难免,敬请原谅。
1.界面图1 Stata界面Stata有4个窗口:1. Stata Command(右下)用于向Stata输入命令;2. Stata Results(右上)用于显示运行结果;3. Review(左上)记录使用过的命令;4. Variables(左下)显示当前memory中的所有变量。
窗口上方是工具栏,其上的按钮依次为(从左到右)Open, Save, Print Graph/Print Log, Log Start/Stop/Suspend, Bring Log to Front, Bring Graph to Front, Do-file Editor, Data Editor, Data Browser, Clear –more- condition, Break。
stata的统计学运用

stata的统计学运用
Stata可以用于各种统计学应用,包括描述统计、假设检验、
回归分析、方差分析、时间序列分析、生存分析等。
描述统计:Stata可以计算数据的均值、中位数、众数、标准差、四分位数等常见的描述统计量,并生成统计报告和图表。
假设检验:Stata可以进行各种假设检验,如t检验、方差分析、卡方检验等。
通过设定显著性水平,可以判断变量之间的差异是否具有统计学意义。
回归分析:Stata可以进行线性回归、逻辑回归、多元回归等。
通过回归分析,可以了解自变量对因变量的影响程度,得到各个变量的系数、显著性等信息。
方差分析:Stata可以进行单因素方差分析、多因素方差分析等。
通过方差分析,可以比较不同组之间的均值是否存在显著差异,用于研究因素对于观测变量的影响。
时间序列分析:Stata提供了一系列用于处理时间序列数据的
命令,可以进行趋势分析、季节性分析、平稳性检验等。
通过时间序列分析,可以了解数据的时间变化规律和趋势。
生存分析:Stata可以进行生存分析,包括Kaplan-Meier法、Cox比例风险模型等。
生存分析用于研究时间至事件发生的概率,常用于医学和流行病学研究。
总之,Stata是一个功能强大的统计软件,可以广泛应用于统计学研究和数据分析领域。
无论是数据描述、假设检验、回归分析、方差分析还是时间序列分析、生存分析等,Stata都提供了相应的工具和命令。
Stata实验指导、统计分析与应用chap05

这个命令语句是在缺失样本的具体数据,只通过样本的统
例如,在检验砖的抗断强度的例子中,假设并不知道
方差为1.21,而进行检验其均值为32.5,这时就需要用 到ttest命令了,具体命令如下: ttest kdqd=32.5 这时就可以得到如图5.2所示的检验结果,在结果图中, 可以看到表格中显示了样本的特性,主要包括样本容 量、样本均值、标准误差、标准差、置信区间。表格 下面是进行的t检验的内容,其中最重的的指标是 “Ha: mean != 32.5”的部分,不难发现检验得到的p 值为0.0302,所以应当拒绝原假设,即不能认为这批 砖的平均抗断强度为32.5。
标准差是否为1.1。
三、实验操作指导
1.正态分布、方差已知的均值检验 在这种情形下,由于Stata没有提供直接的命令进行检验,所
以需要用户自行构建正态分布的统计量进行检验,命令语句 为: quietly summarize
scalar crit=invnormal(1-0.05/2) scalar p=(1-normal(abs(z)))/2 scalar list z crit p 在这一组命令语句中,第一个命令语句是为了求出样本的均 值的大小,并且不显示计算的结果;第二个命令语句是输入 了正态分布统计量的计算公式,目的是为了算出正态分布统 计量的大小;第三个命令语句是为了求出置信度为95%的正 太分布临界值的大小;第四个命令语句输入了p值的计算公式, 是为了求出p值的大小;第五个命令语句是为了列出这些统计 量的大小,以便进行判断。
例如,利用english.dta数据库中的数据,分析两个班
的英语成绩方差是否相等,所使用到的命令为: sdtest score1==score2 执行这一命令,可得到如图5.6所示的结果,这个图中 的表格展示了数据的情况,包括两个变量及其总体的 样本容量、均值、标准误、标准差、置信区间的信息。 在表格的下方展示了方差检验的结果,从中不难看出, 检验的p值为0.3362,不能拒绝原假设,即认为两个班 英语成绩的方差相等。
计量基础与stata应用

计量基础与stata应用
计量经济学是经济学的一个重要分支,它使用数学、统计学和经济学原理来分析和预测经济现象。
在计量经济学中,计量基础是非常重要的一部分,它涉及到如何选择合适的计量方法和模型,以及如何评估模型的可靠性和准确性。
在Stata中应用计量经济学方法时,需要注意以下几点:
数据准备:在开始分析之前,需要准备数据。
Stata提供了各种数据管理功能,如数据导入、清理、转换和统计分析等。
模型选择:根据研究问题和数据特征选择合适的计量模型。
例如,线性回归模型、逻辑斯蒂回归模型、时间序列模型等。
估计模型参数:使用Stata提供的命令和函数来估计模型的参数。
Stata提供了各种估计方法,如最小二乘法、最大似然估计法等。
模型评估:在模型估计完成后,需要对模型进行评估。
可以使用各种统计量来评估模型的可靠性,如R方、调整R方、残差图和诊断检验等。
结果解释:根据估计的参数和评估结果,解释和讨论计量经济学模型的结论。
总之,计量基础在Stata应用中非常重要。
在应用计量经济学方法时,需要注意数据准备、模型选择、参数估计、模型评估和结果解释等方面。
同时,要理解计量经济学的基本原理和假设,以及它们对估计方法和模型选择的影响。
只有掌握了计量基础,才能更好地应用Stata等统计软件进行经济分析和预测。
stata 计量方法(一)

stata 计量方法(一)Stata 计量方法Stata 是一种常用的统计软件,尤其在计量经济学领域得到广泛的应用。
本文将介绍使用 Stata 进行计量方法分析的基本步骤和常用命令。
回归分析回归分析是计量经济学中最基础的方法之一,用于探究一个或多个自变量对一个因变量的影响程度。
在 Stata 中,可以使用reg命令进行回归分析。
reg dependent_variable independent_variable1 independent_variable2 ...例如,以下命令将运行一个简单线性回归,其中自变量为x,因变量为y:reg y x多元回归分析多元回归分析是指使用多个自变量来解释因变量。
在 Stata 中,可以使用reg命令进行多元回归分析。
reg dependent_variable independent_variable1 independent_variable2 ...例如,以下命令将运行一个多元回归模型,其中自变量为x1和x2,因变量为y:reg y x1 x2差分处理差分处理是指对两个或多个时间点的数据进行比较。
在 Stata 中,可以使用diff命令进行差分处理。
diff variable, difference_option例如,以下命令将计算变量x的一阶差分:diff x, difference(1)仪器变量回归仪器变量回归是用于处理自变量与因变量之间存在内生性问题的一种方法。
在 Stata 中,可以使用ivreg命令进行仪器变量回归。
ivreg dependent_variable (endogeneous_variable = instruments) independent_variable1 independent_variable2 ...例如,以下命令将运行一个仪器变量回归模型,其中自变量为x,因变量为y,仪器变量为z:ivreg y (x = z) other_variables总结本文介绍了 Stata 中常用的计量方法分析,包括回归分析、多元回归分析、差分处理和仪器变量回归。
STATA简介及基本应用

clear 用于清空内存中的数据。 use 打开数据文件。例:use C:\1.dta表示 打 开文件路径为C:\1.dta的数据文件。 打开数据文件的其他方法:双击数据文件或 者在菜单栏file下选择open list 显示数据。例:list x表示显示变量x的取 值。 display 计算并且显示相应的结果。常常简写 为di。 例:di 2+3 则运行结果为5。
散点图的绘制( scatter 命令):
(1)单一纵坐标 scatter varname1 varname2 varname3……varnamen varnamel 其中,y轴变量为varname1,……, varnamen,x轴变量为 varnamel (2)双纵坐标轴 twoway (scatter weight t, yscale(range(2300 4000))) (scatter f t, yaxis(2) yscale(axis(2) range(-1 6)))
0
1
2
3
4
5
0
5 f
10 t freq
15
20
1
2
f 3 4 5
0 5 f 10 t weight 15
weight
20
2500 3000 3500 4000
1
0 5 f 10 t 15 weight 20
2
f 3 4 5
weight 2500 3000 3500 4000
练习折线图以及散点图的绘制,尝用两种方法建立数据文件。 练习list describe tabulate命令。 建立新的变量z,使得z = x + y 利用drop命令删除变量z。 注:STATA自带了帮助文档。在help菜单栏可以 查找相应的命令使用帮助,也可以在命令窗口输 入help寻求相应的帮助。例如:help gen则显示关 于gen命令的相应文档。
stata1-5讲义

果一般而言是没有意义的并容易产生误导。可是如何让大家相信这种滥用和误用
计量模型所导致的偏误呢?
由于在社会科学中,被广泛认同的数理模型很少,讨论估计量是否一致或有
偏误的最好办法是假设我们已知某个理论公式及其相应参数,然后按照这个公式
通过蒙特卡洛方法生成假设数据,再来看在什么条件下用什么方法可以获得一致
(2)将其解压到 D:/stata9。 (3)点击 setup 安装>>改变安装路径到 D:/stata9>>选择 Stata/SE 版本。
1.2 启用和退出
(1) 程序→Stata,即可进入 Stata,启动后出现文件对话框,要求输入注册单 位和密码等。
中国人民大学 陈传波
9
chrisccb@
的或渐近正态的估计结果,这种方法已被国外的统计和计量教材大量采用。
本书正是在这两个方面突出了自己的特色。作者 9 年来潜心钻研 STATA,
利用 STATA 处理过农村住户数据、人口普查数据(部分)等大量数据,积累了
丰富的数据处理经验。本书的前 9 讲集中介绍数据处理的知识和技巧,后 9 讲通
过蒙特卡洛模拟帮助读者从直观上理解数理统计和计量的基本理论,并掌握相应
本书从第 10 讲开始,运用蒙特卡洛模拟方法,将基于随机变量的数理统计 和计量经济学的核心思想和方法的黑箱打开,让读者在如同做游戏一样的感觉中 深刻理解抽样分布、假设检验、回归分析等方法的强大魔力和无处不在的陷阱, 这有利于读者批判性地理解他人基于统计数据得出的结论,也很利于读者在自己 运用统计和计量分析时正确对待和解释估计结果。
中国人民大学 陈传波
8
chrisccb@
STATA 十八讲1入门
1 STATA 入门
如何使用Stata进行统计分析和数据可视化

如何使用Stata进行统计分析和数据可视化第一章:Stata统计分析基础Stata是一个功能强大的统计分析软件,广泛应用于社会科学、经济学、医学研究等领域。
在使用Stata进行统计分析之前,我们需要熟悉一些基本概念和操作。
1.1 Stata界面介绍Stata界面分为主窗口和命令窗口。
主窗口用于显示数据和结果,命令窗口用于输入和运行命令。
1.2 导入数据在Stata中,可以通过多种方式导入数据,包括直接输入数据、从其他文件格式导入数据、从数据库导入数据等。
1.3 数据清洗和准备在进行统计分析之前,需要对数据进行清洗和准备。
这包括处理缺失值、异常值,创建新变量,转换数据类型等操作。
1.4 描述统计分析描述统计分析是对数据的基本特征和分布进行描述和分析。
可以使用Stata的命令进行频数统计、均值计算、方差分析等操作。
1.5 统计推断统计推断是通过样本数据对总体特征进行推断。
可以使用Stata进行t检验、方差分析、回归分析等操作。
第二章:Stata数据可视化数据可视化是将统计分析结果以图形或图表的方式展示,可以帮助我们更好地理解和传达数据。
2.1 绘制直方图和箱线图直方图和箱线图可以用来展示数据的分布和异常值情况。
在Stata中,可以使用histogram命令和graph box命令绘制直方图和箱线图。
2.2 绘制散点图和线图散点图和线图可以用来展示变量之间的关系和趋势。
在Stata中,可以使用scatter命令和twoway line命令绘制散点图和线图。
2.3 绘制柱状图和折线图柱状图和折线图适用于展示不同类别或时间点的数据比较。
在Stata中,可以使用bar命令和twoway line命令绘制柱状图和折线图。
2.4 绘制饼图和雷达图饼图和雷达图适用于展示比例或多维数据的分布。
在Stata中,可以使用pie命令和radar命令绘制饼图和雷达图。
第三章:高级统计分析和可视化除了基本的统计分析和数据可视化外,Stata还提供了一些高级功能,可以进行更复杂和深入的统计分析和数据可视化。
Stata统计分析操作方法及界面介绍

Stata统计分析操作方法及界面介绍Stata是一款经济和社会科学领域常用的统计分析软件,具有功能强大、操作简便等特点。
本文将介绍Stata的操作方法以及其界面的主要特点,帮助读者更好地了解和使用这一工具。
一、Stata的安装与启动1. 安装:首先,从Stata的官方网站下载安装程序并运行。
按照提示选择安装路径,并完成安装过程。
2. 启动:安装完成后,双击桌面上的Stata图标即可启动软件。
也可以在开始菜单中找到Stata并点击启动。
二、Stata的界面1. 主界面:Stata的主界面被分为三大部分,分别是命令窗口、结果窗口和变量窗口。
- 命令窗口:用户在这里输入Stata的命令进行数据分析和操作。
- 结果窗口:用户在命令窗口执行命令后,结果会在该窗口中显示。
- 变量窗口:用于展示当前打开的数据文件中的变量信息。
2. 窗口菜单栏:位于主界面的顶部,包含了一系列菜单选项,用于对数据和分析进行操作。
- 文件(File):包含了打开、保存和导出数据文件的选项。
- 编辑(Edit):用于编辑数据文件的选项,如剪切、复制和粘贴。
- 数据(Data):提供了对数据的统计描述和数据变换的功能。
- 统计(Statistics):包含了估计模型、执行统计假设检验等选项。
- 图形(Graphics):用于绘制各类统计图表。
- 理论(Help):提供了关于Stata的帮助文档和资源链接。
三、Stata的基本操作方法1. 数据载入与保存:在Stata中,可以通过`use`命令或者通过界面上的“文件”菜单来打开已有的数据文件,使用`save`命令将当前工作的数据文件保存。
2. 数据查看与编辑:使用`browse`命令可以查看数据文件的内容,使用`edit`命令可以编辑数据。
3. 统计描述:通过`describe`命令可以查看变量的基本描述统计信息,如均值、标准差等。
4. 数据转换:在Stata中,可以使用命令来对数据进行各种转换操作,如创建新变量、合并数据集、排序等。
计量分析与STATA应用

NEU School of Business & Administration
问题及讨论
人大论坛【计量版】之【STATA专版】: /bbs/forum-67-1.html view browse "/bbs/forum-67-1.html“ Statalist在线论坛 /statalist view browse " /statalist "
NEU School of Business & Administration
文件目录的设定
pwd
// 显示stata当前工作的路径
cd D:\stata11\ado\personal
// 进入指定文件夹
sysdir
// stata官方文件的路径
doedit D:\stata11\profile.do // 每次启动时需要立刻执行的命令
首次使用STATA的一些基本设定
界面偏好的设定 1)设定方法
Edit-->Preference-->General Preference 按偏好设定
2)保存设定
Edit-->Preference-->Save Preference set-->New Preferences set 在弹出对话框中任意输入一个名称,如 hy1 window manage prefs save hy1
NEU School of Business & Administration
1.Stata简介
Stata 是何方神圣? ☻ 短小精悍 ☻ 运算速度极快 ☻ 绘图功能卓越 ☻ 更新和发展速度惊人
NEU School of Business & Administration
Stata命令大全 面板数据计量分析与软件实现

Stata命令大全面板数据计量分析与软件实现说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
Stata的统计分析功能介绍
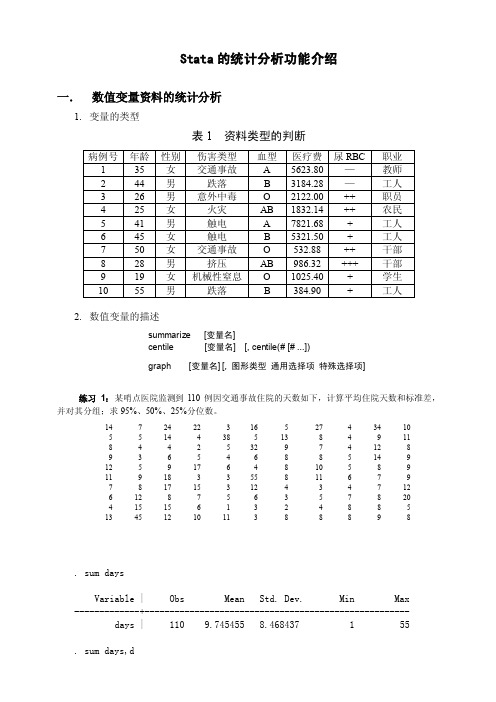
Stata的统计分析功能介绍一.数值变量资料的统计分析1.变量的类型表1 资料类型的判断2.数值变量的描述summarize [变量名]centile [变量名] [, centile(# [# ...])graph [变量名] [, 图形类型通用选择项特殊选择项]练习1:某哨点医院监测到110例因交通事故住院的天数如下,计算平均住院天数和标准差,并对其分组;求95%、50%、25%分位数。
14 7 24 22 3 16 5 27 4 34 105 5 14 4 38 5 13 8 4 9 118 4 4 2 5 32 9 7 4 12 89 3 6 5 4 6 8 8 5 14 912 5 9 17 6 4 8 10 5 8 911 9 18 3 3 55 8 11 6 7 97 8 17 15 3 12 4 3 4 7 126 12 87 5 6 3 5 78 204 15 156 1 3 2 4 8 8 513 45 12 10 11 3 8 8 8 9 8. sum daysVariable | Obs Mean Std. Dev. Min Max-------------+-----------------------------------------------------days | 110 9.745455 8.468437 1 55. sum days,ddays-------------------------------------------------------------Percentiles Smallest1% 2 15% 3 210% 3 2 Obs 11025% 5 3 Sum of Wgt. 11050% 8 Mean 9.745455Largest Std. Dev. 8.46843775% 11 3490% 17 38 Variance 71.7144395% 27 45 Skewness 2.87051799% 45 55 Kurtosis 12.96038gra days,bin(11) ylab(0,0.1,0.2,0.3,0.4,0.5) xlab(0,5,10,15,20,25,30,35,40,45,50,55). gen g=int((days-0)/5)+1. tab gg | Freq. Percent Cum.------------+-----------------------------------1 | 24 21.82 21.822 | 52 47.27 69.093 | 18 16.36 85.454 | 7 6.36 91.825 | 3 2.73 94.556 | 1 0.91 95.457 | 2 1.82 97.278 | 1 0.91 98.1810 | 1 0.91 99.0912 | 1 0.91 100.00------------+-----------------------------------Total | 110 100.00. centile days,centile(2.5,50,97.5)-- Binom. Interp. --Variable | Obs Percentile Centile [95% Conf. Interval]-------------+-------------------------------------------------------------days | 110 2.5 2 1 3*| 50 8 7 8| 97.5 39.575 24.32943 55*Lower (upper) confidence limit held at minimum (maximum) of sample3.t检验用于三种情况:样本均数与总体均数比较;配对数值变量资料的比较;两样本均数的比较;命令格式(ttest命令容许使用[if 表达式]和[in 范围]条件限制):(1)样本均数与总体均数比较的t检验的命令是ttest:ttest 变量名= #valttesti #obs #mean #sd #val练习2:某区10例犬伤患者的治疗费用如下,另一区的平均费用为680元,问两区是否在费用上有区别?病例号: 1 2 3 4 5 6 7 8 9 10 治疗费用(元)730 650 580 550 680 620 600 510 630 590. ttest a=680One-sample t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+--------------------------------------------------------------------a | 10 614 20.06656 63.45602 568.6063 659.3937 ------------------------------------------------------------------------------ Degrees of freedom: 9Ho: mean(a) = 680Ha: mean < 680 Ha: mean ~= 680 Ha: mean > 680t = -3.2891 t = -3.2891 t = -3.2891P < t = 0.0047 P > |t| = 0.0094 P > t = 0.9953. ttesti 10 614 63.456 680结果同上(2)配对样本t检验的命令是ttest:ttest 变量1=变量2练习3:某类别伤害两个医院治疗时间(天)配对研究病例号: 1 2 3 4 5 6 7 8 9 10 甲医院(x0): 7.3 6.8 7.0 6.9 7.1 7.2 6.7 6.5 6.9 7.1 乙医院(x1): 7.1 7.0 6.2 6.0 6.1 7.4 6.5 7.0 6.0 6.9. ttest x0=x1Paired t test------------------------------------------------------------------------------ Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval] ---------+-------------------------------------------------------------------- x0 | 10 6.95 .0763763 .2415229 6.777225 7.122775 x1 | 10 6.62 .1645195 .5202564 6.247831 6.992169 ---------+-------------------------------------------------------------------- diff | 10 .33 .1706524 .5396501 -.0560424 .7160425 ------------------------------------------------------------------------------ Ho: mean(x0 - x1) = mean(diff) = 0Ha: mean(diff) < 0 Ha: mean(diff) ~= 0 Ha: mean(diff) > 0t = 1.9338 t = 1.9338 t = 1.9338P < t = 0.9574 P > |t| = 0.0852 P > t = 0.0426(3)两样本均数比较的t检验ttest 变量1=变量2, unpairedttest 变量, by(分组变量)ttesti #obs1 #mean1 #sd1 #obs2 #mean2 #sd2练习4:两个区对犬伤治疗费用的比较?730 650 580 550 680 620 600 510 630 590 730 650 580 550 甲区:乙区:710 600 740 650 670 660 590 670 770 690 580. ttest v1=v2,unpTwo-sample t test with equal variances------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+--------------------------------------------------------------------v1 | 14 617.8571 17.54675 65.65394 579.9497 655.7646v2 | 11 666.3636 18.2544 60.543 625.6903 707.037---------+-------------------------------------------------------------------- combined | 25 639.2 13.36563 66.82814 611.6147 666.7853---------+--------------------------------------------------------------------diff | -48.50649 25.57778 -101.4182 4.405167------------------------------------------------------------------------------Degrees of freedom: 23Ho: mean(v1) - mean(v2) = diff = 0Ha: diff < 0 Ha: diff ~= 0 Ha: diff > 0t = -1.8964 t = -1.8964 t = -1.8964P < t = 0.0353 P > |t| = 0.0705 P > t = 0.9647二.分类变量资料的χ2检验tabulate var1 var2 [fw=频数变量] [,选择项]tabi其中var1,var2分别表示行变量和列变量,[fw=频数变量]只在变量以频数形式存放时选用。
数据管理 Stata统计分析与应用PPT

format varlist %fmt 或者 format %fmt varlist
显示变量目前所采用的格式:format [varlist]
Page 6
STATA从入门到精通
2.1.3 变量的显示
1re1c】od仍e然命【使令例用:就r2e业c.o1调d】e查v数a有rl据ist集如(rwul表aeg)e[(2.ru-le4)所. 示的一个数据集format.dta,每个变量在Stata中 在本女例性的数任据务中是的抽生取成显一10示个个变样类量本e型并du保c如留at,所下该有:变男量性s用样t数本a字t。e代为替受%教1育4的s程表度,名具体各来说州,0的表示名受称教育,年数因小而于3是,1表字示符受教型育年变数为4到6年 ,后2一表列示列受出教了量育这年些;数分在p类7o。到p9年为,%3表1示1受.0教g育表年数明在1该0到州12,的4表总示受人教口育年,数在是13数到1值5年型,5变表示量受教;育而年数m在1e6d到a18g年e,是表2-15最 1我3们】希有望如将表各2各-个26变州和量表人的2-显2口7示所方的示式的年做两如个龄下数转中据换集位:,其数中,orig显inal.示格式是%9.0g,以浮点型方式存储。我 g生ro成uepx(xp)e—r的—们对建数立希值一,望个并分将命类名变各为量l个o,ge将变xp按e排r量。序的后的显数据示分方为尽式量等做规如模的下x个转子样换本:。 1下中面所利介用s绍这t的a个t命数a令据%创完建1成表4如2s下-9—5所个示—任的务>名。%为a-u1to4. s(即由右对齐改为左对齐);
Page 7
STATA从入门到精通
state Alabama Alaska Arizona Arkansas California Colorado Connecticut Delaware Florida Georgia
使用Stata进行统计数据分析教程

使用Stata进行统计数据分析教程章节一:Stata简介与安装Stata是一款广泛使用的统计软件,由StataCorp开发,并提供了强大的数据分析和数据管理功能。
首先,我们需要了解Stata的基本特点和优势,并学习如何安装Stata软件及其组件包。
为了顺利进行数据分析,安装正确的版本和组件是必不可少的。
章节二:数据导入与数据管理在开始数据分析之前,我们首先需要将数据导入Stata软件中,这涉及到数据的格式转换和读取,包括常见的Excel、CSV等格式。
然后,我们会学习如何对数据进行清洗,删除无效数据、处理缺失数据和异常值等。
此外,我们还会介绍如何创建和修改变量、合并数据集以及数据筛选等高级数据管理功能。
章节三:描述性统计分析描述性统计是最基本的统计方法之一,用于描述数据的分布和性质。
在这一章节中,我们会学习如何使用Stata进行描述性统计分析,包括计算平均数、中位数、标准差、最大值和最小值等统计指标。
同时,我们还会学习如何绘制直方图、箱线图和散点图等图形工具,以更直观地展示数据的分布特征。
章节四:推断统计分析推断统计分析用于从样本数据中推断总体的性质,常用的方法包括假设检验和置信区间估计。
在这一章节中,我们会学习如何使用Stata进行常见的假设检验,如单样本t检验、独立样本t检验和相关样本t检验等。
同时,我们还会介绍如何计算置信区间和进行方差分析等高级统计方法。
章节五:回归分析回归分析是统计学中常用的建模和预测方法,用于描述自变量与因变量之间的关系。
在这一章节中,我们会学习如何使用Stata 进行简单线性回归和多元线性回归分析,包括模型拟合、参数估计和模型诊断。
此外,我们还会介绍如何解决共线性和异方差等常见问题,并讨论如何进行交互效应和非线性回归分析。
章节六:多元统计分析除了回归分析,Stata还提供了丰富的多元统计分析方法,如主成分分析、因子分析和聚类分析等。
在这一章节中,我们会学习如何使用Stata进行多元统计分析,包括降维与因子提取、聚类分析和判别分析等。
计量经济学Stata软件应用1---【Stata软件基本操作】--2次课

一、Stata 简介
Stata命令语句极为简洁明快,用户在学习时极易 上手; Stata命令同时又有极高的灵活性,用户可以 充分发挥自己的聪明才智,熟练应用各种技巧。尽 管Stata也提供了窗口菜单式的操作方式,但强烈建 议大家坚持使用命令行/程序操作方法,这样分析处 理数据时会更加随心所欲。 Stata软件的常用资源
二、Stata常用基本操作
方式 2:直接将结果存入Word或Excel等文本编辑软件 中,即在Stata结果窗口中选择上述计算结果→ 鼠标右 键→Copy Table →打开Excel窗口粘帖,结果按表格方式 呈现。 计算相关系数(基本命令:corr) 键入 corr rjgdp rjcap 回车→显示两个变量的相关系数 矩阵 →依据前述两种方式保存运行结果; 进行简单回归分析(基本命令:reg) 键入 reg rjgdp rjcap 回车(第一个变量rjgdp为被解释变 量,第二个变量rjcap为解释变量) →显示回归结果→依 据前述两种方式保存运行结果;
二、Stata常用基本操作
3、Stata基本操作实例 用Stata对数据进行统计分析 需在命令窗口键入相关Stata命令,回车即执行命令。 计算描述性统计量(基本命令:su) 键入 su rjgdp rjcap 回车→显示两个变量的概要统计量 信息(观测数、平均值、标准差、最小值、最大值) →保存 运行结果,有两种方式: 方式 1:直接保存为Stata的Log文件,必须在su命令之前 点击Stata窗口file菜单中log项中的begin → 并输入要保存 的文件名、选择路径,选择保存类型为Formatted Log或 Log均可(保存的文件后缀名不同) →保存→再输入su命令 → file菜单log项中的close→查看保存的运行结果。
Stata应用

Stata应用导论1数据输入:在命令窗口输入edit,然后按回车键,在弹出的数据编辑中用黏贴或键盘输入的方法输入数据,点击数据编辑窗口上方的Preserve键,以保存数据,然后关闭该窗口即可。
2生成新变量:在命令窗口输入generate <新生成的变量名> = exp<已有的变量名>,式中exp是由现有变量生成新变量的算术或逻辑表达式。
例如,generate age2 = age*age (新变量age2等于age 的平方)。
3显示序列的各统计指标:在命令窗口输入su X1 X2 X3 ……;按回车键即可。
回归估计1OLS:在命令窗口输入regress X1 X2 X3 ……;按回车键即可。
2系数检验:在命令窗口输入以下命令,再按回车键即可。
(1)test X 1 X 1 X 3,分别检验X 1 X 2 X 3是否显著;(2)test X 1=1,检验X 1的系数是否为1;(3)test X 1= X 2,检验X 1与X 2的系数是否相等;(4)test X 1+ X 2=1,检验X 1与X 2的系数之和是否为1。
虚拟变量1根据已有变量x1生成虚拟变量x2:在命令窗口输入gen x2=x1<=n,再按回车键即可,此命令表示当x1的值小于或等于n时,x2相应的值赋值为1、否则赋值为0。
异方差1检验:在命令窗口输入hettest或者输入imtest,white;按回车键即可。
2修正(异方差稳健统计量):在命令窗口输入regress X 1 X 2 X 3,robust;按回车键即可。
时间序列1定义时间序列:在命令窗口输入ttset X 1,format;按回车键即可。
注意:format 为时间序列的格式,具体运用时,根据数据的时间频率用daily、weekly、monthly、quarterly、yearly等代替;而且只需对时间变量进行定义即可。
2取消定义:在命令窗口输入tsset,clear;按回车键即可。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
cd d:\stata10\AOSISAE
set more off
sjlog using part1, replace
* example 1.1
use consume, clear
*(1)
summ income consume
*(2)
summarize income consume if income>8000
*(3)
sort income , stable
summarize income consume in f/5
summarize income consume in -5/l
*(4)
by area, sort: summarize income consume
* example 2.1
use hbp, clear
*(1)
encode sex2, generate(gender) label(sexlb)
*(2)
decode sex, generate(sexstr)
* example 2.2
use destring1, clear
destring, generate(id2 num2 code2 total2 income2) destring, replace
* example 2.3
use destring2, clear
destring date, ignore(" ") replace
* example 2.4
use mdy, clear
tostring year day, replace
* example 2.5
use hdi, clear
list GDP HDI if LMH_income==3 // hdi -> HDI
* example 2.6
use xposexmpl
list
xpose, clear varname
list
xpose, clear varname
list
* example 2.7
use mdy, clear
list month day year mydate mydate2 mydate3
generate edate=mdy(month, day, year)
gen eate2=date(mydate, "MDY")
gen eate3=date(mydate, "MDY", 2020)
gen edate4=monthly(mydate3,"YM",2010)
* example 2.8
use hdi, clear
*(1)
label data "Source: World Development Report(2005)"
*(2)
label variable GDPPER "GDP Percapita: PPP $"
label variable HDI "Human development Index"
* (3) dropped
* label define sexlabel 0 "male" 1 "female"
* label values sex sexlabel
* example 2.9
use category, clear
generate incomecat=recode(income, 10000,20000) generate educat=(educindex>70) // eduindex -> educindex xi c
* example 3.1
use auto, clear
matrix accum A=price weight mpg
matrix XX=A[2...,2...]
matrix Xy=A[2 (1)
matrix b=invsym(XX)*Xy
* example 3.2
use auto, clear
mkmat price
mkmat weight mpg, matrix(X)
matrix b = invsym(X'*X)*X'*price // mpg -> price
* example 3.3
use auto, clear
regress price weight mpg
matrix c = e(b)'
svmat double c, name(bvector)
list bvector1 in 1/5
* example 3.4
use consume, clear
*(1)
summ consume // new command
gen mdev=consume-r(mean) // modified
*(2)
egen stdcons=std(consume), mean(0) std(1) // add the comma *(3)
summ consume
local m=r(mean) // new command
local sd=r(sd) // new command
egen stdinc=std(income), mean(`m') std(`sd') // modified
*(4)
egen consrank=rank(consume),unique
sjlog close, replace。