pytorch iris分类
朴素贝叶斯分类数据集

朴素贝叶斯分类数据集
朴素贝叶斯分类是一种基于贝叶斯定理的简单概率分类器。
它假设特征之间是相互独立的(即朴素)。
以下是一个使用朴素贝叶斯分类器的数据集示例:
数据集名称:Iris 数据集
数据集来源:Iris 数据集是一个常用的机器学习数据集,包含了150 个样本,每个样本有4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和3 个类别标签(山鸢尾、杂种鸢尾和维吉尼亚鸢尾)。
数据集格式:通常以CSV 格式存储,第一列是标签,后面几列是特征。
数据集示例:
```
标签,花萼长度,花萼宽度,花瓣长度,花瓣宽度
山鸢尾,5.1,3.5,1.4,0.2
杂种鸢尾,4.9,3.0,1.7,0.2
维吉尼亚鸢尾,5.6,3.9,5.1,1.8
...
```
这个数据集可以用Python 的Scikit-learn 库来加载和使用,其中包含了高斯朴素贝叶斯分类器、多项式朴素贝叶斯分类器和伯努利朴素贝叶斯分类器等不同的分类器模型。
例如,使用高斯朴素贝叶斯分类器进行分类的代码示例如下:
```python
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建高斯朴素贝叶斯分类器对象gnb = GaussianNB()
# 使用训练数据训练分类器gnb.fit(X, y)
# 对测试数据进行预测
y_pred = gnb.predict(X)
```。
iris标准基本介绍

iris标准基本介绍Iris标准基本介绍Iris标准是一种用于机器学习和数据挖掘的开源软件库,它提供了一系列用于数据处理、特征选择、分类、聚类等任务的算法和工具。
Iris标准由Python语言编写,可运行于多个平台上,并且易于使用和扩展。
Iris标准的主要特点包括:1. 多种数据集支持:Iris标准内置了多个常用的数据集,如鸢尾花数据集、波士顿房价数据集等,用户可以直接使用这些数据集进行实验。
2. 多种算法支持:Iris标准支持多种经典的机器学习算法,如KNN、决策树、随机森林等,并且还提供了一些高级算法,如神经网络、支持向量机等。
3. 数据可视化功能:Iris标准提供了多种数据可视化工具,如散点图、箱线图等,方便用户对数据进行分析和展示。
4. 易于扩展:Iris标准是一个开源软件库,用户可以自由地添加新的算法或工具,并且可以与其他Python库进行无缝整合。
使用 Iris 标准进行机器学习任务的步骤如下:1. 导入所需要的数据集:可以使用Iris标准内置的数据集,也可以导入自己的数据集。
2. 数据预处理:包括数据清洗、特征选择、特征缩放等步骤。
3. 划分训练集和测试集:将数据集划分为训练集和测试集,用于模型训练和评估。
4. 选择算法并进行模型训练:根据任务需求选择适当的算法,并使用训练集进行模型训练。
5. 模型评估:使用测试集对模型进行评估,计算模型的准确率、精确率、召回率等指标。
6. 模型优化:根据评估结果对模型进行优化,如调整超参数、增加特征等。
7. 模型应用:使用优化后的模型对新数据进行预测或分类。
总之,Iris标准是一个功能强大且易于使用的机器学习工具,它为从事机器学习和数据挖掘研究的人员提供了便捷而高效的解决方案。
python随机森林分类构建模型及评估

Python随机森林分类模型及评估1. 简介随机森林(Random Forest)是一种集成学习(Ensemble Learning)方法,它通过构建多个决策树并进行投票或取平均值的方式来进行分类或回归任务。
本文将介绍如何使用Python中的随机森林算法构建分类模型,并对模型进行评估。
2. 数据准备在构建模型之前,我们首先需要准备数据。
随机森林可以用于处理各种类型的数据,包括数值型和类别型特征。
通常情况下,我们需要对数据进行预处理,包括特征选择、缺失值填充、标准化等步骤。
在本例中,我们将使用一个名为iris的经典数据集作为示例。
该数据集包含了150个样本,每个样本有4个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
每个样本还有一个类别标签,表示鸢尾花的种类。
首先,我们需要导入必要的库和数据集:import pandas as pdfrom sklearn.datasets import load_iris# 加载iris数据集data = load_iris()df = pd.DataFrame(data.data, columns=data.feature_names)df['target'] = data.target3. 数据探索在构建模型之前,我们需要对数据进行一些基本的探索,以了解数据的分布、特征之间的关系等信息。
# 查看数据前几行df.head()# 查看数据统计信息df.describe()# 查看类别分布df['target'].value_counts()# 可视化特征之间的关系import seaborn as snssns.pairplot(df, hue='target')4. 特征工程在构建随机森林模型之前,我们可能需要进行一些特征工程操作,以提取更有用的特征或减少特征维度。
常见的特征工程方法包括特征选择、特征变换和特征生成等。
实战:Python支持向量机分类

实战:Python支持向量机分类因为Python中的scikit-learn库集成了支持向量机算法,使用方法较为便捷,因此本次实验选择在Python中使用支持向量机进行分类。
本文用的数据集为鸢尾花(Iris)数据集,这是统计学中一个经典的数据集,其中包含了150条鸢尾花相关数据。
它包含在scikit-learn库的datasets模块中。
因此我们调用load_iris函数来加载数据:鸢尾花数据集的部分数据如表3-9所示,共5列,前4列为样本特征,第5列为类别,分别有3种类别Iris-setosa、Iris-versicolor、Iris-virginica。
表3-9 鸢尾花数据集的部分数据从datasets模块中导入的数据为字典形式,包含data、target、frame、target_names、DESCR等键,其中对我们有用的是data、target、target_names三个键。
data中为样本特征,是一个150行4列的array,其中每行为鸢尾花一个的特征;target是一个一维的array,表示的是类别,数据集中已经将其变为0、1、2三种,对应的分别是Iris-setosa、Iris-versicolor和Iris-virginica。
因为数据是预处理过的,因此可直接进行训练,代码如下:train_test_split:随机划分训练集与测试集。
train_data:所要划分的样本特征集。
train_target:所要划分的样本结果。
train_size:样本占比,如果是整数的话就是样本的数量。
random_state:随机数种子。
随机数种子其实就是该组随机数的编号,在需要重复进行试验时,保证得到一组一样的随机数。
比如每次都填1,在其他参数一样的情况下,得到的随机数组是一样的。
但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:①种子不同,产生不同的随机数;②种子相同,即使实例不同也会产生相同的随机数,代码如下:支持向量机分类器的参数解释如下。
iris原理

iris原理iris原理解析1. 引言欢迎阅读本篇文章,本文将详细解释iris原理。
iris是一种广泛应用于机器学习和模式识别领域的分类算法,它基于模式分类的机制来进行数据分析和预测。
2. iris数据集介绍iris数据集是一种常用的数据集,其中包含了150个采集的鸢尾花样本。
每个样本都包含了四个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度),以及一个对应的标签(鸢尾花的类别)。
iris数据集广泛应用于机器学习的训练和测试中。
3. 数据预处理为了使iris数据集适合iris算法的训练和预测,我们首先需要进行数据预处理,包括以下几个步骤:•数据清洗:去除无效数据、缺失数据和异常值。
•特征选择:根据实际需求选择合适的特征,这里我们选择了萼片长度和花瓣宽度作为特征。
•数据变换:对数据进行归一化,以便提高算法的性能和稳定性。
4. iris原理iris算法是基于统计学原理的一种分类算法,主要包括以下几个步骤:计算距离对于给定的一个待分类样本,首先需要计算它与训练集中每个样本的距离。
这里我们采用欧氏距离作为距离度量的方式,即通过计算样本之间的特征差的平方和的开方来得到距离数值。
确定领域根据计算得到的距离数值,我们可以确定离待分类样本最近的k 个样本,这些样本将构成算法的“领域”。
判断类别对于确定的k个样本,我们根据它们的类别进行统计。
以多数表决的方式,将待分类样本归为最多的类别。
iris算法的优化为了提高算法的性能和泛化能力,我们可以采用以下优化策略:•调整k值:根据实际需求选择合适的k值,一般通过交叉验证来确定最佳的k值。
•特征权重调整:根据特征的重要程度,为不同的特征赋予不同的权重,以提高算法的灵敏度。
•样本加权:为训练集中的样本赋予不同的权重,以应对样本不平衡问题。
5. 总结本文对iris原理进行了详细解释,包括数据预处理、iris算法的原理和优化策略等内容。
通过灵活运用iris算法,可以实现对iris 数据集的分类和预测,进而应用于更广泛的机器学习和模式识别任务中。
用Python实现支持向量机并处理Iris数据集

⽤Python实现⽀持向量机并处理Iris数据集SVM全称是Support Vector Machine,即⽀持向量机,是⼀种监督式学习算法。
它主要应⽤于分类问题,通过改进代码也可以⽤作回归。
所谓⽀持向量就是距离分隔⾯最近的向量。
⽀持向量机就是要确保这些⽀持向量距离超平⾯尽可能的远以保证模型具有相当的泛化能⼒。
当训练数据线性可分时,通过硬间隔最⼤化,学习⼀个线性分类器,即线性可分⽀持向量机;当训练数据近似线性可分时,通过软间隔最⼤化,也学习⼀个线性分类器,即线性⽀持向量机;当训练数据线性不可分时,通过使⽤核技巧,将低维度的⾮线性问题转化为⾼维度下的线性问题,学习得到⾮线性⽀持向量机。
所谓核技巧就是将低维数据映射到⾼维空间的办法。
如果原始数据是有限维的,那么⼀定存在⼀个⾼维特征空间使样本可分。
⽀持向量机的⼀些证明推导公式不在这⾥说明。
我简单说明⼀下⽀持向量机在Python中的实现。
在Python中sklearn算法包已经实现了所有基本机器学习的算法。
直接from sklearn import svm就可以调⽤该算法。
以Iris数据集为例,从UCI数据库()中下载的data⽂件⽐较⼯整,⽆需做进⼀步处理可以直接使⽤。
从⽹上其他地⽅下载下来的csv格式数据集可能⽐较混乱,如下图:这种有样本序号有列名的数据集需要预处理⼀下才⽅便做实验。
处理时需要导⼊pandas,将csv格式转换成便于处理的DataFrame格式。
其中names是设置列名称。
然后是使⽤drop⽅法消除原数据集中的第⼀⾏(列名称)以及第⼀列(样本序号)。
其中('a',axis=1)代表消除的是列名称为a的⼀整列。
(0 ,axis=0)代表消除第0⾏。
最后使⽤to_csv⽅法输出⽂件即可处理完毕。
其中'newiris.csv'是指⽣成⽂件名,sep指的是分割符号(空格为\t),index为⾏索引(即序列号),header为列名称。
基于多层感知机的鸢尾花分类

基于多层感知机(Multilayer Perceptron, MLP)的鸢尾花分类是一种监督学习方法,用于解决多类别分类问题。
在处理鸢尾花数据集时,MLP能够根据鸢尾花四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)来区分三种不同的鸢尾花品种(山鸢尾、变色鸢尾、维吉尼亚鸢尾)。
以下是使用PyTorch框架实现一个多层感知机进行鸢尾花分类的基本步骤:1.数据准备:o加载鸢尾花数据集(Iris dataset),通常可以从sklearn.datasets 或直接下载CSV文件获取。
o将数据划分为训练集和测试集,如使用train_test_split函数划分。
o数据预处理,将数据归一化或标准化到同一尺度。
2.构建模型:o定义一个神经网络模型,包含输入层、隐藏层和输出层。
例如,输入层的大小应与特征数量相同,输出层的大小应与类别数相同(对于鸢尾花分类是3)。
Pythonimport torch.nn as nnclass IrisMLP(nn.Module):def__init__(self):super(IrisMLP, self).__init__()yer1 = nn.Linear(4, 16) # 输入层到第一隐藏层 self.relu = nn.ReLU()self.dropout = nn.Dropout(p=0.2)yer2 = nn.Linear(16, 3) # 第一隐藏层到输出层def forward(self, x):x = self.relu(yer1(x))x = self.dropout(x)x = yer2(x)return x3.损失函数与优化器设置:o使用合适的多类别损失函数,如交叉熵损失(CrossEntropyLoss)。
Pythoncriterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(),lr=0.001)4.训练循环:o遍历训练集样本,执行前向传播得到预测结果,计算损失并反向传播更新权重。
pytorch用resnet101训练分类实例

pytorch用resnet101训练分类实例在PyTorch中,使用ResNet101训练分类任务的基本步骤如下。
首先,确保已经安装了PyTorch和torchvision库。
```bashpip install torch torchvision```然后,你可以使用以下代码作为起点来训练一个ResNet101模型。
```pythonimport torchimport as nnimport as transformsimport as datasetsfrom import DataLoaderfrom import resnet101定义超参数input_size = 2048hidden_size = 1000num_classes = 1000 根据你的数据集类别数量进行更改num_epochs = 25 训练轮数learning_rate = 学习率batch_size = 32 批处理大小数据预处理和加载transform = ([(256),(224),(),(mean=[, , ], std=[, , ])])train_dataset = (root='path_to_your_train_data', transform=transform) 替换为你的训练数据路径train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_dataset = (root='path_to_your_test_data', transform=transform) 替换为你的测试数据路径test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)加载预训练的ResNet101模型,去除全连接层,然后添加自定义的全连接层model = resnet101(pretrained=True)model = (list(())[:-1]) 去除全连接层_module("fc", (in_features=2048, out_features=num_classes)) 添加自定义的全连接层定义损失函数和优化器criterion = () 使用交叉熵损失函数optimizer = ((), lr=learning_rate) 使用Adam优化器训练模型for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader): images的shape 为[batch_size, channels, height, width]outputs = model(images) 前向传播,得到预测结果loss = criterion(outputs, labels) 计算损失值_grad() 清空过去的梯度() 后向传播,计算梯度() 根据梯度更新权重print(f'Epoch [{epoch+1}/{num_epochs}], Step[{i+1}/{len(train_loader)}], Loss: {()}')在测试集上评估模型性能with _grad(): 在测试时不需要计算梯度,所以使用_grad()来关闭梯度计算,提高运行速度。
Python机器学习之旅|手把手带你探索IRIS数据集
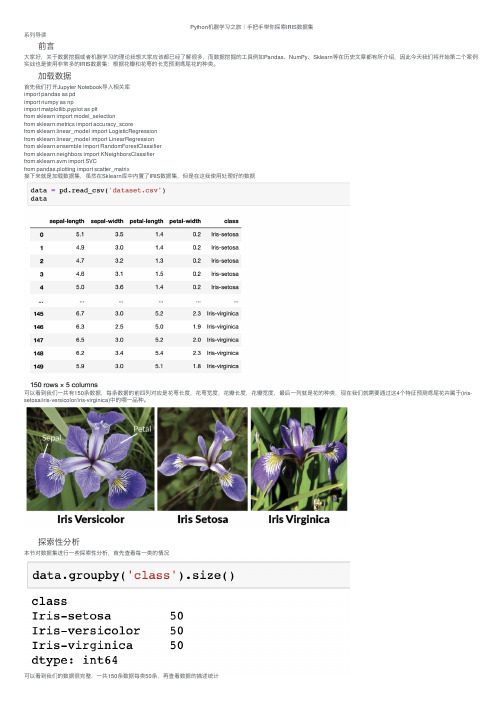
Python机器学习之旅|⼿把⼿带你探索IRIS数据集系列导读前⾔⼤家好,关于数据挖掘或者机器学习的理论我想⼤家应该都已经了解很多,⽽数据挖掘的⼯具例如Pandas、NumPy、Sklearn等在历史⽂章都有所介绍,因此今天我们将开始第⼆个案例实战也是使⽤⾮常多的IRIS数据集:根据花瓣和花萼的长宽预测鸢尾花的种类。
加载数据⾸先我们打开Jupyter Notebook导⼊相关库import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import model_selectionfrom sklearn.metrics import accuracy_scorefrom sklearn.linear_model import LogisticRegressionfrom sklearn.linear_model import LinearRegressionfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.svm import SVCfrom pandas.plotting import scatter_matrix接下来就是加载数据集,虽然在Sklearn库中内置了IRIS数据集,但是在这我使⽤处理好的数据可以看到我们⼀共有150条数据,每条数据的前四列对应是花萼长度,花萼宽度,花瓣长度,花瓣宽度,最后⼀列就是花的种类,现在我们就需要通过这4个特征预测鸢尾花卉属于(iris-setosa/iris-versicolor/iris-virginica)中的哪⼀品种。
探索性分析本节对数据集进⾏⼀些探索性分析,⾸先查看每⼀类的情况可以看到我们的数据很完整,⼀共150条数据每类50条,再查看数据的描述统计接着我们通过箱线图与直⽅图来观察数据的最值,中位数和偏差与数据分布进⼀步,我们可以绘散点图来观察四个变量之间的关联可以看到有些变量之前有着明显的相关性,因此我们可以进⾏预测建模分类现在开始建模分类,和之前的例⼦⼀样,我们将数据集划分为训练集和测试集。
pythonsklearn数据集及分析方法

pythonsklearn数据集及分析方法scikit-learn是一个Python的机器学习库,提供了丰富的数据集和分析方法。
本文将介绍一些常用的scikit-learn数据集和分析方法,帮助读者更好地了解和使用这个库。
首先,scikit-learn提供了许多经典的数据集,可以作为学习和实践的基础。
其中,一些常见的数据集包括iris(鸢尾花)数据集、boston(波士顿房价)数据集和digits(手写数字)数据集。
这些数据集都是经典的机器学习数据集,可以用于分类、回归和聚类等问题。
例如,iris数据集包含了150个样本,分为3个类别,每个样本有4个特征。
我们可以使用这个数据集来训练一个分类器,根据花萼长度、花萼宽度、花瓣长度和花瓣宽度来预测鸢尾花的类别。
除了提供数据集,scikit-learn还提供了许多常用的数据预处理和特征工程方法。
例如,数据缩放是一个常见的数据预处理方法,用于将不同特征的数值范围统一到一定范围内。
scikit-learn提供了多种数据缩放方法,如MinMaxScaler和StandardScaler等。
此外,scikit-learn还提供了特征选择、特征转换和特征生成等功能,可以帮助我们选取最重要的特征、将特征转换成新的表示形式或生成新的特征。
在数据集准备好之后,我们可以使用scikit-learn提供的模型和算法进行训练和预测。
scikit-learn支持各种各样的监督学习和无监督学习算法,如线性回归、逻辑回归、决策树、随机森林、支持向量机、聚类和降维等。
这些算法都有统一的接口,使得我们可以很方便地使用它们。
例如,我们可以使用scikit-learn的线性回归模型来训练一个线性回归器,根据输入特征预测输出变量的值。
在训练模型之后,我们可以使用scikit-learn提供的评估方法对模型进行评估。
scikit-learn提供了多种评估指标,用于衡量分类器和回归器的性能。
例如,对于分类任务,我们可以使用准确率(accuracy)、精确率(precision)、召回率(recall)和F1值(F1-score)等指标来评估模型的性能。
BP神经网络算法程序实现鸢尾花(iris)数据集分类

BP神经⽹络算法程序实现鸢尾花(iris)数据集分类作者有话说最近学习了⼀下BP神经⽹络,写篇随笔记录⼀下得到的⼀些结果和代码,该随笔会⽐较简略,对⼀些简单的细节不加以说明。
⽬录BP算法简要推导应⽤实例PYTHON代码BP算法简要推导该部分⽤⼀个2×3×2×1的神经⽹络为例简要说明BP算法的步骤。
向前计算输出反向传播误差权重更新应⽤实例鸢尾花数据集⼀共有150个样本,分为3个类别,每个样本有4个特征,(数据集链接:)。
针对该数据集,选取如下神经⽹络结构和激活函数神经⽹络组成隐含层神经元个数对准确率的影响调节隐含层神经元的个数,得到模型分类准确率的变化图像如下:梯度更新步长对准确率的影响调节梯度更新步长(学习率)的⼤⼩,得到模型分类准确率的变化图像如下:可见准确率最⾼可达98.6666666666667%PYTHON代码BPNeuralNetwork.py# coding=utf-8import numpy as npdef tanh(x):return np.tanh(x)def tanh_deriv(x):return 1.0 - np.tanh(x) * np.tanh(x)def logistic(x):return 1.0 / (1.0 + np.exp(-x))def logistic_derivative(x):return logistic(x) * (1.0 - logistic(x))class NeuralNetwork:def __init__(self, layers, activation='tanh'):""""""if activation == 'logistic':self.activation = logisticself.activation_deriv = logistic_derivativeelif activation == 'tanh':self.activation = tanhself.activation_deriv = tanh_derivself.weights = []self.weights.append((2 * np.random.random((layers[0] + 1, layers[1] - 1)) - 1) * 0.25) for i in range(2, len(layers)):self.weights.append((2 * np.random.random((layers[i - 1], layers[i])) - 1) * 0.25) # self.weights.append((2*np.random.random((layers[i]+1,layers[i+1]))-1)*0.25) def fit(self, X, y, learning_rate=0.2, epochs=10000):X = np.atleast_2d(X)# atlest_2d函数:确认X⾄少⼆位的矩阵temp = np.ones([X.shape[0], X.shape[1] + 1])# 初始化矩阵全是1(⾏数,列数+1是为了有B这个偏向)temp[:, 0:-1] = X# ⾏全选,第⼀列到倒数第⼆列X = tempy = np.array(y)# 数据结构转换for k in range(epochs):# 抽样梯度下降epochs抽样i = np.random.randint(X.shape[0])a = [X[i]]# print(self.weights)for l in range(len(self.weights) - 1):b = self.activation(np.dot(a[l], self.weights[l]))b = b.tolist()b.append(1)b = np.array(b)a.append(b)a.append(self.activation(np.dot(a[-1], self.weights[-1])))# 向前传播,得到每个节点的输出结果error = y[i] - a[-1]# 最后⼀层错误率deltas = [error * self.activation_deriv(a[-1])]for l in range(len(a) - 2, 0, -1):deltas.append(deltas[-1].dot(self.weights[l].T) * self.activation_deriv(a[l]))deltas.reverse()for i in range(len(self.weights) - 1):layer = np.atleast_2d(a[i])delta = np.atleast_2d(deltas[i])delta = delta[:, : -1]self.weights[i] += learning_rate * layer.T.dot(delta)layer = np.atleast_2d(a[-2])delta = np.atleast_2d(deltas[-1])# print('w=',self.weights[-1])# print('l=',layer)# print('d=',delta)self.weights[-1] += learning_rate * layer.T.dot(delta)def predict(self, x):x = np.atleast_2d(x)# atlest_2d函数:确认X⾄少⼆位的矩阵temp = np.ones(x.shape[1] + 1)# 初始化矩阵全是1(⾏数,列数+1是为了有B这个偏向) temp[:4] = x[0, :]a = temp# print(self.weights)for l in range(len(self.weights) - 1):b = self.activation(np.dot(a, self.weights[l]))b = b.tolist()b.append(1)b = np.array(b)a = ba = self.activation(np.dot(a, self.weights[-1]))return (a)Text.pyfrom BPNeuralNetwork import NeuralNetworkimport numpy as npfrom openpyxl import load_workbookimport xlrdnn = NeuralNetwork([4, 12, 3], 'tanh')x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])y = np.array([0, 1, 1, 0])import openpyxl# 打开excel⽂件,获取⼯作簿对象data = xlrd.open_workbook('BbezdekIris.xlsx')table = data.sheets()[0]nrows = table.nrows # ⾏数ncols = table.ncols # 列数datamatrix = np.zeros((nrows, ncols - 1))for k in range(ncols - 1):cols = table.col_values(k)minVals = min(cols)maxVals = max(cols)cols1 = np.matrix(cols) # 把list转换为矩阵进⾏矩阵操作ranges = maxVals - minValsb = cols1 - minValsnormcols = b / ranges # 数据进⾏归⼀化处理datamatrix[:, k] = normcols # 把数据进⾏存储# print(datamatrix)datalabel = table.col_values(ncols - 1)for i in range(nrows):if datalabel[i] == 'Iris-setosa':datalabel[i] = [1, 0, 0]if datalabel[i] == 'Iris-versicolor':datalabel[i] = [0, 1, 0]if datalabel[i] == 'Iris-virginica':datalabel[i] = [0, 0, 1]datamatrix1 = table.col_values(0)for i in range(nrows):datamatrix1[i] = datamatrix[i]x = datamatrix1y = datalabelnn.fit(x, y)CategorySet = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']P = np.zeros((1, len(y)))P = ya = [0, 1, 3, 5, 4, 7, 8, 1, 5, 1, 5, 5, 1]print(a.index(max(a)))b = nn.predict(x[1])b = b.tolist()print(b.index(max(b)))for i in range(len(y)):Predict = nn.predict(x[i])Predict = Predict.tolist()Index = Predict.index(max(Predict, key=abs))Real = y[i]Category = Real.index(max(Real, key=abs))if Index == Category:P[i] = 1print('样本', i + 1, ':', x[i], ' ', '实际类别', ':', CategorySet[Category], ' ', '预测类别', ':', CategorySet[Index], ' ', '预测正确')else:P[i] = 0print('样本', i + 1, ':', x[i], ' ', '实际类别', ':', CategorySet[Category], ' ', '预测类别', ':', CategorySet[Index], ' ', '预测错误')print('准确率', ':', sum(P) / len(P))Processing math: 100%。
pytorch 二分类 语义分割 评价指标

pytorch 二分类语义分割评价指标
1. 准确率(Accuracy):分类正确的样本数占总样本数的比例,是最常用的评价指标之一。
2. 精确率(Precision):指分类器预测为正例的样本中,真正为正例的比例,即预测为正例的样本中有多少是真正的正例。
3. 召回率(Recall):指所有真正为正例的样本中,被分类器正确预测为正例的比例,即真正为正例的样本中有多少被预测为正例。
4. F1分数(F1 Score):综合考虑精确率和召回率,是精确率和召回率的调和平均数,可以更全面地评价分类器的性能。
5. IoU(Intersection over Union):用于评价语义分割模型的性能,是预测的区域与真实区域的交集与并集之比,可以衡量模型对目标的定位能力和分割准确度。
6. Dice系数:也是用于评价语义分割模型的性能,是预测的区域与真实区域的交集的两倍除以预测区域和真实区域的总和,也可以衡量模型的分割准确度。
python实现神经网络多分类_Pytorch实现神经网络的分类方式

python实现神经网络多分类_Pytorch实现神经网络的分类方式神经网络是一种用于模式识别和机器学习的强大工具,能够对数据进行分类、回归和其他任务的处理。
Pytorch是一个基于Python的深度学习库,提供了构建和训练神经网络所需的丰富功能和工具。
在这篇文章中,我将介绍如何使用Pytorch实现神经网络的多分类任务。
我会解释神经网络的工作原理,并介绍如何准备数据、构建模型、训练和评估模型。
1.准备数据在开始之前,我们首先需要准备数据。
通常来说,数据会以CSV或者其他形式存储,在Pytorch中使用自定义的Dataset类来加载数据。
该类需要实现__len__和__getitem__方法,分别返回数据集的长度和指定索引位置的样本。
如果数据集较大,你可以使用Dataloader类来加载和预处理数据。
这个类可以并行加载样本,提高训练效率。
2.构建模型接下来,我们需要定义我们的神经网络模型。
Pytorch中定义模型的常见方式是使用nn.Module类,并定义__init__和forward方法。
- __init__方法用于定义模型的结构,包括输入层、隐藏层和输出层。
你可以选择不同的层类型,例如全连接层(nn.Linear)、激活层(nn.ReLU)和批归一化层(nn.BatchNorm1d)等。
- forward方法用于定义数据在模型中的传递方式。
你需要将输入数据通过每一层,并返回最终的输出结果。
3.训练模型在模型定义好之后,我们需要定义损失函数和优化器,并开始训练我们的模型。
- 优化器是用于调整模型参数以最小化损失函数的函数。
在Pytorch 中,常用的优化器是随机梯度下降(SGD)优化器和Adam优化器。
4.评估模型一旦模型训练完成,我们可以使用测试集或者交叉验证集来评估模型的性能。
评估指标可以根据任务的不同而不同。
在多分类任务中,常用的评估指标是准确率,即模型正确分类样本的比率。
5.改进模型如果模型的性能不令人满意,你可以尝试改进模型。
在python中利用KNN实现对iris进行分类的方法

from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier
ss = StandardScaler()
X_train = ss.fit_transform(X_train) X_test = ss.transform(X_test)
from sklearn.metrics import classification_report
print classification_report(y_test, y_predict, target_names = iris.target_names)
以上这篇在python中利用KNN实现对iris进行分类的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望 大家多多支持。
这篇文章主要给大家汇总介绍了关于pandas实现数据类型转换的一些小技巧文中通过示例代码介绍的非常详细对大家的学习或者工作具有一定的参考学习价值需要的朋友们下面随着小编来一起学习学习吧
在 python中利用 KNN实现对 iris进行分类的方mport load_iris
knc = KNeighborsClassifier() knc.fit(X_train, y_train) y_predict = knc.predict(X_test)
print 'The accuracy of K-Nearest Neighbor Classifier is: ', knc.score(X_test, y_test)
iris = load_iris()
print iris.data.shape
BP算法实例—鸢尾花的分类(Python)

BP算法实例—鸢尾花的分类(Python)⾸先了解下Iris鸢尾花数据集:Iris数据集(https:///wiki/Iris_flower_data_set)是常⽤的分类实验数据集,由Fisher,1936收集整理。
Iris也称鸢尾花卉数据集,是⼀类多重变量分析的数据集。
数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。
可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪⼀类。
iris以鸢尾花的特征作为数据来源,常⽤在分类操作中。
该数据集由3种不同类型的鸢尾花的50个样本数据构成。
其中的⼀个种类与另外两个种类是线性可分离的,后两个种类是⾮线性可分离的。
该数据集包含了4个属性:Sepal.Length(花萼长度),单位是cm;Sepal.Width(花萼宽度),单位是cm;Petal.Length(花瓣长度),单位是cm;Petal.Width(花瓣宽度),单位是cm;种类:Iris Setosa(1.⼭鸢尾)、Iris Versicolour(2.杂⾊鸢尾),以及Iris Virginica(3.维吉尼亚鸢尾)。
Python源码:1from__future__import division2import math3import random4import pandas as pd567 flowerLables = {0: 'Iris-setosa',8 1: 'Iris-versicolor',9 2: 'Iris-virginica'}1011 random.seed(0)121314# ⽣成区间[a, b)内的随机数15def rand(a, b):16return (b - a) * random.random() + a171819# ⽣成⼤⼩ I*J 的矩阵,默认零矩阵20def makeMatrix(I, J, fill=0.0):21 m = []22for i in range(I):23 m.append([fill] * J)24return m252627# 函数 sigmoid28def sigmoid(x):29return 1.0 / (1.0 + math.exp(-x))303132# 函数 sigmoid 的导数33def dsigmoid(x):34return x * (1 - x)353637class NN:38""" 三层反向传播神经⽹络 """3940def__init__(self, ni, nh, no):41# 输⼊层、隐藏层、输出层的节点(数)42 self.ni = ni + 1 # 增加⼀个偏差节点43 self.nh = nh + 144 self.no = no4546# 激活神经⽹络的所有节点(向量)47 self.ai = [1.0] * self.ni48 self.ah = [1.0] * self.nh49 self.ao = [1.0] * self.no5051# 建⽴权重(矩阵)52 self.wi = makeMatrix(self.ni, self.nh)53 self.wo = makeMatrix(self.nh, self.no)54# 设为随机值55for i in range(self.ni):56for j in range(self.nh):57 self.wi[i][j] = rand(-0.2, 0.2)58for j in range(self.nh):59for k in range(self.no):60 self.wo[j][k] = rand(-2, 2)6162def update(self, inputs):63if len(inputs) != self.ni - 1:64raise ValueError('与输⼊层节点数不符!')6566# 激活输⼊层67for i in range(self.ni - 1):68 self.ai[i] = inputs[i]6970# 激活隐藏层71for j in range(self.nh):72 sum = 0.073for i in range(self.ni):74 sum = sum + self.ai[i] * self.wi[i][j]75 self.ah[j] = sigmoid(sum)7677# 激活输出层78for k in range(self.no):79 sum = 0.080for j in range(self.nh):81 sum = sum + self.ah[j] * self.wo[j][k]82 self.ao[k] = sigmoid(sum)8384return self.ao[:]8586def backPropagate(self, targets, lr):87""" 反向传播 """8889# 计算输出层的误差90 output_deltas = [0.0] * self.no91for k in range(self.no):92 error = targets[k] - self.ao[k]93 output_deltas[k] = dsigmoid(self.ao[k]) * error 9495# 计算隐藏层的误差96 hidden_deltas = [0.0] * self.nh97for j in range(self.nh):98 error = 0.099for k in range(self.no):100 error = error + output_deltas[k] * self.wo[j][k] 101 hidden_deltas[j] = dsigmoid(self.ah[j]) * error 102103# 更新输出层权重104for j in range(self.nh):105for k in range(self.no):106 change = output_deltas[k] * self.ah[j]107 self.wo[j][k] = self.wo[j][k] + lr * change 108109# 更新输⼊层权重110for i in range(self.ni):111for j in range(self.nh):112 change = hidden_deltas[j] * self.ai[i]113 self.wi[i][j] = self.wi[i][j] + lr * change114115# 计算误差116 error = 0.0117 error += 0.5 * (targets[k] - self.ao[k]) ** 2118return error119120def test(self, patterns):121 count = 0122for p in patterns:123 target = flowerLables[(p[1].index(1))]124 result = self.update(p[0])125 index = result.index(max(result))126print(p[0], ':', target, '->', flowerLables[index]) 127 count += (target == flowerLables[index])128 accuracy = float(count / len(patterns))129print('accuracy: %-.9f' % accuracy)130131def weights(self):132print('输⼊层权重:')133for i in range(self.ni):134print(self.wi[i])135print()136print('输出层权重:')137for j in range(self.nh):138print(self.wo[j])139140def train(self, patterns, iterations=1000, lr=0.1):141# lr: 学习速率(learning rate)142for i in range(iterations):143 error = 0.0144for p in patterns:145 inputs = p[0]146 targets = p[1]147 self.update(inputs)148 error = error + self.backPropagate(targets, lr) 149if i % 100 == 0:150print('error: %-.9f' % error)151152153154def iris():155 data = []156# 读取数据157 raw = pd.read_csv('iris.csv')158 raw_data = raw.values159 raw_feature = raw_data[0:, 0:4]160for i in range(len(raw_feature)):161 ele = []162 ele.append(list(raw_feature[i]))163if raw_data[i][4] == 'Iris-setosa':164 ele.append([1, 0, 0])165elif raw_data[i][4] == 'Iris-versicolor':166 ele.append([0, 1, 0])167else:168 ele.append([0, 0, 1])169 data.append(ele)170# 随机排列数据171 random.shuffle(data)172 training = data[0:100]173 test = data[101:]174 nn = NN(4, 7, 3)175 nn.train(training, iterations=10000)176 nn.test(test)177178179if__name__ == '__main__':180 iris()。
python利用逻辑回归进行分类实验报告

python利用逻辑回归进行分类实验报告逻辑回归是一种常用的分类算法,它可以用来解决二分类问题。
在本篇文章中,我们将使用Python来进行逻辑回归的分类实验,并对实验结果进行分析和解释。
我们需要导入所需的库和数据集。
在Python中,我们可以使用scikit-learn库来进行逻辑回归模型的建立和训练。
同时,我们还需要使用一个合适的数据集来进行分类实验。
在本次实验中,我们选择使用鸢尾花数据集(Iris Dataset)作为我们的样本数据。
鸢尾花数据集是一个经典的分类问题数据集,它包含了150个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),并且分为3类(Setosa、Versicolor、Virginica)。
我们将使用该数据集来建立一个模型,来预测鸢尾花的类别。
接下来,我们需要对数据集进行预处理。
首先,我们需要将数据集分为特征集和标签集。
特征集是用来训练模型的输入数据,而标签集是对应的输出结果。
我们可以使用鸢尾花数据集中的前4个特征作为特征集,将鸢尾花的类别作为标签集。
然后,我们将数据集分为训练集和测试集。
训练集用来训练模型,而测试集用来评估模型的性能。
在本次实验中,我们选择将数据集的70%作为训练集,30%作为测试集。
可以使用scikit-learn库中的train_test_split函数来进行数据集的划分。
接下来,我们可以使用逻辑回归算法来建立模型。
在scikit-learn 库中,逻辑回归模型的类为LogisticRegression。
我们可以创建一个逻辑回归对象,并使用训练集来训练模型。
训练完成后,我们可以使用测试集来评估模型的性能。
常用的评估指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-Score)。
在本次实验中,我们将使用准确率来评估模型的性能。
我们可以对模型进行解释和分析。
通过观察模型的系数(Coefficients),可以了解各个特征对于分类结果的影响程度。
iris数据集分类例题

iris数据集分类例题Iris数据集是一个非常经典的机器学习数据集,常用于分类问题的示例。
这个数据集包含了150个样本,分为3个类别,Setosa、Versicolor和Virginica。
每个样本有4个特征,花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width)。
接下来,我将从多个角度来回答这个问题,以便全面地介绍Iris数据集的分类例题。
1. 数据集的探索与可视化:首先,我们可以通过统计描述来了解数据集的基本信息,例如样本数量、特征数量等。
然后,我们可以使用散点图、箱线图等可视化工具,展示不同类别之间的特征分布情况,以及特征之间的相关性。
2. 数据预处理:在进行分类任务之前,我们通常需要对数据进行预处理。
这可能包括数据清洗、特征选择、特征缩放等步骤。
对于Iris数据集而言,由于特征之间的单位差异不大,通常不需要进行特征缩放。
但是,如果特征之间的差异较大,我们可以使用标准化或归一化等方法。
3. 模型选择与训练:对于分类问题,我们可以选择不同的机器学习算法或深度学习模型来训练。
常见的分类算法包括逻辑回归、支持向量机、决策树、随机森林、K近邻等。
而深度学习模型可以选择使用神经网络、卷积神经网络等。
我们可以将数据集分为训练集和测试集,使用训练集来训练模型,并使用测试集来评估模型的性能。
4. 模型评估与调优:在训练完成后,我们需要评估模型的性能。
常见的评估指标包括准确率、精确率、召回率、F1值等。
如果模型的性能不理想,我们可以尝试调整模型的超参数,例如正则化参数、学习率等,以提高模型的性能。
5. 结果解释与应用:最后,我们可以解释模型的结果,并将其应用于实际问题中。
对于Iris数据集而言,我们可以根据花萼长度、花萼宽度、花瓣长度和花瓣宽度来预测鸢尾花的类别,从而实现鸢尾花的分类识别。
综上所述,以上是关于Iris数据集分类例题的回答。
Iris数据集

Iris数据集Iris数据集是一种常用的机器学习数据集,用于分类问题的研究和实验。
该数据集包含了150个样本,每个样本有4个特征,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。
这些特征都以浮点数表示,并且都被归一化到0-1的范围内。
数据集中的样本被分为3个类别,分别是山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。
每个类别包含50个样本,可以通过样本的类别标签进行分类任务的训练和测试。
Iris数据集是由英国统计学家和生物学家Ronald Fisher在1936年收集整理的。
它成为了机器学习领域中经典的数据集之一,被广泛应用于分类算法的评估和比较。
在使用Iris数据集进行分类任务时,可以将数据集划分为训练集和测试集,通常采用70%的数据作为训练集,30%的数据作为测试集。
训练集用于训练分类模型,测试集用于评估模型的性能和泛化能力。
常见的分类算法,如决策树、支持向量机和神经网络,都可以在Iris数据集上进行训练和测试。
通过对数据集的特征进行分析和建模,可以预测新样本的类别,并对不同类别之间的特征差异进行分析和理解。
为了更好地评估分类模型的性能,可以使用交叉验证方法。
交叉验证将数据集划分为K个子集,每次使用K-1个子集作为训练集,剩下的一个子集作为验证集,重复K次,最后取平均值得到模型的性能评估结果。
除了分类任务,Iris数据集还可以用于聚类分析、特征选择和可视化等机器学习任务。
通过对数据集的探索和分析,可以深入理解不同特征之间的关系和数据分布的特点。
总之,Iris数据集是一个经典的机器学习数据集,用于分类问题的研究和实验。
通过对数据集的分析和建模,可以训练出分类模型,并对新样本进行分类预测。
同时,该数据集也可以用于其他机器学习任务的研究和实验,具有广泛的应用价值。
pytorch 分类问题一般方法

pytorch 分类问题一般方法
在PyTorch中解决分类问题的一般步骤如下:
1. 数据预处理:首先,加载数据集并进行预处理,例如将图像转换为张量、归一化数据、划分训练集和测试集等。
2. 定义模型:根据问题的特点和数据集的结构,选择合适的模型架构进行定义。
可以使用PyTorch提供的现有模型(如ResNet、VGG等),或者自定义模型。
3. 定义损失函数:根据分类任务的要求,选择合适的损失函数。
常见的分类问题可以使用交叉熵损失函数(CrossEntropyLoss)。
4. 定义优化器:选择优化算法,并设置学习率、动量等超参数。
常用的优化器包括随机梯度下降(SGD)和Adam等。
5. 训练模型:使用训练集对模型进行训练。
将模型输入数据并计算输出,然后计算损失函数,并调用优化器更新模型参数。
重复这个过程直到达到指定的训练轮数或达到停止条件。
6. 模型评估:使用测试集对训练好的模型进行评估。
将测试集输入模型并计算输出,然后与标签进行比较,得出模型在测试集上的准确率或其他指标。
7. 模型部署:将训练好的模型保存下来,以便在生产环境中使用。
可以使用PyTorch的模型保存和加载功能来实现。
需要注意的是,以上步骤中的具体实现方法会根据问题的具体情况而有所不同,例如数据集的大小、模型的复杂度等。
在实际应用中,还可能需要进行模型调优、使用数据增强等技巧来提高模型的性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
pytorch iris分类
您可能是在寻找如何使用PyTorch对Iris数据集进行分类的方法。
然而,代码"iris_multi-classfication.py"并不是实现Iris数据集分类的正确方式。
这是因为该代码片段导入了许多库,但并没有具体实现分类算法。
下面是一个基本的示例,说明如何使用PyTorch对Iris数据集进行多类分类:
首先,我们需要加载数据:
python
复制代码
from sklearn.datasets import load_iris
from torch.utils.data import DataLoader, TensorDataset
# 加载iris数据集
iris = load_iris()
X, y = iris.data, iris.target
然后,我们需要将数据划分为训练集和测试集:
python
复制代码
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
接下来,我们定义我们的神经网络模型。
这里我们使用一个简单的多层感知器(MLP):
python
复制代码
import torch.nn as nn
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.hidden = nn.Linear(4, 10) # 输入层到隐藏层的线性变换,隐藏层大小为10
self.predict = nn.Linear(10, 3) # 隐藏层到输出层的线性变换,输出层大小为3,对应iris的三个分类
def forward(self, x):
x = torch.relu(self.hidden(x)) # 使用ReLU作为激活函数
x = self.predict(x) # 输出层的线性变换
return x
然后,我们需要定义损失函数和优化器:
python
复制代码
import torch.nn.functional as F
from torch import optim
# 定义损失函数,这里使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器,这里使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01) 接下来,我们训练我们的模型:
python
复制代码
for epoch in range(100): # 循环遍历整个数据集多次,这里我们设定为100次
# 前向传播:计算预测值与真实值之间的损失函数的值
outputs = model(X_train)
loss = criterion(outputs, y_train)
# 反向传播:根据损失函数的值调整模型参数
optimizer.zero_grad() # 清空过去的梯度缓存,否则会重复累积梯度,导致模型训练效果不佳。
每次迭代前都需要清空。
loss.backward() # 计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传
播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值反向传播:计算梯度值 # PyTorch中的`backward()`会自动计算出当前张量的梯度和累计所有的梯度到模型参数中。
这里没有用到`backward()`函数,是因为`loss`是直接从`outputs`中得到的损失,所以直接调用`loss.backward()`即可。
# PyTorch中的`backward()`会自动计算出当前张量的梯度和累计所有的梯度到模型参数中。
这里没有用到`backward()`函数,是因为`loss`是直接从`outputs`中得到的损失,所以直接调用`loss.backward()`即可。
# PyTorch中的`backward()`会自动计算出当前张量的梯度和累计所有的梯度到模型参数中。
这里没有用到`backward()`函数,是因为`loss`是直接从`outputs`中得到的损失,所以直接调用`loss.backward()`即可。
# PyTorch中的`backward()`会自动计算出当前张量的梯度和累计所有的梯度到。