心理学多因素实验设计模版
多因素混合设计

三、研究假设
1. 流行音乐对大学生的数字短时记忆能力 有消极影响 ; 2. 轻音乐对大学生的数字短时记忆能力有 积极影响 ; 3. 不同背景音乐对大学生数字短时记忆无 性别差异。
四、实验变量
本研究采用2×2混合实验设计 (一)自变量的选择 1、被试内因素(A因素) :背景音乐 分为流行音乐 (a1) 和 轻音乐( a2)两种水 平; 2、被试间因素(B因素) :性别 分为男(b1) 、女(b2)两个水平。 (二)因变量 规定时间内大学生回忆正确数字的数量 。
• 2.不存在交互作用的数据分析: • 如果对混合设计结果的分析表明交互 作用不显著,那么下一步就是主效应是否 显著。如果自变量存在主效应,并且自变 量有两个以上的水平,那么就进行两个平 均数之间的两两比较,也可运用置信区间 比较两个平均数。
实验数据分析方法:
A×B的交互作用显著吗?
不显著 显著
多因素混合设计
一、研究主题
背景音乐对不同性别大学生的 数字短时记忆的影响
二、问题的提出
音乐在整个社会生活中占有重要位置,它超 越了语言,易化了人与人之间的沟通。人们在听 赏音乐的过程中,音乐信息对疏导大脑的整体功 能起到了良好作用,表现为记忆力增强、思维活 跃,从而使解决问题的能力得到提高。听音乐学 习,是否有利?什么样的音乐才有利于记忆呢? 是不是所有的音乐都能产生这样的效果呢?对男 生和女生的影响是否一样呢?针对研究中的结果 提出教学建议,以便学校能够为学生创设良好的 学习情境,为提高教与学的效率提供依据。通过 在相同条件下记录一项关于背景音乐的实验研究 过程,分析和讨论了背景音乐对数字短时记忆的重 要影响。
(二)选取背景音乐
1、流行音乐:现今广播里经常播放的由一些艺 人演唱的歌曲,如:刘欢,那英的歌曲等,它的旋 律简单,容易记忆。它的曲子配有歌词,且歌词 通俗易懂,易令人沉浸其中。如《征服》。 2、轻音乐:它是来自自然,营造自然,轻松、 动听、结构短小,在同一作品中旋律有规律的重 复,且重复的间隔较长,欣赏这种轻音乐不需严 肃的思考和理智活动,它只给人以美的享受,陶 冶人的情操。如《a walk in the rain》。
第十一章多因素实验设计(正交实验设计)

7
2
3
4
1
499
49
1.7
8
2
4
3
2
480
45
2.0
9
3(3.3)
1
4
4
566
49
3.6
10
3
2
3
3
539
49
2.7
11
3
3
2
2
511
42
2.7
12
3
4
1
1
515
45
2.9
13
4(3.5)
1
2
2
533
49
2.7
14
4
2
1
1
488
49
2.3
15
4
3
4
4
495
49
2.3
16
4
4
3
3
476
42
3.3
K4
(%)
(%)
1
1(2.9)
1(1)
1(25%)
1(34.7%)
545
40
5.0
2
1
2(3)
2(30%)
2(39.7%)
490
46
3.9
3
1
3(5)
3(35%)
3(44.7%)
515
45
4.4
4
1
4(7)
4(40%)
4(49.7
505
45
4.7
5
2(3.1)
1
2
3
492
46
3.2
多因素实验设计
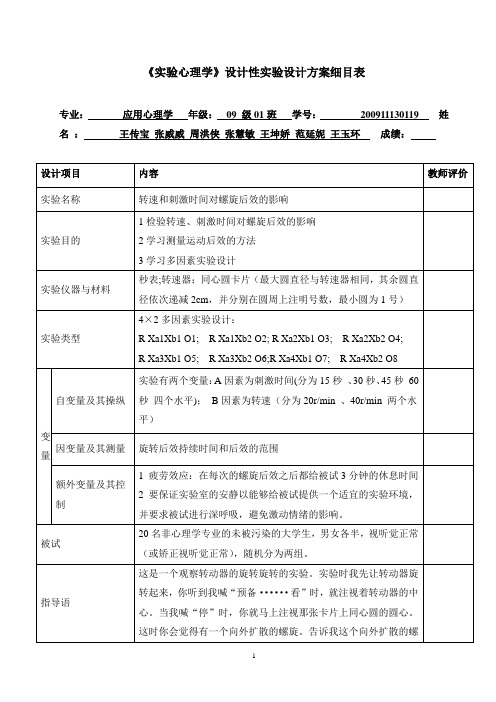
《实验心理学》设计性实验设计方案细目表专业:应用心理学年级:09 级01班学号:200911130119 姓名:王传宝张威威周洪侠张慧敏王坤娇范延妮王玉环成绩:设计项目内容教师评价实验名称转速和刺激时间对螺旋后效的影响实验目的1检验转速、刺激时间对螺旋后效的影响2学习测量运动后效的方法3学习多因素实验设计实验仪器与材料秒表;转速器;同心圆卡片(最大圆直径与转速器相同,其余圆直径依次递减2cm,并分别在圆周上注明号数,最小圆为1号)实验类型4×2多因素实验设计:R Xa1Xb1 O1; R Xa1Xb2 O2; R Xa2Xb1 O3; R Xa2Xb2 O4; R Xa3Xb1 O5; R Xa3Xb2 O6;R Xa4Xb1 O7; R Xa4Xb2 O8变量自变量及其操纵实验有两个变量:A因素为刺激时间(分为15秒、30秒、45秒60秒四个水平);B因素为转速(分为20r/min 、40r/min 两个水平)因变量及其测量旋转后效持续时间和后效的范围额外变量及其控制1 疲劳效应:在每次的螺旋后效之后都给被试3分钟的休息时间2 要保证实验室的安静以能够给被试提供一个适宜的实验环境,并要求被试进行深呼吸,避免激动情绪的影响。
被试20名非心理学专业的未被污染的大学生,男女各半,视听觉正常(或矫正视听觉正常),随机分为两组。
指导语这是一个观察转动器的旋转旋转的实验。
实验时我先让转动器旋转起来,你听到我喊“预备······看”时,就注视着转动器的中心。
当我喊“停”时,你就马上注视那张卡片上同心圆的圆心。
这时你会觉得有一个向外扩散的螺旋。
告诉我这个向外扩散的螺旋的最大范围和第几号圆一样大。
等你再也看不到扩散现象的时候就立即告诉我。
现在咱们可以先做两次。
你要注意掌握扩散范围的标准,以及扩散现象停止的标准,这种标准在整个实验中要前后一致。
心理学多因素实验设计案例

心理学多因素实验设计案例案例:不同音乐类型和学习环境对记忆效果的影响。
一、实验目的。
咱就想知道啊,听着不同类型的音乐,然后在不同的学习环境里,到底对记忆东西有啥不一样的影响呢?是能让我们像超级学霸一样过目不忘,还是变得像金鱼一样只有七秒记忆呢 。
二、实验因素和水平。
1. 音乐类型(因素A)水平一:古典音乐,就像莫扎特、贝多芬那些高大上的曲子,感觉一听就很有文化气息 。
水平二:流行音乐,周杰伦啊、泰勒·斯威夫特之类的,超级抓耳,大街小巷都在放的那种。
水平三:摇滚音乐,比如崔健、AC/DC,充满激情,让你听了就忍不住想摇头晃脑的那种。
2. 学习环境(因素B)水平一:安静的图书馆环境,超安静,只有翻书的沙沙声和偶尔的咳嗽声。
水平二:稍微有点嘈杂的咖啡店环境,有咖啡机的嗡嗡声,人们的低声交谈声。
水平三:家庭环境,可能会有电视的背景音,家人偶尔走动的声音。
三、实验设计类型。
我们采用3×3的完全随机多因素实验设计。
也就是说,我们要把这音乐类型的三个水平和学习环境的三个水平进行各种组合,然后随机分配给不同的参与者。
四、实验对象。
找了90个大学生,为啥是大学生呢?因为他们学习任务多,而且好忽悠……不是,是因为他们比较容易找到,而且处于经常需要记忆知识的阶段 。
五、实验过程。
1. 先把这90个大学生随机分成9组,每组10个人。
2. 对于第一组,让他们戴着耳机听古典音乐,然后坐在模拟图书馆的安静环境里,给他们一篇文章看15分钟,然后把文章拿走,让他们尽可能地回忆文章里的内容,记录下他们能回忆起来的字数。
3. 第二组呢,同样听古典音乐,但是是在模拟咖啡店的嘈杂环境里做同样的事情,记录回忆字数。
4. 第三组听古典音乐,在模拟家庭环境里进行,然后记录。
5. 第四组换成流行音乐,按照上面三种环境分别进行实验,记录回忆字数。
6. 第五组听摇滚音乐,也在三种环境下依次做实验,记录结果。
六、可能的结果和解释。
多因素实验设计实验报告(3篇)

第1篇一、实验目的本研究旨在探讨多因素实验设计在心理学领域中的应用,通过实验验证不同自变量对因变量的影响,并分析自变量之间的交互作用。
本实验选取了两个自变量:实验组别和实验时长,考察其对被试反应时间的影响。
二、实验方法1. 实验对象实验对象为30名大学生,男女各半,年龄在18-22岁之间。
所有被试均无色盲、色弱等视觉障碍。
2. 实验材料实验材料为一系列图片,每张图片包含一个字母,要求被试在看到图片后尽快判断该字母是否为目标字母。
3. 实验设计本实验采用2(实验组别:实验组与对照组)×2(实验时长:短时长与长时长)的多因素实验设计。
其中,实验组别为自变量A,实验时长为自变量B。
4. 实验程序(1)实验前,向被试说明实验目的和实验流程,并要求被试在实验过程中保持专注。
(2)实验过程中,将30名被试随机分为两组,每组15人。
实验组进行短时长实验,对照组进行长时长实验。
(3)短时长实验:实验组被试在30秒内完成所有图片判断任务。
(4)长时长实验:对照组被试在60秒内完成所有图片判断任务。
(5)实验结束后,收集被试的反应时间数据。
5. 数据处理采用SPSS软件对实验数据进行方差分析,以检验自变量A和B对因变量(反应时间)的影响,以及自变量之间的交互作用。
三、实验结果1. 实验组别对反应时间的影响方差分析结果显示,实验组别对反应时间有显著影响(F(1,28) = 8.71,p <0.01)。
具体来说,实验组被试的平均反应时间为523.71毫秒,对照组被试的平均反应时间为598.43毫秒。
2. 实验时长对反应时间的影响方差分析结果显示,实验时长对反应时间有显著影响(F(1,28) = 6.82,p <0.05)。
具体来说,短时长实验组被试的平均反应时间为523.71毫秒,长时长实验组被试的平均反应时间为598.43毫秒。
3. 自变量之间的交互作用方差分析结果显示,实验组别与实验时长之间存在交互作用(F(1,28) = 5.05,p < 0.05)。
(完整版)实验心理学的相关实验设计

1.设计一个多因素实验,要求有一个自变量与语言有关,一个与自变量与语言无关,分别说明:(1)你研究的问题;(2)自变量;(3)因变量;(4)变量控制;(5)实验材料的处理;(6)实验过程;(7)数据的统计处理。
答:(1)我研究的问题是:年龄与文章主题熟悉度对小学儿童阅读理解的影响。
(2)自变量①年龄(被试间变量),分三个水平:8岁(小学一年级儿童)、10岁(小学三年级儿童)、12岁(小学五年级儿童);②文章主题熟悉度(被试内变量),分两个水平:熟悉(和儿童生活紧密相关的文章,如描述游乐园的文章)、不熟悉(儿童很难接触领域的文章,如论述某个生僻物理原理)。
(3)因变量因变量为阅读理解成绩,对被试回答文章后选择题的情况进行评分,每道题答对计1分,答错或未答计0分,共30 题,满分为30分。
每位被试的得分即阅读理解成绩。
(4)变量控制①儿童性别,控制方法:在同一个年龄选择同样数量的男生、女生;②儿童智力水平,控制方法:排除智力水平太高或太低的儿童(教师评定);③文章字数,控制方法:全部选择字数在400左右的文章,字数变动在20字之内;④生字水平,控制方法:将生字控制在5~10个,生字指超出小学语文大纲的汉字。
(5)实验材料①与儿童生活紧密相关的文章3篇,每篇400字左右,包含生字5~10个每篇文章后有5道针对文章内容的选择题,四选一,由五位资深语文教师共同编制;②儿童很难接触领域的文章3篇,每篇400字左右,包含生字5~10个每篇文章后有5道针对文章内容的选择题,四选一,由五位资深语文教师共同编制。
(6)被试选择、材料分配与实验过程共60人。
每个被试均阅读全部的6篇文章,阅读完每篇文章都要完成文章后的选择题,共限时40分钟,文章呈现的顺序在被试间按照拉丁方进行平衡。
(7)数据的统计处理①数据整理:删除得分在平均数上下三个标准差之外的被试数据;②描述统计分析:计算出6个处理水平结合下被试得分的平均数和标准差;③方差分析:使用SPSS软件分析主效应和交互作用。
多因素实验设计

(2)连续测量旳渐进误差。
二、静态变量
对于某些静态旳被试变量我们也极难得出 因果旳关系。
例:Jones(1972)在一项研究中发觉盲童和 正常小朋友相比较,在运动感觉旳精确 性上要好于正常小朋友。我们是否能够 以为眼盲是造成运动感觉好旳原因?
全部旳自然组设计都不能明确地定出因果关系。
MG-IWS
使用此种设计时,先要有相互配正确两组被试。 一组分配到A1,另一组分配到A2。然后两 组都接受B1和B2旳处理。
MG-CWS
除了B1和B2有屡次试验,并使每一位被试旳 渐进误差都被平衡掉。其他和MG-IWS类似。
IWS-CWS
在这种混合设计中,因为两个变量都属于被试内设 计,所以只有一种被试组。
原因设计旳最简朴形式就是试验中有两个自变量,每 个自变量各有两个水平。这就是2×2原因设计,这 种设计共有四种可能旳组合。
原因设计一般使用两个或三个原因,每个原因有2-6个 水平,原因过多或水平过多都将使试验变得十分复 杂而难以进行,而且成果也难以合理地解释。
二、原因设计旳安排
原因设计既能够按照组内设计也能够按照 组间设计进行,混合设计也常作为原因 设计旳一种设计方式。
三、选用设计类型旳考虑
1、我们首先要考虑所采用旳自变量是否需要 特殊旳设计才能够有效地操纵。
2、其次,我们就是要考虑经济、以便、数据 处理旳精确度等。
第二节 原因设计与交互作用
一、原因设计 二、原因设计旳安排 三、交互作用旳意义
一、原因设计
原因设计是有关两个或两个以上变量(原因)旳试验 设计,它旳特点是将试验中旳每个变量旳多种水平 都结合起来进行试验。
每当我们将两组旳差别归因于被试变量旳不同 步,我们都应该小心,看一看被试变量还有 无我们没有发觉旳不同点。当我们把被试按 照一种不同特征分组时,可能把其他不同旳 特征也涉及进去了。
1.8 多因素实验设计

3
A3
A4
8
9
9
8
8
8
7
7
5
12
6
13
7
12
6
11
研究设计流程与关键点
数据录入
A1
A2
S1 3
4
S2 6
6
S3 4
4
S4 3
2
S5 5
4
S6 7
5
S7 5
3
S8 2
3
A3
A4
8
9
9
8
8
8
7
7
5
12
6
13
7
12
6
11
研究设计流程与关键点
数据录入
3 4 8 9 6 6 9 8 4 4 8 8 3 2 7 7 5 4 5 12 7 5 6 13 5 3 7 12 2 3 6 11
研究设计流程与关键点
文章的生字密度、主题两熟因悉素性混对合学实生验阅设读计理解的影响
1.研究假设:当主题熟悉性不同时,生字密度对阅读理解的影响 可能产生变化。 2.自变量:生字密度(B1,B2,B3三个水平)、主题熟悉性(A1,A2两个水平) 被试内变量(三种生字密度):5:1(a1)、10:1(a2)、20:1(a3) 被试间变量(主题熟悉性):非常熟悉、不熟悉 3.因变量:被试的阅读理解测验分数 4.实施处理:这是一个2*3混合实验设计。8名五年级学生随机分配为两组: 一组学生每人阅读三篇生字密度不同的、主题熟悉的文章; 另一组学生每人阅读三篇生字密度不同的、主题不熟悉的文章; 实验实施时,阅读三篇文章分三次进行,用拉丁方平衡学生阅读文章的 先后顺序;
研究设计流程与关键点
心理学实验设计方案【范本模板】

心理学实验设计方案一,实验题目:人类在背诵英语单词时,英语单词的长度和被试背诵的时间是否影响背诵者的记忆效果1假设1。
1选用短的英语单词背诵时,背诵者的记忆效果比选用长的英语单词好;1.2背诵英语单词的时间长的比背诵时间短的记忆效果好2变量及额外变量的操纵方法2.1自变量:单词的长度,背诵时间2.2因变量:背诵者的记忆效果(在分析中,选取单词默写正确个数为2。
3额外变量:被试的性别、智商水平,疲劳效应等2。
3.1额外变量的操控方法:2.3。
1。
1选择性别数量上相等的被试(男10女10)2。
3.1。
2选择在同一智商水平(按韦克斯勒智力量表)的被试2。
3.1.3让被试在实验中休息3被试的选择及分组选取男女被试各10名,每位被试接受四种水平(长单词—长时间、长单词—短时间、短单词-长时间、短单词—短时间)的实验处理4实验实施过程及方法4.1选择100个英语单词(其中,长短单词各50个)作为实验材料,20名被试把他们随机分配到四个处理水平上,每个处理水平上分配5名被试。
4。
2让每组被试记忆单词,短单词选取CET四级词汇中含5-6个字母的单词,长单词选取CET四级词汇中含9—11个字母的单词;记忆的短时间为5分钟,长时间为10分钟.4.3记忆时间到时,让被试默写自己记忆的单词;批改被试默写的单词二、计算机键盘与水平面可有三种倾斜度:0度、10度和15度,试设计一项实验来证明,哪一种倾斜度最有利于输入字符.单因素被试间设计1. 提出假设:在计算机和水平面之间的三种倾斜度中,0度,10度和15度中,打一段相同的材料(使用相同的语言),在完成任务以后,比较一下哪种任务完成的时间是最少的,假设倾斜10度所需要的时间是最少的.2。
被试筛选被试:筛选被试:在对被试进行选择的过程中,需要进行严格的筛选。
在进行最后的测试之前,要对每个被试进行测试。
让所有被试在同一个房间里进行,给他们500字的中文文字,在最后的结果中筛选出在3-4分钟内完成的被试,这样能够排除掉打字技术对成绩的干扰。
多因素实验设计第二章因素型心理实验设计

多因素实验设计第二章因素型心理实验设计《实验心理学》教案(3)应用心理学2002 级03班第二章因素型心理实验设计实验设计是进行心理学实验研究的基本过程和重要保证。
我们将分三个内容来讨论有关于心理实验设计问题:一是因素型实验设计,这是讨论的重点;二是心理学的生态化运动和准实验设计,这是近年来开始受到心理学家关注的新课题;三是实验心理学的逻辑。
我们希望在这三部分内容学习之后,不仅对心理实验设计的方法有所了解,更重要的是对心理学的实验研究方法有一个正确的估价,同时能够培养一种正确的又不是保守和僵化的思想方法。
本章对心理学的实验设计类型进行分析之后,专门讨论因素型心理实验设计。
一、心理实验设计的类型分析什么叫做心理实验设计?那我们先说什么是心理实验:创设或改变一定的条件,以引起被试的某种心理活动以进行观察的心理学研究方法。
其在本质上,还是要进行观察,只不过这种观察不再是被动的,是研究者对被试施加了某种影响或控制,所以心理实验又叫做有控制的观察。
这样一来,我们可以把观察和实验表示成一个维度上的两端,如图2-1所示。
观察法是在保证被研究对象完全真实自然存在的条件下,对其心理和行为的外在表现进行观察,然后推断其心理活动规律的方法;实验法则是在严密控制实验中可能的额外变量的情况下,操纵自变量,观察被研究对象的心理和行为的外在表现,然后推断其心理活动规律的方法;准实验方法和自然实验法均为介于观察法和实验法之间的心理学研究方法,这两种方法都是指对被研究对象有一定的干预和影响,但对实验中可能的额外变量未作严格控制的研究方法,其在一定程度上保证了研究对象的自然存在性。
在图2-1中的坐标上,越靠近右端,实验中对额外变量的控制越严格;越靠近左端,研究中对额外变量的控制越少。
这里不再讨论观察法,所以讨论的范围就被界定为准实验设计和真实验设计。
真实验设计就是要在实验过程中尽量严密地控制实验条件,以探求被试心理活动的因果关系;准实验设计就是不严密的实验设计,其中不求对实验条件进行严密控制,更强调研究情境的自然性和真实性。
实验心理学第五讲真实验(二)多因素实验设计1

典型的两因素实验设计
两因素完全随机实验设计 • 两个自变量都是被试间变量
两因素被试内实验设计 • 两个自变量都是被试内变量
两因素混合实验设计 • 一个自变量是被试内变量,一个是被试间变量
两因素完全随机(被试间)实验 设计
• • •
•
•
基本特点 两个自变量,每个自变量有两个或两个以上的 水平,如p×q个处理水平 两个自变量都是被试间变量 被试随机分配给各处理水平结合 每个被试只接受一个处理水平结合的处理 所需被试量:N=npq,n是接受同一实验条件 的被试的数量
•
SSBX被试(A)的实质 分别计算B因素在a1和a2水 平上的数据,可得到两个单 因素重复测量设计
SS残差(pooled)= SSBX被试(A) =60165.48+50105.12=110270.6 SSBX被试(A):相当于嵌套在a1和a2水平 内的两个单因
三因素实验设计
阅读反应时/ms
580 560 540 520 500 规则 不规则
高频 低频
简单效应检验(simple effect test)
多因素实验设计中,当交互作用显著时, 考察一个因素在另一个因素的每个水平 上的处理效应,以确定该因素的处理效 应在另一个因素的哪个水平上是显著的
可检验的假说
A因素在B的不同水平上可检验的假说 H0:aj(在b1水平) = 0 H0:aj(在b2水平) = 0 ………… B因素在A的不同水平上可检验的一组假说 H0:βk(在a1水平) = 0 H0:βk(在a2水平) = 0 …………
• •
•
基本特点 两个自变量,每个自变量有两个或两个 以上的水平,如p×q个处理水平 两个自变量一个是被试内变量,另一个 是被试间变量 所需被试量:N=np, n是接受同一实验 条件的被试的数量,p是被试间变量的水 平数
多因素完全随机实验设计

第二节 多因素完全随机实验设计对于单因素完全随机实验设计来说,实验的处理数就是自变量的水平数,将被试随机分配到各个处理组上就可以了。
多因素完全随机实验设计则是多个因素的多种水平相互结合,构成多个处理的结合,如二因素二水平,就是有两个自变量,每个自变量有两个水平,则处理的结合共有四个,这种实验设计称为是2×2实验设计;如果一个自变量两个水平,另一个变量是三个水平,则共有6个实验处理,这种实验设计就是2×3实验设计。
如果有三个自变量,其中两个自变量是2个水平,另一个变量有3个水平,则这种实验设计有12个实验处理,叫做2×2×3设计。
这里需要重申以下几点:第一,自变量是研究者操纵的变量,在实验过程中必须是变化了的,也就是说自变量的水平数至少为2。
如果自变量的水平数为1,那就等于说该变量在实验过程中始终保持在一个水平上,它就不是“变”量了。
比方说,一个2×3×1×2实验设计中,实际上只有三个自变量,它们的水平数分别为2、3、2。
第二,实验处理就是自变量在各种水平上结合而成的各种实验条件,实验处理数等于所有自变量水平数的乘积。
如一个2×3×3实验设计,其实验处理数是18,等于说这一实验过程中出现18种实验条件。
第三,对于完全随机实验设计来说,有多少种实验处理就要有多少组实验被试,因为一组被试只参加一种实验条件下的实验。
现在,我们以下面这个假想的实验研究为例来说明多因素完全随机实验设计的模式。
假设某研究者想考察缪勒错觉受箭头方向和箭头张开角度的影响。
研究中的自变量有两个,一个是箭头方向(标记为A ),分为向内和向外两个水平;另一个是箭头张开角度(标记为B ),设置为15度和45度两个水平,因此这是一个2×2实验设计,构成了4种实验处理,如表2-1所示。
研究者从某大学文学院本科二年级一60人的班级随机抽取了20名男生,再将20名男生随机分成相等的四个组,每组5人,每一个组接受一种实验处理,所以,这是一个二因素完全随机实验设计。
心理学与教育研究中的多因素实验设计

心理学与教育研究中的多因素实验设计——舒华第二章几种基本的实验设计第一节单因素完全随机实验设计一、基本特点适用于:研究中有一个自变量,自变量有两个或多于两个水平。
方法:把被试随机分配给自变量的各个水平,每个水平被试只接受一个水平的处理。
二、计算与举例(一)检验的问题与实验设计(二)实验数据及其计算第二节单因素随机区组实验设计一、基本特点适用于:研究中有一个变量,自变量有两个或多个水平(P≥2),研究中还有一个无关变量,也有两个或多个水平(n≥2);并且自变量的水平与无关变量的水平之间没有交互作用。
适合检验的假说:(1)处理水平的总体平均数相等或处理效应为零;(2)区组的总体平均数相等或区组效应为零。
二、计算三、优点:从实验中分离出了一个无关变量的效应,从而减少了实验误差。
第三节单因素拉丁方设计一、基本特点定义:是一个含P行、P列、把P个字母分配给方格的管理方案,其中每个字母在每行中只出现一次。
适用于:(1)研究中自变量与无关变量的水平平均≥2,一个无关变量的水平被分配给P行,另一个则给P列;(2)假定处理水平与无关变量水平之间没有交互作用,(3)随即分配处理水平给个方格单元,每个处理水平仅在每行,每列中出现一次。
无关变量C的四个水平无关变量B的四个水平自变量A的四个水平第四节单因素重复测量实验设计一、基本特点:(也叫被试内设计)基本方法:实验中每个被试接受所有的处理水平目的:利用被试自己做控制,使被试的各方面特点在所有的处理中保持恒定,以最大限度地控制由被试的个体差异带来的变异。
假设:当若干处理水平连续实施给同一被试时,被试接受前面的处理,对接受后面的处理没有长期的影响。
优点:从总变异中分离出了被试间变异,与完全随机实验相比,它提高了实验处理的F检验的敏感性。
第三章两因素完全随机和随机区组实验设计第一节两因素完全随机实验设计一、基本特点与单因素相比:可对两个或多个变量之间的交互作用进行估价不同:每个被试接受的是一个处理的结合,而不是一个处理水平二、举例第二节对交互作用的进一步检验一、交互作用图解二、简单效应检验(一)简单效应的基本特点及其作用分别检验一个因素在另一个因素的每个水平上的处理效应,以便具体地确定它的处理效应在另一个因素的哪个水平上是显著的,在哪些水平上是不显著的。
心理学因果研究的实验设计(多变量)

真实验设计
(二)实验组控制组(等组)前后测设计 形式:实验组 RG1 前测○1 × 后测○2
控制组 RG2 前测○3 —— 后测○4 优点:可以对实验组前后测的差异(○2—○1)和控制
读理解的影响。 被试选择:随机选取20名被试,每人均接受四种
实验处理 IV1:生字密度:有组织/无组织 IV2:主题熟悉性:熟悉/不熟悉 DV:文章阅读理解的成绩
18
多因素被试内设计
表12 文章生字密度和主题熟悉性对学生阅读理解影响的实验处理安排
A1B1 A1B2 A2B1 A2B2
组w
w1
【自变量与因变量同为类型变量】
5
类型IV与连续DV的多因素实验设计
基本类型:
多因素完全随机设计; 多因素随机区组设计; 多因素被试内设计; 多因素混合设计
优势:
既可以探讨多个因素对因变量的影响作用,也可 以对多个自变量之间的交互作用进行估计。
6
类型IV与连续DV的多因素实验设计
基本步骤:
关变量采取了严格的控制并有效地操纵研究变 量。 实验设计中综合采取了随机取样、前测和控制 组等手段。
3030
真实验设计
(一)实验组控制组(等组)后测设计 形式:实验组 RG1 × 后测○1
控制组 RG2 —— 后测○2 优点:采用了随机取样的方法,有效地控制了选择、
选择与成熟交互作用等无关变量对实验结果的干扰; 在实验处理之前没有前测,可避免练习效应的影响; 控制组的设置控制了历史、成熟、测验和统计回归 等无关变量的影响。 局限性:因为没有前测,因而不能进行实验处理前 后差异的比较。 统计思路:应使用独立样本t检验对○1和○2做差异 检验。
读音学习影响研究
IV1:幼儿年龄(3~5岁):3、4、5岁三组; IV2:图形提示:有/无提示 DV:读音学习:正确读音数
多因素实验设计

多变量实验设计在心理学实验设计中,一类实验设计是考察单一自变量(或称为因素)对因变量的影响,这类实验设计称为单变量实验设计(Single-Variable Experiment);另外一类实验设计是考察两个或两个以上的自变量(或因素)对因变量的影响,这类实验设计称为多变量试验设计(Multiple-Variable Experiment)。
多变量实验设计包括多因素组间实验设计、多因素组内实验设计和混合实验设计。
2多因素组间实验设计多因素组间实验设计是单因素组间实验设计的扩展。
在多因素完全随机实验设计中,基本方法是:随机取样被试,并将参加实验的被试分为若干个实验处理组,每组被试分别接受一种实验处理水平的结合。
我们以两因素完全随机实验设计举例,表1中自变量A因素有两个水平,B因素有四个水平。
两个因素共有2×4=8种处理水平的结合,即A1B1,A1B2,A1B3,A1B4,A2B1,A2B2,A2B3,A2B4。
将被试随机分为八组,每组被试接受一个自变量实验处理水平的结合。
实验设计的基本思想是,由于实验处理前,被试是随机分配给各实验处理组的,因而保证了各组被试实验之前无差异。
实验处理后测量到的差异可能来自A因素、B因素,或来自A因素与B因素的交互作用。
表1 两因素完全随机实验设计举例实验处理水平的结合后测实验组1 A1B1 Y实验组2 A1B2 Y实验组3 A1B3 Y实验组4 A1B4 Y实验组5 A2B1 Y实验组6 A2B2 Y实验组7 A2B3 Y实验组8 A2B4 Y3多因素组内实验设计多因素组内(被试内)实验设计是单因素组内实验设计的扩展。
在多因素被试内实验设计中,基本方法是:随机取样被试,参加实验的被试接受全部实验处理水平的结合。
以两因素被试内实验设计举例,表2中自变量A因素有两个水平,B因素有四个水平。
两个因素共有2×4=8种处理水平的结合,即A1B1,A1B2,A1B3,A1B4,A2B1,A2B2,A2B3,A2B4。
多因素实验设计 因素分解

多因素实验设计因素分解交互作用的数量:KCn=K!/n(K-n)!K:因素(自变量)的数量;n:交互作用的次数1 单因素实验设计1.1 单因素完全随机实验设计:分解:SS总变异=SS组间+SS组内计算:SS总变异=[AS]-[Y] df=np-1SS组间=[A]-[Y] df=p-1SS组内= SS总变异-SS组间df=p(n-1)1.2 单因素随机区组实验设计分解:SS总变异=SS处理间+SS处理内=SSA+(SS区组+SS残差)计算:SS总变异=[AS]-[Y] df=np-1SSA=[A]-[Y] df=p-1SS处理内=SS总变异-SS处理间SS区组=[S]-[Y] df=n-1SS残差=SS总变异-SSA-SS区组df=(n-1)(p-1)1.3 单因素拉丁方实验设计分解:SS总变异=SS处理间+SS处理内=SSA+(SSB+SSC+SS单元内+SS残差)计算:SS总变异=[ABCS]-[Y] df=np-1SSA=[A]-[Y] df=p-1SSB=[B]-[Y] df=p-1SSC=[C]-[Y] df=p-1SS单元内=[ABCS]-[ABC] df=p2(n-1)SS残差={[ABC]-[Y]}-SSA-SSB-SSC df=(n-1)(p-2)1.4 单因素重复测量实验设计分解:SS总变异=SS被试间+SS被试内=SS被试间+(SSA+SS残差)计算:SS总变异=[AS]-[Y] df=np-1SS被试间=[S]-[Y] df=n-1SS被试内=SS总变异-SS被试间SSA=[A]-[Y] df=p-1SS残差= SS总变异-SS被试间-SSA df=(n-1)(p-1)2 两因素实验设计2.1 两因素完全随机实验设计分解:SS总变异=SS处理间+SS处理内=(SSA+SSB+SSAB)+SS单元内计算:SS总变异=[ABS]-[Y] df=npq-1SSA=[A]-[Y] df=p-1SSB=[B]-[Y] df=q-1SSAB=[AB]-[Y]-SSA-SSB df=(p-1)(q-1)SS单元内=SS总变异-SSA-SSB-SSABdf=pq(n-1)同质性检验:F=max(SS1组,SS2组,SS3组…SSn组)\min(SS1组,SS2组,SS3组…SSn组)2.2 两因素随机区组实验设计分解:SS总变异=SS处理间+SS处理内=(SSA+SSB+SSAB)+(SS区组+SS残差)计算:SS总变异=[ABS]-[Y] df=npq-1SS区组=[S]-[Y] df=n-1SS处理间=[AB]-[Y]SSA=[A]-[Y] df=p-1SSB=[B]-[Y] df=q-1SSAB=[AB]-[Y]-SSA-SSB df=(p-1)(q-1)SS处理内=SS总变异-SS处理间SS残差=SS总变异-SSA-SSB-SSABdf=(pq-1)(n-1)2.3 两因素混合实验设计分解:SS总变异=SS被试间+SS被试内=(SSA+SS被试A)+(SSB+SSAB +SSB×被试A)计算:SS总变异=[ABS]-[Y] df=npq-1SS被试间=[AS]-[Y]SSA=[A]-[Y] df=p-1SS被试A=SS被试间-SSA df=p(n-1)SS被试内=SS总变异-SS被试间SSB=[B]-[Y] df=q-1SSAB=[AB]-[Y]-SSA-SSB df=(p-1)(q-1)SS B×被试A=SS被试内-SSB-SSABdf=p(q-1)(n-1)2.4 两因素重复测量实验设计分解:SS总变异=SS被试间+SS被试内=SS被试间+(SSA+SS A×被试+SSB+SSB×被试+SSAB+SSA×B×被试)计算:SS总变异=[ABS]-[Y] df=npq-1SS被试间=[S]-[Y] df=n-1SS被试内=SS总变异-SS被试间SSA=[A]-[Y] df=p-1SSA×被试=[AS]-[Y]-SS被试间-SSA df=(p-1)(n-1)SSB=[B]-[Y] df=q-1SSAB=[AB]-[Y]-SSA-SSB df=(p-1)(q-1)SSB×被试=[BS]-[Y]-SS被试间-SSBdf=(q-1)(n-1)SSA×B×被试=SS被试内-SSA-SSA×被试-SSB-SSB×被试-SSAB df=(n-1)(p-1)(q-1)3 三因素实验设计3.1 三因素完全随机实验设计分解:SS总变异=SS处理间+SS处理内=(SSA+SSB+SSC+SSAB+SSAC+SSBC+SSABC)+SS单元内计算:SS总变异=[ABCS]-[Y] df=npqr-1SSA=[A]-[Y] df=p-1SSB=[B]-[Y] df=q-1SSC=[C]-[Y] df=r-1SSAB=[AB]-[Y] df=(p-1)(q-1)SSAC=[AC]-[Y] df=(p-1)(r-1)SSBC=[BC]-[Y] df=(q-1)(r-1)SSABC=[ABC]-[Y]-SSA-SSB-SSC-SSAB-SSAC-SSBC df=(p-1)(q-1)(r-1)SS单元内=SS总变异-SSA-SSB-SSC-SSAB-SSAC-SSBC-SSABC df=pqr(n-1)3.2 三因素混合实验设计3.2.1 重复测量一个因素分解:SS总变异=SS被试间+SS被试内=(SSA+SSC+SSAC+SS被试(AC))+(SSB+SSAB+SSBC+SSABC+SSB×被试(AC))计算:SS总变异=[ABCS]-[Y] df=npqr-1SS被试间=[ACS]-[Y] df=npr(q-1)SSA=[A]-[Y] df=p-1SSC=[C]-[Y] df=r-1SSAC=[AC]-[Y] df=(p-1)(r-1)SS被试(AC)=SS被试间-SSA-SSC-SSAC df=pr(n-1)SS被试内=SS总变异-SS被试间SSB=[B]-[Y] df=q-1SSAB=[AB]-[Y] df=(p-1)(q-1)SSBC=[BC]-[Y] df=(q-1)(r-1)SSABC=[ABC]-[Y]-SSA-SSB-SSC-SSAB-SSAC-SSBC df=(p-1)(q-1)(r-1)SSB×被试(AC)=SS被试内-SSB-SSAB-SSBC-SSABC df=pr(n-1)(q-1)3.2.2 重复测量两个因素分解:SS总变异=SS被试间+SS被试内=(SSA+SS被试(A))+(SSB+SSAB+SSB×被试(A)+SSC+SSAC+ SSC×被试(A)+SSBC+SSABC+SSB×C×被试(A))计算:SS总变异=[ABCS]-[Y] df=npqr-1SS被试间=[AS]-[Y] df=np-1SSA=[A]-[Y] df=p-1SS被试(A)=SS被试间-SSA df=p(n-1)SS被试内=SS总变异-SS被试间SSB=[B]-[Y] df=q-1SSAB=[AB]-[Y]-SSA-SSB df=(p-1)(q-1)SSB×被试(A)=[ABS]-[Y]-SS被试间-SSB-SSAB df=p(n-1)(q-1)SSC=[C]-[Y] df=r-1SSAC=[AC]-[Y]-SSA-SSC df=(p-1)(r-1)SSC×被试(A)=[ACS]-[Y]-SS被试间-SSC-SSAC df=p(n-1)(r-1)SSBC=[BC]-[Y]-SSB-SSC df=(q-1)(r-1)SSABC=[ABCS]-[Y]-SSA-SSB-SSAB-SSAC-SSBC df=df=(p-1)(q-1)(r-1)SSB×C×被试(A)=SS被试内-SSB-SSAB-SSB×被试(A)-SSC-SSAC-SSC×被试(A)-SSBC-SSABC 4三因素重复测量实验设计分解:SS总变异=SS被试间+SS被试内=SS被试间+(SSA+SSA×被试+SSB+SSB×被试+SSC+SSC×被试+SSAB+SSA×B×被试+SSAC+SSA×C×被试+SSBC+SSB×C×被试+SSABC+SS A×B×C×被试)计算:SS总变异=[ABCS]-[Y] df=npqr-1SS被试间=[S]-[Y] df=n-1SS被试内=SS总变异-SS被试间SSA=[A]-[Y] df=p-1SSA×被试=[AS]-[Y]-SS被试间-SSA df=(p-1)(n-1)SSB=[B]-[Y] df=q-1SSB×被试=[BS]-[Y]-SS被试间-SSB df=(q-1)(n-1)SSC=[C]-[Y] df=r-1SSC×被试=[CS]-[Y]-SS被试间-SSC df=(r-1)(n-1)SSAB=[AB]-[Y]-SSA-SSB df=(p-1)(q-1)SSA×B×被试=[ABS]-[Y]-SS被试间-SSA-SSB-SSAB-SSA×被试-SSB×被试df=(p-1)(q-1)(n-1)SSAC=[AC]-[Y]-SSA-SSC df=(p-1)(r-1)SSA×C×被试=[ACS]-[Y]-SS被试间-SSA-SSC-SSAC-SSA×被试-SSC×被试df=(p-1)(r-1)(n-1) SSBC=[BC]-[Y]-SSB-SSC df=(q-1)(r-1)SSB×C×被试=[BCS]-[Y]-SS被试间-SSB-SSC-SSBC-SSB×被试-SSC×被试df=(q-1)(r-1)(n-1) SSABC=[ABC]-[Y]-SSA-SSB-SSAB-SSAC-SSBC df=df=(p-1)(q-1)(r-1)SS A×B×C×被试=SS被试内-SSA-SSA×被试-SSB-SSB×被试-SSC-SSC×被试-SSAB-SSA×B×被试-SSAC-SSA×C×被试-SSBC-SSB×C×被试-SSABC-SSA×B×C×被试5 嵌套实验设计5.1 两因素完全随机嵌套实验设计5.2 三因素完全随机嵌套实验设计。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多因素实验设计
1.两因素完全随机实验设计
(1)模式:
(2)实施过程:如果有自变量p个水平,另一个变量有q个水平,那么实验中含有p*q个处理水平结合。
两个自变量都为被试间变量,被试被随机分配给各处理水平结合,每个被试只接受一个处理
水平结合的处理。
(3)统计方法:单因素方差分析
【简单效应检验】
适用:当两个因素的交互作用是显著的时候,考察一个因素在另一个因素的每个水平上的处理效应,即确定它的处理效应在另一个因素的哪些水平上是显著的。
思路:分别计算某个因素的不同水平上,另外一个因素的不同水平间的差异情况。
(4)优点:克服了因重复产生的练习效应、序列效应。
缺点:难以创设相等的组(被试不同质)。
2.两因素被试内实验设计
(1)模式:
(2)实施过程:如果有自变量p个水平,另一个变量有q个水平,实验中含有p*q个处理水平结合。
两个自变量都是被试内变量,每个被试接受所有处理水平结合的处理。
(3)统计方法:SPSS中的重复测量
(4)优点:能够创设相等的组。
缺点:克服了因重复产生的练习效应、序列效应。
3.两因素混合实验设计
(1)模式:
(2)实施过程:如果有自变量p个水平,另一个变量有q个水平,实验中含有p*q个处理水平结合。
两个变量中一个是被试内变量,另一个是被试间变量。
(3)统计方法:SPSS中的重复测量
(4)优点:有效的控制额外变量,更有利于揭示变量间的因果关系。
缺点:操作繁杂,费时费力。