如何破解字符验证码
基于深度学习的验证码破解技术分析

基于深度学习的验证码破解技术分析随着互联网的发展,验证码逐渐成为了网站和应用程序的必备安全机制。
在保障用户信息安全的同时,验证码也给诸多工程师带来了挑战。
传统的验证码破解方法主要是利用机器学习算法以及OCR(光学字符识别)的方式进行攻击,但随着深度学习技术的发展,基于深度学习的验证码破解技术越来越成为一种新的选择。
本文将详细探讨基于深度学习技术的验证码破解方法,并分析其优劣势以及应用领域等方面的内容。
基于深度学习的验证码破解方法基于深度学习的验证码破解方法主要基于卷积神经网络(CNN)或循环神经网络(RNN)的原理,通过训练模型,识别验证码中的文字。
下面对这两种网络进行详细解析:1.卷积神经网络卷积神经网络(CNN)通过建立多层卷积模块,可以有效处理图像数据并提取出关键特征。
由于验证码破解通常需要处理的是一个图像,因此CNN是一种比较适用的网络结构。
在验证码识别中,CNN的建模过程通常分为四个步骤:(1)图像预处理将验证码进行图像预处理,包括灰度化、二值化等操作。
(2)卷积操作卷积操作是CNN的核心部分。
在输入层上进行滤波操作,提取出特征图像,然后逐层进行卷积操作,从而获得越来越复杂的模型。
(3)全连接层全连接层是用于将前面层卷积所提取出的特征图像进行分类的网络结构。
在训练过程中,可以设计多个全连接层,每个层输出不同类别的概率。
(4)输出层输出层是用于展示分类结果的层,展示分类结果的同时可以计算误差,进行反向传播。
2.循环神经网络循环神经网络(RNN)是一种适用于处理序列化数据的网络结构。
在验证码破解当中,RNN无法直接处理整张验证码图像,但可以将验证码分割成若干部分,然后对每部分进行训练,最终将分割好的结果合并在一起。
与CNN不同,RNN具有记忆单元的结构,可以很好地解决序列化数据中长序列依赖关系的问题。
在RNN模型的训练过程中,需要将前一时刻的状态记录下来,然后将其作为下一时刻的输入。
在这样的结构下,可以很好地实现多个时间点之间的数据共享和序列化数据的自动编码。
高级验证码识别,如何识别高级的验证码

高级验证码识别,如何识别高级的验证码疯狂代码 / ĵ:http://YanZhengMa/Article3424.html验证码识别大致是三步曲,分割,去背景,提取特征码,但是对于一些高级的验证码识别,是需要一些特殊的手段的,了解一下验证码识别的技术同样对我们设计验证码还是很有帮助的下面谈一下高级的验证码识别技术一、验证码的基本知识1. 验证码的主要目的是强制人机交互来抵御机器自动化攻击的。
2. 大部分的验证码设计者并不得要领,不了解图像处理,机器视觉,模式识别,人工智能的基本概念。
3. 利用验证码,可以发财,当然要犯罪:比如招商银行密码只有6位,验证码形同虚设,计算机很快就能破解一个有钱的账户,很多帐户是可以网上交易的。
4. 也有设计的比较好的,比如Yahoo,Google,Microsoft,等。
而国内QQ的中文验证码虽然难,但算不上好。
二、人工智能,模式识别,机器视觉,图像处理的基本知识1)主要流程:比如我们要从一副图片中,识别出验证码;比如我们要从一副图片中,检测并识别出一张人脸。
大概有哪些步骤呢?1.图像采集:验证码呢,就直接通过HTTP抓HTML,然后分析出图片的url,然后下载保存就可以了。
如果是人脸检测识别,一般要通过视屏采集设备,采集回来,通过A/D转操作,存为数字图片或者视频频。
2.预处理:检测是正确的图像格式,转换到合适的格式,压缩,剪切出ROI,去除噪音,灰度化,转换色彩空间这些。
3.检测:车牌检测识别系统要先找到车牌的大概位置,人脸检测系统要找出图片中所有的人脸(包括疑似人脸);验证码识别呢,主要是找出文字所在的主要区域。
4.前处理:人脸检测和识别,会对人脸在识别前作一些校正,比如面内面外的旋转,扭曲等。
我这里的验证码识别,“一般”要做文字的切割5.训练:通过各种模式识别,机器学习算法,来挑选和训练合适数量的训练集。
不是训练的样本越多越好。
过学习,泛化能力差的问题可能在这里出现。
验证码新技术趋势

0x00 简介验证码作为一种辅助安全手段在Web安全中有着特殊的地位,验证码安全和web应用中的众多漏洞相比似乎微不足道,但是千里之堤毁于蚁穴,有些时候如果能绕过验证码,则可以把手动变为自动,对于Web安全检测有很大的帮助。
全自动区分计算机和人类的图灵测试(英语:Completely Automated Public Turing test to tell Computers and Humans Apart,简称CAPTCHA),俗称验证码,是一种区分用户是计算机和人的公共全自动程序。
在CAPTCHA测试中,作为服务器的计算机会自动生成一个问题由用户来解答。
这个问题可以由计算机生成并评判,但是必须只有人类才能解答。
由于计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。
(from wikipedia)大部分验证码的设计者都不知道为什么要用到验证码,或者对于如何检验验证码的强度没有任何概念。
大多数验证码在实现的时候只是把文字印到背景稍微复杂点的图片上就完事了,程序员没有从根本上了解验证码的设计理念。
验证码的形式多种多样,先介绍最简单的纯文本验证码。
纯文本验证码纯文本,输出具有固定格式,数量有限,例如:•1+1=?•本论坛的域名是?•今天是星期几?•复杂点的数学运算这种验证码并不符合验证码的定义,因为只有自动生成的问题才能用做验证码,这种文字验证码都是从题库里选择出来的,数量有限。
破解方式也很简单,多刷新几次,建立题库和对应的答案,用正则从网页里抓取问题,寻找匹配的答案后破解。
也有些用随机生成的数学公式,比如随机数 [+-*/]随机运算符随机数=?,小学生水平的程序员也可以搞定……这种验证码也不是一无是处,对于很多见到表单就来一发的spam bot来说,实在没必要单独为了一个网站下那么大功夫。
对于铁了心要在你的网站大量灌水的人,这种验证码和没有一样。
下面讲的是验证码中的重点,图形验证码。
破解手机验证码的四种“姿势”

破解手机验证码的四种“姿势”作者:来源:《电脑报》2018年第21期这里有最新的黑客研究成果,这里有黑客的最新“黑科技”,这里有权威解读,正所谓知己知彼方能百战不殆。
要想全面抵御黑客的攻击,就必须知道黑客的最新动态。
欢迎志同道合的朋友来投稿,投稿邮箱:285845949@。
在生活中经常会碰到要求输入手机验证码的情景,例如注册账号、找回密码、异地登录等,对黑客而言这是非常讨厌的技术,有没有方法可以破解呢?目前,主流的破解方法如下所示:方法1:利用过滤不严漏洞入侵所为过滤不严就是网站没有做好安全细则规划,验证码模块无法发挥正常作用,黑客随意输入验证码就可以获得通过,多见于新上线的网站和小网站。
如此黑客就可以利用漏洞批量注册马甲账号,或者知道受害者的账号和密码就可以重置数据,令受害者无法登录自己的账号。
方法2:利用无限制漏洞作恶有的网站系统考虑不周到,设计验证码模块没有考虑黑客因素。
例如网站系统设定为每隔60秒就可以向指定手机发送短信,没有发送次数限制、没有对手机号码的限制,于是通过编写Python脚本来计算短信下发时间间隔就可以实现短信轰炸某个人的手机,令一个人彻底崩溃——有的黑客利用这个手法来进行敲诈或者给非法人士充当打手。
方法3:利用未绑定漏洞搞鬼正常情况下,短信验证码只能使用一次,但如果用户的账號和手机号码没有绑定,且网站系统没有设定验证码与手机号码绑定,那么就可以出现一部手机在一定时间间隔内接到两个验证码都可以用,或者一部手机接到的验证码另外一部手机也可以用。
那么黑客就可以远程盗取受害者的验证码,在自己的手机上使用。
方法4:暴力破解验证码短信验证码一般由4位或6位数字组成,如果网站系统或者手机APP服务器未对验证时间、次数进行限制,就存在暴力破解的可能(不一定可以成功,但理论上是可行的,且成功率较大)。
通过黑客攻击抓包,再将短信验证码字段payloads取值范围设置为000000-999999就可以进行暴力破解,根据返回响应包长度判断是否破解成功。
验证码的原理 作用及实现方法

验证码的原理作用及实现方法
验证码的原理是通过给用户提供一种需要人类智能才能解答的问题或者需要输入一串随机生成的字符,用于验证用户的身份。
验证码的作用是防止机器人、恶意软件或者网络爬虫等非人类用户对网站进行自动化操作,同时也可以防止黑客进行暴力破解等恶意活动。
实现验证码的方法有多种,常见的包括:
1. 图片验证码:生成一张包含字符、数字或者图片的验证码图片,用户需要正确识别并输入其中的内容。
2. 数字字母验证码:生成一串包含数字和字母的随机字符串,用户需要将其正确输入。
3. 数学公式验证码:生成一个简单数学公式,用户需要计算出结果并输入。
4. 短信验证码:通过短信将一串随机数字发送给用户,用户需要将其正确输入。
5. 声音验证码:播放一段包含数字、字母或者特定音频的音频文件,用户需要将其中的内容正确输入。
实现验证码的方法取决于具体的应用场景和安全要求,一般需要根据应用需求选
择合适的方式进行开发和部署。
同时,为了提高安全性,验证码通常还会配合其他的防护措施,如IP封禁、人机行为分析等,以保护网站的安全和正常运行。
语序验证码破解思路

语序验证码破解思路
语序验证码是一种常见的人机交互验证方式,通过要求用户按
照特定的语序排序或选择文字来确认其为真实用户而不是机器人。
破解语序验证码的思路可以从以下几个方面展开:
1. 自然语言理解,破解语序验证码需要对文字进行理解和分析。
首先,需要识别并理解验证码中的文字内容,包括词语的意义和语境。
这可以通过自然语言处理技术来实现,例如文本分析、词性标注、句法分析等。
2. 文本识别和分割,对于图形化的语序验证码,需要先进行文
字的识别和分割,将验证码中的文字分离出来。
这需要使用计算机
视觉技术,包括图像处理、文字识别等算法来实现。
3. 语义推理和排序,在识别和理解验证码中的文字后,需要进
行语义推理和排序。
这涉及到对文字之间的逻辑关系进行推断和排序,例如根据语义关联、逻辑关系等来确定正确的语序。
4. 机器学习和深度学习,利用机器学习和深度学习技术,可以
训练模型来识别和理解语序验证码。
通过大量的数据训练,模型可
以学习到文字之间的关系和排序规律,从而提高破解的准确性和效率。
5. 模拟人类行为,最后,可以模拟人类的行为来破解语序验证码,例如利用人工智能技术模拟人类的阅读和理解过程,以及人类在处理语序问题时的思维方式和行为模式。
总的来说,破解语序验证码需要综合运用自然语言处理、计算机视觉、机器学习等多种技术手段,同时也需要对人类语言理解和逻辑推理过程有深入的理解,以便更好地模拟和破解这种人机交互验证方式。
Python破解极验滑动验证码详细步骤

Python破解极验滑动验证码详细步骤⽬录极验滑动验证码实现位移移动需要的基础知识对⽐两张图⽚,找出缺⼝获得图⽚按照位移移动详细代码极验滑动验证码现在极验验证码已经更新到了 3.0 版本,截⾄ 2017 年 7 ⽉全球已有⼗六万家企业正在使⽤极验,每天服务响应超过四亿次,⼴泛应⽤于直播视频、⾦融服务、电⼦商务、游戏娱乐、政府企业等各⼤类型⽹站对于这类验证,如果我们直接模拟表单请求,繁琐的认证参数与认证流程会让你蛋碎⼀地,我们可以⽤selenium驱动浏览器来解决这个问题,⼤致分为以下⼏个步骤1、输⼊⽤户名,密码2、点击按钮验证,弹出没有缺⼝的图3、获得没有缺⼝的图⽚4、点击滑动按钮,弹出有缺⼝的图5、获得有缺⼝的图⽚6、对⽐两张图⽚,找出缺⼝,即滑动的位移7、按照⼈的⾏为⾏为习惯,把总位移切成⼀段段⼩的位移8、按照位移移动9、完成登录实现位移移动需要的基础知识位移移动相当于匀变速直线运动,类似于⼩汽车从起点开始运⾏到终点的过程(⾸先为匀加速,然后再匀减速)。
其中a为加速度,且为恒量(即单位时间内的加速度是不变的),t为时间位移移动的代码实现def get_track(distance):'''拿到移动轨迹,模仿⼈的滑动⾏为,先匀加速后匀减速匀变速运动基本公式:①v=v0+at②s=v0t+(1/2)at²③v²-v0²=2as:param distance: 需要移动的距离:return: 存放每0.2秒移动的距离'''# 初速度v=0# 单位时间为0.2s来统计轨迹,轨迹即0.2内的位移t=0.1# 位移/轨迹列表,列表内的⼀个元素代表0.2s的位移tracks=[]# 当前的位移current=0# 到达mid值开始减速mid=distance * 4/5distance += 10 # 先滑过⼀点,最后再反着滑动回来while current < distance:if current < mid:# 加速度越⼩,单位时间的位移越⼩,模拟的轨迹就越多越详细 a = 2 # 加速运动else:a = -3 # 减速运动# 初速度v0 = v# 0.2秒时间内的位移s = v0*t+0.5*a*(t**2)# 当前的位置current += s# 添加到轨迹列表tracks.append(round(s))# 速度已经达到v,该速度作为下次的初速度v= v0+a*t# 反着滑动到⼤概准确位置for i in range(3):tracks.append(-2)for i in range(4):tracks.append(-1)return tracks对⽐两张图⽚,找出缺⼝def get_distance(image1,image2):'''拿到滑动验证码需要移动的距离:param image1:没有缺⼝的图⽚对象:param image2:带缺⼝的图⽚对象:return:需要移动的距离'''# print('size', image1.size)threshold = 50for i in range(0,image1.size[0]): # 260for j in range(0,image1.size[1]): # 160pixel1 = image1.getpixel((i,j))pixel2 = image2.getpixel((i,j))res_R = abs(pixel1[0]-pixel2[0]) # 计算RGB差res_G = abs(pixel1[1] - pixel2[1]) # 计算RGB差res_B = abs(pixel1[2] - pixel2[2]) # 计算RGB差if res_R > threshold and res_G > threshold and res_B > threshold:return i # 需要移动的距离获得图⽚def merge_image(image_file,location_list):"""拼接图⽚:param image_file::param location_list::return:"""im = Image.open(image_file)im.save('code.jpg')new_im = Image.new('RGB',(260,116))# 把⽆序的图⽚切成52张⼩图⽚im_list_upper = []im_list_down = []# print(location_list)for location in location_list:# print(location['y'])if location['y'] == -58: # 上半边im_list_upper.append(im.crop((abs(location['x']),58,abs(location['x'])+10,116)))if location['y'] == 0: # 下半边im_list_down.append(im.crop((abs(location['x']),0,abs(location['x'])+10,58)))x_offset = 0for im in im_list_upper:new_im.paste(im,(x_offset,0)) # 把⼩图⽚放到新的空⽩图⽚上x_offset += im.size[0]x_offset = 0for im in im_list_down:new_im.paste(im,(x_offset,58))x_offset += im.size[0]new_im.show()return new_imdef get_image(driver,div_path):'''下载⽆序的图⽚然后进⾏拼接获得完整的图⽚:param driver::param div_path::return:'''time.sleep(2)background_images = driver.find_elements_by_xpath(div_path)location_list = []for background_image in background_images:location = {}result = re.findall('background-image: url\("(.*?)"\); background-position: (.*?)px (.*?)px;',background_image.get_attribute('style')) # print(result)location['x'] = int(result[0][1])location['y'] = int(result[0][2])image_url = result[0][0]location_list.append(location)print('==================================')image_url = image_url.replace('webp','jpg')# '替换url /pictures/gt/579066de6/579066de6.webp'image_result = requests.get(image_url).content# with open('1.jpg','wb') as f:# f.write(image_result)image_file = BytesIO(image_result) # 是⼀张⽆序的图⽚image = merge_image(image_file,location_list)return image按照位移移动print('第⼀步,点击滑动按钮')ActionChains(driver).click_and_hold(on_element=element).perform() # 点击⿏标左键,按住不放time.sleep(1)print('第⼆步,拖动元素')for track in track_list:ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform() # ⿏标移动到距离当前位置(x,y)if l<100:ActionChains(driver).move_by_offset(xoffset=-2, yoffset=0).perform()else:ActionChains(driver).move_by_offset(xoffset=-5, yoffset=0).perform()time.sleep(1)print('第三步,释放⿏标')ActionChains(driver).release(on_element=element).perform()详细代码from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWait # 等待元素加载的from mon.action_chains import ActionChains #拖拽from selenium.webdriver.support import expected_conditions as ECfrom mon.exceptions import TimeoutException, NoSuchElementExceptionfrom mon.by import Byfrom PIL import Imageimport requestsimport timeimport reimport randomfrom io import BytesIOdef merge_image(image_file,location_list):"""拼接图⽚:param image_file::param location_list::return:"""im = Image.open(image_file)im.save('code.jpg')new_im = Image.new('RGB',(260,116))# 把⽆序的图⽚切成52张⼩图⽚im_list_upper = []im_list_down = []# print(location_list)for location in location_list:# print(location['y'])if location['y'] == -58: # 上半边im_list_upper.append(im.crop((abs(location['x']),58,abs(location['x'])+10,116)))if location['y'] == 0: # 下半边im_list_down.append(im.crop((abs(location['x']),0,abs(location['x'])+10,58)))x_offset = 0for im in im_list_upper:new_im.paste(im,(x_offset,0)) # 把⼩图⽚放到新的空⽩图⽚上x_offset += im.size[0]x_offset = 0for im in im_list_down:new_im.paste(im,(x_offset,58))x_offset += im.size[0]new_im.show()return new_imdef get_image(driver,div_path):'''下载⽆序的图⽚然后进⾏拼接获得完整的图⽚:param driver::param div_path::return:'''time.sleep(2)background_images = driver.find_elements_by_xpath(div_path)location_list = []for background_image in background_images:location = {}result = re.findall('background-image: url\("(.*?)"\); background-position: (.*?)px (.*?)px;',background_image.get_attribute('style')) # print(result)location['x'] = int(result[0][1])location['y'] = int(result[0][2])image_url = result[0][0]location_list.append(location)print('==================================')image_url = image_url.replace('webp','jpg')# '替换url /pictures/gt/579066de6/579066de6.webp'image_result = requests.get(image_url).content# with open('1.jpg','wb') as f:# f.write(image_result)image_file = BytesIO(image_result) # 是⼀张⽆序的图⽚image = merge_image(image_file,location_list)return imagedef get_track(distance):'''拿到移动轨迹,模仿⼈的滑动⾏为,先匀加速后匀减速匀变速运动基本公式:①v=v0+at②s=v0t+(1/2)at²③v²-v0²=2as:param distance: 需要移动的距离:return: 存放每0.2秒移动的距离'''# 初速度v=0# 单位时间为0.2s来统计轨迹,轨迹即0.2内的位移t=0.2# 位移/轨迹列表,列表内的⼀个元素代表0.2s的位移tracks=[]# 当前的位移current=0# 到达mid值开始减速mid=distance * 7/8distance += 10 # 先滑过⼀点,最后再反着滑动回来# a = random.randint(1,3)while current < distance:if current < mid:# 加速度越⼩,单位时间的位移越⼩,模拟的轨迹就越多越详细a = random.randint(2,4) # 加速运动else:a = -random.randint(3,5) # 减速运动# 初速度v0 = v# 0.2秒时间内的位移s = v0*t+0.5*a*(t**2)# 当前的位置current += s# 添加到轨迹列表tracks.append(round(s))# 速度已经达到v,该速度作为下次的初速度v= v0+a*t# 反着滑动到⼤概准确位置for i in range(4):tracks.append(-random.randint(2,3))for i in range(4):tracks.append(-random.randint(1,3))return tracksdef get_distance(image1,image2):'''拿到滑动验证码需要移动的距离:param image1:没有缺⼝的图⽚对象:param image2:带缺⼝的图⽚对象:return:需要移动的距离'''# print('size', image1.size)threshold = 50for i in range(0,image1.size[0]): # 260for j in range(0,image1.size[1]): # 160pixel1 = image1.getpixel((i,j))pixel2 = image2.getpixel((i,j))res_R = abs(pixel1[0]-pixel2[0]) # 计算RGB差res_G = abs(pixel1[1] - pixel2[1]) # 计算RGB差res_B = abs(pixel1[2] - pixel2[2]) # 计算RGB差if res_R > threshold and res_G > threshold and res_B > threshold:return i # 需要移动的距离def main_check_code(driver, element):"""拖动识别验证码:param driver::param element::return:"""image1 = get_image(driver, '//div[@class="gt_cut_bg gt_show"]/div')image2 = get_image(driver, '//div[@class="gt_cut_fullbg gt_show"]/div')# 图⽚上缺⼝的位置的x坐标# 2 对⽐两张图⽚的所有RBG像素点,得到不⼀样像素点的x值,即要移动的距离l = get_distance(image1, image2)print('l=',l)# 3 获得移动轨迹track_list = get_track(l)print('第⼀步,点击滑动按钮')ActionChains(driver).click_and_hold(on_element=element).perform() # 点击⿏标左键,按住不放time.sleep(1)print('第⼆步,拖动元素')for track in track_list:ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform() # ⿏标移动到距离当前位置(x,y) time.sleep(0.002) # if l>100:ActionChains(driver).move_by_offset(xoffset=-random.randint(2,5), yoffset=0).perform()time.sleep(1)print('第三步,释放⿏标')ActionChains(driver).release(on_element=element).perform()time.sleep(5)def main_check_slider(driver):"""检查滑动按钮是否加载:param driver::return:"""while True:try :driver.get('/api/geetest/')element = WebDriverWait(driver, 30, 0.5).until(EC.element_to_be_clickable((By.CLASS_NAME, 'gt_slider_knob')))if element:return elementexcept TimeoutException as e:print('超时错误,继续')time.sleep(5)if __name__ == '__main__':try:count = 6 # 最多识别6次driver = webdriver.Chrome()# 等待滑动按钮加载完成element = main_check_slider(driver)while count > 0:main_check_code(driver,element)time.sleep(2)try:success_element = (By.CSS_SELECTOR, '.gt_holder .gt_ajax_tip.gt_success')# 得到成功标志print('suc=',driver.find_element_by_css_selector('.gt_holder .gt_ajax_tip.gt_success'))success_images = WebDriverWait(driver, 20).until(EC.presence_of_element_located(success_element))if success_images:print('成功识别')count = 0breakexcept NoSuchElementException as e:print('识别错误,继续')count -= 1time.sleep(2)else:print('too many attempt check code ')exit('退出程序')finally:driver.close()成功识别标志css以上就是Python破解极验滑动验证码的详细内容,更多关于Python极验滑动验证码的资料请关注其它相关⽂章!。
密码的破译方法

密码的破译方法
密码的破译方法有以下几种:
1. 字典攻击:攻击者使用常见密码和词汇构成的字典进行暴力破解,通过尝试不同的组合,直到找到正确的密码。
2. 暴力攻击:攻击者使用计算机程序生成所有可能的密码组合,逐个尝试,直到找到正确的密码。
3. 社会工程学攻击:攻击者通过欺骗、伪装身份或其他手段,诱使用户自行提供密码或其他敏感信息。
4. 针对弱密码的攻击:攻击者通过分析用户习惯和密码规律,猜测或推测出弱密码。
5. 指纹密码破解:攻击者尝试使用指纹模型、虹膜模型等技术手段破译指纹或虹膜密码。
为了保障密码的安全,可以采取以下措施:
1. 使用强密码:使用含有字母、数字和特殊字符的复杂密码,并避免使用常见密码和个人相关的信息。
2. 密码加密:对密码进行加密处理,防止明文被直接泄露。
3. 双因素认证:在密码的基础上,增加使用手机验证码、指纹识别等额外的身份验证方式。
4. 定期更换密码:定期更换密码,减少密码被猜测或攻击的机会。
5. 注意网络安全:提高对网络安全的意识,避免使用公共网络、不信任的电脑或设备输入敏感密码。
总体而言,遵循密码安全原则,使用复杂、独特且难以猜测的密码,以及采取额外的身份验证措施,可以有效提高密码的安全性。
突破百度贴吧的验证码限制

百度,作为国内搜索引擎的大户,为了进一步扩大自己的用户群,专门开设了“百度贴吧”(2003年11月百度贴吧 ()自从诞生以来逐渐成为世界最大的中文交流平台!当用户在百度搜索引擎中搜索出需要搜索的关键字,点击“贴吧”即可进入以关键字为专题的相应贴吧)的服务。
操作简单而又针对性,这是贴吧火极一时的重要原因,可正因为如此,百度贴吧的安全性又怎么样呢?这就是我们今天探讨的话题!相信大家都有在论坛灌水的经历吧?但是如果你连续发表统一内容的东西在论坛中,不久论坛的整个板块就全是你发表的信息了,其他信息全被挤在了后面。
假设你发表的信息够多,版主都删不完时,那么这个论坛基本就报废了!其他的商业论坛也意识到了防止恶意灌水的重要性,纷纷使用了一些防止恶意灌水的措施,有发贴间隔时间的限制、同一IP地址的发贴数限制、内容不能重复等,但是这些都不是今天的重点,由于百度使用的是一个公用发贴表单,允许匿名发帖,需要突破唯一的难点是验证码。
(为了防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试或是防止不断提交某网络信息而采用的一种网络通行方式。
随机生成字符信息放入图片中,防止计算机直接识别。
比如招商银行的网上个人银行,腾讯的QQ社区等等)这时验证码在整个系统中就扮演了了一个至关重要的角色。
如果我们能突破它,写一个自动发布的程序,那么我们来算一算:假设每两秒程序post一次,一分钟就是30次、一小时就有30×60=1800次、一天就有1800×24=43200次!如果我们把发贴程序或是密码穷举程序挂在很多肉鸡上,进行同时工作,那么结果可想而知!笔者曾亲目睹过国内某著名安全论坛就是验证码被人破解,导致被人恶意灌水,最后完全崩溃!当然还有某网络银行也因此类原因导致用户密码被盗等众多事件。
笔者也作如下声明:下文介绍的方法并不是有意针某公司或是某机构,只是作为技术交流,如果部分读者利用本文介绍的方法进行破坏或是穷举他人密码,这已经违法了法律,那么责任由他自己承担,与笔者无关!好了,我们可以进入正题了(以下出现的代码为delphi写的部分源码,为了防止任意利用,我以介绍方法为主,如果读者感兴趣,可以自己组合编写完整,在本文附带的程序中,笔者提供了一个验证码参数确定程序(附源码))。
记录一次谷歌人机验证码破解过程

记录⼀次⾕歌⼈机验证码破解过程前⾔ 哈喽,各位⼩伙伴,你们好呀,今天呢,咱们来说⼀下google,我们都知道,google是⽬前地表最强的搜索引擎了,我们可以借助google庞⼤的搜索资源找到⼀些⾃⼰想要的资源,可能是⼀些收费电影,可能是⼀些奇门⼩说,可能是某个⾓落的种⼦,不管怎么说,google搜索还是挺给⼒的,但是呢,有梯⼦的我们可能都遇到过,我们搜索的多了,会有这种情况 这种验证码呢,叫做ReCaptcha验证码,相对来说,是⽐较繁琐的验证码之⼀ 当然了,ReCaptcha不⽌⾕歌⼀家再⽤,国外的⽹站很多都是使⽤这种验证码,但是在国内不多,因为在国内⽐较容易被墙,所以⽤的少,但是我们是⾼端玩家,在⾃由的internet中,我们怎么可能只局限于国内,下⾯,我们就针对ReCaptcha验证码破解 ⾕歌提供的范例,实际⽹站验证码和这个⼀模⼀样 ReCaptcha验证码样式为什么使⽤第三⽅平台 嗯,看到这可能有⼈会对我不屑⼀顾,说辣鸡才会⽤第三⽅平台,要是按照技术来划分的话,我真的辣鸡,哈哈 但是这⾥要抬杠⼀下,并不是说⽤第三⽅平台就是辣鸡,我们可以想象⼀下,如果是滑动验证码,我们当然有⼀试的能⼒,python可以调⽤OpenCV,看看⽂档,当然是可以实现了,但是有个问题是,你可能针对的⼀个⽹站的滑动验证识别好了,但是可能每个⽹站的滑动验证码都不太⼀样,在⽤OpenCV识别的时候,可能就会识别率低的情况,要是在公司,⼀直完不成任务,嗯,,,等着被炒鱿鱼吧,再说,像⾕歌⼈机个⼈也解决不了,没有NB的机器学习是不可能的,所以只能⽤第三⽅平台,毕竟,完成任务才是⾸要任务为什么推荐2captcha平台 我们先说⼀下现在打码平台机制都有哪些 第⼀种呢,就是打码平台训练好各种各样的数据,⽐如,哪些是花,哪些是车,然后我们把图⽚发送给打码平台,他给我们结果,但是这样会有个问题,如果训练的不好,我们这边的结果也是很不好的,各种不准确,影响效果 第⼆种呢,就是平台雇⼈,我们把整个验证码都给打码平台,平台找⼈帮助我们点击,然后把结果给我们,我们在登录了或者做其他 我们可以看出来,肯定是第⼆种更加灵活地,现在阶段,机器再NB,⾄少在验证码上准确率还是不如⼈的 2captcha平台⽬前采⽤的就是第⼆种⽅式,赚取的是中间差价,但是识别率是我⽤过最⾼的,曾经因为选错了平台,⼀直不成功,加班加点,⿏标都被我砸坏了,唉,所以,选择⼀个合适的平台还是很重要的所需⼯具 Chromedriver:浏览器驱动,可以理解为⼀个没有界⾯的chrome浏览器 Selenium:⽤于模拟⼈对浏览器进⾏点击、输出、拖拽等操作,就相当于是个⼈在使⽤浏览器,也常常⽤来应付反爬⾍措开始⾏动 既来之则安之,选择了2captcha,就要看看⼈家的官⽹啦 打开官⽹ 嗯...纯英⽂,我也看不懂..怎么办呢,别着急,我带你们⼀步⼀步分析主要功能 登录账号 登录完成后,会⾃动跳到主页 第⼀个红⾊圈起来的地⽅表⽰剩余多少钱,没有钱的话记得要氪⾦,否则是不能⽤滴,氪⾦过程这⾥就不多做解释了哈,问题不⼤ 第⼆个红⾊圈起来的地⽅表⽰这是你的唯⼀key,每次请求要带上这个key的,所以要保管好 进⼊主题,研究⽂档 点击红⾊圈的地⽅,API,⼀般API都是⽂档,let's go En....什么玩意..完全看不懂,别慌,往下滑 滑到rates,我们知道,⾕歌⼈机是ReCaptcha,但是三个呢,到底是哪个呢,我就来带⼤家看看 ⾸先点击ReCaptcha(oldmethod),这个是⽼的⽅法,咱也不知道唉,所以就先看看这个吧,从浅到深嘛,这⾥呢,我都直接翻译了⼀下,⽅便我们观看 Look,⼈家也说了,旧⽅法解决ReCaptcha准确率⽐较低,建议使⽤新⽅法,那我们就点击新⽅法去看看 我们找到了,这种属于ReCaptcha v2验证码,确实和⾕歌⼈机挺⼀样的,我们来看⼀下⽂档是怎么写的 然后找到id=g-recaptcha-response的textarea标签,将display:none 这个css删除 将给我们字符串添加到textarea输⼊框点击提交,就完成了 是不是很简单,我们也来试⼀下 打开⾕歌的⽰例样式 我们打开开发者⼯具,搜索data-sitekey,可以看到,真的有⼀个 我们赋值⼀下这个data-sitekey,并且⽤代码获取到最后的结果 然后我们找到 id=g-recaptcha-response 的textarea标签,将他的display属性删除 但是有点不太对 我们的 2captcha的⽰例的 我们可以看到,2captcha是个删除display之后,textarea框是直接展⽰出来的,但是我们删除display之后,基本没⽤丝毫动静,这... 别着急,⼈家都想到了,我们往下滑滑 既然我们不能直接显⽰出来textarea,那就说明我们是隐式的ReCaptcha验证码,其实他的原理呀,也挺简单 如果你学过⼀些前端,会些js,你可能就会想到,虽然我看不到这个textarea,但是通过js我们仍然能更改textarea的数据,只是说,我们⿏标点击不了⽽已,⼈家也说了,看第⼀个红圈的位置,通过此js,我们我们就可以把向2captcha获取的值赋值上,第⼆个圈js是提交表单,其实就是我们⼈点击提交⽽已,只不过是js代码帮我们完成了,这样,我们也完成了⼀个偷天换⽇⼩试⽜⼑ 好嘞,我们就先来⼿动搞⼀下,在上述中,我们已经根据data-sietkey拿到了最后的结果,显然,我们只能通过js完成,那么,我们就试⼀下 通过上述gif看到,我们通过js,确实绕过了点击车辆识别了,其他识别,确实⽅便, 但是我们不可能通过⼈每次这样搞呀,但是因为牵扯到了执⾏js,所以只能使⽤selenium,所以,我们来看⼀下selenium上的效果吧 Look,这样,我们就针对⾕歌⼈机(ReCaptcha)验证码,完成了⾃动登录,如果爬取国外的某某⽹站时,如果遇到了ReCaptcha,我相信⼀定会对你有帮助 完整代码import timefrom selenium import webdriverfrom selenium.webdriver.chrome.webdriver import WebDriverimport requests# 常量driver: WebDriverUSER = {}API_KEY = "xxxxxxxxxxxxxxx"# 初始化def init():global driverdriver = webdriver.Chrome("chromedriver.exe", desired_capabilities=None)def open_google():driver.get("https:///recaptcha/api2/demo")data_sitekey = driver.find_element_by_xpath('//*[@id="recaptcha-demo"]').get_attribute("data-sitekey")# iframe_src = driver.find_element_by_xpath('//*[@id="recaptcha-demo"]/div/div/iframe').get_attribute("src")# iframe_k = url_params_format(iframe_src).get("k")print(data_sitekey)page_url = "https:///recaptcha/api2/demo"# print(iframe_k)u1 = f"https:///in.php?key={API_KEY}&method=userrecaptcha&googlekey={data_sitekey}&pageurl={page_url}&json=1&invisible=1" r1 = requests.get(u1)print(r1.json())rid = r1.json().get("request")u2 = f"https:///res.php?key={API_KEY}&action=get&id={int(rid)}&json=1"time.sleep(25)while True:print(u2)r2 = requests.get(u2)print(r2.json())if r2.json().get("status") == 1:form_tokon = r2.json().get("request")breaktime.sleep(5)wirte_tokon_js = f'document.getElementById("g-recaptcha-response").innerHTML="{form_tokon}";'submit_js = 'document.getElementById("recaptcha-demo-form").submit();'driver.execute_script(wirte_tokon_js)time.sleep(1)driver.execute_script(submit_js)if__name__ == '__main__':init()open_google()Code 谢谢观看,谢谢⽀持。
实例讲解网络验证码的破解

实例讲解网络验证码的破解所谓验证码,就是将一串随机产生的数字或符号,生成一幅图片,图片里加上一些干扰象素(防止OCR),由用户肉眼识别其中的验证码信息,输入表单提交网站验证,验证成功后才能使用某项功能。
不少网站为了防止用户利用机器人自动注册、登录、灌水,都采用了验证码技术。
很多验证码实现都有问题。
比如直接给出用验证码在网页和cookies中。
验证码在网页中的例子://验证用户输入是否和验证码一致if(isset($HTTP_POST_V ARS[’authinput’if(strcmp($HTTP_POST_V ARS[’authnum’],$HTTP_POST_V ARS[’authinput’echo "验证成功!echo "验证失败!//生成新的四位整数验证码请输入验证码:print("校验码不正确第二种要比上一种聪明一点,把验证码值存放在用户Cookies中。
可是由于Cookies是用户可读可写,所以也极易被突破。
curl /index.php -c common_cookie # 接受服务器的初始curl /get_code.php -c $username.cook -b common_cookie # 得到验证码,从cookies中curl /login.php -b $username.cook -d authnum=$authnum -d username=$username -d password=$password # 使用cookies中的验证码登陆更高级的验证码。
(好像本论坛的就是这种。
)有一类验证码比以上两种验证码要高级一些,它使用如下算法:1。
服务器生成一个随机hash。
2。
使用某个算法(不可逆,破解难度高的)将hash转化成为验证码数字,再转化成图片。
3。
hash在cookie中被发送到客户端3。
客户以图片输入验证码,进行登录。
服务器检查f(hash)=验证码。
弱密码破解方法

弱密码破解方法弱密码是指容易被猜测或破解的密码。
对于黑客来说,破解弱密码是入侵系统或者账户的一个常见手段。
在本文中,我将介绍一些黑客常用的弱密码破解方法,并提供一些建议来加强密码的安全性。
1.字典攻击:字典攻击是黑客最常用的破解密码的方法之一。
黑客会使用一个密码列表,里面包含了常用密码、常见的字典词汇和一些常见的组合形式。
黑客会将这个列表与目标账户的密码进行对比,直到找到匹配的密码为止。
2.暴力破解:暴力破解方法是通过尝试所有可能的密码组合来破解密码。
黑客会使用计算机程序来自动化这个过程。
暴力破解可能需要相当长的时间,因为密码破解程序需要尝试所有可能的组合。
3.社会工程学攻击:社会工程学攻击是通过获取目标用户的个人信息来猜测密码。
黑客可能会通过互联网搜索、社交媒体、邮件欺骗、电话骗局等方式获取目标用户的信息,然后使用这些信息来猜测密码。
4.彩虹表攻击:彩虹表是一种预先计算好的密码散列值与密码之间的映射表。
黑客可以使用彩虹表来查找预先计算好的密码散列值,并将其与目标密码的散列值进行对比。
如果找到匹配的密码散列值,黑客就能够得到目标密码。
5. Keylogger攻击:Keylogger(键盘记录器)是一种恶意软件,它可以记录用户在键盘上输入的所有内容,包括密码。
黑客可以通过向目标用户的计算机中安装Keylogger来获取用户的密码。
那么,如何加强密码的安全性呢?1.使用复杂密码:使用包含大小写字母、数字和特殊字符的组合密码,以增加密码的复杂性。
避免使用简单的字典词汇或常见的密码组合。
2.避免使用个人信息:避免在密码中使用与个人信息相关的元素,如姓名、生日、电话号码等。
这些信息很容易通过社会工程学攻击获取。
3.使用两步验证:启用两步验证可以为账户添加额外的安全层。
通常,两步验证需要在输入密码后再进行一次验证,如通过手机验证码或应用生成的验证码。
4.定期更换密码:定期更换密码可以降低密码被破解的风险。
建议每三个月更换一次密码。
验证码绕过的方法

验证码绕过的方法
验证码是一种用于验证用户身份或防止机器人恶意攻击的技术。
然而,一些黑客或攻击者可以使用各种技巧绕过验证码,从而访问受保护的资源或进行恶意活动。
以下是几种常见的验证码绕过方法:
1. OCR技术:OCR(Optical Character Recognition)技术可以识别验证码中的字符,从而绕过验证码。
攻击者可以使用OCR软件或人工智能技术进行识别。
2. 自动化脚本:攻击者可以使用自动化脚本或程序对验证码进行多次尝试,从而尝试猜测正确的答案。
这种方法称为暴力破解。
3. 恶意软件:某些恶意软件可以注入恶意代码,以便绕过验证码或执行其他恶意活动。
4. 社会工程学攻击:攻击者可以使用社会工程学技术,如钓鱼攻击或冒充身份,以获取有效的验证码并绕过安全措施。
为了防止验证码被绕过,网站管理员可以采取以下措施:
1. 使用复杂的验证码:使用难以识别的字符或图像,以增加攻击者绕过验证码的难度。
2. 实施限制:实施限制,如限制尝试次数或实施时间限制,以避免攻击者进行暴力破解。
3. 实施多因素认证:使用多种身份验证方式,如密码和二步验证,以增加安全性。
4. 更新和监控:定期更新验证码和监控验证码活动,以避免攻
击者利用已知漏洞或技术绕过验证码。
浅谈短信验证码漏洞

浅谈短信验证码漏洞前⾔在⽇常的授权测试中,很⼤⼀部分只有⼀个登录界⾯,在这个登录界⾯其实可以测试的东西有很多,⽐如⽤户名枚举,弱密码,验证码,找回密码等等⼀系列问题。
现在的⽹站为了更好的⽤户体验,免去⼤家登录⽹站都要注册的问题,通常都采⽤了发送短信验证码的⽅式来登录,⼀⽅⾯是便捷,另⼀⽅⾯也算是采⽤的动态密码,安全性⽐较⾼,那随之⽽来的验证码的安全性问题也就显现出来了。
⼀短信轰炸漏洞短信轰炸问题其实是最容易想到的,当然对于短信的轰炸问题,还要分⼏类情况看待1.1 ⽆任何限制的短信轰炸这种应该是在短信轰炸中最简单粗暴的⼀种⽅式吧,没有任何限制只需要通过burpsuite去重放数据包即可,然后就可以达到消耗⽬标⽹站的短信数量以及对⼿机号码拥有者造成困扰1.2 有验证码的短信轰炸这个相对于⽆任何限制的短信轰炸是做了限制的,加上了验证码。
如果验证码可以重放的话那还是可以归类到⽆任何限制的短信轰炸中。
如果验证码不能重放并且也不能通过⼿段提前预知,我最常采⽤的⽅法便是python的selenium模块配合验证码识别⼯具去模拟浏览器请求登录,这种⽅式不⽤考虑复杂的交互情况,完全交给浏览器去实现,准确度取决于你验证码识别⼯具的准确度。
⽹上有很多识图⼯具,⽐如各⼤⼚商的OCR等等,或者是github上各位⼤佬的基于机器学习的验证码识别⼯具等等import requestsimport timeimport hashlibfrom selenium import webdriverfrom PIL import Imagefrom bs4 import BeautifulSoupheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:56.0) Gecko/20100101 Firefox/56.0","Accept": "*/*","Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3","X-Forwarded-For": "137.0.0.2","Content-Type": "application/json;charset=utf-8"}proxies = {"http": "http://127.0.0.1:8080","https": "https://127.0.0.1:8080"}def yanzhengma():url = 'http://127.0.0.1:7779'files = open("E:/img/t1.png", 'rb')r = requests.post(url, proxies=proxies, data=files)return r.textdef sendPhone(brower, ph):brower.get('https://xxx.xxx.xxx')phone = brower.find_element_by_xpath("//*[@id=\"mobile\"]")phone.send_keys(ph)path = 'E://img//t.png'imgpath = 'E:/img/t1.png'brower.get_screenshot_as_file(path)im = Image.open(path)box = (1157,320,1274,380)region = im.crop(box)region.save(imgpath)submit = brower.find_element_by_xpath("//*[@id=\"sendSms\"]")image = brower.find_element_by_xpath("//*[@id=\"verifyCode\"]")yzm = yanzhengma()image.send_keys(yzm)submit.click()time.sleep(5)def main():brower = webdriver.Chrome()for i in range(0,10):sendPhone(brower, "11111111111")if __name__ == '__main__':main()先通过屏幕截屏获取整个图⽚,然后再去截取验证码,最后通过验证码识别器识别出验证码后发送到浏览器触发短信轰炸漏洞,该漏洞的危害性主要取决于验证码识别的难易程度以及对发送短信次数的限制。
基于图像处理的验证码破解方法探索

基于图像处理的验证码破解方法探索随着互联网的兴起和快速发展,验证码作为一种有效的安全工具被广泛应用于各种网站和应用程序中。
验证码的目的是防止计算机程序自动化恶意操作,保护用户隐私和网站安全。
然而,今天我们将探索的是基于图像处理的验证码破解方法,从一个略微不同的角度看待这个问题。
在介绍验证码破解方法之前,我们先对验证码的基本原理有一定的了解。
通常,验证码由数字、字母、图形等形式组成,并且经过一定的干扰处理,使得计算机难以理解和识别。
这样,用户需要输入正确的验证码来确认身份。
但是,图像处理技术的快速发展同时也为验证码破解提供了更多的可能性。
首先,我们来研究一下基于图像处理的验证码破解方法中的一种常见的技术-图像识别。
图像识别是指通过计算机程序对图像进行解析和理解,以获得图像中包含的信息。
在验证码破解中,我们可以使用图像识别技术来分析验证码中的字符或图形,并将其转化为计算机可以理解的格式,以便进行自动识别。
这种方法的关键在于如何有效地提取图像中的字符或图形特征,并将其与已知的字符或图形进行比对和匹配。
其次,我们可以探索基于图像处理的验证码破解方法中的另一项技术-图像增强。
图像增强是指通过一系列的图像处理算法来改善图像的质量,并提高图像中有效信息的可见性。
在验证码破解中,我们可以使用图像增强技术来增强验证码图像的对比度、清晰度和边缘等特征,从而使得验证码更易于识别。
这种方法需要充分理解验证码图像的构成和特征,以选择适当的图像增强算法,并针对性地进行调整和优化。
此外,我们还可以尝试基于图像处理的验证码破解方法中的另一项技术-图像分割。
图像分割是指将图像分割成若干个具有相似属性的区域的过程。
在验证码破解中,我们可以通过图像分割技术将验证码图像分割成单个字符或图形的部分,以便更好地进行识别和匹配。
这种方法需要考虑到验证码图像中的字符或图形之间的距离、重叠和干扰等问题,选择合理的图像分割算法,并结合其他图像处理技术进行综合处理。
Python网络爬虫动态验证码识别与破解技术

Python网络爬虫动态验证码识别与破解技术随着互联网的普及,网络爬虫成为了获取大量数据的一种重要手段。
然而,很多网站为了保护信息的安全性,采用了验证码来阻止机器人程序的访问。
虽然验证码对于提高安全性起到了一定的作用,但它也给进行数据采集的爬虫带来了困扰。
为了解决这个问题,研究人员们提出了多种Python网络爬虫动态验证码识别与破解技术。
一、图像处理技术图像处理技术是识别与破解动态验证码的基础。
通过图像处理技术,我们可以识别验证码中的文字或者图形,从而获取验证码的值。
常用的图像处理技术包括图像灰度化、二值化、降噪等。
在Python中,我们可以使用第三方库如OpenCV和PIL来实现图像处理的各种操作。
二、机器学习技术机器学习技术可以提高验证码的自动化识别效果。
通过训练模型,我们可以使爬虫程序自动学习并识别不同类型的验证码。
常用的机器学习算法包括支持向量机(SVM)、卷积神经网络(CNN)等。
在Python中,我们可以使用Scikit-learn和TensorFlow等库来实现机器学习的各种算法。
三、验证码生成技术为了测试验证码识别与破解技术的有效性,研究人员们也提出了验证码生成技术。
通过生成各种不同类型的验证码,我们可以评估识别与破解技术的准确性和鲁棒性。
常见的验证码生成技术包括随机字符生成、干扰线添加等。
在Python中,我们可以使用Captcha和Pillow 等库来生成验证码。
四、深度学习技术深度学习技术是识别与破解复杂动态验证码的有效手段。
通过构建深度神经网络模型,我们可以提高验证码识别的准确率和鲁棒性。
常用的深度学习算法包括循环神经网络(RNN)、长短时记忆网络(LSTM)等。
在Python中,我们可以使用Keras和PyTorch等库来实现深度学习的各种算法。
五、借助第三方服务除了自行开发验证码识别与破解技术,我们还可以借助第三方服务来简化工作流程。
例如,一些第三方服务提供了API接口,可以直接调用进行验证码识别,如Tesseract OCR和百度云OCR等。
使用tesseract-ocr破解验证码详解
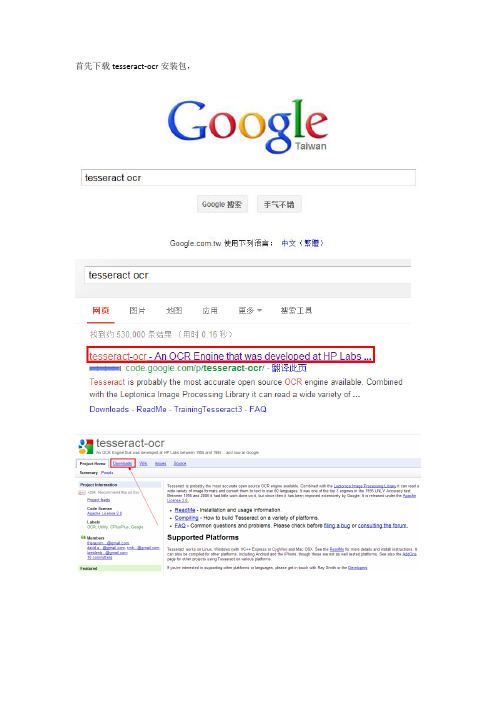
首先下载tesseract-ocr安装包,下载完成后双击tesseract-ocr-setup-3.01-1.exe安装程序进行安装,安装过程中注意不要安装到默认的安装目录C:\Program Files下,请安装到D盘或其他盘符,切记安装路径中最好不要出现空格和中文。
然后一路next即可。
安装完成后打开dos命令行窗口,输入tesseract,然后回车如果你看到如下输入,就表明tesseract-ocr安装成功咯!然后去网上随便下载一张验证码图片,你们图方便就使用我贴的这张来测试吧验证码示例图:然后命令行输入tesseract 1.jpg result -l engTesseract后面1.jpg从当前目录下的1.jpg里提取验证码字符result表示将提取出来的结果存放到当前目录的result.txt文件中,-l(小写字母L): eng表示英文字符集,在eng英文字符集状态下,只能提取英文字符,不能识别中文,如果需要识别中文,那么就需要把下载下来的chi_sim_traineddata压缩包解压,将得到的一个chi_sim.traineddata中文训练文件copy到tesseract-ocr安装目录下的tessdata 文件夹里:刚才输入tesseract 1.jpg result -l eng验证码破解命令后,破解后得到的验证码字符结果就保存在当前目录的result.txt中,当前目录就是C盘,所以你会在C盘根目录下看到自动生成的一个result.txt,用文本编辑器打开它,你会看到如下内容:下面来测试一下提取中文汉字,随便找一段中文内容截图,并另存为jpg图片;假定图片取名为2.jpg,然后命令行输入:tesseract 2.jpg result –l chi_simChi_sim表示使用中文字符集,chi是china缩写,sim是simple的缩写,连一起就表示简体中文字符集,你懂的。
安全性测试入门(五):InsecureCAPTCHA验证码绕过

安全性测试⼊门(五):InsecureCAPTCHA验证码绕过本篇继续对于安全性测试话题,结合DVWA进⾏研习。
Insecure Captcha不安全验证码1. 验证码到底是怎么⼀回事这个Captcha狭义⽽⾔就是⾕歌提供的⼀种⽤户验证服务,全称为:Completely Automated Public Turing Test to Tell Computers and Humans Apart (全⾃动区分计算机和⼈类的图灵测试)。
很巧妙的是,Captcha单独成词的意思就是,抓到你了哟_Captcha在各种海外⽹站被⼴泛⽤于⽤户验证。
⽽在国内,由于众所周知的原因,我们不⽤⾕歌的服务,很多接⼝平台都可以提供类似服务。
⽐如apishop的这个四位验证码服务接⼝:那么验证码到底在⽤户验证的过程中起到什么样的作⽤呢?验证码最⼤的作⽤就是防⽌攻击者使⽤⼯具或者软件⾃动调⽤系统功能就如Captcha的全称所⽰,他就是⽤来区分⼈类和计算机的⼀种图灵测试,这种做法可以很有效的防⽌恶意软件、机器⼈⼤量调⽤系统功能:⽐如注册、登录功能。
我们前⾯讲到的Brute Force字典式暴⼒破解,就必须要使⽤⼯具⼤量尝试登录。
如果这个时候系统有个严密的验证码机制,此类攻击就⽆计可施了。
其⼯作流程如下所⽰:2. 验证码绕过为什么前⽂要在验证码机制前⾯⿊体强调他要是严密的,那当然是如果验证码机制设计不得当,绕过它也只是分分钟的事情。
DVWA提供的试验模块长这个样⼦:我们将其安全级别调到最低,使⽤ZAP做为代理进⾏抓包,填⼊任意密码触发请求,看到请求内容如下:这是个啥⼦意思呢,我们参考⼀下DVWA的后台逻辑:<?phpif( isset( $_POST[ 'Change' ] ) && ( $_POST[ 'step' ] == '1' ) ) {// Hide the CAPTCHA form$hide_form = true;// Get input$pass_new = $_POST[ 'password_new' ];$pass_conf = $_POST[ 'password_conf' ];// Check CAPTCHA from 3rd party$resp = recaptcha_check_answer($_DVWA[ 'recaptcha_private_key'],$_POST['g-recaptcha-response']);// Did the CAPTCHA fail?if( !$resp ) {// What happens when the CAPTCHA was entered incorrectly$html .= "<pre><br />The CAPTCHA was incorrect. Please try again.</pre>";$hide_form = false;return;}else {// CAPTCHA was correct. Do both new passwords match?if( $pass_new == $pass_conf ) {// Show next stage for the user$html .= "<pre><br />You passed the CAPTCHA! Click the button to confirm your changes.<br /></pre><form action=\"#\" method=\"POST\"><input type=\"hidden\" name=\"step\" value=\"2\" /><input type=\"hidden\" name=\"password_new\" value=\"{$pass_new}\" /><input type=\"hidden\" name=\"password_conf\" value=\"{$pass_conf}\" /><input type=\"submit\" name=\"Change\" value=\"Change\" /></form>";}else {// Both new passwords do not match.$html .= "<pre>Both passwords must match.</pre>";$hide_form = false;}}}if( isset( $_POST[ 'Change' ] ) && ( $_POST[ 'step' ] == '2' ) ) {// Hide the CAPTCHA form$hide_form = true;// Get input$pass_new = $_POST[ 'password_new' ];$pass_conf = $_POST[ 'password_conf' ];// Check to see if both password matchif( $pass_new == $pass_conf ) {// They do!$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string( $pass_new = md5( $pass_new );// Update database$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) // Feedback for the end user$html .= "<pre>Password Changed.</pre>";}else {// Issue with the passwords matching$html .= "<pre>Passwords did not match.</pre>";$hide_form = false;}((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);}>代码有点长,但是可以明显看出来,这个机制是很简单的。
网络信息安全中的口令破解技术及其防范

网络信息安全中的口令破解技术及其防范随着网络的普及,我们生活中的许多事情都离不开互联网和电脑,而在日常使用计算机的过程中,口令破解技术成为了我们必须面对的问题。
在这样的情况下,了解并掌握口令破解技术的相关知识以及如何防范口令破解攻击变得尤为重要。
一、口令破解技术的原理口令破解技术是指通过技术手段,尝试获得某个账户的口令或其他验证信息的攻击方式。
口令破解技术主要有以下几种方式:1.暴力破解暴力破解是一种通过不断尝试,不断输入字符的方式来破解密码的手段。
一般情况下,还会以字典攻击等方式来提高破解率。
在暴力破解中,最常用的字典攻击,是攻击者会准备一个包含所有常用单词、名词、短语、生日等信息的列表,然后不停的在目标账户中进行尝试,直到得到正确的口令。
2.社会工程学社会工程学是指通过与被攻击者交流来获取其口令的技术。
例如,攻击者可以通过发送电邮,询问目标账户的口令等方式来进一步得到关于口令的信息。
二、如何防范口令破解攻击1.采用高强度口令并定期更换为了避免暴力破解攻击,我们可以采用高强度口令,尽量使用不同类别的字符组合。
同时,还应该定期更换口令,建议每3个月进行一次更换。
2.定期做好安全检查定期做好安全检查也可以避免口令破解攻击。
建议用户定期对账户进行安全检查,如删除无用账户、启用开发者选项等,这样可以避免口令泄露以及其他漏洞的利用。
3.使用密码管理器使用密码管理器也是一种避免口令破解攻击的方法。
使用密码管理器可以将不同的账户和密码进行集中管理,避免因口令错误或泄露而影响到多个账户的安全。
4.注意对电脑的保护我们在保护口令的同时,也不能忽视对电脑的保护。
电脑中存储的信息,包括口令而言,既可以在电脑失窃或被骇客攻击时,也会造成泄漏。
多加注意电脑的安全,设置密码锁、安装杀毒软件等,可以有效保护我们的个人信息。
5.启用多因素身份验证启用多因素身份验证是一种较为成熟的防范技术。
例如,启用两步验证,除了输入口令之外,还需要输入手机验证码等额外的验证信息,这种方式往往能够极大程度上避免密码泄露。
验证码的识别与改进

2021.51概述传统的验证码识别基本都是基于OCR 来实现。
基于深度学习的验证码识别,主要采取深度学习中的卷积神经网络,再配合机器学习来实现的。
学习2个或多个神经网络模型,再配合算法的训练和学习,则可以验证市面上95%的验证码。
面对当下先进的技术和环境,验证码在系统或是平台上作为第一道防线,还是非常重要的,只要满足一定的条件就可以降低识别率,提高避免率。
2传统的验证码安全策略2.1验证码的概念验证码(CAPTCHA)简单解释即一个答题的验证。
系统向请求发起方提问能正确回答的即是人类,反之则为机器。
2.2验证码的应用从安全角度来讲,验证码经过长期的发展,已成为国内外所有公司必须具备的安全策略。
(1)用户注册方面(2)平台的登录验证,密码的找回和修改(3)支付页面,交易的安全验证(4)绑定电话,银行卡验证验证码应用的场景很多,也是能够防止机器程序恶意撞库、洗库、恶意信息传播、SQL 注入、短信轰炸等的重要措施。
如果没有验证码保护,网站受到攻击将会面临巨大的泄露风险。
2.3验证码的发展趋势目前,市面上很多厂家已经采用多种形式的验证码,来提高黑产的暴力破解的难度,常见的有前端验证码识别、短信验证、图表点选、文字点选、刮刮卡验证、乱序拼图验证等等。
短信交互验证分两种方法,(1)应用网络平台接口实行下发短信;(2)在网页前端提供验证指令。
而字符型验证码,也是常见的并用的最多的一种安全方式,也是黑客主要攻击的一块产业。
将具体通过对字符型验证码进行暴力破解,总结出验证码的缺陷以及改善点,从而降低以及避免验证码被黑客所破解。
3验证码被攻破风险验证码一旦被攻破,轻则使数据库瘫痪,造成大量的虚假用户。
重则利用返回值的内容修改密码和重置密码,直到获取用户的所有信息。
登录如果缺少验证码,攻击者可通过暴力破解的方式非法接管用户账户。
注册如果缺少验证码,将会有大量僵尸用户生成,导致服务器性能下降或崩溃。
网站具有提交表单的功能,并需要由站点管理员审核通过。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5/9/2014
(3)先在x轴方向进行分割:对x轴上每一点,统计y坐标方向上黑点数目。当 黑点数目少于设定的域值时候,认为是字符间的空白区,而黑点数目大于设定 的阈值时则认为是字符区。
(4)有时存在字符相连的情况,为避免两个相连的字符分割失败,对字符的 最大宽度和最小宽度设定阈值 : 当宽度大于最大宽度时候,即认为是两个字符, 需要将分割得到的字符继续分割;如果分割得到的字符宽度小于设定的最小 宽度,则需要进行合并邻近的两个字符进行分割。
5/9/2014
(3)用上述的编码方法分别对 模版与待识别的字符进行编码,然 后计算模版与待识别字符的编码 的相似度。
把一个字当做一幅图,从上往下 一行行扫描,每一行都是由不同 长短的黑色横杠组成的,每种横 杠对应着模式图中的一个编码。
取相似度最高的模版字符为识别 的结果。 如图所示,数字7的编码为 1288886999证码
如何破解字符验证码
小组总结
5/9/2014
起
验证码的英文CAPTCHA 这个词最早 是在2000年由卡内基梅隆大学的Luis von Ahn等学者所提出的。 CAPTCHA 是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自 动区分计算机和人类的图灵测试)的 缩写,是一种区分用户是计算机和人 的公共全自动程序。
5/9/2014
上述破解原理可用OCR (Optical Character Recognition): 光学字符识别来实现 1、下载安装Tesseract-OCR 引擎
2、 使用Tesseract-OCR引 擎识别验证码
5/9/2014
取出所需要读取 的验证码图片
运行之 后可得
5/9/2014
5/9/2014
如何破解字符验证码 1、去噪
(1)由于其 背景色 的亮度与文字或者数字的亮度差别较 大,这样我们就可以通过 设定亮度域值的方法来对它进行二 值化处理,即将图像上的像素点的灰度值设置为0或255, 也就是将整个图像呈现出明显的只有黑和白的视觉效果。 (2)对于干扰线的去除,我们通过对水平方向长度超过图 片二分之一的线直接去除,因为图片文字本身宽度不可能超 过二分之一的图片大小。
(5)利用同样的方法可以进行y轴方向上的分割。 (6)由于验证码文字的随机性,对分割得到的单个字符进行进一步的 边框确定。通过对水平和垂直方向扫描,确定出单个字符的边框。
5/9/2014
2、将分割出的字符与模版匹配,判别字符类型
(1)模版库的建立: 从网络上采集一系列验证码的样本,建立验证码字符样本空间。 比如为字母A~Z和数字0~9。对于每一个样本,我们提取特征, 建立模版。 (2)将得到的图片切割为固定的长度 和宽度。先将字符从水平方向进行扫 描,则每条扫描线都是由黑点或者白 点构成的序列,每条水平扫描线可以 用一个向量表示。 将向量分类为N种模式,比如模式0表 示长的空白段,而模式1代表长的黑点 段。模式2表示一段相对长的白点之后 跟着一段黑点。以此类推得到自己设 计的模式图。
(4)字符验证码:服务器端随 机生成验证码字符串,保存在内 存中,并写入图片或者加入干扰 线条,将图片连同表单发给客户 端。是目前而言最常见的验证码。
5/9/2014
字符验证码的工作流程
(1)、服务器端随机生成验证码字符串,保 存在内存中,并写入图片或者加入干扰线条, 将图片连同表单发给客户端。 (2)、客户端输入验证码,并提交给表单,服务器端获 取客户提交的验证码,和前面产生的的随机数字相比较; 如果相同,则继续进行表单所描述的操作(如登录、注册 等);如果不同,直接将错误信息返回给客户端。避免程 序的继续运行以及访问数据库。
5/9/2014
源
这个问题可以由计算机生成并评判,但 是必须只有人类才能解答。由于计算机 无法解答CAPTCHA的问题,所以回答 出问题的用户就可以被认为是人类。
5/9/2014
(1)由4个随机数字组成的最原始验证码:验证作用几乎为零。
(2)GIF动画验证码 : 防垃圾注入可以达到100%,有 效的同时能增加网站页面的美观效果。 (3)手机验证码:通过发送验证码到手 机,比较准确验证用户的正确性,是最有 效的验证码之一。