C语言冒泡排序及流程图(思路解析)
冒泡法排序流程图

冒泡法排序流程图冒泡排序是一种基本的排序算法,它的原理是相邻的元素之间两两比较,如果顺序错误就进行交换,这样一轮比较下来,最大(或最小)的元素就会移动到最后(或最前)的位置。
冒泡排序的流程图如下:```开始设置列表list,列表长度n循环i从0到n-1嵌套循环j从0到n-i-1比较list[j]和list[j+1]如果list[j] > list[j+1],则交换list[j]和list[j+1]的位置结束内层循环结束外层循环输出排序后的列表list结束```下面我们通过一个例子来解释冒泡排序的具体流程:假设我们有一个列表 [5, 3, 8, 6, 4] 需要进行排序。
第一轮比较:比较 5 和 3,5 > 3,交换位置,列表变为 [3, 5, 8, 6, 4]比较 5 和 8,5 < 8,不交换位置,列表不变比较 8 和 6,8 > 6,交换位置,列表变为 [3, 5, 6, 8, 4]比较 8 和 4,8 > 4,交换位置,列表变为 [3, 5, 6, 4, 8]第一轮比较后,最大的元素 8 移动到了列表的最后。
第二轮比较:比较 3 和 5,3 < 5,不交换位置,列表不变比较 5 和 6,5 < 6,不交换位置,列表不变比较 6 和 4,6 > 4,交换位置,列表变为 [3, 5, 4, 6, 8]第二轮比较后,第二大的元素 6 移动到了列表的倒数第二个位置。
第三轮比较:比较 3 和 5,3 < 5,不交换位置,列表不变比较 5 和 4,5 > 4,交换位置,列表变为 [3, 4, 5, 6, 8]第三轮比较后,第三大的元素 5 移动到了列表的倒数第三个位置。
第四轮比较:比较 3 和 4,3 < 4,不交换位置,列表不变第四轮比较后,第四大的元素 4 移动到了列表的倒数第四个位置。
经过四轮比较和交换操作,列表已经完全有序,最后输出的排序后的列表为 [3, 4, 5, 6, 8]。
冒泡排序快速排序流程图盒图N-S图

冒泡排序快速排序流程图盒图N-S图冒泡排序Exchange=nWhile exchange!=0 Bound=exchangeExchange=0While(j<bound< p="">)R[i]<r< p="">[j+1]R[j]→←R[j+1]Exchange=jExchange=nDo-while(exchange!=0)Bound=exchangeExchange=0Int j=1Do while (j<bound)< p="">J++t R[j]<="">Exchange=j ↓开始Exchange=nExchange >0结束Bound=exchange Exchange=0 J=1J<bound< p="">NNYr[j]>r[j+1]YNr[j]与r[j+1]的值交换 Exchange=j j=j+1快速排序i<j< p="">开始j=end;i=firstr[i]>=r[j]i<j< p="">r[i]<=r[j]r[i] r[j] i++; i<j< p="">r[i] r[j] i++;i++j--Return i; 此时让first=0;end=i-1; 此时让first=i ;end=n;first<end< p="">输出序列 N NNYYNNNYWhile(first < end)i=first;j=end;While(R[i]>=R[j])j--T i<="" p="">R[i] R[j] while(R[i]<=R[j])i++i++T i<="" p="">R[i] R[j]j--First=0; end=i-1; First=i; end=n;输出排完序的数组i<j< p="">i<j< p="">i<j< p="">i=first ;j=end; While (first<="">i++While (r[i]>=r[j]) R[i] R[j]i++i++While (r[i]<=r[j])R[i] R[j] j-- First=0; end=i-1; First=i; end=n; 输出序列一元二次方程求根流程图开始输入a,b,cS=x b=0Nbc x -← Yc=0NY S=”全体实数”” S=“无解”a=0输出SS=”x1”+”x2”△<0YN△←b2-4acab x a b x 2,221--←?+-←S=“无实根”Y</j<></j<></j<></end<></j<></j<></j<></bound<></bound)<></r<></bound<>。
c语言中的冒泡排序

c语言中的冒泡排序冒泡排序是一种基础的排序算法,其思想是依次将相邻的两个数比较,将较大的数移至后面,较小的数移至前面。
如此反复比较,直到整个序列有序为止。
以下是在C语言中实现冒泡排序的步骤:**Step 1:定义数组和变量**首先需要定义一个需要排序的数组和一些临时变量,用于比较两个数的大小和交换两个数的位置。
例如:```c++int arr[] = { 64, 25, 12, 22, 11 };int n = 5; // 数组的长度int i, j, temp;```**Step 2:实现冒泡排序**接下来,需要使用一个循环来依次比较每个数,并将大的数往后移。
在这个循环中,需要再次嵌套一个循环来比较相邻两个数的大小,如果前面的数大于后面的数,则交换它们的位置。
之后再执行下一轮比较,直到将整个数组排序完成为止。
例如:```c++for (i = 0; i < n - 1; i++) {for (j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}```在上面的代码中,第一个循环表示需要执行n-1次比较,因为最后一个数不用与任何数比较;第二个循环则表示当前需要比较的数字范围,每比较一次就将范围缩小1,确保大的数能够快速地“浮”到数组的最后端。
**Step 3:输出结果**最后,我们需要将排好序的数组输出。
例如:```c++for (i = 0; i < n; i++) {printf("%d ", arr[i]);}```上述的代码将打印出 `[11, 12, 22, 25, 64]`。
总结:在C语言中,实现冒泡排序需要经过三个步骤,分别是定义数组和变量、实现冒泡排序和输出结果。
尤其是在实现冒泡排序时,需要使用嵌套循环和临时变量,确保程序能够准确比较大小和交换位置,从而排好整个数组的顺序。
c语言冒号排序法

c语言冒号排序法冒泡排序法是经典的排序算法之一,其基本思想是通过不断交换相邻的元素,使较小的元素逐渐向前移动,从而将整个序列按照从小到大的顺序排序。
冒泡排序法的过程可以用以下的伪代码来描述:for (i = 0; i < n; i++) {for (j = 0; j < n - i - 1; j++) {if (a[j] > a[j + 1]) {swap(a[j], a[j + 1]);}}}其中,n为序列的长度,a为待排序的序列,swap函数用于交换两个元素的值。
上述代码的思路很简单,就是不断比较相邻的两个元素大小,如果前面的元素比后面的元素大,则交换它们的位置。
冒泡排序法的时间复杂度为O(n^2),实现比较简单,但是对于大规模数据的排序效率较低,不过在实际应用中,冒泡排序法还是有一定用处的。
除了上述的基本冒泡排序法,还有一种改进版的冒泡排序法,即冒号排序法。
冒泡排序法每次都需要比较相邻的两个元素,而冒号排序法则将序列分成了两个部分,分别为有序序列和无序序列。
通过不断将无序序列中最大的元素冒号移动到有序序列的末尾,最终就能将整个序列按照从小到大的顺序排序完毕。
冒号排序法的过程可以用以下的伪代码来描述:for (i = 0; i < n - 1; i++) {is_sorted = true;for (j = 0; j < n - i - 1; j++) {if (a[j] > a[j + 1]) {swap(a[j], a[j + 1]);is_sorted = false;}}if (is_sorted) {break;}}其中,is_sorted为布尔型变量,用于判断序列是否已经有序。
在指针i不断向后移动的过程中,指针j从头开始遍历无序序列,并将最大的元素逐渐冒号移动到有序序列的末尾。
如果在一轮冒号排序中,没有发生交换,说明序列已经有序,排序过程可以提前终止。
双向冒泡排序算法c语言

双向冒泡排序算法(C语言)1. 算法原理双向冒泡排序算法是冒泡排序算法的优化版本,它在每一轮的比较中同时从左往右和从右往左进行排序,以提高性能。
该算法的核心思想是通过交替地向左和向右进行冒泡来实现排序。
具体算法步骤如下:1.初始化两个指针left和right,分别指向排序序列的第一个和最后一个元素。
2.从left向right遍历,在遍历过程中不断比较相邻的两个元素,并将较大(或较小)的元素向右(或向左)冒泡,直到right指针达到left位置。
3.更新left指针的位置,即left = left + 1。
4.从right向left遍历,在遍历过程中不断比较相邻的两个元素,并交换位置,将较小(或较大)的元素向左(或向右)冒泡,直到left指针达到right位置。
5.更新right指针的位置,即right = right - 1。
6.重复步骤2~5,直到排序序列中的所有元素都排序完成。
2. 算法实现(C语言)下面是使用C语言实现双向冒泡排序算法的示例代码:#include <stdio.h>void bidirectional_bubble_sort(int arr[], int n) {int left = 0;int right = n - 1;int i, j;while (left < right) {for (i = left; i < right; i++) {if (arr[i] > arr[i + 1]) {int temp = arr[i];arr[i] = arr[i + 1];arr[i + 1] = temp;}}right--;for (j = right; j > left; j--) {if (arr[j] < arr[j - 1]) {int temp = arr[j];arr[j] = arr[j - 1];arr[j - 1] = temp;}}left++;}}int main() {int arr[] = {4, 2, 8, 5, 1, 9, 3, 7, 6};int n = sizeof(arr) / sizeof(arr[0]);printf("Before sorting:\n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}bidirectional_bubble_sort(arr, n);printf("\nAfter sorting:\n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;}3. 算法分析双向冒泡排序算法的时间复杂度和冒泡排序算法相同,都为O(n^2),其中n为排序序列的长度。
起泡法排序c语言

起泡法排序c语言起泡法排序c语言起泡法排序是一种基本的排序算法,也称为冒泡排序。
它的原理是不断比较相邻两个元素的大小,如果前面的元素大于后面的元素,则交换它们。
这样一趟下来,最大(或最小)的元素就会被排到最后(或最前)。
1. 算法步骤起泡法排序算法步骤如下:1. 从数组的第一个元素开始,依次比较相邻两个元素的大小。
2. 如果前面的元素大于后面的元素,则交换它们。
3. 继续比较下一对相邻元素,直到比较到数组末尾。
4. 重复上述步骤,直到所有元素都被排好序。
2. 代码实现以下是使用C语言实现起泡法排序算法的代码:```cvoid bubbleSort(int arr[], int n){int i, j;for(i = 0; i < n-1; i++){for(j = 0; j < n-i-1; j++){if(arr[j] > arr[j+1]){int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;}}}}```该函数接受一个整数数组和数组长度作为参数,并将数组按升序排序。
它使用两个嵌套的循环来比较相邻的元素,并在必要时交换它们。
3. 时间复杂度起泡法排序算法的时间复杂度为O(n^2),其中n是数组中元素的数量。
这是因为该算法需要进行n-1趟排序,每趟排序需要比较n-i-1对相邻元素,并在必要时交换它们。
4. 稳定性起泡法排序算法是一种稳定的排序算法。
这意味着如果数组中有两个相等的元素,它们在排序后仍然保持原来的顺序。
5. 优化虽然起泡法排序算法是一种简单而有效的算法,但它也有一些缺点。
其中最明显的缺点是它的时间复杂度较高,当数组规模很大时,效率会非常低下。
为了提高效率,可以对起泡法排序算法进行一些优化。
以下是几种常见的优化方法:(1)加入标志位:如果某一趟扫描没有发生任何交换,则说明数组已经排好序了,可以直接退出循环。
(2)记录最后一次交换位置:由于每一趟扫描都会将当前未排好序部分中最大(或最小)值移到末尾(或开头),因此可以记录最后一次交换位置,以此来确定下一趟扫描的范围。
冒泡法排序c语言代码

冒泡法排序c语言代码排序算法是计算机科学中最基本、最重要的算法之一。
冒泡排序法是一种简单而又实用的排序算法,它的主要思想是:每次比较相邻的两个数,如果不符合顺序要求,则交换位置,这样一趟下来可以保证最大(小)的数排在最后一个位置,而剩下的数交换位置后能够重新排好序。
下面我们将介绍如何使用C语言编写冒泡排序法。
首先,我们需要声明一个数组,用于存储要排序的数值,如下所示:int a[100];然后需要编写一个函数,用于实现冒泡排序,函数的参数是要排序的数组和数组中元素的数量,函数返回值为0。
函数的实现代码如下:int bubble_sort(int a[], int n){int i, j, temp;for(i = 0; i < n-1; i++) //外层循环,循环n-1次{for(j = 0; j < n-i-1; j++) //内层循环,循环n-i-1次{if(a[j] > a[j+1]) //如果相邻两个数乱序,则交换位置{temp = a[j];a[j] = a[j+1];a[j+1] = temp;}}}return 0; //返回0}让我们对上述的函数进行解释。
首先,我们需要定义三个整型变量i、j和temp,分别表示循环计数器、要交换的变量和交换过程中的临时变量。
然后,我们需要进行两层循环。
外层循环从第一个元素开始,一直到倒数第二个元素,这是因为我们需要同时检查相邻的两个元素,如果检查到了最后一个元素,那么就无法检查其后一个元素,会导致越界错误。
在内层循环中,我们需要比较相邻的两个元素,如果前面的元素大于后面的元素,则交换它们的位置。
在函数的末尾,我们需要返回0作为函数的返回值。
最后,我们需要编写主函数,从用户终端读入数据,并调用上述的冒泡排序函数,对输入的数据进行排序。
主函数的代码如下:printf("请输入要排序的数的个数:\n");scanf("%d", &n);bubble_sort(a, n);printf("排序后的结果为:\n");for(i = 0; i < n; i++)printf("%d ", a[i]);以上代码实现了一个简单的冒泡排序算法,可以对输入的数字进行排序。
冒泡排序实现代码以及图示详解

冒泡排序实现代码以及图⽰详解⼀、冒泡排序冒泡排序(Bubble Sort),是⼀种计算机科学领域的较简单的排序算法。
它重复地⾛访过要排序的元素列,依次⽐较两个相邻的元素,如果顺序(如从⼤到⼩、⾸字母从Z到A)错误就把他们交换过来。
⾛访元素的⼯作是重复地进⾏直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越⼩的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中⼆氧化碳的⽓泡最终会上浮到顶端⼀样,故名“冒泡排序”。
⼆、算法实现原理1. ⽐较相邻的元素。
如果第⼀个⽐第⼆个⼤,就交换它们两个;2. 对每⼀对相邻元素作同样的⼯作,从开始第⼀对到结尾的最后⼀对,在这⼀点,最后的元素理应会是最⼤的数;3. 针对所有的元素重复以上的步骤,除了最后⼀个;4. 持续每次对越来越少的元素重复上⾯的步骤,直到没有任何⼀对数需要⽐较;三、复杂度分析若⽂件的初始状态是正序的,⼀趟扫描即可完成排序。
所需的关键字⽐较次数C和记录移动次数M均达到最⼩值:所以,冒泡排序最好的时间复杂度为:O(n)若初始⽂件是反序的,需要进⾏n-1趟排序。
每趟排序要进⾏n-i次关键字的⽐较(1≤i≤n-1),且每次⽐较都必须移动记录三次来达到交换记录位置。
在这种情况下,⽐较和移动次数均达到最⼤值:冒泡排序的最坏时间复杂度为O(n^2)所以,冒泡排序总的时间复杂度为O(n^2)四、稳定性分析冒泡排序就是把⼩的元素往前调或者把⼤的元素往后调。
⽐较是相邻的两个元素⽐较,交换也发⽣在这两个元素之间。
所以,如果两个元素相等,是不会再交换的;如果两个相等的元素没有相邻,那么即使通过前⾯的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是⼀种稳定排序算法。
五、算法图⽰分析图⽰过程动图展⽰六、JAVA代码实现1//⽐较函数参考2static boolean less(Comparable v, Comparable w) {3return pareTo(w) < 0;4 }5//交换函数6static void exchange(Object[] a, int i, int j) {7 Object swap = a[i];8 a[i] = a[j];9 a[j] = swap;10 }1112public void bubblesort(Comparable[]a){13int n = a.length;14for(int i=0;i<n-1;i++){//记录已经排序的元素的数量15for(int j=0;j<n-i-1;j++){//开始排序,除去了已经排序了的16if(a[j]<a[j+1]){ //降序排列17 swap(a,j,j+1);18 }19 }20 }21 }七、算法优化针对问题:数据的顺序排好之后,冒泡算法仍然会继续进⾏下⼀轮的⽐较,直到arr.length-1次,后⾯的⽐较没有意义的。
c语言 冒泡法

c语言冒泡法冒泡排序是一种简单而常用的排序算法,其原理简单易懂,非常适合初学者学习。
在本文中,我们将详细介绍冒泡排序的实现方法,并分析其时间复杂度、空间复杂度以及优缺点。
首先,让我们来了解一下冒泡排序的基本原理。
冒泡排序通过重复遍历要排序的元素,比较相邻两个元素的大小,如果发现逆序(即左边的元素大于右边的元素),则交换这两个元素的位置。
通过不断地进行这样的比较和交换,最大(或最小)的元素会像气泡一样逐渐“浮”到序列的一端,因此得名冒泡排序。
有了基本原理的了解,让我们来看看冒泡排序的具体实现步骤。
1. 首先,我们需要定义一个数组来存储待排序的元素。
2. 然后,我们使用两层循环对数组进行遍历。
外层循环控制遍历的轮数,内层循环用于比较相邻元素并进行交换。
3. 在内层循环中,我们比较当前元素和下一个元素的大小,如果当前元素较大(或较小)则交换它们的位置。
4. 每一轮循环完成后,我们可以确定一个最大(或最小)的元素已经移动到了序列的末尾,因此可以减少内层循环的遍历次数。
5. 最后,当所有的元素都比较过并排序完成后,我们得到了一个有序的数组。
冒泡排序的时间复杂度为O(n^2),其中n表示待排序数组的长度。
这是因为在最坏情况下,我们需要进行n-1轮比较和交换,每轮比较需要遍历n-i次,其中i是已经排序好的元素个数。
因此,总的比较次数可以近似为n*(n-1)/2,即O(n^2)。
而空间复杂度为O(1),因为我们只需要用到常数个临时变量来进行元素交换。
然而,冒泡排序也有其局限性。
由于其时间复杂度较高,当待排序数组长度较大时,性能会明显下降。
因此,在实际应用中,我们更倾向于选择其他更高效的排序算法,如快速排序或归并排序。
冒泡排序更适用于教学和简单排序需求较小的场景。
综上所述,冒泡排序是一种简单但有效的排序算法,通过多轮比较和交换,逐渐将最大(或最小)的元素浮动到序列的一端,从而实现排序。
虽然冒泡排序的时间复杂度较高,但其思想和实现方式对于初学者学习算法有很大的帮助。
C语言内排序法实验报告

数据结构一:排序方法比较1、冒泡排序属于稳定排序,是一种借助“交换”进行排序的方法。
首先要将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序,则将两个记录交换之,然后比较第二个记录与第三个记录的关键字,以此类推,直至第n-1个记录与第n个记录的关键字进行比较为止,这一过程称为第一趟冒泡排序,其结果使得关键字最大的记录被安置在最后一个记录的位置上;然后进行第二趟冒泡排序,对前N-1个记录进行同样操作;以此类推,直到在一趟排序过程中没有进行过交换记录的操作为止。
2、直接插入排序属于稳定的排序,每次从无序表中取出第一个元素,把它插入到有序表的合适位置,使有序表仍然有序。
第一趟将待比较的数值与它的前一个数值进行比较,当前一数值比待比较数值大的情况下继续循环比较,依次进行下去,进行了(n-1)趟扫描以后就完成了整个排序过程,结束该次循环。
3、快速排序属于不稳定排序,是对起泡排序的一种改进。
它的基本思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
假设待排序的序列为{R.[s],R.[s+1],…….,R.[t]},首先任意选取一个记录,然后按下述原则从新排序记录:将关键字较他小的记录都安置在他的位置之前,将所有关键字较他大的记录都安置在他的位置后面。
由此可以该“枢轴”记录最后所落的位置i作为分界线,将序列{R[s],R[s+1]…….R[t]}分割成两个子序列{R[s],R[s+1]…..R[i-1]}和{R[i+1]……R[t]},这个过程称作一趟快速排序。
一趟快速排序的具体做法是:附设两个指针low和high,它们的初值分别指向数组第一个数据和最后一个数据,将枢轴记录暂存在R[0]的位置上排序过程中只作R[low]或R[high]的单向移动,直至一趟排序结束后再将枢轴记录移至正确位置上。
4、简单选择排序属于不稳定排序,基本思想是,每一趟在n-i+1(i=1,2,…n-1)个记录中选取关键字最小的记录作为有序序列中第i个记录。
c语言 冒泡算法

c语言冒泡算法冒泡算法,又称为气泡排序,是一种简单的排序算法,可以按照升序或降序排列数据集。
它的基本思想是重复地访问数据集,比较相邻两个元素的大小,将较大或较小的元素不断地交换位置,直到整个数据集按照要求排列好为止。
下面,我们将详细介绍冒泡算法的实现步骤和时间复杂度等相关知识。
一、算法原理及流程1.算法原理:冒泡算法是一种比较简单的排序算法。
它的基本思路是从数据集的第一个元素开始,把相邻的两个元素进行比较,如果他们的顺序不对,则交换它们的位置,直到整个数据集都按照要求排序成为止。
冒泡排序有两种基本实现方法,分别是升序排序和降序排序。
在升序排序中,我们要把较小的元素不断地往前移动,直到它们在正确的位置上。
而在降序排序中,则需要把较大的元素往前移动,以达到正确的排序效果。
2.算法流程:冒泡排序的流程非常简单。
它可以用几个基本的步骤来描述,如下所示:1) 比较相邻元素。
如果第一个元素比第二个元素大(或小,根据排序要求而定),就交换它们的位置。
2) 对第一次排序以后的数据集按照第一步骤进行比较,并依次交换元素位置,直到整个数据集按照要求排序完成为止。
3.算法复杂度:冒泡排序的时间复杂度为O(n^2),其中n表示数据集的大小。
假设我们有n个元素要进行冒泡排序,每个元素都需要和其他n-1个元素进行比较,因此需要进行(n-1)+(n-2)+...+1=n*(n-1)/2次比较操作。
实际上,在最坏的情况下,冒泡排序还要进行n次交换操作,因此时间复杂度为O(n^2)。
二、C语言实现以下是使用C语言实现升序冒泡排序的代码:```c#include <stdio.h>#include <stdlib.h>#define N 10void BubbleSort(int a[N], int n){int i, j, temp;for (i = 0; i < n - 1; i++){for (j = 0; j < n - i - 1; j++){if (a[j] > a[j + 1]){temp = a[j];a[j] = a[j + 1];a[j + 1] = temp;}}}}BubbleSort(a, N);for (i = 0; i < N; i++)printf("%d ", a[i]);printf("\n");return 0;}```代码说明:1)定义常量N表示要排序的数据集大小,可以根据实际情况进行修改。
动画演示C语言冒泡排序算法精品PPT课件(绝对精品)

} for(j=0;j<=4;j++)
{ for(i=0;i<5-j;i++) {
if(a[i]>a[i+1]) { temp=a[i]; a[i]=a[i+1]; a[i+1]=temp; } }
} printf("排序后的数字是:"); for(i=0;i<=5;i++) printf("%3d",a[i]); }
进行(5-j)次比较
a[i]>a[i+1]
真
假
( a[i]a[i+1] )
输出a[0]到a[5]
语言程序设计——排序算法
情景导入 冒泡排序 编写程序 调试程序
#include<stdio.h> void main() {
int i,j,temp; int a[6]; printf("请输入6个数;\n"); for(i=0;i<=5;i++)
点击开始
语言程序设计——排序算法
情景导入 冒泡排序 编写程序 调试程序
算法思想 动画演示
第二趟比较
第二趟比较结束找到第二大数8,两两比较4次。
提出问题 填流程图
5 <7 >6 <8 >2 9
点击开始
语言程序设计——排序算法
情景导入 冒泡排序 编写程序 调试程序
算法思想 动画演示
第三趟比较
第三趟比较结束找到第三大数7,两两比较3次。
语言程序设计——排序算法
情景导入 冒泡排序 编写程序 调试程序
冒泡排序链表c语言

冒泡排序链表c语言冒泡排序是一种简单而常用的排序算法,它可以用于对链表进行排序。
在本文中,我们将介绍如何使用C语言实现冒泡排序链表,并解释算法的原理和步骤。
让我们来了解一下冒泡排序的基本原理。
冒泡排序通过多次遍历待排序的元素,比较相邻的两个元素的大小,并根据需要交换它们的位置。
通过这样的比较和交换,最大(或最小)的元素会逐渐“冒泡”到列表的末尾(或开头),从而实现排序。
在链表中实现冒泡排序的思路与数组类似,但需要注意的是,我们无法像数组那样通过下标直接访问链表中的元素。
因此,在链表中进行元素比较和交换时,我们需要修改节点之间的连接关系。
下面是使用C语言实现冒泡排序链表的步骤:1. 遍历链表,确定链表的长度。
这一步是为了确定需要进行多少次排序遍历。
2. 写一个循环,循环次数为链表的长度减1。
每次循环都进行一次完整的遍历和排序。
3. 在每次遍历中,从链表的头部开始,比较相邻节点的值。
如果前一个节点的值大于后一个节点的值,则交换它们的位置。
4. 重复步骤3,直到遍历到链表的倒数第二个节点。
这样可以确保在每次遍历后,链表的最后一个节点都是当前遍历范围内的最大(或最小)值。
5. 重复步骤2和步骤3,直到完成所有的排序遍历。
此时,链表中的元素已经按照从小到大(或从大到小)的顺序排列好了。
以下是冒泡排序链表的C语言代码实现:```c#include <stdio.h>// 定义链表节点的结构体typedef struct Node {int data;struct Node* next;} Node;// 冒泡排序链表的函数void bubbleSortList(Node* head) {if (head == NULL || head->next == NULL) {return;}int len = 0;Node* cur = head;while (cur != NULL) {len++;cur = cur->next;}for (int i = 0; i < len - 1; i++) {cur = head;for (int j = 0; j < len - i - 1; j++) {if (cur->data > cur->next->data) { int temp = cur->data;cur->data = cur->next->data; cur->next->data = temp;}cur = cur->next;}}}// 打印链表的函数void printList(Node* head) {Node* cur = head;while (cur != NULL) {printf("%d ", cur->data);cur = cur->next;}printf("\n");}int main() {// 创建链表Node* head = (Node*)malloc(sizeof(Node)); Node* node1 = (Node*)malloc(sizeof(Node)); Node* node2 = (Node*)malloc(sizeof(Node)); Node* node3 = (Node*)malloc(sizeof(Node)); head->data = 3;node1->data = 2;node2->data = 4;node3->data = 1;head->next = node1;node1->next = node2;node2->next = node3;node3->next = NULL;// 打印排序前的链表printf("排序前的链表:");printList(head);// 对链表进行冒泡排序bubbleSortList(head);// 打印排序后的链表printf("排序后的链表:");printList(head);return 0;}```在上面的代码中,我们首先定义了一个链表节点的结构体,其中包含一个整型数据成员和一个指向下一个节点的指针成员。
冒泡排序流程图

冒泡排序流程图冒泡排序是一种简单且经典的排序算法。
其基本思想是通过相邻元素之间的比较和交换,将较大的元素往后移动,直到所有元素都按照从小到大的顺序排列。
下面是一篇关于冒泡排序的流程图和详细解析。
冒泡排序的流程图如下:```开始冒泡排序设定标志flag为true,表示本轮比较存在交换操作FOR i=0 TO 数组长度-1IF flag为false退出循环flag设为falseFOR j=0 TO 数组长度-i-2IF 第j个元素 > 第j+1个元素交换第j个元素和第j+1个元素flag设为true输出排序后的数组```接下来详细解析一下流程图:1. 首先,开始冒泡排序,并且设置一个标志flag为true,用来表示本轮比较时是否有交换操作。
2. 使用两个嵌套循环来进行比较和交换操作。
外层循环控制比较的轮数,内层循环控制每轮比较的次数。
3. 在内层循环开始前,先判断flag的值是否为false,如果为false,表示上一轮比较没有任何交换操作,即数组已经有序,此时退出循环。
4. 将flag设为false,表示本轮比较开始时还没有交换操作。
5. 进入内层循环,在每轮比较中,依次比较相邻的两个元素,如果前一个元素大于后一个元素,则交换这两个元素。
6. 如果发生交换操作,则将flag设为true,表示本轮比较存在交换操作。
7. 继续进行下一次内层循环,直到内层循环结束。
8. 外层循环递增,继续进行下一轮比较。
9. 循环结束后,输出排序完成的数组。
冒泡排序是一种简单但效率较低的排序算法。
其时间复杂度为O(n^2),其中n为数组的长度。
在最坏情况下,即数组逆序排列时,冒泡排序需要进行大约n*(n-1)/2次比较和交换操作。
在实际应用中,冒泡排序在数据量较大时效率较低,但是由于其实现简单,易于理解,所以在学习算法和理解排序原理时仍然具有一定的参考价值。
同时,冒泡排序也可以通过一些优化措施来提高效率,比如添加一个标志位flag来判断是否进行过交换操作,如果某一轮比较中没有进行任何交换,说明数组已经有序,可以直接退出循环,从而减少无效比较和交换的次数。
c语言冒泡法对十个数排序

c语言冒泡法对十个数排序冒泡排序是一种常见的排序算法,它的基本思想是不断比较相邻的两个数,如果它们的顺序不对就交换位置,一直重复这个过程,直到所有数都排好序为止。
下面我们就来讲解一下如何使用C语言实现冒泡排序对十个数进行排序。
首先,我们需要声明一个包含十个元素的数组,这个数组用来存储我们需要排序的十个数。
```cint arr[10] = {3, 9, 4, 7, 5, 8, 1, 6, 2, 0};```接下来,我们需要使用双重循环来实现冒泡排序。
外层循环控制比较的轮数,内层循环控制每一轮比较的次数。
在每一轮中,我们都需要比较相邻的两个数,如果前面的数比后面的数大,则交换它们的位置。
```cint i, j;for(i = 0; i < 10; i++) // 控制比较的轮数{for(j = 0; j < 9 - i; j++) // 每一轮比较的次数{if(arr[j] > arr[j+1]) // 如果前面的数比后面的数大,则交换它们的位置{int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;}}}```最后,我们再把排好序的数组打印出来,就完成了冒泡排序的整个过程。
下面是完整的代码:```c#include <stdio.h>这段代码可以输出以下结果:这就是冒泡排序算法的基本实现方法。
通过这种方法,我们可以对任意数量的数进行排序,只需要修改数组大小和数组元素的值即可。
这种算法虽然简单,但是在实际应用中还是有很大的局限性,因为它的时间复杂度较高,无法处理大规模的数据。
冒泡排序c语言简单代码

冒泡排序c语言简单代码冒泡排序是十分基础的排序算法,本文将通过c语言的简单代码例子来解释冒泡排序的原理以及如何实现。
1. 算法思路冒泡排序的思路十分简单:遍历数组的每一个元素,若当前元素比后一个元素大,则交换这两个元素的位置,在遍历完一轮后,最后一个元素就是数组中的最大值。
再将整个数组再次遍历,但这次不需要遍历到最后一个元素,而是倒数第二个元素,以此类推,每一轮结束后,未排序部分的最大值就会被放在数组的最后。
2. 实现代码我们可以通过两层嵌套的循环来实现冒泡排序,外层循环控制排序的轮数,内层循环则是用来遍历整个数组的。
下面是对应代码:```cvoid bubble_sort(int arr[], int len) {int temp;for (int i = 0; i < len - 1; i++) {for (int j = 0; j < len - 1 - i; j++) {if (arr[j] > arr[j + 1]) {temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}```3. 代码分析首先定义了一个函数bubble_sort,该函数接受两个参数:一个整形数组和该数组的长度。
接下来就是两层嵌套的for循环,内部for循环用来遍历数组,并通过if语句来判断相邻两个元素的大小,若前一个元素大于后一个,则通过temp变量来保存前一个元素,交换这两个元素的位置,遍历一遍后,最后一个元素就是数组里最大的元素。
当外层for循环完毕时,整个数组就被排序完成。
4. 总结通过c语言的简单代码,我们可以了解冒泡排序的基本原理以及如何实现。
对于初学者来说,这个算法是十分易懂的,但随着数据量的增加,其效率会越来越低,因此在具体应用中需要权衡利弊。
除此之外,其他排序算法同样是程序员们必须熟练掌握的技能,不同的算法将适用于不同的场合,因此需要我们在实践中加以理解和应用。
c语言数组冒泡排序PPT课件

运行结果:
谢谢!
学习永远 不晚。 JinTai College
感谢您的阅读! 为 了 便于学习和使用, 本文档下载后内容可 随意修改调整及打印。
ห้องสมุดไป่ตู้
for(i=1;i<=7;i++) {
for(j=1;j<=8-i;j++) { if(R[j]>R[j+1]) { T=R[j]; R[j]=R[j+1]; R[j+1]=T; } }
} printf("排序后的数字是:"); for(i=1;i<=8;i++)
printf("%d",R[i]; }
用冒泡排序法排列一组数
主讲:朱令
冒泡排序
教学目标:理解冒泡排序的原理 理解冒泡排序的流程图 加深对变量的使用的理解
教学难点:冒泡排序的原理和流程图
冒泡原理:质量大的(大的数据)下沉 质量小的(小的数据)上浮
方法:下沉法和上浮法
例:将一组无序数组排成从小到大 { 49,38,65,97,76,13,27,49 }
原数据和序号 序号 1 2 3 4 5 6 7 8 数据 49 38 65 97 76 13 27 49
第一趟下沉的步骤: 序号 1 2 3 4 5 6 7 8 数据 38 49 65 9776 791673 19237 29479 4997
经过一趟下沉,把最大的数沉到最底了
用流程图把这一趟下沉描述出来:
i=1, T=0
是
否
R[i] R[i 1]
T=R[i]
R[i]=R[i+1]
R[i+1]=T
i=i+1
C语言最常用的六种排序方法详解
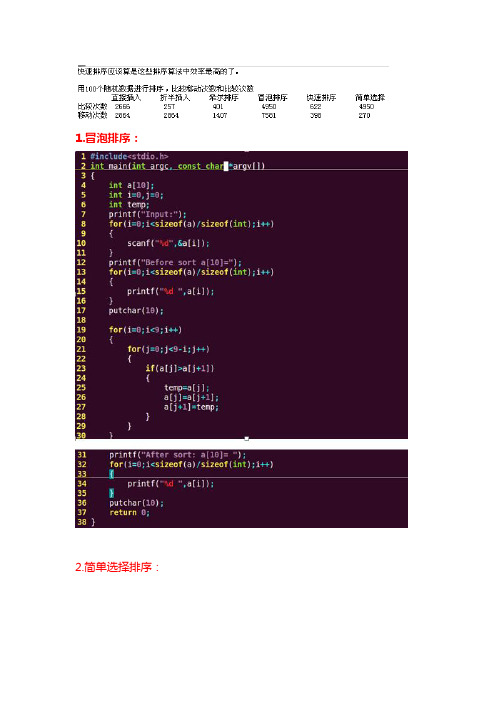
1.冒泡排序:
2.简单选择排序:
3.快速排序:
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。
4.直接插入排序:
5.折半插入排序:
折半插入排序(binary insertion sort)是对插入排序算法的一种改进,在将一个新元素插入已排好序的数组的过程中,寻找插入点时,将待插入区域的首元素设置为a[low],末元素设置为
a[high],则轮比较时将待插入元素与a[m],其中m=(low+high)/2相比较,如果比参考元素小,则选择a[low]到a[m-1]为新的插入区域(即high=m-1),否则选择a[m+1]到a[high]为新的插入区域(即low=m+1),如此直至low<=high不成立,即将此位置之后所有元素后移一位,并将新元素插入a[high+1]。
代码:
6.希尔排序:。
冒泡排序算法流程图

冒泡排序算法流程图冒泡排序是一种简单的排序算法,它也是一种稳定排序算法。
其实现原理是重复扫描待排序序列,并比较每一对相邻的元素,当该对元素顺序不正确时进行交换。
一直重复这个过程,直到没有任何两个相邻元素可以交换,就表明完成了排序。
一般情况下,称某个排序算法稳定,指的是当待排序序列中有相同的元素时,它们的相对位置在排序前后不会发生改变。
假设待排序序列为(5,1,4,2,8),如果采用冒泡排序对其进行升序(由小到大)排序,则整个排序过程如下所示:1) 第一轮排序,此时整个序列中的元素都位于待排序序列,依次扫描每对相邻的元素,并对顺序不正确的元素对交换位置,整个过程如图1 所示。
图1 第一轮排序(白色字体表示参与比较的一对相邻元素)从图1 可以看到,经过第一轮冒泡排序,从待排序序列中找出了最大数8,并将其放到了待排序序列的尾部,并入已排序序列中。
2) 第二轮排序,此时待排序序列只包含前4 个元素,依次扫描每对相邻元素,对顺序不正确的元素对交换位置,整个过程如图2 所示。
图2 第二轮排序可以看到,经过第二轮冒泡排序,从待排序序列中找出了最大数5,并将其放到了待排序序列的尾部,并入已排序序列中。
3) 第三轮排序,此时待排序序列包含前3 个元素,依次扫描每对相邻元素,对顺序不正确的元素对交换位置,整个过程如图3 所示。
图3 第三轮排序经过本轮冒泡排序,从待排序序列中找出了最大数4,并将其放到了待排序序列的尾部,并入已排序序列中。
4) 第四轮排序,此时待排序序列包含前2 个元素,对其进行冒泡排序的整个过程如图4 所示。
图4 第四轮排序经过本轮冒泡排序,从待排序序列中找出了最大数2,并将其放到了待排序序列的尾部,并入已排序序列中。
5) 当进行第五轮冒泡排序时,由于待排序序列中仅剩1 个元素,无论再进行相邻元素的比较,因此直接将其并入已排序序列中,此时的序列就认定为已排序好的序列(如图5 所示)。
图5 冒泡排序好的序列冒泡排序的实现代码为(C 语言):1.#include<stdio.h>2.//交换 a 和 b 的位置的函数3.#define N 54.int a[N]={5,1,4,2,8};5.void swap(int*a,int*b);6.//这是带输出的冒泡排序实现函数,从输出结果可以分析冒泡的具体实现流程7.void BubSort_test();8.//这是不带输出的冒泡排序实现函数,通过此函数,可直接对数组 a 中元素进行排序9.void BubSort_pro();10.int main()11.{12.BubSort_test();13.return0;14.}15.void swap(int*a,int*b){16.int temp;17. temp =*a;18.*a =*b;19.*b = temp;20.}21.22.//这是带输出的冒泡排序实现函数,从输出结果,可以看到冒泡的具体实现流程23.void BubSort_test(){24.for(int i =0; i < N; i++){25.//对待排序序列进行冒泡排序26.for(int j =0; j +1< N - i; j++){27.//相邻元素进行比较,当顺序不正确时,交换位置28.if(a[j]> a[j +1]){29.swap(&a[j],&a[j +1]);30.}31.}32.//输出本轮冒泡排序之后的序列33.printf("第%d轮冒泡排序:", i +1);34.for(int i =0; i < N; i++){35.printf("%d ", a[i]);36.}37.printf("\n");38.}39.}40.41.//这是不带输出的冒泡排序实现函数,通过此函数,可直接对数组 a 中元素进行排序42.void BubSort_pro(){43.for(int i =0; i < N; i++){44.//对待排序序列进行冒泡排序45.for(int j =0; j +1< N - i; j++){46.//相邻元素进行比较,当顺序不正确时,交换位置47.if(a[j]> a[j +1]){48.swap(&a[j],&a[j +1]);49.}50.}51.}52.}运行结果为:。
c语言冒泡排序例子

c语言冒泡排序例子C语言冒泡排序例子冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复交换相邻的两个元素,将较大(或较小)的元素逐渐“冒泡”到待排序序列的顶端。
1. 例子一:升序排序输入数组:[7, 2, 4, 1, 5]步骤一依次比较相邻的两个元素,如果前一个元素大于后一个元素,则交换位置。
比较过程:•第一轮:7 > 2,交换位置,数组变为 [2, 7, 4, 1, 5]•第二轮:7 > 4,交换位置,数组变为 [2, 4, 7, 1, 5]•第三轮:7 > 1,交换位置,数组变为 [2, 4, 1, 7, 5]•第四轮:7 > 5,交换位置,数组变为 [2, 4, 1, 5, 7]步骤二重复步骤一,但是每一轮比较的次数都会减少一个,因为每一轮都会将当前轮次最大(或最小)的元素“冒泡”到最终位置。
比较过程:•第一轮:依次比较相邻的两个元素,数组变为 [2, 4, 1, 5, 7] •第二轮:依次比较相邻的两个元素,数组变为 [2, 1, 4, 5, 7] •第三轮:依次比较相邻的两个元素,数组变为 [2, 1, 4, 5, 7] •第四轮:依次比较相邻的两个元素,数组变为 [1, 2, 4, 5, 7] 步骤三重复步骤二,直到所有元素都排好序。
最终排序结果:[1, 2, 4, 5, 7]2. 例子二:降序排序输入数组:[3, 6, 2, 8, 1]步骤一依次比较相邻的两个元素,如果前一个元素小于后一个元素,则交换位置。
比较过程:•第一轮:3 < 6,不交换位置,数组不变•第二轮:6 > 2,交换位置,数组变为 [3, 2, 6, 8, 1]•第三轮:6 < 8,不交换位置,数组不变•第四轮:8 > 1,交换位置,数组变为 [3, 2, 6, 1, 8]步骤二重复步骤一,但是每一轮比较的次数都会减少一个,因为每一轮都会将当前轮次最大(或最小)的元素“冒泡”到最终位置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、功能:冒泡排序
输入:数组名称(也就是数组首地址)、数组中元素个数
================================================
*/
/*
==================================================== 算法思想简单描述:
在要排序的一组数中,对当前还未排好序的范围内的全部数,自上
而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较
小的往上冒。
即:每当两相邻的数比较后发现它们的排序与排序要
求相反时,就将它们互换。
下面是一种改进的冒泡算法,它记录了每一遍扫描后最后下沉数的
位置k,这样可以减少外层循环扫描的次数。
冒泡排序是稳定的。
算法时间复杂度O(n2)--[n的平方]
===================================================== */
void bubble_sort(int *x, int n)
{
int j, k, h, t;
for (h=n-1; h>0; h=k) /*循环到没有比较范围*/
{
for (j=0, k=0; j<h; j++) /*每次预置k=0,循环扫描后更新k*/
{
if (*(x+j) > *(x+j+1)) /*大的放在后面,小的放到前面*/
{
t = *(x+j);
*(x+j) = *(x+j+1);
*(x+j+1) = t; /*完成交换*/
k = j; /*保存最后下沉的位置。
这样k后面的都是排序排好了的。
*/ }
}
}
}
2
在要排序的一组数中,对当前还未排好序的范围内的全部数,自上
而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较
小的往上冒。
即:每当两相邻的数比较后发现它们的排序与排序要
求相反时,就将它们互换。
下面是一种改进的冒泡算法,它记录了每一遍扫描后最后下沉数的
位置k,这样可以减少外层循环扫描的次数。
冒泡排序是稳定的。
算法时间复杂度O(n^2)
算法实现:
/*
功能:冒泡排序
输入:数组名称(也就是数组首地址)、数组中元素个数
*/
void bubble_sort(int *x, int n)
{
int j, k, h, t;
for (h=n-1; h>0; h=k) /*循环到没有比较范围*/
{
for (j=0, k=0; j<h; j++) /*每次预置k=0,循环扫描后更新k*/
{
if (*(x+j) > *(x+j+1)) /*大的放在后面,小的放到前面*/
{
t = *(x+j);
*(x+j) = *(x+j+1);
*(x+j+1) = t; /*完成交换*/
k = j; /*保存最后下沉的位置。
这样k后面的都是排序排好了的。
*/
}
}
}
}
流程图作参考。