c语言冒泡法详解
C语言链表实现冒泡法排序

C语⾔链表实现冒泡法排序功能是:从键盘输⼊字符以空格隔开当输⼊q或者Q时按回车表⽰输⼊结束先放出main函数int main(){MyNode *myNode = (MyNode *)malloc(sizeof(MyNode));if (NULL == myNode) {return 0;}getNum(myNode);sortList(myNode);printStr(myNode);freeStr(myNode);return 0;}然后就结构体#include <stdio.h>#include <stdlib.h>#include <string.h>typedef struct mynode{long value;struct mynode *next;}MyNode;最后是⼏个⽅法void getNum(MyNode *myNode){char s[20];printf("please input num and end with q/Q\n");scanf("%s", s);while ((strcmp(s, "q") != 0) && (strcmp(s , "Q") != 0)) {MyNode *temp = (MyNode *)malloc(sizeof(MyNode));if (NULL == temp) {return;}temp->value = strtol(s , 0, 0);temp->next = NULL;myNode->next = temp;myNode = myNode->next;scanf("%s", s);}}void printStr(MyNode *node){if (node == NULL) {return;}MyNode *temp = node;while (temp->next != NULL) {printf("%ld ", temp->next->value);temp = temp->next;}}void sortList(MyNode *node){if (NULL == node) {return;}MyNode *startP = node->next;MyNode *nextP = node->next;while (startP->next != NULL) {nextP = startP->next;while (nextP->next != NULL) {if (startP->next->value > nextP->next->value) { long temp = startP->next->value;startP->next->value = nextP->next->value; nextP->next->value = temp;}nextP = nextP->next;}startP = startP->next;}}void freeStr(MyNode *node){if (NULL == node) {return;}MyNode *old = NULL;while (node != NULL) {printf("d\n");old = node;node = node->next;free(old);}}。
c++冒泡排序法经典代码

c 冒泡排序法经典代码冒泡排序是一种简单的排序算法。
它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
以下是一个用C语言实现的冒泡排序算法的经典代码:```c#include <stdio.h>void bubbleSort(int array[], int size) {for (int step = 0; step < size - 1; ++step) {for (int i = 0; i < size - step - 1; ++i) {if (array[i] > array[i + 1]) {// 交换元素如果前一个元素大于后一个int temp = array[i];array[i] = array[i + 1];array[i + 1] = temp;}}}}// 在主函数中打印排序后的数组void printArray(int array[], int size) {for (int i = 0; i < size; ++i) {printf("%d ", array[i]);}printf("\n");}int main() {int data[] = {-2, 45, 0, 11, -9};int size = sizeof(data) / sizeof(data[0]);bubbleSort(data, size);printf("Sorted Array in Ascending Order:\n");printArray(data, size);}```以上代码中,`bubbleSort`函数用于执行冒泡排序,`printArray`函数用于打印排序后的数组。
在主函数`main`中,我们首先定义了一个待排序的数组,然后计算了数组的大小,然后调用`bubbleSort`函数进行排序,最后调用`printArray`函数打印排序后的数组。
沉底法冒泡法c语言

沉底法冒泡法c语言全文共四篇示例,供读者参考第一篇示例:沉底法和冒泡法是两种常用的排序算法,它们都是基于比较的算法。
在C语言中,可以通过编写相应的代码来实现这两种排序算法。
下面将介绍沉底法和冒泡法的原理和实现方式。
一、沉底法(也称为选择排序)沉底法的原理很简单:依次从未排序的元素中选择最小(或最大)的元素,放到已排序序列的末尾。
具体的实现方式可以通过以下的伪代码来描述:1. 从数组的第一个元素开始,将其标记为已排序序列。
2. 从剩余未排序的元素中找到最小的元素,将其与已排序序列的末尾元素交换位置。
3. 将已排序序列的末尾向后移动一个位置,继续从剩余未排序的元素中找到最小的元素,重复以上步骤,直到所有元素都被排序。
以下是沉底法在C语言中的实现:```cvoid selectionSort(int arr[], int n) {int i, j, minIndex, temp;for (i = 0; i < n - 1; i++) {minIndex = i;for (j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}temp = arr[i];arr[i] = arr[minIndex];arr[minIndex] = temp;}}```二、冒泡法冒泡法的原理是:比较相邻的元素,如果顺序不对则交换位置,直到没有需要交换的元素。
具体的实现方式可以通过以下的伪代码来描述:1. 从数组的第一个元素开始,依次比较相邻的两个元素。
2. 如果左侧的元素大于右侧的元素,则交换它们的位置。
3. 重复以上步骤,直到没有需要交换的元素。
通过以上的代码,我们可以很容易地实现沉底法和冒泡法。
这两种排序算法的时间复杂度都为O(n^2),对于小规模的数据量,它们都是比较有效的排序算法。
对于大规模的数据量,它们的效率相对较低。
c语言中冒泡法

c语言中冒泡法冒泡法是一种简单直观的排序算法,常被用于教学中。
它的实现过程简单易懂,算法效率较低,仅适合小规模数据排序。
下面我们就来深入了解一下什么是冒泡法,以及它的运作原理。
冒泡法排序可以用一个很形象的比喻来描述,在水中有很多气泡,气泡的大小不一,我需要从小到大排序将气泡排列好。
排列的方式就是在一次遍历中,将相邻的两个气泡进行大小的比较,将大的往后移动一位,一直遍历到最后,这样第一大的气泡就会“冒泡”到最后一位。
接着,再次遍历,只不过这一次不需要将最后一位参与比较,依次类推,最终完成排序。
在C语言中实现冒泡排序算法,需要先用数组来存储需要排序的数值,然后通过两重循环来实现。
外层循环控制遍历次数,内层循环进行相邻数值的比较并交换位置。
代码实现类似于下面:```cvoid bubble_sort(int arr[], int len){int i, j, temp;for (i = 0; i < len - 1; i++){for (j = 0; j < len - 1 - i; j++){if (arr[j] > arr[j + 1]){temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}```冒泡排序算法的时间复杂度为O(n^2),因此效率较低。
但是,它的实现过程简单,易于理解,非常适合初学者学习排序算法。
同时,经过改进,冒泡排序算法也被广泛应用于其他领域,例如图像处理中的边缘检测。
总之,冒泡法虽然简单,但可以锻炼我们对算法的理解,增加对编程的把握。
具体算法实现可以根据实际情况进行不同的优化,达到更高的效率和效果。
C语言用函数冒泡排序

C语言程序设计实验报告1实验目的1.透彻理解函数的概念。
2.掌握函数的定义方法。
3.了解函数地形参和实参之间的对应关系及“值传递”地方式。
4.了解函数的返回值的概念。
2实验内容写一主函数输入一数组,写一子函数实现对该数组的冒泡排序并输出。
输入数据:12,21,33,5,19,27,6,4,38,47,29,56,973算法描述流程图主函数:子函数bub:4源程序#include<stdio.h>int bub(int a[13]){int i,j,k;for(j=0;j<13;j++)for(i=0;i<13-j;i++){if(a[i]>a[i+1]){k=a[i+1];a[i+1]=a[i];a[i]=k;}}printf("排序好的数为;");for(i=0;i<13;i++)printf("%4d",a[i]);printf("\n");return 0;}void main(){int m[13],k;for(k=0;k<13;k++)scanf("%d",&m[k]);for(k=0;k<13;k++)printf("%4d",m[k]);printf("\n");bub(m);}5测试数据输入数据:12,21,33,5,19,27,6,4,38,47,29,56,97 6运行结果7出现问题及解决方法开始时不知道如何进行控制循环仅用一个for循环无法实现冒泡排序,只能找出最大值;用两个for循环。
8实验心得C语言在实践中更容易掌握。
c语言 冒泡算法

c语言冒泡算法冒泡算法,又称为气泡排序,是一种简单的排序算法,可以按照升序或降序排列数据集。
它的基本思想是重复地访问数据集,比较相邻两个元素的大小,将较大或较小的元素不断地交换位置,直到整个数据集按照要求排列好为止。
下面,我们将详细介绍冒泡算法的实现步骤和时间复杂度等相关知识。
一、算法原理及流程1.算法原理:冒泡算法是一种比较简单的排序算法。
它的基本思路是从数据集的第一个元素开始,把相邻的两个元素进行比较,如果他们的顺序不对,则交换它们的位置,直到整个数据集都按照要求排序成为止。
冒泡排序有两种基本实现方法,分别是升序排序和降序排序。
在升序排序中,我们要把较小的元素不断地往前移动,直到它们在正确的位置上。
而在降序排序中,则需要把较大的元素往前移动,以达到正确的排序效果。
2.算法流程:冒泡排序的流程非常简单。
它可以用几个基本的步骤来描述,如下所示:1) 比较相邻元素。
如果第一个元素比第二个元素大(或小,根据排序要求而定),就交换它们的位置。
2) 对第一次排序以后的数据集按照第一步骤进行比较,并依次交换元素位置,直到整个数据集按照要求排序完成为止。
3.算法复杂度:冒泡排序的时间复杂度为O(n^2),其中n表示数据集的大小。
假设我们有n个元素要进行冒泡排序,每个元素都需要和其他n-1个元素进行比较,因此需要进行(n-1)+(n-2)+...+1=n*(n-1)/2次比较操作。
实际上,在最坏的情况下,冒泡排序还要进行n次交换操作,因此时间复杂度为O(n^2)。
二、C语言实现以下是使用C语言实现升序冒泡排序的代码:```c#include <stdio.h>#include <stdlib.h>#define N 10void BubbleSort(int a[N], int n){int i, j, temp;for (i = 0; i < n - 1; i++){for (j = 0; j < n - i - 1; j++){if (a[j] > a[j + 1]){temp = a[j];a[j] = a[j + 1];a[j + 1] = temp;}}}}BubbleSort(a, N);for (i = 0; i < N; i++)printf("%d ", a[i]);printf("\n");return 0;}```代码说明:1)定义常量N表示要排序的数据集大小,可以根据实际情况进行修改。
动画演示C语言冒泡排序算法精品PPT课件(绝对精品)

} for(j=0;j<=4;j++)
{ for(i=0;i<5-j;i++) {
if(a[i]>a[i+1]) { temp=a[i]; a[i]=a[i+1]; a[i+1]=temp; } }
} printf("排序后的数字是:"); for(i=0;i<=5;i++) printf("%3d",a[i]); }
进行(5-j)次比较
a[i]>a[i+1]
真
假
( a[i]a[i+1] )
输出a[0]到a[5]
语言程序设计——排序算法
情景导入 冒泡排序 编写程序 调试程序
#include<stdio.h> void main() {
int i,j,temp; int a[6]; printf("请输入6个数;\n"); for(i=0;i<=5;i++)
点击开始
语言程序设计——排序算法
情景导入 冒泡排序 编写程序 调试程序
算法思想 动画演示
第二趟比较
第二趟比较结束找到第二大数8,两两比较4次。
提出问题 填流程图
5 <7 >6 <8 >2 9
点击开始
语言程序设计——排序算法
情景导入 冒泡排序 编写程序 调试程序
算法思想 动画演示
第三趟比较
第三趟比较结束找到第三大数7,两两比较3次。
语言程序设计——排序算法
情景导入 冒泡排序 编写程序 调试程序
c语言几种数组排序方法

常用的c语言排序算法主要有三种即冒泡法排序、选择法排序、插入法排序。
一、冒泡排序冒泡排序:是从第一个数开始,依次往后比较,在满足判断条件下进行交换。
代码实现(以降序排序为例)#include<stdio.h>int main(){int array[10] = { 6,9,7,8,5,3,4,0,1,2 };int temp;for (int i = 0; i < 10; i++){//循环次数for (int j = 0; j <10 - i-1; j++){if (array[j] < array[j+1]){//前面一个数比后面的数大时发生交换temp = array[j];array[j] = array[j+1];array[j + 1] = temp;}}} //打印数组for (int i = 0; i < 10; i++) printf("%2d", array[i]); return 0;}}二、选择排序以升序排序为例:就是在指定下标的数组元素往后(指定下标的元素往往是从第一个元素开始,然后依次往后),找出除指定下标元素外的值与指定元素进行对比,满足条件就进行交换。
与冒泡排序的区别可以理解为冒泡排序是相邻的两个值对比,而选择排序是遍历数组,找出数组元素与指定的数组元素进行对比。
(以升序为例)#include<stdio.h>int main(){int array[10] = { 6,9,7,8,5,3,4,0,1,2 };int temp, index;for (int i = 0; i < 9; i++) {index = i;for (int j = i; j < 10; j++){if (array[j] < array[index])index = j;}if(i != index){temp = array[i]; array[i] = array[index]; array[index] = temp; }for(int i=0;i<10:i++) printf("%2d"array[i])return 0;}三、快速排序是通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
c语言基础算法知识

c语言基础算法知识C语言基础算法知识概述:C语言作为一种广泛应用的编程语言,其基础算法知识对于程序员来说至关重要。
本文将从常见的算法知识入手,介绍C语言中常用的算法及其应用。
一、排序算法排序算法是计算机科学中最基础也是最常用的算法之一。
常见的排序算法有冒泡排序、选择排序、插入排序、快速排序、归并排序等。
这些算法的实现原理各不相同,但都能对一组数据进行排序。
1. 冒泡排序冒泡排序是一种简单直观的排序算法,它重复地遍历待排序的元素,比较相邻的两个元素并将它们交换顺序,直至整个序列有序。
2. 选择排序选择排序是一种简单直观的排序算法,它每次从待排序的数据中选择最小(或最大)的元素,将其放到已排序序列的末尾。
3. 插入排序插入排序是一种简单直观的排序算法,它将待排序的数据分为已排序和未排序两部分,每次从未排序中取出一个元素插入到已排序的合适位置,直至整个序列有序。
4. 快速排序快速排序是一种高效的排序算法,它通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有元素都比另一部分的元素小,然后对这两部分继续进行排序,直至整个序列有序。
5. 归并排序归并排序是一种稳定的排序算法,它采用分治策略,将待排序的数据不断二分,然后对子序列进行排序,最后将排序好的子序列合并成一个有序序列。
二、查找算法查找算法是在一组数据中寻找指定元素的算法。
常见的查找算法有线性查找、二分查找、哈希查找等。
1. 线性查找线性查找是一种简单直观的查找算法,它从待查找的数据中依次比较每个元素,直到找到目标元素或遍历完整个序列。
2. 二分查找二分查找是一种高效的查找算法,它要求待查找的数据必须是有序的,通过每次将查找范围缩小一半,直到找到目标元素或查找范围为空。
3. 哈希查找哈希查找是一种快速的查找算法,它通过将关键字映射到哈希表中的位置,以实现快速定位目标元素。
三、递归算法递归算法是一种重要的算法思想,它通过函数自身的调用来解决问题。
C语言程序设计立体化教程课件:冒泡排序

真题练一练
A A B
C
课后练一练
1、从键盘输入任意10个同学的 大学英语成绩,用“冒泡法”对 10个分数排序(由大到小)后 输出相应的名次。
预习下讲 选择排序算法
5
13
23
34
56
冒泡排序演示动画 输入6个数,(34,2,56,5,13,23)用“冒泡 法”对6个数排序(由小到大)。
趟数-i
每趟比较
2
5
13
23
34
56 次数—j
i=3
不交换 不交换 不交换
3
第3趟排完后: 2
5
13
23
34
56
冒泡演示结论
(1)对于6个数的排序,需进行5趟冒泡, 第i趟比较次数需进行6-i次两两比较。
for(i=1;i<=5;i++) // i是控制冒泡的趟数 for( j=0;j<6-i;j++) // j是每趟比较次数的控制 if(a[ j]>a[ j+1]) {t=a[ j]; a[ j]=a[ j+1]; a[j+1]=t;} //当遇到前者a[ j]比后者a[ j+1]大时,进行交换,否则不交换
(2)对于n个数的排序,需进行n-1趟冒泡, 第i趟比较次数需进行n-j次两两比较。
冒泡排序实现 输入任意6个整数用“冒泡法”对6个数排序(由小到大)。
#include <stdio.h> main() {int a[6], i,j,t; printf("请输入任意的6个整数:\n"); for(i=0;i<6;i++) scanf("%d",&a[i]);
C语言经典算法大全

C语言经典算法大全1. 冒泡排序(Bubble Sort):比较相邻的元素,如果顺序错误就交换位置,直到整个序列有序。
2. 快速排序(Quick Sort):选择一个中间元素作为基准,将序列分成两部分,左边的元素都小于等于基准,右边的元素都大于等于基准,然后递归地对两个子序列进行排序。
3. 插入排序(Insertion Sort):将元素逐个插入到已经排序的序列中,直到整个序列有序。
4. 选择排序(Selection Sort):每次选择一个最小(或最大)的元素放到有序序列的末尾(或开头),直到整个序列有序。
5. 归并排序(Merge Sort):将序列分成若干个子序列,对每个子序列进行排序,然后再将已排好序的子序列合并成一个有序序列。
6. 希尔排序(Shell Sort):将序列划分成若干个小的子序列分别进行直接插入排序,然后逐渐减小子序列的间隔直到整个序列有序。
7. 堆排序(Heap Sort):利用堆这种数据结构进行排序,构建一个大(或小)根堆,依次将根节点(最大或最小值)和最后一个节点交换位置,然后重新调整堆。
8. 计数排序(Counting Sort):统计每个元素的出现次数,然后根据统计结果,将元素按照顺序放入相应位置,从而实现排序。
9. 桶排序(Bucket Sort):将元素分到不同的桶中,桶内元素进行排序,然后按照桶的顺序将元素取出,从而实现排序。
10.基数排序(Radix Sort):根据元素的位数进行排序,首先排个位,然后排十位,以此类推,直到排完最高位。
除了上述排序算法之外,C语言中还有许多其他经典算法,例如二分查找、递归、深度优先、广度优先、贪心算法、动态规划等等。
这些算法都有各自的特点和应用场景,对于提高编程水平和解决实际问题都有很大的帮助。
总结起来,掌握C语言的经典算法对于编程爱好者来说是非常重要的。
它们可以帮助我们更好地理解计算机科学的基本原理和数据结构,提高我们编写程序的能力和效率。
c语言结构体链表冒泡排序

c语言结构体链表冒泡排序在C 语言中,如果你有一个包含结构体的链表,并且希望对链表中的元素进行冒泡排序,下面是一个简单的例子代码:```c#include <stdio.h>#include <stdlib.h>// 定义结构体struct Node {int data;struct Node* next;};// 创建新节点struct Node* createNode(int data) {struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));newNode->data = data;newNode->next = NULL;return newNode;}// 向链表尾部添加节点void appendNode(struct Node head, int data) {struct Node* newNode = createNode(data);if (*head == NULL) {*head = newNode;return;}struct Node* last = *head;while (last->next != NULL) {last = last->next;}last->next = newNode;}// 打印链表void printList(struct Node* head) {struct Node* current = head;while (current != NULL) {printf("%d -> ", current->data);current = current->next;}printf("NULL\n");}// 冒泡排序函数void bubbleSort(struct Node* head) {int swapped, i;struct Node *ptr1, *lptr = NULL;// 如果链表为空或只有一个节点,无需排序if (head == NULL)return;do {swapped = 0;ptr1 = head;while (ptr1->next != lptr) {if (ptr1->data > ptr1->next->data) {// 交换节点数据int temp = ptr1->data;ptr1->data = ptr1->next->data;ptr1->next->data = temp;swapped = 1;}ptr1 = ptr1->next;}lptr = ptr1;} while (swapped);}int main() {struct Node* head = NULL;// 向链表中添加节点appendNode(&head, 4);appendNode(&head, 2);appendNode(&head, 7);appendNode(&head, 1);appendNode(&head, 9);printf("原始链表: ");printList(head);// 对链表进行冒泡排序bubbleSort(head);printf("排序后的链表: ");printList(head);return 0;}```在这个例子中,`bubbleSort` 函数用于对链表进行冒泡排序。
C语言常用9种算法

C语言常用9种算法C语言是一门广泛应用于编程领域的语言,具有丰富的算法库和功能。
在C语言中,有许多常用的算法可以帮助程序员解决各种问题。
本文将介绍C语言中常用的9种算法,以帮助读者深入了解和应用这些算法。
1.顺序算法:顺序算法是一种简单但有效的方法,通过逐个比较目标元素和数组中的元素来寻找指定值。
该算法适用于小规模的数据集,时间复杂度为O(n)。
2.二分算法:二分算法是一种高效的方法,适用于已排序的数组。
该算法通过将目标值与数组的中间元素进行比较,并根据比较结果将范围缩小一半。
时间复杂度为O(log n)。
3.冒泡排序算法:冒泡排序算法是一种简单但低效的排序方法,通过反复交换相邻的元素将较大的元素逐渐移至数组的末尾。
时间复杂度为O(n^2)。
4.选择排序算法:选择排序算法是一种简单但较为高效的排序方法,通过找到最小元素并将其放置在数组的起始位置,逐个选择剩余元素中的最小值,直到完成排序。
时间复杂度为O(n^2)。
5.插入排序算法:插入排序算法是一种简单而且对小数据集很有效的排序方法,通过将未排序的元素依次插入已排序的序列中,逐步构建有序的序列。
时间复杂度为O(n^2)。
6.快速排序算法:快速排序算法是一种高效的排序方法,通过选择一个基准值将数组分割成两个子数组,较小的值放在基准值的左边,较大的值放在右边。
然后对子数组进行递归排序。
时间复杂度为O(n log n)。
7.归并排序算法:归并排序算法是一种稳定而且高效的排序方法,通过将数组递归地分成两个子数组,然后合并这些子数组以得到排序结果。
时间复杂度为O(n log n)。
8.哈希算法:哈希算法是一种用于将数据映射到特定位置的算法,可以快速访问数据。
C语言提供了多种哈希算法库,例如MD5和SHA1等,用于数据完整性校验和密码存储等应用场景。
9.图算法:图算法是一类用于处理图结构的算法,包括广度优先、深度优先和最短路径算法等。
通过这些算法,可以实现许多图相关的问题,如寻找社交网络中的最短路径或者查找网络拓扑结构等。
c语言气泡法排序

c语言气泡法排序以C语言气泡法排序为标题气泡法排序是一种简单且常用的排序算法,它通过不断地比较相邻的元素并交换位置来实现排序。
本文将介绍气泡法排序的原理和实现,并对其时间复杂度和优化方法进行探讨。
一、气泡法排序的原理及实现气泡法排序的原理很简单,它重复地走访要排序的元素列,依次比较相邻的两个元素,如果顺序错误则交换位置。
通过多次的遍历和交换,最终可以将序列按照从小到大(或从大到小)的顺序排列。
以下是气泡法排序的C语言实现代码:```c#include <stdio.h>void bubbleSort(int arr[], int n) {int i, j;for (i = 0; i < n - 1; i++) {for (j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}int main() {int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);bubbleSort(arr, n);printf("排序后的数组:\n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;}```在上述代码中,我们定义了一个`bubbleSort`函数来实现气泡法排序。
通过嵌套的循环,我们可以遍历整个数组并比较相邻的元素。
如果前一个元素大于后一个元素,则交换它们的位置。
通过这样的遍历和交换操作,我们可以将最大(或最小)的元素逐渐“冒泡”到数组的末尾。
二、气泡法排序的时间复杂度和优化方法气泡法排序的时间复杂度为O(n^2),其中n是待排序数组的长度。
C语言最常用的六种排序方法详解
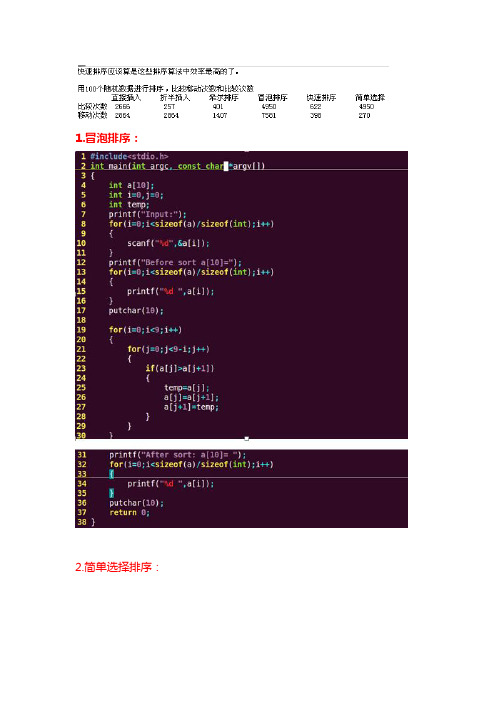
1.冒泡排序:
2.简单选择排序:
3.快速排序:
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。
4.直接插入排序:
5.折半插入排序:
折半插入排序(binary insertion sort)是对插入排序算法的一种改进,在将一个新元素插入已排好序的数组的过程中,寻找插入点时,将待插入区域的首元素设置为a[low],末元素设置为
a[high],则轮比较时将待插入元素与a[m],其中m=(low+high)/2相比较,如果比参考元素小,则选择a[low]到a[m-1]为新的插入区域(即high=m-1),否则选择a[m+1]到a[high]为新的插入区域(即low=m+1),如此直至low<=high不成立,即将此位置之后所有元素后移一位,并将新元素插入a[high+1]。
代码:
6.希尔排序:。
冒泡排序c语言简单代码

冒泡排序c语言简单代码冒泡排序是一种基本的排序算法,其主要思想是通过不断交换相邻的元素,将较小的元素逐渐“冒泡”到数组的前面,较大的元素逐渐“沉底”,最终实现整体有序的效果。
下面是一份简单的冒泡排序C语言代码:```c#include <stdio.h>void bubbleSort(int arr[], int n){int i, j;for (i = 0; i < n - 1; i++) // 外层循环控制排序轮数{for (j = 0; j < n - i - 1; j++) // 内层循环控制每轮排序次数{if (arr[j] > arr[j + 1]) // 如果前一个元素比后一个元素大,则交换它们的位置{int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}int main(){int arr[] = { 5, 1, 4, 2, 8 };int n = sizeof(arr) / sizeof(arr[0]); // 计算数组长度 int i;printf('排序前的数组:');for (i = 0; i < n; i++)printf('%d ', arr[i]);printf('');bubbleSort(arr, n); // 调用冒泡排序函数printf('排序后的数组:');for (i = 0; i < n; i++)printf('%d ', arr[i]);printf('');return 0;```在上述代码中,bubbleSort函数实现了冒泡排序的核心逻辑,外层循环控制排序轮数,内层循环控制每轮排序次数,通过比较相邻元素的大小交换它们的位置。
在主函数中,我们先输出排序前的数组,然后调用冒泡排序函数,再输出排序后的数组,最后返回0表示程序正常结束。
C语言课件(冒泡排序法)

R[i] ≤ R[i + 1]
否
T=R[i] R[i]=R[i+1] R[i+1]=T i=i+1
否
i>7
是
一个完整的程序来表示这个算法: 一个完整的程序来表示这个算法
#include"stdio.h" main() { int R[8]; int T=0; int i,j; printf("请输入8个整数:"); for(i=1;i<=8;i++) scanf("%d",&R[i]); for(i=1;i<=7;i++) { for(j=1;j<=8-i;j++) { if(R[j]>R[j+1]) { T=R[j]; R[j]=R[j+1]; R[j+1]=T; } } } printf("排序后的数字是:"); for(i=1;i<=8;i++) printf("%d",R[i]; }
原数据和序号
序号 数据
1 49
2 38
3 65
4 97
5 76
6 13
7 27
8 49
第一趟下沉的步骤: 第Байду номын сангаас趟下沉的步骤:
序号 数据
1 38
2 49
3 65
4 76 97
5 13 97 76
6 27 97 13
7 49 97 27
8 97 49
经过一趟下沉, 经过一趟下沉,把最大的数沉到最底了
用流程图把这一趟下沉描述出来: 用流程图把这一趟下沉描述出来: i=1, T=0
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
这种方法的基本思想是,将待排序的元素看作是竖着排列的“气泡”,较小的元素比较轻,从而要往上浮。在冒泡排序算法中我们要对这个“气泡”序列处理若干遍。所谓一遍处理,就是自底向上检查一遍这个序列,并时刻注意两个相邻的元素的顺序是否正确。如果发现两个相邻元素的顺序不对,即“轻”的元素在下面,就交换它们的位置。显然,处理一遍之后,“最轻”的元素就浮到了最高位置;处理二遍之后,“次轻”的元素就浮到了次高位置。在作第二遍处理时,由于最高位置上的元素已是“最轻”元素,所以不必检查。一般地,第i遍处理时,不必检查第i高位置以上的元素,因为经过前面i-1遍的处理,它们已正确地排好序。
void doit(float* in,int count)
{
int x;
int y;
float temp;
for(y=0;y<count-1;y++)
{
for(x=1;x<count-y;x++)
{
if((*(in+x))>(*(in+x-1)))
{
temp=(*(in+x-1));
(*(in+x-1))=(*(in+x));
(2)改变扫描方向的冒泡排序
①冒泡排序的不对称性
能一趟扫描完成排序的情况:
只有最轻的气泡位于R[n]的位置,其余的气泡均已排好序,那么也只需一趟扫描就可以完成排序。
【例】对初始关键字序列12,18,42,44,45,67,94,10就仅需一趟扫描。
需要n-1趟扫描完成排序情况:
当只有最重的气泡位于R[1]的位置,其余的气泡均已排好序时,则仍需做n-1趟扫描才能完成排序。
(1)初始
R[1..n]为无序区。
(2)第一趟ቤተ መጻሕፍቲ ባይዱ描
从无序区底部向上依次比较相邻的两个气泡的重量,若发现轻者在下、重者在上,则交换二者的位置。即依次比较(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);对于每对气泡(R[j+1],R[j]),若R[j+1].key<R[j].key,则交换R[j+1]和R[j]的内容。
冒泡排序的最坏时间复杂度为O(n2)。
(3)算法的平均时间复杂度为O(n2)
虽然冒泡排序不一定要进行n-1趟,但由于它的记录移动次数较多,故平均时间性能比直接插入排序要差得多。
(4)算法稳定性
冒泡排序是就地排序,且它是稳定的。
5、算法改进
上述的冒泡排序还可做如下的改进:
(1)记住最后一次交换发生位置lastExchange的冒泡排序
}
if(!exchange) //本趟排序未发生交换,提前终止算法
return;
} //endfor(外循环)
} //BubbleSort
4、算法分析
(1)算法的最好时间复杂度
若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数C和记录移动次数M均达到最小值:
Cmin=n-1
Mmin=0。
在每趟扫描中,记住最后一次交换发生的位置lastExchange,(该位置之前的相邻记录均已有序)。下一趟排序开始时,R[stExchange-1]是有序区,R[lastExchange..n]是无序区。这样,一趟排序可能使当前有序区扩充多个记录,从而减少排序的趟数。具体算法【参见习题】。
【例】对初始关键字序列:94,10,12,18,42,44,45,67就需七趟扫描。
②造成不对称性的原因
每趟扫描仅能使最重气泡"下沉"一个位置,因此使位于顶端的最重气泡下沉到底部时,需做n-1趟扫描。
③改进不对称性的方法
在排序过程中交替改变扫描方向,可改进不对称性。
(2)具体算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上扫描,对R做冒泡排序
int i,j;
Boolean exchange;//交换标志
for(i=1;i<n;i++){ //最多做n-1趟排序
exchange=FALSE;//本趟排序开始前,交换标志应为假
第一趟扫描完毕时,"最轻"的气泡就飘浮到该区间的顶部,即关键字最小的记录被放在最高位置R[1]上。
(3)第二趟扫描
扫描R[2..n]。扫描完毕时,"次轻"的气泡飘浮到R[2]的位置上……
最后,经过n-1趟扫描可得到有序区R[1..n]
注意:
第i趟扫描时,R[1..i-1]和R[i..n]分别为当前的有序区和无序区。扫描仍是从无序区底部向上直至该区顶部。扫描完毕时,该区中最轻气泡飘浮到顶部位置R[i]上,结果是R[1..i]变为新的有序区。
for(j=n-1;j>=i;j--) //对当前无序区R[i..n]自下向上扫描
if(R[j+1].key<R[j].key){//交换记录
R[0]=R[j+1];//R[0]不是哨兵,仅做暂存单元
R[j+1]=R[j];
R[j]=R[0];
exchange=TRUE;//发生了交换,故将交换标志置为真
2、冒泡排序过程示例
对关键字序列为49 38 65 97 76 13 27 49的文件进行冒泡排序的过程
3、排序算法
(1)分析
因为每一趟排序都使有序区增加了一个气泡,在经过n-1趟排序之后,有序区中就有n-1个气泡,而无序区中气泡的重量总是大于等于有序区中气泡的重量,所以整个冒泡排序过程至多需要进行n-1趟排序。
若在某一趟排序中未发现气泡位置的交换,则说明待排序的无序区中所有气泡均满足轻者在上,重者在下的原则,因此,冒泡排序过程可在此趟排序后终止。为此,在下面给出的算法中,引入一个布尔量exchange,在每趟排序开始前,先将其置为FALSE。若排序过程中发生了交换,则将其置为TRUE。各趟排序结束时检查exchange,若未曾发生过交换则终止算法,不再进行下一趟排序。
(*(in+x))=temp;
}
}
}
}
冒泡排序的算法分析与改进
交换排序的基本思想是:两两比较待排序记录的关键字,发现两个记录的次序相反时即进行交换,直到没有反序的记录为止。
应用交换排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
将被排序的记录数组R[1..n]垂直排列,每个记录R[i]看作是重量为R[i].key的气泡。根据轻气泡不能在重气泡之下的原则,从下往上扫描数组R:凡扫描到违反本原则的轻气泡,就使其向上"飘浮"。如此反复进行,直到最后任何两个气泡都是轻者在上,重者在下为止。
冒泡排序最好的时间复杂度为O(n)。
(2)算法的最坏时间复杂度
若初始文件是反序的,需要进行n-1趟排序。每趟排序要进行n-i次关键字的比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
Cmax=n(n-1)/2=O(n2)
Mmax=3n(n-1)/2=O(n2)