利用 MEGA4 构建分子系统进化树
用MEGA构建进化树

如何用MEGA构建进化树MEGA3.1是一个关于序列分析以及比较统计的工具包,其中包括有距离建树法和MP 建树法;可自动或手动进行序列比对,推断进化树,估算分子进化率,进行进化假设测验,还能联机的Web数据库检索。
下载后可直接使用,主要包括几个方面的功能软件:i)DNA 和蛋白质序列数据的分析软件。
ii)序列数据转变成距离数据后,对距离数据分析的软件。
iii)对基因频率和连续的元素分析的软件。
iv)把序列的每个碱基/氨基酸独立看待(碱基/氨基酸只有0和1的状态)时,对序列进行分析的软件。
v)绘制和修改进化树的软件,进行网上blast搜索。
用MEGA构建进化树有以下步骤:1. 16S rDNA测序和参考序列选取从环境中分离到单克隆,去重复后扩增16S rDNA序列并测序,然后与数据库/blast/Blast.cgi比对,找到相似度最高的几个序列,确定一下你分离的细菌大约属于哪个科哪个属,如果相似度达到百分之百那基本可以确定你分离得到的就是Blast到的那个,然后找一到两个同科的,再找一到两个同目的,再找一到两个同纲的细菌,把序列全部下下来,以FSATA形式整合在TXT文档中,如>TS1GCAGTCGAACGATGAAGCCCAGCTTGCTGGGTGGA TTAGTGGCGAACGGGTGAGTAA CACGTGGGTGATCTGCCCTGCACTTCGGGATAAGCCTGGGAAACTGGGTCTAATACCG GA TAGGACCTCGGGA TGCA TGTTCCGGGGTGGAAAGGTTTTCCGGTGCAGGATGGGCC>gi|117572706|gb|EF028124.1| Rhodococcus sp. Atl25 16S ribosomal RNA gene, partial sequence CGATTAGAGTTTGA TCCTGGCTCAGGACGAACGCTGGCGGCGTGCTTAACACATGCAA GTCGAACGATGAAGCCCAGCTTGCTGGGTGGA TTAGTGGCGAACGGGTGAGTAACAC GTGGGTGATCTGCCCTGCACTTCGGGATAAGCCTGGGAAACTGGGTCTAA TACCGGA T>TS2TGCAAGTCGAGCGAATGGA TTAAGAGCTTGCTCTTA TGAAGTTAGCGGCGGACGGGTG AGTAACACGTGGGTAACCTGCCCA TAAGACTGGGATAACTCCGGGAAACCGGGGCTAA TACCGGATAACA TTTTGAACTGCATGGTTCGAAA TTGAAAGGCGGCTTCGGCTGTCACT>gi|56383044|emb|AJ809498.1| Bacillus cereus partial 16S rRNA gene, strain TMW 2.383GA TGAACGCTGGCGGCGTGCCTAA TACATGCAAGTCGAGCGAA TGGATTAAGAGCTTG CTCTTA TGAAGTTAGCGGCGGACGGGTGAGTAACACGTGGGTAACCTGCCCATAAGAC TGGGATAACTCCGGGAAACCGGGGCTAATACCGGATAACATTTTGAACYGCATGGTTC ………………………….………………………….参考序列选择有几个原则:a,不选非培养(unclutured)微生物为参比;b,所选参考序列要正确,里面无错误碱基;c,在保证同属的前提下,优先选择16S rDNA全长测序或全基因组测序的种;d,每个种属选择一个参考序列,如果自己的序列中同一属的较多,可适当选择两个参考序列。
mega4使用说明

MEGA的使用产生背景及简介随着不同物种基因组测序的快速发展,产生了大量的DNA序列信息,这时就需要一种简便而快速的统计分析工具来对这些数据进行有效的分析,以提取其中包含的大量信息。
MEGA就是基于这种需求开发的。
MEGA 软件的目的就是提供一个以进化的角度从DNA和蛋白序列中提取有用的信息的工具,并且,此软件可以免费下载使用。
现在我们使用的是MEGA4的版本。
它主要集中于进化分析获得的综合的序列信息。
使用它我们可以编辑序列数据、序列比对、构建系统发育树、推测物种间的进化距离等。
此软件的输出结果资源管理器允许用户浏览、编辑、打印输入所得到的结果而且所得到的结果具有不同形式的可视化效果。
此外,该软件还能够得出不同序列间的距离矩阵,这是他不同与其他分析软件的地方。
在计算矩阵方面有一些自己的特点:1.推测序列或者物种间的进化距离2.根据MCL(Maximum Composite Likeliood method)的方法构建系统发育树3.考虑到了不同碱基替换的不同的比率,考虑到了碱基转换和颠换的差别。
4.随时可以使用标注:所以的结果输入都可以使用标注,而且标注的内容可以被保存,复制。
具体使用我们以分析20个物种的血红蛋白为例来具体说明此软件的具体使用情况。
一.启动程序1.运行环境:在Windows 95/98, NT, ME, 2000, XP, vista等操作系统下均可使用。
2.下载安装:可以直接登陆进行下载安装,另外还可以从/tools/phylogeny.php中的链接进去。
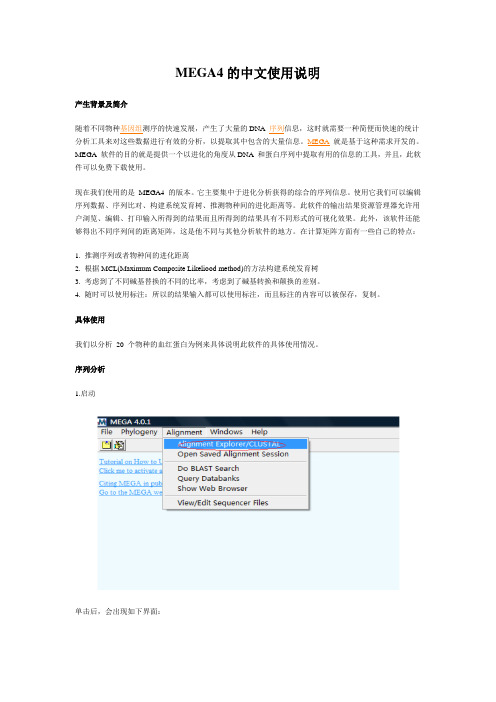
3.双击桌面快捷方式图标,进入主界面;或者从开始菜单,单击图标启动。
二.序列分析。
1.启动单击后,会出现如下界面:这里有三个选项,分别对应三种不同的情况:以下分别予以介绍:Create a new alignment :是在你没有任何比对的时候使用,比如你只有一个fasta格式的序列就可以选择这个选项。
Open a saved alignment session:使用它可以打开一个我们已经比对好的序列文件;Retieve a sequence from a file :这种情况同第一种情况相似,只是不用选择是DNA 还是蛋白质序列比对,选择的也是fasta格式的文件,打开后的界面都是一样的。
Mega的使用以及进化树的绘制

1.MEGA构建系统进化树的步骤2.CLUSTALX进行序列比对1.MEGA构建系统进化树的步骤1. 将要用于构建系统进化树的所有序列合并到同一个fasta格式文件,注意:所有序列的方向都要保持一致( 5’-3’)。
如图:2. 打开MEGA软件,选择"Alignment" - "Alignment Explorer/CLUSTAL",在对话框中选择Retrieve sequences from a file, 然后点OK,找到准备好的序列文件并打开,如图:。
3. 在打开的窗口中选择”Alignment”-“Align by ClustalX” 进行对齐,对齐过程需要一段时间,对齐完成后,最好将序列两端切齐,选择两端不齐的部分,单击右键,选择delete即可,如图:。
4. 关闭当前窗口,关闭的时候会提示两次否保存,第一次无所谓,保存不保存都可以,第二次一定要保存,保存的文件格式是.meg。
根据提示输入Title,然后会出现一个对话框询问是否是Protein-coding nucleotide sequence data, 根据情况选择Yes或No。
最后出现一个对话框询问是否打开,选择Yes,如图:。
5. 回到MEGA主窗口,在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” -“Neighbor-joining”,打开一个窗口,里面有很多参数可以设置,如何设置这些参数请参考详细的MEGA说明书,不会设置就暂且使用默认值,不要修改,点击下面的Compute按钮,系统进化树就画出来了,如图:在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“Minimun-evolution”,如图:在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“Maximun-parsimony”,如图:在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“UPGMA”,如图:6. 最后,使用TreeExplorer窗口中提供的一些功能可以对生成的系统进化树进行调整和美化。
MEGA 软件——系统发育树构建方法

• 双击图标
,
• 下载下来的序列片段保存文件为FASTA格式,打开方式为TXT格式。 • 将Blast对比后所Download的序列筛选后,构建系统发育进化树。 • 构建系统发育树需要测序所得序列1个,Blast对比得出序列5-10个, 构建出的为单枝系统发育进化树。通过这个对比可以确定出所测 定的序列最相似物种,当相似度为99%甚至100%时,基本可以确 定所测定的基因序列所属物种。
ME待测PCR产物送测序后,一个星期左右会得到生物 公司发的邮件,里面包含测序结果的附件,下载后得到文件压缩 包 ,将文件包解压,可以看到文件夹里有文件
• 测序公司会提供一款解读软件Chromas,免安装类型,能够直接 打开测序结果并通过软件直接进入NCBI数据库进行Blast搜索。
• 可培养真菌可以选定对比物种种属后构建大型系统发育进化树, 不可培养真菌则可直接构建系统发育进化树。
• 双击
后打开MEGA软件
MEGA4的中文使用说明
MEGA4的中文使用说明产生背景及简介随着不同物种基因组测序的快速发展,产生了大量的DNA 序列信息,这时就需要一种简便而快速的统计分析工具来对这些数据进行有效的分析,以提取其中包含的大量信息。
MEGA就是基于这种需求开发的。
MEGA 软件的目的就是提供一个以进化的角度从DNA 和蛋白序列中提取有用的信息的工具,并且,此软件可以免费下载使用。
现在我们使用的是MEGA4 的版本。
它主要集中于进化分析获得的综合的序列信息。
使用它我们可以编辑序列数据、序列比对、构建系统发育树、推测物种间的进化距离等。
此软件的输出结果资源管理器允许用户浏览、编辑、打印输入所得到的结果而且所得到的结果具有不同形式的可视化效果。
此外,该软件还能够得出不同序列间的距离矩阵,这是他不同与其他分析软件的地方。
在计算矩阵方面有一些自己的特点:1. 推测序列或者物种间的进化距离2. 根据MCL(Maximum Composite Likeliood method)的方法构建系统发育树3. 考虑到了不同碱基替换的不同的比率,考虑到了碱基转换和颠换的差别。
4. 随时可以使用标注:所以的结果输入都可以使用标注,而且标注的内容可以被保存,复制。
具体使用我们以分析20 个物种的血红蛋白为例来具体说明此软件的具体使用情况。
序列分析1.启动单击后,会出现如下界面:这里有三个选项,分别对应三种不同的情况:以下分别予以介绍:Create a new alignment :是在你没有任何比对的时候使用,比如你只有一个fasta 格式的序列就可以选择这个选项。
Open a saved alignment session:使用它可以打开一个我们已经比对好的序列文件;Retieve a sequence from a file :这种情况同第一种情况相似,只是不用选择是DNA 还是蛋白质序列比对,选择的也是fasta 格式的文件,打开后的界面都是一样的。
以第一种情况为例说明,点击如出现下界面:这里我们分析的是蛋白序列所以选择No。
MEGA4.0构树步骤

MEGA构建系统进化树的步骤1. 将要用于构建系统进化树的所有序列合并到同一个fasta格式文件,注意:所有序列的方向都要保持一致( 5’-3’)。
2. 打开MEGA软件,选择”Alignment” –“Alignment Explorer/CLUSTAL”,在对话框中选择Retrieve sequences from a file, 然后点OK,找到准备好的序列文件并打开。
3. 在打开的窗口中选择”Alignment”-“Align by ClustalX” 进行对齐,对齐过程需要一段时间,对齐完成后,最好将序列两端切齐,选择两端不齐的部分,单击右键,选择delete即可。
4. 关闭当前窗口,关闭的时候会提示两次否保存,第一次无所谓,保存不保存都可以,第二次一定要保存,保存的文件格式是.meg。
根据提示输入Title,然后会出现一个对话框询问是否是Protein-coding nucleotide sequence data, 根据情况选择Yes或No。
最后出现一个对话框询问是否打开,选择Yes。
5. 回到MEGA主窗口,在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny”-“Neighbor-joining”,打开一个窗口,里面有很多参数可以设置,如何设置这些参数请参考详细的MEGA说明书,不会设置就暂且使用默认值,不要修改,点击下面的Compute按钮,系统进化树就画出来了。
6. 最后,使用TreeExplorer窗口中提供的一些功能可以对生成的系统进化树进行调整和美化。
另外,还可以用Word进一步编辑MEGA构建的进化树。
一般说来,MEGA适用于对少量的序列进行比对和画Tree,如需处理大量或海量的序列数据,建议使用ARB。
用BioEdit合并序列:1、打开BioEdit,点击“File”->”New Alignment”;2、“File”->”import”->”Sequence Alignment file”,将全部要合并的序列导入;3、”File“->”Save“ or “Save as”,保存为.fas格式文件。
进化树构建方法-MEGA

利用MEGA 来构建进化树(molecular evolutionary genetics analysis 分子进化遗传分析)打开mega5,选择Align----edit/built alignment----create a new alignment—OK选择DNA/protein出现新的对话框Open------选择已经保存好的用clustalx 经过比对保存的以.aln格式的文件打开之后,出现下面的页面双击文件名可以进行修改的。
我的就是从这里开始修改把A,B,C 都去掉,只留号码就好右键菜单点击delete 删除带※的那一行。
得到下面的图示,点击保存,重新起名字。
之后点击此图内的Alignment 选择Align by clustalW即可。
默认设置即可,点击OK就进行比对了,此后会出现一个过渡对话框,显示的是两两比对和多序列比对的过程之后回到初始页面,就是这个页面之后点File---点开,把刚才保留的文件点开然后出现下面的页面多了几个内容,点击TA的那个框框。
之后出现这样的框框图片然后在主程序中选择phylogeny---construct/test neighbor-joining tree,然后出现下面的页面黄色框框处的的参数是可以改变的,该图为我已经改变好的,把Bootstrap 的值改为1000 Methods根据文献上的参考改为了Kimura2-parameter model.之后点击compute,就出现了,而且还带有必需的支持率即自展值,是用来检验你所计算的进化树分支可信度的。
简单地讲就是把序列的位点都重排,重排后的序列再用相同的办法构树,如果原来树的分枝在重排后构的树中也出现了,就给这个分枝打上一分,如果没出现就给0分,这样经过你给定的repetitions 次(至少1000次)重排构树打分后,每个分枝就都得出分值,计算机会给你换算成bootstrap值。
重排的序列有很多组合,值越小说明分枝的可信度越低,最好根据数据的情况选用不同的构树方法和模型。
怎样使用MEGA建立进化树

怎样使用MEGAt 立进化树如何使用MEGA4.0#立进化树 1、首先是双击软件打开如下图所示|M| ijaKMr3 valj 141 Mrhr ArgrwricQt iVvta“qplii :护 忏冲 i 二客H - I 号筍需.廿星"LIF M ■ H 、-| II ■ DKi -Mjrsrze: H r« r-r r ^c>az^ LCS2、现在是处于DNA序列,而我们要做蛋白质的进化树的话,就如下操作M4. Aligmr>&nl Explof頁H L lQnmt*Ftji Editm e祁3、接下来我们要进行序列的输入,点击左边那个红箭头,贝U出现下面的窗口刚M4: Alfgnment Explorer匚;日屯EJrt S«ar di Aflgmnenl Wfrb $e<)□ d| D ◎日「蹇輻酋1 41象Protein S^quer匚弊1|主曲色"匕色丄4、然后右击sequenee 1,修改名字,如改成DPVFrotejn Sequence?5、然后从Word里复制蛋白质序列,然后在下面的位置粘贴G 辱CopfPTCtfiT X CU,書 f sterna6则可出现如下图的序列了□ QCW1C3 iRWfl Wq^ri[ V^i>n irequ^Ki 幷册枷・1話皿讥曲佰i"—喇・ct Mgeirc 惟■ sy7、然后点击窗口上的保存图标保存 8、重复从3开始,直到你的序列输入完9、序列输入元后进行最后的保存,方法如下垂邑trit 5|讨之斗和"1 of op«r * dow亠 P TOUMT 1 <io-jrr<n接下来打开册b M 罗哥 H*lpi t X t tt b要输入ul7两次保存名字一然后关闭这个窗口出现下面这个窗口■■■MM Jfc接下来就可以建立各种样式的进化树〜乜 MdngHie-r jein^ IMJL* &? Wrigym 佔抽杓也山-« UW3ML ■> ■小h,鼻 陆01申*貝Trfl 和 Hi^Tgrn^ ,HnNkk T ivn HnM "d i-Oi^4*cflArs R 协 FriWrt '^l^diCNHE軒I 匚 fkrti tiiitanr-ri : hy A 护产就 匸沁”-嗯,只是把过程写出来,方便大家建立进化树,不足的地方,大家补充好〜。
MEGA建树步骤

MEGA 4.1 实例讲解建树步骤
---kousyouki
选择Alignment ---- Alignment Explorer/CLUSTAL,出现一个对话框:
根据提示内容,进行选择,在此我选择第一个“Create a new alignment”,出现:
根据自己的序列是核酸还是氨基酸序列进行选择,在此我选择“Yes”,出现:
[CLUSTAL文件(.aln)],如下图:
选择之后,得到:
改了,就像我用汉化版的Clustal X 1.81不可以识别某些序列文件名) ,修改后如下:
右键菜单点击删除Clustal X中附带的“※”号行,修改文件名后可以保存“当前比对结果”,以便下次再用。
然后再补充一下,此软件整合了Clustal X程序,菜单Alignment中选择“Align
by Clustalx”即可。
选择所要比对的序列,单击后出现下面这个对话框:
选择默认设置,点击OK就进行比对了。
此后会出现一个过渡对话框,显示的是两两比对和多序列比对的过程:
等待其运行完成后,可以保存,也可以直接删除,出现对话框:
选择Yes,出现:
SIV-N2,出现:
点击Yes
点击Yes,出现:
当这个序列数据界面出来后,注意软件的主界面发生了一定的变化,多出了几个功能菜单:
选择主界面中的Phylogeny菜单,Bootstrap Test of Phylogeny --- Neighbor-joining…
Bootstrap选择1000次重复,模型选择核酸---p-distance。
Compute后,得出系统结构树,如下:
替换成辐射图:
2009-03-05。
进化树构建之Mega篇,试了好半天才弄明白,赶紧写出来

进化树构建之Mega篇,试了好半天才弄明白,赶紧写出来1. 安装从Mega网站下载安装Mega 4版本按默认安装。
/2. Mega文件生成2.1. 已有Mega文件打开Mega程序的主界面, click me to activate a data file这个操作就打开了mega文件,然后执行相关的操作。
Mega是一个free 软件,所以请大家一定要在参考文献中列出Mega的出处,具体的文本在查看进化树的窗口菜单中点caption就可以得到。
2.2. 无Mega,仅有fasta文件双击准备好的fasta格式的序列文件,默认使用mega打开。
打开后Ctrl - A选定全部,执行Alignment > clustal W(默认参数)转换成meg格式:data > export to > Mega,选择地点和名称,输一个标题,不用蛋白数据了。
关闭这个窗口,程序会询问“open the data file in Mega”,确定,即可打开刚才保存的文件。
3. 建树在标题为Mega 4.的这个窗口中执行建树:建树:phylogeny > construct phylogeny > NJ > Method(NJ) > Gap ( pairwise deletion) > method(nucleotide > jukes-cantor > test > bootstrap > replication(1000) > computer。
此中参数选择是否正确我未知,请各位自行选择。
得到两张图,Original tree / bootstrap consensus tree,用后面那张图,接下来对图形进行修改。
选择outGroup,subTree > root,然后就可以用鼠标去选择外群了,如果是做物种的系统发育关系,则外群应该选择远缘关系的,如果是做群体即一个物种下的,则外群要选择近缘的;子树的翻转和颠倒等等操作,subTree > flip 或者是subTree > roll,选定后用鼠标去点节点就是了。
利用MEGA4构建分子系统进化树
利⽤MEGA4构建分⼦系统进化树利⽤MEGA 4构建分⼦系统进化树-图⽰
1、利⽤Clustal X软件对序列进⾏多重⽐对,保存的⽂件为aln格式。
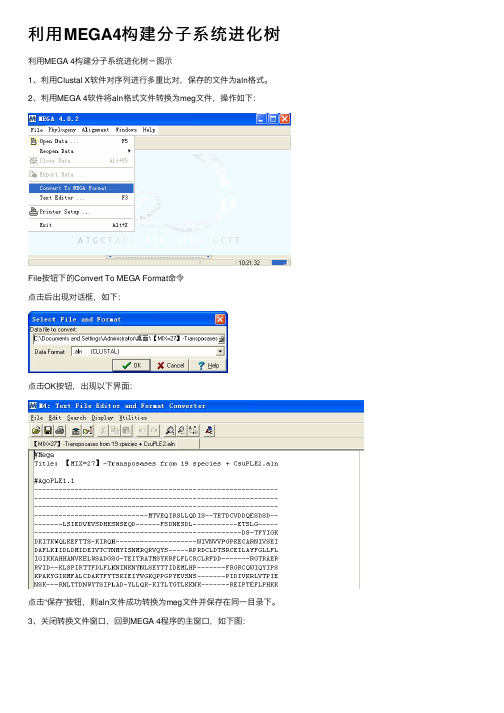
2、利⽤MEGA 4软件将aln格式⽂件转换为meg⽂件,操作如下:
File按钮下的Convert To MEGA Format命令
点击后出现对话框,如下:
点击OK按钮,出现以下界⾯:
点击“保存”按钮,则aln⽂件成功转换为meg⽂件并保存在同⼀⽬录下。
3、关闭转换⽂件窗⼝,回到MEGA 4程序的主窗⼝,如下图:
点击“Click me to activate a data file”按钮,选择之前转换好的meg⽂件并打开,如下图:
选择所输⼊的数据类型(核酸or蛋⽩),之后点击OK即可。
此时,在MEGA4主程序窗⼝的底部出现了我们所输⼊的⽂件名(如下图),之后就可以构建分⼦系统进化树了。
4、通常选择邻接法(neighbor-joining,NJ)构建分⼦系统进化树。
MEGA4的中文使用说明

MEGA4的中文使用说明产生背景及简介随着不同物种基因组测序的快速发展,产生了大量的DNA 序列信息,这时就需要一种简便而快速的统计分析工具来对这些数据进行有效的分析,以提取其中包含的大量信息。
MEGA 就是基于这种需求开发的。
MEGA 软件的目的就是提供一个以进化的角度从DNA 和蛋白序列中提取有用的信息的工具,并且,此软件可以免费下载使用。
现在我们使用的是 MEGA4 的版本。
它主要集中于进化分析获得的综合的序列信息。
使用它我们可以编辑序列数据、序列比对、构建系统发育树、推测物种间的进化距离等。
此软件的输出结果资源管理器允许用户浏览、编辑、打印输入所得到的结果而且所得到的结果具有不同形式的可视化效果。
此外,该软件还能够得出不同序列间的距离矩阵,这是他不同与其他分析软件的地方。
在计算矩阵方面有一些自己的特点:1. 推测序列或者物种间的进化距离2. 根据MCL(Maximum Composite Likeliood method)的方法构建系统发育树3. 考虑到了不同碱基替换的不同的比率,考虑到了碱基转换和颠换的差别。
4. 随时可以使用标注:所以的结果输入都可以使用标注,而且标注的内容可以被保存,复制。
具体使用我们以分析 20 个物种的血红蛋白为例来具体说明此软件的具体使用情况。
启动程序1. 运行环境:在Windows 95/98, NT, ME, 2000, XP, vista 等操作系统下均可使用。
2. 下载安装:可以直接登陆 进行下载安装,另外还可以从/tools/phylogeny.php 中的链接进去。
3. 双击桌面快捷方式图标, 进入主界面;或者从开始菜单,单击图标启动。
序列分析1.启动单击后,会出现如下界面:这里有三个选项,分别对应三种不同的情况:以下分别予以介绍:Create a new alignment :是在你没有任何比对的时候使用,比如你只有一个fasta 格式的序列就可以选择这个选项。
mega建树方法 进化树的建立过程
进化树的建立过程
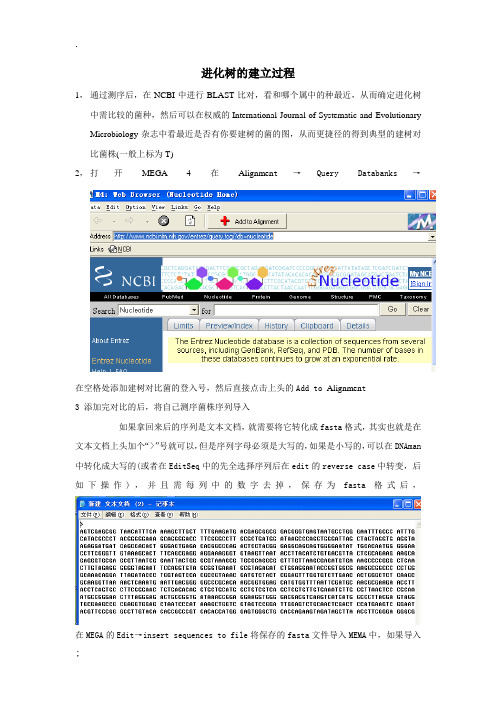
1,通过测序后,在NCBI中进行BLAST比对,看和哪个属中的种最近,从而确定进化树中需比较的菌种,然后可以在权威的International Journal of Systematic and Evolutionary Microbiology杂志中看最近是否有你要建树的菌的图,从而更捷径的得到典型的建树对比菌株(一般上标为T)
2,打开MEGA 4在Alignmen t→Query Databanks→
在空格处添加建树对比菌的登入号,然后直接点击上头的Add to Alignmen t
3 添加完对比的后,将自己测序菌株序列导入
如果拿回来后的序列是文本文档,就需要将它转化成fasta格式,其实也就是在文本文档上头加个“>”号就可以,但是序列字母必须是大写的,如果是小写的,可以在DNAman 中转化成大写的(或者在EditSeq中的先全选择序列后在edit的reverse case中转变,后如下操作),并且需每列中的数字去掉,保存为fasta格式后,
在MEGA的Edit→insert sequences to file将保存的fasta文件导入MEMA中,如果导入
的序列是互补链的话,直接在添加的里面,点击导入链,右击后点击互补就行,选中所有的序列后,在Alignmen t选项中选中Align by clustalw让其自动分析后,在Date选项中输出格式选择为MEGA格式保存
4 再一次启动软件将上一步保存的文件打开,然后在
如上图操作就可以得出进化树,然后在上面直接修改。
MEGA 4构建进化树的步骤

用MEGA 4构建进化树的过程
自己直接从NCBI对测序结果直接Blast,获得的比对结果选取同源性大于96%的序列,直接Download另存为.fasta格式,然后直接用MEGA打开一个序列,对下载的每个序列用记事本打开,检查序列的格式是否统一,再通过该软件的菜单栏的Edit→Insert Sequence From File(添加所要比对的的序列)→Alignment →Align by ClustalW→出现的界面点击OK→Data→Expert Alignment→MEGA Format(保存该文件并命名)→出现界面Protein Coding Nucleotide Sequence Data →点击NO→关闭该比对界面→出现界面Open The Data File in MEGA→点击YES→出现一个新界面,不用管它,点击另一个界面菜单Phylogeny→Bootstrap Test of Phylogeny→根据需要选择自己所要的进化树结构类型。
怎样使用MEGA建立进化树

如何使用MEGA4.0建立进化树1、首先是双击软件打开如下图所示
2、现在是处于DNA序列,而我们要做蛋白质的进化树的话,就如下操作
3、接下来我们要进行序列的输入,点击左边那个红箭头,则出现下面的窗口;
4、然后右击sequence 1,修改名字,如改成DPV
5、然后从Word 里复制蛋白质序列,然后在下面的位置粘贴
6、则可出现如下图的序列了
7、然后点击窗口上的保存图标保存
8、重复从3开始,直到你的序列输入完
9、序列输入完后进行最后的保存,方法如下:
要输入ul7两次保存名字—然后关闭这个窗口。
接下来打开
出现下面这个窗口!
接下来就可以建立各种样式的进化树!
嗯,只是把过程写出来,方便大家建立进化树,不足的地方,大家补充好!
(注:可编辑下载,若有不当之处,请指正,谢谢!)。
用MEGA构建进化树

怎么样用MEGA建坐进化树之阳早格格创做是一个关于序列分解以及比较统计的工具包,其中包罗有距离建立法战MP建立法;可自动大概脚动举止序列比对付,估计进化树,估算分子进化率,举前进化假设考验,还能联机的Web数据库检索.下载后可间接使用,主要包罗几个圆里的功能硬件:i)DNA战蛋黑量序列数据的分解硬件.ii)序列数据转形成距离数据后,对付距离数据分解的硬件. iii)对付基果频次战连绝的元素分解的硬件.iv)把序列的每个碱基/氨基酸独力瞅待(碱基/氨基酸惟有0战1的状态)时,对付序列举止分解的硬件.v)画造战建矫正化树的硬件,举止网上blast搜索.用MEGA建坐进化树有以下步调:1. 16S rDNA测序战参照序列采用从环境中分散到单克隆,去沉复后扩删16S rDNA序列并测序,而后与数据库比对付,找到相似度最下的几个序列,决定一下您分散的细菌约莫属于哪个科哪个属,如果相似度达到百分之百那基础不妨决定您分散得到的便是Blast到的那个,而后找一到二个共科的,再找一到二个共脚段,再找一到二个共目的细菌,把序列齐脚下下去,以FSATA形式调整正在TXT文档中,如>TS1GCAGTCGAACGATGAAGCCCAGCTTGCTGGGTGGATT AGTGGCGAACGGGTGAGTAACACGTGGGTGATCTGCC CTGCACTTCGGGATAAGCCTGGGAAACTGGGTCTAAT ACCGGATAGGACCTCGGGATGCATGTTCCGGGGTGGA AAGGTTTTCCGGTGCAGGATGGGCC>gi|117572706|gb|EF028124.1| Rhodococcus sp. Atl25 16S ribosomal RNA gene, partial sequence CGATTAGAGTTTGATCCTGGCTCAGGACGAACGCTGGC GGCGTGCTTAACACATGCAAGTCGAACGATGAAGCCC AGCTTGCTGGGTGGATTAGTGGCGAACGGGTGAGTAA CACGTGGGTGATCTGCCCTGCACTTCGGGATAAGCCTG GGAAACTGGGTCTAATACCGGAT>TS2 TGCAAGTCGAGCGAATGGATTAAGAGCTTGCTCTTATG AAGTTAGCGGCGGACGGGTGAGTAACACGTGGGTAAC CTGCCCATAAGACTGGGATAACTCCGGGAAACCGGGG CTAATACCGGATAACATTTTGAACTGCATGGTTCGAAA TTGAAAGGCGGCTTCGGCTGTCACT GATGAACGCTGGCGGCGTGCCTAATACATGCAAGTCG AGCGAATGGATTAAGAGCTTGCTCTTATGAAGTTAGCG GCGGACGGGTGAGTAACACGTGGGTAACCTGCCCATA AGACTGGGATAACTCCGGGAAACCGGGGCTAATACCGGATAACATTTTGAA CYGCATGGTTC………………………….………………………….参照序列采用有几个准则:a,不选非培植(unclutured)微死物为参比;b,所选参照序列要精确,内里无过失碱基;c,正在包管共属的前提下,劣先采用16S rDNA齐少测序大概齐基果组测序的种;d,每个种属采用一个参照序列,如果自己的序列中共一属的较多,可适合采用二个参照序列. 2. 序列比对付将整治佳的序列导进,如图接着步调自动运止,得出截止,自动输出 .aln战.dnd 为后缀的二个文献.序列比对付也不妨间接用MEGA去搞.MEGA,如下图所示:4.只可挨启meg要领的文献,然而是它不妨把其余要领的多序列比对付文献变换过去,用.aln要领(Clustal的输出文献)变换.meg文献.面File:Convert to MEGA Format,挨启变换文献对付话框,从脚段文献夹中选中Clustal 对付比分解后所爆收的.aln文献,面打挨启.5. 变换佳的meg文献,会弹出一个提示疑息,面打ok.查看meg序列文献末尾是可平常,若存留clustal. *止,即可简略.面存盘保存meg文献,meg文献会战aln文献保存正在共一个目录.6. 关关变换窗心,回到主窗心,当前面里板上的“Click me to activate a data file”挨启刚刚才的meg文献.如果为蛋黑量序列,采用“protein sequence”,电打“OK”,得到以下图示,数据输进之后的格式,窗心底下有序列文献名战典型.而正在其余一个窗心内,出现以下数据文献面打采用战编写数据分类图标,可对付所采用的序列举止编写,完成后面打close即可.序列编写完成后,可举止保存,面打保存后出现以下界里,面打ok即可.7. 建坐进化树的算法主要分为二类:独力元素法(discrete character methods)战距离依赖法(distance methods).所谓独力元素法是指进化树的拓扑形状是由序列上的每个碱基/氨基酸的状态决断的(比圆:一个序列上大概包罗很多的酶切位面,而每个酶切位面的存留与可是由几个碱基的状态决断的,也便是道一个序列碱基的状态决断着它的酶切位面状态,当多个序列举前进化树分解时,进化树的拓扑形状也便由那些碱基的状态决断了).而距离依赖法是指进化树的拓扑形状由二二序列的进化距离决断的.进化树枝条的少度代表着进化距离.独力元素法包罗最大简约性法(Maximum Parsimony methods)战最大大概性法(Maximum Likelihood methods);距离依赖法包罗除权配对付法(UPGMAM)战邻位贯串法(Neighbor-joining).(1)phylogeny→UPGMA(2)用Bootstrap建坐进化树,MEGA的主要功能便是搞Bootstrap考证的进化树分解,Bootstrap考证是对付进化树举止统计考证的一种要领,不妨动做进化树稳当性的一个度量.百般算法虽然分歧,然而是支配要领基础普遍.进化树的建坐是一个统计教问题.咱们所建坐出去的进化树不过对付真正在的进化关系的评估大概者模拟.如果咱们采与了一个适合的要领,那么所建坐的进化树便会靠近真正在的“进化树”.模拟的进化树需要一种数教要领去对付其举止评估.分歧的算法有分歧的适用目标.普遍去道,最大简约性法适用于切合以下条件的多序列:i 所要比较的序列的碱基不共小,ii 对付于序列上的每一个碱基有近似相等的变同率,iii 不过多的颠换/变换的倾背,iv 所考验的序列的碱基数目较多(大于几千个碱基);用最大大概性法分解序列则不需以上的诸多条件,然而是此种要领估计极其耗时.如果分解的序列较多,有大概要花上几天的时间才搞估计完成.历程如下①参数的树坐:phylogeny→bootstrap test of phylogeny→NJ②系统进化树的尝试要领,不妨采用用Bootstrap,也不妨采用不举止尝试.沉复次数(Replications)常常设定起码要大于100比较佳,随机数种子不妨自己随意设定,不会做用估计截止.普遍采用500大概1000.有许多Model供采用,默认为Kimura 2-paramete r,分歧的Model 有分歧的算法,简曲请参照博业的死物疑息教书籍籍.设定完成,面compute,启初估计.②截止输出:那个历程所耗时间战序列的数量战少短成正比,步调便会爆收那样一个树,该窗心中有二个属性页,一个是本初树,一个是bootstrap考证过的普遍树.树枝上的数字表示bootstrap考证中该树枝可疑度的百分比.截止如下:8. 进化树的劣化:1)利用该硬件可得到分歧树型,如下图所示:除此除中,还不妨有多种树型,根据需要去采用.2)隐现建立的相关疑息:面打图标i.3)面打劣化图标,可举止各项劣化:Tree栏中,不妨举止树型采用:rectangular tree/circle tree/radiation tree.每种树皆不妨举止少度,宽度大概角度等的设定Branch:可对付树枝上的疑息举止建改.Lable:可对付树枝的名字举止建改.Scale:标尺树坐Cutoff:cutoff for consensus tree.普遍为50%. 9、进化树的分类劣化Place root on branch:不妨去回变换.Flip subtree:180度翻转分枝,名字翻转180度.Swab subtree:接换分枝,名字不翻转.Compress/expand subtree与Set divergent time:不妨把共一分枝的基果压缩大概扩展.面打Compress/expand subtree后,正在要压缩的分枝处面打,出现以下界里,正在name/caption 中输进文献名(比圆wwww),其余另有很多的选项,树坐佳了,面打OK.所得到的截止,不妨正在压缩战扩展之间变换. 10. 安排进化树根据所的进化树的效验,要举止安排,包罗多余序列简略、缺累序列增加、种属称呼标注等等,还要根据投稿纯志央供正在PHOTOSHOP中建改等.完成后的进化树应包罗充脚的疑息.自己所搞进化树完成图如下:。
如何用MEGA作进化树(一)

如何⽤MEGA作进化树(⼀)
听说MEGA可以作进化树,听说你还不会,这么巧,我正好会。
曾⼏何时,我们看着别⼈家的进化树这么好看,⼼⾥不由得也想⾃⼰制作⼀下,周末教⼤家怎么绘制进化树吧。
⾸先,⼤家先把数据下载⼀下
⽰例⽂件名: species.fasta
species.fasta 部分序列截图
然后,构建进化树两步⾛
(1)序列⽐对
常见算法:Muscle、ClustalW
①打开MEGA软件,这⾥以7.0版为例,依次按照箭头⽅向进⾏选择
②序列⽐对
经以上步骤后弹出新的对话框:M7:Alignment Explorer
若没有显⽰我们的⽬标fasta⽂件,请注意修改这⾥的⽂件后缀名称
③打开后的species.fasta⽂件
注意:重点来啦!
④然后呢?然后就⽐对好了,查看⼀下⾸位是否⽐对齐,没有⽐齐的碱基就删除掉
⑤最后,将⽐对好序列⽂件进⾏保存就好了,此处保存为mega format,⽂件名为species
(2)构建进化树
常见算法:Neighbor-Joining、Maximum Likelihood
点击Phylogeny构建进化树,可以看出构建进化树的⽅法也有好多种,此处我们选择相对常⽤的NJ⽅法
就这么简单,树就构好了,感觉幸福来得太突然!
通过⼯具栏可以对树的形状进⾏调整
记得把树的⽂本⽂件也保存了,这⾥保存为Newick格式点击上⼀步的export以后,⼜出现下⾯的窗⼝,继续保存。
Mega的使用以及进化树的绘制

Mega的使⽤以及进化树的绘制1.MEGA构建系统进化树的步骤2.CLUSTALX进⾏序列⽐对1.MEGA构建系统进化树的步骤1. 将要⽤于构建系统进化树的所有序列合并到同⼀个fasta格式⽂件,注意:所有序列的⽅向都要保持⼀致( 5’-3’)。
如图:2. 打开MEGA软件,选择"Alignment" - "Alignment Explorer/CLUSTAL",在对话框中选择Retrieve sequences from a file, 然后点OK,找到准备好的序列⽂件并打开,如图:。
3. 在打开的窗⼝中选择”Alignment”-“Align by ClustalX” 进⾏对齐,对齐过程需要⼀段时间,对齐完成后,最好将序列两端切齐,选择两端不齐的部分,单击右键,选择delete即可,如图:。
4. 关闭当前窗⼝,关闭的时候会提⽰两次否保存,第⼀次⽆所谓,保存不保存都可以,第⼆次⼀定要保存,保存的⽂件格式是.meg。
根据提⽰输⼊Title,然后会出现⼀个对话框询问是否是Protein-coding nucleotide sequence data, 根据情况选择Yes或No。
最后出现⼀个对话框询问是否打开,选择Yes,如图:。
5. 回到MEGA主窗⼝,在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” -“Neighbor-joining”,打开⼀个窗⼝,⾥⾯有很多参数可以设置,如何设置这些参数请参考详细的MEGA说明书,不会设置就暂且使⽤默认值,不要修改,点击下⾯的Compute按钮,系统进化树就画出来了,如图:在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“Minimun-evolution”,如图:在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“Maximun-parsimony”,如图:在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“UPGMA”,如图:6. 最后,使⽤TreeExplorer窗⼝中提供的⼀些功能可以对⽣成的系统进化树进⾏调整和美化。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
利用MEGA 4构建分子系统进化树-图示
1、利用Clustal X软件对序列进行多重比对,保存的文件为aln格式。
2、利用MEGA 4软件将aln格式文件转换为meg文件,操作如下:
File按钮下的Convert To MEGA Format命令
点击后出现对话框,如下:
点击OK按钮,出现以下界面:
点击“保存”按钮,则aln文件成功转换为meg文件并保存在同一目录下。
3、关闭转换文件窗口,回到MEGA 4程序的主窗口,如下图:
点击“Click me to activate a data file”按钮,选择之前转换好的meg文件并打开,如下图:
选择所输入的数据类型(核酸or蛋白),之后点击OK即可。
此时,在MEGA4主程序窗口的底部出现了我们所输入的文件名(如下图),之后就可以构建分子系统进化树了。
4、通常选择邻接法(neighbor-joining,NJ)构建分子系统进化树。