数据结构7.5 合并排序
两数组合并排序算法

两数组合并排序算法数组是一种常见的数据结构,它可以存储一组相同类型的元素。
在编程中,合并和排序两个数组是一项常见的任务。
本文将介绍几种常见的数组合并排序算法,并对它们的优缺点进行比较。
1. 暴力法:最简单的方法是将两个数组合并为一个新数组,然后对新数组进行排序。
该方法的时间复杂度为O(nlogn),其中n是两个数组的长度之和。
实现代码:```def merge_sort(arr1, arr2):merged = arr1 + arr2merged.sortreturn merged```该方法的主要缺点是需要额外的空间来存储合并后的数组,并且排序的时间复杂度较高。
2. 归并排序:归并排序是一种分治算法,它将数组分成两个子数组,分别进行排序,然后将两个有序子数组合并为一个有序数组。
该方法的时间复杂度为O(nlogn),其中n是数组的长度。
实现代码:```def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):merged = []i,j=0,0while i < len(left) and j < len(right): if left[i] < right[j]:merged.append(left[i])i+=1else:merged.append(right[j])j+=1while i < len(left):merged.append(left[i])i+=1while j < len(right):merged.append(right[j])j+=1return merged```归并排序的主要优点是稳定性,它保持相等元素的相对顺序。
数据结构排序算法总结表格
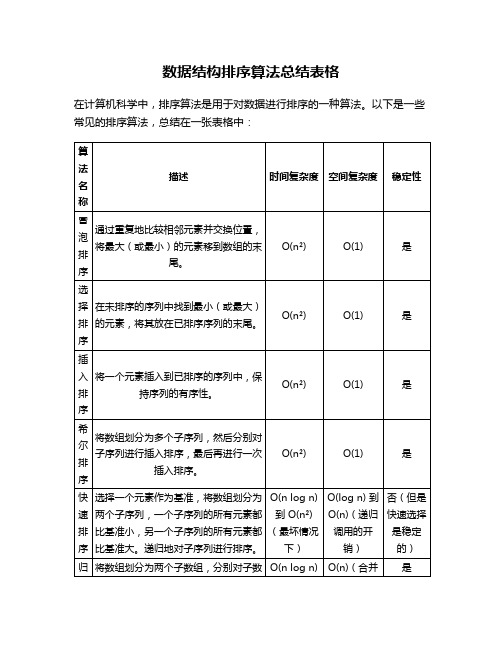
在计算机科学中,排序算法是用于对数据进行排序的一种算法。以下是一些常见的排序算法,总结在一张表格中:
算法名称
描述
时间复杂度
空间复杂度
稳定性
冒泡排序
通过重复地比较相邻元素并交换位置,将最大(或最小)的元素移到数组的末尾。
O(n²)
O(1)
是
选择排序
在未排序的序列中找到最小(或最大)的元素,将其放在已排序
插入排序
将一个元素插入到已排序的序列中,保持序列的有序性。
O(n²)
O(1)
是
希尔排序
将数组划分为多个子序列,然后分别对子序列进行插入排序,最后再进行一次插入排序。
O(n²)
O(1)
是
快速排序
选择一个元素作为基准,将数组划分为两个子序列,一个子序列的所有元素都比基准小,另一个子序列的所有元素都比基准大。递归地对子序列进行排序。
O(n log n)
O(1)(如果从数组创建堆时)
是(但是不稳定)
基数排序
通过按位(或数字的其他属性)对元素进行比较和交换位置来排序数组。是一种稳定的排序算法。
O(nk)(k是数字的位数)
O(n)(如果使用外部存储)
是
O(n log n) 到 O(n²)(最坏情况下)
O(log n) 到 O(n)(递归调用的开销)
否(但是快速选择是稳定的)
归并排序
将数组划分为两个子数组,分别对子数组进行排序,然后将两个已排序的子数组合并成一个有序的数组。递归地进行这个过程。
O(n log n)
O(n)(合并时)
是
堆排序
将数组构建成一个大顶堆或小顶堆,然后不断地将堆顶元素与堆尾元素交换,并重新调整堆结构。重复这个过程直到所有元素都已排序。
c语言分治法实现合并排序算法

c语言分治法实现合并排序算法在计算机科学中,分治算法是一种将问题划分为较小子问题,然后将结果合并以解决原始问题的算法。
其中,合并排序算法就是一种常见的分治算法。
C语言可以使用分治法实现合并排序算法。
该算法的基本思想是将原始数组递归地分成两半,直到每个部分只有一个元素,然后将这些部分合并起来,直到形成一个完整的已排序的数组。
具体实现过程如下:1.首先,定义一个函数merge,该函数将两个已排序的数组合并成一个已排序的数组。
2.然后,定义一个函数merge_sort,该函数使用递归的方式将原始数组分成两个部分,并对每个部分调用merge_sort函数以进行排序。
3.最后,将已排序的两个数组合并到一起,使用merge函数。
以下是C语言代码:void merge(int arr[], int left[], int left_count, int right[], int right_count) {int i = 0, j = 0, k = 0;while (i < left_count && j < right_count) {if (left[i] < right[j]) {arr[k++] = left[i++];} else {arr[k++] = right[j++];}}while (i < left_count) {arr[k++] = left[i++];}while (j < right_count) {arr[k++] = right[j++];}}void merge_sort(int arr[], int size) { if (size < 2) {return;}int mid = size / 2;int left[mid];int right[size - mid];for (int i = 0; i < mid; i++) {left[i] = arr[i];}for (int i = mid; i < size; i++) {right[i - mid] = arr[i];}merge_sort(left, mid);merge_sort(right, size - mid);merge(arr, left, mid, right, size - mid);}int main() {int arr[] = {3, 8, 1, 6, 9, 4, 5, 7, 2};int size = sizeof(arr) / sizeof(arr[0]);merge_sort(arr, size);for (int i = 0; i < size; i++) {printf('%d ', arr[i]);}return 0;}以上代码可以将数组{3, 8, 1, 6, 9, 4, 5, 7, 2}排序成{1, 2, 3, 4, 5, 6, 7, 8, 9}。
算法分析与设计实验报告合并排序快速排序

算法分析与设计实验报告:合并排序与快速排序一、引言算法是计算机科学中非常重要的一部分,它涉及到解决问题的方法和步骤。
合并排序和快速排序是两种经典而常用的排序算法。
本文将对这两种排序算法进行分析和设计实验,通过对比它们的性能和效率,以期得出最优算法。
二、合并排序合并排序是一种分治算法,它将原始数组不断分解为更小的数组,直到最后细分为单个元素。
然后,再将这些单个元素两两合并,形成一个有序数组。
合并排序的核心操作是合并两个有序的数组。
1. 算法步骤(1)将原始数组分解为更小的子数组,直到每个子数组只有一个元素;(2)两两合并相邻的子数组,同时进行排序,生成新的有序数组;(3)重复步骤(2),直到生成最终的有序数组。
2. 算法性能合并排序的最优时间复杂度为O(nlogn),其中n为待排序数组的长度。
无论最好情况还是最坏情况,合并排序的复杂度都相同。
合并排序需要额外的存储空间来存储临时数组,所以空间复杂度为O(n)。
三、快速排序快速排序也是一种分治算法,它将原始数组根据一个主元(pivot)分成两个子数组,一个子数组的元素都小于主元,另一个子数组的元素都大于主元。
然后,递归地对这两个子数组进行排序,最后得到有序数组。
快速排序的核心操作是划分。
1. 算法步骤(1)选择一个主元(pivot),可以是随机选择或者固定选择第一个元素;(2)将原始数组根据主元划分为两个子数组,一个子数组的元素都小于主元,另一个子数组的元素都大于主元;(3)递归地对这两个子数组进行快速排序;(4)重复步骤(2)和(3),直到每个子数组只有一个元素,即得到最终的有序数组。
2. 算法性能快速排序的平均时间复杂度为O(nlogn),其中n为待排序数组的长度。
最坏情况下,当每次选择的主元都是最小或最大元素时,时间复杂度为O(n^2)。
快速排序是原地排序,不需要额外的存储空间,所以空间复杂度为O(1)。
四、实验设计为了验证合并排序和快速排序的性能和效率,我们设计以下实验:1. 实验目的:比较合并排序和快速排序的时间复杂度和空间复杂度。
数据结构实验两个有序顺序表的合并

南昌大学实验报告学生姓名:李木子学号:8000113146 专业班级:软工133 实验类型:□验证□综合□设计□创新实验日期:实验成绩:一、实验项目名称两个有序顺序表的结合二、实验目的顺序表的创建1.实现顺序表的追加2.实现顺序表的显示3.两顺序表的合并三、实验基本原理四、主要仪器设备及耗材电脑,VC6.0五、实验步骤/*******************************************//* 顺序表的创建 *//* 1.实现顺序表的追加 *//* 2.实现顺序表的显示 *//* 3.两顺序表的合并 *//*******************************************/#include <stdio.h>#include <stdlib.h>#define MAXSIZE 100typedef int datatype;/************************************//* 顺序表结构体的定义 *//************************************/typedef struct{datatype a[MAXSIZE];int size;}sequence_list;/************************************//* 函数声明 *//************************************/void init(sequence_list *slt);void append(sequence_list *slt,datatype x);void display(sequence_list slt);int find(sequence_list slt ,datatype x);void dele(sequence_list *slt,datatype x);void sort(sequence_list *s);void combine( sequence_list *s1 ,sequence_list *s2 ,sequence_list *s3);/************************************//* 顺序表的初始化函数 *//************************************/void init(sequence_list *slt){slt->size=0;}/************************************//* 顺序表的追加函数 *//************************************/void append(sequence_list *slt,datatype x){if(slt->size==MAXSIZE){printf("\n顺序表是满的!");exit(1);}slt->a[slt->size]=x ;slt->size=slt->size+1;}/************************************/ /* 顺序表的显示函数 */ /************************************/ void display(sequence_list slt){int i;if(!slt.size){printf("\n顺序表为空");}else{for(i=0;i<slt.size;i++)printf("\n%d\n",slt.a[i]);}}/************************************/ /* 顺序表的查找函数 */ /* 返回所查数据的下标 */ /************************************/ int find(sequence_list slt ,datatype x) {int i=0;while(i<slt.size &&slt.a[i]!=x)i++;return(i<slt.size? i:-1);}/************************************/ /* 顺序表的删除函数 */ /************************************/ void dele(sequence_list *slt,datatype x) {int i=0;i=find(*slt,x);for(;i<slt->size-1;i++)slt->a[i]=slt->a [i+1];slt->size--;}/************************************//* 顺序表的插入函数 *//************************************/ void insert(sequence_list *slt,datatype x) {int i=0;i=find(*slt,x);for(;i<slt->size-1;i++)slt->a[i+1]=slt->a [i];slt->size++;}/************************************//* 顺序表排序 *//************************************/ void sort(sequence_list *s){int i ;int j ;int temp ;for(i=0;i<s->size-1;i++){for(j=i+1;j<s->size;j++){if(s->a[i]>=s->a[j]){temp=s->a[i];s->a[i]=s->a[j];s->a[j]=temp;}}}}/************************************//* 两个有序顺序表连接函数 *//************************************/void combine( sequence_list *s1 , sequence_list *s2 , sequence_list *s3 ) {int i=0;int j=0;int k=0;while( i < s1->size && j < s2->size){if(s1->a[i]<=s2->a[j]){s3->a[k]=s1->a[i];i++;}else{s3->a[k]=s2->a[j];j++;}k++;}if(i==s1->size){while(j<s2->size){s3->a[k]=s2->a[j];k++;j++;}}if(j==s2->size){while(i<s1->size){s3->a[k]=s1->a[i];k++;}}s3->size=k;}/************************************/ /* 主函数 */ /************************************/ int main(){int i ;int j ;int x ;int n ;sequence_list list1 ;sequence_list list2 ;sequence_list list3 ;init(&list1);printf("第一个顺序表元素个数:\n");scanf("%d",&n);printf("第一个顺序表输入:\n");for(i=0; i<n ; i++){scanf("%d",&list1.a[i]);list1.size++;}sort(&list1);printf("排序后\n");display(list1);init(&list2);printf("第二个顺序表元素个数:\n");scanf("%d",&n);printf("第二个顺序表输入:\n");for(i=0; i<n ; i++){scanf("%d",&list2.a[i]);list2.size++;}sort(&list2);printf("排序后\n");display(list2);init(&list3);combine(&list1 ,&list2 ,&list3);printf("表一与表二连接后:\n");display(list3);return0;}六、实验数据及处理结果七、思考讨论题或体会或对改进实验的认识八、参考资料[1]《数据结构(c语言版)(第三版)》,李云清,人民邮电出版社[2]《C语言程序设计》,苏小红,高等教育出版社教你如何用WORD文档(2012-06-27 192246)转载▼标签:杂谈1. 问:WORD 里边怎样设置每页不同的页眉?如何使不同的章节显示的页眉不同?答:分节,每节可以设置不同的页眉。
数据结构第9章 排序

数据结构第9章排序数据结构第9章排序第9章排名本章主要内容:1、插入类排序算法2、交换类排序算法3、选择类排序算法4、归并类排序算法5、基数类排序算法本章重点难点1、希尔排序2、快速排序3、堆排序4.合并排序9.1基本概念1.关键字可以标识数据元素的数据项。
如果一个数据项可以唯一地标识一个数据元素,那么它被称为主关键字;否则,它被称为次要关键字。
2.排序是把一组无序地数据元素按照关键字值递增(或递减)地重新排列。
如果排序依据的是主关键字,排序的结果将是唯一的。
3.排序算法的稳定性如果要排序的记录序列中多个数据元素的关键字值相同,且排序后这些数据元素的相对顺序保持不变,则称排序算法稳定,否则称为不稳定。
4.内部排序与外部排序根据在排序过程中待排序的所有数据元素是否全部被放置在内存中,可将排序方法分为内部排序和外部排序两大类。
内部排序是指在排序的整个过程中,待排序的所有数据元素全部被放置在内存中;外部排序是指由于待排序的数据元素个数太多,不能同时放置在内存,而需要将一部分数据元素放在内存中,另一部分放在外围设备上。
整个排序过程需要在内存和外存之间进行多次数据交换才能得到排序结果。
本章仅讨论常用的内部排序方法。
5.排序的基本方法内部排序主要有5种方法:插入、交换、选择、归并和基数。
6.排序算法的效率评估排序算法的效率主要有两点:第一,在一定数据量的情况下,算法执行所消耗的平均时间。
对于排序操作,时间主要用于关键字之间的比较和数据元素的移动。
因此,我们可以认为一个有效的排序算法应该是尽可能少的比较和数据元素移动;第二个是执行算法所需的辅助存储空间。
辅助存储空间是指在一定数据量的情况下,除了要排序的数据元素所占用的存储空间外,执行算法所需的存储空间。
理想的空间效率是,算法执行期间所需的辅助空间与要排序的数据量无关。
7.待排序记录序列的存储结构待排序记录序列可以用顺序存储结构和和链式存储结构表示。
在本章的讨论中(除基数排序外),我们将待排序的记录序列用顺序存储结构表示,即用一维数组实现。
《数据结构排序》课件

根据实际需求选择时间复杂度和空间 复杂度最优的排序算法,例如快速排 序在平均情况下具有较好的性能,但 最坏情况下其时间复杂度为O(n^2)。
排序算法的适用场景问题
适用场景考虑因素
选择排序算法时需要考虑实际应 用场景的特点,如数据量大小、 数据类型、是否需要稳定排序等 因素。
不同场景适用不同
算法
例如,对于小规模数据,插入排 序可能更合适;对于大规模数据 ,快速排序或归并排序可能更优 。
排序的算法复杂度
时间复杂度
衡量排序算法执行时间随数据量增长而增长的速率。时间复杂度越低,算法效 率越高。常见的时间复杂度有O(n^2)、O(nlogn)、O(n)等。
空间复杂度
衡量排序算法所需额外空间的大小。空间复杂度越低,算法所需额外空间越少 。常见的空间复杂度有O(1)、O(logn)、O(n)等。
在数据库查询中,经常需要对结果进行排序,以便用户能够快速找到所需信息。排序算 法的效率直接影响到查询的响应时间。
索引与排序
数据库索引能够提高查询效率,但同时也需要考虑到排序的需求。合理地设计索引结构 ,可以加速排序操作。
搜索引擎中的排序
相关性排序
搜索引擎的核心功能是根据用户输入的 关键词,返回最相关的网页。排序算法 需要综合考虑网页内容、关键词密度、 链接关系等因素。
VS
广告与排序
搜索引擎中的广告通常会根据关键词的竞 价和相关性进行排序,以达到最佳的广告 效果。
程序中的排序应用
数组排序
在程序中处理数组时,经常需要对其进行排 序。不同的排序算法适用于不同类型的数据 和场景,如快速排序、归并排序等。
数据可视化中的排序
在数据可视化中,需要对数据进行排序以生 成图表。例如,柱状图、饼图等都需要对数 据进行排序处理。
吉林大学计算机科学与技术学院专业课考研大纲-专业学位 (2)

计算机考研专业课大纲——专业学位第一部分概述一、考查目标计算机学科专业综合考试包括《数据结构》和《高级语言程序设计》学科专业基础课程。
要求考生比较系统地掌握上述专业基础课程的概念,理论、技能和方法,能够运用所学的知识判断和解决相关的理论问题和实际问题。
二、考试形式和试卷结构试卷满分及考试时间本试卷满分为150分,考试时间为180分钟答题方式:闭卷、笔试三、试卷内容结构数据结构75分高级语言程序设计75分四、试卷题型结构第二部分《数据结构》第三部分《高级语言程序设计》第二部分《数据结构》考查目标1. 熟悉数据结构的相关概念及其分类,数据结构与算法的关系。
掌握线性表、堆栈和队列,数组和字符串等数据结构的存储、操作和应用,树与二叉树的性质与应用算法,图的存储结构和相关算法,排序与查找的典型算法。
2. 掌握算法时空复杂性分析和正确性验证的基本方法。
3.能够综合运用数据结构、算法、数学等多种知识,对问题进行分析、建模,选择或构建合适的数据结构,设计较优算法。
题型结构:包括问答题与算法设计题具体内容:一、绪论(1)数据、数据元素、数据逻辑结构和存储结构的定义及其关系;(2)数据逻辑结构及其分类;(3)算法的定义和特征;(4)算法的正确性证明方法;(5)算法的时间和空间复杂性分析方法及复杂性函数的渐进表示。
二、线性表、堆栈和队列(1)线性结构的概念和特点;(2)顺序存储和链式存储线性表的基本操作;(3)堆栈的定义和两种存储结构下堆栈的基本操作;(4)堆栈在括号匹配和递归中的应用;(5)队列的定义和两种存储结构下队列的基本操作;(6)队列的应用。
三、数组和字符串(1)二维及多维数组的存储原理及寻址方式;(2)矩阵的存储及基本操作;(3)三元组表和十字链表存储的稀疏矩阵的基本操作;(4)字符串的存储及基本操作;(5)模式匹配算法。
四、树与二叉树(1)树的概念、相关术语和表示方法;(2)二叉树的定义和性质;(3)二叉树的顺序存储结构和链接存储结构;(4)二叉树遍历的递归与非递归算法;(5)线索二叉树的定义和操作;(6)树与二叉树的转换;(7)树的链接存储结构,树和森林的遍历算法;(8)树的顺序存储结构;(9)树在并查集实现中的应用。
《数据结构(Java版)(第4版)》样卷及答案

//将 s 中所有空格删除,返回操作后的 s 串
{
int i=0; while (i<s.length() && s.charAt(i)!=' ')
//i 记住第 1 个空格下标
i++;
for (int j=i; j<s.length(); j++) if (s.charAt(j)!=' ') s.setCharAt(i++, s.charAt(j));
String target="aababbabac", pattern="ab", str="aba";
System.out.println("\""+target+"\".replaceAll(\""+pattern+"\", \""+str+"\")=\""+
target.replaceAll(pattern,str)+"\"");
5. mat+(i*n+j)*4=1000+(4*8+5)*4=1148 6. n*(n-1)/2 7. {43,61*,72,96};{43,17,20,32}。解释见《习题解答》第 54 页习 8-9。 8. 见《数据结构(Java 版)(第 4 版)习题解答》第 57 页习 9-4。
二、 问答题(50 分=5 分×10 题)
数据结构-课程内容

一、课程的性质、任务与基本要求(一)课程的性质、任务1.课程的性质《数据结构》是软件技术专业中一门重要的专业必修课程。
它与数学和计算机软件设计有十分密切的关系,是计算机软件专业的一门核心课程,是程序设计、操作系统、数据库等课程的基础。
同时,数据结构技术也广泛应用于信息科学、系统工程、应用数学以及各种工程技术领域。
当我们用计算机来解决实际问题时,就要涉及到数据的表示及数据的处理,而数据表示及数据处理正是《数据结构》课程的主要研究对象,通过这两方面内容的学习,为后续课程,特别是软件方面的课程打下了厚实的知识基础,同时也提供了必要的技能训练。
因此,《数据结构》课程在计算机软件专业中具有重要的作用。
2.课程的任务①本课程实现专业培养目标中所承担的任务:在基础方面,要求学生掌握常用数据结构的基本概念及其不同的实现方法;在技能方面,通过系统学习能够在不同存储结构上实现不同的运算,并对算法设计的方式和技巧有所体会。
②本课程教学内容及教学环节等方面与相关课程的联系与分工:《数据结构》是计算机软件专业的一门核心课程,数据结构技术也广泛应用于信息科学、系统工程、应用数学以及各种工程技术领域。
③本课程相关的先修课及后续课:先修课:《Java语言程序设计基础》或《Python语言程序设计基础》;后续课:程序设计、项目开发、数据库等课程。
(二)基本要求具体要求学生通过各个教学环节达到以下目标:1 通过学习掌握各种数据结构的逻辑结构、物理结构以及在之上实施的算法2 提高程序设计能力和编程质量3 学会分析研究计算机加工的数据对象的特性,能选择适当的数据结构以及相应的算法4 通过本课程的学习,使学生的逻辑分析、抽象思维和程序设计的能力有所提高,培养学生具有优良的程序设计风格5 通过本课程的学习,为后续的软件课程打下良好基础二、主要教学内容及教学要求第一章绪论教学内容1.1 数据结构的概念1.2 算法的概念1.3 算法描述和算法分析概念介绍教学要求⑴领会数据、数据元素和数据项的概念及其相互间关系⑵清楚数据结构的逻辑结构、存储结构的联系与区别,以及在数据结构上施加的运算及其实现⑶掌握“数据结构”的描述及算法的概念⑷掌握描述算法的方法⑸了解进行简单算法分析的方法第二章线性表教学内容2.1 线性表的基本概念和运算2.2 顺序表2.3 链表及其操作2.4 栈和队列教学要求⑴理解线性表的定义及其运算⑵理解顺序表定义、组织形式、结构特征和类型说明⑶掌握在顺序表上实现的插入、删除和查找的算法⑷掌握单链表和循环链表的结构特点及基本操⑸了解双向链表和双向循环链表的结构特点(6) 理解栈的定义、特征及在其上所定义的基本运算(7) 掌握在顺序和动态存储结构上栈基本运算的实现(8) 理解队列的定义、特征及在其上所定义的基本运算(9) 掌握在顺序和动态存储结构上队列基本运算的实现第三章串教学内容4.1 串的基本概念4.2 串的基本操作4.3 串的存储结构4.4 串操作应用举例教学要求⑴掌握串的基本概念、基本运算⑵了解串的存储方式⑶理解串的基本操作算法第四章数组和广义表教学内容4.1 多维数组4.2 特殊矩阵和压缩存储介绍4.3 稀疏矩阵介绍4.4 广义表介绍教学要求(1) 理解多维数组的逻辑结构和数组的顺序分配(2) 了解顺序存储结构上元素在存储区中地址的计算(3) 了解特殊矩阵和压缩存储、稀疏矩阵、广义表等概念第五章树教学内容5.1树的定义和基本术语5.2 二叉树5.3 遍历二叉树5.4 线索二叉树5.5树和森林5.6 哈夫曼树教学要求⑴深刻理解并掌握树的定义、术语⑵领会树的存储结构⑶深刻理解并掌握二叉树的定义、性质及其存储方法⑷掌握二叉树的存储方式、结点结构和类型定义⑸理解并掌握二叉树的三种遍历算法⑹能够运用二叉树的遍历方法解决简单的应用问题⑺了解线索二叉排的定义及构造方法⑻掌握二叉树与树、森林之间相互转换的方法⑼理解哈夫曼树并掌握哈夫曼算法第六章图教学内容6.1 图的定义和基本术语6.2 图的存储结构6.3 图的遍历6.4 生成树和最小生成树6.5拓扑排序6.6关键路径6.7 最短路径教学要求⑴理解图的定义、术语及其含义⑵掌握图存储结构⑶理解并掌握图的遍历方法⑷领会生成树和最小生成树的概念⑸掌握构造最小生成树的算法思想⑹领会拓扑序列和拓扑排序的概念⑺理解并掌握拓扑排序的算法思想⑻理解并掌握关键路径的算法思想⑼理解并掌握最短路径的算法思想第七章查找教学内容7.1 线性表查找7.2 顺序查找7.3折半查找7.4 索引查找7.5 二叉排序树7.6 哈希表查找教学要求⑴掌握查找操作的基本思想⑵理解查找表的基本概念及查找原理⑶掌握在顺序表、有序表、索引表、树表以及哈希表等结构上进行查找操作的方法和算法描述⑷掌握哈希表的组织以及解决冲突的方法⑸能够根据不同场合确定合适的查找方法第八章内部排序教学内容8.1 基本概念8.2 插入排序8.3 交换排序8.4 选择排序8.5 归并排序8.6 基数排序8.7 各种排序方法的比较及应用教学要求⑴理解排序基本概念及内部排序和外部排序、稳定排序和非稳定排序的区别⑵掌握直接插入排序的基本思想、基本步骤和算法⑶掌握希尔排序的基本思想、基本步骤和算法⑷掌握冒泡排序的基本思想、基本步骤和算法⑸掌握快速排序的基本思想、基本步骤和算法⑹掌握直接选择排序的基本思想、基本步骤和算法⑺掌握堆排序的基本思想、基本步骤和算法⑻理解两个有序文件合并的方法和算法⑼了解归并排序的基本思想、基本步骤和算法⑽了解基数排序的基本思想、基本步骤和算法⑾了解根据不同场合确定合适的排序方法。
C语言归并排序(合并排序)算法及代码

C语⾔归并排序(合并排序)算法及代码归并排序也称合并排序,其算法思想是将待排序序列分为两部分,依次对分得的两个部分再次使⽤归并排序,之后再对其进⾏合并。
仅从算法思想上了解归并排序会觉得很抽象,接下来就以对序列A[0], A[l]…, A[n-1]进⾏升序排列来进⾏讲解,在此采⽤⾃顶向下的实现⽅法,操作步骤如下。
(1)将所要进⾏的排序序列分为左右两个部分,如果要进⾏排序的序列的起始元素下标为first,最后⼀个元素的下标为last,那么左右两部分之间的临界点下标mid=(first+last)/2,这两部分分别是A[first … mid]和A[mid+1 … last]。
(2)将上⾯所分得的两部分序列继续按照步骤(1)继续进⾏划分,直到划分的区间长度为1。
(3)将划分结束后的序列进⾏归并排序,排序⽅法为对所分的n个⼦序列进⾏两两合并,得到n/2或n/2+l个含有两个元素的⼦序列,再对得到的⼦序列进⾏合并,直⾄得到⼀个长度为n的有序序列为⽌。
下⾯通过⼀段代码来看如何实现归并排序。
#include <stdio.h>#include <stdlib.h>#define N 7void merge(int arr[], int low, int mid, int high){int i, k;int *tmp = (int *)malloc((high-low+1)*sizeof(int));//申请空间,使其⼤⼩为两个int left_low = low;int left_high = mid;int right_low = mid + 1;int right_high = high;for(k=0; left_low<=left_high && right_low<=right_high; k++){ // ⽐较两个指针所指向的元素if(arr[left_low]<=arr[right_low]){tmp[k] = arr[left_low++];}else{tmp[k] = arr[right_low++];}}if(left_low <= left_high){ //若第⼀个序列有剩余,直接复制出来粘到合并序列尾//memcpy(tmp+k, arr+left_low, (left_high-left_low+l)*sizeof(int));for(i=left_low;i<=left_high;i++)tmp[k++] = arr[i];}if(right_low <= right_high){//若第⼆个序列有剩余,直接复制出来粘到合并序列尾//memcpy(tmp+k, arr+right_low, (right_high-right_low+1)*sizeof(int));for(i=right_low; i<=right_high; i++)tmp[k++] = arr[i];}for(i=0; i<high-low+1; i++)arr[low+i] = tmp[i];free(tmp);return;}void merge_sort(int arr[], unsigned int first, unsigned int last){int mid = 0;if(first<last){mid = (first+last)/2; /* 注意防⽌溢出 *//*mid = first/2 + last/2;*///mid = (first & last) + ((first ^ last) >> 1);merge_sort(arr, first, mid);merge_sort(arr, mid+1,last);merge(arr,first,mid,last);}return;}int main(){int i;int a[N]={32,12,56,78,76,45,36};printf ("排序前 \n");for(i=0;i<N;i++)printf("%d\t",a[i]);merge_sort(a,0,N-1); // 排序printf ("\n 排序后 \n");for(i=0;i<N;i++)printf("%d\t",a[i]); printf("\n");system("pause");return0;}运⾏结果:排序前32 12 56 78 76 45 36排序后12 32 36 45 56 76 78分析上⾯的运⾏结果,通过归并排序成功地实现了对给定序列的排序操作。
两个顺序表的合并算法

两个顺序表的合并算法顺序表是一种线性数据结构,由一系列元素按照一定的顺序存储在连续的存储空间中。
合并两个顺序表是常见的算法问题,其涉及到的操作包括查找、插入和删除。
本文将介绍两种常见的顺序表合并算法:1、插入排序法;2、归并排序法。
两种算法各有特点,从时间复杂度、空间复杂度等方面进行比较,帮助读者选取更适合的算法进行应用。
1. 插入排序法插入排序是一种基本的排序算法,其思想是将一个元素插入到已经有序的序列中,使之仍然有序。
顺序表的合并可以通过构造一个新的顺序表,将原始的两个顺序表按照其中一个顺序表的顺序逐个插入到新的顺序表中。
具体实现如下:```python def merge(array1, array2): result = [] index1 = index2 = 0 while index1 <len(array1) and index2 < len(array2): if array1[index1] <= array2[index2]: result.append(array1[index1]) index1 += 1 else:result.append(array2[index2]) index2 +=array2[index2:] return result ```该方法的时间复杂度为O(n^2),其中n为两个序列的总长度。
每次插入都需要遍历已经存储的新序列,然后进行插入操作。
这种方法较为简单,适用于数据量较小的情况。
2. 归并排序法归并排序是一种分治排序算法,将一个序列分为两个子序列,然后对子序列进行排序并归并。
顺序表的合并可以通过将两个有序的顺序表进行归并的方式,使得归并后的顺序表仍然有序。
归并排序法的合并操作分为两个步骤:- 将两个顺序表分为两个子序列。
- 合并两个子序列并保证顺序。
具体实现如下:```python def merge(array1, array2): result = [] index1 = index2 = 0 while index1 <len(array1) and index2 < len(array2): if array1[index1] <= array2[index2]: result.append(array1[index1]) index1 += 1 else:result.append(array2[index2]) index2 +=array2[index2:] return resultdef mergeSort(array): if len(array)<=1: return array mid = len(array)//2 left = mergeSort(array[:mid]) right =mergeSort(array[mid:]) return merge(left,right)```该方法的时间复杂度为O(nlogn),其中n为两个序列的总长度。
自考数据结构02142-第七章

二、归并排序 1.思想:(2-路归并排序)
① n个记录的表看成n个,长度为1的有序表 ② 两两归并成 n/2 个,长度为2的有序表(n为奇数,则 还有1个长为1的表) ③再两两归并为 n/2 /2 个,长度为4的有序表 . . . 再两两归并直至只剩1个,长度为n的有序表;
共log2n 趟
2. 例:
二、快速排序★
1.基本思想:通过分部排序完成整个表的排 序;
首先取第一个记录,将之与表中其余记录比较并交换,从而将 它放到记录的正确的最终位置,使记录表分成两部分{其一(左边的) 诸记录的关键字均小于它;其二(右边的)诸记录的关键字均大于 它};然后对这两部分重新执行上述过程,依此类推,直至排序完毕。
7.5 归并排序
一、有序序列的合并(两个有序表归并成一个有 序表) 1. 思想:比较各个子序列的第一个记录的 键值,最小的一个就是排序后序列的第一个 记录。取出这个记录,继续比较各子序列现 有的第一个记录的键值,便可找出排序后的 第二个记录。如此继续下去,最终可以得到 排序结果。 2. 两个有序表归并算法 (见P199)
▲排序类型——
内部排序:全部数据存于内存;
排序过程
外部排序:需要对外村进行访问的
内部排序
按方法分
插入排序 交换排序 选择排序 归并排序
▲排序文件的物理表示:数组表示 #define n 100 /*序列中待排序记录的总数*/ typedef struct { int key; /*关键字项*/ anytype otheritem ; /*其他数据项*/ }records; typedef records list[n+1]; list r; r[0] r[1] r[2]….r[n] r[i].key——第i个记录的关键字 ▲排序指标(排序算法分析): 存储空间-空间复杂度 比较次数-时间复杂度
数据结构:第7章 图4-拓扑排序和关键路径

拓扑排序算法
拓扑排序方法: (1)在AOV网中选一个入度为0的顶点(没有前驱) 且输出之; (2)从AOV网中删除此顶点及该顶点发出来的所 有有向边; (3)重复(1)、(2)两步,直到AOV网中所有 顶点都被输出或网中不存在入度为0的顶点。
从拓扑排序步骤可知,若在第3步中,网中所有顶 点都被输出,则表明网中无有向环,拓扑排序成功。 若仅输出部分顶点,网中已不存在入度为0的顶点, 则表明网中有有向环,拓扑排序不成功。
拓扑序列:C1--C2--C3 (3)
C12 C9 C10
C7 C8 C6
C11
拓扑序列:C1--C2--C3--C4 (4)
C7
C12
C12
C8
C8 C9 C10
C6
C9 C10
C6
C11
C11 拓扑序列:C1--C2--C3--C4--C5
(5)
拓扑序列:C1--C2--C3--C4--C5--C7 (6)
在 (b)中,我们用一种有向图来表示课程开设
拓扑排序
1.定义 给出有向图G=(V,E),对于V中的顶点的线性序列 (vi1,vi2,...,vin),如果满足如下条件:若在G中从 顶点 vi 到vj有一条路径,则在序列中顶点vi必在 顶点 vj之前;则称该序列为 G的一个拓扑序列。 构造有向图的一个拓扑序列的过程称为拓扑排序。 2.说明 (1)在AOV网中,若不存在回路,则所有活动可排成 一个线性序列,使得每个活动的所有前驱活动都排 在该活动的前面,那么该序列为拓扑序列. (2)拓扑序列不是唯一的.
2.AOV网实际意义
现代化管理中, 通常我们把计划、施工过程、生产流程、 程序流程等都当成一个工程,一个大的工程常常被划分 成许多较小的子工程,这些子工程称为活动。在整个工 程实施过程中,有些活动开始是以它的所有前序活动的 结束为先决条件的,必须在其它有关活动完成之后才能 开始,有些活动没有先决条件,可以 安排在任意时间开 始。AOV网就是一种可以形象地反映出整个工程中各个 活动之间前后关系的有向图。例如,计算机专业学生的 课程开设可看成是一个工程,每一门课程就是工程中的 活动,下页图给出了若干门所开设的课程,其中有些课 程的开设有先后关系,有些则没有先后关系,有先后关 系的课程必须按先后关系开设,如开设数据结构课程之 前必须先学完程序设计基础及离散数学,而开设离散数 学则必须先并行学完数学、程序设计基础课程。
数据结构-排序PPT课件

O(nlogn),归并排序的平均时间复杂度为O(nlogn)。其中,n为待排序序列的长度。
06
基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
分配和收集
基数排序是一种稳定的排序算法,即相同的元素在排序后仍保持原有的顺序。
文件系统需要对文件和目录进行排序,以便用户可以更方便地浏览和管理文件。
数据挖掘和分析中需要对数据进行排序,以便发现数据中的模式和趋势。
计算机图形学中需要对图形数据进行排序,以便进行高效的渲染和操作。
数据库系统
文件系统
数据挖掘和分析
计算机图形学
02
插入排序
将待排序的元素按其排序码的大小,逐个插入到已经排好序的有序序列中,直到所有元素插入完毕。
简单选择排序
基本思想:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。 时间复杂度:堆排序的时间复杂度为O(nlogn),其中n为待排序元素的个数。 稳定性:堆排序是不稳定的排序算法。 优点:堆排序在最坏的情况下也能保证时间复杂度为O(nlogn),并且其空间复杂度为O(1),是一种效率较高的排序算法。
基数排序的实现过程
空间复杂度
基数排序的空间复杂度为O(n+k),其中n为待排序数组的长度,k为计数数组的长度。
时间复杂度
基数排序的时间复杂度为O(d(n+k)),其中d为最大位数,n为待排序数组的长度,k为计数数组的长度。
适用场景
当待排序数组的元素位数较少且范围较小时,基数排序具有较高的效率。然而,当元素位数较多或范围较大时,基数排序可能不是最优选择。
合并排序

1.合并排序(1)算法思想:合并排序是利用递归和分治技术将数据序列划分成为越来越小的半子表,再递归对半子表排序,最后再用递归将排好序的半子表合并成为越来越大的有序序列。
合并排序包括两个步骤,分别为:1)划分子表2)合并半子表(2)解题思路:首先将数据序列划分为两个半子表,然后再递归地分别对这两个半子表进行合并排序。
最后对两个已排好序的半子表利用合并算法(Merge)合并为一个有序数组。
合并算法步骤:第一步:申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列第二步:设定两个指针,最初位置分别为两个已经排序序列的起始位置第三步:比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置重复步骤3直到某一指针超出序列尾将另一序列剩下的所有元素直接复制到合并序列尾2.快速排序(1)算法思想通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
(2)解题思路:设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为中轴(关键数据),然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。
一趟快速排序的算法是:1)设置两个变量i、j,排序开始的时候:i=0,j=N-1;2)以第一个数组元素作为中轴,赋值给key,即key=A[0];3)从j开始向前搜索,即由后开始向前搜索(j--),找到第一个小于key的值A[j],将A[j]和A[i]互换;4)从i开始向后搜索,即由前开始向后搜索(i++),找到第一个大于key的A[i],将A[i]和A[j]互换;5)重复第3、4步,直到i=j;(3,4步中,没找到符合条件的值,即3中A[j]不小于key,4中A[i]不大于key的时候改变j、i的值,使得j=j-1,i=i+1,直至找到为止。
归并排序详解及应用

归并排序详解及应用归并排序(Merge sort)是一种基于分治策略的经典排序算法。
它将待排序数组分成两个子数组,分别对子数组进行排序,然后将已排序的子数组合并,最终得到完整的有序数组。
归并排序的详细步骤如下:1.分解:将待排序数组不断二分,直到最小单位为单个元素,即子数组长度为1。
2.合并:逐层对已排序的子数组进行合并操作,合并过程中将两个有序子数组合并为一个有序的大数组。
合并操作的具体步骤如下: a. 创建一个辅助数组,用于存放合并后的数组。
b. 定义三个指针,分别指向两个子数组的起始位置和辅助数组的起始位置。
c. 比较两个子数组的当前元素,将较小的元素放入辅助数组,并将相应指针后移。
d. 重复上述比较和放入操作,直到一个子数组的所有元素都放入了辅助数组。
e. 将另一个子数组剩余的元素放入辅助数组。
f. 将辅助数组中的元素复制回原数组对应的位置。
3.递归:不断重复分解和合并的过程,直到最终得到完整的有序数组。
归并排序的时间复杂度为O(nlogn),其中n是待排序数组的长度。
由于归并排序是基于分治策略,它的稳定性和效率使其成为常用的排序算法之一。
归并排序除了基本的排序功能,还具有其他一些应用。
以下是一些常见的应用场景:1.外部排序:归并排序适用于需要对大规模数据进行排序的情况,它可以将数据分割为适合内存容量的块,分别进行排序,然后将排序好的块合并成最终的有序结果。
2.链表排序:与其他排序算法相比,归并排序对链表的排序更加适用。
由于归并排序只需要改变指针的指向来完成合并操作,对于链表而言操作较为高效。
3.并行计算:归并排序可以进行并行化处理,将待排序数组分割为多个部分,分别在不同的处理器或线程上进行排序,然后将排序好的部分合并。
4.大数据处理:在大数据处理中,归并排序可以结合MapReduce等分布式计算框架,将数据分割、排序和合并操作分布在多个计算节点上,加快处理速度。
总的来说,归并排序是一种高效、稳定的排序算法,它的优点在于适用于各种数据类型的排序,并且可以应用到一些特定的场景和算法问题中。
数据结构之——八大排序算法

数据结构之——⼋⼤排序算法排序算法⼩汇总 冒泡排序⼀般将前⾯作为有序区(初始⽆元素),后⾯作为⽆序区(初始元素都在⽆序区⾥),在遍历过程中把当前⽆序区最⼩的数像泡泡⼀样,让其往上飘,然后在⽆序区继续执⾏此操作,直到⽆序区不再有元素。
这块是对⽼式冒泡排序的⼀种优化,因为当某次冒泡结束后,可能数组已经变得有序,继续进⾏冒泡排序会增加很多⽆⽤的⽐较次数,提⾼时间复杂度。
所以我们增加了⼀个标识变量flag,将其初始化为1,外层循环还是和⽼式的⼀样从0到末尾,内存循环我们改为从最后⾯向前⾯i(外层循环所处的位置)处遍历找最⼩的,如果在内存没有出现交换,说明⽆序区的元素已经变得有序,所以不需要交换,即整个数组已经变得有序。
(感谢@站在远处看童年在评论区的指正)#include<iostream>using namespace std;void sort(int k[] ,int n){int flag = 1;int temp;for(int i = 0; i < n-1 && flag; i++){flag = 0;for(int j = n-1; j > i; j--){/*下⾯这⾥和i没关系,注意看这块,从下往上travel,两两⽐较,如果不合适就调换,如果上来后⼀次都没调换,说明下⾯已经按顺序拍好了,上⾯也是按顺序排好的,所以完美!*/if(k[j-1] > k[j]){temp = k[j-1];k[j-1] = k[j];k[j] = temp;flag = 1;}}}}int main(){int k[3] = {0,9,6};sort(k,3);for(int i =0; i < 3; i++)printf("%d ",k[i]);}快速排序(Quicksort),基于分治算法思想,是对冒泡排序的⼀种改进。
快速排序由C. A. R. Hoare在1960年提出。
数据结构排序实验报告

数据结构排序实验报告一、实验目的本次数据结构排序实验的主要目的是深入理解和掌握常见的排序算法,包括冒泡排序、插入排序、选择排序、快速排序和归并排序,并通过实际编程和实验分析,比较它们在不同规模数据下的性能表现,从而为实际应用中选择合适的排序算法提供依据。
二、实验环境本次实验使用的编程语言为 Python 3x,开发环境为 PyCharm。
实验中使用的操作系统为 Windows 10。
三、实验原理1、冒泡排序(Bubble Sort)冒泡排序是一种简单的排序算法。
它重复地走访要排序的数列,一次比较两个数据元素,如果顺序不对则进行交换,并一直重复这样的走访操作,直到没有要交换的数据元素为止。
2、插入排序(Insertion Sort)插入排序是一种简单直观的排序算法。
它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,直到整个数组有序。
3、选择排序(Selection Sort)首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
4、快速排序(Quick Sort)通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
5、归并排序(Merge Sort)归并排序是建立在归并操作上的一种有效、稳定的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
四、实验步骤1、算法实现使用 Python 语言分别实现上述五种排序算法。
为每个算法编写独立的函数,函数输入为待排序的列表,输出为排序后的列表。
2、生成测试数据生成不同规模(例如 100、500、1000、5000、10000 个元素)的随机整数列表作为测试数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
算法MSort (R,n) 合并排序算法MSort. 通过调用MPass(),MSort实 现了两路合并排序。
第七章 排序
7.1 基本概念 7.2 插入排序 7.3 交换排序 7.4 选择排序 7.5 合并排序 7.6 基于关键词比较的排序算法分析 7.7 分布排序 7.8 外排序
1
7.5 合并排序
1、合并
合并(归并):把两个或多个有序文件合并成 一个有序文件。
合并的基本思想:设两个有序表A和B的记 录个数(表长)分别为 al 和 bl,变量 i 和 j 分 别是表A和表B的当前检测指针。设表C是 归并后的新有序表,变量 k 是它的当前存 放指针。
10
一趟合并MPass (R, n, len. X )的基本思想
设文件R中的n个记录已分成一些长度为len的子 文件,两两合并这些子文件,合并成一些长度为 2len的子文件,并放到 X 中.
如果n不是2len的整数倍,则到最后一趟合并可 能遇到两种情况: ① len剩下的记录数2len,可分成一个长度为 len的子文件和另一个长度 len 的子文件, 可 用一次 merge 算法,将它们合并成一个长度 小于2len的子文件. ② 只剩下一个长度 len 子文件, 可将其直接复 制到 X 中.
MP3.[处理长度 2len的子文件] IF ilen–1 n // i nlen, 从i 到n至少有len1个记录 THEN Merge(R, i, ilen1, n. X ) //107页的① ELSE FOR j i TO n DO Xj Rj . ▌//107页的②
12
归并排序算法例
21 25 49 25* 93 62 72 08 37 16 54 len=1
21 25 25* 49 62 93 08 72 16 37 54 len=2
21 25 25* 49 08 62 72 93 16 37 54 len=4
08 21 25 25* 4692 72 93
3、算法分析
一 趟 两 路 合 并 MPass , 要 调 用 Merge 函 数 n/(2len) O(n/len)次,而Merge的复杂度为 O(len). 所以, MPass的复杂度为O(n)
合并排序算法MSort,调用MPass正好log2n 次,所以算法总的时间复杂度为O(nlog2n)
6
Merge算法分析: 关键词比较次数 nt1 记录移动次数为 nt1
7
2、合并排序:
两路合并:一次合并两个有序文件(非排序算法) 合并排序:利用两路合并过程进行排序。 基本思想:设初始文件有 n 个记录,首先把它看
成是 n 个长度为 1 的有序子序列(合并项),先做 两两合并,得到 n/2 个长度为 2 的合并项 (如 果 n 为奇数,则最后一个有序子序列的长度为1); 再做两两合并…,如此重复,最终得到一个长度 为 n 的有序序列。
接着比较703和677,输出677,得
087, 503, 512, 677
703 , 765 空
文件2已空,故只需依序输出703和765,最终得 087, 503, 512, 677, 703, 765
4
l
m m1 n
08 21 25 25* 49 62 72 93 16 37 54
i
j
l
n
C 08 16 21 25 25* 37 49 54 62 72 93 k
16 37 54 len=8
08 16 21 25 25* 37 49 54 62 72 93
len=16
13
两路合并排序算法
算法MSort( R, n) /* X是辅助文件,其记录结构与R相同; len, 子文件长 度,子文件是排好序的; */ MS1. [初始化]
len 1. MS2. [交替合并]
当 i 和 j 都在两个表的表长内变化时, 根据A[i]与B[ j] 的关键词大小, 将关键词小的元素放到 C[k]中;
当 i 和 j 中有一个超出表长时, 则将另一个表的剩余 元素依次复制到表 C从下标 k 开始的相应元素中.
5
合并算法描述:
算法Merge (R, t, m, n. X )/*假定文件( Rt , Rt1, …, Rm)和文件 ( Rm1, Rm2 , …, Rn ) 都已排序, 算法Merge合并这两个文件 得到排好序的新文件 ( Xt , Xt1, …, Xn ) */
② 将数组存储改为链接存储,这样记录移动就变 为指针移动了。
16
M1. [初始化] i t.j m1.k 1.
M2. [比较] WHILE i m AND j n DO ( IF Ki Kj THEN ( Xk Ri.i i1.) ELSE ( Xk Rj . j j1.). k k1. ).
M3. [复制] WHILE i m DO ( XkRi . ii1. kk1.). WHILE j n DO ( Xk Rj . j j1. k k1.). ▌
2
例如,可把文件 { 503, 703, 765 } 和文件 { 087, 512, 677 } 合并到一起,得结果文件 { 087, 503, 512, 677, 703, 765 }. 有一个实现合并的简单方法SM:比较诸文 件的最小项,输出其中的最小者,然后重 复此过程,直到只剩下一个文件并将其输 出为止。
WHILE len n DO ( MPass(R, n, len. X ). len2len. MPass( X, n, len. R ). len2len.). ▌
14
如果 f1(n) O(g1(n)),f2(n) O(g2(n)),则 ⑴ f1(n) f2(n) max{O(g1(n)),O(g2(n))} ⑵ f1(n) f2(n) O(g1(n)g2(n))
辅助存储空间:O(n) 归并排序是稳定的排序方法。
15
通过对合并排序算法分析,不难发现它的两 个缺点:
① 当数据集非常小时,比如只有2个元素,仍然 采用分治策略,影响效率。
② Merge算法基于元素移动,当元素比较大时会 比较费时。
解决办法:
① 对于非常小的数据集,以及前几次归并操作, 调用直接插入排序算法。
8
合并排序过程示例
开始 25 57 48 37 12 92 86 33
第一次 合并
第二次 合并
25, 57
37, 48
25, 37, 48, 57
1, 86, 92
第三次 合并
12, 25, 33, 37, 48, 57, 86, 92
9
算法Merge (R, t, m, n. X ) 合并算法Merge. 假定文件 ( Rt , Rt1, …, Rm) 和文 件( Rm1, Rm2 , …, Rn )均已排序, Merge合并这两 个文件得到排好序的新文件 ( Xt , Xt1, …, Xn ).
11
一趟归并算法 算法MPass(R, n, len. X ) /*简称length为len,2length为
2len, */
MP1.[初始化] i 1.
MP2.[合并] //合并两个长度为len的相邻子文件 WHILE i n–2len1 DO ( Merge(R, i, ilen1, i2len1. X ) . i i2len. ).
3
用上例具体说明方法SM. 开始先比较 503 和 087, 输出 087,得到
087
503 , 703 , 765 512 , 677
接着比较 503 和 512,输出 503,得
703 , 765 087 , 503 512 , 677
接着比较 703 和 512,输出 512,得到
703 , 765 087, 503, 512 677