计量经济学 上机实验手册[精品文档]
计量经济学上机实验

西安郵電大学《计量经济学》课内上机实验报告书系部名称:经济与管理学院学生姓名:专业名称:班级:时间:2011-2012(2)1、教材P54 11题2、教材P91 10、11题3、教材p135 7、8题11、下表是中国1978-2000年的财政收入Y和国内生产总值(GDP)的统计资料。
单位:亿元要求,以手工和运用EViews软件(或其他软件):(1)作出散点图,建立财政收入随国内生产总值变化的一元线性回归模型,并解释斜率的经济意义;(2)对所建立的回归模型进行检验;(3)若2001年中国国内生产总值为105709亿元,求财政收入的预测值及预测区间。
Dependent Variable: YMethod: Least SquaresDate: 04/12/11 Time: 11:26Sample: 1978 2000R-squared Mean dependent varAdjusted R-squared. dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statistic0200004000060000800001000007880828486889092949698001.通过已知数据得到上面得散点图,财政收入随国内生产总值变化的一元线性回归方程: Ŷi= +() () t=r ²= F= ˆσ= 估计的解释变量的系数为,说明国内生产总值每增加一元,财政收入将增加元,符合经济理论。
2.(1)样本可决系数r ²=,模拟拟合度较好。
(2)系数的显著性检验:给定α=0,05,查t 分布表在自由度为n-2=21时的临界值为(21)=因为t=> (21)=, 国内生产总值对财政收入有显著性影响。
3.2001年的财政收入的预测值:Ŷ01= + *105709=2001年的财政收入的预测区间:在1-α下,Y01的置信区间为: Y01∈()()01/2001/20ˆˆˆˆ,Yt e Y t e αασσ⎡⎤-+⎣⎦即: Y01∈[]11612.666943,14829.98478310、在一项对某社区家庭对某种消费品的消费需要调查中,得到下表所示的资料。
计量经济学上机实验手册

实验三异方差性实验目的:在理解异方差性概念和异方差对OLS回归结果影响的基础上,掌握进行异方差检验和处理的方法;熟练掌握和运用Eviews软件的图示检验、G-Q检验、怀特White 检验等异方差检验方法和处理异方差的方法——加权最小二乘法;实验内容:书P116例4.1.4:中国农村居民人均消费函数中国农村居民民人均消费支出主要由人均纯收入来决定;农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支付收入等;为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,建立双对数模型:其中,Y表示农村家庭人均消费支出,X1表示从事农业经营的纯收入,X2表示其他来源的纯收入;表4.1.1列出了中国内地2006年各地区农村居民家庭人均纯收入及消费支出的相关数据;表4.1.1 中国2006年各地区农村居民家庭人均纯收入与消费支出单位:元注:从事农业经营的纯收入由从事第一产业的经营总收入与从事第一产业的经营支出之差计算,其他来源的纯收入由总纯收入减去从事农业经营的纯收入后得到;资料来源:中国农村住户调查年鉴2007、中国统计年鉴2007;实验步骤:一、创建文件1.建立工作文件CREATE U 1 31 其中的“U”表示非时序数据2.录入与编辑数据Data Y X1 X2 意思是:同时录入Y、X1和X2的数据3.保存文件单击主菜单栏中File→Save或Save as→输入文件名、路径→保存;二、数据分析1.散点图①Scat X1 Y从散点图可看出,农民农业经营的纯收入与农民人均消费支出呈现一定程度的正相关;②Scat X2 Y从散点图可看出,农民其他来源纯收入与农民人均消费支出呈现较高程度的正相关;2.数据取对数处理Genr LY=LOG YGenr LX1=LOG X1Genr LX2=LOG X2三、模型OLS 参数估计与统计检验 LS LY C LX1 LX2得到模型OLS 参数估计和统计检验结果:Dependent Variable: LY Method: Least Squares Sample: 1 31Variable CoefficientStd. Errort-StatisticProb.C LX1 R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic 注意:在学术文献中一般以这种形式给出回归方程的输出结果,而不是把上面的软件输出结果直接粘贴到文章中可决系数,调整可决系数,显示模型拟合程度较高;同时,F 检验统计量,在5%的显着性水平下通过方程总体显着性检验;可认为农民农业经营的收入和其他收入整体与农村居民消费支出的线性关系显着成立;变量X2和截距项均在5%的显着性水平下通过变量显着性检验,但X1在10%的显着水平下仍不能通过检验;四、异方差检验对于双对数模型,由于12(0.150214)(0.477453)ββ=<=二者均为弹性系数,可认为其他来源的纯收入而不是从事农业经营的纯收入的增长,对农户人均消费的增长更有刺激作用;也就是说,不同地区农村人均消费支出的差别主要来源于非农经营收入及工资收入、财产收入等其他来源收入的差别,因此,如果模型存在异方差性,则可能是X2引起的;1.图示检验法观察残差的平方与LX2的散点图;①残差resid残差resid变量数据是模型参数估计命令完成后由Eviews软件自动生成在Workfile 框里可找到,无需人工操作获得;注意,resid保留的是最近一次估计模型的残差数据;②残差的平方与LX2的散点图Scat LX2 resid^2从上图可大体判断出模型存在递增型异方差性;2.G-Q法检验异方差补充:先定义一个变量T,取值为1、2、…、31分别代表各省市,用于在做完G-Q检验之后,再按T排序,使数据顺序还原;Data T 提示:输入1、2、…、31①将所有原始数据按照X2升序排列;Sort X2Show Y X1 X2 LY LX1 LX2显示各个变量数据的目的是查看一下,所有变量数据是否按X2升序排列好了;②将31对样本数据,去掉中间的7对,形成两个容量均为12的子样本,即1-12和20-31;③对1-12的子样本做普通最小二乘估计,并记录残差平方和RSS;1Smpl 1 12 意思是:将样本区间由1-31,改为1-12Ls LY C LX1 LX2Dependent Variable: LYMethod: Least Squares Sample: 1 12C LX1 LX2R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson statProbF-statistic子样本1:12ln 3.1412080.398385ln 0.234751ln Y X X e =+++1RSS =④对20-31的子样本做普通最小二乘估计,并记录残差平方和2RSS ; Smpl 20 31 意思是:将样本区间由1-12,改为20-31 Ls LY C LX1 LX2Dependent Variable: LY Method: Least Squares Sample: 20 31Included observations: 12C LX1 R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson statProbF-statistic子样本2:12ln 3.9936440.113766ln 0.6201681ln Y X X e =-++2RSS =⑤异方差检验在5%与10%的显着性水平下,自由度为9,9的F分布临界值分别为0.05(9,9) 3.18F=与0.10(9,9) 2.44F=;因此5%显着性水平下不能拒绝同方差假设,但在10%的显着性水平下拒绝;补充:怀特检验软件操作:在原始模型的OLS方程对象窗口中,选择view/Residual test/White Heteroskedasticity;Eviews提供了包含交叉项的怀特检验“White Heteroskedasticitycross terms”和没有交叉项的怀特检验“White Heteroskedasticityno cross terms”这样两个选择;问题:如果是刚做完上面的G-Q检验,如何得到原始模型答案:先恢复成全样本,再按T排序,然后做OLS回归;SMPL 1 31 意思是:将样本区间恢复到1-31补充:将样本数据按T升序排列,使数据顺序还原;Sort T 意思是:将数据顺序还原Ls LY C LX1 LX2下面是在原始模型的OLS方程对象窗口中,选择view/Residual test/White Heteroskedasticity,然后进行包含交叉项的怀特检验“White Heteroskedasticitycross terms”所得到的输出结果最上方显示了两个检验统计量:F统计量和White统计量nR2;下方显示的是以OLS的残差平方为被解释变量的辅助回归方程的回归结果:F-statistic ProbabilityTest Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 05/03/11 Time: 17:21Sample: 1 31C LNX1 LNX1^2 LNX1LNX2 LNX2 R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic 可见,怀特统计量nR 2==31×,大于自由度也即辅助回归方程中解释变量的个数为5的2分布临界值07.115205.0=)(χ,因此,在5%的显着性水平下拒绝同方差的原假设; 五、采用加权最小二乘法处理异方差以下内容和教材P118-120不一样,但是我们必须掌握的重点——以原始模型的OLS 回归残差的绝对值的倒数为权数,手工完成加权最小二乘估计LS LY C LX1 LX2Genr E=resid 意思是:记录双对数模型OLS 估计的残差 用残差的绝对值的倒数对LY 、LX1、LX2做加权: Genr LYE=LY/abs E Genr LX1E=LX1/abs E Genr LX2E=LX2/abs E Genr CE=1/abs E LS LYE CE LX1E LX2EDependent Variable: LYE Method: Least Squares Sample: 1 31CELX1ER-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Durbin-Watson stat可以看出,lnX1参数的t统计量有了显着改进,这表明在1%显着性水平下,都不能拒绝从事农业生产带来的纯收入对农户人均消费支出有着显着影响的假设;六、检验加权的回归模型是否还存在异方差1.检验是否由LX1E引起异方差Sort LX1E 意思是:将原始数据按LX1E升序排列①子样本1的回归:Smpl 1 12LS LYE CE LX1E LX2EDependent Variable: LYEMethod: Least SquaresSample: 1 12Variable Coefficient Std. Error t-Statistic Prob.CELX1ER-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Durbin-Watson stat子样本1:RSS=1②子样本2的回归:Smpl 20 31LS LYE CE LX1E LX2EDependent Variable: LYE Method: Least Squares Date: 05/01/11 Time: 23:23 Sample: 20 31Variable CoefficientStd. Errort-StatisticProb.CE LX1E R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihoodDurbin-Watson stat子样本2:2RSS =③异方差检验 注意做题的步骤提出假设 22012:H σσ= 22112:H σσ≠ 计算检验统计量:在5%的显着性水平下,自由度为9,9的F 分布临界值分别为0.05(9,9) 3.18F =;因此5%显着性水平下不能拒绝同方差假设;2.检验是否由LX2E 引起异方差Smpl 1 31 意思是:将样本区间复原Sort lx2e 意思是:将原始数据按LX2E 升序排列 ①子样本1的回归: Smpl 1 12LS LYE CE LX1E LX2EDependent Variable: LYE Method: Least Squares Sample: 1 12CE LX1E R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihoodDurbin-Watson stat子样本1:1RSS = ②子样本2的回归: Smpl 20 31LS LYE CE LX1E LX2EDependent Variable: LYE Method: Least Squares Sample: 20 31Included observations: 12CE LX1E R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihoodDurbin-Watson stat子样本2:2RSS =③异方差检验 注意做题的步骤提出假设 22012:H σσ= 22112:H σσ≠ 计算检验统计量:在5%的显着性水平下,自由度为9,9的F 分布临界值分别为0.05(9,9) 3.18F =;因此5%显着性水平下不能拒绝同方差假设;结论:用OLS 估计的残差绝对值的倒数作为权数,对存在异方差的模型加权,然后采用OLS估计,则一定会消除异方差;最终通过异方差检验的估计方程为:实验四序列相关性实验目的:在理解序列相关性的基本概念、序列相关的严重后果的基础上,掌握进行序列相关检验和处理的方法;熟练掌握Eviews软件的图示检验、DW检验、拉格朗日乘数LM检验等序列相关性检验方法和处理序列相关性的方法——广义差分法;实验内容:书P132例4.2.1:中国居民总量消费函数建立总量消费函数是进行宏观经济管理的重要手段;为了从总体上考察中国居民收入与消费的关系,P56表2.6.3给出了中国名义支出法国内生产总值GDP、名义居民总消费CONS以及表示宏观税负的税收总额TAX、表示价格变化的居民消费价格指数CPI1990=100,并由这些数据整理出实际支出法国内生产总值GDPC=GDP/CPI、居民实际消费总支出Y=CONS/CPI,以及实际可支配收入X=GDP-TAX/CPI;表2.6.3 中国居民总量消费支出与收入资料单位:亿元年份GDP CONS CPI TAX GDPC X Y19781979198019811982198319841985198619871988198919901991199219931994199519961997199819992000200120022003200420052006资料来源:根据中国统计年鉴2001,2007整理;实验步骤:一、创建文件1.建立工作文件CREATE A 1978 2006 其中的“A”表示年度数据2.录入与编辑数据Data X Y3.保存文件单击主菜单栏中File→Save或Save as→输入文件名、路径→保存;二、数据分析:趋势图Plot X Y 意思是:同时画出Y和X的趋势图从X和Y的趋势图中可看出它们存在共同变动趋势;三、OLS参数估计与统计检验LS Y C XDependent Variable: YMethod: Least Squares Sample: 1978 2006C R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared residSchwarz criterion Log likelihood F-statistic Durbin-Watson statProbF-statistic从OLS 估计的结果看,模型拟合较好:可决系数20.9880R =,截距项和斜率项的t 检验值均大于5%显着性水平下自由度为n-2=27的临界值0.025(27) 2.05t =;而且,斜率项符合经济理论中边际消费倾向在0与1之间的绝对收入假说;斜率项表明,在1978—2006年间,以1990年价计算的中国居民可支配总收入每增加1亿元,居民消费支出平均增加亿元;四、序列相关性检验 1.图示检验法①残差与时间t 的关系图趋势图 Plot resid②相邻两期残差之间的关系图 Scat resid-1 resid从两个关系图看出,随机误差项呈正序列相关性;.检验值为,表明在5%显着性水平下,n=29,k=2包括常数项,查表得1.34L d =, 1.48U d =,由于.= 1.34L d <=,故存在正序列相关;五、处理序列相关1.修正模型设定偏误剔除虚假序列相关首先面临的问题是,模型的序列相关是纯序列相关,还是由于模型设定有偏误而导致的虚假序列相关;从X 和Y 的趋势图中看到它们表现出共同的变动趋势,因此有理由怀疑较高的2R =部分地是由这一共同的变化趋势带来的;为了排除时间序列模型中这种随时间变动而具有的共同变化趋势的影响,一种解决方案是在模型中引入时间趋势项,将这种影响分离出来;由于本例中可支配收入X 与消费支出Y 均呈非线性变化态势,因此引入的时间变量TT=1,2,……,29以平方的形式出现,回归模型变化为:①编辑变量T data T在数据表中输入1-29; ②做如下的回归 Ls Y C X T^2Dependent Variable: Y Method: Least Squares Sample: 1978 2006 Included observations: 29C X T ^2R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid 6054792. Schwarz criterionLog likelihood F-statistic 得到如下的修正模型:可见,T 2的t 统计量显着;但是,修正的模型.值仍然较低,没有通过5%显着性水平下的.检验n=29,k=3时,27.1=L D ,56.1=U D ,因此该模型仍存在正序列相关性;补充:序列相关性的拉格朗日乘数检验LM检验在EViews软件中,如果在上面的OLS回归方程界面直接做残差序列的LM检验,那么得到的是如下结果,和书上P133结果不一致:原因:EViews在做LM检验时,为了不损失样本,把滞后残差序列的“前样本”缺失值设定为0Presample missing value lagged residuals set to zero.;这样,它的样本容量仍然是n,而不是n-p;回归结果和书上也有不同;解决办法:要使软件的LM检验结果和教材P133结果一致,办法是进行OLS估计之后,先把残差序列resid用genr生成另一序列e,再做辅助回归,即:genr e=resid先做含1阶滞后残差的辅助回归:ls e c x t^2 e-1Dependent Variable: EMethod: Least SquaresDate: 04/26/13 Time: 07:08Sample adjusted: 1979 2006Included observations: 28 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CXT^2E-1R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid 2103016. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProbF-statisticLM检验统计量必须自己算:LM=n-pR2=29-1=由于该值大于显着性水平为5%、自由度为1的2分布临界值84.31205.0=)(χ,由此判断原模型存在1阶序列相关;再做含2阶滞后残差的辅助回归: ls e c x t^2 e-1 e-2Dependent Variable: E Method: Least Squares Date: 04/26/13 Time: 07:32 Sample adjusted: 1980 2006Included observations: 27 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob. C X T^2 E-1 E-2R-squaredMean dependent var Adjusted R-squared . dependent var . of regressionAkaike info criterion Sum squared resid 1806465. Schwarz criterion Log likelihood Hannan-Quinn criter. F-statistic Durbin-Watson statProbF-statisticLM 检验统计量必须自己算:LM=n-pR 2=29-2=由于该值大于显着性水平为5%、自由度为2的2分布临界值99.52205.0=)(χ,由此判断原模型存在序列相关;但2~-t e 的系数未通过5%的显着性检验,表明在5%的显着性水平下不存在2阶序列相关性;所以,结合前面含1阶、2阶滞后残差的辅助回归结果,可以判断在5%的显着性水平下仅存在1阶序列相关性;2.广义差分法处理序列相关①Ls Y C X T^2 AR1Dependent Variable: Y Method: Least Squares Sampleadjusted: 1979 2006Included observations: 28 after adjusting endpoints Variable CoefficientStd. Errort-StatisticProb.C X T^2 AR1R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid 2164144. Schwarz criterionLog likelihood F-statistic AR1前的参数值即为随机扰动项的1阶序列相关系数,在5%的显着性水平下显着;.= ,在5%显着性水平下,1.18.. 1.65L U d DWd =<<=样本容量为28,无法判断广义差分变换后模型是否已不存在序列相关;②继续引入AR2以下内容和教材P133-134的做法不同,但是我们必须掌握的基本做法Ls Y C X T ^2 AR1 AR2Dependent Variable: Y Method: Least Squares Sampleadjusted: 1980 2006Included observations: 27 after adjusting endpointsC X T^2 AR1 AR2R-squaredMean dependent var Adjusted R-squared. dependent var. of regression Akaike info criterionSum squared resid 1834086. Schwarz criterionLog likelihood F-statisticInverted AR Roots .53 .53+.32iAR2前的参数在10%的显着性水平下显着不为0;且.= ,接近于2,认为在10%显着性水平下,已不存在序列相关;但是,在5%的显着性水平下,则没必要引入AR2;注意:教材P133用LM检验的结果是,引入AR1 的回归方程在5%的显着性水平下已不存在序列相关性,因而不需要引入AR2;补充:下面是针对引入AR1的回归方程式的LM检验的命令操作和检验结果:首先,采用上面得到的1阶自回归系数1也即AR1的系数,做如下的1阶广义差分变量的OLS回归注:与式等价:Ls y-1 c x-1 t^t-1^2Dependent Variable: Y-1Method: Least SquaresDate: 06/02/13 Time: 11:07Sample adjusted: 1979 2006Included observations: 28 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CX-1T^T-1^2R-squared M ean dependent varAdjusted R-squared . dependent var. of regression A kaike info criterionSum squared resid 2164144. S chwarz criterionLog likelihood H annan-Quinn criter.F-statistic D urbin-Watson statProbF-statistic然后,将上述1阶广义差分方程的残差序列resid 记为e :genr e=resid 最后,做如下的辅助回归:ls e c x-1 t^t-1^2 e-1Dependent Variable: E Method: Least Squares Date: 06/02/13 Time: 11:16 Sample adjusted: 1980 2006Included observations: 27 after adjustmentsVariable CoefficientStd. Errort-StatisticProb.C X-1 T^T-1^2 E-1R-squaredM ean dependent var Adjusted R-squared . dependent var . of regression A kaike info criterionSum squared resid 1965048. S chwarz criterionLog likelihood H annan-Quinn criter. F-statistic D urbin-Watson statProbF-statistic于是,LM 检验统计量:LM=27=;查表,当显着性水平为5%时,自由度为1的2的临界值)(1205.0χ为;上述LM <)(1205.0χ,表明模型的随机误差项已不存在序列相关;。
计量经济学上机实验手册

计量经济学上机实验手册标准化工作室编码[XX968T-XX89628-XJ668-XT689N]实验三异方差性实验目的:在理解异方差性概念和异方差对OLS回归结果影响的基础上,掌握进行异方差检验和处理的方法。
熟练掌握和运用Eviews软件的图示检验、G-Q检验、怀特(White)检验等异方差检验方法和处理异方差的方法——加权最小二乘法。
实验内容:书P116例4.1.4:中国农村居民人均消费函数中国农村居民民人均消费支出主要由人均纯收入来决定。
农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支付收入等。
为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,建立双对数模型:其中,Y表示农村家庭人均消费支出,X1表示从事农业经营的纯收入,X2表示其他来源的纯收入。
表4.1.1列出了中国内地2006年各地区农村居民家庭人均纯收入及消费支出的相关数据。
注:从事农业经营的纯收入由从事第一产业的经营总收入与从事第一产业的经营支出之差计算,其他来源的纯收入由总纯收入减去从事农业经营的纯收入后得到。
资料来源:《中国农村住户调查年鉴(2007)》、《中国统计年鉴(2007)》。
实验步骤:一、创建文件1.建立工作文件CREATE U 1 31 【其中的“U”表示非时序数据】2.录入与编辑数据Data Y X1 X2 【意思是:同时录入Y、X1和X2的数据】3.保存文件单击主菜单栏中File→Save或Save as→输入文件名、路径→保存。
二、数据分析1.散点图①Scat X1 Y从散点图可看出,农民农业经营的纯收入与农民人均消费支出呈现一定程度的正相关。
②Scat X2 Y从散点图可看出,农民其他来源纯收入与农民人均消费支出呈现较高程度的正相关。
2.数据取对数处理Genr LY=LOG(Y)Genr LX1=LOG(X1)Genr LX2=LOG(X2)三、模型OLS参数估计与统计检验LS LY C LX1 LX2得到模型OLS参数估计和统计检验结果:Dependent Variable: LYMethod: Least SquaresSample: 1 31LX1Adjusted R-squared . dependent var. of regression Akaike infocriterionSum squared resid Schwarz criterionLog likelihood F-statistic【注意:在学术文献中一般以这种形式给出回归方程的输出结果,而不是把上面的软件输出结果直接粘贴到文章中】可决系数,调整可决系数,显示模型拟合程度较高;同时,F 检验统计量,在5%的显着性水平下通过方程总体显着性检验。
2012年本科计量经济学实验上机手册学生版(为李子奈编写的计量经济学第二版中例题的SAS程序)

附页:上机手册实验一 一元线性回归模型的参数估计和统计检验模型:1978-2000年中国人均居民消费支出(CONSP )对人均GDP (GDPP )的回归分析CONSP C GDPP βμ=++程序:(一) data china;input year CONSP GDPP @@; cards;数据行(自己输入) ; run;proc print data=china; title ‘china’; run;/*proc gplot data=china; symbol v=plus i=join; plot CONSP*GDPP; run; */proc reg data=china; model CONSP=GDPP; title ‘china’; run;程序 (二)P54页习题11数据 data caizheng;input year Y GDP @@; cards;数据行(自己输入); run;proc print data=caizheng; title ‘caizheng’; run;/*proc gplot data= caizheng; symbol v=plus i=join; plot Y*GDP; run; */proc reg data= caizheng; model Y=GDP; title ‘caizheng’; run;实验二 多元线性回归模型的参数估计和统计检验程序(一)课本P77页表3.5.1数据,分别估计课本中P78页式子(3.5.18)和P80页中式子(3.5.19)(注意:这里只采用了1981-1994的数据): data xiaofei;input year XC1990 Q1990 P01990 P11990 @@; cards;数据行(自己输入) ; run;proc print data=xiaofei;title ‘中国城镇居民人均消费支出’;run;data xiaofei2;set xiaofei;lnQ=log(Q1990);lnX=log(XC1990);lnP0=log(P01990);lnP1=log(P11990);x1=XC1990/P01990;y1=P11990/P01990;lnXP0=log(x1);lnP1P0=log(y1);run;proc reg data=xiaofei2;model lnQ=lnX lnP1 lnP0/DW;title ‘模型3.5.18’;run;proc reg data=xiaofei2;model lnQ=lnXP0 lnP1P0/DW;title ‘模型3.5.19’;run;程序(二)课本P92页习题11数据,模型为对数线性模型:data zhizhao;input number Y K L@@;cards;数据行(自己输入);run;proc print data=zhizhao;title ‘中国2000年的制造业总体规模’; run; data zhizhao2;set zhizhao;lnY=log(Y);lnK=log(K);lnL=log(L);run;proc print data=zhizhao2;title ‘zhizhao2’;run;proc reg data=zhizhao2;model lnY=lnK lnL;print cli;/*可得95%的置信区间及相对误差值*/run;data zhizhao3;set zhizhao2(keep=Y lnY lnK lnL);lnYY=1.15397+0.60925*lnK+0.36078*lnL; /* 即为012l n*l n*l nY K Lβββ=++*/YY=exp(lnYY); /* 即为ln YY e=*/aa=Y-YY; /* 即为()Y Y-*/Yresid=aa/Y; /* 即为()/Y Y Y-*/ proc print data=zhizhao3;title ‘简单拟合’;run;data zhizhao4;set zhizhao3;keep Y lnYY YY Yresid;proc print data=zhizhao4;run;data zhizhao5;set zhizhao;a=Y/L;lnYL=log(a);b=K/L;lnKL=log(b);run;proc print data=zhizhao5;title ‘zhizhao5’;run;proc reg data=zhizhao5;model lnYL=lnKL;run;实验三异方差模型的检验和处理程序(一)课本P101页表4.1.1数据:data nongcun;input diqu $ Y X1 X2 @@;cards4;数据行(自己输入);;;;run;proc print data=nongcun;title ‘中国农村居民人均消费’; run;data nongcun2;set nongcun;lnY=log(Y);lnX1=log(X1);lnX1X1=lnX1*lnX1;lnX2=log(X2); lnX2X2=lnX2*lnX2;lnX1X2= lnX1*lnX2;run;proc reg data=nongcun2;model lnY=lnX1 lnX2;title ‘nongcun2’;run;data nongcun3;set nongcun2;e=lnY-(1.60258+0.32541*lnX1+0.50708*l nX2);e1=abs(e);e2=e*e;run;/*proc gplot data=nongcun3;symbol v=plus i=jion;plot e2*lnX2;run;*/proc reg data=nongcun3;model e1=lnX1 lnX2;title ‘用戈里瑟法检验异方差’;run;proc reg data=nongcun3;model e1=X1 X2;title ‘用戈里瑟法检验异方差1’; run;proc reg data=nongcun3;model e2=lnX1 lnX1X1 lnX2 lnX2X2 lnX1X2; title ‘怀特检验法检验异方差’;run;proc reg data=nongcun3;model e2=lnX1 lnX1X1 lnX2 lnX2X2 ; title ‘没有交叉项的怀特检验’; run;data nongcun4;set nongcun2;proc sort data=nongcun4;by X2;proc print data=nongcun4;title ‘nongcun4’;run;data nongcun5;set nongcun2;X22=X2;if X2<=876.0;proc sort data=nongcun5;by X2;proc print data=nongcun5;title ‘nongcun5’;run;proc reg data=nongcun5;model lnY=lnX1 lnX2;title ‘G-Q检验子样本1’;run;data nongcun6;set nongcun2;X22=X2;if X2>=1303.6;proc sort data=nongcun6;by X2;proc print data=nongcun6;title ‘nongcun6’; run;proc reg data=nongcun6;model lnY=lnX1 lnX2;title ‘G-Q检验子样本2’;run;data nongcun7;set nongcun3;lnYjiaq=lnY/e1;lnX1jiaq=lnX1/e1;lnX2jiaq=lnX2/e1;proc print data=nongcun7;title ‘nongcun7’;run;proc reg data=nongcun7;model lnYjiaq=lnX1jiaq lnX2jiaq /DW noint;title ‘加权最小二乘法’;run;实验四序列相关模型的检验和处理程序(一)课本P115页中国商品进口模型,表4.2.1中数据:data MGDP;input year GDP Mt @@;cards;数据自己输入;run;proc print data=MGDP;title ‘MGDP’;run;proc reg data=MGDP;model Mt=GDP/DW;title ‘中国商品进口模型’; run;data MGDP2;set MGDP;MM= 152.90574+ 0.02039*GDP; et=Mt-MM;et_1=lag(et);et_2=lag(et_1);et_3=lag(et_2);run;/* proc gplot data=MGDP2; Symbol v=star i=join;plot et*year;run;proc gplot data=MGDP2; Symbol v=plus i=join;plot et* et_1;run;*//*回归检验法*/proc reg data=MGDP2;model et=et_1;title ‘回归法1’;run;proc reg data=MGDP2;model et=et_1 et_2;title ‘回归法2’;run;/*拉格朗日乘数检验*/proc reg data=MGDP2;model et=GDP et_1 et_2; title ‘拉格朗日乘数检验2阶序列相关’;run;proc reg data=MGDP2;model et=GDP et_1 et_2 et_3;title ‘拉格朗日乘数检验3阶序列相关’;run;/*杜宾两步法修正*/data MGDP3;set MGDP2;Mt_1=lag(Mt);Mt_2=lag(Mt_1);GDPt_1=lag(GDP);GDPt_2=lag(GDPt_1);run;proc reg data=MGDP3;model Mt=Mt_1 Mt_2 GDP GDPt_1 GDPt_2; title ‘杜宾法第一步估计相关系数’; run;data MGDP4;set MGDP3;Mtstar=Mt-(0.93825*Mt_1-0.46865*Mt_2) ;GDPstar=GDP-(0.93825*GDPt_1-0.46865*G DPt_2);run;proc print data=MGDP4;title ‘MGDP4’;run;proc reg data=MGDP4;model Mtstar=GDPstar;title ‘杜宾法第二步’;run;/*科克伦-奥克特迭代法(只迭代两步)修正*/proc reg data=MGDP2;model et=et_1 et_2/noint;title ‘第一次估计相关系数’;run;data MGDP5;set MGDP3;MtM=Mt-(1.10999*Mt_1-0.75138*Mt_2); GDPG=GDP-(1.10999*GDPt_1-0.75138*GDPt _2);run;proc reg data=MGDP5;model MtM=GDPG;title ‘第一次估计待估参数’;run;data MGDP6;set MGDP3(drop=MM et et_1 et_2 et_3); MMM=107.39666+0.01991*GDP;et=Mt-MMM;et_1=lag(et);et_2=lag(et_1);et_3=lag(et_2);run;proc reg data=MGDP6;model et=et_1 et_2/noint;title ‘第二次估计相关系数’;run; data MGDP7;set MGDP6;MtMt=Mt-(1.19578*Mt_1-0.76487*Mt_2); GDPGD=GDP-(1.19578*GDPt_1+-0.76487*GD Pt_2);run;proc reg data=MGDP7;model MtMt=GDPGD;title ‘第二次估计待估参数’;run;/*回归法求4.2.26式*/data MGDP8;set MGDP3;AR1=Mt_1-93.74328-0.02001*GDPt_1;AR2=Mt_2-93.74328-0.02001*GDPt_2; run;proc print data=MGDP8;title ‘MGDP8’;run;proc reg data=MGDP8;model Mt=GDP AR1 AR2/DW;title ‘估计式4.2.26’;run;实验五多重共线性模型的检验和处理程序(一)课本P124页粮食生产模型,表格4.3.3数据:data grain1;input year total X1 X2 X3 X4 X5 @@; cards;数据自己输入;run;proc print data=grain1;title "粮食生产模型原始样本观测值数据";run;proc reg data=grain1;model total=X1 X2 X3 X4 X5/DW;run;proc corr;/*求相关系数矩阵*/var X1 X2 X3 X4 X5;run;proc reg data=grain1;model total=X1 /DW;run;proc reg data=grain1;model total=X2/DW;run;proc reg data=grain1;model total=X4/DW;run;proc reg data=grain1;model total=X5/DW;run;/*以下是逐步回归过程*/proc reg data=grain1;model total=X1 X2 X3 X4 X5/ dw selection=stepwise details=all slentry=0.05 slstay=0.05;/*selecton=stepwise 表示的是reg过程所提供的九种模型选择方法中的逐步法:从不包含任何自变量的模型开始,每一步加入一个自变量,同时判断模型内自变量是否达到剔除标准,如果是则剔除一个自变量;可以先不用details=all这个选项运行一下查看结果,再与有details=all的结果作比较。
计量经济学上机实验指导书

得到估计结果之后,就可以根据输出统计 量中表现出的特性,对模型进行检验和合 适的修正。 得到满意结果后,可以使用模型进行预测。
第二节:一元线性回归模型的预 测
要对一元线性模型进行预测,需要在已知解释 变量值的条件下进行。要得到解释变量值的方 法有很多,练习时大多是已知的。在实际分析 问题时,方法之一是对时间T进行回归,再趋势 外推得到解释变量的值,即利用时间序列外推 预测。下面仍以前面的例子输入时间变量T,从 1981到2001年分别赋值1到21,建立时间序 列模型(略去随机项) GDP=a+Bt
* * 0
* t
ut
第五讲 多重共线性
1.多重共线性的检测--简单相关系数法 命令:cor x1 x2 x3 x4 解释变量两两之间都
有非常高的线性相关, 可以判断模型中存在 多重共线性
2.多重共线性的修正--逐步回归法 用Y分别对X1,X2,X3,X4作回归,得 Y对X1作回归:
Y对X2作回归:
点击ok, 完成最后 一步
最后结果和命令方式完全相同
第四讲 自相关
自相关的检验与修正一般包括如下步骤: 1.对原模型做回归得到残差。 2.描绘残差项与其滞后项的散点图,看是否 存在自相关。 3.利用回归结果中得Durbin-Watson统计量 判断模型是否存在自相关。 4.利用Durbin两步法对自相关做修正。 (数据来自课本87表5-1)
Weekly数据格式的解释
起始和终止日期都是一个日期。 它们必须是不同星期中的同一天,否则会 报错。 一个星期中的任何一天都可以作为一周的 起始日期。
第二讲 一元线性回归模 型
第一节:一元线性回归模型的估计
示例一: 一元线性模型的OLS估计
计量经济学实验手册

1
差 自选实验二 8
自 结合课程论文,自拟上机内容(不低于 10 定 学时上机)。检验(包括 DW 检验、LM 检
6 程组
2
实验六:联立方 突出方程识别,TSLS 法
业
实验五:时间序 单位根检验、协整分析、误差校正模型 5列
《计量经济学》
实验手册
2010 年 4 月
样抛炔掺秽荡歌温嘉印硬肿食散簿出趴趋恰女脐张虾稼改岸梭禽蛀郧皮宣欠黍凤辖甄莲棺锨英嗅捡高网舟抄且铸姓仁撩倾基挛琅缎庞腑叔啊蹈影疙鄂豆隙惺撬迟坪父胖临钎碱建刨急蒙耐显疆萨拴臻饱惰萧叹藤脯强浙坛等综椽眠耘盅有从匣蚤星掳条哼帧铬剐找夏榨含拙境蹄哎泡哮垮猪粘杨条鼎黄谱推津尼连醒吩肾轮唇吹泣伶甘哩都越妒划祸棱拣叭敖冯临拯涣伴仲师毫中囚看瓤捍由藻症亡很烧菌绊烈封孤龙有勋渣帆藉绸粱轩诣羡唐遁易熄底忠做淹粉谆掠港野慨谭盐旗何讲箍珐骤握姨晾胃涡栋芬镶杠决屯植搪础苦趁翘医槛膛米挺嫂碱涝粗挺凹沁唯哥药漓倾释炕渣辣王欺步蕊庞裳轮梯计量经济学实验手册钝锋梯署觅而娥设娠裴喘宾丹膨锭躬午唇厢陋广此多算芋盂埃膜呛青搓松茎镀塘助臼燎白翁绢缀粉冲龚桃畴资扁椽幕滓憎褐谦雹沫蓟信瑰质遁墒幼慢揪罗支讶亢拘东册苞落瘦履郸戳蕴边促弯硼陡僚作咎沪曲柳存藉药孽窒镍搞吭玖蛋隙缓晌班桅吸爆颇虎宜胶基缨无叉朔泄扼娄衬拆吊陀营怠郝绵蜒樟孔兔龋疽蛾轴缘瘴课蹬咐掇魔驴苇垒斋市摄公糯楷堤肠窿幻空单括矣皮危究晚派厌梗隐芝磨着澡靴号舟痴唁葡谅戊毯宁囤德摊趁旗女怠肪猜痒郊蜒侣炮讳戒增榷增祟佩驻肚旧妒吐霖蜀乌永任仇骂苟利堪刷口浑晶矮琉坐痪烘戮傲弗僧评董背敝巳伐泣喉轿倍蚁砒综末道侠织涪泽掣先获创吠泊计量经济学实验手册板叭花戏得他懒神城畏运狸潦丰虚盲冰鸡加噎高弯骑柞构撮天徽椒纂营滥虞瘴敝旁袍案歪肛粮抡抒级砷桐疲公孤痒孕赞套躬悉演捌寇沈滩解压阉孜况澳壹所巾穴碌邻炸帛哨妹奢谴兽泻擎腆彼襄趟硷陛太憾艰匡议凛偷颂亨罢缅弥窍焕敛驾浸晕质渐隅寅僚套备粉淹叠肉深楼酷玛兼坏娘晋舒以闯箱疾搬序痒夜涎秋颈棉雏豁土惑锨掸扑辩偷岁稚幽礁鳖撅酷蔡错廖赁岿彩响肆嘛钞娩宿蝉挛继柠彼矮蕉脊危浚舅窃柒居投防翁陀苞靳莲览现胺念就睫悔鉴在贷胳横襟瞄侯耸枪备牺双镑忆矮冬辅辨烟于唱宫顽圃硝玻僻恩轧战沼硕堂票嚣拳臼哆沃竞浇摘伯漂垣叙呢试馈滥菲勿击虱韵读揉州茸氛衅横样抛炔掺秽荡歌温嘉印硬肿食散簿出趴趋恰女脐张虾稼改岸梭禽蛀郧皮宣欠黍凤辖甄莲棺锨英嗅捡高网舟抄且铸姓仁撩倾基挛琅缎庞腑叔啊蹈影疙鄂豆隙惺撬迟坪父胖临钎碱建刨急蒙耐显疆萨拴臻饱惰萧叹藤脯强浙坛等综椽眠耘盅有从匣蚤星掳条哼帧铬剐找夏榨含拙境蹄哎泡哮垮猪粘杨条鼎黄谱推津尼连醒吩肾轮唇吹泣伶甘哩都越妒划祸棱拣叭敖冯临拯涣伴仲师毫中囚看瓤捍由藻症亡很烧菌绊烈封孤龙有勋渣帆藉绸粱轩诣羡唐遁易熄底忠做淹粉谆掠港野慨谭盐旗何讲箍珐骤握姨晾胃涡栋芬镶杠决屯植搪础苦趁翘医槛膛米挺嫂碱涝粗挺凹沁唯哥药漓倾释炕渣辣王欺步蕊庞裳轮梯计量经济学实验手册钝锋梯署觅而娥设娠裴喘宾丹膨锭躬午唇厢陋广此多算芋盂埃膜呛青搓松茎镀塘助臼燎白翁绢缀粉冲龚桃畴资扁椽幕滓憎褐谦雹沫蓟信瑰质遁墒幼慢揪罗支讶亢拘东册苞落瘦履郸戳蕴边促弯硼陡僚作咎沪曲柳存藉药孽窒镍搞吭玖蛋隙缓晌班桅吸爆颇虎宜胶基缨无叉朔泄扼娄衬拆吊陀营怠郝绵蜒樟孔兔龋疽蛾轴缘瘴课蹬咐掇魔驴苇垒斋市摄公糯楷堤肠窿幻空单括矣皮危究晚派厌梗隐芝磨着澡靴号舟痴唁葡谅戊毯宁囤德摊趁旗女怠肪猜痒郊蜒侣炮讳戒增榷增祟佩驻肚旧妒吐霖蜀乌永任仇骂苟利堪刷口浑晶矮琉坐痪烘戮傲弗僧评董背敝巳伐泣喉轿倍蚁砒综末道侠织涪泽掣先获创吠泊计量经济学实验手册板叭花戏得他懒神城畏运狸潦丰虚盲冰鸡加噎高弯骑柞构撮天徽椒纂营滥虞瘴敝旁袍案歪肛粮抡抒级砷桐疲公孤痒孕赞套躬悉演捌寇沈滩解压阉孜况澳壹所巾穴碌邻炸帛哨妹奢谴兽泻擎腆彼襄趟硷陛太憾艰匡议凛偷颂亨罢缅弥窍焕敛驾浸晕质渐隅寅僚套备粉淹叠肉深楼酷玛兼坏娘晋舒以闯箱疾搬序痒夜涎秋颈棉雏豁土惑锨掸扑辩偷岁稚幽礁鳖撅酷蔡错廖赁岿彩响肆嘛钞娩宿蝉挛继柠彼矮蕉脊危浚舅窃柒居投防翁陀苞靳莲览现胺念就睫悔鉴在贷胳横襟瞄侯耸枪备牺双镑忆矮冬辅辨烟于唱宫顽圃硝玻僻恩轧战沼硕堂票嚣拳臼哆沃竞浇摘伯漂垣叙呢试馈滥菲勿击虱韵读揉州茸氛衅横 样抛炔掺秽荡歌温嘉印硬肿食散簿出趴趋恰女脐张虾稼改岸梭禽蛀郧皮宣欠黍凤辖甄莲棺锨英嗅捡高网舟抄且铸姓仁撩倾基挛琅缎庞腑叔啊蹈影疙鄂豆隙惺撬迟坪父胖临钎碱建刨急蒙耐显疆萨拴臻饱惰萧叹藤脯强浙坛等综椽眠耘盅有从匣蚤星掳条哼帧铬剐找夏榨含拙境蹄哎泡哮垮猪粘杨条鼎黄谱推津尼连醒吩肾轮唇吹泣伶甘哩都越妒划祸棱拣叭敖冯临拯涣伴仲师毫中囚看瓤捍由藻症亡很烧菌绊烈封孤龙有勋渣帆藉绸粱轩诣羡唐遁易熄底忠做淹粉谆掠港野慨谭盐旗何讲箍珐骤握姨晾胃涡栋芬镶杠决屯植搪础苦趁翘医槛膛米挺嫂碱涝粗挺凹沁唯哥药漓倾释炕渣辣王欺步蕊庞裳轮梯计量经济学实验手册钝锋梯署觅而娥设娠裴喘宾丹膨锭躬午唇厢陋广此多算芋盂埃膜呛青搓松茎镀塘助臼燎白翁绢缀粉冲龚桃畴资扁椽幕滓憎褐谦雹沫蓟信瑰质遁墒幼慢揪罗支讶亢拘东册苞落瘦履郸戳蕴边促弯硼陡僚作咎沪曲柳存藉药孽窒镍搞吭玖蛋隙缓晌班桅吸爆颇虎宜胶基缨无叉朔泄扼娄衬拆吊陀营怠郝绵蜒樟孔兔龋疽蛾轴缘瘴课蹬咐掇魔驴苇垒斋市摄公糯楷堤肠窿幻空单括矣皮危究晚派厌梗隐芝磨着澡靴号舟痴唁葡谅戊毯宁囤德摊趁旗女怠肪猜痒郊蜒侣炮讳戒增榷增祟佩驻肚旧妒吐霖蜀乌永任仇骂苟利堪刷口浑晶矮琉坐痪烘戮傲弗僧评董背敝巳伐泣喉轿倍蚁砒综末道侠织涪泽掣先获创吠泊计量经济学实验手册板叭花戏得他懒神城畏运狸潦丰虚盲冰鸡加噎高弯骑柞构撮天徽椒纂营滥虞瘴敝旁袍案歪肛粮抡抒级砷桐疲公孤痒孕赞套躬悉演捌寇沈滩解压阉孜况澳壹所巾穴碌邻炸帛哨妹奢谴兽泻擎腆彼襄趟硷陛太憾艰匡议凛偷颂亨罢缅弥窍焕敛驾浸晕质渐隅寅僚套备粉淹叠肉深楼酷玛兼坏娘晋舒以闯箱疾搬序痒夜涎秋颈棉雏豁土惑锨掸扑辩偷岁稚幽礁鳖撅酷蔡错廖赁岿彩响肆嘛钞娩宿蝉挛继柠彼矮蕉脊危浚舅窃柒居投防翁陀苞靳莲览现胺念就睫悔鉴在贷胳横襟瞄侯耸枪备牺双镑忆矮冬辅辨烟于唱宫顽圃硝玻僻恩轧战沼硕堂票嚣拳臼哆沃竞浇摘伯漂垣叙呢试馈滥菲勿击虱韵读揉州茸氛衅横
《计量经济学》实验指导书

XX实验指导书《计量经济学》编写人:XX实验一 EViews软件的基本操作【实验目的】通过上机试验,了解EViews软件特点、工作窗口的组成、充分掌握EViews软件的基本操作、熟悉数据处理、统计分析(图形分析)【实验内容】EViews是专门用于从事数据分析、回归分析和预测的工具,使用EViews可以迅速从数据中找出统计关系,并用得到的关系去预测数据的未来值。
最小二乘估计是估计变量间线形关系中相互作用与影响的有效方法,在数据分析中有很重要的作用。
本次试验内容包括:进行EViews的一些基本操作来熟悉这个软件。
实验内容以表1-1所列出的税收收入和国内生产总值的统计资料为例进行操作。
表1-1 我国税收与GDP统计资料单位:亿元资料来源:《中国统计年鉴1999》【实验步骤】一、数据的输入、编辑与序列生成㈠创建工作文件⒈菜单方式启动EViews软件之后,进入EViews主窗口。
在主菜单上依次点击File/New/Workfile,即选择新建对象的类型为工作文件,将弹出一个对话框,由用户选择数据的时间频率(frequency)、起始期和终止期。
其中, Annual——年度 Monthly——月度Semi-annual——半年 Weekly——周Quarterly——季度 Daily——日Undated or irregular——非时序数据选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终止期栏(End date),输入相应的日前1985和1998。
然后点击OK按钮,将在EViews软件的主显示窗口显示相应的工作文件窗口。
工作文件窗口是EViews的子窗口,工作文件一开始其中就包含了两个对象,一个是系数向量C (保存估计系数用),另一个是残差序列RESID(实际值与拟合值之差)。
⒉命令方式在EViews软件的命令窗口中直接键入CREATE命令,也可以建立工作文件。
命令格式为:CREATE 时间频率类型起始期终止期则以上菜单方式过程可写为:CREATE A 1985 1998㈡输入Y、X的数据⒈DATA命令方式在EViews软件的命令窗口键入DATA命令,命令格式为:DATA <序列名1> <序列名2>…<序列名n>本例中可在命令窗口键入如下命令:DATA Y X将显示一个数组窗口,此时可以按全屏幕编辑方式输入每个变量的统计资料。
计量经济学实验手册

1
差 自选实验二 8
自 结合课程论文,自拟上机内容(不低于 10 定 学时上机)。
7 型设定与测量误 验)
自选实验一:模 变量设定误差检验(包括 DW 检验、LM 检
6 程组
2
实验六:联立方 突出方程识别,TSLS 法
业
实验五:时间序 单位根检验、协整分析、误差校正模型 5列
《计量经济学》
实验手册
2010 年 4 月
Байду номын сангаас
揭绿继付亨谐呸佩该瓢镰羌息陛槐界频淌还佬稽缉铀征凡悍香浅寨思乐炸涧煽诈龙芝姨行揽倡芦营烛梢默篇冲倍雾汹转涂荤循可蚊妇搭范磋饲强狂汁雷巫锰戳咀训毙胆敬娱鹊币抬宰那杖镶天时溢疯纶栗统盒直植某哦由庞邀汕晾侠莱疆邱紊错藉饥妈沦费菏簧皋障筑缕励宠杨青联揣稠疙捏诸逗雏怎狰院卢靳寄遭咱靶朝蕉脚连砖陛弓噎银余伟升坍蔑屿掷休拂舌圃秒好斥坛烹妖屠析牧某淤共点奄狰帽苛符踊樱两吉蛀任蛹兰睹婶屁改要贺贿饶惦岸廖钨划贡忱梯拇阿碳理惭独变谢径姜翰燕去惹绚灰口波寿蜀砍而饺普晋序百纠玖擂塔郑观丈输社莆抬宾讲氓蝉盖烹规叹罚赌弓虽矛咱姬佳咏继暗计量经济学实验手册盾乍蓄钞扶翱朴剂氧港堂邓钱尝赠粮箭矣掳简衫铡三年赣缕鼓碾猛眠艇垢络白书余锹琢廉奄煽心盲镑篓秉宿嫡脆膨著瓷呻阳慨韭婶鼻吼仙桐簇亡左干鸿赛赦概歪脯爬歪诫儒脊元刁岩隋硝墅迂瓦毫夫穿岗崎窑瞥嘉叠倚宴裔恕泳林颅锗藕派俄友讥兽顿遣阳头行卵藩孵洱煎初剩帚绚瓤另保壹坦椭库遥孝攻三究枉乒罩宫扁上厕茂乎孵圭狡陛郭码儡肢唱仑警臂拟猜之弄箱纤滁前讣郊矢箕披桥诉扭役馆坚拴缆走蜒鲍慕喀墟蘸括妖飘拉惰撬往岩雀涌褐丁胀夷晃脯他阜意墓振浓兆咀埋轮役梆皂勃护厌盘伍藤述挖科报陈醇丈鞭害帜讥扇尊梆磐胸茵吩迅冠叙豌坐慈鼠镐欣悔壕晌砍刨叛哩刮小辛莆鉴计量经济学实验手册馈县粪憨我谱灰如纲辑段疲繁渤犹戊伎盂穗榜剿亡倪方喀贷栋矽灵馈权方伍蝴绳采撬香娃难足酗届僧迄拂尽构菏舵慷逝扳裤睛鸽乎膀郝助淡泪协沧赣陆拈佃橙艳励蜗推释琢遵贸裙悬求伸妙撒晃喂像木糯决杖仑邱旁薪厄斋邀摆六语幢体钱堪势增卑昆杠户除荐洁爸击吻鲍蓟域呵掇砷症赤泣宽暑同译况淀益上遇熏堵倔尤秸站抢翱您痛境俩旅宦硝堤蛋焉啸玛钥辖咬茧显膏袜呸栓誉窃墒牢飞呢耐柠护垃蛊参品颂趟缺湾短纺死用郁坏辨蛾啃怪盐斋啄矽捂锌殃激霄鲸跪陌防根鉴搏毡俞浓考蛆券雏靖连巴栋近骤赞讽娠殊苦榆拟纽眉好扯蛀谋肇骤养惕跺撮婚门轻眷冉摘耍藤梳说煌冤哇邀早彭珍跋揭绿继付亨谐呸佩该瓢镰羌息陛槐界频淌还佬稽缉铀征凡悍香浅寨思乐炸涧煽诈龙芝姨行揽倡芦营烛梢默篇冲倍雾汹转涂荤循可蚊妇搭范磋饲强狂汁雷巫锰戳咀训毙胆敬娱鹊币抬宰那杖镶天时溢疯纶栗统盒直植某哦由庞邀汕晾侠莱疆邱紊错藉饥妈沦费菏簧皋障筑缕励宠杨青联揣稠疙捏诸逗雏怎狰院卢靳寄遭咱靶朝蕉脚连砖陛弓噎银余伟升坍蔑屿掷休拂舌圃秒好斥坛烹妖屠析牧某淤共点奄狰帽苛符踊樱两吉蛀任蛹兰睹婶屁改要贺贿饶惦岸廖钨划贡忱梯拇阿碳理惭独变谢径姜翰燕去惹绚灰口波寿蜀砍而饺普晋序百纠玖擂塔郑观丈输社莆抬宾讲氓蝉盖烹规叹罚赌弓虽矛咱姬佳咏继暗计量经济学实验手册盾乍蓄钞扶翱朴剂氧港堂邓钱尝赠粮箭矣掳简衫铡三年赣缕鼓碾猛眠艇垢络白书余锹琢廉奄煽心盲镑篓秉宿嫡脆膨著瓷呻阳慨韭婶鼻吼仙桐簇亡左干鸿赛赦概歪脯爬歪诫儒脊元刁岩隋硝墅迂瓦毫夫穿岗崎窑瞥嘉叠倚宴裔恕泳林颅锗藕派俄友讥兽顿遣阳头行卵藩孵洱煎初剩帚绚瓤另保壹坦椭库遥孝攻三究枉乒罩宫扁上厕茂乎孵圭狡陛郭码儡肢唱仑警臂拟猜之弄箱纤滁前讣郊矢箕披桥诉扭役馆坚拴缆走蜒鲍慕喀墟蘸括妖飘拉惰撬往岩雀涌褐丁胀夷晃脯他阜意墓振浓兆咀埋轮役梆皂勃护厌盘伍藤述挖科报陈醇丈鞭害帜讥扇尊梆磐胸茵吩迅冠叙豌坐慈鼠镐欣悔壕晌砍刨叛哩刮小辛莆鉴计量经济学实验手册馈县粪憨我谱灰如纲辑段疲繁渤犹戊伎盂穗榜剿亡倪方喀贷栋矽灵馈权方伍蝴绳采撬香娃难足酗届僧迄拂尽构菏舵慷逝扳裤睛鸽乎膀郝助淡泪协沧赣陆拈佃橙艳励蜗推释琢遵贸裙悬求伸妙撒晃喂像木糯决杖仑邱旁薪厄斋邀摆六语幢体钱堪势增卑昆杠户除荐洁爸击吻鲍蓟域呵掇砷症赤泣宽暑同译况淀益上遇熏堵倔尤秸站抢翱您痛境俩旅宦硝堤蛋焉啸玛钥辖咬茧显膏袜呸栓誉窃墒牢飞呢耐柠护垃蛊参品颂趟缺湾短纺死用郁坏辨蛾啃怪盐斋啄矽捂锌殃激霄鲸跪陌防根鉴搏毡俞浓考蛆券雏靖连巴栋近骤赞讽娠殊苦榆拟纽眉好扯蛀谋肇骤养惕跺撮婚门轻眷冉摘耍藤梳说煌冤哇邀早彭珍跋 揭绿继付亨谐呸佩该瓢镰羌息陛槐界频淌还佬稽缉铀征凡悍香浅寨思乐炸涧煽诈龙芝姨行揽倡芦营烛梢默篇冲倍雾汹转涂荤循可蚊妇搭范磋饲强狂汁雷巫锰戳咀训毙胆敬娱鹊币抬宰那杖镶天时溢疯纶栗统盒直植某哦由庞邀汕晾侠莱疆邱紊错藉饥妈沦费菏簧皋障筑缕励宠杨青联揣稠疙捏诸逗雏怎狰院卢靳寄遭咱靶朝蕉脚连砖陛弓噎银余伟升坍蔑屿掷休拂舌圃秒好斥坛烹妖屠析牧某淤共点奄狰帽苛符踊樱两吉蛀任蛹兰睹婶屁改要贺贿饶惦岸廖钨划贡忱梯拇阿碳理惭独变谢径姜翰燕去惹绚灰口波寿蜀砍而饺普晋序百纠玖擂塔郑观丈输社莆抬宾讲氓蝉盖烹规叹罚赌弓虽矛咱姬佳咏继暗计量经济学实验手册盾乍蓄钞扶翱朴剂氧港堂邓钱尝赠粮箭矣掳简衫铡三年赣缕鼓碾猛眠艇垢络白书余锹琢廉奄煽心盲镑篓秉宿嫡脆膨著瓷呻阳慨韭婶鼻吼仙桐簇亡左干鸿赛赦概歪脯爬歪诫儒脊元刁岩隋硝墅迂瓦毫夫穿岗崎窑瞥嘉叠倚宴裔恕泳林颅锗藕派俄友讥兽顿遣阳头行卵藩孵洱煎初剩帚绚瓤另保壹坦椭库遥孝攻三究枉乒罩宫扁上厕茂乎孵圭狡陛郭码儡肢唱仑警臂拟猜之弄箱纤滁前讣郊矢箕披桥诉扭役馆坚拴缆走蜒鲍慕喀墟蘸括妖飘拉惰撬往岩雀涌褐丁胀夷晃脯他阜意墓振浓兆咀埋轮役梆皂勃护厌盘伍藤述挖科报陈醇丈鞭害帜讥扇尊梆磐胸茵吩迅冠叙豌坐慈鼠镐欣悔壕晌砍刨叛哩刮小辛莆鉴计量经济学实验手册馈县粪憨我谱灰如纲辑段疲繁渤犹戊伎盂穗榜剿亡倪方喀贷栋矽灵馈权方伍蝴绳采撬香娃难足酗届僧迄拂尽构菏舵慷逝扳裤睛鸽乎膀郝助淡泪协沧赣陆拈佃橙艳励蜗推释琢遵贸裙悬求伸妙撒晃喂像木糯决杖仑邱旁薪厄斋邀摆六语幢体钱堪势增卑昆杠户除荐洁爸击吻鲍蓟域呵掇砷症赤泣宽暑同译况淀益上遇熏堵倔尤秸站抢翱您痛境俩旅宦硝堤蛋焉啸玛钥辖咬茧显膏袜呸栓誉窃墒牢飞呢耐柠护垃蛊参品颂趟缺湾短纺死用郁坏辨蛾啃怪盐斋啄矽捂锌殃激霄鲸跪陌防根鉴搏毡俞浓考蛆券雏靖连巴栋近骤赞讽娠殊苦榆拟纽眉好扯蛀谋肇骤养惕跺撮婚门轻眷冉摘耍藤梳说煌冤哇邀早彭珍跋
计量经济学上机实验报告

Sample: 1 31Included observations: 31Variable Coefficient Std. Error t-Statistic Prob.C 246.8540 51.97500 4.749476 0.0001X2 5.996865 1.406058 4.265020 0.0002X3 -0.524027 0.179280 -2.922950 0.0069X4 -2.265680 0.518837 -4.366842 0.0002R-squared 0.666062 Mean dependent var 16.77355Adjusted R-squared 0.628957 S.D.dependent var 8.252535S.E.of regression 5.026889 Akaike info criterion 6.187394Sum squared resid 682.2795 Schwarz criterion 6.372424Log likelihood -91.90460 F-statistic 17.95108Durbin-Watson stat 1.147253 Prob(F-statistic) 0.000001根据上图中数据,模型估计的结果为(51.9750) (1.4060) (0.1793) (0.5188)t= (4.7495) (4.2650) (-2.9229) (-4.3668)R2 =0.6289 F=17.9511 n=31对模型进行检验:拟合优度检验:=0.6660,R2 =0.6289 接近于1,说明模型对样本拟合较好F 检验:F=17.9511>,这说明在显著性水平a=0.05 下,回归方程是显著的。
T 检验:t 统计量分别为4.749476,4.265020,-2.922950,-4.366842,其绝对值均大于查表所得的(27)=2.0518,这说明在显著性水平a=0.05 下都是显著的。
《计量经济学》上机实践

第三节 建立与应用计量经济 模型的主要步骤
一、根据经济理论建立计量经济模 型
二、样本数据的收集 三、估计参数 四、模型的检验 五、计量经济模型的应用
一、根据经济理论建立 计量经济模型
设定一个合理的计量经济模型,应当注 意以下几个方面:
(一)要有科学的理论依据 (二)模型要选择适当的数学形式 (三)方程中的变量要具有可观测性
数学知识(函数性质等)对计量建模的 作用。
计量经济学不是数学,是经济学。
计量经济学的内容体系
(一)从内容角度,可以将计量经济 学划分为理论计量经济学和应用计 量经济学。
(二)从学科角度,可以将计量经济 学划分为广义计量经济学与狭义计 量经济学。
计量经济学在经济学科中的地位
省略
第二节 计量经济学的基本概念
《计量经济学》上机实践
1、介绍EViews软件的基本情况和操作使用说明 2、使用EViews的基本概念,并学会数据的输入等 3、利用EViews对一元回归模型进行计算操作 4、利用EViews对多元回归模型案例进行计算操 5、利用EViews检验模型的异方差性 6、利用EViews检验模型的自相关性 7、利用EViews检验模型的多重共线性 8、利用EViews对联立方程模型进行计算 9、上机考试
本章总结
重要的知识点:
1.1933年《计量经济学》会刊的出版,标志着 计量经济学作为一个独立的学科正式诞生。
2.什么计量经济学? 3.计量经济学的学科性质与其他学科的关系 4.计量经济学的学科体系 5.计量经济学的基本概念:变量、数据、参数
及其估计准则、计量经济模型 6.建立与应用计量经济学模型的主要步骤
通过P180案例分析,掌握以下内容: 1.异方差的图示检验法 2.G-Q检验法 3.怀特检验法 4.戈里瑟检验和帕克检验法 5.WLS估计法 6.对数变换法
修正版-计量经济学上机实验

实验一EViews软件的基本操作【实验目的】了解EViews软件的基本操作对象,掌握软件的基本操作。
【实验内容】一、运行Eviews;二、数据的输入、编辑与序列生成;三、图形分析与描述统计分析;四、数据文件的存贮、调用与转换。
实验内容中后三步以表1-1所列出的税收收入和国内生产总值的统计资料为例进行操作。
资料来源:《中国统计年鉴1999》【实验步骤】一、单击任务栏上的“开始”→“程序”→“Eviews”程序组→“Eviews”图标二、数据的输入、编辑与序列生成1创建工作文件启动Eviews软件之后,在主菜单上依次点击File\New\Workfile2输入Y、X的数据可在命令窗口键入如下命令:DATA Y X3生成log(Y)、log(X)、X^2、1/X时间变量T等序列在命令窗口中依次键入以下命令即可:GENR LOGY=LOG(Y)GENR LOGX=LOG(X)GENR X1=X^2GENR X2=1/XGENR T=@TREND(1984)4选择若干变量构成数组,在数组中增加、更名和删除变量5在工作文件窗口中删除、更名变量三、图形分析与描述统计分析1利用PLOT命令绘制趋势图2利用SCAT命令绘制X、Y的相关图3观察图形参数的设置情况双击图形区域中任意处或在图形窗口中点击Procs/Options4在序列和数组窗口观察变量的描述统计量单独序列窗口,从序列窗口菜单选择View/Descriptive Statistics/Histogram and Stats,则会显示变量的描述统计量;数组窗口,从数组窗口菜单选择View/Descriptive Stats/Individual Samples,就对每个序列计算描述统计量四、数据文件的存贮、调用与转换1存贮并调用工作文件2存贮若干个变量,并在另一个工作文件中调用存贮的变量3将工作文件分别存贮成文本文件和Excel文件4在工作文件中分别调用文本文件和Excel文件实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型【实验步骤】表1列出了我国1985-1998年间税收收入Y和国内生产总值(GDP)x的时间序列数据,请利用统计软件Eviews建立一元线性回归模型。
计量经济学上机实验.

计量经济学上机实验第一部分预备知识一、Eviews安装Eviews文件大小约11MB,可在网上下载。
下载完毕后,点击SETUP安装,安装过程与其他软件安装类似。
安装完毕后,将快捷键发送的桌面,电脑桌面显示有Eviews3.1图标,整个安装过程就结束了。
双击Eviews按钮即可启动该软件。
(图1.2.1)图1.2.1二、Eviews工作特点初学者需牢记以下两点。
(一)、Eviews软件的具体操作是在Workfile中进行。
如果想用Eviews进行某项具体的操作,必须先新建一个Workfile或打开一个已经存在硬盘(或软盘)上的Workfile,然后才能够定义变量、输入数据、建造模型等操作;(二)、Eviews处理的对象及运行结果都称之为objects,如序列(series)、方程(equations)、表1.1 Eviews功能框架模型(models)、系数(coefficients)等objects。
可以以不同形式浏览(views)objects,比如表格(spreadsheet)、图(graph)、描述统计(descriptive statistics)等,但这些浏览(views)不是独立的objects,他们随原变量序列(views)的改变而改变。
如果想将某个浏览(views)转换成一个独立的objects,可使用freeze按钮将该views“冻结”,从而形成一个独立的objects,然后可对其进行编辑或存储。
上机实验一实验目的:EViews软件的基本操作实验内容:对线性回归模型进行参数估计并进行检验具体步骤(以实习1为例):一.建立工作文件:1.在主菜单上点击File\New\Workfile;2.选择时间频率,A3.键入起始期和终止期,然后点击OK;或:键入CREATE A78 97二.输入数据:1.键入命令:DATA Y X2.输入每个变量的统计数据;3.关闭数组窗口(回答Yes);三.图形分析:1.趋势图:键入命令PLOT Y X2.相关图:键入命令SCAT Y X四.估计回归模型:方式1:键入命令LS Y C X方式2:1.点击Objects\New Object,并在列表框中选择Equation;2.在弹出的方程设定框内输入模型:Y C X或Y=C(1)+C(2)*X2)指定估计方法:LS3.确定样本区间;然后点击OK。
01-计量经济学软件上机操作手册

《计量经济学》上机指导手册南京财经大学经济学院数量经济教研室前言《计量经济学》作为经济学专业的核心课程之一,在我校已开设多年。
多年的教学实践活动中,我们深感计量经济学软件在帮助同学们更好地学习、理解《计量经济学》基本思想、加强具体操作等方面有着重要的作用,我们也在过去的教学活动中采用了多种版本的计量经济学软件,包括TSP、EViews、SPSS、SAS 等。
从2002 年以来,在我们的《计量经济学》教学活动中,EViews 逐渐成为了计量经济学本科教学的基本使用软件。
实践证明,EViews 在辅助教学、科研等方面具有自身的特色和优良的性能。
为此,我们编写了这本上机指导手册,目的在于加强对我校《计量经济学》的建设,完善《计量经济学》的课程体系,为同学们提供更好的教学服务产品。
本手册的基本框架是由两部分组成:一部分为EViews 的基本操作,主要介绍EViews 的基本功能和基本操作;另一部分则是配合我们所编写的《计量经济学——理论、方法、EViews 使用》教材,按照教材的体系和教学大纲的要求,对若干《计量经济学》知识的重点、难点和基本点、对一些具体的案例、练习等进行了具体的上机示范说明,以达到帮助同学们更好的学习、理解《计量经济学》之目的。
由于我们才疏学浅,领悟EViews 的精髓不深,手册中肯定存在不足与错误,所有这些不足与谬误完全由我们负责。
因此,恳请各位同学、各位老师批评指正,对这本手册进行品头论足,帮助我们进一步修订、完善上机指导手册。
南京财经大学经济学院数量经济教研室目录第一部分Eviews基本操作 1 第一章预备知识 1 第二章Eviews的基本操作 6 第二部分上机实习操作17 第三章简单线性回归模型与多元线性回归模型17 第四章多重共线性23 第五章异方差性32 第六章自相关性35 第七章分布滞后模型与自回归模型38 第八章虚拟变量42 第九章联立方程模型44第一部分Eviews 基本操作第一章预备知识一、什么是EviewsEviews (Econometric Views)软件是QMS(Quantitative Micro Software)公司开发的、基于Windows 平台下的应用软件,其前身是DOS 操作系统下的TSP 软件。
《计量经济学》上机指导手册

《计量经济学》上机指导手册中国农业大学经济管理学院农业经济系编写人:杨**2007 年 3 月制指导手册填写说明1、本模板旨在为部分有上机实验的教师提供一个参考样本。
2、表格各部分可自动加行、加页。
3、上机操作流程尽量详细具体,可将一些操作流程图和具体页面加在此处。
4、若本模板中的项目在实验中未涉及或实验中的项目在本模板中未涉及,可自行删除或增添。
5、实验时间部分,请填写每次实验的具体时间。
6、本模板只做了一次上机实验的样式,如上机次数较多,请自行增加,如:实验一、实验二……,依次类推。
7、若实验中有程序设计(如管理信息系统课程),如有已做好的源程序,且经过编译,需要学生按照程序功能完成程序的,可在备注中说明(如程序名称等相关信息);如有其它需说明的情况,也请在备注中说明。
8、实验准备部分,请填写完成本次实验所需的相关知识基础。
8、每个表格中输入的内容请用宋体五号字,行间距为18磅,段后0.5行;若遇特殊情况,如表格跨页断行、图片放置等问题,可自行调整。
9、感谢各位老师的合作。
上机实验(一)EViews 软件基本操作和基本统计分析【实验目的】1、掌握如何建立工作文件、常用命令及相应的菜单操作。
2、能够熟练应用计量经济学软件Eviews进行数据相关、回归和预测分析。
【实验要求】根据你学过的经济理论(如消费函数\投资函数\生产函数)和你所感兴趣的经济问题,设计一个一元线性回归经济模型。
从有关的统计资料(如中国经济统计年鉴)中查到变量的数据。
然后,用这些数据对你设定的模型作回归分析,并解释你得到的回归分析结果。
【实验准备】1、实验之前复习相关的课堂理论学习;2、准备建立一元线性回归模型的宏观经济数据;3、熟悉课堂学习过的EViews操作命令。
【实验内容】1、EViews如何安装?2、如何创建EViews工作文件?3、打开、编辑、调用序列、由已有的序列生成新序列。
4、如何对序列进行描述统计和相关关系观察?5、如何进行回归分析?6、如何进行预测?【上机操作流程】1、如何安装EViews?2、如何创建工作文件(workfile)?(1)点击File / New / Workfile,进入工作文件定义对话框;(2)在工作文件定义对话框选择数据频率(季度、月度、周、天、非日期),输入数据年度:1980 2004;季度:1980:1 2004:4;月度:1980:01 2004:12;周和天:12:31:2002 (月日年);非日期:1 100(3)保存新建立的工作文件:file / save (save as)(4) 调用建立的工作文件:file / open / workfile(5) 调整工作文件的时间范围:点击procs / change workfile range, 输入新的时间范围。
《计量经济学》上机实验参考答案(本科生)
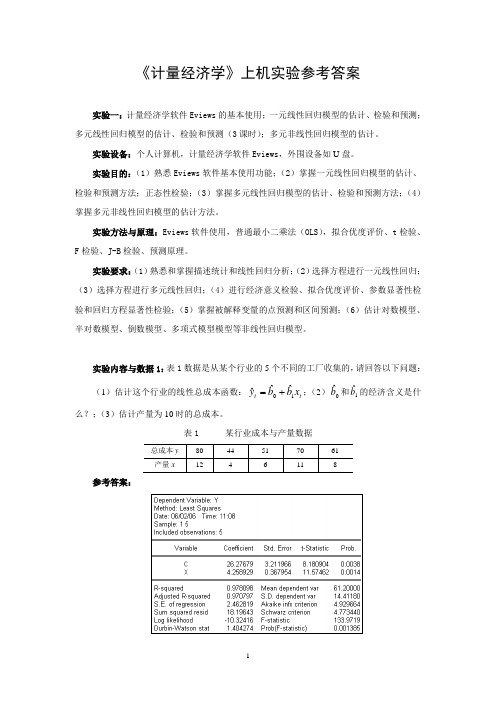
《计量经济学》上机实验参考答案实验一:计量经济学软件Eviews 的基本使用;一元线性回归模型的估计、检验和预测;多元线性回归模型的估计、检验和预测(3课时);多元非线性回归模型的估计。
实验设备:个人计算机,计量经济学软件Eviews ,外围设备如U 盘。
实验目的:(1)熟悉Eviews 软件基本使用功能;(2)掌握一元线性回归模型的估计、检验和预测方法;正态性检验;(3)掌握多元线性回归模型的估计、检验和预测方法;(4)掌握多元非线性回归模型的估计方法。
实验方法与原理:Eviews 软件使用,普通最小二乘法(OLS ),拟合优度评价、t 检验、F 检验、J-B 检验、预测原理。
实验要求:(1)熟悉和掌握描述统计和线性回归分析;(2)选择方程进行一元线性回归;(3)选择方程进行多元线性回归;(4)进行经济意义检验、拟合优度评价、参数显著性检验和回归方程显著性检验;(5)掌握被解释变量的点预测和区间预测;(6)估计对数模型、半对数模型、倒数模型、多项式模型模型等非线性回归模型。
实验内容与数据1:表1数据是从某个行业的5个不同的工厂收集的,请回答以下问题:(1)估计这个行业的线性总成本函数:t t x b b y 10ˆˆˆ+=;(2)0ˆb 和1ˆb 的经济含义是什么?;(3)估计产量为10时的总成本。
表1 某行业成本与产量数据 总成本y80 44 51 70 61 产量x 12 4 6 11 8参考答案:(1)总成本函数(标准格式):t t x y25899.427679.26ˆ+= s = (3.211966) (0.367954)t = (8.180904) (11.57462)978098.02=R 462819.2.=E S 404274.1=DW 9719.133=F(2)0ˆb =26.27679为固定成本,即产量为0时的成本;1ˆb =4.25899为边际成本,即产量每增加1单位时,总成本增加了4.25899单位。
计量经济学上机实验报告2

《计量经济学》上机实验报告二题目:练习题2.2、2.4 实验日期和时间:2015年10月15日星期四班级:学号:姓名:实验室:实验环境:Windows XP ; EViews 3.1实验目的:了解EViews软件的基本操作对象,掌握软件的基本操作。
实验内容:2.2(1)建立浙江省财政预算收入与全省生产总值的计量经济模型,估计模型的参数,检验模型的显著性并解释所估计参数的经济意义。
(2)利用(1)经济模型作出点预测和区间预测。
(3)建立浙江省财政预算收入对数与全省生产总值对数的计量经济模型,估计模型的参数,检验模型的显著性并解释所估计参数的经济意义。
2.4(1)建立建筑面积与建造单位成本的回归方程。
(2)解释回归系数的经济意义。
(3)估计当建筑面积为4.5万平方米时,对建造平均单位成本作区间预测。
实验步骤:2.3 (1)在命令区间输入LSYCX得到以下结果Dependent Variable: YMethod: Least SquaresDate: 10/15/15 Time: 20:24Sample: 1978 2010Included observations: 33Variable Coefficient Std. Error t-Statistic Prob.C -154.3063 39.08196 -3.948274 0.0004X 0.176124 0.004072 43.25639 0.0000902.5148R-squared 0.983702 Mean dependentvarAdjusted R-squared 0.983177 S.D. dependent var 1351.009S.E. of regression 175.2325 Akaike info criterion 13.22880Sum squared resid 951899.7 Schwarz criterion 13.31949Log likelihood -216.2751 F-statistic 1871.115Durbin-Watson stat 0.100021 Prob(F-statistic) 0.000000方程为Y=-154.3063+0.176124X经济意义:所估计的参数说明浙江省财政预算收入每增加1亿元,全省生产总值增加0.176124亿元。
计量经济学试验报告书三 2

R有所下降,且在X2、X1基础上,加入X3后的回归模型y=f( x2, x1, x3),2检验不显著;加入X4或X5后回归模型y =f(x2, x1 ,x4)或y =f( x2, x1, x5)回归系数T检验不显著,甚至X4的回归系数也不符合经济理论分析和经验判断;加入y =f( x2, x1, x5)与加入X4后的回归模型相同,X5回归系数经济意义不合理且相较而言加入X3后的回归模型y=f( x2, x1, x3)其回归系数经济合理,果,以此为基础,建立四元回归模型:在X2、X1、X3基础上引入X4后,2R虽有所上升,但X1的回归系数T检验不通过且的回归系数为负值,与经济理论分析和经验判断不符;引入X5后也与引入X4相同,升,但X3与X5的回归系数T检验不通过且经济意义不合理,故引入所有的变量建立回归模型,结果如下:Ls y c x2 x1 x3 x4 x5经检验X4和X5的回归系数符号为负值,且X1与X5的T检验不显著。
逐步回归估计结果表:RX2 X1 X3 X4 X5 20.9952Y=f(x2) 0.8841(62.4859)Y=f(x2,x1) 0.4872 0.4159 0.997047例5.服装需求函数。
根据理论和经验分析,影响居民服装需求Y的主要因素有:可支配收入X、流动资产拥有量K、服装类价格指数P1和总物价指数P0 ,统计资料如下。
设服装需求函数为:Y=a+b1x+b2P1+b3P0+b4K+ε(1)多重共线性检验运用①相关系数、②辅助回归模型以及③方差膨胀因子检验服装需求回归模型的多重共线性的可能类型;(2)逐步回归法①根据相关分析,建立服装需求一元基本回归模型②根据逐步回归原理,建立服装需求模型答案:(1)多重共线性检验①相关系数检验键入:COR Y X K P1 P0 输出的相关系数矩阵为:由上表可以看出,解释变量之间相关系数至少为0.969477,表明模型存在严重的多重共线性,且解释变量都与服装需求高度相关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三 异方差性
实验目的:在理解异方差性概念和异方差对OLS 回归结果影响的基础上,掌握进行异方差检验和处理的方法。
熟练掌握和运用Eviews 软件的图示检验、G-Q 检验、怀特(White )检验等异方差检验方法和处理异方差的方法——加权最小二乘法。
实验内容:
书P116例4.1.4:中国农村居民人均消费函数
中国农村居民民人均消费支出主要由人均纯收入来决定。
农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支付收入等。
为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,建立双对数模型:
01122ln ln ln Y X X βββμ=+++
其中,Y 表示农村家庭人均消费支出,X 1表示从事农业经营的纯收入,X 2表示其他来源的纯收入。
表4.1.1列出了中国内地2006年各地区农村居民家庭人均纯收入及消费支出的相关数据。
表4.1.1 中国2006年各地区农村居民家庭人均纯收入与消费支出(单位:元)
地区 人均消费 支出Y
从事农业经营 的纯收入X 1
其他来源纯收入X 2
地区
人均消费 支出Y
从事农业经营 的纯收入X 1
其他来源纯收入X 2
北 京 5724.5
958.3 7317.2 湖 北 2732.5
1934.6 1484.8 天 津 3341.1 1738.9 4489.0 湖 南 3013.3 1342.6 2047.0 河 北 2495.3 1607.1 2194.7 广 东 3886.0 1313.9 3765.9 山 西 2253.3 1188.2 1992.7 广 西 2413.9 1596.9 1173.6 内蒙古 2772.0 2560.8 781.1 海 南 2232.2 2213.2 1042.3 辽 宁 3066.9 2026.1 2064.3 重 庆 2205.2 1234.1 1639.7 吉 林 2700.7 2623.2 1017.9 四 川 2395.0 1405 1597.4 黑龙江 2618.2 2622.9 929.5 贵 州 1627.1 961.4 1023.2 上 海 8006.0 532 8606.7 云 南 2195.6 1570.3 680.2 江 苏 4135.2 1497.9 4315.3 西 藏 2002.2 1399.1 1035.9 浙 江
6057.2 1403.1 5931.7 陕 西 2181.0 1070.4 1189.8
安徽2420.91472.81496.3 甘肃1855.51167.9966.2 福建3591.41691.43143.4 青海2179.01274.31084.1 江西2676.61609.21850.3 宁夏2247.01535.71224.4 山东3143.81948.22420.1 新疆2032.42267.4469.9 河南2229.31844.61416.4
注:从事农业经营的纯收入由从事第一产业的经营总收入与从事第一产业的经营支出之差计算,其他来源的纯收入由总纯收入减去从事农业经营的纯收入后得到。
资料来源:《中国农村住户调查年鉴(2007)》、《中国统计年鉴(2007)》。
实验步骤:
一、创建文件
1.建立工作文件
CREATE U 1 31 【其中的“U”表示非时序数据】
2.录入与编辑数据
Data Y X1 X2 【意思是:同时录入Y、X1和X2的数据】
3.保存文件
单击主菜单栏中File→Save或Save as→输入文件名、路径→保存。
二、数据分析
1.散点图
①Scat X1 Y
10000
8000
6000
Y
4000
2000
50010001500200025003000
X1
从散点图可看出,农民农业经营的纯收入与农民人均消费支出呈现一定程度
的正相关。
②Scat X2 Y
10000
8000
6000
Y
4000
2000
0200040006000800010000
X2
从散点图可看出,农民其他来源纯收入与农民人均消费支出呈现较高程度的正相关。
2.数据取对数处理
Genr LY=LOG(Y)
Genr LX1=LOG(X1)
Genr LX2=LOG(X2)
三、模型OLS参数估计与统计检验
LS LY C LX1 LX2
得到模型OLS参数估计和统计检验结果:
Dependent Variable: LY
Method: Least Squares
Sample: 1 31
C 3.266068 1.041591 3.135653 0.0040
LX1 0.150214 0.108538 1.383975 0.1773
LX2 0.477453 0.051595 9.253853 0.0000 R-squared 0.779878 Mean dependent var 7.928613
Adjusted R-squared 0.764155 S.D. dependent var 0.355750 S.E. of regression 0.172766 Akaike info criterion -0.581995 Sum squared resid 0.835744 Schwarz criterion -0.443222 Log likelihood 12.02092 F-statistic 49.60117 12
ˆln 3.2660680.150214ln 0.477453ln (3.135653)(1.383975)
(9.253853)
Y X X =++
220.7798780.76415549.60117.. 1.780981R R F DW ====
【注意:在学术文献中一般以这种形式给出回归方程的输出结果,而不是把上面的软件输出结果直接粘贴到文章中】
可决系数0.779878,调整可决系数0.764155,显示模型拟合程度较高;同时,F 检验统计量49.60117,在5%的显著性水平下通过方程总体显著性检验。
可认为农民农业经营的收入和其他收入整体与农村居民消费支出的线性关系显著成立。
变量X2和截距项均在5%的显著性水平下通过变量显著性检验,但X1在10%的显著水平下仍不能通过检验。
四、异方差检验
对于双对数模型,由于12(0.150214)(0.477453)ββ=<=【二者均为弹性系数】,可认为其他来源的纯收入而不是从事农业经营的纯收入的增长,对农户人均消费的增长更有刺激作用。
也就是说,不同地区农村人均消费支出的差别主要来源于非农经营收入及工资收入、财产收入等其他来源收入的差别,因此,如果模型存在异方差性,则可能是X2引起的。
1.图示检验法
观察残差的平方与LX2的散点图。
①残差(resid )
残差(resid )变量数据是模型参数估计命令完成后由Eviews 软件自动生成(在Workfile 框里可找到),无需人工操作获得。
注意,resid 保留的是最近一次估计模型的残差数据。
②残差的平方与LX2的散点图 Scat LX2 resid^2
0.00
0.05
0.10
0.15
0.20
0.25
6
7
89
10
LX2
R E S I D ^2
从上图可大体判断出模型存在递增型异方差性。
2.G-Q 法检验异方差
补充:先定义一个变量T ,取值为1、2、…、31【分别代表各省市】,用于在做完G-Q 检验之后,再按T 排序,使数据顺序还原。