SAS软件与统计应用论文
SAS数据分析与统计

SAS数据分析与统计SAS是一种常用的数据分析与统计软件,被广泛应用于各个领域的数据分析工作中。
它具有强大的数据处理和统计分析能力,能够帮助用户从庞大的数据中获取有价值的信息。
本文将详细介绍SAS的相关特点和应用。
首先,SAS具有强大的数据处理能力。
用户可以通过SAS对数据进行导入、整理和清洗,将各种格式的数据转换为SAS可识别的格式。
此外,SAS还支持对数据集进行合并、拆分和排序等操作,提供了丰富的数据处理函数和方法,方便用户进行复杂的数据处理工作。
其次,SAS拥有多种统计分析方法。
用户可以利用SAS进行描述性统计、推断统计、回归分析、聚类分析、因子分析等各种统计分析工作。
SAS提供了丰富的统计函数和过程,用户可以根据具体的需求选择合适的方法进行数据分析。
此外,SAS还支持高级统计技术,如时间序列分析、生存分析、多元分析等,满足不同领域的数据分析需求。
此外,SAS还具有数据可视化功能。
用户可以利用SAS进行数据可视化,通过绘制图表、制作报表等方式直观地展示数据分析结果。
SAS提供了丰富的统计图表类型,如柱状图、折线图、散点图等,用户可以根据数据类型和目的选择合适的图表类型进行数据可视化。
另外,SAS还有自动化分析和报告生成功能。
用户可以通过编写SAS语言进行数据分析和处理的自动化,提高数据处理效率和准确性。
SAS还支持批处理模式,用户可以将多个SAS任务整合为一个批处理程序,实现自动化执行和报告生成。
在实际应用中,SAS被广泛应用于各个领域的数据分析与统计工作。
例如,在金融领域,SAS被用于风险管理、信用评估、投资组合分析等工作;在医疗领域,SAS被用于临床试验数据分析、医疗成本分析等工作;在市场调研领域,SAS被用于数据挖掘、市场预测、客户分析等工作;在制造业领域,SAS被用于质量控制、生产优化、供应链管理等工作。
总之,SAS作为一种全面、灵活和高效的数据分析与统计工具,为各个领域的用户提供了强有力的支持。
SAS课程论文

SAS课程论文城乡居民医疗保健消费支出分析城乡居民医疗保健消费支出分析摘要:医疗保健消费支出在居民消费支出中占有重要地位,在一定程度上反映着国家医疗制度与居民生活水平的情况。
分析历年城乡居民医疗保健消费支出具有一定的现实意义。
本文用SAS软件,对1996—2009年的统计数据进行各种分析。
其中包括,城乡居民医疗保健消费支出发展趋势,以及城乡差异显著性分析。
关键词:医疗保健消费支出城乡居民一、引言改革开放以来,我国进入了高速发展阶段,人民生活水平有了很大提高。
与此同时,城乡医疗保健消费支出的发展趋势是怎样的?城镇与农村居民在医疗保健上的支出到底有着怎样的差距?带着这些问题,本文进行了下文的分析。
二、数据的选取和录入本文选取数据为1996—2009年全国城镇和农村家庭人均每年的医疗保健消费支出,数据均来源于国家统计局网站的统计年鉴。
在SAS中录入数据如下:data payment;input year urban rural@@;cards;1996 143.28 58.261997 179.68 62.451998 205.16 68.131999 245.59 70.022000 318.07 87.572001 343.28 96.612002 430.08 103.942003 475.98 115.752004 528.15 130.562005 600.85 106.452006 620.54 191.512007 699.09 210.242008 786.2 245.972009 856.41 287.54;run;proc print ;run;运行后得到结果:三、数据分析(一)画出时间数列图为了看清楚城乡家庭人均医疗保健消费支出逐年的发展趋势,有必要画出时间数列图进行分析。
城乡家庭人均医疗保健消费支出时间序列图其中,细线为城镇的时间序列,粗线为农村的时间数列。
从上图可以看出,从1996年到2009年,城乡人均医疗保健消费支出总体都呈现出增长趋势,但是城镇增长速度大于农村。
SAS论文 统计分析与应用 sas统计分析

SAS统计分析与应用学号:xxxxxxxx班级:xxx姓名:xxx第一早第——早:摘要,”,”,”2.1 研究目的”,””2.2采用方法,,,,,,,2.3理论知识.,,,,,,,第三章第四章第五早第六章第七章数据预处理及具体模型,,,,,,,3.1建立的数据集3.2主要程序.,,,计算结果及分析,,,,,,,,4.1使用INSIGHT模块做主成分分析的步骤,,,,,,,4.2主成分的结果分析总结分析””,,”,参考文献,,,,,,,,,附录,,,,,,,,,,SAS系统是世界公认的权威性统计软件之一,是一个大型集成信息分析管理系统。
本次论文是用SAS系统对2007各地区农村居民家庭平均每人现金现金支出状况进行分析采用的数据是北京、天津等省农村居民家庭平均每人现金现金支出状(原始数据见附录)。
选出31省的情况作为统计分析数据,其中分析的项目为:期内现金支出、生产费用支出、家庭经营费用支出、农业生产支出、牧业生产支出、购买生产性固定资产支出、税费支出、生活消费现金支出、财产性支出、转移性支出,次用变量XI、X2、X3、X4、X5、X6、X7、X8、X9、X10。
运用SAS软件,运用主成分分析的方法对数据进行处理:(一)对于所选取的统计数据用MEANS过程进行简单描述统计分析,得出数据平均值、数据标准(二)对于所选取的统计数据用 INSIGHT模块做主成分分析计算协方差矩阵的特征值或是计算相关系数矩阵的特征值(Eigenvalue )、简单统计量、相关系数矩阵、相关系数矩阵的特征值以及相关系数矩阵的特征向量。
系统默认计算相关系数矩阵的特征值和特征向量。
(三)由相关系数矩阵的两个最大特征值的特征向量,可以写出第一、第二主成分以及第三主成分的得分。
从以上结论分析可以知道影响各地区地区农村居民家庭平均每人现金支出的主要因素,从、可以更好的帮助国家调节国民经济和产业结构,使人民的生活更加富裕。
关键字:主成分分析、简单统计量、相关系数矩阵、相关系数矩阵的特征值及特征向量。
SAS统计分析及应用

INFILE ‘文件名’ 选项;
SET语句
功能 CARDS与DATALINES功能相
同,均用于标志数据块的 开始
从外部文件中读入数据块
将所读入的数据存放在缓存 中,也可用OUTPUT语句 强制输出一条新记录
对数据集中的数据进行编辑, 也可将指定数据集的内容 复制到新建数据集中
五、SAS程序的过程步
SAS数据集等价于关系数据库系统中的一个表, 实际上一个SAS数据集有时也称作一个表。 在数据库术语中一个观测称作一个记录,一 个变量称作一个域。
在C0401数据集中:
有 5个观测,分别代表5个学生的情况, 每个学生有5个数据,
分别为姓名、性别、数学成绩、语文成绩、平均分 此数据集有5个变量, 变量名依次为NAME、SEX、MATH、CHINESE和AVG
功能 将数据集按指定变量排序 将数据集中数据列表输出 绘统计图 对指定的数值变量作详细的统计描述 对指定的数值变量作简单的统计描述 对指定的分类变量作统计描述和检验 非参数检验 进行t检验 进行方差分析 拟合一般线性模型 拟合线性回归模型 进行相关分析 拟合Logistic回归模型 拟合cox比例风险模型
SAS程序的书写规则与程序注释 SAS对程序的书写格式比较灵活,大小写一般不区 分(字符串中要区分大小写),
SAS程序与其它编程语言相似,采用缩进格式,使得 源程序结构清楚,容易读懂。
SAS程序的程序注释有以下两种格式: 注释语句:以星号“*”开始,可占多行,以分号 “;”结束。~ 注释段落:用“/*”和“*/”包括起来的任何字符,可 占多行。
SAS有三个最重要的子窗口: 程序窗口(PROGRAM EDITOR) 运行记录窗口(LOG) 输出窗口(OUTPUT)。
sas论文

sas论文
SAS(Statistical Analysis System)是一个全面的数据分析工具,广泛应用于统计分析、数据挖掘、预测建模、操作研究和商业智能等领域。
SAS论文可以涵盖各种主题,例如:
1. 统计分析:使用SAS进行概述统计、假设检验、方差分析、回归分析、多元分析等统计方法的应用研究。
2. 数据挖掘:使用SAS进行数据清洗、数据预处理、特征选择、模式发现、聚类分析、预测建模等数据挖掘任务的实践研究。
3. 预测建模:利用SAS进行时间序列分析、回归模型、决策树、神经网络、支持向量机等方法对未知数据进行预测和建模的研究。
4. 操作研究:使用SAS进行线性规划、整数规划、动态规划、决策优化等操作研究问题的建模和求解方法的研究。
5. 商业智能:应用SAS的商业智能工具和技术进行数据分析、报表生成、数据可视化等内容的研究与应用。
在撰写SAS论文时,可以包括SAS代码的使用和结果的解释,还可以进行实证分析和案例研究,展示SAS在实际问题中的
应用和效果。
此外,学术研究中的SAS论文还应包含相关理论基础、研究
方法的选择和质量保证等方面的论述,以确保研究的科学性和可靠性。
总之,SAS论文可以围绕统计分析、数据挖掘、预测建模、操作研究和商业智能等领域展开,融合SAS工具的使用和相关理论的研究,为学术界和实践领域提供有价值的研究成果。
SAS_QC在统计质量管理中的功能与应用

2、判 断 是 否 控 制 界 限 和 存 在 趋 势
从和 R 控制图可以看出, 此过程是处于受控状态, 因为
该钢棒直径都控制在上下控制线之间, 因此无需进行修改
控制界限。从控制图上可以看出它们在中心线周围, 上下控
制线之间呈旋螺式运动, 即不存在趋势。
3、制 作 控 制 用 控 制 图
第一步, 先 saving contronl limits
proc print data=bangs noobs;
run;
title 'Mean and Range Chart for Diameters';
symbol v=dot;
proc shewhart data=wafers graphics;
xrchart diamtr*batch;
run;
由于篇幅限制对 40 个子群体的和 R 控制图略。
一、产品数据的性能分析 对 产 品 数 据 的 性 能 分 析 , SAS 系 统 是 通 过 调 用 过 程 CAPABILITY 实现的。过程 CAPABILITY 提供了对产品数据
性能分析的多种统计和图形功能。 1、过程 CAPABILITY 提供概括描述变量特性的各种常
用 统 计 量Βιβλιοθήκη ( 矩 统 计 量 、次 序 统 计 量 、分 位 点 等 ) ; 反 映 工 序 过
2、过 程 CAPABILITY 提 供 很 强 的 利 用 图 形 表 现 数 据 分 布 的 功 能 , 提 供 统 计 中 表 现 数 据 分 布 最 常 用 的 图 形— ——直 方图的制作, 提供了显示对分析数据拟合多种分布的功能, 如 正 态 分 布 密 度 曲 线 图 、对 数 正 态 分 布 、指 数 分 布 、威 布 尔 分 布 、咖 玛 分 布 、贝 塔 分 布 密 度 曲 线 ; 显 示 数 据 的 经 验 分 布 和拟合的累积分布曲线; 还提供灵活的选择图形色彩的功 能 , 自 定 义 其 图 形 坐 标 轴 、图 例 、标 题 、脚 注 、注 释 、颜 色 、字 体、符号标记等, 以加强图象的效果。
SAS软件在生物统计上的应用

F
Value
Prob>F 0.0001
3.61688 24.184 0.14956
14 2.09381
C Total 17 12.94444 Root MSE(均方根误差) 0.38673 R-square 0.8382
Dep Mean (因变量均值) 1.94444
C.V. 19.88884 Parameter Estimates
Adj R-sq
0.8036
Parameter Standard T for H0: Variable DF Estimate Error Parameter=0 INTERCEP 1 0.036598 0.26296650 Prob>|T| 0.139 0.8913
X1 1
X2 X3 1 1
11. 1
6.5
15. 3
17. 7
5.9
10. 6
8.3
6.0
8.5
10. 1
3.5
1 直线回归分析(Linear Regression)
首先在PROGRAM EDITOR 窗口中输入如下信息: data linear; input x y @@; cards; 77 8.8 64 7.9 62 8.9 72 7.7 71 8.6 83 8.1 79 9.1 94 5.6 104 8.5 96 7.6 61 4.9 90 8.1 81 12 122 15.7 65 11.9 130 11.1 111 6.5 160 15.3
例如 国营大岭农村橡胶树大型系比二组无性系,1960年刺检干胶量(毫克)与1965年正式割胶 产量(克)如下,试求正式割胶量回归于刺检干胶量的回归方程。
SAS期末论文

摘要:本文回归分析SAS运用SAS软件对GDP的4个影响因素进行多元统计分析,首先对于数据进行编程录入,录入后对GDP进行单变量进行必要的分析,并对于数据进行正态性检验,然后对于5组变量进行多元分析,并对于方程和系数进行F检验和T检验,并建立回归模型,对GDP影响因素的贡献做出正确的分析。
关键字:国内生产总值固定资产投资引言:从1978年改革开放到2007年,中国经济经历了一个增长的“神话”30年来,我国的GDP年均增长率达到9.8%。
即使以再挑剔的眼光来看,这也是一个了不起的成就,那么接下来的一个问题就是:在过去的30年中,是什么原因使中国能保持如此高速的增长?是固定资产投资,第三产业增加值,人均GDP,工业总产值的增加?如果这些个因素都起到了一定的作用,那么它们的作用有多大?除此之外,我国的高速增长能否继续下去以及如何更好地促进我国的国的长期经济增长也都是值得关注的问题。
因此,对中国经济增长因素的分析,无论在理论上还是实证上,都有着重要的意义。
在影响经济增长的各种因素中,固定资产投资一般会受到特别的关注。
随着我国经济的不断发展以及改革开放的深入,研究经济的发展状况及分析经济发展的各个因素,成为决策部门的一个重要课题。
影响我国各地区经济发展的因素有很多,而如何定量化地分析和揭示影响各地区社会经济发展的主要因素及潜在综合因素的影响,是制定切实可行的缩小差距、促进地区经济协调发展的对策的重要基础之一。
理论综述:决定GDP的因素主要有固定资产投资,工业总产值,第三产业增加值等等因素,本文通过对几大因素的回归分析,从而体现出哪几个因素对于GDP 增长起着重要的作用,而哪几个因素是必不可少的,而哪些个因素是要剔除的。
(一)数据选取:本文选取数据为90年到08年的国内生产总值、人均GDP、第三产业增加值、固定资产投资和工业总产值,数据均来源于国家统计局网站中国统计年鉴2009(二)数据录入:首先运行SAS软件并在编辑器内编辑如下内容,使得国内生产总值为因变量,而人均GDP、第三产业增加值、固定资产投资和工业总产值为自变量。
统计软件sas在《多元统计分析》中的应用研究

技术创新49「统计软件SAS在《多元统计分祈》中的◊池州学院数学与计算机科学系张敏珏殷丽霞周恺《多元统计分析》是财经类院校统计学专业骨千课程之一,随着大数据时代的到来,做好统计软件对该课程的教辅工作巳经势在必行。
本文提出了SAS软件辅助《多元统计分析》课堂教学的优越性,并结合实践教学,就SAS存在的问题,给予相应的对策研究分析。
多元统计分析是从经典统计学中发展起来的一个分支,是 应用数理统计学来研究多变量(多指标)统计规律的一门科学。
在经济管理、气象水文、信号处理、生物医学等关乎国计民生的众多领域中有着广泛的应用。
近些年,随着计算机科学,大数据与人工智能等技术的迅猛发展,《多元统计分析》课程教学模式也发生了些许变化一教师在课堂上不再一味分析理论基础,推敲计算过程,而是在重视统计分析基本方法的同时,弱化繁琐的计算步骤,借助统计软件对数据进行分析处理,得出相应的统计结论,即由book statistics向computer statistic曙变,强化了统计软件在教学中的应用叫在目前全世界近百个统计软件产品中,SAS(Statistical Analysis System)由于使用简便、操作灵活、统计功能强大、绘制图表直观等特点,成为了统计学专业师生首选分析工具。
本文就《多元统计分析》课程中弓I入SAS软件辅助教学提出以下几点看法。
1统计软件SAS辅助《多元统计分析》教学的优越性1.1凸显统计结论的直观性,激发学生的学习兴趣在传统的《多元统计分析》教学范例分析中,大多数教师根据已有数据,通过求解检验统计值来说明统计问题,采用生动直观的图表说明统计结论甚少,这就导致课堂教学过于呆板,提不起学生学习的积极性。
当前,SAS软件特有的动态演示系统和拟合检验功能可使抽象的统计结论变得直观、形象,从而改善了传统课堂教学中的不足。
例如,判断一组数据是否来自正态分布,借助SAS软件,不仅能得到相关检验统计值(见表1),还可获取该组数据的拟合分布曲线(见图1),根据图1中的拟合分布曲线,学生很容易判断该组数据来自正态分布。
SAS与统计分析(sasinsight)

第一章 引论第一节 SAS与统计分析SAS系统是美国SAS软件研究所的产品,是一个用于决策支持的大型集成信息系统。
SAS系统经过二十多年的发展,以其卓越的数据处理能力,为在线数据分析、数据仓库、数据挖掘和决策支持提供了全面的解决方案。
SAS系统的发展始终离不开它的强大的数据分析功能,而且随着SAS系统的发展,其分析功能也与它在信息技术上的发展相辅相成,发展得更加深入、广泛和强大。
SAS系统的分析功能是散布在几乎所有的模块之中,较为集中的具有统计分析功能的是SAS/STAT、SAS/QC、SAS/INSIGHT、SAS/ETS等一些模块。
SAS系统的分析功能也在不断的发展之中,它随时地把用户需要的和学术研究中得到的一些有效的实用分析方法加入到SAS的不同模块之中,例如多变量分析中的偏最小二乘法便是一例。
在SAS系统分析功能的使用上,除了提供编程调用外,SAS对一些常用的分析功能都提供了简便的菜单系统,使用户不用编程就可以享用SAS 的许多深入的分析功能。
对常用的一些统计分析方法而言,SAS/INSIGHT、分析员应用和直接编程都可以达到同样的目的。
一般来说,SAS/INSIGHT 最为直观,便于步步深入;分析员应用可提供自动形成的程序,而且在属性数据分析和功效函数计算方面较INSIGHT强;编程是功能最强的,尤其是一些特殊或深入的分析功能只能用编程实现,但相对来说,编程较难熟练掌握。
下面我们就结合SAS/INSIGHT和分析员应用来介绍常用的一些统计分析方法。
第二节 SAS/INSIGHTSAS/INSIGHT是一个交互式的数据探索和分析的工具,用这一软件可以:l 通过多窗口连动的图象和分析结果,对数据进行探索l 分析单变量分布l 用相关和主成分研究多变量间的关系l 用方差分析和回归分析说明、拟合变量间关系的模型一、 区间型变量 ( interval variable ) 和列名型变量( nominal variable ):在SAS数据集中,变量的两种类型为:l 字符型变量l 数值型变量;在SAS/INSIGHT中,为了区分变量在分析中的不同作用,变量又按其测量水平分为:l 区间型变量:区间型变量必须是数值型变量,可以对其观测值进行各种四则运算,计算各种统计量;l 列名型变量:列名型变量可以是数值型的,也可以是字符型的,在INSIGHT中常起分类作用。
医学数据统计处理与SAS软件的应用

在生物统计学中,SAS软件可以 用于基因组学、蛋白质组学和生 物信息学等领域的数据分析和挖 掘。
SAS软件的基本操作
数据导入与整理
使用SAS软件的数据导入功能,将不同 格式的数据导入到软件中进行整理和清
洗。
统计分析
根据研究目的和数据特征选择合适的 统计分析方法,如描述性统计、T检
验、卡方检验和回归分析等。
提高研究质量
准确的数据统计处理能够减少研究误差,提高研究结果的可靠性和 可重复性。
辅助决策制定
基于数据分析,可以为医疗政策制定、资源配置等提供决策支持。
医学数据统计处理的基本流程
数据收集
根据研究目的和范围收集相关数据,确保数 据的准确性和完整性。
数据分析
运用统计分析方法对数据进行处理和分析, 挖掘数据中的潜在规律和信息。
变量处理
对导入的数据进行变量处理,包括变 量类型转换、缺失值处理和异常值检 测等。
结果输出
将统计分析结果输出到SAS软件的报 表或图表中,以便更好地展示和解释 分析结果。
03
医学数据预处理
数据清洗
缺失值处理
对于缺失的数据,可以采用插值、删 除或使用特定的方法进行处理,如多 重插补或基于模型的预测。
推论性统计分析
总结词
推论性统计分析用于根据样本数据推断总体特征,包括参数估计和假设检验等。
详细描述
推论性统计分析是统计分析中最为重要的部分,可以通过样本数据来推断总体的参数值,并进行假设检验来验证 假设是否成立。在SAS软件中,可以使用PROC TTEST、PROC FREQ等过程来进行推论性统计分析。
高级统计分析
总结词
高级统计分析包括回归分析、方差分析、主成分分析等方法,用于揭示数据之间的复杂关系和规律。
SAS统计分析及应用

SAS统计分析及应用SAS(Statistical Analysis System)是一个集成的软件系统,用于统计分析和数据管理。
它提供了广泛的统计分析功能,以及强大的数据处理和管理功能。
SAS被广泛应用于各个领域的研究和应用中。
本文将从SAS的基本功能、统计分析和数据管理方面,介绍SAS的应用和优势。
首先,SAS的基本功能包括数据检索和管理、数据清洗和转换、统计分析和数据可视化等。
通过SAS可以轻松地导入和导出各种类型的数据文件,包括Excel、CSV、数据库等。
对于大型数据集,SAS提供了高效的数据检索和管理工具,可以快速找到所需的数据,并进行操作和处理。
此外,SAS还具有强大的数据清洗和转换功能,可以对数据进行格式化、合并、计算等操作,使数据变得更加准确和易于分析。
同时,SAS提供了丰富的统计方法和算法,可以进行多变量分析、回归分析、时间序列分析等,满足不同领域和问题的需求。
最后,SAS通过图形和报表等方式,提供了直观和易于理解的数据可视化工具,帮助用户更好地理解和解释数据。
在统计分析方面,SAS具有多种强大的统计方法和算法。
例如,SAS可以进行描述统计分析,计算数据的均值、标准差、百分位数等。
此外,SAS还提供了多种变量分析方法,包括方差分析、卡方检验、t检验等,可以用于比较不同组别或处理之间的差异。
对于多变量分析,SAS提供了主成分分析、聚类分析和判别分析等方法,可以从多个变量中挖掘出主要特征和模式。
此外,SAS还提供了回归分析、时间序列分析等高级方法,用于建模和预测。
SAS在数据管理方面也有很大的优势。
首先,SAS提供了丰富的数据处理和管理功能,可以对大规模数据进行操作和处理。
SAS的语言和语法简单易学,可以轻松进行数据清洗、转换和计算等操作。
此外,SAS还具有高效的数据存储和检索机制,可以处理大规模数据集,保证数据的安全和完整性。
同时,SAS提供了多种数据处理和处理方式,包括数据集、数据步和PROCSQL等,满足不同数据处理需求。
SAS统计软件在本科实践教学中的应用

SAS统计软件在本科实践教学中的应用摘要:在教学实践中,应用了SAS软件的SAS/BASE、SAS/STAT和SAS/GRAPH等3个模块的部分功能。
教学效果表明,SAS统计软件在本科教学中应用效果良好。
关键词:SAS;统计软件;农业资源;教学实践0引言SAS(StatisticsAnalysisSystem)是当前国际上最有知名度的三大统计软件之一,它在数据处理和分析中能明显提高分析效率。
国际学术界有条不成文的规定,凡是用SAS统计分析的结果在国际学术交流中可以不必说明算法,由此可见其权威性和信誉度。
随着现代农业的逐步推进,EXCEL已无法满足现代科学研究及农业生产的需求。
本科生应该具备应用SAS统计软件基础,才能符合现代社会对科技人才的需求,这也是当前本科生综合素质培养的要求之一。
1SAS统计软件在教学中的应用据国内外研究资料表明,全世界土壤中缺硫现象越趋突出。
本研究企图研究硫肥对甘草的肥效,且用SAS软件进行数据处理从而得出科学结论。
根据文献硫肥用量,新疆农大本科生在教师指导下自设实验方案:所有处理施用同量的过磷酸钙、尿素、硫酸钾再施用不同水平的硫磺、硫酸钙和硫酸铵,实验中观测甘草苗数及株高,数据用SAS/STAT及SAS/GRAPH处理并进行分析。
1.1数据分析中的应用1.1.1SAS独立性样本T检验独立性样本T检验的方法是用来比较施用及未施用硫肥这两组数据的平均值和标准差,从而判断两种情况的数据是否具有显著性差异。
TEST过程提供t检验,从“分析菜单”中选择“比较均值”,再从“方法”里选择“独立性样本T检验”。
按两组数据方差相等的假设,观察未施用硫肥和施用硫肥的情况,苗数的均值及标准差都是施肥明显大于未施肥,说明硫肥的使用给甘草的生长发育带来明显的影响。
1.1.2SAS/ANOV A方差分析方差分析和协方差分析在SAS系统中由SAS/STA T模块的ANOV A(AnalysisOfVariance)过程来完成。
SAS统计软件案例应用分析
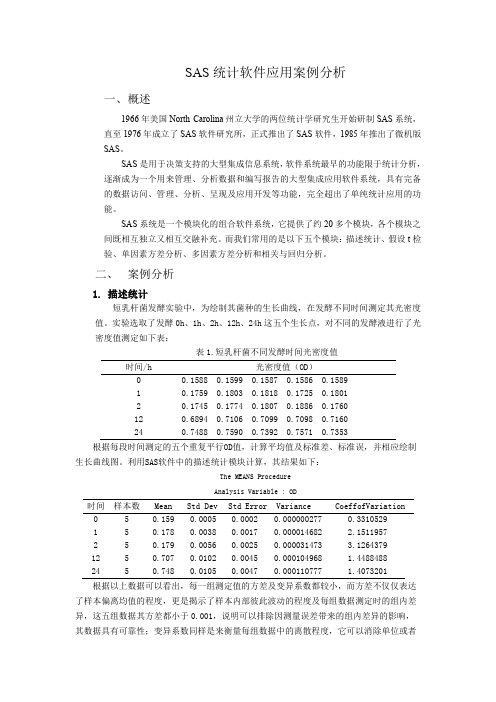
SAS统计软件应用案例分析一、概述1966年美国North Carolina州立大学的两位统计学研究生开始研制SAS系统,直至1976年成立了SAS软件研究所,正式推出了SAS软件,1985年推出了微机版SAS。
SAS是用于决策支持的大型集成信息系统,软件系统最早的功能限于统计分析,逐渐成为一个用来管理、分析数据和编写报告的大型集成应用软件系统,具有完备的数据访问、管理、分析、呈现及应用开发等功能,完全超出了单纯统计应用的功能。
SAS系统是一个模块化的组合软件系统,它提供了约20多个模块,各个模块之间既相互独立又相互交融补充。
而我们常用的是以下五个模块:描述统计、假设t检验、单因素方差分析、多因素方差分析和相关与回归分析。
二、案例分析1.描述统计短乳杆菌发酵实验中,为绘制其菌种的生长曲线,在发酵不同时间测定其光密度值。
实验选取了发酵0h、1h、2h、12h、24h这五个生长点,对不同的发酵液进行了光密度值测定如下表:表1.短乳杆菌不同发酵时间光密度值时间/h 光密度值(OD)0 0.1588 0.1599 0.1587 0.1586 0.15891 0.1759 0.1803 0.1818 0.1725 0.18012 0.1745 0.1774 0.1807 0.1886 0.176012 0.6894 0.7106 0.7099 0.7098 0.716024 0.7488 0.7590 0.7392 0.7571 0.7353根据每段时间测定的五个重复平行OD值,计算平均值及标准差、标准误,并相应绘制生长曲线图。
利用SAS软件中的描述统计模块计算,其结果如下:The MEANS ProcedureAnalysis Variable : OD时间样本数Mean Std Dev Std Error Variance CoeffofVariation0 5 0.159 0.0005 0.0002 0.000000277 0.33105291 5 0.178 0.0038 0.0017 0.000014682 2.15119572 5 0.179 0.0056 0.0025 0.000031473 3.126437912 5 0.707 0.0102 0.0045 0.000104968 1.448848824 5 0.748 0.0105 0.0047 0.000110777 1.4073201根据以上数据可以看出,每一组测定值的方差及变异系数都较小,而方差不仅仅表达了样本偏离均值的程度,更是揭示了样本内部彼此波动的程度及每组数据测定时的组内差异,这五组数据其方差都小于0.001,说明可以排除因测量误差带来的组内差异的影响,其数据具有可靠性;变异系数同样是来衡量每组数据中的离散程度,它可以消除单位或者平均数不同对两个或多个数据变异程度比较的影响,更加客观描述了每组数据的可靠性。
SAS统计分析软件应用分析

(2)比较运算符 = ^= > >= < <=
(3)逻辑运算符
and/& 逻辑与 x>2 and y>3
or/|
逻辑或 x>2 or y>3
Not/^ 逻辑非
<>
最大 3<>5;结果为5
><
最小 3><5;结果为3
||
连接 A=‘my name is’; B=‘SAS’; C=A||B;
那么C=“my name is SAS”
SAS统计分析软件应用分析
第一节 SAS软件简介
1966年美国North Carolina州立大学的两位生物 统计学研究生开始研制SAS系统,直至1976年成立了 SAS软件研究所,正式推出了SAS软件,1985年推出 微机版SAS。
SAS是用于决策支持的大型集成信息系统,软件 系统最早的功能限于统计分析,逐渐成为一个用来管 理、分析数据和编写报告的大型集成应用软件系统, 具有完备的数据访问、管理、分析、呈现及应用开发 等功能,完全超出了单纯统计应用的功能。属于世界 领先,使用最为广泛的统计软件之一。
资源管理器窗口
❖ Results
结果索引窗口
SAS常用功能键
7
第二节 SAS软件的使用基础
8
二、SAS的工作窗口
❖ Editor窗口 主要用于打开SAS程序文件(*.sas)、编辑 和修改SAS程序、并提交全部或部分SAS程序。
❖ LOG窗口 显示有关的SAS会话和提交SAS程序的信息, 包括程序的出错信息等(*.log)
2.SAS数据集名和变量名 (1)32个字符之内, (2)第一个字母必须为字母或_;第二个以后可以为字母或
浅析SAS软件在医学统计中的应用

浅析SAS软件在医学统计中的应用SAS的中文含义就是统计分析系统,它主要是通过数十个专用模块而构成的,功能比较全面,包括数据的访问,数据的管理,数据的存储,还有应用开发,报告编制,计量经济学,运筹方法学,图形处理以及数据分析等。
医学统计学会涉及到医学领域的很多学科,其方法比较复发,而且工作起来计算量也比较庞大。
最近这些年来,医学基因组学和临床试验统计学理论及其方法都在不断地发展和深入着。
因此,笔者认为作为医学领域的相关统计人员除了要将医学统计学的基本理论掌握好以外,还需要对相关的软件操作知识做出必要的了解和认识。
因此,笔者接下来将主要谈一谈SAS软件在医学统计当中应用的相关问题。
1 SAS软件在医学统计中的统计描述在医学当中最为常见的两种资料类型分别是定量资料和分类资料,因此在对数据进行处理的时候就需要对资料的类型和分析情况作出了解,这样在对资料进行描述的时候就能够根据特殊的情况选择合适的方法[1]。
1.1定量资料的统计描述所谓定量资料的统计描述就是对离散趋势和集中趋势进行描述,在描述性统计当中,频数分析和频数描述是两种最为常用的方法,如果我们想要对数据进行了解和认识,那么我们首先就需要从频数分析开始。
进行频数分析需要编制频数表,在编制频数表的时候需要将所有的观察结果按照一定的顺序做出排列,需要在排列的顺序当中去发现观察值的分布规律。
也可以对某一个变量的频数进行频数分析,编制相应的频数分布表,这样就可以将该变量的分布类型揭示出来。
频数分析能够将远离群体的某些可疑值发现,因此频数表能够对频数分布的两个重要特征做出表示,一个是集中趋势,另一个就是离散趋势。
我们根据频数表所绘制出来的直方图就能够更加直观地将资料的分布特征观察出来[2]。
在SAS软件当中,我们可以通过分析员来对频数做出频数分析,通过编程做出频数统计。
频数分析能够将定量变量的相关资料的分布情况和集中情况进行一定的描述。
但是,如果我们想要更多的了解一些关于集中趋势和离散趋势的确切信息,那么我们就需要对于一些相关的描述性指标作出必要的计算[3]。
SAS论文

目录摘要 (2)一基本原理与方法 (3)1.1 研究目的: (3)1.2 采用方法: (3)1.3 理论知识: (3)1.3.1主成分分析的基本思想 (3)1.3.2主成分分析的数学模型 (5)二数据预处理 (7)三运行结果及分析 (8)四分析与建议 (14)五参考文献 (14)六附录 (14)摘要本文通过SAS 软件来研究2009各地区农村居民家庭平均每人现金支出状况进行分析采用的数据是北京、天津等省农村居民家庭平均每人现金支出状(原始数据见附录)。
主要运用“分析家”模块进行主成分分析。
为了更好的帮助国家调节国民经济和产业结构,使人民的生活更加富裕,我们选出31省的情况作为统计分析数据,分别为期内现金支出、生产费用支出、家庭经营费用支出、农业生产支出、牧业生产支出、购买生产性固定资产支出、税费支出、生活消费现金支出、财产性支出、转移性支出,次用变量X1、X2、X3、X4、X5、X6、X7、X8、X9 、X10。
运用SAS 软件对以上统计数据用“分析家”模块做主成分分析计算协方差矩阵的特征值或是计算相关系数矩阵的特征值(Eigenvalue )、简单统计量、相关系数矩阵、相关系数矩阵的特征值以及相关系数矩阵的特征向量。
系统默认计算相关系数矩阵的特征值和特征向量。
从分析结果数据可以知道影响各地区地区农村居民家庭平均每人现金支出的主要因素,从而可以更好的帮助国家调节国民经济和产业结构,使人民的生活更加富裕。
关键字: 主成分分析、insight模块、简单统计量、相关系数矩阵、相关系数矩阵的特征值及特征向量。
一、基本原理与方法1.1研究目的:利用 SAS 软件的分析,对各地区农村居民家庭平均每人现金支出的主要影响因素有一个大致的了解;有利于国家的宏观调控,从而可以促进全民经济更好的发展。
1.2采用方法:①描述统计量:MEANS②检验:使用INSIGHT 模块主成分分析。
1.3理论知识:SAS 是由美国北卡罗莱纳州的SAS institute 公司开发的一种统计软件,它被广泛应用在商业、科研领域。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
摘要本学期通过对《SAS软件与统计应用》这门课的学习,让我知道SAS系统是一个大型的应用软件系统,具有完备的数据访问、管理、分析、呈现,以及应用开发功能。
这篇文章运用主成分分析综合评价方法,对1999年我国西部地区教育人力资源发展水平进行处理和分析,采用的是西藏,新疆等西部省份教育人力资源发展水平(原始数据见附录)。
选出14个省的情况作为统计分析数据,其中分析的项目为:每百万人口学校数;每十万人口毕业生数;每十万人口招生数;每十万人口在校生数;每十万人口研究生数;每十万人口教职工数;每十万人口专职教师数;高级教师占专职教师的比例;每所学校在校生数;生师比。
依次用A1,A2,A3,A4,A5,A6,A7,A8,A9,A10表示。
用“分析家”作主成分分析,并且对数据进行如下处理:第一:对于所选取的统计数据进行简单描述统计分析,得出数据的平均值、数据标准差,最大值,最小值等。
第二:对于所选取的统计数据用”analyst”作主成分分析计算相关系数矩阵的特征值、上下特征值之差、各主成分的方差贡献率、以及累积贡献率。
第三:由相关系数矩阵的两个最大特征值的特征向量,可以写出第一、第二主成分的得分。
第四:在“insight”里面绘制了散点图。
由图可知,在散点图越靠向右上角的地区,教育人力资源发展水平越高,越靠向左上角的地区,教育人力资源发展水平越低。
从以上结论分析可以知道影响各省份教育人力资源发展水平的主要因素,从而可以更好地帮助国家调整教育人力资源结构,更好地发展我国西部教育事业。
关键字:analyst 主成分分析教育人力资源发展 MEANS过程目录第一章基本介绍 (3)1.1 研究目的 (3)1.2 采用方法 (3)1.3 理论知识 (3)第二章数据预处理 (3)第三章具体模型 (4)3.1 建立数据集 (4)3.2 具体模型(程序) (4)运行结果及分析 (5)4.1 使用“分析家”做主成分分析的步骤 (5)4.2 主成分的结果分析 (7)参考文献 (11)附录 (13)第一章基本介绍1.1 研究目的通过SAS软件分析,对1999年我国西部地区教育人力资源发展水平有一个大致了解。
随着国家教育方针的调整,西部各地区为了促进本地区的教育发展,分别采取了各种措施,教育方面的发展有了显著地成就。
本文通过SAS软件分析,对1999年我国西部地区教育人力资源发展水平有一个大致了解,从而可以更好地帮助国家调整(优化)教育人力资源结构,使人民的受教育水平更加优越。
1.2 采用方法(1)描述性统计量:means。
(2)检验:使用analyst模块进行主成分分析。
1.3 理论知识Means过程(均值过程):用于对数据型变量产生针对单个变量的简单描述性统计。
proc means过程时,会对所有数值型变量进行操作,得到各变量的非缺失观测数N,均值MEAN,标准差STD DEV,最大值Max和最小值Min五种统计值,但means过程可以计算16种统计量。
主成分分析:是对于原先提出的所有变量,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。
主成分分析是数学上对数据降维的一种方法。
其基本思想是设法将原来众多的具有一定相关性的指标(比如p个指标),重新组合成一组新的互不相关的综合指标来代替原来指标。
通常数学上的处理就是将原来p个指标作线性组合,作为新的综合指标。
在所有的线性组合中所选取的F1应该是方差最大的,故称F1为第一主成分。
如果第一主成分不足以代表原来p个指标的信息,再考虑选取F2即选第二个线性组合。
为了有效地反映原有信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1,F2)=0。
称F2为第二主成分,依此类推可以构造出第三、第四、…、第p个主成分。
第二章数据预处理对数据较少的程序,可以用DATA步建立永久的SAS集。
永久的SAS集,由定义逻辑库与定义数据集两步完成。
逻辑库定义通过LIBNAME语句完成,数据集定义用DATA 语句实现。
指定逻辑库的命令语句为全程语句,其格式如下:LIBNAME <逻辑库名> "<路径>";指定要建立数据集的命令语句格式如下:DATA <逻辑库名>.<数据集名>;LIBNAME语句把磁盘中的子目录与用户定义的逻辑库名连接起来。
用此方法根据已知的数据就可以建立生成以下的数据集。
第三章具体模型3.1 建立数据集2012年11月19日星期一下午12时19分55秒 5 Obs region A1 A2 A3 A4 A5 A6 A7 A8 A9 A101 海南0.66 49 64 191 12.0 47 19 0.33 2914 10.1602 广西0.62 41 69 192 34.0 40 18 0.33 3113 10.4503 山西0.72 61 118 193 60.0 74 30 0.33 4092 10.1704 内蒙古0.80 46 77 211 53.0 71 32 0.36 2617 7.4305 四川0.75 66 112 314 164.0 77 32 0.39 4199 10.1006 重庆0.50 41 77 211 120.0 53 21 0.37 4192 10.1007 贵州0.54 28 67 152 21.0 35 16 0.33 2823 8.9508 云南0.57 38 66 176 49.0 44 20 0.38 3079 83619 西藏 1.56 42 65 157 3.9 68 30 0.14 1005 5.10010 陕西 1.19 100 188 496 398.0 140 55 0.36 4173 9.90011 甘肃0.71 55 90 246 113.0 65 27 0.31 3480 9.23012 青海 1.18 49 68 183 17.0 68 34 0.20 1558 5.32013 宁夏0.92 49 83 242 25.0 73 33 0.33 2624 7.52014 新疆0.96 66 110 305 51.0 96 42 0.30 3180 7.2303.2 具体模型(程序)Data work.data1;input region $1-10 A1 A2 A3 A4 A5 A6 A7 A8 A9 A10;cards;海南0.66 49 64 191 12 47 19 0.33 2914 10.16 广西0.62 41 69 192 34 40 18 0.33 3113 10.45 山西0.72 61 118 193 60 74 30 0.33 4092 10.17 内蒙古0.8 46 77 211 53 71 32 0.36 2617 7.43 四川0.75 66 112 314 164 77 32 0.39 4199 10.1 重庆0.5 41 77 211 120 53 21 0.37 4192 10.1 贵州0.54 28 67 152 21 35 16 0.33 2823 8.95 云南0.57 38 66 176 49 44 20 0.38 3079 8361 西藏 1.56 42 65 157 3.9 68 30 0.14 1005 5.1陕西 1.19 100 188 496 398 140 55 0.36 4173 9.9甘肃0.71 55 90 246 113 65 27 0.31 3480 9.23 青海 1.18 49 68 183 17 68 34 0.2 1558 5.32 宁夏0.92 49 83 242 25 73 33 0.33 2624 7.52 新疆0.96 66 110 305 51 96 42 0.3 3180 7.23 ;run;proc print;run;第四章运行结果及分析4.1 使用“分析家”做主成分分析的步骤1) 在“分析家”中打开数据集work.data1;2) 选择菜单“Statistics(统计)” “Multivariate(多元分析)” “Principal Components(主成分分析)”,打开“Principal Components”对话框;3) 在对话框中输入主成分分析的变量,如图4-1;图4-14) 单击“Statistics(统计)”按钮,打开“Principal Components:Statistics”对话框;在“# of components:”右边的框中指定主成分的个数10,如图4-2,单击“OK”返回;图4-25) 单击“Save Data”按钮,打开“Principal Components:Save Data”对话框,在该对话框中可选择存储数据。
选中“Create and save scores data”,如图4-3所示。
单击“OK”返回;图4-36) 单击“Plots”按钮,打开“Principal Components:Plots”对话框,可以设置图形输出。
在“Scree Plot (碎石图)”选项卡中(图4-4),选中“Create scree plot(建立碎石图)”复选框。
在“Component Plot (成分图)”选项卡中(图4-5),选中“Create component Plot(建立成分图)”复选框。
图4-4图4-54.2 主成分的结果分析输出的数字分析结果包括4个部分:简单统计量、相关系数矩阵、相关系数矩阵的特征值以及相关系数矩阵的特征向量。
1) 图4-6给出变量的简单统计量,图中显示10项指标中A9(每所学校在校生数)、A5(每十万人口研究生数)、A4(每十万人口在校生数)是最为重要的,其标准差远远高出其他变量图4-62) 图4-7可得:A2(每十万人口毕业生数)与A3(每十万人口招生数)、A4(每十万人口在校生数)、A6(每十万人口教职工数);A7(每十万人口专职教师数)与A6(每十万人口教职工数与);A4(每十万人口在校生数)与A3(每十万人口招生数)、A5(每十万人口研究生数)有较强的相关性。
图4-73) 图4-8给出相关系数矩阵的特征值(Eigenvalues)、上下特征值之差(Difference)、各主成分的方差贡献率(proportion)以及累积贡献率(Cumulative)图4-8相关系数矩阵的特征值即各主成分的方差,可以看出,第一主成分的方差贡献率为58.54%,第二主成分的方差贡献率为34.40%,第三主成分的方差贡献率为3.05%。
说明第一、二主成分方差贡献率已经达到85%以上,可以很好地概括这组数据。