语义网和语义网格中的本体研究综述
动态本体构建的国内外研究现状综述

动态本体构建的国内外研究现状综述1. 引言1.1 动态本体构建的国内外研究现状综述动态本体构建是近年来信息学领域一个备受关注的研究方向,它是指在本体知识库的基础上,对知识的结构和内容进行不断的更新和演化,以适应不断变化的需求和环境。
动态本体构建的研究范围涉及多个学科领域,包括计算机科学、人工智能、知识图谱等。
国内外学者们在这一领域进行了大量的研究工作,取得了丰硕的成果。
在国内,动态本体构建的研究也逐渐受到重视,一些知名高校和科研机构积极开展相关研究项目。
国内学者们在动态本体构建的理论框架、方法技术、应用领域等方面取得了令人瞩目的进展,为我国在这一领域的研究和发展贡献了力量。
而在国外,动态本体构建的研究也蓬勃发展,一些国际知名研究机构和学者在这一领域进行了深入探讨,并取得了许多创新成果。
国外学者们的研究成果不仅在学术界产生了广泛影响,也在工业界得到了广泛应用。
动态本体构建的国内外研究现状呈现出蓬勃发展的趋势,有望为相关领域的发展带来新的突破和机遇。
接下来我将对动态本体构建的意义、国内外研究现状、方法技术、应用领域以及发展趋势等方面进行更详细的综述和分析。
2. 正文2.1 动态本体构建的意义动态本体构建是知识图谱建设中的重要环节,它利用本体表达形式对领域知识进行建模和表示,可以帮助计算机理解和推理领域知识。
动态本体构建的意义主要体现在以下几个方面:1. 知识表示与共享:动态本体构建可以帮助将领域知识以结构化的形式表示出来,使得不同系统之间能够共享知识,提高信息检索和推理效率。
2. 知识推理与智能搜索:通过构建动态本体,可以实现知识之间的关联和推理,实现智能搜索和推荐等功能,提升用户体验。
3. 语义一致性与数据质量:动态本体构建可以帮助保障数据的语义一致性,减少数据冗余和错误,提高数据质量和准确性。
4. 领域应用创新与发展:动态本体构建为各个领域的应用提供了基础支撑,可以促进各种创新应用的发展,推动领域的进步和发展。
语义网中的本体构建与推理研究

语义网中的本体构建与推理研究随着互联网技术的不断发展,人们在网络上获取信息变得越来越容易,然而,这些信息往往是海量的、杂乱无章的,并不便于机器自动处理。
因此,我们需要一种能够理解信息含义的方式,来帮助我们更好地处理这些信息。
这就是语义网的基本思想。
语义网(Semantic Web)的核心是充分地使用信息的语义,通过构建本体(Ontology)、推理等手段来实现Web资源的高效利用和共享。
本体是语义网的基石本体是语义网中的核心概念。
顾名思义,本体就是用于描述实体及其关联关系的模型。
它是对某一领域中实体、概念、属性和关系等的描述,以及这些描述之间的约束、规则等。
本体的目的是消除不同人、不同组织、不同机器对同一概念的不同解释,为不同使用者提供一个一致的、标准的基础。
因此,本体的构建关系到语义网的推广和应用。
本体构建的方法本体构建的方法可以大致分为三大类:手工构建法、半自动化构建和自动化构建。
手工构建是最早出现的一种本体构建方式。
其优点在于可以高度抽象地描述概念,缺点在于速度慢、成本高。
半自动化构建则是在手工构建的基础上,在人工干预的情况下涉及到自动化工具,优点在于缩短了构建时间。
自动化构建是一种基于机器学习的方法,具有时间成本低、可扩展性好等优点。
本体推理的方法本体推理是指通过基于本体知识的逻辑推断,从本体中出发,再结合外部实例数据,推导出新的知识或结论,从而完善和扩展本体的过程。
本体推理的方法可以大致分为逻辑推理和规则推理。
逻辑推理是利用逻辑形式化地表示本体知识,然后进行逻辑推理的过程。
逻辑推理需要对本体进行形式化表示,从而使推理结果是形式化规则所允许的。
规则推理是指利用基于规则或规则表示的推理方法,利用规则的强特定性来完成推理任务。
本体构建和推理的应用完善的本体和推理技术可以帮助我们更好地利用和共享网络信息。
下面分别介绍几个应用。
1. 语义搜索语义搜索可以从网络数据中精确提取用户所需信息。
在语义搜索中,可以利用本体中的概念间关系,由搜索关键词推断出更适合用户需求的结果,从而不必对搜索结果进行手工筛选。
语义网概念及技术综述

语义网概念及技术综述语义网(Semantic Web)是一种由 W3C(World Wide Web Consortium)推广的,基于 XML(eXtensible Markup Language)和 RDF(Resource Description Framework)等技术的网络,它旨在增强网络信息的语义表达和机器可读性,从而使得计算机能够更好地理解和处理网络信息。
一、语义网的概念语义网是一种以“数据”为中心的网络,它通过使用 XML、RDF 等技术,将网络信息以机器可读的方式进行组织和表达。
与传统的 Web 相比,语义网更加强调信息的结构和含义,而不是简单的文本表现形式。
因此,语义网被认为是 Web 的一个重要发展阶段,是实现智能 Web 的关键步骤。
二、语义网的技术1.XMLXML 是构建语义网的基础技术之一,它是一种用于描述数据的标记语言。
XML 可以用来表示数据结构,并且可以很好地与 HTML、HTTP 等现有网络技术集成。
通过 XML,我们可以将数据以机器可读的方式进行组织和表达,从而使得计算机可以更好地处理和理解数据。
2.RDFRDF 是另一种构建语义网的关键技术,它是一种用于描述资源及其关系的模型。
RDF 将每个资源视为一个三元组,包括主体、属性和值三个部分。
通过这种方式,我们可以将网络信息以一种通用的、机器可读的方式进行描述和组织,从而实现数据的共享和重用。
3.RDFSRDFS 是 RDF 的扩展,它增加了一些新的概念和规则,例如类、子类关系、属性限制等。
这些概念和规则可以帮助我们更好地描述和组织数据,并且可以用于构建更加复杂的语义网应用。
4.OWLOWL 是另一种基于 RDF 的语言,它提供了更加丰富的概念和规则,例如类、属性、关系等。
OWL 提供了三种不同的表达层次,分别是 OWL Lite、OWL DL 和OWL Full,以满足不同应用场景的需求。
OWL 可以用于描述更加复杂的概念和关系,并且可以用于构建更加高级的语义网应用。
语义网、语义网格和语义网络

等 。语 义 网就是 想弥补 这 方面 的不 足 , 网页扩 展 了 为
1 语 义 网
1 1 语 义 网的概 念 .
随着互 联 网 的飞速发 展 和广泛 应用 , 其缺 陷也 逐
渐暴露出来 , 如搜索 引擎智能程度低 , 网页功能单调
计算机 可处理 的语 义信 息。互 联 网 的创始 人 T i m Bres e 20 enr. 于 00年 l e L 2月 l 日在 X 0 0的会 8 M 0 议上正式提 出语义网 , 他对语义 网的定义如下 : 语 “ 义 网是 一个 网 , 它包 含 了文档 或 文 档 的一 部 分 , 述 描 了事物问的明显关 系, 且包含语义信息 , 以利 于机器 的 自动处理 ” 。语义 网 的 出发 点是 通过 改 变 现 有互 联 网依 靠文字 信 息来共 享资 源 的模式 , 过本 体来 描 述 通 语义信息 , 达到语义级 的共享 , 提高 网络服务 的智能 化、 自动化 。 20 年 Tm Bre . 01 i enr ke为未来 的 We s b发展提 出了 基 于语义 的体 系结构 , 其体 系结构 中, 一层 是 U i 在 第 n - cd 和 U I它是整个 语义 We oe R, b的基 础 , n oe 统 一 U id( e 编码 ) 处理资源 的编码 ,R( U I统一资源标识 ) 负责标 识资 源 ; 二层是 X L+ 第 M 名空 间 +X L模 式 , M 用于 表示数 据 的内容和结构 ; 第三层是 R F+ D D R F模式 , 用于描述资
语义web中的本体学习OntologyLearningfortheSemanticWeb

2.3 数据的导入和处理技术
文档的收集、导入和处理步骤 使用一个以本体为中心的文档爬虫来搜集网上 的相关文档。 使用自然语言处理技术来进行文档的处理。 使用一个文档包装器将半结构化文档(如领域 字典)转换成本体学习框架可以识别的格式 (如RDF格式)。 将处理过的文档转换为本体学习算法可以识别 的格式。
抽取词条
分类关系的抽取:(1)使用层次聚类技术(2)
使用模式匹配技术(字典)
非分类关系的抽取:使用基于关联规则的挖掘
算法
2.4 本体学习算法
本体维护算法
本体的修剪(发现和删除无关的概念)
(1)基线修剪(2)相对修剪
本体的精练(对本体的精细调整和增量扩展)
主要思想是先找出未知的词条,然后从本体中 找出与其相似的概念并提交给用户,最后由用 户决定该未知词条的意义。
FCA-Merge(第 三步):从概念格 生成新本体
2.3 数据的导入和处理技术
合并 本体1中的Hotel 本体2中的Hotel 本 体 2中 的 Accommodation
合并 生成新概念或关系
合并
2.3 数据的导入和处理技术
FCA-Merge算法小结
输入:两个本体和一个自然语言文档集 输出:一个合并过的本体。 对输入数据有如下要求: 文档集应该和每个源本体都相关。 文档集应该包含源本体中的所有概念。 文档集应该能够很好的分离概念。
3.本体的评价
精度 学习生成的本体
手工生成的本体
precisionOL =
| CompRef | | Comp|
召回率
recallOL =
| CompRef | | Ref|
Hale Waihona Puke 其中,Ref是参照本体中元素的集合, Comp是比较本体中元素的集合。
语义网技术的发展与应用

语义网技术的发展与应用随着互联网的普及与数据的爆炸式增长,我们越来越需要一种更加高效、准确、智能的方式来处理和利用数据。
而语义网技术就是能够满足这种需求的一种新型数据处理技术。
本文将从语义网技术的定义、发展历程以及其应用前景三个方面来展开论述。
一、语义网技术的定义语义网技术,即语义网(Semantic Web),是一种基于网络的、带有语义的数据处理技术。
它能让机器理解文字和语言,并对其进行推理和应用,从而赋予数据更多的深层次的含义和价值。
语义网技术的核心是对于不同类型的信息进行统一整合、归纳和处理,以达到复杂、多样性数据间的自动化共享和交流。
二、语义网技术的发展历程语义网技术的历史可以追溯到英国人蒂姆·伯纳斯·李(Tim Berners-Lee)在1989年提出“万维网”(World Wide Web)的想法。
他最初创意是为了方便科学研究者之间的信息交流,而在此基础上,李提出了语义网的概念,即将现有的万维网变成一个更加智能化的平台,以减少数据匮乏、信息无效的情况。
20世纪90年代,随着万维网上的信息爆炸式增长,语义网技术逐渐得到了人们的重视。
在2001年,万维网联盟(W3C)发布了语义网指导方针,正式确立了语义网技术的标准化。
此后,每年W3C都会发布新的语义网推荐规范,不断完善和拓展语义网的功能和应用范畴。
三、语义网技术的应用前景语义网技术的应用前景非常广泛,可以用于企业管理、电子商务、智能家居、医疗健康、金融投资、灾害预警等多个领域。
以下是具体的几个应用实例:1.企业管理:语义网技术可以建立起一个完整、集成的企业数据体系,实现对企业内部数据和知识的有效管理与共享。
2.电子商务:语义网技术可以将产品和服务的信息进行语义化,方便消费者搜索和比较,提高电子商务的效率。
3.智能家居:语义网技术可以将家居设备和服务进行互联化,实现智能化的管理和控制,提升家庭生活质量和安全性。
4.医疗健康:语义网技术可以整合医学知识和患者数据,实现个性化的医疗服务和健康管理。
语义数字图书馆研究综述

为数据 层 、 本体层和知识层 , 完成提供 向上访 问的接 口、 分别 向
上提供语义服务及为上层用户提供知识查 询服 务。 田欣 [提 出 8 ] 的模型 中, 知识 本体 内容参考杜威 十进分类法 , 构建出完整 的知
关键词组或语 句群 , 利用构建的领域本体 , 在知识库中搜索用户
真正需要检索 的信息。 熊燕子 研究了基于 O - 语 义服务描 WL S 述的数字图书馆网格 应用模 型的实现方式 : 采用 O WL本体描述
语言模型来设计领域本体 , 利用基于 O WL语言 的 We b服务描述
收稿 日期 :0 1 1— 3 2 1- 2 2
语 义 数 字 图 书 馆 研 究 综 述 水
郝 慧, 胡 娟
( 京 工业 大学 图书 馆 , 京 ,0 14 北 北 10 2 )
摘
要: 简述 了国内外语义数 字图书馆 的研 究进展 情况 , 出国 内的研 究主要 集 中在 指
基于本体( 义 ) 语 的数 字 图 书馆 模 型 或框 架 方 面 , 实验 和 系统 实现 方 面 的研 究较 少 , 而
的检索 , 实现语 义层 次上 的信息互操作 , 而有效地提高数字图 从 书馆 的信息服务效率 。而本体的 目的是用来捕获相关领域 的知 识, 提供对该领 域知识 的共 同理解 , 确定该 领域内共同认可 的词 汇 ,并从不 同层次的形式化模式上给出这些词汇和词汇间相互
本体论及语义搜索引擎

本体论及语义搜索引擎什么是本体论本体论是一个用于描述概念和实体的系统,它包括概念的定义、概念之间的关系以及实体的分类和属性。
本体论的目的是为了帮助人们更好地理解和组织知识。
本体论可以被应用在各种领域,例如人工智能、知识管理和语义网等。
在人工智能领域,本体论被用于构建智能系统,并帮助这些系统更好地理解和处理语言信息。
在知识管理领域,本体论被用于组织和管理知识资源,提高信息的利用效率。
在语义网领域,本体论被用于建立语义资源库,实现跨语言、跨平台的信息交换和共享。
语义搜索引擎的介绍语义搜索引擎是一种能够理解用户意图和查询语句的搜索引擎。
与传统的关键字搜索不同,语义搜索引擎能够理解语义关系、概念和实体,并根据这些关系和信息提供相关性更高的搜索结果。
语义搜索引擎的原理是基于本体论的,通过将查询语句转化成本体论表示,然后在本体库中查找匹配的实体和概念,从而提供相关性更高的搜索结果。
例如,用户查询“国际足球巨星”时,传统搜索引擎可能将结果与关键词“足球”、“国际”、“巨星”相关的页面列出来,而语义搜索引擎则能够理解“国际足球巨星”实际上是指一些具有国际知名度的足球明星,从而提供更准确和相关的搜索结果。
本体论在语义搜索引擎中的应用本体论在语义搜索引擎中发挥着重要作用,它被用于建立和维护本体库,以及将查询语句转换为本体论表示。
建立本体库建立本体库需要考虑多种因素,例如本体类别、本体之间的关系、实体和属性。
本体库的建立需要从已有的知识库和信息源中获取信息,并根据本体论的原则将其整理分类。
本体库的建立需要不断地维护和更新,以适应用户需求和领域发展。
转换查询语句为本体论表示查询语句需要通过语义分析和处理,转换为本体论表示。
其中,语义分析是将自然语言文本转换为机器可以理解的语义表示,语义处理是将这个语义表示映射到本体库中的概念和实体上。
语义分析和处理需要运用一些自然语言处理技术和机器学习算法,例如命名实体识别、词性标注、句法分析和语义角色标注等。
利用本体进行网格资源匹配的尝试

关键 词 : 本 体 ; 网格 ; 资源 匹配 ; 义 网 语 中 图号 : TP 0 . 3 21 文献标 志码 : A
网格是 在异构 、 态环境 中实现 资源共 享和协 动
1 2 本 体 .
作 的技术. 网格 环境下 , 在 资源 可能属 于不 同组织 .
利 用 本体进 行 网格 资源 匹配 的尝 试
李 宝敏 ,刘 琼
( 西安丁业大学 计算 机科 学与T程学 院 两安 70 3 ) 10 2
摘
要 : 现 有 的 网格 资源 匹配方 法是把 对资 源的描述 和约 束进行 精确 的语 法 匹配 , 其灵 活性
差 , 于扩展 新 的概 念或特 征. 难 引入语 义 网 中本体 的概念 , 用本体进 行 网格 资源 匹配 , 照 资 利 按 源 匹配的要 求 . 构建 网格 需 求方与提供 方共 享的 网格 资源本 体 , 通过 本 体 、 背景 知 识 和 匹配 规
源匹配进 而获 得满 足需求 的资源 , 从而保 证 配 的
灵活性 、 可扩 展性 和准确性 .
本体能通 过本 体语 言编 码 , 计算 机 可 读 , 可 以 使 且
1 相关技术
1 1 网格资 源 .
被计算 机处理 ; 共 享 , ④ 本体 体 现 的 是共 同认 可 的 知识 , 映 的是相关 领域 内公认 的概 念集. 反 本体 的 目标 是捕 获 相关领 域 的公 有知 识 , i 提
有不 同 的约 束 , 以动 态地 增 减 , 户 也 会对 资 源 可 用 提 出特定 的要求 , 因此 对 网格 资源 配方法 的研 究 有很 重要 的意 义. 是 现 有 的 网格 资源 匹配 方法 , 但
语义网格在中医药知识共享与服务的应用

服务模式创新背景:传统的中医药知 识服务模式主要以文献服务为主,缺 乏对知识的深度挖掘和整合,无法满 足用户个性化、精准化的需求。基于 语义网格的中医药知识服务模式能够 实现对知识的深度挖掘和整合,提高 知识服务的智能化和个性化水平。
服务模式创新内容:基于语义网格的 中医药知识服务模式主要包括智能化 推荐、个性化定制、社区交流等模块 。其中,智能化推荐模块能够根据用 户的历史行为和偏好,推荐相关的中 医药知识和资源,个性化定制模块能 够根据用户的特定需求,提供个性化 的中医药知识和服务,社区交流模块 能够为用户提供一个交流和分享的平 台,促进知识的传播和共享。
语义网格在中医药知识共享 与服务的应用
2023-11-08
contents
目录
• 引言 • 语义网格技术概述 • 中医药知识共享与服务现状分析 • 语义网格在中医药知识共享与服务的应用
方案 • 实证分析与效果评估 • 总结与展望
01
引言
研究背景与意义
01
中医药知识的传承和发展
中医药作为中国传统的医学体系,具有丰富的理论和实践经验。然而,
02
语义网格技术概述
语义网格的定义
语义网格是一种基于语义技术的网格计算模型,旨在实现网络资源的高效组织和 智能利用。
它结合了语义网和网格计算的优势,将网络中的各种资源、数据和服务进行语义 化处理,以便更好地被计算机理解和利用。
语义网格的体系结构
语义网格体系结构包括三个主要层次 :底层基础设施层、中间语义网格层 和上层应用层。
服务模式创新技术:基于语义网格的 中医药知识服务模式主要采用人工智 能、自然语言处理、数据挖掘等先进 技术实现。其中,人工智能技术能够 实现智能化推荐和个性化定制等功能 ,自然语言处理技术能够实现自然语 言文本的自动处理,数据挖掘技术能 够从海量数据中挖掘出有价值的信息 。
语义网介绍及体系结构分析

语义网介绍及体系结构分析作者:暂无来源:《声屏世界》 2015年第13期张海亮随着网络的迅猛发展,网页上的信息成指数增长,网页已经成为最主要的信息交流渠道。
由于HTML本身的局限性而导致网页上缺乏足够的语义信息,难以实现WEB信息的自动化处理,因此WWW、HTTP和HTML的创始人Tim Berners-Lee在一般万维网的基础上提出了语义网的概念,从而大大改进了人类思维和机器思维之间的差异,提高了机器自动处理网络上信息的能力。
语义网是对未来网络的一个设想,现在与WEB 3.0这一概念结合在一起,是3.0网络时代的特征之一。
简单地说,语义网是一种智能网络,它不但能够理解词语和概念,而且还能够理解它们之间的逻辑关系,可以使交流变得更有效率和价值。
语义网和人工智能中的语义网络是两个不同的概念,所以它采用的方法与自然语言处理不同。
它对现有的WEB进行了语义扩展,从而使其上面的信息能够被计算机理解和处理,从功能上看它将是一个能够“理解”人类信息的智能网络。
在其体系结构中,第一层是Unicode(统一编码)和URI,它是整个语义网的基础。
Unicode是处理资源的编码,URI负责标识资源;第二层是XML+名空间+XML模式,用于表示数据的内容和结构;第三层是RDF和RDF模式,用于描述资源及其类型;第四层是本体词汇,用于描述各种资源之间的联系;第五层是逻辑,在前面四层的基础上进行逻辑推理操作;第六层是验证,根据逻辑陈述进行验证以得出结论;第七层是信任,在用户间建立信任关系。
其中,第二、三、四层是一个语义网的关键层,用于表示WEB信息的语义,也是现在语义网研究的热点所在。
可扩展标记语言XML让每个人都能创建自己的信息标签,来对网页或页面的部分文字进行注释。
资源描述框架RDF的基本结构是对象、属性和值所组成的三元组,也就相当于一个句子中的主语,动词和宾语。
这些三元组可以用XML语法来表示。
用这种结构描述并由机器处理大量数据,是非常自然的方法。
语义网和语义网格中的本体研究综述

语义网和语义网格中的本体研究综述余一娇1,2(1 华中师范大学语言学系,武汉,430079)(2 华中科技大学计算机学院 武汉 430074)E-mail: yjyu@摘要:本体是语义网和语义网格研究中的一种重要方法。
文中首先介绍本体的定义、本体的四元素表示法和六元组表示方法,以及本体的设计分析生命周期;然后回顾语义网研究中曾产生过巨大影响的七种本体语言。
通过分析众多文献的观点,文中提出在将来我们应重点针对 DAML+OIL 和OWL两种本体语言进行深入研究。
文中还列举出了本体在生物信息计算和网络管理领域应用的两个实例。
最后根据语义网格和本体研究现状,提出了利用本体研究语义网格服务质量的基本思路和研究方法。
关键词:本体 本体语言 DAML+OIL OWL 语义网 语义网格 服务质量1.前 言Ontology在哲学领域常译为“存在论”,是指关于事物是否存在思考的学科。
在计算机科学和人工智能领域则译为“本体”,其词义与哲学中的“存在论”大相径邻。
1993年美国Stanford大学知识系统实验室的Gruber博士在文献[1]中定义:本体是用来帮助程序和人共享知识的概念的规范描述 (An ontology is the specification of conceptualizations, used to help programs and humans share knowledge.),后来该定义得到了进一步发展和完善[2]。
文献[1]还指出:概念化是关于世界上的实体,如:事物、事物之间的关系和约束条件的知识表达。
而规范一词是强调这种表达是用一种固定的形式来描述。
从我们已经阅读的多篇相关文献来看,几乎所有论文都接受了上述关于本体的定义。
迅速增加的Web页面数量、丰富的页面内容和时新的消息,为知识工程领域的科学家实现面向终端用户的应用研究、开发带来了极好的机会。
在Internet上实现基于语义的信息检索和情报收集,无疑是广大因特网用户的迫切需求。
语义网本体构建方式研究的开题报告

语义网本体构建方式研究的开题报告一、研究背景随着互联网的进一步发展,越来越多的数据被发布在互联网上,数据量呈现爆炸式的增长。
而这些数据往往分散在各个网站、数据库及各种应用程序中,缺乏相应的结构化描述,难以进行有效的管理和利用。
语义网(Semantic Web)技术的出现,可以将这些数据以统一的方式互相链接和交换,为利用这些数据提供了更好的途径。
语义网建立在本体(Ontology)的基础上。
本体是一种用来描述事物之间概念关系的形式化表示方法,是语义网的核心。
本体描述了现实世界中的概念和概念之间的关系,使得计算机可以根据定义的本体进行知识推理,从而达到语义的理解和知识的共享的目标。
本体构建是语义网技术中的核心问题之一,其中包括本体的设计、本体的实现、本体的测试等一系列问题。
因此,如何有效地构建本体,一直是语义网相关研究的热点之一。
二、研究目的本研究旨在探讨语义网本体构建的方法和技术,通过对现有本体构建工具的研究与分析,设计和实现一个支持本体构建的工具,并对其进行测试和评估,以提高语义网本体构建的效率和质量。
三、研究内容1. 国内外研究现状的分析通过对语义网本体构建的相关文献进行全面的调研,了解国内外本体构建的研究现状和发展趋势,寻找当前研究存在的问题和不足。
2. 本体构建的方法和技术介绍本体的基本概念和本体构建的方法和技术,包括本体设计的基本原则,本体的开发过程,本体语言的选择,本体构建的工具和平台等方面的内容。
3. 本体构建工具的研究和设计基于现有的本体构建工具进行研究和分析,以及对本体构建应用的需求和技术特点进行综合考虑,设计和实现一个支持本体构建的工具。
4. 本体构建工具的测试和评估通过对所设计实现的本体构建工具进行测试和评估,探讨本体构建效率和质量的提升方法。
四、研究意义1. 对语义网本体构建方法和技术进行深入探究,为今后的本体构建工作提供参考和指导。
2. 开发一个支持本体构建的工具,可以提高本体构建的效率和质量,为推动语义网技术的发展做出贡献。
基于语义网格的数字图书馆知识组织中领域本体构建研究

应用到数字 图书馆 的知识组织 中。 细论述 了领域本体的概 念, 详 构建原则 , 体构建步骤 , 用的构建工具, 具= 选 阐述 了图书馆界 在本体 构建中的技 术和人 员优势 . 以及将语 义网格应用到在数 字图书馆建设 中的前景和意义,
【 bt c]h tlhs nle e x t g r l snte osutnod ili ae,i us ecnet fh m nintgd A s at eaie a aa zd h ii o e n r i f it b r sdcs dt oc e e at e r r T rc y t e sn p b m i h c t co ga lr i s e h p ot s c ,i
【 e od ]e at dDgalr i ; id n l y K y rsSm n c n ; it b r sFe to w ig ili ae lo og
随着数 字图书馆的发展 , 实现信 息资源深度整合共 享 、 开展一站 式 知识服务成为 图书馆开展信息服务 的新方式 . 但是分布式数据源的 异构性制约 了图书馆信息服务。 如何屏蔽和消除异构数 据源的影 响成 为图书馆信 息整合 中亟待解决的问题 。 数据源的异构可以分为 四个层 次: 系统异构 、 语法异构 、 结构异构 和语义异构 数字图书馆各个 系统 可能存在着 不同的元数据方案 ,相同的术语可能存在不 同的语义 . 不 同的术语 的语义又可能相关 , 因此语 义异构是最难消除 的 随着语义 网格概念的提出以及在 图书馆领域的应用 . 国内外 图书馆界和计算机 界提出了利用本体整合异构数据源 的方案 . 这迅速成为 图书馆数据源 整合的一个新兴 的研究与应用领域Ⅲ 。下一代数字 图书馆将呈现 以网 格为运行环境 , We 资源相融合 . 和 b 实现面向全球开放模式的特点 效进行机器支持 的检索 、 析 、 解 处理和交换 , 以进行跨文献单元 、 难 数 据类型 、 数据层次和系统范 围的信息挖掘 、 、 抽取 综合分析描述 、 转换 , 也难 以与其他领域 的数据格式或数据处理 系统互操作[ 异构系统之 5 1 间互操作难 以实现 . 形成一个个信息孤岛 基于 以上现 实 . 单靠元数据 已经不能 完全地 、 系统地体现 资源对 象 问复杂的关联关系 . 也不能完全解决资源的异构问题 为了实现虚 拟 资源体 系的语 义导航 、 语义查询 . 字图书馆需要采用一种新 的技 数 术 和方法来实现元数据之 间的互操作 .于是提出了语 义网格的概念 . 语 义 We b和网格技术开始应用 到数字 图书馆的建设 中 语 义 We 采 b 用其他一些技术来 帮助对 页面 中包含的信 息资源进行语 义标 注 、 分类 和组织 . 网格技 术在数字 图书馆 中应用 . .而 可以更好 地让计 算机和人 们协 同工作 . 发现处理数据 的可用资源 . 对数据进行集成
语义网中OWL本体概述及其构建方法研究
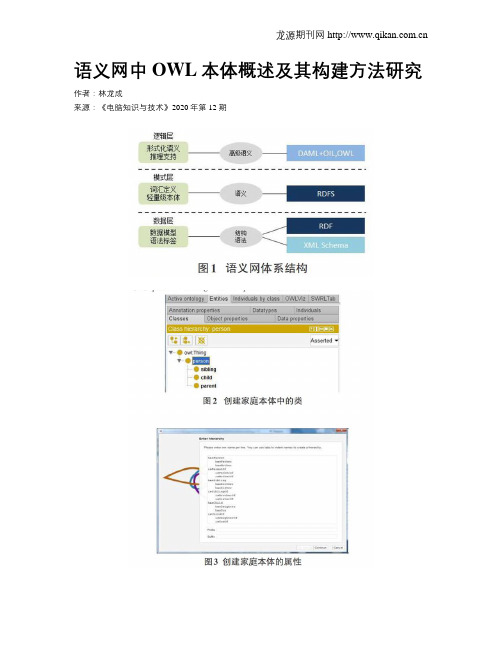
语义网中OWL本体概述及其构建方法研究作者:林龙成来源:《电脑知识与技术》2020年第12期摘要:近年来,语义网(Semantic Web)以其良好的知识表达、交流、共享和推理能力,已被各个领域广泛接受,语义网是当前Web的延伸。
而本体是语义网的关键,利用本体语言对Web上已有的信息进行更为有意义的组织和编码,从而实现机器与人之间的有效通信。
本文对语义网和本体语言进行了分析,并在此基础上阐述了基于Protege的OWL本体构建技术。
关键词:语义网;本体;OWL;Protege中图分类号:TP393 文献标识码:A文章编号:1009-3044(2020)12-0203-02万维网是一个由数百万个文档组成的分布式存储库,覆盖了广泛的多学科信息,在这些文档中提取和检索特定的信息是一项烦琐的工作。
为了提高关联度,需要向语义Web(Web3.0)和本体论方向发展。
语义Web是当前Web的扩展,其中Web上已有的信息被有意义地编码并赋予一个明确定义的结构,从而使计算机和人类以高效的方式进行通信。
在语义网中,所有的信息都有明确的含义,使机器能够解释、处理、推理和派生新的知识,以支持实时应用中的特定任务。
随着语义网的迅速发展,支持本体功能的语言层出不穷。
Web本体语言(OWL)、资源描述框架(RDF)和资源描述框架模式(RDFS)是语义网的基本表示语言。
本体是语义网的关键,它将一个特定领域的相关概念编码成机器可读的格式,在这种格式中,机器可以处理和理解编码的知识,Web本体语言OWL是一种在Web上定义本体的语言,从类、属性和个体的角度描述一个域,并且可以包含对这些对象特性的丰富描述。
1语义网语义网的概念是由万维网的发明者Tim Berners Lee在1996年提出的,目标是将当前的信息转换成机器友好的语言,语义网并不是一个独立的网络,而是当前网络的扩展,它赋予信息明确的含义,使得信息共享和重用成为可能,计算机和人们能够更好地协同工作。
什么是语义网络,如何使用它来解决人类问题?

什么是语义网络,如何使用它来解决人类问题?语义网络是一种用于表达语义(意义)的无向图模型,最初由语言学家和心理学家共同提出并用于理解语言和思维的本质。
它被广泛应用于自然语言处理、人工智能、知识图谱和信息检索等领域。
语义网络模型可以用于构建知识图谱、建立专家系统及知识库等各种应用,助力解决人类问题。
一、语义网络的构成和原理语义网络通常由节点和关系两部分组成。
节点代表具体的对象或概念,关系则代表节点之间的语义关系。
语义网络的构建可以基于概念层次结构、本体论、信任度等原则。
在语义网络模型中,节点和关系都具有不同的属性和语义信息,如标签、级别、属性、上下位关系等。
通过不同的节点和关系的组合,可以形成复杂的语义信息网络。
语义网络模型的主要原理是语义相关性。
每一个节点都代表一个语义概念,节点之间的关系则代表各种语义关联,包括上下位关系、同义词关系、反义词关系、部分与整体关系等。
比如,“苹果”和“水果”之间就有一种上下位关系,而“苹果”和“梨”之间则属于同义词关系。
二、语义网络的应用领域1.自然语言处理语义网络是自然语言处理的重要技术之一,通常用于构建自然语言理解模型。
借助语义网络模型,计算机可以更好地理解人类语言,从而实现机器翻译、信息提取、对话系统等应用。
2.知识图谱知识图谱是一个基于语义的知识库系统,由节点和关系构成,用于以统一语义形式呈现和管理人类知识。
语义网络是构建知识图谱的重要技术之一,可用于解决知识获取、知识表达、知识推断和知识共享等问题。
3.专家系统专家系统是一种基于知识推理的计算机程序,利用人工智能技术帮助人类解决复杂问题。
语义网络模型可用于构建专家系统中的知识库和推理引擎,从而实现专家系统的智能化。
4.信息检索语义网络模型可用于构建搜索引擎的语义关联模型,从而提高搜索结果的质量和准确性。
通过语义网络模型,搜索引擎可以更好地理解用户查询的语义,从而精准匹配相关文档。
三、语义网络的优缺点优点:1. 语义网络能够建立更加准确的语义关联,利于形成高质量的语义知识库和专家系统;2. 语义网络可解释性强,易于为人类所理解,为人工智能的发展提供了宝贵的经验;3. 语义网络利于自然语言处理,帮助计算机更好地理解和应用人类语言。
近十年来汉语词汇本体研究述评

近十年来汉语词汇本体研究述评近十年来,随着中国经济的快速发展和国际地位的提升,汉语词汇本体研究也在逐渐受到重视。
汉语词汇本体研究是对汉语词汇意义和使用规律的研究,是语言学中的重要领域。
本文将对近十年来汉语词汇本体研究的进展进行述评。
一、汉语词汇本体研究的理论基础近十年来,汉语词汇本体研究的理论基础逐渐丰富和完善。
在传统的语言学理论基础上,结合现代语言学以及心理学、认知科学等学科的研究成果,逐渐形成了一套系统的汉语词汇本体研究理论框架。
在这一理论框架下,研究者对汉语词汇的本质特征、意义构成、语境使用等方面进行了深入研究,为汉语词汇本体研究奠定了坚实的理论基础。
近十年来,汉语词汇本体研究的重点领域涵盖了词汇意义的认知结构、语义类别与范畴、词语语用功能、词义辨析、语义变化、词语语境等方面。
对词汇意义的认知结构进行了深入研究,揭示了词汇在认知加工过程中的特点和规律,为深入理解词汇的意义构成提供了重要的认知基础。
对词语的语用功能进行了较为细致的探讨,揭示了词汇在语用交际中的作用和特点,为语境中词语的选择和应用提供了重要的理论支撑。
近十年来,随着信息技术的不断发展,汉语词汇本体研究的方法与技术也得到了较大的进步。
采用了许多先进的研究手段和技术手段,利用大数据技术对汉语词汇的使用情况进行统计分析,利用计算机辅助研究工具对语料库进行词汇本体分析等等,这些新的研究方法和技术为汉语词汇本体研究提供了重要的支撑,推动了汉语词汇本体研究的深入发展。
近十年来,汉语词汇本体研究在理论和方法上取得了一系列的成果,不仅丰富了汉语词汇本体研究的理论框架,还提供了大量的实证研究数据和案例分析,这些成果对于推动汉语词汇本体研究的进一步发展具有重要的意义。
也要看到,汉语词汇本体研究仍然存在不少问题,理论体系尚不够完善,实证研究数据还不够充分,研究方法和技术还有待进一步提升等。
未来的研究工作还需在这些方面进行深入探讨和研究。
语义文本相似度计算方法研究综述

语义文本相似度计算方法研究综述目录一、内容概括 (2)1.1 研究背景 (3)1.2 研究意义 (3)1.3 文献综述目的与结构 (5)二、基于词向量的语义文本相似度计算 (5)2.1 词向量表示方法 (7)2.2 基于词向量的相似度计算方法 (8)2.3 词向量模型优化 (9)三、基于深度学习的语义文本相似度计算 (10)3.1 循环神经网络 (11)3.2 卷积神经网络 (13)3.3 自注意力机制 (14)四、基于图的方法 (15)4.1 图表示方法 (16)4.2 图上采样与聚类 (18)4.3 图匹配算法 (19)五、混合方法 (21)5.1 结合多种表示方法的混合策略 (22)5.2 不同任务间的知识迁移 (23)六、评估与优化 (24)6.1 评估指标 (25)6.2 算法优化策略 (26)七、应用领域 (28)7.1 自然语言处理 (29)7.2 信息检索 (30)7.3 问答系统 (32)7.4 多模态语义理解 (33)八、结论与展望 (34)8.1 研究成果总结 (35)8.2 现有方法的局限性 (37)8.3 未来发展方向 (38)8.4 对研究者的建议 (39)一、内容概括语义文本表示与相似度计算方法:首先介绍了语义文本表示的基本概念和方法,包括词向量、句子向量、文档向量等,以及这些表示方法在相似度计算中的应用。
基于统计的方法:介绍了一些基于统计的文本相似度计算方法,如余弦相似度、Jaccard相似度、欧几里得距离等,分析了它们的优缺点及应用场景。
基于机器学习的方法:介绍了一些基于机器学习的文本相似度计算方法,如支持向量机(SVM)、朴素贝叶斯(NB)、最大熵模型(ME)等,讨论了它们的原理、优缺点及适用性。
深度学习方法:重点介绍了近年来兴起的深度学习方法在语义文本相似度计算中的应用,如循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)等,分析了它们在文本相似度计算中的性能及局限性。
论弗雷格的语义观和本体论

郑州轻工业大学学报(社会科学版) 2023年12月 第24卷第6期 JOURNALOFZHENGZHOUUNIVERSITYOFLIGHTINDUSTRY(SOCIALSCIENCEEDITION) Vol.24No.6Dec.2023收稿日期:2023-04-20基金项目:国家社科基金青年项目(18CZX046)作者简介:王铜静(1985—),女,河南省开封市人,郑州轻工业大学讲师,博士,硕士生导师,主要研究方向:语言哲学、科学哲学;赵亚丽(1997—),女,河南省上蔡县人,郑州轻工业大学硕士研究生,主要研究方向:马克思主义理论。
论弗雷格的语义观和本体论王铜静,赵亚丽郑州轻工业大学马克思主义学院,河南郑州450001摘要:语义三角是当代语言哲学的基本研究框架,弗雷格的语义三角观独具特色,其由语言符号、涵义和指称三者构成。
弗雷格的语义三角观特色首先体现在其别具一格的三元本体论预设上;其次体现在对语言采取的分层分析策略,即语言层面、语义层面、本体论层面上。
弗雷格借助数学中的函数概念来分析日常语句,用自变元-函数分析取代传统逻辑的主词-谓词分析,并由此产生了语言上专名与概念词的区分,语义结构上对象与概念的区分,以及本体论上外在世界、内在世界与第三域的区分。
关键词:弗雷格式语义三角观;分层分析策略;语义观;本体论中图分类号:B5 文献标识码:A DOI:10.12186/2023.06.004文章编号:2096-9864(2023)06-0029-08 弗雷格被奉为分析哲学之父,开辟了语言哲学研究先河。
达米特给予弗雷格极高评价,他认为弗雷格为哲学带来了可以媲美笛卡儿的哲学领域变革,如果说笛卡儿使得认识论成为近代哲学的起点,那么同样地,“对于弗雷格来说,在任何哲学研究中,首要任务是对意义的分析”[1],因此意义理论理当成为整个学科(指哲学———引者注)的起点。
《概念文字》孕育了弗雷格的语言哲学思想,其后的一系列重要文章,如《函数与概念》《论概念和对象》《论涵义和指称》等,都是《概念文字》思想的延伸,从中可以看到弗雷格特色鲜明的分层分析策略。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
语义网和语义网格中的本体研究综述余一娇1,2(1 华中师范大学语言学系,武汉,430079)(2 华中科技大学计算机学院 武汉 430074)E-mail: yjyu@摘要:本体是语义网和语义网格研究中的一种重要方法。
文中首先介绍本体的定义、本体的四元素表示法和六元组表示方法,以及本体的设计分析生命周期;然后回顾语义网研究中曾产生过巨大影响的七种本体语言。
通过分析众多文献的观点,文中提出在将来我们应重点针对 DAML+OIL 和OWL两种本体语言进行深入研究。
文中还列举出了本体在生物信息计算和网络管理领域应用的两个实例。
最后根据语义网格和本体研究现状,提出了利用本体研究语义网格服务质量的基本思路和研究方法。
关键词:本体 本体语言 DAML+OIL OWL 语义网 语义网格 服务质量1.前 言Ontology在哲学领域常译为“存在论”,是指关于事物是否存在思考的学科。
在计算机科学和人工智能领域则译为“本体”,其词义与哲学中的“存在论”大相径邻。
1993年美国Stanford大学知识系统实验室的Gruber博士在文献[1]中定义:本体是用来帮助程序和人共享知识的概念的规范描述 (An ontology is the specification of conceptualizations, used to help programs and humans share knowledge.),后来该定义得到了进一步发展和完善[2]。
文献[1]还指出:概念化是关于世界上的实体,如:事物、事物之间的关系和约束条件的知识表达。
而规范一词是强调这种表达是用一种固定的形式来描述。
从我们已经阅读的多篇相关文献来看,几乎所有论文都接受了上述关于本体的定义。
迅速增加的Web页面数量、丰富的页面内容和时新的消息,为知识工程领域的科学家实现面向终端用户的应用研究、开发带来了极好的机会。
在Internet上实现基于语义的信息检索和情报收集,无疑是广大因特网用户的迫切需求。
2001年5月,Web之父Tim Berners-Lee和合作者在《Scientific American》杂志上发表了“The Semantic Web”一文。
文中正式提出了语义网的概念,鉴于Tim Berners-Lee在Web领域的巨大影响,该文后来一直被公认为是开辟语义网研究的源头文献。
为了实现知识的共享和重用,语义网研究中引入本体技术是最近几年来的发展趋势,且正在被不断的实践。
知识工程和人工智能学科针对本体技术进行研究已有多年历史,其中最有影响的科学研究组织是美国Stanford大学的知识系统实验室。
该实验室的Gruber博士以及Deborah L. McGuiinness博士都对本体和语义网本体研究作出了巨大的贡献。
本文的结构安排如下:第二部分介绍本体的表示方法和本体开发的生命周期;第三部分介绍语义网研究中的本体语言发展过程以及多种本体语言之间的关系;第四部分介绍本体在语义网研究中的应用实例;第五部分讨论我们今后一年的研究思路和研究目标。
2. 本体的表示与本体开发关于本体的定义如今在计算机科学领域已比较统一,但在具体的应用环境中如何规范化描述本体至今还缺乏统一的标准。
目前有两种本体表示方法应用比较广泛,第一是传统的四元素表示方法、第二是较新的六元组表示法。
前者源于Gruber博士的观点,后者则是2002年由新加坡南洋理工大学的Myo Myo Naing博士在一篇国际会议论文中提出。
前者在世界范围内得到了比较高的认同,但是形式过于灵活,不易掌握。
后者因为定义规范,可操作性强,得到了广大国内研究者的欢迎。
2.1 四元素的本体表示方法四元素表示方法的基本思想是:一个本体中的四个主要元素是:概念(concepts)、关系(relations)、实例(instances)和公理(axioms)[3]。
四元素表示法在IEEE Intelligent System 等杂志上发表的论文中比较常见,但遗憾的是我还没有找到讨论四元素形式化描述本体的源头性论文。
以下介绍是根据文献[3]中的介绍翻译而成。
由于该文作者来自生物信息计算领域,文中所举例子都是生物和化学领域的一些领域知识。
为了更好的介绍本体,在一些自己已彻底明白的地方使用了自己举的例子。
有些重要的定义附了原文,避免误解。
概念表示某个领域中一类实体或事物的集合。
通常概念可以分成两大类,一类是简单概念(primitive concepts),另一类是定义的概念(defined concepts)。
简单概念是那些只有必要条件的类成员关系 (primitive concepts are those which only have necessary conditions (in terms of their properties) for membership of the class.)。
例如:正方形是四个角都是直角的四边形。
因此所有的正方形的四个角都是直角,但允许一些四个角都是直角的四边形不是正方形。
定义的概念是指关于一个事物是另一个类成员的既充分、又必要的描述(Defined concepts are those whose description is both necessary and sufficient for a thing to be a member of the class.)。
例如:“三好学生”是学习好、身体好、思想好的学生。
三好学生一定是学习好、身体好、思想好,而学习好、身体好、思想好的学生就是三好学生。
关系描述概念和概念的属性的交互(Relations describe the interactions between concepts or a concept's properties.)。
关系也可以分为两大类:一种是树状分类学关系;另一种是联合关系。
分类学将概念组织成子类-超类状的概念树结构(Taxonomies that organize concepts into sub- super-concept tree structures.)。
最常见的分类形式是:专门化关系(Specialization relationships)通常被认为是“××是一种××”的关系。
例如:博士生是研究生,而研究生是学生。
部分关系(Partitive relationships)是描述一个概念部分的是另一个概念。
例如:部分博士研究生是在职的工作人员。
联合关系是指树状结构概念之间的横向关系。
常见的联合关系如下所示。
主格关系描述概念的名称(Nominative relationships describe the names of concepts)。
位置关系描述一个概念与其他概念的的相互位置关系(Locative relationships describe the location of one concept with respect to another)。
结合的关系表示功能,处理概念(Associative relationships that represent, for example, the functions, processes a concept has or is involved in, and other properties of the concept)。
还有一些其它的关系类型,如因果关系(causative' relationships)等。
与概念一样,关系也可以被组织成分类树状的结构。
关系也有属性,这些属性可深入刻画、描述概念之间的关系。
它们包括:一个关系必须抓住(hold on)一个概念是否具有普遍的必要性;一个关系是否可以随意或者可选的抓住一个概念;一个概念关系链是否严格的遵守确定的概念;关系的势;关系是否是可传递的。
实例是概念表示的具体的事物,如:华中师范大学是概念“大学”的一个实例。
严格的说,一个本体不应该包括任何实例,因为它被假设为一个具体领域的概念化。
一个本体与相关的实例的组合就是我们如今所称呼的知识库(knowledge base)。
然而判断一个东西是否是某个概念的实例实际上是很困难的,通常它依赖于具体的应用。
例如:化学元素是个概念,钾是化学元素的一个实例。
但是关于钾是化学元素的一个实例的判定却是有争议的,因为钾本身是一个概念,它表示不同的钾和钾的同位素。
上述问题是知识管理研究中的一个公开问题。
最后,公理是用来限制类和实例的取值范围,公理中包括许多具体的规则和约束。
2.2 本体的六元组表示方法新加坡南洋理工大学的Myo Myo Naing 博士定义的六元组本体表示方法被国内研究者的接受程度比较高。
以下是六元组表示方法的具体介绍[4]。
{}log ,,,,,C R An Onto y C A R A H X =其中C 表示概念的集合。
A C表示多个属性集合组成的集合,其中每个属性集合对应于一个概念。
R 是一个关系集合。
A R 是由多个属性集合组成的集合,其中每个属性集合对应于R 中的一个关系。
H表示概念之间的层次结构关系,X 表示公理集合[1]。
C 中的每个元素C i 表示同质、并且能够用相同属性集A C (c i )描述的对象。
关系集R 中的每个元素r i (c p , c q )是一个二元组,表示概念c p 与c q 之间的二元关系。
关系r i 的属性可以用A R (r i )来表示。
序偶(c p , c q )是H 中的元素,它表示c p 与c q 是父子关系或者超集-子集的关系。
X 中的元素实际上是概念、关系属性之间的一些约束条件[4]。
为了深入描述本体的表示方法,以下列出了一个大学本体描述实例[4]。
学校里有学生、博士生、教授等多种不同身份的人,只要把这些关于人的身份的名词归纳起来,就得到了概念集合C univ 中的元素。
每一类事物都有自己的属性,把这些属性都列出来就是A C 中的内容,从例一中不难验证A C是一个关于集合的集合。
根据实际领域中的客观事实,不难找出两个不同的概念之间的相互关系,从而生成R。
其它三个元素的生成,也很类似。
从该例可见,如何找出不同概念之间的关系,其实主要是依赖领域专家的观点,而不是计算机工作者的想当然。
从以上大学本体的描述实例不难发现,只要有一定的离散数学基础,根据实际需求,形式化定义、描述应用系统所必需的本体从方法上来看并不是十分困难。
从大学中的人物身份和关系的本体实例来看,写一个本体,与我们过去做面向对象的程序设计或者关系数据库分析与设计依然有相通之处。
也就是说过去的经验,在本体设计中可以应用。
比较四元素本体表示法与六元组表示法,我觉得它们在本质上是大同小异。