Logit和Probit模型的比较结果
解释概率模型:Logit,Probit以及其他广义线性模型

主讲人:xxx 2018.12.17
1
目录
1 介绍
2 广义线性模型和对其系数的解释
3 二分的logit和probit模型
44 序列logit和probit模型
5 有序logit和probit模型
6 多类别logit模型 7 条件logit模型
8 泊松回归模型
9
总结
2
一、介绍
在社会学家的工具箱里,最基本的统计方法就是对一个连续的线性的因变量(或者可以转化成线 性的)进行回归分析。然而很多社会科学家研究的对象是无法用经典的回归模型来分析的,因为很多 的态度、行为、特点,决定以及事件(无论本质上是连续的或者不连续的)是用离散的.虚拟的、序列 的或者简单来说,非连续的方法来测量的。
对比为了避孕而进行了绝育手术和 没有进行绝育手术,婚姻状况变量的 估计值为-2.80。取指数后所得出的结 果是0.061。相较不去绝育而言,未婚 女性做避孕手术的比数只是已婚女性 做这个手术比数的0.061倍
连续变量:年龄
40
给定自变量后的预测概率 我们可以根据等式6.1和等式6.2计算出预测 概率,如右图,我们也可以画出概率的条形 图如下图。
多类别logit模型:
[6.1]
[6.2]
37
在使用多类别logit模型时,一个重要的问
等式6.1和等式6.2可以推出如下:
题就是在无关选择之间独立性的假设,或者称
做IIA。简单来说,IIA的特性明确了每任意两
个选择(回答类别)的概率的比例都不应系统性
多类别logit的关系函数:
地受到其他任何选择的影响。这是一个非常重 要的前提假设,每当使用本章里面定义的多类
划分处理此类数据的一些统计模型常常根据数据的种类来代表和讨论,比如“二分数据分析”、 “序列数据分析”、“类别数据分析”或者“离散选择分析”,或者作为一个特别的模型,比方说 logit或者probit 模型。这些相关联的统计方法的共同特点就是它们都是对某事件的概率来建模。因此, 在本书里,我将所有分析事件概率的统计模型统一称为“ 概率模型”。我们讨论的概率模型包括二 分的,序列的,有序的logit和probit,多类别logit,条件logit,以及泊松回归模型。
probit模型与logit模型

probit模型与lo git模型2013-03-30 16:10:17probit模型是一种广义的线性模型。
服从正态分布。
最简单的pr obit模型就是指被解释变量Y是一个0,1变量,事件发生地概率是依赖于解释变量,即P(Y=1)=f(X),也就是说,Y=1的概率是一个关于X的函数,其中f(.)服从标准正态分布。
若f(.)是累积分布函数,则其为Log istic模型Logit模型(Logitmodel,也译作“评定模型”,“分类评定模型”,又作Logi sticregres sion,“逻辑回归”)是离散选择法模型之一,属于多重变量分析范畴,是社会学、生物统计学、临床、数量心理学、市场营销等统计实证分析的常用方法。
逻辑分布(Logist ic distri butio n)公式P(Y=1│X=x)=exp(x’β)/1+exp(x’β)其中参数β常用极大似然估计。
Logit模型是最早的离散选择模型,也是目前应用最广的模型。
Logit模型是Luc e(1959)根据IIA特性首次导出的;Marsch ark(1960)证明了Log it模型与最大效用理论的一致性;Marley (1965)研究了模型的形式和效用非确定项的分布之间的关系,证明了极值分布可以推导出Logi t 形式的模型;McFadd en(1974)反过来证明了具有Log it形式的模型效用非确定项一定服从极值分布。
此后Logi t模型在心理学、社会学、经济学及交通领域得到了广泛的应用,并衍生发展出了其他离散选择模型,形成了完整的离散选择模型体系,如Probi t模型、NL模型(Nest Logitmodel)、MixedLogit模型等。
模型假设个人n对选择枝j的效用由效用确定项和随机项两部分构成:Logit模型的应用广泛性的原因主要是因为其概率表达式的显性特点,模型的求解速度快,应用方便。
logit模型与probit模型估计的系数标准误

logit模型与probit模型估计的系数标准误一、引言中文很多论文为了显得高大上,故意写的让人看不懂。
例如在使用PSM模型时,一般都会写使用logit回归0,1虚拟变量,得到倾向得分值。
其实,在使用patch2命令时,可以直接得到相应的结果,这些模型都被大牛编写了外部命令,并进行了发布。
下一章节以一篇论文的形式重现PSM实证过程,重点介绍下patch2的用法和几种匹配模型。
本文主要阐述logit的原理以及如何操作。
面板数据做二元值问题有专门的命令,具体可以help xtlogit。
其实,这些命令的本质是一样的。
后期有机会会更新一些不同命令得到相同结果的操作。
这些内容更新完毕,最后给大家送点福利,以自己的一篇论文的数据和代码说明PSM-DID具体操作过程。
具体更新为:PSM(III)——patch2PSM(IV)——PSM-DID二、二元Logit模型实证分析中,会遇到被解释变量为“是/否”或者政策事件“发生/未发生”的情形。
此时被解释变量可以标记为0或者1。
例如分析企业社会责任息披露的影响因素(披露为1,未披露为0),此时被解释变量就为二值变量或者0-1变量。
对于这样的被解释变量,Stata 连享会推文二元选择模型:probit 还是 logit?一文中采用模特卡罗模拟发现,使用线性概率模型将生成不一致的估计结果。
因此,考虑使用概率模型克服估计有偏的情况,即二元Logit模型。
在分析企业社会责任息披露的影响因素中,被解释变量yi 为企业是否披露息,y i 的取值为0或1,将y i 看作随机变量Y i 的实现值:Y i 取1的概率为π i ,取0的概率为1-π i ,Y i 服从参数为π i 的(0-1)分布,Y i 的分布率为显然,当y i = 1时,Y i 的概率为π i ;当y i = 0时,Y i的概率为1-π i 。
Y i 的期望和方差为,所以,Y i 的期望和方差只取决于π i ,任何影响概率的因素会同时影响均值和方差。
上市公司分配现金股利概率的probit和logit模型对比研究

收稿 日期 :0 0—0 21 8—2 1
作者简介 : 付连军 , 讲师 , 主要从事企业财务问题实证分析等 方 面的研究 ; 马传兵 , 副教授 , 主要从事 企业无形 资产 与 心竞争力 等 核
方面的研究 ; 嵇冉 , 副教授 , 主要从事 产业经济 与应用统 计‘ 分析等 方
面 的研 究 。E—m il nuf@yh ocn.i a:ajnn ao.o c i q
第1 0卷 第 6期
2 0正 01
中 国
发
展
Vo . 0 No 6 11 . De . c 2 0 01 21
1 2月
Ch n v lp e t i a De eo m n
上 市 公 司 分 配 现 金 股 利 概 率 的 po i和 l i模 型 对 比研 究 rbt o t g
收效应 有 反应 , 而各 公 司问 的 股利 发 放 存 在 较大 差
征 的现 代理 财 阶段 。股利政 策是 现代 公 司理财 的核 心 内容 之一 , 既是 公 司前 期 筹 资 和 投 资 活动 的必 它
然 结果 和延续 , 同时 符合 公 司 当前 发 展 战 略 的股 利 政策 , 又可使 公 司获 得 长 期 稳定 发 展 的条 件 。现 金
股 利是用 货 币资金 形 式 支 付 的股 利 , 种 股 利 形 式 这 既是上 市公 司常用 也 是 投 资 者容 易接 受 的方 式 , 但 无 疑会大 量增 加公 司现 金 流 出 , 给公 司形 成 重 大 资 金 支付压 力 。规模 较小 且处 于发展 初期 的公 司通 常
不发 放现 金股利 , 而公 司认 为 自己 已足 够 成 熟 并有
企 业微 观个 体财 务 特 征 的考 察 人 手 , 据 著 名经 济 根 学 家 Mcae F dn的行为 理性 选择 剖视 理论 , 利用 Po— rb
Logistic模型与Probit模型用于上市公司财务预警的比较

组准则被这些有强烈盈余管理动机的企业所利用。假设 3、假 营绩效。
设 5 得到验证。
【注】 本文系教育部人文社科基金资助项目“基于会计准
实行新会计准则后,亏损公司(LOSS×NAS)与剔除非流 则变迁的上市公司盈余管理研究 ”(项目编号 :09XJA790006)
动资产处置净损益后的营业外收入占利润总额的比例(ZD2) 的阶段性研究成果。
但是,进行线性回归所得估计值可能远离[0,1]。此外,通常情
“壳”资源,即使上市公司面临破产危险,也会有其他企业将其 况下因变量 p 与自变量 xi 并非呈线性关系,而是呈 S 型曲线 接收(即借壳上市),所以企业申请破产的可能性很小。然而, 关系,这说明不能直接通过线性回归对二分变量进行拟合。然
将上市公司被特别处理视为陷入财务困境可解决这一概念界 而,对因变量进行 Logit 变换便可解决这两个问题。通过这种
为全面的评价,但是由于选取的指标比较多,增强了分析的复 杂性,并且这些指标反映的信息存在一定的重叠。因此,必须 选出那些最能区分 ST 公司和非 ST 公司状况的指标。下面的 数据处理皆运用 SPSS16.0 软件完成。
表3
多重共线性检验结果
T-1
T-2
TOL VIF TOL VIF
X1 0.807 1.239 0.759 1.317
二、研究设计
X1、X4、X5、X6、X9、X10、X11、X13、X14、X15、X16、X17、 T-2 X24、X27 T-3 X1、X4、X11、X14、X16、X17
1. 样本选取。首先,为避免出现年度效应和高估模型的
从表 2 可以看出,X1、X、X11、X14、X16 和 X17 在三年
预测能力,选择近三年来新增的被 ST 公司(排除因非经营性 中的差异都显著。因此,从各年变量选取的统一角度来讲,可
离散因变量模型(Logit 模型,Probit模型)

(2)估计:用 logit 法估计。 模型形如:
Y ( x)
(调用数据库和程序E:\logit)
模型结果:
Stata 命令:logit y score d1
Logit estimates Log likelihood = -3.979482
Number of obs =
LR chi2(2)
yi F ( X i B) i
eZ F(Z) 1 eZ (Z)
模型 yi ( Xi B) i
f
(Z)
F'(Z)
eZ (1 eZ )2
(Z )(1 (Z ))
线性化 pi ( Xi B)
∵
(Z )
eZ 1 eZ
pi ( X i B) eXiB 1 pi 1 ( X i B)
( X i B) x j
f (XiB) j
(四) 分布函数F的选取
选取分布函数F的原则:
0 F(XiB) 1
X i B F ( X i B) 1
X i B F ( Xi B) 0
F是单调函数
按照上述原则F取作累计分布函数。 下面介绍三种不同分布函数下的计量模型:
内容
二元选择模型的三类模型介绍 二元选择模型的估计: 二元选择模型的检验: 二元选择模型的应用
一、 二元选择模型
二元选择模型的理论模型 二元选择模型经济计量的一般模型 线性概率模型(LPM) Logit 模型 Probit 模型
(一) 二元选择模型的理论模型
效用是不可观测的只能观测到选择行为uiii11??x1??uiii000??x??uuiiiii1010?????x10????iiy?????ix第i个个体选择1的效用第i个个体不选择1选择0的效用1000iiiiyyyy???????????选择1不选择1选择0二二元选择的经济计量一般模型ftft???11011iiiiipyxpyppff????????????????????iiiixxxx101iieyxppf???????ixyeyx???yfxb???12
比较logit 模型和probit 模型

European Journal of Scientific ResearchISSN 1450-216X Vol.27 No.4 (2009), pp.548-553© EuroJournals Publishing, Inc. 2009/ejsr.htmThe Comparison Logit and Probit Regression Analyses inEstimating the Strength of Gear TeethA.A. ShariffCentre For Foundation Studies In Science, University of Malaya50603 Kuala Lumpur, MalaysiaE-mail: asma@.myA. ZaharimFaculty of Engineering and Built EnvironmentK. SopianSERI University Kebangsaan Malaysia, Bangi, Selangor, MalaysiaAbstractLogit and probit are two regression methods which are categorised under Generalized Linear Models. Both models can be used when the response variables in theanalyses are categorical in nature. For the case of the strength of gear teeth data, it can be interms of counted proportions, such as r teeth fail out of n teeth tested. In this paper, the twomodels, logit and probit are discussed and the methods of analysis are compared forsimulated data sets obtained from experimental procedure called staircase design (SCD)experiment. For the analysis, the response variable is the proportion failing and theexplanatory variable is the corresponding load. The analysis is also compared with theexplanatory variable of logarithm of load. The population distributions of strengthsconsidered are normal and Weibull distribution and 1000 SCD experiments are simulated.The sampling distributions of the various estimators are then compared for bias, standarddeviation, and mean squared error for the two contrasting population distributions ofstrength. It is found that, a regression of the logit on the logarithm of load seems to be themost robust approach if normality of strengths is in doubt.Keywords:Logit, probit, regression analysis, counted proportion, gear teeth, staircase design.1. IntroductionFor ordinary linear regression, the response variable is always quantitative and continuous in nature. When the response variables are categorical and in particular binary, that is, it can assume only two values (a ‘yes-no’ or ‘fail-survive’) or in terms of counted proportions (r fail out of n tested) we are led to consider some other models which are more appropriate than ordinary linear regression. An important characteristic of data in which the response variables are binary is that the response variables must lie between 0 and 1. Therefore fitting these data using ordinary linear regression can give prediction for the proportion of above one or less than zero, which would be meaningless. On the otherThe Comparison Logit and Probit Regression Analyses in Estimating the Strength of Gear Teeth 549hand what we actually need in this situation is a regression model which will predict the proportion ofoccurrences, p (let us call them p instead of y ) at certain levels of x .For this type of data, in particular, when the response variables are in terms of countedproportions, the relationship between response variables p and explanatory variables x is a non-linearcurved relationship (S-shaped) curve which is usually called sigmoid . The S-shaped behaviour is verycommon in modeling binomial responses as a function of predictors and also makes use of theassumption that the responses are from underlying binomial or binary distribution. The purpose oflogistic modelling (and also probit) is the same as other modelling techniques used in statistics, that is,to find a model that fits the data best and is the simplest, yet physically reasonable in describing therelationship between the response and the explanatory variables [1]. There is little to distinguishbetween logit and probit models. Both curves are so similar as to yield essentially identical results. Itwas found that probit and logit analysis applied to the same set of data produce coefficient estimateswhich differ approximately by a factor of proportionality, and that factor should be about 1.8 [2].2. Materials and Methods2.1. Logit Versus Probit Regression Techniques Logit model can be presented asp Z Z =+exp()exp()1 (1) where p is the proportion of occurrences, Z =βββ011+++x x k k ... and x x k 1... are the explanatory variables. The inverse relation of equation (1) isZ p p =−⎛⎝⎜⎞⎠⎟ln 1 (2) that is, the natural logarithm of the odds ratio, known as the logit. It transforms p which is restricted tothe range [0, 1] to a range [,]−∞∞ .Probit regression analysis involves modeling the response function with the normal cumulativedistribution function. The probit of a proportion p is just the point on a normal curve with mean 0 andstandard deviation 1 which has this proportion to the left of it.The model can be presented asΦ−==+++1011()...p Z x x k k βββ (3) where p is the proportion and Φ−1 is the inverse of the cumulative distribution function of the standard normal distribution. That is,p Z u du Z ==−−∞∫Φ()exp(/)1222π (4) is the cumulative distribution function of the standard normal distribution.For logistic and probit regression, the binomial, rather than the normal distribution describesthe distribution of the errors and will be the statistic upon which the analysis is based. The principlesthat are used for ordinary linear regression analysis could be adapted to fit both regressions. However,instead of using least square method to fit the model, for logistic and probit regressions, it is moreappropriate to use maximum likelihood estimate. The likelihood function is given asL p p i r i mi n r i i i =−=−∏()11,where the p i are defined in terms of the parameters ββ0,...,k and the known values of the predictorvariables. This has to be maximized with respect to the parameters.550A. A. Shariff, A. Zaharim and K. Sopian2.2. Experimental Design Gear teeth are commonly tested by applying oscillatory loads, using a special machine called pulsator-test machine. In the experiment, the test specimen, in this case the gear tooth is subjected to vibrations of a resonant spring/mass system. When this happens, it experiences stresses and crack propagation takes place. Eventually, after certain number of cycles the tooth fails. The number of cycles to failure can then be recorded. If the tooth does not fail after a certain fixed number of cycles, it is considered to have survived in the experiment. The experimental procedure used is the well-known staircase design (SCD). SCD experiment is also known as sensitivity testing or ‘up-and-down’ method [3] where the testing of specimens is made close to the anticipated mean level. In the experiment the first test piece should be tested at a load level assumed to be near the mean value of the fatigue strength. If failure occurs before N cycles, the next test piece is tested at one step, a fixed change in load, below the first load level. Otherwise, the next test at the load one step above the first level. This procedure is continued until all the pieces have been tested. The increment between load levels should be equal for steps up and down and should be approximately one standard deviation of the fatigue strength distribution. Since the data obtained are categorical in nature, particularly in terms of counted proportions, fatigue strength of a gear is then determined by analysing the data obtained using appropriate statistical techniques, in this case logit and probit.2.3. Analysis For SCDThe results obtained in the experiment are then analysed using logit and compared with probit. Thelogit transformation of p is defined by ln(p p1−, and the lines ln()p px 101−=+ββ are fitted, using maximum likelihood. A comparison is made with fitting the line,ln()ln p px 101−=+ββ which is equivalent to assuming a log-normal distribution of strengths.For probit, results of SCD experiment are analysed by fitting the lineΦ−=+101()p x ββwhere p is the proportion failing and x is the corresponding load. This is equivalent to assuming a normal distribution of strengths. Then a comparison is made withΦ−=+101()ln p x ββThe estimated mean fatigue strength, μ, and the lower 1% point of the distribution of fatiguestrength, .x 099, are the values of x corresponding to p =05. and p =001. respectively. The standarddeviation can be estimated from ( )/..σμ=−x 099233 .The methods of analysis have been compared for simulated data sets. The population distribution of strengths is specified and 1000 SCD experiments are simulated. The sampling distributions of the various estimators can thus be compared for bias, standard deviation, and mean squared error. Two contrasting population distributions of strength are considered:(i). normal distribution with mean of 20.0 and standard deviation of 2.0;(ii).W eibull distribution [4 – 6], which has a cumulative distribution function F(x) defined by Pr()()exp[(/)]X x F x x b c <==−−1),with shape parameter, c = 2, and scale parameter, b = 22.56. These parameter values correspond to a mean of 20 and standard deviation of 10.45. The probability density functions of both distributions are plotted in Figure 1. The Weibull distribution has a substantial area near zero. This might be realistic forThe Comparison Logit and Probit Regression Analyses in Estimating the Strength of Gear Teeth 551the strength of a component being tested under extreme conditions, as in an accelerated testing programme. It could also be interpreted as strength above some minimum value.Figure 2: Probability density function of normal (,.)μσ==2020 and Weibull (,.45)μσ==2010distributionIn the simulation, each SCD used 50 test specimens. There are 1000 independent SCD experiments within a simulation. Each specimen put on test is randomly selected from the 50 specimens. For the normal distribution the load increment is chosen to be 2, while for the Weibull distribution it is chosen to be 6, since the standard deviation for this distribution is larger.Results obtained from the above experiments are analysed using logit and then compared with probit analyses for each distribution. The means and standard deviations of the estimated mean, standard deviation and lower 1% point of the strength distribution are computed from 1000 SCD experiments for each distribution.These results are tabulated in Table 1; the standard deviations of these statistics are shown in brackets, and the root mean square error (RMSE) is also calculated using the formula552A. A. Shariff, A. Zaharim and K. Sopian Table 1:Results of Staircase Experiments Analysed by Probit and Logit Regression Techniques with the load on a linear scale for Each Distribution.RMSE (standard deviation)(bias)22=+where, bias = (actual value - mean of estimated value).These RMSE values are presented in square brackets. Table 2 shows results for the logit and probit analysis using a logarithmic scale for load.Table 2: Results of Staircase Experiments Analysed by Probit and Logit Regression Techniques with the loadon a logarithmic scale for Each DistributionThe Comparison Logit and Probit Regression Analyses in Estimating the Strength of Gear Teeth 553 3. Results and DiscussionTable 1 indicates that for load on linear scale, results obtained by probit analysis are more realistic with less error as compared to logit for normal distribution of strength. Logit analysis appears to overestimate the standard deviation and hence underestimate the lower one percent point of the distribution. However, for the Weibull distribution, which has a large standard deviation, both methods predict negative lower 1% points which are physically impossible.Regressing the sample probit against the logarithm of load (refer to Table 2) gives estimates with a smaller standard deviation and, somewhat surprisingly, a slightly smaller mean squared error. Regressing logit of the sample proportion against the logarithm of load is a slight improvement on the probit analysis and aconsiderable improvement on a regression of logit against load.When sampling from both normal and Weibull distributions the regression of the logit against the logarithm of load gives an estimate of the lower 1% point with the smallest mean squared error. Overall, a regression of the logit on the logarithm of load seems to be the most robust approach if normality of strengths is in doubt.References[1]Hosmer, D.W., & Lemeshow, S. (1989). Applied Logistic Regression. Wiley Series inProbability and Mathematical Science. Wiley-Interscience Publication.[2]Aldrich, J.H. & Nelson, F.D. (1984). Linear Probability, Logit and Probit Models. SageUniversity Paper series on Quantitative Applications in the Social Sciences, 07-045. Beverly Hills and London: Sage Pubns.[3]Lloyd, D. K., & Lipow, M. (1989). Reliability: managements, methods, and mathematics(Second ed.). American Society for Quality Control.[4]ISO/CD 12107. (1997). Draft for Public Comment, Metallic Materials - Fatigue Testing -Statistical Planning and Analysis of Data, British Standard Institution.[5]Weibull, W. (1961). Fatigue Testing and the Analysis of Results. Pergamon Press. Oxford.[6]Crowder, M.J., Kimber, A.C., Smith, R.L. & Sweeting, T.J. (1991). Statistical Analysis ofReliability Data. Chapman and Hall.。
解释概率模型:Logit,Probit以及其他广义线性模型

[6.2]
37
在使用多类别logit模型时,一个重要的问
等式6.1和等式6.2可以推出如下:
题就是在无关选择之间独立性的假设,或者称
做IIA。简单来说,IIA的特性明确了每任意两
个选择(回答类别)的概率的比例都不应系统性 地受到其他任何选择的影响。这是一个非常重
多类别logit的关系函数:
察到的和估计出来的两者之间的比数比的差就会消失。
10
给定自变量后的预测概率
这些预测的概率告诉我们每一组里面有多少成员有过性行为,给出了一个简单、直观的理 解。基于logit 模型,预测大约55%的黑人男性有过性行为,白人女性青少年有过性行为仅为大
约15%。
11
发生某事件概率的边际效应
我们去看解释变量对发生某事件的概率所带来的边际效应。可以用下面的等式来表示:
35
发生某事件概率的边际效应
对事件概率的边际效应: 利用上面的公式我们可以得到在这个例子中的边 际效应如右图所示可以看出:AFQT得分,用偏导数 和用预测概率差两个方法都能给出基本相同的结果。 (AFQT是连续变量);如果计算入伍时的婚姻状况 可以看出,用两种方法计算出被分配到高级任务的概 率减少了大约相差5%。(入伍时的婚姻状况是二元变 量)在有二分自变量的时候,使用偏导数的方法产生
确的值其实是在这两个值之间或接近这两个值。
在一些特殊情况logit和probit模型得出的估计是差得非常远的,这样就一定要去考虑使用最
合适的模型了。对于尾端比重很大的分布来说,我们更应该考虑logit模型。
16
四、序列logit和probit模型
有时,一些因变量的结果是多样的,但它们并不是一些完全离散的毫无关联的类别。这些反应的类 别可以看做一系列阶段。晚期的响应是嵌套在早期的响应里面的。例如,结婚的决定是分两个阶段的: 一个人是否计划结婚,然后就是这个婚姻是否会在结束了某种教育程度之前开始(例如完成高中或者大 学学历)。
二值因变量模型_14.2Probit和Logit模型

对外经济贸易大学计量经济学I n t r o d u c t i o n t o E c o n o m e t r i c s导论二值因变量模型:Probit和Logit模型Probit和Logit回归在线性概率模型中,y=1 的概率是x 的线性函数:P (y= 1|x) = β0+ β1x在非线性概率模型中:对于β1>0,Pr(y= 1|x)是x的单增函数;010 ≤ P(y= 1|x) ≤ 1 对所有的x都成立。
02我们希望构造一个非线性函数来刻画此概率。
例如一个“S-curve”的函数。
Probit回归用标准正态分布的累积分布函数Φ(z)来建模y=1 的概率。
令z= β+ β1x,那么Probit回归模型的形式为P(y= 1|x) = Φ(β0+ β1x)其中Φ为标准正态分布的分布函数,z= β0+ β1x是probit模型的“z-value” or “z-index”.例如: 假设β= -2, β1= 3, x=0.4, 那么P(y= 1|x=0.4) = Φ(-2 + 3×0.4) = Φ(-0.8)Pr(z≤ -0.8) = 0.2119该函数的“S-shape”满足了我们的需要:对于β1>0,P(y = 1|x ) 是x 的单增函数010 ≤ P(y = 1|x ) ≤ 1 对于所有的x 都成立02为什么要使用标准正态分布的累积分布函数?便于使用–可以查正态分布表的到相关的概率值(在相关的软件中也很容易得到)相对直观的理解:β0+ β1x = z-value01β1对应于x变化一个单位时z-value 的变化02给定x,β0+β1x是预测的z-value 03. probit deny p_irat, r;Iteration 0: log likelihood = -872.0853Iteration 1: log likelihood = -835.6633Iteration 2: log likelihood = -831.80534Iteration 3: log likelihood = -831.79234Probit estimates Number of obs= 2380Wald chi2(1) = 40.68Prob> chi2 = 0.0000 Log likelihood = -831.79234 Pseudo R2 = 0.0462 ------------------------------------------------------------------------------| Robustdeny | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+----------------------------------------------------------------p_irat| 2.967908 .4653114 6.38 0.000 2.055914 3.879901 _cons | -2.194159 .1649721 -13.30 0.000 -2.517499 -1.87082 ----------------------------------------------------------------------------P(deny=1|P Iratio)= Φ(-2.19 + 2.97×P/I ratio)(0.16) (0.47)还款收入比前面的系数是正的: 是否符合实际?01标准差的理解和普通的回归一样02 P(deny=1| P Iratio)= Φ(-2.19 + 2.97×P/I ratio )(0.16) (0.47)STATA Example: HMDA data 当P/I ratio 从0.3 增加到0.4:04 P(deny=1| P Iratio =0.4)= Φ (-2.19+2.97×0.4) = Φ (-1.00) =0.159被拒概率的预测值从0.097 升至0.15905概率预测值:03 P(deny=1| P Iratio =0.3)= Φ (-2.19+2.97×0.3) = Φ (-1.30) = 0.097多个自变量的Probit回归模型Pr(Y= 1|X1, X2) = Φ (β0+ β1X1+ β2X2)Φ 是正态分布的累积分布函数.01z= β0+ β1X1+ β2X2是此probit模型的“z-value”或者“z-index”.02β1是固定X2,X1变化一个单位对z-score 的效应。
第四章01变量的回归模型Logistic回归Probit回归

0
1
Predict- 0
697
46
ion
1
2
1
•False Positive Rate(FPR) = 2/(697+2)=0.29% •True Positive Rate(TPR) = 1/(46+1)=2.12%
定义两种不同的分类错误 P(ST=1|X)>0.3
True Response
0
1
Predict- 0
9.2.2上市公司出现9.2.1条所列情形之一的,应当在收到审计报告之日起两个工作日内向本所报告 ,并提交上市公司董事会书面意见。 9.2.3本所收到上市公司上述报告后五个工作日内,或者在报请中国证监会认可的期限内,决定 是否对该公司股票实行特别处理。上市公司应当按照本所的要求在其股票交易实行特别处理之前 一交易日作出公告,其股票在公告日停牌一天,公告后第一个交易日复牌并实行特别处 理。
其表现特征就是在其股票名称前冠以“ST”字样
上海证券交易所股票上市规则(二00一年六月八日)
第九章特别处理 第一节基本原则 9.1.1上市公司出现财务状况或其他状况异常,导致投资者难于判断公司前景,权益可能受到损 害的,本所将对公司股票交易实行特别处理。
9.2.1上市公司出现以下情形之一的,为财务状况异常: (一)最近两个会计年度的审计结果显示的净利润均为负值; (二)最近一个会计年度的审计结果显示其股东权益低于注册资本,即每股净资产低于 股票面值; (三)注册会计师对最近一个会计年度的财务报告出具无法表示意见或否定意见的审计 报告; (四)最近一个会计年度经审计的股东权益扣除注册会计师、有关部门不予确认的部分 ,低于注册资本; (五)最近一份经审计的财务报告对上年度利润进行调整,导致连续两个会计年度亏损 ;
比较线性模型和Probit模型、Logit模型
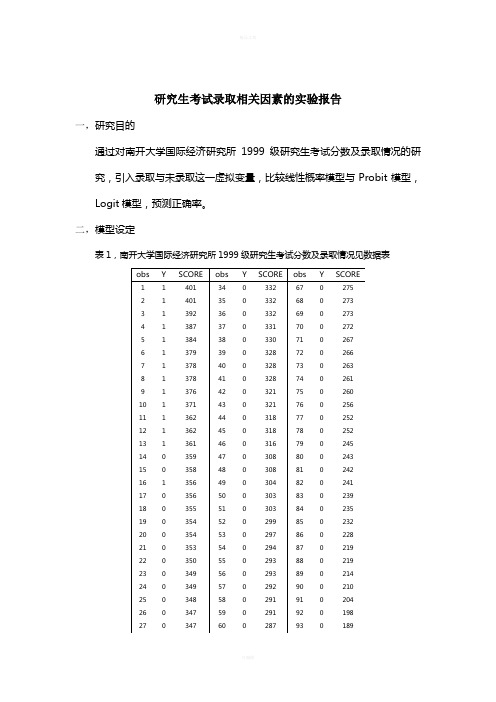
研究生考试录取相关因素的实验报告一,研究目的通过对南开大学国际经济研究所1999级研究生考试分数及录取情况的研究,引入录取与未录取这一虚拟变量,比较线性概率模型与Probit模型,Logit模型,预测正确率。
二,模型设定表1,南开大学国际经济研究所1999级研究生考试分数及录取情况见数据表定义变量SCORE :考生考试分数;Y :考生录取为1,未录取为0。
上图为样本观测值。
1. 线性概率模型 根据上面资料建立模型i i i SCORE B B Y μ++=*21用Eviews 得到回归结果如图:Dependent Variable: Y Method: Least Squares Date: 12/10/10 Time: 20:38Sample: 1 97Included observations: 97VariableCoefficientStd. Error t-Statistic Prob.C -0.847407 0.159663 -5.307476 0.0000 SCORE0.0032970.0005216.3259700.0000R-squared0.296390 Mean dependent var 0.144330 Adjusted R-squared 0.288983 S.D. dependent var 0.353250 S.E. of regression 0.297866 Akaike info criterion 0.436060 Sum squared resid 8.428818 Schwarz criterion 0.489147 Log likelihood -19.14890 F-statistic 40.01790 Durbin-Watson stat0.359992 Prob(F-statistic) 0.000000参数估计结果为: iY ˆ-0.847407+0.003297 i SCORESe=(0.159663)( 0.000521) t=(-5.307476) (6.325970) p=(0.0000) (0.0000)预测正确率:Forecast: YF Actual: YForecast sample: 1 97Included observations: 97Root Mean Squared Error0.294780Mean Absolute Error 0.233437Mean Absolute Percentage Error8.689503Theil Inequality Coefficient 0.475786Bias Proportion 0.000000Variance Proportion 0.294987Covariance Proportion 0.7050132.Logit模型Dependent Variable: YMethod: ML - Binary Logit (Quadratic hill climbing) Date: 12/10/10 Time: 21:38Sample: 1 97Included observations: 97Convergence achieved after 11 iterations Covariance matrix computed using second derivativesVariable Coefficient Std. Error z-Statistic Prob.C-243.7362125.5564-1.9412480.0522SCORE0.679441 0.350492 1.938536 0.0526Mean dependent var 0.144330 S.D. dependent var 0.353250 S.E. of regression 0.115440 Akaike info criterion 0.123553 Sum squared resid 1.266017 Schwarz criterion 0.176640 Log likelihood -3.992330 Hannan-Quinn criter. 0.145019 Restr. log likelihood -40.03639 Avg. log likelihood -0.041158 LR statistic (1 df) 72.08812 McFadden R-squared 0.900282Probability(LR stat) 0.000000Obs with Dep=0 83 Total obs 97Obs with Dep=114得Logit 模型估计结果如下p i = F (y i ) =)6794.07362.243(11i x e +--+ 拐点坐标 (358.7, 0.5)其中Y=-243.7362+0.6794X预测正确率Forecast: YF Actual: YForecast sample: 1 97 Included observations: 97Root Mean Squared Error 0.114244 Mean Absolute Error0.025502Mean Absolute Percentage Error 1.275122Theil Inequality Coefficient 0.153748Bias Proportion 0.000000Variance Proportion 0.025338Covariance Proportion 0.9746623.Probit模型Dependent Variable: YMethod: ML - Binary Probit (Quadratic hill climbing) Date: 12/10/10 Time: 21:40Sample: 1 97Included observations: 97Convergence achieved after 11 iterations Covariance matrix computed using second derivativesVariable Coefficient Std. Error z-Statistic Prob.C-144.456070.19809-2.0578330.0396SCORE0.4028680.196186 2.0535040.0400 Mean dependent var0.144330 S.D. dependent var0.353250 S.E. of regression0.116277 Akaike info criterion0.122406 Sum squared resid 1.284441 Schwarz criterion0.175493Log likelihood-3.936702 Hannan-Quinn criter.0.143872 Restr. log likelihood-40.03639 Avg. log likelihood-0.040585LR statistic (1 df)72.19938 McFadden R-squared0.901672 Probability(LR stat)0.000000Obs with Dep=083 Total obs97Obs with Dep=114Probit模型最终估计结果是p i = F(y i) = F (-144.456 + 0.4029 x i) 拐点坐标(358.5, 0.5)预测正确率Forecast: YFActual: YForecast sample: 1 97Included observations: 97Root Mean Squared Error0.115072Mean Absolute Error 0.025387Mean Absolute Percentage Error 1.216791Theil Inequality Coefficient 0.154476Bias Proportion 0.000084Variance Proportion 0.020837Covariance Proportion 0.979080预测正确率结论:线性概率模型RMSE=0.294780 MAE=0.233437 MAPE=8.689503Logit模型RMSE=0.114244 MAE=0.025502 MAPE=1.275122Probit模型RMSE=0.115072 MAE=0.025387 MAPE=1.216791由上面结果可知线性概率模型的RMSE、MAE、MAPE 均远远大于Logit模型和Probit模型,说明其误差率比Logit模型和Probit模型大很多,所以正确率远远小于Logit模型和Probit模型。
stata名师16 Logit、probit模型及其stata实现

兰大管理学院 杨利雄
Poisson model
Poisson回归模型:
y exp[ exp( x u)][exp( x u)] / h!
h
MLE估计
兰大管理学院 杨利雄
Poisson模型stata实现
Example17.3(p607) Data:CRIME1.RAW
兰大管理学院 杨利雄
pi G( xi ui )
兰大管理学院 杨利雄
Logit model
系数的解释
p( y 1| x) G ( x) pi G ( xi ) p g ( x) x
其中g为密度函数。 x增加一个单位,概率增加 g ( x)
兰大管理学院 杨利雄
线性概率模型
当被解释变量只能取值0,1时,这样的线性回 归模型又叫概率模型。 比如y变量为衡量促销活动中消费者“买”或 “不买”的变量;促销的规模等作为解释变量 x,建立模型: y xu “买”的概率 p( y 1| x) x
兰大管理学院 杨利雄
outline
Logit model Probit model
Tobit model
Poisson model
兰大管理学院 杨利雄
Logit、probit模型及其stata实现
很多定性的变量,可以转化为取值为0、1的数 量化变量。例如,促销活动中消费者买或不买 某商品。 另一种特例:某些变量取值只能为正数。如计 数变量,只能取值0,1,2,3,。。。 问题:当这样的变量做被解释变量时,怎么解 决?
解决思路: 1,推导概率
Probit Model vs Logit Model

if U * U * 1i 2i if U * U * 1i 2i
* U * U * yi 1i 2i
(Unobserved variable)
Probit Model
y* x u i i i
1 y i 0
Assume:
if if
y* 0 i y* 0 i
' i ' i
Maxim umchangeoccurs when I i x i 0
The logit model
The logit model uses the logistic distribution instead of the normal distribution for our model
F(x i )
'
1 1 e
' xi
T hedensit y funct ionis f x i
'
1 e
' xi
e
' xi
2
T hemarginaleffectof a changein xij is st ill Pi e ' f xi j ' xi x ij 1 e
Picture of LPM
ˆ y
1
0
X X0 X1
Problems of LPM
• Predictions outside 0-1 range. • Heteroscedasticity
– This can be solved and a estimated GLS estimator developed.
probit logit 解析表达式 -回复

probit logit 解析表达式-回复题目:[Probit Logit 解析表达式]——一步一步解析导言:Probit和Logit模型是在统计学中常用的概率模型,用于建模分类和回归问题。
本文将详细解析Probit和Logit模型的表达式,解释其数学意义和应用背景。
让我们一步一步地开始吧!第一步:概率模型基础在进一步解析Probit和Logit模型之前,让我们先了解一些概率模型的基础知识。
概率模型是用来描述随机变量与其分布之间的关系的模型,常用于处理分类和回归问题。
在分类问题中,我们希望将样本分为不同的类别。
而在回归问题中,我们则是希望建立输入和输出之间的关系模型。
第二步:Probit模型的表达式与解析Probit模型是一种基于正态分布的概率模型,用于建模二分类问题。
其表达式如下:Φ(β⋅X) = P(Y=1)其中,Φ(·)代表标准正态分布的累积分布函数,β是模型参数,X是输入特征向量,Y是输出变量。
解析:1. Probit模型的表达式中,β和X的点积β⋅X 反映了输入特征对输出概率的影响。
2. 通过正态分布的累积分布函数Φ(·),将线性变换β⋅X 转化为一个概率值P(Y=1)。
正态分布的形状决定了概率分布的形式。
应用背景:1. Probit模型常用于金融、医疗等领域,如市场波动性预测、疾病诊断等问题。
2. 在金融领域,Probit模型可以用于预测某一股票是否会上涨或下跌,为投资者提供决策依据。
第三步:Logit模型的表达式与解析Logit模型是一种基于逻辑分布的概率模型,同样用于建模二分类问题。
其表达式如下:sigmoid(β⋅X) = P(Y=1)其中sigmoid(·)代表逻辑函数(sigmoid function),β是模型参数,X是输入特征向量,Y是输出变量。
解析:1. Logit模型的表达式中,β和X的点积β⋅X 表示了输入特征对输出概率的影响,与Probit模型类似。
logistic回归、probit回归与poission回归

问题
1. 令因变量两个水平对应的值为0、1,概率为1-p、 p,则显然我们也可以用多重回归进行分析?为 什么要用logistic回归分析?
2. logistic回归回归系数、模型评估、参数估计、 假设检验等与之前的回归分析有何不同?
3. 因变量为二分变量时既可以用logistics回归也可 以用probit回归,那么probit回归及其与logistic 回归的异同之处
logistic回归的数学表达式为: ln p X T
1 p
logistic回归的分类: (1)二分类资料logistic回归: 因变量为两分类变量的资料,
可用非条件logistic回归和条件logistic回归进行分析。非条 件logistic回归多用于非配比病例-对照研究或队列研究资料, 条件logistic回归多用于配对或配比资料。 (2)多分类资料logistic回归: 因变量为多项分类的资料, 可用多项分类logistic回归模型或有序分类logistic回归模型 进行分析。
总例数 ng
199 170 101 416
阳性数 d g
63 63 44 265
阴性数 ng dg
136 107 57 151
首先确定变量的赋值或编码:
1 吸烟 X1 0 不吸烟
1 饮酒 X2 0 不饮酒
1 病例 Y 0 对照
观
在logistic过程步
察
中加“descending”
例 数
选项的目的是使 SAS过程按阳性
率(y=1)拟合模
型,得到阳性病
例对应于阴性病
例的优势比。
OR值
OR的95%CI
logistic回归和probit回归预测公司被ST的概率(应用)

logistic回归和probit回归预测公司被ST的概率(应⽤)1.适合阅读⼈群:知道以下知识点:盒状图、假设检验、逻辑回归的理论、probit的理论、看过回归分析,了解AIC和BIC判别准则、能⾃⼰跑R语⾔程序2.本⽂⽬的:⽤R语⾔演⽰⼀个相对完整的逻辑回归和probit回归建模过程,同时让⾃⼰复习⼀遍在学校时学的知识,记载下来,以后经常翻阅。
3.本⽂不涉及的部分:(1)逻辑回归和probit回归参数估计的公式推导,在下⼀篇写;(2)由ROC曲线带来的阈值选择,在下下⼀篇写;(3)本⽂⽤的数据取⾃王汉⽣⽼师《应⽤商务统计分析》第四章⾥的数据,直接描述性分析和建模,没有涉及到数据预处理。
4.废话少说,上程序:#适合⼈群:知道以下知识点:盒状图、假设检验、逻辑回归的理论、probit的理论、看过回归分析,了解AIC和BIC判别准则、能读R语⾔程序1.#########读⼊数据##############a=read.csv("C:/Users/Thinkpad/Desktop/ST.csv",header=T)a1=a[a$year==1999,-1] #训练集a2=a[a$year==2000,-1] #测试集a1[c(1:5),]2.####初步描述性分析######boxplot(ARA~ST,data=a1,main="ARA") #画出各变量与ST的盒状图,初步查看因变量单独和各个解释性变量的关系par(mfrow=c(3,2)) #只是初步的描述性分析,没有控制其他因素的影响,没有经过严格的统计检验boxplot(ASSET~ST,data=a1,main="ASSET")boxplot(ATO~ST,data=a1,main="ATO")boxplot(GROWTH~ST,data=a1,main="GROWTH")boxplot(LEV~ST,data=a1,main="LEV")boxplot(ROA~ST,data=a1,main="ROA")boxplot(SHARE~ST,data=a1,main="SHARE")par(mfrow=c(1,1))glm0.a=glm(ST~1,family=binomial(link=logit),data=a1) ####逻辑回归时:计算模型的整体显著性⽔平#####glm1.a=glm(ST~ARA+ASSET+ATO+GROWTH+LEV+ROA+SHARE, #结果为7.4e-05,说明模型整体⾼度显著,也就是说所考虑的7个解释性变量中,⾄少有⼀个与因变量有关,具体哪⼀个不知道family=binomial(link=logit),data=a1)anova(glm0.a,glm1.a)1-pchisq(30.565,7)glm0.b=glm(ST~1,family=binomial(link=probit),data=a1) ####probit回归时:计算模型的整体显著性⽔平#####glm1.b=glm(ST~ARA+ASSET+ATO+GROWTH+LEV+ROA+SHARE, #和逻辑回归结果⼀样,显著family=binomial(link=probit),data=a1)anova(glm0.b,glm1.b)1-pchisq(31.702,7)####看看是哪个⾃变量对因变量有影响#####Anova(glm1.a,type="III") #对模型glm1.a做三型⽅差分析summary(glm1.a)Anova(glm1.b,type="III") #对模型glm1.b做三型⽅差分析summary(glm1.b)3.#######模型选择时要解决的问题:(1)选哪个模型;(2)选哪个阈值。
类别数据分析 第四讲

I. 二分结果数据(Binary Response Data )的另一种模型: 1. Probit 模型- 在实际运用方面与 logit 模型十分类似P(Y=1|X)=G(α+β1X 1+…βk X k ),此处G 是一个范围在 0 与 1之间的概率密度函数(p.d.f.)。
- 与logit 模型相比,Probit 模型在数学上更容易一般化(generalize ), 例如转换成Tobit 模型。
- 在计量经济学上得到更广泛的运用。
与logit 模型相比,运用Probit 模型的两个特点:i)假定概率函数为常态分布: 在logit 模型中:p X X i i i =+=+-+Λ()exp[()]αβαβ11在probit 模型中:p X udu i i X i=+=--∞+⎰Φ()exp()αβπαβ12122l p h i与logistic 函数类似,在probit 模型中概率密度函数的设定是以均值为中心的对称形式。
通常probit 模型可以被纳入一般线性模型GLM 的架构中, (以logit 模型为例,左手边的是对数型态的发生比率log [p/(1-p)] ),但是由于这个函数太过复杂,我们 用Ф-1(X) 来表示:Ф-1(X)=α+βX此处 Ф-1(X) 指的是:- 累积正态分布密度的反函数(inverse of the cumulative normal density function;) – 又称为 “probit”!ii) 第二个特点: 可以用于出现应变量出现选择性偏误而部份无法观察的情况,这也是计量经济学家喜好probit 模型的原因。
Y*=a+bX+eY* 只能被部份观察到,可以表示为 Y=1 if Y*≥0=0 if Y*<0 假设e~ N(0, σ2), 此时:P(Y*≥0|X) = P(a+bX+e≥0)= P[e≥-(a+bX)]= P(e<a+bX)= P[e/σ<a/σ+(b/σ)]= P[ε< α+βX]=12122παβexp()--∞+⎰uduX其实这就是probit模型,在 Y*只能部分被观察到的条件下可以转换成Tobit模型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
误差项
品味差异
IIA
面板数据
概率计算方法
Logit
极值分布
可以表示,但有局限性(只能表示可以观测到的品味差异)
选项不相关
通过面板数据只能得到可观测变量的动态机制
计算方法比较简单,可以直接计算
Probit
正态分布
可以表现随机品味差异(因为可以把随机系数的均值和方差转到协方差中表现出)
选项可以相关
通过面板数据可以得到可观测变量和不可观测变量的动态机制
计算比较难,多重积分无法进行,只能使用仿真的方法来计算