C17 受限因变量模型和样本选择纠正
第十八章-离散选择模型和受限因变量模型

第18章 离散选择模型和受限因变量模型 18.1概述在经典计量经济学模型中,被解释变量通常被假定为连续变量,但在现实的经济决策中经常面临许多选择问题。
在这样的决策问题中,或者选择问题中,人们必须对可供选择的方案作出选择。
通常被解释变量是连续的变量,但此时的因变量只取有限多个离散的值。
例如:人们对交通工具的选择,是选择坐轻轨、地铁还是公共汽车;某大型企业是否合并另一企业;对某一方案的建议持强烈反对、反对、中立、支持和强烈支持5种态度,可以分别用0,1,2,3和4表示。
以这样的选择结果作为被解释变量建立的计量经济学模型,称为离散被解释变量数据计量经济学模型(models with discrete dependent variables ),或称为离散选择模型(DCM ,discrete choice model )。
如果被解释变量只能有两种选择,称为二元选择模型(binary choice model );如果被解释变量有多种选择,称为多元选择模型(multiple choice model )。
20世纪70和80年代,离散选择模型普遍应用于经济布局、企业定点、交通问题、就业问题、购买决策等经济决策领域的研究。
在实际中,还会经常遇到因变量受到某种限制的情况,这种情况下,取得样本数据来自总体的一个子集,可能不能完全反映总体。
例如,小时工资、住房价格和名义利率都必须大于零。
这时需要建立的经济计量模型称为受限因变量模型(limited dependent variable model )。
这两类模型经常用于调查数据的分析中。
本章将讨论三类模型及其估计方法和软件操作。
一是定性(观测值为离散的或者表示排序);二是截取或者截断问题;三是观测值为整数值的计数模型。
18.2二元因变量模型在这个模型中,被解释变量只取两个值,可以是代表某件事发生与否的虚拟变量,也可以是两个决策中选一个,称为二元因变量模型。
例如:对样本个体是否就业的研究,个体的年龄、教育背景、种族、婚姻状况以及其他可观测的特征,作为解释变量,目的是研究个体这些特征对个体就业概率的研究。
伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解-第17章 限值因变量模型和样本选择纠正【圣才

第17章限值因变量模型和样本选择纠正17.1复习笔记一、二值响应的对数单位和概率单位模型1.线性概率模型的不足(1)拟合出来的概率可能小于0或大于1;(2)任何一个解释变量(以水平值形式出现)的偏效应都是不变的。
二值响应模型的核心是响应概率:()()12P 1x P 1 k y y x x x ===⋅⋅⋅,,,其中,用x 表示全部解释变量所构成的集合。
2.设定对数单位和概率单位模型(1)二值响应模型在LPM 中,响应概率对一系列参数j β是线性的,为避免LPM 的局限性,考虑二值响应模型:()()()01101x k k P y G x x G x βββββ==++⋅⋅⋅+=+其中,G 是一个取值范围严格介于0和1之间的函数:对所有实数z,都有0﹤G(z)﹤1。
这就确保估计出来的响应概率严格地介于0和1之间。
(2)函数G 的各种非线性形式①对数单位模型中,G 是对数函数:()()()()exp /1exp G z z z z =+=Λ⎡⎤⎣⎦对所有的实数z,它都介于0和1之间。
它是一个标准逻辑斯蒂随机变量的累积分布函数。
②概率单位模型中,G 是标准正态的累积分布函数,可表示为积分()()()d z G z z v vφ-∞=Φ≡⎰其中,()z φ是标准正态密度函数()()()1/222exp /2z z φπ-=-也确保了对所有参数和x j 的值都严格介于0和1之间。
③两个模型中G 函数都是增函数,在z=0时增加的最快,在z →-∞时,()0G z →,而在z →∞时,()1G z →。
(3)两种函数形式的推导对数单位和概率单位模型都可以由一个满足经典线性模型假定的潜变量模型推导出来。
令y *为一个由0y x e ββ*=++,y=1[y *﹥0]决定的无法观测变量或潜变量。
在其中引入记号1[·]来定义一个二值结果。
函数1[·]被称为指标函数,它在括号中的事件正确时取值1,而在其他情况下取值0。
C17受限因变量模型和样本选择纠正

第17章 受限因变量模型和样本选择纠正摘要: C7中的线性概率模型是受限因变量(limited dependent variable (LDV))模型的一例子,其容易解释,但有其缺陷,本章介绍的logit 模型和probit 模型更为常用,但解释相对困难。
实际应用中,离散和连续是相对的,也就是说,实际离散的经济变量可能也适用于因变量离散的模型建模。
本节介绍的模型包括Tobit 模型,用于应对角点解响应(corner solution response);泊松回归模型(计数模型),用于建模LDV 只能取非负整数的情况;截断数据模型和对样本选择的纠正。
受限因变量模型更容易在横截面数据中被使用。
样本选择的纠正通常都源于横截面或面板数据。
17.1 二值响应的logit 模型和probit 模型线性概率模型的缺陷?二值响应模型(binary response model )关注的核心问题是响应概率(response probability):.P (y =1│x )=P(y =1|x 1,x 2,…,x n ) logit 模型和probit 模型的设定为此,需要先建一个连接函数:,P (y =1│x )=G (β0+β1x 1+β2x 2+…+βk x k )=G(β0+xβ)其中G(.)是一个取值于(0,1)的函数。
常见的连接函数有:,G (z )=exp (z )[1+exp (z )]=Λ(z)该函数是标准logistic随机变量的累积分布函数:常见的连接函数还有标准正态的累积分布函数,G 可以被表示为:G (z )=Φ(z )≡x ∫‒∞ϕ(v)dv ,.ϕ(v )=(2π)‒1/2exp(‒z 22)使用上述两个连接函数,我们分别建立了logit 模型和probit 模型。
关于logit 模型和probit 模型的推导:y ∗=β0+xβ+e ,并定义,为示性函数。
y =I(y ∗>0) I要求满足CLM 假设或高斯-马尔科夫假设。
第十三章 离散选择模型和受限因变量模型

y i − F (x ′ ∂l (β ) N iβ) ) = ∑ f (x ′ i β xi =0 1 − F ( x′ ∂β i =1 F (x ′ i β )( i β ))
(13.2.4)
ˆ 。在概率单 我们可以从等式(13.2.4 )中解出参 数β 的最大似然估计量 β pb ˆ 位模型中, F (x ′ i β ) 是正态密度的累计分布函数,要解出最大似然估计量 β pb ,需 要运用数值运算方法。 在线性概率模型的情形下,等式(13.2.4)变成: ∂l (β ) N y i − xi′β = ∑ x =0 ′ i ∂β i =1 x ′ i β (1 − x i β ) (13.2.5)
(13.1.5)
y i = 1 , 如果 y ∗ i >0;
y i = 0 , 如果 y ∗ i ≤0 。 从(13.1.5)中,我们有: Pr {y i = 1 | x i } = Pr{ε i > − x i′β | xi } = 1.3 Logit 模型 如果我们选择 F (•) 为标准 logistic 分布函数时,这时 ′ F (x′ i β ) = G (x i β ) = e x′i β 1 + e x′i β (13.1.7)
N y i − F (x ′ iβ) =∑ f (x i′β ) xi 1 − F ( x′ i =1 F (x ′ i β )( i β ))
(13.2.3)
′ ′ 这里, f (x ′ i β ) = F ( xi β ) 是分布密度函数。让(13.2.3)式等于0,我们得到一阶 条件:
∗ 于 y∗ i >0;当当我们观测到 y i = 0 ,实际上就等价于 yi ≤ 0 。
受限因变量模型共66页

3、法律是最保险的头盔。——爱·科 克 4、一个国家如果纲纪不正,其国风一 定颓败 。—— 塞内加 5、法律不能使人人平等,但是在法律 面前人 人是平 等的。 ——波 洛克
谢谢
11、越是没有本领的就越加自命不凡。——邓拓 12、越是无能的人,越喜欢挑剔别人的错儿。——爱尔兰 13、知人者智,自知者明。胜人者有力,自胜者强。——老子 14、意志坚强的人能把世界放在手中像泥块一样任意揉捏。——歌德 15、最具挑战性的挑战莫过于提升自我。——迈克尔·F·斯特利
C17 受限因变量模型和样本选择纠正范文

第17章受限因变量模型和样本选择纠正摘要: C7中的线性概率模型是受限因变量(limited dependent variable (LDV))模型的一例子,其容易解释,但有其缺陷,本章介绍的logit模型和probit模型更为常用,但解释相对困难。
实际应用中,离散和连续是相对的,也就是说,实际离散的经济变量可能也适用于因变量离散的模型建模。
本节介绍的模型包括Tobit模型,用于应对角点解响应(corner solution response);泊松回归模型(计数模型),用于建模LDV只能取非负整数的情况;截断数据模型和对样本选择的纠正。
受限因变量模型更容易在横截面数据中被使用。
样本选择的纠正通常都源于横截面或面板数据。
17.1 二值响应的logit模型和probit模型线性概率模型的缺陷?二值响应模型(binary response model)关注的核心问题是响应概率(response probability):.logit模型和probit模型的设定为此,需要先建一个连接函数:,其中G(.)是一个取值于(0,1)的函数。
常见的连接函数有:,该函数是标准logistic随机变量的累积分布函数:常见的连接函数还有标准正态的累积分布函数,G可以被表示为:.使用上述两个连接函数,我们分别建立了logit模型和probit模型。
关于logit模型和probit模型的推导:并定义,为示性函数。
要求满足CLM假设或高斯-马尔科夫假设。
显然当服从均值为0的正态分布,或者logistic分布,其都关于0点对称,则有:,也即:.从该推导中我们知道,但由于的不可观测性本身的含义并不直观,也并不很有用,虽然和中x的影响方向具有一致性(这一点由下面推导保证)。
我们关心解释变量对y的偏效应,由于(.)的非线性,对连续变量的情形就得依赖于偏导技术:,其中为概率密度函数,由于,所以偏效应的方向取决于 。
一个有趣的结论是:任意两个自变量的偏效应之比等于其系数之比。
《数量经济学讲义》第十七章 离散和受限因变量模型

if yi* 0 if yi定义为0值。我们称这些数据在0处进行了左归并
(left censored)。更一般地,Eviews允许在任意有限点上的左边和右边截取
(归并),所以
yi cyii* ci
if yi* ci if ci yi* ci if ci yi*
Pr ( yi 0 xi , ) F(xi )
给出了这样的设定以后,我们就能用极大似然估计方法估计模型的参数。 极大似然函数为
n
( ) log L( ) ( yi log(1 F (xi )) (1 yi ) log F (xi )) i0
极大似然函数的一阶条件是非线性的,所以得到参数估计需要一种迭代
的解决方法。缺省地,EViews使用二阶导数用于参数估计的协方差矩阵的迭
代和计算。
有两种对这种设定的重要的可选择的解释。首先,二元变量经常作为一种
潜在的变量规定被生成。假定有一个未被观察到的潜在变量
y
* i
,它与x是线性
相关的:
yi* xi ui
这里
u
是随机扰动。然后被观察的因变量由
i
yi*是否超过临界值来决定
if yi* 1
if 1 yi* 2
M if M yi*
i 是临界值。M是分类的个数。为了估计这个模型,从Equation Specification对
话框,选择估计方法Ordered。
§17.3 检查回归模型
受限因变量(Limied dependent variable)指因变量的观测值是连续的,但 是受到某种限制,得到的观测值并不反映因变量的实际状态。例如在一些环境 中,只能部分地观察到因变量。在调查数据中,在特定水平之上的收入数据经 常被编成密码以保护其机密性。这类问题经常出现在“检查”、“调查”活动 中,因此也称为“检查”(Censored Regression Models)。
受限因变量模型

用计量经济模型反映选择行为
行为主体从事的每项活动都可以看作是一种选择; 行为主体有其偏好; 人们的行为有其规则; 在经济分析中,通常认为选择基于效用最大化标准。 研究中需要考虑:
行为理论基础 计量经济学模型方法
模型设定 统计理论和数据 估计方法
应用分析
行为假定
就可以选择的活动而言,行为主体的偏好具有传递 性和完备性。 每项选择都有其相应的效用水平Uijt 每个行为主体都试图获得最大效用,当Ui1t > Ui2t 时, 行为主体会选择第一项活动。 然而我们无法观测效用本身,我们只有通过观察行 为主体做出的选来揭示其偏好
LR = -2(Lr– Lur )~ c2q 如果未受约束似然值与受约束似然值相等,说明模型效果差,未通过 检验;相反,如果未约束似然值远大于约束似然值,说明所设自变 量通过检验,模型总体效果较好。它对应于线性模型中的F值。
拟合优度
对于线性概率模型,可以直接用得到R2来判断拟合优度; Probit 模型和Logit模型没有R2,因而需要利用其他方法来反 映拟合优度。 一种方法是利用对数似然值计算伪R2(pseudo R2)或 McFadden R2,该值也被称作似然值比值指数,定义为1 – Lur/Lr
必要时给出选项 得到估计结果
用EVIEWS估计有限因变量模型
得到结果后可以在VIEW子菜单下调用:
Coefficient tests各种对系数的统计检验 Residual tests对残差的统计检验 Expectation-Prediction Table 可以得到正确和错 误推断的比例 Goodness-of-Fit Tests检验拟合优劣
得到的参数不会相同 但分析结论不会有大的差别 因而通常基于模型的统计表现和经验来决定取舍
机器学习模型的样本选择问题及解决方法

机器学习模型的样本选择问题及解决方法随着机器学习在各个领域的应用不断扩大,样本选择问题成为了一个关键的挑战。
机器学习模型的性能和泛化能力很大程度上取决于所选用的样本集。
因此,如何选择恰当的样本集来训练机器学习模型成为了一个关键问题。
1. 问题描述样本选择问题是指如何从大量的数据中选择最适合训练模型的样本。
在实际应用中,数据集可能包含大量的噪声、冗余和不相关的信息,直接使用全部数据进行训练会导致模型性能下降和泛化能力不足。
2. 样本选择的重要性样本选择对于机器学习模型的训练和预测具有重要影响。
一方面,选择了高质量的样本可以减少噪声和冗余的影响,提升模型的性能和泛化能力。
另一方面,样本选择还可以减少训练和预测的计算成本,提高算法效率。
3. 样本选择的解决方法为了解决样本选择问题,研究者们提出了多种方法和技术。
下面介绍几种常见的解决方法。
3.1 随机选择最简单和常见的样本选择方法是随机选择。
这种方法通过随机抽样的方式,从原始数据集中选择一部分样本进行训练。
随机选择的优点在于简单且易于实现,但由于没有考虑样本的相关性和重要性,可能选择到不具有代表性的样本,导致模型性能下降。
3.2 欠采样和过采样欠采样和过采样是两种常见的解决样本不均衡问题的方法。
在机器学习任务中,由于不同类别样本数量的不平衡,会导致模型对多数类别的预测效果较好,而对少数类别的预测效果较差。
欠采样通过减少多数类别样本数量来平衡样本分布,而过采样则通过复制少数类别样本或生成合成样本来增加少数类别样本数量。
3.3 主动学习主动学习是一种基于挑选对模型有较大帮助的样本的学习方法。
主动学习通过在每次迭代中,选择最不确定或最具有代表性的样本进行标注,提高模型性能。
这种方法通常需要一个合适的样本选择准则,如最大化信息增益、最大化模型的边界等。
3.4 增量学习增量学习是一种动态样本选择方法,它通过持续地接收新数据并逐步调整模型,来适应数据分布的变化。
增量学习可以避免全量重新训练模型的时间和计算成本,并且可以有效地处理数据流和在线学习的场景。
受限因变量模型颜莹

Chapter 6 受限因变量模型本章讨论的一类模型是被关注的因变量的取值受到限制.有时候这种限制不需要特别的处理,但有时候这种限制却是实质性的.从条件期望的角度看,如果限制的信息是确定的,例如,y 只取有限个离散值,如1y =(表示赞成),0y =(表示反对).于是,()E Y X 用线性回归模型的方式来表示就不合适了.我们将依据y 受不同限制的情况处理几类不同的非线性模型,并给出非线性模型的常用估计检验方法—极大似然方法.按理,非线性模型是下篇的内容,之所以要介绍受限因变量模型是因为它的背景与多元回归模型有关. 另外,本章的附录部分简单的介绍非线性理论,这是伍书的第12章. §1.离散响应模型有时,我们只能观察到y 处于某种状态,用1表示,用0表示不处于该状态.如1y =(就业),0y =(失业),或y 仅有几种很少的状态可供选择,我们把y 仅取有限的离散值情况称为离散响应模型.特别,y 仅取0、1为值称为二元响应模型.同样,影响y 的状态的因素称为解释变量或相关变量,X 可能包括有关个体的各种情况,如教育程度,年龄,性别…等,它们都有可能影响y 的就业状态.关注的问题:X 中j X 多大程度上影响了y 的状态? 这个问题准确的表达是,设1()(1)(1)k p x P y X P y X X ====,是一个条件概率.解释变量j X 可以是连续型的也可以是离散型的.那么对连续变量j X ,就用边际效应(1)()j jP y X p x X X ∂=∂=∂∂反映j X 对y 状态的影响,对二元变量k X ,(取0,1为值.)就用差分效应 1111(.......,1)(.......,0)k k p x x p x x ---反映K X 对y 状态的影响.以上两式,如果()p x 已知就没有问题了.问题是如何确定()p x ? (1)二元响应的线性概率模型最简单的是认为()(1)p x P y X ==仍是X 的线性函数,改写成:01122(1)k k P y X X X X X βββββ==++++=.∵(1)()P y X p x ==,则(0)1()P y X p x ==-.y 是一个二元分布. ∴()()E y X p x =,且()()[1()]Var y X p x p x =-. ∴()E y X X β=,且()(1)Var y X X X ββ=-.这说明,如果用线性投影来拟合()E y X ,则存在条件异方差.(方差与样本X 有关)注意:采用线性概率模型,未知参数β的含义,当j X 取连续值(1)j jP y X X β∂==∂;当jX 取离散值,(1,(0,j j j P X P X β==-=其余不变)其余不变). 由()E y X X β=,利用y X βε=+,给定样本y ,1k X X .可得β的一致估计OLS β∧.又由()Var y X 存在条件异方差,故OLS β∧不是有效的,再改用加权最小二乘(WLS )加以修正,做法是,对所有满足条件ˆ01i y <<的样本,定义标准差ˆi σ=然后ˆ/i i y σ对ˆ1/i σ,1ˆˆ, 1i i ik i x x i N σσ=.做回归,得WLS β∧,可增加有效性.关于检验,所有关于β的t 检验、F 检验以及部分参数为0的检验,用稳健的异方差协差矩阵和标准差都是有效的.但是线性概率模型在理论上是有欠缺的,因为拟合值有可能不在[0,1]区间内,即使都在[0,1]中,但预测值y 随着其解释变量i X 不断增加或减少,终将导致y 不在[0,1]区间内,这与概率的意义是不相符的.尽管如此,如果主要目的是估计X 中每个解释变量对y 影响的平均概率,那么一些预测值不在[0,1]中影响不大,线性概率模型不必对X 取极端值给出一个好的估计. (2) 二元响应的指数(Index )模型(probit 和 logit 模型)考虑二元响应的概率有形式:(1)()()P y X G X p x β===. 这里z R ∀∈,0()1G z <<.1(1,)k X X X =,0()K βββ'=.特别()G Z Z =就是线性概率模型.因为先把X β理解成一个指数(Index ),函数G 再把指数X β映射成一个响应函数()p x .故称模型为指数模型,在实践中G 一般取累积分布函数的形式.如果G 是某一随机变量的分布函数,那么二元响应的指数模型可以从存在潜在变量的线性模型中得到解释:设*y X e β=+,且*1(0)y y =>.*y 不可观测,但如果*0y >则可观测1y =,e 是关于原点对称与X 不相关的连续型随机变量.如果G 是e 的分布函数,那么()()G z P e z =<, 且1()(),G z G z z R --=∀∈.因此,*(1)(0)()()1()()P y X P y X P e X X G X G X p x βββ==>=>-==--=.注:没有特别的理由要求e 是关于原点对称的.但为了方便,对二元响应模型已作为一种习惯限制.没有此限制二元响应模型就不能看成是存在潜在变量的模型.二元响应不采用存在潜在变量的说法是因为无法准确定义潜在变量的含义和测量单位,从而参数i β的大小也没有特定的意义.另外,一般对G 的要求也不非要是分布函数,只要满足()G z 在[0,1]区间即可,但在实际应用时,有两个常用的选择,一个是e 服从标准正态分布,称Probit 模型;另一个是e 服从标准Logistic 分布,称为Logit 模型.1.当e 服从标准正态分布,则G 的分布函数形式为()()()zG z z v dv φ-∞=Φ=⎰2.当e 服从Logistic 的分布,则exp()()()1exp()z G z z z λ==+,有性质()()[1()]Z Z Z λλλ'=-.于是,在指数模型中,i β的含义就不如线性概率模型那样明显. 因为当i X 连续时,()()i ip x g X x ββ∂=∂,且()()dG Z g Z dZ =. ∴如果G 是分布函数,则()0g z >,z ∀.故i β的符号给出了对y 的正影响和负影响,而i β的大小则没有太大的增量意义.另外,当G 的密度g 关于原点对称时,0X β=,g 取得最大值,从而i X 在0X β=时对y 有最大影响.其次当K X 是二元解释变量,那么当0K X =改变到1,其他变量不变,对y 产生的偏效应就是011220112211(.......)(.......)k k k k G X X X G X X X ββββββββ--++++-++++该值是依赖于其他解释变量i X 取值,不过k β的符号同样能决定k X 对y 产生的偏效应是正还是负.一般的,当1K k X c =改变到2k c ,其他变量不变,那么对y 产生的偏效应就是011221011222(.......)(.......)k k k k G X X c G X X c ββββββββ++++-++++. 由()()i ip x g X x ββ∂=∂,有时也常用()/100i g X ββ表示i X 改变百分之一对y 产生的偏效应.偏效应比:()()ii j jp x p x x x ββ∂∂=∂∂,当i X 和j X 是连续型时,则不依赖G 的分布函数. (3)二元响应的极大似然估计和检验给定样本观测值,1,t t X x t n ==(0 1)t t t Y y y or ==,要求极值:11max (,,, 1.....)n n t P Y y Y y X t n β===. ∵1111{0}{1}(,1)[1()][()]n n t i i y y Prob Y y Y y X t n G X G X ββ======∏-∏,∴11()()[1()]i inyy i i i L G X G X βββ-==∏-.11ln ()ln ()(1)ln[1()]nni i i i i i L y G X y G X βββ===+--∑∑.由一阶条件,()0L ββ∂=∂,即ln ()0jL ββ∂=∂ 1j K =.得,1()1[]0()1()ni i ii j i i G X y y G X G X ββββ=∂--=∂-∑ 1j K =.这是一个关于β的非线性方程组,采用非线性方程算法可求得β的极大似然估计量ˆβ. 注:一般情况下,上述方程要有解,要求样本容量是n 和自变量个数k 及y 的均值y 满足条件min{,(1)}ny n y k -≥.含义是,y 取1的个数和取0的个数都必须大于k .例如t y 都取1,则方程无解.∴当G 取标准正态公布,()()t tj t jG X X X βφββ∂=∂ 1j K =,2(2)()x x φ-=.∴一阶条件就是表示成11[]()0()1()nt ttj t t t t y y X X X X φβββ=--=Φ-Φ∑ 1j K =.又当G 取Logistic 分布,exp()()()1exp()z G z z z λ==+,()()[1()]t tj t t jX X X X λβλβλββ∂∴=-∂1j K =.∴一阶条件就是表示成11[1()](1)()0nntjt t tj t t t t Xy X X y X λβλβ==---=∑∑ 1j K =.简化成1[()]0ntjt t t Xy X λβ=-=∑ 1j K =.故Logit 模型在算法上要方便些.进一步可以求得,极大似然估计ˆβ的协方差矩阵的估计为: 121ˆ[()]ˆ()ˆˆ()[1()]n i i i t i i g X X X Avar G X G X ββββ-=⎛⎫'= ⎪ ⎪-⎝⎭∑. 有了估计、渐近方差和标准差,我们就可以做各种假设检验.特别,部分系数为零的检验,在有极大似然函数的前提下,又可以方便的增加似然比检验LR.考察(1,)()(,)P y X Z G X Z p x z βγ==+=. 欲检验0:0H γ=.除了用Wald 检验和LM 检验外,用似然比检验LR.2ˆˆ2[ln ()ln ()]ur r QLR L L ββχ=-.ˆur β是无约束下的极大似然估计,ˆrβ是带约束的极大似然估计,Q 是0γ=的个数. 又当Z 的维数很大,用Wald 检验和LR 检验计算量很大,采用LM 方法更为可取.记ˆˆ()i i G G X β=,ˆˆ()i i g g X β=,ˆˆi i i u y G =-.已从极大似然估计中获得.i i on X ,得非中心决定系数2u R .0:0H γ=真下,22u QLM NR χ=.(该方法还可以推广到检验00:H γγ=.) 接下来讨论Probit 、Logit 和线性概率LP 结果的比较.因为Probit 、Logit 和LP 施加不同的变换()G X β,所以得到的极大似然估计ˆβ不能简单的进行比较.因为对j X 的一个微小变化而言,ˆˆˆ(1)[()]j j P y X g X X ββ∆=≈∆,所以,为了比较j X 增加一个单位的偏效应,我们调整ˆ()g X β归“1”.因此,如果Probit 、Logit 、LP 而言,ˆX β接近于0,那么,对Probit ,(0)0.4g ≈;对Logit ,(0)0.25g ≈;对LP ,(0)1g =.所以,0.250.40.625=,用log ˆ0.625it β与ˆprobit β相比.同理,ˆ2.5LP β与ˆprobit β相比;ˆ4LP β与log ˆitβ相比.一般的,j X 连续,用11ˆˆ[()]Nj i i N g X ββ-=∑作为总体上的平均值代替(0)g ,然后再调整,进行比较.另外,二元响应模型也存在解释变量X 有内生性的问题,以及类似二阶段极大似然估计方法.也可以把二元响应模型扩大到面板数据模型上,(1,)()it it i i i P y X c G X c β==+. 这涉及到更多非线性估计和检验的理论,这是下学期的内容,不再深入讨论下去了. (参见伍书第15章) §2.截取回归模型简介因变量y 可能受到客观条件的限制,使其在某一范围外的数据无法得到,或是有意不取.由于结果的数据受到限制,且解释变量是在结果受限条件下获得的数据,此意味着样本i X 和i y 不再独立.从条件期望的角度看,即使()E Y X X β=是正确设定,但如果要限制0y >,本质上会产生(,0)E y X y >对模型中未知参数β的非线性依赖.导致OLS 方法一致性不成立,不再是一个好的估计,只能改用极大似然方法保证大样本下估计的一致性.因变量受限的截取回归模型通俗的说法是,因变量“掐头”或“去尾”.例如,调查个人收入只能在一定范围内得到;又例如调查寿命大于80岁以上的一般用80岁代替.另一种说法是所谓角点解,问题不再是因变量部分不可观测,而是结果依赖于最优选择,且最优选择的特征是y 以正的概率取0值.因为(0)0P y X =>,从而我们关注0y >时的()E y X 就不再是线性的了.例如,慈善捐赠,关注的是捐赠了0y >的那部分.我们把截取Tobit 模型写成:设*i i i y X u β=+是正确设定,且*i y 不能完全观测.但可观测的i y ,*max(,)i i i y y c =为“去尾”或*min(,)i i i y y c =为“掐头”.且i u 在给定i X 、i c 条件下,2,(0,)i i i u X c N σ.特别0i c =,则*max(,0)i i y y =表示非负观测限制.也称为标准截取Tobit 模型.所以,()(0)0(0)(,0)(0)(,0)E y X P y X P y X E y X y P y X E y X y ==+>>=>>*(0)(0)()([/][/])(/)P y X P y X P u X X P u X X X βσβσβσ>=>=>-=>-=Φ (/)(,0)(,0)(/)u u X X E y X y E X u X y X E X X βφβσβββσσσσβσ⎡⎤⎛⎫>=+>=+>-=+ ⎪⎢⎥Φ⎝⎭⎣⎦注:(0,1)zN ,那么,()()1(). E z z c c c c R φ>=-Φ∀∈.()()() c c c c R λφ=Φ∀∈称为逆米尔斯比.所以,(/)()(/)()(/)(/)(/)X E y X X X X X X X φβσβσβσβσβσφβσβσ⎡⎤=Φ+=Φ+⎢⎥Φ⎣⎦.()(0)(,0)(,0)(0)(/)j jjjE y X P y X E y X y E y X y P y X X X X X βσβ∂>>=>+>=Φ∂∂∂.称(/)X βσΦ为标度因子.ˆˆˆ(/)(0)X P y X βσΦ=>,它是给定X 和ˆβ时正响应的概率.ˆˆ(/)X βσ∴Φ接近于1,截取Tobit 模型与多元回归就没有太多区别. 截取Tobit 模型的估计与检验涉及到麻烦的非线性计算,这是下学期的内容,略.需要提出的是,截取Tobit 模型有二种变形.我们知道,截取Tobit 模型对解释变量X 是没有任何限制的.一种变形是,因变量y 的受限导致了X 的样本i X 受限,甚至是有意不取.我们将此处理成Probit 的响应形式. 模型:1111y X u β=+,且2221[0]y X u δ=+>.假定:2y 是一个二元选择变量,当220X u δ+>时等于1.1y 受限于2y ,只有21y =时才是可观测的.1X 是X 的子集,且2y 和X 可观测.又,X 与1u 、2u 不相关,2(0,1)u N ,且1212()E u u u γ=.注:这里关注的模型尽管是线性多元回归,1111y X u β=+,但样本1i y 和1i X 都受到限制. 另一种变形是Tobit 的响应形式.模型:1111y X u β=+,且222max[,0]y X u δ=+.假定:2y 是一个截取选择变量,1y 受限于2y ,只有当2220y X u δ=+>时才是可观测的.1X 是X 的子集,且2y 和X 可观测.又,X 与1u 、2u 不相关,但222(0,)u N τ,且1212()E u u u γ=. 关于模型的背景、估计和检验都是下学期的内容,不再讨论下去了.要提醒的是,这些非线性模型都是多元回归模型受到约束变形而来.。
第07章离散因变量和受限因变量模型

7.1.1 线性概率模型及二元选择模型的形式
为了深刻地理解二元选择模型,首先从最简单的线性概率 模型开始讨论。线性概率模型的回归形式为:
yi 1x1i 2 x2i k xki ui (7.1.1)
i 1, 2,,N
其中:N是样本容量;k是解释变量个数;xj为第j个个体特征 的取值。例如,x1表示收入;x2表示汽车的价格;x3表示消费 者的偏好等。设 yi 表示取值为0和1的离散型随机变量:
第七章 离散因变量和受限因变量模型
通常的经济计量模型都假定因变量是连续的,但是在 现实的经济决策中经常面临许多选择问题。人们需要在可 供选择的有限多个方案中作出选择,与通常被解释变量是 连续变量的假设相反,此时因变量只取有限多个离散的值。 例如,人们对交通工具的选择:地铁、公共汽车或出租车; 投资决策中,是投资股票还是房地产。以这样的决策结果 作为被解释变量建立的计量经济模型,称为离散被解释变 量数据计量经济学模型(models with discrete dependent variables),或者称为离散选择模型(discrete choice model, DCM)。
④ LR统计量检验除了常数以外所有系数都是0的假 设,这类似于线性回归模型中的统计量,测试模型整体的 显著性。圆括号中的数字表示自由度,它是该测试下约束 变量的个数。
17
⑤ Probability(LR stat)是LR检验统计量的P值。 在零假设下,LR检验统计量近似服从于自由度等于检
验下约束变量的个数的2分布。
1
在实际中,还会经常遇到因变量受到某种限制的情况, 这种情况下,取得的样本数据来自总体的一个子集,可能 不能完全反映总体。这时需要建立的经济计量模型称为受 限因变量模型(limited dependent variable model)。这两 类模型经常用于调查数据的分析中。
计量经济学前沿限制因变量模型和估计

处理方法2:用抵押贷款申请是否被拒绝作为因变量建立多元回归模 型,探讨保持其他条件不变(相同)旳条件下,种族旳 差别对贷款申请是否被拒绝旳影响。
* 问题3: 方法2 能回答下列问题1 所提出旳问题吗?
6
Copyright © 2003 Prentice-Hall, ቤተ መጻሕፍቲ ባይዱnc.
(0.083)
Pr( y | P / I ratio,black) F (4.13 5.37P / I ratio 1.27black)
(0.35) (0.96)
(0.15)
22
Copyright © 2003 Prentice-Hall, Inc.
23
Copyright © 2003 Prentice-Hall, Inc.
13
Copyright © 2003 Prentice-Hall, Inc.
处理LPM不足思绪
定义: Pr( y 1| X ) G(0 1X i1 2 X i2 ) G(zi ) (3)
其中, G 是一种取值范围严格介于0 ~ 1之间旳函数,
对全部实数 z , 都有
0 G(z) 1
当
z
二值因变量模型
* 问题1:除种族不同外,两个条件完全相同旳人走进一家银行申请一
笔抵押贷款,目旳是购置一套房子,两套房子旳条件也完全相同,他 们是否有同等可能性让他们旳抵押贷款申请被接受?
怎样精确地检验种族歧视旳统计证据?
处理方法1 :用抵押贷款申请被拒绝旳比重来比较不同种 族旳人是否受到同等旳待遇.
P(Y 1| X ) jx j
▪ 回归系数能够用OLS 措施进行估计,而且一般旳(异方差 稳健旳)OLS原则误能够用来假设检验和构造置信区间
离散因变量和受限因变量模型

目录
• 引言 • 离散因变量模型 • 受限因变量模型 • 模型估计与检验 • 实证分析与应用举例 • 研究结论与展望
01
引言
目的和背景
1
探究离散因变量和受限因变量的模型选择和应用
2
分析离散因变量和受限因变量模型的优缺点
3
为实际数据分析提供理论支持和指导
离散因变量和受限因变量的定义与特点
步骤
首先,根据模型设定和观测数据构建似然函数;然后,通过对似然函数求导并令其等于零,得到 参数的最大似然估计值;最后,利用数值优化算法求解最大似然估计值。
优点
最大似然估计法具有一致性、有效性和渐近正态性等优良性质,且适用于多种类型的离散因变量 和受限因变量模型。
拟合优度检验
1
目的
拟合优度检验用于评估模型对数据的拟 合程度,即检验模型是否能够充分解释 观测数据的变异。
研究不足与局限性分析
当前研究主要集中在模型的应用和比较方面, 对模型的理论性质和统计推断的深入研究相对 较少。
在处理复杂数据和实际问题时,现有模型可能 存在局限性,如无法处理高维数据、非线性关 系等。
在实际应用中,模型的假设条件可能难以满足, 如随机抽样、误差项独立同分布等,这可能影 响模型的估计结果和解释力度。
03
适用于因变量为有序分类的情况,如评级、满意度等。
计数模型
Poisson回归
适用于计数数据,假设事件发生的次数服从泊松分布。
负二项回归
当计数数据的方差大于均值时,使用负二项回归,考虑了数据的 过度分散。
零膨胀模型
适用于存在过多零计数的情况,通过零膨胀参数对零计数进行建 模。
03
受限因变量模型
伍德里奇计量经济学导论第5版笔记和课后习题详解

伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解目录第1章计量经济学的性质与经济数据1.1复习笔记1.2课后习题详解第一篇横截面数据的回归分析第2章简单回归模型2.1复习笔记2.2课后习题详解第3章多元回归分析:估计3.1复习笔记3.2课后习题详解第4章多元回归分析:推断4.1复习笔记4.2课后习题详解第5章多元回归分析:OLS的渐近性5.1复习笔记5.2课后习题详解第6章多元回归分析:深入专题6.1复习笔记6.2课后习题详解第7章含有定性信息的多元回归分析:二值(或虚拟)变量7.1复习笔记7.2课后习题详解第8章异方差性8.1复习笔记8.2课后习题详解第9章模型设定和数据问题的深入探讨9.1复习笔记9.2课后习题详解第二篇时间序列数据的回归分析第10章时间序列数据的基本回归分析10.1复习笔记10.2课后习题详解第11章OLS用于时间序列数据的其他问题11.1复习笔记11.2课后习题详解第12章时间序列回归中的序列相关和异方差性12.1复习笔记12.2课后习题详解第三篇高级专题讨论第13章跨时横截面的混合:简单面板数据方法13.1复习笔记13.2课后习题详解第14章高级的面板数据方法14.2课后习题详解第15章工具变量估计与两阶段最小二乘法15.1复习笔记15.2课后习题详解第16章联立方程模型16.1复习笔记16.2课后习题详解第17章限值因变量模型和样本选择纠正17.1复习笔记17.2课后习题详解第18章时间序列高级专题18.1复习笔记18.2课后习题详解第19章一个经验项目的实施19.2课后习题详解本书是伍德里奇《计量经济学导论》(第5版)教材的学习辅导书,主要包括以下内容:(1)整理名校笔记,浓缩内容精华。
每章的复习笔记以伍德里奇所著的《计量经济学导论》(第5版)为主,并结合国内外其他计量经济学经典教材对各章的重难点进行了整理,因此,本书的内容几乎浓缩了经典教材的知识精华。
(2)解析课后习题,提供详尽答案。
互助问答第246期:关于受限因变量的模型选择问题(回答更正)

互助问答第246期:关于受限因变量的模型选择问题(回答更
正)
老师您好,我的问题是:
对于T obit左侧截断模型的适用范围是不是只适用于大量存在零的情况?那对于被解释变量的形式为0-1之间的概率的情况,可以使用Tobit模型吗?如果不可以,想请教老师们使用什么模型比较好呢?谢谢老师!
有些时候因变量不能任意取值,而是受到一定的限制。
比如,当因变量为人的不同职业(工人,农民,教师,医生),或者企业的专利个数时,就不能取值为小数;当因变量为概率时,只能在[0,1]之间取值。
在这里对不同的情况进行一个简要的总结。
(1)因变量为0-1之间的概率(比如某天下雨的概率),并且没有在两端出现堆积(比如取值为0或取值为1的观测值特别多),通常用OLS就行了。
(2)因变量是0-1的比率值,且没有出现堆积,用分数回归即可,用fractional logit或者fractional probit模型。
比如说,假如因变量是“某场考试学生作弊被发现的次数/某场学生实际作弊的次数”,它的值大于等于0,小于等于1,这种情况用分数回归,stata命令为fracreg probit;
(3)假如因变量有堆积,且为离散的情况,比如说公司专利,大部分公司的专利数量都是0,有些公司有1个,有些有2个,有些10个,这种零堆积的离散情况,就用计数模型,而且是zip;
(4)假如因变量有堆积,且其他值连续分布,比如说对某类型保险费用的支出,很多人支出为0的情况,适合用tobit模型。
第五章 选择模型与受限因变量
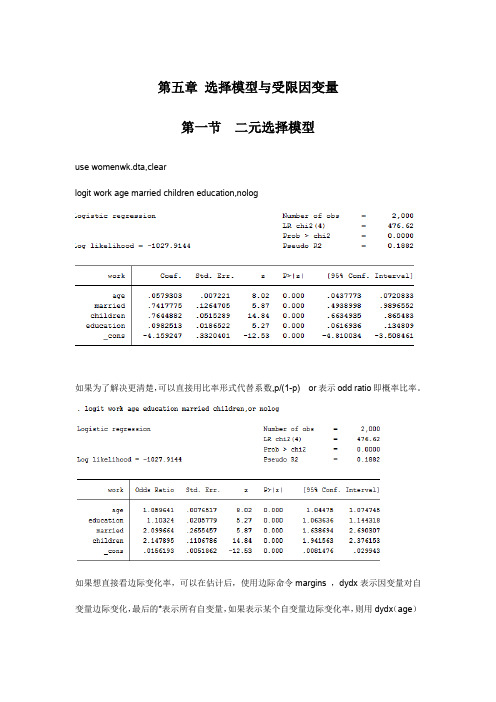
第五章选择模型与受限因变量第一节二元选择模型use womenwk.dta,clearlogit work age married children education,nolog如果为了解决更清楚,可以直接用比率形式代替系数,p/(1-p) or表示odd ratio即概率比率。
如果想直接看边际变化率,可以在估计后,使用边际命令margins ,dydx表示因变量对自变量边际变化,最后的*表示所有自变量,如果表示某个自变量边际变化率,则用dydx(age)第二节多元选择模型use nomocc2.dta,查看数据假设方案选择独立条件下,直接使用多元logit估计。
因变量是职业occ(共有五个选项低技术劳动者、手艺人、蓝领、白领、专业人士),自变量是白人、教育、经验。
其系数解释为相对于对比职业(专业),各自变量对应的概率。
如,对于一个白人来说,与选择专业化工作对比而言,更不可能选择服务与手艺人(z检验通过),但是否选择白领、蓝领则未必。
系数值随着对照方案的不同而有所差异。
可以更换对照方案:mlogit occ white ed exper,base(1) 这里的base(1)就是将第一类职业menial(服务人员)作为对照方案。
其结果如下:仍以白人为例,与成为一名服务人员相比,白人成为一名专业技术职位的可能性更大,其检验概率为0.019.但是,成为一名手工艺者的可能性却不大。
教育(ed)系数与检验结果类似。
在估计的基础上,我们可以预测一个人以后到底会选择什么样的职业,利用模型进行预测predict oc1 oc2 oc3 oc4 oc5list oc1 oc2 oc3 oc4 oc5 in 5/10 即在预测后,显示第五个至第十个对象选择某种职业的结果。
因变量不同数值代表不同的方案,各个方案概率和为 1. 多项选择是二项选择的自然推广,因无法同时识别所有系数,所以会将某方案作为“参照方案base category”,然后令其相应系数为0.然后利用最大似然法进行估计。
第六章_受限因变量模型__颜莹

Chapter 6 受限因变量模型本章讨论的一类模型是被关注的因变量的取值受到限制。
有时候这种限制不需要特别的处理,但有时候这种限制却是实质性的。
从条件期望的角度看,如果限制的信息是确定的,例如,y 只取有限个离散值,如1y =(表示赞成),0y =(表示反对)。
于是,()E Y X 用线性回归模型的方式来表示就不合适了。
我们将依据y 受不同限制的情况处理几类不同的非线性模型,并给出非线性模型的常用估计检验方法—极大似然方法。
按理,非线性模型是下篇的内容,之所以要介绍受限因变量模型是因为它的背景与多元回归模型有关。
另外,本章的附录部分简单的介绍非线性理论,这是伍书的第12章。
§1。
离散响应模型有时,我们只能观察到y 处于某种状态,用1表示,用0表示不处于该状态。
如1y =(就业),0y =(失业),或y 仅有几种很少的状态可供选择,我们把y 仅取有限的离散值情况称为离散响应模型。
特别,y 仅取0、1为值称为二元响应模型。
同样,影响y 的状态的因素称为解释变量或相关变量,X 可能包括有关个体的各种情况,如教育程度,年龄,性别…等,它们都有可能影响y 的就业状态。
关注的问题:X 中j X 多大程度上影响了y 的状态?这个问题准确的表达是,设1()(1)(1)k p x P y X P y X X ==== ,是一个条件概率。
解释变量j X 可以是连续型的也可以是离散型的。
那么对连续变量j X ,就用边际效应(1)()j jP y X p x X X ∂=∂=∂∂反映j X 对y 状态的影响,对二元变量k X ,(取0,1为值。
)就用差分效应 1111(.......,1)(.......,0)k k p x x p x x ---反映K X 对y 状态的影响。
以上两式,如果()p x 已知就没有问题了。
问题是如何确定()p x ? (1)二元响应的线性概率模型最简单的是认为()(1)p x P y X ==仍是X 的线性函数,改写成:01122(1)k k P y X X X X X βββββ==++++= 。
第十章定性选择模型与受限因变量模型ppt文档

第五个问题是在线性概率模型中R,2 以及R 2 不再是
合适的拟合优度测度。事实上,此问题不仅是线性概 率模型的问题,而是所有定性选择模型的问题。较好 一点的测度是模型正确预测的观测值的百分比。首先, 我们将每一预测归类为1或0。如果拟合值大于等于0.5, 则认为因变量的预测值为1。若小于0.5,则认为因变 量的预测值为0。然后,将这些预测值与实际发生的情 况相比较,计算出正确预测的百分比:
CPA的系数估计值0.4意味着家庭收入不变的情 况下,一个学生的增加一个点(如从3.0到4.0),该 生决定去读研的概率的估计值增加0.4。
INCOME的系数估计值0.002表明,一个学生的 成绩不变,而家庭收入增加1000美元(单位为千美 元),该生决定去读研的概率的估计值增加0.002。
LPM模型中,解释变量的变动与虚拟因变量值为 1的概率线性相关,因而称为线性概率模型。
正确预测观测 比值 正 的确 观 百预 测 分测 值的 总观 数 10测 0 值
需要指出的是,这个测度也不是很理想,但预测结
果的好坏,并非定性选择模型唯一关心的事,这类模
型常被用于研究影响人们进行某个决策的因素。让我
们来看一个竞选的例子。假设候选人甲和乙二人竞选
某市市长,我们可以用一个二元选择模型来研究影响 选民决策的因素,模型为:
C A N D 1 i 0 1 I N C O M E i 2 A G E i 3 M A L E i u i
其中:
1 如果第i个选民投候选人甲的票
C A N D1i
0
如果第i个选民不投候选人甲票 的
I NCO i M 第 iE 个选民的家庭 位收 :入 千( 美单 元)
AGEi 第i个选民的年龄
尽管因变量在这个二元选择模型中只能取两个 值:0或1,可是该学生的的拟合值或预测值为0.8。 我们将该拟合值解释为该生决定读研的概率的估计值。 因此,该生决定读研的可能性或概率的估计值为0.8。 需要注意的是,这种概率不是我们能观测到的数字, 能观测的是读研还是不读研的决定。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第17章受限因变量模型和样本选择纠正摘要: C7中的线性概率模型是受限因变量(limited dependent variable (LDV))模型的一例子,其容易解释,但有其缺陷,本章介绍的logit模型和probit模型更为常用,但解释相对困难。
实际应用中,离散和连续是相对的,也就是说,实际离散的经济变量可能也适用于因变量离散的模型建模。
本节介绍的模型包括Tobit模型,用于应对角点解响应(corner solution response);泊松回归模型(计数模型),用于建模LDV只能取非负整数的情况;截断数据模型和对样本选择的纠正。
受限因变量模型更容易在横截面数据中被使用。
样本选择的纠正通常都源于横截面或面板数据。
17.1 二值响应的logit模型和probit模型线性概率模型的缺陷?二值响应模型(binary response model)关注的核心问题是响应概率(response probability):.logit模型和probit模型的设定为此,需要先建一个连接函数:,其中G(.)是一个取值于(0,1)的函数。
常见的连接函数有:,该函数是标准logistic随机变量的累积分布函数:常见的连接函数还有标准正态的累积分布函数,G可以被表示为:.使用上述两个连接函数,我们分别建立了logit模型和probit模型。
关于logit模型和probit模型的推导:并定义,为示性函数。
要求满足CLM假设或高斯-马尔科夫假设。
显然当服从均值为0的正态分布,或者logistic分布,其都关于0点对称,则有:,也即:.从该推导中我们知道,但由于的不可观测性本身的含义并不直观,也并不很有用,虽然和中x的影响方向具有一致性(这一点由下面推导保证)。
我们关心解释变量对y的偏效应,由于(.)的非线性,对连续变量的情形就得依赖于偏导技术:,其中为概率密度函数,由于,所以偏效应的方向取决于 。
一个有趣的结论是:任意两个自变量的偏效应之比等于其系数之比。
此外,偏效应方程告诉我们偏效应依赖于密度函数的位置和 的大小,从而logit模型和probit模型的最大偏效应位置出现在和=0.25.而对于二值变量情形,则其偏效应相对来说容易确定,例如,是一个二值变量,则其偏效应为:。
其它离散变量情况类似。
考虑如下问题的偏效应:.对于上述问题,有时还要考虑响应概率相对于一个解释变量的弹性:对的弹性为: ;对的弹性为: ;对含解释变量交互项的模型可能会更难处理,可依赖于偏导数讨论。
logit和probit模型的极大似然估计极大似然法(maximum likelihood estimation , MLE)是基于条件分布的估计量,故一般其是有效估计和考虑了异方差性。
其可用于对受限因变量模型的估计。
假定有一个样本量为n的样本,为了得到极大似然估计量,需要给出在给定下的分布函数:,对上述方程取自然对数:),对上述方程求和,得到对数似然函数:,则最大化上述函数可求得的MLE估计量,记为,对数似然函数值一般是负值。
极大似然估计量一般是一致的、渐近正态的和渐近有效的(Wooldrige,2002,C13)。
其标准误和检验统计量一般统计软件都会提供。
●多重约束性检验有三种常用的排除性约束检验统计量:Lagrange multiplier or score test(Wooldrige,2002,C15);Wald test(Wooldrige,2002,C13)和likelihood ratio (LR) test。
下面介绍似然比检验的思想:如果部分变量的确对y有联合显著性,那么去掉它们,对数似然函数取值应该有比较大的降低,从而可以构造似然比统计量:LR=2(),表示无约束模型的对数似然值,而表示有约束模型的对数似然值,那么在原假设(检验q个排除性约束)成立的情况下,有LR.●解释Logit 和Probit模型的估计值拟合优度指标之一:正确预测百分数(percent correctly predicted),若,则定义,若,则定义,该变量是对的预测值,当表示预测对了,否则表示做了不正确的预测,所以只需要计算成立的对数。
分类给出正确预测百分比数是更好的选择。
关于临界值0.5的争议: 假如,那么可能发生的可能性很小,所以一种替代方法是将临界值定为,但可能在对进行0预测时会犯更大错误。
更有效地方法是使用搜索的方法确定临界值,以使正确预测百分比达到最大。
拟合优度指标之二:伪(pseudo R-squared)为McFadden(1974)建议的指标1-,表示只有截距项的模型的对数似然值。
请解释?拟合优度指标之三:=G()为拟合概率,其也是对的估计值,考察和的相似度!拟合优度本身对经济问题研究是相对次要的,下面讨论相对重要的偏效应(在其它条件不变的情形下的显著关系探讨)。
连续情形下,,此时通常的做法是在均值、中位数等重要的分位点进行讨论。
还有一种做法是提供各个变量的均值来生成对的调整因子:,此时被称为平均值处的偏效应(partial effect at the average(PEA)),但这种做法有两个缺陷,一、对离散变量而言,其平均值代表什么含义?二、如果模型中的变量涉及到了函数变换,那么究竟是函数变换前取平均(统计软件默认)还是变换后求平均?一种替代法是使用平均偏效应(average partial effect (APE)):.离散变量情形下,自变量的离散偏效应为:,特别是对于二值变量有同样可以定义离散情形下的平均偏效应。
三种模型的比例因子的关系,LPM的g(0)=1;而logit的g(0)约为0.4, Probit约为0.25.Probit模型等同样面临内生性问题,问题的解决可以考虑类似于2SLS的思路(Wooldrige,2002,C15)。
在Probit模型的情形下,有两个问题:一、 e的非正态性,二、e的异方差性(假如 Var(e|x) 依赖于 x, 则响应概率不再具有形式 G(0 + x),而依赖于方差的形式。
17.2 用于角点解响应的Tobit模型另一类重要的受限因变量以在0值处取一个不可忽略的概率,而在正值时大致连续为特征。
我们可以用线性模型来拟合该因变量,但要注意:1)拟合值可能取负值;2)以水平值出现的解释变量对的偏效应是常数;3)可能是异方差的;4)y的条件分布不再是正态,因此只能实施渐近的统计推断。
为此,建立Tobit模型:并定义.从而,=1-,而当y>0时,其基于的条件密度函数为:, 为标准正态密度函数。
估计问题仍然可以使用极大似然估计:需要给出在给定下的分布函数:,对上述方程求和,得到对数似然函数:,则最大化上述函数可求得和的MLE估计量。
同样可以建立三种常用的排除性约束检验统计量:Lagrange multiplier or score test(Wooldrige,2002,C15);Wald test(Wooldrige,2002,C13)和likelihood ratio (LR) test。
对Tobit估计值的解释如果我们仅仅要解释,那么直接使用就够了,但是我们想解释。
此时需注意有两个条件期望:和:=λ,其中λ;最后一个等式成立是因为=.最后可得,.(1)从该方程可以看出,1)仅用的样本,不能一致的估计出;2)可以证明(1)式的右边为正数,也即(1)保证y拟合值非负的代价是,以一个复杂的非线性式子替换线性模型的线性关系;3)偏效应的估计还是要依赖于求偏导的方法:λλλ.可见,的偏效应并非只取决于 ,还取决于一个调整因子,该因子是的函数,可以证明该调整因子严格介于0和1之间。
进一步可得:,可见对的偏效应的方向和 的正负号相同,也同于对的偏效应方向。
有了偏效应函数,那么弹性公式也可以写出。
如果为离散变量,则其偏效应可仿造logit或Probit模型的做法。
关于偏效应的实际解释,也可以借鉴Logit或Probit模型的做法。
例如,先求出平均值处的,然后用这个调整因子乘以连续变量的估计值。
同Logit和Probit模型,在平均值处的偏效应(PAE)可能不如平均偏效应(APE)可取。
由于,所以调整因子总在0和1之间,并且在0的取值越少, Tobit模型和OLS参数估计值越接近。
x离散时的偏效应度量,也可借鉴Logit和Probit模型的类似讨论。
Tobit模型中的设定问题Tobit模型极大的依赖于满足条件正态分布,否则,我们不知道我们在估计什么。
正因有该假设,则的偏效应依赖于调整因子,而且对的影响和对影响有密切的联系。
而在线性模型时,我们却往往可以放心的进行统计推断。
检验Tobit 是否恰当(评价Tobit)一种方法是估计一个Probit模型,那么该模型的系数,从而若Tobit模型合适,的估计值应该和的估计值较为渐近。
如果Tobit模型不合适,那么可以选择对和具有不同影响的模型(例如,Hurdle model 或者Two-part model, Wooldrige,2002,C16)。
17.3 泊松回归模型非负因变量的另一个常见例子是计数变量(count variable),即其可以取非负整数(0,1,2,…)。
该模型的一种解决思路是,使用指数函数:,来保证对的预测取正数。
解释上也很简单,两边取对数后有:,从而系数有一个对数-水平值的解释,或者有一个更为精确的比例变化解释:=exp()-1.由于指数函数的非线性特征,我们又要依赖于极大似然估计方法和拟极大似然估计方法(quasi-maximum likelihood estimation)。
假定y的条件分布为正态已不再合适,合适的假定是假定其服从泊松分布(Poisson distribution),从而的条件概率为:,h=0,1,2,….在估计出参数值后,该分布列能给出任意取值的概率。
对一个样本量为n的样本,有如下的对数似然函数:( ), 最大化上式可以得到的MLE估计值。
在连续变量时,可以将OLS估计值和泊松回归模型的估计值做比较。
事实上由于,从而从APE的比例因子实际上就是y的样本均值。
从而直接比较和即可。
泊松分布的高阶矩都由其一阶矩决定,这往往和实际不符合。
此时需要对某些统计量例如标准误进行调整。
办法是假定,其中时满足泊松分布的假设,一般情形是,此时被称为过度散布(overdispersion),与散布不足(underdispersion)对应。
估计思路是先估计.泊松模型的优点在于不管泊松分布假设是否成立,仍能得到的一致和渐近正态估计量(Wooldrige,2002,C19),此时的估计量称为拟极大似然估计(QMLE)。
有效地排除性约束检验仍然是似然比检验或者拟似然比检验(quasi-likelihood ratio test)。