受限因变量模型
第十八章-离散选择模型和受限因变量模型

第18章 离散选择模型和受限因变量模型 18.1概述在经典计量经济学模型中,被解释变量通常被假定为连续变量,但在现实的经济决策中经常面临许多选择问题。
在这样的决策问题中,或者选择问题中,人们必须对可供选择的方案作出选择。
通常被解释变量是连续的变量,但此时的因变量只取有限多个离散的值。
例如:人们对交通工具的选择,是选择坐轻轨、地铁还是公共汽车;某大型企业是否合并另一企业;对某一方案的建议持强烈反对、反对、中立、支持和强烈支持5种态度,可以分别用0,1,2,3和4表示。
以这样的选择结果作为被解释变量建立的计量经济学模型,称为离散被解释变量数据计量经济学模型(models with discrete dependent variables ),或称为离散选择模型(DCM ,discrete choice model )。
如果被解释变量只能有两种选择,称为二元选择模型(binary choice model );如果被解释变量有多种选择,称为多元选择模型(multiple choice model )。
20世纪70和80年代,离散选择模型普遍应用于经济布局、企业定点、交通问题、就业问题、购买决策等经济决策领域的研究。
在实际中,还会经常遇到因变量受到某种限制的情况,这种情况下,取得样本数据来自总体的一个子集,可能不能完全反映总体。
例如,小时工资、住房价格和名义利率都必须大于零。
这时需要建立的经济计量模型称为受限因变量模型(limited dependent variable model )。
这两类模型经常用于调查数据的分析中。
本章将讨论三类模型及其估计方法和软件操作。
一是定性(观测值为离散的或者表示排序);二是截取或者截断问题;三是观测值为整数值的计数模型。
18.2二元因变量模型在这个模型中,被解释变量只取两个值,可以是代表某件事发生与否的虚拟变量,也可以是两个决策中选一个,称为二元因变量模型。
例如:对样本个体是否就业的研究,个体的年龄、教育背景、种族、婚姻状况以及其他可观测的特征,作为解释变量,目的是研究个体这些特征对个体就业概率的研究。
受限因变量模型及其半参数估计

·综述·受限因变量模型及其半参数估计*薛小平1史东平2王彤1△受限因变量(1imiteddependentvariable)指因变量的观测值是连续的,但是受到某种限制,得到的观测值并不完全反映因变量的实际状态。
例如在某次流行病学调查中,我们将能够代表人体健康状况的某个指标作为因变量,从而研究影响人体健康状况的各种因素,现要测量该指标的水平,但是由于仪器的检测极限问题,在某个水平之上或之下的值我们观测不到,在实际应用中通常就用这个极限水平的值来代替那些我们观(truncatedregressionmodel)selectionmodel)。
当这些模型中的潜在误差项已知是正态分布,或者更一般地来说,已知误差项分布函数的参数形式时,通过最大似然法或者其他基于似然的估计过程可以获得一致和渐近正态分布的估计量CI,2]。
然而这些估计量对误差项分布的假设非常敏感,当对误差项的参数分布形式假定不正确时,基于似然的估计量是不一致的【3】。
即使误差项的密度函数被正确设定了,误差项的异方差性也会导致参数估计的不一致【4.5】。
在医学应用中一般不能限制误差项的分布形式和方差齐性,而基于似然的估计方法对这些假定非常敏感,因而一些放松这些假定条件的~致估计方法包括非参数和半参数估计陆续被提出,本文主要概括介绍几种半参数估计。
虽然这些模型已用于时间序列或纵向数据的分析中,这里仍将把注意力限于横截面数据的应用上。
Tobit模型和断尾回归模型Tobit模型是Tobin【6】首次提出的,适用于在正值上大致连续分布但包含一部分以正概率取值为零的结医疗保险费用支出为零,因此,虽然年度家庭医疗保险费用支出的总体分布散布于一个很大的正数范围内,但在数字零上却相当集中。
T0bit模型容易定义为:y’=80+ze+弘3,=max(O。
y。
)该方程意味着当y’>0时,所观测到的变量,=y。
,*山西省高校青年学术带头人基金资助。
伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解-第17章 限值因变量模型和样本选择纠正【圣才

第17章限值因变量模型和样本选择纠正17.1复习笔记一、二值响应的对数单位和概率单位模型1.线性概率模型的不足(1)拟合出来的概率可能小于0或大于1;(2)任何一个解释变量(以水平值形式出现)的偏效应都是不变的。
二值响应模型的核心是响应概率:()()12P 1x P 1 k y y x x x ===⋅⋅⋅,,,其中,用x 表示全部解释变量所构成的集合。
2.设定对数单位和概率单位模型(1)二值响应模型在LPM 中,响应概率对一系列参数j β是线性的,为避免LPM 的局限性,考虑二值响应模型:()()()01101x k k P y G x x G x βββββ==++⋅⋅⋅+=+其中,G 是一个取值范围严格介于0和1之间的函数:对所有实数z,都有0﹤G(z)﹤1。
这就确保估计出来的响应概率严格地介于0和1之间。
(2)函数G 的各种非线性形式①对数单位模型中,G 是对数函数:()()()()exp /1exp G z z z z =+=Λ⎡⎤⎣⎦对所有的实数z,它都介于0和1之间。
它是一个标准逻辑斯蒂随机变量的累积分布函数。
②概率单位模型中,G 是标准正态的累积分布函数,可表示为积分()()()d z G z z v vφ-∞=Φ≡⎰其中,()z φ是标准正态密度函数()()()1/222exp /2z z φπ-=-也确保了对所有参数和x j 的值都严格介于0和1之间。
③两个模型中G 函数都是增函数,在z=0时增加的最快,在z →-∞时,()0G z →,而在z →∞时,()1G z →。
(3)两种函数形式的推导对数单位和概率单位模型都可以由一个满足经典线性模型假定的潜变量模型推导出来。
令y *为一个由0y x e ββ*=++,y=1[y *﹥0]决定的无法观测变量或潜变量。
在其中引入记号1[·]来定义一个二值结果。
函数1[·]被称为指标函数,它在括号中的事件正确时取值1,而在其他情况下取值0。
C17受限因变量模型和样本选择纠正

第17章 受限因变量模型和样本选择纠正摘要: C7中的线性概率模型是受限因变量(limited dependent variable (LDV))模型的一例子,其容易解释,但有其缺陷,本章介绍的logit 模型和probit 模型更为常用,但解释相对困难。
实际应用中,离散和连续是相对的,也就是说,实际离散的经济变量可能也适用于因变量离散的模型建模。
本节介绍的模型包括Tobit 模型,用于应对角点解响应(corner solution response);泊松回归模型(计数模型),用于建模LDV 只能取非负整数的情况;截断数据模型和对样本选择的纠正。
受限因变量模型更容易在横截面数据中被使用。
样本选择的纠正通常都源于横截面或面板数据。
17.1 二值响应的logit 模型和probit 模型线性概率模型的缺陷?二值响应模型(binary response model )关注的核心问题是响应概率(response probability):.P (y =1│x )=P(y =1|x 1,x 2,…,x n ) logit 模型和probit 模型的设定为此,需要先建一个连接函数:,P (y =1│x )=G (β0+β1x 1+β2x 2+…+βk x k )=G(β0+xβ)其中G(.)是一个取值于(0,1)的函数。
常见的连接函数有:,G (z )=exp (z )[1+exp (z )]=Λ(z)该函数是标准logistic随机变量的累积分布函数:常见的连接函数还有标准正态的累积分布函数,G 可以被表示为:G (z )=Φ(z )≡x ∫‒∞ϕ(v)dv ,.ϕ(v )=(2π)‒1/2exp(‒z 22)使用上述两个连接函数,我们分别建立了logit 模型和probit 模型。
关于logit 模型和probit 模型的推导:y ∗=β0+xβ+e ,并定义,为示性函数。
y =I(y ∗>0) I要求满足CLM 假设或高斯-马尔科夫假设。
第十八章-离散选择模型和受限因变量模型

第18章离散选择模型和受限因变量模型18.1概述在经典计量经济学模型中,被解释变量通常被假定为连续变量,但在现实的经济决策中经常面临许多选择问题。
在这样的决策问题中,或者选择问题中,人们必须对可供选择的方案作出选择。
通常被解释变量是连续的变量,但此时的因变量只取有限多个离散的值。
例如:人们对交通工具的选择,是选择坐轻轨、地铁还是公共汽车;某大型企业是否合并另一企业;对某一方案的建议持强烈反对、反对、中立、支持和强烈支持5种态度,可以分别用0,1,2,3和4表示。
以这样的选择结果作为被解释变量建立的计量经济学模型,称为离散被解释变量数据计量经济学模型(models with discrete dependent variables),或称为离散选择模型(DCM,discrete choice model)。
如果被解释变量只能有两种选择,称为二元选择模型(binary choice model);如果被解释变量有多种选择,称为多元选择模型(multiple choice model)。
20世纪70和80年代,离散选择模型普遍应用于经济布局、企业定点、交通问题、就业问题、购买决策等经济决策领域的研究。
在实际中,还会经常遇到因变量受到某种限制的情况,这种情况下,取得样本数据来自总体的一个子集,可能不能完全反映总体。
例如,小时工资、住房价格和名义利率都必须大于零。
这时需要建立的经济计量模型称为受限因变量模型(limited dependent variable model)。
这两类模型经常用于调查数据的分析中。
本章将讨论三类模型及其估计方法和软件操作。
一是定性(观测值为离散的或者表示排序);二是截取或者截断问题;三是观测值为整数值的计数模型。
18.2二元因变量模型在这个模型中,被解释变量只取两个值,可以是代表某件事发生与否的虚拟变量,也可以是两个决策中选一个,称为二元因变量模型。
例如:对样本个体是否就业的研究,个体的年龄、教育背景、种族、婚姻状况以及其他可观测的特征,作为解释变量,目的是研究个体这些特征对个体就业概率的研究。
02-14.5 其他受限因变量模型

素。通过调查取得了市民收入(INC)与支持与否( y )的数
据,其中如果选民支持则yi取0,中立取1,不支持取2。
2、受限因变量模型
现实的经济生活中,有时会遇到这样的问题,因
变量是连续的,但是受到某种限制,也就是说所
得到的因变量的观测值来源于总体的一个受限制
乘出租车,乘公共汽车,还是骑自行车。
多元选择模型
上述3个例子代表了多元选择问题的不同类型。前两个
例子属于有序选择问题,所谓“有序”是指在各个选择项
之间有一定的顺序或级别种类。而第3个例子只是同一
个决策者面临多种选择,多种选择之间没有排序,不
属于有序选择问题。
与一般的多元选择模型不同,有序选择问题需要建立
数据,来自于美国国势调查局[U.S.Bureau of the
Census(Current Population Survey, 1993)],其中y
表示已婚妇女工作时间, x1~ x4分别表示已婚妇
女的未成年子女个数、年龄、受教育的年限和丈
夫的收入。
2.1 删失回归模型
例
删失模型的实例
只要已婚妇女没有提供工作时间,就将工作时间
换句话说,yi*的所有负值被定义为0值。我们称
这些数据在0处进行了左截取(删失)(left
censored)。而不是把观测不到的 yi* 的所有负
值简单地从样本中除掉。删失回归模型的一种典
型处理方法,也称为Tobit模型。
2.1 删失回归模型
例
删失模型的实例
本例研究已婚妇女工作时间问题,共有50个调查
作零对待,符合删失回归模型的特点。
2.2 截断回归模型
第十章定性选择模型与受限因变量模型

尽管因变量在这个二元选择模型中只能取两个值:0或1,可是该学生的的拟合值或预测值为 0.8。我们将该拟合值解释为该生决定读研的概率的估计值。因此,该生决定读研的可能性或概率 的估计值为0.8。需要注意的是,这种概率不是我们能观测到的数字,能观测的是读研还是不读研 的决定。
对斜率系数的解释也不同了。在常规回归中,斜率系数代表的是其他解释变量不变的情况下, 该解释变量的单位变动引起的因变量的变动。而在线性概率模型中,斜率系数表示其他解释变量不 变的情况下,该解释变量的单位变动引起的因变量等于1的概率的变动。
对每个观测值,我们可根据(10.3)式计算因变量的拟合值或预测值。在常规OLS回归中,因变 量的拟合值或预测值的含义是,平均而言,我们可以预期的因变量的值。但在本例的情况下,这种 解释就不适用了。假设学生甲的平均分为3.5,家庭年收入为5万美元,Y的拟合值为
Y ˆ 0 .7 0 .4 3 .5 0 .0 0 2 5 0 0 .8
f( Y ix i;β ) [ G ( x iβ ) ] Y i[ 1 G ( x iβ ) ] 1 Y i,Y i 0 ,1 ln li( β ) Y iln [ G ( x iβ ) ] ( 1 Y i) ln [ 1 G ( x iβ ) ]
n
lnL(β) lnli(β) i1
0.13
Observations:30
ARRdejsu2=idst0ue.ad5l8Sum=Ro02f.5S3quares =3.15
F-statistic = 11.87
t-Statistic -2.65 3.25 3.08 0.02
p-Value 0.01 0.00 0.00 0.98
如表所示,INCOME的斜率估计值为正,且在1%的水平上显著。年龄和性别不变的情况下,收 入增加1000元,选择候选人甲的概率增加0.0098。
受限因变量模型及其半参数估计

=ma ( , x 0 )
布, 该方 法 就是 对称 的修 剪 因变 量 即 重 新 修剪 断 尾 分
将把 注意 力 限于横截 面 数据 的应 用上 。 T bt 型和 断尾 回归 模型 o i模
To i模型 是 T bn6 次 提 出 的 , 用于 在 正 值 bt 0 i【 首 适 上大致 连 续分 布但 包含 一部分 以正概 率取 值 为零 的结 果 变 量。 比如 , 在任 一给 定年 份 , 相 当数 量 的家庭 的 有 医疗保 险 费用支 出为 零 , 因此 , 然年度 家庭 医疗保 险 虽 费 用支 出 的总体 分 布 散布 于 一 个 很 大 的 正 数 范 围 内, 但 在数 字零 上却 相 当集 中。T bt 型 容 易定义 为 : o i模
当v ≤0时 , Y 。 以上 是 将截 取 点 设 为零 , 实 则 =0 事 上截 取 l 点 可 以为 临界 可 以对 所有 的 i 是 一 样 都 的, 但在 多数 情 况 下 随着 i的 特 征 而 变 化 , 且 C 既 并 可 以从 上截 取 也可 以从 下 截 取 还可 以两 边 同时截 取 。 在 这些 更 广泛 的情 况 下 我 们 称模 型 为截 取 回归 模 型 。 T bt 型 事实 上 是截 取 回 归模 型 在 左 端 截 取 点 为 0 o i模
时 的特 殊情 况 。
应用 中通 常就 用这 个极 限水 平 的值来 代替 那 些我 们观
测不 到 的值 。受 限因变 量模 型主 要包 括 断尾 回归模 型
(rnae ges nmo e) To i模 型 (o i mo e) tu ctdr rsi d 1、 bt e o tbt d1
第06章 离散因变量和受限因变量模型_s

(7.1.2)
又因为E(ui ) = 0 ,所以 E(yi ) = xi,xi =(x1i , x2i ,…, xki ), =(1 , 2 ,…, k ),从而有下面的等式:
E ( yi ) P( yi 1) pi xi β
(7.1.3)
4
式(7.1.3)只有当xi 的取值在(0,1)之间时才成立,否则就会
记为1,不买记为0。是否买车与两类因素有关系:一类是车
本身所具有的属性,如价格、型号等;另一类是决策者所具 有的属性如收入水平、对车的偏好程度等。如果我们要研究 是否买车与收入之间的关系,即研究具有某一收入水平的个 体买车的可能性。因此,二元选择模型的目的是研究具有给
定特征的个体作某种而不作另一种选择的概率。
2
7.1.1
线性概率模型及二元选择模型的形式
为了深刻地理解二元选择模型,首先从最简单的线性概率 模型开始讨论。线性概率模型的回归形式为:
yi 1 x1i 2 x2i k xki ui
i 1 , 2 , , N
(7.1.1)
其中:N是样本容量;k是解释变量个数;xj 为第j个个体特征 的取值。例如,x1表示收入;x2表示汽车的价格;x3表示消费 者的偏好等。设 yi 表示取值为0和1的离散型随机变量:
图7.3 Options对话框
18
(3)预测
从方程工具栏选择Procs/Forecast(Fitted Probability /Index),然后单击想要预测的对象。既可以计算拟合概 ˆ ˆ ˆ 率, p 1 F ( x β ) ,也可以计算指标 x i β 的拟合值。
i
像其他方法一样,可以选择预测样本,显示预测图。 如果解释变量向量xt 包括二元因变量yt 的滞后值,选择 Dynamic选项预测,EViews使用拟合值 pt 1 得到预测值; ˆ 而选择Static选项,将使用实际的(滞后的)yt-1 得到预测 值。 对于这种估计方法,无论预测评价还是预测标准误差 通 常 都 无 法 自 动 计 算 。 后 者 能 够 通 过 使 用 View/ Covariance Matrix 显 示 的 系 数 方 差 矩 阵 , 或 者 使 用 @covariance函数来计算。
互助问答第22问 关于受限因变量模型的三个问题

问:关于受限因变量模型的三个问题。
(1)受限因变量模型,比如Probit、Tobit模型等都采用MLE估计,如果是正态分布且同方差(i.i.d),则估计结果是一致且服从正态分布。
如果存在误设(不服从正态分布或者异方差)则采用QMLE估计,在条件期望正确设定(一阶矩)的情况下,估计仍然是一致的。
那么,是否意味在做这些模型检验的时候,就不必关注异方差和正态分布检验?(2)若对受限因变量模型仍然要关注异方差和正态分布检验,如何检验?现有的实证文章中很少有对这些问题进行检验,都是直接应用。
Tobit模型用tobcm 命令来检验正态分布,异方差用哪个命令?(3)发现异方差和非正态分布,如何修正?答:当Probit和Tobit模型的正态分布假设不成立或存在异方差问题时,模型中的Beta系数一般是不一致的。
但这个问题到底多严重,学界看法是不一致的。
比如Wooldridge的看法就是:我们不应该只强调系数的估计是否一致,因为我们关心的根本不是系数本身,而是自变量的局部效应(Partial effects,比如在运行完Probit后,用margins命令生成的效应)——在线性模型中,系数也就是局部效应,但在Probit和Tobit等非线性模型中,两者不是一回事。
在Wooldridge的高级教科书中(Wooldridge 2010),他举了一个例子:真实分布是Logit,但研究者误用了Probit,尽管系数估计值有明显差异,但是自变量的局部效应没什么显著区别。
他在中级教科书中(Wooldridge 2016)提到:如果偏离正态同方差假设不严重,Tobit模型得到的自变量的局部效应依然是可靠的。
这或许就是现在实证研究较少检验正态和同方差的原因之一。
如果你在乎这些问题,也还是有一些方法的。
比如hetprobit命令就可以检验及纠正Probit模型中可能存在的异方差问题。
除此之外,大量的命令都是第三方命令而非系统自带。
我个人的看法是:与其直接检验正态分布或同方差,还不如通过诸如变换模型形态等方式验证结果(局部效应)是否稳健。
Tobit模型估计方法与应用

Tobit模型估计方法与应用一、本文概述本文旨在全面探讨Tobit模型估计方法及其应用。
Tobit模型,也称为截取回归模型或受限因变量模型,是一种广泛应用于经济学、社会学、生物医学等领域的统计模型。
该模型主要处理因变量在某一范围内被截取或受限的情况,例如,当因变量只能取正值或只能在某一特定区间内变动时。
本文首先将对Tobit模型的基本理论进行阐述,包括模型的设定、参数的估计方法以及模型的检验等方面。
随后,文章将详细介绍Tobit模型在各个领域中的应用案例,包括工资水平、耐用消费品需求、医疗支出等方面的研究。
通过这些案例,我们将展示Tobit模型在处理受限因变量问题时的独特优势和应用价值。
文章还将对Tobit模型的发展趋势和前景进行展望,以期为相关领域的研究提供有益的参考和启示。
二、Tobit模型的基本原理Tobit模型,也称为受限因变量模型或截取回归模型,是一种广泛应用于经济学、社会学、生物医学等领域的统计模型。
该模型主要处理因变量受到某种限制或截取的情况,例如因变量只能取正值、只能在某个区间内取值等。
Tobit模型的基本原理基于最大似然估计法,通过构建似然函数来估计模型的参数。
截取机制:在Tobit模型中,因变量的取值受到某种截取机制的限制。
这种截取机制可以是左截取、右截取或双侧截取。
左截取意味着因变量只能取大于某个阈值的值,右截取则意味着因变量只能取小于某个阈值的值,而双侧截取则限制了因变量的取值范围在两个阈值之间。
潜在变量:在Tobit模型中,通常假设存在一个潜在变量(latent variable),它是没有受到截取限制的因变量。
潜在变量与观察到的因变量之间的关系由截取机制决定。
潜在变量通常假设服从某种分布,如正态分布。
最大似然估计:在给定截取机制和潜在变量分布的假设下,可以通过构建似然函数来估计Tobit模型的参数。
似然函数反映了观察到的数据与模型参数之间的匹配程度。
通过最大化似然函数,可以得到模型参数的估计值。
计量经济学_历史回顾与未来展望

计量经济学:历史回顾与未来展望程振源(华南师范大学经济与管理学院、华南市场经济研究中心广东广州510006)摘要:该文回顾了计量经济学的发展历程,指出了计量经济学研究未来可能的发展方向。
计量经济学;回顾;展望关键词:世界计量经济学学会于1930年12月29日成立,其会刊《计量经济学》杂志也于1933年正式创刊。
该学会的成立及其会刊的创刊是计量经济学发展史上的重要里程碑,标志着计量经济学这一学科的正式诞生,极大地推动了计量经济学的研究与发展。
计量经济学在经济学中的地位日渐突出,其取得的成就令人瞩目。
例如,从1969年诺贝尔经济学奖设立以来,因在计量经济学方面的杰出贡献而获奖的人数在经济学各分支学科中名列榜首。
1969年首届诺贝尔经济学奖获得者就是计量经济学家弗里希。
1.上世纪30~50年代计量经济学的研究1.1单方程模型上世纪30年代,以首届诺贝尔经济学奖得主弗里希为代表的计量经济学家致力于单方程计量经济学模型的研究。
但不久就将研究的重点转向了联立方程模型。
此后,单方程模型就一直未受到计量经济学家们的重视。
只是在上世纪70年代偶尔有少数几个学者涉足单方程模型这一领域,如Goldberger和Griliches(1977)等人。
1.2联立方程模型上世纪40至50年代,计量经济学家们主要致力于联立方程模型的研究,Haavelmo(1944)开创了该领域研究的先河。
不久,Andson和Rubin提出了联立方程模型的有限信息极大似然估计法(LIML)。
但该估计法过于繁琐,于是,Theil(1956)提出了两阶段最小平方法(2SLS)。
与有限信息极大似然估计法相比,两阶段最小平方法具有更稳定的性质。
并且该方法计算简便,因此很快得到推广。
但从严格意义上讲,两阶段最小平方法并不像有限信息极大似然估计法那样是一种联立方程估计法。
如果方程是过度识别的,那么对于两阶段最小平方法来说,采用何种方法对方程进行正态化是至关重要的(而有限信息极大似然估计法对标准化来说具有不变性),这与联立概念是相违背的。
第五讲 受限因变量时间序列以及panel模型

2. Logit 估计 —- 最大似然法估计法 我们观察不到 p (拥有住房的概率) , 而只观察到 Y 的结果 (拥有住房 Y=1, 或不拥有住房 Y=0) ,如何估计参数? 一般用最大似然法估计法估计参数。因为 Y 服从贝努里分布,我们有 Pr(Yi = 1) = pi Pr(Yi = 0) = 1 - pi 假设我们得到 n 个观测值的随机样本,令 fi(Yi)表示 Yi=1 或 Yi=0 的概率, 于是观测到 n 个 Y 值的联合分布概率(joint probability)为
ln f (Y1 , Y2 ,..., Yn ) = ∑[Yi ln pi + (1 − Yi ) ln(1 − pi )]
i =1 n
n
= ∑[Yi ln pi − Yi ln(1 − pi ) + ln(1 − pi )]
i =1 n
⎡ ⎛ p i ⎞⎤ n = ∑ ⎢Yi ln⎜ ⎟⎥ + ∑ ln(1 − pi ) ⎜1− p ⎟ i =1 ⎣ i =1 i ⎠⎦ ⎝
---------------------| yhat| 0 | 1 | Y 0 18 3 1 3 8
----------+-----------
----------------------
(2)pseudo-R2 最常用的是 McFadden(1974)提出的 pseudo-R2 McFadden pseudo R 1
T
β 2β 3 ~χ 2 5β 3β 0 (2) Nonlinear restrictions: g(β)=0 H :β β g β β β 1 W 0 g β
T
1
∂g β var β ∂βT
∂g β ∂βT
计量经济学前沿第七讲限制因变量模型与估计evmi

Pr(Y | P / Irartio,black) 0.091 0.559P / Iratio 0.177black
(0.029) (0.089)
(0.025)
Pr( y | P / I ratio,black) (2.26 2.74P / I ratio 0.71black)
(0.16) (0.44)
二值响应的 Probit 和 Logit 模型
▪ 二值响应的 Probit 和 Logit 模型的大多数应用中,主要目 的是为了解释 x 对响应概率的影响,通过 G(z) 将各解释 变量与相应概率联系起来。
Pr( y 1| X ) G(0 1X i1 2 X i2 ) G(zi ) (3)
▪ 方程(4)(5)关于解释变量和参数都是非线性的,应用 最大似然估计法 MLE(Maximun Likelihood Estimation) 估计参数。
17
Copyright © 2003 Prentice-Hall, Inc.
Probit 模型的估计
估计方法:
1. MLE 最大似然估计
2. 利用分组数据求得 的估计值 ,用传统的
Probit 和 Logit 模型的估计
▪ 给定解释变量和二元因变量的观察值
▪ Probit 模型估计
0 1X i1 2 X i 2
▪
Pr( y
Logit
1| X ) (
模型估计
0
1
X
i1
2
X
i2
)
(t )dt
(4)
Pr( y
1|
X
)
G(zi )
1
1 e( 0 1Xi1 2 Xi 2 )
(5)
住房价格,对已购房者p > 0,对未购房者p = 0
第五章 选择模型与受限因变量
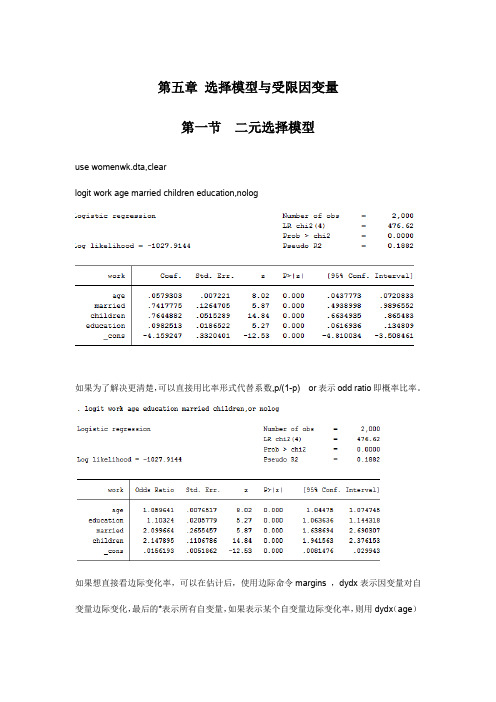
第五章选择模型与受限因变量第一节二元选择模型use womenwk.dta,clearlogit work age married children education,nolog如果为了解决更清楚,可以直接用比率形式代替系数,p/(1-p) or表示odd ratio即概率比率。
如果想直接看边际变化率,可以在估计后,使用边际命令margins ,dydx表示因变量对自变量边际变化,最后的*表示所有自变量,如果表示某个自变量边际变化率,则用dydx(age)第二节多元选择模型use nomocc2.dta,查看数据假设方案选择独立条件下,直接使用多元logit估计。
因变量是职业occ(共有五个选项低技术劳动者、手艺人、蓝领、白领、专业人士),自变量是白人、教育、经验。
其系数解释为相对于对比职业(专业),各自变量对应的概率。
如,对于一个白人来说,与选择专业化工作对比而言,更不可能选择服务与手艺人(z检验通过),但是否选择白领、蓝领则未必。
系数值随着对照方案的不同而有所差异。
可以更换对照方案:mlogit occ white ed exper,base(1) 这里的base(1)就是将第一类职业menial(服务人员)作为对照方案。
其结果如下:仍以白人为例,与成为一名服务人员相比,白人成为一名专业技术职位的可能性更大,其检验概率为0.019.但是,成为一名手工艺者的可能性却不大。
教育(ed)系数与检验结果类似。
在估计的基础上,我们可以预测一个人以后到底会选择什么样的职业,利用模型进行预测predict oc1 oc2 oc3 oc4 oc5list oc1 oc2 oc3 oc4 oc5 in 5/10 即在预测后,显示第五个至第十个对象选择某种职业的结果。
因变量不同数值代表不同的方案,各个方案概率和为 1. 多项选择是二项选择的自然推广,因无法同时识别所有系数,所以会将某方案作为“参照方案base category”,然后令其相应系数为0.然后利用最大似然法进行估计。
2011管理统计-二元选择模型和受限因变量

第20页,共28页。
(2)下截取(左截取)
定义类似于上截取模型。一个特殊的下截取模 型,TOBIT模型
yi
0
yi*
if if
yi* 0 yi* 0
例1,研究人们在一个月中酒方面的花费就是一个例子。有相当多的人在酒方面的 花费为零。我们不是简单的将这些观测从样本中去掉,而是建立Tobit模型。
如果Y*大于某值(如C),我们只能观察到 y=c.
第19页,共28页。
考虑潜变量模型
yi* xiβ ui
被观察数据y与潜变量 的关系 yi*
yi
yi* c
if yi* c if yi* c
即:y min( y*, c)
例如,在电影或者球赛的门票销售中,由于受到场地的限制, 门票的需求量超过了座位数C时,我们只能观察到Y=C。
L为无约束似然值,L0为参数为0约束下的似然值。
概率的正确预测率
检查Y=1或0的概率的正确性,判断拟合的好坏
预测值与真实值的相关系数
相关系数高,表明拟合越好
第14页,共28页。
4、模型的选择
直接比较三种概率模型的系数是没有意义的
线性概率模型可用于问题的初步分析 Logit模型,系数含义可以通过机会比得以解释
。
Y的期望
E(Y | Y 0) (x' ) x' (x' ) (x' )[x' (x' )]
第27页,共28页。
可以得到:
E(Yi | xi ) ( xi' )
xi
第28页,共28页。
第4页,共28页。
二、线性概率模型
1、线性概率模型: 例如,研究居民的收入和是否购买住房的关系
tobit模型回归结果的置信区间

tobit模型回归结果的置信区间摘要:一、Tobit模型简介二、Tobit模型的回归结果三、Tobit模型回归结果的置信区间四、结论与启示正文:一、Tobit模型简介Tobit模型,又称截尾回归模型或受限因变量模型,是一种特殊类型的回归模型。
它主要用于分析因变量受到某种限制的情况,例如在家庭医疗保险费用支出的研究中,尽管总体分布散布于一个大的正数范围内,但在数字0上却相当集中。
这种模型可以有效地解决因变量受限的问题,具有较强的实用性。
二、Tobit模型的回归结果在Tobit模型中,回归结果通常包括系数估计和标准误差。
系数估计反映了自变量对因变量的影响程度,而标准误差则表示系数的可信度。
但由于Tobit模型的特殊性,其回归结果的解读需谨慎。
三、Tobit模型回归结果的置信区间Tobit模型的回归结果的置信区间计算与其他线性回归模型有所不同。
由于Tobit模型的特殊结构,通常采用t分布来计算置信区间。
具体步骤如下:1.计算t统计量:t统计量=系数估计/标准误差。
2.查找t分布表:根据自由度(通常为样本量减去1)和显著性水平(如1%-99%),查找对应的t值。
3.计算置信区间:置信区间=系数估计±t值*标准误差。
四、结论与启示Tobit模型在处理受限因变量问题时具有较强实用性,但其回归结果的解读和置信区间的计算较为复杂。
在进行Tobit模型分析时,研究者需要充分了解模型的原理和方法,以获得准确的回归结果和有效的解释。
同时,Tobit模型也为其他受限因变量问题的研究提供了借鉴和启示,有助于拓展和深化相关领域的研究。
【注】:以上内容仅适用于Tobit模型的基本应用,实际操作中可能需要根据具体的研究设计和数据特性进行调整。
在进行Tobit模型分析时,建议先进行数据清洗和预处理,以确保数据的质量和适用性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用计量经济模型反映选择行为
行为主体从事的每项活动都可以看作是一种选择; 行为主体有其偏好; 人们的行为有其规则; 在经济分析中,通常认为选择基于效用最大化标准。 研究中需要考虑:
行为理论基础 计量经济学模型方法
模型设定 统计理论和数据 估计方法
应用分析
行为假定
就可以选择的活动而言,行为主体的偏好具有传递 性和完备性。 每项选择都有其相应的效用水平Uijt 每个行为主体都试图获得最大效用,当Ui1t > Ui2t 时, 行为主体会选择第一项活动。 然而我们无法观测效用本身,我们只有通过观察行 为主体做出的选来揭示其偏好
LR = -2(Lr– Lur )~ c2q 如果未受约束似然值与受约束似然值相等,说明模型效果差,未通过 检验;相反,如果未约束似然值远大于约束似然值,说明所设自变 量通过检验,模型总体效果较好。它对应于线性模型中的F值。
拟合优度
对于线性概率模型,可以直接用得到R2来判断拟合优度; Probit 模型和Logit模型没有R2,因而需要利用其他方法来反 映拟合优度。 一种方法是利用对数似然值计算伪R2(pseudo R2)或 McFadden R2,该值也被称作似然值比值指数,定义为1 – Lur/Lr
必要时给出选项 得到估计结果
用EVIEWS估计有限因变量模型
得到结果后可以在VIEW子菜单下调用:
Coefficient tests各种对系数的统计检验 Residual tests对残差的统计检验 Expectation-Prediction Table 可以得到正确和错 误推断的比例 Goodness-of-Fit Tests检验拟合优劣
得到的参数不会相同 但分析结论不会有大的差别 因而通常基于模型的统计表现和经验来决定取舍
对Probit 模型和Logit模型的解释
利用概率模型做分析时,我们关心的通常是X的变 化如何影响概率P(y = 1|x),即∂p/ ∂x。 对于线性概率函数,X的影响可以很容易的从其回 归系数得知。 对于Probit 模型和Logit模型,计算这一影响的方法 较为复杂:
该方程推断的y 的值表示做出该选择的概率。 一个问题是,由线性概率方程推断得出的概率值可能落在区 间[0,1]之外,因而只有在均值附近才较为可靠。
二元因变量模型
由于线性概率函数的取值仅为0或1,因而误差项与 模型参数β出现相关,即e或是等于-β΄X,或是等 于1-β΄X,因而存在异方差问题。 此时线性概率模型违反了相同方差的古典假定,这 使得对模型做的统计检验失效。 随着计量经济学软件的不断发展,现在已经很少使 用线性概率模型。
家庭或个人特征是否影响到选择
家庭收入是否对读研究生构成重要限制? 个人的学习能力是否影响到读研的决策?
推断不同条件下的研究生规模变化
提高费用/就业机会增加/居民收入增加
推断个人的行为
哪些学生最有可能报考研究生
有限因变量模型
(Limited dependent variable models)
在有些文献中,有限因变量模型也被称为离散型选 择模型(Discrete Choice Models) 有限因变量模型的一般形式可以表达为:
行为主体选择第一项活动意味着Ui1t > Ui2t
随机效用函数 (Random Utility Functions)
形式:Uij = j + i’xij + i’zi + eij
j为与特定选择j相联系的常数项
xij 为选择j所具有的特性(Attributes) i为反映行为主体偏好的权重 zi 为行为主体的特征 i为行为主体特征的权重 eij为效用函数中不可观察的随机成分,假定E(eij)=0, Var(eij)=1
概率模型
FZ
1
线性概率函数
Z*
Z
概率函数模型
如前面所述,利用概率模型做推断时可能会遇到计 算值超出0~1区间的情况。 为了解决这一问题,我们用概率函数G(b0 + xb)来模 拟事件发生的概率,该函数应满足0<G(z)<1。 常用的分布和模型形式有:
正态分布→ Probit模型 Logistic分布→ Logit模型 Gompertz分布→极端值(Extreme value)模型
二元因变量模型
二元因变量模型是有限因变量模型的一种特殊形式。
因变量取值仅为0或1的情况。
我们可以将其看作是一种选择决策模型,当选择时y=1,未 选择时y=0; 我们可以用线性概率模型来研究这种情况,模型可以写作
P(y = 1|x) = b1x1 + … + KxK+e j 表示当xj 变化时概率的变化
∂p/ ∂xj = g(b0 +xb)bj, 式中g(z)表示dG(z)/dz
从公式可以看出,边际效果随x的变化而改变。
对Probit 模型和Logit模型的解释
因而,对三种形式的函数中X的系数直接做比较是 不正确的; 但仍可以通过比较估计系数的符号和显著性来确定 哪些变量最可能产生影响及其影响方向; 为了比较X变化所产生影响效果的大小,我们需要 计算相应的导数(一般取自变量的均值做计算); 有些计量经济学软件(如Stata)可以直接提供这些 结果。
29
无序多元选择模型
产生系数限制的原因:
P3 P3 P1 P3 P2 log P log P log P log P log P 2 1 2 1 1 31 31 X 21 21 X 31 无序多元选择模型 有序因变量模型(Ordered data)
多元选择模型基本概念
对于多元选择模型,可以根据因变量的性质分为有 序和无序两种类型。 无序模型:因变量Y表示观察对象的类型归属,例 如: 例1:上班的交通工具有走路、自行车、公共汽 车、出租车、自有汽车等。 例2:结构调整中农民主产品的选择,如蔬菜、 果树、动物养殖、水产养殖等。
对于无序的选择模型,其行为选择假定出于优化一 个随机效用函数。 考虑第i个消费者面临j种选择,假定选择j的效用为: Uij zij eij j,那么我们假定其获得的效用高 如果消费者选择了 于其他选择。 考虑效用比较的概率函数
Pr ob U ij U ik 所有的k j 就误差分布形式做出假定后得到可以估计的模型。
26
多元选择模型基本概念
有序模型:观察到的因变量Y表示出按数值大小 (ordered)或重要性 (ranked)排序的分类结果:
例1:教育水平分文盲、小学、初中、高中、大学、研究 生等 例2:农民就业分纯农业、兼业、非农业等 例3:收入水平分级 例4:考试成绩分优秀、良好、及格和不及格等
27
无序多元选择模型
似然值比率检验
对于线性概率模型,我们可以利用F统计值或LM统计值检验 是否可以排除某些变量; 对于Probit 模型和Logit模型,则需要采取新的方式进行这样 的检验; 在利用最大似然法估计Probit 模型和Logit模型时,我们同时 也获得了对数似然值; 我们可以估计有系数限制和没有系数限制的模型,然后利用 得到的两个对数似然值进行检验,相应的统计值为:
这意味着以下限制条件:
32 31 21 32 31 21
即只需要估计系统中的两个方程便可以得到所有参 数。
式中Lur和Lr分别为包括所有解释变量的对数似然值和只包括常数项 的对数似然值
另一种方式是根据模型做出的正确推断
当计算出的概率大于0.5时认为事件发生了,即有y = 1,反之则认为 事件未发生。 用列表的方式可以反映出正确推断的比例,在EVIEWS下可以直接生 成。
用EVIEWS估计有限因变量模型
第五章 受限因变量模型
本章内容
第一节 二元选择模型
线性概率模型
PROBIT模型 LOGIT模型 极端值模型 拟合优度测定 第二节 多元选择模型
无序多元选择模型
有序因变量模型(Ordered data) 计数模型(Count data)
第三节 删改与截取模型
删改数据或截取数据
模型估计中的问题 受限因变量模型(TOBIT模型) 模型估计方法与统计检验
随机效用函数帮助建立了行为基础与观察到的数据 之间的关系。
行为选择:考虑二元选择模型
涉及“是”或“否”的决策
例如是否攻读研究生
模型:读研究生获得的净效用
U读研 = +1读研费用 + 2预期收益 + 1家庭收入 + 2个人能力 + e 如果净效用为正,那么选择读研究生(简化模型,真实中还要与其 他选择进行比较,那是多元选择模型,此处不表)
使用的数据
因变量:1为读研,0为不读研 解释变量
X1读研收费+间接费用, X2研究生工资增量 Z1家庭收入,Z2读研前学习成绩
显示出的偏好
读研者U读研 > 0,定义Y=1 未读研者U读研 < 0,定义Y=0
行为选择:考虑二元选择模型
由模型分析可以获得的信息
研究生的社会经济特性是否具有重要意义
降低成本是否有助于吸引更多学生? 就业市场好坏是否对读研究生有重要影响
不同分布的特征
Probit 模型
G(z)的一种可选形式是标准正态累积分布函数,此 即Probit模型。
1 Zi s 2 2 Pi G Zi e ds 2 式中s是误差项,假定服从标准正态分布; P代表事件发生的概率。
估计指标Z,需要应用累计正态分布函数的逆函数 Zi G1 P i X i 由于Probit模型是参数非线性函数,因而不能用OLS 方法估计,需要用最大似然法来估计。
EVIEWS包括估计单方程有限因变量模型的程序; 在录入数据和给出变量表后,调用指令:
Quick->Estimate equation ->模型选项