1.如何用spss对利克特量表进行简单分析
“保姆级”操作教程 手把手教你SPSS分析数据实战这也太方便了吧

保姆级操作教程 | 手把手教你SPSS分析数据实战这也太方便了吧数据分析是现代社会研究中不可或缺的一部分。
而SPSS作为一款功能强大且易于使用的统计分析软件,受到了许多研究人员和学生的青睐。
本文将手把手教你如何使用SPSS进行数据分析,让你的研究工作更加高效和准确。
步骤1:导入数据首先,打开SPSS软件并点击菜单栏上的“文件”选项。
然后选择“打开”并浏览你存储数据集的位置。
选择相应的数据文件,并点击“打开”。
现在,你的数据集就已经成功导入。
步骤2:查看数据在导入数据后,你可以通过点击菜单栏上的“数据视图”选项来查看数据。
在数据视图中,你可以浏览和编辑数据。
如果你想查看数据的统计摘要信息,可以点击菜单栏上的“变量视图”选项。
步骤3:数据清理在进行数据分析之前,你需要对数据进行清理。
这包括处理缺失值、异常值和离群值等。
SPSS提供了一系列用于数据清理的功能,例如删除无效数据、替换缺失值等。
你可以使用菜单栏上的“转换”选项来执行这些操作。
步骤4:选择统计分析方法在进行数据清理后,接下来需要选择合适的统计分析方法。
SPSS提供了多种常用的统计分析方法,例如描述统计、相关分析、回归分析、t检验等。
你可以根据自己的研究目的和数据类型选择相应的方法。
步骤5:进行统计分析一旦你选择了合适的统计分析方法,你可以点击菜单栏上的“分析”选项,并选择相应的分析方法。
然后,你需要选择要分析的变量,并设置相应的参数。
点击“确定”后,SPSS将自动进行统计分析,并生成相应的结果。
步骤6:解读结果进行完统计分析后,你需要对分析结果进行解读。
SPSS会生成各种统计指标和图表,用于帮助你理解数据。
你可以查看参数估计值、置信区间、显著性水平等信息,并根据这些结果进行推断和判断。
步骤7:报告和呈现结果最后,你需要将分析结果进行报告和呈现。
SPSS提供了生成报告和图表的功能,你可以根据需要选择相应的样式和格式。
在报告中,你可以总结分析结果、提出结论,并展示相关的图表和图形。
SPSS软件应用具体操作及结果分析剖析

SPSS软件操作练习参考书:《生物统计学》张勤主编(第2版)一、均数差异显著性检验(一)单个样本t测验(二)独立样本测验(两个样本重组比较)(三)两个样本配对比较二、方差分析(一)单因素方差分析(样本量相等、样本量不等)三、相关回归分析相关分析:Analyze→Correlate→Bivariate(简单相关)相关回归:Analyze→Regression→Linear 注意:Dependent:因变量y Independent:自变量x四、卡方测验(一)独立性:Date Weight→Cases→Frequency Variable(观察值)→okAnalyze→Descriptive Statistics→Crosstabs→Row(行)、Columns(列)→Statistics→Chi-Square (二)适合性测验:Date Weight→Cases→Frequency Variable(观察值)→okAnalyze→Nonparametric Tests→Chi-Squareic(注意比例的填写)五、两因素方差分析(一)两因素无重复值方差分析(二)两因素有重复值方差分析一、均数差异显著性检验(一)单个样本t测验P66 例5.1One-Samp le Test-1.03516.316-1.00000-3.0486 1.0486VittdfSig. (2-tailed)MeanDif ferenceLower Upper 95% Confidence Interv al of the Dif f erence Test Value = 21由结果可知:t=-1.035 sig=0.316>0.05 该批罐头的平均维生素C 与规定的21mg/g 无显著差异。
注:Sig.(2-tailed) 双侧检验概率 95% confidence.... 差值的95%置信下线和置信上线(二)独立样本测验(两个样本重组比较) P70 例5.3Independent Samples Test.812.389-.92310.378-.81000.87744-2.76507 1.14507-.9239.363.379-.81000.87744-2.783251.16325Equal v ariancesassumedEqual v ariances not assumed增重FSig.Lev ene's Test f or Equality of Variancest dfSig. (2-tailed)MeanD if f erenceStd. Error D if f erenceLower U pper 95% Conf idence Interv al of the D if f erence t-test f or Equality of Means由结果可知:两样本方差齐质性测验中 F=0.812 Sig=0.389>0.05 方差同质,因此选择t=-0.923 Sig=0.378>0.05 两种不同饲料对香猪生长无显著差异。
利用SPSS进行量表分析

第五节利用SPSS进行量表分析在第五章调查研究中,我们介绍了量表的类型、编制的步骤及其应用,在本节将介绍利用SPSS 软件对量表进行处理分析。
在获取原始数据后,我们利用SPSS对量表可以作出三种分析,即项目分析、因素分析和信度分析。
项目分析,目的是找出未达显著水准的题项并把它删除。
它是通过将获得的原始数据求出量表中题项的临界比率值——CR值来作出判断。
通常,量表的制作是要经过专家的设计与审查,因此,题项一般均具有鉴别度,能够鉴别不同受试者的反应程度。
故往往在量表处理中可以省去这一步。
因素分析,目的是在多变量系统中,把多个很难解释,而彼此有关的变量,转化成少数有概念化意义而彼此独立性大的因素,从而分析多个因素的关系。
在具体应用时,大多数采用“主成份因素分析”法,它是因素分析中最常使用的方法。
信度分析,目的是对量表的可靠性与有效性进行检验。
如果一个量表的信度愈高,代表量表愈稳定。
也就表示受试者在不同时间测量得分的一致性,因而又称“稳定系数”。
根据不同专家的观点,量表的信度系数如果在以上,表示量表的信度甚佳。
但是对于可接受的最小信度系数值是多少,许多专家的看法也不一致,有些专家定为以上,也有的专家定位以上。
通常认为,如果研究者编制的量表的信度过低,如在以下,应以重新编制较为适宜。
在本节中,主要介绍利用SPSS软件对量表进行因素分析。
一、因素分析基本原理因素分析是通过求出量表的“结构效度”来对量表中因素关系作出判断。
在多变量关系中,变量间线性组合对表现或解释每个层面变异数非常有用,主成份分析主要目的即在此。
变量的第一个线性组合可以解释最大的变异量,排除前述层次,第二个线性组合可以解释次大的变异量,最后一个成份所能解释总变异量的部份会较少。
主成份数据分析中,以较少成份解释原始变量变异量较大部份。
成份变异量通常用“特征值”v1.0 可编辑可修改表示,有时也称“特性本质”或“潜在本质”。
因素分析是一种潜在结构分析法,其模式理论中,假定每个指针(外在变量或称题项)均由两部分所构成,一为“共同因素”、一为“唯一因素”。
用spss软件分析进行效度和信度分析具体的操作步骤

用spss软件分析进行效度和信度分析具体的操作步骤在SPSS中,专门用来进行测验信度分析的模块为Scale下的Reliability Analysis;使用Data Reduction之下的Factor模块,可以利用因素分析的方法来进行测验的建构效度检验;至于项目分析则没有专门的模块可以之间进行计算分析,但是却可以利用Summarize下的Frequencies、Correlate下的Bivariate 和Compare Mean下的Independent-Samples T Test来计算几个常用的项目分析指标。
3 m6 ]$ l8 a6 j w% K0 ^一、信度分析' M, k! n+ y# CReliability Analysis模块主要功能是检验测验的信度,主要用来检验折半信度、库李及a系数以及Hoyt信度系数值。
至于重测信度和复本信度,只需将样本在二次(份)测验的分数的数据合并到同一数据文件之后,利用Correlate之下的Bivariate求其相关系数,即为重测或复本信度;而评分者信度则就就是使用的Spearman等级相关及Kendall和谐系数。
表1 Reliability Analysis模块的Model选项的参数及对应中文术语3 V O/ m5 i% P; N6 l' a: `. P- I/ c: J9 X/ ~关键字功能; R% v( ?! T8 L) q* L$ ~Alpha Cronbach a系数Split-half 折半信度,n是第二分量表的题数( e3 N, N6 w4 l% N( d8 A3 c4 ]Guttman Guttman最低下限真实信度法0 o+ n; n/ ^2 d& BParallel 各题目变异数同质时的最大概率(maximum-likelihood)信度3 Q( _- Z9 }( aStrict parallel 各题目平均数与变异数均同质时的最大概率信度7 p, x- S9 ?; J: p! k5 H5 i7 h/ l7 Q) Q表2 Reliability Analysis模块的Statistics部分选项的参数及对应中文术语- X9 d% L( ~; ^5 L关键字功能F test Hoyt信度系数4 D3 A9 Y. c, u4 `Friedman Chi Friedman等级变异数分析及Kendall和谐系数; [ H" S. [- z eCochran Chi Cochran’s Q检验,适用于答案为二分(如是非题)的量表+ _" z+ v3 I& C2 e& cHotelling’s T Hotelling’s T2 检验& g" S5 S' K& t- fTukey’s Tukey的可加性检验3 o6 O8 T* B4 `! ^; b1 S- c* oIntraclass 量表内各题目平均数相关系数+ \$ Z9 m! B8 m7 u% k6 E$ f$ R/ j8 j5 N# V: m二、效度分析4 d4 ^5 T& @ n6 d' a0 G, b' T. u9 T7 n" d2 [即因素分析的方法。
spss项目分析操作步骤SPSS常用分析方法操作步骤

spss项目分析操作步骤SPSS常用分析方法操作步骤导读:就爱阅读网友为您分享以下“SPSS常用分析方法操作步骤”资讯,希望对您有所帮助,感谢您对的支持!SPSS常用分析方法操作步骤一、单变量单因素方差分析例题:某个年级有三个班,现在对他们的一次数学考试成绩进行随机抽(见下表),试在显著性水平0.005下检验各班级的平均分数有无显著差异(数据文件:数学考试成绩.sav)。
(1)建立数学成绩数据文件。
(2)选择“分析” →“比较均值” →“单因素方差”,打开单因素方差分析窗口,将“数学成绩”移入因变量列表框,将“班级”移入因子列表框。
(3)单击“两两比较”按钮,打开“单因素ANOVA两两比较”窗口。
(4)在假定方差齐性选项栏中选择常用的LSD检验法,在未假定方差齐性选项栏中选择T amhane’s检验法。
在显著性水平框中输入0.05,点击继续,回到方差分析窗口。
(5)单击“选项”按钮,打开“单因素ANOV A选项”窗口,在统计量选项框中勾选“描述性”和“方差同质性检验”。
并勾选均值图复选框,点击“继续”,回到“单因素ANOV A选项”窗口,点击确定,就会在输出窗口中输出分析结果。
二、单变量多因素方差分析研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。
分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异(数据文件:粘虫.sav)。
(1)建立数据文件“粘虫.sav”。
(2)选择“分析” →“一般线性模型” →“单变量”,打开单变量设置窗口。
(3)分析模型选择:此处我们选用默认;(4)比较方法选择:在窗口中单击“对比”按钮,打开“单变量:对比”窗口进行设置,单击“继续”返回;(5)均值轮廓图选择:单击“绘制”按钮,设置比较模型中的边际均值轮廓图,单击“继续”返回;(6)“两两比较”选择,用于设置两两比较检验,本例中设置为“温度”和“湿度”。
三、相关分析调查了29人身高、体重和肺活量的数据见下表,试分析这三者之间的相互关系。
利用SPSS进行量表分析

第五节利用SPSS进行量表分析在第五章调查研究中,我们介绍了量表的类型、编制的步骤及其应用,在本节将介绍利用SPSS 软件对量表进行处理分析。
在获取原始数据后,我们利用SPSS对量表可以作出三种分析,即项目分析、因素分析和信度分析。
项目分析,目的是找出未达显著水准的题项并把它删除。
它是通过将获得的原始数据求出量表中题项的临界比率值——CR值来作出判断。
通常,量表的制作是要经过专家的设计与审查,因此,题项一般均具有鉴别度,能够鉴别不同受试者的反应程度。
故往往在量表处理中可以省去这一步。
因素分析,目的是在多变量系统中,把多个很难解释,而彼此有关的变量,转化成少数有概念化意义而彼此独立性大的因素,从而分析多个因素的关系。
在具体应用时,大多数采用“主成份因素分析”法,它是因素分析中最常使用的方法。
信度分析,目的是对量表的可靠性与有效性进行检验。
如果一个量表的信度愈高,代表量表愈稳定。
也就表示受试者在不同时间测量得分的一致性,因而又称“稳定系数”。
根据不同专家的观点,量表的信度系数如果在0.9以上,表示量表的信度甚佳。
但是对于可接受的最小信度系数值是多少,许多专家的看法也不一致,有些专家定为0.8以上,也有的专家定位0.7以上。
通常认为,如果研究者编制的量表的信度过低,如在0.6以下,应以重新编制较为适宜。
在本节中,主要介绍利用SPSS软件对量表进行因素分析。
一、因素分析基本原理因素分析是通过求出量表的“结构效度”来对量表中因素关系作出判断。
在多变量关系中,变量间线性组合对表现或解释每个层面变异数非常有用,主成份分析主要目的即在此。
变量的第一个线性组合可以解释最大的变异量,排除前述层次,第二个线性组合可以解释次大的变异量,最后一个成份所能解释总变异量的部份会较少。
主成份数据分析中,以较少成份解释原始变量变异量较大部份。
成份变异量通常用“特征值”表示,有时也称“特性本质”或“潜在本质”。
因素分析是一种潜在结构分析法,其模式理论中,假定每个指针(外在变量或称题项)均由两部分所构成,一为“共同因素”、一为“唯一因素”。
1.如何用spss对利克特量表进行简单分析

如何用SPSS对李克特量表进行简单分析
第一步:建立数据
1. 打开SPSS
2. 在左下角点“variable view变量视图”
3. 在左上角输入“调查问卷”——将“Type类型”调成“sting字符型”——“Decimals小数点”位数改成“0”
4. 从第二行开始依次输入“问题1,问题2,问题N”,
5. 每个问题都在“Values变量值”输入:变量值Values框中为“1”/标签Label框中“非常不同意”点“add添加”;然后依次输入2不同意3不一定4同意5非常同意
6. 以同样的方式输完所有的问题
第二步:输入数据
1. 左下角选“Data View数据视图”
2. 将每份问卷每道题的结果输入对应的框中
3. 以同样的方式将150份问卷输入
第三步:分析数据
(这里只介绍到最简单的统计量<如下>)
1.在标题栏选择“Analyze分析”——“Description statistics描述性统计”——“Frequencies 频数分析”
2.在频数分析对话框中,从左框选择要分析的问题到右框中
3.选择“Statistics统计”出现对话框
4.选择对应输出项即可:Mean平均数Std. deviation标准差variance方差range极差max 最大min最小
5.同时也可以用“charts图表”选择要输出的图形
6.点击“OK确定”即可
7.然后再Output表中读取分析结果。
SPSS常用分析方法操作步骤

SPSS常用分析方法操作步骤一、单变量单因素方差分析例题:某个年级有三个班,现在对他们的一次数学考试成绩进行随机抽(见下表),试在显著性水平0.005下检验各班级的平均分数有无显著差异(数据文件:数学考试成绩.sav)。
(1)建立数学成绩数据文件。
(2)选择“分析”→“比较均值”→“单因素方差”,打开单因素方差分析窗口,将“数学成绩”移入因变量列表框,将“班级”移入因子列表框。
(3)单击“两两比较”按钮,打开“单因素ANOV A两两比较”窗口。
(4)在假定方差齐性选项栏中选择常用的LSD检验法,在未假定方差齐性选项栏中选择Tamhane’s检验法。
在显著性水平框中输入0.05,点击继续,回到方差分析窗口。
(5)单击“选项”按钮,打开“单因素ANOV A选项”窗口,在统计量选项框中勾选“描述性”和“方差同质性检验”。
并勾选均值图复选框,点击“继续”,回到“单因素ANOV A选项”窗口,点击确定,就会在输出窗口中输出分析结果。
二、单变量多因素方差分析研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。
分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异(数据文件:粘虫.sav)。
(1)建立数据文件“粘虫.sav”。
(2)选择“分析”→“一般线性模型”→“单变量”,打开单变量设置窗口。
(3)分析模型选择:此处我们选用默认;(4)比较方法选择:在窗口中单击“对比”按钮,打开“单变量:对比”窗口进行设置,单击“继续”返回;(5)均值轮廓图选择:单击“绘制”按钮,设置比较模型中的边际均值轮廓图,单击“继续”返回;(6)“两两比较”选择,用于设置两两比较检验,本例中设置为“温度”和“湿度”。
三、相关分析调查了29人身高、体重和肺活量的数据见下表,试分析这三者之间的相互关系。
(1)建立数据文件“学生生理数据.sav”。
(2)选择“分析”→“相关”→“双变量”,打开双变量相关分析对话框。
(3)选择分析变量:将“身高”、“体重”和“肺活量”分别移入分析变量框中。
利用SPSS分析李克特量表的数据

利用SPSS分析李克特量表的数据
求高手帮忙教我如何将李克特量表的数据录入,利用SPSS 分析?
其实这个问题,不是一个很难的问题,但却是大部分刚刚学习数据分析的人都会遇到的问题。
这个问题其实可以分三步处理:1、录入数据2、上传数据3、分析数据
一、录入数据
数据分析的第一步是要把数据录入到表格中,整理成标准格式后再导入到分析软件中进行分析。
SPSS录入的数据需为原始数据,比如有100个样本或被试,则应该有100行;1行代表1个样本或被试;1列代表1个属性;而不能是已经进行过统计的数据。
说明如下:
SPSSAU整理
二、上传数据
录入好的数据可以上传到在线版SPSS(SPSSAU)进行智能化分析。
SPSSAU系统当前支持EXCEL格式(包括xls和xlsx)和SPSS格式(SAV)数据。
需要说明的是
算法只认识数字,因此针对非数字格式数据,SPSSAU智能化处理如下:
SPSSAU官方帮助手册截图
●上图中标题1,标题2,标题4,标题6共4列全部均为数字;SPSSAU不进行任
何处理
●标题5中全部为文字,SPSSAU则自动将文字替换成数字,并对数字设置标签,A
用1表示,B用2表示,C用3表示,D用4表示,E用5表示
●标题3中部分为文字,部分为数字;则spssau会将文字处理成
NULL值,数字不
变。
三、分析数据
这个部分一两句话不好讲清楚,捡重点来说,数据分析的核心是拥有数据分析思维。
而如何培养数据分析思维,这个在之前的文章里已经说过了,就不再赘述了,有需要的小伙伴可自行学习。
利用SPSS软件对量表进行因素分析

本节将介绍利用SPSS软件对量表进行处理分析。
在获取原始数据后,我们利用SPSS对量表可以作出三种分析,即项目分析、因素分析和信度分析。
项目分析,目的是找出未达显著水准的题项并把它删除。
它是通过将获得的原始数据求出量表中题项的临界比率值——CR值来作出判断。
通常,量表的制作是要经过专家的设计与审查,因此,题项一般均具有鉴别度,能够鉴别不同受试者的反应程度。
故往往在量表处理中可以省去这一步。
因素分析,目的是在多变量系统中,把多个很难解释,而彼此有关的变量,转化成少数有概念化意义而彼此独立性大的因素,从而分析多个因素的关系。
在具体应用时,大多数采用“主成份因素分析”法,它是因素分析中最常使用的方法。
信度分析,目的是对量表的可靠性与有效性进行检验。
如果一个量表的信度愈高,代表量表愈稳定。
也就表示受试者在不同时间测量得分的一致性,因而又称“稳定系数”。
根据不同专家的观点,量表的信度系数如果在0.9以上,表示量表的信度甚佳。
但是对于可接受的最小信度系数值是多少,许多专家的看法也不一致,有些专家定为0.8以上,也有的专家定位0.7以上。
通常认为,如果研究者编制的量表的信度过低,如在0.6以下,应以重新编制较为适宜。
在本节中,主要介绍利用SPSS软件对量表进行因素分析。
一、因素分析基本原理因素分析是通过求出量表的“结构效度”来对量表中因素关系作出判断。
在多变量关系中,变量间线性组合对表现或解释每个层面变异数非常有用,主成份分析主要目的即在此。
变量的第一个线性组合可以解释最大的变异量,排除前述层次,第二个线性组合可以解释次大的变异量,最后一个成份所能解释总变异量的部份会较少。
主成份数据分析中,以较少成份解释原始变量变异量较大部份。
成份变异量通常用“特征值”表示,有时也称“特性本质”或“潜在本质”。
因素分析是一种潜在结构分析法,其模式理论中,假定每个指针(外在变量或称题项)均由两部分所构成,一为“共同因素”、一为“唯一因素”。
利用SPSS进行量表分析

第五节利用SPSS进行量表分析在第五章调查研究中,我们介绍了量表的类型、编制的步骤及其应用,在本节将介绍利用SPSS 软件对量表进行处理分析。
在获取原始数据后,我们利用SPSS对量表可以作出三种分析,即项目分析、因素分析和信度分析。
项目分析,目的是找出未达显著水准的题项并把它删除。
它是通过将获得的原始数据求出量表中题项的临界比率值——CR值来作出判断。
通常,量表的制作是要经过专家的设计与审查,因此,题项一般均具有鉴别度,能够鉴别不同受试者的反应程度。
故往往在量表处理中可以省去这一步。
因素分析,目的是在多变量系统中,把多个很难解释,而彼此有关的变量,转化成少数有概念化意义而彼此独立性大的因素,从而分析多个因素的关系。
在具体应用时,大多数采用“主成份因素分析”法,它是因素分析中最常使用的方法。
信度分析,目的是对量表的可靠性与有效性进行检验。
如果一个量表的信度愈高,代表量表愈稳定。
也就表示受试者在不同时间测量得分的一致性,因而又称“稳定系数”。
根据不同专家的观点,量表的信度系数如果在0.9以上,表示量表的信度甚佳。
但是对于可接受的最小信度系数值是多少,许多专家的看法也不一致,有些专家定为0.8以上,也有的专家定位0.7以上。
通常认为,如果研究者编制的量表的信度过低,如在0.6以下,应以重新编制较为适宜。
在本节中,主要介绍利用SPSS软件对量表进行因素分析。
一、因素分析基本原理因素分析是通过求出量表的“结构效度”来对量表中因素关系作出判断。
在多变量关系中,变量间线性组合对表现或解释每个层面变异数非常有用,主成份分析主要目的即在此。
变量的第一个线性组合可以解释最大的变异量,排除前述层次,第二个线性组合可以解释次大的变异量,最后一个成份所能解释总变异量的部份会较少。
主成份数据分析中,以较少成份解释原始变量变异量较大部份。
成份变异量通常用“特征值”表示,有时也称“特性本质”或“潜在本质”。
因素分析是一种潜在结构分析法,其模式理论中,假定每个指针(外在变量或称题项)均由两部分所构成,一为“共同因素”、一为“唯一因素”。
SPSS简易分析流程详解
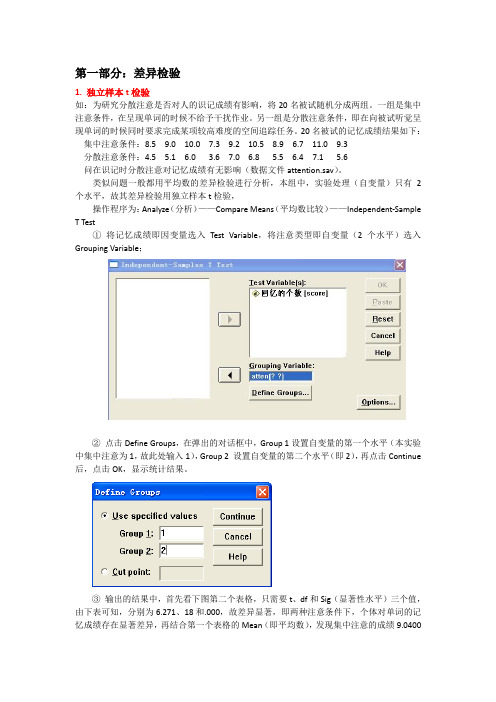
第一部分:差异检验1. 独立样本t检验如:为研究分散注意是否对人的识记成绩有影响,将20名被试随机分成两组。
一组是集中注意条件,在呈现单词的时候不给予干扰作业。
另一组是分散注意条件,即在向被试听觉呈现单词的时候同时要求完成某项较高难度的空间追踪任务。
20名被试的记忆成绩结果如下:集中注意条件:8.5 9.0 10.0 7.3 9.2 10.5 8.9 6.7 11.0 9.3分散注意条件:4.5 5.1 6.0 3.6 7.0 6.8 5.5 6.4 7.1 5.6问在识记时分散注意对记忆成绩有无影响(数据文件attention.sav)。
类似问题一般都用平均数的差异检验进行分析,本组中,实验处理(自变量)只有2个水平,故其差异检验用独立样本t检验,操作程序为:Analyze(分析)——Compare Means(平均数比较)——Independent-Sample T Test①将记忆成绩即因变量选入Test Variable,将注意类型即自变量(2个水平)选入Grouping Variable;②点击Define Groups,在弹出的对话框中,Group 1设置自变量的第一个水平(本实验中集中注意为1,故此处输入1),Group 2 设置自变量的第二个水平(即2),再点击Continue 后,点击OK,显示统计结果。
③输出的结果中,首先看下图第二个表格,只需要t、df和Sig(显著性水平)三个值,由下表可知,分别为6.271、18和.000,故差异显著,即两种注意条件下,个体对单词的记忆成绩存在显著差异,再结合第一个表格的Mean(即平均数),发现集中注意的成绩9.0400大于分散注意的成绩5.4600,故集中注意的记忆效果显著高于分散注意。
2. 相关样本t检验基本过程与独立样本t检验类似,操作程序为:Analyze(分析)——Compare Means(平均数比较)——Paired-Sample T Test例题:从某小学三年级随机抽取20名儿童做样本,分别在学期初和学期末进行了推理测验,结果如下(数据文件:Test.sav):学生编号 1 2 3 4 5 6 7 8 9 10学期初 12 13 12 11 10 13 14 15 15 11学期末 14 14 11 15 11 14 14 17 15 14学生编号 11 12 13 14 15 16 17 18 19 20学期初 13 12 11 10 13 14 15 15 11 12学期末 14 14 11 15 14 14 16 18 15 14①分两次分别点击“学期初成绩”和“学期末成绩”两个变量,如下图所示,Current Selections 显示两个变量后,点击中间的小三角选入Paired Variables后点击OK,显示结果;②输出结果的理解和分析与独立样本t检验相同。
统计分析:SPSS数据分析实用技巧

统计分析:SPSS数据分析实用技巧概述本文将介绍一些常用的SPSS数据分析实用技巧,旨在帮助用户充分利用SPSS 软件进行高效的统计分析。
下面将针对不同类型的数据进行详细说明。
描述性统计分析描述性统计是最基础的分析方法,通过对样本数据的整体特征进行概括性描述,可以提供关于变量中心趋势、离散程度和偏斜度等信息。
•均值(Mean):计算变量取值的平均数,反映变量的中心趋势。
•标准差(Standard Deviation):衡量变量取值离散程度大小。
•频数(Frequency):展示各个取值对应的频数。
•百分比(Percentage):将频数转化为百分比形式,更直观地了解每个群体占比。
单因素方差分析(ANOVA)单因素方差分析是一种适用于多组间连续型变量比较的方法,它可以检验多个组别之间是否存在统计显著差异。
步骤: 1. 导入数据集,并指定自变量和因变量。
2. 进行方差检验,获取显著性水平和F值。
3. 利用事后比较方法(如LSD、Tukey)进行多重比较。
相关分析相关分析用于研究两个变量之间的关系强度和方向。
SPSS提供了一系列相关分析方法,包括皮尔逊相关系数和斯皮尔曼秩相关系数等。
步骤: 1. 导入数据集,并选取需要进行相关分析的两个变量。
2. 运行相关分析命令,得到相关系数和显著性水平。
3. 对结果进行解读:正值表示正向关系,负值表示负向关系,接近0表示无明显关系。
回归分析回归分析是一种用于研究自变量与因变量之间关系的统计方法。
SPSS提供了多种回归模型,例如线性回归、多元线性回归和逻辑回归等。
步骤:1. 导入数据集,并选择自变量和因变量。
2. 运行相应的回归模型命令,获取参数估计值、显著性水平及拟合指标(如R-square)。
3. 解读结果:参数估计值表示自变量对因变量的影响程度,显著性水平反映影响是否具有统计学意义。
因子分析因子分析是一种常用的数据降维方法,用于发现潜在的变量(因子)并减少原始变量的数量。
如何用spss做问卷的结构效度分析

如何用spss做问卷的结构效度分析?问:因子分析里面Descriotives里面KMO和巴特利检验就可以了吗?除此之外,还要做什么啊?请高手赐教点简单易懂又能说明效度问题的,谢谢啦!问题补充:提取因子的个数怎么确定?是选特征值大于1的吗?还有,因子载荷怎么算?是在输出结果中直接可以看到吗?本人刚接触spss,请多多指教!答:首先必须要做KMO和Bartlett球形检验,这个你应该会了吧,如果这两个检验合格的话说明数据是适合做因子分析的。
然后提取因子后,看主因子解释总变异的百分比和个因子的因子载荷,主因子解释总变异一般若大于60%的和因子载荷大于0.6的话说明结构效度很好。
pS: ,如果题目没有规定就是选特征值大于1的,如果题目事先要提取几个因子,那么在操作的时候,用SPSS那个因子分析的选项里面有一个地方可以著名,因子载荷在输出的结果直接可以看到(rotated compoment matrpx),一定要是旋转后的因子载荷用spss进行效度分析?我要对我的问卷调查数据做一个信度和效度分析。
信度分析我会了,就是看Cronbach’s Alpha 系数。
效度分表面效度、准则效度和构建效度,前面两项只要说明一下,但是构建效度要用SPSS分析,我想是在因子分析里面吧?就是不知道哪个值代表效度。
答:因子分析的效度分析主要的指标可以看,因子提取的方差累积贡献率,如果因子提取的越少且方差累积率又不低的话(一般如果2个因子达到40%以上的贡献率就算可以的了),就可以认为因子分析的效度还可以。
除此之外,你可以用因子分析里面Descriotives里面KMO和巴特利检验(battele,不知道是不是这样写的),KMO的值如果>0.5,则说明因子分析的效度还行,可以进行因子分析;另外,如果巴特利检验的P<0.001,说明因子的相关系数矩阵非单位矩阵,能够提取最少的因子同时又能解释大部分的方差,即效度可以。
利克特量表的实施步骤

利克特量表的实施步骤引言利克特量表(Likert Scale)是一种常用的心理测量工具,用于评估人们对于某种观点、态度或看法的倾向性。
该量表通常包含多个陈述性项,被测者需要选择自己在某个陈述上所持有的看法,从而得出对应的得分。
本文将介绍利克特量表的实施步骤,包括设计量表、进行预测试、收集数据以及分析结果等内容。
步骤1:设计量表在设计利克特量表之前,需要明确测量的对象和目的。
确定需要评估的观点或态度,并明确构建量表的目的。
然后根据目的设计适当数量的陈述性项。
陈述性项应该覆盖多个维度,并保证表达明确、简洁,避免歧义。
步骤2:进行预测试在正式使用利克特量表之前,进行预测试是非常重要的。
通过预测试,可以评估量表的语言表达是否清晰明了,能够准确地反映被测者的意见和态度。
预测试的样本应包括与目标样本相似的人群,他们的意见和态度可以作为调整量表的依据。
步骤3:选择适当的评分尺度利克特量表一般采用5或7点评分尺度,其中1代表“非常不同意”或“非常不满意”,7代表“非常同意”或“非常满意”。
选择评分尺度时,需要考虑被测者的认知负荷和理解能力,保证被测者能够准确理解并作出选择。
步骤4:收集数据在收集数据之前,需要明确目标样本的特征和数量,并确定合适的样本调查方式。
可以选择在线调查或面对面调查等方式进行数据收集。
确保问卷设计合理、简洁明了,并给被测者提供足够的时间和空间进行选择。
步骤5:数据分析在得到足够数量的有效数据后,可以进行数据分析。
常用的分析方法包括计算平均分、频率分布等。
可以通过统计软件(如SPSS)进行数据分析,得出相应的统计结果。
步骤6:结果解释与应用根据数据分析结果,可以得出对被测者观点、态度的评估指标。
根据评估结果,可以进行进一步的数据解释和应用。
在解释结果时,需要注意结果的客观性,并结合实际背景进行恰当的解读。
不同的评估指标可以用于支持决策、改进工作或推动相关研究等。
结论利克特量表是一种常用的心理测量工具,能够评估人们的观点和态度。
利克特量表的实施步骤答案

利克特量表的实施步骤答案引言在心理测试中,利克特量表是一种用来评估个体态度和观点的常用工具。
它可以用来测量个体对于不同主题或情境的态度,从而帮助研究者了解他们的观点和态度。
本文将介绍利克特量表的实施步骤答案,以帮助研究者正确使用该工具。
利克特量表的概述利克特量表是在1932年由美国心理学家雷蒙德·利克特(Raymond Cattell)首次提出的。
它是一种用数字评分的形式来测量个体对于某个观点或态度的偏好程度。
通常利克特量表由一系列陈述性语句组成,被被试者评估为自己的观点和态度的程度,包括喜好程度、同意程度或重要性。
通过对这些陈述语句进行评分,研究者可以得到一个关于被测者观点和态度的量化结果。
利克特量表的实施步骤答案下面将介绍利克特量表的实施步骤答案,以帮助研究者正确实施这项工具。
1.设计量表–首先,确定研究的主题和目的。
根据研究的内容,明确要测量的特定观点和态度。
–接下来,编写一系列陈述性语句,涵盖了研究主题的不同方面。
这些陈述性语句应该是客观、简明扼要的,并且是可以用数字评分的形式来描述的。
–确保陈述性语句的顺序是随机的,以避免观察者偏差。
2.评分方式–对陈述性语句进行评分时,通常采用五点评分法。
被测者可以选择从1到5之间的一个数字,来表示他们对于这个陈述性语句的态度或偏好程度。
常用的分数解释是1表示非常不同意,5表示非常同意。
–确定好分数的解释和含义,并将其告知参与者。
这样可以确保被测者理解如何进行评分。
3.问卷发放–准备好利克特量表的问卷,并确保在问卷上列出相关的陈述性语句和对应的评分选项。
–随机选择一定数量的被测者,向他们发放问卷。
可以通过面对面访问、邮寄、电子邮件等方式进行问卷的发放。
–保证被测者对于利克特量表的指导和评分方式有清晰的理解。
4.数据收集和分析–在收集到足够数量的问卷后,将数据整理和录入电子表格中。
确保数据的准确性和完整性。
–对每个陈述性语句的评分进行统计分析,计算平均值和标准偏差,以及其他需要的统计指标。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如何用SPSS对李克特量表进行简单分析
第一步:建立数据
1. 打开SPSS
2. 在左下角点“variable view变量视图”
3. 在左上角输入“调查问卷”——将“Type类型”调成“sting字符型”——“Decimals小数点”位数改成“0”
4. 从第二行开始依次输入“问题1,问题2,问题N”,
5. 每个问题都在“Values变量值”输入:变量值Values框中为“1”/标签Label框中“非常不同意”点“add添加”;然后依次输入2不同意3不一定4同意5非常同意
6. 以同样的方式输完所有的问题
第二步:输入数据
1. 左下角选“Data View数据视图”
2. 将每份问卷每道题的结果输入对应的框中
3. 以同样的方式将150份问卷输入
第三步:分析数据
(这里只介绍到最简单的统计量<如下>)
1.在标题栏选择“Analyze分析”——“Description statistics描述性统计”——“Frequencies 频数分析”
2.在频数分析对话框中,从左框选择要分析的问题到右框中
3.选择“Statistics统计”出现对话框
4.选择对应输出项即可:Mean平均数Std. deviation标准差variance方差range极差max 最大min最小
5.同时也可以用“charts图表”选择要输出的图形
6.点击“OK确定”即可
7.然后再Output表中读取分析结果。