SPSS概览--数据分析实例详解
SPSS教程医学统计之星张文彤

对 Windows 操作界面不熟悉的朋友可参见 SAS 入门第一课中的相关内容。对 数据表界面操作不熟悉的朋友可先学习一下 EXCEL 的操作(因为它的帮助是中文 的)。
有的 SPSS 系统打开时会出现一个导航对话框,请单击右下方的 Cancer 按钮, 即可进入上面的主界面。
1.1.2 定义变量
让我们把要做的事情理理顺:首先要做的肯定是打开计算机(废话),然后 进入瘟 98 或瘟 2000(还是废话,以下省去废话 2 万字),在进入 SPSS 后,具 体工作流程如下:
1. 将数据输入 SPSS,并存盘以防断电。 2. 进行必要的预分析(分布图、均数标准差的描述等),以确定应采 用的检验方法。 3. 按题目要求进行统计分析。 4. 保存和导出分析结果。 下面就按这几步依次讲解。
该资料是定量资料,设计为成组设计,因此我们需要建立两个变量,一个变 量代表血磷值,习惯上取名为 X,另一个变量代表观察对象是健康人还是克山病 人,习惯上取名为 GROUP。
对数据的统计分析格式不太熟悉的朋友请先学习统计软件第一课。 选择菜单 Data==>Define Variable。系统弹出定义变量对话框如下: 该变量定义对话框在 SPSS 10.0 版中已被取消,这里的操作只适合 9.0~7.0 版的用户。
第一列的名称已经改为了“group”,这就是我们所定义的新变量 “group”。 现在我们来建立变量 X。单击第一行第二列的单元格,然后选择菜单 Data==>Define Variable,同样,将变量名改为 X,然后确认。此时 SPSS 的数 据管理窗口如下所示:
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,通系电1,力过根保管据护线生高0不产中仅工资2艺料22高试2可中卷以资配解料置决试技吊卷术顶要是层求指配,机置对组不电在规气进范设行高备继中进电资行保料空护试载高卷与中问带资题负料2荷试2,下卷而高总且中体可资配保料置障试时2卷,32调需3各控要类试在管验最路;大习对限题设度到备内位进来。行确在调保管整机路使组敷其高设在中过正资程常料1工试中况卷,下安要与全加过,强度并看工且25作尽52下可22都能护可地1关以缩于正小管常故路工障高作高中;中资对资料于料试继试卷电卷连保破接护坏管进范口行围处整,理核或高对者中定对资值某料,些试审异卷核常弯与高扁校中度对资固图料定纸试盒,卷位编工置写况.复进保杂行护设自层备动防与处腐装理跨置,接高尤地中其线资要弯料避曲试免半卷错径调误标试高方中等案资,,料要编试求5写、卷技重电保术要气护交设设装底备备置。4高调、动管中试电作线资高气,敷料中课并设3试资件且、技卷料中拒管术试试调绝路中验卷试动敷包方技作设含案术,技线以来术槽及避、系免管统不架启必等动要多方高项案中方;资式对料,整试为套卷解启突决动然高过停中程机语中。文高因电中此气资,课料电件试力中卷高管电中壁气资薄设料、备试接进卷口行保不调护严试装等工置问作调题并试,且技合进术理行,利过要用关求管运电线行力敷高保设中护技资装术料置。试做线卷到缆技准敷术确设指灵原导活则。。:对对在于于分调差线试动盒过保处程护,中装当高置不中高同资中电料资压试料回卷试路技卷交术调叉问试时题技,,术应作是采为指用调发金试电属人机隔员一板,变进需压行要器隔在组开事在处前发理掌生;握内同图部一纸故线资障槽料时内、,设需强备要电制进回造行路厂外须家部同出电时具源切高高断中中习资资题料料电试试源卷卷,试切线验除缆报从敷告而设与采完相用毕关高,技中要术资进资料行料试检,卷查并主和且要检了保测解护处现装理场置。设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。
spss的数据分析案例

- -关于某公司474名职工综合状况的统计分析报告一、数据介绍:本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。
通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析1、频数分析。
基本的统计分析往往从频数分析开始。
通过频数分析能够了解变量的取值状况,对把握数据的分布特征非常有用。
此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
Statistics首先,对该公司的男女性别分布进行频数分析,结果如下:上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。
其次对原有数据中的受教育程度进行频数分析,结果如下表:Educational Level (years)上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。
且接受过高于20年的教育的人数只有1人,比例很低。
2、描述统计分析。
再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。
SPSS概览--数据分析实例详解

SPSS概览--数据分析实例详解1.1数据的输入和保存1.1.1SPSS的界面1.1.2定义变量1.1.3输入数据1.1.4保存数据1.2数据的预分析1.2.1数据的简单描述1.2.2绘制直方图1.3按题目要求进行统计分析1.4保存和导出分析结果1.4.1保存文件1.4.2导出分析结果盼望了解SPSS10.0版具体情况的朋友请参见本网站的SPSS10.0版抢鲜报道。
例1.1某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下,问该地急性克山病患者与健康人的血磷值是否不同〔卫统第三版例4.8〕?患者:0.841.051.201.201.391.531.671.801.872.072.11健康人:0.540.640.640.750.760.811.161.201.341.351.481.561.87解题流程如下:1.将数据输入SPSS,并存盘以防断电。
2.进行必要的预分析〔分布图、均数标准差的描述等〕,以确定应采纳的检验方法。
3.按题目要求进行统计分析。
4.保存和导出分析结果。
下面就按这几步依次讲解。
§1.1数据的输入和保存1.1.1SPSS的界面当打开SPSS后,展现在我们面前的界面如下:请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。
请注意窗口顶部显示为“SPSSforWindowsDataEditor”,说明现在所看到的是SPSS的数据治理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
特别的,工具栏下方的是数据栏,数据栏下方那么是数据治理窗口的主界面。
该界面和EXCEL极为相似,由假设干行和列组成,每行对应了一条记录,每列那么对应了一个变量。
由于现在我们没有输入任何数据,因此行、列的标号基本上灰色的。
请注意第一行第一列的单元格边框为深色,说明该数据单元格为当前单元格。
有的SPSS系统打开时会出现一个导航对话框,请单击右下方的Cancer按钮,即可进入上面的主界面。
SPSS数据分析实例

• 例2.1:某克山病区测得11例克山病患者与13名健康人 的血磷值(mmol)如下,问该地急性克山病患者与健康人 的血磷值是否相同
患者:0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80
1.87 2.07 2.11
健康人:0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20
t检验的假设如下: H0:两总体均数相同,μ1 =μ2
H1:两总体不均数相同,μ1 ≠μ2
两样本t检验对数据的要求: 1.小样本时要求分布不太偏 2.小样本时要求方差齐
∴应该先判断该数据是否符合t检验要求,即对数据进行简单描述
2.2.1 数据的简单描述
选择菜单项 分析
பைடு நூலகம்
描述统计
描述
,
系统弹出对话框
选择描述变量
取消文件拆分,不然会影响以后的统计分析
选择菜单项 数据 拆分文件 ,选择 分析所有个案,不创建组
2.2.2 绘制直方图
选择菜单项 Graph Histogram ,系统弹出对话框
将变量x选入Variable选择框内,单击ok,结果浏览窗口绘制出直方图
数据的分布不是特别偏, 没有十分突出的离群值 t检验具有一定的耐受性,稍稍偏离要求一点不 会影响统计分析结果
∴可以直接采用参数分析方法来分析,因是两样本均数的比较,确定采用 成组设计两样本均数比较的t检验来分析
2.3 按题目要求进行统计分析
用SPSS来做两样本均数比较的t检验,选择
分析
均值比较
独立样本T检验
出现t检验对话框
将变量x选入test对话框, 变量group选入grouping Variable对话框,Define Groups钮变黑,在Define Group两个框内分别输入1 和2,在这ok
手把手教你怎么用SPSS分析数据

使用SPSS软件进行数据分析文档通过自己论证属实。
【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(∏ρινχιπαλ χομπονεντσ),因此对此栏不作变动,就是认可了主成分分析方法。
大学生spss数据分析案例

大学生spss数据分析案例大学生SPSS数据分析案例。
在大学教育中,数据分析是一个非常重要的环节,尤其是对于社会科学和商业管理专业的学生来说。
SPSS(Statistical Package for the Social Sciences)是一个专业的统计分析软件,广泛应用于学术研究和商业决策中。
本文将以一个大学生SPSS数据分析案例为例,介绍如何使用SPSS进行数据分析。
案例背景:某大学社会科学专业的学生对大学生活满意度进行了调查,并收集了相关数据,包括学生的性别、年级、专业、宿舍类型、课程质量、宿舍环境、社交活动等方面的信息。
现在需要对这些数据进行分析,以了解不同因素对大学生活满意度的影响。
数据准备:首先,需要将调查所得的数据录入SPSS软件中,确保数据的准确性和完整性。
在录入数据时,要注意将不同的变量分别录入不同的列中,以便后续的分析和处理。
数据分析:1. 描述统计分析。
首先,可以对各个变量进行描述统计分析,包括计算均值、标准差、频数分布等。
通过描述统计分析,可以直观地了解各个变量的分布情况,为后续的分析提供基础。
2. 相关性分析。
接下来,可以进行各个变量之间的相关性分析,通过相关系数的计算来了解不同变量之间的关联程度。
例如,可以分析学生的性别、年级、专业与大学生活满意度之间的相关性,以及宿舍类型、课程质量、社交活动等因素对大学生活满意度的影响程度。
3. 方差分析。
针对分类变量,可以进行方差分析,比较不同组别之间的均值差异是否显著。
例如,可以分析不同年级、不同专业的学生对大学生活满意度的差异情况,以及不同宿舍类型对大学生活满意度的影响是否显著。
4. 回归分析。
最后,可以利用回归分析来探讨不同因素对大学生活满意度的影响程度。
通过建立回归模型,可以了解各个自变量对因变量的影响情况,以及它们之间的关系强度和方向。
结论与建议:通过以上的数据分析,可以得出不同因素对大学生活满意度的影响程度,为学校和相关部门提供决策建议。
spss的数据分析报告范例

关于某地区361个人旅游情况统计分析报告一、数据介绍:本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好 4代表积极性非常好);额外收入,一类变量。
通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析,以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析1、频数分析。
基本的统计分析往往从频数分析开始。
通过频数分地区359个人旅游基本状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性情况的基本分布。
统计量积极性性别N有效359359缺失00首先,对该地区的男女性别分布进行频数分析,结果如下性别频率百分比有效百分比累积百分比有效女19855.255.255.2男16144.844.8100.0合计359100.0100.0表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为44.8%和55.2%,该公司职工男女数量差距不大,女性略多于男性。
其次对原有数据中的旅游的积极性进行频数分析,结果如下表:积极性频率百分比有效百分比累积百分比有效差17147.647.647.6一般7922.022.069.6比较好7922.022.091.6好24 6.7 6.798.3非常好 6 1.7 1.7 100.0合计359100.0 100.0其次对原有数据中的积极性进行频数分析,结果如下表 :其次对原有数据中的是否进通道进行频数分析,结果如下表 :Statistics通道 NValid359Statistics通道N Valid359Missing这说明,在该地区被调查的359个人中,有没走通道的占81.6%,占绝大多数。
spss入门基本操作ppt课件

Independent Samples Test
Levene's Test for Equality of Variances
t-test for Equality of Means
F Sig. t
95% Confidence
df
Sig. (2- Mean Std. Error tailed) Difference Difference
17
§1.3 按题目要求进行统计分析
下面我们要用SPSS来做成组设计两样本均数比较的t检验,选 择Analyze==>Compare Means==>Independent-Samples T test,系统弹出两样本t检验对话框如下:
18
将变量X选入test框内,变量group选入grouping框内,注意这时 下面的Define Groups按钮变黑,表示该按钮可用,单击它,系统 弹出比较组定义对话框如右图所示:
22
1.4.2 导出分析结果 文件倒是保存了,但问题还没有完全解决:我们从来写文章什么的 都用的是文字处理软件,尤其是WORD,可WORD不能直接读取 SPO格式的文件,怎么办呢?没关系,SPSS提供了将结果导出为纯 文本格式或网页格式的功能,在结果浏览窗口中选择菜单 File==>Export,系统会弹出Exprot Output对话框如下
现在,第一、第二列的名称均为深色显示,表明这两列已 经被定义为变量,其余各列的名称仍为灰色的“var”,表 示尚未使用。同样地,各行的标号也为灰色,表明现在还 未输入过数据,即该数据集内没有记录。
7
1.1.3 输入数据 在Data View中输入相应的数据,一个单元格输入一个数据, Group中输入1代表患者,2代表健康人。
spss的数据分析案例

精心整理关于某公司474名职工综合状况的统计分析报告一、数据介绍:本次分析的数据为某公司474名职工状况统计表,其中共包含^一变量,分别是:id (职工编号),gender(性别),bdate(出生日期),edcu (受教育水平程度),jobcat (职务等级),salbegin (起始工资),salary (现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)<通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、I ■以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析■■ ] I ■.1、频数分析。
基本的统计分析往往从频数分析开始。
通过频数分析能够了解变量的取值状况,对把握数据的分布特征非常有用。
此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu (受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
精心整理上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。
/ 「’--了/其次对原有数据中的受教育程度进行频数分析,结果如下表:Educati on alLevel(years).4 .4 99.8 20 2上表及其直方图说I I明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占 总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。
且接受过高于20年的 教育的人数只有1人,比例很低。
2、描述统计分析。
再通过简单的频数统计分析了解了职工在性别和受教育水平• J ' P t ,- J上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识, 这就需要通过计算基本描述统计的方法来实现。
spss的数据分析报告范例

spss的数据分析报告范例SPSS数据分析报告范例一、引言数据分析是现代科学研究的重要环节,在统计学中,SPSS作为一种广泛应用的数据分析软件,为研究人员提供了丰富的功能和工具。
本报告旨在使用SPSS对某项研究的数据进行分析,并整理并呈现结果,以帮助读者深入了解数据的含义,并得出有关数据的结论。
二、研究背景与目的在这一部分,我们将简要介绍研究的背景和目的。
本次研究旨在调查大学生的学习焦虑水平与其学业成绩之间的关系。
通过收集相关数据并使用SPSS进行分析,我们希望能够揭示大学生学习焦虑对学业成绩的影响程度,并为教育管理者和辅导员提供数据支持。
三、研究设计与方法在这一部分,我们将介绍研究的设计和采用的方法。
本研究采用问卷调查的形式,使用了由专家设计的学习焦虑量表和学业成绩评估表。
我们在某大学的三个院系中选取了500名大学生作为样本,并通过邮件方式发送问卷,并以匿名方式收集数据。
四、数据分析与结果本节将展示SPSS分析后的数据结果。
首先,我们将进行数据清洗和描述性统计分析。
然后,我们将使用相关性分析和回归分析来探究学习焦虑与学业成绩之间的关系。
1.数据清洗和描述性统计针对收集到的数据,我们进行了数据清洗,包括去除不完整或无效数据。
然后,我们进行了描述性统计分析,包括计算样本量、均值、标准差和分布情况。
2.相关性分析为了探究学习焦虑与学业成绩之间的关系,我们进行了相关性分析。
根据SPSS的输出结果,我们发现学习焦虑与学业成绩之间存在显著的负相关关系(r=-0.35, p<0.05),表明学习焦虑水平越高,学业成绩越低。
3.回归分析为了更深入地了解学习焦虑对学业成绩的影响程度,我们进行了回归分析。
回归分析结果显示,学习焦虑是预测学业成绩的显著因素(β=-0.25, p<0.05)。
这表明学习焦虑对学业成绩有着一定的负向影响。
五、讨论与结论根据数据分析的结果,我们得出以下结论:1.学习焦虑与学业成绩之间存在显著的负相关关系,即学习焦虑水平越高,学业成绩越低。
spss数据分析案例

spss数据分析案例SPSS是一种常用的统计分析软件,它可以对大规模数据进行处理和分析。
以下是一个使用SPSS进行数据分析的案例。
假设有一家电商公司想要了解其在线购买行为的一些关键指标,以便他们能够做出更好的决策。
为了达到这个目标,该公司收集了一些关于客户在线购买的信息,包括购买金额、购买时间、购买地点等。
为了更好地理解数据,他们将这些信息保存在一个CSV文件中,并使用SPSS对数据进行分析。
首先,他们导入CSV文件到SPSS中,并通过查看数据的前几行对数据进行初步了解。
然后,他们对数据的各个字段进行描述性统计分析,包括平均值、中位数、最大值、最小值等。
这样他们可以对数据的分布和变化有一个整体的了解。
接下来,他们为每个字段制作了一些图表,以更直观地了解数据。
例如,他们可以绘制一个柱状图来表示每个地点的购买次数,从而了解销售最好的地点。
他们还可以制作一个折线图来显示每月的购买金额,以发现季节性变化。
然后,他们对数据进行了透视分析,以找出一些有用的信息。
例如,他们可以对数据按照购买地点进行透视分析,并计算每个地点的总购买金额。
这样他们可以确定哪些地点对总销售额做出了更大的贡献。
此外,他们还可以使用SPSS进行相关性分析,以找出一些字段之间的关系。
例如,他们可以计算购买金额和购买时间之间的相关系数,以了解购买金额是否受到购买时间的影响。
最后,他们对数据进行了回归分析,以预测未来的销售情况。
他们可以使用购买金额作为因变量,其他字段作为自变量,构建一个回归模型,并通过模型预测未来的销售额。
通过以上的分析,该电商公司可以更好地了解其在线购买行为,找到销售最好的地点和销售最好的时间,并预测未来的销售情况。
基于这些信息,他们可以做出更好的决策,例如增加在销售最好的地点的推广活动或优化在销售最好的时间的库存管理。
综上所述,SPSS可以帮助企业对大规模数据进行分析,从而更好地了解数据,做出更好的决策。
这个案例只是SPSS数据分析的一个示例,实际应用可以更加多样化和复杂化。
spss的数据分析案例

s p s s的数据分析案例(总11页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--关于某公司474名职工综合状况的统计分析报告一、数据介绍:本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。
通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析1、频数分析。
基本的统计分析往往从频数分析开始。
通过频数分析能够了解变量的取值状况,对把握数据的分布特征非常有用。
此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
Statistics首先,对该公司的男女性别分布进行频数分析,结果如下:上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为%和%,该公司职工男女数量差距不大,男性略多于女性。
其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的%,其次为15年,共有116人,占中人数的%。
且接受过高于20年的教育的人数只有1人,比例很低。
2、描述统计分析。
再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。
2024版SPSS数据案例分析

通过方差分析,发现不同社会群体在态度上存在显著差异, 并进一步通过事后检验(Post hoc tests)确定哪些群体之 间存在差异
26
聚类分析在社会科学领域应用举例
研究问题
能否将受访者按照他们在某一社会现象上的行为特征进行分类?
分析方法
采用K-means聚类分析对受访者的行为特征进行聚类
2024/1/27
20
假设检验在医学领域应用举例
假设检验的基本原理
假设检验是一种统计推断方法,用于检验某个假设是否成立。在医学领域中,假设检验常用于比较两组或多组患 者的治疗效果是否有显著差异。
应用举例
例如,一项研究旨在比较两种不同药物对某种疾病的治疗效果。研究人员可以将患者随机分为两组,分别接受两 种不同的药物治疗。通过收集患者的治疗结果数据,并使用假设检验方法进行分析,可以确定哪种药物的治疗效 果更好。
SPSS数据案例分析
2024/1/27
1
CATALOGUE
目 录
2024/1/27
• 数据导入与预处理 • 数据分析方法介绍 • SPSS软件操作指南 • 案例一:医学领域数据分析应用举
例 • 案例二:社会科学领域数据分析应
用举例 • 总结与展望
2
01
CATALOGUE
数据导入与预处理
2024/1/27
多因素方差分析
研究多个自变量对一个因变量的 影响,通过比较不同组间的均值 差异来判断哪些自变量对因变量 有显著影响。
2024/1/27
10
回归分析
线性回归分析
研究一个或多个自变量对一个因变量的线性关系,通过建立线性回 归方程来预测因变量的值。
多元线性回归分析
研究多个自变量对一个因变量的线性关系,通过建立多元线性回归 方程来预测因变量的值,并可以分析自变量之间的交互作用。
SPSS问卷数据分析操作实例

SPSS问卷数据分析操作实例在当今社会,数据的收集和分析对于了解各种现象、解决问题以及做出决策起着至关重要的作用。
问卷作为一种常见的数据收集工具,通过合理设计和有效发放,可以获取大量有价值的信息。
而 SPSS (Statistical Package for the Social Sciences)作为一款功能强大的统计分析软件,为我们处理和分析问卷数据提供了便捷和高效的途径。
接下来,我将通过一个具体的实例,为您详细介绍如何使用 SPSS 进行问卷数据分析。
假设我们进行了一项关于消费者对某品牌手机满意度的调查,共收集了 500 份有效问卷。
问卷中包含了消费者的个人信息(如年龄、性别、职业等)、对手机外观、性能、价格、售后服务等方面的满意度评价(采用 1-5 分的评分制,1 分为非常不满意,5 分为非常满意)以及是否会推荐给他人等问题。
首先,打开 SPSS 软件,将问卷数据导入到软件中。
SPSS 支持多种数据格式的导入,如 Excel、CSV 等。
在导入数据后,我们需要对数据进行初步的整理和检查,确保数据的完整性和准确性。
接下来,我们对消费者的个人信息进行描述性统计分析。
选择“分析” “描述统计” “频率”,将年龄、性别、职业等变量放入变量框中,点击“确定”。
这样,我们可以得到这些变量的频数分布、百分比、均值、中位数等统计量,从而了解调查对象的基本特征。
对于满意度评价的变量,我们可以计算其均值和标准差,以了解消费者对各方面的平均满意度水平和差异程度。
选择“分析” “描述统计” “描述”,将满意度评价变量放入变量框中,勾选“均值”和“标准差”,点击“确定”。
为了进一步探究不同性别、年龄或职业的消费者在满意度方面是否存在差异,我们可以进行方差分析或独立样本 t 检验。
例如,如果要比较男性和女性消费者在手机性能满意度上的差异,选择“分析” “比较均值” “独立样本 t 检验”,将性能满意度变量作为检验变量,性别变量作为分组变量,点击“确定”。
spss的数据分析案例

关于某公司474名职工综合状况的统计分析报告一、数据介绍:本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。
通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析1、频数分析。
基本的统计分析往往从频数分析开始。
通过频数分析能够了解变量的取值状况,对把握数据的分布特征非常有用。
此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
Statistics首先,对该公司的男女性别分布进行频数分析,结果如下:上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。
其次对原有数据中的受教育程度进行频数分析,结果如下表:Educational Level (years)上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。
且接受过高于20年的教育的人数只有1人,比例很低。
2、描述统计分析。
再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。
spss-数据分析实例详解图文

优化策略
根据数据分析结果调整销售策略 ,如定价、促销方式等。
预测模型
利用时间序列分析、神经网络等 模型预测未来销售趋势。
相关性分析
探究销售量与价格、促销活动等 因素的关系。
实例三:人力资源数据分析
总结词
通过SPSS进行人力资源数据分析,可以优化人员 配置和提高员工满意度。
数据收集
收集员工信息,包括年龄、性别、学历、绩效等。
01
描述性统计分析是对数据进行初步处理和分析的过程,包括计 算数据的均值、中位数、众数、标准差等统计指标。
02
在SPSS中,可以通过选择“分析”菜单中的“描述统计”选项
来进行描述性统计分析。
描述性统计分析可以帮助我们了解数据的分布情况、异常值和
03
数据的中心趋势等。
数据可视化
数据可视化是将数据以图形或图表的形式呈现的过程,可以帮助我们更好地理解数 据和发现数据中的规律和趋势。
大数据处理
云端化服务
为了更好地满足用户的灵活性和可扩 展性需求,SPSS可能会推出基于云端 的服务模式,提供更加便捷和高效的 数据分析服务。
随着大数据时代的来临,SPSS可能会 加强在大数据处理和分析方面的能力, 以应对大规模数据集的处理需求。
THANKS FOR WATCHING
感谢您的观看
探索性统计
进行因子分析、主成分分析等,深入挖掘数据背后的结构。
可视化问题
图表选择
根据分析目的选择合适的图表类型,如柱状 图、折线图、饼图等。
图表组合
将多个图表组合在一起,形成综合性的可视 化报告。
图表定制
调整图表样式、颜色、字体等,提高图表的 可读性和美观度。
动态可视化
SPSS分析实例
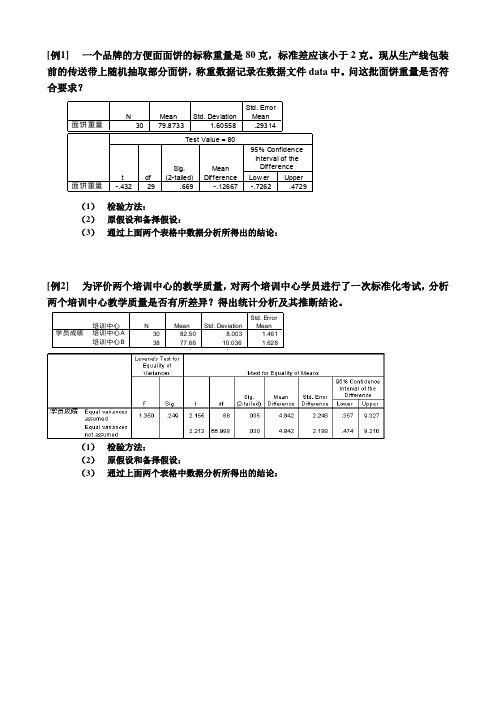
[例1]一个品牌的方便面面饼的标称重量是80克,标准差应该小于2克。
现从生产线包装前的传送带上随机抽取部分面饼,称重数据记录在数据文件data中。
问这批面饼重量是否符(1)检验方法:(2)原假设和备择假设:(3)通过上面两个表格中数据分析所得出的结论:[例2]为评价两个培训中心的教学质量,对两个培训中心学员进行了一次标准化考试,分析(1)检验方法:(2)原假设和备择假设:(3)通过上面两个表格中数据分析所得出的结论:[例3]某康体中心的减肥班学员入班时的体重数据和减肥训练一个月后的体重数据记录在数据文件data中,试分析一个月的训练是否有效。
(1)检验方法:(2)原假设和备择假设:(3)通过上面两个表格中数据分析所得出的结论:(4)可以绘制_________图,直观显示前后体重的变化趋势。
[例4]为了解非计算机专业对计算机课程教学的意见,在金融系和统计系本科生中进行了一次抽样调查,得到了390名学生的调查数据。
试据此推断两系本科生对计算机课程教学的意见是否一致。
(1)检验方法:(2)原假设和备择假设:(3)通过上面两个表格中数据分析所得出的结论:(4)可以通过_________图直观地比较不同系别的满意度。
[例5]为了试验某种减肥药物的性能,测量11个人在服用该药以前以及服用该药1个月后、2个月后、3个月后的体重。
那么请问在这4个时期,11个人的体重有无发生显著的变化?(1)通过上面输出结果表格,可判断使用的检验方法:(2)原假设和备择假设:(3)结论:[例6]数据文件“Employee data.sav”记录了474名职工的基本信息(1)绘制复式条形图来表示不同性别的雇佣类别情况;(2)对起始薪金绘制茎叶图,说明图中信息;(3)通过箱图描绘不同雇佣类别的职工当前薪金情况,得出结论;(4)分析起始薪金的确定与什么因素有关,说明下面两表分别用的分析方法,并比较两表的结果。
控制变量起始薪金教育水平(年)雇佣类别 & 经验(以月计)起始薪金相关性 1.000 .461显著性(双侧). .000df 0 470 教育水平(年)相关性.461 1.000显著性(双侧).000 .df 470 0[例7]考察数码相机成像元器件像素数是否会对产品销量产生显著影响(设显著性水平α=0.05)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章SPSS概览--数据分析实例详解1.1 数据的输入和保存1.1.1 SPSS的界面1.1.2 定义变量1.1.3 输入数据1.1.4 保存数据1.2 数据的预分析1.2.1 数据的简单描述1.2.2 绘制直方图1.3 按题目要求进行统计分析1.4 保存和导出分析结果1.4.1 保存文件1.4.2 导出分析结果希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。
例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)?患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87解题流程如下:1.将数据输入SPSS,并存盘以防断电。
2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采用的检验方法。
3.按题目要求进行统计分析。
4.保存和导出分析结果。
下面就按这几步依次讲解。
§1.1 数据的输入和保存1.1.1 SPSS的界面当打开SPSS后,展现在我们面前的界面如下:请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。
请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
特别的,工具栏下方的是数据栏,数据栏下方则是数据管理窗口的主界面。
该界面和EXCEL极为相似,由若干行和列组成,每行对应了一条记录,每列则对应了一个变量。
由于现在我们没有输入任何数据,所以行、列的标号都是灰色的。
请注意第一行第一列的单元格边框为深色,表明该数据单元格为当前单元格。
有的SPSS系统打开时会出现一个导航对话框,请单击右下方的Cancer 按钮,即可进入上面的主界面。
1.1.2 定义变量该资料是定量资料,设计为成组设计,因此我们需要建立两个变量,一个变量代表血磷值,习惯上取名为X,另一个变量代表观察对象是健康人还是克山病人,习惯上取名为GROUP。
对数据的统计分析格式不太熟悉的朋友请先学习统计软件第一课。
选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:该变量定义对话框在SPSS 10.0版中已被取消,这里的操作只适合9.0~7.0版的用户。
对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
好,先来建立分组变量GROUP。
请将变量名改为GROUP,然后单击OK 按钮。
有没有搞错?!折腾了半天就改个名字!难道连变量格式、标签等都不改?是这样的,在SPSS中所有的数据均以最大位数保存(好象是双精度),也就是说,上面虽然默认只有两位小数,但那指的是计算精度,实际保存的数据位数是非常长的(可以输入Pi值试一下)。
在绝大多数情况下,SPSS给出的默认数据类型和数据精度完全可以满足需要,只是不太好看而已。
至于标签等比较花哨的选项,反正我也很少用。
现在我们才刚刚入门,一切从简。
以后我会详细介绍各种设置的用法。
在第一列灰色的“var”上双击,同样会弹出定义变量对话框。
现在SPSS的数据管理窗口如下所示:第一列的名称已经改为了“group”,这就是我们所定义的新变量“group”。
现在我们来建立变量X。
单击第一行第二列的单元格,然后选择菜单Data==>Define Variable,同样,将变量名改为X,然后确认。
此时SPSS的数据管理窗口如下所示:现在,第一、第二列的名称均为深色显示,表明这两列已经被定义为变量,其余各列的名称仍为灰色的“var”,表示尚未使用。
同样地,各行的标号也为灰色,表明现在还未输入过数据,即该数据集内没有记录。
1.1.3 输入数据我们先来输入变量X的值,请确认一行二列单元格为当前单元格,弃鼠标而用键盘,输入第一个数据0.84,此时界面显示如图A所示:图A 图B请注意:在回车之前,你输入的数据在数据栏内显示,而不是在单元格内显示,现在回车,界面如图B所示:首先,当前单元格下移,变成了二行二列单元格,而一行二列单元格的内容则被替换成了0.84;其次,第一行的标号变黑,表明该行已输入了数据;第三,一行一列单元格因为没有输入过数据,显示为“.”,这代表该数据为缺失值。
用类似的输入方式,我们将患者的血磷值输入完毕,并将相应的变量GROUP均取值为1,此时数据管理窗口如下所示:从第12行开始输入健康人的数据,并将相应的GROUP变量取值为2。
最终该数据集应该有24条记录。
1.1.4 保存数据选择菜单File==>Save,由于该数据从来没有被保存过,所以弹出Save as 对话框如下:单击保存类型列表框,可以看到SPSS所支持的各种数据类型,有DBF、FoxPro、EXCEL、ACCESS等,这里我们仍然将其存为SPSS自己的数据格式(*.sav文件)。
在文件名框内键入Li1_1并回车,可以看到数据管理窗口左上角由Untitled变为了现在的变量名Li1_1。
为什么这里的对话框会出现汉字?是这样的,需要从编程的角度来解释:SPSS在弹出该对话框时会调用Windows系统的公用函数,由于我们用的是中文Windows系统,所以调用出来的就是中文。
§1.2 数据的预分析1.2.1 数据的简单描述首先我们需要知道数据的基本情况,如均数、标准差等。
选择Analyze==>Descriptive Statistics==>Descriptives菜单,系统弹出描述对话框如下:如果按SPSS标准的叫法,这里应该是调用了Descriptives过程,为了避免太生硬,我们称为调用对话框,等大家熟悉SPSS了以后,在统计分析各章中可能两种称呼会混用。
该对话框可分为左右两大部分,左侧为所有可用的侯选变量列表,右侧为选入变量列表。
我们只需要描述X,用鼠标选中X,单击中间的,变量X的标签就会移入右侧,注意这时OK按钮变黑,表明已经可以进行分析了,单击它,系统会弹出一个新的界面如下所示:该窗口上方的名称为SPSS for Windows Viewer,即(结果)浏览窗口,整个的结构和资源管理器类似,左侧为导航栏,右侧为具体的输出结果。
结果表格给出了样本数、最小值、最大值、均数和标准差这几个常用的统计量。
从中可以看到,24个数据总的均数为1.2846,标准差为0.4687。
我们以上的做法对吗?当然有问题!光看总的描述是不够的,还应当看看分组的描述情况。
这里要用到文件分割功能,请切换回数据管理窗口,选择Data==>Split File菜单,系统弹出文件分割对话框如下:选择单选按钮Organize output by groups,将变量GROUP选入右侧的选入变量框,单击OK钮,此时界面不会有任何改变,但请再做一次数据描述,你就可以看到现在数据是分Group=1和Group=2两种情况在描述了!从描述可知两组的均数和标准差分别为1.5209、1.0846和0.4218、0.4221。
如果定义了文件分割,则它会在以后的所有统计分析中起作用,直到你重新定义文件分割方式为止。
1.2.2 绘制直方图统计指标只能给出数据的大致情况,没有直方图那样直观,我们就来画个直方图瞧瞧!选择Graphs==>Histogram,系统会弹出绘制直方图对话框如下:将变量X选入Variable选择框内,单击OK按钮。
此时结果浏览窗口内会绘制出如下两个直方图:两组的数据没有特别偏的分布,也没有十分突出的离群值,因此无须变换,可以直接采用参数分析方法来分析。
综合设计类型,最终确定采用成组设计两样本均数比较的t检验来分析。
最后,我们还要取消变量分割,免得它影响以后的统计分析,再次调出变量分割对话框,选择单选按钮中的“Analyze all cases, do not creat group”,单击OK按钮就可以了。
§1.3 按题目要求进行统计分析下面我们要用SPSS来做成组设计两样本均数比较的t检验,选择Analyze==>Compare Means==>Independent-Samples T test,系统弹出两样本t检验对话框如下:group选入grouping框内,注意这时下面的Define Groups按钮变黑,表示该按钮可用,单击它,系统弹出比较组定义对话框如右图所示:该对话框用于定义是哪两组相比,在两个group框内分别输入1和2,表明是变量group取值为1和2的两组相比。
然后单击Continue按钮,再单击OK按钮,系统经过计算后会弹出结果浏览窗口,首先给出的是两组的基本情况描述,如样本量、均数等(糟糕,刚才的半天工夫白费了),然后是t检验的结果如下:可见该结果分为两大部分:第一部分为Levene's方差齐性检验,用于判断两总体方差是否齐,这里的戒严结果为F = 0.032,p = 0.860,可见在本例中方差是齐的;第二部分则分别给出两组所在总体方差齐和方差不齐时的t检验结果,由于前面的方差齐性检验结果为方差齐,第二部分就应选用方差齐时的t检验结果,即上面一行列出的t= 2.524,ν=22,p=0.019。
从而最终的统计结论为按α=0.05水准,拒绝H0,认为克山病患者与健康人的血磷值不同,从样本均数来看,可认为克山病患者的血磷值较高。
§1.4 保存和导出分析结果1.4.1 保存结果文件前面我们已经做出了分析结果,但是,可是,可但是,但可是呢?再好的结果只要一断电就会全部消失(废话),对于这一问题人们早已想出了三种解决办法,他们分别是:∙需要结果的时候再运行一次分析程序。
∙用笔将结果抄在纸上。
∙直接保存结果文件。
显然,最方便快捷、最符合信息时代特征的就是第三种方法,在结果浏览窗口中(注意:一定要在结果浏览窗口中)选择菜单File==>Save,由于该结果也从来没有被保存过,所以弹出和前面保存数据时极为相似的一个Save as对话框,和前面相比,他唯一的区别就是文件的保存类型只有View Files(*.spo)一种。