SPSS概览数据分析实例详解
SPSS简单数据分析报告

精选范文、公文、论文、和其他应用文档,希望能帮助到你们!SPSS简单数据分析报告目录一、数据样本描述 (4)二、要解决的问题描述 (4)1 数据管理与软件入门部分 (4)1.1 分类汇总 (4)1.2 个案排秩 (5)1.3 连续变量变分组变量 (5)2 统计描述与统计图表部分 (5)2.1 频数分析 (5)2.2 描述统计分析 (5)3 假设检验方法部分 (5)3.1 分布类型检验 (5)3.1.1 正态分布 (5)3.1.2 二项分布 (6)3.1.3 游程检验 (6)3.2 单因素方差分析 (6)3.3 卡方检验 (6)3.4 相关与线性回归的分析方法 (6)3.4.1 相关分析(双变量相关分析&偏相关分析) (6)3.4.2 线性回归模型 (6)4 高级阶段方法部分 (6)三、具体步骤描述 (7)1 数据管理与软件入门部分 (7)1.1 分类汇总 (7)1.2 个案排秩 (8)1.3 连续变量变分组变量 (10)2 统计描述与统计图表部分 (11)2.1 频数分析 (11)2.2 描述统计分析 (14)3 假设检验方法部分 (16)3.1 分布类型检验 (16)3.1.1 正态分布 (16)3.1.2 二项分布 (17)3.1.3 游程检验 (18)3.2 单因素方差分析 (22)3.3 卡方检验 (24)3.4 相关与线性回归的分析方法 (26)3.4.1 相关分析 (26)3.4.2 线性回归模型 (28)4 高级阶段方法部分 (32)4.1 信度 (32)一、数据样本描述本次分析的数据为某公司474名职工状况统计表,其中共包含11个变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。
SPSS统计分析实例讲解

SPSS统计分析实例讲解引言在社会科学研究和商业分析中,统计分析是一个重要的工具,可以帮助我们理解数据背后的规律和关系。
SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,具有强大的数据处理和分析功能。
本文将通过一个实例,介绍如何使用SPSS进行统计分析。
实例背景假设我们是一家快餐连锁店的运营经理,我们想了解不同分店的顾客满意度与相关因素之间的关系。
为了实现这个目标,我们收集了以下三个变量的数据:1.顾客满意度:用于评估顾客对快餐店的满意程度,以1-10的等级进行评分。
2.服务质量:用于评估不同分店提供的服务质量,以1-5的等级进行评分。
3.价格水平:用于评估不同分店的价格水平,以1-5的等级进行评分。
我们希望通过分析这些数据,了解不同分店的服务质量和价格水平对顾客满意度的影响。
数据分析步骤步骤一:载入数据首先,我们需要将收集到的数据导入SPSS软件进行分析。
打开SPSS软件,点击菜单栏中的文件(File),选择导入(Import),然后选择收集到的数据文件进行导入。
步骤二:数据清洗在进行数据分析之前,我们需要对数据进行清洗,以确保数据的准确性和一致性。
一般来说,数据清洗包括以下几个方面的处理:•去除缺失值:检查数据中是否存在缺失值,如果有,可以删除含有缺失值的观测样本或者使用合适的方法进行填补。
•标准化变量:如果不同变量的测量单位和量级存在差异,可以对变量进行标准化处理,使得它们具有可比性。
•检查异常值:检查数据中是否存在异常值,如果有,可以进行修正或者删除。
•数据转换:对于非正态分布的变量,可以进行对数变换或者其他适当的转换,以满足统计分析的前提条件。
步骤三:描述性统计分析描述性统计分析是对数据的整体情况进行概括和描述的统计方法。
通过描述性统计分析,我们可以了解数据的中心趋势、离散程度和分布形态等。
在SPSS中,可以使用以下方法进行描述性统计分析:•平均值:计算变量的平均值,以反映数据的中心趋势。
《SPSS实例分析》PPT课件

SPSS软件例题分析
1
Base system(基本统计系统) ACF(时间序列研究中的自动相关分析) Aggregate(数据文件的汇总) Anova(方差分析) Autorecode(变量自动赋值处理) Correlations(相关分析) Crosstabs(列联表处理) Curvefit(11种曲线模型的拟合) Date(变量定义与数据录入) Descriptives(均数、标准差等的描述性统计 Examine(数值分布形式的探究) Fit(定义程序运行条件) Flip(数据行列转换) Frequencies(频数表分析)
定义描述分布特征 的两个指标:偏度 系数(Skewness) 和峰度系数
(Kurtosis) 32
第三章 均数间的比较
§3.1 Means过程 和上一章所讲述的几个专门的描述过程相比,
Means过程的优势在于各组的描述指标被放在一起 便于相互比较,并且如果需要,可以直接输出比较 结果,无须再次调用其他过程。显然要方便的多。
36
选入的描述 统计量
对分组变量进行单因素方差分析 检验线性相关性
37
Statistics框 可选的描述统计量。它们是:
sum,number of cases 总和,记录数
mean, geometric mean, harmonic mean 均数,几何均
spss操作手册

spss操作⼿册第⼀章 SPSS概览--数据分析实例详解1.1 数据的输⼊和保存1.1.1 SPSS的界⾯1.1.2 定义变量1.1.3 输⼊数据1.1.4 保存数据1.2 数据的预分析1.2.1 数据的简单描述1.2.2 绘制直⽅图1.3 按题⽬要求进⾏统计分析1.4 保存和导出分析结果1.4.1 保存⽂件1.4.2 导出分析结果 欢迎加⼊SPSS使⽤者的⾏列,⾸先祝贺你选择了权威统计软件中界⾯最为友好,使⽤最为⽅便的SPSS来完成⾃⼰的⼯作。
由于该软件极为易学易⽤(当然还⾄少要有不太⾼的英语⽔平),我们准备在课程安排上做⼀个新的尝试,即不急于介绍它的界⾯,⽽是先从⼀个数据分析实例⼊⼿:当你将这个例题做完,SPSS的基本使⽤⽅法也就已经被你掌握了。
从下⼀章开始,我们再详细介绍SPSS各个模块的精确⽤法。
我们教学时是以SPSS 10.0版为蓝本讲述的--什么?你还在⽤7.0版!那好,由于10.0版在数据管理的界⾯操作上和以前版本有较⼤区别,本章我们将特别照顾⼀下⽼版本,在数据管理界⾯操作上将按9.0及以前版本的情况讲述,但具体的统计分析功能则按10.0版本讲述。
没关系,基本操作是完全⼀样的。
好,说了这么多废话,等急了吧,就让我们开始吧!希望了解SPSS 10.0版具体情况的朋友请参见本⽹站的SPSS 10.0版抢鲜报道。
例1.1 某克⼭病区测得11例克⼭病患者与13名健康⼈的⾎磷值(mmol/L)如下, 问该地急性克⼭病患者与健康⼈的⾎磷值是否不同(卫统第三版例4.8)?患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康⼈: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87让我们把要做的事情理理顺:⾸先要做的肯定是打开计算机(废话),然后进⼊瘟98或瘟2000(还是废话,以下省去废话2万字),在进⼊SPSS后,具体⼯作流程如下:1. 将数据输⼊SPSS,并存盘以防断电。
SPSS概览数据分析实例详解

SPSS概览数据分析实例详解SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于各个领域的数据分析。
在SPSS中,数据分析可以通过不同的统计方法、图表和输出来进行。
下面是一个关于如何使用SPSS进行数据分析的实例详解。
假设我们有一个关于一所大学学生的调查数据集,包括以下信息:性别、年龄、所在学院、GPA(平均绩点)、社交媒体使用时间和每周学习时间等变量。
我们想要使用SPSS对这些数据进行一些分析,以了解学生的特征与他们的学习表现之间是否存在关联。
首先,我们需要导入数据集到SPSS中。
在SPSS中,你可以点击“File”菜单,选择“Open”选项来导入数据集(通常是一个Excel或CSV文件)。
导入后,你将在SPSS的“Data Editor”窗口中看到你的数据。
然后,我们可以开始进行数据的概览。
在SPSS中,你可以使用“Frequencies”命令来查看变量的分布情况。
点击“Analyze”菜单,选择“Descriptive Statistics”选项,然后点击“Frequencies”选项。
在弹出的对话框中,你需要选择你想要分析的变量。
比如,你可以选择年龄、GPA和每周学习时间这三个变量。
点击“OK”按钮后,SPSS会生成一个报告,展示这些变量的频数、百分比和其他统计信息。
接下来,我们可以使用SPSS的图表功能来可视化数据。
在SPSS中,你可以点击“Graphs”菜单,选择“Chart Builder”选项来创建图表。
在“Chart Builder”窗口中,你可以选择不同的图表类型,例如柱状图、散点图或箱线图。
比如,你可以选择创建一个散点图来展示GPA与每周学习时间之间的关系。
然后,你需要将变量拖动到图表的相应位置上。
比如,你可以将GPA拖动到纵坐标(Y轴)上,将每周学习时间拖动到横坐标(X轴)上。
点击“OK”按钮后,SPSS会生成一个散点图,展示这两个变量之间的关系。
大学生spss数据分析案例

大学生spss数据分析案例在大学生活中,数据分析是一项非常重要的技能,尤其是对于学习社会科学的学生来说。
SPSS(Statistical Package for the Social Sciences)是一个非常常用的统计分析软件,它可以帮助我们对数据进行分析和处理。
在本文中,我们将以一个实际案例为例,介绍大学生如何运用SPSS进行数据分析。
首先,我们需要明确我们的研究目的和问题。
假设我们想要研究大学生的学习成绩和课堂参与度之间的关系。
我们收集了一份包括学习成绩和课堂参与度的数据,接下来我们将使用SPSS进行分析。
第一步,我们需要导入数据。
在SPSS软件中,我们可以通过导入Excel文件的方式将我们收集到的数据导入到软件中。
一旦数据导入完成,我们就可以开始进行数据的清洗和整理工作。
我们需要检查数据是否存在缺失值或异常值,并进行处理。
接着,我们可以进行描述性统计分析。
通过SPSS,我们可以轻松地计算出数据的均值、标准差、最大值、最小值等统计指标,从而更好地了解我们的数据特征。
比如,我们可以计算出学习成绩和课堂参与度的平均值、标准差,以及两者之间的相关性。
然后,我们可以进行相关性分析。
通过SPSS的相关性分析功能,我们可以计算出学习成绩和课堂参与度之间的相关系数,从而判断它们之间是否存在显著的相关关系。
通过相关性分析,我们可以更好地理解两个变量之间的关系,为后续的研究提供参考。
最后,我们可以进行回归分析。
通过SPSS的回归分析功能,我们可以建立一个模型,来预测学习成绩和课堂参与度之间的关系。
我们可以通过回归系数和显著性检验来判断模型的拟合程度,并进行模型的诊断和改进。
通过以上的数据分析过程,我们可以得出结论,进一步探讨学习成绩和课堂参与度之间的关系。
这个案例不仅可以帮助大学生更好地理解SPSS软件的使用方法,还可以帮助他们在日常学习和研究中更好地运用数据分析方法。
希望本文能对大学生们有所帮助,引发更多关于数据分析的思考和讨论。
SPSS数据分析实例
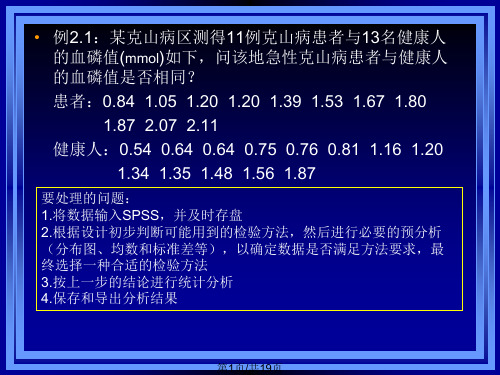
t检验的假设如下: H0:两总体均数相同,μ1 =μ2
Байду номын сангаас
H1:两总体不均数相同,μ1 ≠μ2
两样本t检验对数据的要求: 1.小样本时要求分布不太偏 2.小样本时要求方差齐
第18页/共19页
感谢您的欣赏
第19页/共19页
• 例2.1:某克山病区测得11例克山病患者与13名健康人 的血磷值(mmol)如下,问该地急性克山病患者与健康人 的血磷值是否相同? 患者:0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人:0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87
应该观察分组描述情况 选择菜单项 数据 拆分文件 ,系统弹出对话框
选择 比较组 ,将变量group选入分组方式框,点击确定
第11页/共19页
再做一次数据描述,输出结果
根据描述结果,可判断检验结果多半会拒绝H0。
取消文件拆分,不然会影响以后的统计分析
选择菜单项 数据 拆分文件 ,选择 分析所有个案,不创建组
∴应该先判断该数据是否符合t检验要求,即对数据进行简单描述
第8页/共19页
2.2.1 数据的简单描述
选择菜单项 分析
描述统计
描述
,
系统弹出对话框
选择描述变量
第9页/共19页
选择所需描述变量x,点击ok
系统弹出新界面
结果浏览窗口
导航栏
具体输出结果
SPSS概览--数据分析实例详解

SPSS概览--数据分析实例详解1.1数据的输入和保存1.1.1SPSS的界面1.1.2定义变量1.1.3输入数据1.1.4保存数据1.2数据的预分析1.2.1数据的简单描述1.2.2绘制直方图1.3按题目要求进行统计分析1.4保存和导出分析结果1.4.1保存文件1.4.2导出分析结果盼望了解SPSS10.0版具体情况的朋友请参见本网站的SPSS10.0版抢鲜报道。
例1.1某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下,问该地急性克山病患者与健康人的血磷值是否不同〔卫统第三版例4.8〕?患者:0.841.051.201.201.391.531.671.801.872.072.11健康人:0.540.640.640.750.760.811.161.201.341.351.481.561.87解题流程如下:1.将数据输入SPSS,并存盘以防断电。
2.进行必要的预分析〔分布图、均数标准差的描述等〕,以确定应采纳的检验方法。
3.按题目要求进行统计分析。
4.保存和导出分析结果。
下面就按这几步依次讲解。
§1.1数据的输入和保存1.1.1SPSS的界面当打开SPSS后,展现在我们面前的界面如下:请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。
请注意窗口顶部显示为“SPSSforWindowsDataEditor”,说明现在所看到的是SPSS的数据治理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
特别的,工具栏下方的是数据栏,数据栏下方那么是数据治理窗口的主界面。
该界面和EXCEL极为相似,由假设干行和列组成,每行对应了一条记录,每列那么对应了一个变量。
由于现在我们没有输入任何数据,因此行、列的标号基本上灰色的。
请注意第一行第一列的单元格边框为深色,说明该数据单元格为当前单元格。
有的SPSS系统打开时会出现一个导航对话框,请单击右下方的Cancer按钮,即可进入上面的主界面。
大学生spss数据分析案例

大学生spss数据分析案例大学生SPSS数据分析案例。
在大学教育中,数据分析是一个非常重要的环节,尤其是对于社会科学和商业管理专业的学生来说。
SPSS(Statistical Package for the Social Sciences)是一个专业的统计分析软件,广泛应用于学术研究和商业决策中。
本文将以一个大学生SPSS数据分析案例为例,介绍如何使用SPSS进行数据分析。
案例背景:某大学社会科学专业的学生对大学生活满意度进行了调查,并收集了相关数据,包括学生的性别、年级、专业、宿舍类型、课程质量、宿舍环境、社交活动等方面的信息。
现在需要对这些数据进行分析,以了解不同因素对大学生活满意度的影响。
数据准备:首先,需要将调查所得的数据录入SPSS软件中,确保数据的准确性和完整性。
在录入数据时,要注意将不同的变量分别录入不同的列中,以便后续的分析和处理。
数据分析:1. 描述统计分析。
首先,可以对各个变量进行描述统计分析,包括计算均值、标准差、频数分布等。
通过描述统计分析,可以直观地了解各个变量的分布情况,为后续的分析提供基础。
2. 相关性分析。
接下来,可以进行各个变量之间的相关性分析,通过相关系数的计算来了解不同变量之间的关联程度。
例如,可以分析学生的性别、年级、专业与大学生活满意度之间的相关性,以及宿舍类型、课程质量、社交活动等因素对大学生活满意度的影响程度。
3. 方差分析。
针对分类变量,可以进行方差分析,比较不同组别之间的均值差异是否显著。
例如,可以分析不同年级、不同专业的学生对大学生活满意度的差异情况,以及不同宿舍类型对大学生活满意度的影响是否显著。
4. 回归分析。
最后,可以利用回归分析来探讨不同因素对大学生活满意度的影响程度。
通过建立回归模型,可以了解各个自变量对因变量的影响情况,以及它们之间的关系强度和方向。
结论与建议:通过以上的数据分析,可以得出不同因素对大学生活满意度的影响程度,为学校和相关部门提供决策建议。
统计学课SPSS数据分析实战案例

统计学课SPSS数据分析实战案例SPSS(统计分析系统)是一款常用的统计软件,被广泛应用于社会科学、商业、医学等领域的数据分析工作中。
通过这个案例,我们将运用SPSS软件进行数据分析,以展示统计学课的实战应用。
案例背景假设你是一位市场研究员,你的公司正在调查消费者对某产品的满意度。
你已经收集了一份随机抽样的数据集,包含了消费者的满意度评分以及他们的一些个人信息。
你的任务是对这些数据进行分析,以了解消费者满意度与个人信息之间是否存在关联。
数据集说明数据集包括了500个消费者的信息,具体变量如下:1. 变量1:满意度评分(连续变量,取值范围从1到10);2. 变量2:性别(分类变量,取值为男性和女性);3. 变量3:年龄(连续变量);4. 变量4:收入水平(分类变量,取值为低、中、高三个层次);5. 变量5:购买次数(连续变量,表示过去一年内购买该产品的次数)。
数据分析步骤以下是对这份数据集进行分析的步骤:1. 数据清洗和准备首先,我们需要检查数据集中是否存在缺失值或异常值,并进行数据清洗。
在SPSS中,我们可以使用数据查看和数据清洗的功能来完成这一步骤。
确保数据集中的每一列都没有缺失值,并且所有的异常值已经得到恰当的处理。
2. 描述性统计分析接下来,我们可以使用SPSS的描述性统计分析功能,对数据集进行描述性统计分析。
我们可以计算满意度评分、年龄和购买次数的平均值、标准差、最小值、最大值,并生成频数分布表和柱状图。
3. 相关性分析为了确定满意度评分与其他个人信息变量之间的关联性,我们可以使用SPSS的相关性分析功能。
通过计算满意度评分与性别、年龄、收入水平和购买次数之间的相关系数,我们可以评估它们之间的相关性。
4. 单因素方差分析我们可以使用SPSS进行单因素方差分析,以了解不同收入水平的消费者在满意度评分上是否存在显著差异。
通过观察方差分析表和显著性水平,我们可以得出初步结论。
5. 多元线性回归分析最后,我们可以使用SPSS的多元线性回归分析功能来建立一个回归模型,以预测满意度评分。
spss案例分析

1、某班共有28个学生,其中女生14人,男生14人,下表为某次语文测验的成绩,请用描述统计方法分析女生成绩好,还是男生成绩好。
方法一:频率分析(1) 步骤:分析→描述统计→频率→女生成绩、男生成绩右移→统计量设置→图表(直方图)→确定 (2) 结果:统计量女生成绩男生成绩N有效 1515 缺失73 73 均值 69.9333 67.0000 中值 71.0000 72.0000 众数 76.00a48.00a标准差 8.91601 14.53567 方差 79.495 211.286 全距 30.00 46.00 极小值 54.00 43.00 极大值 84.00 89.00 和1049.001005.00a. 存在多个众数。
显示最小值(3)分析:由统计量表中的均值、标准差及直方图可知,女生成绩比男生成绩好。
方法二:描述统计(1)步骤:分析→描述统计→描述→女生成绩、男生成绩右移→选项设置→确定(2)结果:(3)分析:由描述统计量表中的均值、标准差、方差可知,女生成绩比男生成绩好。
2、某公司经理宣称他的雇员英语水平很高,现从雇员中随机随出11人参加考试,得分如下:80、81、72、60、78、65、56、79、77、87、76,请问该经理的宣称是否可信?(1)方法:单样本T检验H 0:u=u,该经理的宣称可信H 1:u≠u,该经理的宣称不可信(2)步骤:①输入数据:(80,81,…76)②分析→比较均值→单样本T检验→VAR00001右移→检验值(75)→确定(3)结果:单个样本统计量N 均值标准差均值的标准误VAR00001 11 73.73 9.551 2.880(4)分析:由单个样本检验表中数据知t=0.668>0.05,所以接受H,即该经理的宣称是可信的。
3、某医院分别用 A 、B 两种血红蛋白测定仪器检测了16名健康男青年的血红蛋白含量(g/L ),检测结果如下。
问:两种血红蛋白测定仪器的检测结果是否有差别?仪器A :113,125,126,130,150,145,135,105,128,135,100,130,110,115,120 ,155仪器B :140,150,138,120,140,145,135,115,135,130,120,133,147,125,114,165(1)方法:配对样本t 检验H 0:u 1=u 2,两种血红蛋白测定仪器的检测结果无差别 H 1:u 1≠u 2,两种血红蛋白测定仪器的检测结果有差别(2)步骤:①输入两列数据:A 列(113,125,…155);B 列(140,125,…165);②分析→比较均值→配对样本t 检验→仪器A 、仪器B 右移→确定(3)结果:成对样本统计量均值 N标准差 均值的标准误对 1仪器A 126.38 16 15.650 3.912 仪器B134.501613.7703.442(4)分析:由成对样本检验表的Sig 可见t =0.032小于0.05,所以拒绝H 0,即两种血红蛋白测定仪器的检测结果有差别。
spss案例分析报告精选文档

s p s s案例分析报告精选文档TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-S p s s分析身高与体重的相互影响一、案例介绍:这是某幼儿园学生的身高体重数据,数据中主要包括编号,学生姓名,性别,学生年龄,每个学生的体重以及身高数值。
主要是看下幼儿园学生体重与身高的相互关系。
二、研究案例的目的:分析幼儿园学生身高体重的相互关系和影响。
三、下面是数据来源:四、研究的方法:主要是使用spss中的描述统计分析和线性回归分析;在描述统计分析中主要是分析出身高体重的最大值和最小值、均值,在图表中可以看出身高的最大值;在线性回归分析中主要是采用身高为自变量,体重为因变量来进行分析的。
五、研究的结果:1)描述分析:打开文件“某班23名同学的身高、体重、年龄数据”,通过菜单兰中的分析选项,进行描述性分析,选择体重和身高,求最大值最小值和均值,得到如下结果:从结果看出,该班学生样本数为23,体重最小值为13.7kg,最大值为23kg,平均体重为17.7167kg。
身高最小值为105cm,最大值为116cm,平均身高为108.85cm。
以身高为例子,选择描述中的频率选项可以得出分布,在频率对话框的图形选项中,选择条形图,即可用图形直观看到结果。
从图形中可以很直观的看出不同身高段的人数分布情况,其中108cm左右的人数最多。
从表格中则可以清楚地看到具体数目。
2)线性回归分析:选择分析——回归——线性,在弹出的对话框中,以身高作为自变量,体重作为因变量,结果如下:从表中可以得出。
R=0.223,即两者具有弱相关性。
从图表中,可以看出它们之间的线性关系大概可以表示为y=-0.139x+2.617 六、研究结论:从描述分析和回归分析可以身高和体重的相关性是相对比较弱的,也就是弱相关性。
基于SPSS软件的临床数据分析实例

06
结果可视化与报告撰写
结果可视化技巧和方法
01
02
03
图表类型选择
根据数据类型和分析目的 选择合适的图表类型,如 柱状图、折线图、散点图 等。
色彩搭配
合理运用色彩,突出重要 信息,提高图表的可读性 和美观度。
标注与说明
在图表中添加必要的标注 和说明,帮助读者更好地 理解数据和分析结果。
应的干预措施。
生存分析及其在临床研究中的应用
生存分析概念
生存分析是一种用于研究事件发生时间及其 相关因素的统计方法,尤其适用于存在删失 数据的情况。在临床研究中,生存分析常用 于评估患者生存时间、疾病复发时间等。
在临床研究中的应用
生存分析可用于评估不同治疗方案对患者生 存时间的影响,以及识别影响患者生存时间 的危险因素。例如,在肿瘤临床试验中,可 以通过生存分析比较不同治疗组的患者生存 曲线,评估治疗方案的疗效。同时,还可以 结合多因素分析,探讨患者年龄、性别、病
数据来源及特点
01
医学实验数据
通常来源于临床试验、观察性研究或医学调查,具有样本量小、变量多
、数据结构复杂等特点。
02
电子病历数据
从医院信息系统中提取,包含患者基本信息、诊断、治疗、检查等多方
面的数据,具有数据量大、信息丰富、结构化和非结构化并存等特点。
03
生物信息学数据
如基因表达、蛋白质组学等高通量数据,具有数据维度高、噪声大、需
聚类分析及其在临床研究中的应用
聚类分析概念
聚类分析是一种无监督学习方法,用于将相 似的对象归为一类,使得同一类内的对象尽 可能相似,而不同类间的对象尽可能不同。
在临床研究中的应用
spss的数据分析案例

精心整理关于某公司474名职工综合状况的统计分析报告一、数据介绍:本次分析的数据为某公司474名职工状况统计表,其中共包含^一变量,分别是:id (职工编号),gender(性别),bdate(出生日期),edcu (受教育水平程度),jobcat (职务等级),salbegin (起始工资),salary (现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)<通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、I ■以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析■■ ] I ■.1、频数分析。
基本的统计分析往往从频数分析开始。
通过频数分析能够了解变量的取值状况,对把握数据的分布特征非常有用。
此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu (受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
精心整理上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。
/ 「’--了/其次对原有数据中的受教育程度进行频数分析,结果如下表:Educati on alLevel(years).4 .4 99.8 20 2上表及其直方图说I I明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占 总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。
且接受过高于20年的 教育的人数只有1人,比例很低。
2、描述统计分析。
再通过简单的频数统计分析了解了职工在性别和受教育水平• J ' P t ,- J上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识, 这就需要通过计算基本描述统计的方法来实现。
spss案例大数据分析报告
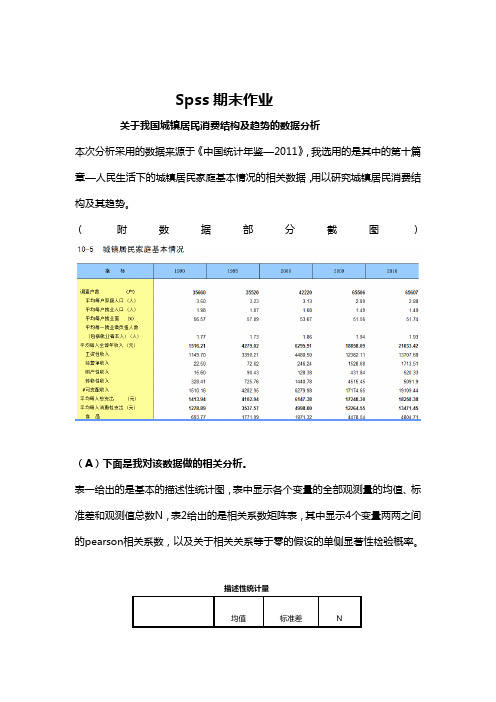
Spss期末作业关于我国城镇居民消费结构及趋势的数据分析本次分析采用的数据来源于《中国统计年鉴—2011》,我选用的是其中的第十篇章—人民生活下的城镇居民家庭基本情况的相关数据,用以研究城镇居民消费结构及其趋势。
(附数据部分截图)(A)下面是我对该数据做的相关分析。
表一给出的是基本的描述性统计图,表中显示各个变量的全部观测量的均值、标准差和观测值总数N,表2给出的是相关系数矩阵表,其中显示4个变量两两之间的pearson相关系数,以及关于相关关系等于零的假设的单侧显著性检验概率。
描述性统计量均值标准差N表1 描述性统计表相关性食品衣着居住家庭设备用品及服务食品Pearson 相关性 1 .998**.991**.995**显著性(单侧).000 .001 .000平方与叉积的和 1.300E7 4000739.197 4039135.855 2468266.142协方差3250108.892 1000184.799 1009783.964 617066.535N 5 5 5 5 衣着Pearson 相关性.998** 1 .985**.994**显著性(单侧).000 .001 .000平方与叉积的和4000739.197 1235103.975 1238672.922 760246.419协方差1000184.799 308775.994 309668.230 190061.605N 5 5 5 5 居住Pearson 相关性.991**.985** 1 .996**显著性(单侧).001 .001 .000平方与叉积的和4039135.855 1238672.922 1279080.565 775005.410协方差1009783.964 309668.230 319770.141 193751.352N 5 5 5 5 家庭设备用品及服务Pearson 相关性.995**.994**.996** 1 显著性(单侧).000 .000 .000平方与叉积的和2468266.142 760246.419 775005.410 473179.063协方差617066.535 190061.605 193751.352 118294.766N 5 5 5 5相关性食品衣着居住家庭设备用品及服务食品Pearson 相关性 1 .998**.991**.995**显著性(单侧).000 .001 .000平方与叉积的和 1.300E7 4000739.197 4039135.855 2468266.142协方差3250108.892 1000184.799 1009783.964 617066.535N 5 5 5 5 衣着Pearson 相关性.998** 1 .985**.994**显著性(单侧).000 .001 .000平方与叉积的和4000739.197 1235103.975 1238672.922 760246.419协方差1000184.799 308775.994 309668.230 190061.605N 5 5 5 5 居住Pearson 相关性.991**.985** 1 .996**显著性(单侧).001 .001 .000平方与叉积的和4039135.855 1238672.922 1279080.565 775005.410协方差1009783.964 309668.230 319770.141 193751.352N 5 5 5 5 家庭设备用品及服务Pearson 相关性.995**.994**.996** 1 显著性(单侧).000 .000 .000平方与叉积的和2468266.142 760246.419 775005.410 473179.063协方差617066.535 190061.605 193751.352 118294.766N 5 5 5 5 **. 在 .01 水平(单侧)上显著相关。
SPSS简明教程绝对受用

第一章SPSS概览--数据分析实例详解1.1 数据的输入和保存1.1.1 SPSS的界面1.1.2 定义变量1.1.3 输入数据1.1.4 保存数据1.2 数据的预分析1.2.1 数据的简单描述1.2.2 绘制直方图1.3 按题目要求进行统计分析1.4 保存和导出分析结果1.4.1 保存文件1.4.2 导出分析结果希望了解SPSS 10.0版具体情况的朋友请参见本的SPSS 10.0版抢鲜报道。
例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)?患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87解题流程如下:1.将数据输入SPSS,并存盘以防断电。
2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采用的检验方法。
3.按题目要求进行统计分析。
4.保存和导出分析结果。
下面就按这几步依次讲解。
§1.1 数据的输入和保存1.1.1 SPSS的界面当打开SPSS后,展现在我们面前的界面如下:请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。
请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
特别的,工具栏下方的是数据栏,数据栏下方则是数据管理窗口的主界面。
该界面和EXCEL极为相似,由若干行和列组成,每行对应了一条记录,每列则对应了一个变量。
由于现在我们没有输入任何数据,所以行、列的标号都是灰色的。
请注意第一行第一列的单元格边框为深色,表明该数据单元格为当前单元格。
spss案例大数据分析报告

spss案例大数据分析报告目录1. 内容概要 (2)1.1 案例背景 (2)1.2 研究目的和重要性 (4)1.3 报告结构 (5)2. 数据分析方法 (5)2.1 数据收集与处理 (7)2.2 分析工具介绍 (8)2.3 变量定义和描述性统计分析 (9)3. 数据集概述 (11)3.1 数据来源 (11)3.2 数据特征描述 (12)3.3 数据清洗与处理 (13)4. 数据分析结果 (15)4.1 描述性统计分析结果 (16)4.2 推断性统计分析结果 (18)4.3 回归分析结果 (19)4.4 多变量分析结果 (20)5. 案例分析 (21)5.1 问题识别 (22)5.2 数据揭示的趋势和模式 (23)5.3 具体案例分析 (24)5.3.1 案例一 (26)5.3.2 案例二 (28)5.3.3 案例三 (29)6. 结论和建议 (30)6.1 数据分析总结 (31)6.2 战略和操作建议 (33)6.3 研究的局限性 (33)1. 内容概要本次SPSS案例大数据分析报告旨在通过对某一特定领域的大规模数据集进行深入分析和挖掘,揭示数据背后的规律、趋势以及潜在价值。
报告首先介绍了研究背景和研究目的,阐述了在当前时代背景下大数据的重要性和价值。
概述了数据来源、数据规模以及数据预处理过程,包括数据清洗、数据整合和数据转换等步骤。
报告重点介绍了运用SPSS软件进行数据分析的方法和过程,包括数据描述性分析、相关性分析、回归分析、聚类分析等多种统计分析方法的运用。
通过一系列严谨的统计分析,报告揭示了数据中的模式、关联以及预测趋势。
报告总结了分析结果,并指出了分析结果对于决策制定、业务发展以及学术研究等方面的重要性和意义。
报告内容全面深入,具有针对性和实用性,为企业决策者、研究人员和学者提供了重要参考依据。
1.1 案例背景本报告旨在通过对大数据技术的应用,为特定行业中的决策者提供深入的分析见解。
在当前数据驱动的时代,企业可以参考这一解析来优化其战略方向、业务流程及终极客户体验。
SPSS相关分析案例讲解

SPSS相关分析案例讲解在数据分析领域中,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件。
它提供了丰富的数据处理和统计分析功能,可以帮助研究人员和数据分析师有效地处理和分析数据。
本文将通过一个案例来讲解SPSS中的相关分析方法及其应用。
案例背景:某电子商务公司想要了解他们网站上不同产品类别的销售情况与顾客满意度之间的关系。
为了达到这个目标,他们进行了一项调查,收集了一份包含产品类别、销售额和顾客满意度的数据集。
数据集的字段说明:- 产品类别(Product Category):包括电子产品、家居用品和服装三个类别。
- 销售额(Sales):表示每个产品类别的销售额,以美元为单位。
- 顾客满意度(Customer Satisfaction):以1到5的评分表示顾客对产品类别的满意程度,其中1表示非常不满意,5表示非常满意。
问题陈述:基于以上数据集,我们的目标是分析不同产品类别的销售额与顾客满意度之间的相关关系。
解决方案:为了解决这个问题,我们将使用SPSS中的相关分析方法来计算销售额和顾客满意度之间的相关系数,并进行统计显著性检验。
以下是具体步骤:步骤1:导入数据首先,我们需要将数据导入SPSS软件。
打开SPSS软件,选择"File"菜单中的"Open"选项,并选择包含数据的文件。
确保数据文件的格式是兼容的,并正确地导入数据。
步骤2:描述性统计分析在进行相关分析之前,我们可以先对数据进行描述性统计分析,以了解数据的基本情况。
选择"Analyze"菜单中的"Descriptive Statistics"选项,然后选择"Explore"选项。
将"Sales"和"Customer Satisfaction"字段拖动到"Dependent List"和"Independent List"框中,然后点击"OK"按钮。
spss-数据分析实例详解图文

优化策略
根据数据分析结果调整销售策略 ,如定价、促销方式等。
预测模型
利用时间序列分析、神经网络等 模型预测未来销售趋势。
相关性分析
探究销售量与价格、促销活动等 因素的关系。
实例三:人力资源数据分析
总结词
通过SPSS进行人力资源数据分析,可以优化人员 配置和提高员工满意度。
数据收集
收集员工信息,包括年龄、性别、学历、绩效等。
01
描述性统计分析是对数据进行初步处理和分析的过程,包括计 算数据的均值、中位数、众数、标准差等统计指标。
02
在SPSS中,可以通过选择“分析”菜单中的“描述统计”选项
来进行描述性统计分析。
描述性统计分析可以帮助我们了解数据的分布情况、异常值和
03
数据的中心趋势等。
数据可视化
数据可视化是将数据以图形或图表的形式呈现的过程,可以帮助我们更好地理解数 据和发现数据中的规律和趋势。
大数据处理
云端化服务
为了更好地满足用户的灵活性和可扩 展性需求,SPSS可能会推出基于云端 的服务模式,提供更加便捷和高效的 数据分析服务。
随着大数据时代的来临,SPSS可能会 加强在大数据处理和分析方面的能力, 以应对大规模数据集的处理需求。
THANKS FOR WATCHING
感谢您的观看
探索性统计
进行因子分析、主成分分析等,深入挖掘数据背后的结构。
可视化问题
图表选择
根据分析目的选择合适的图表类型,如柱状 图、折线图、饼图等。
图表组合
将多个图表组合在一起,形成综合性的可视 化报告。
图表定制
调整图表样式、颜色、字体等,提高图表的 可读性和美观度。
动态可视化
SPSS分析实例
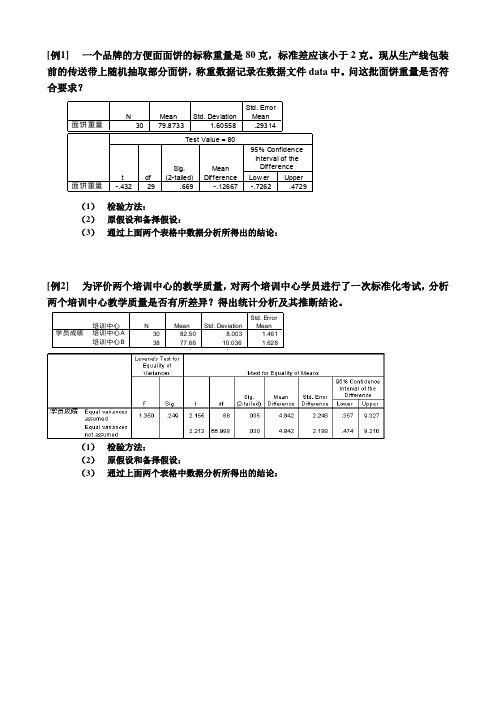
[例1]一个品牌的方便面面饼的标称重量是80克,标准差应该小于2克。
现从生产线包装前的传送带上随机抽取部分面饼,称重数据记录在数据文件data中。
问这批面饼重量是否符(1)检验方法:(2)原假设和备择假设:(3)通过上面两个表格中数据分析所得出的结论:[例2]为评价两个培训中心的教学质量,对两个培训中心学员进行了一次标准化考试,分析(1)检验方法:(2)原假设和备择假设:(3)通过上面两个表格中数据分析所得出的结论:[例3]某康体中心的减肥班学员入班时的体重数据和减肥训练一个月后的体重数据记录在数据文件data中,试分析一个月的训练是否有效。
(1)检验方法:(2)原假设和备择假设:(3)通过上面两个表格中数据分析所得出的结论:(4)可以绘制_________图,直观显示前后体重的变化趋势。
[例4]为了解非计算机专业对计算机课程教学的意见,在金融系和统计系本科生中进行了一次抽样调查,得到了390名学生的调查数据。
试据此推断两系本科生对计算机课程教学的意见是否一致。
(1)检验方法:(2)原假设和备择假设:(3)通过上面两个表格中数据分析所得出的结论:(4)可以通过_________图直观地比较不同系别的满意度。
[例5]为了试验某种减肥药物的性能,测量11个人在服用该药以前以及服用该药1个月后、2个月后、3个月后的体重。
那么请问在这4个时期,11个人的体重有无发生显著的变化?(1)通过上面输出结果表格,可判断使用的检验方法:(2)原假设和备择假设:(3)结论:[例6]数据文件“Employee data.sav”记录了474名职工的基本信息(1)绘制复式条形图来表示不同性别的雇佣类别情况;(2)对起始薪金绘制茎叶图,说明图中信息;(3)通过箱图描绘不同雇佣类别的职工当前薪金情况,得出结论;(4)分析起始薪金的确定与什么因素有关,说明下面两表分别用的分析方法,并比较两表的结果。
控制变量起始薪金教育水平(年)雇佣类别 & 经验(以月计)起始薪金相关性 1.000 .461显著性(双侧). .000df 0 470 教育水平(年)相关性.461 1.000显著性(双侧).000 .df 470 0[例7]考察数码相机成像元器件像素数是否会对产品销量产生显著影响(设显著性水平α=0.05)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章SPSS概览--数据分析实例详解1.1 数据的输入和保存1.1.1 SPSS的界面1.1.2 定义变量1.1.3 输入数据1.1.4 保存数据1.2 数据的预分析1.2.1 数据的简单描述1.2.2 绘制直方图1.3 按题目要求进行统计分析1.4 保存和导出分析结果1.4.1 保存文件1.4.2 导出分析结果希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。
例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)?患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87解题流程如下:1.将数据输入SPSS,并存盘以防断电。
2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采用的检验方法。
3.按题目要求进行统计分析。
4.保存和导出分析结果。
下面就按这几步依次讲解。
§1.1 数据的输入和保存1.1.1 SPSS的界面当打开SPSS后,展现在我们面前的界面如下:请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。
请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
特别的,工具栏下方的是数据栏,数据栏下方则是数据管理窗口的主界面。
该界面和EXCEL极为相似,由若干行和列组成,每行对应了一条记录,每列则对应了一个变量。
由于现在我们没有输入任何数据,所以行、列的标号都是灰色的。
请注意第一行第一列的单元格边框为深色,表明该数据单元格为当前单元格。
有的SPSS系统打开时会出现一个导航对话框,请单击右下方的Cancer 按钮,即可进入上面的主界面。
1.1.2 定义变量该资料是定量资料,设计为成组设计,因此我们需要建立两个变量,一个变量代表血磷值,习惯上取名为X,另一个变量代表观察对象是健康人还是克山病人,习惯上取名为GROUP。
对数据的统计分析格式不太熟悉的朋友请先学习统计软件第一课。
选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:该变量定义对话框在SPSS 10.0版中已被取消,这里的操作只适合9.0~7.0版的用户。
对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
好,先来建立分组变量GROUP。
请将变量名改为GROUP,然后单击OK 按钮。
有没有搞错?!折腾了半天就改个名字!难道连变量格式、标签等都不改?是这样的,在SPSS中所有的数据均以最大位数保存(好象是双精度),也就是说,上面虽然默认只有两位小数,但那指的是计算精度,实际保存的数据位数是非常长的(可以输入Pi值试一下)。
在绝大多数情况下,SPSS给出的默认数据类型和数据精度完全可以满足需要,只是不太好看而已。
至于标签等比较花哨的选项,反正我也很少用。
现在我们才刚刚入门,一切从简。
以后我会详细介绍各种设置的用法。
在第一列灰色的“var”上双击,同样会弹出定义变量对话框。
现在SPSS的数据管理窗口如下所示:第一列的名称已经改为了“group”,这就是我们所定义的新变量“group”。
现在我们来建立变量X。
单击第一行第二列的单元格,然后选择菜单Data==>Define Variable,同样,将变量名改为X,然后确认。
此时SPSS的数据管理窗口如下所示:现在,第一、第二列的名称均为深色显示,表明这两列已经被定义为变量,其余各列的名称仍为灰色的“var”,表示尚未使用。
同样地,各行的标号也为灰色,表明现在还未输入过数据,即该数据集内没有记录。
1.1.3 输入数据我们先来输入变量X的值,请确认一行二列单元格为当前单元格,弃鼠标而用键盘,输入第一个数据0.84,此时界面显示如图A所示:图A 图B请注意:在回车之前,你输入的数据在数据栏内显示,而不是在单元格内显示,现在回车,界面如图B所示:首先,当前单元格下移,变成了二行二列单元格,而一行二列单元格的内容则被替换成了0.84;其次,第一行的标号变黑,表明该行已输入了数据;第三,一行一列单元格因为没有输入过数据,显示为“.”,这代表该数据为缺失值。
用类似的输入方式,我们将患者的血磷值输入完毕,并将相应的变量GROUP均取值为1,此时数据管理窗口如下所示:从第12行开始输入健康人的数据,并将相应的GROUP变量取值为2。
最终该数据集应该有24条记录。
1.1.4 保存数据选择菜单File==>Save,由于该数据从来没有被保存过,所以弹出Save as 对话框如下:单击保存类型列表框,可以看到SPSS所支持的各种数据类型,有DBF、FoxPro、EXCEL、ACCESS等,这里我们仍然将其存为SPSS自己的数据格式(*.sav文件)。
在文件名框内键入Li1_1并回车,可以看到数据管理窗口左上角由Untitled变为了现在的变量名Li1_1。
为什么这里的对话框会出现汉字?是这样的,需要从编程的角度来解释:SPSS在弹出该对话框时会调用Windows系统的公用函数,由于我们用的是中文Windows系统,所以调用出来的就是中文。
§1.2 数据的预分析1.2.1 数据的简单描述首先我们需要知道数据的基本情况,如均数、标准差等。
选择Analyze==>Descriptive Statistics==>Descriptives菜单,系统弹出描述对话框如下:如果按SPSS标准的叫法,这里应该是调用了Descriptives过程,为了避免太生硬,我们称为调用对话框,等大家熟悉SPSS了以后,在统计分析各章中可能两种称呼会混用。
该对话框可分为左右两大部分,左侧为所有可用的侯选变量列表,右侧为选入变量列表。
我们只需要描述X,用鼠标选中X,单击中间的,变量X的标签就会移入右侧,注意这时OK按钮变黑,表明已经可以进行分析了,单击它,系统会弹出一个新的界面如下所示:该窗口上方的名称为SPSS for Windows Viewer,即(结果)浏览窗口,整个的结构和资源管理器类似,左侧为导航栏,右侧为具体的输出结果。
结果表格给出了样本数、最小值、最大值、均数和标准差这几个常用的统计量。
从中可以看到,24个数据总的均数为1.2846,标准差为0.4687。
我们以上的做法对吗?当然有问题!光看总的描述是不够的,还应当看看分组的描述情况。
这里要用到文件分割功能,请切换回数据管理窗口,选择Data==>Split File菜单,系统弹出文件分割对话框如下:选择单选按钮Organize output by groups,将变量GROUP选入右侧的选入变量框,单击OK钮,此时界面不会有任何改变,但请再做一次数据描述,你就可以看到现在数据是分Group=1和Group=2两种情况在描述了!从描述可知两组的均数和标准差分别为1.5209、1.0846和0.4218、0.4221。
如果定义了文件分割,则它会在以后的所有统计分析中起作用,直到你重新定义文件分割方式为止。
1.2.2 绘制直方图统计指标只能给出数据的大致情况,没有直方图那样直观,我们就来画个直方图瞧瞧!选择Graphs==>Histogram,系统会弹出绘制直方图对话框如下:将变量X选入Variable选择框内,单击OK按钮。
此时结果浏览窗口内会绘制出如下两个直方图:两组的数据没有特别偏的分布,也没有十分突出的离群值,因此无须变换,可以直接采用参数分析方法来分析。
综合设计类型,最终确定采用成组设计两样本均数比较的t检验来分析。
最后,我们还要取消变量分割,免得它影响以后的统计分析,再次调出变量分割对话框,选择单选按钮中的“Analyze all cases, do not creat group”,单击OK按钮就可以了。
§1.3 按题目要求进行统计分析下面我们要用SPSS来做成组设计两样本均数比较的t检验,选择Analyze==>Compare Means==>Independent-Samples T test,系统弹出两样本t检验对话框如下:group选入grouping框内,注意这时下面的Define Groups按钮变黑,表示该按钮可用,单击它,系统弹出比较组定义对话框如右图所示:该对话框用于定义是哪两组相比,在两个group框内分别输入1和2,表明是变量group取值为1和2的两组相比。
然后单击Continue按钮,再单击OK按钮,系统经过计算后会弹出结果浏览窗口,首先给出的是两组的基本情况描述,如样本量、均数等(糟糕,刚才的半天工夫白费了),然后是t检验的结果如下:可见该结果分为两大部分:第一部分为Levene's方差齐性检验,用于判断两总体方差是否齐,这里的戒严结果为F = 0.032,p = 0.860,可见在本例中方差是齐的;第二部分则分别给出两组所在总体方差齐和方差不齐时的t检验结果,由于前面的方差齐性检验结果为方差齐,第二部分就应选用方差齐时的t检验结果,即上面一行列出的t= 2.524,ν=22,p=0.019。
从而最终的统计结论为按α=0.05水准,拒绝H0,认为克山病患者与健康人的血磷值不同,从样本均数来看,可认为克山病患者的血磷值较高。
§1.4 保存和导出分析结果1.4.1 保存结果文件前面我们已经做出了分析结果,但是,可是,可但是,但可是呢?再好的结果只要一断电就会全部消失(废话),对于这一问题人们早已想出了三种解决办法,他们分别是:∙需要结果的时候再运行一次分析程序。
∙用笔将结果抄在纸上。
∙直接保存结果文件。
显然,最方便快捷、最符合信息时代特征的就是第三种方法,在结果浏览窗口中(注意:一定要在结果浏览窗口中)选择菜单File==>Save,由于该结果也从来没有被保存过,所以弹出和前面保存数据时极为相似的一个Save as对话框,和前面相比,他唯一的区别就是文件的保存类型只有View Files(*.spo)一种。