介绍一下Python中webbrowser的用法
python 爬虫的原理

python 爬虫的原理Python web crawler (Python爬虫) is a powerful tool used to extract and store information from websites. It operates by sending HTTP requests to web pages, retrieving the HTML content, and parsing and extracting the desired data. Python爬虫是一种强大的工具,用于从网站提取和存储信息。
它通过向网页发送HTTP请求,检索HTML内容,并解析和提取所需数据来运行。
One of the key principles behind Python web crawlers is web scraping. Web scraping involves extracting information from websites, typically using programs to simulate human web browsing and retrieving information from web pages. Python web crawlers are commonly used for web scraping tasks, such as extracting product information from e-commerce sites or gathering data for research and analysis. Python爬虫背后的一个关键原则是网络爬取。
网络爬取涉及从网站提取信息,通常使用程序模拟人类浏览网络,并从网页中检索信息。
Python爬虫通常用于网络抓取任务,例如从电子商务网站提取产品信息或收集研究和分析数据。
python中browser用法

在Python中,"browser"通常是指一个用于在Web浏览器中打开URL或查看HTML页面的库或工具。
然而,Python并没有内置的"browser"模块或函数。
以下是一些在Python中使用浏览器的方法:1. 使用webbrowser模块:```pythonimport webbrowser# 打开指定的URLwebbrowser.open('需要访问的网址')```2. 使用第三方库如selenium:首先需要安装selenium库,可以使用pip进行安装:```shellpip install selenium```然后可以使用以下代码打开浏览器并导航到指定的URL:```pythonfrom selenium import webdriver# 创建一个Chrome浏览器实例driver = webdriver.Chrome()# 打开指定的URLdriver.get('需要访问的网址')# 在浏览器中关闭driver.quit()```注意:使用selenium需要安装相应的浏览器驱动程序,例如ChromeDriver。
3. 使用第三方库如pyppeteer:首先需要安装pyppeteer库,可以使用pip进行安装:```shellpip install pyppeteer```然后可以使用以下代码打开浏览器并导航到指定的URL:```pythonimport asynciofrom pyppeteer import launchasync def main():# 创建一个Chrome浏览器实例browser = await launch()page = await browser.newPage()await page.goto('需要访问的网址')await browser.close()asyncio.get_event_loop().run_until_complete(main())```注意:使用pyppeteer也需要安装相应的浏览器驱动程序,例如ChromeDriver。
micropython webrepl用法

micropython webrepl用法MicroPython是一种小巧而强大的Python 3解释器,专为嵌入式设备和微控制器设计。
在许多物联网项目中,MicroPython成为了开发者的首选,其中的一个原因是它提供了一种名为WebREPL的功能,使得用户能够通过Web界面访问和控制MicroPython设备。
本文将介绍MicroPython WebREPL的用法。
1. 准备工作在使用WebREPL之前,需要先确保以下准备工作已完成:- 您的MicroPython设备已正确连接到计算机,并且通过串口进行通信。
- 您已经安装了最新版本的MicroPython固件,该固件支持WebREPL功能。
- 您的计算机和设备在同一个局域网中,并且可以相互通信。
2. 启用WebREPL要启用MicroPython的WebREPL功能,您需要按照以下步骤操作:- 将MicroPython设备连接到计算机,并打开设备的串口终端。
- 在终端中输入`import webrepl_setup`命令,并按照提示完成WebREPL的配置。
- 配置完成后,您将被要求设置WebREPL的密码。
请确保密码足够强大,以保护设备的安全性。
3. 连接到设备一旦WebREPL功能已启用并配置完毕,您可以通过以下步骤连接到MicroPython设备:- 打开一个支持JavaScript的Web浏览器,并访问WebREPL的网页界面。
- 在网页界面的“Host”字段中输入MicroPython设备的IP地址,并在“Password”字段中输入您之前设置的WebREPL密码。
- 点击“Connect”按钮,如果一切正常,您将成功连接到MicroPython 设备。
4. 使用WebREPL连接成功后,您可以使用WebREPL执行以下操作:- 在WebREPL的终端中,您可以像在MicroPython设备的串口终端中一样输入命令,并执行它们。
例如,您可以使用`import`命令导入模块,执行自定义的脚本等。
webbrowser.register参数

webbrowser.register参数webbrowser 是 Python 的标准库之一,用于在默认的浏览器中打开 URL 或文件。
其中的 register 方法用于注册一个应用程序的名称,以便可以通过该名称打开 URL 或文件。
webbrowser.register(name, handler, force=False) 的参数解释如下:name: 应用程序的名称。
例如,你可以使用 "firefox"、"chrome"、"ie" 等作为名称,但这些名称并不是所有系统都支持。
更常见的做法是使用 "open",这样在大多数系统上都可以工作。
handler: 一个函数,用于处理 URL 或文件。
这个函数应该接受一个 URL 或文件路径作为参数,并返回一个响应代码。
force: 布尔值,默认为 False。
如果为 True,则即使已经有一个名为 name 的浏览器关联,也会强制重新注册。
一个简单的例子:pythonimport webbrowserdef my_browser(url):print("Opening URL in default browser...")webbrowser.open(url)# 注册浏览器webbrowser.register('mybrowser', my_browser)# 使用新注册的浏览器打开 URLwebbrowser.open('https:wangzhi ', 'mybrowser')在上面的例子中,我们定义了一个简单的 my_browser 函数,然后使用 webbrowser.register 将其注册为一个新的浏览器名称"mybrowser"。
之后,我们使用 webbrowser.open 并指定"mybrowser" 来打开一个 URL。
webbrowser 用法

一、webbrowser 的定义与作用webbrowser,即网页浏览器,是一种用于访问互联全球信息站网页的软件工具。
通过webbrowser,用户可以输入网页位置区域并访问网页内容,浏览器还可以展示各种网页元素,如文字、图片、视瓶和动画等。
由于其重要作用,webbrowser在现代社会中被广泛使用,成为人们日常生活中不可或缺的工具之一。
二、webbrowser 的基本使用方法在使用webbrowser时,我们通常需要了解一些基本的使用方法,以便更加高效地浏览网页内容。
1. 打开 webbrowser要打开webbrowser,只需在计算机桌面或程序菜单中找到已安装的浏览器图标,并双击打开即可。
常见的webbrowser包括Google Chrome、Mozilla Firefox、Microsoft Edge和Safari等。
用户可以根据自己的喜好和需求选择合适的浏览器。
2. 输入全球信息站在webbrowser的位置区域栏中输入网页的URL位置区域,即可打开相应的网页。
用户也可以利用webbrowser提供的搜索引擎功能,在搜索框中输入关键词进行网页搜索。
3. 浏览网页内容一旦打开了网页,用户可以通过滚动页面、点击信息或者进行搜索等操作来浏览网页内容。
webbrowser还提供了书签功能,用户可以将常用的网页添加到书签栏中,以便快速访问。
4. 下载和管理文件webbrowser允许用户在网页上下载各种文件,如文档、图片、音频和视瓶等。
用户可以在下载管理器中查看和管理已下载的文件。
5. 多标签浏览现代webbrowser支持多标签浏览功能,用户可以在同一个浏览器窗口中打开多个标签页,方便在不同页面之间进行切换和比较。
6. 清除浏览数据webbrowser还提供清除浏览数据的功能,用户可以清除浏览历史、缓存文件和 Cookie 等数据,以保护个人隐私并提升浏览速度。
三、webbrowser 的高级功能与技巧除了基本的浏览网页功能外,webbrowser还具有一些高级功能和技巧,可以帮助用户更好地利用浏览器。
python的webbrowser模块支持对浏览器进行一些操作

python的webbrowser模块支持对浏览器进行一些操作python的webbrowser模块支持对浏览器进行一些操作主要有以下三个方法:webbrowser.open(url, new=0, autoraise=True)webbrowser.open_new(url)webbrowser.open_new_tab(url)在webbrowser.py文件中,我们可以看到源码:############################################# ###########def open(url, new=0, autoraise=True):for name in _tryorder:browser = get(name)if browser.open(url, new, autoraise):return Truereturn Falsedef open_new(url):return open(url, 1)def open_new_tab(url):return open(url, 2)############################################# ########### 可以看出后面两个方法,都是建立在第一个方法open()方法上面的。
所以我们需要了解webbrowser.open()方法:webbrowser.open(url, new=0, autoraise=True)在系统的默认浏览器中访问url地址,如果new=0,url会在同一个浏览器窗口中打开;如果new=1,新的浏览器窗口会被打开;new=2新的浏览器tab会被打开。
而webbrowser.get()方法可以获取到系统浏览器的操作对象。
webbrowser.register()方法可以注册浏览器类型,而允许被注册的类型名称如下:Type Name Class Name Notes'mozilla' Mozilla('mozilla')'firefox' Mozilla('mozilla')'netscape' Mozilla('netscape')'galeon' Galeon('galeon')'epiphany' Galeon('epiphany')'skipstone' BackgroundBrowser('skipstone')'kfmclient' Konqueror() (1)'konqueror' Konqueror() (1)'kfm' Konqueror() (1)'mosaic' BackgroundBrowser('mosaic')'opera' Opera()'grail' Grail()'links' GenericBrowser('links')'elinks' Elinks('elinks')'lynx' GenericBrowser('lynx')'w3m' GenericBrowser('w3m')'windows-default' WindowsDefault (2)'macosx' MacOSX('default') (3)'safari' MacOSX('safari') (3)'google-chrome' Chrome('google-chrome')'chrome' Chrome('chrome')'chromium' Chromium('chromium')'chromium-browser' Chromium('chromium-browser')Notes:1. “Konqueror” is the file manager for the KDE desktop environment for Unix, and only makes sense to use if KDE isrunning. Some way of reliably detecting KDE would be nice; the KDEDIR variable is not sufficient. Note also that the name “kfm” is used even when using the konqueror command with KDE 2 —the implementation selects the best strategy for running Konqueror.2. Only on Windows platforms.3. Only on Mac OS X platform。
python webbrowser 原理

Python是一种高级编程语言,可以用于开发各种类型的应用程序,包括Web应用程序。
Python中的webbrowser模块提供了一个简单的接口来打开URL和网页,本文将详细介绍python webbrowser模块的原理和使用方法。
一、webbrowser模块介绍webbrowser模块是Python标准库中的一部分,它提供了一种简单的方式来在默认的Web浏览器中打开URL、网页和文件。
这个模块不需要额外安装,因此非常适合用于编写可移植的Python程序。
webbrowser模块可以在Windows、Mac OS和Linux等操作系统上正常工作。
二、webbrowser模块原理webbrowser模块的原理非常简单,它利用操作系统的默认方法来打开URL和网页。
在Windows系统中,webbrowser模块使用os.startfile()函数来打开默认的Web浏览器。
在Mac OS系统中,webbrowser模块使用subprocess.Popen()函数来执行open命令。
在Linux系统中,webbrowser模块使用xdg-open命令来打开默认的Web浏览器。
webbrowser模块的可移植性非常好。
三、webbrowser模块的基本用法使用webbrowser模块非常简单,只需要导入模块并调用open()函数即可。
下面是webbrowser模块的基本用法示例:import webbrowserwebbrowser.open('这个示例会在默认的Web浏览器中打开Python官方全球信息湾。
如果要在新的浏览器窗口中打开网页,可以使用open_new()函数。
如果要在新的浏览器标签页中打开网页,可以使用open_new_tab()函数。
四、webbrowser模块的高级用法除了打开URL和网页之外,webbrowser模块还提供了一些高级的功能。
可以使用get()函数来获取默认的Web浏览器名称、命令和控制选项。
使用Python实现简单的浏览器

使用Python实现简单的浏览器随着互联网的普及,浏览器成为人们日常生活中不可或缺的工具。
而Python作为一种功能强大且易于学习的编程语言,也可以用来实现简单的浏览器。
本文将介绍如何使用Python来实现一个简单的浏览器,让我们一起来探索吧!1. 准备工作在开始之前,我们需要确保已经安装了Python解释器。
同时,我们还需要安装一个名为tkinter的Python标准库,它提供了创建图形用户界面的功能。
如果你使用的是Python 3.x版本,tkinter库应该已经自带了,无需额外安装。
2. 创建一个简单的浏览器窗口首先,我们导入tkinter库,并创建一个窗口作为我们浏览器的界面:示例代码star:编程语言:pythonimport tkinter as tkimport webbrowserdef open_url():url = entry.get()webbrowser.open_new(url)root = ()root.title("Simple Browser")label = bel(root, text="Enter URL:")label.pack()entry = tk.Entry(root, width=50)entry.pack()button = tk.Button(root, text="Go", command=open_url)button.pack()root.mainloop()示例代码end在上面的代码中,我们创建了一个简单的GUI窗口,包括一个标签用于显示”Enter URL:“的提示信息,一个文本框用于输入URL,以及一个按钮用于打开输入的URL链接。
3. 实现基本功能接下来,我们需要实现浏览器的基本功能,包括前进、后退、刷新等操作。
我们可以通过在窗口中添加按钮,并绑定相应的事件来实现这些功能:示例代码star:编程语言:pythondef go_back():webbrowser.open_new("对应网址")def go_forward():webbrowser.open_new("对应网址")def refresh():entry.delete(0, tk.END)back_button = tk.Button(root, text="Back", command=go_back)back_button.pack(side=tk.LEFT)forward_button = tk.Button(root, text="Forward", command=go_forward)forward_button.pack(side=tk.LEFT)refresh_button = tk.Button(root, text="Refresh", command=refresh)refresh_button.pack(side=tk.LEFT)示例代码end在上面的代码中,我们分别定义了go_back()、go_forward()和refresh()函数,并将它们分别绑定到”Back”、“Forward”和”Refresh”按钮上。
Python怎么调用系统命令

Python怎么调用系统命令Python经常被称作“胶水语言”,因为它能够轻易地操作其他程序,轻易地包装使用其他语言编写的库。
在Python/wxPython环境下,执行外部命令或者说在Python程序中启动另一个程序的方法,下面就让店铺教大家Python怎么调用系统命令。
Python调用系统命令的方法1、os.system(command)os.system()函数用来运行shell命令。
此命令可以方便的调用或执行其他脚本和命令#打开指定的文件 >>>os.system('notepad *.txt')这个调用相当直接,且是同步进行的,程序需要阻塞并等待返回。
返回值是依赖于系统的,直接返回系统的调用返回值,所以windows 和Linux是不一样的。
2、wx.Execute(command, syn=wx.EXEC_ASYNC, callback=None)若置syn为wx.EXEC_ASYNC则wx.Excute函数立即返回,若syn=wx.EXEC_SYNC则等待调用的程序结束后再返回。
callback是一个wx.Process变量,如果callback不为None且syn=wx.EXEC_ASYNC,则程序结束后将调用wx.Process.OnTerminate()函数。
os.system()和wx.Execute()都利用系统的shell,执行时会出现shell窗口。
如在Windows下会弹出控制台窗口,不美观。
下面的两种方法则没有这个缺点。
3、import subprocesssubprocess.Popen(args, bufsize=0, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=False, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0) subprocess.call(["cmd", "arg1", "arg2"],shell=True)Note:1. 参数args可以是字符串或者序列类型(如:list,元组),用于指定进程的可执行文件及其参数。
python实现随机调用一个浏览器打开网页

python实现随机调⽤⼀个浏览器打开⽹页前两天总结了⼀下但那仅仅是总结⼀下⽽已,今天本⽂来实战演练⼀下依然使⽤的是 webbrowser 这个模块来调⽤浏览器关于的三种打开⽅式在上⼀篇⽂章中已经说过了,这⾥不再赘述如果没有特意注册,那么将会是使⽤默认的浏览器来打开⽹页,如下:#默认浏览器#coding:utf-8import webbrowser as web #对导⼊的库进⾏重命名def run_to_use_default_browser_open_url(url):web.open_new_tab(url)print 'run_to_use_default_browser_open_url open url ending ....'真正的注册⼀个⾮默认浏览器:这⾥先⽤的firfox浏览器#firefox浏览器def use_firefox_open_url(url):browser_path=r'C:\Program Files (x86)\Mozilla Firefox\firefox.exe'#这⾥的‘firefox'只是⼀个浏览器的代号,可以命名为⾃⼰认识的名字,只要浏览器路径正确web.register('firefox', web.Mozilla('mozilla'), web.BackgroundBrowser(browser_path))#web.get('firefox').open(url,new=1,autoraise=True)web.get('firefox').open_new_tab(url)print 'use_firefox_open_url open url ending ....'解释⼀下这个注册函数当前的⽤法web.register() 它的三个参数第⼀个为⾃⼰给浏览器重新命的名字,主要⽬的是为了在之后的调⽤中,使⽤者能够找到它第⼆个参数,可以按照这样上⾯的例⼦这样写,因为python本⾝将⼀些浏览器实例化了,但是还是推荐将其赋值为 None ,因为这个参数没有更好,毕竟有些浏览器python本⾝并没有实例化,⽽这个参数也不影响它的使⽤第三个参数,⽬前所知是浏览器的路径,不知道有没有别的写法当然,这⾥只是在这⾥的⽤法,函数本⾝的意思可以去源⽂件中查看下⾯给我⼀些测试的实例:#coding:utf-8import webbrowser as web #对导⼊的库进⾏重命名import osimport time#默认浏览器def run_to_use_default_browser_open_url(url):web.open_new_tab(url)print 'run_to_use_default_browser_open_url open url ending ....'#firefox浏览器def use_firefox_open_url(url):browser_path=r'C:\Program Files (x86)\Mozilla Firefox\firefox.exe'#这⾥的‘firefox'只是⼀个浏览器的代号,可以命名为⾃⼰认识的名字,只要浏览器路径正确web.register('firefox', web.Mozilla('mozilla'), web.BackgroundBrowser(browser_path))#web.get('firefox').open(url,new=1,autoraise=True)web.get('firefox').open_new_tab(url)print 'use_firefox_open_url open url ending ....'#⾕歌浏览器def use_chrome_open_url(url):browser_path=r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'web.register('chrome', None,web.BackgroundBrowser(browser_path))web.get('chrome').open_new_tab(url)print 'use_chrome_open_url open url ending ....'#Opera浏览器def use_opera_open_url(url):browser_path=r'C:\Program Files (x86)\Opera\launcher.exe'web.register('opera', None,web.BackgroundBrowser(browser_path))web.get('chrome').open_new_tab(url)print 'use_opera_open_url open url ending ....'#千影浏览器def use_qianying_open_url(url):browser_path=r'C:\Users\Administrator\AppData\Roaming\qianying\qianying.exe'web.register('qianying', None,web.BackgroundBrowser(browser_path))web.get('qianying').open_new_tab(url)print 'use_qianying_open_url open url ending ....'#115浏览器def use_115_open_url(url):browser_path=r'C:\Users\Administrator\AppData\Local\115Chrome\Application\115chrome.exe'web.register('115', None,web.BackgroundBrowser(browser_path))web.get('115').open_new_tab(url)print 'use_115_open_url open url ending ....'#IE浏览器def use_IE_open_url(url):browser_path=r'C:\Program Files (x86)\Internet Explorer\iexplore.exe'web.register('IE', None,web.BackgroundBrowser(browser_path))web.get('IE').open_new_tab(url)print 'use_IE_open_url open url ending ....'#搜狗浏览器def use_sougou_open_url(url):browser_path=r'D:\Program Files(x86)\SouExplorer\SogouExplorer\SogouExplorer.exe'web.register('sougou', None,web.BackgroundBrowser(browser_path))web.get('sougou').open_new_tab(url)print 'use_sougou_open_url open url ending ....'#浏览器关闭任务def close_broswer():os.system('taskkill /f /IM SogouExplorer.exe')print 'kill SogouExplorer.exe'os.system('taskkill /f /IM firefox.exe')print 'kill firefox.exe'os.system('taskkill /f /IM Chrome.exe')print 'kill Chrome.exe'os.system('taskkill /f /IM launcher.exe')print 'kill launcher.exe'os.system('taskkill /f /IM qianying.exe')print 'kill qianying.exe'os.system('taskkill /f /IM 115chrome.exe')print 'kill 115chrome.exe'os.system('taskkill /f /IM iexplore.exe')print 'kill iexplore.exe'#测试运⾏主程序def broswer_test():url='https://'run_to_use_default_browser_open_url(url)use_firefox_open_url(url)#use_chrome_open_url(url)use_qianying_open_url(url)use_115_open_url(url)use_IE_open_url(url)use_sougou_open_url(url)time.sleep(20)#给浏览器打开⽹页⼀些反应时间close_broswer()if __name__ == '__main__':print '''''******************************************* Welcome to python of browser **** Created on 2017-05-07 **** @author: Jimy _Fengqi *******************************************'''broswer_test()好了,上⾯的程序是测试实例,下⾯对这些内容做⼀个整合,简化⼀下代码,来实现本⽂的根本⽬的#coding:utf-8import timeimport webbrowser as webimport osimport random#随机选择⼀个浏览器打开⽹页def open_url_use_random_browser():#定义要访问的地址url='https://'#定义浏览器路径browser_paths=[r'C:\Program Files (x86)\Mozilla Firefox\firefox.exe',r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe',r'C:\Program Files (x86)\Opera\launcher.exe',r'C:\Users\Administrator\AppData\Roaming\qianying\qianying.exe',r'C:\Users\Administrator\AppData\Local\115Chrome\Application\115chrome.exe',r'C:\Program Files (x86)\Internet Explorer\iexplore.exe',r'D:\Program Files(x86)\SouExplorer\SogouExplorer\SogouExplorer.exe']#选择⼀个浏览器def chose_a_browser_open_url(browser_path,url):#如果传⼊的浏览器位置不存在,使⽤默认的浏览器打开if not browser_path:print 'using default browser to open url'web.open_new_tab(url)#使⽤默认浏览器,就不再结束进程else:#判断浏览器路径是否存在if not os.path.exists(browser_path):print 'current browser path not exists,using default browser'#浏览器位置不存在就使⽤默认的浏览器打开browser_path=''chose_a_browser_open_url(chose_a_browser_open_url,url)else:browser_task_name=browser_path.split('\\')[-1]#结束任务的名字browser_name=browser_task_name.split('.')[0]#⾃定义的浏览器代号print browser_nameweb.register(browser_name, None,web.BackgroundBrowser(browser_path))web.get(browser_name).open_new_tab(url)#使⽤新注册的浏览器打开⽹页print 'using %s browser open url successful' % browser_nametime.sleep(5)#等待打开浏览器kill_cmd='taskkill /f /IM '+browser_task_name#拼接结束浏览器进程的命令os.system(kill_cmd) #终结浏览器browser_path=random.choice(browser_paths)#随机从浏览器中选择⼀个路径chose_a_browser_open_url(browser_path,url)if __name__ == '__main__':print '''''******************************************* Welcome to python of browser **** Created on 2017-05-07 **** @author: Jimy _Fengqi *******************************************'''open_url_use_random_browser()PS:本程序在windows上⾯运⾏,python版本是2.7以上这篇python实现随机调⽤⼀个浏览器打开⽹页就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
WebBrowser控件使用详解
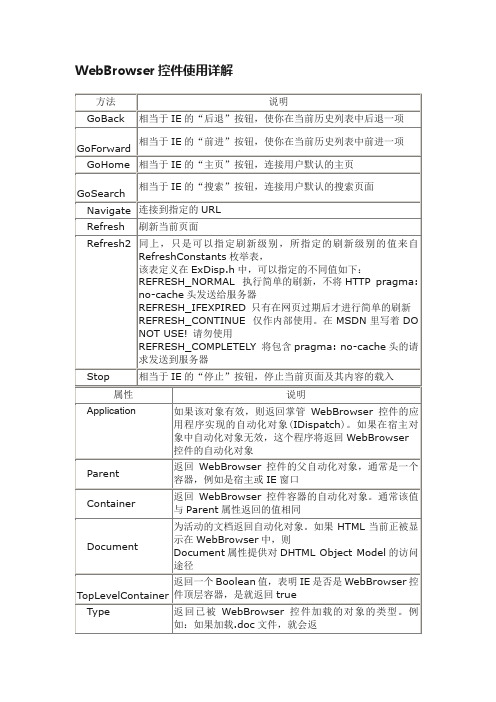
WebBrowser控件使用详解WebBrowser 的事件Private Events Description BeforeNavigate2 导航发生前激发,刷新时不激发CommandStateChange 当命令的激活状态改变时激发。
它表明何时激活或关闭Back和Forward菜单项或按钮DocumentComplete 当整个文档完成是激发,刷新页面不激发DownloadBegin 当某项下载操作已经开始后激发,刷新也可激发此事件DownloadComplete当某项下载操作已经完成后激发,刷新也可激发此事件NavigateComplete2 导航完成后激发,刷新时不激发NewWindow2 在创建新窗口以前激发OnFullScreen 当FullScreen属性改变时激发。
该事件采用VARIENT_BOOL的一个输入参数来指示IE是全屏显示方式(VARIENT_TRUE)还是普通显示方式(VARIENT_FALSE)OnMenuBar 改变MenuBar的属性时激发,标示参数是VARIENT_BOOL类型的。
VARIANT_TRUE是可见,VARIANT_FALSE是隐藏OnQuit 无论是用户关闭浏览器还是开发者调用Quit方法,当IE退出时就会激发OnStatusBar 与OnMenuBar调用方法相同,标示状态栏是否可见。
OnToolBar 调用方法同上,标示工具栏是否可见。
OnVisible 控制窗口的可见或隐藏,也使用一个VARIENT_BOOL类型的参数StatusTextChange 如果要改变状态栏中的文字,这个事件就会被激发,但它并不理会程序是否有状态栏TitleChange Title有效或改变时激发一些使用技巧1.禁止右键看到很多关于WebBrowser控件禁止右键的提问,回复的方法很多,其中有提到使用微软提供的Webbrowser扩展COM服务器对象(WBCustomizer.dll),但是该方法在我们想使用Webbrowser编辑网页(Webbrowser1.Document.execCommand "editMode")的时候有很多弊端,比如不能显示选中的文本等。
webbrowser用法

webbrowser是Python中内置的一个模块,用于控制Web浏览器的操作。
它可以启动默认的Web浏览器,打开指定的URL,还可以在浏览器中执行JavaScript代码等操作。
以下是一些常用的webbrowser函数及其用法:1. webbrowser.open(url, new=0, taboolaexec=False):打开指定的URL。
new参数指定是否在新窗口中打开URL,如果为1,则在新窗口中打开,否则在当前窗口中打开。
taboolaexec参数指定是否使用Taboola广告。
2. webbrowser.open_new(url):在新窗口中打开指定的URL。
相当于webbrowser.open(url, new=1)。
3. webbrowser.open_new_tab(url):在新标签页中打开指定的URL。
4. webbrowser.get().open(url, new=0, autoraise=True):打开指定的URL。
autoraise参数指定是否将浏览器窗口置于最前面。
5. webbrowser.get().open_new(url):在新窗口中打开指定的URL。
6. webbrowser.get().open_new_tab(url):在新标签页中打开指定的URL。
7. webbrowser.get().execute_script(script):在当前浏览器中执行JavaScript脚本。
需要注意的是,使用webbrowser模块时需要先导入webbrowser库。
另外,不同的浏览器有不同的处理方式,因此在使用webbrowser时需要根据具体情况选择合适的浏览器。
webrepl用法

webrepl用法
WebREPL是MicroPython的一个功能,它允许您通过Web浏览器与MicroPython设备进行交互。
以下是WebREPL的用法:
1. 启用WebREPL,首先,您需要在MicroPython设备上启用WebREPL。
要做到这一点,您需要连接到设备的串行控制台,并输入以下命令,import webrepl_setup。
然后按照提示设置密码。
2. 连接到WebREPL,一旦WebREPL被启用,您可以通过浏览器连接到设备。
在浏览器中输入设备的IP地址,然后输入之前设置的密码。
这将打开一个WebREPL终端,允许您通过浏览器与设备进行交互。
3. 文件传输,除了交互式控制台,WebREPL还允许您通过浏览器上传和下载文件到MicroPython设备。
这使得在设备上运行Python脚本变得非常方便。
4. 安全性考虑,由于WebREPL通过网络连接,因此在使用时需要考虑安全性。
确保您的设备的网络连接是安全的,并且密码是复杂的,以防止未经授权的访问。
总之,WebREPL是一个非常方便的工具,可以让您通过Web浏览器与MicroPython设备进行交互,并且可以方便地传输文件。
但是在使用时,一定要注意安全性,以防止未经授权的访问。
希望这些信息能够帮助您更好地理解WebREPL的用法。
web scraperb步骤

一、确定目标全球信息站需要确定要爬取数据的目标全球信息站。
在选择目标全球信息站时,需要确保该全球信息站允许爬取数据,并且没有明确的禁止条款。
需要分析目标全球信息站的结构和页面布局,以便更好地编写爬取程序。
二、获取网页内容通过网络请求,可以获取目标全球信息站的网页内容。
可以使用Python中的requests库或者其他网络请求库来发送HTTP请求,并获取网页的HTML内容。
在进行网络请求时,需要注意设置适当的headers,以模拟浏览器的行为,避免被全球信息站识别为爬虫程序而被拒绝访问。
三、解析网页内容获取网页内容后,需要解析HTML内容,提取出目标数据。
可以使用Python中的BeautifulSoup库或者lxml库来解析HTML内容,通过选择器或者XPath来定位和提取需要的数据。
在解析网页内容时,需要注意处理异常情况,如网页加载失败、或者目标数据未找到的情况。
四、保存数据在提取出目标数据后,需要将数据保存到合适的数据存储介质中,如CSV文件、数据库等。
可以使用Python中的pandas库或者其他数据处理库来保存数据到CSV文件,或者使用SQLAlchemy等ORM库将数据保存到数据库中。
在保存数据时,需要注意数据的格式转换和去重等处理。
五、定时任务如果需要定期爬取数据,可以使用Python中的schedule库或者其他定时任务库来实现定时运行爬取程序。
通过设置定时任务,可以自动化地爬取数据,并将数据保存到合适的存储介质中,实现数据定期更新和持久化。
六、反爬处理在爬取数据的过程中,可能会遇到目标全球信息站对爬虫程序的反爬措施,如验证码、IP封锁等。
针对这种情况,可以使用代理IP池、请求头随机化、使用浏览器渲染引擎等方式来规避反爬策略,确保爬取数据的顺利进行。
总结通过以上步骤,可以实现一个简单的Web Scraper程序,用于爬取目标全球信息站的数据。
在实际开发中,需要结合具体的目标全球信息站和数据需求,设计合理的爬取策略和程序架构,以确保数据的高效、稳定地爬取和保存。
.net webbrowser用法

一、.NET WebBrowser控件简介.NET WebBrowser控件是一种能够嵌入到Windows窗体应用程序中的浏览器控件,它允许用户在应用程序中浏览网页内容。
这个控件基于Internet Explorer引擎,因此它能够支持大多数IE的功能和特性。
通过使用.NET WebBrowser控件,开发者可以实现在自己的应用程序中显示网页内容,而无需用户离开应用程序去打开外部浏览器。
二、.NET WebBrowser控件的基本用法1. 在窗体中添加WebBrowser控件要在窗体中添加WebBrowser控件,首先需要在Visual Studio的工具箱中找到WebBrowser控件,然后将其拖放到窗体中即可。
2. 加载网页使用WebBrowser控件加载网页十分简单,只需要通过控件的Navigate方法传入网页URL即可实现。
例如:webBrowser1.Navigate("");3. 获取当前网页URL开发者可以通过WebBrowser控件的Url属性获取当前正在浏览的网页的URL,从而实现在应用程序中显示当前网页的位置区域。
4. 前进和后退WebBrowser控件提供了GoBack和GoForward方法,可以让用户在浏览历史记录中进行前进和后退操作。
5. 控制浏览器的其他功能除了上述基本功能外,WebBrowser控件还提供了许多其他功能,例如刷新页面、停止加载、打印页面等。
开发者可以根据自己的需求使用这些功能来控制WebBrowser控件的行为。
三、.NET WebBrowser控件的高级用法1. 与JavaScript交互通过WebBrowser控件的Document属性,开发者可以获取当前网页的DOM结构,并且可以执行JavaScript代码来修改网页内容或与网页进行交互。
2. 处理网页事件WebBrowser控件提供了许多事件,例如DocumentCompleted、Navigating等,开发者可以通过订阅这些事件来处理网页加载完成、用户点击信息等操作。
Python标准库3.4.3-webbrowser-21.1

Python标准库3.4.3-webbrowser-21.121.1. webbrowser — Convenient Web-browser controllerSource code: Lib/webbrowser.py 翻译:Z.F.The webbrowser module provides a high-level interface to allow displaying Web-based documents to users. Under most circumstances, simply calling the open() function from thismodule will do the right thing.webbrowser模块提供⼀个⾼阶的接⼝来为⽤户显⽰基于web的⽂档,在⼤多数情况下,简单的调⽤open()函数就可以正常的⼯作。
Under Unix, graphical browsers are preferred under X11, but text-mode browsers will be used if graphical browsers are not available or an X11 display isn’t available. If text-mode browsers are used, the calling process will block until the user exits the browser.在Unix环境中,图形化的浏览器有更⾼的优先级在X11环境中,如果图形化的浏览器不可⽤,或者X11图形显⽰不可⽤,则使⽤⽂本模式的浏览器。
如果使⽤⽂本模式的浏览器,则调⽤进程是阻塞的,直到⽤户退出。
If the environment variable BROWSER exists, it is interpreted as the os.pathsep-separated list of browsers to try ahead of the the platform defaults. When the value of a list partcontains the string %s, then it is interpreted as a literal browser command line to be used with the argument URL substituted for %s; if the part does not contain %s, it is simplyinterpreted as the name of the browser to launch. [1]如果有环境变量 BROWSER,它被解释为os.pathsep分割的浏览器列表,并处于系统默认值之前,当列表的值之中含有字符串%s时,它将被解释为⼀个字⾯的浏览器命令,并使⽤url参数代替%s,如果不包含%s,则简单的解释为要使⽤的浏览器的名字。
介绍一下Python中webbrowser的用法

介绍一下Python中webbrowser的用法
介绍一下Python中webbrowser的用法
webbrowser模块提供了一个高级接口来显示基于Web的文档,大部分情况下只需要简单的调用open()方法。
webbrowser定义了如下的异常:exception webbrowser.Error, 当浏览器控件发生错误是会抛出这个异常webbrowser有以下方法:webbrowser.open(url[, new=0[, autoraise=1]])这个方法是在默认的浏览器中显示url, 如果new = 0, 那么url会在同一个浏览器窗口下打开,如果new = 1, 会打开一个新的窗口,如果new = 2, 会打开一个新的tab, 如果autoraise =true, 窗口会自动增长。
webbrowser.open_new(url)在默认浏览器中打开一个新的窗口来显示url, 否则,在仅有的浏览器窗口中打开urlwebbrowser.open_new_tab(url)在默认浏览器中当开一个新的tab 来显示url, 否则跟open_new()一样webbrowser.get([name]) 根据name返回一个浏览器对象,如果name为空,则返回默认的浏览器webbrowser.register(name, construtor[, instance])注册一个名字为name的浏览器,如果这个浏览器类型被注册就可以用get()方法来获取。
1。
python的startbrowser指令

python的startbrowser指令什么是Python的startbrowser指令以及如何使用它?Python的startbrowser指令是一个可以在Python中启动默认的Web浏览器的模块。
它使得Python能够通过脚本启动Web浏览器,以方便展示Web页面、进行网站UI测试或自动化爬取数据等用途。
在本文中,将以一步一步的方式介绍如何使用Python的startbrowser指令。
1. 确认Python版本首先,需要确保已经在计算机上安装了Python,并且知道要运行Python脚本的版本。
Python 2和Python 3有不同的方法来启动浏览器。
在本文中,我们将使用Python 3以演示如何使用startbrowser指令。
2. 导入webbrowser模块在Python脚本中,必须首先导入名为webbrowser的模块。
为此,可以在脚本顶部添加以下代码:pythonimport webbrowser3. 使用webbrowser模块的open()函数在已导入webbrowser模块后,可以使用它的open()函数来启动浏览器。
open()函数接受一个字符串参数,表示要在浏览器中打开的URL。
例如,以下代码将在默认浏览器中打开GitHub网站:pythonimport webbrowserurl = "webbrowser.open(url)如果要在脚本中打开不同类型的URL(如本地文件),则需要将打开的URL字符串分配给与您的系统相关联的应用程序。
4. 添加浏览器选项可以使用open()函数中的可选参数来添加浏览器选项。
这些选项是在打开URL 时使用的并且与不同的浏览器有关。
例如,以下示例使用Google Chrome浏览器并指定浏览器窗口的大小:pythonimport webbrowserurl = "chrome_path = "C:/ProgramFiles/Google/Chrome/Application/chrome.exe %s"webbrowser.get(chrome_path).open(url, new=2)在上面的示例中,chrome_path参数表示Chrome浏览器的路径。
Python网络爬虫的使用技巧

Python网络爬虫的使用技巧Python 网络爬虫的使用技巧在如今信息爆炸的时代,我们获取所需信息的方式也在不断变化。
网络爬虫作为一种强大的工具,能够帮助我们从网络中快速获取所需数据。
Python 作为一种灵活易用且功能丰富的编程语言,被广泛应用于网络爬虫的开发。
在本文中,我们将讨论一些 Python 网络爬虫的使用技巧,帮助您更好地实现您的爬虫需求。
一、选择合适的网络爬虫库Python 提供了多个网络爬虫库,如 Requests、Scrapy 等。
选择合适的库对于开发高效的爬虫至关重要。
如果您只需要简单地发送 HTTP 请求并获取响应,Requests 库是一个不错的选择。
如果您需要开发更为复杂的爬虫,比如爬取多个页面并解析数据,Scrapy 则是一个更好的选择。
Scrapy 提供了强大的框架和许多内置功能,使您能够更便捷地处理页面间的导航、数据解析和持久化等任务。
二、设定适当的请求头和代理当进行网络爬取时,合理设置请求头和代理将有助于规避反爬机制。
有些网站可能会检测请求头中的 User-Agent 字段,因此我们可以设置一个合理的 User-Agent 值,使我们的爬虫看起来更像一个正常的浏览器请求。
另外,一些网站可能会限制同一个 IP 地址的请求频率,我们可以使用代理服务器进行请求,以避免被封禁。
三、处理网页响应在获取到网页响应后,我们需要对其进行合适的处理。
首先,我们需要考虑网页的编码问题。
有些网页可能没有指定编码,可以使用第三方库 chardet 来自动检测编码。
其次,我们需要解析网页,提取我们需要的数据。
对于 HTML 格式的网页,可以使用第三方库 BeautifulSoup 进行解析。
对于 JSON 格式的数据,可以使用内置的 json 模块进行处理。
四、处理动态加载的数据有些网站使用AJAX 或JavaScript 动态加载数据,这给爬虫带来了一定的挑战。
我们可以使用第三方库 Selenium 来模拟浏览器行为,实现动态加载数据的爬取。
Python如何设置指定窗口为前台活动窗口

Python如何设置指定窗⼝为前台活动窗⼝Python程序运⾏时,打开了多个窗⼝,使⽤win32gui模块可以设置指定的某⼀个窗⼝为当前活动窗⼝。
import re, timeimport webbrowserimport win32gui, win32con, win32com.clientdef _window_enum_callback(hwnd, wildcard):'''Pass to win32gui.EnumWindows() to check all the opened windows把想要置顶的窗⼝放到最前⾯,并最⼤化'''if re.match(wildcard, str(win32gui.GetWindowText(hwnd))) is not None:win32gui.BringWindowToTop(hwnd)# 先发送⼀个alt事件,否则会报错导致后⾯的设置⽆效:pywintypes.error: (0, 'SetForegroundWindow', 'No error message is available') shell = win32com.client.Dispatch("WScript.Shell")shell.SendKeys('%')# 设置为当前活动窗⼝win32gui.SetForegroundWindow(hwnd)# 最⼤化窗⼝win32gui.ShowWindow(hwnd, win32con.SW_MAXIMIZE)if __name__ == '__main__':webbrowser.open("https:///")time.sleep(1)win32gui.EnumWindows(_window_enum_callback, ".*%s.*" % config.window_name)#此处为你要设置的活动窗⼝名说明⼀点:有⼈会遇到这个错误(好吧,我也遇到了):pywintypes.error: (0, 'SetForegroundWindow', 'No error message is available')Stack Overflow上的解决⽅法是添加如下代码:shell = win32com.client.Dispatch("WScript.Shell")shell.SendKeys('%')即先发送⼀个alt key事件,这个错误就会避免,后⾯的设置才会有效。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
介绍一下Python中webbrowser的用法
webbrowser模块提供了一个高级接口来显示基于Web的文档,大部分情况下只需要简单的调用open()方法。
webbrowser定义了如下的异常:exception webbrowser.Error, 当浏览器控件发生错误是会抛出这个异常webbrowser有以下方法:webbrowser.open(url[, new=0[, autoraise=1]])这个方法是在默认的浏览器中显示url, 如果new = 0, 那么url会在同一个浏览器窗口下打开,如果new = 1, 会打开一个新的窗口,如果new = 2, 会打开一个新的tab, 如果autoraise =true, 窗口会自动增长。
webbrowser.open_new(url)在默认浏览器中打开一个新的窗口来显示url, 否则,在仅有的浏览器窗口中打开urlwebbrowser.open_new_tab(url)在默认浏览器中当开一个新的tab来显示url, 否则跟open_new()一样webbrowser.get([name]) 根据name返回一个浏览器对象,如果name为空,则返回默认的浏览器webbrowser.register(name, construtor[, instance])注册一个名字为name的浏览器,如果这个浏览器类型被注册就可以用get()方法来获取。
1。