SPSS菜单说明
spss软件操作步骤
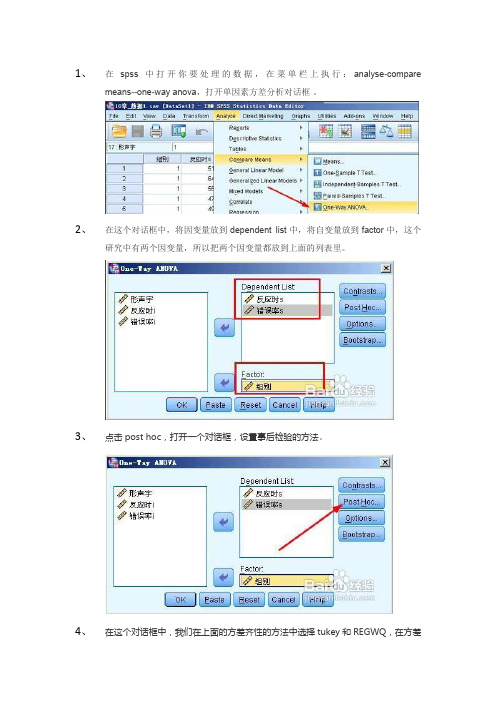
1、在spss中打开你要处理的数据,在菜单栏上执行:analyse-comparemeans--one-way anova,打开单因素方差分析对话框。
2、在这个对话框中,将因变量放到dependent list中,将自变量放到factor中,这个研究中有两个因变量,所以把两个因变量都放到上面的列表里。
3、点击post hoc,打开一个对话框,设置事后检验的方法。
4、在这个对话框中,我们在上面的方差齐性的方法中选择tukey和REGWQ,在方差不齐性的方法中选择dunnetts,点击continue继续。
5、回到了anova的对话框,点击options按钮,设置要输出的基本结果。
6、这里选择描述统计结果和方差齐性检验,点击continue按钮。
7、点击ok按钮,开始处理数据。
8、我们看到的结果中,第一个输出的表格就是描述统计,从这个表格里我们可以看到均值和标准差,在研究报告中,通常要报告这两个参数。
9、接着看方差齐性检验,方差不齐性的话是不能够用方差齐性的方法来检验的,还好,这里显示,显著性都没有达到最小值0.05,所以是不显著的,这证明方差是齐性的。
10、接着看单因素方差分析表,反应时sig值不显著,而错误率达到了显著的水平,这说明实验处理对错误率产生了影响,但是对反应时没有影响。
11、接着看事后检验,因为反应时是没有显著差异的,所以就不必再看反应时的事后检验,直接看错误率的事后检验,从图中标注的红色方框可以看到,第一组和二三组都有显著的差异,而第二组和第三组没有显著差异。
关于dunnet方法,它适合在方差不齐性的时候使用,因为方差齐性,不必去看这个方法的检验结果了。
12、最后我们看这个表格,这里有两个检验方法都是在方差齐性的时候使用的,我们从红色方框可以看出第一组分为一组,第二三组分为一组,它的意思是上面的结果是一致的。
SPSS基本界面介绍

菜单栏下的每个按钮控件到底都有哪些功能呢?为了更直观了解, 如下表1.1。
表1.1 菜单栏功能表
பைடு நூலகம்
数据视图 数据视图,顾名思义,就是指可以直观地看到自己要处理的数据。其形 如Excel,界面也是很美观的,如图1.2。
图1.2 数据视图
区域1:序列,如Excel中的行; 区域2:变量列,如Excel中的列。 数据视图是比较简单的,也就是可以直观看到每个单元格的数据,可以 对单元格的数据进行编辑。
经过时间的沉淀,SPSS的界面和功能都有了很大的改进, 而本文是依托SPSS24.0,也是SPSS的最新版本,展示下它 美观而强大的外表。
数据编辑窗口 SPSS基本界面包括:数据编辑窗口、结果输出窗口、对象编辑窗口、语法编辑窗口和脚 本编写窗口。虽然SPSS拥有这么多功能界面,不过本文主要就我们最常用的“数据编辑 窗口”和“结果输出窗口”进行介绍。
首先,当然是“数据编辑窗口”,请看图1.1。
图1.1 数据编辑器窗口
标题栏——用于定义文件/数据处理的标题内容; 菜单栏——重要的功能按钮,SPSS数据分析的核心; 常用工具栏——方便快捷方式; 数据编辑和显示区域——形如Excel,可对单元格中的内容进行输入 和编辑,是数据编辑和文件导入后显示的区域; 视图转换按钮——可以在数据和变量之间进行自由切换; 状态栏——显示数据处理的状态。
SPSS菜单命令详解剖析

purchase:选
Compare effectiveness of campaigns(control Package Test):比较活动效果〔把握包装检验〕
Apply scores from a model File:应用来自模型文 件的得分
1.6.9 Graphs菜单
Chart Builder 图形生成器
Graphboard Template Chooser 图形模板选择
1Bar
条形图
3-D Bar
三维条形图
Line
线图
Area
面积图
Pie
饼图
High-Low 凹凸图
Box Plot
箱图
Error Bar
误差条图
Population Pyramid 人口金字塔图
Scatter/Dot 散点图
Histogram 直方图
状态栏显示 工具条栏显示 菜单编辑器 字体 显示/隐蔽格线 显示/隐蔽变量值标签 标记错误数据 查看自变量 变量定义窗口和数据编辑
窗口转换
1.6.5 Data菜单
Define Variable Properties
定义变量属性
Set Measurement Level for Unknown 设置未知测量级别
SPSS帮助主题 用户指南 统计辅导学习 统计训练指导 语句命令参考
研发中心 关于SPSS版本信息 算法 SPSS官方主页 版本更新检查
1.7 SPSS中英文界面的转换
当首次安装软件时,SPSS界面为英文显示,此时可以承受如 下方法将其转换为中文界面。
1. 选择菜单栏中的【Edit(编辑)】菜单中的【Option(选项)】 命令。
数据汇总 正交设计 复制数据集 分割文件 选择观测量 观ompute Variable Count Values within Cases Shift Values Recode into Same Variables Recode into Different Variables Automatic Recode Visual Binning Optimal Binning
Spss软件常用菜单含义与功能介绍
SPSS软件常用菜单含义与功能介绍图1:SPSS运行窗口1、计算产生变量根据已经存在的变量,经过函数计算后,建立新变量或替换员原量的值。
图2:计算产生变量图3:分类汇总1、描述性统计(1)频数分布分析:通过频数分布表、直方图,以及集中趋势和离散趋势的各种统计量,描述数据的分布特征。
(2)描述性统计分析:计算描述数据的集中趋势和离散趋势的各种统计量,还可以做标准化变换(变成均值为0,方差为1的数据)。
(3)探索性分析:判断数据有无离群点(outliers),极端值(extreme values);进行正态分布检验和方差齐性检验;了解数据指标之间差异的特征。
(1)双变量相关分析:分析两个变量之间是否存在相关关系。
(2)偏相关分析:剔除其他变量的影响的情况下,计算两变量之间的相关系数。
3、聚类分析与判别分析(1)系统聚类:最常用的聚类方法。
(2)判别分析:判别所研究的对象属于哪一类的统计方法。
(1)线性回归:一个因变量(dependent )与多个自变量(independents )之间存在线性数量关系。
(2)曲线拟合:可以完成11种曲线的自动拟合(根据需要进行选择),并进行参数估计与检验,绘制拟合图形等。
自变量(independent )只能选一个或者使用时间作为自变量(time: 即使用1,2,3,…,),即只能做一元函数的曲线拟合。
因变量(dependent )可以选多个,将分别做多个一元函数的拟合。
模型Models 模型名称 模型表达式Linear 线性模型 01*y b b x =+ Logarithmic对数模型01*ln y b b x =+Inverse 逆模型 01/y b b x =+ Quadratic 二次模型 2012**y b b x b x =++ Cubic 三次模型 230123***y b b x b x b x =+++Compound 复合模型 01*x y b b =Power 幂模型 10*b y b x = S S 型模型 01/b b x y e +=Growth 生长模型 01*b b x y e += Exponential 指数模型 1*0*b x y b e =LogisticLogistic 模型011/(1)b b x y e --=+一般可以先选择所有的11种模型,再根据结果选择最佳模型。
SPSS菜单说明

Analyze统计
General Linear Model——Univariable 单因变量方差分析
Correlate相关——Bivariate 双变量相关 Regression回归分析——Linear 线性回归
Curve Estimation曲线预测模型 Scale——Reliability Analysis可靠性分析
File 文件
New新建——Data 数据库 Open打开 Save 保存 Save as 另存 Print 打印
Edit 编辑
Undo撤消 Cut 剪切 Copy复制 Paste粘贴 Clear清除
Data数据
Define variable定义变量 Insert variable插入变量 Insert case插入案例 Go to case查找 Sort cases排序 Transpose 转置 Select cases选择案例
Transform转化
Compute 生成新变量 Recode转化成新变量
Analyze统计
Summarize概括数据——Frequencies频率 Descriptives描述 Explore探索 Crosstabs交叉表格
Analyze统计
Tables表格组——Basic tables基本表 General tables总表
Multiple response tables多重反应表 Tables of frequencies频率表
Analyze统计
Compare means比较平均值—Means平均值 One-Sample T Test一维样本T检验
Independent-Samples T Test 独立样本T检验 Paired-Samples T Test配对样本T检验 Nhomakorabea(信度分析)
spss菜单

位小数 5. Lable栏:定义变量名标签,该处可使用中文
6. Values栏:定义变量值标签 7. Missing栏:定义变量缺失值。SPSS默认缺失值用 “.”表示,一般用默认的 8. Columns栏:定义显示列宽,使用很少。实际使用
时,可直接拖动改变列宽
6. Analyze(统计菜单):一系列统计方法的应用 7. Graphs(作图菜单):统计图的制作 8. Utilities(用户选项菜单):命令解释、字体选择、 文件信息、定义输出标题、窗口设计等 9:Windows(窗口管理菜单):窗口的排列、选择、 显示等 10. Help(求助菜单):帮助文件的调用、查寻、显 示等 点击菜单选项即可激活菜单,并弹出下拉式子 菜单,可根据自己的需求再点击子菜单的选项, 完成所需的功能
(三)数据录入
1. 直接录入 若数据量较少、处理方法单一时可将数据直接 录入SPSS中 2.从其它数据库中引入 先用Excel建立数据库,再用复制粘贴的方式从 Excel中将数据转入SPSS 逐一选取File——Open——Data可打开已保存 的SPSS数据文件或其他类型的数据文件。单击 “文件类型”下拉菜单,选择要打开的数据文件 类型
四、SPSS菜单栏简介
1. File(文件管理菜单):文件的调入、存储、显 示和打印等
2. Edit(编辑菜单):文本内容的选择、拷贝、剪 贴、寻找和替换等
3. View(视图菜单):选择窗口状态等 4. Data(数据管理菜单):数据变量定义、数据格 式选定、观察对象的选择、排序、加权、筛选、数 据文件的转换、连接、汇总等 5. Transform(数据转换处理菜单):数值的计算、 重新赋值、缺失值替代等
五、分析数据准备 (一)变量定义
SPSS的Data菜单说明

Data 菜单说明:简单命令:包括插入变量、插入记录和到达某条记录,这些功能都可以用鼠标在数据界面上直接完成,很少会使用菜单调用。
常用的简单过程:包括排序、拆分文件、选择记录和加权记录。
变量与数据文件Data 菜单说明:简单命令:包括插入变量、插入记录和到达某条记录,这些功能都可以用鼠标在数据界面上直接完成,很少会使用菜单调用。
常用的简单过程:包括排序、拆分文件、选择记录和加权记录。
变量与数据文件属性向导:用于定义数据字典,或者将预定义的数据字典直接引入当前数据文件,对于大型或者连续性的数据分析项目而言,这是一个非常有用的功能。
数据重构向导:用于进行数据转制,或者对重复测量数据进行长型、宽型记录格式间的转换。
文件合并过程:用于生成实施联合分析所需的设计。
其他过程:包括定义日期变量过程、数据汇总过程和查找重复记录向导。
Sort cases :记录排序。
Split file :记录拆分。
Select cases不需要分析全部的数据,而是按照要求分析其中的一部分。
Weight cases:记录加权。
默认情况下,每行就是一条记录,但是有时非常麻烦。
这时候可以使用频数格式录入数据,即相同取值的观测只录入一次,另加一个频数变量用于记录该数据出现了多少次。
Aggregate 数据汇总:分类汇总就是按照指定的分类变量对观测值进行分组。
分类汇总的分类变量可以指定多个,称为多重分类汇总。
Define variable properties :变量属性定义向导,用于对数据集中已存在的变量进一步定义其属性。
Copy Data Properties :用于将定义好的数据字典直接应用到当前文件中。
Identifying Duplicate cases :查找个别变量值重复,或者所有数值完全重复的记录。
Restructure :根据用户的要求改变数据的排列格式。
Transpose:用于对数据进行行列转置。
主要用于编成,进行矩阵运算时的矩阵转置操作。
SPSS详细操作指导

SPSS操作指导社会统计学软件包(SPSS)20世纪60年代由美国斯坦福大学的3位研究生研制开发,使国际上最有影响力的统计软件之一,广泛用于社会学、经济学、生物学、教育学、心理学等各个领域。
一、SPSS数据文件管理1、建立一个数据文件菜单“文件”——“新建”——“数据”;(1)单击“变量视图”。
标签:变量名不能超过8个字符,所以需要输入相应变量的文字解释说明。
值:一般适用于定类变量和定序变量。
缺失:定义缺失值没有缺失值,系统默认选项。
离散缺失值,制定3个数值为缺失值。
缺失值的范围。
列:定义列宽测量:尺度指定距和定比数据,用于代表连续数据;有序代表定序数据;名义代表定类数据。
(2)单击“数据视图”进行数据的直接录入。
注意:开放题和简单单选题录入相似。
多选题的录入比较复杂。
多选题又称为多重应答,是社会调查和市场调研中极为常见的一种数据记录类型。
录入时可以采用两类:多重二分法、多重分类法。
多重二分法是指在编码的时候,对应每一个选型都要定义一个变量,有几个选项就有几个变量,这些变量均为二分类,它们各自代表对一个选项的选择结果。
如1代表选择,0代表未选。
多重分类法是利用多个变量来对一个多选题的答案进行定义,这些变量须为数值型变量,利用值标签将答案标出,所有变量采用一套值标签。
适合于选项较多的情况。
2、读取外部数据一般使用EXCEL数据。
菜单“文件”——“打开”——“数据”,调出打开文件对话框,在文件类型下拉列表中选择EXCEL类型。
二、数据整理数据整理的功能主要集中在“数据”和“转换”两个主菜单下。
1、数据“数据”——“个案排序”。
“数据”——“转置”。
“数据”——“选择个案”。
“数据”——“分类汇总”;分组变量一般是离散变量,而汇总变量一般是连续变量。
要同时计算一个变量的两个统计量时需要将该变量移入两次汇总变量。
“数据”——“合并文件”;添加个案是指纵向合并样本量;添加变量是指横向合并变量。
未匹配变量中*变量为工作数据文件中的变量,+为外部数据文件中的变量。
理解SPSS的基本使用方法

理解SPSS的基本使用方法SPSS(Statistical Product and Service Solutions)是一款专业的统计分析软件,广泛应用于社会科学、医学、商业、市场调研等领域。
它的可视化操作界面和丰富的分析功能,使得用户能够直观地理解和分析样本数据,从而更好地做出合理的决策。
本文将介绍SPSS的基本使用方法。
一、数据输入数据输入是使用SPSS进行数据分析的第一步,数据源可以是Excel表格、文本文件、Access数据库等。
首先打开SPSS软件,选择菜单栏中的“File”-“Open”-“Data”打开数据源。
在打开的Windows窗口中,选择所需的数据源,并点击“Open”进行加载,接着进行数据文件格式定义,导入数据时需选择文件格式。
在这里我们选择“Excel”,选择“Sheet1”标签页中需要分析的数据,并点击“OK”按钮即可。
二、数据清理在进行数据分析前,需要对数据进行清理和整理。
数据的清理包括去除异常值、缺失数据、重复数据等。
在SPSS中,可以通过菜单栏中的“Transform”-“Recode into Different Variables”-“Old and New Values”对异常值进行清理。
针对缺失值,可使用“Analyze”-“Missing Values”进行数据填充,或使用菜单栏中的“Transform”-“Compute Variable”创建新变量填充数据。
而针对重复数据,则可以使用“Data”-“Select Cases”对数据进行去重处理。
三、数据描述和分析数据描述和分析是SPSS的核心功能之一,主要包括数据的计数、描述性统计、方差分析、回归分析等。
在SPSS中,通过菜单栏中的“Analyze”进行各种数据分析,如“Descriptive Statistics”用于计算统计量,如平均值、标准差等;“One-Way ANOVA”用于分析方差;“Regression”用于进行回归分析等。
spss软件使用教程

spss软件使用教程SPSS(Statistical Package for the Social Sciences)是一款用于统计分析的软件,可以对大量数据进行处理、分析和呈现。
以下是一个简单的SPSS软件使用教程,帮助您快速上手:1. 打开SPSS软件:点击桌面上的SPSS图标或通过开始菜单打开软件。
2. 创建新的数据文件:选择“文件”菜单中的“新建”选项,或使用快捷键Ctrl + N,然后选择“数据集”。
3. 导入数据:在数据文件中导入数据,可以从Excel、CSV文件等导入。
选择“文件”菜单中的“打开”选项,或使用快捷键Ctrl + O,然后选择需要导入的数据文件。
4. 数据清理与变量设置:导入数据后,您可以对数据进行清理和变量设置。
使用“数据”菜单中的“变量查看器”选项,可以查看已导入数据的变量和数据类型。
若存在缺失值或异常值,可以使用“数据”菜单中的“数据清理”选项进行处理。
5. 数据分析:使用SPSS进行数据分析的主要功能是“统计”菜单。
您可以选择不同的统计方法,如描述统计、方差分析、回归分析等。
选择相应的统计方法后,设定变量和分析选项,然后点击“确定”进行分析。
6. 数据可视化:SPSS提供了丰富的数据可视化功能,可以通过图表、统计图、散点图等方式呈现数据。
选择“图表”菜单中的“创建”选项,选择所需的图表类型,然后指定变量和数据类型。
7. 输出结果:分析完成后,您可以查看并保存分析结果。
选择“窗口”菜单中的“输出”选项,可以查看结果,也可以导出为PDF、Excel等格式。
8. 存储与使用分析模板:您可以保存自己常用的分析和设置为模板,以便日后使用。
选择“文件”菜单中的“存储”选项,保存当前工作为模板文件。
以上是SPSS软件的基本使用教程,希望能帮助您快速上手该软件。
记住,熟能生巧,多实践和尝试,您将掌握更多的数据分析技能。
SPSS 10.0高级教程十四:Survival菜单详解

SPSS 10.0高级教程十四:Survival菜单详解(1)对于急性病的疗效考核,一般可以用治愈率、病死率等指标来评价,但对于肿瘤、结核及其他慢性疾病,其预后不是短期内所能明确判断的,这时可以对病人进行长期随访,统计一定期限后的生存和死亡情况以判断疗效,这就是生存分析。
生存分析是用于以处理生存时间(survival time)为反应变量、含有删失数据一类资料的统计方法。
所谓生存时间,狭义地讲是从某个标准时点起至死亡止,即患者的存活时间。
例如,患有某病的病人从发病到死亡或从确诊到死亡所经历的时间。
广义地说,“死亡”可定义为某研究目的“结果”的发生,如宫内节育器的失落,疾病的痊愈,女孩月经初潮的到来等(生存分析中往往统指各“死亡”为失效)。
此类资料的生存时间变量多不符从正态分布,且常含有删失值,故不适于用传统的数据分析方法如t检验或线性回归进行分析。
根据不同的研究目的和资料类型,可采用不同的分析方法,如寿命表、Kaplan-Meier法、Cox回归模型等分析方法进行分析。
而这正是下面我将要给大家介绍的主要内容。
“喂,你在这里说的都是些什么呀?又是删失、又是Cox的,搞的我一头雾水。
”那位给我提意见了。
列位看官切莫着急,且听在下慢漫道来。
所谓删失值,就是因各种原因对随访对象的随访可能失访或终检(censoring),如研究对象由于其他原因死亡、研究者与病人失去了联系及直到对资料作总结时随访对象还活着但尚未发生所规定的事件。
这种数据就叫做删失值,也叫做截尾数据。
能处理截尾数据是生存分析的一个优点。
Cox回归是一种多变量的生存分析方法。
这是本世纪60~70年代发展起来的、应用于生存资料分析的比例分险模型(the proportional hazard model)。
1972年,英国统计学家D.R.Cox的研究工作使得比例分险模型的理论和实用性更大地推进了一步。
因此许多统计学者就把它称为Cox比例风险或Cox回归。
spss基本操作完整版

spss基本操作完整版SPSS(Statistical Package for the Social Sciences)是一款广泛应用于数据分析和统计建模的软件。
它提供了一系列强大的功能和工具,可以帮助用户处理和分析大量的数据,从而得到准确的结果并支持决策制定。
本文将介绍SPSS的基本操作,并分享一些常用功能的使用方法。
一、数据导入与编辑在使用SPSS进行数据分析之前,首先需要导入要分析的数据,并对其进行编辑和整理。
下面介绍SPSS中的数据导入与编辑的基本操作。
1. 导入数据打开SPSS软件后,点击菜单栏中的"文件"选项,再选择"打开",然后选择要导入的数据文件(一般为Excel、CSV等格式)。
点击"打开"后,系统将自动将数据导入到SPSS的数据视图中。
2. 数据编辑在数据视图中,我们可以对导入的数据进行编辑,例如添加变量、删除无效数据、更改数据类型等操作。
双击变量名或者右键点击变量名,可以对变量属性进行修改。
通过点击工具栏上的"变量视图"按钮,可以进入变量视图进行更复杂的编辑。
二、数据清洗与处理数据清洗和处理是数据分析的重要步骤,它们能够提高数据的质量和可靠性。
下面介绍SPSS中的数据清洗与处理的基本操作。
1. 缺失值处理在实际的数据分析过程中,往往会遇到一些数据缺失的情况。
SPSS 提供了处理缺失值的功能,例如可以使用平均值或众数填补缺失值,也可以剔除含有缺失值的样本。
2. 数据筛选与排序当数据量较大时,我们通常需要根据一定的条件筛选出符合要求的数据进行分析。
SPSS提供了数据筛选和排序的功能,可以按照指定的条件筛选数据,并可以按照某个或多个变量进行数据排序。
三、统计分析SPSS作为统计分析的重要工具,提供了丰富的统计分析功能,下面介绍部分常用的统计分析方法。
1. 描述统计描述统计是对数据进行整体概述的统计方法,包括计数、求和、平均值、中位数、标准差、最大值、最小值等指标。
SPSS各模块菜单含义

Absolute deviationAbsolute numberAbsolute residualsAcceleration arrayAcceleration in an arbitrary direction Acceleration normalAcceleration space dimension Acceleration tangentialAcceleration vectorAcceptable hypothesisAccumulationAccuracyAcrossActual frequencyAdaptive estimatorAdditionAddition theoremAdditivityAdjusted rateAdjusted valueAdmissible errorAggregationAlternative hypothesisAmong groupsAmountsAnalysis of correlationAnalysis of covarianceAnalysis of regressionAnalysis of time seriesAnalysis of varianceAngular transformationANOVA (analysis of variance)ANOVA ModelsArcingArcsine transformationArea under the curveAREGARIMAArithmetic grid paperArithmetic meanArrhenius relationAssessing fitAssociative lawsAsymmetric distributionAsymptotic biasAsymptotic efficiencyAsymptotic varianceAttributable riskAttribute dataAttributionAutocorrelationAutocorrelation of residualsAverageAverage confidence interval length Average growth rateBar chartBar graphBase periodBayes' theoremBell-shaped curveBernoulli distributionBest-trim estimatorBiasBinary logistic regressionBinomial distributionBisquareBivariate CorrelateBivariate normal distributionBivariate normal populationBiweight intervalBiweight M-estimatorBlockBMDP(Biomedical computer programs) BoxplotsBreakdown boundCanonical correlationCaptionCaptionCase-control studyCategorical variableCatenaryCauchy distributionCause-and-effect relationshipCellCellCensoringCenter of symmetryCentering and scalingCentral tendencyCentral valueCHAID -χ2 Automatic Interaction Detector ChanceChance errorChance variableCharacteristic equationCharacteristic rootCharacteristic vectorChebshev criterion of fitChernoff facesChi-square testCholeskey decompositionCircle chartClass intervalClass mid-valueClass upper limitClassified variableCluster analysisCluster samplingCodeCoded dataCodingCoefficient of contingencyCoefficient of determinationCoefficient of multiple correlation Coefficient of partial correlation Coefficient of production-moment correlation Coefficient of rank correlationCoefficient of regressionCoefficient of skewnessCoefficient of variationCohort studyColumnColumn effectColumn factorCombination poolCombinative tableCommon factorCommon regression coefficientCommon valueCommon varianceCommon variationCommunality varianceComparabilityComparison of bathesComparison valueCompartment modelCompassionComplement of an eventComplete associationComplete dissociationComplete statisticsCompletely randomized designComposite eventComposite eventsConcavityConditional expectationConditional likelihoodConditional probabilityConditionally linearConfidence intervalConfidence limitConfidence lower limitConfidence upper limitConfirmatory Factor Analysis Confirmatory researchConfounding factorConjointConsistencyConsistency checkConsistent asymptotically normal estimate Consistent estimateConstrained nonlinear regression ConstraintContaminated distributionContaminated GausssianContaminated normal distribution ContaminationContamination modelContingency tableContourContribution rateControlControlled experimentsConventional depthConvolutionCorrected factorCorrected meanCorrection coefficientCorrectnessCorrelation coefficientCorrelation indexCorrespondenceCountingCountsCovarianceCovariantCovariateCox RegressionCriteria for fittingCriteria of least squaresCritical ratioCritical regionCritical valueCross-over designCross-section analysisCross-section surveyCrosstabsCross-tabulation tableCube rootCumulative distribution function Cumulative probabilityCurvatureCurvatureCurve fitCurve fittingCurvilinear regression Curvilinear relationCut-and-try methodCycleCyclistD testData acquisitionData bankData capacityData deficienciesData handlingData manipulationData processingData reductionData setData sourcesData transformationData validityData-inData-outDead timeDegree of freedomDegree of precisionDegree of reliability DegressionDenominatorDensity functionDensity of data points Dependent variableDependent variableDerivative matrixDerivative-free methodsDesignDeterminacyDeterminantDeterminantDeviationDeviation from averageDiagnostic plotDichotomies CountedDichotomous variableDifferential equationDirect standardizationDiscrete variableDISCRIMINANTDiscriminant analysisDiscriminant coefficient Discriminant functionDispersionDisproportionalDisproportionate sub-class numbers Distribution freeDistribution shapeDistribution-free method Distributive lawsDisturbanceDose response curveDouble blind methodDouble blind trialDouble exponential distribution Double logarithmicDownDownward rankDual-space plotDUDDuncan's new multiple range method EffectEigenvalueEigenvectorEllipseEmpirical distributionEmpirical probabilityEnumeration dataEqual sun-class numberEqually likelyEquivarianceError of estimateError type IError type IIEstimandEstimated error mean squares Estimated error sum of squares Euclidean distanceEventEventExceptional data point Expectation planeExpectation surfaceExpected valuesExperimentExperimental sampling Experimental unitExplanatory variable Exploratory data analysis Explore SummarizeExponential curveExponential growth EXSMOOTHExtended fitExtra parameterExtrapolationExtreme observationExtremesF distributionF testFactorFactor analysisFactor AnalysisFactor scoreFactorialFactorial designFalse negativeFalse negative errorFamily of distributionsFamily of estimatorsFanningFatality rateField investigationField surveyFinite populationFinite-sampleFirst derivativeFirst principal componentFirst quartileFisher informationFitted valueFitting a curveFixed baseFixed FactorsFluctuationFootnoteForecastFour fold tableFourthFraction blowFractional errorFrequencyFrequency polygonFrontier pointFunction relationshipGamma distributionGauss incrementGaussian distributionGauss-Newton incrementGeneral censusGENLOG (Generalized liner models) Geometric meanGini's mean differenceGLM (General liner models) Goodness of fitGradient of determinantGraeco-Latin squareGrand meanGross errorsGross-error sensitivityGroup averagesGrouped dataGuessed meanHalf-lifeHampel M-estimators HappenstanceHarmonic meanHazard functionHazard rateHeadingHeavy-tailed distribution Hessian arrayHeterogeneityHeterogeneity of varianceHierarchical classification Hierarchical clustering method High-leverage point HILOGLINEARHingeHistogramHistorical cohort studyHolesHOMALSHomogeneity of variance Homogeneity testHuber M-estimatorsHyperbolaHypothesis testing Hypothetical universe Impossible event IndependenceIndependent variableIndexIndirect standardization IndividualInertiaInference bandInfinite populationInfinitely greatInfinitely smallInfluence curveInformation capacityInitial conditionInitial estimateInitial levelInteractionInteraction termsInterceptInterpolationInterquartile rangeInterval estimationIntervals of equal probability Intrinsic curvatureInvarianceInverse matrixInverse probabilityInverse sine transformation IterationJacobian determinantJoint distribution function Joint probabilityJoint probability distributionK means methodKaplan-MeierKaplan-Merier chartKendall's rank correlationKineticKolmogorov-Smirnove testKruskal and Wallis testKurtosisLack of fitLadder of powersLagLarge sampleLarge sample testLatin squareLatin square designLayerLeakageLeast favorable configuration Least favorable distributionLeast significant differenceLeast square methodLeast-absolute-residuals estimates Least-absolute-residuals fitLeast-absolute-residuals line LegendL-estimatorL-estimator of locationL-estimator of scaleLevelLife expectanceLife tableLife table methodLight-tailed distribution Likelihood functionLikelihood ratioline graphLinear correlationLinear equationLinear programmingLinear regressionLinear RegressionLinear trendLoadingLocation and scale equivariance Location equivarianceLocation invarianceLocation scale familyLog rank testLogarithmic curveLogarithmic normal distribution Logarithmic scaleLogarithmic transformationLogic checkLogistic distributionLogit transformationLOGLINEARLognormal distributionLost functionLow correlationLower limitLowest-attained varianceLSDLurking variableMain effectMajor headingMarginal density function Marginal probabilityMarginal probability distribution Matched dataMatched distributionMatching of distribution Matching of transformation Mathematical expectation Mathematical modelMaximum L-estimatorMaximum likelihood methodMeanMean squares between groupsMean squares within groupMeans (Compare means)MedianMedian effective doseMedian lethal doseMedian polishMedian testMinimal sufficient statistic Minimum distance estimation Minimum effective doseMinimum lethal doseMinimum variance estimator MINITABMinor headingMissing dataModel specificationModeling StatisticsModels for outliersModifying the modelModulus of continuityMorbidityMost favorable configuration Multidimensional Scaling (ASCAL) Multinomial Logistic Regression Multiple comparisonMultiple correlationMultiple covarianceMultiple linear regression Multiple responseMultiple solutionsMultiplication theorem MultiresponseMulti-stage samplingMultivariate T distribution Mutual exclusiveMutual independenceNatural boundaryNatural deadNatural zeroNegative correlationNegative linear correlation Negatively skewedNewman-Keuls methodNK methodNo statistical significance Nominal variableNonconstancy of variability Nonlinear regression Nonparametric statistics Nonparametric test Nonparametric testsNormal deviateNormal distributionNormal equationNormal rangesNormal valueNuisance parameterNull hypothesisNumeratorNumerical variableObjective functionObservation unitObserved valueOne sided testOne-way analysis of variance Oneway ANOVAOpen sequential trialOptrimOptrim efficiencyOrder statisticsOrdered categoriesOrdinal logistic regression Ordinal variableOrthogonal basisOrthogonal design Orthogonality conditions ORTHOPLANOutlier cutoffsOutliersOVERALSOvershootPaired designPaired samplePairwise slopesParabolaParallel testsParameterParametric statistics Parametric testPartial correlationPartial regressionPartial sortingPartials residualsPatternPearson curvesPeelingPercent bar graph PercentagePercentilePercentile curvesPercentile ValuesPeriodicityPermutationP-estimatorPie graphPitman estimatorPivotPlanarPlanar assumptionPLANCARDSPoint estimationPoisson distributionPolishingPolled standard deviationPolled variancePolygonPolynomialPolynomial curvePopulationPopulation attributable riskPositive correlationPositively skewedPosterior distributionPower of a testPrecisionPredicted valuePreliminary analysisPrincipal component analysisPrior distributionPrior probabilityProbabilistic modelprobabilityProbability densityProduct momentProfile traceProportionProportion allocation in stratified random sampling ProportionateProportionate sub-class numbersProspective studyProximitiesPseudo F testPseudo modelPseudosigmaPurposive samplingQR decompositionQuadratic approximationQualitative classificationQualitative methodQuantile-quantile plotQuantitative analysisQuartileQuick ClusterRadix sortRandom allocationRandom blocks designRandom eventRandom Factors RandomizationRangeRank correlationRank sum testRank testRanked dataRateRatioRaw dataRaw residualRayleigh's testRayleigh's ZReciprocalReciprocal transformation RecordingRedescending estimators Reducing dimensionsRe-expressionReference setRegion of acceptance Regression coefficient Regression sum of square Rejection pointRelative dispersion Relative numberReliability Reparametrization ReplicationReport SummariesResidual sum of square ResistanceResistant lineResistant techniqueR-estimator of location R-estimator of scale Retrospective studyRidge traceRidit analysisRotationRoundingRowRow effectsRow factorRXC tableSampleSample regression coefficient Sample sizeSample standard deviation Sampling errorSAS(Statistical analysis system ) ScaleScatter diagramSchematic plotScore testScreeningSEASONSecond derivativeSecond principal componentSEM (Structural equation modeling) Semi-logarithmic graphSemi-logarithmic paperSensitivity curveSeparateSequential analysisSequential data setSequential designSequential methodSequential testSerial testsShort-cut methodSigmoid curveSign functionSign testSigned rankSignificance testSignificant figureSimple cluster samplingSimple correlationSimple random samplingSimple regressionsimple tableSine estimatorSingle-valued estimateSingular matrixSingular ValueSkewed distributionSkewnessSlash distributionSlopeSmirnov testSource of variationSpearman rank correlationSpecific factorSpecific factor varianceSpectraSpherical distributionSpreadSPSS(Statistical package for the social science) Spurious correlationSquare root transformationStabilizing varianceStandard deviationStandard errorStandard error of differenceStandard error of estimateStandard error of rateStandard normal distributionStandardizationStarting valueStatisticStatistical controlStatistical graphStatistical inferenceStatistical tableSteepest descentStem and leaf displayStep factorStepwise regressionStorageStrataStratified samplingStratified samplingStrengthStringencyStructural relationshipStudentized residualSub-class numbersSubdividingSufficient statisticSum of productsSum of squaresSum of squares about regressionSum of squares between groupsSum of squares of partial regressionSummarySure eventSurveySurvivalSurvival rateSuspended root gramSymmetrySystematic errorSystematic samplingTagsTail areaTail lengthTail weightTangent lineTarget distributionTaylor seriesTendency of dispersionTesting of hypothesesTheoretical frequencyTime seriesTitleTolerance intervalTolerance lower limitTolerance upper limitTorsionTotal sum of squareTotal variationTransformationTreatmentTrendTrend of percentageTrialTrial and error methodTuning constantTwo sided testTwo-stage least squaresTwo-stage samplingTwo-tailed testTwo-way analysis of varianceTwo-way tableType I errorType II errorUMVUUnbiased estimateUnconstrained nonlinear regressionUnequal subclass numberUngrouped dataUniform coordinateUniform distributionUniformly minimum variance unbiased estimate UnitUnordered categoriesUpper limitUpward rankVague conceptValidityVARCOMP (Variance component estimation) VariabilityVariableVarianceVariationVarimax orthogonal rotationVolume of distributionW testWeibull distributionWeightWeighted Chi-square testWeighted linear regression method Weighted meanWeighted mean squareWeighted sum of squareWeighting coefficientWeighting methodW-estimationW-estimation of locationWidthWilcoxon paired testWild pointWild valueWinsorized meanWithdrawWLSYouden's indexZ testZero correlationZ-transformationPCT OF CASEPCT OF RESPONSEMODE绝对离差绝对数绝对残差加速度立体阵任意方向上的加速度法向加速度加速度空间的维数切向加速度加速度向量可接受假设累积准确度报表中列控制变量 COLUMN实际频数自适应估计量相加加法定理可加性调整率校正值容许误差聚集性备择假设组间总量相关分析协方差分析回归分析时间序列分析方差分析角转换方差分析方差分析模型弧/弧旋反正弦变换曲线面积评估从一个时间点到下一个时间点回归相关时的误差季节和非季节性单变量模型的极大似然估计算术格纸算术平均数艾恩尼斯关系拟合的评估结合律非对称分布渐近偏倚渐近效率渐近方差归因危险度属性资料属性自相关残差的自相关平均数平均置信区间长度平均增长率条形图条形图基期Bayes定理钟形曲线伯努力分布最好切尾估计量偏性二元逻辑斯蒂回归二项分布双平方二变量相关双变量正态分布双变量正态总体双权区间双权M估计量区组/配伍组BMDP统计软件包箱线图/箱尾图崩溃界/崩溃点典型相关纵标目说明病例对照研究分类变量悬链线柯西分布因果关系单元表单元终检对称中心中心化和定标集中趋势中心值卡方自动交互检测机遇随机误差随机变量特征方程特征根特征向量拟合的切比雪夫准则切尔诺夫脸谱图卡方检验/χ2检验乔洛斯基分解圆图组距组中值组上限分类变量聚类分析整群抽样代码编码数据编码列联系数决定系数多重相关系数偏相关系数积差相关系数等级相关系数回归系数偏度系数变异系数队列研究列列效应列因素合并组合表共性因子公共回归系数共同值公共方差公共变异共性方差可比性批比较比较值分部模型伸缩补事件完全正相关完全不相关完备统计量完全随机化设计联合事件复合事件凹性条件期望条件似然条件概率依条件线性置信区间置信限置信下限置信上限验证性因子分析证实性实验研究混杂因素联合分析相合性一致性检验相合渐近正态估计相合估计受约束非线性回归约束污染分布污染高斯分布污染正态分布污染污染模型列联表边界线贡献率对照对照实验常规深度卷积校正因子校正均值校正系数正确性相关系数相关指数对应计数计数/频数协方差共变协变量 必须为连续型数值变量Cox回归拟合准则最小二乘准则临界比拒绝域临界值交叉设计横断面分析横断面调查交叉表复合表立方根分布函数累计概率曲率/弯曲曲率曲线拟和曲线拟合曲线回归曲线关系尝试法周期周期性D检验资料收集数据库数据容量数据缺乏数据处理数据处理数据处理数据缩减数据集数据来源数据变换数据有效性数据输入数据输出停滞期自由度精密度可靠性程度递减分母密度函数数据点的密度应变量/依变量/因变量因变量深度导数矩阵无导数方法设计确定性行列式决定因素离差离均差诊断图多项式二分法二分变量微分方程直接标准化法离散型变量判断判别分析判别系数判别值散布/分散度不成比例的不成比例次级组含量分布无关性/免分布分布形状任意分布法分配律随机扰动项剂量反应曲线双盲法双盲试验双指数分布双对数报表中行控制变量 ROW 降秩对偶空间图无导数方法新复极差法/Duncan新法实验效应特征值特征向量椭圆经验分布经验概率单位计数资料相等次级组含量等可能同变性估计误差第一类错误第二类错误被估量估计误差均方估计误差平方和欧式距离事件事件异常数据点期望平面期望曲面期望值实验试验抽样试验单位说明变量探索性数据分析探索-摘要指数曲线指数式增长指数平滑方法扩充拟合附加参数外推法末端观测值极端值/极值F分布F检验因素/因子因子分析因子分析因子得分阶乘析因试验设计假阴性假阴性错误分布族估计量族扇面病死率现场调查现场调查有限总体有限样本一阶导数第一四分位数费雪信息量拟合值曲线拟合定基固定因素变量 必须为分类变量随机起伏表下注预测四格表四分点左侧比率相对误差频率频数多边图界限点泛函关系伽玛分布高斯增量高斯分布/正态分布高斯-牛顿增量全面普查广义线性模型几何平均数基尼均差一般线性模型拟和优度/配合度行列式的梯度希腊拉丁方总均值重大错误大错敏感度分组平均分组资料假定平均数半衰期汉佩尔M估计量偶然事件调和均数风险均数风险率标目重尾分布海森立体阵不同质方差不齐组内分组系统聚类法高杠杆率点多维列联表的层次对数线性模型折叶点直方图历史性队列研究空洞多重响应分析方差齐性齐性检验休伯M估计量双曲线假设检验假设总体不可能事件独立性自变量指标/指数间接标准化法个体特征根推断带无限总体无穷大无穷小影响曲线信息容量初始条件初始估计值最初水平交互作用交互作用项截距内插法四分位距区间估计等概率区间固有曲率不变性逆矩阵逆概率反正弦变换迭代雅可比行列式分布函数联合概率联合概率分布逐步聚类法评估事件的时间长度Kaplan-Merier图Kendall等级相关动力学柯尔莫哥洛夫-斯米尔诺夫检验Kruskal及Wallis检验/多样本的秩和检验/H检验峰度失拟幂阶梯滞后大样本大样本检验拉丁方拉丁方设计表层泄漏最不利构形最不利分布最小显著差法最小二乘法最小绝对残差估计最小绝对残差拟合最小绝对残差线图例L估计量位置L估计量尺度L估计量水平预期期望寿命寿命表生命表法轻尾分布似然函数似然比线图直线相关线性方程线性规划直线回归线性回归线性趋势载荷位置尺度同变性位置同变性位置不变性位置尺度族时序检验对数曲线对数正态分布对数尺度对数变换逻辑检查逻辑斯特分布Logit转换多维列联表通用模型对数正态分布损失函数低度相关下限最小可达方差最小显著差法的简称潜在变量主效应主辞标目边缘密度函数边缘概率边缘概率分布配对资料匹配过分布分布的匹配变换的匹配数学期望数学模型极大极小L估计量最大似然法均数组间均方组内均方均值-均值比较中位数半数效量半数致死量中位数平滑中位数检验最小充分统计量最小距离估计最小有效量最小致死量最小方差估计量统计软件包宾词标目缺失值模型的确定模型统计离群值模型模型的修正连续性模发病率最有利构形多维尺度/多维标度多项逻辑斯蒂回归多重比较复相关多元协方差多元线性回归多重选项多解乘法定理多元响应多阶段抽样多元T分布互不相容互相独立自然边界自然死亡自然零负相关负线性相关负偏q检验q检验无统计意义名义变量变异的非定常性非线性相关非参数统计非参数检验非参数检验正态离差正态分布正规方程组正常范围正常值多余参数/讨厌参数无效假设分子数值变量目标函数观察单位观察值单侧检验单因素方差分析单因素方差分析开放型序贯设计优切尾优切尾效率顺序统计量有序分类序数逻辑斯蒂回归有序变量正交基正交试验设计正交条件正交设计离群值截断点极端值多组变量的非线性正规相关迭代过度配对设计配对样本成对斜率抛物线平行试验参数参数统计参数检验偏相关偏回归偏排序偏残差模式皮尔逊曲线退层百分条形图百分比百分位数百分位曲线分位值周期性排列P估计量饼图皮特曼估计量枢轴量平坦平面的假设生成试验的计划卡点估计泊松分布平滑合并标准差合并方差多边图多项式多项式曲线总体人群归因危险度正相关正偏后验分布检验效能精密度预测值预备性分析主成分分析先验分布先验概率概率模型概率概率密度乘积矩/协方差截面迹图比/构成比按比例分层随机抽样成比例成比例次级组含量前瞻性调查亲近性近似F检验近似模型伪标准差有目的抽样QR分解二次近似属性分类定性方法分位数-分位数图/Q-Q图定量分析四分位数快速聚类基数排序随机化分组随机区组设计随机事件随机因素变量 必须为分类变量随机化极差/全距等级相关秩和检验秩检验等级资料比率比例原始资料原始残差雷氏检验雷氏Z值倒数倒数变换记录回降估计量降维重新表达标准组接受域回归系数回归平方和拒绝点相对离散度相对数可靠性重新设置参数重复报告摘要剩余平方和耐抗性耐抗线耐抗技术位置R估计量尺度R估计量回顾性调查岭迹Ridit分析旋转舍入行行效应行因素RXC表样本样本回归系数样本量样本标准差抽样误差SAS统计软件包尺度/量表散点图示意图/简图计分检验筛检季节分析二阶导数第二主成分结构化方程模型半对数图半对数格纸敏感度曲线报表中表控制变量 SEPARATE 贯序分析顺序数据集贯序设计贯序法贯序检验法系列试验简捷法S形曲线正负号函数符号检验符号秩显著性检验有效数字简单整群抽样简单相关简单随机抽样简单回归简单表正弦估计量单值估计奇异矩阵奇异值偏斜分布偏度斜线分布斜率斯米尔诺夫检验变异来源斯皮尔曼等级相关特殊因子方差频谱球型正态分布展布SPSS统计软件包假性相关平方根变换稳定方差标准差标准误差别的标准误标准估计误差率的标准误标准正态分布标准化起始值统计量统计控制统计图统计推断统计表最速下降法茎叶图步长因子逐步回归存层(复数)分层抽样分层抽样强度严密性结构关系学生化残差/t化残差次级组含量分割充分统计量积和离差平方和回归平方和组间平方和偏回归平方和报表中汇总变量必然事件调查生存分析生存率对称系统误差系统抽样标签尾部面积尾长尾重切线目标分布泰勒级数离散趋势假设检验理论频数时间序列标题容忍区间容忍下限容忍上限扰率总平方和总变异转换处理趋势百分比趋势试验试错法细调常数双向检验二阶最小平方二阶段抽样双侧检验双因素方差分析双向表一类错误/α错误二类错误/β错误方差一致最小无偏估计简称无偏估计无约束非线性回归不等次级组含量不分组资料均匀坐标均匀分布方差一致最小无偏估计单元无序分类上限升秩模糊概念有效性方差元素估计变异性变量方差变异方差最大正交旋转容积W检验威布尔分布权数加权卡方检验/Cochran检验加权直线回归加权平均数加权平均方差加权平方和权重系数加权法W估计量位置W估计量宽度威斯康星配对法/配对符号秩和检验野点/狂点野值/狂值缩尾均值失访加权变量尤登指数Z检验零相关Z变换复选次数占个案数的比例复选次数占总次数的比例众数。
spss操作指南

案例一——SPSS介绍学习目标:初步认识SPSS软件的内容一、SPSS界面说明SPSS for Windows是SPSS的Windows版本,具有Windows软件的共同特点,其界面十分友好,打开SPSS程序就会出现图1-2界面。
标题栏菜单栏工具栏数据栏标签图1-2 SPSS 11.5 for Windows 界面该界面为SPSS 的数据编辑窗口,其组成部分及主要功能如下:1. 标题栏:功能与其它Windows软件一致。
2.菜单栏:由10个菜单项组成,每个菜单包括一系列功能。
各菜单的主要功能如下。
2.1 File:文件操作菜单。
单击Fil e,有图1-3下拉菜单,主要功能包括:·New:新建数据编辑窗口、语句窗口、结果输出窗口等;·Open和Open Database:打开数据编辑窗口、语句窗口、结果输出窗口等;·Read Text Data:读入文本文件;·Save和Save As:保存文件;·Display Data Info:显示数据的基本信息;·Prin t和Print Preview:将数据管理窗口中的数据以表格的形式打印出来。
图1-3 File菜单项的下拉菜单图1-4 Edit菜单项的下拉菜单2.2 Edit:文件编辑菜单。
主要用于数据编辑,如图1-4,主要功能包括:·UndoRedo或modify cell values:撤消或恢复刚修改过的观测值;·cut,copy,paste:剪切、拷贝、粘贴指定的数据;·paste variables:粘贴指定的变量;·clear:清除所选的观测值或变量;·find:查找数据。
2.3 View:视图编辑菜单。
用于视图编辑,进行窗口外观控制。
包含显示/隐藏切换、表格特有的隐藏编辑/显示功能及字体设置等功能。
2.4 Data:数据文件建立与编辑菜单。
SPSS常用分析方法操作步骤

SPSS常用分析方法操作步骤SPSS是一款常用的统计分析软件,可以用于数据处理、数据分析、数据可视化等任务。
下面将介绍SPSS常用的分析方法及其操作步骤。
一、描述性统计1.打开SPSS软件,在菜单栏选择“统计”-“概要统计”-“描述性统计”。
2.将需要进行描述性统计的变量拉入“变量”框中,点击“统计”按钮选择需要计算的统计量,例如均值、中位数、标准差等。
3.点击“图表”按钮可以选择绘制直方图、箱线图等图表形式。
确定参数后点击“OK”按钮,即可得到描述性统计结果。
二、相关分析1.打开SPSS软件,在菜单栏选择“分析”-“相关”-“双变量”。
2.将需要进行相关分析的变量拉入“变量1”和“变量2”框中,点击“OK”按钮即可得到相关系数。
3.如果需要进行多变量相关分析,可以选择“分析”-“相关”-“多变量”来进行操作。
三、T检验1.打开SPSS软件,在菜单栏选择“分析”-“比较手段”-“独立样本T检验”或“相关样本T检验”。
2.将需要进行T检验的变量拉入“因子”框中,点击“OK”按钮即可得到T检验结果。
四、方差分析1.打开SPSS软件,在菜单栏选择“分析”-“一般线性模型”-“一元方差分析”。
2.将需要进行方差分析的因变量拉入“因变量”框中,将因子变量拉入“因子”框中,点击“OK”按钮即可得到方差分析结果。
3.如果需要进行多因素方差分析,可以选择“分析”-“一般线性模型”-“多元方差分析”来进行操作。
五、回归分析1.打开SPSS软件,在菜单栏选择“回归”-“线性”。
2.将需要进行回归分析的因变量和自变量拉入对应的框中,点击“统计”按钮选择需要计算的统计量,例如R平方、标准误差等。
3.如果想同时进行多个自变量的回归分析,可以选择“方法”选项卡,在“逐步回归”中进行设置。
六、聚类分析1.打开SPSS软件,在菜单栏选择“分析”-“分类”-“聚类”。
2.将需要进行聚类分析的变量拉入“加入变量”框中,点击“聚类变量”按钮选择需要进行聚类的变量。
SPSS基本操作讲解

SPSS基本操作讲解SPSS是一种常用的统计分析软件,具有强大的数据处理和分析功能。
在使用SPSS进行数据分析时,我们需要进行一些基本操作来导入数据、整理数据、进行统计分析和绘制图表。
下面将从四个方面介绍SPSS的基本操作。
一、数据导入和整理1. 导入数据:将数据导入SPSS,可以通过菜单栏的“文件”-“打开”来选择要导入的数据文件,也可以直接拖拽数据文件到SPSS窗口中。
导入的数据文件可以是Excel、CSV等格式。
2.查看数据:导入数据后,可以通过菜单栏的“数据”-“查看数据”来查看导入的数据。
可以查看数据的全部内容或部分内容,以便对数据进行了解。
二、数据的统计分析1.描述统计分析:可以通过菜单栏的“分析”-“描述性统计”来进行描述性统计分析,包括均值、标准差、最小值、最大值、中位数等指标。
可以选择需要分析的变量,也可以选择按照分类变量进行分组分析。
2.参数统计分析:可以通过菜单栏的“分析”-“参数估计”来进行参数统计分析,包括t检验、方差分析、回归分析等。
选择相应的分析方法后,可以设定自变量和因变量,进行参数估计和显著性检验。
3. 非参数统计分析:可以通过菜单栏的“分析”-“非参数检验”来进行非参数统计分析,比如Wilcoxon符号秩检验、Mann-Whitney U检验、Kruskal-Wallis检验等。
选择相应的分析方法后,可以设定自变量和因变量,进行非参数统计分析。
三、数据的处理和转换1.数据清洗:在数据分析过程中,往往需要对数据进行清洗,去除异常值、缺失值等。
可以通过菜单栏的“数据”-“选择特定数据”来选择其中一列数据,并根据设定的条件进行数据筛选和清洗。
2.数据缺失处理:可以通过菜单栏的“数据”-“缺失值处理”来处理缺失值。
可以选择将缺失值替换为均值、中位数或者一些固定值,也可以根据自己的需要进行其他处理方法。
3.数据变量的转换:在进行统计分析时,有时需要对数据变量进行转换。
可以通过菜单栏的“数据”-“转换变量”来进行数据变量的转换,比如对变量进行对数变换、标准化等。
SPSS的主要菜单与基础统计

SPSS的主要菜单与基础统计1. 简介SPSS(Statistical Package for Social Sciences)是一款用于统计分析和数据管理的软件。
它提供了一系列的统计工具和功能,方便用户进行数据分析、建模和可视化等操作。
本文将介绍SPSS的主要菜单和一些基础统计方法。
2. 主要菜单SPSS的主要菜单位于顶部菜单栏,包括文件(File)、编辑(Edit)、数据(Data)、转换(Transform)、分析(Analyze)、图表(Graphs)、窗口(Windows)和帮助(Help)等菜单。
2.1 文件(File)菜单在文件(File)菜单中,用户可以新建、打开或保存SPSS数据文件。
此外,还可以对数据文件进行导入、导出和打印等操作。
2.2 编辑(Edit)菜单编辑(Edit)菜单提供了一系列编辑数据的选项。
用户可以在此菜单中进行数据的复制、粘贴、删除和查找等操作。
2.3 数据(Data)菜单数据(Data)菜单提供了对数据进行预处理和数据管理的功能。
用户可以在此菜单中对数据进行排序、逻辑运算和缺失值处理等操作。
2.4 转换(Transform)菜单转换(Transform)菜单包含了一些数据转换和重构的功能。
用户可以在此菜单中进行数据的合并、拆分和重编码等操作。
2.5 分析(Analyze)菜单分析(Analyze)菜单是SPSS最主要的功能菜单之一,包含了各种统计分析方法和模型。
用户可以在此菜单中进行描述统计、方差分析、回归分析等各类统计方法。
2.6 图表(Graphs)菜单图表(Graphs)菜单提供了多种可视化图表的绘制功能。
用户可以在此菜单中绘制柱状图、折线图、散点图等各种统计图表。
2.7 窗口(Windows)菜单窗口(Windows)菜单用于管理SPSS界面的窗口和视图。
用户可以在此菜单中打开、关闭或排列各个窗口。
2.8 帮助(Help)菜单帮助(Help)菜单提供了SPSS的帮助文档和在线资源的访问。
Spss菜单解释

SpssData菜单Transform菜单Accuracy 精确度,actual frequency 实际频数,adjusted value 校正值,alternative hypothesis 备选假设,analysis of convariance 协方差分析,analysis of variance, ANOV A 方差分析,arithmetic mean 算数均数,asymmetric distribution 非对称分布,autocorrelation 自相关,censored data 截尾数据,censoring 删失失访终检,central limit theorem 中心极限定理,central tendency 集中趋势,chance error 随机误差,class mid-value 组中值,cluster analysis 聚类分析,cluster sampling 整群抽样,coding 编码,coefficient of contingency 列联系数,coefficient of correlation 相关系数,bar chart 条图,bayes theorem 贝叶斯定理,bias 偏性,binomial distribution 二项分布,bivariate normal distribution 双变量正态分布,block 区组,box plot 箱图,canonical correlation 典型相关,case-control study 病例一一对照研究,categorical variable 分类变量,cell 单元,coefficient of determination 决定系数,coefficient ofpartial correlation 偏相关系数,coefficient of product-moment correlation 积差相关系数,coefficient of rank correlation 等级相关系数,coefficient of regression 回归系数,coefficient of variation 变异系数,coefficient of skewness 偏度系数,cohort study 队列研究,communality variance 公共方差,comparability 可比性,complete association 完全相关,complete random design 完全随机设计,degree of freedom 自由度,conditional likelihood 条件似然,conditional probability 条件概率,confidence interval CI 可信(置信)区间,confidence limit CL 可信(置信)限,confirmatory factor analysis 验证性因子分析,confirmatory research 验证性研究,degree of reliability 可靠度,density function 密度函数,dependent variable 因变量,deviation 离差,discrete variable 离散变量,discriminant analysis 判别分析,conjoint analysis 联合分析,consistency test 一致性检验,constraint 约束,contingency table 列联表,contribution rate 贡献率,control 对照控制,controlled experiments 对照实验,correction 校正,correction for continuity 连续性校正,correlation 相关,correlation analysis 相关分析,correlation coefficient 相关系数,distribution 分布,distribution-free method 任意分布方法分布自由方法,dose response curve 剂量反应曲线,dummy variable 哑变量虚拟变量,eigenvalue 特征值特征根,eigenvector 特征向量,equivariance 等方差,error 误差,error of estimate 估计误差,estimated value 估计值,correspondence analysis 对应分析,counts 计数频数,covariance 协方差,Cox regression Cox回归,criteria for fitting 拟合准则,critical value 临界值,cross-over design 交叉设计,cross-section analysis 横断面分析,eigenvalue特征值,特征根eigenvector 特征向量equivariance等方差error误差error of estimate估计误差estimated value估计值euclidean distance欧氏距离event事件expected values期望值design of experiment实验设计exploratory data analysis探索性数据分析exponential curve指数曲线extrapolation外推法extremes极端值,极值,forecast预测fourfold table四格表frequency频数frequency distribution 频数分布general linear model, GLM一般线性模型generalized linear model广义线性模型geometric mean几何均数goodness of fit拟合优度,half-life半衰期harmonic mean调和均数hazard function风险函数,hazard rate风险率heterogeneity异质heterogeneity of variance方差不齐heteroscedasticity 方差不齐hierarchical clustering method分层聚类法histogram直方图homogeneity同质,齐性,homogeneity of variance同方差性homogeneity test齐性检验homoscedasticity方差齐性hypothesis test假设检验,independence独立性independent variable自变量initial mean vectors初始凝聚点interaction交互效应intercept截距interpolation 插值inter-quartile range四分位数间距,interval estimation区间估计inverse matrix逆矩阵iteration迭代,K-means method K-均值聚类法Kaplan-Merier curve Kaplan-Merier 曲线kendall srank correlationKendall等级相关Kolmogorov-Smirnov test K-S检验Kruskal and Wallis test K-W检验,H检验kurtosis峰度L lack offit拟合劣度,失拟Latin square design拉丁方设计least square method最小二乘法legend图例level水平level of significance统计意义水平,life table寿命表likelihood function似然函数likelihood ratio test似然比检验line graph线图linear线性linear correlation直线相关linear equation线性方程linear programming线性规划linear regression线性回归,linear trend线性趋势loading载荷log-rank test时序检验logarithmic scale对数尺度logistic regression logistic回归logit transformation logit转换loglinear model对数线性模型M main effect主效应matched data配对资料matching匹配maximum likelihood method最大似然法maximum likelihood ratio test似然比检验,mean均值mean square,MS均方measurement bias测量性偏倚median中位数median effective dose半数效量median lethal dose半数致死量median survival time中位生存时间median test中位数检验M-estimators M估计量minimumlethal dose最小致死量missing value缺失值multidimensional scaling analysis, MDS多维尺度分析,multinomial distribution多项分布multiple comparison多重比较multiple correlation复相关,多重相关multiple covariance多元协方差multiple linear regression多重线性回归multiple response多重应答,多选题multistage sampling多级抽样multivariate regression多元回归multivariate statistical analysis多变量统计分析,多元统计分析,negative correlation负相关no statistical significance无统计学意义nominal variable名义变量nonlinear regression非线性回归nonparametric statistics非参数统计nonparametric test非参数检验normal distribution正态分布null hypothesis原假设,无效假设numerical variable数值变量O observation unit 观察单位observed value观测值odds ratio,OR优势比,比数比,one-sided test单侧检验one-way ANOV A单因素方差分析optimum allocation最优分配order statistics顺序统计量ordered categories有序分类orthogonal experimental design正交试验设计outlier异常值,离群值overall survey普查P paired design配对设计paired(matched)t-test配对t检验parameter参数,parametric statistics参数统计parametric test参数检验partial correlation 偏相关partial likelihood偏似然函数partial regression coefficient偏回归系数path analysis路径分析percent bar graph百分条图percentage百分比,百分数percentile百分位数,位点periodicity周期性pie graph饼图,圆图,placebo安慰剂point estimation点估计Poisson distribution Poisson分布polynomial curve多项式曲线population总体population mean 总体均值positive correlation正相关posterior distribution后验分布power ofa test检验效能power ofstatistics检验效能precision精度principal component analysis主成分分析prior distribution先验分布product moment乘积矩,协方差,product-limit method乘积极限法proportion构成比prospective study前瞻性研究P-value P值Q qualitative evaluation定性评价qualitative method定性方法quantile-quantile plot Q-Q图quantitative analysis定量分析quantitative evaluation定量评价quartile四分位数questionnaire问卷quick cluster 快速聚类,random event随机事件random sampling随机抽样randomization随机化randomized allocation随机分配randomized block design随机区组设计randomized control trial随机对照试验randomized double blind control trial随机双盲对照试验range极差,全距rank correlation等级(秩)相关rank sum test秩和检验,ranked data等级资料rate率ratio比raw data原始资料regression analysis回归分析regression coefficient 回归系数regression SS回归平方和relative number相对数relative risk,RR相对危险度reliability可靠度,信度replacement level更替水平,residual 残差residual standard deviation 剩余标准差,residual sum of square残差平方和ridge trace岭迹ridit analysis Ridit 分析risk ratio危险比,风险比rotation旋转r×c table r×c表S sample样本sample size 样本量sampling error抽样误差sampling fraction抽样比sampling study抽样研究sampling survey抽样调查,scale测量尺度scatter diagram散点图score test比分检验screening筛检selection bias选择性偏倚semilogarithmic line graph半对数线图sequential design序贯设计sign test符号检验signed rank符号秩significance level显著性水准significance test显著性检验simple correlation简单相关simple regression简单回归,skewness偏度slope斜率spearman rank correlationspearman等级相关spherical distribution球型分布standard deviation,SD标准差,标准离差standard error,SE标准误,标准误差standard normal distribution标准正态分布standardization标准化standardized partial regression coefficient标准化偏回归系数statistic统计量statistical control统计控制,statistical graph统计图statistical inference统计推断statistical significance统计学意义statistical table统计表stem and leaf graph茎叶图step-wise method逐步法strata层(复数)stratification分层stratified cluster sampling分层整群抽样stratified sampling分层抽样structural equation modeling结构方程模型sum ofsquares离差平方和sum ofsquares of deviations from mean 离均差平方和,survey调查survival analysis生存分析survival curve生存曲线survival probability生存概率survival rate生存率survival time生存时间symmetry对称synthetic index综合指数synthetical evaluation综合评价systematic error 系统误差,systematic sampling系统抽样T t-distribution t分布tendency of dispersion 离散趋势test statistic检验统计量testing of hypotheses假设检验theoretical frequency理论频数time series analysis时间序列分析,t-test t检验two-sided test双侧检验two-stage least squares method二阶段最小二乘法two-stage sampling二阶段抽样two-step cluster 两步聚类法two-tailed probability双尾概率two-tailed test双侧检验two-way ANOV A两因素方差分析two-way table双向表type I error I类错误type II error II类错误,unbiased estimate无偏估计uniform distribution均匀分布upper limit上限u-test u检验V variable变量variance方差variance component estimation方差分量估计varimax orthogonal rotation方差最大化正交旋转,weight权重weighted linear regressionmethod 加权直线回归weighting method加权法Z zero correlation零相关z-transformation标准正态(z)变换,各种情形下最常用统计检验方法索引1 单变量连续但样本t检验有序多分类单样本秩和检验无序多分类单样本x2检验二分类二项分布确切概率法2 因变量:连续变量单个自变量:连续相关分析,回归分析有序多分类单因素方差分析,结果解释时利用有序信息无序多分类单因素方差分析二分类两样本 检验多个自变量:连续变量为主线形回归模型分类变量为主方差分析模型,和回归模型实际上等价3 因变量:有序分类变量单个自变量:连续有序分类的Logistic回归有序多分类秩相关分析、CMH x2无序多分类多样本秩和检验(H检验)二分类两样本秩和检验(W检验)多个自变量:连续变量为主有序分类的判别分析,有序分类的Logistic回归分类变量为主有序分类的Logistic回归4 因变量:无序分类变量单个自变量:连续无序分类的Logistic回归有序多分类可将自因变量交换后分析无序多分类x2检验,深入分析可用对数线性模型二分类x2检验多个自变量:连续变量为主判别分析、无序分类的Logistic回归分类变量为主无序分类的Logistic回归5 因变量:二分类变量单个自变量:连续二分类Logistic回归有序多分类可将自/因变量交换后分析无序多分类x2检验,二分类的Logistic回归二分类四格表x2检验,确切概率法多个自变量:连续变量为主判别分析、二分类Logistic回归、两法结果实际等价分类变量为主二分类Logistic回归6 多元分析方法考察的特征需要由多个因素量来表示,同时研究多个自变量对他们的影响:多元方差分析模型、多元回归模型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hierarchical Cluster 样本聚类和变量聚类 Discriminate 判别分析
Statistics统计
Data Reduction——Factor 因子分析 Scale——Reliability Analysis可靠性分析
P-P图 Q-Q图
转置数据库时注意首先打开SPSS软件, 然后新建
New Nonparametric Tests 非参数检验
——Chi-Square 卡方经验
Graphs图
Gallery图形转换 Interactive交互式图——Bar条图
Dot点图 Line 线图 Ribbon条带图 Drop-Line垂线图 Pie饼图
Graphs图
Bar条图 Line线图 Area面积图 Pie饼图 Scatter散点图 Histogram直方图
Statistics统计
Custom tables表格组——Basic tables基本表 General tables总表
Multiple response tables多重反应表 Tables of frequencies频率表
Statistics统计
Compare means比较平均值—Means平均值 One-Sample T Test一维样本T检验
Independent-Samples T Test独立样本T检验 Paired-Samples T Test配对样本T检验 One-Way ANOVA一维方差分析
Statistics统计
General Linear Model——Univariable单因变量 方差分析
Correlate相关——Bivariate 双变量相关 Regression回归分析——Linear 线性回归
Transform转化
Compute 生成新变量 Recode转化成新变量
Statistics统计
Summarize概括数据——Frequencies频率 Descriptives描述 Explore探索
Crosstabs交叉表格 Layered reports分层报告 Case summaries概述案例
SPSS菜单说明
File 文件
New新建——Data 数据库 Open打开 Save 保存 Save as 另存 Print 打印
Edit 编辑
Undo撤消 Cut 剪切 Copy复制 Paste粘贴 Clear清除
Data数据
Define variable定义变量 Insert variable插入变量 Insert case插入案例 Go to case查找 Sort cases排序 Transpose 转置 Select cases选择案例