数据库保留字
数据库命名规范

数据库命名规范数据库命名规范是指在设计和管理数据库时,为数据库、数据表、字段等各个元素命名时应遵循的一些规则和约定。
良好的数据库命名规范可以提高数据库的可读性、可维护性和易用性。
下面是一个较为详细的数据库命名规范,总计1000字。
1. 数据库命名规范1.1 数据库名应该具有描述性,能够清晰地表达数据库所存储的数据的含义。
1.2 数据库名应该使用小写字母,并可以使用下划线(_)进行分隔,以提高可读性。
1.3 不要使用特殊字符、空格或保留字作为数据库名。
2. 表命名规范2.1 表名应该使用小写字母,并可以使用下划线(_)进行分隔,以提高可读性。
2.2 表名应使用单数形式,避免使用复数形式。
2.3 表名应具有描述性,能够清晰地表达表的含义。
3. 字段命名规范3.1 字段名应使用小写字母,并可以使用下划线(_)进行分隔,以提高可读性。
3.2 字段名应具有描述性,能够清晰地表达字段的含义。
3.3 字段名应使用名词或名词短语,避免使用动词作为字段名。
3.4 字段名不应过长,一般不超过30个字符。
3.5 字段名不应使用保留字,以免造成歧义。
4. 主键命名规范4.1 主键字段名应使用表名加上“_id”的形式,以提高可读性。
4.2 主键字段名应具有描述性,能够清晰地表达主键的含义。
4.3 主键字段名应使用具体的名词,不应使用抽象的名词作为主键字段名。
5. 外键命名规范5.1 外键字段名应使用被关联表名加上“_id”的形式,以提高可读性。
5.2 外键字段名应具有描述性,能够清晰地表达外键的含义。
5.3 外键字段名应使用被关联表的主键字段名作为前缀,以区分不同的外键。
6. 索引命名规范6.1 索引名应使用小写字母,并可以使用下划线(_)进行分隔,以提高可读性。
6.2 索引名应具有描述性,能够清晰地表达索引的含义。
6.3 索引名应使用被索引的字段名作为前缀,以便于识别和管理。
7. 视图命名规范7.1 视图名应使用小写字母,并可以使用下划线(_)进行分隔,以提高可读性。
数据库字段命名规范

数据库字段命名规范数据库字段命名规范是指在设计和命名数据库表的时候,应该遵守的一些规则和规范,目的是为了提高数据库的可读性、可维护性和可扩展性。
1. 使用有意义的名称:字段名称应该能够清晰地表达其含义和作用,避免使用缩写或者过于简短的名称。
2. 采用统一的命名约定:选择一种命名风格(如驼峰命名法、下划线命名法等)并坚持使用,以确保数据库表结构的一致性。
3. 保持简洁性:尽量使用简短的字段名称,避免过长的名称,以提高可读性和节省存储空间。
4. 使用小写字母:字段名称应该使用小写字母,以提高可读性和避免不同数据库系统的大小写敏感问题。
5. 避免使用保留字:避免使用数据库系统中的保留字作为字段名称,以避免引起语法错误。
6. 使用具体的名称:字段名称应该尽量具体,能够准确地描述其内容,避免使用模糊或泛称的名称。
7. 使用无歧义的名称:字段名称应该避免多义词或容易引起歧义的词语,以确保字段含义的清晰性。
8. 使用可读性强的命名:字段名称应该使用常见的英文词汇或词组,以提高可读性和降低错误的可能性。
9. 不要使用表名作为字段名称的前缀:表名已经在上下文中明确了,不需要在字段名称中重复出现。
10. 使用一致的术语和约定:尽量在整个数据库中使用一致的术语和约定,以便理解和维护数据库结构。
11. 遵循数据库范式:根据数据库范式的要求,设计和命名数据库表的字段,以确保数据的一致性和完整性。
12. 避免冗余和重复的字段:尽量不要在数据库表中创建冗余或重复的字段,以避免数据不一致和浪费存储空间。
13. 使用正确的数据类型:根据字段的含义和数据的特性,选择适当的数据类型,并在字段名称中反映出来,以提高数据库的性能和数据的准确性。
14. 遵守命名约定:在命名字段时,应遵守公司或团队的命名约定,以确保数据库结构的统一和一致性。
15. 尽量使用英文命名:在多语言环境下,建议使用英文命名字段,以避免文字编码和翻译带来的问题。
16. 使用前缀或后缀来表示字段的类型或用途:例如,可以使用"fk_"或"_id"来表示外键字段,使用"_date"或"_time"来表示日期或时间字段。
数据库字段名称命名规则

数据库字段名称命名规则
数据库字段名称命名规则是数据库设计规范中的重要内容之一。
一个好的命名规则可以帮助开发人员更好地理解数据库表中的字段,提高代码的可读性和可维护性。
下面是常见的数据库字段名称命名规则:
1. 命名规则:通常采用全小写字母和下划线的方式进行命名,字段名长度最多为 32 个字符,禁止超过 32 个字符。
2. 禁使 MySQL 保留字:在命名规则中,禁使 MySQL 保留字,例如_、auto_、master_等。
3. 业务或产品线相关:字段名应该与业务或产品线相关,以便更好地理解字段的含义和用途。
4. 采用英语命名:字段名应该采用英语命名,以便更好地理解其含义。
如果英语翻译可以参考常术语来选择相应的英语单词。
5. 字段名必须是名词的复数形式:字段名必须是名词的复数形式,以便更好地描述字段的含义和用途。
6. 多个名词采下划线分割单词:如果字段名包含多个名词,应该采用下划线将它们分割开。
7. 命名与实际情况相符:在命名规则中,应该尽可能命名与实际情况相符,例如将用户 ID 字段命名为 user_id。
8. 避免使用单个字符或特殊字符:在命名规则中,应该避免使用单个字符或特殊字符,以免导致字段名混淆或无法正确解析。
9. 命名一致:在多个表中使用相同的字段时,应该遵循一致的
命名规则,以便更好地理解数据之间的关系。
不同的数据库管理系统 (DBMS) 可能有不同的命名规则,因此在实际开发中应该根据实际情况进行命名。
Oracle笔记(2):KeyWords关键字和保留字

Oracle笔记(2):KeyWords关键字和保留字Oracle关键字通过PD建模,⽣成SQL语句导⼊Oracle中执⾏,⽣成表都没有问题。
但是在删除,添加记录的过程中⽼是抛出异常,⽐如“表或视图不存在”;这是⽣成的PL\SQL语句:View Code1/*==============================================================*/2/* Table: "Branch" */3/*==============================================================*/4create table "Branch"5 (6 "Branch_id" INTEGER not null,7 "Branch_name" NVARCHAR2(32),8 "Type" NVARCHAR2(32),9 Y BINARY_DOUBLE,10 X BINARY_DOUBLE,11 "Mark" NVARCHAR2(256),12constraint PK_BRANCH primary key ("Branch_id")13 );1415/*==============================================================*/16/* Table: "CurrentBranchStatistic" */17/*==============================================================*/18create table "CurrentBranchStatistic"19 (20 "Branch_id" INTEGER,21 "Number" INTEGER22 );可以看到表名和字段名都被加了双引号,⽽且有些字段还⽤了关键字,如Number,Type通过v$reserved_words视图可以查看关键字信息。
保留字的名词解释

保留字的名词解释在计算机编程领域中,保留字是指被编程语言所预留并具有特殊用途的一组单词或符号。
这些保留字在编程语言中具有特殊含义,不能被用作变量名或标识符,以免引起歧义或混淆。
保留字的使用是为了规范编程语言的语法和语义,确保程序代码的可读性和有效性。
保留字的数量和具体内容取决于不同的编程语言。
例如,在C语言中,常见的保留字包括"int"、"float"、"if"、"for"等,这些关键字用于定义变量类型、控制流程和循环结构等。
而在Python语言中,常见的保留字则包括"def"、"if"、"while"、"import"等,这些关键字用于定义函数、条件语句、循环语句和模块引入等。
保留字的存在给编程语言带来了一定的限制和约束。
首先,程序员在编写代码时需要遵守保留字的使用规则,不能把保留字作为变量名或标识符来使用,否则会导致编译或解释错误。
其次,当编程语言更新或升级时,新增的保留字不可避免地会与旧有的程序代码产生冲突,需要进行相应的修改和调整。
因此,对于程序员来说,熟悉和理解编程语言的保留字是编写高质量代码的基础。
除了常见的编程语言中的保留字外,一些特殊用途的领域也存在自定义的保留字。
例如,在数学建模和统计分析领域,常用的保留字包括"sum"、"max"、"min"等,这些关键字用于表示计算总和、最大值、最小值等数学操作。
在数据库领域,SQL语言中的保留字包括"select"、"from"、"where"等,用于查询和操作数据库中的数据。
这些领域特定的保留字在相应的工具和语言中具有重要的作用,帮助用户快速进行数据处理和分析。
数据库操作语法错误(SQLsyntaxerror)之两步走
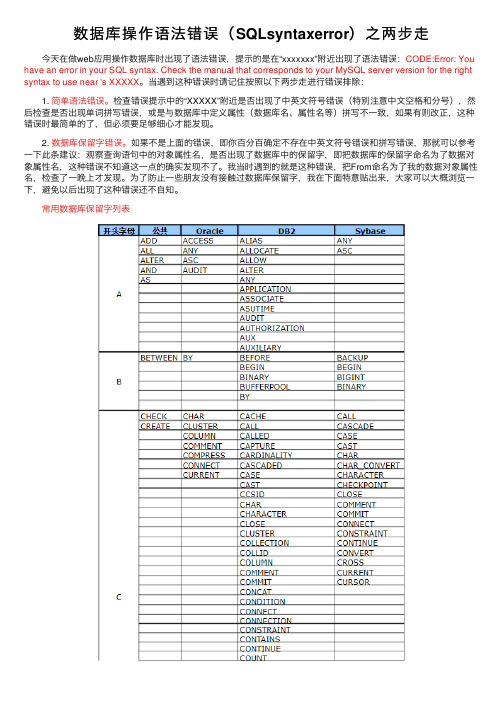
数据库操作语法错误(SQLsyntaxerror)之两步⾛ 今天在做web应⽤操作数据库时出现了语法错误,提⽰的是在“xxxxxxx”附近出现了语法错误:CODE:Error: You have an error in your SQL syntax. Check the manual that corresponds to your MySQL server version for the right syntax to use near 's XXXXX。
当遇到这种错误时请记住按照以下两步⾛进⾏错误排除: 1. 简单语法错误。
检查错误提⽰中的“XXXXX”附近是否出现了中英⽂符号错误(特别注意中⽂空格和分号),然后检查是否出现单词拼写错误,或是与数据库中定义属性(数据库名、属性名等)拼写不⼀致,如果有则改正,这种错误时最简单的了,但必须要⾜够细⼼才能发现。
2. 数据库保留字错误。
如果不是上⾯的错误,即你百分百确定不存在中英⽂符号错误和拼写错误,那就可以参考⼀下此条建议:观察查询语句中的对象属性名,是否出现了数据库中的保留字,即把数据库的保留字命名为了数据对象属性名,这种错误不知道这⼀点的确实发现不了。
我当时遇到的就是这种错误,把From命名为了我的数据对象属性名,检查了⼀晚上才发现。
为了防⽌⼀些朋友没有接触过数据库保留字,我在下⾯特意贴出来,⼤家可以⼤概浏览⼀下,避免以后出现了这种错误还不⾃知。
常⽤数据库保留字列表 以上就是博主为⼤家介绍的这⼀板块的主要内容,这都是博主⾃⼰的学习过程,希望能给⼤家带来⼀定的指导作⽤,有⽤的还望⼤家点个⽀持,如果对你没⽤也望包涵,有错误烦请指出。
如有期待可关注博主以第⼀时间获取更新哦,谢谢!版权声明:本⽂为博主原创⽂章,未经博主允许不得转载。
oracle表名命名规则

Oracle表名命名规则1. 任务简介在Oracle数据库中,表是存储数据的基本单位,表名的命名规则对于数据库的管理和开发非常重要。
本文将介绍Oracle表名的命名规则和要求,以帮助读者规范命名表名。
2. 命名规则Oracle表名的命名必须遵循一定的规则,以保证表名的唯一性和合法性。
2.1 字符集•表名只能使用ASCII字符集中的字母(A-Z,a-z)、数字(0-9)和下划线(_)。
•表名不能使用其他特殊字符,如空格、逗号等。
2.2 长度限制•表名长度不能超过30个字符。
•表名区分大小写。
2.3 保留字•表名不能使用Oracle保留字作为表名。
•Oracle数据库的保留字包括一些关键字,如SELECT、INSERT、UPDATE等。
Oracle保留字的列表可以在官方文档中找到。
3. 命名建议为了方便管理和使用Oracle数据库,命名表名时应当遵循一些命名建议。
3.1 名称表达含义•表名应当能够准确地表达其所存储数据的含义。
•表名应尽量简洁明了,易于理解。
3.2 使用下划线•在表名中,可以使用下划线来分隔单词,提高可读性。
•例如,可以将一个表名命名为”employee_info”,而不是”employeeinfo”。
3.3 避免缩写和简写•在命名表名时,应避免过多的缩写和简写,以免造成歧义和困扰。
•例如,应当使用”customer”而不是”cust”。
3.4 使用大小写规范•表名的大小写可以采用不同的规范,例如全大写、全小写或者首字母大写。
•无论采用哪种规范,应在整个数据库中保持一致。
4. 表名示例下面是一些符合Oracle表名命名规则的示例:1.employee2.department3.order_info4.product_category5. 总结在设计和管理Oracle数据库时,合理命名表名是非常重要的。
遵循表名命名规则和命名建议,可以提高数据库的可读性和可维护性,减少命名歧义和错误。
总体来说,Oracle表名的命名规则包括字符集、长度限制和保留字的限制。
数据库的基本语法及操作

数据库的基本语法及操作结构化查询语⾔包含6个部分:1、数据查询语⾔(DQL:Data Query Language):其语句,也称为“数据检索语句”,⽤以从表中获得数据,确定数据怎样在应⽤程序给出;保留字SELECT是DQL(也是所有SQL)⽤得最多的动词,其他DQL常⽤的保留字有WHERE,ORDER BY,GROUP BY和HAVING。
这些DQL保留字常与其它类型的SQL语句⼀起使⽤。
2、数据操作语⾔(DML:Data Manipulation Language):其语句包括动词INSERT、UPDATE和DELETE。
它们分别⽤于添加、修改和删除。
3、事务控制语⾔(TCL):它的语句能确保被DML语句影响的表的所有⾏及时得以更新。
包括COMMIT(提交)命令、SAVEPOINT(保存点)命令、ROLLBACK(回滚)命令。
4、数据控制语⾔(DCL):它的语句通过GRANT或REVOKE实现权限控制,确定单个⽤户和⽤户组对数据库对象的访问。
某些RDBMS可⽤GRANT或REVOKE控制对表单个列的访问。
5、数据定义语⾔(DDL):其语句包括动词CREATE,ALTER和DROP。
在数据库中创建新表或修改、删除表(CREAT TABLE 或 DROP TABLE);为表加⼊索引等。
6、指针控制语⾔(CCL):它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT⽤于对⼀个或多个表单独⾏的操作。
1. 数据库引擎:InnoDB:⽀持事务, ⽀持外键⽀持崩溃修复能⼒并发控制修改缺点:读写效率低占⽤空间⼤MyISAM :⽀持静态型动态型,压缩型优势:占⽤空间少,插⼊时候⽐较⾼数据的完整性Memory:默认使⽤hash索引放在内存中,处理速度快临时表缺点:放⼊内存,断电后,就失效了。
安全性差=不能建⽴太⼤的表1.2 创建数据库:语法:CREATE DATABASE [IF NOT EXISTS] <数据库名>[[DEFAULT] CHARACTER SET <字符集名>][[DEFAULT] COLLATE <校对规则名>];<数据库名>:创建数据库的名称。
数据库字典表命名

数据库字典表命名
在数据库中,表名是一个非常重要的元素,因为它不仅代表了表的结构和内容,还反映了表所代表的业务逻辑。
以下是一些关于数据库字典表命名的建议:
1、清晰性:表名应该清晰地反映其内容或用途。
例如,如果表用于存储用户信息,可以考虑命名为users。
2、简洁性:避免使用过长的名称,这会使查询和管理变得困难。
例如,user_profile_info可能比user_full_details更简洁。
3、避免使用保留字:例如,不要使用table、select等作为表名。
4、使用下划线:在多个单词的表名中,使用下划线而不是空格或连字符。
例如,user_profile而不是user profile或user-profile。
5、避免使用数字和特殊字符:除非有特定的业务需求,否则避免在表名中使用数字和特殊字符。
6、后缀和前缀:有时为了组织或分类目的,可能会在表名中添加后缀或前缀。
例如,以业务部门或项目名称开头的表名。
7、避免使用非描述性的缩写:除非该缩写是业界公认并且广泛使用的。
8、考虑未来的扩展性:当命名表时,考虑未来可能的功能或业务扩展。
9、保持一致性:在整个数据库中保持命名的一致性,这有助于团队成员之间的沟通和理解。
10注释:除了良好的命名外,为表添加注释也是一个好习惯,可以
解释表的目的、用途和其他重要信息。
数据库字段名称命名规则

数据库字段名称命名规则
数据库字段名称命名规则是一个系统性规范,旨在确保数据库设计和开发过程中的一致性和可维护性。
以下是一些常见的命名规则: 1. 命名规范:库名、表名、字段名禁止使用 MySQL 保留字,并且必须是名词的复数形式,使用写字母,多个名词采下划线分割单词。
2. 常英语命名:库名、表名、字段名建议使用英语命名,以便见名知意,与业务、产品线等相关联。
3. 命名与实际含义关联:字段名应该与实际含义相关联,有助于理解数据库表中的数据和字段的作用。
4. 长度限制:库名、表名、字段名长度应该限制在 32 个字符以内,为了减少传输量和提高规范性,建议不超过 32 个字符。
5. 缩写规则:当字段名过长时,可以使用缩写来减少长度。
例如,“性别”可以缩写为“gender”。
6. 主键命名规则:主键按照 PKtable 的规则命名,其中 table 为数据库表名,column 为字段名。
7. 唯一键命名规则:唯一键按照 UKtablecolumn 的规则命名,其中 table 为数据库表名,column 为字段名。
8. 外键命名规则:外键按照 FKparentchildnn 的规则命名,其中 parent 为表名,child 为表名,nn 为序列号。
遵循这些规则可以帮助开发人员更好地设计和开发数据库表,提高数据库的可维护性和可读性。
同时,也有助于团队协作和代码规范。
postgresql 用户名规则

postgresql 用户名规则PostgreSQL 用户名规则在使用PostgreSQL 数据库时,我们需要为每个用户指定一个用户名。
然而,PostgreSQL 对用户名有一些规则和限制。
本文将介绍PostgreSQL 的用户名规则,以帮助您正确设置用户。
1. 长度限制:用户名的长度不得超过63 个字符。
这是因为PostgreSQL 使用系统表存储用户名,并且这些表中的字段长度有限制。
2. 字符限制:用户名只能由字母、数字和下划线组成。
不允许使用空格、特殊字符或汉字作为用户名的一部分。
3. 区分大小写:PostgreSQL 严格区分用户名的大小写。
例如,"admin" 和 "Admin" 是两个不同的用户名。
4. 保留字:不能使用PostgreSQL 的保留字作为用户名。
保留字是数据库内部使用的关键字,用于定义语法和命令。
如果使用保留字作为用户名,可能会导致语法错误或不可预知的行为。
5. 开始和结尾字符:用户名不能以数字或下划线开头,也不能以下划线结尾。
这是为了避免与系统保留的用户名冲突。
6. 不重复:每个用户名在数据库中必须是唯一的。
不能使用已经存在的用户名来创建新用户。
为了更好地理解这些规则,下面我们将通过一些示例来说明。
示例一:合法用户名合法的用户名包括"john_doe"、"user123"、"admin" 等。
它们都满足了上述规则,长度在限制范围内,由字母、数字和下划线组成。
示例二:非法用户名非法的用户名包括"John Doe"(包含空格)、"user@123"(包含特殊字符)和"管理员"(包含汉字)。
它们违反了上述规则,不符合用户名的要求。
示例三:保留字作为用户名PostgreSQL 的保留字包括"select"、"insert"、"update" 等。
MySQL5.7中的关键字与保留字详解

MySQL5.7中的关键字与保留字详解什么是关键字和保留字关键字是指在SQL中有意义的字。
某些关键字(例如SELECT,DELETE或BIGINT)是保留的,需要特殊处理才能⽤作表和列名称等标识符。
这⼀点对于内置函数的名称也适⽤。
如何使⽤关键字和保留字⾮保留关键字允许作为标识符,不需要加引号。
如果您要适⽤保留字作为标识符,就必须适⽤引号。
举个例⼦,BEGIN和END是关键字,但不是保留字,因此它们⽤作标识符不需要引号。
INTERVAL是保留关键字,必须加上引号才能⽤作标识符。
12 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23mysql>mysql> use hoegh;Database changedmysql>mysql> CREATE TABLE interval (begin INT, end INT); ERROR 1064 (42000):mysql>mysql> CREATE TABLE`interval` (begin INT, end INT); Query OK, 0 rows affected (0.42 sec)mysql>mysql> show create table`interval`;+----------+---------------------------------------------------------| Table| Create Table+----------+---------------------------------------------------------| interval | CREATE TABLE`interval` (`begin` int(11) DEFAULT NULL,`end` int(11) DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=latin1 |+----------+---------------------------------------------------------1 row in set(0.00 sec)mysql>我们看到,第⼀条语句中表名使⽤了保留字interval,执⾏失败;第⼆条语句对interval加了引号,执⾏成功。
MySQL中的关键字和保留字解释

MySQL中的关键字和保留字解释引言:在数据库领域中,关键字和保留字是非常重要的概念。
对于MySQL这样的关系型数据库管理系统来说,了解和正确使用关键字和保留字是非常关键的。
本文将对MySQL中的关键字和保留字进行深入解释和探讨,帮助读者更好地理解和应用这些概念。
一、关键字和保留字的区别在MySQL中,关键字和保留字都是指在数据库系统中有特殊含义的单词。
然而,它们之间存在着一些微妙的差别。
关键字是指被MySQL系统定义并保留的单词,用于表示特定的操作、属性或者语法结构。
关键字在MySQL中有严格的语法限制,不能用作标识符(例如表名、列名等),否则会导致语法错误。
保留字是指在MySQL中可能被将来的版本定义为关键字的单词。
虽然当前版本中的保留字可能是合法的标识符,但为了避免将来的冲突,最好不要将这些单词用作标识符。
二、常见的MySQL关键字和保留字MySQL中的关键字和保留字有很多,下面我们将逐个进行解释和说明。
1. SELECT:SELECT是MySQL中最常用的关键字之一,用于从一个或多个表中检索数据。
SELECT语句的基本语法是SELECT 列名(或 *)FROM 表名。
2. INSERT:INSERT关键字用于将数据插入到指定的表中。
INSERT语句的语法是INSERT INTO 表名 (列1, 列2, ...) VALUES (值1, 值2, ...)。
3. UPDATE:UPDATE关键字用于更新指定的表中的数据。
UPDATE语句的语法是UPDATE 表名 SET 列名1=值1, 列名2=值2, ... WHERE 条件。
4. DELETE:DELETE关键字用于从指定的表中删除数据。
DELETE语句的语法是DELETE FROM 表名 WHERE 条件。
5. CREATE:CREATE关键字用于创建新的数据库、表、索引等对象。
CREATE语句的语法是CREATE DATABASE 数据库名、CREATE TABLE 表名等。
sql表命名规则

sql表命名规则SQL表命名规则是数据库设计中的重要部分,它有助于保持数据的清晰、一致和易于理解。
一个好的表名应该简洁、有意义,并且遵循一定的命名规范。
以下是一个关于SQL 表命名规则的介绍,涵盖了常见的命名约定、最佳实践以及一些示例。
一、命名约定1. 使用小写字母:大多数数据库系统对大小写敏感,因此建议使用小写字母来命名表。
这样可以避免在不同系统之间出现大小写不一致的问题。
2. 使用下划线分隔单词:为了提高可读性,建议使用下划线(_)来分隔多个单词。
例如,`users_profile`。
3. 避免使用特殊字符:避免在表名中使用特殊字符,如空格、标点符号等。
特殊字符可能会引起查询错误或混淆。
4. 避免使用保留字:避免使用数据库系统的保留字作为表名。
保留字是数据库系统预定义的、具有特殊意义的词汇,如`SELECT`、`FROM`等。
5. 使用前缀或后缀:为了区分不同的表或表类型,可以使用前缀或后缀来命名表。
例如,`tbl_users`(前缀)或`users_tbl`(后缀)。
二、最佳实践1. 保持简洁:表名应该简洁明了,避免使用过长的名称。
过于复杂的名称会使查询和维护变得困难。
2. 使用有意义的名称:表名应该描述表中存储的数据内容或相关属性。
避免使用无意义或抽象的名称。
3. 避免使用数字或符号:避免在表名中使用数字或符号,除非有特殊需求。
数字和符号可能会使查询变得复杂,并且难以阅读和理解。
4. 使用单数或复数形式:根据数据库系统的语法规则和编程语言的约定,选择使用单数或复数形式来命名表。
确保在整个数据库设计中保持一致。
5. 避免使用下划线开头的名称:在某些数据库系统中,以下划线开头的名称可能会被视为私有字段或隐藏字段。
因此,避免在表名中使用下划线开头。
三、示例以下是一些示例,展示了符合SQL表命名规则的表名:1. 用户信息表:`users_info`2. 产品分类表:`products_categories`3. 订单明细表:`orders_details`4. 员工薪资表:`employees_salaries`5. 客户反馈表:`customer_feedback`这些示例遵循了上述的命名约定和最佳实践,使得表名简洁明了、有意义且易于理解。
数据库表字段命名规范与最佳实践

数据库表字段命名规范与最佳实践概述:随着信息技术的迅猛发展和数据的不断增长,数据库在我们日常生活和工作中扮演着重要的角色。
在设计数据库时,合理的字段命名是至关重要的。
良好的字段命名可以增加代码可读性、降低开发难度、提高数据库的性能和维护效率。
本文将介绍数据库表字段命名的规范以及最佳实践。
一、规范性命名准则1. 语义化命名:字段名应能清晰地表达字段所表示的含义,避免使用缩写或者数值代替含义。
2. 使用英文单词:字段名应使用英文单词而不是拼音或其他语言,确保字段名的一致性和易读性。
3. 使用小写字母:字段名应全部使用小写字母,避免使用大写字母或者混合大小写,以确保跨平台兼容和可移植性。
4. 使用下划线分隔单词:字段名应使用下划线(_)分隔多个单词,例如"first_name",而不是使用驼峰命名法,例如"firstName"。
5. 避免使用保留字:字段名不得与数据库中的保留字相同,避免引起语法错误。
6. 简洁明了:字段名应尽可能简洁明了,避免过长或者冗余的命名。
7. 统一命名风格:在同一个数据库中,应确保所有字段的命名风格保持一致,增加可维护性和可读性。
8. 显性表达关系:字段名应体现字段与相关表和关系之间的联系和意义。
二、常用字段命名实践1. 主键id:通常情况下,每个表都应该有一个主键字段,用于唯一标识表中的每条记录。
主键字段的命名可以使用表名加上“_id”的方式,例如"user_id"。
2. 外键:外键字段负责建立和维护表与表之间的关联关系。
外键字段的命名可以使用关联的表名加上"_id"的方式,例如"order_id"。
3. 时间戳:在某些场景下,需要记录数据的创建时间和更新时间。
可以使用"created_at"和"updated_at"作为字段名,分别用于记录数据的创建和更新时间。
数据库表命名规范

数据库表命名规范数据库表命名规范是指在设计和创建数据库表时所遵循的一套规则和规范。
这些规则和规范可以帮助开发者更好地维护数据库的结构和一致性,以增强系统的可读性、可维护性和可扩展性。
以下是一些常见的数据库表命名规范:1. 使用有意义的名字:表名应该能够清晰地表达其所代表的实体或概念。
起一个简洁、直观、能准确反映其含义的名字能够帮助开发者更好地理解表的用途和关系。
2. 使用单数形式:表名应该使用单数形式,例如"employee"而不是"employees"。
这是因为表中的每一行都代表一个实体,而表名则代表了这个实体的全体集合。
3. 使用小写字母和下划线:表名应该使用小写字母,并可以使用下划线来分隔单词,例如"order_detail"。
这样可以提高可读性,并且避免与数据库引擎或操作系统的命名规则冲突。
4. 避免使用保留字和关键字:表名应该避免使用数据库系统中的保留字和关键字,以免引起命名冲突和不可预测的行为。
5. 使用一致的命名约定:在整个数据库中,应该使用一致的命名约定,例如使用相同的前缀或后缀来表示特定类型的表。
这样可以增强系统的可读性和一致性,并且方便进行数据库维护和查询。
6. 简洁而明确的命名:表名应该尽量简洁,避免冗长和复杂的命名。
同时,表名也应该能够清晰地表达其所代表的实体或概念,以增强可读性。
7. 使用英文单词:表名应该使用英文单词,避免使用缩写、拼音或其他非英文的命名方式。
这是因为英文是数据库和编程领域的通用语言,使用英文单词可以提高系统的可读性和可理解性。
8. 不包含特殊字符:表名应该避免使用特殊字符,例如空格、逗号、引号等。
这样可以避免引起命名冲突和不可预测的行为,同时也可以提高系统的兼容性和可移植性。
9. 遵循命名约定:表名应该遵循特定的命名约定或命名规范,例如使用驼峰命名法或下划线命名法。
这可以增强系统的一致性和可读性,并且方便进行数据库维护和查询。
数据库表 名称创建规则

数据库表名称创建规则数据库表的命名是数据库设计中非常重要的一部分,良好的命名规则可以提高代码可读性、易于维护和使用。
下面是一些常用的数据库表名称创建规则的参考内容:1. 使用单数名词:表名通常使用单数名词,例如:`user`、`order`、`product`等。
这样命名规则可以更好地与实际对象对应,更易于理解。
2. 使用小写字母:表名应该使用小写字母,避免使用大写字母或者混合大小写的命名方式。
这样可以提高跨平台的兼容性,避免在不同数据库中出现大小写不一致的问题。
3. 使用下划线命名法:表名使用下划线命名法,即单词之间用下划线分隔,例如:`user_info`、`product_detail`等。
这种命名规则可以提高可读性,使表名更加清晰、易于理解。
4. 使用有意义的表名:表名应该具备描述性,能够准确反映表中数据的含义。
避免使用模糊、不具备描述性的名词和缩写的表名,例如:`tb1`、`dt2`等。
一个好的表名应该能够让其他开发人员一目了然地了解该表的作用和含义。
5. 避免使用保留字:避免使用数据库系统中的保留字作为表名,以免引起命名冲突和错误。
可以通过查阅相关数据库的保留字列表来避免使用这些保留字作为表名。
6. 使用清晰的单词组合:表名可以使用多个单词组合,以更好地描述表所包含的数据。
例如,可以将多个单词组合在一起来命名表名,例如:`user_address`、`product_category`等。
这样可以增加表名的表达力,能够更好地反映表的结构和功能。
7. 避免过长的表名:尽量避免使用过长的表名,以免在编程中不方便使用和书写。
一般来说,表名的长度应该控制在30个字符以内。
8. 使用一致的命名风格:在整个数据库设计中,应该保持表名的命名风格一致,以便于统一管理和维护。
例如,可以统一使用下划线命名法,并且遵循相同的表名前缀或后缀。
总而言之,数据库表的命名规则是一个非常重要的方面,可以通过使用单数名词、小写字母、下划线命名法、有意义的表名、避免使用保留字、使用清晰的单词组合、避免过长的表名和保持一致的命名风格等方式来创建规范的表名,提高数据库的可读性和可维护性。
数据库标识符

数据库标识符
数据库标识符(Database Identifier)是用来唯一地标识数据库对象的标识符,例如表、列、索引、视图等。
在关系数据库中,每个表都有一个独特的名字,这就是表的标识符。
数据库标识符的命名规则:
1. 只能使用字母、数字和下划线(_)。
2. 第一个字符必须是字母。
3. 标识符不能超过 30 个字符。
在 SQL 语句中,数据库标识符需要用反引号(`)括起来,如下所示:
```
SELECT `column_name` FROM `table_name` WHERE `condition`; ```
在编写 SQL 语句时,应该尽量避免使用数据库保留字作为标识符,否则可能导致语法错误。
如果必须使用保留字作为标识符,需要用反引
号括起来。
例如,下面的 SQL 语句在 MySQL 中会报错:
```
SELECT user, password FROM users;
```
因为 user 和 password 都是 MySQL 的保留字。
应该改成下面的形式:
```
SELECT `user`, `password` FROM `users`;
```
总之,数据库标识符是关系数据库中一个非常重要的概念,正确使用
标识符可以帮助我们避免许多语法错误,提高 SQL 语句的可读性和可维护性。
【IT专家】在列名中使用保留字

本文由我司收集整编,推荐下载,如有疑问,请与我司联系在列名中使用保留字2013/03/31 7063 this is some simple code but I just don’t know why I can’t use this word as the entity of the table这是一些简单的代码,但我不知道为什么我不能将这个词用作表的实体CREATE TABLE IF NOT EXISTS users(key INT PRIMARY KEY NOT NULL AUTO_INCREMENT,username VARCHAR(50) NOT NULL, I realized I can’t use “key”if I use key the mysql will ask me to check the syntax but if I use “id” or any others the table will be created.我意识到我不能使用“密钥”,如果我使用密钥,mysql 将要求我检查语法,但如果我使用“id”或任何其他人将创建表。
Anyone know how I can create the entity name into key? Not something important since I can just use id instead of key but since I found this error I wonna see if there’s away to get it work.任何人都知道如何将实体名称创建为密钥?不是很重要,因为我可以使用id 而不是key 但是因为我发现了这个错误,我想知道是否有办法让它工作。
15You can still use key if you want to. Just wrap it with backtick,如果您愿意,您仍然可以使用密钥。
常见的数仓命名规则

常见的数仓命名规则数据仓库的命名规则在数据仓库领域,命名规则对于数据管理和数据分析非常重要。
一个合理的命名规则可以提高数据仓库的可维护性和可理解性。
下面是一些常见的数仓命名规则:1. 表名和字段名要有意义:表名和字段名应该准确地描述数据的含义。
避免使用模糊或不明确的名称,以免给数据分析带来困扰。
2. 使用下划线分隔单词:为了增加可读性,建议在表名和字段名中使用下划线来分隔单词。
例如,"user_id"比"userID"更易于理解。
3. 使用缩写词:在命名中使用常见的缩写词可以节省空间并提高可读性。
例如,使用"cust_id"代替"customer_id"。
4. 避免使用特殊字符:在命名中避免使用特殊字符,如空格、斜杠、反斜杠等。
这些字符在某些数据库中可能引起问题。
5. 使用一致的命名风格:在整个数据仓库中使用一致的命名风格可以提高可维护性。
例如,可以选择使用小写字母和下划线的组合来命名所有的表和字段。
6. 避免使用过长的命名:命名应该简洁明了,不要过于冗长。
过长的命名可能会导致命名混乱和错误。
7. 命名应具有层次结构:表名和字段名应该具有层次结构,以反映数据的关系。
例如,可以使用"dim_"前缀表示维度表,"fact_"前缀表示事实表。
8. 避免使用保留字:在命名中避免使用数据库中的保留字,以免引起冲突。
9. 使用可排序的命名:为了方便排序和查找,建议在命名中使用有意义的排序规则,如按照字母顺序或按照日期顺序。
10. 命名要具有可扩展性:命名应该具有可扩展性,以便将来可以方便地添加新的表和字段。
一个好的数据仓库命名规则可以提高数据管理和数据分析的效率,减少错误和混乱。
在命名时要注意清晰、简洁、有意义,并保持一致性和可扩展性。
这样可以使数据仓库更易于理解和维护,提高数据分析的准确性和可靠性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
REGR_AVGY
REGR_COUNT
REGR_INTERCEPT
REGR_R2
REGR_SLOPE
REGR_SXX
REGR_SXY
REGR_SYY
REINDEX
RELATIVE
RELEASE
RELOAD
RENAME
REPEAT
REPEATABLE
REPLACE
PARAMETER_SPECIFIC_SCHEMA
PARAMETERS
PARTIAL
PARTITION
PASCAL
PASSWORD
PATH
PCTFREE
PERCENT
PERCENT_RANK
PERCENTILE_CONT
PERCENTILE_DISC
PLACING
PLAN
IDENTIFIED
IDENTITY
IDENTITY_INSERT
IDENTITYCOL
IF
IGNORE
ILIKE
IMMEDIATE
IMMUTABLE
IMPLEMENTATION
IMPLICIT
IN
INCLUDE
INCLUDING
INCREMENT
INDEX
INDICATOR
REPLICATION
BETWEEN
BIGINT
BINARY
BIT
BIT_LENGTH
BITVAR
BLOB
BOOL
BOOLEAN
BOTH
BREADTH
BREAK
BROWSE
BULK
BY
C
CACHE
CALL
CALLED
CARDINALITY
CASCADE
CASCADED
CASE
GRANTED
GRANTS
GREATEST
GROUP
GROUPING
HANDLER
HAVING
HEADER
HEAP
HIERARCHY
HIGH_PRIORITY
HOLD
HOLDLOCK
HOST
HOSTS
HOUR
HOUR_MICROSECOND
HOUR_MINUTE
HOUR_SECOND
INT3
INT4
INT8
INTEGER
INTERSECT
INTERSECTION
INTERVAL
INTO
INVOKER
IS
ISAM
ISNULL
ISOLATION
ITERATE
JOIN
K
KEY
KEY_MEMBER
KEY_TYPE
KEYS
KILL
LANCOMPILER
MLSLABEL
MOD
MODE
MODIFIES
MODIFY
MODULE
MONTH
MONTHNAME
MORE
MOVE
MULTISET
MUMPS
MYISAM
NAME
NAMES
NATIONAL
NATURAL
NCHAR
NCLOB
NESTING
NEW
NEXT
NO
NO_WRITE_TO_BINLOG
FOR
FORCE
FOREIGN
FORTRAN
FORWARD
FOUND
FREE
FREETEXT
FREETEXTTABLE
FREEZE
FROM
FULL
FULLTEXT
FUNCTION
FUSION
G
GENERAL
GENERATED
GET
GLOBAL
GO
GOTO
GRANT
CUBE
CUME_DIST
CURRENT
CURRENT_DATE
CURRENT_DEFAULT_TRANSFORM_GROUP
CURRENT_PATH
CURRENT_ROLE
CURRENT_TIME
CURRENT_TIMESTAMP
CURRENT_TRANSFORM_GROUP_FOR_TYPE
OVERLAY
OVERRIDING
OWNER
PACK_KEYS
PAD
PARAMETER
PARAMETER_MODE
PARAMETER_NAME
PARAMETER_ORDINAL_POSITION
PARAMETER_SPECIFIC_CATALOG
PARAMETER_SPECIFIC_NAME
NOAUDIT
NOCHECK
NOCOMPRESS
NOCREATEDB
NOCREATEROLE
NOCREATEUSER
NOINHERIT
NOLOGIN
NONCLUSTERED
NONE
NORMALIZE
NORMALIZED
NOSUPERUSER
NOT
NOTHING
NOTIFY
COLLATION_NAME
COLLATION_SCHEMA
COLLECT
COLUMN
COLUMN_NAME
COLUMNS
COMMAND_FUNCTION
COMMAND_FUNCTION_CODE
COMMENT
COMMIT
COMMITTED
COMPLETION
COMPRESS
CONTAINS
CONTAINSTABLE
CONTINUE
CONVERSION
CONVERT
COPY
CORR
CORRESPONDING
COUNT
COVAR_POP
COVAR_SAMP
CREATE
CREATEDB
CREATEROLE
CREATEUSER
CROSS
CSV
COMPUTE
CONDITION
CONDITION_NUMBER
CONNECT
CONNECTION
CONNECTION_NAME
CONSTRAINT
CONSTRAINT_CATALOG
CONSTRAINT_NAME
CONSTRAINT_SCHEMA
CONSTRAINTS
CONSTRUCTOR
ASSERTION
ASSIGNMENT
ASYMMETRIC
AT
ATOMIC
ATTRIBUTE
ATTRIBUTES
AUDIT
AUTHORIZATION
AUTO_INCREMENT
AVG
AVG_ROW_LENGTH
BACKUP
BACKWARD
BEFORE
BEGIN
BERNOULLI
PLI
POSITION
POSTFIX
POWER
PRECEDING
PRECISION
PREFIX
PREORDER
PREPARE
PREPARED
PRESERVE
PRIMARY
PRIOR
PRIVILEGES
PROC
PROCEDURAL
PROCEDURE
PROCESS
DISABLE
DISCONNECT
DISK
DISPATCH
DISTINCT
DISTINCTROW
DISTRIBUTED
DIV
DO
DOMห้องสมุดไป่ตู้IN
DOUBLE
DROP
DUAL
DUMMY
DUMP
DYNAMIC
DYNAMIC_FUNCTION
DYNAMIC_FUNCTION_CODE
OPENQUERY
OPENROWSET
OPENXML
OPERATION
OPERATOR
OPTIMIZE
OPTION
OPTIONALLY
OPTIONS
OR
ORDER
ORDERING
ORDINALITY
OTHERS
OUT
OUTER
OUTFILE
OUTPUT
OVER
OVERLAPS
CAST
CATALOG
CATALOG_NAME
CEIL
CEILING
CHAIN
CHANGE
CHAR
CHAR_LENGTH
CHARACTER
CHARACTER_LENGTH
CHARACTER_SET_CATALOG
CHARACTER_SET_NAME
CHARACTER_SET_SCHEMA
MEDIUMTEXT
MEMBER
MERGE
MESSAGE_LENGTH
MESSAGE_OCTET_LENGTH
MESSAGE_TEXT