Cache控制器设计实验
根据spim的cache实验

汕头大学实验报告学院: 工学院系: 计算机系专业: 计算机科学与技术年级: 13实验时间: 2015.6.16 姓名: 林子伦学号: 2013101030实验名称:基于SPIM-CACHE的Cache实验一.实验目的:(1)熟悉SPIM-CACHE模拟器环境(2)深入认识CACHE的工作原理及其作用。
二.实验内容:(1)阅读实验指导书资料(虚拟教室提供了英文论文的电子版本);(2)下载SPIM-CACHE软件,理解英文论文的基本内容之后,给出几种典型的cache配置,运行英文论文提供的代码,记录运行时CACHE命中率等重要数据;(3)运行Fig.4代码,了解mapping functions 即映射规则(4)运行Fig.7代码,了解temporal and spatial locality 即时空局部性,进一步理解cache的工作原理;(5)运行Fig.8代码,运行学习replacement algorithms 即替代算法,理解其工作原理。
三.实验地点,环境实验地点:软件工程实验室实验环境:操作系统:Microsoft Windows 8 中文版处理器:Intel(R) Core(TM) i3-3120M CPU @ 2.50GHz 2.50GHz内存: 4.00GB(3.82GB 可用)四.实验记录及实验分析(80%):4.1实验前配置:1) 按下图配置好Spim设置2)关于实验中cache设置如下(具体配置根据下面实验要求)——》——》Cache size ——cache大小Block size ——块大小Mapping ——组相连4.2实验一:fig4.s实验目的:Algorithm and corresponding code to study mapping functions Cache配置:256-B size, 16-B line size, four-way set associative实验操作:1) Ctrl+O 打开运行代码fig4.s代码如下:.data 0x10000480Array_A: .word 1,1,1,1,2,2,2,2.data 0x10000CC0Array_B: .word 3,3,3,3,4,4,4,4.text.globl _start_start: la $2,Array_Ali $6,0li $4,8loop: lw $5,0($2)add $6,$6,$5addi $2,$2,4addi $4,$4,-1bgt $4,$0,loop2) 按F5运行程序,得到结果如下图Instruction cache’s hit rate : 0.792453Data cache’s hit rate : 0.7500004.3实验二:fig7.s实验目的:Algorithm and corresponding code to study temporal and spatial locality4.3.1 spatial localityCache配置:256-B size, four-way set associative, 分别定义block size为16,8,4B实验操作:1) Ctrl+O 打开运行代码fig7.s代码如下:.data 0x10000480Array_A: .word 1,1,1,1,2,2,2,2.data 0x10000CC0Array_B: .word 3,3,3,3,4,4,4,4.text.globl __start__start: li $8,1#这里要得到教程里的0.75,0.5,0 这里的$8里一定要为1ext_loop: la $2,Array_Ala $3,Array_Bli $6,0 #sum=0li $4,8 #number of elementsloop: lw $5,0($2)lw $7,0($3)add $6,$6,$5 #sum=sum+arrayA[i]add $6,$6,$7 #sum=sum+arrayB[i]addi $2,$2,4addi $3,$3,4addi $4,$4,-1addi $8,$8,-1bgt $8,$0,ext_loop.end2)按F5运行程序Block size:16B命中率为0.75Block size:8B命中率为0.5Block size:4B命中率为04.3.2 temporal localityCache配置:256-B size, 16-B line size, four-way set associative实验操作:1) Ctrl+O 打开运行代码fig7.s代码如下:(代码中N每次改写为1或5或10或100).data 0x10000480Array_A: .word 1,1,1,1,2,2,2,2.data 0x10000CC0Array_B: .word 3,3,3,3,4,4,4,4.text.globl __start__start: li $8,N #N=1,5,10,100ext_loop: la $2,Array_Ala $3,Array_Bli $6,0 #sum=0li $4,8 #number of elementsloop: lw $5,0($2)lw $7,0($3)add $6,$6,$5 #sum=sum+arrayA[i]add $6,$6,$7 #sum=sum+arrayB[i]addi $2,$2,4addi $4,$4,-1bgt $4,$0,loopaddi $8,$8,-1bgt $8,$0,ext_loop.end2) 按F5运行程序N=1命中率为0.759036。
一种带Cache加速的HyperRAM控制器设计与验证

现代电子技术Modern Electronics TechniqueMar. 2024Vol. 47 No. 62024年3月15日第47卷第6期0 引 言随着嵌入式系统的不断演进,CPU 与内存之间数据交换速率要求越来越高,对存储器接口的要求日益增加[1‐2]。
为满足数据快速传输和处理的需求,新一代存储器技术应运而生,其中包括了备受瞩目的HyperRAM 存储器。
与传统存储器技术相比,HyperRAM 具有更高的读写速度和更低的访问延迟,适用于对数据访问速度要求较高的应用场景,使其成为各种嵌入式系统的理想选择[3‐4]。
然而,在大规模数据处理和频繁读写操作的情况下,HyperRAM 的原始接口可能面临性能瓶颈。
Cache 缓冲作为一种常见的高速存储器,被广泛应用于处理器和系统的设计中[5],允许暂存频繁读取的数据,从而减少对主存储器的频繁访问,提高数据读写效率和性能。
将Cache 缓冲引入HyperRAM 存储器接口,有望进一步提高对频繁访问的数据的命中率,优化存储器访问模式,从而实现更高速的数据传输和更优化的系统性能[6‐7]。
本文基于HyperRAM 的逻辑功能,设计了一种基于AMBA 总线的HyperRAM 控制器,同时内部设计了高速缓存Cache 模块,以提高读写速率,降低存储器的访问频率。
经测试,所设计的控制器能稳定工作在166 MHz 频率下,同时写入数据与读出数据能够保持一致,数据未出现丢帧、误码现象,系统性能稳定可靠。
1 HyperRAM 控制器的设计图1为本文HyperRAM 控制器设计的总体框图。
HyperRAM 控制器由AHB Interface 模块、APB InterfaceDOI :10.16652/j.issn.1004‐373x.2024.06.015引用格式:邹敏,鲁澳宇,邹望辉,等.一种带Cache 加速的HyperRAM 控制器设计与验证[J].现代电子技术,2024,47(6):91‐96.一种带Cache 加速的HyperRAM 控制器设计与验证邹 敏1, 鲁澳宇1, 邹望辉1, 喻 华2(1.长沙理工大学 物理与电子科学学院, 湖南 长沙 410114; 2.广东华芯微特集成电路有限公司, 湖南 长沙 410205)摘 要: 针对目前可穿戴设备上对存储设备性能要求高、体积小、功耗低等问题,在FPGA 上实现了一款可拓展的高性能HyperRAM 控制器,并引入Cache 缓存加速设计,以提高对频繁访问数据的命中率和优化存储器访问模式,实现更高速的数据传输和优化的系统性能。
硬件cache机制设计logisim

硬件cache机制设计logisim硬件缓存(或称为Cache)是计算机系统中的一种高速存储设备,用于存储最近经常被访问的数据,以提高系统的性能。
硬件缓存机制在计算机系统中起到了至关重要的作用,因此对其进行设计是非常重要的。
硬件缓存的设计需要考虑许多方面,包括缓存大小、缓存行大小、替换策略、写策略等,下面将对这些方面进行详细介绍。
首先是缓存大小。
缓存大小指的是缓存能够存储的数据量。
缓存大小直接影响到缓存的性能,缓存越大,可以存储的数据量就越多,命中率也会更高。
但是由于缓存是高速存储设备,所以缓存的大小受到成本和芯片大小等方面的限制。
通常情况下,缓存的大小是有限的,需要根据系统的需求进行合理的配置。
其次是缓存行大小。
缓存行大小指的是缓存中每一行能够存储的数据大小。
在硬件缓存中,数据是以块的形式存储在缓存中的,每一个块被称为一个缓存行。
缓存行的大小对于缓存的性能有很大的影响。
如果缓存行的大小过小,会导致更频繁的缓存失效和更多的访存操作。
如果缓存行的大小过大,会导致更多的数据移动和更高的冷启动成本。
因此,需要根据系统的访存模式和访存数据的特征来选择合适的缓存行大小。
接下来是替换策略。
替换策略用于确定当缓存已满时,该替换哪一行的数据。
常见的替换策略有最近最久未使用(LRU)、最不经常使用(LFU)、随机等。
不同的替换策略对于缓存的命中率和性能影响很大。
LRU替换策略会将最长时间未被访问的数据替换出去,LFU替换策略会将使用次数最少的数据替换出去。
在设计替换策略时,需要综合考虑缓存行的使用频率和外存访问的特点。
最后是写策略。
写策略用于确定当缓存中的数据被修改时,何时将修改的数据写回到内存中。
常见的写策略有写直达(Write Through)和写回(Write Back)。
写直达是指每次修改缓存中的数据时,同时将修改的数据写回到内存中。
写回是指只有当缓存行被替换出去时,才将修改的数据写回到内存中。
写策略的选择主要考虑的是数据的一致性和性能的权衡。
实验4 Cache性能分析

4 Cache性能分析4.1实验目的加深对Cache的基本概念及其工作原理的理解;掌握降低Cache不命中率的各种方法以及这些方法对提高Cache性能的好处;理解常见替换算法(LRU与随机法)的基本思想以及它们对Cache性能的影响。
4.2实验平台实验平台采用Cache模拟器MyCache。
4.3实验内容阅读理解课件“第7章存储系统简化版”的“7.2.2节映象规则”(19-26屏)、“7.2.5节替换算法(30-31屏)、7.2.6节写策略(42-44屏)”、“7.3节降低Cache不命中率”(52-63屏)。
4.3.1 Cache容量对不命中率的影响1)启动MyCache,点击“复位”,把各参数设置为默认值,选择一个地址流文件,比如all.din。
2)选择不同的Cache容量,分别2KB、4KB、8KB、16KB、32KB、64KB、128KB、256KB。
分别执行模拟器(点“执行到底”按钮),自己列表记录各种情况下的不命中率。
Cache容量2KB 4KB 8KB 16KB 32KB 64KB 128KB 256KB 不命中率100% 9.87% 4.48% 2.65% 1.42% 0.89% 0.60% 0.49%3)以容量为横坐标,画出不命中率随Cache容量变化的曲线,并指明地址流文件名。
根据该模拟结果,写出你得出的结论。
答:在其他变量一定的情况下,随着Cache容量的变大不命中率逐渐减小最后趋于稳定。
4.3.2相联度对不命中率的影响1)点击“复位”按钮,把各参数设置为默认值,此时的Cache 容量为64KB 。
选择一个地址流文件,比如all.din 。
2)选择不同的Cache 相联度,分别直接映像、2路、4路、8路、16路和32路。
分别执行模拟器(点“执行到底”按钮),自己列表记录各种情况下的不命中率。
相联度 直接映像 2路 4路 8路 16路 32路 不命中率 0.89% 0.53% 0.47% 0.45%0.44%0.44%3)把Cache 容量设置为256KB ,重复第2)步工作,记录各种情况下的不命中率。
2路组相连cache设计课程设计

2路组相连cache设计课程设计一、课程目标知识目标:1. 学生能理解2路组相连Cache的基本概念、原理与结构。
2. 学生能掌握Cache的映射方式、替换策略,以及2路组相连Cache的具体实现方法。
3. 学生能运用所学知识分析2路组相连Cache的性能指标,如命中率、缺失率等。
技能目标:1. 学生具备运用硬件描述语言(如Verilog、VHDL等)设计2路组相连Cache的能力。
2. 学生能够使用相关工具(如ModelSim等)对2路组相连Cache进行仿真与调试。
3. 学生能够通过实验和数据分析,评估2路组相连Cache的性能,并提出优化方案。
情感态度价值观目标:1. 培养学生对计算机组成原理中存储系统知识的学习兴趣,激发其探索精神。
2. 培养学生具备团队协作精神,提高沟通与表达能力。
3. 培养学生关注技术发展,认识到存储技术在现代计算机系统中的重要性。
课程性质:本课程为计算机组成原理的实践课程,以理论为基础,侧重于培养学生的实际操作能力和创新思维。
学生特点:学生已具备一定的数字电路基础和计算机组成原理知识,具有一定的编程和仿真经验。
教学要求:结合学生特点,通过本课程的学习,使学生能够掌握2路组相连Cache的设计与实现,提高其解决实际工程问题的能力。
教学过程中注重理论与实践相结合,强调学生动手能力的培养。
通过课程目标分解,确保学生在知识、技能和情感态度价值观方面的全面发展。
二、教学内容1. 2路组相连Cache的基本原理与结构- Cache的基本概念及其在计算机存储体系中的作用- 2路组相连Cache的映射方式、组相联结构特点2. Cache的替换策略与设计方法- 随机替换、先进先出(FIFO)和最近最少使用(LRU)等替换策略- 2路组相连Cache的具体设计方法与实现步骤3. 硬件描述语言及仿真工具的使用- 硬件描述语言(如Verilog、VHDL)的基本语法- ModelSim等仿真工具的使用方法4. 2路组相连Cache的设计与实现- 依据教学大纲,按照指定的进度完成Cache的设计与仿真- 评估Cache性能,分析命中率、缺失率等指标5. 优化方案探讨- 针对现有2路组相连Cache设计,提出可能的优化措施- 分析优化方案对Cache性能的影响教学内容根据课程目标进行选择和组织,保证科学性和系统性。
计算机组成原理之Cache模拟器的实现

实验一Cache模拟器得实现一、实验目得(1)加深对Cache得基本概念、基本组织结构以及基本工作原理得理解。
(2)掌握Cache容量、相联度、块大小对Cache性能得影响。
(3)掌握降低Cache不命中率得各种方法以及这些方法对提高Cache性能得好处。
(4)理解LRU与随机法得基本思想以及它们对Cache性能得影响.二、实验内容与步骤1、启动Cachesim2、根据课本上得相关知识,进一步熟悉Cache得概念与工作机制。
Cache概念:高速缓冲存Cache工作机制:大容量主存一般采用DRAM,相对SRAM速度慢,而SRAM速度快,但价格高。
程序与数据具有局限性,即在一个较短得时间内,程序或数据往往集中在很小得存储器地址范围内。
因此,在主存与CPU之间可设置一个速度很快而容量相对较小得存储器,在其中存放CPU当前正在使用以及一个较短得时间内将要使用得程序与数据,这样,可大大加快CPU访问存储器得速度,提高机器得运行效率3、依次输入以下参数:Cache容量、块容量、映射方式、替换策略与写策略.(1)Cache容量:启动CacheSim,提示请输入Cache容量,例如1、2、4、8、、、、、、。
此处选择输入4。
(2)块容量:如下图所示,提示输入块容量,例如1、2、4、8、、、、、、。
此处选择输入16。
(3)映射方式:如下图所示,提示输入主存储器与高速缓存之间得assoiativity方法(主存地址到Cache地址之间得映射方式),1代表直接映射(固定得映射关系)、2代表组相联映射(直接映射与全相联映射得折中)、3代表全相联映射(灵活性大得映射关系)。
此处选择全相联映射。
(4)替换策略:如下图所示,提示输入替换策略,1代表先进先出(First-In—First—Out,FIFO)算法、2代表近期最少使用(Least RecentlyUsed,LRU)算法、3代表最不经常使用(Least Frequently Used,LFU)、4代表随机法(Random)。
计组实验报告

计组实验报告【实验名称】:基于MIPS的Cache设计与实现【实验目的】:通过设计、模拟和测试基于MIPS的Cache,理解和掌握Cache的基本原理和实现方法,加深对计算机组成原理的理解和应用。
【实验设备】:Xilinx ISE Design Suite 14.7、Verilog HDL仿真工具、Mars模拟器。
【实验原理】Cache是计算机系统中重要的存储器层次结构,它可以提高访问速度,降低访问延迟。
Cache是一种由高速存储器和控制电路组成的存储器,它的作用是缓存主存中最近使用过的指令和数据,当下一次需要使用这些指令和数据时,可以直接从Cache中获取,而不需要访问主存,从而提高访问速度。
计算机系统中的Cache存储器既可以用硬件实现,也可以用软件实现。
MIPS Cache包括指令Cache和数据Cache两个部分。
指令Cache用于存储CPU需要的指令,而数据Cache用于存储CPU需要的数据。
Cache中的每一个存储块叫做一个Cache 行,每一个Cache行包括若干字块,每一个字块包括若干字节。
Cache行的大小一般是2^n 个字节。
Cache使用一种叫做Cache命中的技术,通过判断当前CPU需要的数据是否在Cache中来确定是否需要访问主存。
如果当前CPU需要的数据在Cache中,则称为Cache命中,可以直接从Cache中获取数据;如果当前CPU需要的数据不在Cache中,则称为Cache未命中,需要从主存中获取数据。
Cache有三种常见的替换算法:随机替换算法、先进先出(FIFO)替换算法和最近最少使用(LRU)替换算法。
随机替换算法是最简单的方法,它实现起来比较简单,但是效率不高。
FIFO替换算法是一种比较简单的替换算法,它在实现的时候需要维护一个队列来保证替换最早进入Cache的数据,但是这种算法无法适应程序的访存局部性。
LRU替换算法是一种比较复杂的替换算法,它需要维护一个使用时间序列来记录各数据块被使用的时间,当需要替换时,选择使用时间最旧的数据块替换掉。
074-王楠-计组实验五Cache控制器设计实验

延安大学计算机学院实验报告专用纸学号1110218014074 姓名王楠班级计科18 课程名称计算机组成原理实验项目名称Cache控制器设计实验任课教师指导教师实验组别第组同组者教师评语及成绩:实验成绩:教师签字:(请按照实验报告的有关要求书写,一般必须包括:1、实验目的;2、实验内容;3、实验步骤与方法;4、实验数据与程序清单;5、出现的问题及解决方法;6、实验结果、结果分析与体会等内容。
)【1】实验目的(1)掌握Cache控制器的原理及其设计方法。
(2)熟悉CPLD应用设计及EDA软件的使用。
【2】实验原理1、采用直接映像方式的cache控制器图1直接映像方式2、采用CPU首先访问Cache,若在Cache中找不到目标地址,则从MEM单元中读入到Cache。
图2 Cache系统框图3、按区号、块号、块内地址访问目标地址,系统默认存储每个块的首地址,若同时访问同一块中的其他地址,将出现新访问的地址覆盖与之在同一块的另一块号。
【3】实验步骤(1)使用Quartus II 软件编辑实现相应的逻辑并进行编译,直到编译通过,Cache 控制器在EPM1270芯片中对应的引脚如图2-2-5所示,框外文字表示IO号,框内文字表示该引脚的含义(本实验例程见‘安装路径\Cpld \CacheCtrl\CacheCtrl.qpf’工程)(2)关闭实验系统电源,按图2-2-6连接实验电路,并检查无误,图中将用户需要连接的信号用圆圈标明(3)打开实验系统电源,将生成的POF文件下载到EMP1270中去,CPLD单元介绍见实验1.2。
(4)将时序与操作台单元的开关KK3置为‘运行’档,CLR信号由CON单元的CLR模拟给出,按动CON单元的CLR按钮,清空区表。
(5)预先往主存写入数据:联机软件提供了机器程序下载功能,以代替手动读写主存,机器程序以指定的格式写入到以TXT为后缀的文件中,机器指令的格式如下:如$P 1F 11,表示机器指令的地址为1FH,指令值为11H,本次实验只初始化00-0FH共16个单元,初始数据如下,程序中分号‘;'为注释符,分号后面的内容在下载时将被忽略掉。
计算机组成原理实验报告

湖南师范大学工程与设计学院计算机组成原理实验报告姓名:年级:2014级专业:计算机科学与技术学号:**********任课教师:***开课时间:2015~2016学年第二学期湖南师范大学工程与设计学院实验数据报告单实验课程:计算机组成原理实验题目:基本运算器实验实验日期:2016年 6月13日专业:计算机年级:2014级班级:五班姓名:一.实验目的:1.了解运算器的组成结构2.掌握运算器的工作原理二..实验内容:主要内容:该试验旨在了解运算器内部运算过程及组成结构,并能进行一些简单的数据运算。
该实验通过一片CPLD来实现运算器部件的功能,在接好的实验电路上,用CMA软件将数据加载加入内存,最终实现通过设置CON单元的S3、S2、S1、S0以及时序T1、T2、T3、T4的不同值来实现不同的功能。
表现在:用S3、S2、S1、S0的不同值并配合CN的值来实现将寄存器A、寄存器B中的两个数进行逻辑运算、移位运算、算术运算,并且加上时间脉冲的加入,并且能够准确的实现值的输出。
结果体现在:用FC灯亮表示有进位,FZ灯亮表示零标志,D7…D0灯显示通过运算后得出来的值。
三.实验原理图:图一(运算器原理图)四.实验数据与分析:0000:功能是F=A(直通),因为A=65,所以F=65,且没有进位,标志位也没有变化,所以FC=0,FZ=0. 0001: 功能是F=B (直通),因为A=A7,所以F=A7,且没有进位,标志位也没有变化,所以FC=0,FZ=0. 0010: 功能是F=AB,也就是A与B的逻辑与,所以F=25, 且没有进位,标志位也没有变化,所以FC=0,FZ=0. 0011:功能是F=A+B,也就是A与B的逻辑或,所以F=E7, 且没有进位,标志位也没有变化,所以FC=0,FZ=0. 0100: 功能是F=/A,0101:功能是F=A不带进位循环右移B(取低三位)位。
0110:功能是当CN=0时,F=A逻辑右移一位;当CN=1时,F=A带进位逻辑右移一位。
实验5 Cache实验

深圳大学实验报告课程名称:计算机系统(2)实验项目名称:Cache实验学院:计算机与软件学院专业:计算机与软件学院所有专业指导教师:罗秋明报告人:学号:班级:实验时间:2017年6月6日实验报告提交时间:2017年6月9日教务处制一、实验目标:了解Cache对系统性能的影响二、实验环境:1、个人电脑(Intel CPU)2、Fedora 13 Linux 操作系统三、实验内容与步骤1、编译并运行程序A,记录相关数据。
2、不改变矩阵大小时,编译并运行程序B,记录相关数据。
3、改变矩阵大小,重复1和2两步。
4、通过以上的实验现象,分析出现这种现象的原因。
程序A:#include <sys/time.h>#include <unistd.h>#include <stdio.h>main(int argc,char *argv[]){float *a,*b,*c, temp;long int i,j,k,size, m;struct timeval time1,time2;if(argc<2) {printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);exit(-1);} //ifsize=atoi(argv[1]);m =size*size;a=(float*)malloc(sizeof(float)*m);b=(float*)malloc(sizeof(float)*m);c=(float*)malloc(sizeof(float)*m);for(i=0;i<size;i++) {for(j=0;j<size;j++) {a[i*size+j]=(float)(rand()%1000/100.0);b[i*size+j]=(float)(rand()%1000/100.0);}gettimeofday(&time1,NULL);for(i=0;i<size;i++){for(j=0;j<size;j++){c[i*size+j]=0;for(k=0;k<size;k++)c[i*size+j]+=a[i*size+k]*b[k*size+j];}gettimeofday(&time2,NULL);_sec-=_sec;_usec-=_usec;if(_usec<0L) {_usec+=1000000L;_sec-=1;}printf("Executiontime=%ld.%6ld seconds\n",_sec,_usec);} //forreturn(0);}//main程序B:#include <sys/time.h>#include <unistd.h>#include <stdio.h>main(int argc,char *argv[]){float *a,*b,*c,temp;long int i,j,k,size,m;struct timeval time1,time2;if(argc<2){printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);exit(-1);}size=atoi(argv[1]);m=size*size;a=(float*)malloc(sizeof(float)*m);b=(float*)malloc(sizeof(float)*m);c=(float*)malloc(sizeof(float)*m);for(i=0;i<size;i++)for(j=0;j<size;j++){a[i*size+j]=(float)(rand()%1000/100.0);c[i*size+j]=(float)(rand()%1000/100.0);}gettimeofday(&time1,NULL);for(i=0;i<size;i++)for (j=0;j<size;j++){b[i*size+j]= c[j*size+i];for (i=0;i<size;i++)for(j=0;j<size;j++){c[i*size+j]= 0;for (k=0;k<size;k++)c[i*size+j]+=a[i*size+k]*b[j*size+k];} //forgettimeofday(&time2,NULL);_sec-=_sec;_usec-=_usec;if(_usec<0L){_usec+=1000000L;_sec-=1;}printf("Executiontime=%ld.%6ld seconds\n",_sec,_usec);}//forreturn(0);}四、实验结果及分析1、用C语言实现矩阵(方阵)乘积一般算法(程序A),填写下表:分析:由下图1,可得到上表的结果,程序主要代码如下所示,对二维数组b是跳跃的,类似下表1的访问顺序,这样导致了程序的空间局部性很差:for(j=0;j<size;j++){c[i*size+j] = 0;for (k=0;k<size;k++)c[i*size+j] += a[i*size+k]*b[k*size+j];}表1图22、程序B是基于Cache的矩阵(方阵)乘积优化算法,填写下表:分析:由下图4可以得到上表的数据,由下面主要代码可知,优化后的代码访问数组b的顺序类似下图3,这样相对程序A对cache的命中率大大得到了提高:for(j=0;j<size;j++){c[i*size+j] = 0;for (k=0;k<size;k++)c[i*size+j] += a[i*size+k] *b[j*size+k];} //for表2以下图说明为什么程序B的空间局部性好:图43、优化后的加速比(speedup)加速比定义:加速比=优化前系统耗时/优化后系统耗时;所谓加速比,就是优化前的耗时与优化后耗时的比值。
王楠-计组实验五Cache控制器设计实验

074-王楠-计组实验五C a c h e控制器设计实验(共4页)-本页仅作为预览文档封面,使用时请删除本页-延安大学计算机学院实验报告专用纸学号姓名王楠班级计科18课程名称计算机组成原理实验项目名称Cache控制器设计实验任课教师指导教师实验组别第组同组者教师评语及成绩:实验成绩:教师签字:(请按照实验报告的有关要求书写,一般必须包括:1、实验目的;2、实验内容;3、实验步骤与方法;4、实验数据与程序清单;5、出现的问题及解决方法;6、实验结果、结果分析与体会等内容。
)【1】实验目的(1)掌握Cache控制器的原理及其设计方法。
(2)熟悉CPLD应用设计及EDA软件的使用。
【2】实验原理1、采用直接映像方式的cache控制器图1直接映像方式2、采用CPU首先访问Cache,若在Cache中找不到目标地址,则从MEM单元中读入到Cache。
图2 Cache系统框图3、按区号、块号、块内地址访问目标地址,系统默认存储每个块的首地址,若同时访问同一块中的其他地址,将出现新访问的地址覆盖与之在同一块的另一块号。
【3】实验步骤(1)使用Quartus II 软件编辑实现相应的逻辑并进行编译,直到编译通过,Cache 控制器在EPM1270芯片中对应的引脚如图2-2-5所示,框外文字表示IO号,框内文字表示该引脚的含义(本实验例程见‘安装路径\Cpld \CacheCtrl\’工程)(2)关闭实验系统电源,按图2-2-6连接实验电路,并检查无误,图中将用户需要连接的信号用圆圈标明(3)打开实验系统电源,将生成的POF文件下载到EMP1270中去,CPLD单元介绍见实验。
(4)将时序与操作台单元的开关KK3置为‘运行’档,CLR信号由CON单元的CLR模拟给出,按动CON单元的CLR按钮,清空区表。
(5)预先往主存写入数据:联机软件提供了机器程序下载功能,以代替手动读写主存,机器程序以指定的格式写入到以TXT为后缀的文件中,机器指令的格式如下:如$P 1F 11,表示机器指令的地址为1FH,指令值为11H,本次实验只初始化00-0FH共16个单元,初始数据如下,程序中分号‘;'为注释符,分号后面的内容在下载时将被忽略掉。
Cache模拟实验
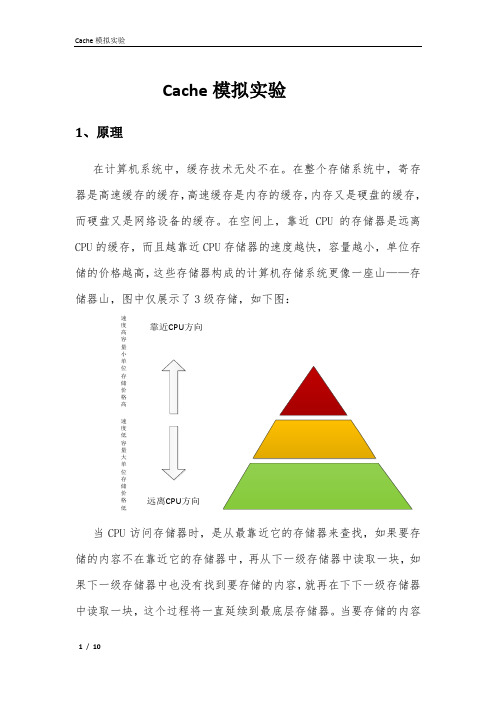
Cache 模拟实验1、原理在计算机系统中,缓存技术无处不在。
在整个存储系统中,寄存器是高速缓存的缓存,高速缓存是内存的缓存,内存又是硬盘的缓存,而硬盘又是网络设备的缓存。
在空间上,靠近CPU 的存储器是远离CPU 的缓存,而且越靠近CPU 存储器的速度越快,容量越小,单位存储的价格越高,这些存储器构成的计算机存储系统更像一座山——存储器山,图中仅展示了3级存储,如下图:靠近CPU 方向速度高容量小单位存储价格高速度低容量大单位存储价格低远离CPU 方向当CPU 访问存储器时,是从最靠近它的存储器来查找,如果要存储的内容不在靠近它的存储器中,再从下一级存储器中读取一块,如果下一级存储器中也没有找到要存储的内容,就再在下下一级存储器中读取一块,这个过程将一直延续到最底层存储器。
当要存储的内容调入到靠近它的存储器中之后,CPU再从其中存取所需的内容。
这个过程就叫Cache。
Cache是以块为单位进行的,块的大小有上层存储的大小来决定,一般Cache用一个4元组来描述——(S,E,B,m),S是上层存储器的分组数,用s来表示S占用的位数,E是每个组中包含的行数,B是一行中真正存储数据的字节数,用b来表示B占用的位置,m是存储系统的地址线的宽度。
为了便于Cache的管理还要有一个标志位,用来标识本行数据是否有效,这个有效标志不会出现在内存地址中;除此之外,还有标志位,这个标志位是出现在内存地址中的,我们用t 来表示。
内存地址,包含t,s和b。
如下图:t bits 标志s bits 组索引上图就是Cache的一行的单独内容,整个Cache就是这样的数据结构的集合,现在举个例子来综合进行说明,假如m=8,b=2,E=1,s=2,那么t就等于m-b-s,也就是t=4。
此外E=1,也就是每一个组中包含一行。
CPU假如读取0x00地址的内容,从Cache中读取要分3步进行,首先,确定组,地址0x00的二进制表示 0000 0000B,bit2和bit3,就是组的索引,可以确定是第0组。
实验二-Cache性能分析

实验二-C a c h e性能分析-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN实验四 Cache性能分析实验目的1.加深对Cache的基本概念、基本组织结构以及基本工作原理的理解;2.掌握Cache容量、相联度、块大小对Cache性能的影响;3.掌握降低Cache不命中率的各种方法以及这些方法对提高Cache性能的好处;4.理解LRU与随机法的基本思想以及它们对Cache性能的影响。
实验平台Cache模拟器MyCache,《计算机系统结构实验教程》附书光盘中提供,清华大学出版社。
设计:张晨曦教授(),版权所有。
开发:程志强。
实验内容及步骤首先要掌握MyCache模拟器的使用方法。
(见节)4.3.1 Cache容量对失效率的影响1.启动MyCache。
2.用鼠标点击“复位”按钮,把各参数设置为默认值。
3.选择一个地址流文件。
方法:选择“访问地址”下的“地址流文件”选项,然后点击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
4.选择不同的Cache容量,包括:2KB,4KB,8KB,16KB,32KB,64KB,128KB,256KB,分别执行模拟器(点击“执行到底”按钮),然后在表中记录各种情况下的失效率。
地址流文件名: C:\Documents and Settings\user\桌面\Cache性能分析\MyCache模拟器\地址流\5.根据该模拟结果,你能得出什么结论Cache容量越大,失效率越低。
4.3.2 相联度对失效率的影响1.用鼠标点击“复位”按钮,把各参数设置为默认值。
这时的Cache容量为64KB。
2.选择一个地址流文件。
方法:选择“访问地址”下的“地址流文件”选项,然后点击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
3.选择不同的Cache相联度,包括:直接映象,2路,4路,8路,16路,32路,分别执行模拟器(点击“执行到底”按钮),然后在表中记录各种情况下的失效率。
cache控制器设计实验课程设计

cache控制器设计实验课程设计一、课程目标知识目标:1. 让学生理解Cache控制器的基本原理和功能,掌握Cache的工作流程和设计要点。
2. 使学生掌握Cache映射技术和替换策略,并能分析其优缺点。
3. 帮助学生了解Cache性能评估指标,学会使用相关工具进行性能分析。
技能目标:1. 培养学生运用所学知识进行Cache控制器设计的能力,能够完成简单的Cache控制器电路搭建和调试。
2. 提高学生运用相关软件工具进行Cache性能分析和优化方案设计的能力。
情感态度价值观目标:1. 培养学生对计算机组成原理和硬件设计的兴趣,激发学生的创新意识和探索精神。
2. 培养学生良好的团队协作精神,提高沟通与表达能力。
3. 引导学生认识到Cache技术在我国计算机产业发展中的重要性,增强学生的国家使命感和责任感。
课程性质分析:本课程为计算机组成原理与设计领域的实验课程,以Cache控制器设计为主题,结合理论知识,培养学生的实践能力和创新能力。
学生特点分析:学生具备一定的计算机组成原理知识,具有一定的编程和硬件基础,但对Cache控制器设计的相关知识掌握不足,需要通过本课程进行深入学习。
教学要求:1. 结合理论知识,注重实践操作,提高学生的动手能力。
2. 引导学生主动探索,培养学生的创新思维。
3. 强化团队合作,锻炼学生的沟通与协作能力。
4. 注重过程评价,关注学生的学习成果和素质提升。
二、教学内容1. Cache基础知识回顾:介绍Cache的概念、作用,以及Cache与主存、CPU的关系。
相关教材章节:第一章 计算机系统概述2. Cache控制器设计原理:讲解Cache控制器的基本组成、工作原理,重点介绍Cache映射技术、替换策略和写策略。
相关教材章节:第三章 存储系统3. Cache控制器设计方法:介绍Cache控制器的设计流程,包括电路设计、仿真和验证等环节。
相关教材章节:第六章 数字电路设计4. Cache性能评估:讲解Cache性能指标,如命中率、缺失率等,介绍性能评估方法和工具。
2路组相连cache设计课程设计

2路组相连cache设计课程设计一、课程目标知识目标:1. 学生理解2路组相连Cache的基本原理,掌握其数据存储和访问机制。
2. 学生掌握Cache的映射方式,能解释2路组相连映射的特点及其优势。
3. 学生能够运用Cache概念,计算出命中率和缺失率,理解其性能指标。
技能目标:1. 学生具备设计和实现2路组相连Cache的能力,能够使用相关工具或软件模拟其工作过程。
2. 学生能够分析Cache性能,针对给定场景提出优化策略,提高存储系统的效率。
情感态度价值观目标:1. 培养学生对计算机组成原理中存储系统知识的学习兴趣,增强其对硬件基础知识的重视。
2. 学生通过小组合作完成任务,培养团队协作能力和沟通技巧,提高解决问题的信心和自主学习能力。
3. 学生能够认识到存储技术在实际应用中的重要性,激发对相关领域技术发展的关注和探索精神。
课程性质:本课程为计算机科学与技术专业课程,以理论讲授与实践操作相结合的方式展开。
学生特点:学生已具备一定的计算机硬件基础知识,具有较强的逻辑思维能力和动手操作能力。
教学要求:结合课程性质和学生特点,通过本课程的学习,使学生在理解理论知识的基础上,能够独立设计和实现2路组相连Cache,提高其解决实际问题的能力。
同时,注重培养学生的团队协作和情感态度价值观,为后续相关课程学习打下坚实基础。
二、教学内容1. Cache基本概念与原理- Cache的作用与意义- Cache的分类与结构- 2路组相连Cache的存储原理2. Cache映射方式- 直接映射、全相连映射与组相连映射- 2路组相连映射的特点与优势- 映射策略对Cache性能的影响3. Cache性能分析- 命中率与缺失率的计算- Cache性能指标:访问时间、带宽等- 影响Cache性能的因素4. 2路组相连Cache设计- 设计原理与步骤- Cache容量、块大小和组数的选取- 地址映射与替换策略5. Cache优化策略- 降低缺失率的策略- 提高命中率的策略- 性能优化案例分析6. 实践操作- 使用工具或软件模拟2路组相连Cache- 设计和实现2路组相连Cache,并分析性能- 针对给定场景,提出并实施优化策略教学内容安排与进度:本教学内容分为6个部分,按照教材章节顺序进行。
实验五 Cache模拟器

主存由2n个可编址的字组成,每个字有惟一的n位地址。
为了与映射,将主存与缓存都分成若干块,每块内又包含若干个字,小相同(即块内的字数相同)。
这就将主存的地址分成两段:高它主要由 Cache存储体、地址映射变换机构、 Cache替换机构几大模块组成。
①Cache存储体:以块为单位与主存交换信息,为加速 Cache与主存之间的调动,主存大多采用多体结构,且 Cache访存的优先级最高。
②地址映射变换机构:是将CPU送来的主存地址转换为 Cache地址。
由于主存和 Cache的块大小相同,块内地址都是相对于块的起始地址的偏移量(即低位地址相同),因此地址变换主要是主存的块号(高位地址)与 Cache块号间的转换。
而地址变换又与主存地址以什么样的函数关系映射到 Cache中(称为地址映射)有关,这些内容可详见4.3.2节。
如果转换后的 Cache块已与CPU欲访问的主存块建立了对应关系,即已命中,则CPU可直接访问 Cache存储体。
如果转换后的 Cache块与CPU欲访问的主存块未建立对应关系,即不命中,此刻CPU在访问主存时,不仅将该图中每个主存块只与一个缓存块相对应,映射关系式为:总之,这种方式所需的逻辑电路甚多,成本较高,实际的 Cache还要采用各种措施来减少地处的比较次数。
组相联映射组相联映射是对直接映射和全相联映射的一种折中。
它把 Cache分为每组有R块,并有以下关系:i=j mod Q其中,i为援存的组号,j为主存的块号。
某一主存块按模Q将其映射到缓存的第i组内,如图4.56所示。
组相联映射的主存地址各段与直接映射(参见图4.54)相比,还是有区别的。
图4.54 Cache字块地址字段由c位变为组地址字段q位,且q=C-r,其中2c表示 Cache的总块数,2q表示 Cache的分组个数,2r表示组内包含的块数。
主存字块标记字段由t 位变为s=t+r位。
为了便于理解,假设c=5,q=4,则r=c-q=1。
cache性能分析及优化实验报告

实验报告实验名称:计算机原理cache性能分析及优化实验学员:张英杰学号: 201008040092 培养类型: 4+1军人年级:任职培训队专业:计算机科学与技术所属学院:计算机学院指导教员:唐玉华职称:研究员实验室:校计算机中心四号院机房实验日期: 2010.12.1—2010.12.19国防科学技术大学训练部制《实验报告》填写说明1.学员完成人才培养方案和课程标准要所要求的每个实验后,均须提交实验报告。
2.实验报告封面必须打印,报告内容可以手写或打印。
3.实验报告内容编排及打印应符合以下要求:(1)采用A4(21cm×29.7cm)白色复印纸,单面黑字打印。
上下左右各侧的页边距均为3cm;缺省文档网格:字号为小4号,中文为宋体,英文和阿拉伯数字为Times New Roman,每页30行,每行36字;页脚距边界为2.5cm,页码置于页脚、居中,采用小5号阿拉伯数字从1开始连续编排,封面不编页码。
(2)报告正文最多可设四级标题,字体均为黑体,第一级标题字号为4号,其余各级标题为小4号;标题序号第一级用“一、”、“二、”……,第二级用“(一)”、“(二)” ……,第三级用“1.”、“2.”……,第四级用“(1)”、“(2)” ……,分别按序连续编排。
(3)正文插图、表格中的文字字号均为5号。
一实验概述(一)实验目的1.掌握Cache的基本概念、基本组织结构2.掌握影响Cache性能的三个指标3.了解相联度对Cache的影响4.了解块大小对Cache的影响5.了解替换算法对Cache的影响6.了解Cache失效的分类及组成情况7.了解一些基本的Cache性能优化方法(选做)(二)实验步骤1.运行模拟器SimpleScalar2.在基本配置情况下运行矩阵乘计算程序统计Cache失效次数,并统计三种不同类型的失效3.改变Cache容量,统计各种失效的次数,并进行分析4.改变Cache的相联度,统计各种失效的次数,并进行分析5.改变Cache块大小,统计各种失效的次数,并进行分析6.改变Cache的替换策略,统计各种失效次数,并分析7.对给出的矩阵乘计算程序进行适当改写以优化cache性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验3 Cache 控制器设计
1、实验目的
(1)掌握Cache控制器的原理及其设计方法。
(2)熟悉FPGA应用设计及EDA 软件的使用。
(3) 熟悉Vivado软件的使用及FPGA应用设计。
2、实验原理
Cache是介于CPU与主存之间的小容量存储器,包括管理在内的全部功能由硬件实现,对程序员是透明的,在一定程度上解决了CPU与主存之间的速度差异、与主存容量相比,Cac he的容量特不小,它保存的内容只是内存内容的一个子集,且Cache与主存的数据交互以块为单位、把主存中的块放到Cache中时必须把主存地址映射到Cache中,即确定位置的对应关系,并采纳硬件实现,以便CPU给出的访存地址能够自动变换成Cache地址。
由于程序访问的局部性,使得主存的平均读出时间接近Cache的读出时间,大大提高了CPU的访存效率、
地址映射方式有全相联方式、直截了当相联方式、组相联方式,本实验采纳的是直截了当方式,这种变换方式简单而直截了当,硬件实现特不简单,访问速度也比较快,然而块的冲突率比较高、其主要原则是:主存中一块只能映象到Cache的一个特定的块中、假设主存的块号为B,Cache的块号为b,则它们之间的映象关系能够表示为:b=B mod Cb其中,Cb是Cache的块容量、设主存的块容量为Mb,区容量为Me,则直截了当映象方法的关系如图3、19所示。
把主存按Cache的大小分成区,一般主存容量为Cache容量的整数倍,主存每一个分区内的块数与Cache的总块数相等、直截了当映象方式只能把主存各个区中相对块号相同的那些块映象到Cache中同一块号的那个特定块中、例如,主存的块0只能映象到Cache的块0中,主存的块1只能映象到Cache的块1中,同样,主存区1中的块Cb(在区1中的相对块号是0)也只能映象到Cache 的块0中、依照上面给出的地址映象规则,整个Cache地址与主存地址的低位部分是完全相同的。
图1直截了当相联映像方式
直截了当映象方式的地址变换过程如图1所示,主存地址中的块号B与Cache地址中的块号b 是完全相同的、同样,主存地址中的块内地址W与Cache地址中的块内地址w也是完全相同的,主存地址比Cache地址长出来的部分称为区号E、
图2直截了当相联地址变换
在程序执行过程中,当要访问Cache时,为了实现主存块号到Cache块号的变换,需要有一个存放主存区号的小容量存储器,这个存储器的容量与Cache的块数相等,字长为主存地址中区号E 的长度,另外再加一个有效位。
在主存地址到Cache地址的变换过程中,首先用主存地址中的块号去访问区号存储器(按地址访问)、把读出来的区号与主存地址中的区号E进行比较,依照比较结果与与区号在同一存储字中的有效位情况作出处理。
假如区号比较结果相等,有效位为‘1’,则Cache 命中,表示要访问的那一块差不多装入到Cache中了,这时Cache地址(与主存地址的低位部分完全相同)是正确的。
用这个Cache地址去访问Cache,把读出来的数据送往CPU。
其她情况均为
Cache没有命中,或称为Cache失效,表示要访问的那个块还没有装入到Cache中,这时,要用主存地址去访问主存储器,把读出来的一个字送往CPU,同时,把包括被访问字在内的一块都从主存储器中读出来,送往Cache的相应块。
Cache与CPU以及存储器的连接如图3所示,本实验要在FPGA中实现Cache及其地址变换逻辑(也叫Cache控制器),采纳直截了当相联地址变换,只考虑CPU从Cache读数据,不考虑CPU写回数据的情况。
Cache控制器顶层模块如图4所示,主存地址为A7…A0,共8位,区号E取3位,如此Cache地址还剩5位,因此Cache容量为32个单元,块号B取3位,那么Cache分为8块,块内地址W取2位,则每块为4个单元、图4中,WCT为写Cache块表信号,CLR为系统总清零信号,A7…A0为CPU访问内存的地址,M为Cache失效信号,CA4…CA0为Cache地址,MD7…MD0为主存送Cache的数据,D7…D0为Cache送CPU数据,T2为系统时钟,RD为CPU访问内存读信号,LA1与LA0为块内地址。
图3Cache系统图
图4 Cache控制器顶层模块图
3、实验内容
(1)在Vivado软件中,使用D触发器作为存储一个二进制代码的存储单元,设计一个8位的存储单元模块,依照基于硬件描述语言的设计流程输入该电路,进行编译、仿真验证后生成存储单元模块供上层设计调用。
(2)依照对实验原理的描述,使用这个8位的存储单元构成一个32*8位的Cache存储体,并在Vivado软件中实现该电路,进行编译、仿真验证后生成Cache存储体模块供上层调用。
(3)参照上面两步,在Vivado软件中实现一个4位的存储单元模块;然后使用这个4位存储单元构成一个8*4位的区表存储器,用来存放区号与有效位、由图2可知,还需要实现一个区号比较器,假如主存地址的区号E与区表中相应单元中的区号相等,且有效位为1,则Cac he命中,否则Cache失效,标志位为M,M为0时表示Cache失效、最后,编译、仿真验证后生成区表存储器模块供上层调用、
(4)当Cache命中时,就将Cache存储体中相应单元的数据送往CPU,这个过程比较简单;当Cache失效时,需要将主存中相应块中的数据读出写入Cache中,如此Cache控制器就要产生访问主存储器的地址与主存储器的读信号,由于每块占4个单元,因此需要连续访问4次主存,这就需要一个低地址发生器、在Vivado软件中,依照基于VerilogHDL的设计流程输入一个2位计数器,用于产生低2位地址00~11,进行编译、仿真验证后生成低地址发生器模块供上层调用。
(5)将产生的低2位地址与CPU给出的高6位地址组合起来,形成访问主存储器的地址,M能够作为主存的读信号。
如此在时钟T2的控制下,就能够将主存中相应的块写入Cac he的相应块中,最后再修改区表。
在Vivado软件中,参照图4给出的Cache存储器顶层模块,依照基于VerilogHDL的设计流程输入该电路,进行编译、仿真验证后生成编程文件。
考虑题:对比分析全(组)相联映射与直截了当映射方式的区不、如何在Vivado软件中实现全(组)相联映射方式的Cache存储器?
顶层模块图
CPU 读内存时与CACHE MEM之间的连接信号。