文件语义检索
语义Web技术对高校档案信息检索工作的应用价值

妊蓝拈案2018 02/80
vork Discussion工 作 探 讨
学成才 ”的能力 ),以达到改善机器 的检 索性能之 目
当前 ,应用文本类档案语 义检 索最大的困境是这
的 。第 二 ,以 “本 体 ” (Ontology)作 为知 识 库 的基 础 , 可实现领域知识 的共享 与复用 。Studer等认为 : “本 体 ”是共 享 概 念模 型 明确 的形 式 化 规 范 说 明 。L1J“本 体 ”
万 维 网 联 盟 (W 3C) 的 蒂 姆 ·伯 纳 斯 .李 (Tim Berners.Lee)在 1 998年 提 出了 语义 网 (Semantic Web1 的 概 念 。所 谓 “语 义 网 ” , 是指 能 够 根 据 语 义 进 行 分 析判断 的网络 ,可让 计算机担纲 “智 能导航工具 ”。 其核 心技 术 是 在 w w w 上 为 文 档 设置 可 使 计 算 机 认 知 的语义 ,进而将互联 网塑造为可通用的信息交换媒介 。 其技术创新在于建立 “知识本体”。目前 ,以 “本体论 ” 为核心 的语义 网技术 ,正在 形成一套能够 实现异 构系 擎”在应用 中的效果 尚未达到人们所 期盼 的理想境界 ,特别是正确 回答 问题 的稳定性还较差 。 此外, 由于 “本体 ”等相关检索技术 的专业 性很强 ,
目前 的语义检索技术 ,主要有潜在语义检索和基 于本 体 的语义检索两种类 型,其中知识库、 “本体 ” 与信 息库是构成基于 “本体 ”语义检索模 型的三 大支 柱 。这项技 术对高校档案信息检索工作 的应用价 值主 要 表 现 为:第 一 ,知 识库 作 为 推 理和 知 识 积 累 的基 础 , 可把 用户的 问题提高 到知识 (概念 )层面 。知识 库像 人脑存放知识,可始终处于 “自增长 、白循环 ”状态 , 其 丰 富 程 度 决 定 系 统 检 索 能力 的 高 低 。档 案 信 息 语 义 检索所要做的,就是通过知识库打造如 同 Google“知 识图谱 ”(Knowledge Graph)这类 能模拟人类大脑 “自 增 长 、 白循 环 ” 的智 慧 引擎 。 “知 识 图谱 ”技 术 创 新 的关 键 是 : 用 “搜 索 +知 识 库 ” 的方 式 来 组 织 海 量 网 络 档 案 信 息 ,通 过 存储 海 量 节 点 (Reference point,相 当于 一个词条或者一个页面 ),在不 同数据之 间建立 有 效 链 接 (使 每 个 条 目之 间形 成 密 切 的 关 联 ), 并 以 此 关 联 来 构造 “谱 系 网络 ”,再采 用 自然 语言 处 理 (NLP) 技 术 作 词 法 分 析 及 分 词 、词 性 标 注 、句 法 分 析 、语 义 和 语 境 分 析 等 ,让 机 器 在 向用 户 的 反 馈 和 评 价 学 习 的 过程 中,不 断更新知识库 (提高 “培养 思维”和 “自
Patentics和Incopat在语义检索中的比较
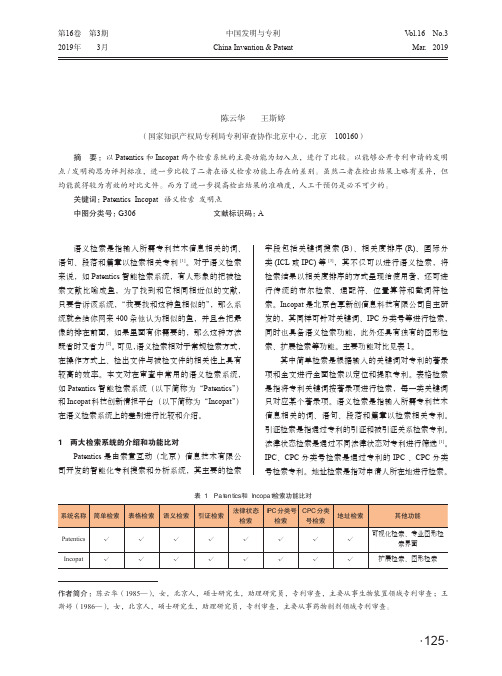
第16卷 第3期2019年 3月中国发明与专利China Invention & PatentV ol.16 No.3Mar. 2019Patentics和Incopat在语义检索中的比较陈云华 王斯婷(国家知识产权局专利局专利审查协作北京中心,北京 100160)摘 要:以Patentics 和Incopat 两个检索系统的主要功能为切入点,进行了比较。
以能够公开专利申请的发明点/发明构思为评判标准,进一步比较了二者在语义检索功能上存在的差别。
虽然二者在检出结果上略有差异,但均能获得较为有效的对比文件。
而为了进一步提高检出结果的准确度,人工干预仍是必不可少的。
关键词:Patentics Incopat 语义检索 发明点中图分类号: G306文献标识码:A语义检索是指输入所需专利技术信息相关的词、语句、段落和篇章以检索相关专利[1]。
对于语义检索来说,如Patentics 智能检索系统,有人形象的把被检索文献比喻成鱼,为了找到和它相同相近似的文献,只要告诉该系统,“我要找和这种鱼相似的”,那么系统就会给你网来400条他认为相似的鱼,并且会把最像的排在前面,如果里面有你需要的,那么这种方法既省时又省力[2]。
可见,语义检索相对于常规检索方式,在操作方式上、检出文件与被检文件的相关性上具有较高的效率。
本文对在审查中常用的语义检索系统,如Patentics 智能检索系统(以下简称为“Patentics ”)和Incopat 科技创新情报平台(以下简称为“Incopat ”)在语义检索系统上的差别进行比较和介绍。
1 两大检索系统的介绍和功能比对Patentics 是由索意互动(北京)信息技术有限公司开发的智能化专利搜索和分析系统,其主要的检索字段包括关键词搜索(B )、相关度排序(R)、国际分类(ICL 或IPC)等[3],其不仅可以进行语义检索,将检索结果以相关度排序的方式呈现给使用者,还可进行传统的布尔检索、通配符、位置算符和截词符检索。
文件检索综合报告

文件检索综合报告一、引言随着信息技术的飞速发展,大量的数据和信息被产生、存储和管理。
如何从这些海量的数据中快速、准确地找到所需的信息,已经成为了一个亟待解决的问题。
文件检索技术应运而生,它通过对文件内容的分析,为用户提供高效、准确的信息检索服务。
本报告将对文件检索技术的原理、方法、应用及发展趋势进行综合分析。
二、文件检索技术原理文件检索技术主要通过对文件的内容进行分析,建立索引,然后根据用户的查询需求,在索引中进行匹配,最后返回与用户需求相关的文件。
文件检索技术的核心是文本分析和索引构建。
文本分析主要包括分词、词性标注、实体识别等任务,其目的是将文本转化为计算机可以处理的形式;索引构建则是将分析后的文本表示为一种便于检索的数据结构,如倒排索引、签名文件等。
三、文件检索方法文件检索方法主要分为两大类:基于关键词的方法和基于语义的方法。
1. 基于关键词的方法基于关键词的方法主要是通过分析用户输入的关键词,然后在文件中查找包含这些关键词的文件。
这种方法简单直观,但容易出现误检和漏检的情况。
为了提高检索的准确性,可以采用一些优化策略,如布尔查询、权重调整等。
2. 基于语义的方法基于语义的方法主要是通过对文件的内容进行深入分析,提取出文件中的语义信息,然后根据这些语义信息进行检索。
这种方法可以提高检索的准确性,但计算复杂度较高。
常见的基于语义的检索方法有向量空间模型、概率潜在语义分析(PLSA)等。
四、文件检索应用文件检索技术在各个领域都有广泛的应用,如:1. 搜索引擎:搜索引擎是文件检索技术的典型应用,它通过对网页内容的分析,为用户提供高质量的搜索结果。
2. 企业知识管理:企业知识管理需要对大量的文档进行检索,以便员工能够快速找到所需的信息。
文件检索技术可以帮助企业实现这一目标。
3. 电子图书馆:电子图书馆需要对大量的图书、期刊等进行检索,文件检索技术可以为电子图书馆提供高效的检索服务。
4. 法律领域:法律领域需要对大量的法律法规、案例等进行检索,文件检索技术可以帮助法律人员快速找到所需的信息。
ocr全文检索逻辑

OCR全文检索逻辑一、引言随着数字化时代的到来,越来越多的文档被电子化保存,其中包括纸质文档的扫描件。
在这些电子文档中搜索特定信息变得越来越重要。
OCR(Optical Character Recognition)技术的出现为文本提取和全文检索提供了有效的解决方案。
本文将探讨OCR全文检索的逻辑和相关技术。
二、OCR全文检索的定义OCR全文检索是一种基于OCR技术的文本检索方法,旨在从电子化或数字化的文档中提取和匹配特定的关键词、短语或句子。
它不仅可以检索可编辑的文本,也可以检索图像或扫描文件中的文本。
OCR全文检索可以帮助用户快速定位到需要的信息,提高工作效率。
三、OCR全文检索的工作原理1.文字识别:OCR全文检索首先要进行文字识别,将图像或扫描文件中的文本提取出来。
这一步骤需要用到OCR技术,将图像转换为可编辑的文本。
2.文本处理:提取到的文本需要进行清洗和处理,去除冗余信息,只保留有意义的内容。
这个过程可能包括文本去噪、分词、词干化等操作。
3.索引建立:为了能够快速检索文本,需要将处理后的文本建立索引。
索引建立是通过将文本划分为不同的单词或短语,并为每个单词或短语建立索引,以便能够根据关键词或短语进行快速搜索。
4.检索匹配:当用户输入关键词或短语时,系统会根据建立的索引进行匹配,并返回与之相关的文档或文本片段。
四、OCR全文检索的应用场景1.文档管理:OCR全文检索可以用于电子化文档的管理。
用户可以根据文件名、关键词或内容在海量文档中快速检索到所需的文档。
2.法律和金融领域:在法律和金融领域,有大量的文档需要整理和检索。
OCR全文检索可以帮助从庞大的数据中快速找到所需的法律条款、案例或金融报表等信息。
3.历史研究:研究人员在历史研究中常常需要查阅大量的历史文献和档案。
OCR全文检索可以大大提高他们的工作效率,帮助他们快速找到所需的信息。
4.教育研究:教育工作者和研究人员可以利用OCR全文检索技术对大量的教育文献进行检索和分析,以支持他们的教学和研究工作。
基于Tika语义分析的文档内容检索服务研究

的[ 1 ] o L u c e n e 提 供 的 用 于索 引和 查 询 的A P I 接 口可 以
f o r ( i n t i =l ; i <d a t a F i l e s . 1 e n g t h ; i + + ) { / / 对所 有 文 件 进 行遍 历
I n p u t S t r e a m i s =n e w F i l e l n p u t S t r e a r n ( i f l e ) ;
容。
图1 L u c e n e和 T i k a 结合构建搜索应用
F i g . 1 Co mb i n e dLu c e n e a n dT i k at o c o n s t r u c t a s e a r c ha p p l i c a t i o n
S i m p l e F S Di r e c t o r y ( i n d e x Di r ) ,
f s C o n i f g ) ; / / 采 用 文件 目录 存储 索 引
F i l e [ ] d a t a F i l e s =d a t a Di r . 1 i s t F i l e s O; / / 获取 目录 下
井 冈山大学学报( 自然科学版)
6 1
档 ,T i k a能 自动 甄别 文 件类 型 ,调用 相应 的解析 器 进 行 分 析 ,并 能 自动识 别 文档 的编 码 和语 言 。T i k a 的p a r s e方 法接 受 要被 解析 文档 的文件名 ,并将 分
析结 果 写入 Me t . a d a m 元 数据 集合 中。利用 t i k a对 象的 p a r s e T o S t r i n g方 法 可 分 析提 取 文件 的文 本 内
数据库与知识发现中的信息检索和分类

数据库与知识发现中的信息检索和分类随着互联网的发展以及信息化进程的推进,人们对于信息的需要越来越迫切。
然而,信息爆炸的时代也给人们带来了新的问题:海量的信息需要被整合、分类、检索和管理。
为此,数据库与知识发现成为了信息管理领域中的重要分支,其中的信息检索和分类技术更是成为了解决信息管理问题的重要手段。
一、数据库与知识发现中的信息检索数据库是信息系统中的核心,其主要作用是存储和管理数据。
在大型信息系统中,数据种类繁多,其中包括结构化数据和非结构化数据。
前者是指以表格、关系等结构形式呈现的数据,比如在关系型数据库中存储的数据;非结构化数据则是指以文本、图像、音频等形式呈现的数据,比如在文件系统中存储的文本文件、图像和音频文件。
这些数据中包含了大量的信息,但是这些信息并不一定适合直接使用。
这时就需要通过信息检索技术将需要的信息从数据中检索出来。
信息检索是指从大量的非结构化或半结构化数据中通过对关键字或查询语句进行处理,找出与其匹配的数据,并通过各种方式展现给用户的过程。
传统的信息检索方法主要是基于文本关键字的检索方法,用户输入一个或多个与信息相关的关键字,然后系统返回包含这些关键字的文档。
然而,这种方法存在着一些问题:首先,无法对检索结果进行有效的排序和分类,用户需要花费大量时间来查找其需要的信息;其次,由于用户输入的关键字可能存在歧义,因此导致检索结果的准确性和召回率无法得到保证。
近年来,随着自然语言处理和机器学习等技术的不断发展,信息检索技术也得到了快速的发展和改进,针对上述问题提出了更为有效的解决方案。
1.1 基于语义的信息检索基于语义的信息检索是一种将自然语言处理技术与信息检索技术结合起来的方法,旨在提高信息检索的准确率和召回率。
该方法通过将自然语言处理技术应用到信息检索中,将关键字之间的语义相似性考虑在内,从而更好地理解用户的查询意图,提高检索结果的质量。
如今,基于语义的信息检索已成为信息检索技术中的重要分支之一。
文件检索实验报告模板

文件检索实验报告模板1. 实验目的本实验主要目的是通过设计并实现文件检索系统,了解和掌握文件检索的基本原理和技术,以及对文件进行建立索引并进行关键字检索的方法。
2. 实验环境- 操作系统:Windows 10- 开发工具:Python 3.9.2- 依赖库:PyQt5, Whoosh3. 实验过程3.1 数据准备首先,我们在本地选择一些文本文件作为实验的数据集,包括文章、新闻、报告等。
这些文件将被用于建立索引和进行关键字检索。
3.2 文件索引在系统中,我们使用Whoosh库来建立文件的索引。
首先,我们需要定义文件的索引结构,包括文件名、路径、内容等字段。
然后,我们通过遍历数据集中的所有文件,将文件的这些信息添加到索引中。
3.3 关键字检索通过Whoosh库提供的API,我们可以方便地进行关键字检索。
用户可以在系统界面中输入关键字,并点击搜索按钮进行检索。
系统会根据用户输入的关键字查询索引,并返回匹配的文件列表。
3.4 界面设计为了方便用户使用,我们设计了一个简单的图形界面。
用户可以通过界面中的输入框输入关键字,并点击搜索按钮进行检索。
搜索结果将以列表形式展示在界面中的另一个窗口中,用户可以选择点击某一项来打开对应的文件。
4. 实验结果经过实验,我们成功地建立了文件的索引并实现了关键字检索功能。
用户可以通过输入关键字来搜索他们感兴趣的文件,并且可以通过点击搜索结果来打开对应的文件。
实验结果表明,我们设计的文件检索系统能够满足用户的需求,并具有良好的检索性能。
5. 实验总结通过本次实验,我们深入了解了文件检索的原理和技术,并实践了文件检索系统的设计与实现。
实验过程中,通过使用Whoosh库,我们学会了如何建立文件索引和进行关键字检索。
同时,通过设计简单的图形界面,我们使文件检索系统更加易用和友好。
实验结果表明,我们成功完成了实验目标,并取得了满意的效果。
然而,我们也发现了一些不足之处。
首先,我们的文件检索系统只能处理文本文件,并不能处理其他类型的文件。
基于语义的文献检索系统研究

基于语义的文献检索系统研究摘要:为引导用户沿着感兴趣的文献快速找到相关文献,提出了基于语义的文献检索系统。
通过对文献和文献间的语义关系进行分析,构建出文献领域本体,定义了推理规则,并利用Jena提供的推理机制,实现了文献领域本体的语义推理。
从而帮助和引导用户快速有效地查找到相关文献。
关键词:语义;文献检索;本体;语义推理;Jena0引言随着信息技术的发展,网络资源快速增长,人们已经越来越习惯于在网络上检索自己所需要的学术文献资源。
对于文献的浏览和检索,传统的基于关键字的文献检索和浏览方式难以对大量信息进行多角度揭示,同时,关注的文献信息形式单一,忽视了文献之外的信息及关系,使得浏览和检索效率不高。
特别是对于初次进入某个研究领域的人员,由于对该领域的认识还比较模糊,总是希望能从一篇本领域的文献中找到与之关联的文献,这些文献间的关联关系包括:引用文献、被引用文献、同引文献、同被引文献等。
引用和被引用这两种关联用来描述文献实体之间的关系,引导用户沿着感兴趣的文献找到相关文献,从而帮助用户尽快定位到目标文献。
本文通过对文献和文献间的关联关系进行分析,研究文献间存在的语义关系,构建文献领域本体,为科研人员提供适合的文献信息,帮助研究人员快速有效地查找文献信息。
1基于语义的文献检索模型1.1语义网环境下的语义检索语义网是一套包括网络信息存储、组织、表示、安全认证等各个方面的完整体系,涉及XML、Ontology、数字签名等技术和方法,本体是概念模型的明确的规范说明。
在语义网环境下实现语义检索实际上就是要将Ontology所反映的语义关系应用到对信息资源的标引和检索中,具体就是要通过对相关文件的解析和推理在语义层面实现信息检索,并以适当和友好的界面与用户进行交互。
要实现语义网环境下的语义检索,关键是要解决以下5个问题:(1)Ontology的建立问题。
这要求有本领域专家的参与,并且要借助于辅助工具。
目前基于统计学的Ontology自动创建技术正在研究之中。
结合描述性文本的三维模型语义检索方法

结合描述性文本的三维模型语义检索方法王羡慧;覃征;庄春晓;张选平【摘要】To improve the retrieval performance of 3D model, concerning the problem that the semantic-based 3D model retrieval system is hard to support customers' subjective words, a 3D model semantic retrieval method based on content and descriptive text was proposed. This method constructed a semantic tree for 3D models firstly. Then, it calculated the similarity among the input and node of tree by the word statistics method, and got some 3D models from those nodes with high similarity,and a smaller 3D models set by semantic constraint. Finally, user input' s 3D model examples may match the shape similarity in the smaller set of 3D model through semantic constraint, and returned search results to users. The WordNet definitions of some words were as input in experiments. The experimental results on PSB show that this method performs better than the content-based 3D model retrieval method on recall-precision.%为了提高三维模型的检索性能,针对当前三维模型检索系统的语义检索功能无法支持用户的主观性描述文字的问题,提出一种基于内容和描述性文本结合的三维模型语义检索方法.该方法首先为三维模型构造语义树;然后,利用语料统计的方法,计算输入的描述性文本和语义树节点扩充信息的相关程度,将相关度较高的一部分节点的三维模型实例提取出来,得到一个经过语义约束的较小的三维模型集合;最后,使用用户输入的三维模型实例在这个经过语义约束的较小的三维模型集合里进行形状相似性匹配,依据匹配度的大小返回给用户三维模型检索结果.实验中,使用WordNet对一些名词的释义作为描述性文本输入.在普林斯顿大学的PSB三维模型数据集上的实验结果表明,该方法在大多数类别中的查准率-查全率性能好于传统的基于内容的三维模型检索方法.【期刊名称】《计算机应用》【年(卷),期】2011(031)001【总页数】6页(P1-5,36)【关键词】三维模型;语义检索;描述性文本;WordNet【作者】王羡慧;覃征;庄春晓;张选平【作者单位】西安交通大学计算机科学与技术系,西安710049;西安交通大学计算机科学与技术系,西安710049;清华大学软件学院,北京100084;西安交通大学计算机科学与技术系,西安710049;西安交通大学计算机科学与技术系,西安710049【正文语种】中文【中图分类】TP391.40 引言基于内容的三维模型检索[1-3]通过对视觉特征的相似性匹配来查找用户所需的三维模型。
关于检索的名词解释

关于检索的名词解释检索的意思是什么呢?怎么用检索来造句?下面是为你整理检索的意思,欣赏和精选造句,供大家阅览!检索是指从文献资料、网络信息等信息集合中查找到自己需要的信息或资料的过程。
传统文献资料需要提取题名、作者、出版年、主题词等作为索引,而在网络时代,计算机可以对全文进行索引,即文中每一个词都能成为检索点。
在因特网上进行检索主要有目录浏览和使用搜索引擎两种方式;搜索引擎是最为常用的一种网络检索工具。
1. 检查搜索。
宋吴曾《能改斋漫录;记事一》:“学官集同舍检索,因得其金。
”2. 指工具书索引。
如化工文献检索、历史大事记检索等。
3.检索也有目录之意。
检索与搜索近义。
现今不少招标文件中给出的格式中都能看到“检索”二字作为目录使用。
同时具有让投标人按照招标文件要求准备所需材料以供招标人备查之意。
检索造句欣赏一、很多知识根本不需要储备,只需要检索就可以了。
二、我把自己的藏书进行了分类整理,并建立起了检索目录,这下子就一劳永逸,用起来非常方便了。
三、利用该系统可查询任一网格点的气候要素值,检索作物气象指标、地理信息及农业统计信息等,快速制作作物种植区划。
四、你可以通过快速检索、高级检索和专利号来检索该数据库。
五、方法通过文献检索,查阅大量相关媒介恙螨与恙虫病传播关系研究的最新的文献资料。
六、如果您要检索一个不同的环境参数,那么这就是您应该插入改变之处的地方。
七、本文对这19个种编列了检索表,对每一个种均附有同物异名的订正、形态描述、显微照片及分析讨论。
八、确保代码的网站是干净的,无差错,以便检索器可以轻松地访问它。
九、主要原因是大部分的被调查机构在自动检索上的增长。
十、文中给出了中国角麦蛾属分种检索表和雌雄外生殖器特征图。
十一、首选测量将被保存在数据库和表单中的默认页设置检索。
十二、请求作出实用新型专利检索报告的,应当提交请求书,并指明实用新型专利的专利号。
十三、不过,它冗繁的菜单界面在检索报纸的时候依然十分不便,而让杂志赢取受众的精美图片的风采也被埋没了。
语义检索——专利检索技巧与方法

HENANKEJI·ZHISHICHANQUAN 2018.03专利导航语义检索——专利检索技巧与方法李时玉郭建伟孙沫卿(北京市科学技术情报研究所信息资源部,北京100044)摘要:本文介绍了在高端专利检索分析工具进行专利语义检索的方法。
诉讼盘点主要是关注Acacia Research Corporation 的诉讼情况。
热点资讯介绍了SIVANTOS PTE.LTD 的智能耳机及该公司的专利情况。
关键词:语义检索;分析工具中图分类号:G306;G354文献标识码:A文章编号:1003-5168(2018)09-0053-02Semantic Retrieval—Patent Retrieval Tips and MethodsLI Shiyu 1,GUO Jianwei 2,SUN Moqing 3(Beijing Institute of Science and Technology Information Information Resources Department ,Beijing 100044)Abstract:This paper instroduces the method of semantic retrieval of patent in high-end patent searchand analysis tools.Litigation inventory is mainly concerned about Acacia Research Corporation's litigation sta⁃tus.Hot information on the SIVANTOS PTE.LTD smart headset and the company's patent situation.Key words:Semantic retrieval ;analyzing tool1引言语义检索[1]可直接使用,仅须提供与所需主题相关的文本块。
文档检索程序-概述说明以及解释

文档检索程序-概述说明以及解释1.引言1.1 概述在当今信息爆炸的时代,我们每天面临着海量的文档信息,如何高效地检索和获取所需的文档成为了一项重要的任务。
为了解决这一问题,文档检索程序应运而生。
文档检索程序是一种用于在大规模文档集合中检索所需文件的程序。
它可以通过关键词、短语或其他指定的检索条件来快速定位所需的文档,并返回给用户。
文档检索程序的主要目标是提供高效、准确的文档检索服务。
它通过建立索引和采用各种检索算法来实现这一目标。
通过索引,文档检索程序将每个文档的内容和特征提取出来,并存储到一个专门的数据库中,以便快速进行检索。
检索算法则负责根据用户的查询条件和索引数据库中存储的信息,找到最相关的文档并进行排名。
文档检索程序的功能多样,不仅可以进行关键词检索,还可以通过时间、作者、文件类型等多个维度进行检索。
此外,文档检索程序还可以提供分类、过滤和排序等功能,帮助用户更加高效地管理和利用文档资源。
文档检索程序的发展对个人、企业和社会都具有重要意义。
对于个人用户来说,它可以帮助我们更快捷地找到所需的资料,提高工作和学习效率。
对于企业来说,它可以帮助管理者更好地组织和利用企业内部的文档资源,提升企业的竞争力和创新能力。
对于社会来说,文档检索程序有助于促进信息共享和传播,推动社会进步和发展。
本文将着重介绍文档检索程序的定义和功能。
通过对文档检索程序的深入了解和分析,我们可以更好地理解和利用这一技术,提高我们的信息搜索和管理能力。
同时,本文还将对文档检索程序的未来发展进行展望,探讨其在不同领域的应用前景。
1.2文章结构文章结构部分的内容主要是介绍文章的组织结构和各个章节的内容概要。
通过对文章的结构进行清晰的说明,读者可以更好地理解整篇文章的逻辑脉络和内容分布。
在本篇文章中,文章结构包括以下几个章节:1. 引言:- 1.1 概述:介绍本文的背景和研究意义,简要说明文档检索程序的重要性和应用场景。
- 1.2 文章结构:本章节,将对整篇文章的组织结构和各个章节的内容进行概要介绍,为后续的内容提供一个整体框架。
文件检索论文

《文件检索及写作》结业论文[文档副标题]专业名称:机械设计制造及其自动化学生学号:*************学生姓名:***任课老师: 彭晓玲老师2015年10月13日信息检索效率的探讨摘要在信息技术迅速发展的推动下,传统信息服务机构和网络信息服务运营商逐步走上由信息服务向知识服务的转型之路。
在这种趋势下,信息检索也由过去单纯的字符匹配逐步转向面向内容、基于知识的信息检索。
在这里简单探讨一下基于知识服务的信息检索效率的基本概念和评价指标,剖析语义分析程度、信息模型、检索方法和信息收录范围等主要影响因素,最后通过一个实例,对比分析说明知识服务将提高用户信息检索的效率。
关键词:知识服务;信息检索:效率引言进入知识经济时代,知识管理、知识服务的理念得到广泛认同,信息检索技术也由基于关键词的信息检索逐步转向针对文章内容的基于知识的信息检索。
后者不再是基于字符的机械匹配,而是更强调语义,模拟人类的思维方式,从语义和概念出发,自动分析信息资源的语义信息,查找和发现具有相关知识单元的信息资源。
较之前者,其检索结果更准确,更贴近用户需求。
信息检索是将信息按照一定的规律组织起来,找到所需信息的过程和技术,简单的说,就是信息的有序化识别和查找。
信息检索效率就是实施识别和查找过程的效率。
信息检索效率不仅是影响信息检索工具价值的重要因素,也是评价信息检索技术发展的重要指标。
目录1、信息检索效率31.1、检全率 (3)1.2、检准率 (3)1.3、友好性 (3)1.4、检索耗时 (3)2、影响因素分析 (3)2.1、语义分析程度 (3)2.1.1、语义分析 (4)2.1.2、语义分析的内容 (4)2.1.3、语义分析对检索效率的影响 (4)2.2、检索模型 (4)2.2.1、布尔模型 (5)2.2.2、向量模型 (5)2.2.3、概率模型 (5)2.2.4、基于本体的信息检索模型 (5)2.3、检索方法 (5)2.3.1、目录式检索 (6)2.3.2、搜索引擎 (6)2.3.3、在线数据库查询 (6)2.4、信息收录范圈 (6)3 、检索实倒分析 (6)4 、结束语 (7)5 、参考文献 (7)1信息检索效率基于知识服务的主要评价指标有检全率、检准率、友好性和检索耗时。
浅议专利文献检索工具--PATENTICS

IT大视野数码世界 P.54浅议专利文献检索工具——PATENTICS 于晨君 国家知识产权局专利局通信发明审查部摘要:对PATENTICS智能化专利搜索和分析系统的主要检索功能、检索方式进行介绍,为科研人员以及专利使用人员进行专利文献检索提供指导和帮助。
关键词:PATENTICS 专利 语义检索一、前言近年来,我国知识产权事业发展成绩显著。
截止2018年,我国国内(不含港澳台)发明专利拥有量达到160.2万件,每万人口发明专利拥有量达到11.5件。
随着科技的发展和进步,专利申请文件数量日益增长,专利资源已经成为各专业领域的主要信息源。
出于对知识产权的保护以及经济利益的驱动,专利申请文件中记载了世界上最先进的科技成果。
因此,科研人员可以通过专利文献了解产业的发展和技术现状以准确地确定研发方向。
那么快速检索某个技术领域的专利文献,或者通过某一篇专利文献追踪检索获取相关产业的发展现状是十分重要的科研准备手段。
关于专利文献的检索,常用的检索方法是:首先选择数据库,确定基本的检索主题,其次表达检索要素,最后构建检索式。
检索要素的基本形式主要有关键词和分类号两种,除此以外以申请人、发明人为入口也可以高效地获得检索目标。
在表达检索要素和构建检索式中,还涉及到检索要素的同义词扩展,而对同义词扩展的准确性、广泛性以及上下位概念的扩展都会直接影响到检索结果和效率。
对于分类号,如IPC分类号、CPC分类号、日本专利文献常用的FI、FT分类号都需要经过专业学习才能较为准确地掌握。
另外,针对不同的数据库,还需要检索人员掌握不同数据库适用的截词符、命令算符。
为了快速命中检索目标,掌握专业的检索策略、检索技巧以及积累专业领域的技术知识是十分必要的。
因此,常规的专利文件检索对普通科技人员来说难度比较高,工作量也很大。
二、PATENTICS系统简介Patentics智能化专利搜索和分析系统针对专利文献的检索提供了比较全面的数据库,支持较多国别的专利数据检索,除了中文专利外,还包括美国、欧洲、日本、韩国等很多国家和地区的专利数据。
信息检索的途径、方法和步骤

目 录
• 信息检索的途径 • 信息检索的方法 • 信息检索的步骤 • 信息检索的技巧和注意事项 • 信息检索的应用和发展趋势
信息检索的途径
径,通过关键词搜索,可以快速找到 相关的网页、图片、视频等资源。
更准确和有用的信息。
信息检索的步骤
03
确定信息需求
01
明确问题的性质
在开始信息检索之前,首先要明 确需要解决的问题是什么,以便 有针对性地查找相关信息。
02
确定所需信息的类 型
根据问题的性质,确定所需信息 的类型,如文献、数据、图片等。
03
确定所需信息的范 围
确定所需信息的主题、领域、时 间等范围,有助于缩小检索范围, 提高检索效率。
信息检索在商业领域的应用
市场调研
企业在进行市场调研时,需要收集大量的市场信息和竞争情报。信息检索技术可以帮助企业快速查找和筛选相关信息 ,为市场策略制定提供依据。
品牌监测
企业需要实时监测品牌声誉和形象,了解公众对品牌的认知和评价。信息检索技术可以帮助企业收集和分析社交媒体 、新闻网站等平台上的品牌相关信息,为企业形象管理提供支持。
THANKS.
这些信息通常具有较高的权威性和参 考价值,对于企业和学术研究具有一 定的指导意义。
个人和专家咨询
个人和专家咨询是通过与专业人士直接交流来获取信息的途径。
这种途径的信息质量较高,但受限于个人或专家的知识范围和主观性。
信息检索的方法
02
关键词搜索
总结词
关键词搜索是最基本的信息检索方法,通过输入关键词来获取相关的信息。
总结词
在获取信息时,应关注信息来源的权威性和可靠性, 以确保所获取信息的准确性和可信度。
智能化检索系统中语义检索的使用策略

智能化检索系统中语义检索的使用策略摘要:根据申请文件的语义排序和结合改写语义分词排序三种不同类型的语义基准进行讨论,只有合撰写特定和检索目标,分别从布尔检索结合案件申请号语义排序、结合权利要求文本适的语义基准才能提高语义检索效率,快速精准定位目标文献。
关键词:布尔检索语义排序语义分词随着智能语义技术的发展,专利智能检索的时代已经来临。
现有各大商业数据库如智慧芽、Patentics、Himmpat等均开发出智能化检索平台。
“工欲善其事,必先利其器”。
为了提高检索效率,国知局今年新上线试运行的智能检索系统是S系统的升级化系统,在传统布尔检索的基础上提供了强大的语义检索功能,以及更为友好的浏览功能,并整合了更多的数据库实现更便捷的跨库检索[1]。
由于语义检索的先天优势,智能检索的最大意义是能够在难以筛选的文献中将目前文献提前。
结合传统的布尔检索构件检索式,限定检索结果在一定的范围内,然后进行语义排序,在有限的范围内明显提高相关度高的对比文件的排序,快速精准获得有效对比文件,缩短检索时长,提高检索效率。
因此,本文结合实际案例,初步探讨智能化检索系统中布尔与语义融合策略,如何利用布尔检索的经验融合语义检索实现快速高效的检索,希望能够对智能化检索系统的应用提供一些参考。
布尔检索结合案件申请号语义排序在以案件申请号为语义基准进行排序时,系统基于语音模型提取全文信息并以相关度进行排序,也是最简便的排序方式。
对于申请文件撰写规范,技术领域准确,整体上发明构思明确,关键技术特征表达清晰准确的案件,在布尔检索限定的范围内,结合申请号语义基准,从整体上进行语义排序,特别适用检索X类文献。
案例1,其涉及一种锅炉快速及应急冷却系统,权利要求1限定了包括锅炉、设备、连接所述锅炉与所述设备的导热管道、以及设置在所述导热管道上的主泵机,其特征在于,冷却系统还设置有置换模块,所述置换模块包括高位罐和低位罐,所述高位罐和所述低位罐均与所述导热管道通过置换管道连通,所述高位罐设置在冷却系统的最高处,所述低位罐设置在冷却系统的最低处,所述高位罐中装有置换介质,所述高位罐、所述低位罐与所述导热管道的连接处均设置有阀门。
gbt26761

GBT26761 文档一、引言GBT26761 是指国家标准 GB/T 26761《信息技术语义网基本标准》。
本文档将介绍 GBT26761 的背景、目的、适用范围以及相关术语和定义。
二、背景随着互联网的快速发展和信息化时代的到来,人们对于信息的管理和利用有了更高的要求。
为了使不同的计算机能够相互交流和理解各自的语义信息,语义网的概念应运而生。
GBT26761 的制定旨在为语义网的发展和应用提供基本的标准和规范。
三、目的GBT26761 的目的在于:1.确定语义网的基本标准,提供统一的语义描述方式;2.促进计算机之间的信息交流,提高信息的有效利用率;3.推动语义网技术的发展和应用,为信息时代的发展做出贡献。
四、适用范围GBT26761 适用于语义网的各个方面,包括语义描述语言、语义标注、语义查询等。
不同的组织和个人都可以根据GBT26761 进行语义网相关技术的开发和应用。
五、术语和定义在 GBT26761 中,涉及到一些相关的术语和定义,下面是其中的一些重要概念:1.语义网:指通过为网页和其他信息资源添加语义标注,实现网站间信息的共享和互操作的网络环境。
2.语义描述语言:指用于描述实体、属性和关系的语言。
3.语义标注:指通过对文档和资源进行语义化的标签或属性添加,以支持语义网的存储和检索。
4.语义查询:指基于语义描述的信息检索方式,通过语义关联性来提高搜索结果的准确性和相关性。
六、结论GBT26761 是语义网基本标准的重要文件,对于推动语义网技术的发展和应用具有重要意义。
通过统一的标准和规范,可以提高计算机间信息交流的效率,进一步推动信息技术的发展。
七、参考文献[1] 国家标准 GB/T 26761《信息技术语义网基本标准》八、附录GBT26761 中涉及到的术语和定义的详细说明可以参考附录部分。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
文件语义检索
文件语义检索是一种基于语义理解和自然语言处理技术的信息检索方法,它的目标是通过对文件内容的深入理解,提供更准确、更精确的检索结果。
本文将介绍文件语义检索的原理、应用领域以及相关技术的发展趋势。
一、文件语义检索的原理
文件语义检索是基于自然语言处理和语义理解技术的,它通过将用户的查询语句与文件内容进行语义匹配,从而实现更精确的检索结果。
具体来说,文件语义检索可以分为以下几个步骤:
1. 文本预处理:对文件内容进行分词、词性标注、命名实体识别等预处理操作,以便于后续的语义理解和匹配。
2. 语义理解:通过语义解析技术,将用户的查询语句转化为语义表示,包括词义消歧、句法分析、语义角色标注等。
3. 语义匹配:将用户的查询语义与文件内容的语义进行匹配,计算匹配度并排序,从而得到与用户查询相关的文件。
4. 结果生成:根据匹配得分,生成最终的检索结果,可以按照相关性、时间顺序、重要性等进行排序。
文件语义检索在许多领域都有广泛的应用,以下是一些常见的应用场景:
1. 文档检索:可以帮助用户快速找到所需的文档,提高工作效率。
2. 知识管理:可以帮助用户从大量的知识库中查找相关的知识,支持知识的共享和利用。
3. 问答系统:可以帮助用户回答各种问题,提供准确的答案。
4. 情感分析:可以帮助用户分析文本中的情感倾向,如评论、新闻报道等。
5. 舆情监测:可以帮助用户监测社交媒体、新闻报道中的舆情信息,及时了解公众对某一事件的态度和反应。
三、文件语义检索技术的发展趋势
随着自然语言处理和人工智能技术的不断发展,文件语义检索技术也在不断进步。
以下是一些文件语义检索技术的发展趋势:
1. 深度学习:深度学习技术在文件语义检索中的应用越来越广泛,通过神经网络模型可以提取更丰富、更准确的语义特征。
2. 多模态检索:将文本、图像、音频等多种模态的信息进行整合,提供更全面、更准确的检索结果。
3. 领域知识的利用:利用领域知识可以提高文件语义检索的准确性,例如利用医学知识进行医学文献的检索。
4. 个性化检索:根据用户的偏好和历史行为,提供个性化的检索结果,满足用户的特定需求。
5. 实时检索:实时检索是文件语义检索的一个重要发展方向,可以帮助用户及时获取最新的信息。
文件语义检索是一种基于语义理解和自然语言处理技术的信息检索方法,具有广泛的应用领域和发展前景。
随着技术的不断进步,文件语义检索将能够为用户提供更准确、更精确的检索结果,帮助用户更高效地获取所需信息。