神经网络基于BP网络的多层感知器实验报告
神经网络基于BP网络的多层感知器实验报告

神经网络基于BP网络的多层感知器实验报告二、基于BP网络的多层感知器一:实验目的:1、理解多层感知器的工作原理2、通过调节算法参数了解参数的变化对于感知器训练的影响3、了解多层感知器局限性二:实验原理:BP的基本思想:信号的正向传播误差的反向传播–信号的正向传播:输入样本从输入层传入,经各隐层逐层处理后,传向输出层。
–误差的反向传播:将输入误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号来作为修正各单元权值的依据。
1、基本BP算法的多层感知器模型:2、BP学习算法的推导:当网络输出与期望输出不等时,存在输出误差E将上面的误差定义式展开至隐层,有进一步展开至输入层,有调整权值的原则是使误差不断地减小,因此应使权值的调整量与误差的梯度下降成正比,即η∈(0,1)表示比例系数,在训练中反应学习速率 BP算法属于δ学习规则类,这类算法被称为误差的梯度下降(Gradient Descent)算法。
<实验步骤>1、用Matlab编程,实现解决该问题的单样本训练BP网络,设置一个停止迭代的误差Emin和最大迭代次数。
在调试过程中,通过不断调整隐层节点数,学习率η,找到收敛速度快且误差小的一组参数。
产生均匀分布在区间[-4,4]的测试样本,输入建立的模型得到输出,与Hermit多项式的期望输出进行比较计算总误差(运行5次,取平均值),并记录下每次迭代结束时的迭代次数。
(要求误差计算使用RME,Emin 设置为0、1)程序如下:function dyb %单样本程序 clc; close all; clear; x0=[1:;-4:0、08:4];%样本个 x0(1,:)=-1; x=x0'; yuzhi=0、1;%阈值j=input('请输入隐层节点数 j = ');%隐层节点数 n=input('请输入学习效率 n = ');%学习效率 w=rand(1,j); w=[yuzhi,w]; %输出层阈值 v=rand(2,j); v(1,:)=yuzhi;%隐层阈值err=zeros(1,); wucha=0; zhaosheng=0、01*randn(1,);%噪声erro=[]; ERRO=[];%误差,为画收敛曲线准备 Emin=0、1;d=zeros(1,); for m=1: d(m)=hermit(x(m,2));%期望 end;o=zeros(1,); j=zeros(1,j); =zeros(1,j); p=1; q=1; azc=0; acs=0; for z=1:5 while q<30000 Erme=0; for p=1:y=zeros(1,j); for i=1:j j(1,i)=x(p,:)*v(:,i);y(1,i)=1/(1+exp(-j(1,i))); end; y=[-1 y];o(p)=w*y'+zhaosheng(p);%噪声 wucha = d(p)-o(p);err(1,p)=1/2*wucha^2; erro=[erro,wucha]; for m=1:j+1w(1,m)=w(1,m)+n*wucha*y(1,m); end; for m=1:jv(:,m)=v(:,m)+n*wucha*w(1,m)*y(1,m)*(1-y(1,m))*x(p,:)'; end q=q+1; end; for t=1:; Erme=Erme+err(1,t); end;err=zeros(1,); Erme=sqrt(Erme/); ERRO=[ERRO,Erme]; ifErme<Emin break; end; end; azc=azc+Erme; acs=acs+q; end disp('最终误差:'); pinjunwucha=1/5*azc figure(1);plot(x(:,2),d,'--r'); hold on; plot(x(:,2),o,'--b'); disp('次数:'); pjcx=1/5*acs figure(2); plot(ERRO); figure(3); plot(x(:,2),d,'--rp');endfunction F =hermit(x)%hermit子函数 F =1、1*(1-x+2*x^2)*exp(-x^2/2);end运行结果如下:表格1、单样本BP算法平均最小误差学习率结点数0、050、070、10、120、150、1880、09650、08590、019530、09450、08740、0925100、09680、09440、09830、09200、08210、0982120、08860、08560、08850、09460、08340、0928150、09150、09270、08780、09240、07380、08442、实现解决该问题的批处理训练BP网络,调整参数如上。
BP神经网络实验报告

作业8编程题实验报告(一)实验内容:实现多层前馈神经网络的反向传播学习算法。
使用3.2节上机生成的数据集对神经网络进行训练和测试,观察层数增加和隐层数增加是否会造成过拟合。
(二)实验原理:1)前向传播:以单隐层神经网络为例(三层神经网络),则对于第k 个输出节点,输出结果为:在实验中采用的激励函数为logistic sigmoid function 。
考虑每一层节点中的偏差项,所以,在上式中:)()(00,1l l j b w x ==在实验中,就相应的需要注意矢量形式表达式中,矢量大小的调整。
2)BP 算法:a) 根据问题,合理选择输入节点,输出节点数,确定隐层数以及各隐层节点数;b) 给每层加权系数,随机赋值;c) 由给定的各层加权系数,应用前向传播算法,计算得到每层节点输出值,并计算对于所有训练样本的均方误差;d) 更新每层加权系数:其中,⎪⎩⎪⎨⎧⋅⋅⋅-=∑+j i ji l i l i i i l i a h w a h d y 其它层,最后一层)('(),(')()1()()(δδe) 重复c),d )迭代过程,直至迭代步数大于预设值,或者每次迭代误差变化值小于预设值时,迭代结束,得到神经网络的各层加权系数。
(三)实验数据及程序:1)实验数据处理:a) 训练样本输入节点数据:在实验中,所用数据中自变量x 的取值,为0—1的25个随机值,为了后续实验结果的分析,将其从小到大排序,并加上偏差项,神经网络的输出节点最终训练结果,即为训练得到的回归结果;b) 训练样本标签值:在实验中,采用的激励函数为logistic sigmoid function ,其值域为[0,1],所以,在神经网络训练前,需要对训练样本标签值进行归一化处理;c) 神经网络输出节点值:对训练样本标签值进行了归一化处理,相应的,对于输出节点,需要反归一化处理。
2)实验程序:实现函数:[Theta]=BP(input_layer_size,hidden_layer_size,hidden_layer_num,num_labels,Niter,leta,X,Y)输入参数:input_layer_size:输入节点数;hidden_layer_size:隐层节点数(对于单隐层,输入值为一数值,对于多隐层,为一矢量);hidden_layer_num:隐层数;num_labels:输出节点数;Niter:为预设的迭代步数;leta:学习速率,即更新步长;X,Y:分别为训练样本输入特征值以及标签值。
感知器和BP网络设计及应用

学号:1001314197人工神经网络实验报告实验一感知器和BP网络设计及应用实验1 感知器和BP网络设计及应用题目一初步认识Matlab人工神经网络工具箱一、实验目的初步了解人工神经网络工具箱。
二、实验容认识人工神经网络工具箱包含的主要功能函数及分类。
三、实验步骤(1) 在命令窗口键入help nnet(2) 描述人工神经网络工具箱划分的主要函数模块,并在每类下挑选3-4个函数,说明其主要功能。
四、实验结果>> help nnetNeural Network ToolboxVersion 6.0 (R2008a) 23-Jan-20081.Graphical user interface functions.图形用户界面函数nnstart - Neural Network Start GUI 神经网络启动图形用户界面GUInctool - Neural network classification tool 神经网络分类工具nftool - Neural Network Fitting Tool 神经网络拟合工具nntraintool - Neural network training tool 神经网络训练工具work creation functions. 网络生成函数cascadeforwardnet – Cascade-forward neural network. 级联神经网络competlayer - Competitive neural layer. 竞争神经层distdelaynet - Distributed delay neural network. 分布式延迟神经网络elmannet - Elman neural network. Elman 神经网络ing networks. 网络使用network - Create a custom neural network. 创建一个定制的神经网络sim - Simulate a neural network. 模拟神经网络init - Initialize a neural network. 初始化一个神经网络adapt - Allow a neural network to adapt. 神经网络的适应train - Train a neural network. 训练一个神经网络4.Simulink support. 仿真支持gensim - Generate a Simulink block to simulate a neural network. 生成Simulink模块来模拟神经网络setsiminit - Set neural network Simulink block initial conditions 设置神经网络Simulink模块初始条件getsiminit - Get neural network Simulink block initial conditions 获得神经网络Simulink模块初始条件neural - Neural network Simulink blockset. 神经网络Simulink 模块集5.Training functions. 训练函数trainb - Batch training with weight & bias learning rules. 批处理具有权重和偏差学习规则的训练trainbfg - BFGS quasi-Newton backpropagation. BFGS 拟牛顿反向传播trainbr - Bayesian Regulation backpropagation. 贝叶斯规则的反向传播trainbu - Unsupervised batch training with weight & bias learning rules. 无监管的批处理具有权重和偏差学习规则的训练6.Plotting functions. 绘图函数plotconfusion - Plot classification confusion matrix. 图分类混淆矩阵ploterrcorr - Plot autocorrelation of error time series. 误差自相关时间序列图ploterrhist - Plot error histogram. 误差直方图plotfit - Plot function fit. 绘图功能(函数)配合题目2 感知器的功能及初步设计一、实验目的掌握感知器的功能。
人工智能实验报告-BP神经网络算法的简单实现[参照]
![人工智能实验报告-BP神经网络算法的简单实现[参照]](https://img.taocdn.com/s3/m/23d1cd32cdbff121dd36a32d7375a417866fc1dc.png)
人工神经网络是一种模仿人脑结构及其功能的信息处理系统,能提高人们对信息处理的智能化水平。
它是一门新兴的边缘和交叉学科,它在理论、模型、算法等方面比起以前有了较大的发展,但至今无根本性的突破,还有很多空白点需要努力探索和研究。
1人工神经网络研究背景神经网络的研究包括神经网络基本理论、网络学习算法、网络模型以及网络应用等方面。
其中比较热门的一个课题就是神经网络学习算法的研究。
近年来己研究出许多与神经网络模型相对应的神经网络学习算法,这些算法大致可以分为三类:有监督学习、无监督学习和增强学习。
在理论上和实际应用中都比较成熟的算法有以下三种:(1) 误差反向传播算法(Back Propagation,简称BP 算法);(2) 模拟退火算法;(3) 竞争学习算法。
目前为止,在训练多层前向神经网络的算法中,BP 算法是最有影响的算法之一。
但这种算法存在不少缺点,诸如收敛速度比较慢,或者只求得了局部极小点等等。
因此,近年来,国外许多专家对网络算法进行深入研究,提出了许多改进的方法。
主要有:(1) 增加动量法:在网络权值的调整公式中增加一动量项,该动量项对某一时刻的调整起阻尼作用。
它可以在误差曲面出现骤然起伏时,减小振荡的趋势,提高网络训练速度;(2) 自适应调节学习率:在训练中自适应地改变学习率,使其该大时增大,该小时减小。
使用动态学习率,从而加快算法的收敛速度;(3) 引入陡度因子:为了提高BP 算法的收敛速度,在权值调整进入误差曲面的平坦区时,引入陡度因子,设法压缩神经元的净输入,使权值调整脱离平坦区。
此外,很多国内的学者也做了不少有关网络算法改进方面的研究,并把改进的算法运用到实际中,取得了一定的成果:(1) 王晓敏等提出了一种基于改进的差分进化算法,利用差分进化算法的全局寻优能力,能够快速地得到BP 神经网络的权值,提高算法的速度;(2) 董国君等提出了一种基于随机退火机制的竞争层神经网络学习算法,该算法将竞争层神经网络的串行迭代模式改为随机优化模式,通过采用退火技术避免网络收敛到能量函数的局部极小点,从而得到全局最优值;(3) 赵青提出一种分层遗传算法与BP 算法相结合的前馈神经网络学习算法。
BP神经网络在多传感器数据融合中的应用

BP神经网络在多传感器数据融合中的应用摘要:提出一种基于多传感器神经网络融合的机动目标估计算法,利用BP 神经网络的函数逼近能力,将BP神经网络与卡尔曼滤波器相结合构成一个估计器,该算法可以对来自经不同噪声污染的传感器信息加以充分利用,在改善估计性能的同时又保持估计滤波的计算结构尽可能简单。
仿真结果表明所提出的估计滤波算法在估计应用上优于一般的加权估计算法,提高了估计算法的精度。
关键词:BP神经网络卡尔曼滤波数据融合一、引言数据融合是指对来自多个传感器的信息进行融合,也可以将来自多个传感器的信息和人机界面的观测事实进行信息融(这种融合通常是决策级融合)。
提取征兆信息,在推理机作用下.将征兆与知识库中的知识匹配,做出故障诊断决策,提供给用户。
在基于信息融合的故障诊断系统中可以加入自学习模块.故障决策经自学习模块反馈给知识库.并对相应的置信度因子进行修改,更新知识库。
同时.自学习模块能根据知识库中的知识和用户对系统提问的动态应答进行推理。
以获得新知识。
总结新经验,不断扩充知识库,实现专家系统的自学习功能。
多传感器数据融合是20世纪70年代以来发展起来的一门新兴边缘学科,目前已经成为备受人们关注的热门领域。
多传感器数据融合是一门新兴技术,在军事和非军事领域中都碍到了广泛应用、多传感器数据融合技术汲取了人工智能、模式识别、统计估计等多门学科的相关技术,计算机技术的快速发展以及数据融合技术的成熟为数据融合的广泛应用提供了基础。
多传感器信息融合状态估计是多传感器信息融合学科的一个重要分支。
多传感器数据融合的基本原理就像是人脑综合处理信息的过程一样,它充分利用多个传感器资源,通过对各种传感器及其观测信息的合理支配与使用,将各传感器在空间和时间上的互补与冗余信息依据某种优化准则组合起来,产生对观测环境的一致性解释和描述。
目前有两种常用的信息融合方法:一种方法是状态融合方法,另一种方法是观测融合方法。
状态融合方法又可分为集中式kalman滤波[1]和分散式kalman滤波。
BP神经网络--使用多层感知器网络进行数据分类

姓名: 学号:
目
录
1
输入层、隐含层以及输出层神经元个数的确定
2 3
4
权值的初始化 创建网络和网络结束条件
神经网络学习曲线
目
录
1
输入层、隐含层以及输出层神经元个数的确定
输入层的神经元由样本数 据的特征个数决定。训练 的数据中,一共15列,第 1个属性是该数据对应的类 别,第2个至15个属性是 特征值,所以一输入层神 经元个数是14个。
2
权值的初始化
权值初始化
实验之初 权值赋初值是通过net=init(net) 来自动实现的,每一次训练初 始化的结果都不一样;
改进后的实验 经过多次试验,找到一些使识 别率达到100%的权值。保存下 来权值,在接下来的实验中使 用
权值初始化
保存 w1=net.iw{1,1};%当前输入层权值 theta1=net.b{1};%当前输入层阀值 w2=net.lw{2,1};%当前隐含层权值 %theta2=net.b{2};%当前隐含层阀值 解释
logsig logsig
tansig .... tansig
purelin purelin
purelin ... purelin
traingdx trainlm
traingdx ... trainlmΒιβλιοθήκη 70%~96% 90%附近
90%(结合适当的权值) ... 100%(结合适当的权值)
创建网络和结束条件
权值设置 net.iw{1,1} = w1; net.lw{2,1} = w2; net.b{1}=theta1; net.b{2}=theta2;
3
创建网络和网络结束条件
基于bp神经网络的深层感知器预测模型

利用基于时间序列的 ARMA 模型与常规 BP 神经网
络相结合,通过实验证明了组合预测模型比单一预
测模型能够获得更准确的结果[6]。
不过以上研究运用的组合预测模型所使用的
常规 BP 神经网络的 BP 算法存在收敛速度缓慢、学
习精确度不高和局部极小等缺点。本文采用基于
深度学习思想的深层神经网络(Deep Neural Net⁃
的随意性和盲目性。在大数据的浪潮中,善于利用数据进行财政收入的预测与分析,将大量繁琐零碎的数据转换成有用的
决策信息具有非常重要意义。目前,财政收入组合预测模型大都采用的都是三层神经网络结构;文章结合当前财政收入组
合预测方法和深层学习思想,提出了一种基于 BP 神经网络的深层神经网络预测模型。它是四层神经网络结构,并以西安的
。目前常
用的预测方法有回归分析法、时间序列分析法、灰
[3~4]
色预测法和神经网络法等
。财政收入数据及其
相关影响因素数据的变化往往具有随机性和非线
性变化的特点,并且它们之间也具有非常复杂的非
线性相关关系。目前,许多学者运用组合预测模型
来进行预测研究。如范敏等运用灰色预测和常规
BP(Back Propagation)神经网络组合模型对地方财
Prediction Model of Deep Sensor Based on BP Neural Network
CHEN Tong
ZHOU Xiaohui
(College of Computer,Xi'an University of Post and Telecommunications,Xi'an
ture,by using the data of Xi'an 's fiscal revenue as the test sample,the model is proved to be of high precision,fast convergence
BP神经网络实验报告

BP神经网络实验报告一、引言BP神经网络是一种常见的人工神经网络模型,其基本原理是通过将输入数据通过多层神经元进行加权计算并经过非线性激活函数的作用,输出结果达到预测或分类的目标。
本实验旨在探究BP神经网络的基本原理和应用,以及对其进行实验验证。
二、实验方法1.数据集准备本次实验选取了一个包含1000个样本的分类数据集,每个样本有12个特征。
将数据集进行标准化处理,以提高神经网络的收敛速度和精度。
2.神经网络的搭建3.参数的初始化对神经网络的权重和偏置进行初始化,常用的初始化方法有随机初始化和Xavier初始化。
本实验采用Xavier初始化方法。
4.前向传播将标准化后的数据输入到神经网络中,在神经网络的每一层进行加权计算和激活函数的作用,传递给下一层进行计算。
5.反向传播根据预测结果与实际结果的差异,通过计算损失函数对神经网络的权重和偏置进行调整。
使用梯度下降算法对参数进行优化,减小损失函数的值。
6.模型评估与验证将训练好的模型应用于测试集,计算准确率、精确率、召回率和F1-score等指标进行模型评估。
三、实验结果与分析将数据集按照7:3的比例划分为训练集和测试集,分别进行模型训练和验证。
经过10次训练迭代后,模型在测试集上的准确率稳定在90%以上,证明了BP神经网络在本实验中的有效性和鲁棒性。
通过调整隐藏层结点个数和迭代次数进行模型性能优化实验,可以发现隐藏层结点个数对模型性能的影响较大。
随着隐藏层结点个数的增加,模型在训练集上的拟合效果逐渐提升,但过多的结点数会导致模型的复杂度过高,容易出现过拟合现象。
因此,选择合适的隐藏层结点个数是模型性能优化的关键。
此外,迭代次数对模型性能也有影响。
随着迭代次数的增加,模型在训练集上的拟合效果逐渐提高,但过多的迭代次数也会导致模型过度拟合。
因此,需要选择合适的迭代次数,使模型在训练集上有好的拟合效果的同时,避免过度拟合。
四、实验总结本实验通过搭建BP神经网络模型,对分类数据集进行预测和分类。
神经网络实验报告

电气工程学院神经网络实验报告院系:电气工程学院专业:电气工程及其自动化实验二基于BP网络的多层感知器一实验目的:1.理解基于BP网络的多层感知器的工作原理2.通过调节算法参数的了解参数的变化对BP多层感知器训练的影响3.了解BP多层感知器的局限性二实验内容:1.根据实验内容推导出输出的计算公式以及误差的计算公式2.使用Matlab编程实现BP多层感知器3.调节学习率η及隐结点的个数,观察对于不同的学习率、不同的隐结点个数时算法的收敛速度4.改用批处理的方法实验权值的收敛,并加入动量项来观察批处理以及改进的的算法对结果和收敛速度的影响。
三.实验原理以及过程的推导1. 基本BP 算法的多层感知器模型下面所示是一个单输入单输出的BP多层感知器的模型,它含有一个隐层。
输出O输出层X0 X下面对误差和权值的调整过程进行推导对于单样本的输入X i则隐层的输出:y i=f1(net j);net j=(x i*v i)输出层的输出:O=f2(net);net=(w i*y i)变换函数:1f1=xe-1+f2=x;当网络输出与期望输出不等时,存在输出误差E1(d-o)2;E=2计算各层的误差:把误差分配到各层以调整各层的权值,所以,各层权值的调整量等于误差E对各权值的负偏导与学习率的乘积,计算得到对权值W 和权值V 的调整量如下: 将上面的式子展开到隐层得: E=21(d-o)2=21[d- f 2(net)]=21[d-f 2( iji i iy w ∑==1)]将上式展开到输入层得: E=21(d-o)2=21[d- f 2(net)]=21[d-f 2( ij i i i w∑==1f 1(i ji i i x v ∑==1))]调整权值的原则是使误差不断地减小,因此应使权值的调整量与误差的梯度下降成正比,即Δw j =-jW E ∂ηΔv j =-jVE∂η计算得到对各权值的调整为:Δw j =η*(d(1,p)-o(1,p))*y(1,i)Δv j = *(d(1,p)-o(1,p))*w(1,i)*y(1,i)*(1-y(1,i))*x(1,p)其中P 为第P 个样本:四 实验步骤Step 1 初始化对权值矩阵W 、V 赋随机数,将样本模式计数器p 和训练次数计数器q 置于1,误差E 置0,学习率η设为0~1 内的小数,网络训练后的精度Emin 设为一个正的小数;Step 2 输入训练样本对,计算各层输出用当前样本X p 、d p 对向量数组X 、d 赋值,用下式计算Y 和O 中各分量 y i =f 1(net j );net j=(x i*v i)O=f2(net j);net=(w i*y i)Step 3 计算网络输出误差设共有P 对训练样本,网络对于不同的样本具有不同的误差2Step 4 计算各层误差信号:各层的误差信号为误差E对各层权值的偏导Step 5 调整各层权值Δw=η*(d(1,p)-o(1,p))*y(1,i)Δv=*(d(1,p)-o(1,p))*w(1,i)*y(1,i)*(1-y(1,i))*x(1,p)Step 6 检查是否对所有样本完成一次轮训若p<P,计算器p=p+1,q=q+1,返回Step 2, 否则转到Step 7Step 7 检查网络总误差是否达到精度要求当用E RME作为网络的总误差时,若满足E RME<E min,训练结束,否则E 置0,p 置1,返回Step 2。
神经网络实验报告

基于神经网络的数字识别系统一、实验目的通过对本系统的学习开发,对计算机人工智能和神经网络有一定的认识,了解人工智能和网络神经学习的基本方法和思路。
构建BP网络实例,熟悉前馈网络的原理及结构。
二、实验原理反向传播网络(Back propagation Network,简称BP网络)是对非线形可微分函数进行权值训练的多层前向网络。
BP网络可以看作是对多层感知器网络的扩展,即信息的正向传播及误差数据的反向传递。
BP网络主要可以应用于模式分类、函数逼近以及数据压缩等等。
这里使用了一种较为简单的BP网络模型,并将其应用于一个实例:数字0到9的识别。
反向传播(BP)算法是一种计算单个权值变化引起网络性能变化值的较为简单的方法。
BP算法过程从输出节点开始,反向地向第一隐含层(即最接近输入层的隐含层)传播由总误差引起的权值修正。
BP网络不仅含有输入节点和输出节点,而且含有一层或多层隐(层)节点。
输入信号先向前传递到隐节点,经过作用后,再把隐节点的输出信息传递到输出节点,最后给出输出结果。
网络拓扑结构三、实验条件1.执行环境在装有Visual C++ 6.0运行库的Windows XP系统上运行。
2.编译环境Microsoft Visual C++ 6.0 。
3.运行方式该程序的可执行文件名为:LwNumRec.exe双击运行进入操作界面:然后进入具体的操作:(1)训练网格首先,打开图像(256色):其次输入归一化宽度与高度:再次对Bp网络参数进行设置:最后进行训练,并输出训练结果:(2)进行识别首先,打开图像(256色);其次输入归一化宽度与高度;再次,进行归一化处理,点击“一次性处理”(相当于手动逐步执行步骤1~8);处理后结果:最后,点击“识”或者使用菜单找到相应项来进行识别。
识别的结果为:1.通过BP网络各项参数的不同设置,观察BP算法的学习效果。
2.观察比较BP网络拓扑结构及其它各项参数变化对于训练结果的影响。
人工智能神经网络实验报告

神经网络实验报告一.实验目的(1)熟悉Matlab/Simulink的使用.(2)掌握BP神经网络的基本原理和基本的设计步骤.(3)了解BP神经网络在实际中的应用.(4)针对简单的实际系统, 能够建立BP神经网络控制模型.二、实验内容BP神经网络神经网络的概念、原理和设计是受生物、特别是人脑神经系统的启发提出的. 神经网络由大量简单的处理单元来模拟真实人脑神经网络的机构和功能以及若干基本特性,是一个高度复杂的非线性自适应动态处理系统.BP网络是1986年由Rinehart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一. BP网络能学习和存贮大量的输入- 输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程. 它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小. BP神经网络模型拓扑结构包括输入( input) 、隐层( hide layer)和输出层(output layer) ,如图1所示.三、基于BP神经网络的手写数字识别3.1 输入向量与目标向量首先对手写数字图像进行预处理,包括二值化、去噪、倾斜校正、归一化和特征提取,生成BP神经网络的输入向量Alphabet和目标向量Tar2get. 其中Alphabet选取40 ×10的矩阵,第1列到第10列代表0~9的数字. Target为10 ×10的单位矩阵,每个数字在其所排顺序位置输出1,其他位置输出0.3. 2 BP神经网络的构建BP算法由数据流的前向计算(正向传播)和误差信号的反向传播两个过程构成. 正向传播时,传播方向为输入层→隐层→输出层,每层神经元的状态只影响下一层神经元. 若在输出层得不到期望的输出,则转向误差信号的反向传播流程. 通过这两个过程的交替进行,在权向量空间执行误差函数梯度下降策略,动态迭代搜索一组权向量,使网络误差函数达到最小值,从而完成信息提取和记忆过程.首先考虑正向传播,设输入层有n个节点,隐层有p个节点,输出层有q个节点. 输入层与隐层之间的权值为vk i, 隐层与输出层之间的权值为w jk. 隐层的传递函数为f1 ( x) ,输出层的传递函数为f2 ( x) ,则隐层节点的输出为输出层节点的输出为通过式(1) 和(2) 可得BP神经网络完成n维到q维的映射. 其次考虑反向传播. 在反向传播中,需要对不理想的权值进行调整, B P神经网络的核心要务即在于调权. 定义误差函数, 设输入P个学习样本,用x1 , x2 , ⋯, xp 来表示. 第p个样本输入网络得到输出ypj ( j = 1, 2, ⋯, q) ,其误差为式中为期望输出. P个样本的全局误差为将式(3) 代入得输出层权值的变化采用累计误差BP算法调整wjk 使全局误差E变小,即式(5) 中η为学习率. 现定义误差信号为将式(3) 代入可得第一项为第二项为输出层传递函数f2 ( x) 的偏微分将式(7) 和(8) 代入可得误差信号为则输出层各神经元权值△wjk 调整公式将式(9)代入可定义为在得到输出层权值调整公式后, 需要定义隐层权值△vk i 调整公式根据输出层各神经元权值△wjk 调整公式推导过程,可得△vk i 为3. 3 网络的训练神经网络的训练过程是识别字符的基础, 十分重要,直接关系到识别率的高低. 输送训练样本至B P神经网络训练, 在梯度方向上反复调整权值使网络平方和误差最小. 为使网络对输入向量有一定鲁棒性,可先用无噪声的样本对网络进行训练,直到其平方和误差最小,再用含噪声的样本进行训练,保证网络对噪声不敏感. 训练完毕, 把待识别数字送BP神经网络中进行仿真测试.三、实验结果与分析权值初始化为( - 1, 1) 之间的随机数, 期望误差为0. 01, 最大训练步数5000, 动量因子为0.95,隐层和输出层均采用“logsig”函数, 手写数字的识别结果如图2 ( a) ~( e) 所示,以数字4为例给出处理过程对1000个手写数字(每个数字取100幅不同的图像) 进行识别,其识别结果如表1所示.四、结论针对传统的手写数字识别中识别率和可靠性不高的情况, 提出了将B P神经网络应用于数字识别,并通过实验,证实B P神经网络算法识别率较高,具备可行性.。
多层神经网络实验报告

一、实验目的本次实验旨在通过构建和训练一个多层神经网络,深入理解多层神经网络的工作原理,掌握其训练方法和参数调整技巧,并验证其在特定问题上的应用效果。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 框架:TensorFlow4. 数据集:MNIST手写数字数据集三、实验内容1. 多层神经网络结构设计本实验采用一个具有一个输入层、一个隐藏层和一个输出层的多层感知器(MLP)结构。
输入层有784个神经元,对应MNIST数据集中的每个像素;隐藏层有128个神经元;输出层有10个神经元,对应数字0到9。
2. 激活函数与损失函数- 激活函数:输入层和隐藏层使用ReLU函数,输出层使用Softmax函数。
- 损失函数:使用交叉熵损失函数(Cross-Entropy Loss)。
3. 优化器与学习率- 优化器:使用Adam优化器。
- 学习率:初始学习率为0.001,采用学习率衰减策略。
4. 数据预处理- 数据归一化:将MNIST数据集中的像素值归一化到[0, 1]区间。
- 数据增强:随机旋转、缩放和剪切图像,提高模型的泛化能力。
四、实验步骤1. 导入必要的库```pythonimport tensorflow as tffrom tensorflow.keras.datasets import mnistfrom tensorflow.keras.models import Sequentialfrom yers import Dense, Flatten, Dropoutfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras.losses import SparseCategoricalCrossentropy from tensorflow.keras.metrics import SparseCategoricalAccuracyfrom tensorflow.keras.preprocessing.image import ImageDataGenerator ```2. 加载MNIST数据集```python(train_images, train_labels), (test_images, test_labels) =mnist.load_data()```3. 数据预处理```pythontrain_images = train_images / 255.0test_images = test_images / 255.0```4. 构建模型```pythonmodel = Sequential([Flatten(input_shape=(28, 28)),Dense(128, activation='relu'),Dropout(0.5),Dense(10, activation='softmax')])```5. 编译模型```pythonpile(optimizer=Adam(learning_rate=0.001),loss=SparseCategoricalCrossentropy(from_logits=True),metrics=[SparseCategoricalAccuracy()])```6. 训练模型```pythonmodel.fit(train_images, train_labels, epochs=10, batch_size=64, validation_split=0.1)```7. 评估模型```pythontest_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)print('\nTest accuracy:', test_acc)```五、实验结果与分析1. 训练过程在训练过程中,模型的准确率逐渐提高,损失函数逐渐减小。
bp实验报告
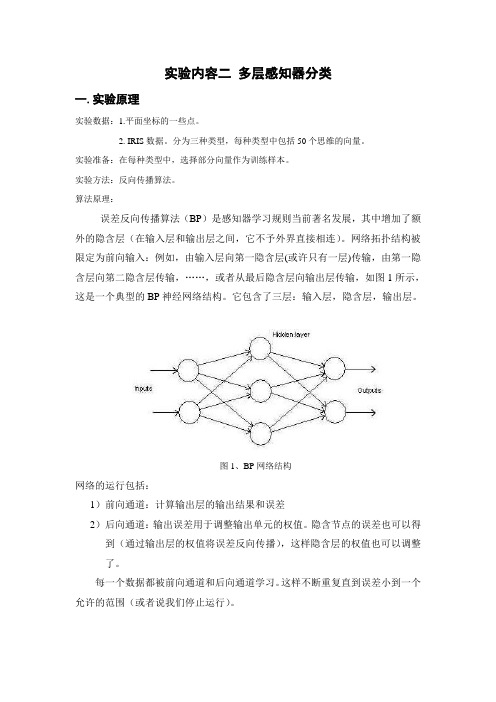
实验内容二多层感知器分类一.实验原理实验数据:1.平面坐标的一些点。
2. IRIS数据。
分为三种类型,每种类型中包括50个思维的向量。
实验准备:在每种类型中,选择部分向量作为训练样本。
实验方法:反向传播算法。
算法原理:误差反向传播算法(BP)是感知器学习规则当前著名发展,其中增加了额外的隐含层(在输入层和输出层之间,它不予外界直接相连)。
网络拓扑结构被限定为前向输入:例如,由输入层向第一隐含层(或许只有一层)传输,由第一隐含层向第二隐含层传输,……,或者从最后隐含层向输出层传输,如图1所示,这是一个典型的BP神经网络结构。
它包含了三层:输入层,隐含层,输出层。
图1、BP网络结构网络的运行包括:1)前向通道:计算输出层的输出结果和误差2)后向通道:输出误差用于调整输出单元的权值。
隐含节点的误差也可以得到(通过输出层的权值将误差反向传播),这样隐含层的权值也可以调整了。
每一个数据都被前向通道和后向通道学习。
这样不断重复直到误差小到一个允许的范围(或者说我们停止运行)。
BP 网络最常用的工作形式是这样的: 1)权值和阈值随机取为很小的数据2)输入训练采样,按下面3)—5)步运行每一采样值 3)计算网络中每一层的输出()()()(1)()()()l l l l l x f s f w x θ-==+ (i ) 4)计算训练误差()()'(()()l l l j q j j j d x f s ∂=-,输出层误差 (ii ) 1()'()(1)(1)1()l n l l l l jjkj k f s w +++=∂=∂∑,隐含层和输入层误差(iii ) 5)修正权值和阈值(1)()()(1)()()[1][]([][1])l l l l l l j i j i j i j i j i w k w k x w k w k μη+-+=+∂+-- (iv ) (1)()()()()[1][]([][1])l l l l l jj j j j k k k k θθμηθθ++=+∂+-- (v ) 6)所有采样值都完成了3)—5)步后,一次训练周期结束。
BP神经网络实验报告

BP神经网络实验报告BP神经网络实验报告一、实验目的本实验的目的是熟悉MATLAB中神经网络工具箱的使用方法,同时通过编程实现BP网络逼近标准正弦函数,来加深对BP网络的了解和认识,理解信号的正向传播和误差的反向传递过程。
二、实验原理传统的感知器和线性神经网络无法解决线性不可分问题,因此在实际应用过程中受到了限制。
而BP网络却拥有良好的繁泛化能力、容错能力以及非线性映射能力,因此成为应用最为广泛的一种神经网络。
BP算法将研究过程分为两个阶段:第一阶段是信号的正向传播过程,输入信息通过输入层、隐层逐层处理并计算每个单元的实际输出值;第二阶段是误差的反向传递过程,若在输入层未能得到期望的输出值,则逐层递归的计算实际输出和期望输出的差值(即误差),以便根据此差值调节权值。
这种过程不断迭代,最后使得信号误差达到允许或规定的范围之内。
基于BP算法的多层前馈型网络模型的拓扑结构如下图所示:BP算法的数学描述:三层BP前馈网络的数学模型如下图所示。
三层前馈网中,输入向量为X=(x1,x2.xi。
xn)T;隐层输入向量为Y=(y1,y2.___。
y_m)T;输出层输出向量为O=(o1,o2.ok。
ol)T;期望输出向量为d=(d1,d2.dk。
dl)T。
输入层到隐层之间的权值矩阵用V表示,V=(v1,v2.其中列向量vj 为隐层第j个神经元对应的权向量;v_j。
v_m)Y,隐层到输出层之间的权值矩阵用W表示,W=(w1,w2.wk。
wl),其中列向量wk为输出层第k个神经元对应的权向量。
下面分析各层信号之间的数学关系。
对于输出层,有:yj=f(netj)。
j=1,2.mnetj=∑vijxi。
j=1,2.m对于隐层,有:Ok=f(netk)。
k=1,2.l___∑wjk*yi。
k=1,2.lj=1其中转移函数f(x)均为单极性Sigmoid函数:f(x)=1/(1+e^-x),具有连续、可导的特点,且f'(x)=f(x)[1-f(x)]。
基于多层感知器的深度神经网络研究

基于多层感知器的深度神经网络研究随着人工智能的迅速发展,深度学习已经成为了解决大规模数据处理和分析问题的主流方法之一。
其中,深度神经网络是深度学习最重要的组成部分之一。
而基于多层感知器的深度神经网络则是深度学习中使用最广泛的模型之一。
多层感知器(Multi-Layer Perceptron, MLP)是一种传统的人工神经网络模型,由输入层、隐藏层和输出层组成,其中每一层都由多个节点组成。
每个节点计算一个加权和,并将其传递给下一层的节点。
其中,隐藏层通常使用非线性激活函数(如sigmoid、ReLU等)来增加网络的非线性表示能力。
基于多层感知器的深度神经网络,则是将多层感知器模型扩展到多个隐藏层的情况下。
相比于传统的单层或浅层神经网络模型,深度神经网络可以通过多层的非线性变换来提高网络的表达能力,从而在复杂任务上取得更好的性能。
在深度神经网络的训练过程中,最常用的优化算法是反向传播算法(BackPropagation,BP),它利用梯度下降来更新网络参数,使得网络的预测结果与训练数据的真实值之间的误差最小。
近年来,随着深度学习的发展,还涌现出了一系列新的优化算法,如 AdaGrad、Adam等。
除了优化算法之外,深度神经网络在训练过程中还需要关注一些其他的问题,如过拟合、梯度消失、权值初始化等。
针对这些问题,也出现了一些解决方案与技术。
目前,深度学习在许多领域都取得了显著的成果,如自然语言处理、图像识别、语音识别等。
其中,深度神经网络模型作为深度学习中的核心组成部分,也成为了各种应用的基础。
随着越来越多的数据被生产和存储,深度神经网络也有着广阔的应用前景。
总之,基于多层感知器的深度神经网络是深度学习中一种重要的模型。
它通过多个非线性变换来提高网络的表达能力,进而在各个领域的应用上都有着广泛的应用。
未来,随着深度学习技术的不断发展与完善,基于多层感知器的深度神经网络也必将迎来更广泛的应用场景与应用需求。
BP神经网络实验

实验算法BP神经网络实验【实验名称】BP神经网络实验【实验要求】掌握BP神经网络模型应用过程,根据模型要求进行数据预处理,建模,评价与应用;【背景描述】神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。
BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。
其基本组成单元是感知器神经元。
【知识准备】了解BP神经网络模型的使用场景,数据标准。
掌握Python/TensorFlow数据处理一般方法。
了解keras神经网络模型搭建,训练以及应用方法【实验设备】Windows或Linux操作系统的计算机。
部署TensorFlow,Python。
本实验提供centos6.8环境。
【实验说明】采用UCI机器学习库中的wine数据集作为算法数据,把数据集随机划分为训练集和测试集,分别对模型进行训练和测试。
【实验环境】Pyrhon3.X,实验在命令行python中进行,或者把代码写在py脚本,由于本次为实验,以学习模型为主,所以在命令行中逐步执行代码,以便更加清晰地了解整个建模流程。
【实验步骤】第一步:启动python:命令行中键入python。
第二步:导入用到的包,并读取数据:(1).导入所需第三方包import pandas as pdimport numpy as npfrom keras.models import Sequentialfrom yers import Denseimport keras(2).导入数据源,数据源地址:/opt/algorithm/BPNet/wine.txtdf_wine = pd.read_csv("/opt/algorithm/BPNet/wine.txt", header=None).sample(frac=1) (3).查看数据df_wine.head()第三步:数据预处理(1).划分60%数据p = 0.6cut = int(np.ceil(len(df_wine) * p))(2).划分数据集df_wine_train = df_wine.iloc[:cut]df_wine_test = df_wine.iloc[cut:](3).类别标识编码(深度学习常用手段,类别1 = (1,0),类别2 = (0,1),类别3 = (0,0)) label_train = pd.DataFrame(df_wine_train[0])label_train["one-hot_1"] = label_train[0].map(lambda x: 1 if (x == 1) else 0) label_train["one-hot_2"] = label_train[0].map(lambda x: 1 if (x == 2) else 0) label_train["one-hot_3"] = [1]*len(label_train)(4).数据标准化,获取每列均值,标准差avg_col = df_wine_train.mean()td_col = df_wine_train.std()(5).标准化结果df_train_norm = (df_wine_train - avg_col) / td_col(6).整理数据df_train_norm=df_train_norm.drop([0], axis=1).join(label_train[["one-hot_1", "one-hot_2"]]) (7).构建神经网络需要的数据结构df_train_net = np.array(df_train_norm)train_data_x = df_train_net[:, 0:13]train_data_y = df_train_net[:, 13:]第四步:搭建神经网络(1).构建神经网络,模型为13->10->20->2 网络model = Sequential()(2).建立全连接层-首层需要指定输入层维度model.add(Dense(units=10, # 输出维度,即本层节点数input_shape=(13,), # 输入维度activation="sigmoid", # 激活函数use_bias=True, # 使用偏置kernel_regularizer=keras.regularizers.l2(0.001) # 正则化))model.add(Dense(units=20, # 输出维度,即本层节点数输入维度自动适配上一层activation="sigmoid", # 激活函数use_bias=True, # 使用偏置kernel_regularizer=keras.regularizers.l2(0.001) # 正则化))model.add(Dense(units=2, # 输出维度,即本层节点数输入维度自动适配上一层activation="sigmoid", # 激活函数,use_bias=True, # 使用偏置kernel_regularizer=keras.regularizers.l2(0.001) # 正则化))第五步:定义模型训练方法,损失函数,停止规则以及训练参数并训练网络(1).建立评估函数,优化方法:随机梯度下降法SGDsgd = keras.optimizers.SGD(lr=0.01, # 学习速率decay=1e-7, # 每次更新后的学习率衰减值momentum=0.8, # 学习动量nesterov=True # 确定是否使用Nesterov动量)(2).设计目标误差函数,以及训练方法pile(loss='mean_squared_error', optimizer=sgd)(3).提前结束训练的阈值,下面参数,观察误差,连续5次无改善.则结束训练early_stopping = keras.callbacks.EarlyStopping(monitor='loss', patience=5, verbose=0, mode='auto')(4).模型训练,写入数据,目标,迭代次数,批数,训练详情(0不显示),训练提早结束条件model.fit(train_data_x, train_data_y, epochs=1000, batch_size=32, verbose=1, callbacks=[early_stopping])第六步:模型应用于测试集,并输出准确率(1).模型预测label_test = pd.DataFrame(df_wine_test[0])label_test["one-hot_1"] = label_test[0].map(lambda x: 1 if (x == 1) else 0)label_test["one-hot_2"] = label_test[0].map(lambda x: 1 if (x == 2) else 0)(2).标准化结果df_test_norm = (df_wine_test - avg_col) / td_col(3).整理数据df_test_norm = df_test_norm.drop([0], axis=1).join(label_test[["one-hot_1", "one-hot_2"]]) (4).构建神经网络需要的数据结构df_test_net = np.array(df_test_norm)test_data_x = df_test_net[:, 0:13]test_data_y = df_test_net[:, 13:]predicted = model.predict(test_data_x)F1 = pd.DataFrame(predicted)F1.columns = ["predicted_1", "predicted_2"]F1["predicted_1"] = F1["predicted_1"].map(lambda x: 1.0 if (x > 0.5) else 0.0)F1["predicted_2"] = F1["predicted_2"].map(lambda x: 1.0 if (x > 0.5) else 0.0)F2 = pd.DataFrame(test_data_y)F2.columns = ["test_1", "test_2"]F = F1.join(F2)acc = len(F[(F["predicted_1"] == F["test_1"]) & (F["predicted_2"] == F["test_2"])]) * 1.0 / len(F)(5).输出准确率print("准确率%s " % (acc))第七步:可以通过以下命令执行python文件,查看最终结果python /opt/algorithm/BPNet/BPNet.py。
基于BP算法的多层感知器设计

01
02
多层感知器 是一 种单 向按误 差传播 的多层前馈 网络模 型 , 为 目前应用 最广泛 、 究最基 本 的网络模 型之一 , 作 研 多 层感知器具有非 线性映射能力 高的突 出特点 , 在处 理图像 、
0
识别模式 和优化测算 、函数逼 近以及 自适应 控制等方 面都
发挥 了重要 的作用 。
对 于 一 些 复 杂 的 问题 , 况 也 同 样 如 此 , 就 导 致 了 网络 收 情 这
及论证 , 于梯度法进行相关计算 。 基
多层感 知器 是 B P网络 的实质 ,P网络 实际 上是一 种 B 以B P算法为基础 的多层前 向网络 , 以很好地解决 非线 性 可 可分 问题 , 弥补 了单层感 知器 的缺憾 , 并且 具有操 作 简单 、 可行性高 、 运行稳定等优 势 , 渐成为十 分常用 的神经 网络 逐
2 全 局 优 化 性 不 高 )
B P算法本身是根据梯度下 降法来进 行计算 的 ,其算法 的规则还不够完善 , 于贪 婪的计算方 法 , 属 可以使权重值集 中于某个点 , 这样 的计算结 果通常可能 产生局部 的极 小值 , 但 不能保证该结果为误差的全局最优化。针对这一 问题 , 附 加动量法可以有效地解决。
国内在研究概念图的过程中 , 注重借鉴国外 的研究成果 。 很
的过程才能更好 地发挥 , 而这方面 的涉及 面较广 , 如教育 改 革、 政策 中对概念 图制作 的要求 、 念图 软件 的推广 、 生 概 师 对其制作技术的重视程度等 。另外 , 在教学过程中对 概念 图 绘制 的时间及效果的控制需要一 定的经验 和技 巧 ,这些也 许是桎梏概念图迅猛发展 的决定性 因素 。 () 3 概念 图不 是万 能的。并不是所有的教学采用 概念 图 都会产生 比传统教学更好 的效果 。另外 , 对于程序性 知识 的 效果要优于理论性知识的效果 。因此 , 选择适合概念图特点 和 功 能 的教 学 内容 , 促 进 教 学 效果 。 会 () 4 缺乏 以人 为本 的思想 。概念图能检验并完善学 习者 的认知结构 , 激发学生 的创 造性思维 , 但是 国内大量研究 只 是在 概念 图与课程整合 的过 程 中概 述 了对学 习者的影 响 , 并没有 真正站在学生的角度分析 如何设计 概念图才能对学
多层感知器实验报告总结

一、实验背景随着人工智能和机器学习技术的不断发展,多层感知器(Multilayer Perceptron,MLP)作为一种重要的前向神经网络模型,在图像识别、自然语言处理等领域得到了广泛应用。
本次实验旨在通过实现一个简单的多层感知器模型,加深对MLP的理解,并验证其在实际应用中的效果。
二、实验目的1. 理解多层感知器的基本原理和结构;2. 掌握多层感知器的实现方法;3. 通过实验验证多层感知器在非线性分类问题上的应用效果。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 库:NumPy、TensorFlow四、实验内容1. 多层感知器模型搭建(1)输入层:根据实际问题,确定输入层的节点数。
例如,在图像识别问题中,输入层节点数等于图像像素数。
(2)隐藏层:确定隐藏层的层数和每层的节点数。
通常情况下,随着层数的增加,模型的性能会提高,但过深的网络可能导致过拟合。
(3)输出层:根据实际问题,确定输出层的节点数。
例如,在二分类问题中,输出层节点数为1。
(4)激活函数:选择合适的激活函数,如Sigmoid、ReLU等。
2. 损失函数和优化算法(1)损失函数:常用的损失函数有均方误差(MSE)和交叉熵(Cross-Entropy)等。
(2)优化算法:常用的优化算法有梯度下降(Gradient Descent)、Adam等。
3. 模型训练(1)将数据集划分为训练集和测试集。
(2)使用训练集对模型进行训练,并不断调整参数。
(3)使用测试集对模型进行评估,以验证模型的性能。
4. 模型评估(1)计算模型的准确率、召回率、F1值等指标。
(2)可视化模型预测结果,分析模型的性能。
五、实验结果与分析1. 实验数据本次实验以MNIST数据集为例,MNIST数据集包含0-9数字的手写图像,共有60000个训练样本和10000个测试样本。
2. 实验结果(1)模型准确率:在训练集和测试集上,多层感知器的准确率分别为98.5%和96.2%。
神经网络基于BP网络的多层感知器实验报告

神经网络及应用实验报告实验二、基于BP网络的多层感知器一:实验目的:1. 理解多层感知器的工作原理2. 通过调节算法参数了解参数的变化对于感知器训练的影响3. 了解多层感知器局限性二:实验原理:BP的基本思想:信号的正向传播误差的反向传播–信号的正向传播:输入样本从输入层传入,经各隐层逐层处理后,传向输出层。
–误差的反向传播:将输入误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号来作为修正各单元权值的依据。
1.基本BP算法的多层感知器模型:2.BP学习算法的推导:当网络输出与期望输出不等时,存在输出误差E将上面的误差定义式展开至隐层,有进一步展开至输入层,有调整权值的原则是使误差不断地减小,因此应使权值的调整量与误差的梯度下降成正比,即η∈(0,1)表示比例系数,在训练中反应学习速率BP算法属于δ学习规则类,这类算法被称为误差的梯度下降(Gradient Descent)算法。
<实验步骤>1. 用Matlab编程,实现解决该问题的单样本训练BP网络,设置一个停止迭代的误差E min和最大迭代次数。
在调试过程中,通过不断调整隐层节点数,学习率η,找到收敛速度快且误差小的一组参数。
产生均匀分布在区间[-4,4]的测试样本,输入建立的模型得到输出,与Hermit多项式的期望输出进行比较计算总误差(运行5次,取平均值),并记录下每次迭代结束时的迭代次数。
(要求误差计算使用RME,Emin 设置为0.1)程序如下:function dyb %单样本程序clc;close all;clear;x0=[1:101;-4:0.08:4];%样本101个x0(1,:)=-1;x=x0';yuzhi=0.1;%阈值j=input('请输入隐层节点数 j = ');%隐层节点数n=input('请输入学习效率 n = ');%学习效率w=rand(1,j);w=[yuzhi,w]; %输出层阈值v=rand(2,j);v(1,:)=yuzhi;%隐层阈值err=zeros(1,101);wucha=0;zhaosheng=0.01*randn(1,101);%噪声erro=[];ERRO=[];%误差,为画收敛曲线准备Emin=0.1;d=zeros(1,101);for m=1:101d(m)=hermit(x(m,2));%期望end;o=zeros(1,101);netj=zeros(1,j);net=zeros(1,j);p=1;q=1;azc=0;acs=0;for z=1:5while q<30000Erme=0;for p=1:101y=zeros(1,j);for i=1:jnetj(1,i)=x(p,:)*v(:,i);y(1,i)=1/(1+exp(-netj(1,i)));end;y=[-1 y];o(p)=w*y'+zhaosheng(p);%噪声wucha = d(p)-o(p);err(1,p)=1/2*wucha^2;erro=[erro,wucha];for m=1:j+1w(1,m)=w(1,m)+n*wucha*y(1,m);end;for m=1:jv(:,m)=v(:,m)+n*wucha*w(1,m)*y(1,m)*(1-y(1,m))*x(p,:)'; endq=q+1;end;for t=1:101;Erme=Erme+err(1,t);end;err=zeros(1,101);Erme=sqrt(Erme/101);ERRO=[ERRO,Erme];if Erme<Emin break;end;end;azc=azc+Erme;acs=acs+q;enddisp('最终误差:');pinjunwucha=1/5*azc figure(1);plot(x(:,2),d,'--r'); hold on;plot(x(:,2),o,'--b'); disp('次数:'); pjcx=1/5*acs figure(2); plot(ERRO); figure(3);plot(x(:,2),d,'--rp'); endfunction F = hermit(x)%hermit 子函数 F = 1.1*(1-x+2*x^2)*exp(-x^2/2); end运行结果如下:-4-3-2-101234训练样本与测试样本input xo u t p u t y-4-3-2-101234Hermit 多项式曲线与BP 网络输出曲线0204060801001201401600.20.40.60.811.21.4收敛曲线表格1. 单样本BP 算法平均最小误差2. 实现解决该问题的批处理训练BP网络,调整参数如上。
基于BP神经网络的图像压缩--神经网络实验报告

一、实验名称基于BP神经网络的图像压缩二、实验目的1.熟悉掌握神经网络知识;2.学习多层感知器神经网络的设计方法和Matlab实现;3.进一步了解掌握图像压缩的方式方法,分析仿真图像压缩效果。
三、实验要求1.学习神经网络的典型结构;2.了解BP算法基本思想,设计BP神经网络架构;3.利用BP算法解决图像压缩的质量问题;4.谈谈实验体会与收获。
四、实验步骤(一)分析原理,编写程序本实验主要利用BP神经网络多层前馈的模式变换能力,实现数据编码和压缩。
采用输入层、隐含层、输出层三层网络结构。
输入层到隐含层为编码过程,对图像进行线性变换,隐含层到输出层为网络解码过程,对经过压缩后的变换系统进行线性反变换,完成图像重构。
其主要步骤有以下五步:1.训练样本构造基于数值最优化理论的训练算法,采用Levenberg-Marquardt方法,将训练图像的所有像素点作为压缩网络的输入,对图像进行划分。
将原始图像分成4×4的互不重叠的像素块,并将每个像素快变形为16×1的列向量,将原始数据转化为16×1024的矩阵。
对输入数据进行预处理,像素块矩阵进行尺度变换,即归一化处理。
为了将网络的输入、输出数据限定在[0,1]的区间内,本实验采用均值分布预处理方法。
将待处理图像的灰度范围[x min,x max],变换域为[y min,y max],设待处理的像素灰度值为x i,则对于所有过程的映射y i满足公式:y i =xminmax min)min)( max(---xxxiyy+xmin其主要程序为:P = []; %将原始数据转化为16*1024的矩阵for i = 1:32for j = 1:32I2 = I((i-1)*4 + 1:i*4,(j-1)*4 + 1:j*4);i3 = reshape(I2,16,1);II = double(i3);P_1 = II/255; %矩阵归一化处理P = [P,P_1];endend2.创建神经网络将图像样本集作为输入和理想信号训练BP网络,设此网络图像压缩比为S,网络输入层节点数为n i,隐含层节点数为n h,则压缩比:niS =nh本实验将原始图像数据转化为16×1024的矩阵数据,网络输入层节点数为n i =64,隐含层节点数要求小于输入层节点数,则分别取n h 为4、8、12、16进行实验。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
神经网络及应用实验报告实验二、基于BP网络的多层感知器一:实验目的:1. 理解多层感知器的工作原理2. 通过调节算法参数了解参数的变化对于感知器训练的影响3. 了解多层感知器局限性二:实验原理:BP的基本思想:信号的正向传播误差的反向传播–信号的正向传播:输入样本从输入层传入,经各隐层逐层处理后,传向输出层。
–误差的反向传播:将输入误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号来作为修正各单元权值的依据。
1.基本BP算法的多层感知器模型:学习算法的推导:当网络输出与期望输出不等时,存在输出误差E将上面的误差定义式展开至隐层,有进一步展开至输入层,有调整权值的原则是使误差不断地减小,因此应使权值的调整量与误差的梯度下降成正比,即η∈(0,1)表示比例系数,在训练中反应学习速率BP算法属于δ学习规则类,这类算法被称为误差的梯度下降(Gradient Descent)算法。
<实验步骤>1. 用Matlab编程,实现解决该问题的单样本训练BP网络,设置一个停止迭代的误差E min和最大迭代次数。
在调试过程中,通过不断调整隐层节点数,学习率η,找到收敛速度快且误差小的一组参数。
产生均匀分布在区间[-4,4]的测试样本,输入建立的模型得到输出,与Hermit多项式的期望输出进行比较计算总误差(运行5次,取平均值),并记录下每次迭代结束时的迭代次数。
(要求误差计算使用RME,Emin 设置为)程序如下:function dyb %单样本程序clc;close all;clear;x0=[1:101;-4::4];%样本101个x0(1,:)=-1;x=x0';yuzhi=;%阈值j=input('请输入隐层节点数 j = ');%隐层节点数 n=input('请输入学习效率 n = ');%学习效率w=rand(1,j);w=[yuzhi,w]; %输出层阈值v=rand(2,j);v(1,:)=yuzhi;%隐层阈值err=zeros(1,101);wucha=0;zhaosheng=*randn(1,101);%噪声erro=[];ERRO=[];%误差,为画收敛曲线准备Emin=;d=zeros(1,101);for m=1:101d(m)=hermit(x(m,2));%期望end;o=zeros(1,101);netj=zeros(1,j);net=zeros(1,j);p=1;q=1;azc=0;acs=0;for z=1:5while q<30000Erme=0;for p=1:101y=zeros(1,j);for i=1:jnetj(1,i)=x(p,:)*v(:,i);y(1,i)=1/(1+exp(-netj(1,i)));y=[-1 y];o(p)=w*y'+zhaosheng(p);%噪声wucha = d(p)-o(p);err(1,p)=1/2*wucha^2;erro=[erro,wucha];for m=1:j+1w(1,m)=w(1,m)+n*wucha*y(1,m);end;for m=1:jv(:,m)=v(:,m)+n*wucha*w(1,m)*y(1,m)*(1-y(1,m))*x(p,:)'; endq=q+1;end;for t=1:101;Erme=Erme+err(1,t);err=zeros(1,101);Erme=sqrt(Erme/101); ERRO=[ERRO,Erme];if Erme<Emin break; end;end;azc=azc+Erme;acs=acs+q;enddisp('最终误差:');pinjunwucha=1/5*azcfigure(1);plot(x(:,2),d,'--r');hold on;plot(x(:,2),o,'--b');disp('次数:');pjcx=1/5*acsfigure(2);plot(ERRO);figure(3);plot(x(:,2),d,'--rp');endfunction F = hermit(x)%hermit子函数 F = *(1-x+2*x^2)*exp(-x^2/2); end运行结果如下:-4-3-2-101234训练样本与测试样本input x o u t p u t y表格1. 单样本BP 算法平均最小误差2. 实现解决该问题的批处理训练BP 网络,调整参数如上。
产生均匀分布在区间[-4,4]的测试样本,输入建立的模型得到输出,与Hermit 多项式的期望输出进行比较计算总误差(运行5次,取平均值),并记录下每次迭代结束时的迭代次数。
程序如下:function pcl %批处理close all;clc;x=[-4::4];%样本101个j=input('请输入隐层节点数 j = ');%隐层节点数 n=input('请输入学习效率 n = ');%学习效率a=;%动量系数w=rand(1,j);v=rand(1,j);err=zeros(1,101);wucha=0;zhaosheng=*randn(1,101);%噪声erro=[];ERRO=[];%误差,为画收敛曲线准备Emin=;d=zeros(1,101);for m=1:101d(1,m)=hermit(x(m));%期望 end;o=zeros(1,101);netj=zeros(1,j);net=zeros(1,j);y=zeros(1,j);p=1;q=1;azc=0;acs=0;for z=1:5while q<30000Erro=0;Erme=0;for p=1:101for i=1:jnetj(1,i)=v(1,i)*x(1,p);y(1,i)=1/(1+exp(-netj(1,i))); end;o(1,p)=w*y'+zhaosheng(p);%噪声wucha=d(1,p)-o(1,p);%误差err(1,p)=1/2*wucha^2;erro=[erro,wucha];q=q+1;end;for t=1:101;Erro=Erro+erro(t);Erme=Erme+err(1,t);end;erro=[];for m=1:j;w(1,m)=w(1,m)+n*Erro*y(1,m);v(1,m)=v(1,m)+n*Erro*w(1,m)*y(1,m)*(1-y(1,m))*x(1,p); end;Erme=sqrt(Erme/101);ERRO=[ERRO,Erme];if Erme<Emin break;end;end;azc=azc+Erme;acs=acs+q;enddisp('平均误差:');pjwc=1/5*azcfigure(1);plot(x,d,'--r');hold on;plot(x,o,'--b');disp('平均次数:');pjcs=1/5*acsfigure(2);plot(ERRO);figure(3);plot(x,d);endfunction F = hermit(x) %hermit子函数F = *(1-x+2*x^2)*exp(-x^2/2);end运行结果如下:表格2. 批处理BP算法平均最小误差5810123. 对批处理训练BP算法增加动量项调整参数如上,记录结果,并与没有带动量项的批处理训练BP算法的结果相比较程序如下:function jdlx %加动量项close all;clc;x=[-4::4];%样本101个j=input('请输入隐层节点数 j = ');%隐层节点数n=input('请输入学习效率 n = ');%学习效率a=;%动量系数w=rand(1,j);v=rand(1,j);err=zeros(1,101);wucha=0;zhaosheng=*randn(1,101);%噪声 erro=[];ERRO=[];%误差,为画收敛曲线准备 Emin=;d=zeros(1,101);for m=1:101d(1,m)=hermit(x(m));%期望 end;o=zeros(1,101);netj=zeros(1,j);net=zeros(1,j);y=zeros(1,j);p=1;q=1;acs=0;for z=1:5while q<30000Erro=0;Erme=0;for p=1:101for i=1:jnetj(1,i)=v(1,i)*x(1,p);y(1,i)=1/(1+exp(-netj(1,i))); end;o(1,p)=w*y'+zhaosheng(p);%噪声wucha=d(1,p)-o(1,p);%误差err(1,p)=1/2*wucha^2;erro=[erro,wucha];q=q+1;for t=1:101;Erro=Erro+erro(t);Erme=Erme+err(1,t);end;erro=[];for m=1:j;if m==1w(1,m)=w(1,m)+n*Erro*y(1,m);elsew(1,m)=w(1,m)+n*Erro*y(1,m)+a*w(1,m-1);endv(1,m)=v(1,m)+n*Erro*w(1,m)*y(1,m)*(1-y(1,m))*x(1,p); end;Erme=sqrt(Erme/101);ERRO=[ERRO,Erme];if Erme<Emin break; end;end;azc=azc+Erme;acs=acs+q;enddisp('平均误差:');pjwc=1/5*azcfigure(1);plot(x,d,'--r');hold on;plot(x,o,'--b');disp('平均次数:');pjcs=1/5*acsfigure(2);plot(ERRO);figure(3);plot(x,d);endfunction F = hermit(x) %hermit 子函数F = *(1-x+2*x^2)*exp(-x^2/2);end运行结果如下:-4-3-2-101234训练样本与测试样本input xo u t p u t y4. 对批处理BP 算法改变参数:学习率η、迭代次数、隐层节点数,观察算法的收敛发散,以及测试误差的变化(对每个参数取几个不同参数,分别运行5次,结果取平均值)。