实验三_香农编码
编码理论实验报告

一、实验目的1. 理解编码理论的基本概念和原理;2. 掌握哈夫曼编码和香农编码的方法;3. 熟悉编码效率的计算方法;4. 培养编程能力和实践操作能力。
二、实验原理1. 编码理论:编码理论是研究信息传输、存储和处理中信息压缩和编码的理论。
其目的是在保证信息传输质量的前提下,尽可能地减少传输或存储所需的数据量。
2. 哈夫曼编码:哈夫曼编码是一种根据字符出现频率进行编码的方法,字符出现频率高的用短码表示,频率低的用长码表示,从而达到压缩数据的目的。
3. 香农编码:香农编码是一种基于信息熵的编码方法,根据字符的概率分布进行编码,概率高的字符用短码表示,概率低的字符用长码表示。
4. 编码效率:编码效率是指编码后数据长度与原始数据长度的比值。
编码效率越高,表示压缩效果越好。
三、实验内容1. 使用MATLAB软件实现哈夫曼编码和香农编码;2. 对给定信源进行编码,并计算编码效率;3. 对比哈夫曼编码和香农编码的效率。
四、实验步骤1. 编写哈夫曼编码程序:首先,统计信源中各个字符的出现频率;然后,根据频率构造哈夫曼树;最后,根据哈夫曼树生成编码。
2. 编写香农编码程序:首先,计算信源熵;然后,根据熵值生成编码。
3. 编码实验:对给定的信源进行哈夫曼编码和香农编码,并计算编码效率。
4. 对比分析:对比哈夫曼编码和香农编码的效率,分析其优缺点。
五、实验结果与分析1. 哈夫曼编码实验结果:信源:'hello world'字符频率:'h' - 2, 'e' - 1, 'l' - 3, 'o' - 2, ' ' - 1, 'w' - 1, 'r' - 1, 'd' - 1哈夫曼编码结果:'h' - 0'e' - 10'l' - 110'o' - 1110' ' - 01'w' - 101'r' - 100'd' - 1001编码效率:1.52. 香农编码实验结果:信源:'hello world'字符频率:'h' - 2, 'e' - 1, 'l' - 3, 'o' - 2, ' ' - 1, 'w' - 1, 'r' - 1, 'd' - 1香农编码结果:'h' - 0'e' - 10'l' - 110'o' - 1110' ' - 01'w' - 101'r' - 100'd' - 1001编码效率:1.53. 对比分析:哈夫曼编码和香农编码的效率相同,均为1.5。
实验四_香农编码
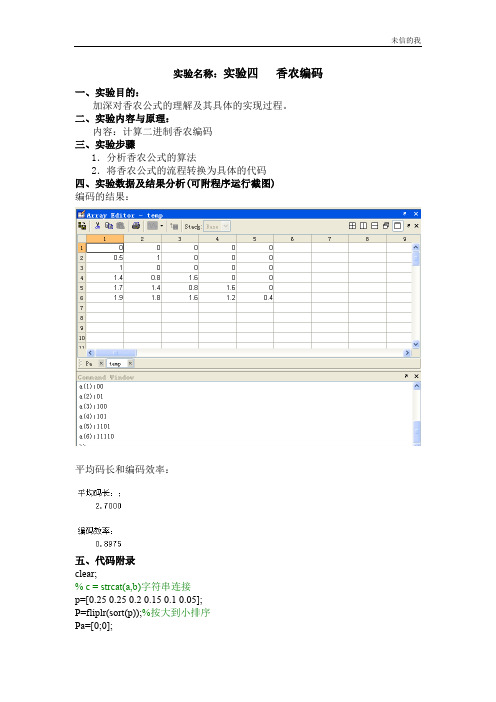
实验名称:实验四香农编码一、实验目的:加深对香农公式的理解及其具体的实现过程。
二、实验内容与原理:内容:计算二进制香农编码三、实验步骤1.分析香农公式的算法2.将香农公式的流程转换为具体的代码四、实验数据及结果分析(可附程序运行截图)编码的结果:平均码长和编码效率:五、代码附录clear;% c = strcat(a,b)字符串连接p=[0.25 0.25 0.2 0.15 0.1 0.05];P=fliplr(sort(p));%按大到小排序Pa=[0;0];%累加和的定义----第一行为累加和,第二行为Ki %求累加和for x=1for y=1:1:5%Pa(x,y)=1;Pa(x,y+1)=P(x,y)+ Pa(x,y);endend%ceil 是取向离它最近的大整数圆整for i=2for j=1:1:6Pa(i,j)=ceil( -log2(P(1,j)) );endend%信源熵H=0;L=0;for i=1:1:6H=H-P(i)*log2(P(i));L=L+P(i)*Pa(2,i);endu=H/L;disp('平均码长:;');disp(L);disp('编码效率:');disp(u);%求各符号的编码temp=[];%临时的编码值:1:6for m=1:1:6fprintf('a(%d):',m);for n=1:1:abs(Pa(2,m))temp(m,n)=Pa(1,m)*2;if temp(m,n)>=1O(m,n)=1;Pa(1,m)=temp(m,n)-1;elseO(m,n)=0;Pa(1,m)=temp(m,n);endfprintf('%d',O(m,n));endfprintf('\n');end六、其他:实验总结、心得体会及对本实验方法、手段及过程的改进建议等。
实验起初是想把累加和及Ki和编码放在一个二维矩阵中,但具体的实现较为复杂,所以最后改为逐行存放并成功完成了实验。
信息论 实验四 香农编码

实验四 香农编码一、实验目的:掌握香农编码的方法二、实验内容:对信源123456,,,,,()0.250.250.020.150.10.05a a a a a a X P X ⎧⎫⎛⎫=⎨⎬ ⎪⎝⎭⎩⎭进行二进制香农编码。
并计算其平均码长,信源熵,和编码效率。
三、实验步骤(1)将信源符号按概率从大到小的顺序排列。
(2)用Pa (i )表示第i 个码字的累加概率(3)确定满足下列不等式的整数K (i ),并令K (i )为第i 个码字的长度22log ()()1log ()Pa i K i Pa i -≤<-(4)将Pa (i )用二进制表示,并取小数点后K (i )位最为a (i )的编码四、实验数据及结果分析(1)将信源符号按概率从大到小的顺序排列。
P=(0.25 0.25 0.2 0.15 0.1 0.05);(2)用Pa (i )表示第i 个码字的累加概率。
Pa=(0 0.2500 0.5000 0.7000 0.8500 0.9500)(3)确定满足下列不等式的整数K (i )。
K=(2 2 3 3 4 5)(4)将Pa (i )用二进制表示,并取小数点后K (i )位最为a (i )的编码0001100101110111110(5)计算其平均码长,信源熵,和编码效率平均码长 L=2.7信源熵H=2.4232编码效率xiaolv=0.89749五、代码附录N=input('N='); %输入信源符号的个数s=0;L=0;H=0;Pa=zeros(1,6);for i=1:NP(i)=input('P=');%输入信源符号概率分布s=s+P(i);endif s~=1error('不符合概率分布');endP=sort(P,'descend');Pa(1)=0;for i=2:NPa(i)=Pa(i-1)+P(i-1);enddisp(Pa);for i=1:Na=-log2(P(i));if mod(a,1)==0 %计算第i个码字的长度K(i)=a;elseK(i)=fix(a+1);endL=L+P(i)*K(i); %计算平均码长H=H-P(i)*log2(P(i));%计算信源熵Endxiaolv=H/L; %计算编码效率for i=1:Nfor j=1:K(i)W(i,j)=fix(Pa(i)*2);Pa(i)=Pa(i)*2-fix(Pa(i)*2);fprintf('%d',W(i,j));endfprintf('\n');end六,实验总结:通过该实验,掌握了香农编码。
实验四-香农编码

海南大学信息科学技术学院信息安全专业《信息论与编码》实验报告一、 实验目的:了解掌握香农编码二、 实验环境:CodeBlocks三、 实验要求编程,对某一离散无记忆信源实现香农编码,输出消息符号及其对应的码字。
设离散无记忆信源⎭⎬⎫⎩⎨⎧=⎪⎪⎭⎫ ⎝⎛01.010.015.017.018.019.020.0)(7654321a a a a a a a X p X ,∑==ni ia p 11)(。
二进制香农编码过程如下: 1、将信源发出的N 个消息符号按其概率的递减次序依次排列。
2、按下式计算第i 个消息的二进制代码组的码长,并取整。
3、为了编成唯一可译码,首先计算第i 个消息的累加概率4、将累加概率Pi (为小数)变成二进制数5、除去小数点,并根据码长li ,取小数点后li 位数作为第i 个消息的码字。
四、 实验过程:代码:#include<stdio.h>#include<math.h>void main(){int i,n, j,k;float sum=0;float p[100]={0}; //无记忆信源X 的概率分布float m;float Pa[100]={0}; //累加概率的数组int l[100];char c[100][100];printf("请输入信源X的个数:");scanf("%d",&n);printf("请输入p[X]的概率分布\n");for(i=0;i<n;i++)scanf("%f",&p[i]);for(i=0;i<=n;i++) //判断概率和为1sum=sum+p[i];while(sum!=1){printf("错误输入,请重输\n");printf("请输入x的个数\n");scanf("%d",&n);printf("\n");printf("请输入p[i]的概率分布\n");for(i=0;i<n;i++)scanf("%f",&p[i]);for(i=0;i<n;i++)sum=sum+p[i];}for(j=0;j<n-1;j++) //将概率按从大到小排序 for(i=0;i<n-1-j;i++)if(p[i]<p[i+1]){m=p[i];p[i]=p[i+1];p[i+1]=m;}printf("p[i]由大到小的顺序为\n:");for(i=0;i<n;i++)printf("%5.2f",p[i]);printf("\n");Pa[0]=0;for(j=1;j<n+1;j++) //计算累加概率{Pa[j]=Pa[j-1]+p[j-1];}printf("累加和Pi为:");for(j=0;j<n;j++)printf("%5.2f",Pa[j]);printf("\n");printf("码长:");for(i=0;i<n;i++) //计算码长{m=log(1/p[i])/log(2);if(m==(int)m)l[i]=(int)m;elsel[i]=(int)(m+1);}for(i=0;i<n;i++)printf(" %d ",l[i]);printf("\n");for(i=0;i<n;i++) //将累加概率转换成二进制数{for(k=0;k<l[i];k++){Pa[i]=Pa[i]*2;if(Pa[i]>=1){Pa[i]=Pa[i]-1;c[i][k]='1';}else{c[i][k]='0';}}}for(i=0;i<n;i++){for(k=0;k<l[i];k++)printf("%c",c[i][k]);printf("\n");}}五、实验结果:。
《信息论与编码技术》实验教案

技术选型
根据实际需求选择合适的差错控制编码技术, 包括线性分组码、卷积码等。
实现与测试
通过编程实现所选差错控制编码技术的编码和解码过程,并进行测试和性能分 析。
04
现代编码技术实验
Turbo码编译码原理及性能评估
Turbo码基本原理
介绍Turbo码的结构、编码原理、迭代译码原理等基本概念。
编译码算法实现
《信息论与编码技术》实验教案
目录
• 课程介绍与实验目标 • 信息论基础实验 • 编码技术基础实验 • 现代编码技术实验 • 信息论与编码技术应用案例分析 • 课程总结与展望
01
课程介绍与实验目标
信息论与编码技术课程概述
课程背景
信息论与编码技术是通信工程、 电子工程等专业的核心课程,主 要研究信息的传输、存储和处理 过程中的基本理论和方法。
2. 根据概率分布生成模拟信源序列;
03
离散信源及其数学模型
3. 计算信源熵、平均符号长度等参数;
4. 分析实验结果,理解信源熵的物理 意义。
信道容量与编码定理验证
实验目的
理解信道容量的概念、计算方法和物理意义,验证香农编码定理的正确性。
实验内容
设计并实现一个信道模拟器,通过输入不同的信道参数和编码方案,计算并输出信道容量、误码率等关键参数。
数据存储系统中纠删码技术应用
纠删码基本原理
阐述纠删码的基本概念、原理及其在数据存储系统中的应用价值。
常用纠删码技术
介绍常用的纠删码技术,如Reed-Solomon码、LDPC码等,并分 析其性能特点。
纠删码技术应用实践
通过实验,将纠删码技术应用于数据存储系统中,评估其对系统可 靠性、数据恢复能力等方面的提升效果。
信息论与编码实验报告

实验一:计算离散信源的熵一、实验设备:1、计算机2、软件:Matlab二、实验目的:1、熟悉离散信源的特点;2、学习仿真离散信源的方法3、学习离散信源平均信息量的计算方法4、熟悉 Matlab 编程;三、实验内容:1、写出计算自信息量的Matlab 程序2、写出计算离散信源平均信息量的Matlab 程序。
3、将程序在计算机上仿真实现,验证程序的正确性并完成习题。
四、求解:1、习题:A 地天气预报构成的信源空间为:()⎥⎦⎤⎢⎣⎡=⎥⎦⎤⎢⎣⎡6/14/14/13/1x p X 大雨小雨多云晴 B 地信源空间为:17(),88Y p y ⎡⎤⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦⎣⎦ 小雨晴 求各种天气的自信息量和此两个信源的熵。
2、程序代码:p1=[1/3,1/4,1/4,1/6];p2=[7/8,1/8];H1=0.0;H2=0.0;I=[];J=[];for i=1:4H1=H1+p1(i)*log2(1/p1(i));I(i)=log2(1/p1(i));enddisp('自信息I分别为:');Idisp('信息熵H1为:');H1for j=1:2H2=H2+p2(j)*log2(1/p2(j));J(j)=log2(1/p2(j));enddisp('自信息J分别为');Jdisp('信息熵H2为:');H23、运行结果:自信息量I分别为:I = 1.5850 2.0000 2.0000 2.5850信源熵H1为:H1 = 1.9591自信息量J分别为:J =0.1926 3.0000信源熵H2为:H2 =0.54364、分析:答案是:I =1.5850 2.0000 2.0000 2.5850 J =0.1926 3.0000H1 =1.9591; H2 =0.5436实验2:信道容量一、实验设备:1、计算机2、软件:Matlab二、实验目的:1、熟悉离散信源的特点;2、学习仿真离散信源的方法3、学习离散信源平均信息量的计算方法4、熟悉 Matlab 编程;三、实验内容:1、写出计算自信息量的Matlab 程序2、写出计算离散信源平均信息量的Matlab 程序。
香农编码

temp=P[i]; P[i]=P[i+1]; P[i+1]=temp; } } for(int i=0;i<6;i++) cout<<P[i]<<" "; cout<<endl; for(i=0;i<6;i++) { Pax[0]=0.0; Pax[i+1]=Pax[i]+P[i]; } cout<<"概率累加和为:"<<endl; for(i=0;i<6;i++) cout<<Pax[i]<<" "; cout<<endl; for(i=0;i<6;i++) { double m=log(1/P[i])/log(2); if(m-int(m)==0) machang[i]=log(1/P[i])/log(2); else machang[i]=int(m)+1; cout<<P[i]<<"的码长为:"<<machang[i]<<endl; } for(i=0;i<6;i++) { for(int j=0;j<machang[i];j++) { int n=int(Pax[i]*2); cout<<n; if((Pax[i]*2-1)>0) { Pax[i]=Pax[i]*2-1; continue; } if((Pax[i]*2-1)==0) Pax[i]=Pax[i]*2-1; else Pax[i]=Pax[i]*2; } cout<<endl; }
香农编码的MATLAB实现

• (2)令 p(a0) = 0,用 pa (aj)(j = i+1)表示第 i 个码字的累加概率,则:
j 1
pa (a j ) p(ai ) i0
j 1,2,..., n
二、实验原理
1. 香农编码步骤
• (3)令 ki 为第 i 个码字的码长,按照下式计算 出各概率对应的码字长度 ki :
三、实验内容
• (5)十进制小数转换成二进制小数
➢ k_max = max(k);
➢ bin = zeros(n,k_max);
% 对二进制小数矩阵初始化
➢ for i = 1:n
➢ for j = 1:k_max
➢
bin(i,j)=floor(pa(i)*2); % 将累加概率转换成二进制
➢
pa(i)=pa(i)*2-floor(pa(i)*2);
三、实验内容
• (7)计算平均码长、信息率和编码效率
➢ K = sum(p.* k); % 平均码长
➢ R = K;
% 信息率
➢ eff = H/R; % 编码效率
三、实验内容
• (8)输出结果
➢ disp(['信源分布 P(X) = [',num2str(p),']']); ➢ disp('编码结果:'); ➢ for i = 1:n ➢ disp([num2str(p(i)),' -> ' ,num2str(codeword(i,:))]); ➢ end ➢ disp(['信源熵 H(X) = ' ,num2str(H),' (bit/sign)']); ➢ disp(['平均码长 K = ' ,num2str(K),' (bit/sign)']); ➢ disp(['信息率 R = ' ,num2str(R),' (bit/sign)']); ➢ disp(['编码效率 η = ' ,num2str(eff)]);
信息论霍夫曼、香农-费诺编码

信息论霍夫曼、香农-费诺编码LT二、实验原理:1、香农-费诺编码首先,将信源符号以概率递减的次序排列进来,将排列好的信源符号划分为两大组,使第组的概率和近于相同,并各赋于一个二元码符号”0”和”1”.然后,将每一大组的信源符号再分成两组,使同一组的两个小组的概率和近于相同,并又分别赋予一个二元码符号。
依次下去,直至每一个小组只剩下一个信源符号为止。
这样,信源符号所对应的码符号序列则为编得的码字。
译码原理,按照编码的二叉树从树根开始,按译码序列进行逐个的向其叶子结点走,直到找到相应的信源符号为止。
之后再把指示标记回调到树根,按照同样的方式进行下一序列的译码到序列结束。
如果整个译码序列能够完整的译出则返回成功,否则则返回译码失败。
2、霍夫曼编码霍夫曼编码属于码词长度可变的编码类,是霍夫曼在1952年提出的一种编码方法,即从下到上的编码方法。
同其他码词长度可变的编码一样,可区别的不同码词的生成是基于不同符号出现的不同概率。
生成霍夫曼编码算法基于一种称为“编码树”(coding tree)的技术。
算法步骤如下:(1)初始化,根据符号概率的大小按由大到小顺序对符号进行排序。
(2)把概率最小的两个符号组成一个新符号(节点),即新符号的概率等于这两个符号概率之和。
(3)重复第2步,直到形成一个符号为止(树),其概率最后等于1。
(4)从编码树的根开始回溯到原始的符号,并将每一下分枝赋值为1,上分枝赋值为0。
三、实验环境matlab7.1四、实验内容1、对于给定的信源的概率分布,用香农-费诺编码实现图像压缩2、对于给定的信源的概率分布,用霍夫曼编码实现图像压缩五、实验过程1.香农-费诺编码编码1function c=shannon(p)%p=[0.2 0.15 0.15 0.1 0.1 0.1 0.1 0.1] %shannon(p)[p,index]=sort(p)p=fliplr(p)n=length(p)pa=0for i=2:npa(i)= pa(i-1)+p(i-1) endk=ceil(-log2(p))c=cell(1,n)for i=1:nc{i}=”tmp=pa(i)for j=1:k(i)tmp=tmp*2if tmp>=1tmp=tmp-1 c{i(j)='1'elsec{i}(j) = '0' endendendc = fliplr(c)c(index)=c编码2clc;clear;A=[0.4,0.3,0.1,0.09,0.07,0.04]; A=fliplr(sort(A));%降序排列[m,n]=size(A);for i=1:nB(i,1)=A(i);%生成B的第1列end%生成B第2列的元素a=sum(B(:,1))/2;for k=1:n-1ifabs(sum(B(1:k,1))-a)<=abs(sum(B(1:k+1, 1))-a)break;endendfor i=1:n%生成B第2列的元素if i<=kB(i,2)=0;elseB(i,2)=1;endend%生成第一次编码的结果END=B(:,2)';END=sym(END);%生成第3列及以后几列的各元素j=3;while (j~=0)p=1;while(p<=n)x=B(p,j-1);for q=p:nif x==-1break;elseif B(q,j-1)==xy=1;continue;elsey=0;break;endendif y==1q=q+1;endif q==p|q-p==1B(p,j)=-1;elseif q-p==2B(p,j)=0;END(p)=[char(END(p)),'0'];B(q-1,j)=1;END(q-1)=[char(END(q-1)),'1']; elsea=sum(B(p:q-1,1))/2;for k=p:q-2abs(sum(B(p:k,1))-a)<=abs(sum(B(p:k+1, 1))-a);break;endendfor i=p:q-1if i<=kB(i,j)=0;END(i)=[char(END(i)),'0'];elseB(i,j)=1;END(i)=[char(END(i)),'1'];endendendendendC=B(:,j);D=find(C==-1);[e,f]=size(D);if e==nj=0;elsej=j+1;endendBAENDfor i=1:n[u,v]=size(char(END(i))); L(i)=v;avlen=sum(L.*A)2. 霍夫曼编码function c=huffman(p)n=size(p,2)if n==1c=cell(1,1)c{1}=''returnend[p1,i1]=min(p)index=[(1:i1-1),(i1+1:n)] p=p(index)n=n-1[p2,i2]=min(p)index2=[(1:i2-1),(i2+1:n)] p=p(index2);i2=index(i2)index=index(index2)p(n)=p1+p2c=huffman(p)c{n+1}=strcat(c{n},'1')c{n}=strcat(c{n},'0') index=[index,i1,i2]c(index)=c。
香农编码

cin>>p[i];
}
排序函数:void sort(double p[])
{
double t;
for (int i=0;i<f;i++)
{
for(int j=f-1;j>i;j--)
{
if (p[j]>p[j-1])
{t=p[j];p[j]=p[j-1];p[j-1]=t;}
{
x=pp[i];
for(int m=1;m<l[i]+1;m++)
{
x=x*2.0;
if(x>=1.0){c[j]=1;x=x-1.0;}
else{c[j]=0;}
j++;
}
}
}
输出函数:
void output(int l[],int c[],double p[],double pp[])
{
int m=0;
cout<<endl;
m=m+j;
}}
求解结果:
例5.1.2的求解结果
五、总结
一上机才发现,自己C和C++又该复习了,主要是很多语法怎么使用都记不太清楚了,但是以前通过复习的资料,自己还是很快很够把握一些基本的知识了,所以编写程序不是特别的难了,对于香农编码而言,主要是弄清楚各个步骤,像求码长、累加和、概率排序,每个模块建立一个函数,使得程序简单易读,自己的思路也更清晰明了。编码的原理我们都很清楚,主要就是在一些C和C++基本知识上的巩固才能做好这次的实验。
二进制香农编码的步骤如下:(1)、将信源符号按概率从大到小的顺序排列(2)、对第j个前的概率进行累加得到pa(aj)(3)、由-logp(ai) ki<1-logp(ai)求得码字长度ki (4)、将pa(aj)用二进制表示,并取小数点后ki位作为符号ai的编码。
信息论编码实验四香农编码(可打印修改)

事也掌握香农编码的一般算法和香农编码算法中的二进制编码算法。 一开始做实验的时候,如果任意给定一个信源模型,要求编程实现其二进制香农编码,
输出编码结果对我而言有很大的难度,但是通过这次的实验,这些操作对我而言驾轻就熟 不在话下了。这次实验让我学到了很多,很有意义。
Hale Waihona Puke D(:,1)=y';%把 y 赋给零矩阵的第一列 for i=2:n
D(1,2)=0;%令第一行第二列的元素为 0 D(i,2)=D(i-1,1)+D(i-1,2);%第二列其余的元素用此式求得,即为累加概率 end for i=1:n D(i,3)=-log2(D(i,1));%求第三列的元素 D(i,4)=ceil(D(i,3));%求第四列的元素,对 D(i,3)向无穷方向取最小正整数 end D A=D(:,2)';%取出 D 中第二列元素 B=D(:,4)';%取出 D 中第四列元素 for j=1:n C=deczbin(A(j),B(j))%生成码字 function [C]=deczbin(A,B)%对累加概率求二进制的函数 C=zeros(1,B);%生成零矩阵用于存储生成的二进制数,对二进制的每一位进行操作 temp=A;%temp 赋初值 for i=1:B%累加概率转化为二进制,循环求二进制的每一位,A 控制生成二进制的位数 temp=temp*2; if temp>=1 temp=temp-1; C(1,i)=1; else C(1,i)=0; end end
实验四 香农编码
一、实验目的
1、理解香农编码的概念。 2、掌握香农编码的一般算法 3、掌握香农编码算法中的二进制编码算法。 4、任意给定一个信源模型,编程实现其二进制香农编码,输出编码结果。
信息论与编码实验指导书

没实验一 绘制二进熵函数曲线(2个学时)一、实验目的:1. 掌握Excel 的数据填充、公式运算和图表制作2. 掌握Matlab 绘图函数3. 掌握、理解熵函数表达式及其性质 二、实验要求:1. 提前预习实验,认真阅读实验原理以及相应的参考书。
2. 在实验报告中给出二进制熵函数曲线图 三、实验原理:1. Excel 的图表功能2. 信源熵的概念及性质()()[]()[]())(1)(1 .log )( .)( 1log 1log )(log )()(10 , 110)(21Q H P H Q P H b nX H a p H p p p p x p x p X H p p p x x X P X ii i λλλλ-+≥-+≤=--+-=-=≤≤⎩⎨⎧⎭⎬⎫-===⎥⎦⎤⎢⎣⎡∑四、实验内容:用Excel 或Matlab 软件制作二进熵函数曲线。
具体步骤如下:1、启动Excel 应用程序。
2、准备一组数据p 。
在Excel 的一个工作表的A 列(或其它列)输入一组p ,取步长为0.01,从0至100产生101个p (利用Excel 填充功能)。
3、取定对数底c ,在B 列计算H(x) ,注意对p=0与p=1两处,在B 列对应位置直接输入0。
Excel 中提供了三种对数函数LN(x),LOG10(x)和LOG(x,c),其中LN(x)是求自然对数,LOG10(x)是求以10为底的对数,LOG(x,c)表示求对数。
选用c=2,则应用函数LOG(x,2)。
在单元格B2中输入公式:=-A2*LOG(A2,2)-(1-A2)*LOG(1-A2,2) 双击B2的填充柄,即可完成H(p)的计算。
4、使用Excel 的图表向导,图表类型选“XY 散点图”,子图表类型选“无数据点平滑散点图”,数据区域用计算出的H(p)数据所在列范围,即$B$1:$B$101。
在“系列”中输入X值(即p值)范围,即$A$1:$A$101。
信息论与编码实验报告

实验报告课程名称:信息论与编码姓名:系:专业:年级:学号:指导教师:职称:年月日目录实验一信源熵值的计算 (1)实验二 Huffman信源编码 (5)实验三 Shannon编码 (9)实验四信道容量的迭代算法 (12)实验五率失真函数 (15)实验六差错控制方法 (20)实验七汉明编码 (22)实验一 信源熵值的计算一、 实验目的1 进一步熟悉信源熵值的计算 2熟悉 Matlab 编程二、实验原理熵(平均自信息)的计算公式∑∑=--==qi i i qi i i p p p p x H 1212log 1log )(MATLAB 实现:))(log *.(2x x sum HX -=;或者))((log *)(2i x i x h h -= 流程:第一步:打开一个名为“nan311”的TXT 文档,读入一篇英文文章存入一个数组temp ,为了程序准确性将所读内容转存到另一个数组S ,计算该数组中每个字母与空格的出现次数(遇到小写字母都将其转化为大写字母进行计数),每出现一次该字符的计数器+1;第二步:计算信源总大小计算出每个字母和空格出现的概率;最后,通过统计数据和信息熵公式计算出所求信源熵值(本程序中单位为奈特nat )。
程序流程图:三、实验内容1、写出计算自信息量的Matlab 程序2、已知:信源符号为英文字母(不区分大小写)和空格。
输入:一篇英文的信源文档。
输出:给出该信源文档的中各个字母与空格的概率分布,以及该信源的熵。
四、实验环境Microsoft Windows 7Matlab 6.5五、编码程序#include"stdio.h"#include <math.h>#include <string.h>#define N 1000int main(void){char s[N];int i,n=0;float num[27]={0};double result=0,p[27]={0};FILE *f;char *temp=new char[485];f=fopen("nan311.txt","r");while (!feof(f)) {fread(temp,1, 486, f);}fclose(f);s[0]=*temp;for(i=0;i<strlen(temp);i++){s[i]=temp[i];}for(i=0;i<strlen(s);i++){if(s[i]==' ')num[26]++;else if(s[i]>='a'&&s[i]<='z')num[s[i]-97]++;else if(s[i]>='A'&&s[i]<='Z')num[s[i]-65]++;}printf("文档中各个字母出现的频率:\n");for(i=0;i<26;i++){p[i]=num[i]/strlen(s);printf("%3c:%f\t",i+65,p[i]);n++;if(n==3){printf("\n");n=0;}}p[26]=num[26]/strlen(s);printf("空格:%f\t",p[26]);printf("\n");for(i=0;i<27;i++){if (p[i]!=0)result=result+p[i]*log(p[i]);}result=-result;printf("信息熵为:%f",result);printf("\n");return 0;}六、求解结果其中nan311.txt中的文档如下:There is no hate without fear. Hate is crystallized fear, fear’s dividend, fear objectivized. We hate what we fear and so where hate is, fear is lurking. Thus we hate what threatens our person, our vanity andour dreams and plans for ourselves. If we can isolate this element in what we hate we may be able to cease from hating.七、实验总结通过这次实验,我们懂得了不必运行程序时重新输入文档就可以对文档进行统计,既节省了时间而且也规避了一些输入错误。
实验三哈夫曼编码

实验三哈夫曼编码一、实验目的和任务1、 理解信源编码的意义;2、 熟悉 MATLAB 程序设计;3、 掌握哈夫曼编码的方法及计算机实现;4、 对给定信源进行香农编码,并计算编码效率;二、实验原理介绍1、把信源符号按概率大小顺序排列, 并设法按逆次序分配码字的长度;12.......n p p p ≥≥≥2、在分配码字长度时,首先将出现概率 最小的两个符号的概率相加合成一个概率;3、把这个合成概率看成是一个新组合符号地概率,重复上述做法直到最后只剩下两个符号概率为止;4、完成以上概率顺序排列后,再反过来逐步向前进行编码,每一次有二个分支各赋予一个二进制码,可以对概率大的赋为零,概率小的赋为1;5、从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
三、实验设备介绍1、计算机2、编程软件MATLAB6.5以上四、实验内容和步骤对如下信源进行哈夫曼编码,并计算编码效率。
12345670.200.190.180.170.150.100.01X a a a a a a a P ⎡⎤⎡⎤=⎢⎥⎢⎥⎣⎦⎣⎦(1)计算该信源的信源熵,并对信源概率进行排序;(2)首先将出现概率最小的两个符号的概率相加合成一个概率,把这个合成 概率与其他的概率进行组合,得到一个新的概率组合,重复上述做法,直到只剩下两个概率为止。
之后再反过来逐步向前进行编码,每一次有两个分支各赋予一个二进制码。
对大的概率赋“1”,小的概率赋“0”。
(3)从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
(4)计算码字的平均码长得出最后的编码效率。
实验代码:。
实验二 Shannon编码

实验二Shannon编码一、实验目的及要求a)实验目的1.通过本实验实现信源编码——Shannon编码2.编写M文件实现,掌握Shannon编码方法b)实验要求1.了解Matlab中M文件的编辑、调试过程2.编写程序实现Shannon编码算法二、实验步骤及运行结果记录a)实验步骤1.输入Shannon编码程序2.运行程序,按照提示输入相应信息,并记录输入信息,及运行结果。
3.思考:在程序中加入排序子程序,使其在输入信源概率时,不要求输入顺序。
b)实验结果y =0.2000 0 2.3219 3.00000.1900 0.2000 2.3959 3.00000.1800 0.3900 2.4739 3.00000.1700 0.5700 2.5564 3.00000.1500 0.7400 2.7370 3.00000.1000 0.8900 3.3219 4.00000.0100 0.9900 6.6439 7.0000code =000;code = 001;code = 011;code =100;code = 101;code =1110;code =1111110三、实验流程图(附一)四、程序清单,并注释每条语句(附二)五、实验小结香农编码是码符号概率大的用短码表示,概率小的是用长码表示,程序中对概率排序,最后求得的码字就依次与排序后的符号概率对应。
此程序缺点是,第一个码字都是以0开始,因为对累加概率求二进制后,小数点后的数都是0,取几位由码长确定,而香农编码是不唯一的,如果手动编码就不存在这样的问题。
后面求得的编码没有下标就需要注意是与上面排序后的信源符号对应。
附一附二N=input('请输入信源符号个数:')%输入信源符号个数p=zeros(1,N);%生成1*4的零矩阵for i=1:Np(1,i)=input('请输入各信源符号出现的概率:')%输入各个信源符号的概率endp=fliplr(sort(p));%将概率从大到小进行排序if abs(sum(p)-1)>10e-10error('输入概率不符合概率分布')%检验所输入的概率是否正确endy=zeros(N,4);%生成N*4零矩阵for i=1:Ny(i,1)=p(1,i);%将各个符号出现的概率放入y矩阵的第一列中y(1,2)=0;if i>1y(i,2)=y(i-1,2)+y(i-1,1); %第二列其余的元素用此式求得,即为累加概率endy(i,3)=log2(1./p(i))%求各个信源符号的信息熵放入y矩阵的第三列中y(i,4)=ceil(y(i,3))%求码长endA=y(:,2);%取出y中的第二列元素B=y(:,4);%取出y中的第四列元素for i=1:Ncode=shannoncode(A(i),B(i))%生成码字endfunction [C]=shannoncode(A,B)%对累加概率求二进制的函数C=zeros(1,B);%生成零矩阵用于存储生成的二进制数,对二进制的每一位进行操作temp=A;%temp赋初值for i=1:B%累加概率转化为二进制,循环求二进制的每一位,A控制生成二进制的位数 temp=temp*2;if temp>1temp=temp-1;C(1,i)=1;elseC(1,i)=0;endendend。
《信息论与编码技术》实验教案

《信息论与编码技术》实验教案一、实验目的与要求1. 实验目的(1)理解信息论的基本概念和原理;(2)掌握信息编码的基本方法和技术;(3)培养动手实践能力和团队协作精神。
2. 实验要求(1)熟悉信息论与编码技术的基本理论;(2)具备一定的编程能力;(3)遵守实验纪律,按时完成实验任务。
二、实验内容与步骤1. 实验内容(1)信息熵的计算;(2)信源编码;(3)信道编码;(4)误码率分析;(5)编码技术的应用。
2. 实验步骤(1)实验讲解:了解实验目的、原理和实验设备;(2)信源熵的计算:根据给定的信源符号概率计算信源熵;(3)信源编码:采用香农编码和哈夫曼编码对信源进行编码;(4)信道编码:选择一种信道编码方案(如卷积编码或汉明编码),对编码后的数据进行信道编码;(5)误码率分析:通过模拟传输过程,分析不同编码方案下的误码率性能;(6)编码技术的应用:探讨编码技术在实际通信系统中的应用。
三、实验原理与方法1. 信息熵的计算信息熵是衡量信源不确定性的一种度量,采用香农熵公式计算。
2. 信源编码香农编码和哈夫曼编码是无损压缩编码方法,通过为符号分配唯一的编码,减少传输过程中的冗余信息。
3. 信道编码卷积编码和汉明编码是有损压缩编码方法,通过增加冗余信息,提高传输过程中的可靠性。
4. 误码率分析通过模拟传输过程,比较不同编码方案下的误码率性能。
5. 编码技术的应用探讨编码技术在实际通信系统中的应用,如数字通信、无线通信等。
四、实验器材与软件1. 实验器材(1)计算机;(2)实验箱;(3)调试器;(4)示波器。
2. 实验软件(1)编程语言软件(如C/C++、Python等);(2)仿真软件(如MATLAB、Multisim等)。
五、实验结果与评价1. 实验结果(1)完成信源熵的计算;(2)得到信源编码和信道编码的代码;(3)通过模拟传输过程,得到不同编码方案下的误码率性能;(4)分析编码技术在实际通信系统中的应用。
实验2:Shannon编码

k =1 i −1
3)按下式计算第 i 个消息的二元代码组的码长 li
1 li = log ; p ( si ) 4)将累加概率 F ( si ) 变换成二进制小数,根据码长 li 取小数点后 li 个二进制符号作为
实验 2:香农编码 :香农编码
学生姓名: 学生姓名: 学 号:
一、实验室名称:信息与编码课程组 实验室名称: 二、实验项目名称:香农编码 实验项目名称: 三、实验原理: 实验原理: 实验原理 1)将 q 个信源符号按概率大小递减排列 p ( s1 ) ≥ p ( s 2 ) ≥ L ≥ p ( s q ) ;
: 六、实验器材(设备、元器件) 实验器材(设备、元器件)
PC 机一台,装有 VC++6.0 或其它 C 语言集成开发环境。
七、实验步骤及操作: 实验步骤及操作:
1)排序; 2)计算码长; 3)递归调用香农算法得到相应的码字。
八、实验数据及结果分析: 实验数据及结果分析:
s 2 s3 s4 s5 s6 s 7 s8 S s1 题目:已知信源: = ,给出其一个 P 0.20, 0.18, 0.17, 0.15, 0.15, 0.05, 0.05, 0.05 香农码,并求其平均码长和编码效率。
第 i 个消息的码字。 实验目的: 四、实验目的: (1)进一步熟悉Shannon编码过程;(2)掌握C语言递归程序的设计和调试技术。以巩固 课堂所学编码的相关知识。 五、实验内容: 实验内容:
s2 , L , sq S s1 , 对于给定的信源 = P ,利用香农编码方法编出其中一种码。 p ( s1 ), p ( s 2 ),L , p ( s q 结及心得体会: 心得体会 本实验让我学习了使用 识有了进一步了解。
实验二香农编码的计算与分析

实验二香农编码的计算与分析The final edition was revised on December 14th, 2020.实验二香农编码的计算与分析一、[实验冃的]1、理解香农第一定理指出平均码长与信源之间的关系。
2、加深理解香农编码具有的重要理论意义。
3、掌握Shannon编码的原理。
4、掌握Shannon编码的方法和步骤。
3、熟悉shannnon编码的各种效率二、[实验环境]windows XP, MATLAB 7三、[实验原理]香农第一定理:设离散无记忆信源为I SI I 5\s2 ■….sq[_ ^p(s2) .... p(sq)嫡为H(S),其N次扩展信源为种编鲁盟駕擁驚爲缢席每籍黑霧需為證器到-竺+丄厶空logr N N logr当\ts时lim H = H Q)」\jxN瓦是平均码长四、[实验内容]人是匕对应的码字长度r-l1、根据实验原理,设计shannon编码方法,在给定C •SP 二L J<厂si s2 s3 s4 s5 s6 s7丿条件下,实现香农编码并算出编码效率。
2、请自己构造两个信源空间,根据求Shannon编码结果说明其物理意义。
五、[实验过程]每个实验项目包括:1)设计思路2)实验中岀现的问题及解决方法;要求:1)有标准的实验报告(10分)2)程序设计和基本算法合理(30分)3)实验仿真具备合理性(30分)4)实验分析合理(20分)5)能清晰的对实验中出现的问题进行分析并提出解决方案(10分)附录:程序设计与算法描述参考⑴)按降序排列概率的函数%[p,x]二arnxy(P)为按降序排序的函数%%P为信源的概率矢量,x为概率元素的下标矢量%%p为排序后返回的信源的概率矢量%%乂为排序后返回的概率元素的下标矢量%function[p,x]=array(P) n=length(P);X=l:n;P=[P; XI;for i=l:nmax 二P(lj); maxN=i; MAX=P(:,i);for j=i:n if(max<P(l j)) MAX=P(: j); max 二P(l,j); maxN=j;endendif (maxN>l)if (i<n)for k=(maxN-l):-l:iP(:,k+l)=P(:,k);endendendP(:,i)=MAX;endP=P(1,:);x 二P(2,:);(2) Shannon编码算法% shannon编码生成器%%函数说明:%% [W.L.q]=shannon(p)为Shannon 编码函数 %% P为信源的概率矢量,W为编码返回的码字%%L%编码返回的平均码字长度,q为编码概率%| ir \■/11 * ^T> ^T> ^T> 【管function [W,L,q] =shannon(p)%提示错误信息%if (length(伽d(pv=0))〜=0)error('Not a component*); %判断是否符合概率分布条件%1)排序if (abs(sum(p)-l)> 1 Oe-10)error(r Not a do not add up to 1') %判断是否符合概率和为1 end [p,x]=array(p); % 2)计算代码组长度1 l=ceil(-log2(p));% 3)计算累加概率PP(l)=0;n=len gtli(p);for i=2:nP(i)=P(M)+p(M);end% 4)求得二进制代码组W%町将十进制数转为二进制数for i=I:nforj=l:l(i) temp(i,j)=floor(P(i)*2); P(i)=P(i)*2-temp(i,j);endend%3给\¥赋ASCII码值,用于显示二进制代码组W for i=l:n forj=l:l(i)if (temp(ij)==0)W(i,j)=4 &elseW(i,j)=49;endendendL=sum(p.*I); %计算平均码字长度H=entropyl(p,2); % 计算信源嫡q=H/L; %计算编码效率for i=l:nB{i)=x(i);end% [n,m]=size(W);% TEMP=32*ones(n,6);% W=[W,TEMP];% W=W ;% [n,m]=size(W);% W=reshape(W, 1 ,n*m);% W=sprintfC%s,,W);[m,n]=size(W);TEMP=blanks(m);W=[W,TEMP\TEM P、TEMP];[m,n]=size(W);W=reshape(W\ 1,m*n);sO・很好!输入正确,编码结果如下:s^'Shannon编码所得码字W : s2=*Shannon编码平均码字长度L : s3=Shannon编码的编码效率q : disp(sO); disp(sl),disp(B),disp(W); disp(s2),disp(L);disp(s3),disp(q);。
信息论与编码-曹雪虹-课后习题答案 (2)

《信息论与编码》-曹雪虹-课后习题答案第二章2.1一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下状态转移矩阵为:1/21/201/302/31/32/30p ⎛⎫ ⎪= ⎪ ⎪⎝⎭设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩2.2 由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =0.8,(0|11)p =0.2,(1|00)p =0.2,(1|11)p =0.8,(0|01)p =0.5,(0|10)p =0.5,(1|01)p =0.5,(1|10)p =0.5。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==(0|11)(10|11)0.2p p == (0|10)(00|10)0.5p p == (1|00)(01|00)0.2p p == (1|01)(11|01)0.5p p ==(1|11)(11|11)0.8p p == (1|10)(01|10)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩2.3 同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求:(1) “3和5同时出现”这事件的自信息; (2) “两个1同时出现”这事件的自信息;(3) 两个点数的各种组合(无序)对的熵和平均信息量; (4) 两个点数之和(即2, 3, … , 12构成的子集)的熵; (5) 两个点数中至少有一个是1的自信息量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三 香农编码
一、实验目的:
1、理解香农编码的基本原理及其特点;
2、熟练掌握香农编码的方法步骤;
3、熟练地用Matlab 编写香农编码的程序。
二、实验仪器
计算机、Matlab 仿真软件
三、实验原理
香农编码属于不等长编码,通常将经常出现的消息编成短码,不常出现的消息编成长码,从而提高通信效率。
二进制香农编码的步骤如下:
(1) 将信源符号按概率从大到小的顺序排列;
(2) 对第i 个消息的累加概率:-==∑1
1()i i k k P p x
(3) 确定满足下列不等式的整数码长:-≤<-+22log ()log ()1i i i p K p
(4) 将累加概率P I 变换成二进制数;
(5) 根据码字长度写出对应的码字。
题目:有离散无记忆信源[X]=[x1,x2,x3,x4,x5,x6],相应的概率矩阵为[P(X)]=[0.25, 0.25, 0.2, 0.15 , 0.1, 0.05],对该信源进行二进制香农编码,并计算平均码长和编码效率。
四、实验内容
利用MATLAB 编程完成上述题目的程序实现。
五、实验要求
1、提前预习实验,认真阅读实验原理以及相应的参考书;
2、详细写出香农编码的基本步骤;
3、通过matlab 实现香农编码,画出程序流程图;
4、对给定的任一个信源,均能通过上述程序给出编码结果,并分析实验结果。
5、按实验要求书写报告内容。