实验二 香农编码
编码理论实验报告

一、实验目的1. 理解编码理论的基本概念和原理;2. 掌握哈夫曼编码和香农编码的方法;3. 熟悉编码效率的计算方法;4. 培养编程能力和实践操作能力。
二、实验原理1. 编码理论:编码理论是研究信息传输、存储和处理中信息压缩和编码的理论。
其目的是在保证信息传输质量的前提下,尽可能地减少传输或存储所需的数据量。
2. 哈夫曼编码:哈夫曼编码是一种根据字符出现频率进行编码的方法,字符出现频率高的用短码表示,频率低的用长码表示,从而达到压缩数据的目的。
3. 香农编码:香农编码是一种基于信息熵的编码方法,根据字符的概率分布进行编码,概率高的字符用短码表示,概率低的字符用长码表示。
4. 编码效率:编码效率是指编码后数据长度与原始数据长度的比值。
编码效率越高,表示压缩效果越好。
三、实验内容1. 使用MATLAB软件实现哈夫曼编码和香农编码;2. 对给定信源进行编码,并计算编码效率;3. 对比哈夫曼编码和香农编码的效率。
四、实验步骤1. 编写哈夫曼编码程序:首先,统计信源中各个字符的出现频率;然后,根据频率构造哈夫曼树;最后,根据哈夫曼树生成编码。
2. 编写香农编码程序:首先,计算信源熵;然后,根据熵值生成编码。
3. 编码实验:对给定的信源进行哈夫曼编码和香农编码,并计算编码效率。
4. 对比分析:对比哈夫曼编码和香农编码的效率,分析其优缺点。
五、实验结果与分析1. 哈夫曼编码实验结果:信源:'hello world'字符频率:'h' - 2, 'e' - 1, 'l' - 3, 'o' - 2, ' ' - 1, 'w' - 1, 'r' - 1, 'd' - 1哈夫曼编码结果:'h' - 0'e' - 10'l' - 110'o' - 1110' ' - 01'w' - 101'r' - 100'd' - 1001编码效率:1.52. 香农编码实验结果:信源:'hello world'字符频率:'h' - 2, 'e' - 1, 'l' - 3, 'o' - 2, ' ' - 1, 'w' - 1, 'r' - 1, 'd' - 1香农编码结果:'h' - 0'e' - 10'l' - 110'o' - 1110' ' - 01'w' - 101'r' - 100'd' - 1001编码效率:1.53. 对比分析:哈夫曼编码和香农编码的效率相同,均为1.5。
信息论与编码实验2-实验报告

信息论与编码实验2-实验报告信息论与编码实验 2 实验报告一、实验目的本次信息论与编码实验 2 的主要目的是深入理解和应用信息论与编码的相关知识,通过实际操作和数据分析,进一步掌握信源编码和信道编码的原理及方法,提高对信息传输效率和可靠性的认识。
二、实验原理(一)信源编码信源编码的目的是减少信源输出符号序列中的冗余度,提高符号的平均信息量。
常见的信源编码方法有香农编码、哈夫曼编码等。
香农编码的基本思想是根据符号出现的概率来分配码字长度,概率越大,码字越短。
哈夫曼编码则通过构建一棵最优二叉树,为出现概率较高的符号分配较短的编码,从而实现平均码长的最小化。
(二)信道编码信道编码用于增加信息传输的可靠性,通过在发送的信息中添加冗余信息,使得在接收端能够检测和纠正传输过程中产生的错误。
常见的信道编码有线性分组码,如汉明码等。
三、实验内容与步骤(一)信源编码实验1、选取一组具有不同概率分布的信源符号,例如:A(02)、B (03)、C(01)、D(04)。
2、分别使用香农编码和哈夫曼编码对信源符号进行编码。
3、计算两种编码方法的平均码长,并与信源熵进行比较。
(二)信道编码实验1、选择一种线性分组码,如(7,4)汉明码。
2、生成一组随机的信息位。
3、对信息位进行编码,得到编码后的码字。
4、在码字中引入随机错误。
5、进行错误检测和纠正,并计算错误纠正的成功率。
四、实验结果与分析(一)信源编码结果1、香农编码的码字为:A(010)、B(001)、C(100)、D (000)。
平均码长为 22 比特,信源熵约为 184 比特,平均码长略大于信源熵。
2、哈夫曼编码的码字为:A(10)、B(01)、C(111)、D (00)。
平均码长为 19 比特,更接近信源熵,编码效率更高。
(二)信道编码结果在引入一定数量的错误后,(7,4)汉明码能够成功检测并纠正大部分错误,错误纠正成功率较高,表明其在提高信息传输可靠性方面具有较好的性能。
实验二信源熵的计算及信源编码实验

⎥⎦⎤⎢⎣⎡=⎥⎦⎤⎢⎣⎡01.01.015.017.018.019.02.0)(7654321x x x x x x x X P X 实验二 信源熵的计算及信源编码实验实验目的:1、掌握信源熵、疑义度、噪声熵、联合熵和信源的二次扩展信源的熵的计算。
2、掌握哈夫曼编码的Matlab 实现方法。
3、掌握香农编码的Matlab 实现方法。
实验内容与步骤:一、信源熵H(X)、疑义度H(X|Y)、噪声熵H(Y|X)、联合熵H(XY)和信源二次扩展信源的熵H(X 2)的计算已知信源:接到如图所示的信道上,求在该信道上传输信息的信源熵H(X)、疑义度H(X|Y)、噪声熵H(Y|X)、联合熵H(XY)和信源二次扩展信源的熵H(X 2)结果:联合概率:px1y1 =0.4500px1y2 =0.0500px2y1 = 0.1000px2y2 = 0.4000Y 的概率:py1 =0.5500py2 =0.4500疑义度:px1_y1=0.8182px2_y1 =0.1818px1_y2 =0.1111px2_y2 = 0.8889信源熵:HX =1HY = 0.9928HXY =1.5955疑义度:HX_Y = 0.6027噪声熵:HY_X = 0.5955二次扩展信源熵:H_X = 2二、 香农编码实验设信源共7个符号消息,其数学模型如下其香农编码过程如下:0.8 0.1 0.2 X1X2 y1 y2 0.9根据分析模型编写M文件进行仿真,记录结果。
结果:十进制转二进制:c =0 0 0c =0 0 1c =0 1 1c =1 0 0c =1 0 1c =1 1 1 0c =1 1 1 1 1 1 0三、Huffman编码实验1)编写计算信息熵的M文件求信源X=[x1,x2,X3,X4,X5,X6,X7,X8,x9],其相应的概率为p=[0.2,0.15,0.13,0.12,0.1,0.09,0.08,0.07,0.06];利用编写的程序计算信息熵,并记录数值。
《信息论与编码技术》实验教案

技术选型
根据实际需求选择合适的差错控制编码技术, 包括线性分组码、卷积码等。
实现与测试
通过编程实现所选差错控制编码技术的编码和解码过程,并进行测试和性能分 析。
04
现代编码技术实验
Turbo码编译码原理及性能评估
Turbo码基本原理
介绍Turbo码的结构、编码原理、迭代译码原理等基本概念。
编译码算法实现
《信息论与编码技术》实验教案
目录
• 课程介绍与实验目标 • 信息论基础实验 • 编码技术基础实验 • 现代编码技术实验 • 信息论与编码技术应用案例分析 • 课程总结与展望
01
课程介绍与实验目标
信息论与编码技术课程概述
课程背景
信息论与编码技术是通信工程、 电子工程等专业的核心课程,主 要研究信息的传输、存储和处理 过程中的基本理论和方法。
2. 根据概率分布生成模拟信源序列;
03
离散信源及其数学模型
3. 计算信源熵、平均符号长度等参数;
4. 分析实验结果,理解信源熵的物理 意义。
信道容量与编码定理验证
实验目的
理解信道容量的概念、计算方法和物理意义,验证香农编码定理的正确性。
实验内容
设计并实现一个信道模拟器,通过输入不同的信道参数和编码方案,计算并输出信道容量、误码率等关键参数。
数据存储系统中纠删码技术应用
纠删码基本原理
阐述纠删码的基本概念、原理及其在数据存储系统中的应用价值。
常用纠删码技术
介绍常用的纠删码技术,如Reed-Solomon码、LDPC码等,并分 析其性能特点。
纠删码技术应用实践
通过实验,将纠删码技术应用于数据存储系统中,评估其对系统可 靠性、数据恢复能力等方面的提升效果。
香农编码

temp=P[i]; P[i]=P[i+1]; P[i+1]=temp; } } for(int i=0;i<6;i++) cout<<P[i]<<" "; cout<<endl; for(i=0;i<6;i++) { Pax[0]=0.0; Pax[i+1]=Pax[i]+P[i]; } cout<<"概率累加和为:"<<endl; for(i=0;i<6;i++) cout<<Pax[i]<<" "; cout<<endl; for(i=0;i<6;i++) { double m=log(1/P[i])/log(2); if(m-int(m)==0) machang[i]=log(1/P[i])/log(2); else machang[i]=int(m)+1; cout<<P[i]<<"的码长为:"<<machang[i]<<endl; } for(i=0;i<6;i++) { for(int j=0;j<machang[i];j++) { int n=int(Pax[i]*2); cout<<n; if((Pax[i]*2-1)>0) { Pax[i]=Pax[i]*2-1; continue; } if((Pax[i]*2-1)==0) Pax[i]=Pax[i]*2-1; else Pax[i]=Pax[i]*2; } cout<<endl; }
二元香农编码例题

二元香农编码(Binary Shannon Encoding)是一种用于数据压缩和通信的编码方法。
它基于香农信息理论,通过将输入数据转换为二进制形式,以实现更高的数据压缩和传输效率。
假设我们要对一组数据 "ABCD" 进行二元香农编码。
首先,我们需要确定每个字符的二进制位数。
对于一个由四个字符组成的数据,我们可以使用4位二进制来表示。
接下来,我们将每个字符转换为二进制形式。
对于字母 "A",我们可以使用ASCII 码进行转换,得到二进制表示为 "0100"。
同理,我们可以得到 "B"、"C" 和 "D" 的二进制表示分别为 "0101"、"0110" 和 "0111"。
然后,我们将这些二进制位组合在一起,形成一个二进制数。
对于 "ABCD",其二进制表示为 "0100 0101 0110 0111"。
因此,对于输入数据 "ABCD",其二元香农编码为 "0100 0101 0110 0111"。
在接收端,我们可以将这些二进制位解码回原始的字符形式,即 "ABCD"。
总之,二元香农编码通过将输入数据转换为二进制形式,实现了更高的数据压缩和传输效率。
在处理大量数据时,它能够显著降低存储和传输成本。
编码实验报告

实验一香农编码一、实验目的1.了解香农编码的基本原理及其特点;2.熟悉掌握香农编码的方法和步骤;3.掌握C语言或者Matlab编写香农编码的程序。
二、实验要求对于给定的信源的概率分布,按照香农编码的方法进行计算机实现.三、实验原理给定某个信源符号的概率分布,通过以下的步骤进行香农编码1.信源符号按概率从大到小排列2.对信源符号求累加概率,表达式: G i=G i-1+p(x i)3.求自信息量,确定码字长度。
自信息量I(x i)=-log(p(x i));码字长度取大于等于自信息量的最小整数。
4.将累加概率用二进制表示,并取小数点后码字的长度的码。
四、实验报告1.画出程序设计的流程图,2.写出程序代码,3.写出在调试过程中出现的问题,4.对实验的结果进行分析1.画出程序设计的流程图2.写出程序代码N=input('N='); %输入信源符号的个数s=0;l=0;H=0;for i=1:Np(i)=input('p='); %输入信源符号概率分布矢量,p(i)<1s=s+p(i)H=H+(-p(i)*log2(p(i)));I(i)=-log2(p(i)); %计算信源信息熵endif abs(s-1)>0,error('不符合概率分布')endfor i=1:N-1for j=i+1:Nif p(i)<p(j)m=p(j);p(j)=p(i);p(i)=m;endendend %按概率分布大小对信源排序for i=1:Na=-log2(p(i));if mod(a,1)==0w=a;elsew=fix(a+1);end %计算各信源符号的码长l=l+p(i)*w; %计算平均码长endl=l;n=H/l; %计算编码效率P(1)=0for i=2:NP(i)=0;for j=1:i-1P(i)=P(i)+p(j);endend %计算累加概率for i=1:Nfor j=1:wW(i,j)=fix(P(i)*2);P(i)=P(i)*2-fix(P(i)*2);endend %将累加概率转化为L(i)位二进制码字disp(W) %显示码字disp(l) %显示平均码长disp(n) %显示编码效率disp(I) %显示自信息3.写出在调试过程中出现的问题不知该如何编写程序实现将累加概率转化为L(i)位二进制码字。
香农编码实验报告

《信息论与编码》实验报告题目信源编码实验指导教师学院专业班级姓名学号日期目录一、香农编码 (3)实验目的 (3)实验要求 (3)编码算法 (3)调试过程 (3)参考代码 (4)调试验证 (7)实验总结 (7)二、哈夫曼编码 (8)实验目的 (8)实验原理 (8)数据记录 (9)实验心得 (10)一、香农编码3、Shannon 编码算法 1:procedure SHANNON(q,{Pi })2: 降序排列{Pi } 3: for i=1 q do 4: F(i s ) 5:i l 2[]log 1/()i p s 6:将累加概率F(i s )(十进制小数)变换成二进制小数。
7:取小数点后i l 个二进制数字作为第i 个消息的码字。
8:end for9:end procedure------------------------------------------------------------------------------------------------------------------4、调试过程1、fatal error C1083: Cannot open include file: 'unistd.h': No such file or directoryfatal error C1083: Cannot open include file: 'values.h': No such file or directory原因:unistd.h 和values.h 是Unix 操作系统下所使用的头文件纠错:删去即可2、error C2144: syntax error : missing ')' before type 'int'error C2064: term does not evaluate to a function原因:l_i(int *)calloc(n,sizeof(int)); l_i 后缺少赋值符号使之不能通过编译纠错:添加上赋值符号3、error C2018: unknown character '0xa1'原因:有不能被识别的符号纠错:在错误处将不能识别的符号改为符合C 语言规范的符号4、error C2021: expected exponent value, not ' '原因:if(fabs(sum-1.0)>DELTA); 这一行中DELTA 宏定义不正确11()i k k p s -=∑纠错:# define DELTA 0.0000015、error C2143: syntax error : missing ';' before '}'原因:少写了“;”号纠错:在对应位置添加上“;”号5、参考代码# include<stdio.h># include<math.h># include<stdlib.h># include<string.h># define DELTA 0.000001/*精度*/void sort(float*,int);/*排序*/int main(void){register int i,j;int n; /*符号个数*/int temp;/*中间变量*/float *p_i; /*符号的概率*/float *P_i; /*累加概率*/int *l_i; /*码长*/char * *C; /*码集合*//*用sum来检验数据,用p来缓存了中间数据*/float sum,p;/*输入符号数*/fscanf(stdin,"%d",&n);/*分配内存地址 */p_i=(float *)calloc(n,sizeof(float));P_i=(float *)calloc(n,sizeof(float));l_i=(int *)calloc(n,sizeof(int));/* 存储信道传输的概率*/for(i=0;i<n;i++)fscanf(stdin,"%f",&p_i[i]);/*确认输入的数据*/sum=0.0;for(i=0;i<n;i++)sum+=p_i[i];if(fabs(sum-(1.0))>DELTA)fprintf(stderr,"Invalid input data \n");fprintf(stdout,"Starting…\n\n");/*以降序排列概率*/sort (p_i,n);/*计算每个符号的码长*/for(i=0;i<n;i++){p=(float)(-(log(p_i[i])))/log(2.0);l_i[i]=(int)ceil(p);}/*为码字分配内存地址*/C=(char **)calloc(n,sizeof(char *));for(i=0;i<n;i++){C[i]=(char *)calloc(l_i[i]+1,sizeof(char));C[i][0]='\0';}/*计算概率累加和*/P_i[0]=0.0;for(i=1;i<n;i++)P_i[i]=P_i[i-1]+p_i[i-1];/*将概率和转变为二进制编码*/for(i=0;i<n;i++){for(j=0;j<l_i[i];j++){/*乘2后的整数部分即为这一位的二进制码元*/ P_i[i]=P_i[i]*2;temp=(int)(P_i[i]);P_i[i]=P_i[i]-temp;/*整数部分大于0为1,等于0为0*/if(temp==0)C[i]=strcat(C[i],"0");elseC[i]=strcat(C[i],"1");}}/*显示编码结果*/fprintf(stdout,"The output coding is :\n");for(i=0;i<n;i++)fprintf(stdout,"%s",C[i]); fprintf(stdout,"\n\n");/*释放内存空间*/for(i=n-1;i>=0;i--)free(C[i]);free(C);free(p_i);free(P_i);free(l_i);exit(0);}/*冒泡排序法*/void sort(float *k,int m){int i=1;/*外层循环变量*/int j=1;/*内层循环变量*/int finish=0;/*结束标志*/float temp;/*中间变量*/while(i<m&&!finish){finish=1;for(j=0;j<m-i;j++){/*将小的数后移*/if(k[j]<k[j+1]){temp=k[j];k[j]=k[j+1];k[j+1]=k[j];finish=0;}i++;}}}6、调试验证:程序结果:7、实验总结1949年香农在《有噪声时的通信》一文中提出了信道容量的概念和信道编码定理,为信道编码奠定了理论基础。
信息论与编码实验报告

信息论与编码实验报告一、实验目的信息论与编码是一门涉及信息的度量、传输和处理的学科,通过实验,旨在深入理解信息论的基本概念和编码原理,掌握常见的编码方法及其性能评估,提高对信息处理和通信系统的分析与设计能力。
二、实验原理(一)信息论基础信息熵是信息论中用于度量信息量的重要概念。
对于一个离散随机变量 X,其概率分布为 P(X) ={p(x1), p(x2),, p(xn)},则信息熵H(X) 的定义为:H(X) =∑p(xi)log2(p(xi))。
(二)编码原理1、无失真信源编码:通过去除信源中的冗余信息,实现用尽可能少的比特数来表示信源符号,常见的方法有香农编码、哈夫曼编码等。
2、有噪信道编码:为了提高信息在有噪声信道中传输的可靠性,通过添加冗余信息进行纠错编码,如线性分组码、卷积码等。
三、实验内容及步骤(一)信息熵的计算1、生成一个离散信源,例如信源符号集为{A, B, C, D},对应的概率分布为{02, 03, 01, 04}。
2、根据信息熵的定义,使用编程语言计算该信源的信息熵。
(二)香农编码1、按照香农编码的步骤,首先计算信源符号的概率,并根据概率计算每个符号的编码长度。
2、确定编码值,生成香农编码表。
(三)哈夫曼编码1、构建哈夫曼树,根据信源符号的概率确定树的结构。
2、为每个信源符号分配编码,生成哈夫曼编码表。
(四)线性分组码1、选择一种线性分组码,如(7, 4)汉明码。
2、生成编码矩阵,对输入信息进行编码。
3、在接收端进行纠错译码。
四、实验结果与分析(一)信息熵计算结果对于上述生成的离散信源,计算得到的信息熵约为 184 比特/符号。
这表明该信源存在一定的不确定性,需要一定的信息量来准确描述。
(二)香农编码结果香农编码表如下:|信源符号|概率|编码长度|编码值|||||||A|02|232|00||B|03|174|10||C|01|332|110||D|04|132|111|香农编码的平均码长较长,编码效率相对较低。
香农编码

cin>>p[i];
}
排序函数:void sort(double p[])
{
double t;
for (int i=0;i<f;i++)
{
for(int j=f-1;j>i;j--)
{
if (p[j]>p[j-1])
{t=p[j];p[j]=p[j-1];p[j-1]=t;}
{
x=pp[i];
for(int m=1;m<l[i]+1;m++)
{
x=x*2.0;
if(x>=1.0){c[j]=1;x=x-1.0;}
else{c[j]=0;}
j++;
}
}
}
输出函数:
void output(int l[],int c[],double p[],double pp[])
{
int m=0;
cout<<endl;
m=m+j;
}}
求解结果:
例5.1.2的求解结果
五、总结
一上机才发现,自己C和C++又该复习了,主要是很多语法怎么使用都记不太清楚了,但是以前通过复习的资料,自己还是很快很够把握一些基本的知识了,所以编写程序不是特别的难了,对于香农编码而言,主要是弄清楚各个步骤,像求码长、累加和、概率排序,每个模块建立一个函数,使得程序简单易读,自己的思路也更清晰明了。编码的原理我们都很清楚,主要就是在一些C和C++基本知识上的巩固才能做好这次的实验。
二进制香农编码的步骤如下:(1)、将信源符号按概率从大到小的顺序排列(2)、对第j个前的概率进行累加得到pa(aj)(3)、由-logp(ai) ki<1-logp(ai)求得码字长度ki (4)、将pa(aj)用二进制表示,并取小数点后ki位作为符号ai的编码。
信息论与编码(第二版)曹雪虹(最全版本)答案

《信息论与编码(第二版)》曹雪虹答案第二章2.1一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下状态转移矩阵为:1/21/201/302/31/32/30p ⎛⎫ ⎪= ⎪ ⎪⎝⎭设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ 2.2 由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =0.8,(0|11)p =0.2,(1|00)p =0.2,(1|11)p =0.8,(0|01)p =0.5,(0|10)p =0.5,(1|01)p =0.5,(1|10)p =0.5。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==(0|11)(10|11)0.2p p == (0|10)(00|10)0.5p p == (1|00)(01|00)0.2p p == (1|01)(11|01)0.5p p == (1|11)(11|11)0.8p p == (1|10)(01|10)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩2.3 同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求: (1) “3和5同时出现”这事件的自信息; (2) “两个1同时出现”这事件的自信息;(3) 两个点数的各种组合(无序)对的熵和平均信息量; (4) 两个点数之和(即2, 3, … , 12构成的子集)的熵; (5) 两个点数中至少有一个是1的自信息量。
信息论与编码实验指导书

没实验一 绘制二进熵函数曲线(2个学时)一、实验目的:1. 掌握Excel 的数据填充、公式运算和图表制作2. 掌握Matlab 绘图函数3. 掌握、理解熵函数表达式及其性质 二、实验要求:1. 提前预习实验,认真阅读实验原理以及相应的参考书。
2. 在实验报告中给出二进制熵函数曲线图 三、实验原理:1. Excel 的图表功能2. 信源熵的概念及性质()()[]()[]())(1)(1 .log )( .)( 1log 1log )(log )()(10 , 110)(21Q H P H Q P H b nX H a p H p p p p x p x p X H p p p x x X P X ii i λλλλ-+≥-+≤=--+-=-=≤≤⎩⎨⎧⎭⎬⎫-===⎥⎦⎤⎢⎣⎡∑四、实验内容:用Excel 或Matlab 软件制作二进熵函数曲线。
具体步骤如下:1、启动Excel 应用程序。
2、准备一组数据p 。
在Excel 的一个工作表的A 列(或其它列)输入一组p ,取步长为0.01,从0至100产生101个p (利用Excel 填充功能)。
3、取定对数底c ,在B 列计算H(x) ,注意对p=0与p=1两处,在B 列对应位置直接输入0。
Excel 中提供了三种对数函数LN(x),LOG10(x)和LOG(x,c),其中LN(x)是求自然对数,LOG10(x)是求以10为底的对数,LOG(x,c)表示求对数。
选用c=2,则应用函数LOG(x,2)。
在单元格B2中输入公式:=-A2*LOG(A2,2)-(1-A2)*LOG(1-A2,2) 双击B2的填充柄,即可完成H(p)的计算。
4、使用Excel 的图表向导,图表类型选“XY 散点图”,子图表类型选“无数据点平滑散点图”,数据区域用计算出的H(p)数据所在列范围,即$B$1:$B$101。
在“系列”中输入X值(即p值)范围,即$A$1:$A$101。
信息论与编码曹雪虹课后习题答案

《信息论与编码》-曹雪虹-课后习题答案 第二章2.1一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p uu =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下 状态转移矩阵为:设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ 2.2 由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =0.8,(0|11)p =0.2,(1|00)p =0.2,(1|11)p =0.8,(0|01)p =0.5,(0|10)p =0.5,(1|01)p =0.5,(1|10)p =0.5。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩2.3 同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求:(1) “3和5同时出现”这事件的自信息; (2) “两个1同时出现”这事件的自信息; (3) 两个点数的各种组合(无序)对的熵和平均信息量;(4) 两个点数之和(即2, 3, … , 12构成的子集)的熵;(5) 两个点数中至少有一个是1的自信息量。
香农三大定理[宝典]
![香农三大定理[宝典]](https://img.taocdn.com/s3/m/71be0b29b80d6c85ec3a87c24028915f804d8499.png)
香农三大定理首先我们要知道香农三大定理,这样有助于我们理解香农极限。
香农第一定理(可变长无失真信源编码定理)设信源S的熵H(S),无噪离散信道的信道容量为C,于是,信源的输出可以进行这样的编码,使得信道上传输的平均速率为每秒(C/H(S)-a)个信源符号.其中a可以是任意小的正数, 要使传输的平均速率大于(C/H(S))是不可能的。
于是,C/H(S)便是可变长无失真信源编码的香农极限。
香农第二定理(有噪信道编码定理)设某信道有r个输入符号,s个输出符号,信道容量为C,当信道的信息传输率R码长N足够长,总可以在输入的集合中(含有r^N个长度为N 的码符号序列),找到M (M<=2^(N(C-a))),a为任意小的正数)个码字,分别代表M个等可能性的消息,组成一个码以及相应的译码规则,使信道输出端的最小平均错误译码概率Pmin达到任意小,此时的信道容量即为信道的香农极限。
香农第三定理(保失真度准则下的有失真信源编码定理)设R(D)为一离散无记忆信源的信息率失真函数,并且选定有限的失真函数,对于任意允许平均失真度D>=0,和任意小的a>0,以及任意足够长的码长N,则一定存在一种信源编码W,其码字个数为M<=EXP{N[R(D)+a]},而编码后码的平均失真度D'(W)<=D+a。
D'(W)即为平均失真度的香农极限。
总而言之,香农极限是在香农三大定理的极值,也就是其极限情况。
2001年2月24日,当代最伟大的数学家和贝尔实验室最杰出的科学家之一,84岁的香农(Claude Elwood Shannon)博士不幸去世。
香农1916年生于美国,1940年获得麻省理工学院数学博士学位和电子工程硕士学位。
1941年他加入了贝尔实验室数学部,在此工作了15年。
1948年6月和10月,由贝尔实验室出版的《贝尔系统技术》杂志连载了香农博士的文章《通讯的数学原理》,该文奠定了香农信息基本理论的基础。
实验二 Shannon编码

实验二Shannon编码一、实验目的及要求a)实验目的1.通过本实验实现信源编码——Shannon编码2.编写M文件实现,掌握Shannon编码方法b)实验要求1.了解Matlab中M文件的编辑、调试过程2.编写程序实现Shannon编码算法二、实验步骤及运行结果记录a)实验步骤1.输入Shannon编码程序2.运行程序,按照提示输入相应信息,并记录输入信息,及运行结果。
3.思考:在程序中加入排序子程序,使其在输入信源概率时,不要求输入顺序。
b)实验结果y =0.2000 0 2.3219 3.00000.1900 0.2000 2.3959 3.00000.1800 0.3900 2.4739 3.00000.1700 0.5700 2.5564 3.00000.1500 0.7400 2.7370 3.00000.1000 0.8900 3.3219 4.00000.0100 0.9900 6.6439 7.0000code =000;code = 001;code = 011;code =100;code = 101;code =1110;code =1111110三、实验流程图(附一)四、程序清单,并注释每条语句(附二)五、实验小结香农编码是码符号概率大的用短码表示,概率小的是用长码表示,程序中对概率排序,最后求得的码字就依次与排序后的符号概率对应。
此程序缺点是,第一个码字都是以0开始,因为对累加概率求二进制后,小数点后的数都是0,取几位由码长确定,而香农编码是不唯一的,如果手动编码就不存在这样的问题。
后面求得的编码没有下标就需要注意是与上面排序后的信源符号对应。
附一附二N=input('请输入信源符号个数:')%输入信源符号个数p=zeros(1,N);%生成1*4的零矩阵for i=1:Np(1,i)=input('请输入各信源符号出现的概率:')%输入各个信源符号的概率endp=fliplr(sort(p));%将概率从大到小进行排序if abs(sum(p)-1)>10e-10error('输入概率不符合概率分布')%检验所输入的概率是否正确endy=zeros(N,4);%生成N*4零矩阵for i=1:Ny(i,1)=p(1,i);%将各个符号出现的概率放入y矩阵的第一列中y(1,2)=0;if i>1y(i,2)=y(i-1,2)+y(i-1,1); %第二列其余的元素用此式求得,即为累加概率endy(i,3)=log2(1./p(i))%求各个信源符号的信息熵放入y矩阵的第三列中y(i,4)=ceil(y(i,3))%求码长endA=y(:,2);%取出y中的第二列元素B=y(:,4);%取出y中的第四列元素for i=1:Ncode=shannoncode(A(i),B(i))%生成码字endfunction [C]=shannoncode(A,B)%对累加概率求二进制的函数C=zeros(1,B);%生成零矩阵用于存储生成的二进制数,对二进制的每一位进行操作temp=A;%temp赋初值for i=1:B%累加概率转化为二进制,循环求二进制的每一位,A控制生成二进制的位数 temp=temp*2;if temp>1temp=temp-1;C(1,i)=1;elseC(1,i)=0;endendend。
信息论与编码(第二版)曹雪虹(最全版本)答案
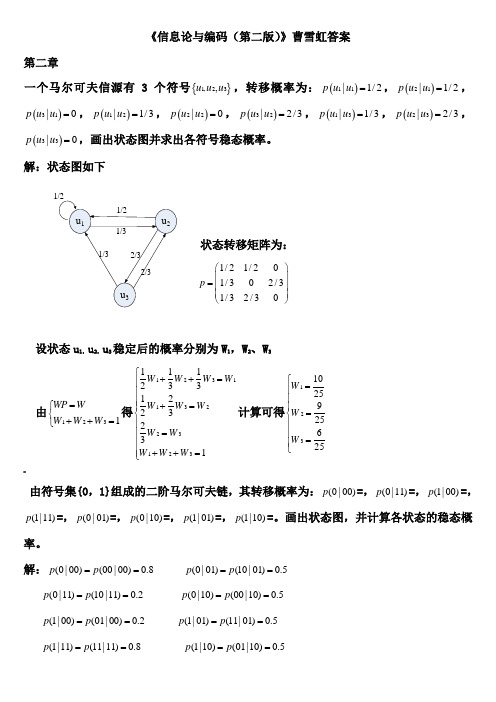
《信息论与编码(第二版)》曹雪虹答案第二章一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下状态转移矩阵为:1/21/201/302/31/32/30p ⎛⎫ ⎪= ⎪ ⎪⎝⎭设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ -由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =,(0|11)p =,(1|00)p =,(1|11)p =,(0|01)p =,(0|10)p =,(1|01)p =,(1|10)p =。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==(0|11)(10|11)0.2p p == (0|10)(00|10)0.5p p == (1|00)(01|00)0.2p p == (1|01)(11|01)0.5p p == (1|11)(11|11)0.8p p == (1|10)(01|10)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求:》(1) “3和5同时出现”这事件的自信息;(2) “两个1同时出现”这事件的自信息;(3) 两个点数的各种组合(无序)对的熵和平均信息量; (4) 两个点数之和(即2, 3, … , 12构成的子集)的熵; (5) 两个点数中至少有一个是1的自信息量。
信息论与编码-曹雪虹-课后习题答案

《信息论与编码》-曹雪虹-课后习题答案 第二章2.1一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p uu =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下 状态转移矩阵为:设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ 2.2 由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =0.8,(0|11)p =0.2,(1|00)p =0.2,(1|11)p =0.8,(0|01)p =0.5,(0|10)p =0.5,(1|01)p =0.5,(1|10)p =0.5。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩2.3 同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求:(1) “3和5同时出现”这事件的自信息; (2) “两个1同时出现”这事件的自信息; (3) 两个点数的各种组合(无序)对的熵和平均信息量;(4) 两个点数之和(即2, 3, … , 12构成的子集)的熵;(5) 两个点数中至少有一个是1的自信息量。
信息论与编码(第二版)曹雪虹(版本)答案
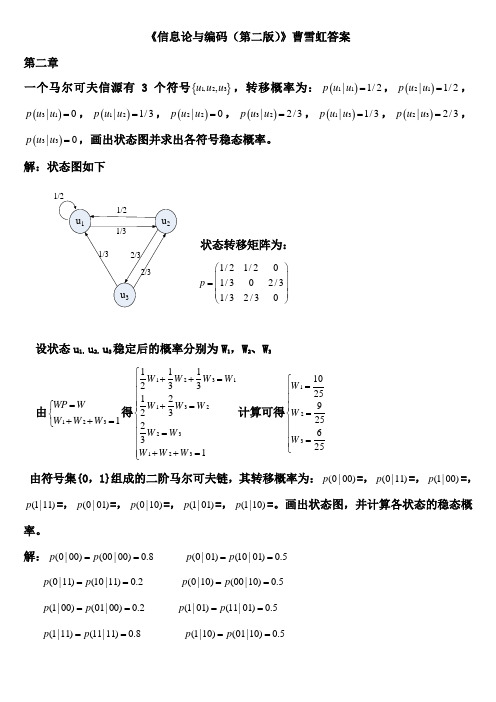
《信息论与编码(第二版)》曹雪虹答案第二章一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下状态转移矩阵为:1/21/201/302/31/32/30p ⎛⎫ ⎪= ⎪ ⎪⎝⎭设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ 由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =,(0|11)p =,(1|00)p =,(1|11)p =,(0|01)p =,(0|10)p =,(1|01)p =,(1|10)p =。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==(0|11)(10|11)0.2p p == (0|10)(00|10)0.5p p == (1|00)(01|00)0.2p p == (1|01)(11|01)0.5p p == (1|11)(11|11)0.8p p == (1|10)(01|10)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求: (1) “3和5同时出现”这事件的自信息; (2) “两个1同时出现”这事件的自信息;(3) 两个点数的各种组合(无序)对的熵和平均信息量; (4) 两个点数之和(即2, 3, … , 12构成的子集)的熵; (5) 两个点数中至少有一个是1的自信息量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Pi p( xk )
k 1
4.将累加概率 Pi 变成二进制数; 5.取 Pi 二进制数的小数点后 Ki 位即为该消息符号的二进制码字。 五、实验步骤 1.根据实验原理,设计香农编码程序; 2.输入一组信源消息符号概率,可以求香农编码、平均码长和编码效 率。 六、实验注意事项 1.香农编码是码符号概率大的用短码表示,概率小的是用长码表示, 程序中需要对概率进行排序,对此我们调用 MATLAB 的库函数; 2.最后需要注意的是,求得的码字依次与排序后的符号概率对应; 3.向无穷方向取最小正整数位 ceil 函数。 七、实验结果 香农编码程序:
第 页
陕西科技大学实验报告
八、思考题 举例说明香农编码在现实中有实际作用,列举一个例子,并简要说 明? 可以抓住语言结构的冗余性以及语言中字母、 词的使用频度等统 计特性。 使用香农信息论信息量等观点, 来研究中文与英文的信息量, 从而比较科技大学实验报告
1.将信源消息符号按其出现的概率大小依次排列: P ( X 1 ) P ( X 2 ) ,, P ( X n ) 2.确定满足下列不等式整数码长 Ki ; log2p(x i ) K i log 2 p(x i ) 1 3.为了编成唯一可译码,计算第 i 个消息的累加概率;
close all; clc; n=input('输入信源符号个数:'); p=zeros(1,n); for i=1:n p(1,i)=input(' 输 入 信 源 符 号 概 率:'); end if sum(p)<1||sum(p)>1 error('输入概率不符合概率分布') end y=fliplr(sort(p));
第 页
陕西科技大学实验报告
D=zeros(n,4); D(:,1)=y'; for i=2:n D(1,2)=0; D(i,2)=D(i-1,1)+D(i-1,2); end for i=1:n D(i,3)=-log2(D(i,1)); D(i,4)=ceil(D(i,3)); end D A=D(:,2)'; B=D(:,4)'; Code_length=0; for j=1:n Code_length=Code_length+p(j)*D(j, 4); end H=0; for j=1:n H=H+p(j)*log2(1/p(j)); end for j=1:n fprintf('输入信源符号概率为%f 的 码字为:',p(1,j)); C=deczbin(A(j),B(j)); disp(C) end Efficiency=H/(Code_length) fprintf('平均码长:\n'); disp(Code_length) fprintf('\n 香农编码效率:\n'); disp(Efficiency) A:累加概率;B:码子长度。 function [C]=deczbin(A,B) C=zeros(1,B); temp=A; for i=1:B temp=temp*2; if temp>1 temp=temp-1; C(1,i)=1; else C(1,i)=0; end end
陕西科技大学实验报告
班级 实验日期 学号 室温 姓名 报告日期 实验组别 成绩
报告内容:(目的和要求、原理、步骤、数据、计算、小结等) 实验名称:实验二 香农编码 一、实验目的 1.了解香农编码的基本原理及其特点; 2.熟悉掌握香农编码的方法和步骤; 3.掌握 MATLAB 编写香农编码的程序。 二、实验内容 1.根据香农编码的方法和步骤,用香农编码编写程序; 2.用编写的源程序验证书中例题的正确性。 三、实验仪器、设备 1.计算机-系统最低配置 256M 内存、P4 CPU; 2. MATLAB 编程软件。 四、实验原理 1.香农编码原理: 香农第一定理指出了平均码长与信源之间的关系, 同时也指出了可以 通过编码使平均码长达到极限值,这是一个很重要的极限定理。香农 第一定理指出,选择每个码字的长度 Ki 满足下式: I ( X i ) K I ( X i ) 1, i 就可以得到这种码,这种编码方法就是香农编码。 2.香农编码算法: