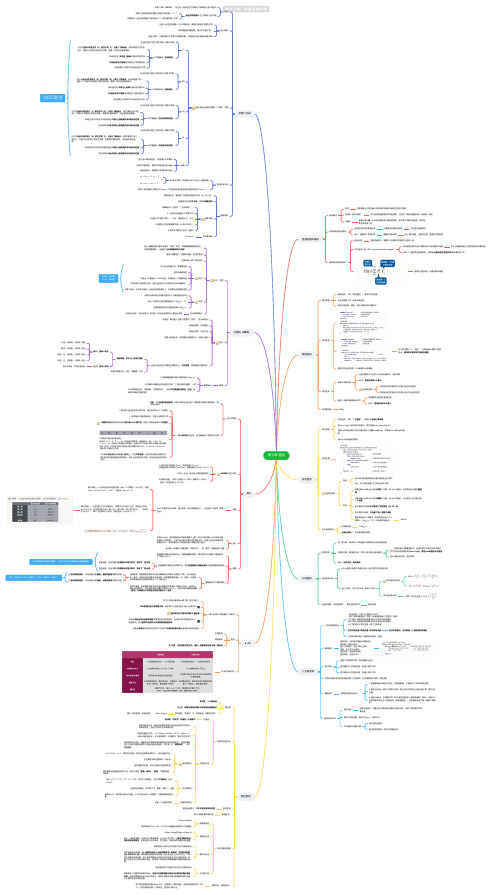
【思维导图】数据结构与算法-递归,排序
《数据结构与算法 》课件

数据结构在人工智能中的优化可以提升算法的效率和准确性,例如通过使用哈希表实现快速特征匹配,提高图像识别速度。
THANK YOU
定义与分类
添加边、删除边、查找路径等。
基本操作
图中的边可以是有方向的,也可以是无方向的。节点之间可以有多种关系,如邻接、相连等。
特性
社交网络、交通网络、路由协议等。
应用场景
05
排序与查找算法
冒泡排序:通过重复地遍历待排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
详细描述
链表的优势在于可以动态调整大小,插入和删除操作仅需修改指针,时间复杂度为O(1)。但链表访问特定元素需要从头部遍历,效率较低。
VS
栈和队列是特殊的线性数据结构,它们遵循特定的操作规则。栈遵循后进先出(LIFO)原则,队列遵循先进先出(FIFO)原则。
详细描述
栈用于保存按照后进先出顺序访问的数据元素,常见的操作有压栈、弹栈和查看栈顶元素。队列用于保存按照先进先出顺序访问的数据元素,常见的操作有入队、出队和查看队首元素。
03
线性数据结构
数组是线性数据结构中的基本形式,它以连续的内存空间为基础,用于存储固定长度的同类型元素。
数组具有固定的长度,可以通过索引直接访问任意元素。它适合于需要快速访问数据的场景,但插入和删除操作需要移动大量元素,效率较低。
详细描述
总结词
总结词
链表是一种线性数据结构,它通过指针链接各个节点,节点包含数据和指向下一个节点的指针。
数据结构--排序算法总结

数据结构--排序算法总结概述排序的分类:内部排序和外部排序内部排序:数据记录在内存中进行排序外部排序:因排序的数据量大,需要内存和外存结合使用进行排序这里总结的八大排序是属于内部排序:当n比较大的时候,应采用时间复杂度为(nlog2n)的排序算法:快速排序、堆排序或归并排序。
其中,快速排序是目前基于比较的内部排序中被认为最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短。
———————————————————————————————————————————————————————————————————————插入排序——直接插入排序(Straight Insertion Sort)基本思想:将一个记录插入到已排序好的有序表中,从而得到一个新的,记录数增1的有序表。
即:先将序列的第1个记录看成一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
要点:设立哨兵,用于临时存储和判断数组边界直接插入排序示例:插入排序是稳定的,因为如果一个带插入的元素和已插入元素相等,那么待插入元素将放在相等元素的后边,所以,相等元素的前后顺序没有改变。
算法实现:[cpp]view plain copy1.#include<iostream>ing namespace std;3.4.void print(int a[], int n ,int i)5.{6. cout<<i<<":";7.for(int j= 0; j<8; j++){8. cout<<a[j] <<" ";9. }10. cout<<endl;11.}12.13.void InsertSort(int a[],int n)14.{15.int i,j,tmp;16.for(i=1;i<n;++i)17. {18.// 如果第i个元素大于第i-1个元素,直接插入19.// 否则20.// 小于的话,移动有序表后插入21.if(a[i]<a[i-1])22. {23. j=i-1;24. tmp=a[i]; // 复制哨兵,即存储待排序元素25. a[i]=a[i-1]; // 先后移一个元素26.while(tmp<a[j])27. {28.// 哨兵元素比插入点元素小,后移一个元素29. a[j+1]=a[j];30. --j;31. }32. a[j+1]=tmp; // 插入到正确的位置33. }34. print(a,n,i); // 打印每一趟排序的结果35. }36.}37.38.int main()39.{40.int a[8]={3,1,5,7,3,4,8,2};41. print(a,8,0); // 打印原始序列42. InsertSort(a,8);43.return 0;44.}分析:时间复杂度:O(n^2)———————————————————————————————————————————————————————————————————————插入排序——希尔排序(Shell Sort)基本思想:先将整个待排序的记录序列分割成为若干子序列,分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录依次进行直接插入排序。
初中数学七年级上册思维导图

初中数学七年级上册思维导图一、数与代数1. 实数有理数整数正整数、负整数、0分数正分数、负分数无理数不能表示为两个整数比的数无理数的近似值2. 代数式代数式的概念代数式的化简代数式的求值3. 方程与不等式一元一次方程方程的解法方程的应用一元一次不等式不等式的解法不等式的应用二、几何1. 平面几何点、线、面角锐角、直角、钝角角的度量多边形三角形等腰三角形、等边三角形、直角三角形四边形矩形、正方形、平行四边形、梯形圆圆的性质圆的周长、面积2. 空间几何立体图形长方体、正方体、圆柱、圆锥、球立体图形的表面积、体积三、统计与概率1. 统计数据的收集与整理数据的表示表格、条形图、折线图、扇形图数据的分析平均数、中位数、众数2. 概率概率的概念概率的计算概率的应用四、数学思维方法1. 分类讨论法2. 类比法3. 归纳法4. 反证法五、数学应用与建模1. 数学在实际生活中的应用金融领域利息计算、复利计算工程领域测量、绘图、计算科学研究数据分析、实验设计2. 数学建模建模的基本步骤提出问题、建立模型、求解模型、验证模型常见的数学模型线性模型、非线性模型、概率模型六、数学思维导图的制作与应用1. 思维导图的制作方法确定中心主题画出分支填充内容修饰美化2. 思维导图的应用场景学习规划项目管理决策分析七、数学与科技的发展1. 数学在科技领域的重要性计算机科学算法设计、数据结构机器学习、深度学习物理学量子力学、相对论2. 数学与其他学科的交叉融合数学与生物学遗传算法、神经网络数学与经济学博弈论、优化理论八、数学教育的创新与改革1. 数学教育的现状与问题教学方法单一学生兴趣不高创新能力培养不足2. 数学教育的创新策略案例教学法项目式学习翻转课堂在线教育3. 数学教育的改革方向注重学生个性化发展培养学生的数学思维提高学生的数学应用能力初中数学七年级上册思维导图一、数的认识1. 整数自然数:0, 1, 2, 3,正整数:1, 2, 3,负整数:1, 2, 3,整数:自然数和负整数的统称2. 分数真分数:分子小于分母的分数假分数:分子大于或等于分母的分数分数的基本性质:分子分母同时乘以或除以同一个非零整数,分数的值不变3. 小数小数的表示方法:整数部分和小数部分小数的性质:小数点向右移动一位,相当于乘以10;小数点向左移动一位,相当于除以10二、数的运算1. 整数的运算加法:将两个整数相加减法:将一个整数从另一个整数中减去乘法:将两个整数相乘除法:将一个整数除以另一个非零整数2. 分数的运算加法:将两个分数的分子相加,分母保持不变减法:将一个分数的分子从另一个分数的分子中减去,分母保持不变乘法:将两个分数的分子相乘,分母相乘除法:将一个分数的分子乘以另一个分数的分母,分母乘以另一个分数的分子3. 小数的运算加法:将两个小数的小数部分相加,整数部分相加减法:将一个小数的小数部分从另一个小数的小数部分中减去,整数部分相减乘法:将两个小数相乘除法:将一个小数除以另一个非零小数三、方程与不等式1. 方程一元一次方程:ax + b = 0(a, b为常数,x为未知数)方程的解:使方程成立的未知数的值2. 不等式一元一次不等式:ax + b > 0 或 ax + b < 0(a, b为常数,x 为未知数)不等式的解集:满足不等式的未知数的值的集合四、函数与图形1. 函数定义:函数是一种特殊的关系,每个输入值对应唯一的输出值表示方法:函数关系可以用函数表达式、函数图像、函数表格等方式表示2. 图形直线:一次函数的图像抛物线:二次函数的图像双曲线:反比例函数的图像五、统计与概率1. 统计数据的收集与整理:收集数据、整理数据、制作统计图表数据的分析与解释:分析数据、得出结论、解释结论2. 概率概率的定义:某个事件发生的可能性概率的计算:根据事件发生的次数和总次数计算概率初中数学七年级上册思维导图六、几何图形的认识1. 点、线、面点:没有长度、宽度和高度的几何元素线:只有长度没有宽度和高度的几何元素面:具有长度和宽度的几何元素2. 平面图形三角形:由三条线段组成的闭合图形四边形:由四条线段组成的闭合图形圆:由一个点到平面上所有点的距离相等的点的集合3. 空间图形立方体:由六个正方形面组成的立体图形圆柱:由两个平行圆面和一个侧面组成的立体图形圆锥:由一个圆面和一个侧面组成的立体图形七、几何图形的性质1. 三角形的性质内角和定理:三角形的内角和等于180度等腰三角形的性质:底角相等,底边上的高、中线、角平分线互相重合直角三角形的性质:直角边上的高、中线、角平分线互相重合2. 四边形的性质平行四边形的性质:对边平行且相等,对角相等,对角线互相平分矩形的性质:四个角都是直角,对边平行且相等,对角线互相平分且相等菱形的性质:四个角都是直角,对边平行且相等,对角线互相垂直平分3. 圆的性质圆的周长公式:C = 2πr(r为圆的半径)圆的面积公式:A = πr²圆的性质:圆心到圆上任意一点的距离都相等八、几何图形的计算1. 三角形的计算三角形的周长:三条边的长度之和三角形的面积:底乘以高除以22. 四边形的计算四边形的周长:四条边的长度之和四边形的面积:根据不同类型的四边形使用相应的公式计算3. 圆的计算圆的周长:2πr圆的面积:πr²九、综合应用1. 实际问题运用所学的数学知识解决实际问题,如计算面积、周长、体积等培养学生的应用意识和解决问题的能力2. 数学建模将实际问题抽象成数学模型,运用数学知识解决问题培养学生的建模能力和创新能力3. 数学探究通过探究活动,让学生发现数学规律,提高学生的探究能力和思维能力初中数学七年级上册思维导图十、数学思维与方法1. 逻辑推理通过观察、分析、归纳等方法,培养学生的逻辑思维能力帮助学生理解数学概念、性质、定理之间的关系2. 数学建模将实际问题抽象成数学模型,运用数学知识解决问题培养学生的建模能力和创新能力3. 数学探究通过探究活动,让学生发现数学规律,提高学生的探究能力和思维能力十一、数学素养与能力1. 数感培养学生对数的敏感性,能够快速、准确地理解和处理数学信息2. 空间观念培养学生对几何图形的认识和空间想象能力,提高学生的空间思维能力3. 解决问题的能力培养学生运用数学知识解决实际问题的能力,提高学生的应用意识和实践能力4. 创新能力培养学生的创新思维,鼓励学生尝试不同的解题方法和思路5. 合作与交流能力培养学生与他人合作交流的能力,提高学生的团队协作能力和沟通能力初中数学七年级上册思维导图一、数与代数1. 实数有理数整数正整数、负整数、0分数正分数、负分数无理数不能表示为两个整数比的数无理数的近似值2. 代数式代数式的概念代数式的化简代数式的求值3. 方程与不等式一元一次方程方程的解法方程的应用一元一次不等式不等式的解法不等式的应用二、几何1. 平面几何点、线、面角锐角、直角、钝角角的度量多边形三角形等腰三角形、等边三角形、直角三角形四边形矩形、正方形、平行四边形、梯形多边形的内角和定理2. 空间几何立体图形正方体、长方体、圆柱、圆锥、球立体图形的表面积与体积三、统计与概率1. 数据的收集与整理数据的收集方法数据的整理方法2. 数据的描述平均数、中位数、众数极差、方差、标准差3. 概率概率的基本概念概率的计算方法概率的应用四、数学思维方法1. 归纳法从具体到一般从特殊到一般2. 类比法通过相似性进行推理3. 反证法假设结论不成立,推出矛盾,从而证明结论成立4. 构造法通过构造实例来解决问题五、数学建模1. 建模的基本步骤确定问题建立模型求解模型验证模型2. 常见的数学模型线性模型二次模型指数模型3. 数学建模的应用在实际生活中的应用在科学研究中的应用初中数学七年级上册思维导图六、数学实验与探究1. 实验的设计与实施确定实验目的设计实验方案实施实验并记录数据分析实验结果2. 探究的方法与技巧观察法实验法归纳法类比法3. 数学实验与探究的应用解决实际问题深化数学理解培养创新思维七、数学文化1. 数学发展史古代数学近现代数学2. 数学家的故事中国数学家外国数学家3. 数学与生活的关系数学在科技发展中的作用数学在日常生活中的应用八、数学学习方法1. 课堂学习专心听讲积极思考勇于提问2. 自主学习制定学习计划完成课后作业复习巩固3. 合作学习与同学交流讨论分享学习资源相互帮助、共同进步九、数学素养的培养1. 数学思维逻辑思维抽象思维空间思维2. 数学能力计算能力推理能力解决问题的能力3. 数学品质耐心细心持之以恒初中数学七年级上册思维导图十、数学竞赛与拓展1. 数学竞赛简介数学竞赛的类型数学竞赛的级别数学竞赛的报名时间及方式2. 数学竞赛的备考策略基础知识的巩固解题技巧的提升模拟试题的训练3. 数学竞赛的意义激发学习兴趣培养竞争意识提高数学能力十一、数学与科技1. 数学在科技领域的作用计算机科学数据分析2. 数学在工程技术中的应用建筑设计机械制造通信技术3. 数学在生活中的创新数学与艺术数学与体育数学与游戏十二、数学教育改革与发展1. 新课程标准的实施课程目标的调整教学内容的更新教学方法的改革2. 数学教育技术的发展信息技术与数学教育的融合在线教育平台的建设虚拟现实技术在数学教学中的应用3. 数学教育的国际交流与合作国际数学竞赛的参与数学教育研究的合作数学教师培训的国际交流初中数学七年级上册思维导图一、数与代数1. 整数加减法加法:将两个数合并成一个数的运算。
王道数据结构 第七章 查找思维导图-高清脑图模板
每次调整的对象都是“最小不平衡子树”
插入操作
在插入操作,只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡
在A的左孩子的左子树中插入导致不平衡
由于在结点A的左孩子(L)的左子树(L)上插入了新结点,A的平衡因子由1增
至2,导致以A为根的子树失去平衡,需要一次向右的旋转操作。
LL
将A的左孩子B向右上旋转代替A成为根节点 将A结点向右下旋转成为B的右子树的根结点
RR平衡旋转(左单旋转)
而B的原左子树则作为A结点的右子树
在A的左孩子的右子树中插入导致不平衡
由于在结点A的左孩子(L)的右子树(R)上插入了新结点,A的平衡因子由1增
LR
至2,导致以A为根的子树失去平衡,需要两次旋转操作,先左旋转再右旋转。
将A的左孩子B的右子树的根结点C向左上旋转提升至B结点的位置
本质:永远保证 子树0<关键字1<子树1<关键字2<子树2<...
当左兄弟很宽裕时,用当前结点的前驱、前驱的前驱来填补空缺 当右兄弟很宽裕时,用当前结点的后继、后继的后继来填补空缺
兄弟够借。若被删除关键字所在结点删除前的关键字个数低于下限,且与此结点 右(或左)兄弟结点的关键字还很宽裕,则需要调整该结点、右(或左)兄弟结 点及其双亲结点及其双亲结点(父子换位法)
LL平衡旋转(右单旋转)
而B的原右子树则作为A结点的左子树
在A的右孩子的右子树中插入导致不平衡
由于在结点A的右孩子(R)的右子树(R)上插入了新结点,A的平衡因子由-1
减至-2,导致以A为根的子树失去平衡,需要一次向左的旋转操作。
RR
将A的右孩子B向左上旋转代替A成为根节点 将A结点向左下旋转成为B的左子树的根结点
数据结构常考的5个算法

数据结构常考的5个算法1. 递归算法递归是一种将问题分解为相同或相似的子问题解决的方法。
在递归算法中,一个函数可以调用自己来解决更小规模的问题,直到遇到基本情况,然后递归返回并解决整个问题。
递归算法通常用于解决需要重复执行相同操作的问题,例如计算斐波那契数列、计算阶乘、树和图的遍历等。
递归算法的主要特点是简洁、易理解,但在大规模问题上可能效率较低。
以下是一个使用递归算法计算斐波那契数列的示例代码:def fibonacci(n):if n <= 1:return nelse:return fibonacci(n-1) + fibonacci(n-2)2. 排序算法排序算法用于将一组数据按照一定顺序进行排列。
常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序等。
•冒泡排序逐渐交换相邻的元素,将较大的元素逐渐“冒泡”到最后的位置。
•选择排序每次选择最小(或最大)的元素,并将其放置在已排序部分的末尾。
•插入排序通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
•快速排序通过选择一个基准元素,将数组分割为左右两部分,对左右两部分分别递归地进行快速排序。
•归并排序将数组分成两个子数组,分别对两个子数组进行排序,然后将两个有序子数组合并为一个有序数组。
以下是一个使用快速排序算法对数组进行排序的示例代码:def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr)//2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)3. 查找算法查找算法用于在数据集合中查找特定元素的位置或存在性。
数据结构--排序算法介绍

数据结构--排序算法总结概述排序的分类:内部排序和外部排序内部排序:数据记录在内存中进行排序外部排序:因排序的数据量大,需要内存和外存结合使用进行排序这里总结的八大排序是属于内部排序:当n比较大的时候,应采用时间复杂度为(nlog2n)的排序算法:快速排序、堆排序或归并排序。
其中,快速排序是目前基于比较的内部排序中被认为最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短。
———————————————————————————————————————————————————————————————————————插入排序——直接插入排序(Straight Insertion Sort)基本思想:将一个记录插入到已排序好的有序表中,从而得到一个新的,记录数增1的有序表。
即:先将序列的第1个记录看成一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
要点:设立哨兵,用于临时存储和判断数组边界直接插入排序示例:插入排序是稳定的,因为如果一个带插入的元素和已插入元素相等,那么待插入元素将放在相等元素的后边,所以,相等元素的前后顺序没有改变。
算法实现:[cpp]view plain copy1.#include<iostream>ing namespace std;3.4.void print(int a[], int n ,int i)5.{6. cout<<i<<":";7.for(int j= 0; j<8; j++){8. cout<<a[j] <<" ";9. }10. cout<<endl;11.}12.13.void InsertSort(int a[],int n)14.{15.int i,j,tmp;16.for(i=1;i<n;++i)17. {18.// 如果第i个元素大于第i-1个元素,直接插入19.// 否则20.// 小于的话,移动有序表后插入21.if(a[i]<a[i-1])22. {23. j=i-1;24. tmp=a[i]; // 复制哨兵,即存储待排序元素25. a[i]=a[i-1]; // 先后移一个元素26.while(tmp<a[j])27. {28.// 哨兵元素比插入点元素小,后移一个元素29. a[j+1]=a[j];30. --j;31. }32. a[j+1]=tmp; // 插入到正确的位置33. }34. print(a,n,i); // 打印每一趟排序的结果35. }36.}37.38.int main()39.{40.int a[8]={3,1,5,7,3,4,8,2};41. print(a,8,0); // 打印原始序列42. InsertSort(a,8);43.return 0;44.}分析:时间复杂度:O(n^2)———————————————————————————————————————————————————————————————————————插入排序——希尔排序(Shell Sort)基本思想:先将整个待排序的记录序列分割成为若干子序列,分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录依次进行直接插入排序。
《大话数据结构》第二章:算法(思维导图)

2. 算法定义算法是解决特点问题求解步骤的描述, 在计算机中表现为指令的有限序列, 并且每条指令表示一个或多个操作。
没有通用的算法, 就像没有万能药一样。
特定的问题,有特定的对应的算法。
特性输入算法具有0个或多个输入。
输出算法至少有1个或多个输出。
有穷性指算法在执行有限的步骤之后, 自动结束而不会出现无限循环, 并且每个步骤在可接受的时间内完成。
确定性算法的每一步骤都具有确定的含义, 不会出现二义性。
可能性算法的每一步都必须是可行的, 也就是说每一步都能够通过执行有限次数完成。
设计算法的要求正确性指算法至少应该具有输入、输出和加工处理无歧义性、能正确反应问题的需求、能够得到问题的正确答案。
可读性算法设计的另一目的是为了便于阅读、理解和交流。
健壮性当输入数据不合法时, 算法也能做出相关处理, 而不是产生异常或莫名其妙的结果。
时间效率高和存储量低算法最好用最少的存储空间,花费最少的实际,办成同样的事。
算法的度量方法事后统计方法通过设计好的测试程序和数据, 利用计算机计时器多不同算法编制的程序的运行时间进行比较, 从而确定算法效率的高低。
具有很大缺陷:编号程序后才能发现程序的运行时间, 若算法很糟糕,不就是竹篮打水一场空。
不同计算机硬件和软件各有不同会造成结果的不同。
(操作系统、编译器、运行框架、处理器的不同)很难设计算法的测试数据, 小的测试数据往往无法测试出算法的真正的效率。
事前分析估算方法在计算机程序编制前, 一句统计方法对算法进行估算。
对于运行时间的影响因素:算法采用的策略、方法编译产生的代码指令问题的输入规模(指输入量的多少)机器执行指令的速度时间复杂度如何推导大O阶?1. 用常数1取代运行时间中所有加法常数(忽略加法常数)2. 在修改后的运行次数函数中, 只保留最高阶项。
3. 如果最高阶项存在且不是1, 则去除与这个项相乘的常数。
得到的结果就是大O阶。
常数阶O(1)线性阶O(n)对数阶O(logn)平方阶O(n^2)用的时间复杂度所耗费的时间从小到大依次是:。
数据结构之排序算法详解(含代码)

C/C++版数据结构之排序算法今天讨论下数据结构中的排序算法。
排序算法的相关知识:(1)排序的概念:所谓排序就是要整理文件中的记录,使之按关键字递增(或者递减)次序罗列起来。
(2)稳定的排序方法:在待排序的文件中,若存在多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,该排序方法是稳定的。
相反,如果发生改变,这种排序方法不稳定。
(3)排序算法的分类(分为5类):插入排序、选择排序、交换排序、归并排序和分配排序。
(4)排序算法两个基本操作:<1>比较关键字的大小。
<2>改变指向记录的指针或者挪移记录本身。
具体的排序方法:插入排序<1>插入排序(Insertion Sort)的思想:每次将一个待排序的记录按其关键字大小插入到前面已经排好序的子记录中的适当位置,直到全部记录插入完成为止。
<2>常用的插入排序方法有直接插入排序和希尔排序。
(1)直接插入排序<1>算法思路:把一个记录集(如一个数组)分成两部份,前半部份是有序区,后半部份是无序区;有序区一开始有一个元素r[0],无序区一开始是从r[1]到之后的所有元素;然后每次从无序区按顺序取一个元素r[i],拿到有序区中由后往前进行比较,每次比较时,有序区中比r[i]大的元素就往后挪移一位,直到找到小于r[i]的元素,这时r[i]插到小元素的后面,则完成一趟直接插入排序。
如此反复,从无序区不断取元素插入到有序区,直到无序区为空,则插入算法结束。
<2>算法演示://直接插入排序:#include<iostream>using namespace std;void InsertSort(int r[],int n);int main(){int r[]={24,1,56,2,14,58,15,89};InsertSort(r,8);for(int i=0;i<8;i++){cout<<r[i]<<' ';}cout<<endl;return0;}void InsertSort(int r[],int n){for(int i=1;i<n;i++){for(int j=i-1,s=r[i];s<r[j] && j>=0;j--){r[j+1]=r[j];}r[j+1]=s;}}复制代码(2)折半插入排序<1>算法思路:我们看到在直接插入排序算法中,需要在有序区查找比r[i]的小的元素,然后插入到这个元素后面,但这里要注意这个元素是从无序区算第一个比r[i]小的元素。
程序设计数据结构与递归算法知识点总结

程序设计数据结构与递归算法知识点总结在程序设计的广阔领域中,数据结构和递归算法是两个至关重要的概念。
它们不仅是构建高效、可靠程序的基石,也是解决各种复杂问题的有力工具。
接下来,让我们一同深入探索这两个重要的知识点。
一、数据结构数据结构是指数据的组织、存储和管理方式。
不同的数据结构适用于不同的场景,选择合适的数据结构可以极大地提高程序的性能和效率。
1、数组数组是一种线性的数据结构,它将相同类型的元素存储在连续的内存空间中。
通过索引可以快速访问数组中的元素,但插入和删除操作可能会比较耗时,因为需要移动大量的元素。
例如,如果要存储一个班级学生的成绩,使用数组是一个不错的选择。
2、链表链表则是由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
链表的插入和删除操作比较方便,只需修改指针即可,但访问特定位置的元素需要从头开始遍历。
当需要频繁进行元素的添加和删除操作时,链表比数组更具优势。
3、栈栈是一种特殊的线性表,遵循“后进先出”的原则。
就像一个叠起来的盘子,最后放上去的盘子最先被拿走。
在函数调用、表达式求值等场景中,栈有着广泛的应用。
4、队列队列遵循“先进先出”的原则,就像排队买票一样,先排队的人先买到票。
常用于需要按照顺序处理元素的场景,如消息队列、任务队列等。
5、树树是一种非线性的数据结构,常见的有二叉树、二叉搜索树、AVL 树等。
二叉搜索树在查找、插入和删除操作上具有较好的平均性能。
6、图图用于表示对象之间的关系,可以分为有向图和无向图。
在路径规划、社交网络分析等领域有着重要的应用。
二、递归算法递归是指一个函数在其函数体中直接或间接调用自身的一种方法。
递归算法的核心是将一个大问题分解为相同性质的小问题,通过解决小问题来逐步解决大问题。
例如,计算阶乘的递归函数可以这样写:```pythondef factorial(n):if n == 0 or n == 1:return 1else:return n factorial(n 1)```在这个例子中,`factorial`函数不断调用自身,将计算`n`的阶乘转化为计算`n 1`的阶乘,直到`n`为 0 或 1 时返回 1。
北京林业大学《数据结构与算法》课件PPT 第8章 排序

Typedef struct {
//定义每个记录(数据元素)的结构
KeyType key ;
//关键字
InfoType otherinfo; //其它数据项
}RedType ;
Typedef struct {
//定义顺序表的结构
RedType r [ MAXSIZE +1 ]; //存储顺序表的向量
北京林业大学信息学院
(21,25,49,25*,16,08)
*表示后一个25 将序列存入顺序表L中,将L.r[0]作为哨兵
初态:
完成!
210暂存568*
021816
21516
2425591*
2459*
214569*
49 08
0 123456
i=2 i=3 i=4 i=5 i=6
北京林业大学信息学院
插入排序的基本思想:
有序序列R[1..i-1]
无序序列 R[i..n]
R[i]
有序序列R[1..i] 无序序列 R[i+1..n]
北京林业大学信息学院
插入排序的基本步骤:
1.在R[1..i-1]中查找R[i]的插入位置, R[1..j].key R[i].key< R[j+1..i-1].key; 2.将R[ j+1..i-1]中的所有记录均后移一个位置; 3.将R[i] 插入到R[j+1]的位置上。
//r[0]一般作哨兵或缓冲区
int length ; //顺序表的长度
}SqList ;
北京林业大学信息学院
排序算法分类
规则不同
插入排序 交换排序 选择排序 归并排序
时间复杂度不同
简单排序O(n2) 先进排序O( nlog2n )
数据结构-排序PPT课件

O(nlogn),归并排序的平均时间复杂度为O(nlogn)。其中,n为待排序序列的长度。
06
基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
分配和收集
基数排序是一种稳定的排序算法,即相同的元素在排序后仍保持原有的顺序。
文件系统需要对文件和目录进行排序,以便用户可以更方便地浏览和管理文件。
数据挖掘和分析中需要对数据进行排序,以便发现数据中的模式和趋势。
计算机图形学中需要对图形数据进行排序,以便进行高效的渲染和操作。
数据库系统
文件系统
数据挖掘和分析
计算机图形学
02
插入排序
将待排序的元素按其排序码的大小,逐个插入到已经排好序的有序序列中,直到所有元素插入完毕。
简单选择排序
基本思想:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。 时间复杂度:堆排序的时间复杂度为O(nlogn),其中n为待排序元素的个数。 稳定性:堆排序是不稳定的排序算法。 优点:堆排序在最坏的情况下也能保证时间复杂度为O(nlogn),并且其空间复杂度为O(1),是一种效率较高的排序算法。
基数排序的实现过程
空间复杂度
基数排序的空间复杂度为O(n+k),其中n为待排序数组的长度,k为计数数组的长度。
时间复杂度
基数排序的时间复杂度为O(d(n+k)),其中d为最大位数,n为待排序数组的长度,k为计数数组的长度。
适用场景
当待排序数组的元素位数较少且范围较小时,基数排序具有较高的效率。然而,当元素位数较多或范围较大时,基数排序可能不是最优选择。
数据结构排序算法总结

数据结构排序算法总结数据结构是计算机科学中的核心概念之一,它是指一组数据元素和一组对这些数据元素操作的规则。
排序算法是数据结构中的一种常见操作,它的目的是重新排列一个数据结构中的元素,使其按照特定的顺序排列。
排序算法可以分为内部排序和外部排序两类,内部排序是指所有数据能够一次性加载到内存中进行排序,而外部排序则是指数据量太大,无法一次性加载到内存中进行排序,需要借助外部存储进行排序。
在接下来的内容中,我将对常见的排序算法进行总结,包括插入排序、选择排序、冒泡排序、归并排序、快速排序、堆排序和计数排序。
首先,插入排序是一种简单直观的排序算法,它的思想是将待排序的元素逐个插入到已经排序好的序列中。
插入排序的时间复杂度为O(n^2),空间复杂度为O(1)。
其次,选择排序是一种简单直观的排序算法,它的思想是每次选择待排序序列中的最小(或最大)元素,放到已排序序列的末尾。
选择排序的时间复杂度为O(n^2),空间复杂度为O(1)。
再次,冒泡排序是一种简单直观的排序算法,它的思想是重复地交换相邻的未排序元素,直到已排序序列的末尾。
冒泡排序的时间复杂度为O(n^2),空间复杂度为O(1)。
然后,归并排序是一种分治法的经典排序算法,它的思想是将待排序序列分成两个子序列,分别进行排序,然后将两个已排序子序列合并成一个有序序列。
归并排序的时间复杂度为O(nlogn),空间复杂度为O(n)。
接下来,快速排序是一种分治法的高效排序算法,它的思想是选取一个枢纽元素将待排序序列分成两个子序列,分别进行排序,然后将两个已排序子序列和枢轴元素合并成一个有序序列。
快速排序的时间复杂度为O(nlogn),空间复杂度为O(logn)。
此外,堆排序是一种利用堆数据结构进行排序的算法,它的思想是将待排序序列构建成一个最大堆或最小堆,然后每次将堆顶元素与末尾元素交换,并重新调整堆,直到整个序列有序。
堆排序的时间复杂度为O(nlogn),空间复杂度为O(1)。
王道数据结构 第六章 图思维导图
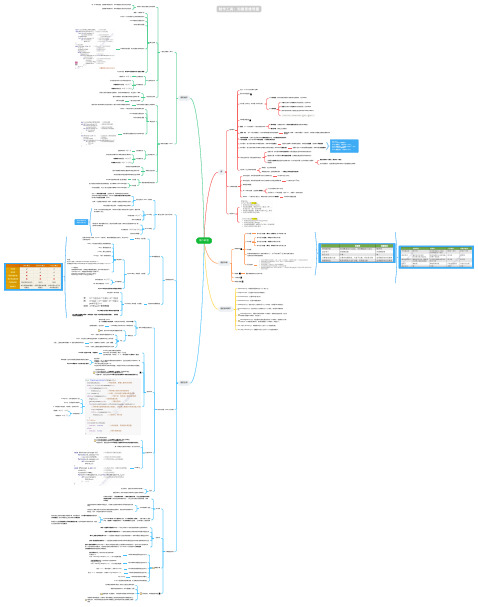
ve(源点)=0
ve(k)
=
Ma
x{ve(j)+Weight(vj
v, k )},vj
v 为
k
的任意前驱
1.求所有事件的最早发生时间ve()
按逆拓扑排序序列,依次求各个顶点的vl(k):
vl(汇点)=ve(汇点)
vl(k)
=
Min{vl(j)-W
eight(vj
v, k )},vj
常见考点:
对于n个顶点的无向图G,
若G是连通图,则最少有n
-1条边,
若G是非连通图,则最多可能有Cn2−
1
条边
对于n个顶点的有向图G,
若G是强连通图,则最少有
n条边
子图/生成子图(子图包括所有顶点)
强连通分量:有向图中的极大强连通子图(必须强连通且保留尽可能多的边)
连通图的生成树是包含图中全部顶点的一个极小连通子图(边尽可能的少但要保 持连通)
n个顶点对应2Cn2
条边
几种特殊的图
稀疏图/稠密图 树:不存在回路,且连通的无向图
n个顶点的树必有n-1条边 常见考点:n个顶点的图,若|E|>n-1,则图中一定存在回路
有向树:一个顶点的入度为0,其余顶点的入度均为1的有向图
有向树不是强连通图
常见考点
邻接矩阵
图的存储
无向图
第i个结点的度 = 第i行(或第i列)的非零元素个数
每一轮时间复杂度:O(2n)
时间复杂度
最短路径问题
Dijkstra算法不适用于有负权值的带权图 算法思想:动态规划
Floyd算法(带权图,无权图)
各顶点间的最短路径
递归及递归算法图解

递归问题的提出
第一步:将问题简化。 – 假设A杆上只有2个圆盘,即汉诺塔有2层,n=2。
A
B
C
递归问题的提出
A
B
C
对于一个有 n(n>1)个圆盘的汉诺塔,将n个圆盘分 为两部分:上面的 n-1 个圆盘和最下面的n号圆盘。将 “上面的n-1个圆盘”看成一个整体。
– 将 n-1个盘子从一根木桩移到另一根木桩上
1
当n 1时
n ! n (n 1)! 当n 1时
long int Fact(int n)
{ long int x;
if (n > 1)
{ x = Fact(n-1);
/*递归调用*/
return n*x; }
else return 1;
/*递归基础*/
}
Fact(n) 开始 传进的参数n N n>1
两种不同的递归函数--递归与迭代
21
(2)递归和迭代有什么差别?
递归和迭代(递推)
迭代(递推):可以自递归基础开始,由前向后依次计算或直
接计算;
递归:可以自递归基础开始,由前向后依次计算或直接计算;
但有些,只能由后向前代入,直到递归基础,寻找一条路径, 然后再由前向后计算。
递归包含了递推(迭代),但递推(迭代)不能覆盖递归。
递归的概念 (5)小结
战德臣 教授
组合 抽象
构造 递归
用递归 定义
用递归 构造
递归计 算/执行
递归 基础
递归 步骤
两种不同的递归函数
递归
迭代
两种不同的递归函数--递归与迭代
20
(1)两种不同的递归函数?
递归和递推:比较下面两个示例
数据结构中的树、图、查找、排序

数据结构中的树、图、查找、排序在计算机科学中,数据结构是组织和存储数据的方式,以便能够有效地对数据进行操作和处理。
其中,树、图、查找和排序是非常重要的概念,它们在各种算法和应用中都有着广泛的应用。
让我们先来谈谈树。
树是一种分层的数据结构,就像是一棵倒立的树,有一个根节点,然后从根节点向下延伸出许多分支节点。
比如一个家族的族谱,就可以用树的结构来表示。
最上面的祖先就是根节点,他们的后代就是分支节点。
在编程中,二叉树是一种常见的树结构。
二叉树的每个节点最多有两个子节点,分别称为左子节点和右子节点。
二叉搜索树是一种特殊的二叉树,它具有特定的性质,即左子树中的所有节点值都小于根节点的值,而右子树中的所有节点值都大于根节点的值。
这使得在二叉搜索树中查找一个特定的值变得非常高效。
二叉搜索树的插入和删除操作也相对简单。
插入时,通过比较要插入的值与当前节点的值,确定往左子树还是右子树移动,直到找到合适的位置插入新节点。
删除节点则稍微复杂一些,如果要删除的节点没有子节点,直接删除即可;如果有一个子节点,用子节点替换被删除的节点;如果有两个子节点,通常会找到右子树中的最小节点来替换要删除的节点,然后再删除那个最小节点。
接下来,我们聊聊图。
图是由顶点(也称为节点)和边组成的数据结构。
顶点代表对象,边则表示顶点之间的关系。
比如,社交网络中的用户可以看作顶点,用户之间的好友关系就是边。
图可以分为有向图和无向图。
有向图中的边是有方向的,就像单行道;无向图的边没有方向,就像双向车道。
图的存储方式有邻接矩阵和邻接表等。
邻接矩阵用一个二维数组来表示顶点之间的关系,如果两个顶点之间有边,对应的数组元素为 1,否则为 0。
邻接表则是为每个顶点建立一个链表,链表中存储与该顶点相邻的顶点。
图的遍历是图算法中的重要操作,常见的有深度优先遍历和广度优先遍历。
深度优先遍历就像是沿着一条路一直走到底,然后再回头找其他路;广度优先遍历则是先访问距离起始顶点近的顶点,再逐步扩展到更远的顶点。
快速排序递归详解流程图(大框架)

(9)
Байду номын сангаас
Input:{49},[4,3]
结束(4>=3),(7)出栈
(8) Input:{65},[5,5]
Input:{97}, [7,7]
结束(5>=5), sortlist(8)出栈, sortlist(6)出栈 结束(7>=7), (9)出栈,(5)出栈, (1)出栈
快速排序流程----图解
序:由于心里没有全面的调用经过图序,画了一个以供回忆。 这个图解,还原出快速排序的调用架构图。为了保证架构完整,去掉了划分过程 分析,直接用了划分后的结果。 说明如下: 1. sortlist函数原型为:Void sortlist(int a[], int l, int h); 图中input的解释:假设注释input为: {54, 37, 26}, [0,2],则表示low为0, high为2 2.注意快速排序,最核心的几样东西: 2.1 初始序列,low, high边界。(见每次的input) 2.2 划分过程。(图中没表现出来) 2.3 划分后得到的: 分界点,左右两个子序列。(见划分后的注释://result{13},27,{38} ) 2.4 流程:像二叉树。有一个根,生成了第1层左叶子,右叶子,它们分别生出了第2 层左右叶子,依次发展下去。每次都是最上层的子叶子先处理完(左边的叶子处理干净 了(出栈后),再去处理右边的叶子,然后该子叶子处理完)。然后它再作为父叶子的左右叶 子,依次处理,出栈。一层层出栈,最终返回到根,处理、出栈。整个过程完毕。这 样把每个子序列都排好序了。没学过二叉树,描述的可能不到位,自己总结用的,希 没学过二叉树, 没学过二叉树 描述的可能不到位,自己总结用的, 望有高手能给个宝贵意见啥的,一起分享,讨论进步^_^ 望有高手能给个宝贵意见啥的,一起分享,讨论进步 3. 图中红色字:表示分界点的坐标。